Minimum-Latency Aggregation Scheduling is a significant problem in wireless sensor networks. The key challenge is to find an effective solution to aggregate data from all sensors to the sink with minimum aggregation latency. In this article, we propose a novel data aggregation scheduling algorithm under the physical interference model. First, the algorithm partitions the network into square cells according to the communication range of a sensor. Second, a node is selected randomly as the aggregated node to receive the data from the other nodes in the same cell. Finally, a data aggregation tree, which consists of multiple disjoint paths, is constructed to aggregate data from all aggregated nodes to the sink. We empirically proved that the delay of the aggregation schedule generated by our algorithm is (K+1)2Δ−K−1+2λ time-slots at most, where K is a constant depending on the sensors transmitting power, the signal-to-interference-plus-noise-ratio threshold, and the path-loss exponent; represents the maximal number of nodes in a cell; and denotes the number of cells at a row/column in a square network area. Simulation results also show that our algorithm achieves lower average latency than the previous works.
Data aggregation1,2 is an important technique in wireless sensor networks (WSNs), which is the combination of data coming from different sensors according to a certain aggregation function (e.g. maximum, minimum, or/and average values of all data), and eliminates unnecessary packet transmission by filtering out redundant sensor data. However, data aggregation will increase the transmission latency because data cannot be sent immediately until all data are aggregated by a sensor.3 On the contrary, collision will occur when two or more sensors send data simultaneously to their common neighbor. Once the collision occurs, the sensor has to spend more time retransmitting data.4 Therefore, for some delay sensitive applications such as intruder detection, medical care, fire monitoring, and battle field monitoring in WSNs, it is essential to adopt an effective data aggregation schedule method to transmit data from sensors to the sink as fast as possible.
Currently, many researchers have investigated the Minimum-Latency Aggregation Scheduling (MLAS) problem. For example, most existing research works5–13 studied the MLAS problem under the protocol interference model and bound the aggregation latency of , where is the network radius and is the maximum node degree. However, the protocol interference model does not accurately reflect wireless interference in reality. In contrast, the physical interference model14 is more realistic and captures the cumulative interference between links more accurately. Due to the challenge of handling the cumulative interference effect, only a few previous works15–22 studied the MLAS problem under the physical interference model.
In this article, we continue to explore the MLAS problem under the physical interference model with the same transmission power. We design a novel data aggregation scheduling algorithm, which is called Data Aggregation Scheduling based on Multi-Path Routing Structures (DAS-MPRS) algorithm. The algorithm partitions first the network into square cells according to the sensor’s communication range. Then, an aggregated node is selected randomly in each cell so as to receive data from other nodes in the same cell. Finally, a data aggregation tree is constructed by using multiple disjoint paths to connect the aggregated nodes. The aggregated data are transmitted one by one along these disjoint paths. The main contributions are summarized as follows:
The time of constructing a data aggregation tree by DAS-MPRS algorithm is less than that of the existing algorithms. In general, the existing algorithms15–17 establish an aggregation tree based on the connected dominating set (CDS) or maximal independent set (MIS). It has to spend additional time seeking out an MIS and some connectors to form a data aggregation tree. However, our algorithm selects randomly a node in each cell and a data aggregation tree is formed by using multiple disjoint paths to connect these nodes. Especially, when a node or a link fails during the data aggregation, the existing algorithms have to spend more time reconstructing an aggregation tree. Nevertheless, DAS-MPRS algorithm will take less time to reconstruct an aggregation tree by selecting randomly a new node to replace the failure node in the same cell.
The latency bounds of DAS-MPRS algorithm is , where is a constant depending on the sensors transmitting power, the signal-to-interference-plus-noise-ratio (SINR) threshold, and the path-loss exponent; is the maximal number of nodes in a cell; and denotes the number of cells at a row/column in a square network area. Currently, the best result17 for the MLAS problem is bounded by , as far as we know. Simulation results show that our algorithm achieves lower average latency than the previous works.
The remainder of this article is organized as follows. The “Related works” section summarizes the relevant work and the section “System model and problem statement” formulates the problem of MLAS. A detailed description of DAS-MPRS algorithm is given in the section “Algorithm design” and the performance analysis of the algorithm is presented in the section “Algorithm analysis and performance evaluation.” The final section concludes the main findings.
Related works
The MLAS problem has been proved to be non-deterministic polynomial (NP)-hard under the protocol interference model.5 Chen et al.5 designed an approximate algorithm with a latency bound of , where is the network radius and is the maximum node degree. Subsequently, Zhu and Hu6 propose a new approximate algorithm with the performance ratio of , where is the set of sensors containing source data, is the maximal number of sensors within the transmission range of any sensor, and is a constant. Constructing a data aggregation tree based on MIS, Huang et al.7 raised a new approximation algorithm whose latency bound is . However, Yu et al.8 discovered that a collision-free schedule cannot be derived in some cases. Hence, they put forward a distributed algorithm which has latency of , where is the network diameter. Unfortunately, the upper bound of Yu et al.’s algorithm8 is worse than that of Huang et al.’s algorithm.7 Realizing the disadvantage of these algorithms, Wan et al.,9 Ren et al.,10 and Xu et al.11 proposed some improved approximate algorithms whose latency is bounded by , , and , respectively. Considering the common neighboring dominators, Nguyen et al.12 made further improvement for the above works, and designed a new collision-free scheduling algorithm which has the latency of . Recently, Guo et al.13 designed a distributed scheduling algorithm based on a novel cluster-based aggregation tree, which has a latency bound of , where is the maximum degree and is the inferior network radius.
Although the protocol interference model has been used in many studies, it ignores cumulative interference caused by the other concurrently transmitting nodes. Moscibroda et al.23 demonstrated experimentally that real-world phenomena cannot be captured adequately under the protocol interference model. Thus, researchers moved to investigate the MLAS problems under the physical interference model proposed by Gupta and Kumar.14 Under this interference model, whether a packet is received successfully by the receiver depends on the received signal strength, the background noise level, and the cumulative interference caused by simultaneously transmitting nodes. Compared with the protocol interference model, the physical interference model can capture the cumulative interference more accurately in the real wireless environment. Li et al.15 designed a scheduling algorithm whose latency is bounded by exploiting the uniform power scheme, where R is the network radius, is the maximum node degree and, K is a model-specific constant depending on the sensor node’s transmitting power, the SINR threshold, the path-loss exponent, and so on. Thereafter, Xu et al.16 proposed an improved approximation algorithm with a latency bound of . Recently, Xu et al.17 designed a new data aggregation scheduling algorithm whose latency is bounded by , which has the best result for the MLAS problem under the physical interference model, as far as our awareness is concerned. In addition, An et al.18 made the milestone contribution to prove the NP-completeness of the MLAS problem under the physical interference model. Subsequently, Lam et al.19 demonstrated that MLAS problem is the approximable (APX)-hardness in the metric SINR model without power control.
In addition, researchers studied the same problem with power control, that is, the node’s transmission power is unlimited. Wang and Baras20 designed a distributed algorithm achieving the time-latency bound of , where is the logarithm of the ratio between the lengths of longest and shortest links in the network. Later, Lam et al.21 proposed an approximate algorithm using time-slots at most to complete the aggregation task, where is the network radius. Recently, Li et al.22 presented a distributed algorithm whose latency is bounded by and a centralized algorithm with a latency bounded by , where is the number of nodes.
System model and problem statement
Network model
Assume that a WSN consists of a number of sensor nodes, which has the same transmission power, and the sink, which is responsible for gathering data from all sensor nodes. All the nodes are distributed randomly in the Euclidean plane. Any node cannot send and receive simultaneously. Under the physical interference model, a node , which receives a data packet from a node , may be interfered by other nodes which send data concurrently. Therefore, a receiver successfully receives a message from its sender if and only if it satisfies the following condition
where denotes node u’s transmission power, is the Euclidean distance between node and node , is ambient noise, 17,22 denotes the path-loss exponent, is the minimum SINR required for a message to be successfully received, and is the set of concurrently transmitting nodes, which are scheduled in the same time-slot.
According to equation (1), a node u can communicate with a node v if and only if their communication distance . Obviously, if the communication distance is comparatively close to , it will reduce the number of simultaneous transmitting nodes due to communication interference. For instance, when the communication link , a packet is transmitted successfully from node u to node v if and only if there is no other simultaneous transmission. Hence, we set the node’s transmission radius , where is a constant which is considered by Li et al.15 and Xu et al.17 Thus, a WSN can be modeled as an undirected graph , where V is the set of nodes, represents the sink, and an edge exists if the communication distance .
Problem statement
Assume that time is divided into equal-sized slots normalized to one and each node is assigned a time-slot to transmit data. The problem is to design a feasible scheduling sequence , where is the length of schedule or the schedule latency, denotes the set of nodes being scheduled at time-slot . A correct aggregation schedule sequence must satisfy the following conditions:
Any sensor node should be scheduled exactly once, that is, , ;
A node cannot act as a transmitter and a receiver in the same time-slot;
For each time-slot , node u’s data should be successfully received by the corresponding receiver node , that is, ;
Data are aggregated from to at time-slot k, for all , and all the data are aggregated to the sink at time-slots, that is, .
The MLAS problem studied in this article can be formally defined as follows: Given a WSN that consists of a number of sensors and the sink, and their locations, supposing each sensor has a piece of data to be transmitted to the sink, the goal is to design a valid aggregation schedule satisfying the above four conditions and minimize the total number of schedule latency.
Algorithm design
In this section, we present a novel data aggregation scheduling algorithm, which is called DAS-MPRS algorithm, to minimize the schedule latency. The algorithm has two main phases: constructing an aggregation tree and scheduling data from all sensors to the sink. In the first phase, the plane is partitioned into small square cells with the same edge length. Then, a node is selected randomly to act as an aggregated node in each cell. Finally, an aggregation tree is constructed by using multiple disjoint paths to connect the aggregated nodes located at the cells with the same column or row. With regard to each cell, an edge is created from an ordinary node to the aggregated node. In the second phase, the data are collected first by the aggregated node in each cell. Then, the aggregated data are transmitted from the aggregated nodes to the sink according to the aggregation tree.
Network partition
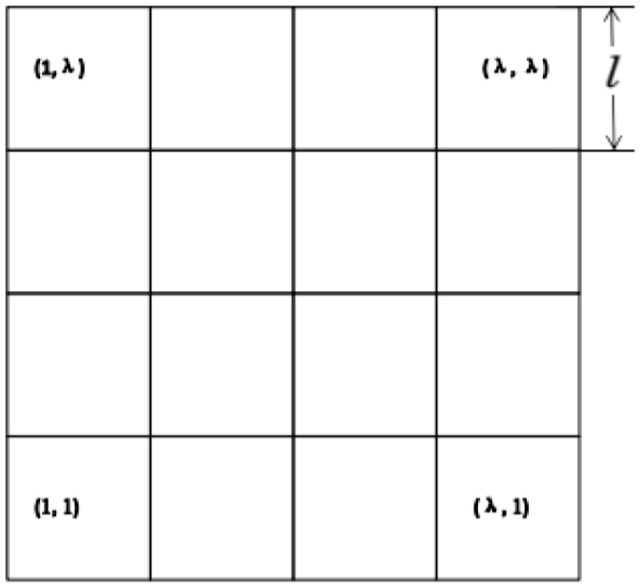
Given that the whole network is distributed in a square region with side length , we partition the network into small square cells with edge length , by a group of horizontal and vertical lines. In order for the sensors in a cell to transmit their data to the sensors in the neighboring cells (sharing a common side), we set , which is mentioned in the section “Network model.” The divided network is shown in Figure 1. Let denote the number of cells in a row or column, we assign each cell positive integer coordinates (i, j) , and a cell with coordinates (i, j) is denoted by cell . Accordingly, the bottom-left corner cell is denoted by and the upper-right corner cell is called .
Network partition.
Construction of a data aggregation tree
After partitioning the network into many small square cells, we select randomly a node as the aggregated node in each cell. Let denote the aggregated node in the cell , and we also assume that the sink is denoted by . That is to say, the sink may be located at the cell . For convenience of description, an aggregated node is called a supernode if it has the same row with , denoted by .
A data aggregation tree is constructed according to the following rules:
For each node in cell , a directed link is created from to .
For the aggregated node , a directed link is formed from to if . Otherwise, a directed link is created from to .
Similarly, for every supernode, a directed edge is created from to if . Otherwise, a directed edge is created from to .
The construction process of a data aggregation tree is shown in Figure 2. In order to optimize description of the data aggregation scheduling in the following section, we introduce two concepts as follows.
Primary path. A primary path is the path which connects the aggregated nodes with the same row and its endings is a supernode.
Backbone path. A backbone path is the path connecting the supernodes and its endings is the sink.
Construction of a data aggregation tree.
For instance, there are 16 primary paths and 2 backbone paths in Figure 2.
Data aggregation scheduling
In this section, we describe more details of the DAS-MPRS algorithm (see Algorithm 1). To describe conveniently, assume that the sink is located at the top-right corner cell . Note that when the sink is located at any position of the network, we can achieve the same results by making a little modification of our algorithm.
Algorithm 1 DAS-MPRS algorithm
1: Partition the deployment plane into square cells with side length ; 2: Select randomly a node to act as an aggregated node in the cell ; 3: Set ; 4: Set be the number of cells in each row or column; 5: Color the cells with colors so that the distance of any two cells with the same color is at least ; 6: for to do 7: for to do 8: Let be the set of the cells with the same color; 9: Pick an unscheduled node in each cell of , and send its data to the corresponding aggregated node; 10: end for 11: end for 12: Construct the primary path by a set of the aggregated nodes located at the cells with the same row; 13: Color these primary paths using colors so that the distance of any two paths with the same color is at least ; 14: Divide all primary paths into different groups, denoted by ; 15: Schedule the first group ; 16: for to do 17: Wait time-slots; 18: Schedule the group ; 19: end for 20: Schedule the supernodes one by one along the backbone path which begins at the start node of the path and finishes at the sink.
The data transmission schedule begins at the nodes in each cell. When data are transmitted, however, it may incur interference caused by other concurrent data transmissions. To make the concurrent data transmissions more successfully, we set , where and . Then, we color the cells with colors so that the distance between any two cells with the same color is at least. In this way, when at most one node from every cell with a monotone color transmits simultaneously, the transmissions are interference-free. Finally, it will take several rounds to transmit data from the ordinary node to their corresponding aggregated node in the cell . In each round, at most one ordinary node will be selected from a cell to be scheduled and only the nodes from the cells with the same color can be scheduled simultaneously.
After all ordinary nodes’ data have been transmitted in each cell, the aggregated nodes send data to their corresponding supernode from far to near along the primary path. To guarantee that the nodes in each primary path can transmit data simultaneously and successfully, we use colors to color these primary paths so that the distance of any two paths with the same color is at least . Here the distance of two paths and is the minimum Euclidean distance between any two nodes u and v, where u is any node of path and v is any node of the path , respectively. Let denote a group of paths with the same color, it is not difficult to find that all primary paths can be divided into different groups.
Next, we schedule iteratively each group until all groups have been scheduled. Assume that the first group begins transmitting data at the time-slot , then the second group is assigned at the time-slot , and we schedule the third group at the time-slot , and so on, the last group is scheduled at the time-slot . Namely, we schedule a group every time-slots. Consider every group being scheduled, nodes are scheduled one by one along the primary path, beginning at the start node of the path and finishing at the end of the path. This process is repeated until all the data from the aggregated nodes are aggregated to their corresponding supernode.
Finally, supernodes are scheduled one by one along the backbone path, beginning at the start node of the path and finishing at the sink.
Algorithm analysis and performance evaluation
In this section, we reveal first that the schedule obtained by DAS-MPRS algorithm is correct. Then, we analyze the time latency achieved by our algorithm. Finally, we estimate the performance of our algorithm through simulations.
Correctness
In the following, we prove that DAS-MPRS algorithm is correct. Theorem 1 formally gives a feasible value of to guarantee that at most one node in each cell with the same color can be scheduled simultaneously without transmission interference. Theorem 2 illustrates that DAS-MPRS algorithm is correct.
Theorem 1
Assume that the network is divided into cells with side length , and we set , where . If we use colors to color these cells such that the distance between any two cells with the same color is at least, when at most one node from every cell with a monotone color transmits simultaneously, the transmissions are interference-free.
Proof
We demonstrate that all transmissions being scheduled at the time-slot t are received successfully by the intended receivers, that is, their SINR values are sufficiently high.
Without loss of generality, consider any link being scheduled at time-slot t, where denotes the transmitter and is the corresponding receiver. Let denotes the transmitter set at time-slot t. For , r and v are located in different cell with the distance , where (i and j are positive integers and they both cannot be zero). Obviously, because they are located in the adjacent cells (sharing a common side). Since there is at most one node being scheduled in a cell at time-slot t, we can obtain the cumulative interference at the receiver r from all the other nodes transmitting data at time-slot t as follows
where .
Thus, the SINR value of the receiver r can be computed as follows
Theorem 2
DAS-MPRS algorithm can find a feasible schedule sequence , that is, for every time-slot , the nodes can be scheduled successfully.
Proof
As mentioned in the “Algorithm design” section, the data transmission schedule of DAS-MPRS algorithm is divided into two phases. In the first phase, the data are transmitted from the ordinary nodes to the aggregated node. It is apparent that Theorem 2 is correct according to Theorem 1. The reason is that there is one node at most in each cell transmitting its data to the aggregated node and distance between any two nodes being scheduled in the same time-slot is at least.
In the second case, aggregated data are transmitted from the aggregated nodes toward the sink along the primary paths or the backbone path. For each group of primary path, if there is one node at most in a primary path to be scheduled, the nodes from the same group can be scheduled simultaneously and successfully according to Theorem 1 because the distance between any two nodes is at least . On the contrary, for each primary path, the nodes are scheduled one by one along the path , starting at and ending at . Thus, we can schedule a group every time-slots because the distance of any two nodes being scheduled in the same time-slot is at least. According to Theorem 1, these nodes can be scheduled simultaneously without transmission interference.
Latency analysis
Theorem 3
The time latency achieved by DAS-MPRS algorithm is at most, where is the maximal number of nodes in a cell and denotes the number of cells at a row/column in the square network area.
Proof
Let be the maximal number of nodes in a cell, it is obvious that there are at most ordinary nodes in a cell. According to DAS-MPRS algorithm, there are different colors to color all cells. The transmissions are interference-free when at most one node from each cell with a monotone color transmits simultaneously. For every cell with the same color, it needs time-slots at most to schedule data from ordinary nodes to aggregated node. Therefore, it will take time-slots at most to schedule all the ordinary nodes.
Next, we divide the primary paths into groups and schedule a group every time-slots according to DAS-MPRS algorithm. That is to say, if the first group is scheduled at time-slots , then the last group can be scheduled at time-slot . In addition, it will take time-slots for the last group to transmit data. Hence, it needs to schedule all the aggregated nodes on the primary paths.
Finally, it will spend time-slots for the supernodes transmitting their data to the sink.
To sum up, the sink needs at most time-slots to aggregate all sensors’ data by DAS-MPRS algorithm.
Performance evaluation
In this section, we evaluate the performance of our algorithm by conducting extensive simulations. Particularly, we compare our algorithm with the algorithm proposed by Xu et al.,17 denoted by Xu’s algorithm. It has the best result for the MLAS problem under the physical interference model with fixed transmission power, as far as our awareness is concerned. In our simulation, the nodes are distributed randomly in a square area of 10,000 m2 (100 m × 100 m) with the number of nodes n = 1000–2000 step by 100. We set ,, and , which is the same settings as Xu et al.17 We implement the two algorithms in MATLAB 2010 and run the programs on a ThinkPad with a 2-core CPU (2.5 GHz) and 2 GB RAM. All our results presented are the average of 100 trials.
We first compare the time expenditures of constructing an aggregation tree with different nodes in the network. The results are presented in Figure 3. Obviously, the time spent by Xu’s algorithm is higher than that of DAS-MPRS algorithm along with the increasing number of nodes. As a matter of fact, constructing an aggregation tree by Xu’s algorithm is divided into three phases, that is, selecting a topology center, constructing a breadth first search (BFS) tree, and finding a CDS. In the first phase, the time complexity of choosing a node as a topology center is if the classical Bellman-Ford algorithm is applied. For the second phase, the time complexity is when it uses BFS algorithm to construct a BFS tree. It also has a time complexity of for finding a CDS. In summary, Xu’s algorithm requires a computational complexity of . However, randomly selecting a node to act as the aggregated node in each cell has a complexity of in DAS-MPRS algorithm. Connecting these aggregated nodes to form an aggregation tree is no more than iteration. So the time complexity of constructing an aggregation tree by DAS-MPRS algorithm is .
The comparison of time expenditures of constructing an aggregation tree.
Next, we measure the aggregation latency of the two algorithms with different combinations of and values. Note that the time latency is defined as the number of time-slots needed to aggregate all required data from sensors to the sink. Since and , we experiment with set to 3, 4, and 5, and to 1, 2, and 4, respectively. The results are presented in Figure 4.
Figure 4 shows that the aggregation latency obtained by Xu’s algorithm and our algorithm is larger with smaller , which represents less path loss of power and thus larger interference from neighbor nodes, and with larger , corresponding to higher SINR requirement. Generally, the aggregation latency is decided mainly by the number of colors and the maximal number of nodes in a cell. The number of colors of Xu’s algorithm is , where , , and (see Xu et al.17 for detailed discussion of Xu’s algorithm), while ours is , where and . It is not difficult to find that smaller and larger values lead to a larger number of colors needed. The more colors required, the more aggregation latencies will be needed. The results showed in Figure 4 illustrate this discovery.
On the contrary, as shown in Figure 4, both of algorithms’ latencies increase as the number of nodes increases under the case that the value of and are fixed. If we fix the value of and , the nodes transmission radius has no change because and . Thus, the value of in DAS-MPRS algorithm and the network radius in Xu’s algorithm have no change or little change as the number of nodes increases. So the variation of latency generated by these algorithms is influenced mainly by the networks’ density. That is to say, as the number of nodes increases, the network node’s degree also increases. Thus, the time latency required by the two algorithms raises very obviously. During the data scheduling, we indicate that the node’s degree formed by Xu’s algorithm is larger than that of DAS-MPRS algorithm. So Figure 4 shows that time latency required by DAS-MPRS algorithm is lower than Xu’s algorithm.
Figure 5 demonstrates comparison results when we set the number of nodes . Note that the nodes transmission radius changes according to the value of . When increases, the value of and the network radius R decrease, and the latency generated by the two algorithms decreases. When reaches a critical value, both algorithms can obtain the best performance. As continues to increase, the performance of both algorithms becomes worse and worse. On one hand, the value of and the network radius will decline apparently, but the degree of nodes will grow greatly. So the time-slots will be increased accordingly. On the other hand, when increases to some degree, only a few communication links can be scheduled simultaneously.
The comparison of aggregation latency when the value of varies.
The DAS-MPRS algorithm has better performance than Xu’s algorithm in any case; nevertheless, these results are achieved under the assumption that every cell must contain at least one node. This is a serious drawback of the DAS-MPRS algorithm. For instance, the algorithm fails if a cell in the network is empty.
Conclusion
In this article, we study the MLAS problem under the physical interference model in wireless sensors networks and propose a simple data aggregation scheduling algorithm with the upper latency bound of , whose performance is better than that of the existing algorithms under the assumption that every cell must contain at least a node. The main difference from the existing algorithms is that it constructs an aggregation tree using multi-path routing structures rather than CDSs. Compared with the existing methods, it creates rapidly an aggregation tree and uses low latency to aggregate data from all nodes to the sink. However, some interesting questions are left for future research. The first one is to extend the proposed algorithms to deal with a more general path-loss model. The second one is to design an effective data aggregation method that has the asymptotically optimum performance guarantee under the physical interference model with power control.
Footnotes
Handling Editor: Suat Ozdemir
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is supported by Social Science Foundation of Hunan Province, China (No. 16YBA050) and Science Research Project of Department Education of Hunan Province, China (No. 2016C0270).
References
1.
ChenHMinenoHMizunoT. A meta-data-based data aggregation scheme in clustering wireless sensor networks. In: Proceedings of the 2006 7th IEEE international conference on mobile data management, Nara, Japan, 10–12 May 2006, p.154. New York: IEEE.
2.
HuFMayCCaoX. Data aggregation in distributed sensor networks: towards an adaptive timing control. In: Proceedings of the 2006 3rd IEEE international conference on information technology: new generations, Las Vegas, NV, 10–12 April 2006, pp.256–261. New York: IEEE.
3.
KrishnamachariBEstrinDWickerS. The impact of data aggregation in wireless sensor networks. In: Proceedings of the 22nd international conference on distributed computing systems workshops, Vienna, 2–5 July 2002, pp.575–578. New York: IEEE.
4.
LiYChenCSSongYQet al. Real-time QoS support in wireless sensor networks: a survey. IFAC Proc Volume2007; 40(22): 373–380.
5.
ChenXHuXZhuJ. Minimum data aggregation time problem in wireless sensor networks. In: JiaXWuJHeY (eds) Mobile ad-hoc and sensor networks (MSN 2005), vol. 3794 (Lecture notes in computer science). Berlin; Heidelberg: Springer, 2005, pp.133–142.
6.
ZhuJHuX. Improved algorithm for minimum data aggregation time problem in wireless sensor networks. J Syst Sci Complex2008; 21(4): 626–636.
7.
HuangSCWanPJVuCTet al. Nearly constant approximation for data aggregation scheduling in wireless sensor networks. In: Proceedings of the 26th IEEE international conference on computer communications (INFOCOM 2007), Anchorage, AK, 6–12 May 2007, pp.366–372. New York: IEEE.
8.
YuBLiJLiY. Distributed data aggregation scheduling in wireless sensor networks. In: Proceedings of IEEE international conference on computer communications (INFOCOM 2009), Rio de Janeiro, Brazil, 19–25 April 2009, pp.2159–2167. New York: IEEE.
9.
WanPJHuangSCHWangLet al. Minimum-latency aggregation scheduling in multihop wireless networks. In: Proceedings of the 10th ACM international symposium on mobile ad hoc networking and computing (MobiHoc 2009), New Orleans, LA, 18–21 May 2009, pp.185–193. New York: ACM.
10.
RenMGuoLLiJ. A new scheduling algorithm for reducing data aggregation latency in wireless sensor networks. Int J Comm Netw Syst Sci2010; 3(8): 679–688.
11.
XuXHLiXYMaoXFet al. A delay-efficient algorithm for data aggregation in multihop wireless sensor networks. IEEE T Parall Distr2011; 22(1): 163–175.
12.
NguyenTDZalyubovskiyVChooH. Efficient time latency of data aggregation based on neighboring dominators in WSNs. In: Proceedings of the 2011 IEEE global telecommunications conference (GLOBECOM 2011), Kathmandu, Nepal, 5–9 December 2011, pp.1–6. New York: IEEE.
GuptaPKumarPR. The capacity of wireless networks. IEEE T Inform Theory2000; 46(2): 388–404.
15.
LiXYXuXHWangSGet al. Efficient data aggregation in multi-hop wireless sensor networks under physical interference model. In: Proceedings of the IEEE 6th international conference on mobile ad-hoc and sensor systems (MASS 2009), Macau (S.A.R.), China, 12–15 October 2009, pp.353–362. New York: IEEE.
16.
XuXHLouWLiuXet al. Delay efficient link and aggregation scheduling under physical interference model. In: Proceedings of the IEEE 8th international conference on mobile ad-hoc and sensor systems (MASS 2011), Valencia, 17–22 October 2011, pp.421–429. New York: IEEE.
17.
XuXLiXYSongM. Efficient aggregation scheduling in multihop wireless sensor networks with SINR constraints. IEEE T Mobile Comput2013; 12(12): 2518–2528.
18.
AnMKLamNXHuynhDTet al. Minimum latency data aggregation in the physical interference model. Comput Commun2012; 35(18): 2175–2186.
19.
LamNXTranTAnMKet al. A note on the complexity of minimum latency data aggregation scheduling with uniform power in physical interference model. Theor Comput Sci2015; 569: 70–73.
20.
WangBBarasSJ. Minimizing aggregation latency under the physical interference model in wireless sensor networks. In: Proceedings of the IEEE 3rd international conference on smart grid communications (SmartGridComm, 2012), Tainan, Taiwan, 5–8 November 2012, pp.19–24. New York: IEEE.
21.
LamNXAnMKHuynhDTet al. Scheduling problems in interference-aware wireless sensor networks. In: Proceedings of the 2013 IEEE international conference on computing networking and communications, San Diego, CA, 28–31 January 2013, pp.783–789. New York: IEEE.
22.
LiHWuCHuaQSet al. Latency-minimizing data aggregation in wireless sensor networks under physical interference model. Ad Hoc Netw2014; 12(1): 52–68.
23.
MoscibrodaTWattenhoferRZurichEet al. Protocol design beyond graph-based models. In: Proceedings of the ACM workshop on hot topics in networks (HotNets-V, 2006), Irvine, CA, 29–30 November 2006, pp.25–30. New York: ACM.