
Abstract
In this article, I provide an overview of existing community-contributed commands for executing event studies. I assess which command could have been used to conduct event studies that have appeared in the past 10 years in 3 leading accounting, finance, and management journals. The older command
1 Introduction
Event studies represent a standardized method to measure and statistically assess stock price reactions to unanticipated events. For instance, Ball and Brown (1968) use this method to show that earnings surprises move stock prices. Fama et al. (1969) show that stock splits have a positive average impact on stock prices. Since the publication of these two seminal articles, event studies have become a workhorse method whenever researchers want to test whether any news event has an impact on stock prices. The scenarios range from dividend announcements (for example, Asquith and Mullins [1983]; Kane, Lee, and Marcus [1984]), mergers and acquisitions (for example, Capron and Pistre [2002]; Halpern [1983]), and changes in legislation and corporate litigation (for an overview, see Bhagat and Romano [2002a]; Bhagat and Romano [2002b]) to celebrity endorsement of products (for example, Agrawal and Kamakura [1995]), nuclear catastrophes (for example, Bowen, Castanias, and Daley [1983]; Hill and Schneeweis [1983]), and hurricanes (for example, Lamb [1998]).
In the past decades, several software solutions for conducting event studies have emerged, most notably the SAS®-based Eventus® software, which has been directly embedded into the Wharton Research Data Services (WRDS) platform and thus has become a gold standard for event studies that focus on U.S. firms. Nevertheless, probably because only top-ranked universities and other top research institutions have access to WRDS and Eventus, free event-study software packages in other programming environments (for example, R and Python) have become available. Also, Stata users can currently draw on three different community-contributed commands (in chronological order of their first appearance on the Statistical Software Components archive of the Boston College Department of Economics):
In this article, I analyze which of the three commands is suitable for which type of event study. My analysis reveals that the chronological order of appearance does not represent stages of evolution. Instead, each command is applicable to different types and tasks within the universe of event-study designs or has certain features that make it more or less suitable for specific types and tasks. The older command
My analysis is based on three pillars. First, I identify the conceptual characteristics of event studies. Instead of reiterating the statistical fundamentals of the event-study method, which have already been presented elsewhere (for example, Corrado [2011]; Kothari and Warner [2007]; MacKinlay [1997]), I focus on what conceptually constitutes an event study, that is, what researchers are aiming for when using this research design, and whether or how the three community-contributed commands meet these user demands. Second, I back my assertions by analyzing all event studies that have been published in three leading field journals: the Journal of Accounting Research, the Journal of Finance, and Management Science, during the period 2009–2018. Third, I assess the practical features and limitations of the three commands with respect to run time, consistency, and handling of thinly traded stocks.
My analysis does not focus on input and output routines because their usefulness is in the eye of the beholder, while test statistics, benchmark models, maximum sample sizes, and run times are established features. Note, though, that in my opinion the oldest command,
2 Conceptual characteristics of event studies and community-contributed commands
2.1 Elements of event studies
In this section, I outline my framework of the three core elements, three supplemental elements, and two overarching principles of event studies, which will allow me to evaluate which of the three community-contributed event-study commands are most suitable for which empirical setting. In this framework (see table 1), the event leads the ranking of core elements because researchers are typically interested in measuring the impact of a specific event type on stock prices, for example, earnings announcements, stock splits, or dividend cuts. The firm and the event date (time) have to be properly identified but pose a methodological challenge rather than being at the center of the research.
Elements and principles of event studies

Because firms per se are not important and the focus is on the event, stock price reactions are aggregated across firms to eliminate random variation in returns not associated with the event. This corresponds to the overarching principle of aggregation (Corrado 2011, 212). Nevertheless, the firm ranks second in my list of core elements because many event studies aim at identifying how the impact of an event depends on firm characteristics, for example, firm size, magnitude of earnings surprise (Collins and Kothari 1989), or audit quality (Teoh and Wong 1993). In fact, as my analysis in the next section will show, these cross-sectional type of studies constitute a majority (97 out of 180 sample articles). Firms as individual objects, however, are rarely the object of research interest, and stock price reactions are either measured on an aggregated basis or hypothesized to be in a functional (linear) relationship with firm characteristics.
Time ranks third because researchers are typically not interested in whether an event has an impact on stock prices on a particular calendar day. For instance, it is unlikely that a researcher wants to analyze whether a stock split affects stock prices differently when announced on March 3 compared with September 15. In fact, the event-study method invokes the concept of event time, which is a timeline relative to the event day. For instance, if a similar event took place for Firm A on March 3 and Firm B on September 15, calendar days March 2, 3, and 4 and September 14, 15, and 16 are redefined as days [−1], [0], and [+1], respectively. Thus, the researcher’s or his or her software’s first and very important task is to rearrange the stock return data and put them onto a common timeline that is relative to the event dates. This corresponds to the overarching principle of synchronization.
The event-study method distinguishes itself from a simple examination of stock returns by properly addressing the problem of confounding events and by defining test statistics (statistical hypotheses testing) that address various econometric issues. Confounding events are events other than the event of research interest that potentially impact stock prices. They can be of macroeconomic (affecting all firms to some extent) or firm-specific (presumably affecting only one firm) character. The event-study method is well designed to eliminate the impact of macroeconomic events without significant loss of observations. By calculating and assessing abnormal return relative to a market index or multiple-factor model, researchers can effectively address the effect of overall market movements on event firms’ stock returns (MacKinlay 1997, 17–20). For instance, researchers can effectively address the effects of unanticipated changes in interest rates or terrorist attacks without even identifying these events. However, the event study method is incapable of addressing firm-specific confounding events. Those have to be identified by the researcher and taken into account by modifying the sample selection, potentially leading to some loss of observations.
2.2 Software requirements
From the above-described elements of event studies, several desirable features of eventstudy software solutions can be derived. They should assist the user in transforming the event and stock return data from common databases such as WRDS/CRSP, Datastream, or Yahoo! Finance from calendar time to event time. To that end, the command should, based on a common stock identifier and a date variable, merge a list of events with a dataset of stock returns. It should then rearrange the data to achieve an event-time structure with the date variable taking a value of zero at the event date (synchronization). This data management task is very important because it can be very time consuming and prone to error if executed manually using spreadsheet software.
The second core task any complete event-study software can perform is the calculation of abnormal returns against a benchmark model. Standard benchmark models are the constant mean return (COMEAN) model, the market model with a single market index as benchmark, and factor models such as the Fama and French (1993) three-factor model. Further, the software should be capable of calculating cumulative average abnormal returns (CAARs) and buy-and-hold average abnormal returns (Barber and Lyon 1997).
The third feature an event-study software should have is the implementation of statistical testing to assess (cumulative) average abnormal returns against the null hypothesis of them being zero. In fact, most of the methodological literature on event studies centers on the specification and empirical power of different parametric and nonparametric test statistics such as the crude dependence-adjustment t test by Brown and Warner (1980, 1985), the Patell (1976) Z statistic, the Corrado (1989) rank test, the Boehmer, Musumeci, and Poulsen (1991) parametric test with correction for event-induced volatility changes, the Kolari and Pynnönen (2010) adjustment of the Boehmer, Musumeci, and Poulsen (1991) test for cross-correlation, and the generalized rank (GRANK) test for CAARs (Kolari and Pynnönen 2011).
The fourth desirable feature of an event-study software package is its ability to present results and other output. Test statistics and statistical significance level should be tabulated alongside (cumulative) average abnormal returns. Further, a graphical presentation of CAARs is desirable because this is a standard presentation format in journal articles. The event-study software should report on events that had to be excluded and the reasons for their exclusion. Cumulative abnormal returns (CARs) should be made available for cross-sectional analysis.
2.3 Features of community-contributed commands
Table 2 summarizes the features of the three community-contributed commands. Although
Features of community-contributed event-study commands
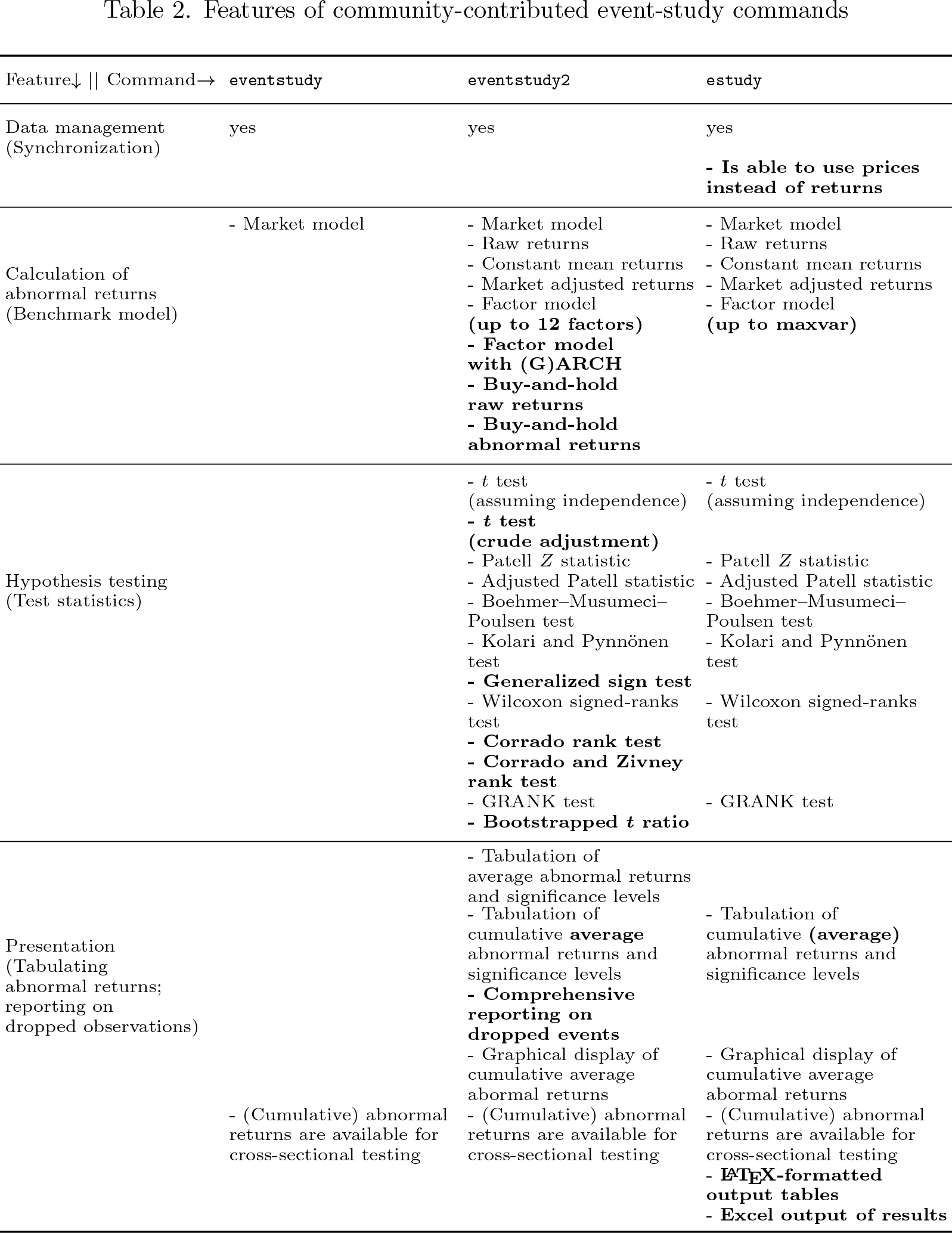
Table 2 also presents the differences in features of
The
To conclude my conceptual comparison of the three community-contributed commands, I clearly see the relative merits of the
3 Applicability to event studies in leading field journals
To substantiate my analysis of the usefulness of the three community-contributed eventstudy commands, I collect and analyze all studies that appeared between 2009 and 2018 in the Journal of Finance, Journal of Accounting Research, and Management Science and show which applied the event-study method either as their main method of analysis or as a tool to calculate abnormal returns for other purposes, for example, control variables. 1 The analysis in total comprises 180 articles, of which 55 appeared in the Journal of Accounting Research (17.5% of all articles that appeared in this journal during that period); 71 in the Journal of Finance (10.1%); and 54 in Management Science (3.0%). Thus, the event-study design can be considered one of the most prominent research methods in the journals’ domains.
To assess the level of applicability of the three community-contributed commands, I evaluate them against the journal articles across two dimensions: the benchmark model that has been used in the study to calculate abnormal returns and the test statistics that have been used; see table 3. If a community-contributed command supports all benchmark models and all calculations of test statistics that are applied in a journal article, I classify its level of applicability as “fully applicable” with respect to that study. If a command supports at least one of the applied benchmark models and at least one test statistic, I classify its level of applicability as “partially applicable”. If the command is neither fully nor partially applicable, I classify it as “not applicable” with respect to that study.
Applicability of community-contributed event-study commands

The information in this table is based on 180 articles published in the three journals between 2009 and 2018. The benchmark models and test statistics that are applied in these studies (see table 5 in the appendix) are then mapped to the features of community-contributed event study commands displayed in Table 2. If a command supports all benchmark models, all calculations of test statistics that are applied in a journal article, and the required data management tasks, its level of applicability is defined as “fully applicable” with respect to that study. If a command supports at least one of the applied benchmark models, at least one test statistic, and the required data management tasks, its level of applicability is defined as “partially applicable”. If the command is neither fully nor partially applicable, it is defined as “not applicable”.
The command
Some further descriptive statistics of the journal articles are of interest to evaluate how convenient the community-contributed commands are.
4 Practical limitations
4.1 Run time
Run time can represent a material constraint in applying event study commands. To compare the three community-contributed commands, I create sample datasets by extracting return data from CRSP for the period 2005–2014. I randomly assign one event date per firm and ensure that all return data are available during the estimation window beginning 249 and ending 11 trading days before the event date as well as during the event window ranging from 10 trading days before to 10 trading days after the event. On the event date, I add 0.05 to the return variable to simulate an event causing an abnormal return of 5%. Further, I add a randomly generated
3
market index return variable. To simulate run time, I randomly select subsamples between 50 and 2,050 events, in steps of 100, and 6 larger samples of 5,000, 10,000, 30,000, 60,000, 90,000, and 120,000 events. I use Stata/MP4 16 on an Intel Xeon Gold 6126 CPU with 2.60 GHz, 2 sockets, 24 cores, and 48 logical processors. Nevertheless, because Stata/MP 16 will use a maximum of four logical processors, the run times are not expected to differ materially from those on common desktop PCs. However, for testing
When one compares run times across community-contributed commands, it is important to recall some of their conceptual differences; see figure 1 for a visual comparison.
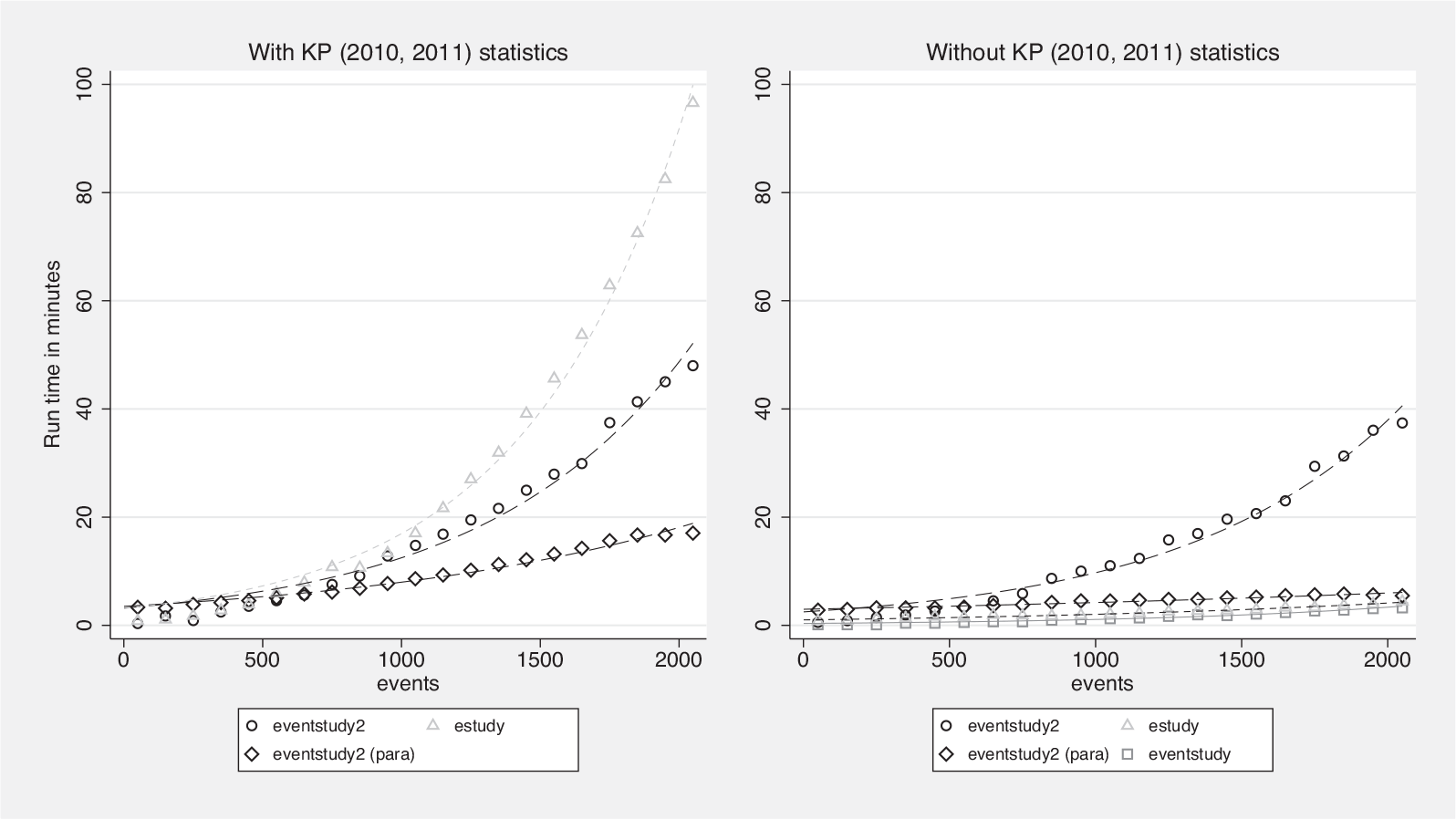
Execution times of event studies with 50 to 2,050 events
The left graph in figure 1 plots the run times for
The right graph in figure 1 shows the run time when
As I demonstrated in my analysis of published event studies in section 3, most event studies comprise more than only a few thousand events. Therefore, I record the run time in hours of the three community-contributed commands for studies with samples of 5,000, 10,000, 30,000, 60,000, 90,000, and 120,000 events, if feasible, in table 4. I measure run times with and without the calculation of the KP (2010, 2011) statistics (as in figure 1).
Run time in hours of community-contributed event-study commands

Most notably, my tests reveal that
Without being asked to calculate KP (2010, 2011) statistics,
To conclude on the issue of run time,
4.2 Consistency of results and thin trading
While calculation times, as demonstrated in the previous subsection, differ substantially across the three community-contributed event-study commands, the abnormal returns and test statistics they calculate should be consistent. To test this presumption, I use the previously described setting with 100 randomly selected event samples and repeat the analysis 100 times, each time using each of the 3 commands on the selected sample. I calculate CAARs for days [0], [1], [0; 1], and [−1; 1] as well as the KP (2010) statistics when using
However, in real-world settings, researchers commonly have to handle stock return data when stocks trade infrequently (thin trading). Let us assume the following scenario: a stock has a continuously compounded abnormal return of −2% on the event day [0] and +2% on the day after the event day [+1]. On the event day, however, the stock is not traded, which means that its abnormal return is not observable. The day after the event day, when the stock resumes trading, the observable abnormal return will be 0 because the closing price on this day will match the closing price on the day before the event day [−1]. How should an event-study command handle such situations? Ideally, it recognizes that the return observed on day [+1] is a cumulated return and excludes it from the calculation of the abnormal return on day [+1]. Nevertheless, it should include this return observation in the calculation of the CAARs, CAAR[0, 1]. Further, the missing return on day [0] should not be set to 0 but excluded from the calculation of the average abnormal event day return, AAR[0].
To get a better understanding of the ability of three community-contributed commands to handle thin trading, I artificially and randomly define half the event day [0] returns as thinly traded, which means that the return is compounded into the following day [+1] before being set to missing. Before introducing thin trading, I add a random return to the return on day [0] and subtract the same return on day [+1]. Thus, we know the true AAR[0] and AAR[+1] as well as that the CAAR[0, +1] and CAAR[−1, +1] are truly 0. Again, I perform 100 runs of 100 randomly selected samples using each of the three community-contributed event-study commands.
The upper left graph in figure 2 shows plots of measured average abnormal event day [0] returns on artificially induced abnormal returns. All three commands provide estimates that are close to the ideal 45
◦
-line through the origin and are thus unbiased. Thus, none of the three commands erroneously attributes a zero return to the missing return observations that result from thin trading or nontrading. However, the results differ with respect to day [+1] (upper right graph), where

CAAR calculation with thin trading on the event day
The lower left graph in figure 2 demonstrates that this error is mitigated in the calculating of CAAR[0, 1] by
To conclude, all three commands provide consistent results if thin trading is not present. If, however, thin trading is an issue and the return data are trade-to-trade returns, only
5 Conclusion
All three commands discussed in this article,
Finally, because I am often asked about that via email or most recently at the 2020 Stata Conference, I would like to briefly explain the differences between the three community-contributed commands and the Stata code that is offered at the Princeton University website.
6
The Princeton code is a very useful starting point for writing one’s own event-study code because it provides a good overview on how to initially organize the data. However, it does not provide any advanced hypothesis testing or input–output routines. Developing an event-study command takes years of intense work.
Footnotes
Acknowledgments
I thank Joe Newton (the editor) and an anonymous referee for their valuable contributions. I also thank the attendees of the 2020 Stata Conference and all users whose feedback has substantially improved this article and the
Notes
A Appendix
Below are tables of event studies in three leading field journals published during the period 2009–2018.