
Abstract
Due to the advantages of large-scale, data-centric and wide application, wireless sensor networks have been widely used in nowadays society. From the physical layer to the application layer, the multiply increasing information makes the data aggregation technology particularly important for wireless sensor network. Data aggregation technology can extract useful information from the network and reduce the network load, but will increase the network delay. The non-exchangeable feature of the battery of sensor nodes makes the researches on the battery power saving and lifetime extension be carried out extensively. Aiming at the delay problem caused by sleeping mechanism used for energy saving, a Distributed Collision-Free Data Aggregation Scheme is proposed in this article to make the network aggregate data without conflicts during the working states periodically changing so as to save the limited energy and reduce the network delay at the same time. Simulation results verify the better aggregating performance of Distributed Collision-Free Data Aggregation Scheme than other traditional data aggregation mechanisms.
Introduction
Wireless sensor network (WSN) consists of a numerous sensor nodes to form a multi-hop ad hoc network system in a self-organized manner. 1 WSN has very widespread applications, which can achieve real-time monitoring of the battlefield, targeting the target, monitoring crop irrigation, and so on. 2 For the most practical large-scale applications, the sensors may be thrown by airplanes in special environments. 3 Considering the requirements of large quantities, low cost, and wide distribution area, it is impossible to replace the battery of the node artificially, 4 so the problem of energy efficiency of great importance in WSN. How to use energy efficiently to maximize the lifetime is a top challenge for WSNs.
In the working process, the nodes will sense and receive a variety of information. The amount of data to be analyzed will increase in stages and also face data fusion problems with various heterogeneous networks or systems. 5 Therefore, collision-free and efficient data aggregation mechanism is an indispensable part for WSN. The duration it takes to aggregate information from the sensor node to the sink node is called the data aggregation latency. 6 It is a critical step in minimizing the data aggregation latency throughout the network’s work. The collision-free data transmission between nodes is the basis for reducing the data aggregation delay. Collision-free can ensure an unblocked communication channel, increase the efficiency, and save energy so that the delay of the data aggregation will be decreased. Searching for the fastest collision-free scheduling (FCFS) has raised the concern of people. When a sensor node simultaneously listens to signals from different transmitters, the collision will occur due to interference between the signals. 7 At this time, the sensor node cannot receive any signals, so the sender should send a signal packet to other nodes instead of sending a signal directly. 8 The retransmission of data packets will not only increase conflict probability but also lead to a large amount of energy consumption and time delay. 9 Therefore, a mechanism to minimize the delay without conflicts is the key to solve the FCFS problem.
In addition, the battery of the sensor node cannot be changed artificially, so how to reduce the consumption of energy has also become a key problem in WSNs. 10 Many methods to save energy by periodically switching the working states have been proposed recently, most of which will use a short period of time in the positive state to receive or transmit information and the rest of the time to sleep so as to save energy in each working period (WP). 11 However, it can exert a sleep waiting time in this way, that is, when the transmitter sends the data to the receiver, it needs to wait until the receiver’s state is positive, which will inevitably lead to network delay. 12
From the above, it is necessary to reduce the delay caused by work states converting conflicts so as to solve the problem of FCFS and save the energy of the network. The main contributions of this article include in following:
Some equations and models are given for the proposed scheme.
Proposing a two main parts Distributed Collision-Free Data Aggregation Scheme (DCF-DAS): DAT (Date Aggregation Tree) to minimize the data aggregation by controlling the number of the node’s child node and FCFS is designed to reduce the WP of the node required for data aggregation and save the power of the node.
We do a mass of simulations to verify the correctness of the mechanism. The results show that DCF-DAS is superior to the classical improved data aggregation scheduling (IAS) and scheduling algorithm (SA) in time delay.
The rest of the article is organized as follows. We present the related work in section “Related work.” Section “Preliminaries” introduces the model of network, delay, conflict, and formulation. Our scheme DCF-DAS is proposed in section “Proposed DCF-DAS.” In section “Simulation analysis,” simulation results are analyzed to evaluate the DCF-DAS. Finally, we conclude this article in section “Conclusion.”
Related work
Data aggregation plays a significant role in WSNs, and the problem of minimizing the delay in this technique is NP-hard and many researches contribute to solve this problem. Yu and Li
13
analyze the time cost that complete the aggregation in SA, and the algorithm shows that the time required is not lager than
Preliminaries
Network model
Assuming the node set
Node v and edge e in graph G.
In the data aggregation mechanism proposed in this article, the lifetimes of all sensor nodes are divided into several equal periods. Each time period is called a WP, and each WP is divided into a number of fixed time slots (TS). The sensor node can randomly select one of the TS as its working TS, and the remaining in the same WP as the sleeping TS. For the sake of explaining the conflict avoidance, the case of receiving one packet in one working TS is considered. Nodes can send data packets to their parent nodes in any working TS, but can only receive data packet from its child nodes in the randomly selected working TS. The same TS cannot be used to send and receive simultaneously. In the whole network, all the nodes can aggregate different data packets received from their child nodes into one packet and then send it to their parent nodes. After the sink node receives the necessary data in the network, the data aggregation is achieved. An example is shown as Figure 2.

Time slot division of sensor nodes.
Figure 2 shows the WP and TS assignment of nodes u and v, where there is
Delay model
The time delay required for data to be transmitted from sensor node v to sink node s is called the end-to-end delay of node v, noted as

where

where in the data aggregation tree (DAT), node v’s parent node is node u.
Conflict model and conflict set
Conflict model
Assuming that the transmitting radius is R and the interfering radius is R′ for sensor nodes. There is

Two conflict models in the conflict-free data aggregation scheme: (a) primary collision model and (b) secondary collision model.
In the primary collision model as shown in Figure 3(a), the transmission range of all nodes denoted by R and node y lies both in the communication radius of node x and node z. If x and z send data to node y in the same WP, node y cannot receive any data from x or z because y has only one working TS in a WP.
From above, it can be seen that the condition that v and u can transmit data successfully should satisfy the following two points: (1)
Conflict set
In order to avoid the conflicts mentioned above during the process of data aggregation, each sensor node can define its own conflict set. During aggregation, for each node, it should be ensured that the communication link does not conflict with the link of the node in its conflict set when sending data packet to their parent node. With the aggregation process carrying forward, the conflict set of a node will also be constantly updated. As long as there is a node to satisfy any one of the following three conditions of some other node a, the node will be included in the conflict set of node a, which can be called
Condition 1. It is the child node of node
Condition 2. It is the child of a’s neighbor node b, where node b satisfies
Condition 3. It is

The conflict set of one node.
Figure 5 illustrates the node’s conflict set. The conflict nodes of
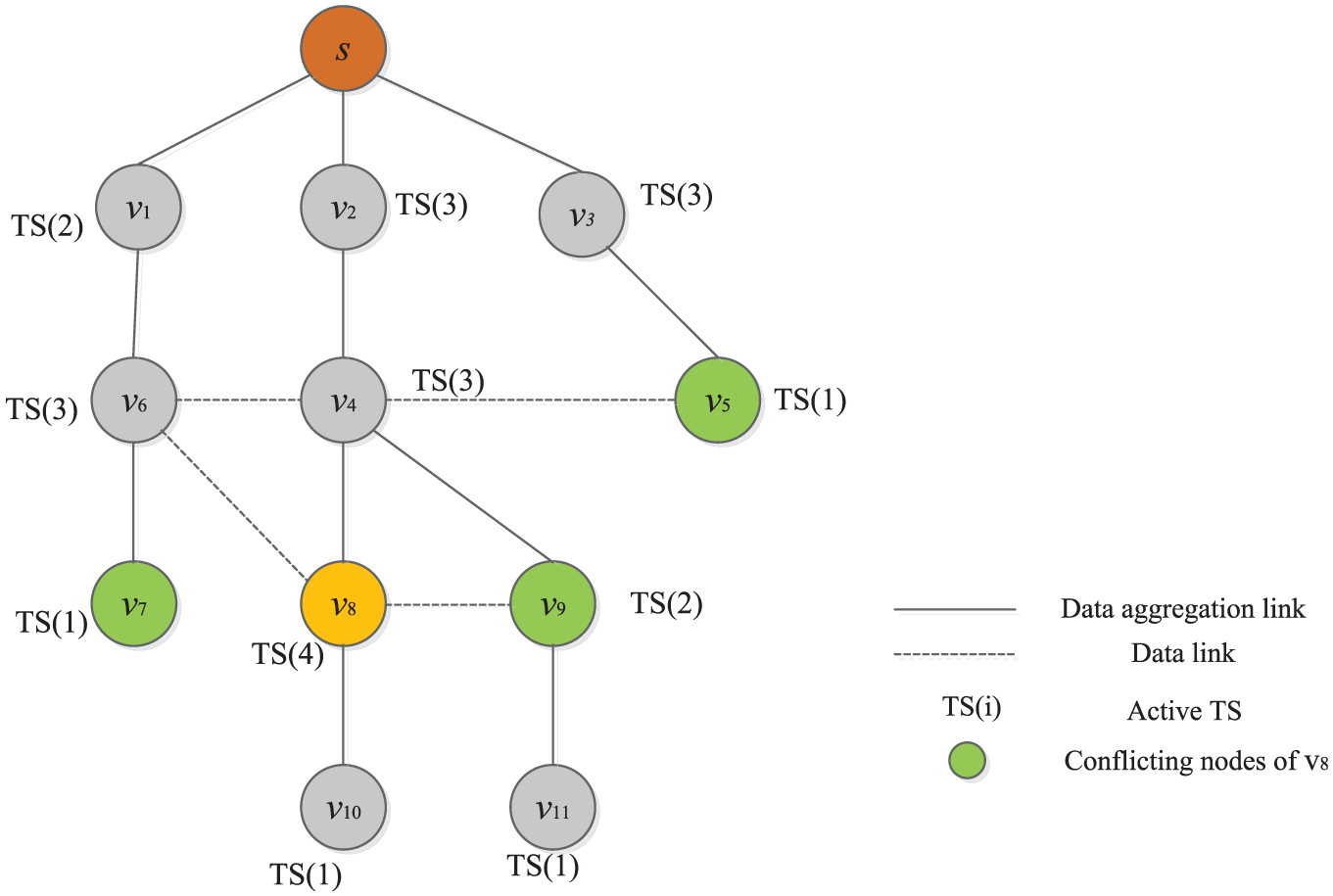
The conflict set of nodes.
Problem formulation model
Assuming

where

To avoid conflicts, the parent node only allows receiving the data packet from only one child node in one WP. Then equations (5) and (6) will be obtained from equations (3) and (4)


where
Let

In this article, a collision-free data aggregation mechanism is designed, in which the data collected by the sensor nodes is delivered to the sink nodes as fast as possible without any conflict, that is, the value of N is minimized by the data aggregation scheme.
Proposed DCF-DAS
The realization of the proposed DCF-DAS is mainly divided into two parts. (1) Establishment of DAT. During the data tree establishment, each parent node must wait until all the packets from the child nodes are collected before performing data aggregation. The larger the number of child nodes is, the longer the aggregation delay will be. Limiting the number of child nodes can effectively reduce the parent node data aggregation time. Therefore, in the establishment of data tree, a threshold k is preset for the environment, and the maximum number of child nodes owned by each parent node is adopted to control the number of child nodes so as to reduce the aggregation delay. When some special cases occur, like fewer nodes in the network or low node density, little number of child nodes are allowed to the maximum number of child node exceed to the value of k, but the number of parent nodes of such child nodes is required to be minimized. (2) Establishment of FCFS. After the DAT being established, an FCFS is proposed, by which the node will select the WP to send the data packet to its parent node according to the data aggregation algorithm, making all the data packets can be sent to the sink node without any conflict.
Establishment of DAT
It is necessary to consider that multiple nodes transmit data without conflict in the same WP to reduce the data aggregation delay. The more nodes there are with child nodes in the network, the longer time the data aggregation will require. Energy plays a crucial factor affecting the network lifetime, since changing the batteries of the nodes in WSN is impossible. In order to save the energy consuming of the entire network, the nodes will periodically change the working states. The nodes randomly select a time slot within each WP as their own working slot and the rest of the time into sleeping state (as mentioned in section “Network model”), which can effectively avoid the energy consumption that is caused by the state in working for a long time. On the contrary, it may extend the WP of the node to collect the data from all its child nodes in high network density. Therefore, the establishment process of DAT should take full account of the delay generated by the nodes with multi-child nodes.
Accordingly, the following theorem exists: Given a DAT, in the collision-free data aggregation mechanism, the value of the data time delay N is not less than the maximum number of one node’s child nodes number in the network. That is
Main variables during the establishment of DAT are listed in Table 1:
Variables and explanations.

In Table 1,
The establishment of DAT is divided into the Start-up stage and the Main stage. In the Start-up stage, nodes can be divided into two categories: Special and Normal. A Special node looks for its only parent node. In the Start-up stage, the Normal node may also be transformed to be a Special node. The Start-up stage ends when there is no Special node in the current network, and then the Main stage is executed. In the Main stage, the sink node is set as the first catalytic node, which can find its own child nodes to continue the DAT establishment. When a node cannot find any more child nodes, it will send a TRA (TRAPPED) message to its parent node. The Main stage ends when all child nodes of sink node s send TRA messages to s, and then the DAT has been established.
The pseudocode of Start-up stage is shown as follows:

The details of the Start-up stage are shown as follows. All nodes should be initialized at first. As the DAT has not been formed yet, the node may not find any parent node in DAT. So, u does not have any child node and the number of candidate parent and neighbor node of u are same, that is,
Data aggregation enters the Main stage when there is not any Special node in the current network. The pseudocode of Main phase is shown as follows.

When the number of child nodes of the sink node is equal to the number of its neighbors, DAT has already been formed in the Start-up stage. Otherwise, the following steps will be taken: The sink node becomes the first catalytic node in the network and begins to search for its own child node, and the state of the sink node changes from WAIT to ACTIVATED. When the state of the sink node is not COMPLETE, the catalytic node u sends a CH-FIND message (find the child node) to its one-hop neighbor except for those nodes that have been selected u as their parent node in the Start-up stage. Each neighbor node v receiving the CH-FIND message will send an ASK-JOIN message to node u, in order to notify u that v wants to be u’s child node. After receiving the ASK-JOIN message from one or more neighbor nodes successfully, u will set a backoff time
The pseudocode of Procedure 1 is shown as follows.

Procedure 1 shows the procedure that node u takes node v into its own child nodes set
When v receives an ACC-JOIN from u, v will confirm u as its parent node and sends a confirm join message CON-JOIN to its one-hop neighbor. If the label of v is Special before being added to the DAT, the state of v is converted to COMPLETE; otherwise, it is converted to ACTIVATED to continue searching for its child node. Another neighbor node i of node u in the state WAIT will judge the value of the number of child nodes of node u
The pseudocode for Procedure 2 is shown as follows.

In Procedure 2, node u will send a CH-FIND message to its one-hop neighbor again. If receiving no ASK-JOIN messages, node u will send a TRA message to its parent node, and the state will be converted to COMPLETE. If node u happens to receive an ASK-JOIN message, it will begin to carry out the line 11 in Main stage. When the sink node s no longer receives any ASK-JOIN message, the establishment of DAT is completed.
During the establishment of DAT, the status of node is changing. A node may have four states as WAIT, ACTIVATED, LISTEN, and COMPLETE. The conversion relation of four states is shown in Figure 6.

States transition for different nodes: (a) other nodes and (b) aggregation nodes.
Figure 6(a) depicts the states of other nodes (expect aggregation nodes). Normal node is initially in WAIT, and keeping WAIT state if it satisfies the following two conditions: not receive any ACC-JOIN message and another is that the number of its candidate parent is more than one; otherwise, it will change the state into ACTIVATIED. When the candidate parent of the node is 1, it became a Special node and the state is still in WAIT until it receives ACC-JOIN message, and then its state is in COMPLETE. The node which is in state ACTIVATIED will keep the state if it does not select a new catalyst or the number of its child node is less than k; otherwise, the node is being LISTEN and hold the mode if it finds a new catalyst after sending CH-FIND messages. The node in state ACTIVATIED and LISTEN can change into COMPLETE when the node cannot find any catalyst and no new catalyst is found after sending CH_FIND messages, respectively. Figure 6(b) describes the states of the aggregation nodes. The aggregation node is in WAIT state in Start-up phase, and then in ACTIVATIED when the Start-up stage is finish and the number of the child node and neighbor of aggregation node are not equal. If the node does not select any new catalyst or the number of its child node is less than k, the state is constant. The node will in LISTEN when the new catalyst is found and it will keep in LISTEN if the catalyst node is found after the aggregation node sending CH-FIND message; otherwise, the state will be in COMPLETE.
Establishment of FCFS
The FCFS is proposed based on the establishment of DAT, which will be described in detail in this section. Relative variables are shown in Table 2.
Main stored variables and explanations.

In Table 2,
The pseudocode of FCFS is shown as follows.

The specific process of FCFS will be discussed as follows: first, the stored variables of the nodes in WSN are initialized, and the WP is not selected yet to send the data packets to their parent nodes. For the convenience of subsequent description, the node which determines the WP to send the data packet to its parent node is called certain node; otherwise, it is called uncertain node. For any uncertain node u, it can select the WP first if all its child nodes are certain nodes and
Node u now sends a CON_WP (confirm the WP) message to its two-hop neighbors, informing them that it has become a certain node. In this case, if the collision set of the uncertain node v which receives CON_WP contains the node u, node v adds
Simulation analysis
Network simulator 2 is adopted to evaluate the performance of DCF-DAS. First, different values of k are taken and compared in terms of different values of TS, node densities (represented by different network side lengths), and the numbers of nodes. The optimal value of k is obtained by analyzing the minimum number of WP required to complete data aggregation. Second, using the value of k obtained above as the maximum number of node’s child node in the DAT, DCF-DAS is compared with SA 13 and IAS 21 still from the above three aspects to verify the effectiveness of the proposed mechanism. Assuming that the communication radius of the sensor node is 30 m and the node randomly select a working TS in 0–TS-1 in the simulation, the sink node is deployed in the upper left corner of the entire area, and all results are taken from the average value of 10 times experimental results.
Determination of k
To obtain the optimal value of k to achieve the fast data aggregation, several special values of k are selected to observe the total number of WPs required to complete the aggregation at different values of TS. So the purpose of this section is to get the optimal value of k and the value obtained can be used in the simulation experiment. The total number of nodes in the simulation experiment is 400, and Figure 7 shows the relationship between TS and WP under different values of k when the network length (NL) is 50, 100, and 200 m, respectively. As it can be seen in Figure 7(a), when the network density is large, that is, when the node’s average number of neighbor nodes is large, the condition of k = 1 can complete the data aggregation quickly. Figure 7(b) and (c) shows that when the network density reduces, the condition with k = 2 makes the data aggregation be completed faster than those with other values of k. The total number of WP decreases with the increase in TS, because the increasing TS which can be selected could increase the possibility of free-collision transmission.

The relationship between number of WP and TS with different values of k: (a) NL = 50, (b) NL = 100, and (c) NL = 200.
The above is the number of WP required for the nodes to complete data aggregation with different TS settings. It can be concluded that when the node deployment density is large, k can take 1 for faster data aggregation. On the contrary, the condition of k = 2 can achieve good results. The following analysis will focus on the total WP required to complete the aggregation with node deployment density changing and different values of k. The total number of nodes in Figure 8 is still 400, and the values of TS in Figure 8(a)–(c) are 2, 10, and 100, respectively. The simulation results are as follows.

The relationship between number of WP and network side with different values of k: (a) TS = 2, (b) TS = 10, (c) TS = 100.
The simulating results show that no matter whether the value of TS is large or small, the condition of k = 2 will take the shortest time for data aggregation. Therefore, it can be simply concluded that when the node density is large, the setting of k = 1 is the optimal choice, while in other conditions the setting of k = 2 will get better performance. In the simulations above, the number of nodes is fixed. Now the number of nodes is variable, the optimal value of k will be discussed by setting different node densities and TS. Figure 9 shows the relationship between the WP required for data aggregation and the number of nodes with different values of k. In Figure 9(a)–(c), the length of the network is set to be 50, 200, and 200 m, respectively. The TS’ values are set to be 100, 100 and 10, respectively. The simulation results are as follows.

The relation between number of WP and number of nodes with different values of k: (a) NL = 50 TS = 100, (b) NL = 200 TS = 100, and (c) NL = 200 TS = 10.
Compared with Figure 9(a) and (b), we can see that when the value of TS is the same and the network density is small, the setting of k = 1 can not only finish the data aggregation faster but also reduce the total WP compared to that of k = 2, which verifies the correctness of the conclusion above. It also shows that when the TS value is large, the aggregation performance with k = 1 is superior to that of other k values.
To sum up, when node deployment density is large or the value of TS is high in the network, k = 1 will be prone to obtain good aggregation performance, otherwise k = 2 is a better choice for other network conditions. Based on this, the proposed mechanism DCF-DAS will be compared with some classical data aggregation mechanisms to verify the effectiveness and correctness.
DCF-DAS validity verification
In order to verify the effectiveness of the proposed DCF-DAS, the classical IAS and SA are adopted as the comparisons in simulation experiments, where SA is a most used centralized data aggregation scheme. Two parts of DCF-DAS (DAT and FCFS) are separately evaluated to fully verify the proposed mechanism.
Taking the condition with k = 1 as an example (the following condition are the same when k = 2), the correctness and effectiveness of the DAT algorithm can be verified by comparing IAS with
Figure 10 shows the relationship between the total WP required for completing the aggregation and the value of TS under different data aggregation schemes. Assuming that the network sides are 50, 100, and 200 m in Figure 10(a)–(c), respectively, and the total number of nodes is 400. It can be concluded from the calculated results that in these three cases, the total WP required to complete the data aggregation of

The relation between number of WP and TS: (a) NL = 50, (b) NL = 100, and (c) NL = 200.
Figure 11 shows the relationship between the total WP required to complete the aggregation and the node deployment density under different data aggregation mechanisms. In Figure 11(a)–(c), the TS number of nodes in the network is set to be 2, 10, and 100, respectively, and the total number of nodes is 400. Statistical results from the experimental data show that the total WP required by

The relation between number of WP and network side: (a) TS = 2, (b) TS = 10, (c) TS = 100.
Figure 12 shows the relationship between the total number of WP required to complete the aggregation and the number of nodes in the network under different data aggregation mechanisms. In Figure 12(a)–(c), it is assumed that the network side is 200, 200, and 50 m, respectively. The TS is 10, 100, and 50, respectively. The statistical results from the experimental data show that the total WP required to complete the data aggregation by

The relation between number of WP and number of nodes: (a) NL = 200 TS = 10, (b) NL = 200 TS = 100, and (c) NL = 50 TS = 50.
The simulation shows that DCF-DAS, especially k = 2, can achieve less delay among the three algorithms (DCF-DAS, IAS and SA) and IAS is inferior relatively in terms of different number of TS, length of network side, and number of nodes. The proposed DCF-DAS adopts the working mode of node periodically changing the working state, so it can save more energy than IAS, since the sensor nodes of IAS are working all the time, which can lose a lot of energy. Compared with the centralized scheme SA, the distributed data aggregation scheme DCF-DAS can extensively reduce the time delay. The scheme in this article may not be the optimal algorithm to deal with the time delay in data aggregation, but from the aspect of collision-free, it is superior to some traditional mechanism. To sum up, the proposed DCF-DAS data aggregation scheme can effectively shorten the aggregation time required than other widely used mechanisms.
Conclusion
Aiming at the problem of time delay brought in by data aggregation in WSNs, this article proposes a DCF-DAS consisting of the two major components as the DAT and the FCFS for data aggregation. DAT will provide data aggregation topology for FCFS by controlling the number of child nodes. The whole mechanism takes the way of node periodically changing the working states to alleviate the node energy consumption. FCFS can shorten the total WP needed to complete the data aggregation of the whole network. In simulating experiments, the WP required for data aggregation is taken as the metrics based on DCF-DAS, IAS, and SA in terms of different numbers of TS, network deployment densities, and numbers of nodes. Statistical results show that DCF-DAS proposed in this article can reduce the time delay more effectively than other widely used mechanisms. The main advantages of this article is to design a data aggregation algorithm which is conflict free, using the limited number of child nodes to avoid the conflict and retransmission when transmitting the message, and then reduce the time needed to complete the data aggregation. We give a priority to collision-free to avoid retransmitting; therefore, the energy can be saved. Our current work focused on minimizing the time delay and collision-free in data aggregation in fixed network forms, and we will focus on the construction of the data aggregation algorithm in the condition of moving nodes in the future and improve the algorithm to guarantee the effectiveness, since the topological structure of the dynamic network is changing irregularly.
Footnotes
Handling Editor: Jaime Lloret
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (61771186), Postdoctoral Research Project of Heilongjiang Province (LBH-Q15121), and University Nursing Program for Young Scholars with Creative Talents in Heilongjiang Province (UNPYSCT-2017125).