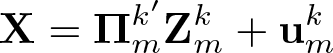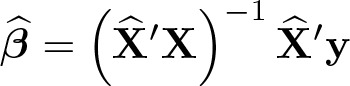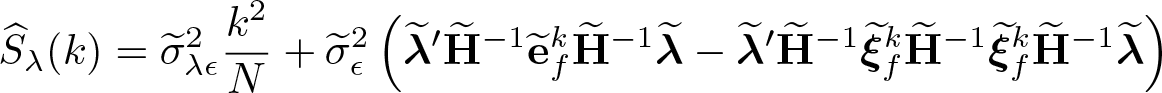We developed a command, csa2sls, that implements the complete subset averaging two-stage least-squares (CSA2SLS) estimator in Lee and Shin (2021, Econometrics Journal 24: 290–314). The CSA2SLS estimator is an alternative to the two-stage least-squares estimator that remedies the bias issue caused by many correlated instruments. We conduct Monte Carlo simulations and confirm that the CSA2SLS estimator reduces both the mean squared error and the estimation bias substantially when instruments are correlated. We illustrate the usage of csa2sls in Stata with an empirical application.
The two-stage least-squares (2SLS) estimator is one of the most widely used methods in applied economics. Theoretically, the optimal instrument can be achieved by the conditional mean function of the first-stage regression. However, in practice, practitioners working with a finite sample face a crucial question of how many instruments one should use, especially when there are many instruments available. This is partly due to the well-known tradeoff between bias and variance when the number of instruments increases. Donald and Newey (2001) show this point clearly with a higher-order Nagar expansion and propose choosing the optimal number of instruments that minimizes the mean squared errors (MSEs). Kuersteiner and Okui (2010) propose a model averaging approach for the first-stage regression and show that it achieves the optimal weight. These other approaches, however, require the practitioner to either know the order of importance among instruments (Donald and Newey 2001) because the method chooses the first few important instruments or estimate the optimal weights for the instruments (Kuersteiner and Okui 2010).
As an alternative, Lee and Shin (2021) propose a model-averaging approach that uses all size-k subsets of the set of available instruments in a cross-sectional regression model. This new approach is named the complete subset averaging two-stage least-squares (CSA2SLS) estimator. One advantage of the CSA2SLS estimator is that, because it uses all subsets, it does not require knowledge of the order of importance among instruments. Furthermore, averaging models using equal weights reduces potential efficiency loss in finite samples. This is because when estimated weights (instead of equal weights) are used, these become additional parameters in the model and therefore cause inefficiency when there are many models to be averaged.
We developed a command, csa2sls, that implements the CSA2SLS estimator. It selects the optimal number of subset size k that minimizes the approximate MSEs. Because the size of the complete subset grows at the order of 2K, where K is the total number of instruments, CSA2SLS is computationally intensive. To alleviate such a computational burden, the command csa2sls includes options for subsampling and a fast but memory-intensive method.
The remainder of this article is organized as follows. Section 2 introduces the CSA2SLS estimator in Lee and Shin (2021). Section 3 explains the command csa2sls. Section 4 shows results from Monte Carlo experiments that numerically illustrate how the CSA2SLS estimator alleviates some of the issues that arise from many instruments. Section 5 provides an empirical application of csa2sls. Section 6 concludes.
2 CSA2SLS estimator
In this section, we explain the key idea of the CSA2SLS estimator in Lee and Shin (2021). Heuristically speaking, we estimate the first-stage predicted value by model averaging and apply the 2SLS estimation with those predicted values. Given a total of K instruments, we consider all subsets composed of k instruments. We compute a simple average of predicted values across models, and the 2SLS estimator follows immediately. The optimal k is selected by minimizing the approximate MSEs criterion, which will be explained in detail below.
To be concrete, consider the following model generated from an independent and identically distributed sample:
where yi is a scalar outcome variable, Yi is a d1 × 1 vector of endogenous variables, x1i is a d2 × 1 vector of included exogenous variables, zi is a vector of exogenous variables (including x1i), f(·) is an unknown function of z, and ϵi and ui are error terms uncorrelated with zi. Finally, ηi denotes an error term when we project the endogenous regressor Yi into the space of exogenous variable zi. Note that E(ηi|zi) = 0 by construction.
Let y = (y1,…, yN )′, ϵ = (ϵ1,…, ϵN )′, X = (X1,…,XN )′, f = (f1,…,fN )′, and U = (u1,…,uN )′, where fi = f(zi). The set of instruments has the form ZK,i ≡ {ψ1(zi),…, ψK(zi), x1i}′, where ψk’s are functions of zi such that ZK,i is the collection of (K + d2) instruments. Note that the total number of instruments K can increase as N → ∞. We suppress the dependency of K on N for notation simplicity. Let ZK = (ZK,1,…,ZK,N )′ be the collection of ZK,i.
Let M be the number of subsets (or models) with k instruments:
We also suppress the dependency of M on K and k. Let m ∊ {1,…, M} be an index of each model and be a vector of instruments in model m. Then the first-stage regression of model m can be written as
The average predicted value of X is
where is the ordinary least-squares (OLS) estimator of . Then the CSA2SLS estimator is defined as
Using the projection matrices, we can also write the CSA2SLS estimator as a one-step procedure,
where with .
The optimal subset size k is chosen by minimizing the approximate MSE. Let be a preliminary estimator and . The fitted value of f is given as
where consists of exogenous variables plus the preliminary selection of instruments as described above. Let . The residual matrix is denoted by . Define , , and . Then the sample counterpart of the approximate MSE is given by
where
The preliminary estimator can be estimated either by using Mallow’s two-step criterion or by adopting the one-step method. See Lee and Shin (2021) for details.
hasconstant onestep r(#) vce(vcetype) level(#) first small large
noheader depname(depname) perfect]
varlist1 is the list of exogenous variables. varlist2 is the list of endogenous variables. varlist_iv is the list of exogenous variables used with varlist1 as instruments for varlist2.
3.2 Options
noconstant; see [R] Estimation options.
hasconstant indicates that a user-defined constant or its equivalent is specified among the independent variables.
onestep allows the one-step preliminary method. The default is Mallow’s two-step criterion. See Lee and Shin (2021).
r(#) specifies a positive integer for the maximum number of randomly selected subsets when the number of subsets is bigger than #. This is useful because the number of subsets depends exponentially on the number of instruments.
vce(vcetype) specifies the type of standard error reported, which includes types that are robust to some kinds of misspecification (robust) and that allow for intragroup correlation (clusterclustvar). vce(unadjusted) specifies that an unadjusted (nonrobust) variance–covariance estimate matrix be used.
level(#); see [R] Estimation options.
first requests that the first-stage regression results be displayed.
small requests that the degrees-of-freedom adjustment N/(N − k) be made to the variance–covariance matrix of parameters and that small-sample F and t statistics be reported, where N is the sample size and k is the number of parameters estimated. By default, no degrees-of-freedom adjustment is made, and Wald and z statistics are reported. Even with this option, no degrees-of-freedom adjustment is made to the weighting matrix when the generalized method of moments estimator is used.
large turns on the large-sample estimation program. When the sample size is large, the average projection matrices may require a large memory size. The large option must be turned on to avoid an insufficient memory issue. The default is not using this option.
noheader suppresses the display of the summary statistics at the top of the output, displaying only the coefficient table.
depname(depname) specifies to substitute the dependent variable name.
perfect requests that csa2sls not check for collinearity between the endogenous regressors and excluded instruments, allowing one to specify “perfect” instruments. This option may be required when using csa2sls to implement other estimators.
3.3 Stored results
csa2sls stores the following in e():
4 Monte Carlo experiments
In this section, we conduct Monte Carlo simulation studies focusing on the effect of correlated instruments. An independent and identically distributed sample (yi, Yi,zi) is generated from the following simulation design:
where Yi is a scalar endogenous regressor, (β0, β1) is set to be (0, 0.1), and zi is a K-dimensional vector of instruments generated from a multivariate normal distribution N(0, Σz). The diagonal elements of Σz are set to be 1, and the off-diagonal elements are ρz. We set each element of π to be , where 0.1 is the R2 in the first-stage regression. The vector of error terms (ϵi, ui) follows a bivariate normal distribution whose means are zeros and variances are ones. The covariance between ϵi and ui is set to be 0.9. In these simulation studies, K varies in {5, 10, 15, 20} and ρz varies in {0, 0.5, 0.9}. The sample size is set to be n = 100, and the results are from 1,000 replications.
Figure 1 summarizes the simulation results. We report the mean bias and MSE of CSA2SLS along with the performance of the OLS estimator and the 2SLS estimator. First, the CSA2SLS estimator reduces the bias substantially when instruments are correlated (ρz = 0.5, 0.9). As predicted by theory, the bias of 2SLS increases as K increases. Note that when instruments are independent (ρz = 0.0), the difference in the bias between the CSA2SLS estimator and the 2SLS estimator is small. Lee and Shin (2021) prove that the performance of CSA2SLS will be asymptotically equivalent to that of 2SLS when ρz = 0.
Second, the efficiency loss of CSA2SLS is modest. When instruments are correlated, CSA2SLS achieves lower MSEs when K ≥ 10. Like the bias, the MSE gap between CSA2SLS and 2SLS increases as K increases. It is also worthwhile to note that the MSE of CSA2SLS does not change much over different values of K. Finally, the OLS estimator performs the worst in these simulation designs.
To summarize, the CSA2SLS estimator shows a good finite sample performance as predicted by theory. We also observe the increased bias of 2SLS when there are many instruments. We recommend practitioners use the CSA2SLS estimator when they have many correlated instruments.
Mean bias and MSE
5 Empirical illustration
In this section, we illustrate the usage of csa2sls with an empirical application. In this example, we revisit Berry, Levinsohn, and Pakes (1995) and estimate a logistic demand function for automobiles based on pooled cross-sectional data over different markets.
The model is specified as
where Si is the market share of product i with product 0 denoting the outside option, Pi is the endogenous price variable, Xi is a vector of included exogenous variables, and Zi is a set of 10 instruments. The parameter of interest is α0, from which we can calculate the price elasticity of demand. Note that the optimal subset size k is 9 in this empirical example.
We also report correlation coefficients among the instruments. We can confirm that the instruments are divided into two groups and that each group’s instruments are highly correlated with each other.
6 Conclusion
In this article, we presented the CSA2SLS estimator and the corresponding command, csa2sls. The usage of csa2sls was illustrated with an empirical application. The Monte Carlo experiments show that 2SLS is biased when there are many instruments and that CSA2SLS outperforms 2SLS when instruments are correlated with each other. Because CSA2SLS is computationally intensive, an interesting future research question would be to develop a more efficient computation algorithm. An approach based on the stochastic gradient descent (see, for example, Lee et al. [2022]) can be a possible solution.
8 Programs and supplemental material
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231212432 - csa2sls: A complete subset approach for many instruments using Stata
Supplemental Material, sj-zip-1-stj-10.1177_1536867X231212432 for csa2sls: A complete subset approach for many instruments using Stata by Seojeong Lee, Siha Lee, Julius Owusu and Youngki Shin in The Stata Journal
Footnotes
7 Acknowledgments
We would like to thank the editor and an anonymous reviewer for their valuable comments on this article and for their helpful feedback on the program code. Shin is grateful for partial support by the Social Sciences and Humanities Research Council of Canada (SSHRC-435-2021-0244).
8 Programs and supplemental material
To install the software files as they existed at the time of the publication of this article, type
References
1.
BerryS.LevinsohnJ.PakesA.. 1995. Automobile prices in market equilibrium. Econometrica63: 841–890. https://doi.org/10.2307/2171802.
LeeS.LiaoY.SeoM. H.ShinY.. 2022. Fast and robust online inference with stochastic gradient descent via random scaling. In Proceedings of the Thirty-Sixth International Joint Conference on Artificial Intelligence, 7381–7389. Buenos Aires, Argentina: AAAI Press.