
Abstract
Decompositions make it possible to investigate whether gaps between groups in certain outcomes would remain if groups had comparable characteristics. In practice, however, such a counterfactual comparability is difficult to establish in the presence of lacking common support, functional-form misspecification, and insufficient sample size. In this article, the authors show how decompositions can be undermined by these three interrelated issues by comparing the results of a regression-based Kitagawa-Blinder-Oaxaca decomposition and matching decompositions applied to simulated and real-world data. The results show that matching decompositions are robust to issues of common support and functional-form misspecification but demand a large number of observations. Kitagawa-Blinder-Oaxaca decompositions provide consistent estimates also for smaller samples but require assumptions for model specification and, when common support is lacking, for model-based extrapolation. The authors recommend that any decomposition benefits from using a matching approach first to assess potential problems of common support and misspecification.
A fundamental goal of social stratification research is to understand why there are gaps in socioeconomic outcomes between social groups, for example, in terms of educational attainment (Bernardi and Boertien 2017; Krause, Rinne, and Schüller 2015), political behavior (Dassonneville and Kostelka 2021), or health (Mustapha et al. 2017). Decomposition techniques are a common way to examine these gaps; they allow one to assess to what extent observed differences in group characteristics contribute to observed gaps in outcomes. For example, scholars have used decompositions to show how the gender wage gap can be attributed to differences in various wage determinants between women and men, such as educational attainment, labor market experience, and occupational segregation (Blau and Kahn 2017). To this end, decomposition techniques estimate counterfactual group outcomes as if the group differences in relevant characteristics had been eliminated. The reduction between raw and conditional gaps is the part of the observed gap “explained” by the differences in characteristics between groups, and the remaining “unexplained” part implies either group differences in the returns to these characteristics or unobserved heterogeneity.
Decomposition studies are regularly published by statistical offices, for example, on the gender wage gap in Germany (Mischler 2021) or the European Union (EU) (Leythienne and Pérez-Julián 2022), and they inform policymaking targeted at reducing compositional disadvantages of certain groups. On the premise that comparable relevant characteristics should generate the same outcome across groups, the unexplained component is often interpreted as an indicator of discrimination, which is an important policy concern. As this interpretation requires that no relevant characteristics have been omitted, most decomposition studies focus on including ever extending sets of predictors. However, less attention is given to the bias that may arise from methodological issues of decomposition techniques (Strittmatter and Wunsch 2021). For any decomposition to be informative, a valid estimation of group outcomes is required to establish counterfactual comparability between groups for any fixed set of characteristics. In practice, meeting this requirement is challenging for several interrelated methodological reasons, three of which we discuss in this article.
The first issue is that comparability between groups is often limited. When particular combinations of individual characteristics systematically occur in one group but not the other, this lack of common support suggests a structural noncomparability between groups. Common support can be diminished wherever social processes operate in a group-segregating fashion. Regarding wage gaps by gender, such processes include the prescription of care work to women and closure mechanisms like the glass ceiling, which result in employment patterns that are gendered in terms of working hours, labor market experience, and occupations to the extent that some women and men have no comparable counterpart (Djurdjevic and Radyakin 2007; Goraus, Tyrowicz, and Velde 2017; Ñopo 2008). Similarly, school segregation and “White flight” into private schools in the United States can lead to a lack of common support in terms of educational attainment and educational prestige by race and class (Fairlie 2002; Fiel 2013).
From an intersectional perspective, both theory and evidence suggest common support can be particularly low in contexts in which several dimensions of advantage and disadvantage (e.g., gender, race, nativity, class) coincide in the creation of unique group-specific experiences (Black et al. 2008; Crenshaw 1991; McCall 2005; Sprengholz and Hamjediers 2022). Thus, when studying gaps in particular outcomes, researchers need to investigate how comparable different groups are along intersectional lines (e.g., Black women and White women). For example, immigration and integration processes operate in a gendered and racialized way in Germany, and they produce systematic differences in wage-relevant characteristics on many disaggregation levels: between natives and immigrants, between immigrant men and immigrant women, between EU immigrant women and non-EU immigrant women, and so forth (Morokvasic-Müller 2014).
Linear regression-based decompositions, which are very common in the social sciences (Weichselbaumer and Winter-Ebmer 2005), conceal common support issues and establish comparability via some level of extrapolation in a parametric specification, which might or might not be correct. Comparing the incomparable, however, violates the decomposition logic, and several wage decomposition studies confirm that lacking common support can bias the explained and unexplained parts of the decomposition in either direction (Djurdjevic and Radyakin 2007; Goraus et al. 2017; Nicodemo and Ramos 2012; Ñopo 2008; Strittmatter and Wunsch 2021). Beyond bias, ignoring issues of common support in decompositions can also lead to a loss of information: one may miss the most pronounced structural inequalities between groups and thereby discount them as important mechanisms behind observed gaps.
The second issue this study investigates is insufficient sample size, which is closely related to the issue of common support. Random sampling of finite samples ensures representativity, on average, but the smaller the sample, the lower the likelihood of sampling comparable individuals in both groups. A lack of common support in a given sample might be a mere consequence of a limited number of observations for particular characteristics. Thus, careful inspection is needed to ensure that common support is not just a sample size artifact and actually indicates systematic noncomparability between groups.
The third issue is functional-form misspecification. Correct specifications of the relationship between the outcome and its predictors are necessary for the estimation of counterfactual group outcomes, which in turn allow the decomposition into explained and unexplained gaps. With limited model flexibility in terms of functional form and interaction effects, the unexplained and explained components can be biased (Bonaccolto-Töpfer and Briel 2022; Strittmatter and Wunsch 2021). This caveat applies even more when we lack common support, as out-of-support extrapolations are completely dependent on the parametric model applied to the observed sample. For example, a glass ceiling that prevents qualified women from reaching managerial positions (Cotter et al. 2001) means such women generate below-potential wage returns to their characteristics (compared with men). Model-based extrapolations that assume wage returns would not change if these women were actually managers are hardly convincing.
In this work, we illustrate the three issues by applying the popular regression-based Kitagawa-Blinder-Oaxaca (KBO) decomposition (Blinder 1973; Kitagawa 1955; Oaxaca 1973) and Ñopo’s (2008) matching decomposition to both simulated and real-world data. We show that both methods can come to different results under common scenarios with lacking common support, with insufficient sample size, and with functional-form misspecification. KBO estimates are specification dependent, whereas matching directly addresses the common support issue and is robust to functional-form misspecification because of its nonparametric nature. Matching, however, suffers from the curse of dimensionality: the smaller the sample size in relation to the detail of characteristics in the matching set, the higher the risk for too few observations for each combination of characteristics. These methods mark the extremes on the parametric spectrum, so we also offer supplementary results of an intermediate approach in which we match on propensity scores that condense group differences in characteristics into one summary measure. This intermediate method is robust to functional-form misspecification and small samples, but limited common support remains a potential issue.
We therefore suggest that scholars first examine potential problems with respect to misspecification and common support and explore the substantive importance of the latter before relying solely on KBO decompositions. From a theoretical perspective, the systematic lack of common support should not be technically concealed, but instead be seen as a starting point to understand the structural noncomparability between groups as an important mechanism behind gaps in outcomes.
Decomposition via KBO and Matching
We are interested in the decomposition of the raw gap in outcome

where
KBO
There are several variations of the KBO decomposition, all of which use regression techniques to decompose the raw gap into more or less detailed “explained” and “unexplained” components. We focus on the common (and simplest) twofold decomposition. It builds on (1) group-specific vectors of the mean values
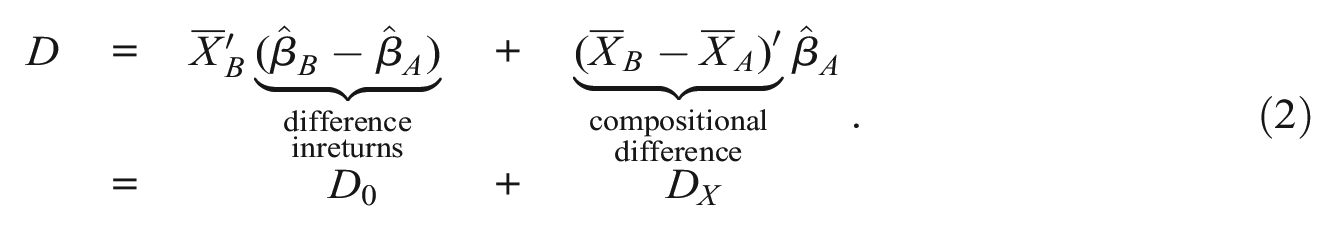
We specify
Matching
Ñopo (2008) proposed an alternative decomposition technique that builds on a matching approach. In a one-to-many exact matching, each individual from group
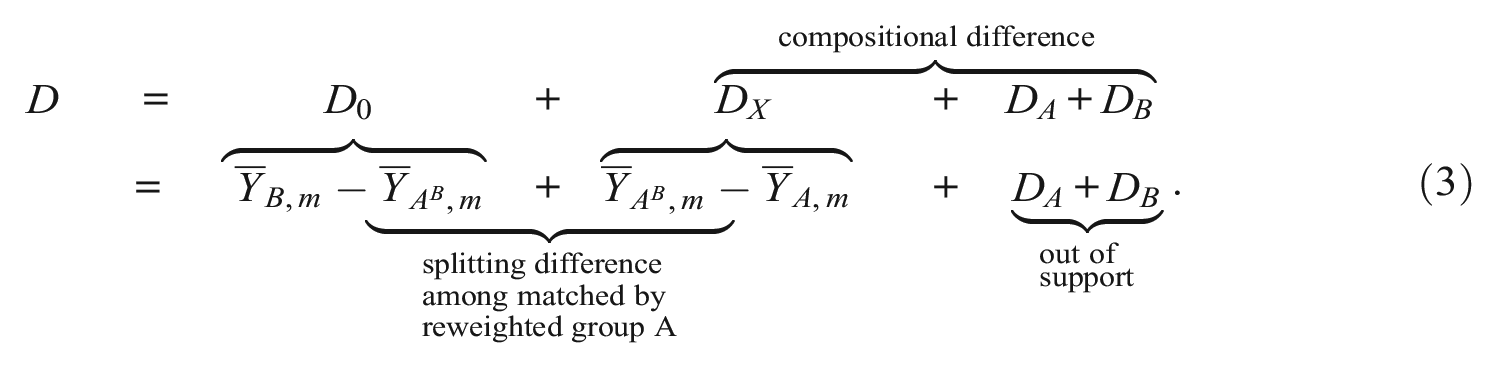
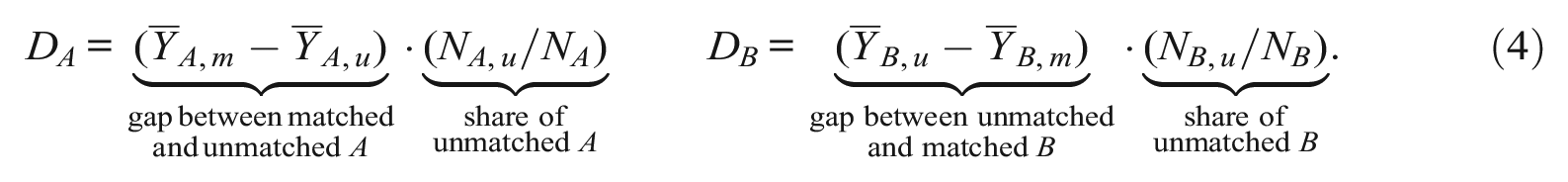
The matching procedure differs from the KBO decomposition in two important ways. First, exact matching estimates the explained
Second, because
In summary, KBO decompositions are highly conditional on the model specification, a problem that is exacerbated when we lack common support. In the presence of misspecification, the relative magnitudes of “explained” and “unexplained” gaps can be misleading (in both directions). Exact matching is not plagued by these issues, but it suffers from the curse of dimensionality, because the number of characteristics and characteristics’ levels we can sensibly match on is limited by sample size. Performing a matching decomposition on an insufficient sample will create artificial common support issues and inflate the components
In the following, we examine the issues of common support, functional-form misspecification, and insufficient sample size using a simulation and a real-world example. In the simulation study, we mirror the usual research process and apply the same model specification to various generated data, some of which aligns with the specification and some of which does not. In the real-world example, we investigate wage gaps in survey data, and show how the results of several KBO specifications relate to the results of a matching decomposition when the data-generating process (DGP) is unknown.
Simulation
Data and Estimands
For the simulation, we set the sample size to 2,000, 10,000, or 50,000 observations, split in half between groups
Default Data-Generating Process
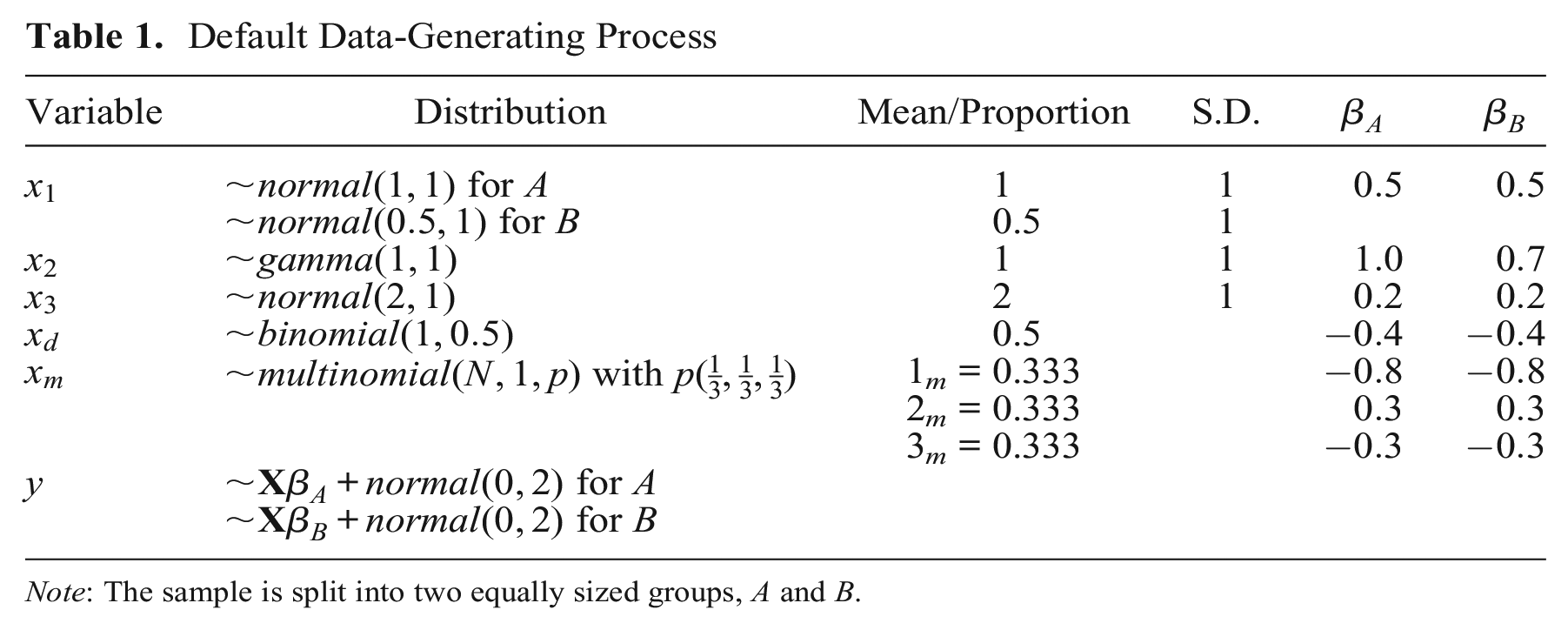
Note: The sample is split into two equally sized groups,
We apply the KBO decomposition and the matching decomposition to the same generated data. For the KBO regressions, we specify the continuous variables
The estimands of interest are all decomposition components for each respective method: for KBO, the unexplained
In the following, we keep the decomposition specifications of both methods constant and vary parts of the DGP to highlight how each component in each decomposition is affected when we vary the sample size, induce functional-form misspecification, and curtail common support. All simulations use Stata version 17.0 and run
Results
Table 2 and Figure 1 present the simulation results. As the specifications of both decomposition methods fit the default DGP, both methods accurately estimate the explained and unexplained part of the gap (panel 1). For the matching, the slight deviation of
Simulation Results
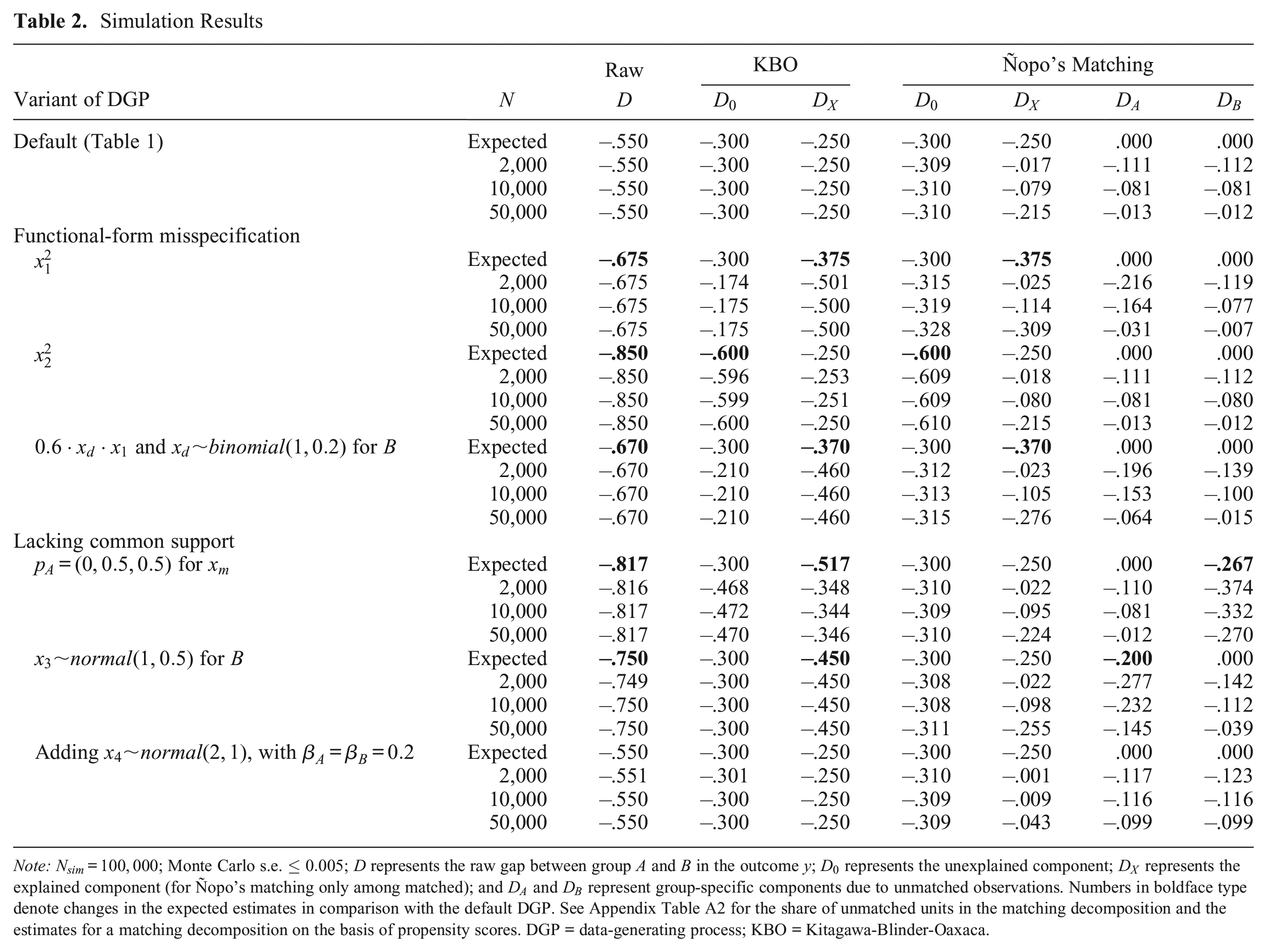
Note:
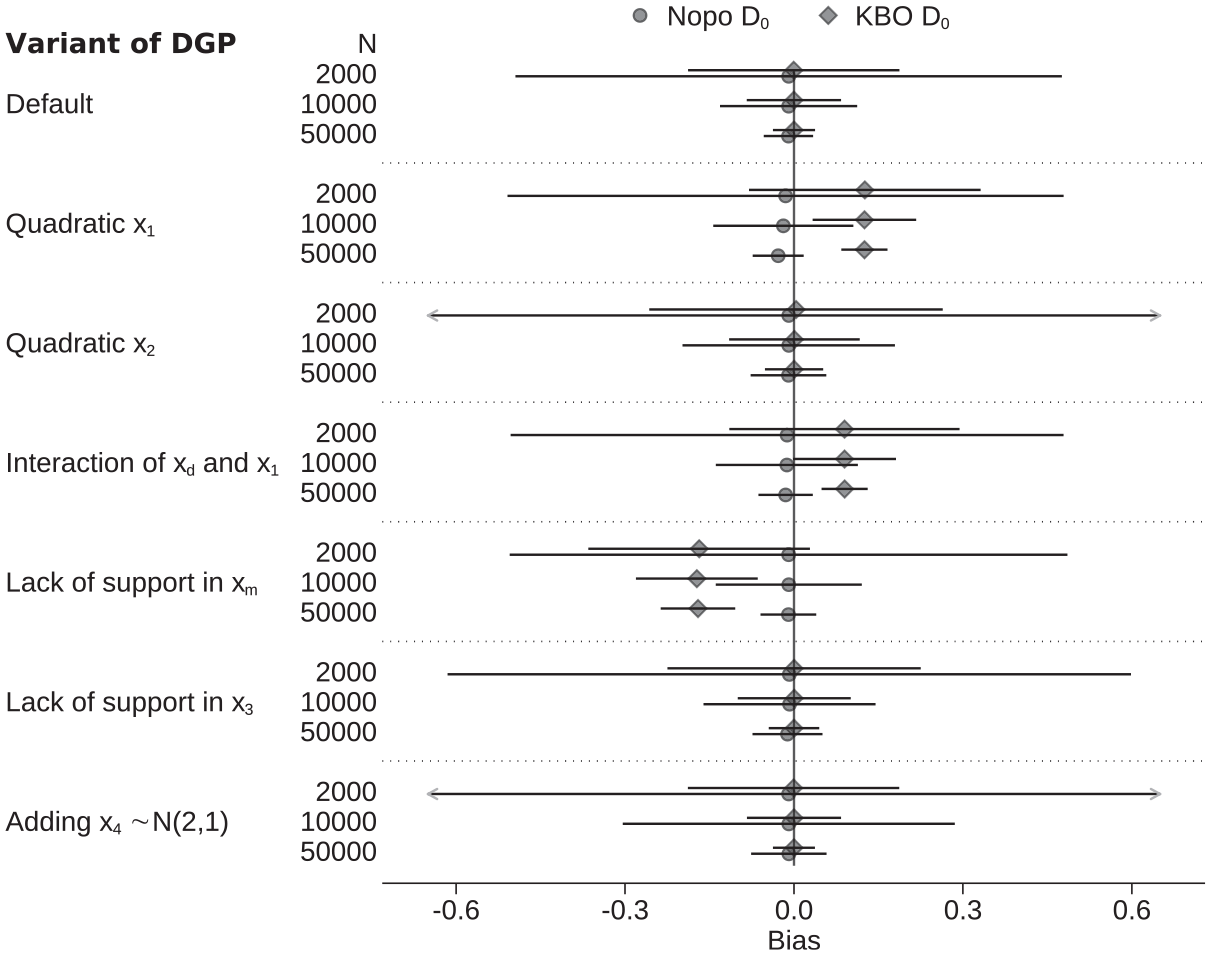
Deviation of estimated unexplained component
Functional-Form Misspecification
KBO and matching estimates begin to differ once we start to vary the DGP parameters. Our first variation in the DGP is a misspecification due to functional form assumptions: we square
Second, we square
In a third variation, we reduce the number of cases for which
Lack of Common Support
Fourth, we induce a lack of common support in the multinomial variable
In a fifth variation, we induce a mean difference and a lack of common support in the continuous variable
Finally, given a usually fixed size of samples, researchers might think about including further determinants in their decomposition, which is another facet of the curse of dimensionality. In a sixth variation of the DGP, we therefore add another independent variable
Propensity Scores
Using different ways of coarsening continuous variables is one way to address the curse of dimensionality in a given sample. Instead of deciles, one could use larger quantiles, categorize continuous variables manually, or use coarsened exact matching (Iacus, King, and Porro 2012). However, the common support bought with broad coarsening can lead to a potential misestimation of
For all except the fifth variant of the DGP, matching on propensity scores provides accurate estimates for all four decomposition components (
Overall, the simulation results highlight several issues that affect the relative size of explained and unexplained components in the different decomposition methods. Because of its nonparametric nature, a Ñopo decomposition via matching is less model dependent than KBO, and therefore less prone to misspecification when variables differ between compared groups (see the first and third variants of the DGP). When we lack common support, matching does not just offer a robust estimation of the unexplained component, but allows one to explore common support issues as a potential mechanism behind the observed gaps in outcomes. However, matching is sensitive with respect to the number of matching variables, their levels, and the number of observations, which also affects the uncertainty of estimates. The components that capture compositional differences—the classic explained component
Application to Real Data
To examine if and how the same issues occur in real-world situations, we use an example from our previous work (Sprengholz and Hamjediers 2022) and apply matching, KBO, and the intermediate approach via propensity scores to the wage gap between immigrant women (group
Sample and Specification
We use German Socio-economic Panel data (version 33.1; Goebel et al. 2019), which is a representative, annual panel of households. We restrict our sample to individuals in private households, aged 21 to 60 years, who are employed and not in education, and reside in western Germany. To boost the sample size, we use waves from 2013 to 2019 and ensure independence across observations by repeatedly selecting one observation per individual from the panel at random. We apply bootstrapping techniques to average across random draws and to estimate standard errors. 8 We define immigrant women as women living in Germany with a foreign country of birth (first-generation immigrants; average sample size across bootstrapped draws from the panel: N = 2,905) and compare them to native men, who are German-born like their parents (average sample size across bootstrapped draws from the panel: N = 6,049; second-generation immigrants are excluded).
We compute individual hourly gross wages from inflation-adjusted monthly gross labor earnings in euros and actual working hours per week.
9
Our predictors map labor market experience, working hours, educational attainment, and occupations as the most important factors behind wage gaps by gender and nativity, and we include age and marital status as further controls. For the matching decomposition, we coarsen the respective variables to keep the number of dimensions feasible. In our final analysis sample, we match on 1,470 strata of unique sets of observed characteristics, on average (see Appendix Table A1). Table 3 shows that matching balanced the groups’ characteristics fairly well. There is little difference between
Descriptive Table After Ñopo Matching Decomposition
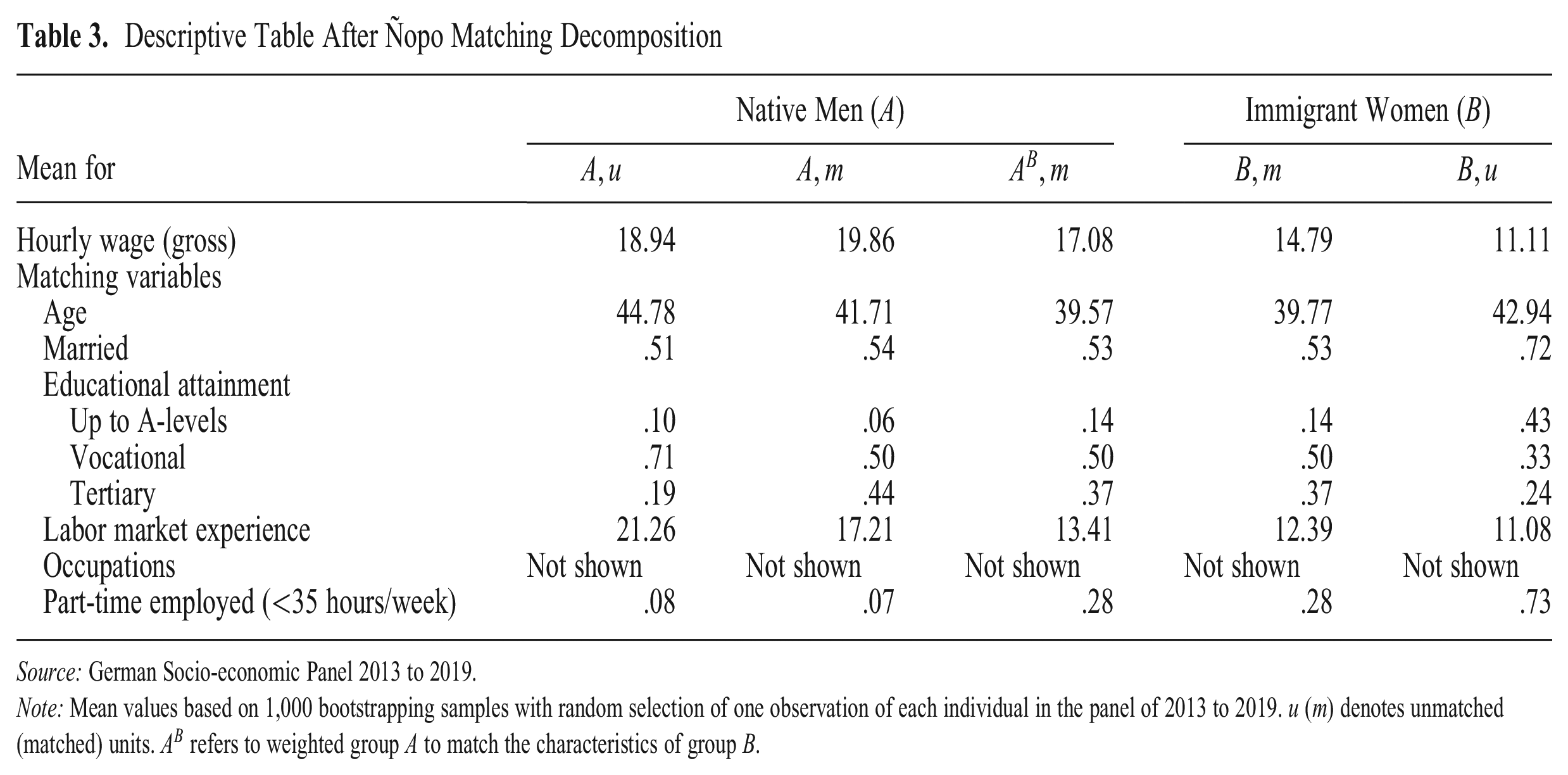
Source: German Socio-economic Panel 2013 to 2019.
Note: Mean values based on 1,000 bootstrapping samples with random selection of one observation of each individual in the panel of 2013 to 2019.
We compare the decomposition results of Ñopo’s matching to the results of different KBO decompositions and a decomposition in which we apply Ñopo’s matching to propensity scores. All specifications use the variables of the matching set as wage predictors, but in several variations. KBO1 includes age, labor market experience, and labor market experience squared as continuous measures. KBO2 relaxes functional form assumptions by including only the coarsened categorical measures of the matching decomposition. KBO3 is a fully interacted version of KBO2, which captures potentially different returns of each characteristic across all strata (e.g., different returns to education across occupations and vice versa). KBO4 is KBO3 with common support (mathematically equivalent to Ñopo), and KBO5 is KBO1 with common support. The PS-Match approach estimates propensity scores with the specification of KBO1 as the predictor function for group membership, rounds the scores to quarter percentage points (a coarsening that ensured sufficient balance after matching), and matches on the scores in Ñopo’s decomposition.
Results
Table 4 provides the decomposition results. The value for the raw wage gap
Matching Decomposition versus KBO Decomposition
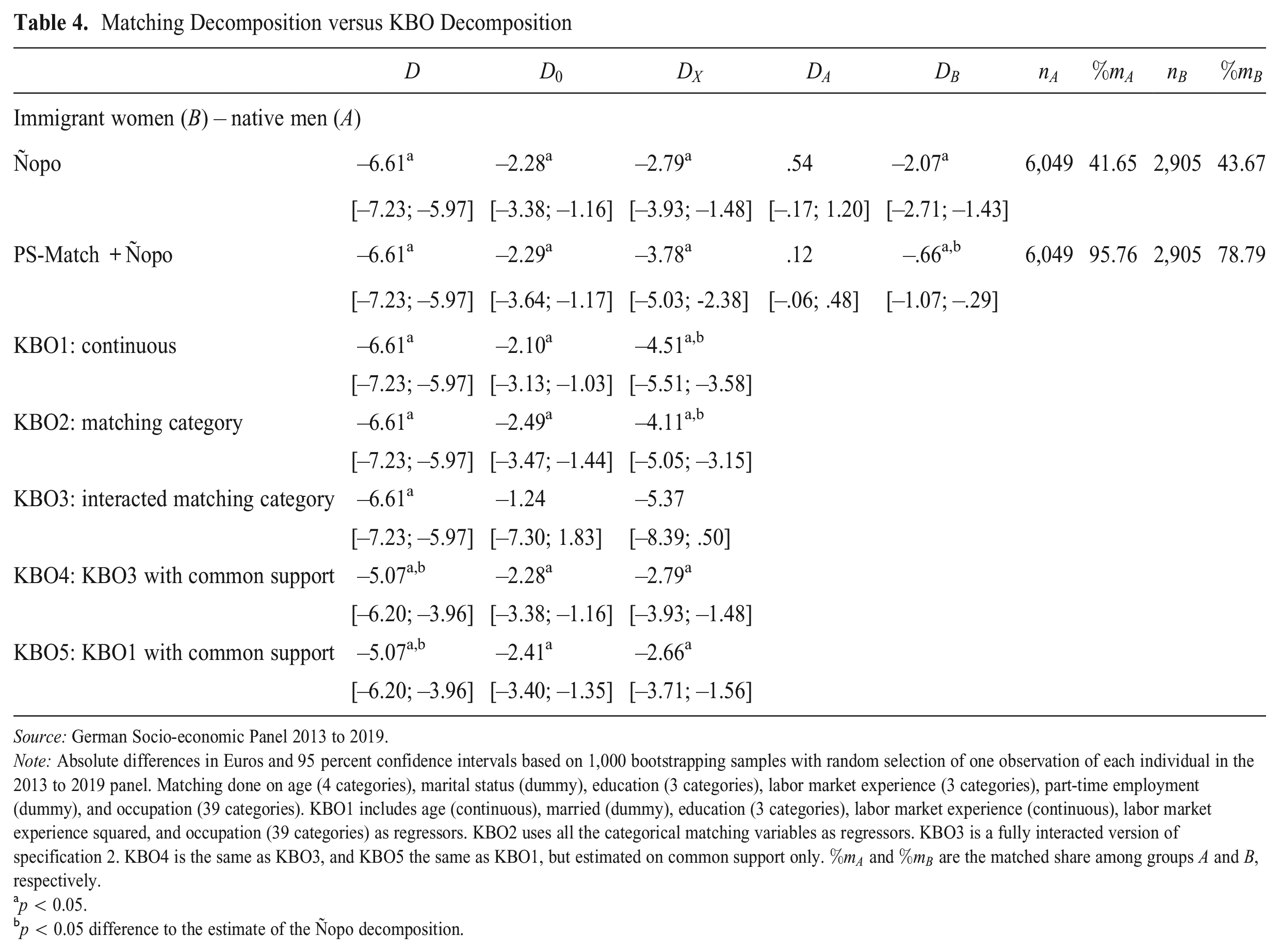
Source: German Socio-economic Panel 2013 to 2019.
Note: Absolute differences in Euros and 95 percent confidence intervals based on 1,000 bootstrapping samples with random selection of one observation of each individual in the 2013 to 2019 panel. Matching done on age (4 categories), marital status (dummy), education (3 categories), labor market experience (3 categories), part-time employment (dummy), and occupation (39 categories). KBO1 includes age (continuous), married (dummy), education (3 categories), labor market experience (continuous), labor market experience squared, and occupation (39 categories) as regressors. KBO2 uses all the categorical matching variables as regressors. KBO3 is a fully interacted version of specification 2. KBO4 is the same as KBO3, and KBO5 the same as KBO1, but estimated on common support only.
p < 0.05.
p < 0.05 difference to the estimate of the Ñopo decomposition.
For Ñopo’s matching, we observe limited common support, with a little over
Comparing the distribution of characteristics by group and matching status (Table 3) can point to mechanisms behind the partial noncomparability of immigrant women and native men and the mechanisms behind the compositional differences that remain among the matched. For example, we observe the strongest difference between unmatched
Finally, after accounting for
Thus, in the present case, neither functional-form decisions nor limited common support lead to KBO estimates of
Discussion
Decompositions allow us to investigate whether outcome gaps between groups would remain if groups had comparable characteristics. However, such a counterfactual comparability is hard to achieve in practice. In this article, we compared the common, regression-based KBO decomposition to Ñopo’s matching decomposition and showed that both methods can come to different results under common scenarios of limited common support, functional-form misspecification, and insufficient sample size. The consistency of KBO decomposition results depended on the model specification and on common support between compared groups. Although the nonparametric matching decomposition was robust against both issues, it suffered from the curse of dimensionality in smaller samples, where lack of common support was an artifact of insufficient sample size but had no substantive meaning. Matching decompositions are thus rather agnostic about the distribution of the specified characteristics and their relationship with the outcome, but they demand a large number of observations to staff all strata. KBO decompositions, on the other hand, provide consistent estimates for samples of any size, but they require assumptions for model specification and, when we lack common support, for model-based extrapolation.
We therefore recommend starting any investigation with a matching decomposition that uses a set of the most important determinants to gauge potential common support issues. If either component
That said, beyond common support, insufficient sample size, and functional-form misspecification, our investigation does not speak to further problems such as omitted variable bias or selection (e.g., into employment in wage decompositions). All these potential issues need to be considered in decomposition analyses, especially when the remaining unexplained component is interpreted as an indicator of discrimination. For such an interpretation to be meaningful, one would also have to consider the “pre-outcome” discrimination behind group differences in the explanatory variables used in the decomposition.
On a more general level, the main takeaway of our methodological discussion for the social sciences is the invitation to carefully consider the broader issues of comparability and generalizability in our work. In decomposition analyses, separating the effects of differences in characteristics from the effects of differences in returns to these characteristics is only possible when a counterfactual comparability of groups can be established. Clearly, assessment of the extent to which groups are actually comparable should be the basis of any estimation of conditional gaps in outcomes, a point that extends to the estimation of treatment effects in experimental settings. For example, audit studies work with a small slice of social reality to manipulate a small set of social categories (e.g., gender and nativity in an otherwise fixed curriculum vitae). In such a setting, it is straightforward to estimate gaps in a particular outcome between groups (e.g., callbacks for job applications), but it remains unclear how these differences would look outside the fixed slice of social reality of the experiment. When we have common support issues in observational data, we deal with the same problem, which would be hidden by technically establishing comparability via some parametric specification. It is therefore our general recommendation for any (and especially intersectional) social science work to think about how plausible variation in a “treatment” really is in the specific setting at hand (Lundberg 2022). Although most systematic differences between groups are fortunately not immutable, comparing the incomparable is always a precarious stretch.
Supplemental Material
sj-pdf-1-smx-10.1177_00811750231169729 – Supplemental material for Comparing the Incomparable? Issues of Lacking Common Support, Functional-Form Misspecification, and Insufficient Sample Size in Decompositions
Supplemental material, sj-pdf-1-smx-10.1177_00811750231169729 for Comparing the Incomparable? Issues of Lacking Common Support, Functional-Form Misspecification, and Insufficient Sample Size in Decompositions by Maik Hamjediers and Maximilian Sprengholz in Sociological Methodology
Footnotes
Appendix
Correction (May 2025):
This article has been updated to correct the following: In Figure 1, the coefficients have been revised to match those reported in Table 2. Additionally, the coefficient for DB on p. 354 has been corrected from −0.256 to −0.270, and the coefficient for DA on p. 355 from 0.146 to 0.145.
Data Note
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.