
Abstract
Recentered influence functions (RIFs) are statistical tools popularized by Firpo, Fortin, and Lemieux (2009, Econometrica 77: 953–973) for analyzing unconditional partial effects on quantiles in a regression analysis framework (unconditional quantile regressions). The flexibility and simplicity of these tools have opened the possibility to extend the analysis to other distributional statistics using linear regressions or decomposition approaches. In this article, I introduce one function and two commands to facilitate the use of RIFs in the analysis of outcome distributions:
Keywords
1 Introduction
Influence functions (IFs) are statistical tools that have been used for analyzing the robustness of distributional statistics, or functionals, to small disturbances in data (Cowell and Flachaire 2007) or as a simplified strategy to estimate asymptotic variances of complex statistics (Cowell and Flachaire 2015; Deville 1999). More recently, Firpo, Fortin, and Lemieux (2009) suggested the use of IFs—specifically, recentered influence functions (RIFs)—as tools to analyze the impact that changes in the distribution of explanatory variables, X, has on the unconditional distribution of Y.
The method introduced by Firpo, Fortin, and Lemieux (2009) focused on the estimation of unconditional quantile regression (UQR), which allows the researcher to obtain partial effects of explanatory variables on any unconditional quantile of the dependent variable. The simplest version of this methodology, referred to as RIF–OLS (ordinary least squares), is easily implemented using the community-contributed command
After its introduction, UQR became a popular method for analyzing and identifying the distributional effects on outcomes in terms of changes in observed characteristics in areas such as labor economics, income and inequality, health economics, and public policy. The potential simplicity and flexibility the methodology offers for the analysis of any distributional statistics also motivated subsequent research to expand the use of RIFs in the framework of regression analysis.
In a recently published article, Firpo, Fortin, and Lemieux (2018) discuss the application of RIF regressions for the variance and Gini coefficients, with emphasis on the generalization of the OB decomposition using RIFs.
2
Borgen (2016), building on the work of Firpo, Fortin, and Lemieux (2009), provides the command
Cowell and Flachaire (2007), for their analysis on the sensitivity of inequality measures to the presence of extreme values, provide IFs for the most commonly used inequality indices, including the Atkinson index, generalized entropy index, and logarithmic variance index. Essama-Nssah and Lambert (2012), who discuss the use of RIF regressions and OB decompositions for the analysis of distributional changes, provide a large set of IFs and RIFs for distributional statistics relevant for policy analysis, including Lorenz and generalized Lorenz ordinates; Foster–Greer–Thorbecke (FGT) poverty indices; and Watts and Sen poverty indices. Most recently, Heckley, Gerdtham, and Kjellsson (2016) examine the use of RIFs for measures of health inequality, with emphases on bivariate rank-dependent concentration indices.
While RIF regressions and RIF decompositions have become important analytical tools in the empirical literature, there are only limited attempts to provide a simplified framework to allow the use of RIFs as a standard analytical tool. Within Stata, only the community-contributed command
In this article, I introduce one function and two commands that aim to facilitate the use of RIFs for regressions and decomposition analysis. The first function,
The rest of this article is structured as follows. Section 2 overviews what IFs are and how they are estimated. Section 3 introduces and explains the use of
2 RIF and distributional statistics
2.1 Distributional statistics: Basics
When analyzing social welfare, inequality, poverty, or any other measure that describes the distributional characteristics of an outcome of interest, it is necessary to have access to one of the following pieces of information. The most common scenario is to have access to the full set of values corresponding to each observation in the population or sample. If the population or sample is of finite size n, it can be referred to as Y = [y 1 , y 2 ,…, yn ], where each yi is the outcome of interest (for example, income) of the ith person.
The second scenario is where we know the distribution of the outcome, based on either the cumulative distribution function (c.d.f.) or the probability distribution function (p.d.f.). Using the function FY (·) to refer to the c.d.f. and fY (·) to the p.d.f., the vector of information required for analyzing distributions can be more briefly written as a set of ordered pairs, FY = [{y, FY (y)}|y ∊ ℝ] or fY = [{y, fY (y)}|y ∊ ℝ], where y represents any real number (generally positive when referring to income). 5 This simply means that if one has access to any of these vectors of information (Y, FY, fy ), any distributional statistic can be derived.
Let us call v(·) a functional that uses all the information contained in Y, FY , or fY to estimate a distributional statistic of Y. This functional can be used to estimate statistics relevant to policy analysis, such as the mean, qth quantile, poverty indices, or inequality indices. To measure the impact a change in the distribution of income will have on the distributional statistic, one can simply compare the indices by swapping the c.d.f. from the observed distribution FY to the ex-post distribution GY . 6 This can be written as follows:

Thus, Δv is the change in the distributional statistic generated by the change in distribution from Fy → Gy . This change can be as large as implying that everyone in the population receives a fixed transfer (shifting the function Fy (·) to the right) 7 or as simple as having a new person (with random income) added to the sample, changing the rankings of everyone in the sample. The first scenario is a simplified example of what DiNardo, Fortin, and Lemieux (1996) used for analyzing changes in the distribution of wages. The second scenario is an exercise that can be used for understanding the definition of IFs and RIFs.
2.2 Estimations of IFs and RIFs: Gâteaux derivative
The thought experiment of adding a new person to a sample can also be considered as a case of data contamination in the original distribution, and (1) can be used to estimate the influence of this thought experiment on the statistic v. Standardizing the change in the statistic Δv with respect to some measure that quantifies the change of the distribution [Δ(GY − FY )] provides a quantification of the rate of change of the statistic v associated with the change of the distribution of Y from FY → GY .

This process can be extended to measure Δ sv for an infinitesimally small change in the distribution function from FY → GY . This idea is what lies behind the Gâteaux derivative, which is a generalization of the directional derivative of a functional. The derivative is used to construct IFs, which can be used as measures of robustness of functionals to data outliers (Hampel 1974) and which facilitate the visualization of the structure of the distributional statistic as a function of the available data. Before we proceed to the formal definition of the IF, it would be useful to formalize the thought experiment just described.
Assume that the observation to be introduced in the sample has an income equal to yi . Because this is the only element of that distribution, its c.d.f., Hy i (y), can be characterized as follows:

This indicates that the distribution Hy i puts mass only at the value yi . 8 With this definition, the distribution GY can be redefined as a combination of the distributions FY and Hy i :

ε is strictly smaller than 1 but larger than 0. In other words, GY is the resulting distribution when the original distribution FY changes in the direction of Hy i . This transformation can also be thought of as a contamination or perturbation of the distribution FY in the direction of Hy i . Equation (2) also helps quantify the magnitude of the change in the distribution when moving from FY → GY (simply, ε). Figure 1 provides a graphical example of the changes we would observe as a result of this contamination of the distribution function FY .

Comparison between original and contaminated distributions. note: The figure represents the contamination of the original distribution using ε = 0.2.
With this last concept in place, we can finally provide the formal definition of the IF:

The IF is a directional derivative that shows the rate of change of the distributional statistic v caused by an infinitesimally small change in the distribution Fy in the direction of Hy i . It can also be interpreted as the influence that observation yi has on the estimation of the distributional statistic v. Take the distributional statistic mean as an example. The statistic and its IF are defined as follows:

The IF indicates that if the distribution Fy were to be contaminated, adding more weight to observations with income yi , the mean would change at a rate of yi −µy . If the change in the distribution is ε, the change of the mean would be Δµy = ε×IF {yi, v(FY )}. Note that the IF will be different for each point of reference yi (contamination point) used for its estimation.
Instead of using the IF directly, Firpo, Fortin, and Lemieux (2009) propose using the recentered version of the statistics, the RIF, which is equivalent to the first two terms of the von Mises (1947) linear approximation of the corresponding distributional statistic v:

This expression can be loosely interpreted as the relative contribution that observation yi has on the construction of the statistic v. It can also be interpreted as an approximation of the statistic v after considering the influence of observation yi . Returning to the example of the mean, the RIF(yi, µF y ) is defined as the observation itself, yi , and it is easy to see that yi is the relative contribution that observation i has on the construction of the mean.
As discussed in Firpo, Fortin, and Lemieux (2009); Cowell and Flachaire (2015); and Essama-Nssah and Lambert (2012), the IF and the RIF have the following properties:




Equation (4) implies that the expected value of IFs constructed using all values of yi is equal to 0. Because of this property, (5) implies that the expected value of RIFs is equal to the distributional statistic itself. Equations (6) and (7) indicate that the asymptotic variance of any statistic can be obtained by estimating the variance of the IF or the RIF based on sample data.
As shown in (3), choosing between IFs or RIFs as dependent variables has no impact in terms of regression analysis other than changes in the intercept in the case of RIF–OLS. This happens because IFs and RIFs are equivalent to each other up to a constant. The advantage of using RIFs, as shown in (5), is that one can use them to recover the underlying distributional statistics using simple averages. This property facilitates the interpretation of RIF regressions and enables the implementation of decomposition analysis.
3 Estimating RIFs: rifvar() egen function
The estimation of RIFs is a task of variable complexity. Some statistics have simple mathematical expressions that require few lines of code to define the corresponding RIF. The easiest example is the RIF for the mean because the RIF mean for any value yi is simply itself. However, other statistics may require many intermediate steps to correctly define their corresponding RIFs.
The community-contributed command
The syntax of the command is as follows:
where varname is the variable being analyzed and newvar is the new variable name where the RIF will be stored, given the restrictions set by
RIF_options allow the user to specify which distributional statistics are used to obtain the RIF statistic. Table 1 provides a detailed list of the statistics that are currently available for estimation. In appendix B, I provide a summary of performance simulation to show how well the RIF standard errors approximate the simulated standard errors for all of these statistics.

* In contrast,
4 RIF regression: rifhdreg
4.1 Standard RIF regression
As previously indicated, IFs and RIFs have been used in statistics as tools for analyzing the robustness of statistics to outliers and as methods to draw statistical inferences from complex statistics (Cowell and Flachaire 2015; Deville 1999; Efron 1982; Hampel 1974). A recently popularized use by Firpo, Fortin, and Lemieux (2009); Heckley, Gerdtham, and Kjellsson (2016); and Essama-Nssah and Lambert (2012) is the estimation of RIF regressions.
Firpo, Fortin, and Lemieux (2009) use this strategy to estimate unconditional partial effects (UPE) of small changes in the distribution of the independent variables
Assume there is a joint distribution function dFY,X
(y,


These expressions simply state that the unconditional c.d.f. (and p.d.f.) of Y can be obtained by integrating the conditional distributions FY
|X
(·) (averaging) across all the realizations of

Next assume that one is interested in analyzing the distributional statistic v(FY ). Based on (8) and (5), respectively, the statistic v can be rewritten as


An intuitive interpretation of (11) is that any distributional statistics v can be written as the average of the RIFs weighted by the joint distribution dFY,X
(y,
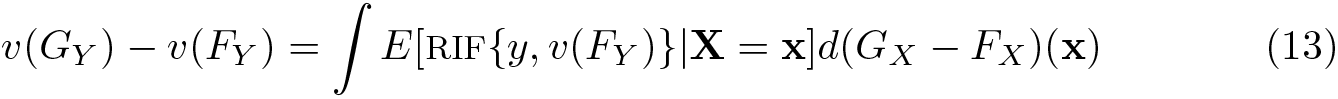
Equations (12) and (13) also imply that if E[RIF{y, v(Fy
)}|
Following Firpo, Fortin, and Lemieux (2009), the simplest approach to estimate RIF regressions is to assume a linear relationship between RIF{y, v(Fy
)} and the explanatory variables
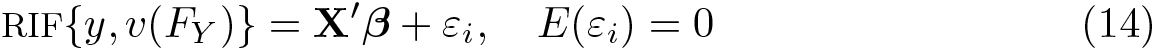
While the use of OLS directly relates the RIF regression to standard regression analysis, some differences in the interpretation exist. In the standard OLS, the typical interpretation of the coefficients is that a one-unit increase in
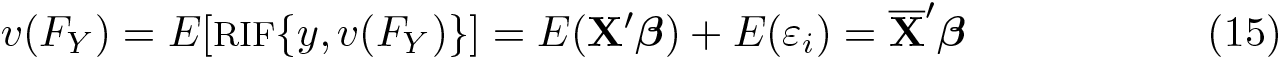

Based on (16), the correct interpretation of the UPE is that if the distribution of xk
changes such that its unconditional average increases by one unit

Taking the unconditional expectations, one obtains the following:

The UPE is now a function of two moments of the unconditional distribution of X, the mean and the variance.
16
An advantage of introducing the term
The estimation of RIF regressions in Stata, under the linearity assumption, is easily implemented using the community-contributed commands
For the estimation of RIF regressions under both scenarios, I introduce the command
The main difference between the
When
Based on the recommendation provided in Firpo, Fortin, and Lemieux (2009) and the simulations presented in appendix A, bootstrap standard errors should be used when the statistics of interest are the unconditional quantiles or statistics related to unconditional quantiles, or at the very least, robust standard errors should be requested.
19
The reason for this is that RIFs for unconditional quantiles require the estimation of density functions, which are taken as known parameters for the estimation of asymptotic standard errors. For the correct estimation of bootstrap standard errors, one should use the
To illustrate the use of this command for the estimation of RIF regressions, table 2 provides the output of RIF regressions for selected distributional statistics, using an excerpt from the Swiss Labor Market Survey available online. 21 For simplicity, only years of education, years of experience, years of job tenure, sex, and single status are used as explanatory variables. At the bottom of the table, the average RIF is reported as a reference point for the UPE interpretation. Three forms of standard errors are reported: the default or OLS standard errors, robust standard errors, and bootstrap standard errors based on 500 repetitions. The estimation corresponding to the Gini rescales the parameters by 100 to help with the interpretation of the estimated coefficients. All interpretations are given in relative terms with respect to the current levels of inequality to make the results comparable across inequality measures.
Determinants of wage inequality

∧ p < 0.1
+ p < 0.05
* p < 0.01
In terms of the standard errors, as expected, OLS standard errors tend to be smaller than robust standard errors for most of the explanatory variables across all models. Bootstrap standard errors, which Firpo, Fortin, and Lemieux (2009) indicate to be the most appropriate for statistical inference, are considerably larger for the regressions that involve quantile statistics. Consistent with the results from the RIF simulations, however, bootstrap errors are similar to the robust standard errors for regressions that focus on the Gini coefficient and variance of log wages. 22
All models have consistent results with different insights for different measures of wage inequality. If the average number of years of education in the population were to increase by one year, the predicted Gini coefficient would drop by just over half a point (2.32% in relative terms), the variance of log wage would drop by 12.7% (−0.036/0.2818), and the ratio of wages held by the richest 10% compared with the poorest 10% by 14.2% (−0.86/6.0285). The log wage gap and wage ratio between the 90th quantile and 10th quantile may also decline, but the change is not statistically significant. Increasing the number of years of experience seems to reduce wage inequality, whereas aging of the population may have a small effect by increasing the gap between the top and bottom of the wage distribution. This is not observed for other statistics that look across the wage distribution.
Perhaps one of the most challenging variable types to interpret in terms of UPE is categorical variables. On one hand, because RIF and standard RIF regressions are meant to estimate the impact of small changes in the distribution of the independent variables, one should not interpret the coefficients of categorical variables as changes from 0 to 1. Otherwise, the exercise implies a large change in the distribution of the categorical variable, from 0% of observations being classified in that group to 100% being classified in that group, which may introduce a large bias on the predicted UPE. 23 On the other hand, based on (15) and (16), one should analyze the UPE as deviations from the observed unconditional averages. For example, if the proportion of women in the population would increase by 10 percentage points, from 47.6% as currently observed to 57.6%, the ratio of wages held by the richest 10% to the poorest 10% would increase by 2.3% (1.437/6.0285 × 0.1) and the predicted Gini coefficient would increase by 1.4% (3.502/24.603 × 0.1).
To illustrate the capabilities of the
Determinants of wage inequality

notes: Standard errors in parentheses.
All models include age, occupation, and single status fixed effects.
∧ p < 0.1
+ p < 0.05
∗ p < 0.01
In this example, controlling for the age and occupation fixed effects is effectively controlling for all linear and nonlinear relationships these variables have with the dependent variable. In this case, the results suggest that increasing the average number of years of education by one year may increase inequality by about 2.9% regardless of the measure of inequality and holding everything else constant. In contrast, if the number of years of experience increases by one unit, inequality would decline between 1.3% to 2.7%, depending on the inequality measure. Also consistent with the results in table 2, if the proportion of women in the sample increases by 10 percentage points, then inequality measured by the interquantile share ratio, the Gini coefficient, and the log variance will increase by 1.4% to 3.3%.
4.2 Inequality treatment effects: Advanced options
As previously described, standard RIF regressions should not be used to estimate the effect of large changes in the distribution of the independent variables, particularly when considering categorical variables. In fact, Essama-Nssah and Lambert (2012) emphasize that one of the main weaknesses of RIF regressions is that coefficients provide only local approximations of the effect of changes in the distribution of the independent variables.
In an attempt to address this weakness, other studies in the literature, including Rothe (2010), Donald and Hsu (2014), Firpo and Pinto (2016), and Firpo, Fortin, and Lemieux (2018), have proposed methodologies for the estimation of what Firpo and Pinto (2016) call inequality treatment effects. In essence, these methodologies use parametric or nonparametric strategies to obtain inverse probability weights that can be used to identify counterfactual distributions and identify the treatment effects on distributional statistics. Paraphrasing Firpo and Pinto (2016), the estimation of inequality treatment effects can be described as follows.
Assume there is a joint distribution function

Empirically, both potential outcomes are never fully observed. Instead, one is able to observe only the realized outcome depending on whether an individual is in part of the treated group:

According to Firpo and Pinto (2016), under the assumption that the distribution of potential outcomes Y
1 and Y
0 are independent from treatment assignment when conditioning on observed characteristics
Recall from (9) that the unconditional c.d.f. can also be written by integrating (averaging) the conditional distributions with respect to

Based on the unconfoundedness assumption, we know that
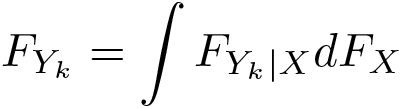
As indicated before, the full distribution of the potential outcomes is never observed. Instead, only the distribution of the realized outcome after treatment has been assigned is available. Using the unconfoundedness assumption again, the observed distribution of the outcome among individuals who are treated and untreated can be defined as

which considers only observations that are in the treated or untreated group. Because the distribution implied by (20) is fully observed, it can be used to identify

where ωk
(

When k = 1, P (T = 1) is the overall probability that an observation is assigned to the treatment group, and P (T = 1|
Once the weights ω
1(

Firpo and Pinto (2016) denominate this as an overall treatment effect, and it is similar to the estimation of average treatment effects.
25
While

Based on (21), treatment effects can be estimated using RIF regressions, fitting the model
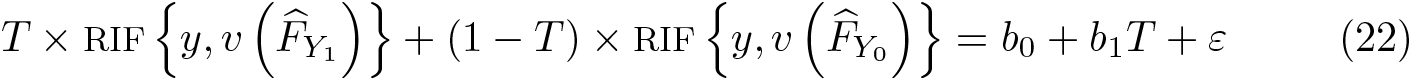
using weighted least squares with weights equal to
Applying conditional expectations with respect to T on both sides of (22) and taking the derivative with respect to T, it is easy to see that the overall inequality treatment effect (average treatment effect) is equal to b 1: 26

The advantage of using RIF regressions for the estimation of treatment effects using specifications similar to (22) is that one can also control for differences in the distribution of characteristics directly by including them as control variables in the model specification. In addition, if the variable T has more than two categories, (22) can still be estimated by using RIFs constructed using all categories in T , and coefficients associated with T can be interpreted as treatment effects, while coefficients of other variables would be interpreted as UPE that are averaged across the distributions defined by T . 27
The command
The first option is
To provide an example showing the estimation of inequality treatment effects using
Estimation of overall treatment effects of gender

∧ p < 0.1
+p < 0.05
∗p < 0.01
The first column in table 4 provides the estimation of overall treatment effects without using any controls. These results provide an estimate of the raw distributional gap between women and men and are most likely to provide biased estimates for treatment effects. Overall, this result indicates that women earn on average about 17.4% lower wages, with a larger gap (24.8%) at the 10th quantile but a somewhat smaller gap (13.9%) at the 90th quantile. This column also suggests that there is somewhat higher wage inequality among women.
The second, third, and fourth columns, which control for differences in characteristics in various ways, suggest that the negative treatment effects of gender at the means and the 10th and 90th quantiles are smaller than the raw gaps would suggest, albeit only marginally. In terms of inequality, after controlling for other characteristics, the results suggest that the treatment effect of gender may not increase inequality as much as the raw gender gap suggests. The three methods used to control for differences in characteristics provide similar results, with the largest differences observed for the treatment effect on the Gini coefficient and the interquantile ratio.
5 RIF decomposition: oaxaca_rif
As previously described, one of the main advantages of standard RIF regressions described in section 4.1 is that they can be easily used to analyze how small changes in the distribution of independent characteristics will affect the distributional statistic v. Furthermore, the modified RIF regression described in section 4.2 can also be used to estimate inequality treatment effects caused by an exogenous treatment.
However, there is often interest in analyzing what factors explain the differences in the distribution between two groups. The OB decomposition is one of the most extensively used methodologies in labor economics that aims to analyze outcome differences between two groups (Blinder 1973; Oaxaca 1973). These differences are characterized as functions of differences in characteristics (composition effect) and differences in coefficients associated with those characteristics (wage structure effect).
While the original methodology was created to analyze differences of outcome means, several articles that followed provided extensions and refinements to extend the analysis to other distributional statistics (see Fortin, Lemieux, and Firpo [2011] for a review). Additionally, under the assumptions of conditional independence (unconfoundedness) and overlapping support, the aggregate structure effect can be identified and interpreted as a treatment effect. 28
Firpo, Fortin, and Lemieux (2018) describe the use of RIF regressions, in combination with a reweighted strategy (DiNardo, Fortin, and Lemieux 1996), as a feasible methodology for decomposing differences in distributional statistics beyond the mean. This is referred to as RIF decomposition. This methodology has three advantages compared with other strategies in the literature: the simplicity of its implementation, the possibility of obtaining detailed contributions of individual covariates on the aggregate decomposition, 29 and the possibility of expanding the analysis to any statistic for which a RIF can be defined. This strategy can be described as follows.
Assume there is a joint distribution function that describes all relationships between the dependent variable Y, the exogenous characteristics

To analyze the differences between groups 0 and 1, the cumulative conditional distribution of Y can be used to calculate the gap in the distributional statistic v:
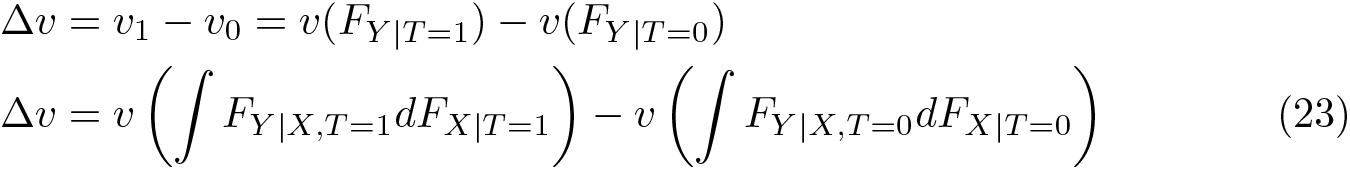
From (23), it is easy to see that differences in the statistics of interest Δv will arise because of differences in the distribution of
To identify how important differences in characteristics (composition effect) and differences in coefficients (wage structure effect) are for explaining the overall gap in the distributional statistic v, it is necessary to create a counterfactual scenario. Define the counterfactual statistic vc as follows:

Using this counterfactual, the gap in the distribution statistic v can be disaggregated into two components:

ΔvX
reflects the gap attributed to differences in characteristics, and ΔvS
reflects the differences attributed to the relationships between Y and

This alternative mirrors the standard OB decomposition, where
The problem of identifying the counterfactual scenario is that the distribution of outcomes and characteristics that the counterfactual distribution

Using the Bayes rule, the reweighting factor ω(

p is the proportion of people in group T = 1, and P (T = 1|
Once these reweighting factors are obtained, (24) is estimated using weighted least squares:
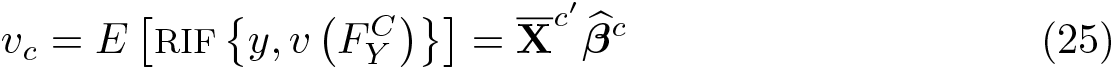
The decomposition components are now defined as
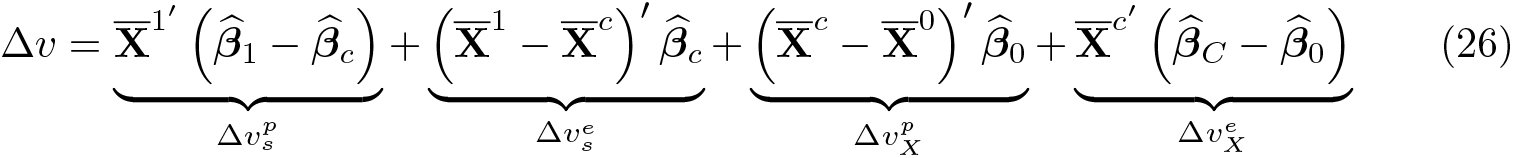
The components
Implementing OB decomposition in Stata is simple. The most popular command used for this type of analysis is the community-contributed command
For estimating these two types of decompositions, I present the
The syntax of the command is as follows:
Parallel to the
The internal syntax of
For standard errors, the default is to report robust standard errors, equivalent to using the
Similarly to the limitations of RIF regressions, the inclusion of linear terms in the model specification accounts only for differences in average characteristics. As shown in (17), one can control for differences in the dispersion of characteristics by simply adding
For the reweighted standard decomposition,
The variables included in the option
As shown for the case of RIF regressions, asymptotic and robust standard errors may not be appropriate for the decomposition of statistics related to quantiles or the Atkinson index. Furthermore, because the reweighting factors ω(
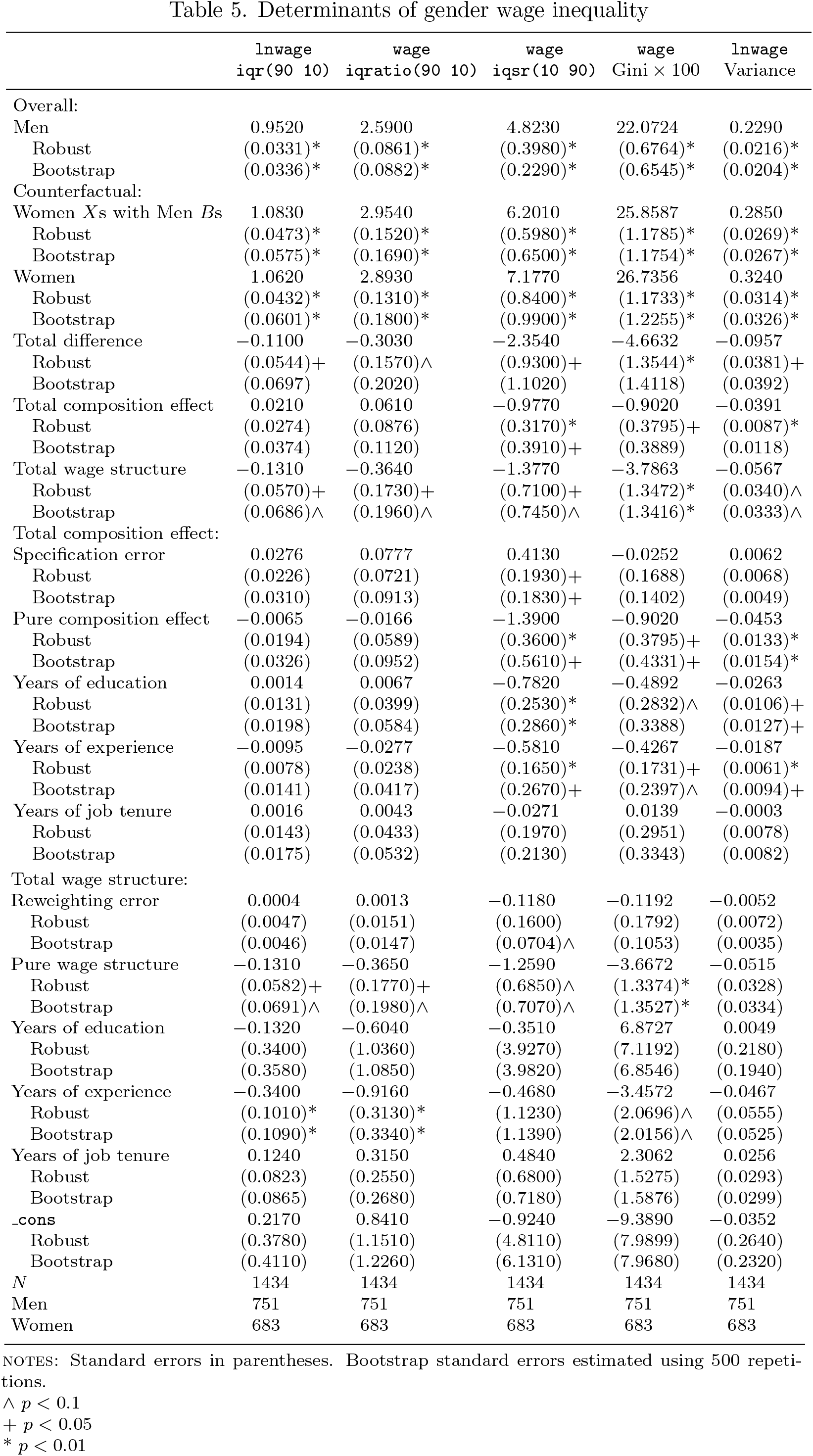
For illustration, I present in table 5 a simple exercise decomposing the same five measures of wage inequality used for the RIF regression example, analyzing differences by gender. Only results for the reweighted RIF decomposition are shown. A logit probability model is used for estimating the reweighting factors, using the same specification as the outcome model.
Determinants of gender wage inequality
∧ p < 0.1
+ p < 0.05
* p < 0.01
In general, all models suggest that inequality is higher among women compared with men. Inequality among women is between 11.5% to almost 48% higher than for men. The smallest gaps are measured for the interquartile ratio, while the largest is observed for the interquantile share ratio of wages. Controlling for differences in the distribution of years of education, tenure, and experience slightly reduces the wage inequality by almost half when looking through the wage distribution (interquantile share ratio and variance of log wages) but seems to have a marginal but increasing effect on the interquantile range and interquantile ratio.
The specification error is small but statistically significant for the interquantile share ratio model, suggesting that higher polynomials should be included to reduce the specification bias. The reweighting error suggests a good-quality reweighting because it is small and nonstatistically significant across models with the exception of the interquantile share ratio, where differences in years of experience are still important for the model.
The detailed decomposition effect suggests that women experience larger wage inequality because they have lower levels of education, experience, and job tenure (improvements in those characteristics seem to reduce wage inequality). The wage structure effect also has a negative contribution to explaining inequality because the inequalityreducing effects of education, experience, and job tenure are smaller for women compared with men.
Similarly to the results for RIF regressions, robust standard errors tend to be smaller than bootstrap standard errors, especially for statistics related to quantiles (in table 4, columns 1–3). Nevertheless, because of the two-step nature of the reweighting process, bootstrap standard errors are still recommended.
6 Conclusions
IFs and RIFs are important statistical tools that can be used to analyze the robustness of statistics to outliers and obtain asymptotic standard errors of otherwise complex distributional statistics (Cowell and Flachaire 2007; Deville 1999). Firpo, Fortin, and Lemieux (2009) expand on this literature proposing the use of RIFs in the context of regression and decomposition analysis. This is a simple strategy to analyze unconditional partial effects on any distributional statistics for which a RIF can be obtained.
This article revises the intuition behind the IF and RIF and briefly discusses the setup under which they can be used for regression and decomposition analysis. To facilitate the implementation of these strategies and make RIFs an easy-to-use tool for the applied econometrician, I introduce one function and two new commands:
Footnotes
7 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Functional statistics and RIFs
This appendix provides the full set of distributional statistics, formulas, and sources.