
Abstract
Localization is one of the key concepts in wireless sensor networks. Different techniques and measures to calculate the location of unknown nodes were introduced in recent past. But the issue of nodes’ mobility requires more attention. The algorithms introduced earlier to support mobility lack the utilization of the anchor nodes’ privileges. Therefore, in this article, an improved DV-Hop localization algorithm is introduced that supports the mobility of anchor nodes as well as unknown nodes. Coordination of anchor nodes creates a minimum connected dominating set that works as a backbone in the proposed algorithm. The focus of the research paper is to locate unknown nodes with the help of anchor nodes by utilizing the network resources efficiently. The simulated results in network simulator-2 and the statistical analysis of the data provide a clear impression that our novel algorithm improves the error rate and the time consumption.
Introduction
Wireless sensor networks (WSNs) have been used in various applications including habitat monitoring, target tracking, disaster management. The advancement in micro electro mechanical systems (MEMS) technology has extended the use of WSNs to a wider zone due to the compactness of nodes. Localization is one of the fields that demands the attention of the research community. The distribution of sensor nodes over wide areas poses challenges in tracking the location of sensor nodes. The computation process of localization should consume the least amount of time, resources and enable accurate location estimation. Inclusion of global positioning system (GPS) modules may not be an obvious solution as there will be a line of sight problem. Using the previously known locations of anchor nodes, the unknown nodes are localized. Basically, there are two approaches for localization: (a) range based and (b) range free. 1 In range-based approach, certain inbuilt hardware devices like GPS are included in sensor nodes. This helps sensor nodes to receive location information. Additional hardware may also be used to apply the techniques like angle of arrival (AoA), time of arrival (ToA), time difference of arrival (TDoA), and so on. On the other hand, in range free approach, the nodes generate the location information taking the required data from their neighbor nodes. Although there are various range-free algorithms for localization of nodes, researchers have preferred DV-Hop algorithm over others due to its simplicity.
DV-Hop localization
The American D Niculescu and B Nath 2 had proposed the DV-Hop localization algorithm using the distance vector routing protocol and GPS. The basic idea of the algorithm is to calculate the distance between the unknown nodes and the anchor nodes from the product of hop distance and the average number of hops. The positions of unknown nodes are calculated using trilateration method. The DV-Hop algorithm follows three stages:
In the first stage, anchor nodes broadcast their information to their neighboring nodes using distance vector exchange agreement. Anchor nodes contain the information (idi, hi, xi, yi) where idi refers to the serial number of the anchor nodes, hi refers to the current hop count initialized to zero, and (xi, yi) refers to the current anchor node azimuth coordinate information.
The second stage uses the following formula to estimate average distance for one hop and is given by

where (Xi, Yi) (Xj, Yj) are the coordinates of the beacon node A and beacon node B, hi is the hop count between A and B. Then the calculated hop size is broadcast to the network. Although there are many beacon nodes in the network, the unknown node accepts the average value of the hop size.
The third stage uses the trilateration method for measuring the distance between unknown nodes and beacon nodes. The equation used in this stage is as follows

where N is the number of anchor nodes and we can write N of such equations. (xi, yi) for [i = 1, 2,…, N] denotes beacon node i’s coordinate information, diu is the distance from unknown node U to the beacon node i. The above equation for i = 1, 2,…, N can be transformed into the AX = b form where
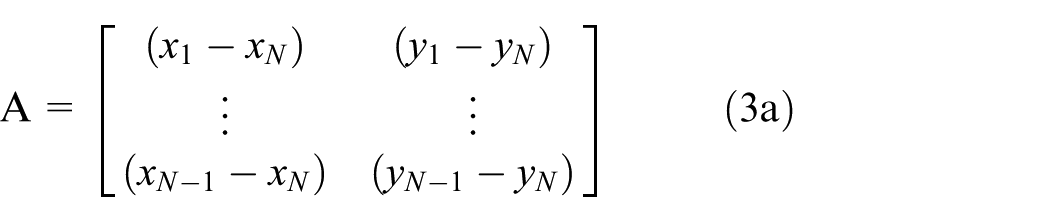


Equation AX = b is solved by least-square method to get the value of x, that is, x = (ATA)−1ATb.
Related work
DV-Hop localization has been considered as one of the primarily used localization algorithms in WSNs. Many researchers have worked on this algorithm to improve its efficiency in terms of complexity and its location accuracy. In the most recent research work, 3 the authors have introduced a hybrid three-dimensional node localization algorithm called DV-Hop-AC-PSO. The algorithm combines the advantages of DV-Hop, ant colony, and particle swarm algorithm. In the proposed algorithm, particle swarm has been adopted to optimize the parameters of the ant colony algorithm, and DV-Hop algorithm is used in the iterative process of ant colony algorithm to improve the localization accuracy. The algorithm lacks behind with higher complexity and dependency of other supportive algorithms.
An improved DV-Hop algorithm 4 has been introduced that uses the weighted average hop distances of anchor nodes with a defined threshold. Weights are calculated to get the average weighted correction factor for the estimation of unknown nodes’ locations. Similarly, a threshold-based improved DV-Hop algorithm has been shown by the researchers in Qian et al. 5 In this approach, each unknown node initially determines a threshold for selecting the information received. This approach also achieves a minimum error by choosing the optimal number of anchor nodes for location calculation. Other weighted average hop distance based algorithms are also used in Yingjie et al. 6 and Pan and Liu. 7
An energy efficient algorithm extended from DV-Hop has been shown in Kumar and Lobiyal. 8 The anchor nodes communicate only one time with the unknown nodes to inform about the coordinates of the anchor nodes. Calculating of hop size at unknown nodes reduces the communication overhead between anchor nodes and unknown nodes. This results in minimization of the energy consumption. In Kumar and Lobiyal, 9 the error reduction method has been shown by the authors. The advanced DV-Hop algorithm uses the effective aspects of the parameters. Using the effective distance, estimated locations of unknown nodes are calculated by two-dimensional (2D) hyperbolic location algorithm. The covariance matrix of range estimation error is used as weight matrix for location error improvement. The authors in El Assaf et al. 10 have derived a mechanism to reduce error further. The authors have computed mean hope size at each unaware node which limits the broadcasting of control messages by the anchor nodes. Another improvement on DV-Hop algorithm has been suggested in Chen and Zhang. 11 The improvement in locating performance has been done by modifying and weighting the average hop distance between anchor nodes. The particle swarm optimization is used to get the accurate location of the unknown nodes. These weighted methods are efficient in reducing location error but are not validated for a mobile sensor network.
An improved DV-Hop has been introduced in Yu and Li. 12 The calculated error is added to the distance between the anchor nodes and the unknown nodes. A similar approach has been shown in another research in Zhang et al. 13 It includes the maximum and the minimum values of hop counts to calculate the location error and also use the error in the correction method. A novel localization algorithm called VAH-DV-Hop has been introduced in Liu et al. 14 The algorithm uses angle method to reduce the negative factors which are caused by routing void and finally, trilateration method is used for the location estimation.
Some researchers have suggested the localization estimation responsibility of anchor nodes in neighbors’ proximity. The same has been researched in Li 15 with different average hop values. This approach is static and does not confirm the dynamic scenario in the network. The research work in Dai et al. 16 shows an improvement in DV-Hop with three modifications. First, the secondary reference node is located by three anchor nodes using trilateration or centroid method. Second, modification depends on the node of the last hop, and finally, it uses the Max–Min method.
Various research have been done to check the effect of localization in presence of mobile anchor nodes. The research work in Guerrero et al. 17 has shown azimuthally defined area localization (ADAL). This algorithm utilizes the anchor nodes with mobility. The concept of azimuth and rotary directional antenna has been used for the purpose. The unknown nodes use the centroid mechanism to estimate their location. Though the approach supports mobility but needs specific hardware as a rotary directional antennas. Localization with a mobile anchor node based on trilateration (LMAT) is proposed in Han et al. 18 The algorithm uses mobile nodes that move along the trilateration trajectory.
A recent work in Han et al. 19 has introduced a mobile anchor based localization algorithm called as mobile anchor assisted localization algorithm based on regular hexagon (MAALRH). This algorithm is based on regular hexagonal in 2D WSNs. This algorithm does not perform effectively when nodes are randomly deployed. In the paper, 20 the authors describe a localization algorithm called mobile anchor centroid localization (MACL) that uses a single mobile anchor. The localization method is based on radio frequency and therefore, extra hardware cost is not required. The single mobile anchor node does not support complete mobile environment and will be more resource exhaustive if the number of unknown nodes increases. In the work, 21 Minimum Connected Dominating Set (MCDS) using dominating set has been introduced. The algorithm consists of three phases. The first phase deals with the searching for a dominating set, the second phase identifies the connectors, and the final phase prunes the generated connected dominating set to get the MCDS. Deactivation of nodes due to power constraint is also taken into consideration for this algorithm with repairing process.
All these improvements in DV-Hop work efficiently to localize an unknown node with better precision, but the drawback occurs when both anchor nodes and unknown nodes are mobile. This issue has been addressed in the previous work,22,23 but it requires rigorous research with the random deployment of the nodes. Therefore, we have developed an algorithm to address these problems of location estimation in the presence of mobile anchors and mobile unknown nodes.
Proposed algorithm
We know that in WSNs, anchor nodes are more privileged in the term of resources and communication as compared to unknown nodes. Thus, utilization of the anchor nodes in an efficient way is the prime goal of our research. In the proposed algorithm, we have considered the unknown nodes in the one-hop neighborhood of each anchor node. Among all the anchor nodes in the set, we have selected only those anchor nodes which are having the maximum degree of connection with one-hop distanced unknown nodes. Such anchor nodes have created the dominating set of anchors. This dominating set acts as the backbone of the network to localize the unknown nodes. Finally, pruning is also used to minimize the size of the backbone consisting of dominating anchor nodes and to avoid redundancy. For example, consider Figure 1.

Topology and aerial distances among anchor nodes and unknown nodes.
The black color nodes numbered from 1 to 5 are the anchor nodes. All the gray color nodes are the unknown nodes in the network. The maximum degree of connectivity will be calculated for each of the anchor nodes depending upon two considerations: range and one-hop neighbors. If two anchor nodes are having the same degree of connection, one anchor node among them will be randomly chosen for the dominating set at a particular iteration. Considering our algorithm for the above example, let us suppose the anchor node numbered 2 has the maximum degree of connectivity with the unknown nodes as it has six neighbors in its range. Therefore, in the first iteration, anchor node numbered 2 is in the dominating set. Similarly, anchor nodes numbered 1 and 3 also become members of that set. These anchor nodes (1, 2, and 3) are covering all the unknown nodes in their vicinity. Therefore, there is no need of adding anchor node 4 and anchor node 5 in the dominating set. This dominating set is connected and it contains the minimum number of nodes, three (minimum requirement for trilateration) out of five anchor nodes to cover up all the unknown nodes and therefore, it is considered as MCDS.
Backbone generation with anchor nodes
A set of anchor nodes A and a set of unknown nodes U have been initialized. An empty dominating set D is initialized to
Generating backbone with anchor nodes.

Calculation of maximum degree in anchor set
The calculation of maximum degree in the set of anchor nodes has been proposed in Algorithm 2. The anchor node set A is given as input for this algorithm. For each of the anchor nodes in the set A, its degree is initialized to 0. The connection status with unknown nodes is checked for each of the anchor nodes in the network. If the connection status is true, the degree of the corresponding anchor node is increased by 1. Thus, once all the degrees of all the anchor nodes are received, the maximum degree is calculated and the anchor node with the highest degree is processed.
Calculation of maximum degree from anchor set.

The function of computing connection status between the anchor and unknown node and the calculation of maximum degree are discussed below.
Determining the connection status
The process of checking the connection status between an anchor node and an unknown node is summarized in Algorithm 3. Each anchor node broadcasts a ReQest Neighbour Set (RQNS) packet, which consists the source address (SrcAddr), leash count variable (Leash_C), the sequence number of the request packet (I_SEQ), and acceptance status (Accept_S). The variable Leash_C is used to control hop count to 1 and therefore initialized to 1. Accept_S is initialized to 0. On receiving RQNS, each unknown node, who is in one-hop neighborhood of anchor node, replies with RePly Neighbourhood Set (RPNS): {SrcAddr, Leash_C = 0, I_SEQ, Accept_S = 1, U_Addr}. U_Addr is the address of the unknown node from where the RPNS is coming to the corresponding anchor node. After receiving the RPNS, the anchor node checks the values of Accept_S and Leash_C. If Accept_S = 1 and Leash_C = 0, then the anchor node enlists the corresponding U_Addr as its one-hop neighbor.
Checking connection status between anchor node and unknown node.

Function returning index of anchor node having maximum degree
An array consisting of the degrees of all anchor nodes has been taken as input to calculate the maximum degree. The first anchor node’s degree is initialized to be the maximum and then compared with rest of all anchor nodes’ degrees. Finally, the index of the node having a maximum degree is returned to Algorithm 1. The method is shown in Algorithm 4.
Calculate maximum (deg[A]).

Pruning process
It may happen that single unknown node is a neighbor of more than one anchor node. Pruning method is used to avoid redundancy of nodes so that the dominating set D is composed of the minimum number of anchor nodes. The method is shown in Algorithm 5. It returns the MCDS which acts as the backbone to locate the unknown nodes.
Pruning of dominating set D.

Network model
The sensor network is modeled using a graph G = (V, E) where V represents the nodes (both the anchor and unknown nodes) and E represents the connectivity set. Considering a as anchor node, u as an unknown node and a, u ∈ V, (a, u) ∈ E iff a and u are within one-hop neighborhood transmission range. The dominating set of graph G is
The features of the nodes and the overall network take part to create a significant effect on the efficiency of localization. We have considered such features as design parameters of our proposed localization algorithm including connectivity, transmission range, and local stability. Each of these metrics has its own priority depending on the service or application. Parametric weights are therefore needed to be included with those design parameters.
Node degree
Each anchor node computes its degree of connectivity with its neighbor nodes as defined in Algorithm 3. The degree of an anchor node a is the total number of unknown nodes within its one-hop distance and is computed as

where Dega is the total degree of an anchor node,
Transmission range
The transmission range Tr of an anchor node is dependable on the application scenario. 24 As network scenario is considered to be dynamic, transmission range varies within the interval of minimum range Trmin and maximum range Trmax. The transmission range Tr is therefore given by

where Random (0, 1) generates a randomized number between 0 and 1.
In our experimentation, we have used three variable scenarios for anchor nodes with minimum and maximum transmission range as (20, 40), (30, 50), and (40, 60), respectively. The transmission range of the unknown nodes is fixed at 35.
Mobility
To compute the mobility, each anchor node in the dominating set requires to calculate the distance from its neighboring unknown nodes. For this purpose, Friis free space propagation model 25 is used. The received power Pr is computed as

where Pr is the power received by the receiving antenna of the anchor node, Pt is the power input to the transmitting antenna, Gt and Gr are the transmitting gain and receiving gain, respectively,
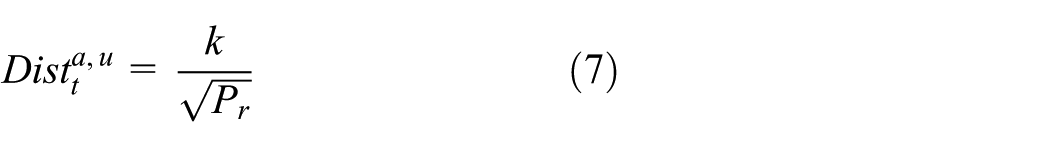
where k is constant and
Relative mobility in the network indicates whether any two nodes are coming closer to or moving away from each other. The relative mobility of an unknown node u with respect to anchor node a at a given time t is given by


where

Implementation and results
In the simulation process, we have considered the number of nodes as 25, 50, 75, and 100, respectively. We have compared our proposed approach and he original DV-Hop algorithm in Figure 2. We have used variable transmission range. The results show the number of anchor nodes required in the backbone for localization process of the unknown nodes. The DV-Hop algorithm and proposed algorithm have been compared on this aspect. Through results, we can observe that proposed algorithm generates a better result, that is, less number of anchor nodes are able to localize all the unknown nodes. The simulation data of proposed algorithm have been statistically analyzed.

Localization of unknown nodes with different transmission ranges.
Simulation-based results
The localization error is inexorable in evaluations. We have considered two metrics to calculate the localization error. The metrics can be described as follows.
Average localization error
It is defined as the ratio of the difference between estimated location and the actual location of all the nodes

Root mean square error
It is defined as the mean square root of squared differences of estimated location and the actual location
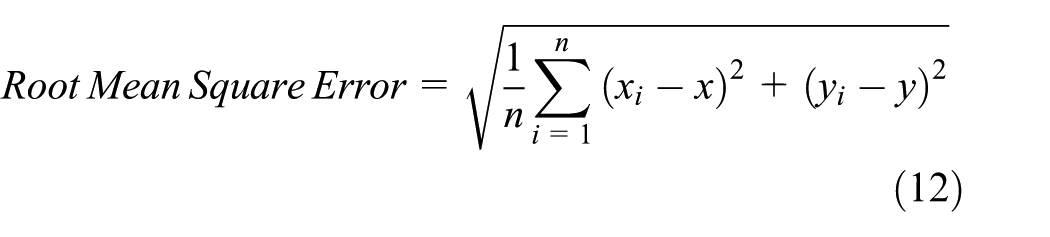
where (x, y) are actual locations, (xi, yi) are estimated locations, and n denotes the number of unknown nodes. The average localization error for different transmission range with variable anchor and unknown nodes has been shown in Table 1. The table also shows the comparison of the average localization error percentage with the algorithm described in Di Franco et al. 22
Average error percentage for different transmission ranges with variable number of unknown nodes.

Statistical analysis of error improvement
The objective of the statistical analysis is to check whether our introduced algorithm is providing an error improvement over the DV-Hop algorithm or not. To examine this, we have set our hypothesis as per the following:
H0: There is no improvement of localization error in our algorithm as compared to the DV-Hop algorithm.
H1: There is a significant improvement of localization error in our algorithm as compared to the DV-Hop algorithm.
To test the above hypothesis, the NS2 simulated data are processed for paired T-test with 0.05 of significance level. We have executed the paired T-test on the average localization error and root mean square error of DV-Hop algorithm and the proposed algorithm. The application of paired T-test has provided the following results shown in Table 2.
Paired T-test results for proposed algorithm and DV-Hop algorithm.

In the above results of paired T-test, it is observed that all the p-values (sig. two-tailed) are <0.05 of significance level. Therefore, the null hypothesis H0 has been rejected and the alternate hypothesis H1 has been accepted. It means that there is a significant improvement using the proposed algorithm over DV-Hop algorithm with respect to average localization error and root mean square error for location estimation. Similarly, the above test is also applied to the algorithm shown in Di Franco et al. 22 and in comparison with our algorithm. We have found the following result shown in Table 3:
H0: There is no improvement of localization error in our algorithm as compared to the algorithm shown in Di Franco et al. 22
H1: There is a significant improvement of localization error in our algorithm as compared to the algorithm in Di Franco et al. 22
Paired T-test results for proposed algorithm and algorithm shown in Di Franco et al. 22

The above result describes that as all the p-values are 0 which is <0.05, it signifies that H0 is rejected and H1 has been accepted. It means that there is a significant improvement of error using the proposed algorithm as compared to the algorithm shown in Di Franco et al. 22
Statistical analysis of time consumption
Considering the scenarios of 25, 50, and 75 nodes, the standard error of the differences between the time consumption of DV-Hop algorithm and the time consumption of proposed algorithm is 0 and therefore, a p-value cannot be computed. It means that the time for localization is neither degraded nor upgraded using the proposed algorithm. But it is noticed in the results of 100 nodes given in Table 4 that the p-value is 0 which is <.05 of significance level. It means that the algorithm is also providing an improvement in time consumption of localization. Similarly, the comparison between the proposed work and the algorithm 22 has also been done in Table 5. All the p-values are significance level of <.05; therefore, it clearly shows that the proposed work has provided a significant improvement in time consumption over the algorithm in comparison.
Paired T-test results for time consumption between proposed algorithm and DV-Hop.

Paired T-test results for time consumption between proposed algorithm and algorithm shown in Di Franco et al. 22

Conclusion
In this article, an algorithm for localization in a WSN by effectively utilizing anchor nodes is proposed. The algorithm uses the concept of MCDS with anchor nodes, which can cover all the unknown nodes for location estimation. The mobility factor for both the anchor nodes and unknown nodes is considered for the algorithm which can be used for wide range of applications. Simulation results show the efficiency of the proposed algorithm that achieves approximately 92.37% accuracy level of estimated location of unknown nodes along with the random mobility. In future, we shall try to optimize the backbone for considering the energy consumption.
Footnotes
Handling Editor: Salvatore Serrano
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.