
Abstract
Signet ring cell carcinoma (SRCC) of the stomach is a rare type of cancer with a slowly rising incidence. It tends to be more difficult to detect by pathologists, mainly due to its cellular morphology and diffuse invasion manner, and it has poor prognosis when detected at an advanced stage. Computational pathology tools that can assist pathologists in detecting SRCC would be of a massive benefit. In this paper, we trained deep learning models using transfer learning, fully-supervised learning, and weakly-supervised learning to predict SRCC in Whole Slide Images (WSIs) using a training set of 1,765 WSIs. We evaluated the models on two different test sets (n = 999, n = 455). The best model achieved a ROC-AUC of at least 0.99 on all two test sets, setting a top baseline performance for SRCC WSI classification.
Keywords
Introduction
According to the Global Cancer Statistics 2018, 1 stomach cancer was responsible for over 1 million new cases in 2018 with an estimated 783,000 deaths, making it the fifth most frequently diagnosed cancer and the third leading cause of cancer death in the world. Importantly, incidence rates are markedly elevated in Eastern Asia (e.g., Japan and Republic of Korea), whereas the rates in Northern America and Northern Europe are generally low and are equivalent to those seen across the African regions. 1 However, a series of studies has shown that the incidence of signet ring cell carcinoma (SRCC) of stomach (a subtype of poorly cohesive carcinoma) has been slowly increasing, especially in the United States. 2 -4 The great majority of SRCC occurs in the stomach, with the rest arising in other organs (e.g., breast, gallbladder, pancreas, urinary bladder, and colon). 5
SRCC is an invasive gastric adenocarcinoma and can be accompanied by diffuse growth of adenocarcinoma cells associated with a wide range of desmoplastic reactions, in particular when infiltrating into the submucosa or beyond. 6 This type of growth is defined as diffuse cancer according to the Lauren classification. 7 In the early stage of the disease, intramucosal SRCC appears as layered cancer cells in the superficial portions of the mucosa without desmoplasia. 8 -10 The typical signet-ring cells contain intracytoplasmic mucin that compresses the nucleus to the periphery of the cell wall, and glandular formations are rarely observed. Due to these morphological appearances, some of the SRCC cells often appear to mimic crushed oxyntic glands, crushed mucous neck cells, the goblet cells of the intestinal metaplasia, and gastric xanthoma (histiocytic aggregation). 11 This makes SRCC more likely to be missed on routine histopathological diagnoses. False negatives have a detrimental impact on the quality and accuracy of the pathological diagnosis, and it should be addressed urgently.
Computational pathology has been gaining momentum over the past decade, in particular due to the large increase in resources that allow the digitization and processing of Haematoxylin and Eosin (H&E) stained glass slides of surgical and biopsy specimens into Whole Slide Images (WSIs). Machine learning, in particular deep learning, has found many applications in computational pathology, such as cancer detection and classification, cell detection and segmentation, and gene mutation expression for a variety of organs and pathologies. 12 -31
Preparing a large fully-annotated training dataset for WSI cancer classification is a tedious, time-consuming task. This is because WSIs are extremely large, with heights and widths in the tens of thousands of pixels, as a result of being scanned at magnifications of ×20 or ×40 in order to reveal cellular-level details. The large image size makes it difficult to train and apply a CNN directly to WSIs due to GPU memory constraints. To bypass the computational constraints, the typically adopted approach is to divide the WSI into a set of fixed-sized tiles. 13,14,20,32 Training of the CNN is done by using the resulting labeled tiles as input. Classification of a WSI is done by applying the CNN in a sliding window fashion, classifying the individual tiles, then aggregating all their classification outputs into a final WSI classification. The aggregation could be as simple as taking the maximum probability output of the tiles or using an RNN model. 13,18 Obtaining a dataset of labeled tiles can either be done by asking pathologists to draw contours on WSIs or to classify pre-extracted, fixed-sized tiles. The latter requires pre-fixing the tile size and having pathologists classify millions of tiles. This is a tedious task. The former is preferable as the tile size can be modified later, and viewing the WSI provides context to pathologists and allows them to draw contours on large cancer infiltration areas; however, it can still be tedious especially with complex cancer infiltration patterns requiring annotations of individual cells. Once annotated, a single WSI can produce thousands of labeled tiles for training. A large dataset of labeled tiles is a requirement for fully-supervised learning.
On the other hand, weakly-supervised learning is an alternative approach and requires only weakly-labeled data. 33 Given that diagnoses of WSIs are readily available from reports, additional annotations by pathologists are not required. Weakly-supervised learning methods, such as multiple instance learning (MIL), 34 can operate directly on the WSIs by using the diagnoses as slide-level labels. This is a highly attractive solution. One particular advantage of MIL is that it can reduce the labeling requirement. MIL was initially proposed in the context of drug discovery, 34,35 and subsequently found many applications in computer vision, 36 including histopathology classification and segmentation. 13,20,23,30,37 -41 The caveat in histopathology applications, however, is that the method tends to require a large training dataset of WSIs in order to work well. This has been demonstrated recently by Campanella et al 13 using a dataset of 44,732 WSIs to classify prostate cancer, basal cell carcinoma, and breast cancer metastases, with a reported Receiver Operator Curve (ROC) area under the curve (AUC) of about 0.98 on 3 test sets of about 1,500 WSIs each. They observed that at least 10,000 WSIs were necessary for training to obtain a good performance. Both weakly- and fully-supervised learning could be used on a dataset that has a combination of detailed cellular-level annotations and slide-level labels.
Only recently has SRCC detection been investigated. 42,43 Li et al 42 set up the MICCAI DigestPath2019 challenge where 1 task was SRCC instance detection. A training dataset was made publicly available consisting of a total of 455 images (of which 77 had SRCC). The images were crops of size 2000 × 2000 pixels extracted from WSIs. A total of 12,381 instances of SRCC were manually annotated; however, the dataset still contains unannotated instances of SRCC. Li et al 42 proposed a semi-supervised framework for SRCC detection where the goal was to train a deep learning network to detect individual SRCC instances using the combination of annotated and unannotated SRCC instances. The model was then evaluated on a test set consisting of 227 images (of which 12 had SRCC). The 1st runner up at the challenge proposed using a specialized loss 43 to separate the contribution of annotated and unannotated training samples resulting in an improvement in SRCC instance detection on the test set. Although there might be some interest from a research perspective in detecting all instances of SRCC in a specimen in order to calculate measurements, such as the karyoplasmic ratio or the degree of atypia, and study their correlations with outcomes. However, from a clinical perspective, all that matters is detecting whether a specimen has SRCC.
In this paper, our aim is the clinical application of detecting SRCC in WSIs. It is not quite known for this particular application which training method is the most appropriate. Annotating individual SRCC cells is a tedious task, and a method that uses minimal annotations would be more desirable if it does not involve a compromise in performance. To this end, we trained several deep learning models using a combination of transfer learning, fully-supervised learning, and weakly-supervised learning. We used a training dataset consisting of a total of 1,765 WSIs of which 100 WSIs had an SRCC diagnosis. A group of pathologists non-exhaustively annotated individual cells suspected of SRCC in all of the 100 WSIs. We performed an investigation of different training methods in order to best understand which aspects contribute to obtaining a good SRCC WSI classification given the available data.
Methods and Materials
Our proposed method for SRCC WSI classification consists of using a CNN trained on tiles extracted from WSIs and using a combination of transfer learning, fully-supervised learning, and weakly-supervised learning to train the models. Figure 1 provides an overview of the training methods.

Overview of the training methods. A, Shows examples of biopsy WSIs in the training dataset. B, Shows an example of the SRCC annotations overlaid digitally on WSIs. The annotations were used to guide the extraction of tiles. C, Shows an overview of the fully-supervised method where balanced batches of tiles are extracted from the WSI to train the CNN classifier. D, Shows an overview of the weakly-supervised method. The method alternates between two steps: inference and training. During inference a frozen CNN classifier is run in a sliding window fashion on each WSI and the top k tiles with the highest probabilities are placed into the training tile set. Once the training tile set reaches a certain size T, the training step is triggered.
Problem Formulation
In histopathology, a pathologist diagnoses a WSI as having cancer if it is seen in any sub-region of the WSI; otherwise, it is diagnosed as not having cancer. This means that if a WSI with cancer were subdivided into a dense grid of smaller fixed-size tiles, then at least one of those tiles must have cancer, even though initially we do not know which tiles have cancer. If the WSI does not have cancer, then none of those tiles have cancer. This type of problem can be formulated generally with MIL. The MIL formulation adopts the concept of labeled bags that contain a collection of instances. A WSI i is considered as a bag Hi
and any tile j sampled from it is considered as a instance
Training Methods
Fully-supervised (FS) learning
When we have labels for all the instances, there is no need to use the bag labels to derive the instance labels, and the MIL formulation becomes the classical fully-supervised (FS) learning method. The training dataset is
Weakly-supervised (WS) learning
When we have labels only for bags or a mix of bags and instances, we can train the model using MIL. The bag label is used to infer the label of the instances. The training alternates between 2 steps: inference and training. Using the model trained so far, the inference step is used to extract a list of candidate tiles for training. During an epoch (one sweep through the entire dataset), we perform a balanced sampling (see Sec.) of tiles by randomly selecting in turn either a positive (
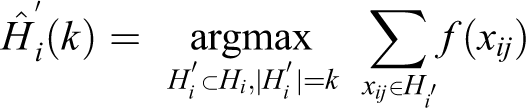
is the subset of top k tiles.
Weakly-supervised with fully-supervised pre-training
We can train the model by first training it with the FS method, and then refining the model further by training it for additional epochs using the WS method.
Class imbalance
The training set was highly imbalanced, where WSIs with the negative class far outnumbered WSIs with the positive class (SRCC). To improve predictive performance on the positive class, we created a balanced sampler by over-sampling tiles from the positive class. This was done by having the tile sampler alternate from picking a fixed number of tiles from either a positive or a negative WSI. For FS, k tiles are picked randomly, whereas with WS, the top k tiles are picked based on their probabilities. The over-sampling ensures that all the negative WSIs are used for training during each epoch.
Deep Learning Model
We used the EfficientNet Convolutional Neural Network (CNN) architecture, 44 which has achieved state-of-the-art accuracy on computer vision datasets while having a smaller number of parameters and a floating point operations per second (FLOPS) values that is an order of magnitude smaller compared to other existing architectures. The architecture uses compound scaling along width, depth, and image resolution of a baseline network, with mobile inverted bottleneck convolution (MBConv) as convolutional units. Different scales of EfficientNet have been trained on the ImageNet dataset. 45 We used the EfficientNet-B1 model architecture which has 7.8 M parameters.
For transfer learning (TL), we initialized the weights of all the convolutional layers with the pre-trained weights on ImageNet. The final classification layer was a fully-connected layer with single output and a sigmoid activation function, and its weights were randomly initialized using the Glorot uniform initializer. 46 During the first epoch, all the weights were frozen except for the weights of the final classification layer; this is so as to prevent random initial weight of the classification layer from destroying the pre-trained weights. After the first epoch, all the weights were unfrozen to become trainable.
Tile Extraction
Tiles were extracted on the fly from the WSIs by direct indexing of locations without loading the entire WSI into memory. For a WSI, the locations were pre-computed as follows: first, we performed tissue detection by thresholding the image using Otsu’s method; this step allowed eliminating a large portion of the white background and reducing unnecessary sampling of tile instances from the background. If annotation are available, then they could be used to further reduce the valid tissue sampling regions. Then, given a stride that allows subdividing the WSI into a grid, we extracted grid cell locations only from the valid tissue regions. These grid cells location were then used to extract tiles at the desired tile size and magnifications. For all the models, we used a fixed tile size of
As tiles were extracted from the WSIs, we randomly applied data augmentation on the fly in the form of tile flips,
WSI Classification
The models were trained as classifiers on the tile level; however, to obtain a WSI classification, the model was applied in a sliding window fashion using a stride of
Heatmap Visualization
We generated two types of heatmaps from the model using two methods: classification probability and Gradient-weighted Class Activation Mapping (Grad-CAM).
47
The former consists in the tiling of the classification probability outputs by mapping each input tile’s
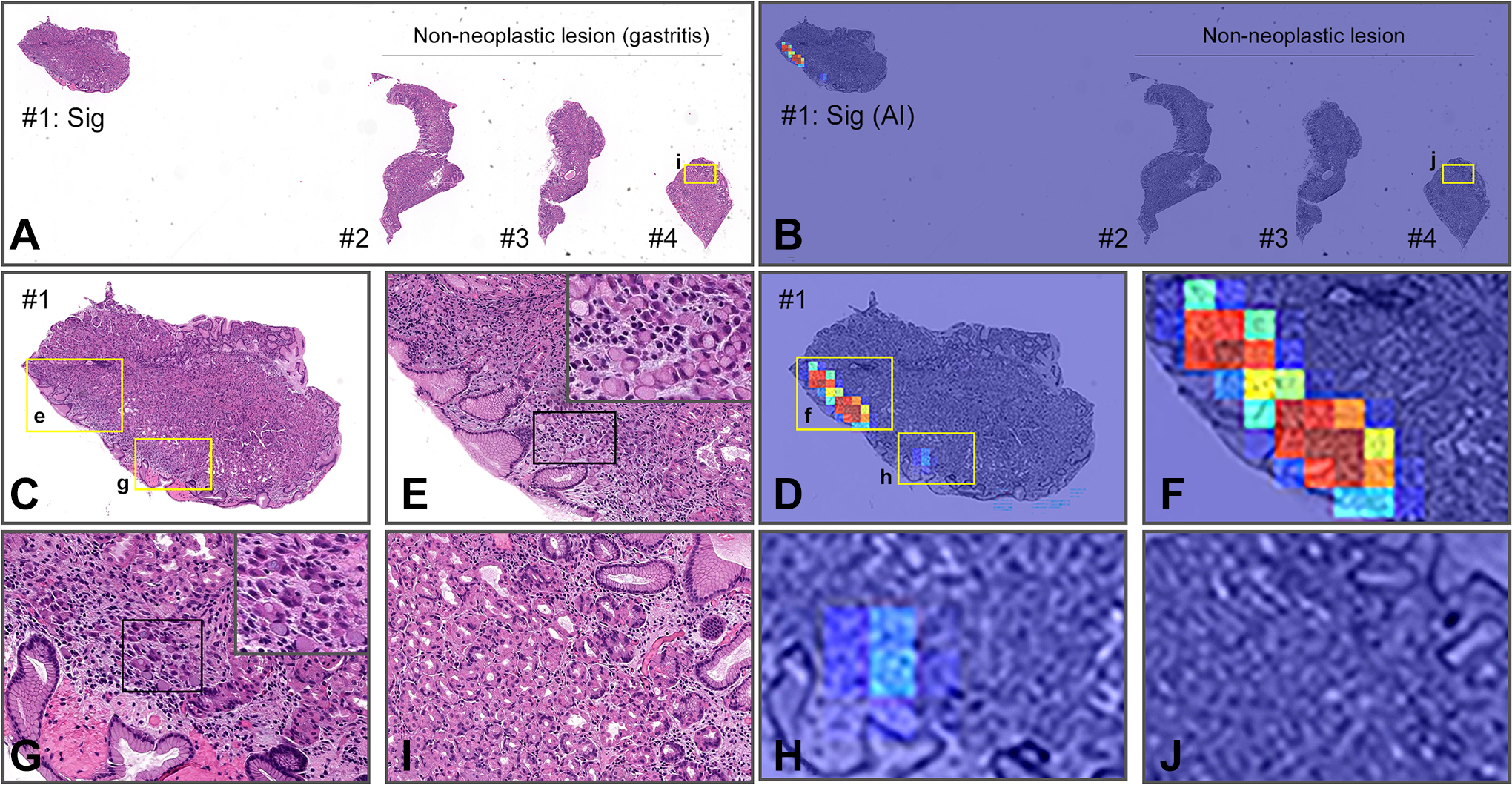
Representative true positive case. There are four endoscopic biopsy fragments in this WSI (A). According to the pathological diagnostic report, #1 is signet ring cell carcinoma and #2-#4 are gastritis (non-neoplastic lesion) (A). When viewed under low magnification, highlighting is visible only in #1 on heatmap image (B). When the highlighted area in #1 is magnified (C), strong and low-signal areas are seen (D); a large number of signet ring cell carcinoma cells (E) are observed in the strong-signal area (F) and a small number of signet ring cell carcinoma cells (G) are seen in the low-signal area (H). Enlargement of the tissue in #4 confirms that it does not contain any signet ring cell carcinoma cells (I and J).

Representative false positive cases. A, is a case chronic gastritis (non-neoplastic lesion). A-D, Pathologically, the false positives might be due to the lymphocytes being mixed around the smooth muscle cells and blood vessels of the muscularis mucosae and the nuclear density of the lymphocytes being similar to SRCC. E, is a case of chronic gastritis (non-neoplastic lesion). E-H, The false positive area includes pyloric glands disrupted by inflammation. Pathologically, the false positive area is suggested as a pyloric gland by comparison with other adjacent pyloric gland(s). However, on practical diagnosis, if such a finding is observed, additional investigation should be performed to confirm that it is a pyloric gland.

Representative false negative cases. In (A) there are four endoscopic biopsy fragments (#1-#4). According to the pathological diagnostic report, (A) #4 has SRCC. In the fragment of (B) #4, a few SRCC cells were observed (C) at high magnification (D). (E) is endoscopic biopsy fragment. According to the pathological diagnostic report, this fragment has tubular adenocarcinoma and SRCC. When viewed under high magnification (F and G), SRCC cells were observed.

Representative Grad-CAM heatmap image for true-positive detection of SRCC cells. (A) Shows non-neoplastic annotations (green lines) of gastric endoscopic biopsy specimens (#1-#3) by pathologists. Tissue fragments #1 and #3 are gastritis and #2 has SRCC cells (A, C, D). Pathologists missed SRCC cells on fragment #2 (A). SRCC cells were visualized only in fragment #2 by Grad-CAM heatmap image (B). At high magnification, in fragment #2, Grad-CAM hotspots (E, F) were overlapped with infiltrating area of SRCC cells (C, D).

Grad-CAM visualization on positive images from the DigestPath2019 dataset. Row (A) shows four annotated images with yellow bounding boxes on SRCC instances. Rows (B-H) show the Grad-CAM outputs from the 7 different models.
Implementation Details
The deep learning models were implemented and trained using TensorFlow. 48 We used OpenSlide 49 to read WSIs on the fly without pre-extracting all the tiles. AUCs were calculated in python using the scikit-learn package 50 and plotted using matplotlib. 51 The 95% CIs of the AUCs were estimated using the bootstrap method 52 with 1,000 iterations.
Datasets
Hospital A and B
For the present retrospective study, 2,824 cases of gastric epithelial lesions HE (hematoxylin & eosin) stained specimens, each from a distinct patient, were collected from the surgical pathology files of Hiroshima University Hospital (Hospital A) and Tokyo IUHW Mita Hospital (Hospital B) after being reviewed by surgical pathologists. The experimental protocols were approved by the Institutional Review Board (IRB) of the Hiroshima University (No. E-1316) and International University of Health and Welfare (No. 19-Im-007). All research activities complied with all relevant ethical regulations and were performed in accordance with relevant guidelines and regulations of each hospital. Informed consent to use histopathological samples and pathological diagnostic reports for research purposes had previously been obtained from all patients prior to the surgical procedures at both hospitals and an opportunity for refusal to participate in research was guaranteed by an opt-out manner.
The combined dataset obtained from both hospitals consisted of 2,824 WSIs of which were divided into sets of 1,765, 60, and 999 for training, validation, and test, respectively. The training set consisted of 100 SRCC, 571 other adenocarcinoma, and 1,094 non-neoplastic lesion, the validation set consisted of 20 SRCC, 20 other adenocarcinoma, and 20 non-neoplastic lesions, and the test set consisted of 78 SRCC, 82 other adenocarcinoma and 839 non-neoplastic lesion. Given that the goal is to train a binary classifier, the cases were grouped into SRCC vs non-SRCC (other adenocarcinoma and non-neoplastic lesions). All cases were solely composed of endoscopic biopsy specimen WSIs. The 100 SRCC WSIs were manually annotated by a group of 11 surgical pathologists who perform routine histopathological diagnoses by drawing around the areas that corresponded to SRCC. The pathologists carried out detailed cellular-level annotations on cells that fit the description of SRCC cells as defined by the World Health Organization (WHO) classification of tumors (i.e., the following three tumor cell morphologies were adopted: (1) a cell with an intracytoplasmic cyst filled with acid mucin, giving the classical signet-ring appearance; (2) a tumor cell with eosinophilic cytoplasmic granules containing neutral mucin with a slightly eccentric nucleus; and (3) a tumor cell in which the cytoplasm is distended, with secretory granules of acid mucin appearing like a goblet cell). 53,54 The other adenocarcinomas subset included the following subtypes: tubular (tub), poorly differentiated (por) and papillary (pap) types which did not include SRCC cells in WSIs. 54 The non-neoplastic subset included the following categories: ulcer, gastritis, regenerative mucosa, fundic gland polyp and almost normal gastric mucosa. Each annotated WSI was observed by at least two pathologists, with the final checking and verification performed by a senior pathologist. All the WSIs were scanned at a magnification of ×20.
DigestPath2019
The DigestPath2019 data (note 1) was obtained from the signet ring task of the DigestPath2019 grand challenge competition, part of the MICCAI 2019 Grand Pathology Challenge Li et al.
42
We used the provided training dataset as a test set given that the classification labels were available. The dataset consisted of 455 images from 99 patients, of which 77 images from 20 patients contained SRCC. The provided images were 2000 × 2000 pixels crops extracted at a magnification of
Experiments and Results
Set-Up
We trained using three different training methodologies: fully-supervised (FS), weakly-supervised (WS), and fully-supervised pre-training followed by weakly-supervised (FS-WS). This resulted in seven different models: FS ×5, FS ×10, FS ×20, FS w/o TL ×10, WS ×10, WS-noanno ×10, and FS+WS ×10.
For the FS method, we training the models using WSIs at three different magnifications
For the WS methods, we trained the models at a magnification of at
We evaluated the models on two test sets: Hospital A & B (n = 999, 78 SRCC, 82 other adenocarcinoma and 839 non-neoplastic lesions) and DigestPath2019 (n = 455, 77 SRCC).
Model Hyperparameters
All models were trained with the same hyperparameters. We used the Adam optimization algorithm
55
with
Model Evaluation
We performed predictions on the WSIs of the test set by using a sliding window with an input tile size of

ROC curves from the 7 different models on the 2 test sets: (A) Hospital A and B and (B) DigestPath2019.
ROC AUCs and Log Losses With Their Associated Confidence Intervals (CIs) for the 2 Test Sets: Hospital A and B and DigestPath2019.

The models displayed good generalization performance on the DigestPath2019 independent test set, which consisted of WSI crops obtained from a different source than the one used for training our models. We used the training set provided by DigestPath2019 as it was publicly available. We could not perform a direct comparison with the reported results of Li et al 42 as the test set is not publicly available.
The WS training method achieved a statistically significantly lower log loss compared to the FS method. Figure 6 shows Grad-CAM visualization of the seven models on four positive images from the DigestPath2019. The models do no seem to pick up on the same areas. The FS+WS ×10 models picked up more SRCC cells than the WS ×10 model.
For the WS method, guiding the sampling of the positive tiles from the annotated regions improved the predictive performance as compared to without using any of the annotations (WS ×10 vs WS-noanno ×10).
Transfer learning was helpful in increasing predictive performance, given that the model trained without transfer learning (FS ×10 w/o TL) mostly achieved the lowest performance on all two test sets.
The model trained at ×20 has a higher false positive rate compared to the model trained at ×10. The model trained at ×5 similarly had a higher false positive rate compared to the model trained at ×10.
An examination of some of the false positive cases showed that they were mostly due to cells exhibiting similar appearance to SRCC. In the chronic gastritis case in Figure 3, the nuclear density of the lymphocytes mimics the appearance of SRCC, which most likely led to the false positive. Figure 5 shows a Grad-CAM visualization of a case used as part of the validation set where a tissue fragment was incorrectly annotated as gastritis (non-neoplastic lesion). It was initially thought to be a false-positive case; however, another inspection by expert pathologists revealed that it is a true-positive detection of SRCC. It was missed by the pathologists performing the annotations potentially due to the presence of only a small number of SRCC cells within a background of chronic inflammatory cells infiltration that have some morphological similarities to SRCC cells, making them difficult to spot. Nonetheless, the models were able to make a correct detection.
Influence of the Top k Parameter
Figure 8 shows the ROC curves for the two test sets. There was a noticeable trend where an increasing k value led to a decrease in the AUC and a noticeable increase in the false positive rate.

ROC curves from varying the top k across the range {1,5,10,15,20} for the WS method using only slide-level labels (WS-noanno).
Running Time
The models overall took between 2-4 days to train on a machine with a single Nvidia Titan V GPU. The prediction time per WSI is dependent of the number of tiles that contain tissue, and it can range from 1k to 10k tiles. Prediction was at an average rate of 150 tiles per second on a single GPU.
Discussion
In this paper we have presented a deep learning application for SRCC WSI classification. The models, based on the EfficientNet-B1 architecture, achieved high ROC AUC performance on two test sets, one of which originated from a different medical institution. We analyzed the performance of different training methodologies and WSI magnifications. Results showed that a WS training method with WSIs at a magnification of ×10 achieved the highest predictive performance.
The use of WS training method achieved better performance than using the FS method alone. This is most likely due to the WS method training on tiles that have the highest probability from both the positive and negative WSIs, while the FS method trains on randomly sampled tiles. At each training iteration, the WS trains on the most confident tiles for the positive class and the most likely to be a false positive for the negative class. This prioritizes the training on reducing the false positive rate, especially given that the WSI aggregation method is max-pooling. As a single false positive tile would result in a false positive classification for the WSI.
An interesting observation from Figure 6 was that the FS+WS
Guiding the sampling of tiles for the WS method improved the predictive performance as observed from comparing WS ×10 vs WS-noanno ×10. This was to be expected given that there was only a small number of positive WSIs. Achieving a high predictive performance without any annotations that restrict the regions from which to sample requires a significantly larger dataset, as from the entire WSI of potentially thousands of tiles only 1 tile is selected for training. Campanella et al 13 observed that at least 10,000 are required to achieve a good performance.
When only WSI labels are available, using only the tile with the maximum probability
The training dataset only contained a small number of positive WSIs (n = 100), and the use of transfer learning has helped in increasing predictive performance, given that the model trained without transfer learning (FS ×10 w/o TL) mostly achieved the lowest performance on all two test sets.
Training at ×10 seems to yield better performance than training at ×20. The model trained at ×10 had a lower false positive rate; this is most likely due to the ×10 model having more context information from the neighboring tissues. In order to confirm an SRCC diagnosis, pathologists typically view a WSI at a low magnification (e.g., ×4 or ×5) and then at a higher magnification to check the cellular morphology. It is more difficult for pathologists to distinguish between SRCC cells and mimicker cells (lymphocytes and histiocytes) if they are viewed in isolation without viewing the neighboring tissues. The lack of context information from the neighboring tissues could be the reason why the ×20 model had a slightly lower predictive performance than the ×10 model. However, going at magnification of ×5 also results in a increase in the false positive rate, and this is most likely due to the loss of cellular-level detail, making it harder to properly detect SRCC. Nonetheless, the model was still capable of predicting SRCC. This result was particularly interesting to pathologists given that they would view the WSI with a magnification of at least ×10 before confirming an SRCC diagnosis.
As a certain element of randomness is involved when training the models, some of the variations in the predictive performance between the models could be attributed to it. However, the majority of the training methods achieved an acceptable high performance, signifying that it is possible to train an SRCC WSI classifier. One potential limitation is that we do not know the extent of how well the models generalize to WSIs from different source, given that most of the WSI test sets came from the same source as the training set. Nonetheless, the good performance on the DigestPath2019 dataset, even though it only consisted of WSI crops, is highly promising. As the model do not achieve AUC of 1.0, then based on the intended application of the models, the threshold can be adjusted to obtain a desired sensitivity and specificity, so there could be a potential risk of over- or under-diagnosis based on the chosen threshold. In addition, we do not know how well the models perform on challenging cases, such as intramucosal SRCC in-situ 56 and mimicker non-neoplastic cells like xanthoma 57 cells, as neither the training or test sets contained any of these.
Conclusion
In this study, we evaluated several different training methods for the task of SRCC WSI classification, and each method has a different requirement on amount of manual annotations. Annotating WSIs can be extremely tedious because of the massive size of the WSI. We have shown that a weakly-supervised method using minimal amounts of annotations can be used to train a WSI SRCC classification model with similar performance as a fully-supervised method, meaning that detailed manual annotations are not required to obtain a model that could be used in a clinical setting. Patients with SRCC tend to have poorer prognosis than patients with other types of gastric carcinoma. 58,59 However, recent studies have shown that the incidence of SRCC has been constantly increasing. 2,4,60 Pathologists sometimes find SRCC more difficult to diagnose compared to other types of gastric carcinoma. 10 An AI model that can assist pathologists in detecting SRCC would be extremely beneficial as it can help them reduce diagnosis errors as well as potentially detect SRCC at an earlier stage and, as a result, significantly improve patient prognosis. 61
Footnotes
Authors’ Note
F.K. and M.T. designed the studies; F.K., M.R., O.I. and M.T. performed experiments and analyzed the data; S.I. performed pathological diagnoses and helped with pathological discussion; K.A. provided pathological cases; F.K., S.I. and M.T. wrote the manuscript; M.T. supervised the project. All authors reviewed the manuscript. The experimental protocols were approved by the Institutional Review Board (IRB) of the Hiroshima University (No. E-1316) and International University of Health and Welfare (No. 19-Im-007). All research activities complied with all relevant ethical regulations and were performed in accordance with relevant guidelines and regulations of each hospital. Informed consent to use histopathological samples and pathological diagnostic reports for research purposes had previously been obtained from all patients prior to the surgical procedures at both hospitals and an opportunity for refusal to participate in research was guaranteed by an opt-out manner.
Acknowledgments
We are grateful for the support provided by Professors Takayuki Shiomi & Ichiro Mori at Department of Pathology, Faculty of Medicine, International University of Health and Welfare; Dr. Ryosuke Matsuoka at Diagnostic Pathology Center, International University of Health and Welfare, Mita Hospital; and Dr. Naoko Aoki (pathologist). We thank the pathologists who have been engaged in the annotation work for this study.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: F.K., M.R., O.I. and M.T. are employees of Medmain Inc.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.