
Abstract
Background
Active targeted case-finding is a cost-effective way to identify individuals with high-risk for early diagnosis and interventions of chronic obstructive pulmonary disease (COPD). A precise and practical COPD screening instrument is needed in health care settings.
Methods
We created four statistical learning models to predict the risk of COPD using a multi-center randomized cross-sectional survey database (n = 5281). The minimal set of predictors and the best statistical learning model in identifying individuals with airway obstruction were selected to construct a new case-finding questionnaire. We validated its performance in a prospective cohort (n = 958) and compared it with three previously reported case-finding instruments.
Results
A set of seven predictors was selected from 643 variables, including age, morning productive cough, wheeze, years of smoking cessation, gender, job, and pack-year of smoking. In four statistical learning models, generalized additive model model had the highest area under curve (AUC) value both on the developing cross-sectional data set (AUC = 0.813) and the prospective validation data set (AUC = 0.880). Our questionnaire outperforms the other three tools on the cross-sectional validation data set.
Conclusions
We developed a COPD case-finding questionnaire, which is an efficient and cost-effective tool for identifying high-risk population of COPD.
Keywords
Introduction
Underdiagnosis is a major challenge worldwide. A recent national cross sectional study in China reported less than 3% of COPD patients were aware of their condition and few of them received a previous pulmonary function test. 1 Other community-based population studies from North and South America, Europe, and Australia have revealed that about 70–80% of these subjects have not been diagnosed with COPD.2–4
Inadequate-utilization of spirometry contributes most to the high-rate of underdiagnosis of COPD. 5 Patients’ poor access to spirometers and lack of expertise in performing and interpreting spirometry limit spirometry-based diagnosis especially in primary care. In addition, a considerable part of the early stage COPD patients with only mild airflow limitation have few or nonspecific symptoms or poor perception of their symptoms. 6 A precise, practical and cost-effective screening strategy is urgently needed for promoting early diagnosis and interventions, especially in high risk population area.
Active targeted case finding in health care setting with screening questionnaires prior to spirometry test has been demonstrated a cost-effective way to identify undiagnosed patients and was recommended in GOLD 2020. 7 Different questionnaires have been reported, e.g. the COPD Population Screener Questionnaire (COPD-PS), 8 based only on a few priori selected items and does not account for risk factors such as occupation, education level, living conditions, and prenatal maternal smoking. These risk factors vary in different countries and regions, and their effects have not been evaluated in COPD screening. Moreover, the previous tools only provided a risk score rather than a predicted probability of having COPD.
In this study, we used statistical learning algorithms on a database of national cross-sectional survey study from China to identify novel predictive patterns of significant clinical characters. We then compared the performance of four statistical learning models to find the best predictive model. Finally, we developed a COPD screening questionnaire and validated its efficacy in a prospective cohort of specialist population.
Methods
Study subjects and study design
The developing data set consists of 5281 participants in the China Pulmonary Health (CPH) cohorts from Shanghai. The design of this national randomized cross-sectional study has been previously described. 1 All participants were >20 years old and received standardized spirometry measurement between June 2012 and February 2014. To further validate our case-finding instrument, we established another prospective observational cohort. Participants who underwent spirometry tests in a tertiary teaching hospital were enrolled between April 2020 and September 2020. Participants were excluded if they were <40 years old; had history of asthma or lung cancer; had history of thoracic or abdominal surgery; admitted to hospital for any cardiac condition in the past month; had heart rate greater than 120 beats per min; were under antibacterial chemotherapy for tuberculosis; were pregnant or breastfeeding; or they did not receive bronchial dilation test. Information for the selected predictors was collected in a face-to-face interview using a questionnaire before or after they underwent spirometry tests. The diagnosis of COPD was based on the objective measure post-bronchodilator FEV1/FVC with value <70%. 9 All participants were provided written informed consent, and the ethics review committees of Beijing Capital Medical University (No. 11-ke-42) and Zhongshan Hospital Fudan University (No. B2019-248 (2)) approved this work.
Data processing
The cross-sectional database consists a total of 643 variables except for spirometry data. We eliminated the variables and samples of high missing rate (Supporting Methods and Supplemental Figure S1), remaining 159 candidate predictors of interest and 4736 participants for modeling. The predictors cover patient demographics (e.g. age, gender, body-mass index (BMI)), respiratory symptoms, activity limitation, depression and anxiety symptoms, medical history and medication, cigarette smoke exposure, occupation and living environment, quality of life, results of physical examination and laboratory tests. We used different impute methods according to the intrinsic logic of original questions, see details in Supplementary Materials - Methods - Data processing and Supplemental Table S1.
Statistical learning models
Firstly, the cross-sectional database were used to establish models for predicting risk of COPD. We evaluated the performance of four statistical learning models on predicting the risk of COPD using the cross-sectional database, including logistic regression (LR), generalized additive model (GAM), extreme gradient boosting (XGBoost), and random forest (RF). Before using the training data to train the model, we tested and determined the value of the hyperparameters for GAM, XGBoost and RF models. After selecting the feature set, the 10-fold cross-validation method was used to determine the values of hyperparameters according to the highest AUC score on the cross-sectional training set using the grid search. Then we retrained the model on the whole cross-sectional training data. Interaction was added accounting for the relationship between age and years of smoking cessation in LR and GAM.
Selection of predictors
To screen for the most effective predictors and optimal prediction model, we randomly selected one-tenth of the cross-sectional survey data as the internal validation data, and the remaining nine-tenths as training data (Supplemental Figure S2). The minimal set of predictors providing the highest average AUC was selected as final predictors based on their integrated importance in the four statistical models (Supporting Methods). The optimal prediction model was selected from the four prediction models for best AUC on cross-sectional internal validation data. Finally, we combined the selected predictors and statistical learning model into a COPD case-finding instrument which directly predicts the probability of having irreversible airway obstruction in spirometry tests for an individual.
Validation
To evaluate the reliability of our COPD case-finding model, we compared performance of our model and other three previously reported approaches by Zarowitz et al. (2011), 10 Kotz et al. (2008) 11 and Price et al. (2006) 12 in COPD case-finding. For each participant in our cross-sectional cohort, we used our model and three previously reported models to predict if he/she had COPD. Then we compared the receiver operating characteristic (ROC) curve and AUC of the four models in identifying spirometry-confirmed COPD cases. The features included in the three previous approaches were presented in Supplemental Table S2.
Determination of cut-off values
We calculated the cut-off values of predicted probability for high-risk population to make positive predict value (PPV) higher than 0.5 and for low-risk population to make negative predictive value (NPV) < 0.02.1,13
Data were expressed as frequencies (percentages) for categorical variables and as means ± SD or median (IQR). Student’s t-test or Mann–Whitney U test were used for comparison of continuous variables as appropriate. Chi squared test was used to compare parametric and categorical variables, respectively. LR and GAM models were implemented in R (stats, mgcv 1.8.33) and the other analysis is carried out by Python (Pandas 1.0.1, Scikit-Learn 0.23.2, pygam 0.8.0, XGBoost 1.0.2). p-values < 0.05 were interpreted as statistically significant.
Results
Participant characteristics
Clinical characteristics of participants in cross-sectional data set and prospective validation data set. a

a Data are presented as % or mean ± SD, p-value are calculated based on Chi-square or Mann–Whitney U test.
Selection of predictors
Statistics of selected predictors of COPD in cross-sectional and prospective data sets. a

aData are presented as n (%), median (IQR1∼ IQR3), or mean ± SD.
bp-value are calculated based on Chi-square test or Mann–Whitney U test.
Modelling
Predictive ability of different models on cross-sectional validation dataset and prospective cohort dataset.

AUC: area under the receiver operating characteristic curve; PPV: positive predictive value; NPV: negative predictive value; NA: not available for the model; LR: logistic regression; GAM: generalized additive model; RF: random forest; XGBoost: extreme gradient boosting; COPD: chronic obstructive pulmonary disease.
aFor each model, we defined probability higher than 0.075 as with risk for COPD, and the others without for COPD to calculate the metrics. We used spirometry-defined COPD as gold standard.
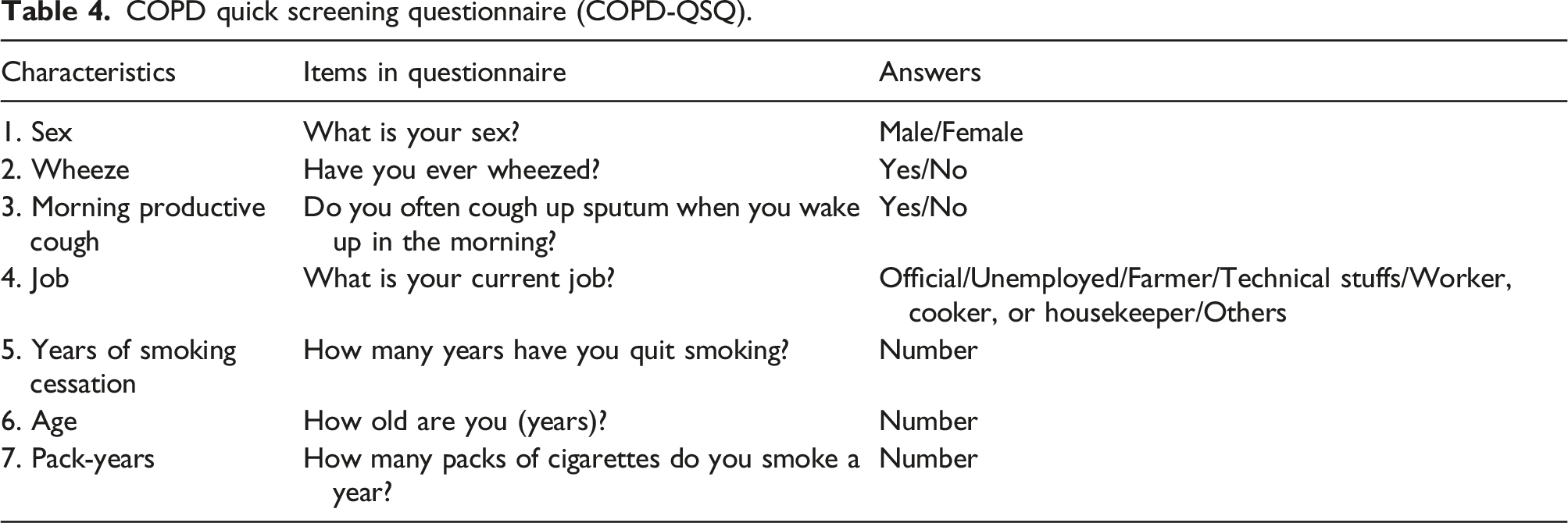
COPD quick screening questionnaire (COPD-QSQ).
Comparison with previous questionnaires
Compared with other three instruments previously reported by Ref. Zarowitz et al. (2011), Kotz et al. (2014) and Price et al. (2006), our COPD-QSQ outperformed the other instruments with an AUC of 0.813 on the cross-sectional data set. (Figure 1) Tools by Kotz et al. (2014) and Price et al. (2006) used LR model and similar predictors and showed similar results on both data sets (AUC 0.770 and 0.774, respectively). Zarowitz et al. (2011) contained the smallest number of questions, while the AUC was lower than other instruments. Comparisons of the area under curve (AUC) between generalized additive model and three previous approaches on the cross-sectional validation data. The models included seven predictors: age, morning productive cough, wheeze, years of smoking cessation, gender, job, and pack-years of smoking.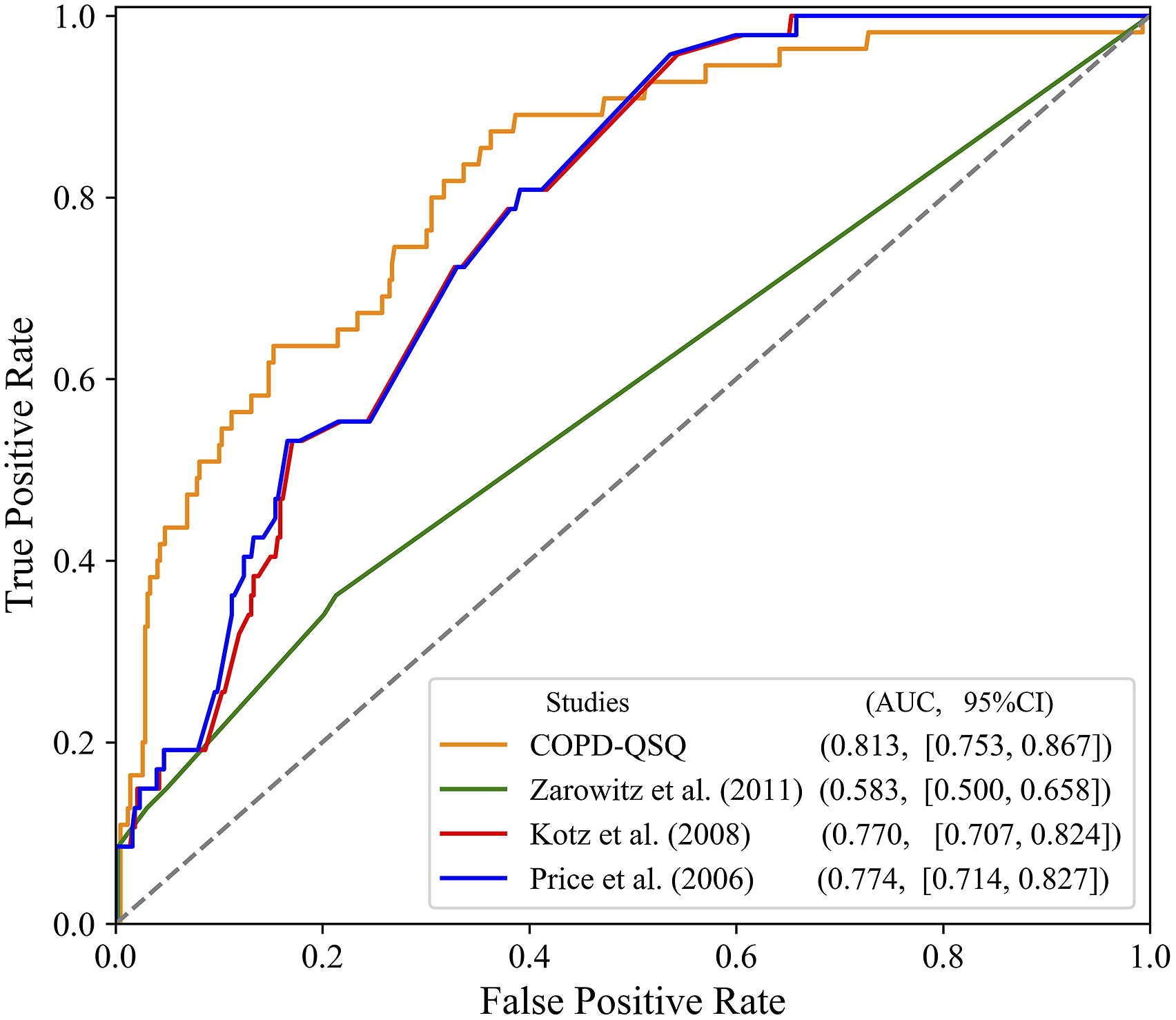
Optimal cut off value for spirometry test
Our questionnaire is aimed at identifying the individuals with high risk of COPD who need further validation by spirometry test, and those with low risk of COPD who shoud not receive spirometry test. To determine the cut-off value of defining high-risk population using our model, balancing between cost and effectiveness, we adopted an optimal PPV of 0.5 to define “high-risk” group, where the corresponding cut-off value in GAM model was 0.265. (Figure 2) It means that individuals who had value of 0.265 need further confirmative spirometry test, and to identify a case with airflow obstruction, two high-risk individuals were required to receive spirometry test. In addition, we also defined a low-risk population who should not receive spirometry test for COPD screening. We used the NPV of 0.98 and the corresponding cut-off value was 0.075, that is, one case with airflow obstruction would be missed among 50 low-risk individuals without spirometry test. (Figure 2) The predicted risk between 0.075 and 0.265 was defined as moderate risk. Positive predictive value (PPV) and negative predictive value (NPV) of generalized additive model prediction results. The red vertical line presents the high-risk cut-off value of 0.265 using generalized additive model (GAM) with an optimal PPV of 0.5. The blue vertical line presents the low-risk cut-off value of 0.075 with an optimal NPV of 0.98 using the same model. The model included seven predictors: age, morning productive cough, wheeze, years of smoking cessation, gender, job, and pack-years of smoking.
Discussion
To our knowledge, this is the first study using advanced statistical learning models to predict the risk of COPD in general population and develop a case-finding instrument for COPD. With the abundant variables in dataset collected from cross-sectional study, we identified seven important predictors showing high predicting power with an average AUC of 0.784 for detecting spirometry-defined COPD patients. The highest AUC was reached by the GAM model as 0.813. The case-finding instrument derived from the selected predictors and GAM model had higher AUC of 0.880 for risk prediction of COPD in our prospective validation cohort.
Our developing data set covered a wide range of potential predictors of COPD in general population, including age, living conditions, income, job, biomass usage, childhood lung infections, and maternal smoking during pregnancy. The participants were not restricted to smokers, which permits the applicability of our model in screening for non-smokers with high risk of COPD. We found predictors (such as age, gender, symptoms and smoking) which have been commonly used in previous case-finding tools,7,8,12,14 and also occupational exposure which has not been included in other case-finding tools. In line with the result, a statement from American Thoracic Society and European Respiratory Society reported that occupational exposure contributed 14% to the burden of COPD, which was twice higher in non-smokers. 15 To keep the simplicity of our case-finding instruments, we classified the occupations into nine classes according to their estimated OR for COPD. In addition, we found years of smoking cessation was of high importance which was not included in other instruments.
Difference in detailed definition of predictors should be accounted for in a screening questionnaire. For each item, the most efficient question were selected from several related candidates using AIC value of stepwise regression and the sum importance ranking from four statistical models. For example, the candidate question related to job included: “your current job?“, “how many years did you had this job?“, “the job you ever had for longest time?“, and “did you exposed to dust, allergens, or noxious gas in your working place?“. Current job performed best than other questions. In spite of cautious selection of predictors, there are special conditions to be considered in clinical application, such as for retired individuals, the last job before retirement is a reasonable substitute to account for occupation factor. In addition, the question “do you ever wheeze” is not limited to a recent period, which would not miss individuals who have chronic and recently onset wheeze, but may also screen out those who ever had acute wheeze and have recovered.
Previously published COPD case-finding models were mostly based on logistic or multivariate regression techniques.16–18 Statistical learning models have been used to predict the risk of mortality after acute stroke and acute myocardial infarction,19,20 the risk of drug toxicity, 21 and the deterioration of patients in critical care units. 22 The large sample size of our study permits usage of advanced statistical learning strategies in developing a case-finding model. The final AUCs of our prediction model were between 0.80 and 0.90, which were higher than those of other instruments. In comparison, our final models outperformed other previously reported models both on the cross-sectional survey data.
Different form ensemble models, GAM adds a non-parametric part to characterize the sub-linearity of factors and has a strict penalty for non-parametric smoothness, which permits better fitting and prediction competence. In addition, GAM provides a calculated probability for each individual, which allows physicians to assess the risk of having COPD and to make clinical decisions accordingly. Also, GAM permits analyzing the pathogenic factors of the examinee. For example, the 2D regression curve in our GAM model (Supplemental Figure S4) provided a moderate high-risk region of age and smoking cessation.
In addition to the advantages of GAM model, our study has some inherent data strengths in both cardinality and degree of database. The training database was derived from a cross-sectional study with strict multi-stage randomized sampling, the sample size of which, to the best of our knowledge, is larger than that of any previous studies.23–25 Also, our predictors were selected from a large candidate pool with four different statistical learning models, underlying the importance of their role in screening. The COPD-QSQ questionnaire developed in this study classifies high-and low-risk population with the probability of having COPD as 50% and 2%, respectively. It provides a feasible, cost-effective, and precise case-finding tool for clinical use in health care settings.
There are also limitations in our study. Firstly, our study population was from a highly industrialized city of China, while the importance of risk factors for COPD differs in different economic and cultural context. There may not be universal equation/questionnaire that fit all countries and regions. Large datasets from different countries and regions are required to further test the generalization ability of our proposed method. Secondly, the cross-sectional database had variables and samples with missing values. Albeit efforts in balancing data saturation and sample size and cautiously imputation, the missing values may still introduce confounding in the final model. However, we noted that the selected features in the final model were biologically plausible and mostly reported as common risk factors of COPD, suggesting the elimination of variables did not miss important information for prediction. Thirdly, our validation cohort included individuals underwent spirometry tests in a generalized tertiary hospital for diverse reasons (eg. mild or severe respiratory symptoms, risk of respiratory disease, pre-operation assessment, and routine respiratory health examination, ect.) Despite of their variety in health background, the population may still different from that of primary or secondary care settings. Forth, individuals with previously diagnosed COPD patients were included in our cohorts, where the prevalence of COPD may higher than its aimed population of COPD screening. The performance of our questionnaire needs further evaluation in multi-center prospective COPD screening studies at different health care settings.
Conclusions
In this study, we proposed a set of predictors to accurately predict risk of COPD and designed a new case-finding questionnaire for COPD called COPD-QSQ. This questionnaire has potential applications in different health care settings to assist physicians in identifying individuals of high risk for COPD.
Supplemental Material
Supplemental Material - Developing and validating a chronic obstructive pulmonary disease quick screening questionnaire using statistical learning models
Supplemental Material for Developing and validating a chronic obstructive pulmonary disease quick screening questionnaire using statistical learning models by Xiaoyue Wang, Hong He, Liang Xu, Cuicui Chen, Jieqing Zhang, Na Li, Xianxian Chen, Weipeng Jiang, Li Li, Linlin Wang, Yuanlin Song, Jing Xiao, Jun Zhang and Dongni Hou in Chronic Respiratory Disease
Footnotes
Author contribution
Xiaoyue Wang and Liang Xu contributed substantially to data collection, patient management, statistical analysis and interpretation, and the writing of the manuscript. Hong He contributed to statistical analysis and writing of the manuscript. Dr Na Li and Ms. Xianxian Chen is the artificial intelligence expert who was responsible for data processing, statistical analysis, methodology design and implementation of the algorithm, and participated in manuscript writing and diagram plotting. Cuicui Chen, Weipeng Jiang, Li Li, Linlin Wang, Jian Wang, Mengzhen Cheng, and Jieqing Zhang contributed to the acquisition, analysis, or interpretation of data. Yuanlin Song contributed to statistical analysis and writing of the manuscript. Zhang Jun and Jing Xiao contributed to administrative, technical, and material support and to critical revision of the manuscript for important intellectual content. Dongni Hou contributed substantially to the study design, data collection, statistical analysis and interpretation, and the writing of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by The National Natural Science Foundation of China (81800008, 81770075, 82041003), National key R&D plan (2020YFC2003700), Science and Technology Commission of Shanghai Municipality (20DZ2261200, 20Z11901000, 20XD1401200), and Shanghai Municipal Key Clinical Specialty (shslczdzk02201).
Ethics statement
All participants were provided written informed consent, and the ethics review committees of Beijing Capital Medical University (No. 11-ke-42) and Zhongshan Hospital Fudan University (No. B2019-248(2)) approved this work.
Availability of data and materials
The corresponding authors had full access to all of the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis. The data are available from the corresponding authors upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.