
Abstract
We discuss a recent development in the set theoretic analysis of data sets characterized by limited diversity. Ragin, in developing his Qualitative Comparative Analysis (QCA), developed a standard analysis that produces parsimonious, intermediate, and complex Boolean solutions of truth tables. Schneider and Wagemann argue this standard analysis procedure is problematic and develop an enhanced standard analysis (ESA). We show, by developing Schneider and Wagemann’s discussion of Stokke’s work on fisheries conservation and by discussing a second illustrative truth table, that ESA has problematic features. We consider how scholars might proceed in the face of these problems, considering the relations between limited diversity and the different methods of reducing truth tables instantiated in Ragin’s QCA and Baumgartner’s Coincidence Analysis.
Keywords
Introduction
We discuss problems embedded in Schneider and Wagemann’s (2012, 2013) proposed enhanced standard analysis (ESA) procedure for Qualitative Comparative Analysis (QCA). Developed by Ragin (1987, 2000, 2008), QCA is a configurational method that seeks nonredundant necessary and sufficient conditions for an outcome. To establish the sufficiency of a condition or a combination of conditions for some outcome, QCA assesses whether the set of cases with the condition(s) is a subset of those with the outcome. To establish necessity, it assesses whether the set of cases with the outcome is a subset of those with the condition(s). Whether QCA establishes causal claims or, less ambitiously, provides complex descriptions and/or predictions, continues to be debated (see, e.g., Cooper and Glaesser 2012a). Here, we put this question to one side.
Ragin has also developed methods for using QCA when sufficiency and necessity might be only approximated to and for using counterfactual analysis to alleviate problems arising from limited diversity (2000, 2008). The term “limited diversity” draws attention to a problem that commonly arises in social research, especially when samples are small: The social world often fails to supply information on all possible combinations of the putatively causal factors picked out by configurational models.
QCA is widely used and there is an increasing demand for texts detailing how it should be employed. An important addition to this literature is Schneider and Wagemann (2012). This book encourages readers to follow recommended procedures by using such subheadings as “Recipe for a Good QCA,” by its claims concerning “ESA,” and through references to “best practice” (e.g., “We add further strategies that go beyond the current best practice approach” [p. 151]). These authors question QCA’s “standard analysis” procedure (Ragin 2008) and develop ESA, claiming this offers an improved procedure for coping with limited diversity (see also Schneider and Wagemann 2013). We believe that ESA has problematic features and that it is unsafe to follow ESA’s procedures without considering unintended perverse effects. This article, addressing crisp set QCA, discusses our concerns.
“Empirical necessary conditions” (ENCs) play a crucial role in Schneider and Wagemann’s arguments and are a key focus here. Insofar as our arguments are sound, as well as raising concerns about ESA, we hope to convince readers that, at the current stage of development of set theoretic methods, best practice recommendations are inherently risky. A less authoritative tone might be more appropriate (Cooper and Glaesser 2011b).
We first discuss Ragin’s treatment of limited diversity, referring to Stokke’s (2004, 2007) work. We then present problematic aspects of ESA, initially discussing the application of ESA to Stokke’s data set and then to an invented truth table. We then discuss the apparent sources of the problems we outline, ending with brief reflections on handling limited diversity and issues needing further debate.
Ragin on Limited Diversity and Counterfactual Analysis: Stokke’s Work
Ragin and Sonnett (2005) note that social phenomena are profoundly limited in their diversity, complicating social analysis. They, like Schneider and Wagemann, discuss Stokke’s (2004, 2007) research on “shaming” as a strategy for improving international regimes’ impact on resource management. Stokke’s 10 cases involve cod stocks in the Barents Sea and the North West Atlantic and Antarctic krill stocks in the southern ocean. Shaming aims to expose fishing practices “to third parties whose opinion matters to the intended target of shaming” (Stokke 2007:503). Stokke employs five conditions likely to lead to successful shaming. These are summarized by Ragin (2008:167): Advice ( Commitment ( Shadow of the future ( Inconvenience ( Reverberation (
Stokke’s 10 cases of shaming are set out in Table 1. In such truth tables, a 1 is used to indicate the presence of a condition or of the outcome, and a 0 their absence. We have added a column to show the absence of the outcome, ∼SUCCESS (∼ indicates negation).
Truth Table (Stokke 2007).
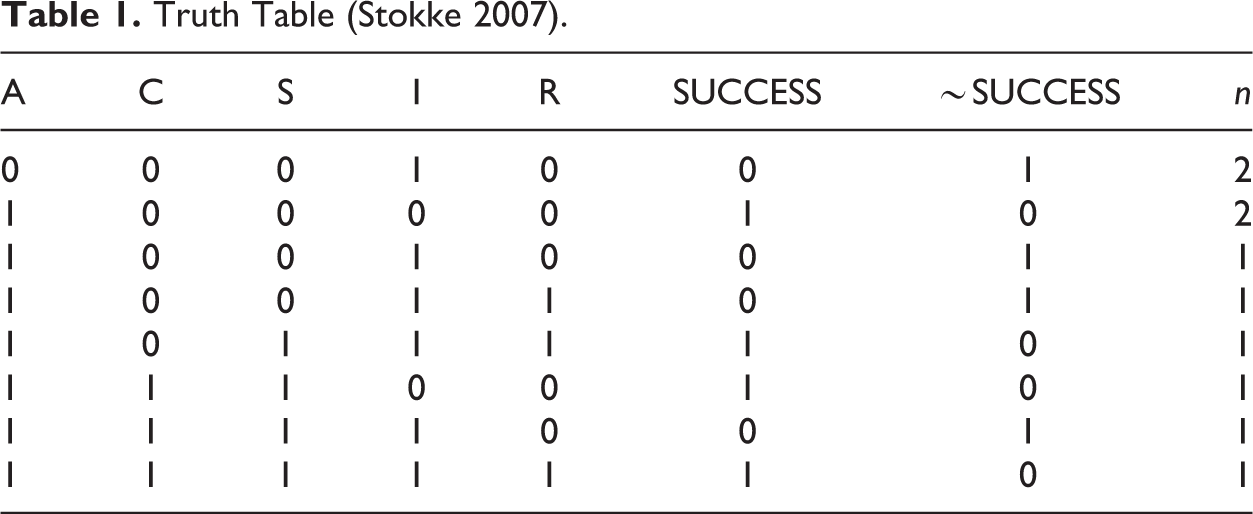
With five conditions, a fully populated truth table has 25 or 32 rows. Table 1 therefore includes eight of 32 possible configurations. The unsimplified solution for sufficiency, using only the empirical information, and where each term represents the combination of one of the conditions or their absence, and the + indicates logical OR, is (Stokke 2007):
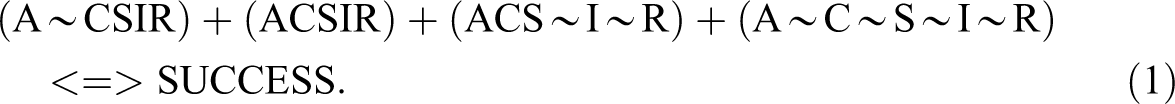
This can be reduced, by Boolean minimization of the first two terms, since the presence or absence of C makes no difference here, to the “complex” solution that is reported by fuzzy set Qualitative Comparative Analysis (fsQCA; Ragin et al. 2006, version 2.5):
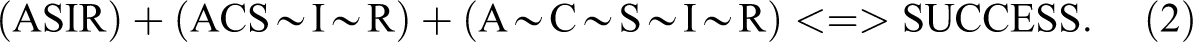
Stokke also lists alternative solutions that depend on different simplifying assumptions (SAs) being made about “logical remainders” (missing rows). SAs allow more parsimonious solutions, by allocating the outcome or its absence to all or some remainder rows. Ragin (2008) notes that the complex solution shown in equation 2 effectively sets all the remainders to “false” (i.e., assumes that, were the missing configurations to exist, they would have the outcome ∼SUCCESS). Ragin also derives a parsimonious solution, allowing the fsQCA software to allocate either SUCCESS or ∼SUCCESS to each remainder row guided purely by the desire to reduce the number of causal conditions in the solution. Ragin argues that, in general, neither of these two extreme options seems attractive. The complex solution may be needlessly complex, insofar as it does not use available easy counterfactual SAs, while a parsimonious solution may be “unrealistically parsimonious due to the incorporation of difficult counterfactuals” (Ragin 2008:163). FsQCA’s parsimonious solution is:
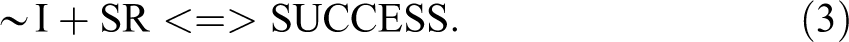
There is actually another parsimonious solution available if fsQCA’s focus on minimal sum models—which aim to minimize the number of prime implicants required to cover the outcome—is dropped (Thiem 2014), but it is one that the literature treated here does not discuss, and we shall therefore only note it in passing: ∼I + CR + ∼CS <=> SUCCESS. Ragin explains that the complex and parsimonious solutions can be seen as end points of a range of solutions that stand in subset or superset relations with one another. Considering just those configurations that have the outcome SUCCESS, the complex solution (equation 2) is a subset of the parsimonious solution (equation 3) since the parsimonious solution includes all of the rows from the complex solution plus additional remainder rows that have been allocated the solution counterfactually.
Ragin notes that other solutions along the complexity/parsimony continuum are possible. Such intermediate solutions are determined by which subsets of the remainders allocated the outcome in generating the parsimonious solution are incorporated in this revised solution (Ragin 2008:165). As he explains, any available intermediate solutions, given the way they are generated, must be supersets of the complex solution and subsets of the parsimonious solution. Which, if any, of the logically available intermediate solutions is to be preferred to the complex solution hinges on decisions about easy and hard counterfactuals (i.e., about which remainders should be incorporated into the intermediate solution).
Ragin (2008:168–71) uses counterfactual reasoning to determine which remainders should be incorporated. For example, he decides, looking at the term ASIR in equation 2, that AS ∼ IR would also be likely to produce successful shaming, since “the fact that it is inconvenient (I) for the targets of shaming to change their behavior does not promote successful shaming.” Condition I, therefore, can be dropped from ASIR by allocating the remainder AS ∼ IR the outcome and minimizing these two to ASR, since whether we have I or ∼I makes no difference to the outcome. By using such reasoning, while also requiring that any term in the intermediate solution must contain the conditions specified in the term of the parsimonious solution of which it is a subset, Ragin (2008:165–66) produces the intermediate solution:
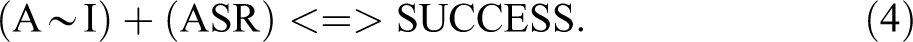
Ragin argues that researchers too often incorporate as many SAs as possible or avoid them altogether, while a better approach would be to “strike a balance between complexity and parsimony, using substantive and theoretical knowledge to conduct thought experiments” to achieve an optimal intermediate solution (2008:172). Importantly, the fsQCA software, as part of its standard analysis, makes available the three solutions. To generate an intermediate solution, the researcher is asked to choose whether, for each condition, the condition should be assumed to contribute to the outcome when present, when absent, or when “present or absent.”
Comparing equations 3 and 4, we can see that the intermediate solution, unlike the parsimonious solution, includes the condition A in each term. Schneider and Wagemann (2012) term condition A an “ENC” since, in Table 1, SUCCESS never occurs without A being present. The fact that A is missing from the parsimonious solution is one motivation for their development of ESA. Ragin (2000:105:254) also noted that parsimonious solutions of limitedly diverse truth tables can omit possible necessary conditions. He proposed separate tests of necessity and, subject to careful reflection on “theory, substantive knowledge, and auxiliary empirical evidence,” the reinsertion of missed necessary conditions into solutions. Ragin and Sonnett (2005) wrote, discussing Stokke’s data set: “Notice … that all four causal combinations … linked to successful shaming include the presence of A,” adding: “This commonality, which could be a necessary condition for successful shaming, would not escape the attention of … a case-oriented researcher.” Stokke argued that the data at hand are compatible with A being a necessary condition (2007:507). Ragin (2008:171) notes that Stokke (2004) includes A in his results, adding A back into equation 3 to give equation 4, having tested for its necessity prior to undertaking sufficiency tests. We now turn to ESA.
Schneider and Wagemann on Stokke’s Work
Schneider and Wagemann (2012, 2013) argue that fsQCA’s standard analysis has weaknesses, claiming it can yield solution formulas that are based on “untenable counterfactual claims” (2012:167). When the user chooses parsimony as the criterion for selecting eligible remainders, “impossible remainders” can be selected, leading to “untenable assumptions” (p. 176). In addition, some unconsidered remainders might actually have provided grounds for good counterfactual claims (p. 177). They also argue that “incoherent counterfactuals” can be used in solutions if the implications of previously derived statements about necessary conditions for the outcome are ignored.
There is much of interest in their discussion of these problems. Here, however, we concentrate on problems arising from the use they make of “ENCs” in both their critical arguments about the standard analysis and in developing ESA. We develop our arguments through focusing on one of two claims Schneider and Wagemann (2012) make concerning the reasons why necessary conditions may become “hidden” in fsQCA-based analyses of sufficiency. They describe “the disappearance of true necessary conditions” as a fallacy that can arise “due to two, mutually nonexclusive features of the data at hand” (p. 221). These are (1) hidden necessary conditions due to incoherent counterfactuals and (2) hidden necessary conditions due to inconsistent truth table rows. They discuss the first with reference to Stokke’s (2007) data set and the second using invented data. Here we discuss just (1). For a critical discussion of (2), see Cooper and Glaesser (2015).
Schneider and Wagemann (2012:222) note that fsQCA’s parsimonious solution of Stokke’s truth table (Table 1) is “
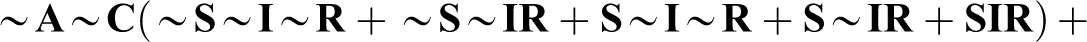
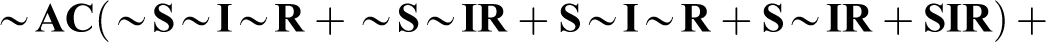
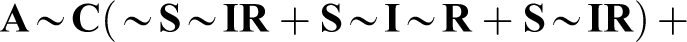
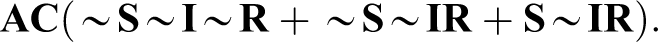
Schneider and Wagemann (2012) note that 10 include the absence of A, adding: “It is because of these incoherent assumptions that the necessary condition A is deemed logically redundant and is minimized away from the parsimonious solution term” (p. 223). For illustration, they note that truth table row 2,
Their solution to this problem is “straightforward: do not make any such incoherent assumptions” (pp. 223–24). In their “enhanced most parsimonious solution,” no use is made of “remainders containing the absence of the necessary condition” (p. 224). They proceed to apply this constraint. This produces the solution “
The question arises of the safety of their approach. There does seem to be a problem. They make use of the empirical necessity of A for SUCCESS, arguing that this implies ∼A should only appear with ∼SUCCESS, as it indeed does in Table 1 (note, though, that we only have one of the 16 logically possible rows including ∼A available). However, there are other ENCs in Table 1 (e.g., condition I is necessary for ∼SUCCESS, the absence of SUCCESS). This statement is logically equivalent to the statement that ∼I is sufficient for SUCCESS and, indeed, looking at the two rows we have containing ∼I (of the 16 that are logically possible), these are associated with SUCCESS.
This opens up a critical line of argument, one drawing on their favored criterion of “incoherence.” Condition I being empirically necessary for ∼SUCCESS implies ∼I is sufficient for SUCCESS. Their ESA-derived solution for SUCCESS (see equation 4 re sufficiency) does not, however, include
There is another worrying consequence of ESA. Schneider and Wagemann say we should draw conclusions concerning remainders from condition A being empirically necessary for success, given it follows that ∼A is sufficient for ∼SUCCESS. Also in Table 1, I is empirically necessary for ∼SUCCESS, implying that ∼I is sufficient for SUCCESS. We have then: ∼A is sufficient for ∼SUCCESS (statement 1) ∼I is sufficient for SUCCESS (statement 2)
Now consider, as an example, the remainder ∼ACS ∼ IR, a subset of both ∼A and ∼I. Statement 1 says it must have the negated outcome. Statement 2 says it must have the outcome. Previously (Cooper et al. 2014), we referred to this as a contradiction. One reviewer of an earlier version of this article pointed out that this was too strong a claim. Statements 1 and 2 will, in fact, not lead to a contradiction as long as we rule out the existence of any configurations that include ∼A and ∼I together. For it to be possible for statements 1 and 2 to be simultaneously true, ∼A and ∼I cannot appear together. Our double use of ESA generates, on the basis of the given data, the strong claim that, if we are to avoid a contradiction, then configurations including ∼A ∼ I cannot exist.
Now, certainly there is no row with ∼A ∼ I in Table 1. However, to avoid a contradiction arising, we are asked to accept that there can be no empirical cases in which a shamer cannot substantiate their criticism of a regime by reference to the regime’s science advisers and in which, at the same time, it would not be inconvenient to make the changes wanted by the shamers. This isn’t, for us, an obviously impossible combination, but whether it is justified or not to make this existence claim would require counterfactual debate between experts in the politics of environmental protection.
In general, Schneider and Wagemann (2012:217) recommend such theory-guided counterfactual reasoning (e.g., as part of their “theory-guided enhanced standard analysis” [TESA]), arguing that logical remainders should be considered as candidate “good counterfactuals,” after “careful theoretical thinking,” irrespective of whether they contribute to parsimony. There is some tension apparent here between ESA and TESA. The irony here is that our double use of ESA, if we are to avoid a contradiction between statements 1 and 2, must rule out—algorithmically—any counterfactual discussion of eight “missing” configurations (those involving ∼A ∼ I) since the ENCs imply their nonexistence. ESA makes claims about the nonexistence of missing configurations, on the basis of the given ENCs.
We have raised concerns about ESA, by exploring its application to Stokke’s data. ESA’s solution for SUCCESS did not include I alone, although its own arguments applied to a second ENC would have led to this result. In addition, ESA, to avoid contradictions, must rule out the existence of some configurations mechanically, although its authors favor theoretical reasoning about such decisions. In the next section, we explore these concerns further, drawing on the analysis of an invented truth table. This will allow us to clarify where ESA’s problems lie.
Can ESA Defeat Itself?
In this section, to clarify the problems to which ESA can lead, we will revisit the problems discussed above but in the context of a simpler truth table. We want to show that, for this truth table, ESA has self-defeating qualities, at least when employing the Quine–McCluskey (QM) minimization algorithm. The truth table is Table 2.
An Invented Truth Table.
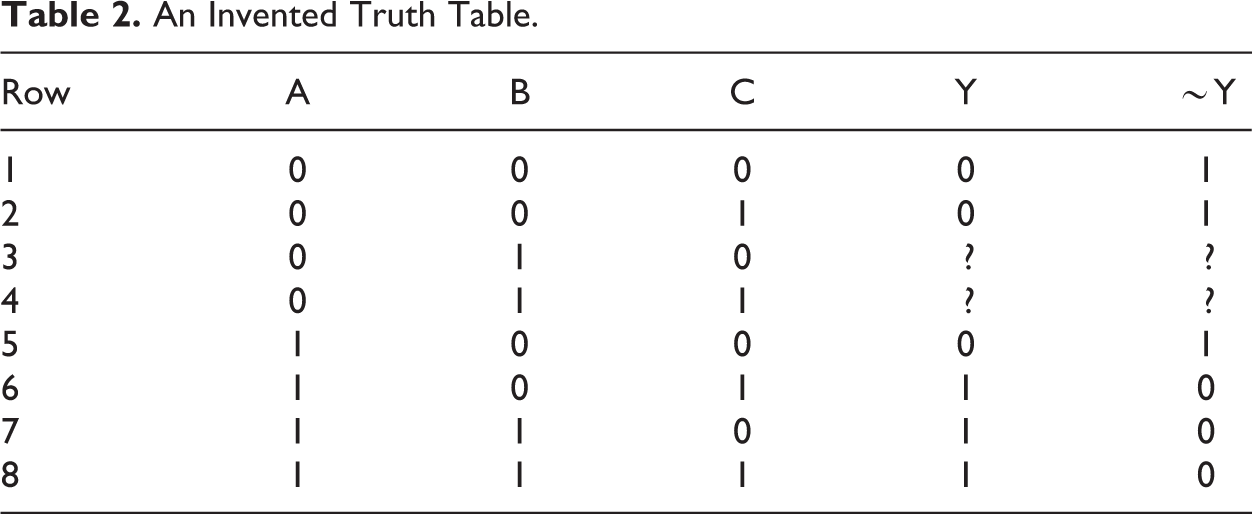
We can see that, empirically, there are two necessary conditions here: A is necessary for Y (statement 3) ∼B is necessary for ∼Y (statement 4)
These are logically equivalent to and therefore imply: ∼A is sufficient for ∼Y (statement 5) B is sufficient for Y (statement 6)
We can again apply ESA twice. Statement 3 rules out rows 3 and 4 being used as SAs for Y. Statement 4 rules out their being used as SAs for ∼Y. The prioritizing of the ENCs leads to the ruling out of rows 3 and 4 as usable SAs. The result is that, on the basis of ESA’s reasoning from ENCs, we must assume that we have only the given six rows to minimize, without any access to SAs. If we employ fsQCA but are constrained not to use rows 3 and 4 as SAs, we obtain these solutions: For Y: AC + AB <=> Y (statement 7). For ∼Y: ∼A ∼ B + ∼B ∼ C <=> ∼Y (statement 8).
Statement 6, derived from an ENC, says that B is sufficient for Y. B does not, however, appear as a stand-alone term in statement 7. Statement 5 says ∼A is sufficient for ∼Y, but ∼A does not appear alone in statement 8. The problem here is that the QM algorithm instantiated in fsQCA cannot deliver the sufficiency results in statements 5 and 6 unless it has access to the logical remainders (rows 3 and 4) that ESA has ruled out. For Table 2, the combination of ENCs, ESA, and fsQCA leads to the problematic claim that statement 7 is the solution for Y, even though it doesn’t include B as a single factor as required by statement 6. We have shown here that ESA, employing QM minimization, in the case of Table 2, is self-defeating. ESA rules out the use of rows 3 and 4 but, without these being available as SAs, it has no way of delivering statements 5 and 6, but 5 and 6 are logically required by its own ENCs.
It is worth noting that, had we not used ESA to rule out rows 3 and 4 as SAs, then fsQCA would have delivered these parsimonious solutions: AC + B <=> Y (statement 9) ∼A + ∼B∼C <=> ∼Y (statement 10)
Here, we have the two single factors. However, given the use of the QM algorithm, these two solutions require the use of contradictory SAs. To obtain statement 9, we must set rows 3 and 4 to have the outcome Y. To obtain statement 10, we must set these to have the outcome ∼Y. An alternative approach, Baumgartner’s (2015) Coincidence Analysis (CNA), drops the QM algorithm, with its one-difference restriction (by which phrase Baumgartner refers to the QM algorithm’s search for rows that share the outcome and differ only in one of the condition columns of the truth table). The focus of CNA is merely on the truth table itself (though this might comprise the configurations and their outcomes given in the empirical data or these plus configurations and outcomes introduced after theoretically informed counterfactual reasoning but before minimization). At the point the table is minimized, no SAs are introduced. The crucial point is that they are not needed, since the algorithm employed to minimize the truth table does not, as in the case of QM, need rows that differ on just one condition in order to move forward through the minimization procedure. As Baumgartner (2015:14–15) notes, “CNA infers causal dependencies not only from the configurations actually contained in truth tables (as does QCA) but also from the fact that certain configurations are not contained therein.” In Table 2, for example, whenever B appears Y does. Nothing in the table contradicts the claim that given B, we see Y. Similarly, nothing contradicts the observation ∼A is sufficient for ∼Y. CNA therefore delivers the solutions in statements 9 and 10 simply by minimizing, using its own algorithm, the given rows.
Discussion
What underlies the problems discussed in the previous two sections? We have seen that ESA makes claims about ENCs and uses these in its procedures for vetting candidate SAs. Now, if we assume that the given data are complete (i.e., that the configurations and associated outcomes in the given truth table fully represent the relevant population for our analyses), then these necessity claims can be regarded as secure. In the case of Stokke’s table, for example, we could safely assume that there are no missing configurations waiting to be found that will have the outcome SUCCESS without A or ∼SUCCESS without I. However, if we make this assumption, then it becomes less clear that we should use any SAs given that we have effectively assumed the nonexistence of all remainders. If we do not assume the data are complete, then the assumption that ENCs represent true necessary conditions, as we have shown, can produce problems.
The QM algorithm encourages scholars to find candidate SAs among remainders because of its one-difference requirement. Without access to SAs, fsQCA, using QM, cannot find ∼I to be sufficient for SUCCESS in the Stokke case or B to be sufficient for Y in the invented truth table. It seems, then, that ESA, if it is to rely on these ENCs to vet SAs, finds itself in a difficult position since, if it makes sense to think about remainders existentially, this can throw doubt on the validity of the empirical necessity claims that ESA will use to vet them. To summarize, either configurations missing from a truth table don’t exist, which allows secure necessity claims to be made on the basis of the table but renders reference to the remainders and their assumed outcomes redundant at best; or some might exist, which can threaten the validity of the necessity claims that ESA wants to use to vet candidate SAs. It is true, in the Stokke case that if A is necessary for SUCCESS, then ∼A should not appear with SUCCESS. But of the 16 possible rows involving ∼A, only one is present. In using the ENC to rule out the 15 remainders having the outcome SUCCESS, ESA goes beyond the available evidence. It does this algorithmically rather than on the basis of theoretical reflection. Can we really be sure that advice from a regime’s own scientists (A) would be needed for SUCCESS in all conceivable cases?
The invented truth table allowed us to see the problem in its simplest form. In that case, ESA itself ruled out the existence of any remainders. Here there could be no coherent, tenable SAs. Without access to these, ESA employing fsQCA, and therefore constrained to use the QM algorithm, could not generate the solution that the ENCs present in the table logically required. Baumgartner’s CNA, employing its alternative minimization algorithm, and making no reference to SAs at all, could deliver the required solution. FsQCA, asked to generate a parsimonious solution, could also generate the required solution but needed to use contradictory SAs.
We do not want to recommend best practice rules. As we argued earlier, such recommendations, at this stage of the development of set theoretic methods, seem premature. With that proviso in mind, it seems to us that faced with limitedly diverse truth tables, there are several routes that usefully might be followed. However, the researcher needs first to make a decision about the missing truth table rows. (1) Are they missing in the sense that some at least could exist in principle but happen to be without data in the truth table at hand? or (2) are there good logical or theoretical reasons for thinking that data for these rows aren’t to be found?
If (2) were to be the case, then there would seem to be an argument for analyzing the given truth table as it is (i.e., without using any SAs). In Ragin’s terms, this would provide a complex solution. However, Baumgartner (2015) has argued that, if set theoretic analysis is to make causal claims about conditions as difference makers, then only the parsimonious solution of such a table can offer correct solutions. Such parsimonious solutions can usually be provided by fsQCA’s standard analysis, although truth tables involving causal chains can cause problems (Baumgartner 2012, 2015) and, sometimes, fsQCA’s parsimonious solutions will include contradictory SAs. The alternative algorithm to QM embedded in Baumgartner’s CNA can produce these parsimonious solutions without any reference to SAs.
If (1) seems to be the case, but it is not possible to access data for the missing rows deemed to be possible, then Ragin’s (2008) arguments for the use of counterfactuals can be turned to. If we aim to analyze a complete empirical table but lack data on some “possible” rows, then, if only to explore the effect of various counterfactual outcomes on the solution, we might run the analysis on the table but expanded by SAs derived by theoretically informed counterfactual reasoning. Such reasoning, of course, will only be as strong—or as weak—as the theories relied on.
Our QCA work has often used large N data sets (Cooper 2005; Cooper and Glaesser 2011a, 2012b; Glaesser and Cooper 2011, 2012, 2014). Here, case knowledge may be lacking and existing theory will be prioritized in any counterfactual reasoning in the face of limited diversity. On the other hand, in some small n settings, existing theory may be in short supply and case knowledge will be prioritized. FsQCA’s standard analysis will prove useful in exploring the effects of counterfactual reasoning of both sorts. In addition, if the analyst wishes to include a remainder that is omitted by standard analysis’s parsimonious solution, this can easily be added after theoretical reflection on the full range of truth table rows, as also recommended by Schneider and Wagemann (2012).
The lesson of this article, however, seems to be that we should analyze this new expanded table as if it were a completed table (i.e., without allowing computer algorithms to add any further SAs, however they are vetted). Going beyond the data to fill in remainders via SAs has been shown, both for Stokke’s data and for our invented truth table, to be a risky approach. The underlying problem with ESA is perhaps the application of logic to derive conclusions from premises whose own status, because of limited diversity, is insecure.
On the basis of the work reported here, we suggest that two issues concerning set theoretic analysis that currently require more discussion are (1) whether the QM algorithm, developed to reduce costs in circuit design, should now be replaced by the alternative instantiated in CNA and (2) the relative merits of parsimonious versus intermediate solutions, especially for those who see Boolean analyses as a part or the whole of a procedure for causal, rather than descriptive, analysis (Baumgartner 2015). Our discussion here will hopefully comprise a useful contribution. We have shown that ESA, used in conjunction with QM, generates problems. ESA, of course, was intended to help resolve problems that QM, given limited diversity, generates. Our discussion shows this to be more difficult than perhaps thought. Avoiding QM, rather than attempting to mitigate its downside via a set of contradiction avoidance strategies, may be beneficial. We suspect that, given a considerable degree of limited diversity, ESA, in conjunction with QM, will often cause the sort of problems we report here. The “coherence” in the use of SAs Schneider and Wagemann seek may often be impossible to achieve while QM’s one-difference approach to minimization is employed. Without QM, the rules offered by ESA may no longer be required.
Footnotes
Acknowledgments
We wish to thank two anonymous referees for their very helpful comments and suggestions.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work has been supported by the United Kingdom’s Economic and Social Research Council (ESRC).