
Abstract
Random forests (Breiman, 2001, Machine Learning 45: 5–32) is a statistical- or machine-learning algorithm for prediction. In this article, we introduce a corresponding new command,
1 Introduction
In recent years, the use of statistical- or machine-learning algorithms has increased in the social sciences. 1 For instance, to predict economic recession, Liu et al. (2017) compared ordinary least-squares regression results with random forest regression results and obtained a considerably higher adjusted R-squared value with random forest regression compared with ordinary least-squares regression (Nyman and Ormerod 2017). In economics, a recent book overviews various statistical-learning algorithms for predicting economic growth and recession (Basuchoudhary, Bang, and Sen 2017). In environmental science, a recent article used learning algorithms, including least absolute shrinkage and selection operator regression, random forest, and neural networks, to predict ragweed pollen concentration based on 27 years of historical data and 85 predictor variables, with the best predictive performance obtained using random forest.
Why does random forest do better than linear regression for prediction tasks? Linear regression makes the assumption of linearity. This assumption makes the model easy to interpret but is often not flexible enough for prediction. Random decision forests easily adapt to nonlinearities found in the data and therefore tend to predict better than linear regression. More specifically, ensemble learning algorithms like random forests are well suited for medium to large datasets. When the number of independent variables is larger than the number of observations, linear regression and logistic regression algorithms will not run, because the number of parameters to be estimated exceeds the number of observations. Random forest works because not all predictor variables are used at once.
Random forest is one of the best-performing learning algorithms. For social scientists, such developments in algorithms are useful only to the extent that they can access an implementation of the algorithm. In this article, we introduce
The outline of this article is as follows: In section 2, we briefly discuss the random forest algorithm. In section 3, we give the syntax of the
2 The random forest algorithm
We first discuss tree-based models because they form the building blocks of the random forest algorithm. A tree-based model involves recursively partitioning the given dataset into two groups based on a certain criterion until a predetermined stopping condition is met. At the bottom of decision trees are so-called leaf nodes or leaves.
Figure 1 illustrates a recursive partitioning of a two-dimensional input space with axis-aligned boundaries—that is, each time the input space is partitioned in a direction parallel to one of the axes. Here the first split occurred on x 2 ≥ a 2. Then, the two subspaces were again partitioned: The left branch was split on x 1 ≥ a 4. The right branch was first split on x 1 ≥ a 1, and one of its subbranches was split on x 2 > a 3. Figure 2 is a graphical representation of the subspaces partitioned in figure 1.

Recursive binary partition of a two-dimensional subspaces

A graphical representation of the decision tree in figure 1
Depending on how the partition and stopping criteria are set, decision trees can be designed for both classification tasks (categorical outcome, for example, logistic regression) and regression tasks (continuous outcome).
For both classification and regression problems, the subset of predictor variables selected to split an internal node depends on predetermined splitting criteria that are formulated as an optimization problem. A common splitting criterion in classification problems is entropy, which is the practical application of Shannon’s (2001) source coding theorem that specifies the lower bound on the length of a random variable’s bit representation. At each internal node of the decision tree, entropy is given by the formula

where c is the number of unique classes and pi is the prior probability of each given class. This value is maximized to gain the most information at every split of the decision tree. For regression problems, a commonly used splitting criterion is the mean squared error at each internal node.
A drawback of decision trees is that they are prone to overfitting, which means that the model follows the idiosyncrasies of the test dataset too closely and performs poorly on a new dataset—that is, the test data. Overfitting decision trees will lead to low general predictive accuracy, also referred to as generalization accuracy.
One way to increase generalization accuracy is to consider only a subset of the observations and build many individual trees. First introduced by Ho (1995), this idea of the random-subspace method was later extended and formally presented as the random forest by Breiman (2001). The random forest model is an ensemble tree-based learning algorithm; that is, the algorithm averages predictions over many individual trees. The individual trees are built on bootstrap samples rather than on the original sample. This is called bootstrap aggregating or simply bagging, and it reduces overfitting. The algorithm is as follows:

Random forest algorithm
Individual decision trees are easily interpretable, but this interpretability is lost in random forests because many decision trees are aggregated. However, in exchange, random forests often perform much better on prediction tasks.
The random forest algorithm more accurately estimates the error rate compared with decision trees. More specifically, the error rate has been mathematically proven to always converge as the number of trees increases (Breiman 2001).
The error of the random forest is approximated by the out-of-bag (
To gain some insight on the complex model, we calculate the so-called variable importance of each variable. This is calculated by adding up the improvement in the objective function given in the splitting criterion over all internal nodes of a tree and across all trees in the forest, separately for each predictor variable. In the Stata implementation of random forest, the variable importance score is normalized by dividing all scores over the maximum score: the importance of the most important variable is always 100%.
3 Syntax
The syntax to fit a random forest model is
with the following postestimation command:
4 Example: Credit card default
Yeh and Lien (2009) and Dheeru and Karra Taniskidou (2017) investigated the predictive accuracy of the probability of default of credit card clients. There are a total of 30,000 observations, 1 response variable, 22 explanatory variables, and no missing values. The response variable is a binary variable that encodes whether the card holder will default on his or her debt, with 0 encoded as “no default” and 1 encoded as “default”. Of the 22 explanatory variables, 10 are categorical variables containing information such as gender, education, marital status, and whether past payments have been made on time or delayed. The remaining 12 continuous explanatory variables contain information on the monthly bill amount and payment amount over 6 months. For a complete list of variables, please refer to appendix A.
In this example, we will investigate the predominant factors that affect credit card default prediction accuracy, and we will contrast the prediction accuracies obtained using random forest and logistic regression.
4.1 Model training and parameter tuning
To start the model-training process, we arrange the data points in a randomly sorted order. When the data are split into training and test data, a random sort order ensures that the training data are random as well. To allow for reproducible results, we set a seed value. Then, we split the dataset into two subsets: 50% of the data are used for training, and 50% of the data are used for testing (validation). In small datasets, a 50-50 split may reduce the size of the training data too much; for this relatively large dataset, a 50-50 split is not problematic. The randomization process mentioned previously ensures that the training data contain observations belonging to all available classes as long as the class probabilities are not heavily imbalanced. Additionally, it removes the model’s potential dependency on the ordering of observations relative to the test data. Finally, because the variable for marital status uses values 0, 1, 2, and 3 to encode unordered categorical information, we need to create four new binary indicator variables for each marital status using the command
Next, we tune the hyperparameters to find the model with the highest testing accuracy. Specifically, we tune the number of iterations (that is, the number of subtrees) and number of variables to randomly investigate at each split,
Usually, tuning parameters in statistical-learning models requires a grid search, that is, an exhaustive search on a user-specified subspace of hyperparameter values. In this case, however, because random forest
To illustrate how the

The

We can see from figure 3, generated by the above code block, that both the
Next, we can tune the hyperparameter
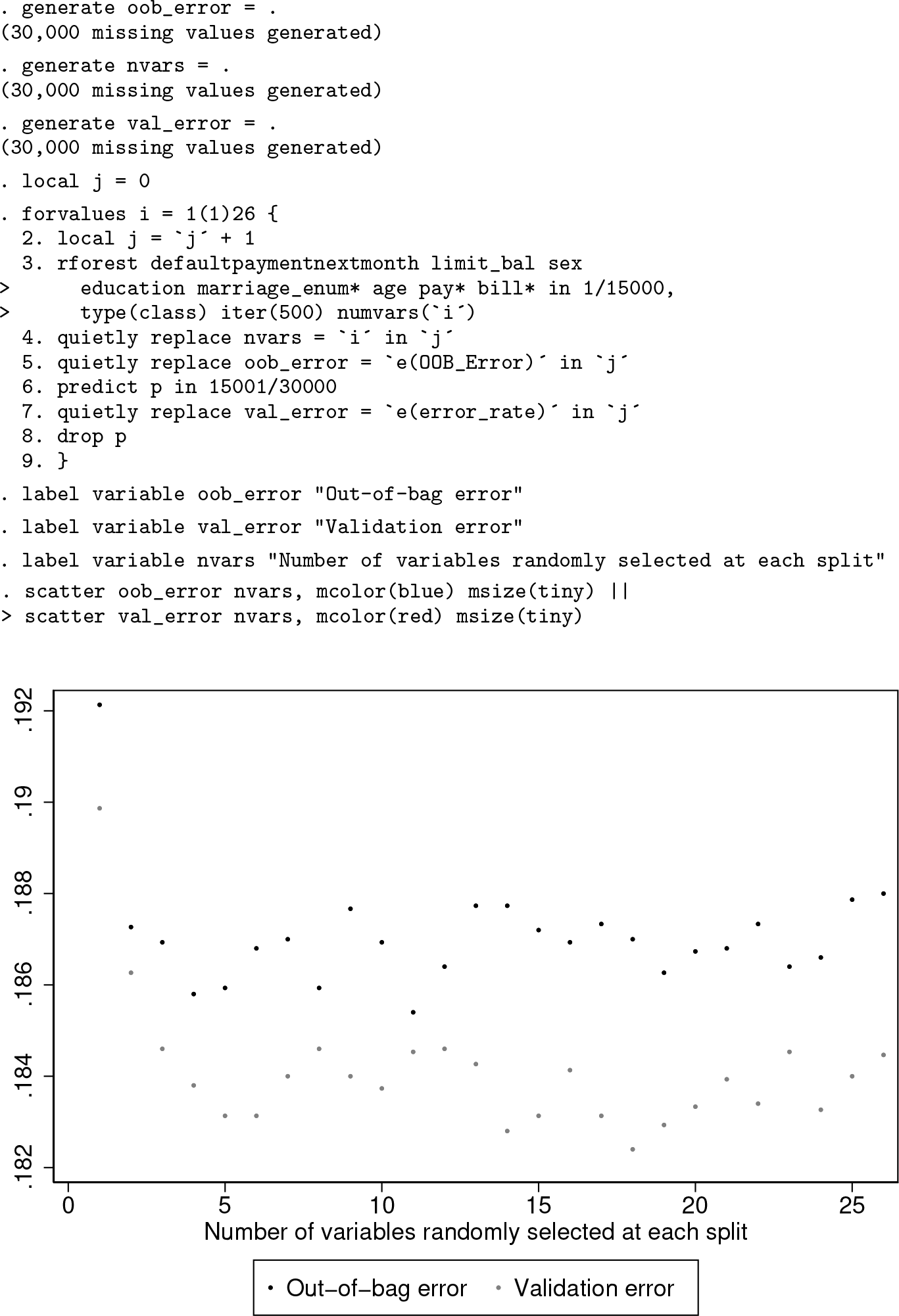
In figure 4, we can see for how many variables the minimum error occurs. The following code automates finding the minimum error and the corresponding number of variables. (This code uses frames and requires Stata 16.)

We can see that at
In principle, the random forest algorithm can output an
4.2 Final model and interpretation of results
As shown in the previous section, we have set the values of the hyperparameters to be

The final
We also would like to ascertain which factors are the most important in the prediction process. Random forests are black boxes in that they do not offer insight on how the predictions are accomplished. The variable-importance scores of each predictor provide some limited insight. The following code segment plots the variable importance:
We can see from figure 5 that the five most important predictors are basic demographic and background information such as gender, education, and marital status (“married” and “single”) as well as the monthly spending limit (

Importance scores of predictor variables
We can see from the histograms in figure 6 that card holders who default on their debt generally have a lower monthly spending limit than those who do not default. Variable importance measures the contribution of an x variable to the model but depends on the set of x variables. Another x variable correlated with the first would rise in importance if the first x variable was excluded.

Histograms of monthly spending limit
4.3 Comparison with logistic regression
Alternatively, credit card debt default can be modeled using logistic regression. The following code returns the prediction accuracy of logistic regression using the same set of predictor variables and the same train-and-test split:

The prediction error obtained using logistic regression is 18.86%, compared with the best-so-far error rate that we have from random forest, which is 18.25%. The difference in error rate is small but might still be meaningful to prevent credit card defaults.
5 Example: Online news popularity
Fernandes et al. (2015) and Dheeru and Karra Taniskidou (2017) investigated the popularity of online news. 2 The data were originally presented at a Portuguese conference on artificial intelligence in 2015. There are a total of 39,644 observations, 1 response variable, and 58 explanatory variables. For this problem, we are interested in the log-scaled number of “shares” an online article obtains based on various nominal and continuous attributes such as whether the article was published on a weekend, whether certain keywords are present, number of images in the article, etc. For a full list of variable names and descriptions, please refer to appendix B.
5.1 Model training and parameter tuning
First, we need to randomize the data as we did for the previous classification example. Then, we generate a new variable for the log-scaled number of shares:

We will use a 50-50 split to partition the data into training and testing sets as in the previous example. To tune the hyperparameters

We can see from the graph that the

Again, we automate finding the minimum error:
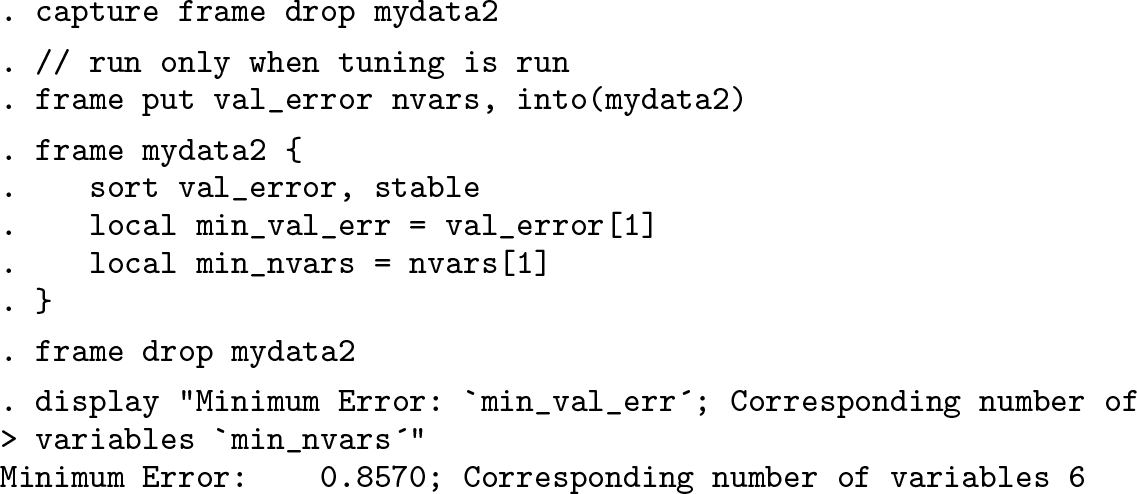
For
5.2 Final model and interpretation of results
The final model has hyperparameter values

The final

Importance score of predictor variables
Whether the article was published on a weekend is the most important predictor. Other important explanatory variables include news channel types and the number of keywords. To obtain more insight on how the log-scaled number of article shares is related to whether the article was published on a weekend, we use the following histogram to illustrate the relationship:
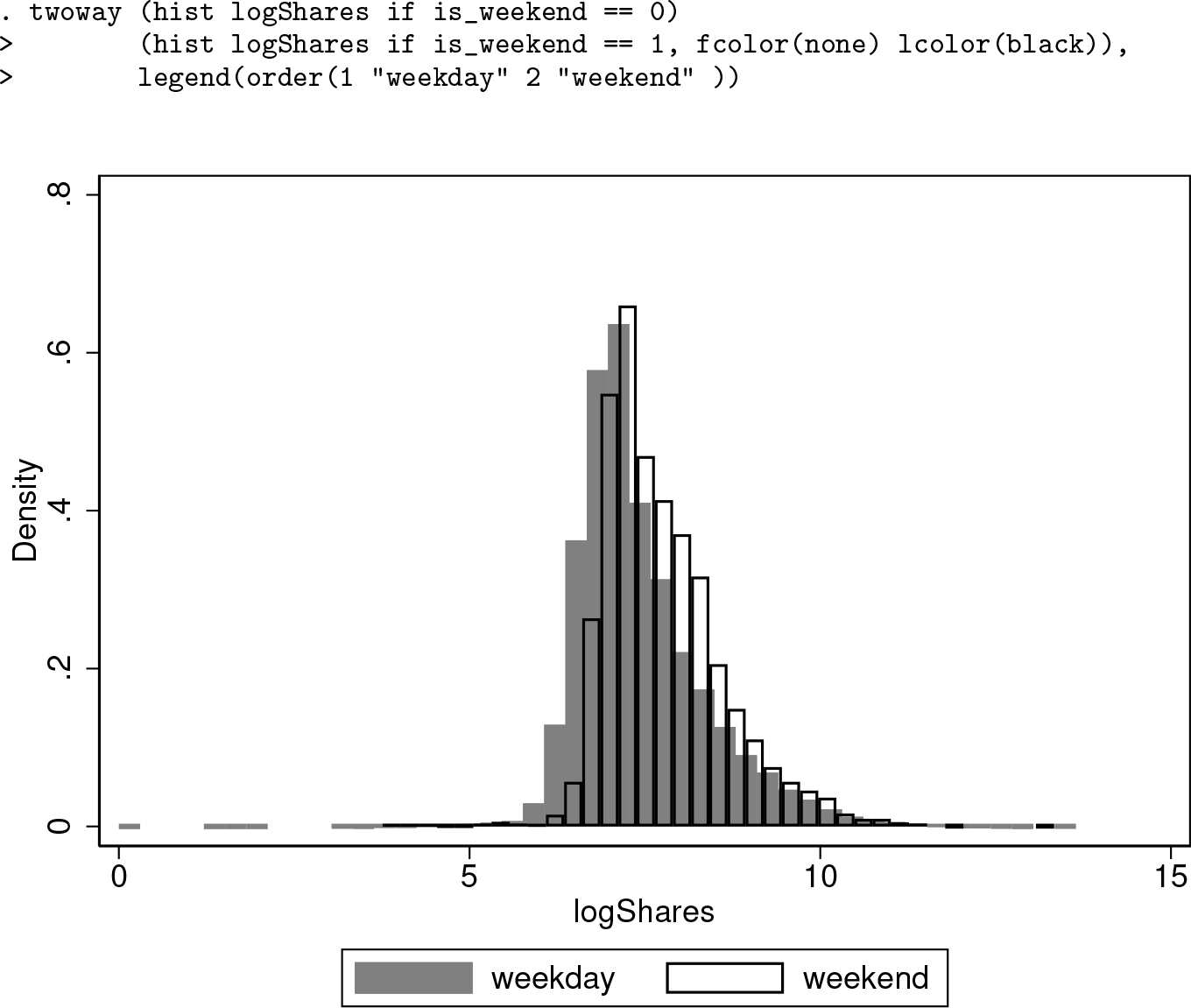
Histograms of log-scaled number of shares
The empirical distributions of log number of shares differ for weekdays versus weekends. This clear shift in empirical distribution helps to explain why the
5.3 Comparison with linear regression
The following code block fits a linear regression model over the same set of dependent and independent variables using the same train-and-test split as shown in the random forest model:

The value of

We can see from the output that the mean squared error is 40.90379, which means the
6 Discussion
The classification and regression examples have illustrated that random forest models usually have higher prediction accuracy than corresponding parametric models such as logistic regression and linear regression. Typically, greater gains in model performance are available for multiclass (multinomial) outcomes and regression than binary outcomes. Misclassification is a fairly insensitive performance criterion. When an improved algorithm changes the estimated classification probabilities for two classes from p 1 = 0.10 and p 2 = 0.90 to p 1 = 0.40 and p 2 = 0.60 for an observation, the resulting classification remains the same. An improvement over logistic regression with its linearity assumption can come either from nonlinearities or from interactions. Additionally, the scope of improvement is reduced when many of the variables are indicator variables; nonlinearities do not exist for indicator variables. In our experience, many of the variables in social sciences are indicator variables. For example, Ing et al. (2019) found that support-vector machines did not improve over logistic regression. Similarly, in our classification example, the improvement of random forest over logistic regression was minor.
In the examples, the values of hyperparameters were determined based on which value gave the lowest testing error. In practice, when there are not enough observations to allow for a train-and-test split, the
While the two examples primarily focused on the typical case of tuning the options
Footnotes
7 Acknowledgments
The software development in Stata was built on top of the Weka Java implementation, which was developed by the University of Waikato. We are grateful to Eibe Frank for allowing us to use the Weka implementation for the plugin.
This research was supported by the Social Sciences and Humanities Research Council of Canada (# 435-2013-0128).
8 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
Notes
A Variable names for classification example
The column names from the variables
B Variable names for regression example
The column names in this table are reproduced based on the original documentation on UCI Machine Learning Repository’s website.