
Abstract
Nowadays, an increasing number of cloud users including both individuals and enterprises store their Internet of things data in cloud for benefits like cost saving. However, the cloud storage service is often regarded to be untrusted due to their loss of direct control over the data. Hence, it is necessary to verify the integrity of their data on cloud storage servers via a third party. In real cloud systems, it is very important to improve the performance of the auditing protocol. Hence, the well-designed and cost-effective auditing protocol is expected to meet with the performance requirement while the data size is very large in real cloud systems. In this article, we also propose an auditing protocol based on pairing-based cryptography, which can reduce the computation cost compared to the state-of-the-art third-party auditing protocol. Moreover, we also study how to determine the number of sectors to achieve the optimal performance of our auditing protocol in a case of the same challenged data. And an equation for computing the optimal number of sectors is proposed to further improve the performance of our auditing protocol. Both the mathematical analysis method and experiment results show that our solution is more efficient.
Keywords
Introduction
Internet of things (IoT) has deep impact on our daily lives. 1 IoT applications can generate a great deal of data, such as heart rate and blood pressure data, water quality, and industrial big data. 2 Nowadays, an increasing number of cloud users including both individuals and enterprises store their IoT data in cloud for benefits like cost saving and ease of data sharing. However, the cloud storage service is often regarded to be untrusted due to their loss of direct control over the data. Because the untrusted cloud storage providers instead delegate managements of the user data, the data on the cloud can be lost due to some possible causes. The disks of the storage servers could be damaged and the maintainer might not successfully restore the lost data. But the cloud storage provider could not inform this error to the affected users. Moreover, cloud storage providers could be dishonest. To recycle the cloud storage space, they could discard the user data that have not been accessed or rarely accessed by the users. Thus, the users must be able to verify periodically the integrity of the data storing in the untrusted cloud storage.
It should be noted that we assume that the verifier cannot use the local copy data when the verifier executes the provable data possession (PDP) protocol. An intuitive way is that the client stores a file to the server and computes a hash value of the file as a metadata stored in the client using a cryptographic hash function, such as MD5 and SHA. Then, the server sends the entire file to the client and the client recalculates a new hash value of the received file and compares the two hash values to verify whether the file is stored correctly in cloud storage. But this way has some critical issues. In real cloud storage system, both the number of files and the data size are very large, it requires a very large amount of bandwidth and time to send these files from the servers to the clients across the network. Hence, traditional integrity checking techniques such as cryptographic hash function cannot meet with the real requirement. That is the first issue. Accordingly, some solutions have used some techniques to solve the first issue, such as RSA-based hash functions3,4 and homomorphic hash functions.5,6
The communication cost can be
To solve the data privacy problem (i.e. the auditor cannot recover the data blocks from the server data proof), these auditing protocols are constructed based on the cryptographic algorithms, such as pairing-based cryptography 8 and homomorphic encryption, 9 to verify the server’s proof while the auditor cannot decrypt and recover the data blocks. To reduce the number of data tags and improve the performance, these auditing protocols also use the data fragment technique to split each data block into sectors, such as Yang and Jia’s 8 solution. But the data fragment technique can increase the computation number of the bilinear pairing of Yang’s auditing protocol, so the computation cost of the algorithm can also increase with the computation number of the bilinear pairing.
Our contributions can be summarized as follows:
We propose an improved secure data storage auditing protocol based on Yang’s solution. Our solution is more efficient than Yang’s using the pre-do the bilinear pairing operation in the user client.
We further improve the performance of our auditing protocol with adjustable parameter of the number of sectors in a case of the same challenged data. The optimal number of sectors can be directly determined by an equation according to the amount of challenged data.
Related work
IoT data can be very important and the vast quantities of data can be keen to be outsourced to cloud. Botta et al. 10 and Díaz et al. 11 have discussed the integration of IoT and cloud computing. In order to guarantee data integrity, integrity verification is always a very important problem on outsourced IoT data. 2 There were many solutions on integrity verification. In some previous solutions, the data owners are responsible for verifying the data integrity of cloud storage. In order to guarantee the justice of data possession, third-party auditing was introduced.12,13 It should meet three requirements (confidentiality, dynamic auditing, and batch auditing).13–15 Recently, several new third-party auditing protocols were proposed to allow the auditor to verify the data integrity on the cloud storage server.8,9,16,17 Wang et al. 9 use homomorphic encryption to solve the data privacy problem. Yang and Jia 8 proposed a new scheme based on pairing-based cryptography to solve the data privacy problem. Both of these two auditing protocols are constructed based on the cryptographic algorithms to verify the server’s proof while the third-party auditor cannot decrypt and recover the data blocks. And Yang and Jia 8 also utilize the data fragment technique to split each data block into sectors to reduce the number of data tags and improve the performance. Yang et al. 18 developed a novel error detection approach based on the scale-free network topology and most of detection operations to support fast detection and locating of errors in big sensor data on cloud. As dynamic data on cloud supporting these operations of insert/delete/modification is a very useful feature, integrity verification should be support dynamic data that allows the data owners update their data on cloud. Liu et al. 19 proposed an auditing scheme with the support both of public auditing and fine-grained updates over variable-sized file blocks instead of a fixed size blocks. Zhang et al. 20 proposed a novel approach based on an upper bound constraint to identify the intermediate data sets which need not be encrypted on cloud and reduce the privacy-preserving cost.
Preliminaries
In this section, we describe the system model and security model for a secure data storage auditing system. More information about the secure data storage auditing can be found in Yang and Jia, 8 Sookhak and colleagues,21,22 and Shin and Kwon. 23
System model
As shown in Figure 1, a secure IoT data Storage auditing system model includes three entities:
Owner who moves their files to the cloud server;
Cloud Server who stores the owner’s data and provides the data access to users;
Auditor who is a third party and responsible for checking the integrity of data stored in the cloud server on behalf of the owner.

System model of the secure data storage auditing system.
A storage auditing protocol consists of five algorithms (KeyGen, TagGen, Chall, Prove, and Verify):
KeyGen is a key generation algorithm that can be used to generate a public key and a secret key by the owner.
TagGen is a tag generation algorithm that can be used to compute a data tag for each data block of an owner’s data file by the owner. And the owner moves the data blocks and the corresponding data tags to the cloud server.
Chall is a challenge algorithm that can be used to randomly choose some data blocks as the challenge data set by the auditor. And the auditor sends the challenge data set to the cloud server.
Prove is a proof algorithm that can be used to generate a data proof to the auditor by the cloud server.
Verify is a verification algorithm that can be used to check the integrity of data file by verifying the correctness of data proof.
Security model
We assume that the auditor is semi-trusted such that they will perform honestly during the whole auditing procedure, but will not be trusted for data confidentiality. And the cloud server may be fully dishonest in terms of the data confidentiality and integrity.
Thus, the secure data storage auditing system can face two main threats: data privacy threat from both of the cloud server and the auditor and data integrity threats from the cloud server. 24 The cloud server and the auditor could be curious to the owner’s data file. The auditing protocol should protect the data privacy against the cloud server and the auditor. And the cloud server may carry out the following attacks: 8
Replace attack. The cloud server may choose another valid pair of data block and data tag to replace the challenged pair of data block and data tag that have been discarded.
Forge attack. The cloud server may forge the data tag of data block and deceive the auditor, if the owner’s secret tag keys are reused for the different versions of data.
Replay attack. The cloud server may generate the proof from the previous proof or other information, without retrieving the actual owner’s data.
Our efficient secure data auditing protocol
Table 1 lists some notations used by algorithms for our secure data storage auditing protocol.
Notations for our secure data storage auditing protocol.

Let
Algorithms for our secure data auditing protocol
Generally, the pairing computation is the most expensive part of pairing-based cryptography. Yang’s secure data storage auditing protocol can protect the data privacy against the auditor using the pairing-based cryptography method. Then, the pairing computation is also a very expensive part of their solution. In this article, we propose an improved secure data storage auditing based on Yang’s one to reduce the total computation cost of one auditing. We let the user pre-do the pairing operation so as to avoid it at the cloud side during the process of auditing. Yang’s secure data auditing protocol includes five algorithms: KeyGen, TagGen, Chall, Prove, and Verify. Our data auditing Protocol also have five algorithms. They are defined as follows and our definitions of TagGen, Chall, and Prove are different with Yang’s.





If the equation holds it outputs 1. Otherwise, it outputs 0.
Correctness analysis
The correctness and verification equation of our improved auditing protocol can be written in detail as follows

From equation (1), the cloud server can pass the auditing, if the data blocks and the data tags are stored correctly. However, if any of the challenged data block or data tag is corrupted or modified, the verification equation will not hold and the cloud server cannot pass the auditing.
Security analysis
We first prove that our improved auditing protocol is provably secure under the security model. Then, we prove that it can guarantee the data privacy.

The cloud server side of our improved auditing protocol is the same as Yang’s. Because Yang’s auditing protocol can resist the three attacks, our improved auditing protocol can also resist them.
On the auditor side, it can get the public key
Performance improvement with adjustable parameter
Suppose that the corrupted probability of each sector of each block on the cloud storage is

Interestingly, we can see that the verifier can choose a constant amount of sectors and can detect any data corruption with the same probability of
We first give some notations to represent the computation cost of basic computational operation in the algorithms of Yang’s secure data storage auditing protocol in Table 2.
The computation cost of basic computational operations.

According to the definitions of three algorithms of Chall, Prove, and Verify, we can formalize the expression of computation cost using some basic computational operations.
So, the total computation cost can expressed as
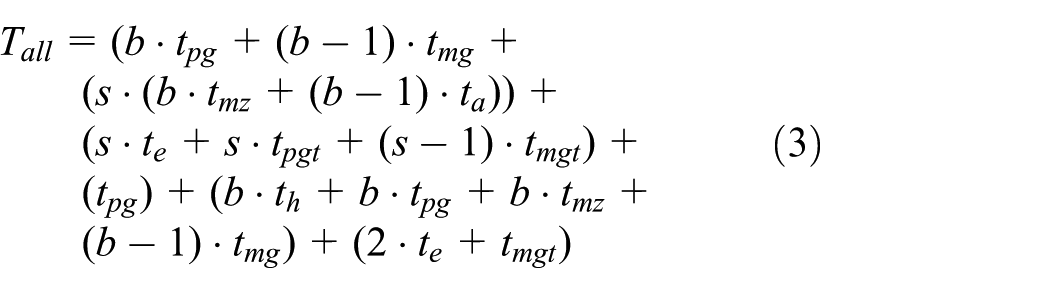
Obviously, we should evaluate the performance of Yang’s secure data storage auditing protocol with the total computation cost of one auditing (Table 3).
The computation cost of some sub-operations in Yang’s solution.

According to the definitions of our three algorithms of Chall, Prove, and Verify, we also formalize the expression of computation cost in Table 4.
The computation cost of some sub-operations in our solution.

The total computation cost of one auditing of our solution can expressed as

According to equations (3) and (4), the difference of the total computation cost between our and Yang’s solution can be expressed as

Generally, the computation cost of a bilinear pairing of two elements of
Moreover, for a confirmation auditing or sampling auditing, in the case of the same total number of sectors (i.e. the same probability of
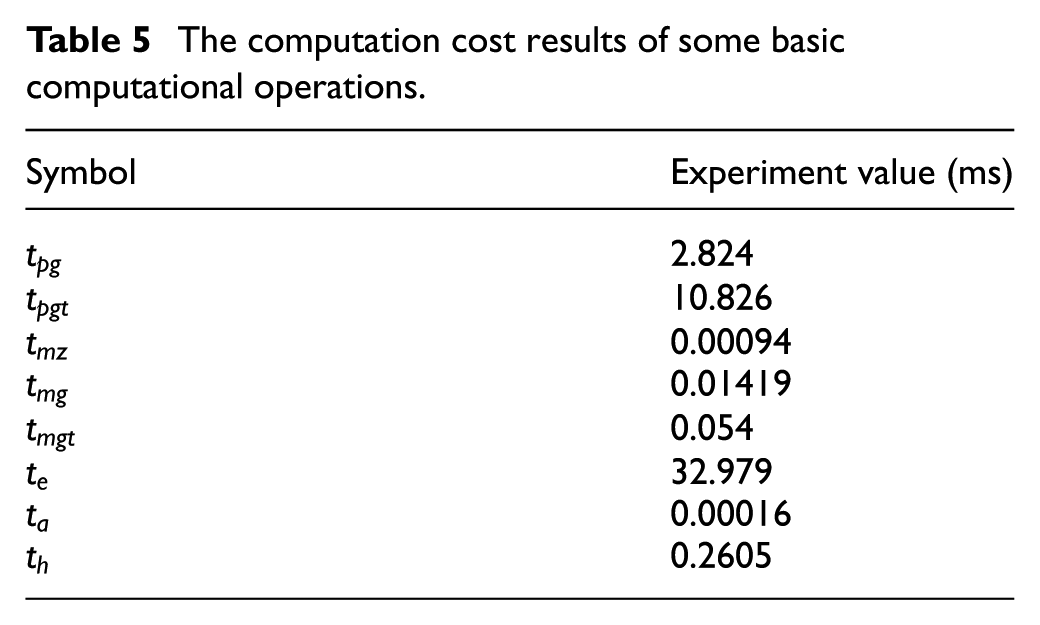
We test the computation cost of basic computational operations listed in Table 2 on a Windows System with an AMD Phenom II X4 810 Processor at 2.60 GHz and 8 GB RAM in the C language based on GNU Multiple Precision Arithmetic Library (GMP) version 4.1 and pairing-based cryptography library version 0.4.7. The elliptic curve group used by us is an MNT d159 curve, which has a 160-bit group order, and the embedding degree of which is 6.
The results are shown in Table 5.
The computation cost results of some basic computational operations.
In this section, our goal is to choose a number of sectors for each data block in order to achieve the optimal performance of the auditing protocol in a case of the same challenged data in bytes. We define the total challenged sectors as

The partial derivative of

So we can get the following two equations to calculate the optimal number of sectors

and

Figure 2 shows the relationship between the computation cost and the number of sectors s by evaluation when the total challenged data in Kbytes is 100, 200, 300, 400, and 500. Figure 2 also shows our solution is more efficient than Yang’s when the total challenged data in Kbytes is 100, 200, 300, 400, and 500.
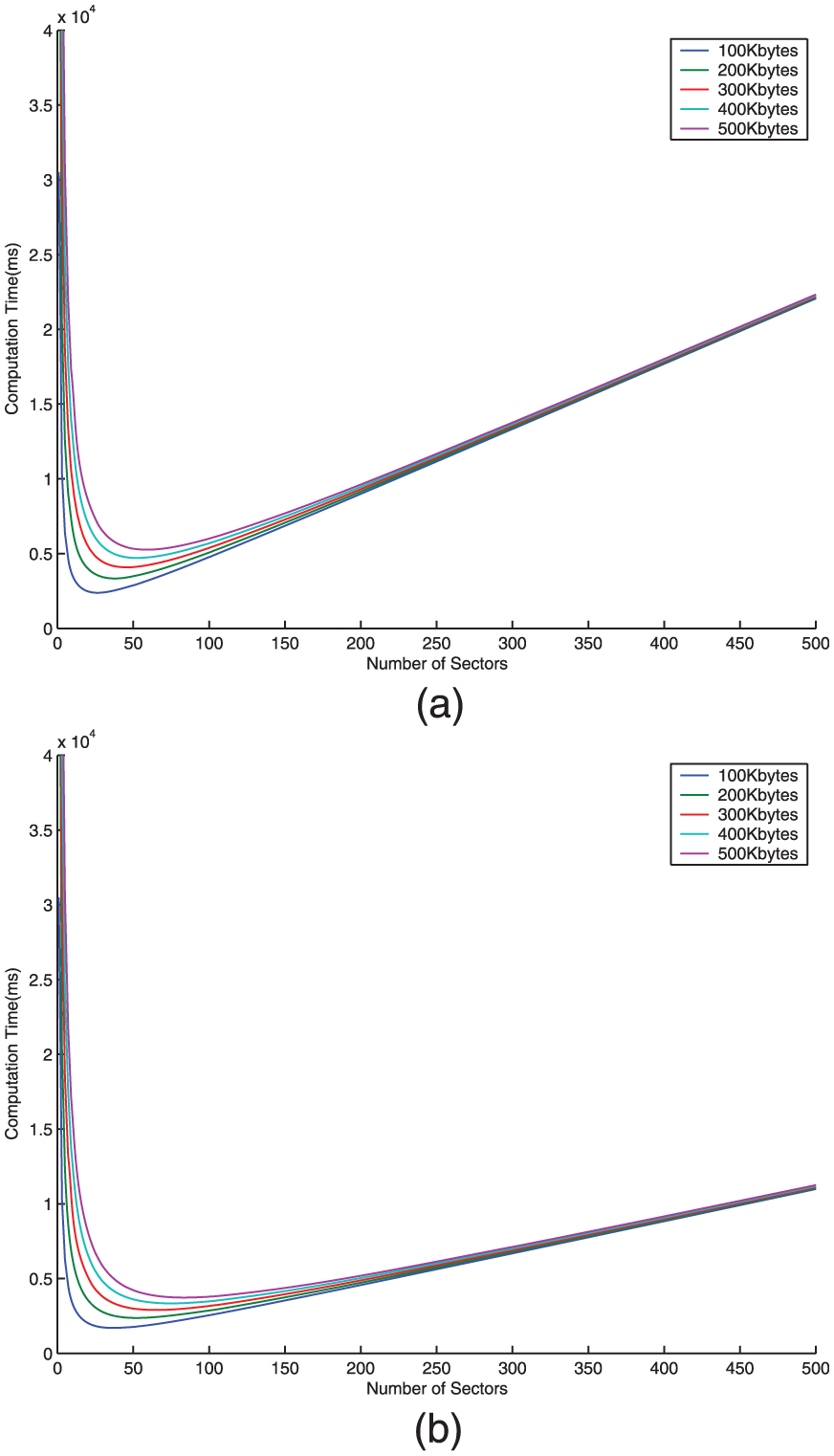
The computation cost versus the number of sectors with a constant challenged data by evaluation: (a) Yang’s solution and (b) our solution.
Table 6 shows the optimal number of sectors s when the total challenged data in Kbytes is 100, 200, 300, 400, and 500 by evaluation.
The optimal number of sectors s with the total challenged data by evaluation.

According to equations (7) and (8), respectively, Figure 3 shows the optimal number of sectors s versus the total challenged data for Yang’s and our solution by evaluation. Moreover, according to equations (3) and (4), Figure 4 shows the optimal total computation cost versus the total challenged data for Yang’s and our solution by evaluation based on the optimal number of sectors in Figure 3. We also show the optimal number of sectors in Figure 4. In the two figures, the total challenged data goes to 1000 Kbytes (i.e. the total number of challenged sectors is 51,200). From Figures 3 and 4, we can see that our solution can achieve the better performance than Yang’s while the optimal number of sectors of our solution is greater than the one of Yang’s solution.

The optimal number of sectors s versus the total challenged data (Kbytes).

The optimal total computation cost versus the total challenged data (Kbytes).
Experiment results and analysis
According to the computation cost of some basic computational operations, we can evaluate the total computation cost of Yang’s and our solutions using equations (3) and (4). Figure 5(a) and (b) shows the total computation cost evaluated using equations (3) and (4).
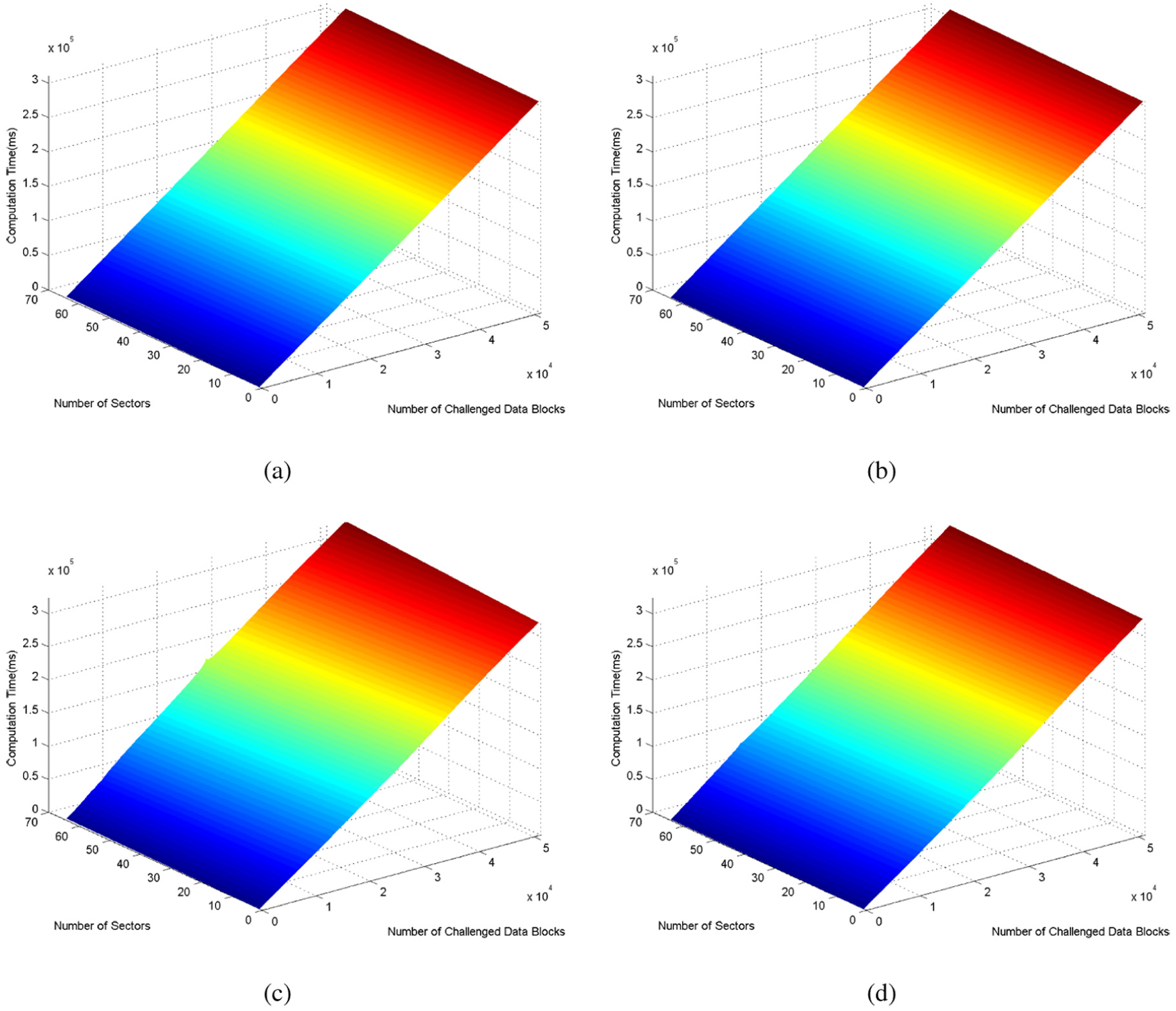
The total computation cost of Yang’s and our solutions: (a) Yang’s solution by evaluation, (b) our solution by evaluation, (c) Yang’s solution by experiment, and (d) our solution by experiment.
We also implement Yang’s and our secure data storage auditing protocol on a Windows System with an AMD Phenom II X4 810 Processor at 2.60 GHz and 8 GB RAM in the C language based on GNU Multiple Precision Arithmetic Library (GMP) version 4.1 and pairing-based cryptography library version 0.4.7. The corresponding experiment results are shown for Yang’s and our solutions in Figure 5(c) and (d).
In Figure 5, as the number of the challenged data increases, the total computation cost of the two solution increases linearly. But we cannot see clearly the difference between Yang’ s and our solutions. So some other figures are shown as follows to illustrate the difference. Figure 6 shows the total computation cost ratio between Yang’s and our solutions. In Figure 6, we can know the total computation cost ratio in a case of the same number of challenged data blocks and the same number of sectors. And in a case of the same number of sectors, as the number of challenged data blocks increases, the total computation cost ratio decreases and goes stable (the ratio is about 1).
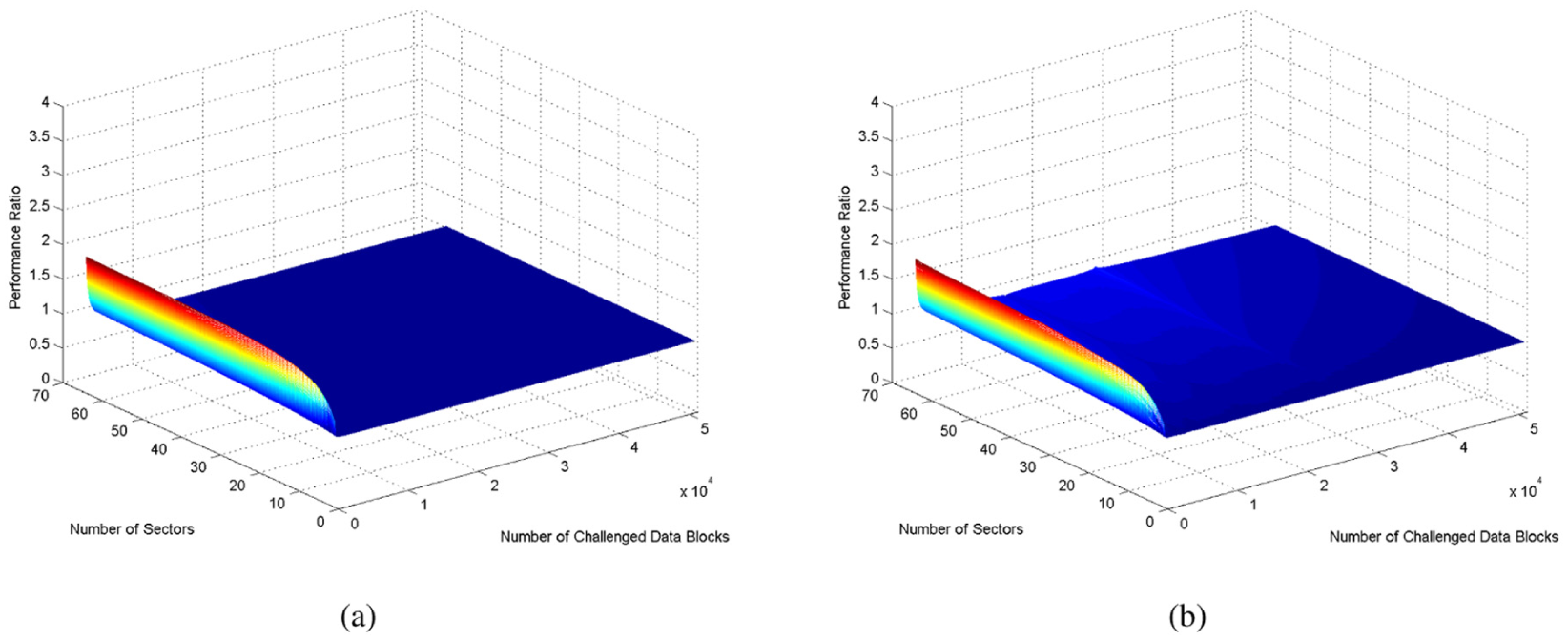
The total computation cost ratio between Yang’s and our solution: (a) by evaluation and (b) by experiment.
We can see the more obvious trend in Figure 7(a) and (c), which are the projection of Figure 6(a) and (b) in the plane of the number of challenged data blocks and the total computation cost. In Figure 7(a) and (c), in a case of the same number of sectors, as the number of challenged data blocks increases, the total computation cost ratio decreases. Moreover, when the number of challenged data blocks is large, the total computation cost ratio is constant (the ratio is about 1).
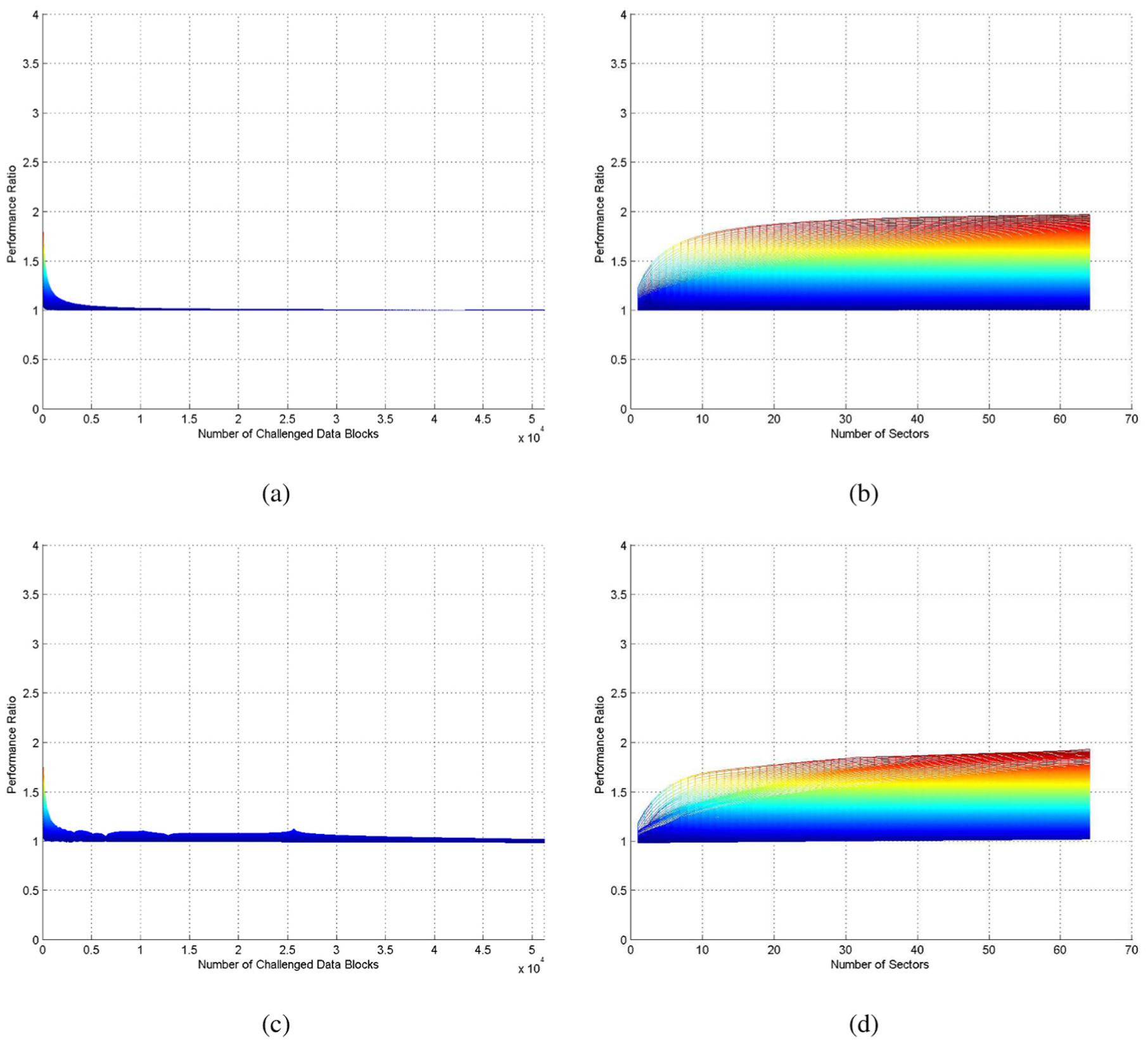
Project figures of Figure 7: (a) the number of challenged data blocks and the total computation cost by evaluation, (b) the number of sectors and the total computation cost by evaluation, (c) the number of challenged data blocks and the total computation cost by experiment, and (d) the number of sectors and the total computation cost by experiment.
We can also see the more obvious trend in Figure 7(b) and (d), which are the projection of Figure 6(a) and (b) in the plane of the number of sectors and the total computation cost. In Figure 7(b) and (d), in a case of the same number of challenged data blocks, as the number of sectors increases, the total computation cost ratio increases.
The total computation cost ratio by experiment in Figure 7 looks a little different with the one by evaluation because there are some other computation costs. But overall our experiment results are consistent with the results by evaluation.
In summary, when the number of challenged data blocks is small, our solution is more efficient than Yang’s in some cases of the same number of challenged data blocks. And as the number of challenged data blocks increases, our solution has the same performance as Yang’s (the performance ratio is about 1). As mentioned above, the number of challenged data (
In Figure 8, we compare the optimal total computation cost versus the total challenged data in bytes for Yang’s and our solution by evaluation and by experiment. We also show the optimal number of sectors in Figure 8. In our experiment, the maximize number of sectors is 64. Therefore, the optimal total computation cost by experiment in Figure 8 looks a little different with the one by evaluation. But overall our experiment results are consistent with the results by evaluation. Figure 8 also shows that our solution is more efficient than Yang’s.

The optimal total computation cost versus the total challenged data (Kbytes) for Yang’s and our solution.
To further illustrate the effectiveness of our solution, we also compare the computation cost versus the size of challenged data in Figure 9 by experiment.

Comparison of computation cost of our solution(s is determined by equation (8)) and Yang’s solution (s=50).
In summary, our solution is more efficient than Yang’s. Equation (8) can be used to evaluate and determine the optimal number of sectors for each data block in order to achieve the optimal performance per executing our auditing protocol in a case of the same amount of challenged data.
Conclusion
In this article, we proposed an improved secure IoT data storage auditing protocol based on Yang’s solution. The performance of our solution was improved by pre-doing the bilinear pairing computation. And then we further improved the performance of our solution by selecting the optimal number of sectors to achieve the optimal performance of executing the auditing protocol. Experiment results show that the performance results are consistent with the results by the mathematical analysis method and our solution is more efficient than Yang’s.
Footnotes
Academic Editor: Xuyun Zhang
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported, in part, by National High Technology Research and Development Program of China (No. 2015AA016008), National Science and Technology Major Project (No. JC201104210032A), National Natural Science Foundation of China (No. 61402136), and Natural Science Foundation of Guangdong Province, China (No. 2014A030313697).