
Abstract
Similarity search in high-dimensional space has become increasingly important in many wireless sensor network applications. However, existing approaches to similarity search is based on the premise that sensed data are centralized to deal with, or sensed data are simple enough to be stored in a relational database. Different from the previous work, we propose a distributed approximate similarity search algorithm to retrieve similar high-dimensional sensed data for query in wireless sensor networks. First, the sensors are divided into several clusters using the distributed clustering method. Furthermore, the sink transmits the compressed hash code set to the cluster heads. Finally, the estimated similarity score is compared with a specified threshold to filter out irrelevant sensed data. Therefore, the higher search precision and energy efficiency can be achieved. Extensive simulation results show that the proposed algorithms provide significant performance gains in terms of precision and energy efficiency compared with the existing algorithms.
Introduction
With the rapid development of the Internet, wireless networks, and sensor technologies, there is an emerging attention in leveraging massive amounts of data available in distributed data source such as wireless sensor networks (WSNs). Processing of large volumes of data is a key challenge for the further WSN applications. 1 Furthermore, the growth of smart devices and WSN applications make sensed data diversified, and a large number of features extracted to represent the sensed data are also very high. 2 Hence, similarity search in high-dimensional space has become the hot research topic in WSN. For example, sensors equipped with visual information collection modules are capable of sensing and storing images. Then, users query the WSN to see which sensors store the images that are similar to “target images,” so the location of the event can be detected.
Over the past decade, many techniques have been proposed for similarity search (also known as nearest neighbor search). For instance, tree-based methods3,4 have been developed to address the fast approximate nearest neighbor search problem. However, almost all tree-based methods suffer from the dimensionality issue with their performance typically degrading to exhaustive linear scan, that is, when the dimensionality exceeds about 10, existing indexing data structures based on space partitioning are slower than the linear-scan approach.
Current studies on high-dimensional similarity search focus on the locality sensitive hashing (LSH) method.5,6 The principle of LSH is to hash similar data items into the same hash code with a high probability by random projections, and multiple hash tables are constructed independently to enlarge the probability. Due to the randomized hashing, the LSH methods suffer from long hash codes and a large number of hash tables. Some improved methods are proposed to overcome the drawback of basic LSH methods, and these methods can be divided into two categories, the data-dependent hashing method 7 and the data-independent LSH method. 8 Although these hashing methods have shown success in high-dimensional similarity search, these approaches are based on centralized architecture. How to optimize the similarity search in a distributed environment is rarely taken into account. In Haghani et al., 9 the authors tried to distribute the LSH-based methods in peer-to-peer (P2P) overlay networks.
However, the similarity search in WSNs has some unique characteristics: (1) the sensed data of the nodes are prone to value fluctuations due to the hardware-cost constraint and outer interference; (2) the centralized hash tables must be avoided to reduce the communication overhead; and (3) each node is aware of its location and sensed data, but has no global knowledge of the WSN. Considering the distributed nature of WSNs, how to acquire feasible solutions to the high-dimensional similarity search in large-scale WSNs is still an open problem.
To this end, we propose a distributed similarity search approach for retrieving the similar high-dimensional sensed data in WSNs. The contributions of this work are summarized as follows:
We propose a distributed LSH-based model via computing the similarity score in the cluster head of WSN, instead of probing hash codes in multiple centralized hash tables. So, energy efficiency and high search accuracy can be achieved.
We propose a distributed approximate similarity search (DASS) algorithm to retrieve the similar high-dimensional sensed data for query in WSNs. More explicitly, the sensors are divided into several clusters using the distributed clustering method, the sink transmits the compressed hash code set to the cluster head, and the similarity score is estimated in a distributed manner.
We propose an effective method to calculate the similarity score to reflect the degree of similarity between the sensed data with the query. Furthermore, the similarity score is compared with the threshold to filter out irrelevant sensed data, resulting in higher similarity search precision and lower energy consumption.
Note that the important aspect of our study design also includes how to use the large image datasets to simulate the large-scale WSN scenario. The idea of our study design is described in detail in the “Simulation” section.
The rest of the article is structured as follows. Section “Related work” reviews the related work. Section “Introduction of basic LSH method and multi-probe LSH method” gives a brief introduction of LSH-based similarity search methods. The details of our algorithms are presented in section “DASS approach.” Performance evaluation results are given in section “Simulation.” Section “Conclusion” concludes the article.
Related work
Similarity search in WSN
Early works of similarity search in WSN focus on database-oriented approach, 10 and a WSN database should provide functions for querying sensed data. Furthermore, in Cheng et al., 11 a distributed database management on WSNs is proposed in an energy-efficient manner. Two Hilbert curve–based approaches12,13 are proposed to tackle the problem of similarity search due to the locality-preserving property of the Hilbert curve. Recently, some studies have turned to the distributed top-k query and range query processing.14,15 In Ye et al., 16 the notion of sufficient set and necessary set is introduced for processing probabilistic top-k in a sensor network with tree topology. At the same time, considering the characteristics of WSN, a distributed spatial–temporal similarity data storage scheme 17 is provided, and a framework 18 is proposed to accelerate query evaluation in content-caching networks using XML metadata.
The methods mentioned above always need to utilize the information of network topologies. Furthermore, the sensed data are always organized as the traditional database. Hence, with the growth of smart devices and applications, these methods are not suitable for high-dimensional similarity search in WSN.
Hashing-based methods
Recently, some methods have been proposed to improve LSH in many aspects. These methods can be divided into two categories, the data-dependent hashing methods and the data-independent hashing methods.
A representative method in the data-dependent hashing methods is spectral hashing (SH), 7 which can produce very compact hash codes by nonlinear functions along the principal directions of the data. However, the assumption of uniform data distribution cannot be applied into practical situation. Furthermore, a variety of data-dependent methods are proposed, including principal component analysis (PCA)-based hashing,19,20 graph-based hashing, 21 semi-supervised hashing, 19 and locally linear hashing. 22 Among these methods, the data distribution and the underlying manifold structure of data are captured to improve the similarity search. Although the above supervised or semi-supervised methods can project high-dimensional data items into more compact codes, they still need to cost much time and energy on training data process, which is difficult to implement in a large-scale WSN.
Among the data-independent hashing methods, random projection has been used widely for designing data-independent hashing techniques. Although these methods have strict performance guarantee, they are less efficient since the hashing functions are not specifically designed for a certain data set. Based on randomized projection, there still have been several efforts to improve the performance of LSH. Multi-probe LSH methods 8 are proposed to extend the candidate set using similar hash codes to reduce the number of hash tables. Furthermore, the query-adaptive method 23 is proposed to generate optimal probe sequence of hash codes, and posteriori multi-probe LSH 24 puts forward a more reliable posteriori model based on some prior knowledge, which helps to accurately select the hash codes to be probed. In Gu et al., 25 a novel probability model and a query-adaptive algorithm are proposed to generate the optimal multi-probe sequence for range queries. At the same time, Bayes’ LSH 26 is presented to perform candidate pruning and similarity estimation using the principle Bayesian approach.
The above approaches to the similarity search problem focus on centralized settings. Considering the distributed nature of WSNs, it is necessary to find an efficient solution to perform high-dimensional similarity search in a distributed manner.
Introduction of basic LSH method and multi-probe LSH method
LSH is an effective approximate similarity search method in centralized system. The main idea of basic LSH is to map similar objects into same hash codes with high probability using LSH functions. A family of LSH functions
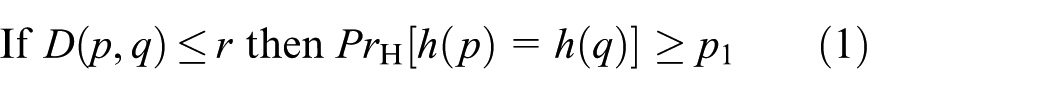

where

where

where

Illustrative examples on the relationship of a hash projection and hash functions.
In practice, the basic LSH method suffers from long hash codes, which requires large
A multi-probe LSH method
8
is proposed to extend candidate set whose data items have similar hash codes of the query item
Given a query item

Illustrative examples on the ideal of the multi-probe LSH methods.
Moreover, two methods of the multi-probe LSH were proposed, which can be summarized as follows:
Step-wise probing (SWP).
8
This method is based on the fact that the data items whose hash codes have fewer hash values different from
Query-directed probing (QDP).
26
In the SWP method, the effect of the hash value position of
Although the multi-probe LSH methods can obtain relatively higher recall rate with fewer hash tables, these approaches are still based on centralized architecture and cannot be used directly in WSN.
DASS approach
As described above, although the LSH-based methods can perform high-dimensional similarity search effectively, they suffer from maintaining multiple centralized hash tables, which may incur high communication overhead. At the same time, the data-dependent hash methods (such as graph-based hashing 21 and semi-supervised hashing 19 ) need to cost much time and energy on training data process. Therefore, we propose a DASS approach for retrieving similar high-dimensional sensed data in WSNs.
Similar to the definition of the p-stable LSH function in equation (3), we define the unquantified hash function as

where data item
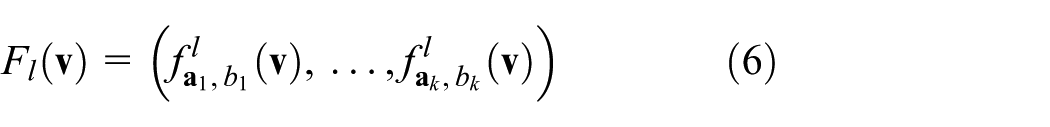
Approximate similarity computation method
Degree of similarity
For a given query item


Probability of similar data item falling into the neighbor intervals.
Note that the interval corresponding to
Hence,

where
As described above, the degree of similarity measured by a pair of hash values is not accurate. In order to overcome the problem, we introduce the concept of the similarity score.
Similarity score
As described above, given a k-dimensional hash code

where

From equations (8) and (9), if the sensed data

Clearly, larger similarity score
Form the definition in equation (10), we need to generate the hash code set

Therefore, when the cluster head receives the unquantified hash code set
Implementation of the DASS algorithm
Based on above analysis, the process of the DASS approach can be described as follows. First, the distributed clustering algorithm
27
is implemented to divide the sensors into several clusters, and cluster head is selected according to the residual energy of each node. Second, the sink node is responsible for projecting a given query item
Now, we present the DASS algorithm for retrieving high-dimensional similar sensed data for query in a distributed manner.
Step 1. The WSN is divided into several clusters
Step 2. The sink node
Step 3.
Step 4. For each
Step 5.
Step 6.
Step 7. Set
Step 8. For l = 1 to L do.
Step 9. Compute the similarity score
Step 10.
Step 11. End for.
Step 12. If
Step 13. End for.
Step 14. The sink node
In the DASS algorithm, compressed
The DASS approach has a higher probability of selecting proper nodes whose sensed data meet the similarity search requirement by filtering out irrelevant sensed data. Furthermore, the calculation of the similarity score has a low computational complexity, and there is no need of maintaining multiple hash tables. Therefore, energy efficiency and high search accuracy can be achieved.
Simulation
In this section, we compare the performance of DASS with existing hashing-based similarity search methods, and we implement various algorithms using MATLAB on a DELL server with Intel 8 core CPU 3.5 GHz and 64 GB RAM. First, the data-dependent hashing methods (such as SH, 7 graph-based hashing, 21 and semi-supervised hashing 19 ) need to cost much time and energy on training data procedure. As we know, it is difficult to train the sensed data over the large-scale WSN to get compact hash codes due to the high communication overhead. Hence, the data-dependent hashing methods are not appropriate for comparison in the simulation. However, the multi-probe LSH methods can obtain relatively higher recall rate with fewer hash tables. We can extend multi-probe LSH to a distributed setting. More specifically, the cluster head evaluates the similarity between the sensed data with the query by comparing the difference between their hash codes. Finally, we repeat each experiment 10 times and report the results based on the average over the 10 runs.
On this basis, we mainly use recall, precision, query ratio, and response ratio to evaluate the high-dimensional similarity search performance. In this article, the following methods are compared:
Data source in WSN
The simulation scenario based on wireless multimedia sensor networks is designed to testify the performance gain. More specifically, the simulation was conducted in a WSN with 269,648 sensor nodes, where a sensed data of each node is represented by a 500-dimensional feature vector of each image from the NUS-WIDE dataset. 28 In the simulation, we query the WSN to see which sensors store the images that are similar to “target images.” Note that the routing techniques, radio frequency power, and topology information of WSN are not the topic of this article.
Performance metrics
We measure the performance of the similarity search algorithm in two aspects: search quality and energy efficiency. For each query item

where
Energy efficiency is measured by query ratio and response ratio. According to equations (3) and (4), we define query ratio and response ratio as follows:

where L is the number of hash code for each query item
Impact of parameters η, k and L
We carry out experiments to test the influence of the threshold η by varying from 0.2 to 0.6. We set k as 12. The results are shown in Figure 4.

Impact of η on (a) recall and (b) precision for different L.
As discussed above, when the similarity score
In Figure 5(a), we set L as 12, from the analysis of equations (9) and (10), the similarity score can be obtained using the negative exponential function, and larger k leads to a lower similarity score. Hence, the recall value corresponding to k from 11 to 14 is in descending order, because the higher hash code dimensions leads to the higher probability of identifying sensed data as irrelevant data. The relationship between precision and k can be analyzed in a similar way in Figure 5(b).
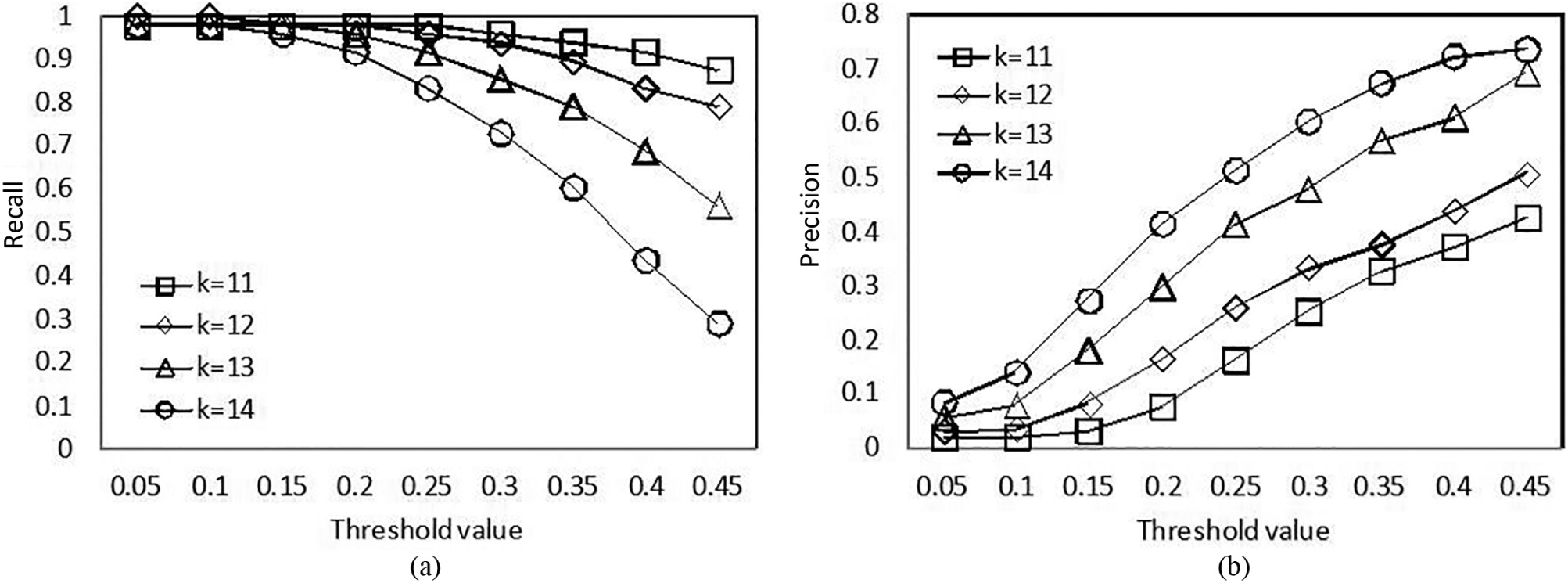
Impact of η on (a) recall and (b) precision for different k.
Performance of DASS in terms of similarity search
In Figure 6(a) and (b), the precision decreases as the recall increases from 0.79 to 0.98, because higher recall leads to more irrelevant sensed data identified as relevant data, which causes the lower precision. Furthermore, the DASS algorithm is non-sensitive to the values of L and k, and can be used in a wide variety of applications.

Precision as a function of recall for different (a) L and (b) k.
Comparison with multi-probe LSH
Finally, we compare the performance of the DASS algorithm with two multi-probe LSH methods, that is, SWP 8 and QDP. 26 Our simulations aim to comprehensively evaluate the performance in terms of precision, query ratio, and response ratio.
Furthermore, in SWP, the non-zero elements’ number of
As described before, higher recall often results in lower precision, which makes energy waste in irrelevant data transmission. Therefore, we set recall as 0.92, 0.96, and 0.98 to evaluate the performance of the algorithms.
Table 1 shows when the value of recall remains fixed, DASS achieves higher precision, smaller response ratio, and query ratio. As defined in equation (13), if query ratio is less than 1, the size of the hash code set is less than the size of the query, that is, smaller query ratio guarantees fewer data transmission. Hence, the proposed algorithms can save the energy consumption compared with the traditional cluster architecture of WSN. Similarly, smaller response ratio guarantees the transmission of fewer query result data. Hence, DASS can meet the energy efficiency requirement of WSN while maintaining high similarity search performance compared to SWP, QDP, and the cluster methods of WSN.
Performance comparisons in terms of precision, response ratio, and query ratio.

LSH: locality sensitive hashing; SWP: step-wise probing; QDP: query-directed probing; DASS: distributed approximate similarity search.
(↑) and (↓) indicate that the larger (smaller) the value, the better the performance; the best results in each evaluation are boldfaced.
As seen in Figure 7, the value of precision decreases with the increase in recall, and the DASS algorithm achieves relatively higher precision than the other two algorithms when recall remains fixed. It can be explained as follows.

Impact of recall on precision for different algorithms.
When we consider the nature of randomized projection in the existing hashing-based algorithms, some irrelevant data items can be selected as relevant data with a certain probability, which often leads to relatively low precision and high communication overhead. While our proposed algorithms take into account multiple hash codes of each data to compute the similarity score, by comparing with the specified threshold, high recall and precision can be obtained in a distributed manner.
Conclusion
Considering the characteristics of WSNs such as high-dimensional sensed data, energy constraint, and distributed architecture, we propose a DASS algorithm to retrieve similar high-dimensional sensed data for query in WSNs. More specifically, each cluster head is responsible for computing the similarity score of each sensed data in its own cluster and comparing the similarity score with a specified threshold to filter out the irrelevant sensed data. Simulation results have demonstrated the effectiveness and superiority of the proposed algorithms in terms of search performance and energy efficiency.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Science Foundation of China (61571233, 61203289, and 61572262), the National Science Foundation of Jiangsu (BK20141427), the key University Science Research Project of Jiangsu Province (14KJA510003), and the National Basic Research Program of China (2011CB302903).