
Abstract
Introduction
Cervical cancer is one of the leading causes of death in women across the world 1 . The treatment and survival chances from this cancer are heavily dependent on the stage at the time of diagnosis. When cervical cancer is diagnosed at an early stage (or precancerous stage) 1 , the chances of survival are very high, and the recovery is also fast. Cervical cytology is the most popular and trusted procedure for the screening of cervical cancer at early stages. This is a physical procedure in which few cells are collected from the cervix and are transferred into a container with special liquid (in case of liquid-based pap smear) to preserve the sample or onto a glass slide (in case of conventional pap smear) for examination under a microscope. This procedure has shown promising results in reducing the mortality rate of cervical cancer in women 2 . This procedure was performed for the screening of cervical cancer across the world. However, this procedure is not available for population-wide screening in underdeveloped and developing countries because of its complexity and tedious nature as it involves a human intervention to manually examine for the abnormal cells in the cytology specimen 3 . But the automation of this examination procedure with computerized techniques like Artificial Intelligence (AI) will increase the efficiency and also reduce the detection time 4 .
Over the last few decades, there has been a lot of research that is done in automating several medical practices with AI via machine learning and deep learning 5 . These methods have shown promising results in the diagnosis of Pneumonia, Brain tumors, Heart diseases, COVID-19, Tuberculosis 6 , and also in the diagnosis of other cancers like breast 7 , lung, and brain. Even in this field, there are several studies that were proposed for the screening of cervical cancer from cervical cytology images3,8‐10. Like, Dong et al. 11 proposed an approach that uses a canny segmentation algorithm to segment the nuclei regions from the cytology images from the single-cell dataset; from these regions edge features, are extracted using adaptive gradient vector flow snake model, and these features are used to train the support vector machine algorithm for classifying normal and abnormal cells. Few other studies were presented in12,13 using the same dataset, where the authors used Fuzzy C means clustering and Radiating-Gradient-Vector Flow (GVF) model for nuclei segmentation. Marinkis et al. 14 performed Benign/Malignant classification on the same dataset using nearest neighbor classifiers trained with features selected using genetic algorithms.
Genctav et al. 15 implemented smear level segmentation based on circularity, uniformity, and nuclear size. In the later part of the study, they also used an unsupervised learning approach to conduct binary classification on a smear level dataset. Their results show improved effectiveness when dealing with challenges associated to poor strained quality. Bora et al. 16 used shape-based nuclei features extracted by the Maximal stable external region (MSER) algorithm followed by thresholding ratio and some morphological operations for smear level segmentation. To analyse the hyperchromatic variations in the nuclei, the scientists employed textual characteristics based on entropy, skewness, and kurtosis, as well as intensity features based on ripplet transform. According to the findings, the updated MSER algorithm can handle pap smear images with worse quality due to inadequate straining and can also remove undesirable structures in the cell.
There were few methods that employed multi-level approaches for segmentation. Like, Zhang et al. 17 used a graph cut method integrated with textual and intensity-based features for segmentation. It was observed that all such methods rely on multi-level segmentation coupled with some post and pre-processing steps. Hence the failure at any level will affect the performance of the segmentation model, which in turn will also have a great effect on the classification accuracy and will increase the diagnosis error. Lu et al. 18 also implemented such a multi-level approach for segmentation, but their method failed on abnormal cells. This might be due to incomplete hand-crafted feature sets preventing the techniques from describing low-level features. However, hand-crafted features do not contain all the structural information of the nuclei; hence they result in poor segmentation performance. To enhance the segmentation performance, nuclei-type-specific criterion values should be used for the segmentation of different types of cervical nuclei with some post and pre-processing. This increases the length of the pipeline, and an error in any step will be convex to the error and will reflect on the subsequent steps.
The disadvantages discussed above can be addressed using deep learning methods. These methods have shown enhanced performance in medical image segmentation, classification, lesion detection19,20. There are few studies that reported enhanced segmentation performance in terms of accuracy and efficiency while using DL methods. Zhao et al. 21 proposed a convolutional neural network-based deformable multipatch ensemble model for single-cell nuclei segmentation on the Herlev dataset. Liu et al. 22 built a segmentation model for single-cell nuclei segmentation by altering the structure of Mask R-CNN and adding fully linked conditional random fields. Lin et al. 23 used morphological convolutional neural networks to conduct multi-class and binary classification of single pap smear pictures. Song et al.24,25 proposed a two-step approach, where in the first step, a deep learning method was used to segment the nuclei, and in the next step, a graph partitioning and superpixel approaches are used for the coarse-to-fine segmentation of the nuclei. A similar two-step approach was proposed by Zhang et al. 26 , where the authors segmented the single-cell nuclei by integrating convolutional neural networks (CNN) with graph-based approaches. Gautam et al. 27 developed a CNN model using transfer learning for single-cell nuclei segmentation.
With this motivation, a fully automatic cervical nuclei segmentation and classification approach was proposed in this paper. The proposed approach consists of a deep learning-based segmentation model, a fusion-based feature extraction model and a classification model. The structure of proposed work is shown in Figure 1. The contributions of the paper are summarised as follows:
The proposed work first segments the data, and then utilizes the segmented data for classification. The segmentation model is designed by modifying the structure of the U-Net model. A residual block with the Squeeze and Excitation (SE) block is used in place of the convolutional layers in each stage of the U-Net encoder-decoder network. This segmentation model was used to segment the nuclei from the cells. From the segmented image, the deep features and hand-crafted features are extracted and fused using the standard concatenation. To remove the redundancy among the extracted features, the PCA method is used before concatenation for feature selection. These fused features are used for training the multi-layer perceptron for classification.

The structure of the proposed work.
The rest of the paper is organized as follows; Section 2 describes the materials and methods used, Section 3 describes experimental results and data used, section 4 presents the discussion, and section 5 concludes the work.
Materials and Methods
Residual SE UNet
In this work, a novel segmentation architecture based on UNet was proposed for the segmentation of nuclei from the pap smear images. The structure of the proposed network is shown in Figure 2. In this network, a residual block with the Squeeze and Excitation (SE) block is used in place of the convolutional layers in each stage of the UNet encoder-decoder network. This Residual SE module is shown in Figure 3. The residual block consists of a stack of two

The structure of the proposed Residual SE UNet.

The structure of the proposed Residual Squeeze and Excitation module.
In segmentation, spatial information is essential to identify the suspicious regions in the images. So, to improve the ability of the network to distinguish between the local and global information and to enhance its learning ability in each stage, an SE block is used after the residual block in this network. The SE block recalibrates the extracted features in two stages; in the first stage, the squeeze operation is performed where the features are globalized channel-wise into a one-dimensional
The network proposed in this work is a 9 level architecture consisting of three parts, namely encoder, decoder, and a bridge. The encoder converts the input image into a compact representation, and the decoder recovers this representation into pixel-wise classification. The bridge acts as a connection between encoder and decoder parts. The encoding block consists of four residual SE modules; specifically, the encoding block uses four downsampling operations after each Residual SE module to extract high-level semantic information. In each Residual SE encoding module, a stride of 2 is applied to the first convolutional layer of the module to downsample the feature map by its half instead of using a pool operation to preserve positional information. Correspondingly, the decoder path consists of four Residual SE modules. There is a concatenation of the feature map from the corresponding encoding path with the upsampled feature map from the previous module. After the last encoding module, there is a
In the segmentation task, the imbalance between the background and the nucleus may result in segmentation bias. To deal with this problem, a loss function based on the dice coefficient is employed in this work. This loss function is presented in equation 1.

Proposed classification model
The proposed multi-feature fusion approach consists of four main parts: (1) fine-tuning the pre-trained models to extract deep features, (2) computing LBP and BoF features for each segmented image, (3) Reducing the dimensions of the extracted features sets using PCA and (4) concatenating the hand-crafted and deep features for training the MLP for classification.
Deep feature extraction
In this work, three deep convolutional neural networks (DCNN), namely VGG19
30
, VGG-F
31
, and CaffeNet
32
, are employed for feature extraction. The VGG19 contains 16 convolutional layers with
The number of neurons in the final dense layer is modified to the number of classes in the dataset to make these models acceptable for the categorization of pap smear pictures. Then the segmented images with size
Hand-crafted feature
In this work, Linear Binary Patterns (LBP)
34
and Bag of Features (BoF)
35
descriptors are used to characterize each image. The LBP descriptor is computed in three steps. For each pixel, the values of its eight neighboring pixels are assigned a binary value based on the center pixel; the value of the neighboring pixel is one of the existing values that is greater than the center pixel and is given zero if it is less than the center pixel. In the next step, these eight binary values are concatenated to form an eight-bit integer taking values from
Principal Component Analysis
For each input image, there are three sets of deep features and two sets of hand-crafted features extracted, each of which has dimensions between 256 to 4096. The PCA algorithm is used on a group-by-group basis to deal with the curse of dimensionality and to select the most discriminative features. Let the
Multi layer perceptron (MLP)
MLP is a multi-layer feed-forward deep neural network with a non-linear mapping of inputs to outputs. MLP is made up of three layers: an input layer, a hidden layer, and an output layer, in which each node is connected with suitable weights to all the nodes in the following layer. For training, MLP employs the backpropagation algorithm, which works by modifying the weights at each node, this backpropagation technique lowers the error transmitted throughout the network. The error



Parameter setting
In this work, there are three types of parameters, namely DCNN based parameters, parameters related to dimensionality reduction, and parameters associated with MLP. Since we have opted for the transfer learning of the pre-trained DCNN’s, only their weights and kernels are fine-tuned, but the structure and other parameters are unchanged. The parameters related to the dimensionality reduction, and MLP are set based on the performance reported on the validation test.
The dimensions of the BoF are based on the size of the visual vocabulary (KBF). Only the KBF is set to different values in this work, whereas the remaining parameters are unchanged. Figure 4 shows the accuracy graph reported by the proposed method on the validation set while varying the size of the KBF; the maximum accuracy is reported when the size of KBF is 150. So the size of the KBF is set as
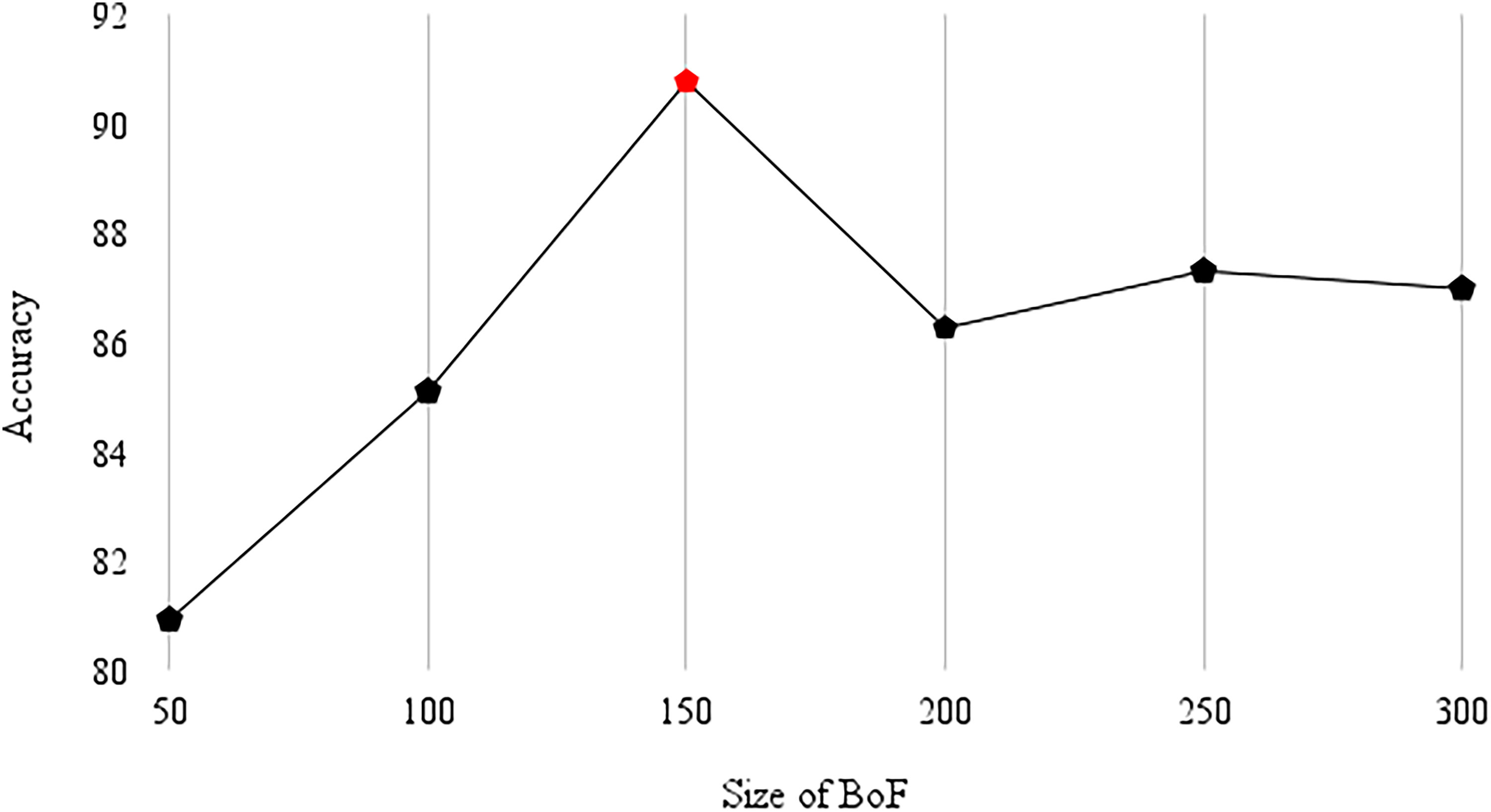
Accuracy reported on the validation set for the variant sizes of BoF.
In PCA-based dimensionality reduction, the threshold value is changed, and other parameters are unchanged. Figure 5 shows the accuracy reported on the validation set by the proposed model with variant thresholds; the maximum accuracy was reported when the threshold was set to
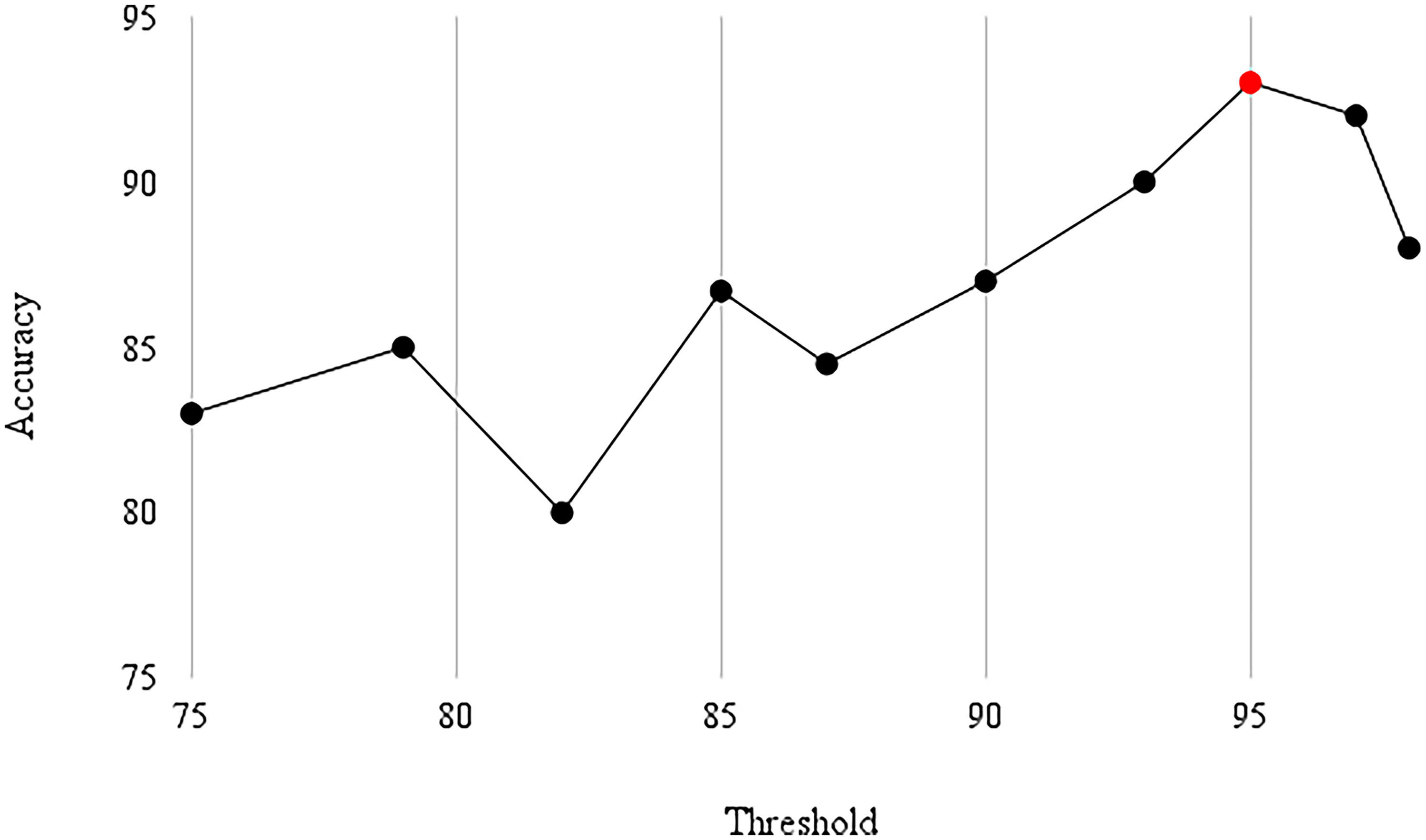
Accuracy reported on the validation set with threshold values.
In MLP, the batch size is changed by keeping the other parameters constant. The batch size is to different values starting from

Accuracy reported on the validation set for different batch sizes.
Experimental Results
Datasets
In this work, we employed three datasets namely Herlev, SIPaKMeD, and ISBI 2014 datasets for evaluation. Among these datasets the Herlev dataset is used for evaluating both segmentation, and classification models. Whereas the SIPaKMeD is used for evaluating the classification model, and the ISBI 2014 is used for evaluating the segmentation model.
Herlev dataset
is collected by the Herlev University Hospital using a microscope and digital camera
39
. The image resolution used while acquiring the image is 0.201

Sample images from the Herlev dataset.
Class Distribution in Herlev Dataset.

SIPaKMeD dataset 42
consists of 4049 isolated cervical cell images, which are manually cropped from 966 cluster cell images of Pap smear slides. The images are captured using a CCD camera adapted to an optical microscope. These cells are divided into five different classes. This class distribution is tabulated in Table 2. Among these the 60% of images from each class are used for training, 20% are used for validation, and the rest 20% are used for testing the model.
Class Distribution In SIPaKMeD Dataset .

ISBI 2014 dataset
is provided as a part of the Overlapping Cervical Cytology Image Segmentation Challenge ISBI 2014. This dataset contains 16 real images, and 945 synthetic images. The real images are of
Performance metrics
Segmentation metrics
The Residual SE UNet is evaluated using pixel-based recall and precision measures. These measures are formulated in equations 5 and 6.
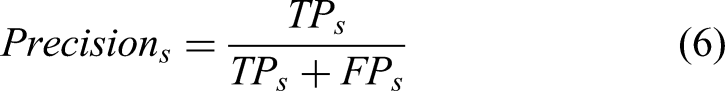
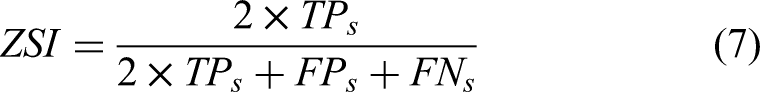
Classification metrics
The classification network is evaluated using accuracy, recall, specificity, precision, and F1-score. The metrics can be calculated using equations 8‐12.


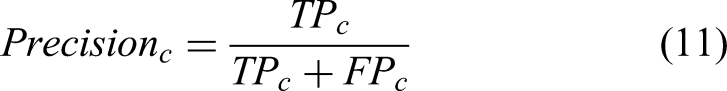

Ablation study
Residual SE UNet
We have also performed an abilation study to understand the efficiency of each module in Residual SE UNet. These ablation experiments are performed on the Herlev dataset. The results of this study are shown in Table 3. From Table 3, it can be seen that there is an performance enhancement with the addition of Residual SE Modules to the standard UNet.
Abilation Study of the Residual SE UNet.

Classification network
In this work, the performance of the Feature Concatenation Approach was assessed using three groups of feature representations. The first group represents the performance reported by the proposed approach while using sole hand-crafted features, the second group represents the performance reported by combining hand-crafted features with the deep features extracted by fully trained models, and the third group presents the performance reported while using hand-crafted features with deep features extracted by the fine-tuned and pre-trained models.
From Table 4, it was observed that the feature representations learned by the transfer learning model reported better classification accuracy than the hand-crafted features. However, the fully-trained models reported worse accuracy than the hand-crafted features. The features extracted by the fully-trained models, when used solely or when combined with the hand-crafted features, also reported worse accuracy than the pre-trained transfer learning models. This shows the advantage of using the transfer learning approach while having data scarcity and other constraints. In addition, the concatenation of deep and hand-crafted features reported significantly better classification accuracy.
Accuracy Reported While Using Different Feature Sets.

Results reported
Segmentation
The proposed Residual SE UNet is evaluated using the Herlev, and the ISBI 2014 datasets. The Table 5 presents the precision, recall, and ZSI scores reported by the proposed model for segmenting the 7 types of cervical nuclei on Hevlev dataset. Furthermore, the average results of 7 types achieved by the Residual SE UNet on both the datasets is compared with the other existing approaches. These results are shown in Tables 6 and 7. The proposed segmentation model reported a precision of
Comparison of Class Specific Precision, Recall, and ZSI Reported by the Residual SE UNet with the Existing Works Employing Herlev Dataset.

Comparison of Average Precision, Recall, and ZSI Reported by the Residual SE UNet with the Existing Works Employing Herlev Dataset.

Comparison of Precision, and Recall Reported by the Residual SE UNet with the Existing Works Employing ISBI 2014 Dataset.

The proposed model reported better average precision, and ZSI than the existing works on Herlev dataset. Also, the proposed model reported better average precision and recall than existing works on ISBI 2014 dataset. Figure 8 shows the qualitative comparison of the segmented output reported by the proposed model and the existing methods on images from the Herlev dataset. It can be observed that the proposed segmentation model can generate accurate nucleus boundaries for a wide variety of nuclei with irregular nuclei shape, size, and non-uniform chromatin distribution.

Qualitative comparison of the proposed model with existing methods. The ground truth boundary is indicated by green color, the boundary predicted by the Residual SE UNet is indicated by red color, the boundary predicted by the Multi-scale hierarchical segmentation algorithm 15 , Mask RCNN + LFC + CRF 22 , Radiating Gradient Vector flow 13 are indicated by orange, yellow and blue colours.
Classification
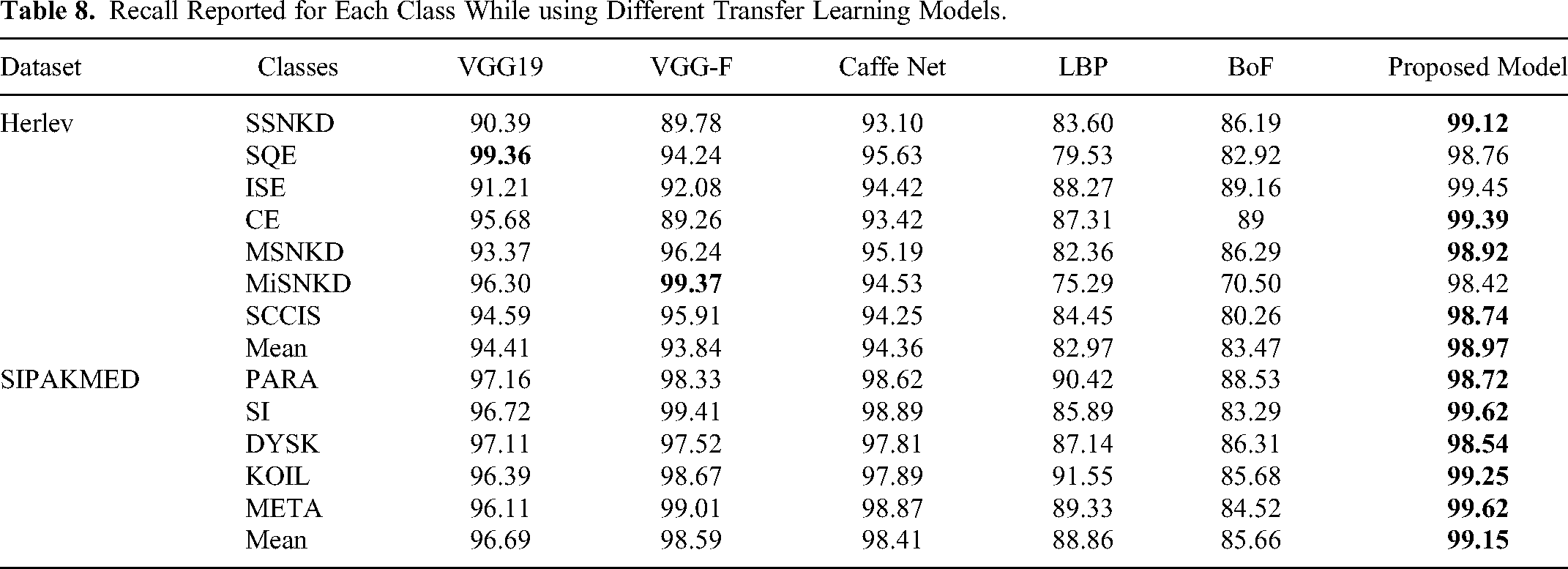
In this work, we evaluated the proposed classification approach by using two datasets namely Herlev, and SIPaKMeD. In medical informatics, recall is considered to be the most important metric48,49. Table 8 presents the recall reported for each class while using hand-crafted features, deep features extracted by transfer learning models, and jointly using both (proposed feature concatenation). The highest recall is highlighted in bold. The proposed feature concatenation approach performed best in 5 out of 7 categories and is also higher than the other feature sets on both the datasets.
Recall Reported for Each Class While using Different Transfer Learning Models.
The proposed feature concatenation approach is also compared with the existing methods39,50,14,12,51‐54. The above methods are downloaded from their public implementations and trained and tested with the same evaluation protocol used by the proposed work on the Herlev, and SIPAKMED datasets for a fair comparison. This comparison in terms of accuracy, recall, and specificity is shown in Table 9. The proposed model reported higher accuracy than the existing works.
Comparison of Accuracy, Recall, and Specificity Reported by the Proposed Model with Other Existing Works on the Herlev, and SIPAKMED Datasets.

Computational complexity
The proposed work is implemented in Pycharm. The overall processing of a pap-smear image of
Discussion
The experimental findings show that the proposed models can accurately segment and classify cervical nuclei from pap smear images with good precision, recall, specificity, and ZSI. The following are the primary points that emphasise the proposed work.
The manual morphological analysis of cellular images for diagnosing cervical cancer from pap smear slides on a large scale is a time-consuming and tedious task. And a manual examination of these slides often contains human error57,58,3, resulting in false-positive/negative findings. Automated segmentation and classification of the nuclei will help rapidly assess pap smear slides on a large scale with zero human error and less diagnostic time than the manual procedure. This work is advantageous as it can segment and classify cervical nuclei with high accuracy, precision, recall, and ZSI, enabling rapid nuclear-quantification analysis.
Even though the proposed segmentation method is computationally more expensive than the multi-scale network 15 (64 vs 59) and Mask R-CNN 22 (64 vs 62) methods, this can be optimized by using sophisticated hardware.
A box plot is presented in Figure 9, which shows the distribution of the ZSI metric reported by the proposed segmentation model, multi-scale network 15 , MaskRCNN 22 , and Radiating Gradient Vector flow 13 on the Harlev test set. The proposed segmentation method has a higher median of ZSI than the other three methods. This demonstrates the proposed segmentation model’s superiority over existing techniques.
The proposed approach does not involve any pipeline methods and pre-processing methods discussed in the literature. It directly takes the pap-smear image as input and segment cervical nuclei. The features extracted from the segmented cervical nuclei and used for the classification. The proposed segmentation and classification models reported higher performance (in terms of precision, recall and ZSI for segmentation task and accuracy, recall, and specificity for classification task) than the existing works that employed pre and post-processing methods(reported in Tables 6 and 9).
Even though our proposed segmentation and classification models enhanced the performance in segmenting and classifying cervical cytopathology cell images, our models have the following limitations. The performance of our algorithms needs further perfection for real preclinical use. Moreover, we have not explored the possibility of any data resampling for balancing the dataset that may result in better performance.

Comparison of ZSI values reported by the Residual SE UNet with existing methods on Herlev dataset.
Conclusion
This work proposes two deep learning-based approaches for the segmentation and classification of cervical nuclei. The segmentation network was designed using the well-known architecture UNet as the backbone, and residual SE modules are designed for efficient feature extraction. These modules are used in place of the convolutional layers in the standard UNet for segmentation. From the segmented nuclei, three sets of deep features and two sets of hand-crafted features are extracted, and PCA is used to reduce these features’ dimensions for concatenation. The single layer perceptron is employed for classification . These methods are trained and evaluated using the Herlev, SIPaKMeD, and ISBI 2014 datasets. Among these datasets the Herlev dataset is used for evaluating both segmentation, and classification models. Whereas the SIPaKMeD is used for evaluating the classification model, and the ISBI 2014 is used for evaluating the segmentation model. Both the segmentation and classification works reported better performance than the existing works in the literature. We anticipate that these methods help for the rapid diagnosis of cervical cancer in the early stage, thus reducing the mortality rate and helping patients for a faster diagnosis. In the future work, different pre-processing methods such as transfer learning, and vision-transformer-based approaches can be studied to diagnose cervical cancer from pap smear images.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the publication of this article: The authors are thankful for the financial support provided by the Intelligent Systems Research Centre (ISRC), Ulster University, UK.