
Abstract
This study focuses on the implementation of an efficient numerical technique for cryosurgery simulations on a graphics processing unit as an alternative means to accelerate runtime. This study is part of an ongoing effort to develop computerized training tools for cryosurgery, with prostate cryosurgery as a developmental model. The ability to perform rapid simulations of various test cases is critical to facilitate sound decision making associated with medical training. Consistent with clinical practice, the training tool aims at correlating the frozen region contour and the corresponding temperature field with the target region shape. The current study focuses on the feasibility of graphics processing unit-based computation using C++ accelerated massive parallelism, as one possible implementation. Benchmark results on a variety of computation platforms display between 3-fold acceleration (laptop) and 13-fold acceleration (gaming computer) of cryosurgery simulation, in comparison with the more common implementation on a multicore central processing unit. While the general concept of graphics processing unit-based simulations is not new, its application to phase-change problems, combined with the unique requirements for cryosurgery optimization, represents the core contribution of the current study.
Introduction
Simulation of heat transfer problems involving phase change is of great importance in the study of thermal injury to biological systems. 1,2 One important application is cryosurgery, which uses controlled freezing to destroy cancerous tumors. 3 Modern cryosurgery is frequently performed as a minimally invasive procedure, with the application of a large number of cooling probes (cryoprobes), in the shape of long hypodermic needles, strategically inserted into the area to be destroyed (the target region). 4 The minimally invasive nature of the cryoprocedure presents unique challenges associated with the appropriate selection of cooling technology (eg, nitrogen boiling versus Joule-Thomson), the selection of the most suitable cryoprobe dimensions, the optimization of the number of cryoprobes and their layout, and the application of the most effective thermal history. 5 –8 Optimal selection of the cryosurgery parameters can reduce the cost of the medical treatment, improve its quality, and minimize posttreatment complications. Furthermore, methodologies for how to select the optimal cryosurgery parameters affect the quality and duration of clinical training. Rapid computer simulations of bioheat transfer can help alleviate these difficulties, both in clinical training and during the planning phase of a specific procedure.
Techniques for computer-assisted planning and training essentially rely on decision making based on an array of solutions to closely related problems, in a process similar to classical optimization methods. 9 Methodologies for defining the corresponding set of problems belong to the general area of optimization, where the objective function for optimization may vary among clinicians based on accepted criteria for cryosurgery success and hardware capabilities. In practice, the most intensively monitored parameter during minimally invasive cryosurgery is the freezing-front location, with the aid of medical imaging. While the cryosurgeons may aim at reaching specific temperatures within the target region, such as the so-called lethal temperature, the clinical practice revolves around matching the freezing-front shape with the shape of the target region. With cryosurgery optimization in mind, this practice has led to the development of the so-called defect region—a quality measure of the geometrical match between a planning isotherm and the shape of the target region. 10 While the defect region is not the only possible measure to guide cryosurgery planning and training, it is perceived as the most intuitive by the authors of this study, closely following current clinical practice. 11
In order to be clinically relevant for planning and training, cryosurgery simulations must be rapidly performed—ideally in a matter of seconds. An efficient numerical scheme and parallel computation appear to be key for the development of computation tools for cryosurgery. 12 Although originally designed for image rendering, the graphics processing unit (GPU) has emerged as a competitive platform for computing massively parallel problems for nongraphical applications. 13,14 Although GPU-based computation appears promising for the application of cryosurgery simulations, its interactive application for planning and training may come with difficulties inherent to GPU-based software architecture. As a part of an ongoing effort to develop computerized planning and training tools for cryosurgery, the objective of the current study is to develop a proof of concept for GPU-based cryosurgery simulations.
In effort to place a realistic runtime target for the current proof-of-concept development, it is assumed by the authors that a complete surgical planning of under 2 minutes is required. This time frame bears negligible impact on the duration of the cryosurgical procedure, being much shorter than the cryoprobes insertion phase. Furthermore, a 2-minute time frame correlates very well with parallel educational objectives during computerized training. 15,16 Although using bubble-packing planning 17 may take only a couple of seconds and execution of 1 heat transfer simulation, the more accurate force-field analogy method may require up to 45 consecutive heat transfer simulations to reach an optimal layout. 6 Using the recently developed finite difference (FD) numerical scheme 18 and central processing unit (CPU)-based computerized framework, 12 each simulation requires approximately 30 seconds to complete on a high-end machine, leading to an overall planning time over 20 minutes. It follows that the current state-of-the-art performance is at least an order of magnitude slower than desired, which sets the target for the current study.
Mathematical Model
Bioheat transfer in this study is modeled with the classic bioheat equation 19 :

where C is the volumetric specific heat of tissue, T the temperature, t the time, k the thermal conductivity of the tissue,
Representative Thermophysical Properties of Biological Tissues Used in the Current Study, Where T is Given in Degrees Kelvin.

The validity and mathematical consistency of the classical bioheat equation has drawn a lot of attention in the literature of the past 6 decades, with greater interest around the 1970s and 1980s. 1,2 Despite the previous controversy, the classical bioheat equation is deemed adequate for the current study, whereas more sophisticated mathematical models may not warrant higher accuracy for cryosurgery computation but will involve greater mathematical complications. 21,22 Typical to bioheat transfer simulations of cryosurgery, the heating effect resulting from blood perfusion is far more significant than the metabolic heat generation, with the latter neglected in the current study. 22
Further note that the dependency of blood perfusion on temperature may represent a more complex behavior than the step-like change described in Table 1. Although the specific behavior may be unknown for the case of prostate freezing, Rabin and Shitzer 22 have already demonstrated that the overall effect of blood perfusion on the size of the frozen region is measured in only a few percent, for the special case of an extremely high blood perfusion rate but in the absence of major blood vessels. Given these prior findings, the simplistic temperature-dependent blood perfusion behavior in the current study is assumed adequate to predict the frozen region size, which is the monitored parameter via medical imaging during prostate cryosurgery.
An efficient numerical scheme to solve Equation 1 has been published previously 18 and is presented here in brief for the completeness of presentation. The numerical scheme is based on a FD approach, using a variable grid size and grid-dependent time intervals, which is well suited for parallel computation. 12 The variable grid size is used in order to reduce the computational cost, where a fine grid is only necessary in regions with steep thermal gradients, such as those around the urethral warmer and cryoprobes, while a coarse grid is used in the rest of the domain. Since the time interval to ensure stability is proportional to the typical grid size to the second power, an area with a coarse grid permits a much larger time step.
The characteristic FD equation for solving Equation 1 is 22
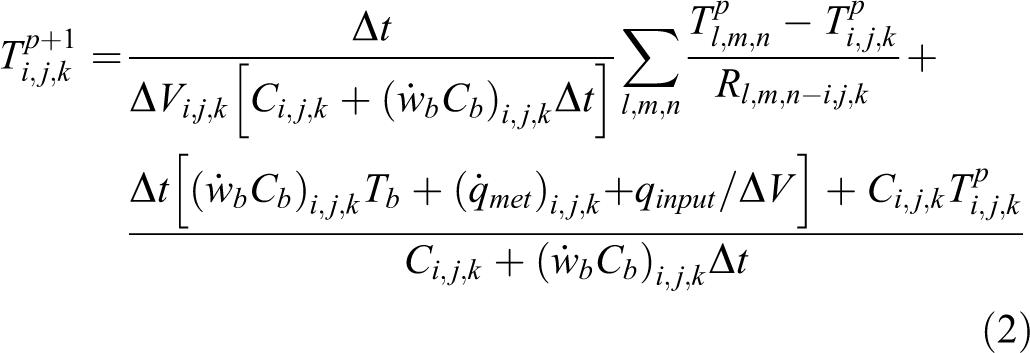
where i, j, and k are the indices of the grid point under consideration, the indices l, m, and n represent its neighboring grid points, p is the time level, V is the element volume associated with the grid point under consideration, and R is the thermal resistance to heat transfer by conduction between grid point i, j, and k and its neighbor l, m, and n. The thermal resistance to heat transfer by conduction in a Cartesian geometry is given by:

where L is the space interval in the direction of heat flow, and A is the representative cross-sectional area perpendicular to the same direction.
Figure 1 schematically illustrates a 2-dimensional (2D) domain, representative of a cross-section during prostate cryosurgery—the focus of the current line of research. For demonstration purposes, Figure 1 includes 2 grid sizes: a general coarse grid and a fine grid around the cryoprobes and the urethra; the urethra runs through the prostate and is warmed by a special heater during cryosurgery. Figure 1 also illustrates the thermal resistance network around a fine grid point and at a transition area between fine and coarse grid. Figure 1 presents a fine-to-coarse grid ratio of 1:3, which corresponds to a grid area ratio of 1:9 in 2D. These ratios illustrate the potential runtime reduction by varying grid size. Consistent with the previous publication by Rossi et al., 18 the simulated domain is assumed much bigger than the frozen region, such that the boundary condition represents constant temperature throughout the simulation—equal to the core-body temperature.

Schematic illustration of a variable grid of 1:3 ratio in the 2D case, representative of a prostate cryosurgery, and the thermal resistance network used for numerical simulations (adopted with permission from 18 ).
The stability criterion for applying Equation 2 is given by 18 :

In the current study, the maximum allowable time interval for the finest grid, ▵tfine, is evaluated first, to be used in the finest grid regions. Next, the maximum allowable time interval for the coarse grid is calculated, ▵tmax, where the time interval for the coarse grid, ▵tcoarse, is selected as the product of the truncated ratio ▵tmax/▵tfine and ▵tfine.
The numerical scheme presented previously was selected as a choice of practice, which has already proven to work well for parallelization of cryosurgery simulations.
12
Other FD techniques may also serve as good candidates for parallel computation of cryosurgery, such as the classical alternating direction implicit (ADI) method.
23
For example, Zeng and coworkers
24
have demonstrated that ADI can be used for parallel computation of cryosurgery, while using the same physical properties compiled by Rabin and Shitzer from previous publications
25
and by applying the same enthalpy approach proposed by Rabin and Korin for phase-change processes
20
and adopted for cryosurgery by Rabin and Shitzer.
22
Although the ADI may be used for parallel computation, we believe that it represents an inferior match for GPU implementation due to the required computation framework for the inherently serial tridiagonal solver. The number of intermediate steps that an ADI solver needs to take in order to solve the tridiagonal matrix for each simulated time interval is proportional to
When the ADI is based on an implicit and unconditionally stable solution, such as the modified Crank-Nicolson method, 23 each time step can be much extended, which represents an advantage. However, the implicit nature of the ADI strategy calls for additional measures to ensure the convergence of the solution and also energy conservation of the numerical scheme, 21 which would heavily tax any GPU-based implementation. Although the explicit scheme used in the current study requires relatively short time steps, its stability is a sufficient condition for convergence and its small time step guarantees energy conservation, 20 a combination that makes it very suitable for the parallel nature of GPU implementation.
As presented in the Introduction, the completion of a cryoprocedure is assumed when the best match between a planning isotherm and the target region is obtained, where this match is evaluated by the defect region value 10 :

where Vt is the volume of the target region, Vs is the volume of the simulated domain, u is a weight function, and Tp is the planning isotherm. For simplicity in presentation, a binary value is selected for the weight function in Equation 5. The defect value varies throughout the simulated procedure: it starts with a value of 1 at the beginning of the procedure, when the entire target region is unfrozen, decreases as the freezing process progresses, gets to a minimum value at some point in time, and then increases again as the external defect grows. The defect region concept is consistent with clinical practice, where the surgeon attempts to correlate the frozen region contour with the target region shape. Monitoring the evolution of the defect region has major implications on the computation cost, especially in GPU-based programming. 27
Results and Discussion
This study focuses on prostate cryosurgery as a developmental model for GPU-based simulations. In the absence of available imaging data to reconstruct the transient frozen region in a clinical setup, results of this study are validated against an established FD numerical scheme, 18 which in turn has been validated against experimental results on a bench-top setup. 28 In essence, this 2-phase validation is particularly useful to study runtime acceleration, when uncertainties in experimental data do not propagate into computer simulations and affect benchmarking results. 29 The current study employs a bubble-packing method as a technique to identify the optimal cryoprobe layout, 6 which has been validated against experimental data independently. 5 The FD implementation scheme has been previously optimized for parallel computation on multicore CPU machines, 12 which represents an appropriate benchmark for GPU-based implementation in the current study.
The GPU implementation and optimization have been conducted in an iterative manner. Below, the key elements of GPU implementation are presented first, the key optimization steps and their relative impact on runtime acceleration are presented next, and benchmarking results against an optimized CPU implementation on selected machines are presented last. Implementation results, optimization analyses, and benchmarking in this study are based on a cancerous prostate model created previously, using a urethral warmer and 12 cryoprobes at a uniform insertion depth, with optimal layout of the probes generated by bubble packing. 17 Figure 2A displays typical results obtained with the simulation code 12 at the point of minimum defect, presented at the largest prostate cross section. The C++ accelerated massive parallelism (AMP) was selected for GPU implementation as a choice of practice, based on its user friendliness as well as its advantage of future graphics interoperability with DirectX.

A typical simulated temperature field at the largest prostate cross section, subject to the operation of a urethral warmer and 12 cryoprobes: (top) temperature field results obtained with a CPU-based parallel computation, using double precision; (bottom) temperature difference between the CPU-based parallel simulation and the optimized GPU-based simulation. All temperature values are given in Celsius degrees.
Conceptually, the current study represents an advanced-stage development, where validation with experimental data is established in 2 consecutive steps. The first step has been completed in previous studies, where the applied FD numerical scheme 18 has been validated against experimental results. 28 That previous study 28 demonstrated mismatch between the predicted freezing-front location and the simulated freezing-front location of less than 4.8%, with an average mismatch of 2.9% (n = 24). Note that the freezing-front location is the monitored parameter during minimally invasive cryosurgery. That 2.9% mismatch has been translated to 0.3 mm of disagreement in the actual freezing-front location, 28 which is much smaller than the resolution in medical imaging for minimally invasive cryosurgery (in the range of 1-2 mm for ultrasound). The second step of comparison with experimental data is presented here, where any new computational development in the current study is validated against the established FD scheme and CPU-based implementation. For example, Figure 2B displays a mismatch of up to 0.4°C between GPU-based and CPU-based simulations of the same case, with a negligible difference in the freezing-front location (less than 0.01 mm, which has no clinical meaning). A wider discussion on the propagation of uncertainty in measurements into cryosurgery simulations has been presented by Rabin. 29
Key Elements in GPU Implementation
With reference to Figure 3, the cryosurgical simulation is composed of a main loop that marches in time subject to the following 6 key operations: (1) field-properties update, where the boundary conditions and material properties are recalculated during each computation cycle, based on the corresponding temperature field; (2) fine-grid temperature calculations subject to small time step intervals (calculated every loop cycle); (3) coarse-grid temperature calculations subject to a corresponding larger time step intervals (in practice calculated only every m loop cycles, where m is the ratio of time step intervals); (4) interpolation of the irregular simulation grid into a regular fine grid in preparation for the next step; (5) calculation of the defect field and its integrated value; and (6) periodic data transfer from the GPU to the host machine for logging and further thermal analyses. Only operations (1) and (2) are executed every time the main loop cycle, where the other operations are performed periodically, based on numerical stability criteria and operational parameters. For this purpose, special tests are scheduled to indicate whether the execution of operations (3) through (4) is due in the current time step.
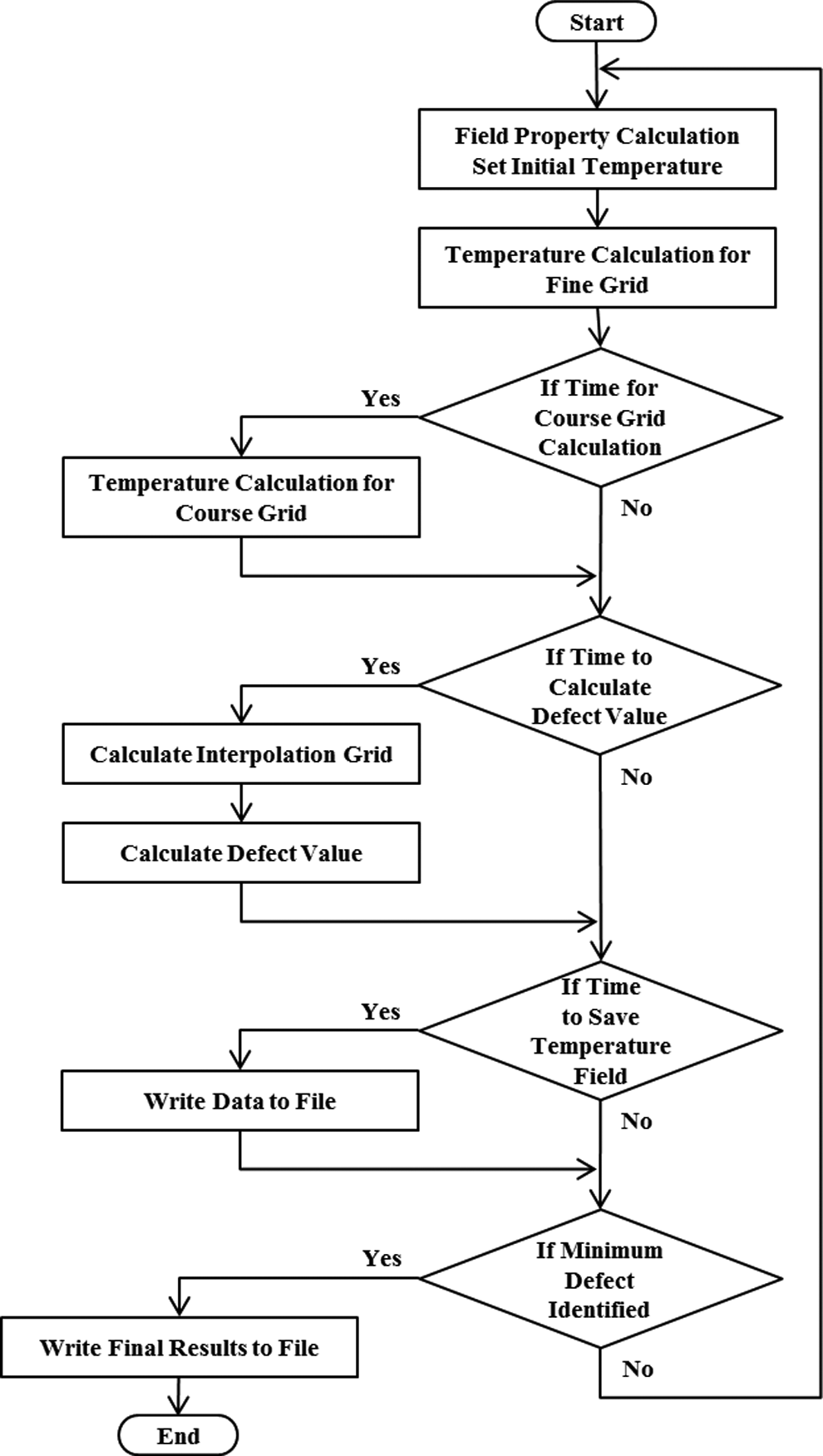
Flowchart representing the cryosurgery simulation framework.
The GPU simulation algorithm stores temperature and thermal conductivity data for each node in the simulation. Other thermal properties such as heat generation and specific heat are calculated ad hoc based on the nodal temperature. In addition, two matrices are used to store the nodal connectivity and thermal resistance data. The iterative optimization process in this study starts with a GPU implementation base-case, designated as naive, and then progresses through various optimization stages to improve runtime performance.
Since most of the simulation algorithm can be modeled as a sparse-matrix vector operation (SPMV), the naive implementation is based on a compressed sparse row (CSR) matrix format for both the matrices of nodal connectivity, thermal resistance, and interpolation. The access pattern for both of these matrices follows the scalar SPMV algorithm, 30 where each thread is responsible for a row in the matrix-vector multiplication operation. In order to calculate the defect value, a reduction operation is applied to the sum of defect values from all interpolation nodes. A cascade algorithm 31 is used for the reduction, where each thread sums a fixed number of elements from the interpolation grid, each processor group sums up an intermediate defect value from all of its individual threads, and finally each processor group copies its partial sum to the CPU where the final reduction occurs. Only one of the above-mentioned steps was run at a time in the naive implementation.
Iterative Optimization Process
Optimization of the GPU-based simulation scheme progressed based on a prioritized list of expected improvements in terms of runtime, with the outcome displayed in Figure 4:
Float precision
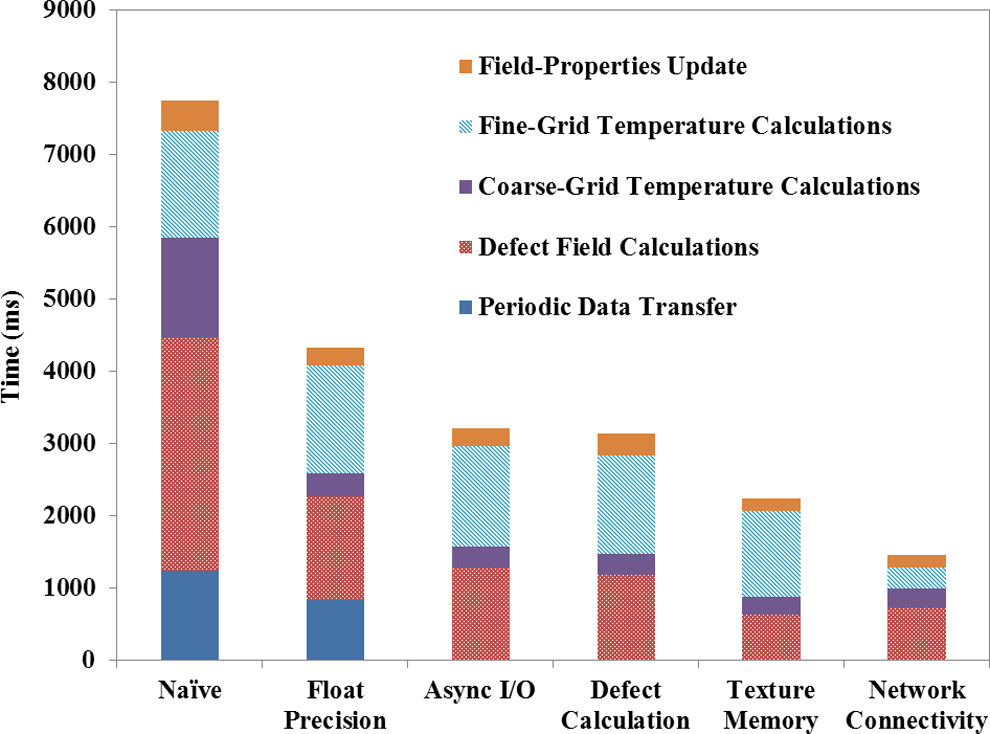
Typical runtime results of successive optimization steps for the GPU implementation, where naive represents the nonoptimized base-case GPU implementation.
Converting from double-precision in the naive implementation to float precision for all applicable parameters dramatically reduced runtime by 44%. No significant degradation of the quality of calculated temperature field (Figure 2B), the defect field, or the time to minimum defect was identified due to the decrease in numerical precision. As can be seen from Figure 2B, the maximum mismatch between the float precision and the CPU-based implementation is 0.4°C, while being practically negligible in the great majority of the field. By reducing to one-half of the amount of data transferred from the global memory, this change speeds up all of the steps in the heat transfer simulation. Most significantly, this change speeds up the defect value calculation, which is the most global memory-intensive process. While no appreciable degradation in the computed temperature field is observed due to the conversion to float precision in the current study, order-of-magnitude reduction in time or space intervals may call for revaluation of the temperature field quality.
2. Asynchronous I/O
Since file I/O can be performed in a separate thread on the CPU, in parallel to GPU operations, asynchronous file operations were tested in the next step of optimization, shifting this costly step to the background. Asynchronous I/O saved additional 14% in terms of runtime with reference to the float precision implementation.
3. Defect calculation
Defect calculations are based on a trilinear interpolation scheme, where each interpolated grid point is calculated based on 8 neighboring nodes. This allows an ELLPACK (ELL) matrix representation to be used instead of CSR. The ELL matrix more efficiently represents the sparse matrix, as it saves only the non-zero entries (8 in this case). Anytime that the ELL representation is used to store a matrix on the GPU, the non-zero entries are arranged so that the first non-zero entry in each row are laid out sequentially in the ELL array, with the pattern continuing for each additional non-zero per row. This layout significantly improves global memory coherency. In the third step of optimization, temperature interpolations and defect calculations were further combined into a single kernel, dramatically reducing the number of global memory operations. Unfortunately, the current optimization effort did not significantly shorten runtime (Figure 4) since the current effort covered only a small portion of the total time spent within this kernel. In practice, the majority of the computation time is devoted to the scheme of defect calculations, which could not be further accelerated. Interestingly, due to the asynchronous I/O operations, it was also observed that modifying this kernel had an adverse effect on the runtime of the field property update kernel.
4. Texture memory
Texture memory is a specially mapped location of global memory, which allows faster lookup and writing times. To take advantage of this special GPU feature, reused data for the execution of the main program loop, such as temperature and thermal properties, were stored in texture memory. Applying texture memory directions reduced the runtime of all kernels by 28% compared to the previous optimization stage and overall reduction of 12% compared with the naive implementation. The only difficulty with using texture memory with C++ AMP is in the need for 2D texture structure in order to contain the large data structures typical to cryosurgery simulations.
5. Network connectivity
Although any node within a uniform grid, either fine or coarse, has connections with 6 neighboring nodes, more connections may develop at the interface between the fine and coarse regions. To calculate this connection network more effectively, a hybrid matrix representation was formulated as follows. The 6 connections within the uniform grid areas are stored in the memory efficient ELL matrix representation. For interface nodes (more than 6 neighbors), these connections are stored in a permutated CSR (PCSR) format, with rows ordered in descending order based on the number of non-zero elements. This hybrid representation is similar to the one presented by Bell and Garland, 30 except for the non-zero entries that do not fit into the ELL representation, which in turn are saved in a PCSR format rather than the coordinate (COO) format suggested by Bell and Garland. 30 In general, the COO format saves a row number, a column number, and a value for each non-zero entry. The PCSR representation has less memory coherency than the COO format when performing sparse matrix vector-like operations. However, for the application of cryosurgery, the PCSR format significantly reduces the amount of computation compared to the COO format, since calculations of the temperature-dependent terms in the update step only need to occur once per row rather than once per non-zero element. The PCSR format does, however, decrease code divergence within a processor group compared to the original CSR format, by processing rows with a similar number of non-zeroes within one group. The real acceleration due to the improved connectivity comes about by storing the majority of the connections in the network in the more efficient ELL representation. Improved network connectivity as described above reduced runtime by 10% compared with the naive implementation.
Computation Platforms and Benchmarking
With all the above-mentioned 5 steps of optimization in mind, the optimized GPU-based code was benchmarked against a CPU-based parallel computation code 12 on the selected computation platforms as listed in Table 2, where the results are displayed in Figure 5. These machines were selected to represent the typical performance of a midrange laptop, a high-end home PC, a gaming PC, and a workstation PC. All heat transfer simulations were run for 201 seconds of simulated runtime, which coincides with the point at which the minimum defect was identified. The grid size used in this study is 1 × 1 × 1 mm3 for the fine grid and 3 × 3 × 1 mm3 for the course grid, resulting in a total of about 80 000 grid points in the entire 3D domain. These grid sizes were chosen in a previous study in order to reduce computational cost. 18
Computer Platform Specifications Used for Benchmarking in the Current Study.

Abbreviations: CPU, central processing unit; GPU, graphics processing unit.
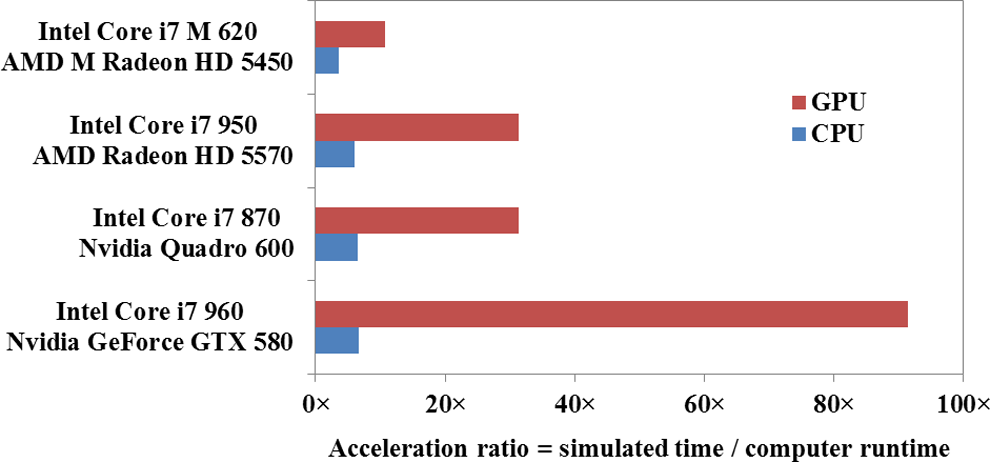
Simulated-to-actual cryoprocedure runtime ratio, for GPU-based (optimized) and CPU-based (optimized) simulations on various platforms, with platform specification listed in Table 2. Note that the GPU-based simulation is benchmarked against a multicore, multithread, and CPU-based simulation in the current study, which in turn was benchmarked against a single-core, single-thread, and CPU-based simulation in a previous study. 12
In all tested cases, the GPU-based implementation was able to significantly outperform the optimized CPU-based implementation. Simulation speed increase ranged from 3× on the laptop and up to 13× on the gaming PC, which housed the most powerful GPU. Note that the CPU-based computation has already been optimized for multiprocessors, 12 where the implementation of the applied FD scheme is trivial using parallel for loops with OpenMP. In the preoptimized CPU implementation, 12 every node was represented as an object that contained all of the material properties and connectivity information with the surrounding nodes. Optimization in that study focused on data restructuring in order to reduce the system memory load, while targeting the more commonly used properties such as conductivity, volume increments, and specific heat. For example, with reference to the preoptimized serial CPU implementation, the optimized and parallelized CPU implementation performed 3.9× faster using Hyper-Threading on all 4 cores of an Intel Core i7 960 on a Hewlett-Packard personal workstation platform. 12 Combining the results of the current study with those previous optimization measures, the optimized GPU-based implementation performs about 50× faster than the serial CPU simulation (3.9× in the previous study × 13× in the current study). Figure 2B displays a very good agreement between the 2 simulation approaches.
Parametric investigation using Nvidia GeForce GTX 580 (512 GPU cores) reveals that simulation runtime is linearly proportional to the number of numerical nodes for larger problems, such as the one used in the current study for benchmarking (about 80 000 nodes). This linear relationship holds as long as the problem is big enough to effectively use the entire GPU memory bandwidth. For example, a 40,000-node problem of similar parameters would run twice as fast, but the relative performance illustrated in Figure 5 would remain unaffected. When additional computational work is called while memory fetches occur, much of it can be fully hidden. 31 However, there is a problem-size threshold below which the computation performance starts to degrade, as the large number of cores becomes underutilized during memory fetches. This occurs when the problem becomes smaller than about 30,000 numerical nodes for the current numerical scheme and the above computation unit. Given the internal GPU architecture, the lower boundary for such a linear behavior cannot be predicted a priori, and the 30,000-node limit was found experimentally in the current study. Similarly, the upper boundary for this linear behavior must be found experimentally, where the higher performance GPU will exhibit a wider linearity range.
When evaluating the scalability of the GPU implementation of the current algorithm, 3 aspects should be bared in mind: (1) three grids are simultaneously used during calculations (small and large grids of simulation and an interpolation grid for defect evaluation), in which kernels are executed on; each numerical grid affects the computation time of a different set of kernels. (2) The number of interface nodes between the small and the large simulation grids affects the computation time, as each large-grid node at the interface has more than the usual 6 neighbors. These interface grid nodes call for additional hardware operations. (3) In the context of clinical practice, the geometrical variation in problem size is expected be relatively small, as the typical candidate for cryosurgery has a prostate volume in the range of 35 to 50 mL. Hence, the comparative results presented previously are quite representative and expected to only vary with hardware performance, rather than with the size of the target region.
In terms of actual runtime for a clinical application, a full-scale GPU-based simulation of cryosurgery can already be achieved in less than 2 seconds (Figure 5). Such a short time can be considered instantaneous for the purpose of providing an early prediction of the cryoprocedures outcome when compared with the actual cryosurgical procedure, which is measured in several minutes or longer. This capability of rapid simulations advances the discussion about cryosurgery computation from merely analyzing a special case to analyzing a battery of cases in effort to improve decision making, which would be an integral part of any computerized planning, 6,18,32 computerized training, 12,16 or an intelligent approach to control of the procedure. Such a battery of cases may contain a varying set of problems in the search for an optimum or a set of “what-if” scenarios for the benefit of training and medical education.
The current trend of increasing the number of cores on modern GPU platforms, combined with the threshold on the effective size of numerical problem, suggests that the effectiveness of GPU technology development may get to the point of diminishing returns, where the GPU may become “too big” for the mathematical problem. However, this would only be true for serial execution of a large array of simulations (each of which is parallelized for GPU implementation). Hence, computer-based decision making associated with advanced GPU systems does not only call for rapid computation techniques but also for advanced decision-making frameworks, where many simulations are concurrently executed on the same system. Consistently, it is suggested that the next generation of computational cryosurgery research should focus on new ways to utilize the rapid advancing technology of GPU-based systems.
Summary and Conclusions
As a part of our ongoing program to develop a computerized training tool for cryosurgery, the current study focuses on decreasing the time necessary to simulate a cryosurgery procedure. For this purpose, a previously developed FD algorithm was implemented on a GPU machine, using C++ AMP. The FD algorithm was chosen for this study due to its demonstrated superiority compared with a finite elements commercial code in a previous study. 12 C++ AMP was chosen for the current study as a choice of practice.
This study discusses several aspects in optimizing GPU-based cryosurgery simulations, with the defect calculations as a key element in computation. Most significant acceleration was achieved by switching to float precision, implementing asynchronous I/O, saving frequently used data in texture memory, and the integration of a hybrid ELL matrix structure to store the nodal connectivity grid. Results of this study demonstrate runtime acceleration of up to 13× compared with multicore-CPU processing, up to 50× compared with sequential CPU processing, up to about 90× compared with actual cryosurgery operation runtime, and an actual runtime of about 2 seconds for a single procedure. The GPU-based implementation reproduced previously simulated cryosurgery cases on a multicore CPU-based implementation within 0.4°C margins, where results of that earlier implementation have been validated experimentally. 28 Additional modifications, like the reduction in stair-casing artifacts, 33 may further be applied to the proposed GPU implementation to improve accuracy and tailor the scheme to other applications. Further performance improvements to the proposed algorithm could include modification of the storage scheme for the resistance matrix, in order to better use the processors-shared memory cache. 30 Although advanced optimization techniques have been proposed for finite-difference methods using regular grids, where calculations are executed to reduce the processor’s global memory load, 34 their development and benchmarking for the type of irregular grid used in the current study is left for future work. This level of performance makes GPU-based computation ideal for computerized planning and training of cryosurgery.
This study is a part of an ongoing effort to develop training and planning tools for cryosurgery, with emphasis on prostate cryosurgery. Prostate cryosurgery presents a unique challenge where many cryoprobes are operated simultaneously, which demands high computation performance for real-time simulations. A previous study has characterized the evolution of prostate cancer as it pertains to geometric deformations, 16 while another study addressed reconstruction of organ models from clinical data. 35 With the current computation capabilities in mind, future studies can now expand on additional cryosurgical applications, when the geometries of the cancer tumors or the cancerous organ become available. These capabilities are particularly useful for cases of multiple cryoprobes and complex geometries.
Footnotes
Authors’ Note
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Cancer Institute or the National Institutes of Health.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by Award Number R01CA134261 from the National Cancer Institute.