
Abstract
We develop a command,
1 Introduction
Conventional instrumental-variables (IV) regression requires that the dependent variable, the endogenous regressor, and the instruments come from the same dataset. But in many cases, researchers can observe only the dependent variable and endogenous regressor in two separate data samples (see Björklund and J¨antti [1997], Miguel [2005], Feldman [2010], Brunner, Cho, and Reback [2012], Siminski [2013], Olivetti and Paserman [2015], among many others). Angrist and Krueger (1992, 1995) propose two estimation strategies—two-sample IV and two-sample two-stage least-squares (TS2SLS)—for such two-sample IV regression models. Under the assumption of strong instruments, both two-sample IV and TS2SLS estimators are consistent. Inoue and Solon (2010) provide valid inference formulas for both estimators under the assumption of strong instruments and show that TS2SLS is more efficient. However, when the first stage is weak, neither estimation strategy is valid following arguments similar to the famous Bound, Jaeger, and Baker (1995) critiques in the classic (one-sample) two-stage IV literature.
In a recent study, Choi, Gu, and Shen (2018) develop weak-instrument robust inference for the two-sample IV regression model with one single endogenous regressor. In this article, we develop a command companion,
Section 2 provides background on the two-sample IV regression model. Section 3 discusses the weak-instrument robust inference methods developed in Choi, Gu, and Shen (2018). Section 4 introduces the new command,
2 Model and background
Let subscript j, j = 1, 2, denote random variables in the first or second dataset with sample size nj . Assume that n 1 /n 2 → τ for some fixed τ > 0. In this article, we consider the following two-sample IV regression model with independent and identically distributed data and a single endogenous regressor,
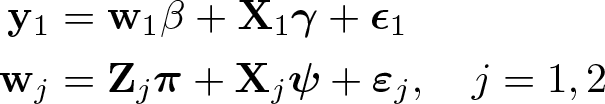
where
TS2SLS follows the idea of classic two-stage least-squares estimation by regressing the outcome variable

where
Under the assumption that the first-stage correlation between the endogenous regressor and instruments is strong, the TS2SLS estimator is consistent and asymptotically normal. Inoue and Solon (2010) provide inference for TS2SLS under the additional assumptions of homoskedasticity and equal moments of [
The additional assumptions on homoskedasticity and equal moments required in Inoue and Solon (2010) could be restrictive in applications. Pacini and Windmeijer (2016) provide TS2SLS inference that is robust to heteroskedasticity and unequal moments of excluded instruments and exogenous regressors, although their results are still not robust to weak instruments. In general, TS2SLS is valid only when the first-stage correlation between instruments and the endogenous regressor is strong.
Table 1 illustrates limitations of the TS2SLS strategy. The data-generating process (DGP) is taken from Choi, Gu, and Shen (2018), where
Table 1 reports the coverage rate of the 95% Inoue and Solon (2010) confidence interval (CI) among 5,000 simulation repetitions as well as the bias and root mean squared error of the TS2SLS estimator. The simulation results show that TS2SLS produces large biases and unreliable CI when the instruments are weak. The 95% CI could have coverage rate as low as 13.7% when there are many weak instruments (k = 10, λ/k = 1). The bias is generally negative when β = 2 and positive when β = −2 because TS2SLS suffers from a classic attenuation bias. The attenuation bias is also inversely proportional to the strength of instruments. See Choi, Gu, and Shen (2018) for more details.
Properties of TS2SLS under weak instruments

Note: Sample sizes are n1 = 5000 and n2 = 1000. Results are based on 5,000 simulation repetitions. The coverage results of the 95% Inoue and Solon (2010) CIs are also reported in Choi, Gu, and Shen (2018).
3 Weak-instrument robust methods
In the following, we introduce the weak-instrument robust inference method discussed in Choi, Gu, and Shen (2018). There are two versions of the method. A benchmark strategy uses the same set of assumptions as Angrist and Krueger (1992, 1995) and Inoue and Solon (2010), except for allowing for potentially weak instruments. The benchmark strategy requires both homoskedasticity and equal moments of excluded instruments and exogenous regressors across the two data samples. In contrast, a fully robust strategy is also considered that makes the two-sample IV inference robust to weak instruments as well as heteroskedasticity and unequal moments. In empirical applications, researchers might want to adopt the fully robust method for its generality and the benchmark method for a direct comparison with the classic Inoue and Solon (2010) results. Starting from this section, we follow the weak inference literature and assume, without loss of generality, that
Consider the weak IV asymptotic where the first-stage parameter π is a local sequence converging to zero:
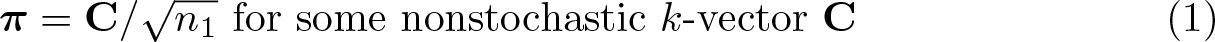
Under this asymptotic, the TS2SLS estimator is no longer consistent. In practice, researchers will consider adopting weak-instrument robust inference methods when the instruments are expected to have weak correlations with the endogenous regressor or when the sample size is small.
3.1 Benchmark weak-instrument robust tests and confidence sets
Let
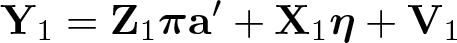
In this section, we follow Inoue and Solon (2010) and assume homoskedasticity and equal moments of [
Consider the two-sided null hypothesis H
0 : β = β
0 with some predetermined significance level α. Let

where
Further define test statistics

Under the weak IV asymptotic in (1) and when the null condition β = β 0 holds, one can show that in the limit, T 1(β 0) follows a χ 2(k) distribution and T 2(β 0) follows a χ 2(1) distribution. When k = 1, both T 2(β 0) and T 3(β 0) reduce to T 1(β 0). When k ≥ 2, the limiting probability of T 3(β 0) exceeding m is

under the null, where K = Γ(k/2)/[π
1/2Γ{(k − 1)/2}] and
Let q
1−α(k) be the (1 − α) quantile of the χ
2(k) distribution. Define the decision rules of the three statistics as “reject the null if T
1(β
0) > q
1−α(k)”, “reject the null if T
2(β
0) > q
1−α(1)”, and “reject the null if T
3(β
0) > q
1−α(1) when k = 1, and reject the null if
We call the test based on T 1(β 0) the two-stage Anderson–Rubin (TSAR) test, the one based on T 2(β 0) the two-stage Kleibergen (TSK) test, and the one based on T 3(β 0) the two-stage conditional likelihood-ratio (TSCLR) test. Note that when k = 1, all three tests give identical results. When k ≥ 2, TSCLR generally has better power performances than the other two methods, but there are also some DGPs where TSAR can outperform. See Choi, Gu, and Shen (2018) for details.
Given the proposed tests, the (1 − α) × 100% confidence sets for β can be obtained by inverting the corresponding tests. Define

The confidence sets have correct coverage in the limit because they are inverted from asymptotically valid tests under the weak IV asymptotics. When the instruments are weak, the confidence sets could be unbounded, which is an essential property for confidence sets to have correct coverage with arbitrarily weak instruments (Dufour 1997). The benchmark confidence sets are computed analytically following the fastcomputation method proposed by Mikusheva and Poi (2006) for the classic (one-sample) Anderson–Rubin, K, and conditional likelihood-ratio confidence sets.
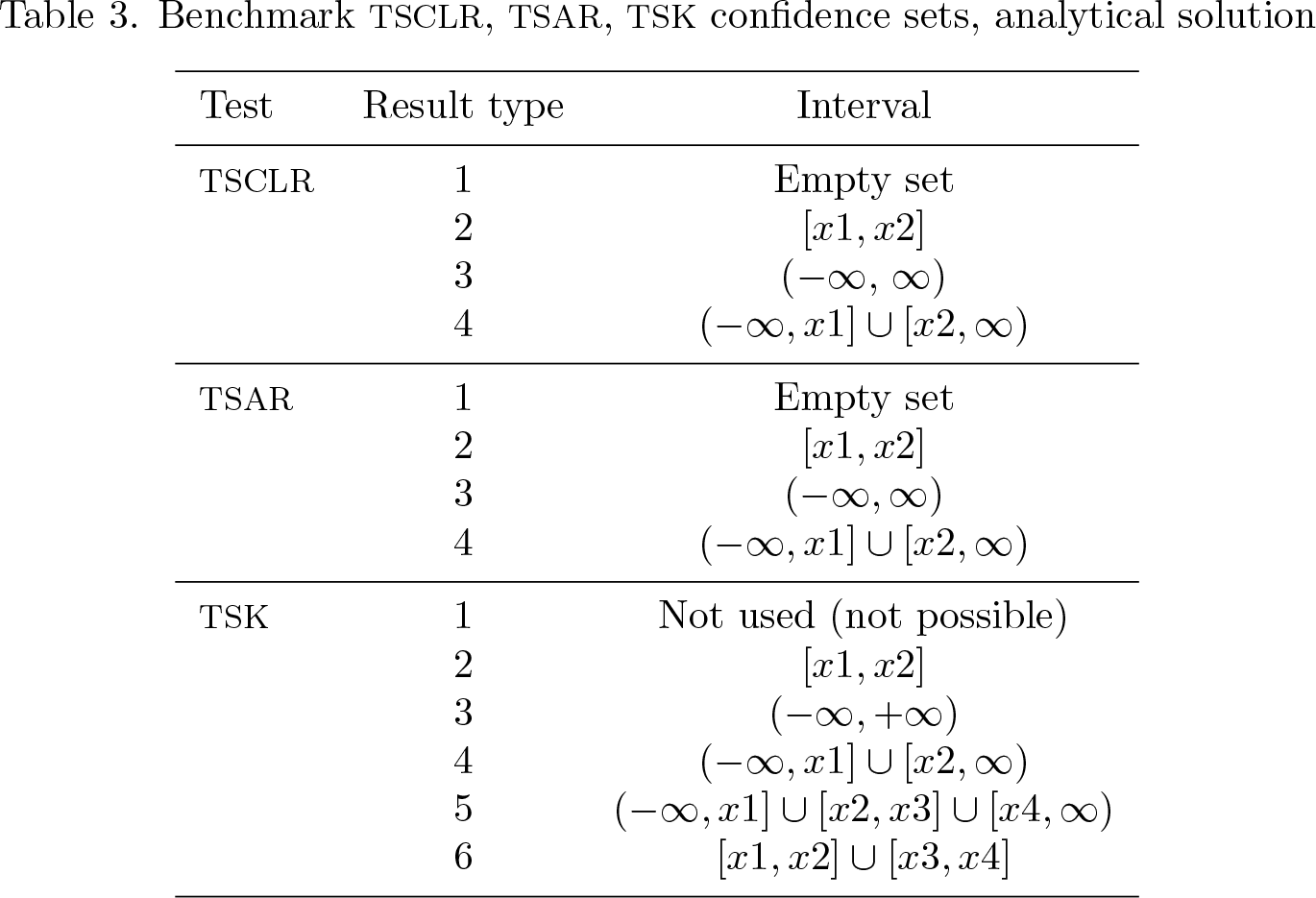
Like the classic K test, the TSK test also has an irregular nonmonotonic power curve when k ≥ 2, resulting in power loss with some DGPs. For confidence sets, TSK can take the form of a union of two finite intervals, that is, [x 1 , x 2] ∪ [x 3 , x 4], while TSAR and TSCLR confidence sets, conditional on boundedness, take only the usual form of a finite interval, or [x 1 , x 2]. Therefore, as with the classic one-sample case (see, for example, Mikusheva and Poi [2006]), the TSK method is generally not recommended in practice.
Table 2 is taken from panels A and B of table 1 in Choi, Gu, and Shen (2018). It uses the same DGP as the one discussed in section 2. Compared with the TS2SLS results reported in table 1, the proposed TSAR, TSCLR, and TSK confidence sets have targeted coverage rates regardless of instrument strength. Panel B of table 2 provides a rough idea about how often the proposed weak-instrument robust confidence sets could be unbounded given various instrument strengths. The panel also shows good power performance of TSCLR and irregular power performance of TSK under some DGPs.
Properties of benchmark weak-instrument robust confidence sets
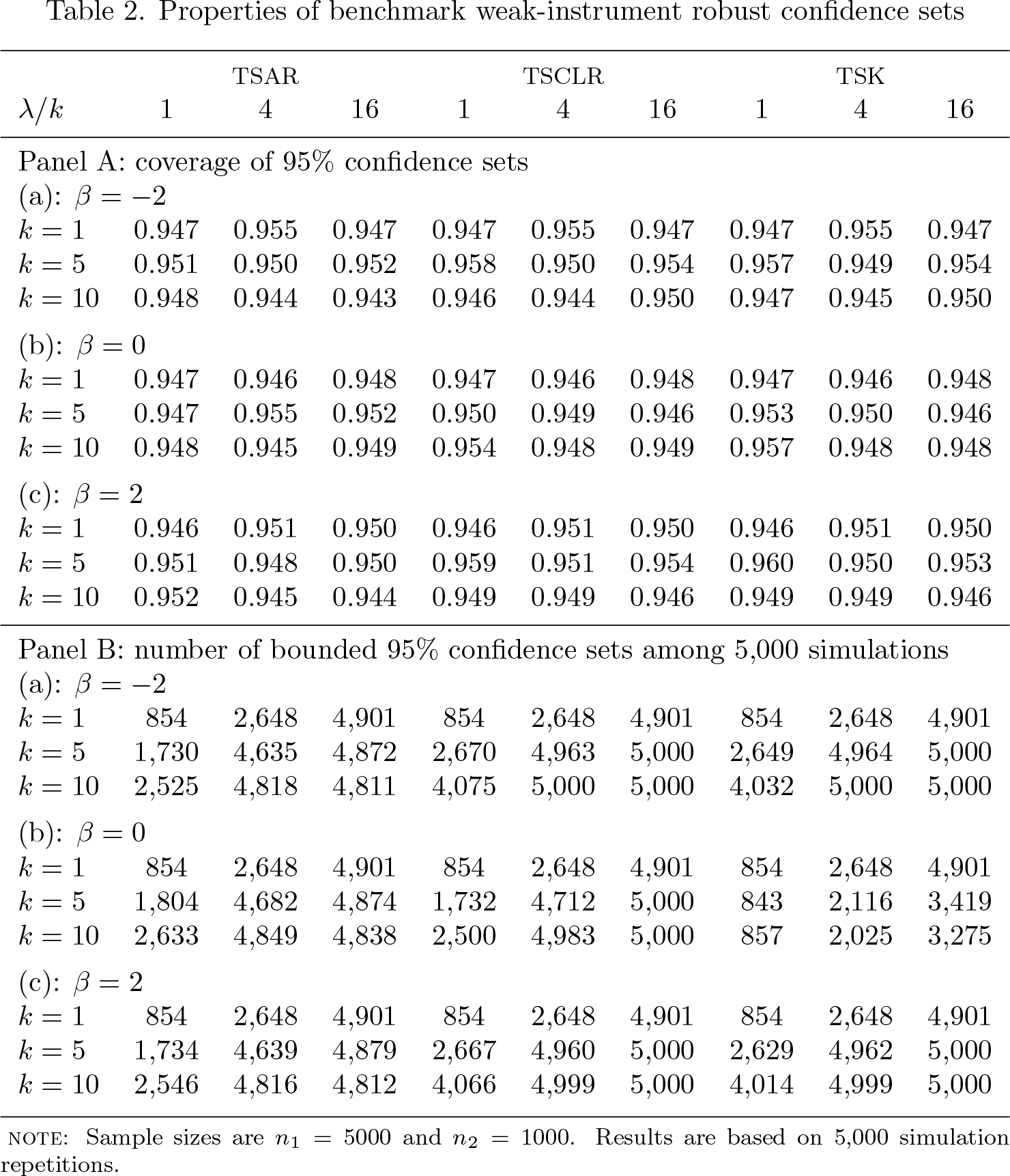
Note: Sample sizes are n1 = 5000 and n2 = 1000. Results are based on 5,000 simulation repetitions.
3.2 Fully robust tests and confidence sets
This section relaxes the assumptions of homoskedasticity and equal moments of excluded instruments and exogenous regressors. Let Σ
z,u
1 and Σ
z,
ε2 be probability limits of

Let

where
Following Magnusson (2010), the robust TSAR, TSK, and TSCLR test statistics for H 0: β = β 0 can be written as

where
Under the null hypothesis, T
1,robust(β
0) and T
2,robust(β
0) have limiting distributions χ
2(k) and χ
2(1), respectively, and T
3,robust(β
0) ⇒ (1/2)(χ
2(1)+χ
2(k−1)−q
β0+[{χ
2(1)+ χ
2(k − 1) + q
β0}2 − 4χ
2(k − 1)q
β0]1/2), where χ
2(1) and χ
2(k − 1) are independent chisquared distributed random variables with 1 and k − 1 degrees of freedom, respectively, given that
As with the benchmark case, one can construct robust TSAR, TSK, and TSCLR confidence sets of β by inverting the robust TSAR, TSK, and TSCLR tests. In the proposed command, these fully robust confidence sets are computed using a grid search. Specifically, we wrote our grid search codes based on the
4 Implementation
By default, the
The two-sample IV regression model requires the use of two data samples.
4.1 Syntax
depvar is the outcome variable.
varlist_exog is the list of exogenous variables.
varlist_endog is the endogenous regressor of the model.
varlist_iv is the list of exogenous variables used together with varlist_exog as instruments for varlist_endog.
4.2 Options
4.3 Stored results

For the benchmark methods, the stored type (that is,
Benchmark TSCLR, TSAR, TSK confidence sets, analytical solution
5 Example
5.1 The case with just-identification
We use the dataset of Currie and Yelowitz (2000) to illustrate implementing the command
The default
For the effects of public housing on monthly rental payments, the CI based on Inoue and Solon (2010) standard errors is [0.151, 0.592]. The weak-instrument robust CI is [0.214, 0.784], which is wider than the nonrobust one. The TSCLR CI is also centered farther away from zero than the TS2SLS CI likely because TS2SLS suffers from an attenuation bias and is biased toward zero. These CI results are also reported in column 1 of table 3 in Choi, Gu, and Shen (2018). The TSCLR CI reported here is slightly different from the one reported in Choi, Gu, and Shen (2018) because of different rounding methods in the two articles. R codes for the empirical applications in Choi, Gu, and Shen (2018) kept three significant digits after the decimal point for benchmark weak-IV robust confidence sets and two significant digits the fully robust confidence sets.

We emphasize that both CIs reported by the default command require the assumptions of homoskedasticity and equal moments. Next, we illustrate the use of the

5.2 The case with overidentification
Now we illustrate the
The following outputs are from the default setting of the

As discussed in Choi, Gu, and Shen (2018), the empirical example of Olivetti and Paserman (2015) is not suitable for heteroskedasticity-robust inference because their regression specifications result in perfect fit for a number of observations in either the first-stage or the reduced-form regressions. Therefore, heteroskedasticity-robust inference cannot be carried out for either TS2SLS or the proposed weak-instrument robust methods. To illustrate the use of our

6 Programs and supplemental materials
Supplemental Material, st0568 - Two-sample instrumental-variables regression with potentially weak instruments
Supplemental Material, st0568 for Two-sample instrumental-variables regression with potentially weak instruments by Jaerim Choi and Shu Shen in The Stata Journal
Footnotes
6 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.