
Abstract
This article is primarily a replication study of Engle and Patton (2001, Quantitative Finance 1: 237–245), but it also serves as a demonstration of the time-series features introduced into Stata over the past two decades. The dataset used in the original study is extended from the end date of the original sample on 22 August 2000 to 1 August 2017 to examine the robustness of the models.
1 Introduction
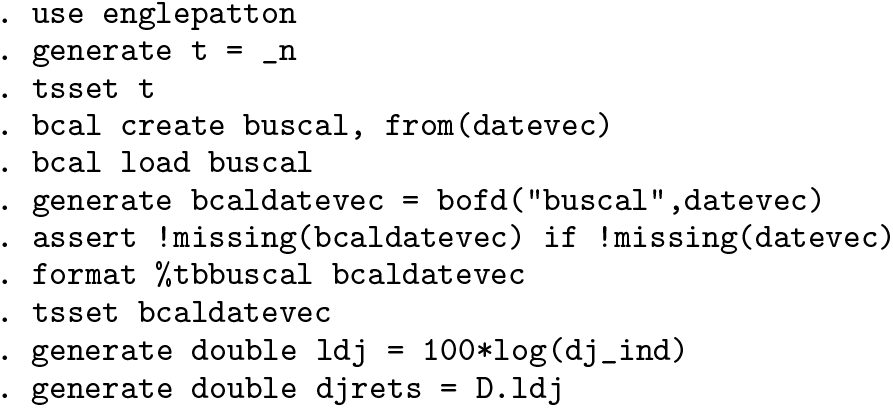
The aim of this project is to reproduce Engle and Patton (2001) “What good is a volatility model” 20 years after it was first published in Quantitative Finance. The data used in the original article (hereafter referred to as EP) consisting of the Dow Jones Industrial Average Index and the three-month U.S. Treasury Bill rate for the period 23 August 1988 to 22 August 2000 are available for download. 1 The sample is later extended to include data up to 1 August 2017. This classic article is a nice introduction to volatility modeling for students of financial econometrics and represents a good target for reproducible research. It is also a vehicle to demonstrate some of the time-series features introduced in Stata over these two decades.
In a seminal article that is regarded as the starting point of the discipline of financial econometrics, Engle (1982) introduced the concept of autoregressive conditional heteroskedasticity (ARCH) to model a time-varying variance using a simple linear model. A generalization of the model due to Bollerslev (1986) is known as generalized autoregressive conditional heteroskedasticity (GARCH). In its simplest form, the model is given by

The fundamental property of the model in (1), known as the GARCH(1,1) model, is that the conditional variance ht
is time varying with an autoregressive component, ht
−
1, and a component driven by unexpected events proxied by the squared disturbance in the previous period,
For illustrative purposes, we do not include additional terms in the mean equation for yt other than the constant term, µ; additional variables can be easily included. Similarly, the assumption of only one lag on both the squared error term, ut 2, and the conditional variance, ht − 1, is only for ease of exposition. Additional terms in ut 2 − 2 , ut 2 − 3 ,… could be added to the variance equation as well as additional autoregressive terms ht − 2 , ht − 3 ,…, leading to a GARCH(p, q) model.
The rest of this article is structured as follows. In section 2, we review the data used by EP and highlight the characteristics of financial returns that give rise to GARCH modeling. In sections 3 to 7, we reproduce and explore the results reported by EP in section 3 of their article. Finally, in section 8, we extend the EP dataset from 22 August 2000 to 1 August 2017. The original models stand up well to this extension of the sample period, despite now including episodes of severe turbulence in the stock market.
2 Summary of the data
The daily data are observed only on days when the Dow Jones Index trades. Simply using the dates provided to
Designated as
The percentage log returns on the Dow Jones Index (
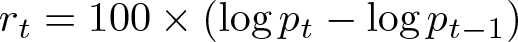
The summary statistics reported in EP table 1 are reproduced as follows:

Estimates of volatility models over varying horizons

As this table shows, the index had a small positive average return of about one-twentieth of one percent per day. The daily variance was 0.8253, implying an average annualized volatility of 14.42%. The annualized volatility is computed as
Figures 1 and 2 reproduce the daily index and returns, respectively. These figures illustrate many of the stylized facts about volatility alluded to in section 2 of EP.

The Dow Jones Industrial Index, 23 August 1988 to 22 August 2000

Returns on the Dow Jones Industrial Index, 23 August 1988 to 22 August 2000
1. From figure 1, it is apparent that the variance of the index changes over time as its growth is accompanied by ever-increasing swings. 2. Figure 2 displays volatility clustering in which periods of turbulence and periods of tranquility tend to cluster in time. The implication of such clustering is that volatility shocks today will influence the expectation of volatility many periods in the future. 3. Volatility is mean reverting. Mean reversion in volatility is generally interpreted as implying a normal level of volatility to which volatility will eventually return. Long-run forecasts of volatility should all converge to this same normal level of volatility, no matter when they are made. Thus, the volatility plot in figure 2 shows no trend. 4. Many proposed volatility models impose the assumption that the conditional volatility of the asset is affected symmetrically by positive and negative innovations. In the ARCH(1) and GARCH(1,1) models, for example, the variance is affected only by the square of the lagged innovation, disregarding the sign of that innovation. For equity returns, it is particularly unlikely that positive and negative shocks—“good news” and “bad news”—have the same impact on volatility. In figure 2, many negative returns are substantially larger than the largest positive returns. Assuming that these negative innovations are linked to bad news, it is reasonable to conjecture that bad news has a greater influence on volatility than does good news of a similar size.
Figure 3 presents the correlograms of the returns and the squared returns series, respectively. It is apparent from the correlogram of the returns that there is very little linear dependence in the series. This result is one of the important predictions of the celebrated efficient markets hypothesis (Fama 1970). Briefly, the efficient markets hypothesis states that current stock prices incorporate all relevant information so that all subsequent price changes represent random departures from previous prices. In an efficient market, therefore, the series of returns should show no time dependence. This result is in stark contrast to the correlogram of squared returns, where much stronger dependence is evident. This plot suggests that squared returns—and volatility—may be predictable.

Correlograms of returns and squared returns
3 A volatility model
The parameters of the GARCH(1,1) model in (1) are estimated by maximum likelihood in Stata using the

The starting value for the conditional variance ht
−
1 may be set in a few ways. The Stata default for

There are two issues of note with these results. The first is that the coefficient estimates obtained here do not quite match those reported in table 2 of EP. The EP estimates of
Estimates of the GARCH(1,1) models fit by EP using the extended data, 23 August 1988 to 1 August 2017. Robust standard errors are in parentheses.

‡ The ω coefficient in the GARCH(1,1)-X model enters the conditional variance in exponentiated form.
The second issue of note relates to the standard errors. The standard errors reported in table 2 of EP are significantly smaller than those reported by Stata. This observation is important and masks an issue that is sometimes glossed over. The maximum likelihood estimates of the parameters of the GARCH model, based on the assumption of Gaussian errors, are consistent even if the true distribution of the innovations is not Gaussian. However, the usual standard errors of the estimators are not consistent when the assumption of Gaussian errors is violated. If the parameters of the model are collected into the vector

where H(

When using the

The conditional expectation of the first derivative taken at t − 1 is
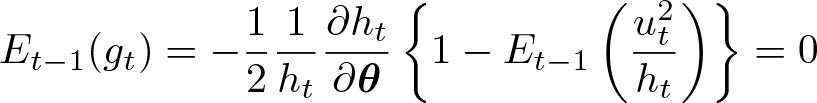
because the variance of standardized residual

requiring only the first derivatives. A consistent estimate of the matrix H(

The discrepancy between the standard errors is then probably due to the difference between the Bollerslev–Wooldridge approach that uses first derivatives and the full sandwich estimator used by Stata. 3
EP states that the choice of a GARCH(1,1) model is based on the Schwarz information criterion (SIC) after fitting GARCH(p, q) models and searching over p ∊ [1, 5] and q ∊ [1, 2]. The results of a similar search in Stata suggest that a GARCH(2,2) model gives the lowest SIC, which is then estimated.

The use of simple information criteria in the selection of GARCH models is known to be problematic (Brooks and Burke 2003). Without knowing exactly how EP computed the SIC, it is not possible to further explore the reasons for the discrepancy. 4 Looking at the parameter estimates of the GARCH(2,2) model, however, it seems that although the specification gives a better SIC it does not look particularly sensible, in that the absolute values of the second-order terms are close in magnitude to the first-order terms. Here, therefore, as in most empirical applications, the GARCH(1,1) specification or some variant of a GARCH(1,1) model is a safe option. In this regard, it is also important to consider the work of Hansen and Lunde (2005), who find that the forecasts of conditional variance obtained from this simple model are always difficult to beat.
The final issue EP deal with in this subsection is whether or not the model has captured all of the persistence in the squared residuals. They suggest examining the correlogram of the standardized squared residuals. If the model’s specification is adequate, the standardized squared residuals should be serially uncorrelated.
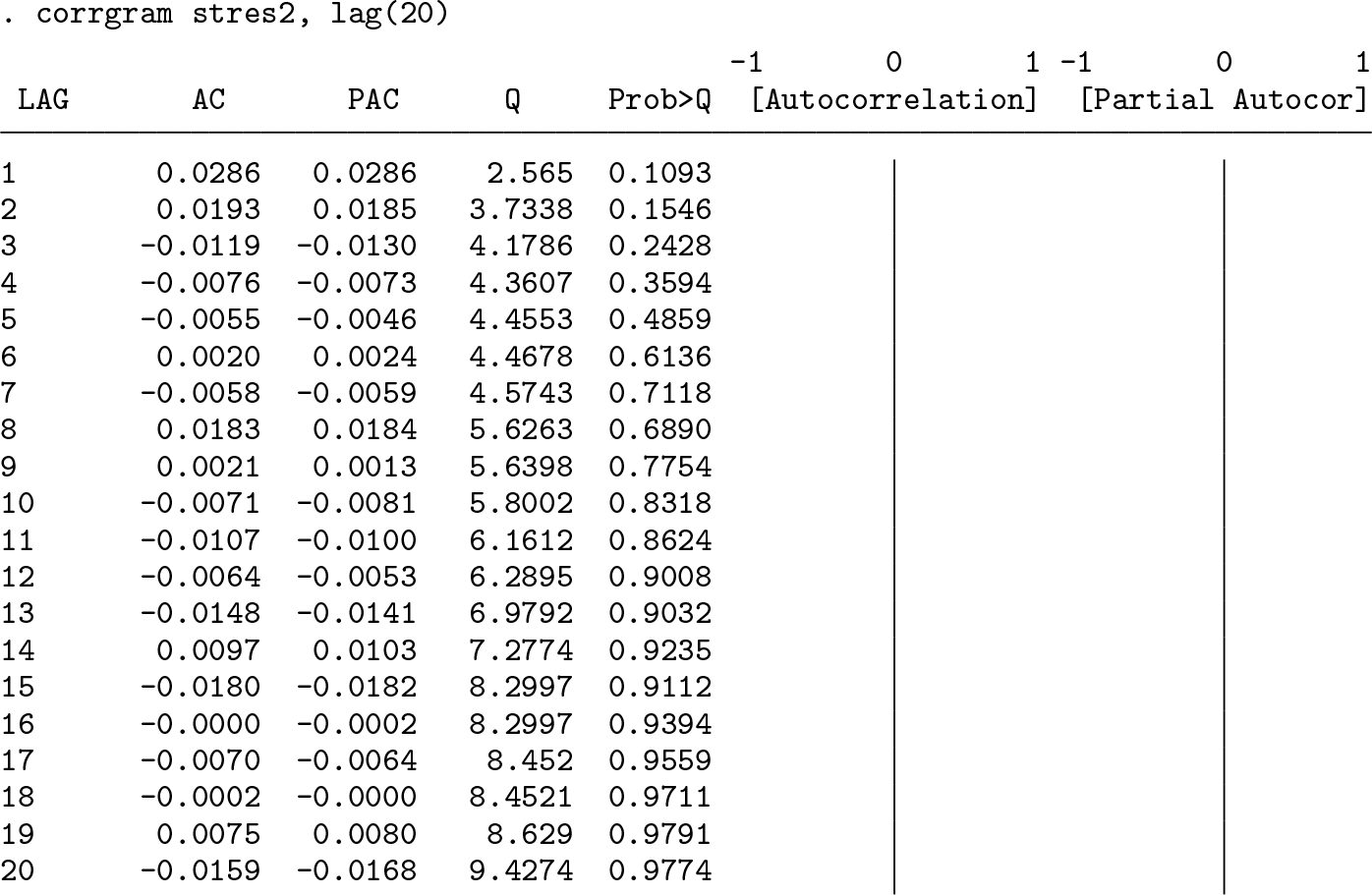
The Ljung–Box Q statistic at the twentieth lag of the standardized squared residuals is 9.4274, which is slightly different from the 8.9545 reported by EP. This slight difference is to be expected given that the parameter estimates and hence the standardized residuals differ slightly, but the overall conclusion holds: the standardized squared residuals are indeed serially uncorrelated.
4 Mean reversion and persistence in volatility
The results for the GARCH(1,1) model indicate that the volatility of returns is very persistent, with

where the long-run level to which volatility reverts is given by

A representation of the k-step-ahead mean-adjusted forecasting equation is given by (see, for example, Zivot [2009] for details)

Substituting (6) into the definition of HL in (4) gives

After simplifying and taking logs, a simple expression for the HL, k, is

The EP parameter estimates indicate an HL of 73 trading days, whereas the results reported here suggest an HL of about 84 trading days.
Notice that, from (6), it is apparent that as k → ∞, the volatility forecast tends to

Although the unconditional variance of an IGARCH(1,1) process does not exist, Lumsdaine (1996) shows that standard asymptotically based inference procedures are generally valid even in the presence of IGARCH effects. 5
The unconditional mean of the GARCH(1,1) process in (5) when calculated for the Dow Jones over the sample period turns out to be 0.8542, which implies that the mean annualized volatility over the sample was 14.77%.

This estimate is slightly different from the 14.67% reported by EP, but this is to be expected given the slight discrepancies in parameter estimates. A plot of the annualized conditional volatility estimates over the sample period is given in figure 4. The conditional volatility is very similar to that plotted by EP. In fact, to the naked eye, the plots are identical notwithstanding the slight differences in parameter estimates.

Estimated conditional volatility using a GARCH(1,1) model, August 1988– August 2000
The mean-reverting behavior of conditional volatility is evident in the patterns of dynamic forecasts of volatility. Following EP, dynamic forecasts of annualized daily volatility are produced starting at 23 August 1995 and 22 August 1997, respectively. The first of these forecasts was made at a date with unusually low volatility, and so the forecasts of volatility increase gradually to the unconditional level. The second forecast was made during a period of high volatility. The forecasts of volatility decrease slowly toward the unconditional level of volatility. Figure 5 demonstrates this pattern clearly. 6

Forecasts of daily return volatility using the GARCH(1,1) model
An alternative way of visualizing the mean reversion of volatility is in terms of figure 6 in EP. Our figure 6 below is based on Stata estimates of the GARCH(1,1) parameters and shows some differences with EP. In particular, the reversion to the mean in EP is not completed even within 200 days. In our figure, the adjustment is completed by about 150 days. The respective HL estimates based on the GARCH models are 73 days (EP) and 84 days (current estimate). Given the size of these half-lives, it seems more appropriate that the adjustment would be complete well before 200 days.

Illustrating mean reversion in the forecasts of daily return volatility using the GARCH(1,1) model
EP suggest examining the volatility of volatility by observing the behavior of the k-period-ahead forecast volatility for different choices of k. In figure 7 below, which is similar to figure 7 of EP, forecasts are presented for horizons of one week (5 days), one quarter (62 days), and one year (252 days). It is expected that the movements in volatility forecasts will become more muted as the horizon increases. At one year ahead, the volatility forecasts should approach the estimated mean obtained from the GARCH(1,1) model of 14.77%. These forecasts are constructed using (6) with the appropriate index k.

Forecast annualized volatilities for different horizons obtained from the GARCH(1,1) model. The solid horizontal line is the unconditional estimate of annualized volatility obtained from the fitted model of 14.77%.
Just as in the original EP article, it is immediately apparent that the movements at shorter horizons are larger than the movements at longer horizons. This pattern is an implication of the mean reversion in volatility.
5 An asymmetric volatility model
Based on the behavior of returns in figure 2, it was conjectured that the sign of the “news”, represented by the prior period’s residual, might influence the magnitude of the response in volatility. We can parameterize this concept in many ways, one of which is the threshold GARCH (or TARCH) model. This model was proposed by Glosten, Jagannathan, and Runkle (1993) and Zakoian (1994), motivated by the exponential GARCH model of Nelson (1991).
In Stata, the

where I(·) is the indicator function that takes the value 1 if (·) is true and 0 otherwise. This implies that the coefficients on the news will differ depending on whether news is good or bad:

The presence of the leverage effect in Stata’s TARCH model requires that the coefficient φ is negative so that bad news has a greater impact on volatility than good news. Asymmetric effects will be present if the estimated φ is statistically distinguishable from 0. This specification is the opposite of that used by EP who define the indicator function as I(ut − 1 > 0). To allow for non-Gaussian errors, we fit the model with a t distribution.

These results confirm the conclusion of EP that the sign of the news has a significant influence on the volatility of returns. The estimate of φ is negative and significant, with the effect on volatility summarized as follows:

In other words, bad news at time t − 1 increases the volatility at time t by 3.5 times as much as good news of the same magnitude. This is a similar effect to that found by EP whose reported leverage effect is about four times greater for bad news. The estimated degrees of freedom of 5.3 strongly rejects Gaussian errors.
6 A model with exogenous volatility regressors
Exogenous regressors are dealt with in Stata by using the

This specification allows the xt variable to take on any values on the real line, while ensuring that the parenthesized expression is strictly positive.
EP used the lagged level of the three-month U.S. Treasury Bill rate as an exogenous regressor in their model of returns, arguing that the Treasury Bill rate is correlated with the cost of borrowing to firms and thus may carry information that is relevant to the volatility of returns. Estimation of the model yields the following results:

The impact of the lagged Treasury Bill rate is significant but not quite as significant as the EP results suggest. The downside of the estimation of the model in this exponentiated form is that it makes direct comparison with EP difficult. Using the

The positive sign on ψ, the lagged Treasury Bill coefficient, indicates that higher interest rates are generally associated with higher levels of volatility of equity returns. This result is taken to confirm those reported by Glosten, Jagannathan, and Runkle (1993), who also find that the Treasury Bill rate is positively related to equity return volatility. The problem, however, is that the coefficient estimate of ψ is insignificant. The problem seems to stem from the standard errors: the coefficients are similar to those reported by EP but the robust standard errors are much larger. Reestimating and using standard errors from the outer product of gradients matrix yields results very similar to EP.


It seems, therefore, that the standard errors reported in table 5 of EP are not robust.
On reflection, to counter the argument that Stata’s convention for dealing with exogenous variables is not as transparent as a simple linear form, there are at least two advantages to the exponentiated form of the
1. The contribution of the exogenous regressors is constrained to be positive. There is, therefore, no instance in which a particular combination of the value of the exogenous variable and its coefficient can cause a negative variance to occur. 2. Imposing this restriction has teased out a significant coefficient on the exogenous regressor when using robust standard errors, a result that is elusive if the nonexponentiated form is used.
7 Aggregation of volatility models
Volatility clustering and non-Gaussian behavior in financial returns is typically seen in weekly, daily, or intraday data. In the final subsection of their empirical example, EP provide evidence consistent with the theoretical result that the empirical results obtained are dependent on the sampling frequency. However, as shown in Drost and Nijman (1993), for GARCH models there is no simple aggregation principle that links the parameters of the model at one sampling frequency to the parameters at another frequency. This means that if a GARCH model is correctly specified for one frequency of data, then it will be misspecified for data with different time scales.
EP fit the simple GARCH(1,1) model on the data, sampled at different frequencies, and compute the HL for each of the models. The results are presented in table 1. While the results indicate that the sampling frequency affects the results in terms of coefficient estimates and HL, they also show that the original estimates presented in EP are quite different from those presented here.
Clearly, these are substantial differences, and while their statistical significance has not been assessed, there is some question as to why the original EP HL estimates are not monotonically increasing; in theory, the persistence of conditional volatility increases with the sampling frequency.
8 Updating the data
To examine how well the volatility models have stood the test of time, the daily dataset for the Dow Jones Index and the U.S. Treasury Bill used in EP are updated to include data to 1 August 2017. The summary statistics for the extended data are as follows.

The small positive average return on the Dow Jones is now even smaller, and the variance is larger. The daily variance of 1.0756 implies an average annualized volatility of 16.46%, which is substantially larger than the 14.42% recorded previously. The returns exhibit slightly less negative skewness but substantially more kurtosis. These changes in summary statistics are consistent with the period of dramatic turbulence experienced during the global financial crisis of 2007–2009.
Table 2 reports the parameter estimates of the three main volatility models fit by EP: the GARCH(1,1), the TARCH(1,1), and the GARCH(1,1)-X with the three-month U.S. Treasury Bill rate used as an exogenous regressor in the conditional variance equation. Robust standard errors based on the Huber/White/sandwich estimator are also reported.
Overall, the models stand up to estimation on this extended sample remarkably well. Several points of interest evident in these estimates are worth mentioning. Turning first to the GARCH(1,1) model, the persistence of the conditional variance is slightly reduced, with the sum of the ARCH and GARCH coefficients now equal to 0.9854, as opposed to 0.9917 in the original sample. This result reflects the extreme swings of volatility experienced during the crisis period. Contrary to the results reported for the original sample, the sum of α and β in the GARCH model is now significantly less than 1.

The unconditional mean of the GARCH(1,1) process when calculated for the updated Dow Jones returns data is 15.89%.

This increase in the value of the unconditional mean is also as expected given the effect of the crisis on return volatility.
The second point of interest is that the leverage parameter φ is once again negative and statistically significant. Furthermore, the size of the effect is approximately doubled from −0.0609 to −0.1240. The preponderance of bad news during the extended sample period appears to have magnified the leverage effect.
Finally, the estimate of the coefficient γ on the Treasury Bill rate in the GARCH(1,1)-X model is now found to be insignificant, even in the exponentiated specification adopted by Stata. This accords with intuition, because for a large part of this extended sample, short-term interest rates were at or near the 0 lower bound.
A plot of the annualized conditional volatility estimates over the sample period is given in figure 8. It is interesting to note how the peak of the conditional variance during the global financial crisis makes the previous peaks during the earlier sample around the dot-com bubble look rather modest.

Estimated conditional volatility using a GARCH(1,1) model on the extended dataset, 23 August 1988–1 August 2017
Although no forecasting exercise is undertaken, the conditional variance is strongly mean reverting with an estimated HL of 47 days. This estimate is almost half of the estimate for the earlier sample and is indicative of a more powerful dynamic process for the conditional variance.
9 Conclusion
The aim of the original EP article was to characterize a volatility model in terms of its ability to forecast volatility and also to capture the stylized empirical facts about conditional volatility. Their article succeeds in doing this and also provides an accessible and useful introduction to volatility modeling. In terms of reproducibility, the results reported by EP stand up well to scrutiny and bring out some differences that prompt thought, particularly with respect to computing standard errors in GARCH models. Interestingly, the GARCH(1,1) model fit on updated data is very similar in terms of coefficient estimates, although the conditional variance process appears to be substantially less persistent when estimated over the longer sample. The model performs well in capturing the volatility around the global financial crisis and the turbulence in the markets during that period.
10 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025797 - “What good is a volatility model?” A reexamination after 20 years
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025797 for “What good is a volatility model?” A reexamination after 20 years by Christopher F. Baum and Stan Hurn in The Stata Journal
Footnotes
10 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.