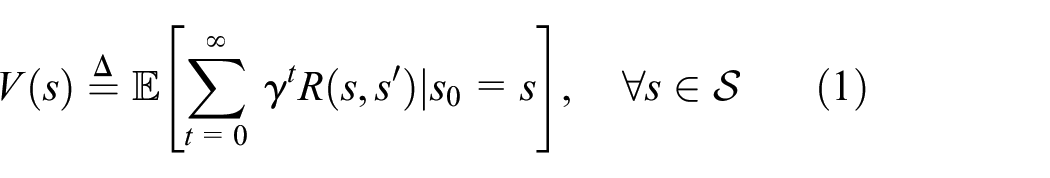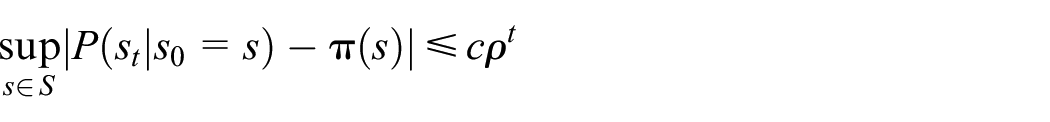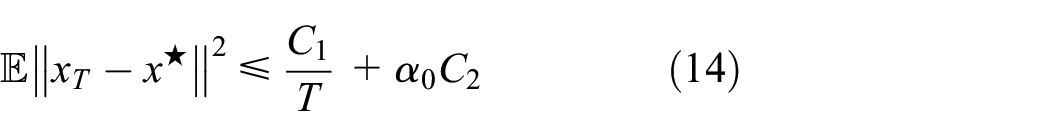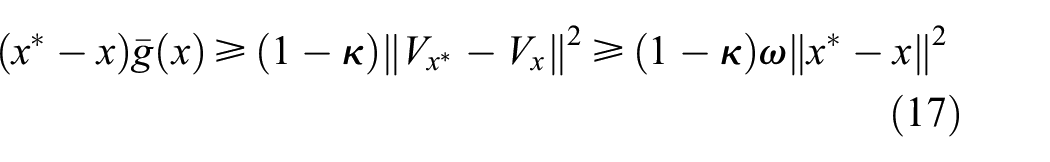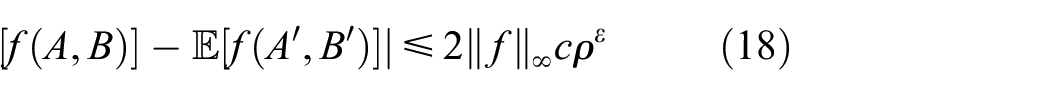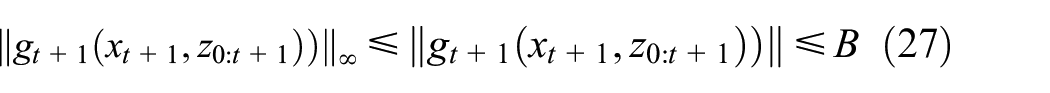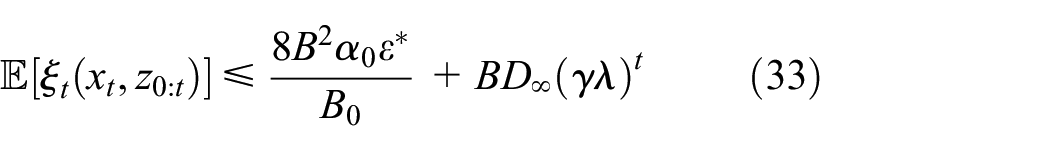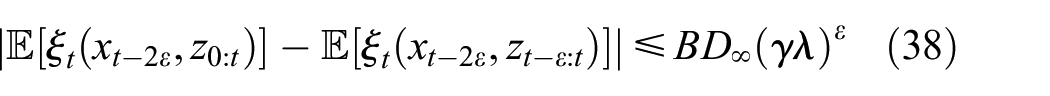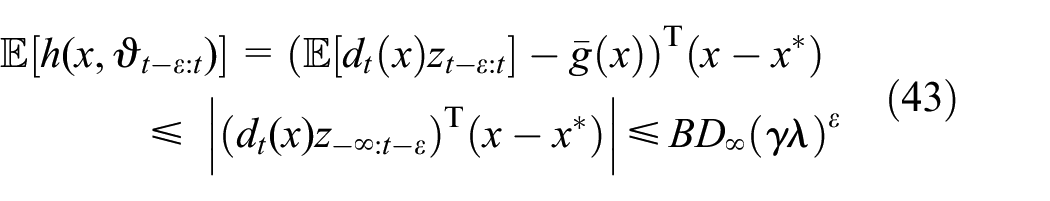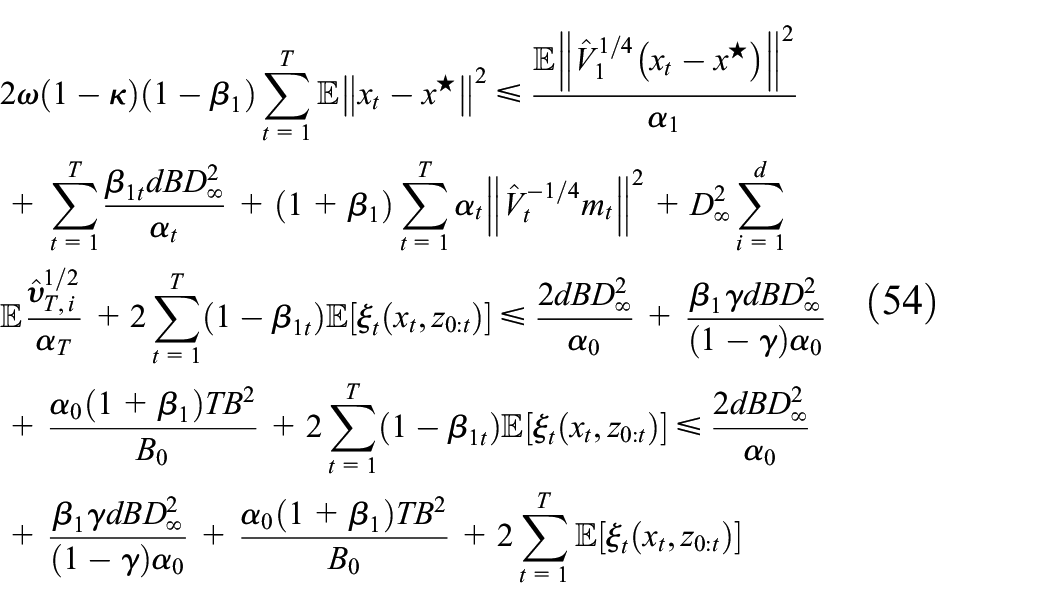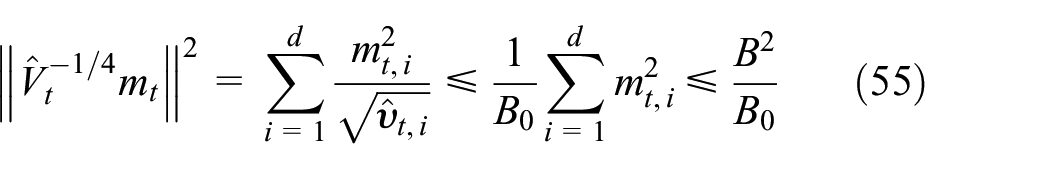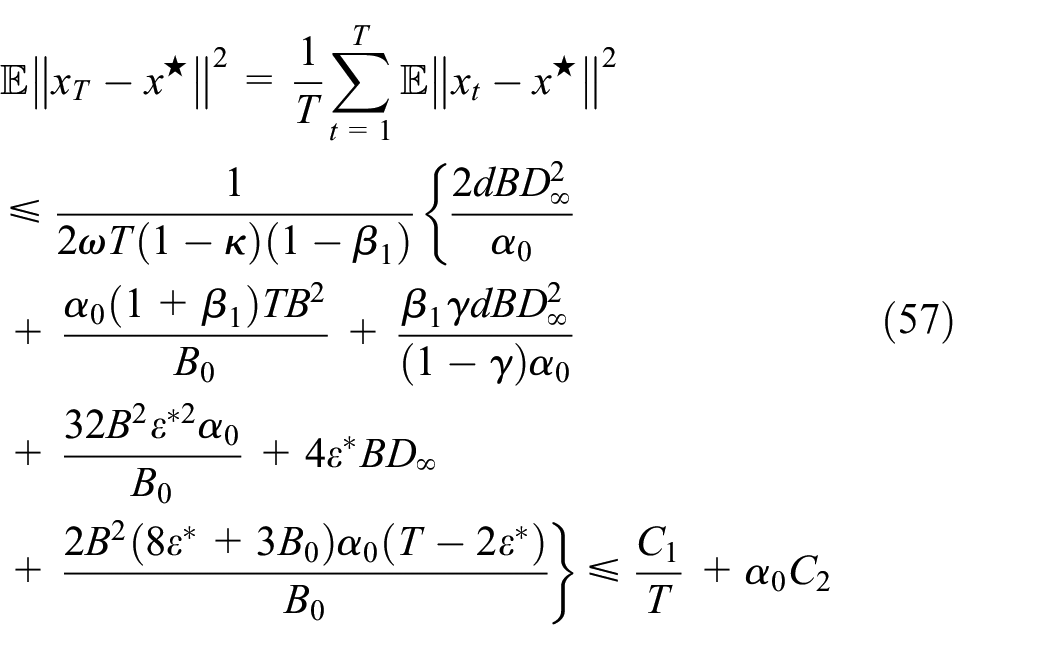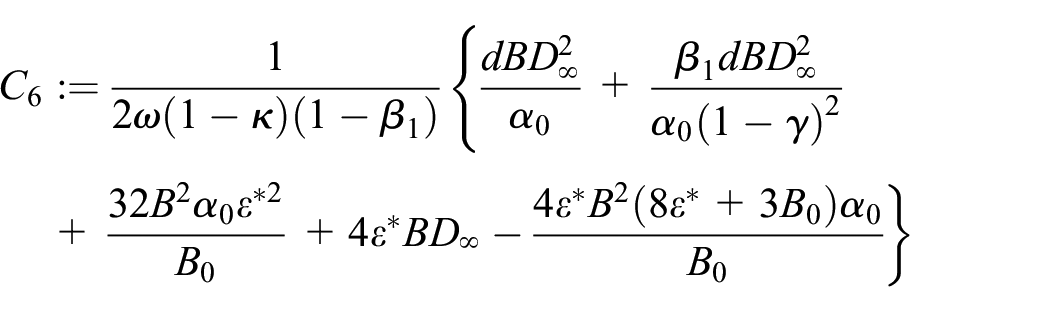Wireless sensor network has been widely used in different fields, such as structural health monitoring and artificial intelligence technology. The routing planning, an important part of wireless sensor network, can be formalized as an optimization problem needing to be solved. In this article, a reinforcement learning algorithm is proposed to solve the problem of optimal routing in wireless sensor networks, namely, adaptive TD() learning algorithm referred to as ADTD() under Markovian noise, which is more practical than i.i.d. (identically and independently distributed) noise in reinforcement learning. Moreover, we also present non-asymptotic analysis of ADTD() with both constant and diminishing step-sizes. Specifically, when the step-size is constant, the convergence rate of is achieved, where is the number of iterations; when the step-size is diminishing, the convergence rate of is also obtained. In addition, the performance of the algorithm is verified by simulation.
The application of artificial intelligence (AI) technology makes the network more intelligent such as improve network resources intelligently,1 intelligent firewall,2 invasion defense,3 congestion control,4,5 and privacy protection.6 In addition, AI technology has also been gradually applied to wireless sensor networks, for instance.7–9 Wireless sensor networks collect, process, and transmit data through sensors and routing strategy is a key problem in data transmission, so we can model it as an optimization problem to be solved by reinforcement learning. Reinforcement learning is the process of interaction between an agent and the environment. That is, the agent observes the states of the environment and takes according actions; then, the environment feeds back corresponding rewards to the agent and transforms to the next state. The goal of reinforcement learning is to find a policy that maximizes the cumulative rewards and this process can be generally formalized as a Markov decision process (MDP). To achieve this goal, we need to design reinforcement learning algorithms.
Under a given strategy, how to evaluate cumulative rewards is considerable for designing a reinforcement learning algorithm and this problem is also known as the policy evaluation problem. Temporal-difference (TD) learning can effectively solve this problem, which was proposed by Sutton.10 People generally combine TD learning with function approximation methods and use function approximator to update the parameter of value function. Furthermore, many scholars have analyzed the performance of TD learning in previous studies.11–14 Recently, the asymptotic analysis of TD learning was presented.15–17 Although the asymptotic analysis is also useful for algorithms, finite-time bounds can be used to quantify convergence rates. Therefore, the finite-time analysis for TD learning has been proved in previous studies.18–21 However, they all studied the non-asymptotic convergence analysis of TD(0) and its variants. In fact, TD(0) is an extreme case of TD(), but the difference is that TD() introduces the eligibility traces vector, which is the weighted sum of the previous gradients. Eligibility traces have obvious computing advantages and can improve the algorithm performance obviously in practical. Therefore, TD() is known to perform better than TD(0), whereas the finite-time analysis is more intricate.
Recently, there are many theoretical analyses of TD ().22,23 etc. In addition, in Srikant and Ying,24 the finite-time bound for TD() with constant step-size was proved. In Bhandari et al.,25 non-asymptotic analysis of TD() was proved by projection. Nevertheless, both of them used SGD algorithm to update parameters and adopted constant step-size, which made the algorithm sensitive to the choice of step-size. In recent years, Adam-type algorithms are a good application in reinforcement learning, such as Gupta et al.,26 Stooke and Abbeel,27 and Papini et al.28 Lately, the finite-time analysis of Adam-type TD(0) under Markov sampling was performed and used the information theory technique to control gradient bias in Xiong et al.20 But this article didn’t extend to TD(). In addition, Sun et al.29 proved the asymptotic convergence of TD() with adaptive gradient descent. Although they used the Adam algorithm, they assumed that the sampling process was independently identically distribution, which is rare in practice and is more subject to Markov distribution. Therefore, how to design an Adam-type TD() algorithm under Markov sampling and analyze its convergence rate is a problem needs to be solved.
To fill this gap, we propose an adaptive TD() algorithm under Markovian noise, referred to as ADTD(). We adopt an Adam-type algorithm to accelerate the convergence rate and reduce sensitivity to step-size selection. Moreover, we also present a non-asymptotic analysis of ADTD() with constant and decreasing step-size, respectively. In addition, we employ projection operators and information theory techniques to control the gradient bias.
Our main contributions are elaborated below:
To solve the routing planning problem in wireless sensor networks, we present an adaptive TD() algorithm referred to as ADTD() under Markov sampling with linear approximation. Moreover, ADTD() combines Adam-type methods, projection operators, and information theory techniques.
Through rigorous convergence analysis, we obtain the error upper bounds between the estimated parameter and the optimal parameter under the condition of different step-sizes. That is to say, when the step-size is constant, the convergence rate of is achieved; when the step-size is diminishing, the convergence rate is , where is the number of iterations.
The main structure of the rest of the article is as follows: In “Related work” section, we comb through the literature. In “Preliminaries” section, we will introduce some basics of TD algorithm. In “Algorithm design and assumptions” section, we present our main algorithm ADTD() and some necessary assumptions. In “Main results” section, we first show the convergence results of ADTD(). In “Convergence analysis” section, which is the most important part of the article, we will prove the convergence analysis in detail. In “Simulations” section, we verify the performance of the algorithm through simulation experiments. In the end, we summarize the work of this article in “Conclusion” section.
Notations: The notation denotes the norm of , and denotes the norm of . The symbol denotes the Hadamard product between the vectors and , and denotes a projection operator. The symbol denotes the transpose of a matrix or vector. The symbol means the term is eliminated when we perform complexity analysis of the algorithm.
Related work
In this section, we will sort out the literature of TD learning and adaptive algorithm and divide it into two parts.
TD learning
As one of the most popular research directions in recent years, reinforcement learning has improved a lot. People constantly enrich its theoretical system especially, which also makes reinforcement learning more widely used in practice than ever before. The TD() algorithm was first proposed by Sutton.10 After this, Dayan30 proved the mean convergence of TD() in. Several scholars proved that TD() can converge with probability 1. Tsitsiklis and Van Roy proved asymptotic error bounds for linear TD() in Dayan and Sejnowski.11 In the last decade, people have put forward GQ(),31 HTD(),32 emphasis TD(),33 and so on. Recently, Bhandari et al.25 used projection proved the finite-time analysis of centralized TD() under Markov sampling, Similarly, in Srikant and Ying,24 although they didn’t use the projection method, they use the Lyapunov function to prove the finite-time bound with constant step-size; however, neither of them took into account the adaptive step-size. Sun et al.29 proved the convergence of adaptive gradient descent TD(), but they assumed that the samples are under i.i.d. noise, which is less practical than Markovian noise. Therefore, we will propose a TD() variant, that is TD() under Markov sampling and combine it with Adam to accelerate the convergence while implementing adaptive step-size.
Adaptive algorithms
Kingma and Ba34 first proposed Adam algorithm in and Adam performs well in practical application. But Reddi et al.35 showed that the Adam algorithm in Kingma and Ba34 might not converge. Therefore, they proposed AMSGrad, which proved the convergence performance of Adam although it only made some modifications to Adam. In addition, many Adam-related analyses were proposed, such as Zou and Shen36 and Li and Orabona.37 We afford the convergence analysis for adaptive TD() with Markov noise.
Preliminaries
In wireless sensor networks, sensor node can be regarded as an agent, the routing table saved by the node represents its environment, and sensor nodes can determine their actions through the routing table and return, that is, the next hop address. General routing strategies have three optimization objectives: the first is to find the fastest path to the target node, the second is to ensure that the information can still be transmitted to the target node when some nodes are interrupted in the transmission process, and the third is to ensure load balancing. We can choose different return functions for different optimization objectives; to ensure load balancing, the goal is to average the number of work times of each node, so the corresponding return at instant can set a function inversely proportional to the number of forwarding times. It can be seen that this process can correspond to the reinforcement learning model; therefore, we can use reinforcement learning algorithm to solve the routing planning problem in wireless sensor networks.
To prepare for the following content, we will introduce some preliminaries about reinforcement learning and TD algorithm.
TD algorithm
MDP describes the main elements of reinforcement learning in a 5-tuple: , where means the finite state space of the environment, represents the actions set that the agent is likely to take, is the probability of transition from one state to the next state, is the reward for moving on to the next state after taking a certain action, and is a discounting factor, indicating that the further away the moment, the less influence on the present. The goal of reinforcement learning is to maximize the cumulative discount reward, which can be named as value function and expressed by , and the form is as follows
where is the next state of and is the return from the transition from state to state .
The above equation can be written as Bellman equation
where is the probability of transition from state to .
In general, we can parameterize the value function as , and the approximation function can be used to approximate real value function . Here we also use linear function approximation, which is more conducive to the subsequent proof. takes the form
where is basis function of , and is characteristic parameters. Just to make the notation more concise, let as a compact matrix
where is the number of states space, and . Then, we get
Thus, and . The parameters of TD algorithm update follow the following rules:
is the estimated error at the current time, which is called TD error. It can be written as
The parameters are updated as follows
We can view as the gradient “” in the traditional stochastic gradient descent method, although it’s not a real gradient. Then, we define as
where is the information observed in environment at the th state transition, like .
The parameters update rule can also be written as
TD(λ) algorithm
The TD() algorithm perfectly explains the relationship between Monte Carlo algorithm and TD algorithm, in which . When , it is TD (0) algorithm, and when , it is Monte Carlo algorithm. Generally speaking, when takes the middle value, it will perform better than the first two extreme algorithms.
Unlike TD(0), TD() has an extra eligibility traces vector . In TD(0), we used the direction of the eigenvector to updating parameter. In TD(), instead of using the direction , the updating parameter uses the direction of the eligibility traces , and follows the update function
is used to capture the influence of each feature on TD error, and by simplifying it, we can write it as
The parameters are updated as follows
Like TD (0), we can also define , which acts the same as “” in the gradient descent method. The definition of is as follows
Parameter updates can also be represented by the following equation
That’s the basics of the original TD() algorithm, but in this article, we consider to add Adam-type algorithm on the original TD(). Therefore, in the next section, we will further improve the algorithm.
Algorithm design and assumptions
In this section, we present the main algorithm in detail and propose some basic assumptions for subsequent convergence analysis.
Algorithm design
Our algorithm combines TD() and AMSGrad. and are hyper-parameters, and . is first-order momentum and is second-order momentum. is a diagonal matrix composed of . Moreover, is a projection operator onto a norm ball less than . The details are in Algorithm 1:
Algorithm 1. ADTD(): Adaptive TD() under Markov Sampling.
fordo where end for
Assumptions
We specify some fundamental assumptions, which are also standard assumptions in previous stuides,24,25,29 and these assumptions always hold throughout the rest of this article.
Assumption 1
The Markov chain associated is ergodic with , which also means the Markov chain mixes uniformly, and the following inequality holds
where is a stationary distribution, and and are all constant.
Assumption 2
We assume that the matrix is linearly independent. Moreover, we assume that .
Assumption 3
We assume that rewards are uniformly bounded. That is, , where is a constant.
Assumption 4
We assume is uniformly bounded. That is, , where is a constant.
Main results
The following content will show the main theoretical results. Specifically, we obtain an upper bound on the error between the estimated parameter and the optimal parameter under the condition of different step-sizes. In the next section, we will prove it in detail.
Theorem 1
Under above Assumptions 1–4, we assume that for any , and , , for . Moreover, we set , and . Let , where is a constant, and represents the number of iterations. Then, Algorithm 1 satisfies
(a) when
where
(b) when
where
Remark 1
Under the constant step-size and some hyper-parameters, the results of Theorem 1 show that ADTD() can converge to a neighborhood of by the rate of , where are constants. Moreover, the error upper bounds between the estimated parameter and the optimal parameter are relative to the number of dimensions of , and the is proportional to the size of the neighborhood.
Theorem 2
Under above Assumptions 1–4, we assume that for any , and , , for . In addition, we initialize , . We set , and , let , where is a constant, and is the number of iterations. Then, we have
(a) when
where
(b) when
where
Remark 2
Similar to Theorem 1, are also constants and time-independent; we can adjust to make a trade-off between convergence speed and convergence accuracy. Let ; ADTD() converges to a neighborhood of by the rate of . Moreover, is relative to the number of dimensions of .
Convergence analysis
In this section, we will analyze the convergence performance of ADTD(). In order to get Theorem 1 and Theorem 2, we need some Lemmas to set the stage first.
Lemma 1
To limit the update direction of , for , we have (Lemma 3)25
where and .
Since the gradient estimation is biased under Markov sampling, we also use information theory techniques to control this bias in this article.
Lemma 2
Under Assumption 1, we assume that A and B are two random variables, , and ; A to B can be described as a Markov process, such that . Let and are independent, drawn from the marginal distributions of and , so For any bounded function , we have (information theory technology, Lemma 3)25
where and .
Furthermore, in order to obtain the final conclusion, we need to get the following results. To ensure the integrity of the article, we repeat the proof of Lemma 3.
Lemma 3
Under Assumptions 2–4, for , we assume that , . Then, for , we have (Lemma 17)25
Proof
According to the definition of , we have
and then take the bounds of and , respectively
where the first equation holds because of the definition of , the first inequality is based on the norm inequality, and the last inequality uses Assumption 1 that , , and .
Next bound
where the first inequality holds since . Plugging (21) and (22) into (20), we can obtain
We note that . Similarly, we can get for . Let ; we can get . As , so , we omit this proof here.
Next, we need to get some useful bounds that will prepare for the final theorem proof.
Lemma 4
Under Assumptions 2–4, for , we assume that , . By Lemma 3, we have . For any , we can obtain the bound as follows
Proof
We use the inductive hypothesis to bound and . We first assume that and ; by the definition of , we obtain
Therefore, we obtain , for .
Next, we bound . We also first assume that , and . By the definition of , we obtain
where the second inequality holds due to Lemma 3
We have . Therefore, we obtain that , for all .
Next, we will discuss the function , which represents the error in the updating direction at instant . We define it as follows
where , and .
To obtain , we first need to obtain some properties of .
Lemma 5
Under Assumptions 2–4, for , we assume that , . Besides, for any . Combining the results of Lemma 3 and Lemma 4, for any , we can obtain the properties as follows (Lemma 19)25
Proof
We just prove the part () of Lemma 5 here. That is to say, satisfies -Lipschitz property. The other parts of Lemma 5 are similar to Bhandari et al.25 and we omit them here
the first inequality holds since , where are four vectors. The last inequality establishes because . In the penultimate inequality, we can easily prove and as follows
Similarly, we can obtain .
Using Lemma 5, we obtain some properties of , and then we can solve for .
Lemma 6
Under Assumptions 1–4 and Lemma 5, considering the step-size sequence is non-increasing, , we can obtain
(1) For
(2) For all
(3) For
Proof
Case (1): When , we obtain
To get the bound on , we have to figure out the three terms, respectively.
Item I: According to the Lipschitz property of in Lemma 5, we can obtain
Item III: Using the information theory technology to bound , we define that is a state sequence from to ; it is also a Markov chain
We define a function
where random variables and were drawn independently from the marginal distributions of and , respectively. So
According to Lemma 2, we get
Using Lemma 5, we obtain
Plugging (42) and (43) into (41), we can obtain
Now, let , merging (35), (38), and (44), we can obtain
where the second inequality holds because step-size sequence is non-increasing, , and , . The last inequality follows from .
Case (2): For all , we obtain
Combining (35) and (38), we can obtain
For the last term of (46)
This last equation follows from .
Therefore, combining (47) with (48), we can obtain
Case (3): For , similar to case (2), we can easily obtain
where the second and the last inequality holds since and
With the assumptions and lemmas in mind, we start to prove Theorem 1; detailed proofs are shown below.
Proof
First, according to the definition of , we have
where the second inequality is established due to Young’s inequality and the last inequality holds because .
Next, we take the expectation of (51)
where the second inequality holds because of Lemma 1 and the third inequality holds since . The last inequality is obtained by Lemma 5 and . is the dimension of , and in Assumption 4.
By rearranging terms of (52) and summing terms from to , we obtain
where the last inequality holds due to , and .
Next, we will discuss the case of
where the second inequality holds since , , , and , and the last inequality follows from
We assume that
When , we obtain
the second inequality holds because of Lemma 6, and the last inequality holds since . Therefore, we can obtain
where
When , we have
In the same way, we can obtain
where
Up to now, we have proved Theorem 1.
Now, we will consider decreasing step-size and the detailed proof is as follows.
Proof
The proof is similar to Theorem 1 before (53). Let , we can prove as follows
where the second inequality holds because and the last inequality establishes since
When , we have
Hence, we can simply obtain
where
When
In the same way, we can obtain
where
Simulations
In this section, we verify the theoretical analysis results through a small ball experiment, which is similar to the experiment in Lin and Ling38 and Lowe et al.39 The agent interacts with the environment and the goal is to find the target node through continuous learning. The return obtained by the agent after each action is inversely proportional to the proximity of the target node, that is, the closer it is to the target node, the greater the return. The settings of experimental parameters are as follows: the discount factor , and hyper-parameters , . We conducted four groups of comparative experiments, and the experimental results are shown in Figures 1–4. Next, we will introduce these figures separately.
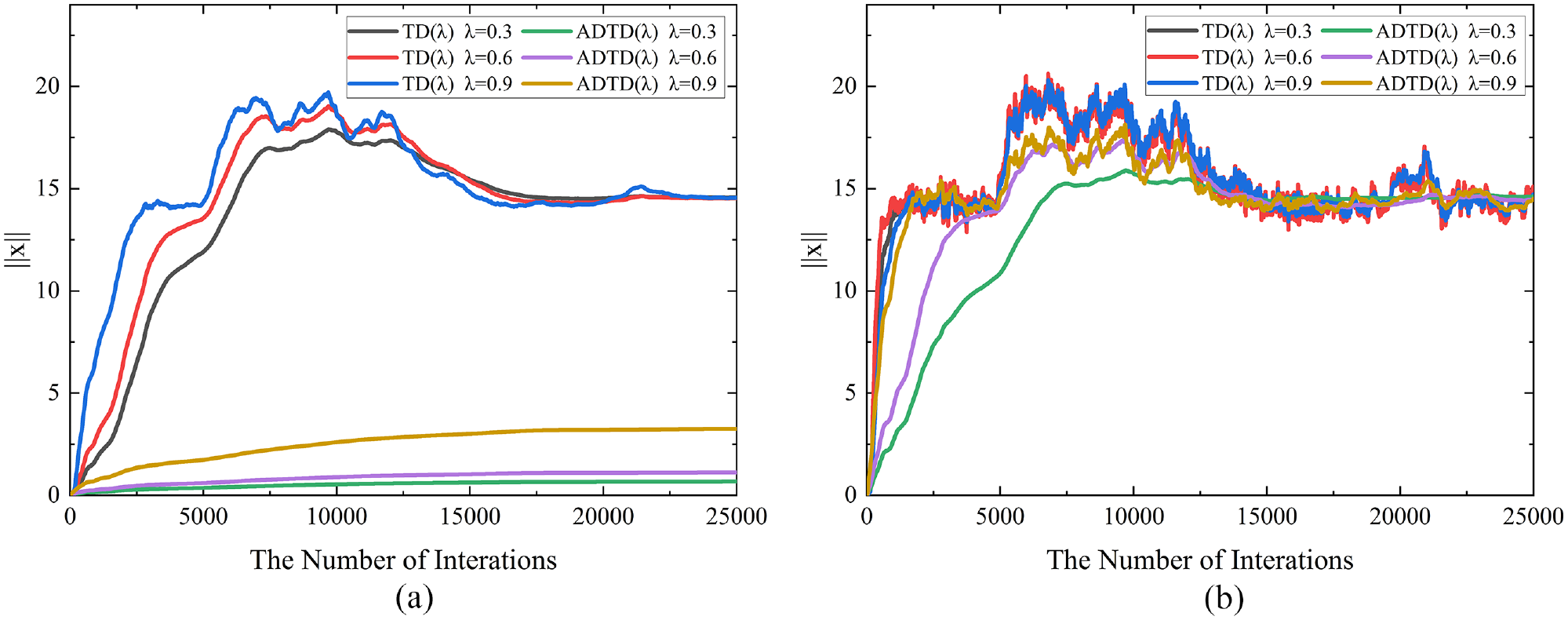
at the same initial step-size and different . (a) Decreasing step-size and (b) constant step-size
at the same initial step-size and different . (a) Decreasing step-size and (b) constant step-size
at the same and different initial step-size . (a) Decreasing step-size and (b) constant step-size
at the same and different initial step-size . (a) Decreasing step-size and (b) constant step-size
The initial step-size in Figures 1 and 2 is and , respectively, and we compared the ordinary TD() algorithm with the ADTD() algorithm under the case of decreaing step-size (Figures 1(a) and 2(a)) and constant step-size (Figures 1(b) and 2(b)). The decreasing step-size is related to and the step-size will be smaller with the increase of time. Because our ordinate is , the change of parameter update of ADTD() algorithm in the case of decreasing step-size will be smaller than that of constant step-size, and because ADTD() algorithm combines AMSGrad algorithm, it will perform faster and more stably to ensure convergence. Experimental results show that our ADTD() algorithm converges faster and is more stable in either case.
In Figure 3, we fix and make the following experiments for decreasing step-size (Figure 3(a)) and constant step-size (Figure 3(b)). Overall, ADTD() algorithm can always converge first at different initial step-size. In Figure 3(b), the parameter update adopts constant step-size, so the parameter update amplitude will increase as the setting increases; it can also be seen that the greater the fluctuation of TD() algorithm with the increase of , the higher the curve for ADTD() algorithm. Therefore, for constant step-size, the smaller the , the more stable the curve. Although the convergence speed is sometimes similar in Figure 3(b), ADTD() algorithm is more stable than TD() algorithm because it uses adaptive algorithm.
In Figure 4, we fixed and make the following experiments for decreasing step-size (Figure 4(a)) and constant step-size (Figure 4(b)). It should be clear that in Figure 4(b), when , the algorithm cannot converge. The reason is that the larger the lambda and alpha, the worse the performance because . At this time, , the scope of is more strict.
Conclusion
We use reinforcement learning to solve the optimal routing problem based on wireless sensor networks. To this end, we propose an adaptive TD() algorithm, referred to as ADTD(). We prove the non-asymptotic analysis of the adaptive TD() algorithm under Markovian sampling. Furthermore, for ADTD() with linear function approximation, we show that the algorithm can converge to the global optimal neighborhood in the case of constant step-size and decreasing step-size. However, under some parameter settings, the oscillation of the algorithm is large and the performance of the algorithm is not much different from that of the original algorithm; combining it with variance reduction technology will further improve the performance of the algorithm.
Footnotes
Handling Editor: Francesc Pozo
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China (61871430, 61976243);the Key Technologies R&D Program of HenanProvince (222102210049); the Scientific and Technological Innovation Team of Colleges and Universities in Henan Province of China (20IRTSTHN018, 21IRTSTHN015
ORCID iDs
Muhua Liu
Mingchuan Zhang
Qingtao Wu
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
1.
SongFAiZZhouY, et al. Smart collaborative automation for receive buffer control in multipath industrial networks. IEEE Trans Industr Inform2020; 16(2): 1385–1394.
2.
HuDHuXJiangW, et al. Intelligent digital image firewall system for filtering privacy or sensitive images. Cogn Syst Res2019; 53: 85–97.
3.
SongFAiZZhangH, et al. Smart collaborative balancing for dependable network components in cyber-physical systems. IEEE Trans Industr Inform2021; 17(10): 6916–6924.
4.
MaHXuDDaiY, et al. An intelligent scheme for congestion control: When active queue management meets deep reinforcement learning. Comput Netw2021; 200: 108515.
5.
KhanSHussainANazirS, et al. Efficient and reliable hybrid deep learning-enabled model for congestion control in 5G/6G networks. Comput Commun2022; 182: 31–40.
6.
SongFZhouYWangY, et al. Smart collaborative distribution for privacy enhancement in moving target defense. Inf Sci2019; 479: 593–606.
7.
LeeKLeeSKimY, et al. Deep learning-based real-time query processing for wireless sensor network. Int J Distrib Sens Netw2017; 13(5): 1550147717707896.
8.
GuoWYanCLuT. Optimizing the lifetime of wireless sensor networks via reinforcement-learning-based routing. Int J Distrib Sens Netw2019; 15(2): 1550147719833541.
9.
Najjar-GhabelSFarzinvashLRazaviSN. Mobile sink-based data gathering in wireless sensor networks with obstacles using artificial intelligence algorithms. Ad Hoc Netw2020; 106: 102243.
10.
SuttonRS. Learning to predict by the methods of temporal differences. Mach Learn1988; 3: 9–44.
11.
DayanPSejnowskiTJ. TD(lambda) converges with probability 1. Mach Learn1994; 14(1): 295–301.
12.
SchapireREWarmuthMK. On the worst-case analysis of temporal-difference learning algorithms. Mach Learn1996; 22(1–3): 95–121.
13.
TsitsiklisJNRoyBV. An analysis of temporal-difference learning with function approximation. IEEE Trans Autom Control1997; 42(5): 674–690.
14.
TsitsiklisJNVan RoyB. Average cost temporal-difference learning. Automatica1999; 35(11): 1799–1808.
15.
HuBSyedUA. Characterizing the exact behaviors of temporal difference learning algorithms using Markov jump linear system theory. In: Proceedings of the 32nd annual conference Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019, pp.8477–8488. San Diego, CA: Neural Information Processing Systems.
16.
TsitsiklisJNRoyBV. Analysis of temporal-difference learning with function approximation. In: Proceedings of the 9th conference Neural Information Processing Systems, Denver, CO, 2–5 December 1996, pp.1075–1081. San Diego, CA: Neural Information Processing Systems.
17.
DevrajAMMeynSP. Zap Q-learning. In: Proceedings of the 30th conference Neural Information Processing Systems, Long Beach, CA, 4–9 December 2017, pp.2235–2244. San Diego, CA: Neural Information Processing Systems.
18.
KordaNPrashanthL. On TD(0) with function approximation: concentration bounds and a centered variant with exponential convergence. PMLR2015; 37: 626–634.
19.
DalalGSzörényiBThoppeG, et al. Finite sample analyses for TD(0) with function approximation. In: Proceedings of the 32nd AAAI conference on artificial intelligence, New Orleans, LA, 2 February 2018, pp.6144–6160. Menlo Park, CA: Association for the Advancement of Artificial Intelligence.
20.
XiongHXuTLiangY, et al. Non-asymptotic convergence of Adam-type reinforcement learning algorithms under Markovian sampling. In: Proceedings of the 34th AAAI conference on artificial intelligence, Vancouver, BC, Canada, 2–9 February 2021, pp.10460–10468. Menlo Park, CA: Association for the Advancement of Artificial Intelligence.
21.
WangGLuSGiannakisG, et al. Decentralized TD tracking with linear function approximation and its finite-time analysis. In: Proceedings of the 34th international conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. Red Hook, NY: Curran Associates Inc.
22.
AltahhanA. True online TD(λ)-replay an efficient model-free planning with full replay. In: Proceedings of the international joint conference on neural networks (IJCNN), Glasgow, 19–24 July 2020. New York: IEEE.
23.
ChenZMaguluriSTShakkottaiS, et al. A Lyapunov theory for finite-sample guarantees of asynchronous Q-learning and TD-learning variants. CoRR2021; abs/2102.01567, https://arxiv.org/abs/2102.01567
24.
SrikantRYingL. Finite-time error bounds for linear stochastic approximation and TD learning. PMLR2019; 99: 2803–2830.
25.
BhandariJRussoDSingalR. A finite time analysis of temporal difference learning with linear function approximation. PMLR2018; 75: 1691–1692.
26.
GuptaHSrikantRYingL. Finite-time performance bounds and adaptive learning rate selection for two time-scale reinforcement learning. In: Proceedings of the 33rd annual conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019, pp.4706–4715. San Diego, CA: Neural Information Processing Systems.
PapiniMPirottaMRestelliM. Adaptive batch size for safe policy gradients. In: Proceedings of the 30th international conference on Neural Information Processing Systems, 4–9 December 2017, Long Beach, CA, pp.3591–3600. San Diego, CA: Neural Information Processing Systems.
29.
SunTShenHChenT, et al. Adaptive temporal difference learning with linear function approximation. CoRR2020; abs/2002.08537, https://arxiv.org/abs/2002.08537
30.
DayanP. The convergence of TD(λ) for general λ. Mach Learn1992; 8: 341–362.
31.
MaeiHRSuttonRS. GQ (λ): A general gradient algorithm for temporal-difference prediction learning with eligibility traces. In: Proceedings of the 3rd conference on Artificial General Intelligence, vol. 1, Lugano, 5–8 March 2010. pp.91–96. Amsterdam: Atlantis Press.
32.
WhiteAMWhiteM.Investigating practical linear temporal difference learning. In: Proceedings of the 15th international conference on Autonomous Agents and Multiagent Systems, Singapore, 9–13 May 2016, pp.494–502. New York: ACM.
33.
SuttonRSMahmoodARWhiteM. An emphatic approach to the problem of off-policy temporal-difference learning. J Mach Learn Res2016; 17: 1–29.
34.
KingmaDPBaJ. Adam: A method for stochastic optimization. In: Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, 7–9 May 2015.
ZouFShenL. On the convergence of AdaGrad with momentum for training deep neural networks. CoRR2018; abs/1808.03408. http://arxiv.org/abs/1808.03408
37.
LiXOrabonaF. On the convergence of stochastic gradient descent with adaptive stepsizes. In: Proceedings of the 22nd international conference on Artificial Intelligence and Statistics, vol. 89, Naha, Japan, 16–18 April 2019, pp.983–992. New: PMLR.
38.
LinQLingQ. Decentralized TD(0) with gradient tracking. IEEE Signal Process Lett2021; 28: 723–727.
39.
LoweRWuYTamarA, et al. Multi-agent actor-critic for mixed cooperative-competitive environments. In: Advances in Neural Information Processing Systems 30: annual conference on Neural Information Processing Systems, Long Beach, CA, 4–9 December 2017, pp.6379–6390. San Diego, CA: Neural Information Processing Systems.