
Abstract
Objectives
Neuropsychological test batteries, which accurately and comprehensively assess cognitive functions, are a crucial approach in the early detection of and interventions for cognitive impairments. However, these tests have yet to gain wide clinical application in China owing to their complexity and time-consuming nature. This study aimed to develop the Computerized Neurocognitive Battery for Chinese-Speaking participants (CNBC), an autorun and autoscoring cognitive assessment tool to provide efficient and accurate cognitive evaluations for Chinese-Speaking individuals.
Methods
The CNBC was developed through collaboration between clinical neurologists and software engineers. Qualified volunteers were recruited to complete CNBC and traditional neurocognitive batteries. The reliability and validity of the CNBC were evaluated by analyzing the correlations between the measurements obtained from the computerized and the paper-based assessment and those between software-based scoring and manual scoring.
Results
The CNBC included 4 subtests and an autorun version. Eighty-six volunteers aged 51-82 years with 7-22 years of education were included. Significant correlations (0.256-0.666) were observed between paired measures associated with attention, executive function, and episodic memory from the CNBC and the traditional paper-based neurocognitive batteries. This suggests a strong construct validity of the CNBC in assessing these cognitive domains. Furthermore, the correlation coefficients between manual scoring and system scoring ranged from 0.904-1.0, indicating excellent inter-rater reliability for the CNBC.
Interpretation
A novel CNBC equipped with automated testing and scoring features was developed in this study. The preliminary results confirm its strong reliability and validity, indicating its promising potential for clinical utilization.
Keywords
Introduction
Cognitive impairment refers to deficits in neurocognitive domains—including learning and memory, attention, language, perceptual-motor development, execution function, and social cognition—that may lead to the decline of an individual’s daily or social ability. 1 The underlying etiologies may be neurodegenerative diseases (such as Alzheimer’s disease and frontotemporal lobe degeneration) or other causes (such as cerebrovascular disease, trauma, poisoning, and emotional disorders). Regarding severity, cognitive impairment can be classified into mild cognitive impairment (MCI) and severe cognitive impairment (dementia). Subclinical cognitive changes not evident on formal testing—termed subjective cognitive decline (SCD)—have also been found to be important in predicting future cognitive impairment. It has been widely recognized that the interventions for cognitive impairment should be advanced to at least the MCI stage—or even the SCD stage—to preserve individuals’ cognitive function as long as possible and reduce the burden on families and society. 2 Early intervention should be based on the accurate evaluation of cognitive functions. It usually requires the usage of neuropsychological test batteries, which combine multiple tests to assess the functions of several neurocognitive domains. Traditionally, these tests are administered by professional neuropsychologists—who instruct the participants face-to-face on completing various tasks and make assessments based on their performances—and take 1 to 2 hours for each participant. Such neuropsychological resources and services are widely available and regarded as standard procedures for clinical practice and relevant research in Western countries.
Fully developed computerized neuropsychological batteries complementary to traditional batteries have also been developed for English-speaking participants, such as the Penn Computerized Neurocognitive Battery (Penn CNB) from the University of Pennsylvania, 3 the Cambridge Neuropsychological Testing Automated Battery (CANTAB) from the University of Cambridge, 4 and the Cogstate computerized cognitive assessment battery developed by the Cogstate Cognitive Science Company. 5 The Penn CNB focuses on the following 4 cognitive domains: executive control, episodic memory, complex cognition, and social cognition and is frequently utilized in functional neuroimaging research and large-scale clinical and genomic studies. In order to enhance its sensitivity in detecting cognitive impairments, Penn CNB encompasses a comprehensive range of test content and presents high levels of difficulty, which poses challenges for Chinese middle-aged and older adults with relatively lower levels of education. The CANTAB serves as a comprehensive tool for evaluating multiple cognitive subdomains and is accompanied by specialized hardware, allowing for standardized testing. However, although widely utilized in scientific research, clinical trials, and health care settings in Europe and the United States, CANTAB requires a fee for usage and currently lacks a Chinese version and normative data for the Chinese population. The Cogstate battery, which comprises 8 test tasks, also involves a fee. The initial validation studies of the Chinese version of the Cogstate battery primarily targeted patients with schizophrenia. 6 However, the memory assessment component of the battery lacks a delayed recall task, limiting its ability to assess impairment in episodic memory, since a decline in delayed recall of episodic memory is considered an early and specific neuropsychological change in Alzheimer’s disease. 7 Moreover, the subtest has not been automated and requires the assistance of test administrators to facilitate participant completion. Hence, despite their comprehensive assessment of various cognitive domains and wide utilization internationally, the 3 computerized cognitive assessment batteries are not suitable for evaluating and diagnosing cognitive impairments in Chinese middle-aged and older adults.
As for the cognitive assessment of Chinese-speaking participants, although there are applicable cognitive assessment batteries standardized to local populations, such neuropsychological resources are only available in a limited number of tertiary hospitals owing to the unbalanced economic levels in different areas of China, resulting in the lack of financial support for memory clinics and limited health personnel trained to administer cognitive assessments in less developed areas of China. Since more than 50 million people in China have been estimated to have a cognitive impairment, among which nearly 40 million have MCI, 8 there are substantial gaps in neuropsychological assessment resources to meet actual needs.
To address this problem, the present study aimed to develop and initially validate a computerized cognitive assessment battery with autorun and autoscoring systems for Chinese-speaking participants. To our knowledge, no similar study has previously been published.
Methods
Participants and Procedures
Chinese-speaking participants aged 50 years or older with reasonable vision, hearing, and ability to communicate in verbal or written Chinese were recruited from the Memory Clinic and the Inpatient Department of Neurology, Sichuan Provincial People’s Hospital, Chengdu, China and nearby communities. Patients with a history of major depression, schizophrenia, epilepsy, significant head injury, substance abuse, alcoholism, or other severe physical disorders that would hinder the completion of the study procedures were excluded. Informed consent was obtained from all participants, and the study protocol was approved by the Institutional Ethics Committee.
The demographic information and past history of the participants were collected during the first interview. Then, neuropsychological test batteries were administered by certified psychometrists. All the tests were translated and adapted from Western countries harmonized with Chinese culture and validated in the Chinese population. Each participant received the following battery of neuropsychological tests: Auditory Verbal Learning Test (AVLT)9,10; shape-Trail Making Test (STT) 11 ; Rey-Osterrieth Complex Figure Test (ROCF)12,13; Digit Span Test (DST) 14 and Boston Naming Test (BNT) 15 and Animal Fluency Test (AFT). 16 Raw scores from these neuropsychological tests were extracted to evaluate the functions of the following 4 cognitive domains: memory, attention, visuospatial function, language and executive function. The Z-score (Z = (raw score - mean)/standard deviation [SD]) of each rated item was also calculated to evaluate the cognitive state of the participants. Our study employed the Jak/Bondi diagnostic criteria for MCI 17 to assess the cognitive function of the participants, using 6 indicators from 4 basic tests or the score of Functional Activity Questionnaire (FAQ) for diagnosis. The specific criteria are as follows: Impairment in 2 tests within the same cognitive domain (>1SD); or 1 test score impaired (>1SD) in 3 cognitive domains (memory, executive, language); or a FAQ scale score greater than 9.
Afterward, the participants completed the CNBC tasks under the auditory or written guidance of the software system; the raw scores of each task were recorded automatically and could be exported when necessary. Meanwhile, 1 researcher rated the performance of each participant manually. To minimize distractions, CNBC was administrated in a separate room using a standard Windows computer with Java. The screen resolution of the test computers should be set to 1920 × 1080 pixels. The participants were asked to turn off their phones and wear headsets to listen to the instructions for CNBC. The operation of the CNBC test interface is only done by clicking with the mouse (including press numbers, select pictures, or drag graphics). Before the formal test, a brief video and pre-test practice were provided to familiarize the participants with the software and mouse operations. Thus, the formal test required minimal manual guidance.
Description of the CNBC
The computerized battery comprised 4 tests targeting attention, processing speed, working memory, episodic memory, visuospatial function, and executive function, including computerized DST (cDST), computerized STT (cSTT), computerized Complex Figure Puzzle Test (cCFPT), computerized Picture Memory and Sorting Test (cCOMS) and an autorun version of CNBC. These tests were developed in Chengdu, China under the joint efforts of clinical neurologists (Sichuan Provincial People’s Hospital) and software engineers (YiWei Medical Technology Co.Ltd., Shenzhen, China), which could be accessed for free through the website https://scale.drbraintele.com after applying and obtaining authorization. The instructions for CNBC were simultaneously displayed in text on the screen and presented as voice recordings in Chinese Mandarin. Animation demonstration and practice items were presented before the test items to ensure that the examinee fully understood the instructions. The operation of CNBC can be completed by clicking the mouse (including pressing numbers, selecting pictures or dragging graphics), without input through the touchpad and keyboard. Test items were designed to be completed and scored without the need for qualitative ratings or verbal analysis. The design and development of CNBC draw on the principles and formats of traditional tests to assess various cognitive functions. However, due to the inherent differences between electronic devices and traditional media, there are significant differences in the specific operations, answer methods, and scoring methods. In addition, the traditional test scales used in this study are all open-source and have been localized for Chinese-speaking participants. An automated scoring system was also established, enabling the system to automatically calculate the raw scores and Z scores of each test indicator and generate a cognition assessment report. CNBC’s norm calculation is based on the test results of a reference group with normal cognitive function. However, due to the high requirements of rolling basis on software development, such as server and data storage capabilities, CNBC’s norms are uploaded after calculation. We plan to collect more test data and update the norms regularly. Upon the completion of software development, the system underwent rigorous pretesting by the development team with extensive feedback obtained from experts in neuropsychology, neurologists, and the software development team. Through this iterative process, numerous issues were identified and resolved, leading to continuous improvements in interface design, scale content, voice prompts, and playback speed.
Some of the iterative processes of CNBC are as follows: 1. Optimization in voice broadcasting: We initially used real human recordings as the guide for participants to answer questions, but the recording process was time-consuming and expensive. If the text of the announcement needed to be modified, it required re-recording. Therefore, we changed the broadcasting method to use iFlytek’s voice-over package to announce text. This package allows you to choose the gender, speech rate, tone, and pitch of the announcer. During the iteration process, based on user experience, we ultimately chose a female voice with clear enunciation, speaking Mandarin; an appropriate speech rate (about 200 words per minute) and moderate tone; a smooth and natural delivery with appropriate pauses, which helps participants better understand the questions. 2. Optimizations of scale content: In the cDST test, after the participant listens to the digital voice broadcast, they only have 1 chance to click on the number. If they click correctly, they move on to the next question. This operation avoids subjects from changing their answers repeatedly and extending the response time. In the cCFPT pre-test, when the scoring criteria were set to within 30 pixels of the component center from the original coordinates, there were sometimes inconsistencies between software scoring and manual scoring. Through iterative optimization, we adjusted the scoring criteria to within 15 pixels, which brought the software scoring closest to manual scoring. On the report page of the cCFPT test, the original image and the completed image by the subject need to be displayed to facilitate manual review of the accuracy of the computer scoring. 3. Optimization in interface design: Considering that the participants included in this study are middle-aged and elderly individuals aged 50 and above, many of them find it difficult to read due to vision problems, which leads to a longer time spent answering questions. In the pre-test phase, the font size displayed on our answer interface was small, and the mouse cursor was not clearly visible on the screen, which slowed down the participants’ response speed. Therefore, we appropriately increased the font size and highlighted the mouse position with a bright red color, which further helped participants to answer questions smoothly.
This optimization process was conducted until a relatively refined and applicable level of usability was reached. The final version of CNBC was briefly described as follows: 1) Computerized Digital Span Test (cDST): cDST was an adaptation of the Chinese version of DST, which measures the function of attention and working memory. The participants were auditorily exposed to a sequence of digits. Immediately afterward, they were asked to click the correct digits shown on the screen in the same order. The number of digits increased from 3 to 12 in the forward part. In the backward part, the participants were asked to click the digits in the opposite order and the number of digits increased from 2 to 10. 2) Computerized Shape Trail Test (cSTT): STT is a culture-fair variant of the Trail Making Test and is thus more suitable for Chinese-speaking participants.
11
The cSTT was adapted from the Chinese version of STT to provide a computerized measure of the ability of “set-shifting”. In Part A of cSTT, participants were instructed to make connections by clicking the digit buttons randomly arranged and shown on the screen in the proper order from 1-25. In Part B of cSTT, 2 sets of numbers (from 1-25) were randomly arranged and displayed on the screen with each number of 1 set enclosed by a circle and the other set by a square. The participants were asked to make lines by clicking the digit buttons in alternating order between the 2 sets of numbers. The time in seconds for completing Part A and Part B were automatically recorded as raw scores. Auditory and visual reminders were presented for incorrect connections, the numbers of which were also recorded. 3) Computerized Complex Figure Puzzle Test (cCFPT): cCFPT was developed based on an equivalent Complex Figure Test to ROCF to provide a computerized tool to assess visuo-constructional ability and visual memory.
18
However, it was not feasible to score hand drawings by image recognition software, requiring comparative accuracy as manual scoring. Thus, the complex figure was deconstructed into 17 components, each matched with an interference component with a similar appearance. The examinees were first required to reproduce a figure identical to the 1 displayed on the screen by selecting the correct components and moving them to appropriate positions in the puzzle area (copy trial). Then, they were asked to repeat the above procedures twice without displaying the original figure 5 minutes later (short-term delayed recall, SDR) and 30 minutes later (long-term delayed recall, LDR). For each step, the maximum score was 34 points (17 points for selecting the correct components and 17 points for moving them to the correct positions). 4) Computerized Common Object Memory and Sorting Test (cCOMS): cCOMS was developed as a counterpart of the AVLT in CNBC. However, it was not feasible to collect examinees’ answers verbally in cCOMS since existing speech recognition technologies failed to meet the CNBC requirement of scoring accuracy and automation due to the confounding of accents and dialects. Thus, Format-unified color photographs of everyday objects—including a comb, umbrella, tree, knife, cup, banana, chair, scissors, eyeglasses, and clock—were used as stimuli for cCOMS. Across 3 learning trials, each photo was shown for 2 seconds in the center of the screen 1 after another in a fixed order. The examinees were asked to remember both the objects and the sequence in which they were shown. After each round of display, the examinees were asked to identify the 10 objects among 20 photographs (10 original objects and 10 distracters) and drag them to the answer boxes successively in the order that they had been displayed. Five minutes (short-term delayed recall, SDR) and 30 minutes later (long-term delayed recall, LDR), the participants were asked to repeat the identification and sequencing tasks using another set of distracters. In the recognition trial, 20 objects were displayed 1 at a time in random order and the participants were asked to select “Yes” or “No” to determine whether the object had been shown in the learning trial. For each learning and recall trial, the full score was 20 points (10 points each for correct identification and correct ordering). For the recognition trial, 1 point was given when it was correctly determined whether an object was displayed in the learning trial. The maximum score was 20 points. 5) Autorun version of CNBC: To make the test battery more time-saving and efficient, an autorun version of CNBC was developed by organizing the test procedures as follows: cCFPT copy trial, cCOMS learning trials, cCFPT SDR, cCOMS SDR, cSTT, cDST, cCFPT LDR, and cCOMS LDR. The time limit for each procedure was determined after repeated pretests to make it performable for most examinees. The completion of the autorun CNBC was estimated to take 40-55 minutes, which is much shorter than the time to perform the 4 tests 1 after another.
Statistical Analyses and Sample Size Calculation
All statistical analyses were performed using the Statistical Package for Social Sciences (SPSS) version 22.0 (IBM Corporation, Armonk, NY), and a P-value of <0.05 was considered statistically significant. Continuous variables were presented as mean ± SD or median and interquartile range where appropriate and the Mann–Whitney U test or the t test was used to examine the differences between the 2 groups. Categorical variables were expressed as proportions, and a chi-square test was applied in the comparison between groups. Spearman’s rank correlation or Pearson’s correlation was adopted to analyze the strength of the correlations between CNBC subtests and traditional neuropsychological tests when investigating the validity and reliability of CNBC. Raw scores were used for both computerized and traditional neuropsychological measures. Correlation coefficients (r) were interpreted based on effect size using the convention proposed by Cohen for use in behavioral sciences 19 : small effect = .10, medium effect = .30, and large effect = .50. The accuracy requirements of the present study were set to be a type II error rate (false negatives) of ≤0.2 and effect size of 0.3 and a type I error rate (false positives) of ≤0.05. Thus, the sample size calculated via GPower 3.1.9.7 was ≥82 using the statistical test of correlation: point biserial model in the test family of t-tests (two-tailed). 20
Results
Demographics and Performance Characteristics of CNBC
Baseline Characteristics of the Participants.
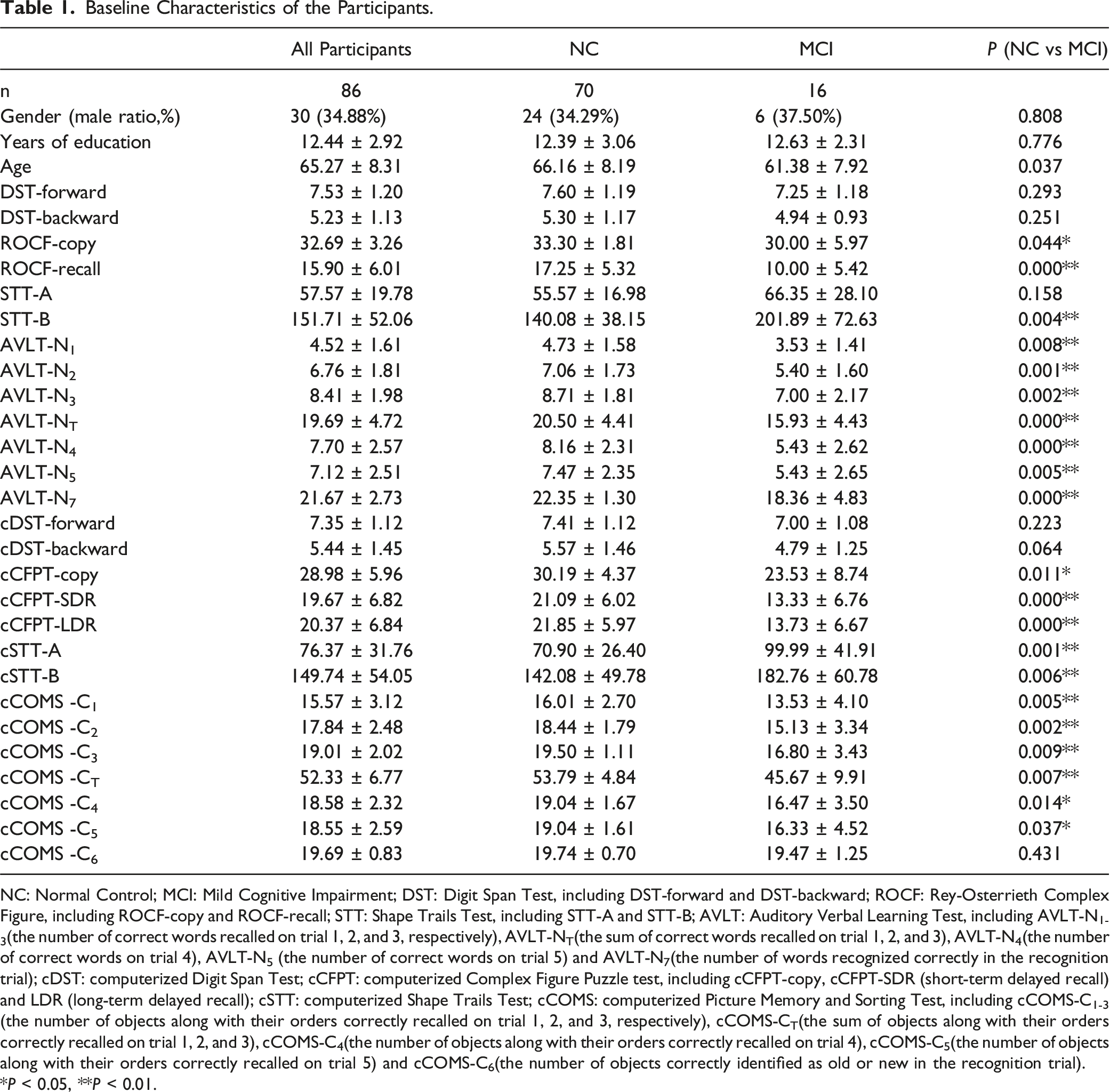
NC: Normal Control; MCI: Mild Cognitive Impairment; DST: Digit Span Test, including DST-forward and DST-backward; ROCF: Rey-Osterrieth Complex Figure, including ROCF-copy and ROCF-recall; STT: Shape Trails Test, including STT-A and STT-B; AVLT: Auditory Verbal Learning Test, including AVLT-N1-3(the number of correct words recalled on trial 1, 2, and 3, respectively), AVLT-NT(the sum of correct words recalled on trial 1, 2, and 3), AVLT-N4(the number of correct words on trial 4), AVLT-N5 (the number of correct words on trial 5) and AVLT-N7(the number of words recognized correctly in the recognition trial); cDST: computerized Digit Span Test; cCFPT: computerized Complex Figure Puzzle test, including cCFPT-copy, cCFPT-SDR (short-term delayed recall) and LDR (long-term delayed recall); cSTT: computerized Shape Trails Test; cCOMS: computerized Picture Memory and Sorting Test, including cCOMS-C1-3 (the number of objects along with their orders correctly recalled on trial 1, 2, and 3, respectively), cCOMS-CT(the sum of objects along with their orders correctly recalled on trial 1, 2, and 3), cCOMS-C4(the number of objects along with their orders correctly recalled on trial 4), cCOMS-C5(the number of objects along with their orders correctly recalled on trial 5) and cCOMS-C6(the number of objects correctly identified as old or new in the recognition trial).
*P < 0.05, **P < 0.01.
Correlations Between Cognitive Indicators of Participants With Normal Cognition and Demographic Parameters (Age and Education Years).
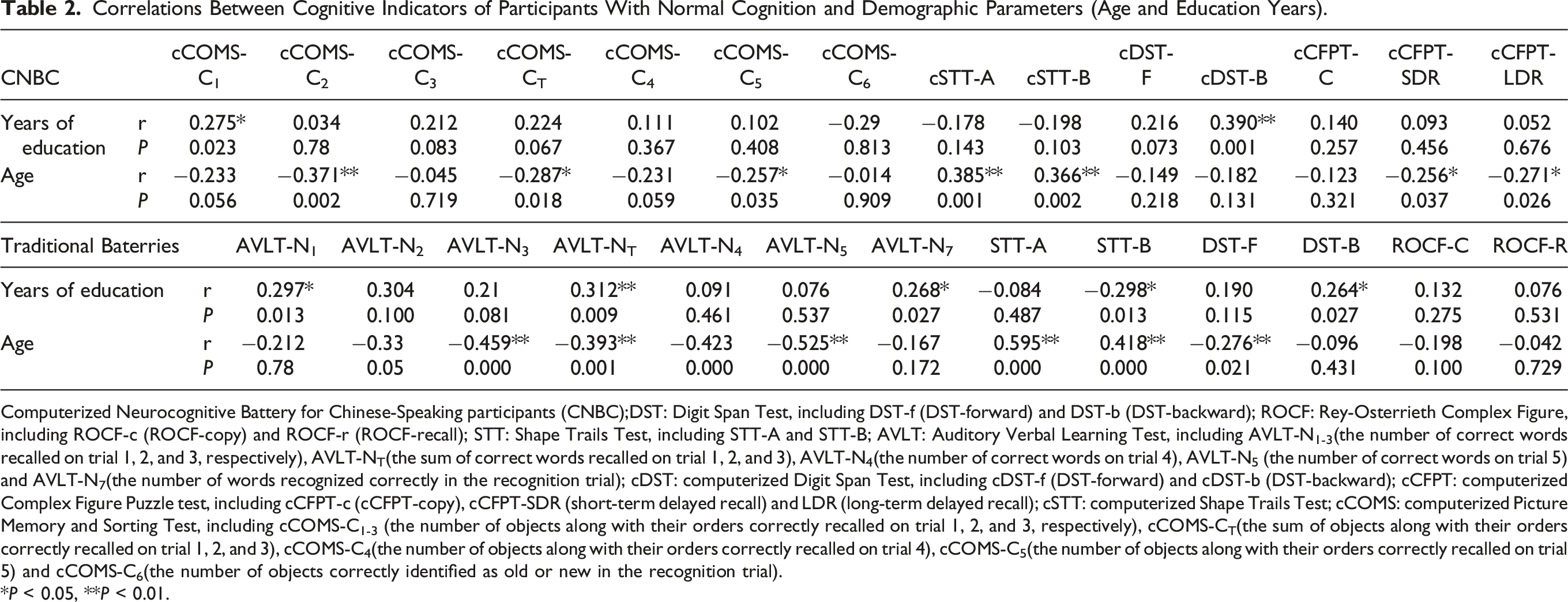
Computerized Neurocognitive Battery for Chinese-Speaking participants (CNBC);DST: Digit Span Test, including DST-f (DST-forward) and DST-b (DST-backward); ROCF: Rey-Osterrieth Complex Figure, including ROCF-c (ROCF-copy) and ROCF-r (ROCF-recall); STT: Shape Trails Test, including STT-A and STT-B; AVLT: Auditory Verbal Learning Test, including AVLT-N1-3(the number of correct words recalled on trial 1, 2, and 3, respectively), AVLT-NT(the sum of correct words recalled on trial 1, 2, and 3), AVLT-N4(the number of correct words on trial 4), AVLT-N5 (the number of correct words on trial 5) and AVLT-N7(the number of words recognized correctly in the recognition trial); cDST: computerized Digit Span Test, including cDST-f (DST-forward) and cDST-b (DST-backward); cCFPT: computerized Complex Figure Puzzle test, including cCFPT-c (cCFPT-copy), cCFPT-SDR (short-term delayed recall) and LDR (long-term delayed recall); cSTT: computerized Shape Trails Test; cCOMS: computerized Picture Memory and Sorting Test, including cCOMS-C1-3 (the number of objects along with their orders correctly recalled on trial 1, 2, and 3, respectively), cCOMS-CT(the sum of objects along with their orders correctly recalled on trial 1, 2, and 3), cCOMS-C4(the number of objects along with their orders correctly recalled on trial 4), cCOMS-C5(the number of objects along with their orders correctly recalled on trial 5) and cCOMS-C6(the number of objects correctly identified as old or new in the recognition trial).
*P < 0.05, **P < 0.01.
Construct Validity and Inter-rater Reliability of CNBC
Correlations Between Corresponding Indicators of CNBC and Traditional Batteries.
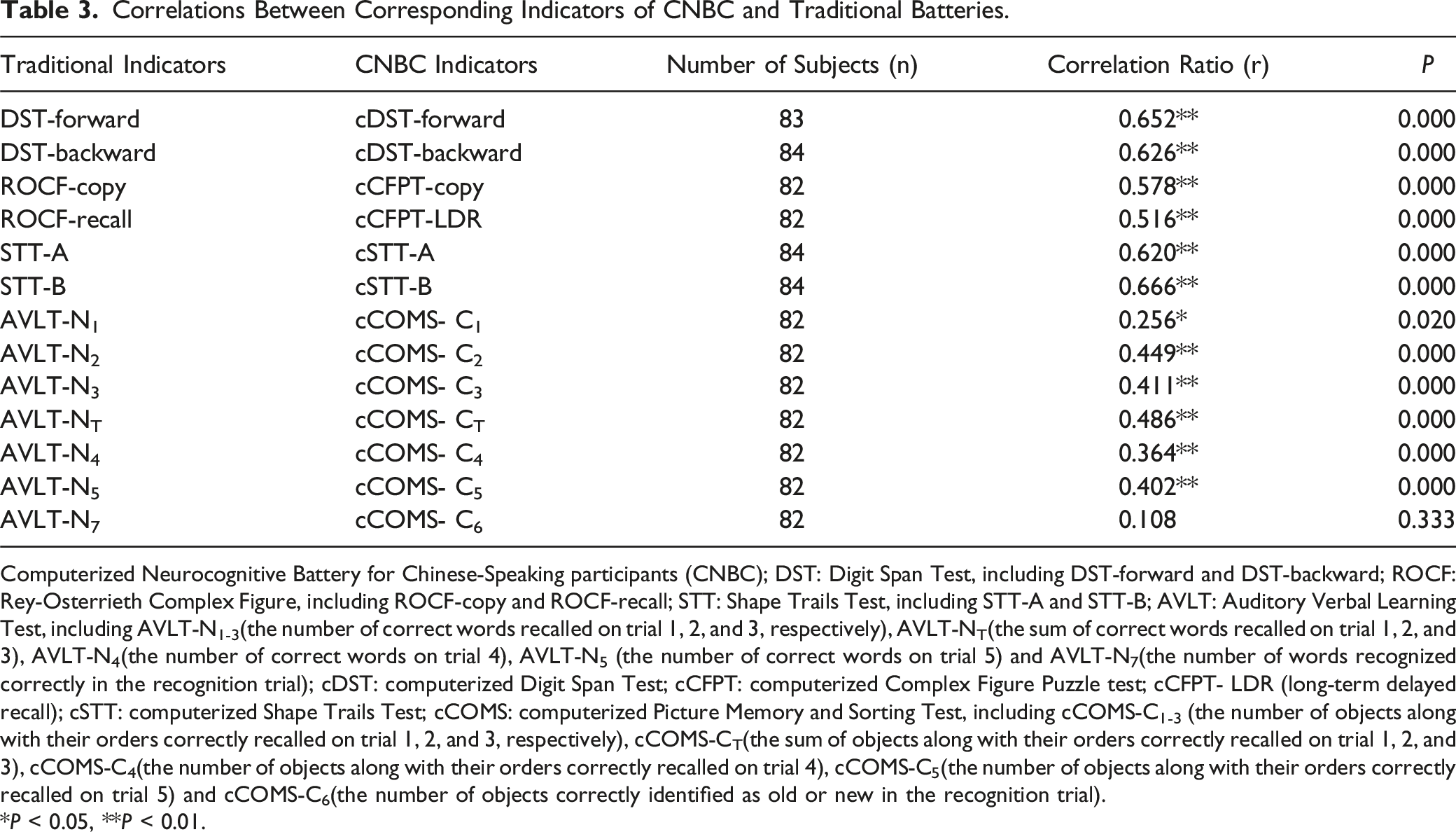
Computerized Neurocognitive Battery for Chinese-Speaking participants (CNBC); DST: Digit Span Test, including DST-forward and DST-backward; ROCF: Rey-Osterrieth Complex Figure, including ROCF-copy and ROCF-recall; STT: Shape Trails Test, including STT-A and STT-B; AVLT: Auditory Verbal Learning Test, including AVLT-N1-3(the number of correct words recalled on trial 1, 2, and 3, respectively), AVLT-NT(the sum of correct words recalled on trial 1, 2, and 3), AVLT-N4(the number of correct words on trial 4), AVLT-N5 (the number of correct words on trial 5) and AVLT-N7(the number of words recognized correctly in the recognition trial); cDST: computerized Digit Span Test; cCFPT: computerized Complex Figure Puzzle test; cCFPT- LDR (long-term delayed recall); cSTT: computerized Shape Trails Test; cCOMS: computerized Picture Memory and Sorting Test, including cCOMS-C1-3 (the number of objects along with their orders correctly recalled on trial 1, 2, and 3, respectively), cCOMS-CT(the sum of objects along with their orders correctly recalled on trial 1, 2, and 3), cCOMS-C4(the number of objects along with their orders correctly recalled on trial 4), cCOMS-C5(the number of objects along with their orders correctly recalled on trial 5) and cCOMS-C6(the number of objects correctly identified as old or new in the recognition trial).
*P < 0.05, **P < 0.01.
Correlations Between AVLT and cCOMS Indicators in NC Participants With 7-12 years of Education and Those With with More than12 years of Education, Respectively.
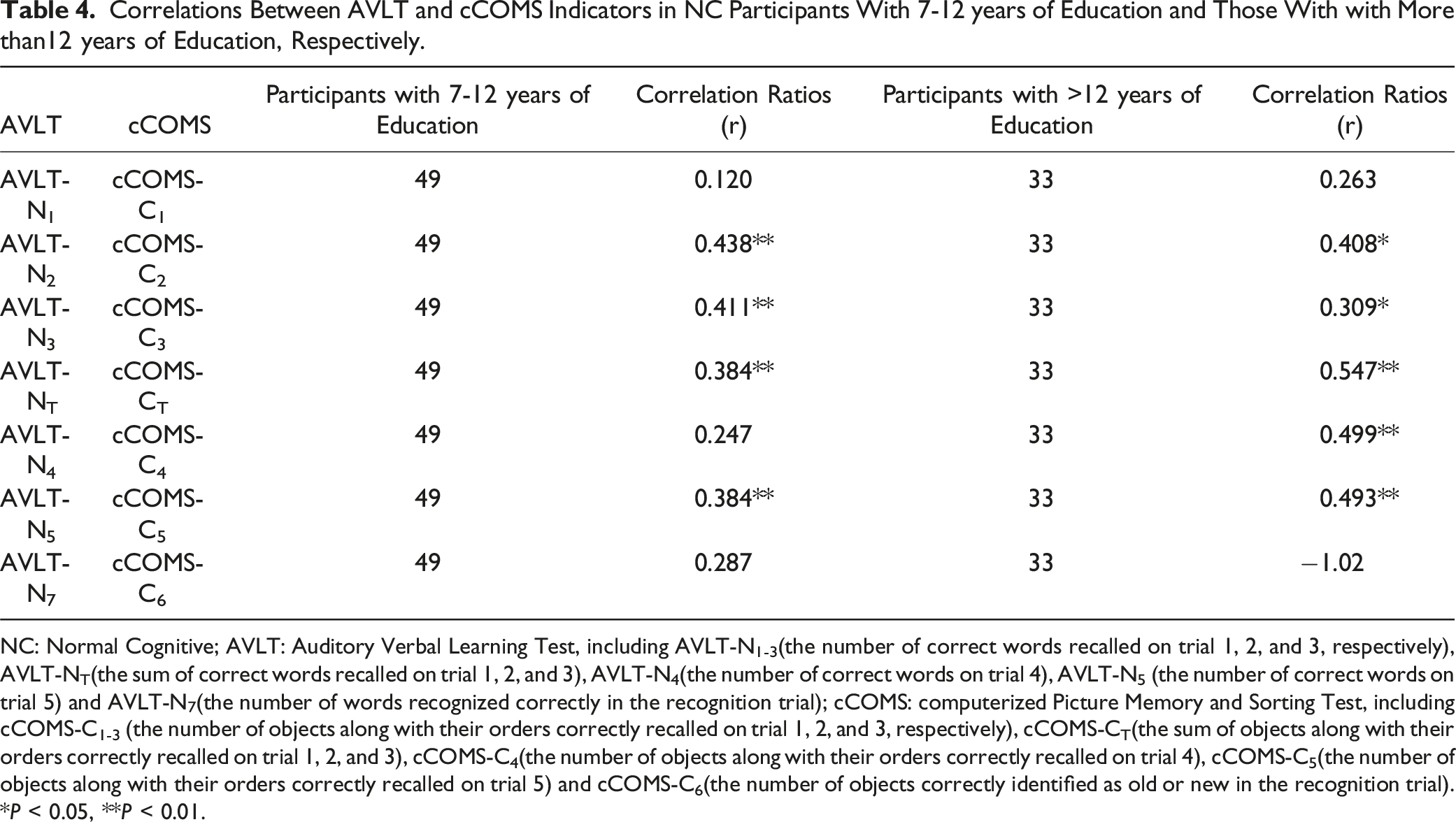
NC: Normal Cognitive; AVLT: Auditory Verbal Learning Test, including AVLT-N1-3(the number of correct words recalled on trial 1, 2, and 3, respectively), AVLT-NT(the sum of correct words recalled on trial 1, 2, and 3), AVLT-N4(the number of correct words on trial 4), AVLT-N5 (the number of correct words on trial 5) and AVLT-N7(the number of words recognized correctly in the recognition trial); cCOMS: computerized Picture Memory and Sorting Test, including cCOMS-C1-3 (the number of objects along with their orders correctly recalled on trial 1, 2, and 3, respectively), cCOMS-CT(the sum of objects along with their orders correctly recalled on trial 1, 2, and 3), cCOMS-C4(the number of objects along with their orders correctly recalled on trial 4), cCOMS-C5(the number of objects along with their orders correctly recalled on trial 5) and cCOMS-C6(the number of objects correctly identified as old or new in the recognition trial).
*P < 0.05, **P < 0.01.
Correlations Between Scoring Results of the Human Rater and the Autoscoring System of CNBC
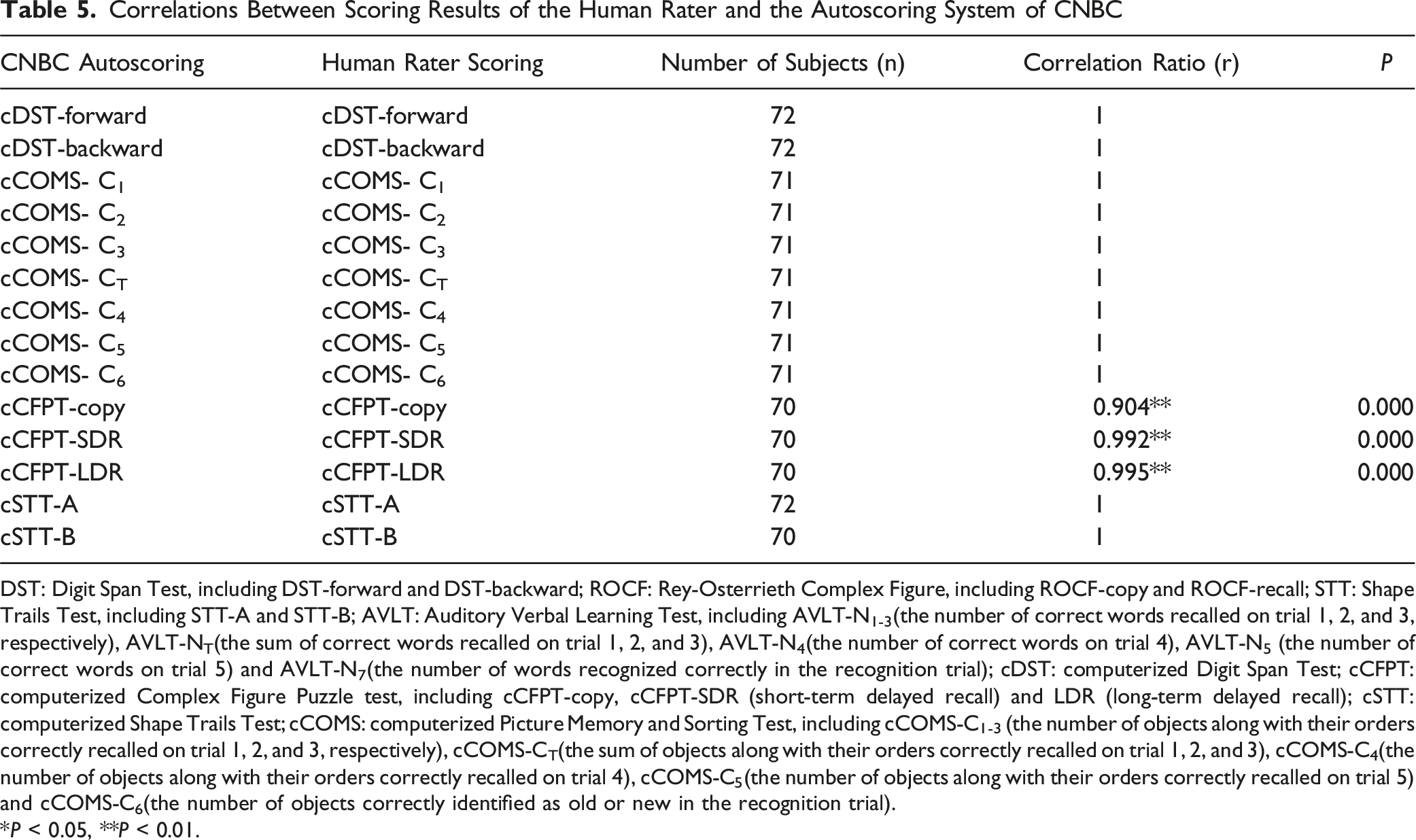
DST: Digit Span Test, including DST-forward and DST-backward; ROCF: Rey-Osterrieth Complex Figure, including ROCF-copy and ROCF-recall; STT: Shape Trails Test, including STT-A and STT-B; AVLT: Auditory Verbal Learning Test, including AVLT-N1-3(the number of correct words recalled on trial 1, 2, and 3, respectively), AVLT-NT(the sum of correct words recalled on trial 1, 2, and 3), AVLT-N4(the number of correct words on trial 4), AVLT-N5 (the number of correct words on trial 5) and AVLT-N7(the number of words recognized correctly in the recognition trial); cDST: computerized Digit Span Test; cCFPT: computerized Complex Figure Puzzle test, including cCFPT-copy, cCFPT-SDR (short-term delayed recall) and LDR (long-term delayed recall); cSTT: computerized Shape Trails Test; cCOMS: computerized Picture Memory and Sorting Test, including cCOMS-C1-3 (the number of objects along with their orders correctly recalled on trial 1, 2, and 3, respectively), cCOMS-CT(the sum of objects along with their orders correctly recalled on trial 1, 2, and 3), cCOMS-C4(the number of objects along with their orders correctly recalled on trial 4), cCOMS-C5(the number of objects along with their orders correctly recalled on trial 5) and cCOMS-C6(the number of objects correctly identified as old or new in the recognition trial).
*P < 0.05, **P < 0.01.
Discussion
This study developed a CNBC comprising the following 4 distinct subtests: cDST, cSTT, cCFPT, and cCOMS. These subtests were primarily designed to assess attention, executive function, episodic memory, and visuospatial abilities. The development of the CNBC was a scientific and meticulous process that integrated an automated testing and scoring system that reduced manual assistance as far as possible. The automatic administration of the battery typically took approximately 50 minutes per session. Its standardized procedures for voice prompts and question display ensured consistency throughout the assessment, optimizing efficiency while reducing potential scoring errors caused by tester intervention, operational variability, and inter-rater discrepancies. This approach saved valuable resources and enhanced the reliability and accuracy of the testing and scoring process.
In terms of the validation of the CNBC, it exhibits excellent content validity since the system was designed by adopting or referencing the testing format of well recognized paper-based cognitive assessment batteries with established norms in the field of cognitive evaluation in China,12,21 combining with computer software development techniques. To investigate its construct validity and inter-rater reliability (Table 3; Table 5), the test performances of 86 participants were analysed, and the results revealed significant correlations (0.364-0.666) between key indicators assessing attention, executive function, and episodic memory. This indicates strong construct validity Furthermore, the high correlation coefficients (0.904-1.0) between manual scoring and system scoring demonstrate excellent inter-rater reliability. Altogether, these findings affirm the promising clinical potential of the CNBC.
Some previous studies have compared the performances of computerized and paper-based cognitive tests. Gur et al examined the correlation between the 2 in a sample of 92 healthy individuals. The findings indicated significant correlation coefficients of 0.52 (P = 0.0001) and 0.53 (P = 0.0001) for measures assessing executive function and memory function, respectively. 22 Zhong et al. examined the construct validity of the Chinese version of the Cogstate Battery (CSB-C). The results revealed a correlation coefficient of 0.28 between the CSB-C and paired measures assessing attention in traditional comprehensive assessment batteries. 6 Additionally, for measures evaluating memory function, the correlation coefficients ranged from 0.36-0.62. In the validation study of the Penn CNB memory tests, the researchers analyzed the correlation between the computerized tests and paper-based ones (eg, the California Verbal Learning Test), finding a moderate correlation (0.30-0.49). 23 One recently published study, which validates a pad-version Hopkins Verbal Learning Test-Revised (HVLT-R) in Chinese participants, finds that the correlation coefficients between the Pad-HVLT-R and its paper-and-pencil version are moderately significant (around 0.50). 24 Comparing to these previous studies, the indicators evaluating attention (cDST, cSTT-A) and executive function (cSTT-B) in CNBC exhibit stronger construct validity (r > 0.60). This might be attributed to the close adherence of cDST and cSTT to the design of their paper-based versions, resulting in relatively smaller changes in format and content.
Meanwhile, the indicators rating episodic memory (cCFPT-recall and cCOMS-recall, r: 0.40-0.50) in CNBC showed comparable construct validity to those in the previous studies, which was weaker than those evaluating attention and executive function in CNBC. It might be attributed to the following reasons: the delayed recall components of cCFPT and cCOMS cannot be implemented in the form of free recall commonly used in paper-based memory tests due to the inability to accurately recognize speech or hand-drawing input which posed a challenge in achieving automated testing. Alternative input methods (eg, typing) either impose high demands on the participants or require operator assistance, which also hinders the realization of automated testing. Consequently, for cCFPT, the recall task involved selecting and assembling components to recreate the target figure. Although there were distractor components, it still incorporates a form of cue-based recall, leading to the reduction of task difficulty. This alteration in test format, specifically in the nature of the recall tasks, may have impacted the correlation between cCFPT-recall and the RCOF test. Similar issues also applied to the correlation between cCOMS and AVLT recall test. Similar influencing factors have been reported in previous studies.23,24 For example, the PennCNB study used a calibrated scale for the California Verbal Learning Test, which has a format similar to AVLT, and reported comparable correlations of corresponding indicators to our results. 23 Nevertheless, when designing cCOMS, in order to address the potential difficulty reduction associated with solely relying on image selection, which is akin to recognition tasks, the present study implemented a sequential selection task that requires participants to choose the target image from a set of 20 pictures in a specific order in cCOMS. This design aimed to ensure a comparable level of difficulty to the picture-based AVLT and COMT, which do not require sequential recall.10,12,25
Still, the correlation coefficients between cCOMS and AVLT recall tests (0.364 and 0.402) indicated a slightly lower construct validity compared to that between cCFPT and ROFT recall tests (r = 0.516). This discrepancy may be attributed to the different impacts of education levels on cCOMS and AVLT, resulting in the further reduction of the correlations. As shown in Table 4, compared to participants with lower education levels, participants with higher levels of education exhibited a greater number of significant and stronger correlations between the corresponding measures of cCOMS and AVLT, especially the key indicators (delayed recall). Previous research has shown that the education level substantially influences AVLT scores, resulting in its inapplicability and significant variations among individuals with lower education (eg, a primary school education) or those who are illiterate.10,12 By contrast, picture-based memory tests are less susceptible to the impact of education level.12,25 The stronger influences of education level on AVLT might lead to the reduction of the correlations between cCOMS and AVLT in lower educated participants in the present study. These results also indicated that cCOMS may exhibit greater generalizability and broader applicability compared to AVLT.
The present study successfully developed the CNBC, which improved the testing efficiency and reduced the occupation of personnel by implementing an automated testing and scoring system. To assess the accuracy of the software scoring, we evaluated the inter-rater reliability by examining the correlation between the automatically generated scores and raters’ manually assigned scores. The study results demonstrated a high correlation coefficient of 1 between the system scores and the manual scores for cDST, cSTT, and cCOMS (Table 5). This indicates a strong agreement between the automated scoring and the manual scoring for these 3 tests. The consistency can be attributed to the identical scoring rules employed in both versions and the objective measures used such as counting the number of correct responses or measuring the time taken to complete the tasks. The correlation coefficients between the system scores and the manual scores for cCFPT range from 0.904-0.995, suggesting a minor variation between the 2 (Table 5). This discrepancy may arise owing to differences in how the system and human raters assess the accuracy of component positioning in cCFPT. To enable automated scoring, the software engineers devised a method wherein the position coordinates for each component of cCFPT were determined based on the original image. During the puzzle-solving process, participants were instructed to accurately place the components in their designated positions. The software then assigned a position score by assessing the deviation between the center of the component and the original coordinates, with a tolerance of 15 pixels. By contrast, manual judgment is unable to achieve the same level of precision. Consequently, minor discrepancies may occur among some participants, but their overall impact remains negligible. Overall, the software-based scoring of CNBC demonstrates high accuracy, making it a reliable substitute for manual scoring.
In addition, the participants in this study were divided into the following 2 groups based on their cognitive function: NC and MCI groups. The 2 groups showed no significant differences in general characteristics such as gender, age, and education level. However, the MCI group exhibited significantly lower scores in multiple cognitive function assessments compared to the normal group. Ten out of the 13 pairs of score indicators from the traditional scales and 11 out of 14 pairs from the CNBC showed significant differences between the 2 groups (Table 1). The results imply that CNBC might distinguish NC individuals from MCI with comparable sensitivity to the traditional scales. However, it is important to validate these findings in larger sample sizes to establish the discriminant validity of CNBC.
The present study has a few limitations. First, the sample size was relatively small; it is necessary to expand the sample size in future studies to further validate the reliability and validity of CNBC. Second, the accurate recognition of input speech is challenging owing to factors such as accents, dialects, and the current limitations of speech recognition technology. Consequently, CNBC has not yet developed tests specifically targeting language function, neither did other computerized neurocognitive batteries. Moreover, due to technique limitations and the design priority of test automation, the delayed recall tests of the CNBC did not implement the form of free recall; other electronic memory scales also have similar issues. However, a sequential selection task was designed in cCOMS to address the potential difficulty reduction as mentioned above.
In conclusion, this study has successfully introduced a novel full-automatic computerized cognitive assessment battery tailored to the middle-aged and older adult Chinese population and conducted an initial validation. The results have demonstrated excellent reliability and validity of the battery, with potentially heightened sensitivity in detecting cognitive impairments, indicating its strong potential for clinical application and wide-scale implementation. It is necessary to enhance the sample size to further corroborate the reliability and validity of the assessment battery and evaluate its diagnostic efficacy specifically in individuals with cognitive impairments.
Footnotes
Acknowledgments
The authors would like to thank Chunhui Luo, Jialing Zhao and other software engineers from YiWei Medical Technology Co.Ltd. For program writing and software architecture.
Author Contributions
F. Y. designed the study, supervised the data collection and wrote the paper. J. Z. collected the data, carrying out the statistical analysis and assisted with writing the article. Z. H., X. L. and L. Y. assisted in the data collecting.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was carried out in Chengdu, China, and funded by grants from the STI 2030-Major Projects 2022ZD0208500 and the Sichuan Provincial Cadre Health Research Projects (2023-205).