
Abstract
This study explores the use of generative AI tools in qualitative research, specifically to enhance thematic analysis (TA). Traditional TA, while widely adopted in marketing, is inherently labor-intensive and prone to researcher biases. The method proposed here, generative AI-augmented thematic analysis (GAATA), addresses these limitations by using gen AI tools to automate and augment the data analysis process. GAATA comprises three phases: prompt designing, code generation/validation, and theme generation/validation. The method leverages the capabilities of multiple gen AI tools to generate initial codes and themes. These codes/themes are then validated and refined by human researchers, thereby increasing reliability and reflexivity in the TA process. A set of generic prompt templates are provided to enable researchers with less technical expertise to use GAATA. An empirical comparison between GAATA and traditional thematic analysis (TA) is then undertaken. The emergent themes are validated across four dimensions: conceptual mapping, thematic specificity, theoretical alignment, and time efficiency. GAATA, augmenting gen AI with structured human oversight, offers a scalable, robust alternative that accelerates and enriches thematic analysis in market research.
Keywords
Introduction
Qualitative research can provide deep insights into consumer behavior, preferences, and perceptions - critical for developing effective marketing strategies (Belk, 2013). Traditionally, this has involved methods such as focus groups, interviews, and ethnographies, all of which demand rigor and researcher reflexivity throughout data analysis and interpretation. Thematic analysis (Braun & Clarke, 2006), is a widely adopted approach for analyzing qualitative data in marketing (Cooper et al., 2023). This approach centers on the systematic identification, analysis, and subsequent reporting of thematic structures (patterns of meaning) embedded within qualitative data. The traditional (manual) execution of TA is both labor-intensive and time-consuming (Nowell et al., 2017). However, the integration of digital tools into TA allows researchers to handle larger qualitative datasets more efficiently, easing the demands of manual approaches (Bazeley, 2020; Hitch, 2024).
AI is reshaping the qualitative research domain (Christou, 2023; Hitch, 2024; Morgan, 2023), facilitating the systematic storage, retrieval and analysis of vast quantities of data. Thus, leading to increased attention across several fields including healthcare (Briganti & Le Moine, 2020; Kanaparthi, 2022) and the application of AI technologies in various contexts including sentiment analysis and keyword clustering (Chakriswaran et al., 2019). The advent of generative intelligence, however, is a particularly important advancement for qualitative researchers, representing a departure from previous applications of AI. Gen AI tools, equipped with capabilities to analyze and generate human-like text, hold promise for automating and augmenting the data analysis process. With interpretive methods, researcher bias is a longstanding issue. Although bracketing is a well-established practice for demonstrating rigor (Creswell & Miller, 2000; Tufford & Newman, 2012), it has been criticized as inherently difficult and subject to the very biases which it seeks to control (LeVasseur, 2003). Qualitative researchers have therefore sought ways to minimize the influence of their own subjectivity to preserve the integrity of the phenomenon under study. Others, however, argue that researcher biases are inseparable from the interpretive process and play a central role within it (Hirschman, 1986). Indeed, the process of obtaining insight is embedded in a dynamic relationship between researcher and data (Hitch, 2024). Thus, despite the technological advances, integration of gen AI into qualitative market research remains nascent. Significant gaps persist in respect to methodological frameworks capable of leveraging gen AI tools effectively without compromising the depth of consumer or marketer insights (Gupta et al., 2024; Kshetri et al., 2023). Therefore, the purpose of this study is to introduce and evaluate a structured framework - ‘Generative AI-Augmented Thematic Analysis’ (GAATA), which uses gen AI to augment the thematic analysis of qualitative data. It seeks to answer the question: Can a carefully designed, prompt-based gen AI generate codes and themes that match the quality of those produced by experienced human analysts?
Literature Review
Gen AI and Qualitative Research
Recent studies have begun to recognize the potential of gen AI in TA (Katz et al., 2023; Yan, Echeverria, et al., 2023; Zhang et al., 2023), signifying an opportunity to further explore it’s ethical and rigorous use in this context. Recent advancements in gen AI, particularly within the domain of Natural Language Processing (NLP), offer novel avenues for language inferences such as answering questions (Devlin et al., 2019). Gen AI tools use large language models (LLMs), trained on vast datasets (Sallam, 2023; Yan, Sha, et al., 2023), enabling them to produce original content that closely mirrors human language patterns (Brown et al., 2020; Meng et al., 2023). Beyond text generation, these models are also capable of interpreting context, offering explanations, and assisting in TA (Amarasinghe et al., 2023; Andres Felipe Zambrano, 2023b). Andres Felipe Zambrano (2023a) notes that gen AI tools are embedded with extensive pre-trained knowledge and thereby possess the capacity to identify data patterns that may not be immediately apparent to human cognition; thereby enhancing manual TA.
Gen AI and Thematic Analysis
Ongoing debate surrounds the application of gen AI tools in TA (Morgan, 2023; Van Dis et al., 2023). The arguments in favor are extensive (Christou, 2023), while criticism broadly centers on three fundamental themes: (1) A central critique of using gen AI in TA is the tool’s ability to comprehend complex human experiences and social contexts (Yan, Echeverria, et al., 2023; Yan, Sha, et al., 2023). Researchers argue that while gen AI can identify textual patterns, meaning generation is based on research questions and it lacks the capacity for nuanced insight which is critical for in-depth TA (Gebreegziabher et al., 2023; Yan, Echeverria, et al., 2023). Indeed, contextuality and ambiguity, both of which are inherent to human language, remain an ongoing challenge (Hitch, 2024). Particularly, because the fundamental advantage of qualitative research methods are that they facilitate the discovery of nuance (Fischer & Guzel, 2023; Nowell & Albrecht, 2019). (2) The potential for inherent biases in AI algorithms raises concerns about the representativeness and fairness of the identified themes (Mittermaier et al., 2023). These biases might reflect in the themes generated by AI. (3) In identifying themes, the lack of transparency in data processing potentially undermines credibility. Transparency is critical to developing a trustworthy understanding of a particular phenomenon (Denzin & Lincoln, 2011; Patton, 2023).
In the following sub-sections, we investigate how humans can employ gen AI tools to augment qualitative data analysis and thereby address the above limitations. More details on precise mitigation strategies are presented in the Approach section.
Prompts: Increasing Human Intervention in Gen AI Data Analysis
Prompts are used to instruct gen AI tools to perform tasks (Bozkurt & Sharma, 2023). The quality of prompts determines the response (output) generated by gen AI (Poola, 2023). A well-crafted prompt acts as a bridge between the user’s intent and the tool’s capabilities, guiding it towards generating desired outputs that are accurate, relevant, and insightful (Kan et al., 2023).
The following prompt types are described in the literature (Bello, 2023; Ekin, 2023; OpenAI, 2024): (1) zero-shot prompting, where responses are entirely based on pre-trained knowledge on the context of the task; (2) one-shot prompting, where the responses are based on an example provided in the prompt and then gen AI models generate responses similar to the example; (3) few-shot prompting, where responses are based on more than one example elaborating how the output should be generated. Few-shot prompting is useful for tasks that require nuanced responses such as in TA.
Prompt Engineering
Recent studies note that effective use of gen AI varies across domains, and that domain-specific knowledge used in prompts is essential for optimizing performance (Tian et al., 2024; Wang & Jin, 2023). Further, Zhang et al. (2023) argue that prompt engineering should consider the specific application context to guide the gen AI tool towards an effective response. The context may include a range of information that varies from the research goal to the expected structure of the gen AI response. Hence, domain knowledge and context are essential inputs required by gen AI tools in generating effective responses (output).
Best Practices for Prompt Engineering
Gen AI tool developers hold that it is essential to apply specific best practices in prompt engineering. These practices are designed to enhance the clarity, specificity, and overall effectiveness of the prompts, thereby improving gen AI’s responses (Huit, 2024). Appendix A synthesizes prompt engineering guidelines based on insights from OpenAI’s resources and related expert advice (Zhang et al., 2023).
Reflexive Thematic Analysis (RTA)
While many researchers have contributed to developing TA, Liu (2023) argues that an over-emphasis on structured methodologies has turned TA into a ‘bucket filling’ deductive process, where it should be a creative and inductive process. Braun and Clarke (2006) is the most frequently cited paper in the field of TA 1 . The authors propose a six-step methodology which they revisit and subsequently update (Clarke & Braun, 2013, 2017). They lament how the research community has overlooked the underlying assumptions of their original method, particularly with regard to identifying underdeveloped themes using domain summaries (Braun & Clarke, 2019). Domain summary themes focus on summarizing diverse meanings expressed within a specific topic, where the themes often resemble data collection questions. In order to to produce domain summaries as themes, Braun and Clarke (2019) introduced Reflexive Thematic Analysis (RTA), that offers a tripartite typology for TA, updating their earlier method as follows: (i) Coding reliability: Emphasis on replicability of codes - to control for researcher subjectivity/biases and the reliability of measurement; (ii) Codebook: A codebook is a flexible, evolving guide used by researchers to document and refine codes as they engage in the coding process. Unlike structured or fixed codebooks used in other thematic approaches, the codebook in RTA is dynamic and reflects the researcher’s reflexive engagement with the data; and (iii) Reflexivity: Emphasizes the researcher’s active role in identifying themes, acknowledging that coding is influenced by the researcher’s perspectives and insights.
RTA has been widely adopted across various fields of qualitative enquiry owing to its flexibility and rigor. The method allows researchers to engage deeply with their data, ensuring that themes are developed through an iterative process of coding and thematic refinement. Additionally, RTA’s emphasis on reflexivity and the active role of the researcher aligns well with contemporary qualitative paradigms, making it a popular choice for studies exploring complex social phenomena (Byrne, 2022; Kiger & Varpio, 2020).
Research Approach
This study develops a novel gen AI-enhanced RTA methodology using design science research (DSR) principles. Following Hevner (2007) and Vom Brocke et al. (2020), we consider three key design principles: relevance, rigor and evaluation. Figure 1 illustrates the design rationale underpinning the proposed gen AI-enhanced RTA methodology. Design Science Approach for the Study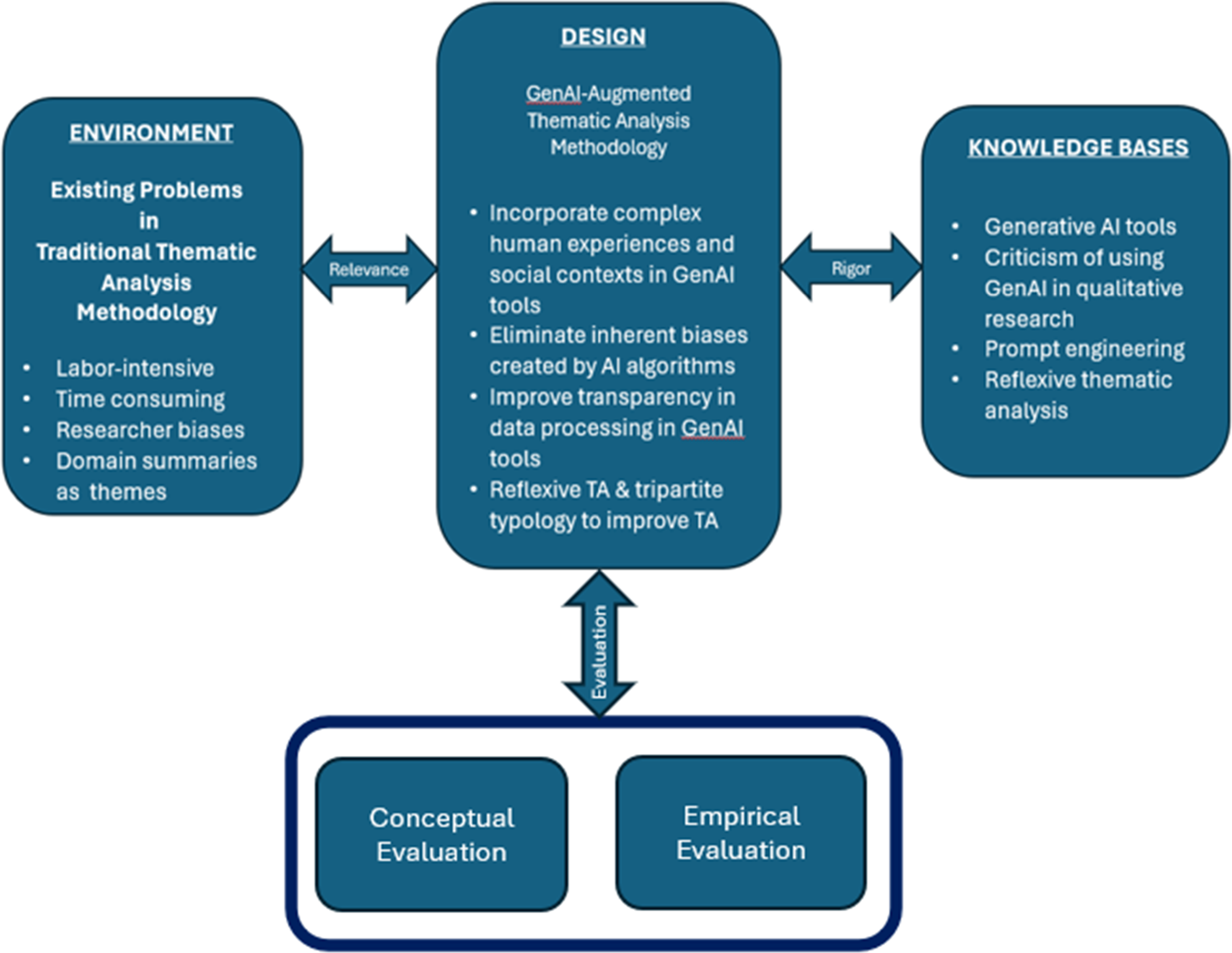
Relevance of the Problem
As highlighted in the introduction, timely decision-making requires rapid analysis of large qualitative datasets (Kaplan & Haenlein, 2020). Traditional thematic analysis, involving manual data immersion and iterative coding—is cognitively demanding, time-consuming, and inefficient for large-scale studies (Nowell et al., 2017; Terry et al., 2017). These constraints limit its applicability in fast-paced environments. Researchers are consequently exploring gen AI tools in pursuit of quicker, more scalable insights (Kaplan & Haenlein, 2020).
Rigor of the Proposed TA Methodology
Gen AI tools can automate coding and theme generation, significantly reducing the time and effort required for data analysis (Brown et al., 2020). These tools can process large volumes of data swiftly, maintaining consistency and objectivity in coding, which enhances the reliability of the analysis (Bhatia et al., 2021). Moreover, gen AI-driven TA can uncover deeper patterns and insights that might be overlooked in manual analysis, providing richer and more nuanced understandings of qualitative data (Smith & McGannon, 2018). However, it is important to address the limitations of gen AI too and focus on how they enhance RTA process.
Addressing the Limitations of Gen AI in Qualitative Research
In our literature review, we noted three potential limitations in using gen AI tools in qualitative research. We now outlined how these can be overcome. (1) Human experiences and contextual understanding
Few-shot prompting (above) incorporating contextual information within prompts (Ahmed et al., 2024), can enhance gen AI’s grasp of complex human experiences. Few-shot prompts can progressively introduce details to overcome zero-shot prompts’ lack of context. Human researcher oversight is crucial, with rigorous review and validation of all AI-generated codes/themes at each stage. (2) Biases in gen AI algorithms
Employing multiple gen AI tools for data analysis can mitigate bias, i.e., using one tool to generate initial codes or themes, and a second to validate them. This approach leverages the different LLMs employed by each gen AI tool, enabling comparative analysis and identification of inconsistencies. Human review can then rectify any potential biases introduced by the various gen AI algorithms. (3) Transparency in data processing
Incorporating clear instructions within prompts can enhance transparency. Prompts for code generation can instruct the gen AI tool to list all excerpts or quotes to create each code, allowing researchers to manually validate them. Additionally, prompts can specify an analytical framework (guiding rules) and request evidence from the source data to justify the framework’s use in generating results. This enhances transparency and enables researchers to maintain a clear audit trail which is an established tenet of qualitative rigor.
Gen AI Augmentation to Facilitate Reflexive Thematic Analysis
Gen AI can effectively augment the RTA process by facilitating the three RTA principles proposed by Braun and Clarke (2019) as follows. (1) Coding reliability
Few-shot prompts guided by domain concepts and research goals could be used to generate more reliable and replicable codes using gen AI. Further, coding reliability can be improved by tool triangulation (using two gen AI tools, as we do). (2) Codebook development
Few-shot prompts designed with guiding rules for data analysis can serve as a framework to generate codes/themes. Multiple iterations of the prompts can run until saturation is reached, and the generated codes/themes can then be compiled into a single document that acts as a codebook. (3) Reflexive approach
Human involvement is crucial for validating and amending themes/codes generated by gen AI at each step of the TA process. This ensures human oversight and control, acknowledging the researcher’s critical role in interpreting and analysing the data. In summary, prompt engineering, gen AI tool triangulation, and human review and validation are the criteria for addressing the limitations of using gen AI tools in qualitative research.
Design and Evaluation of the Methodology
Gen AI can effectively augment the RTA process when its limitations are properly managed through prompt engineering, tool triangulation and human validation. We propose GAATA—a gen AI-augmented TA methodology that supports, rather than replaces, human interpretation while maintaining reflexivity. To evaluate GAATA, we systematically compared its codes and themes with those from traditional RTA using a multi-criteria framework. Coding agreement was measured using a five-step mapping protocol and Cohen’s Kappa. Themes were compared based on conceptual overlap, specificity, and theoretical alignment. A broader conceptual comparison further assessed GAATA’s validity, reliability, and utility.
Gen AI Augmented Thematic Analysis (GAATA)
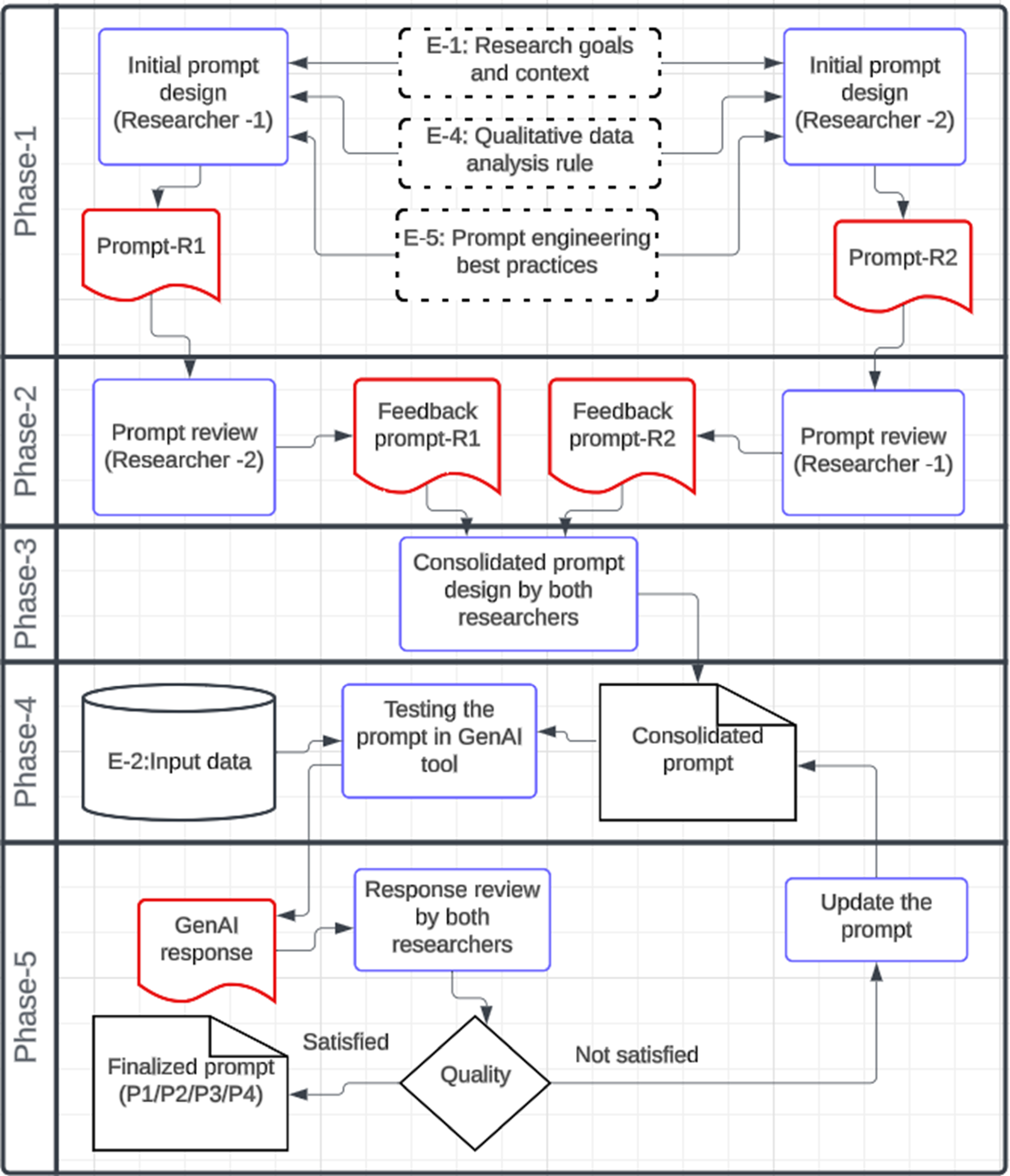
GAATA consists of eight distinct step that integrate two gen AI tools to systematically generate, validate, and refine eight analytical artefacts
2
, thereby conducting Reflexive Thematic Analysis (RTA) under human oversight. Figure 2 provides an overview of this methodological flow. GAATA (Gen AI-Augmented Thematic Analysis)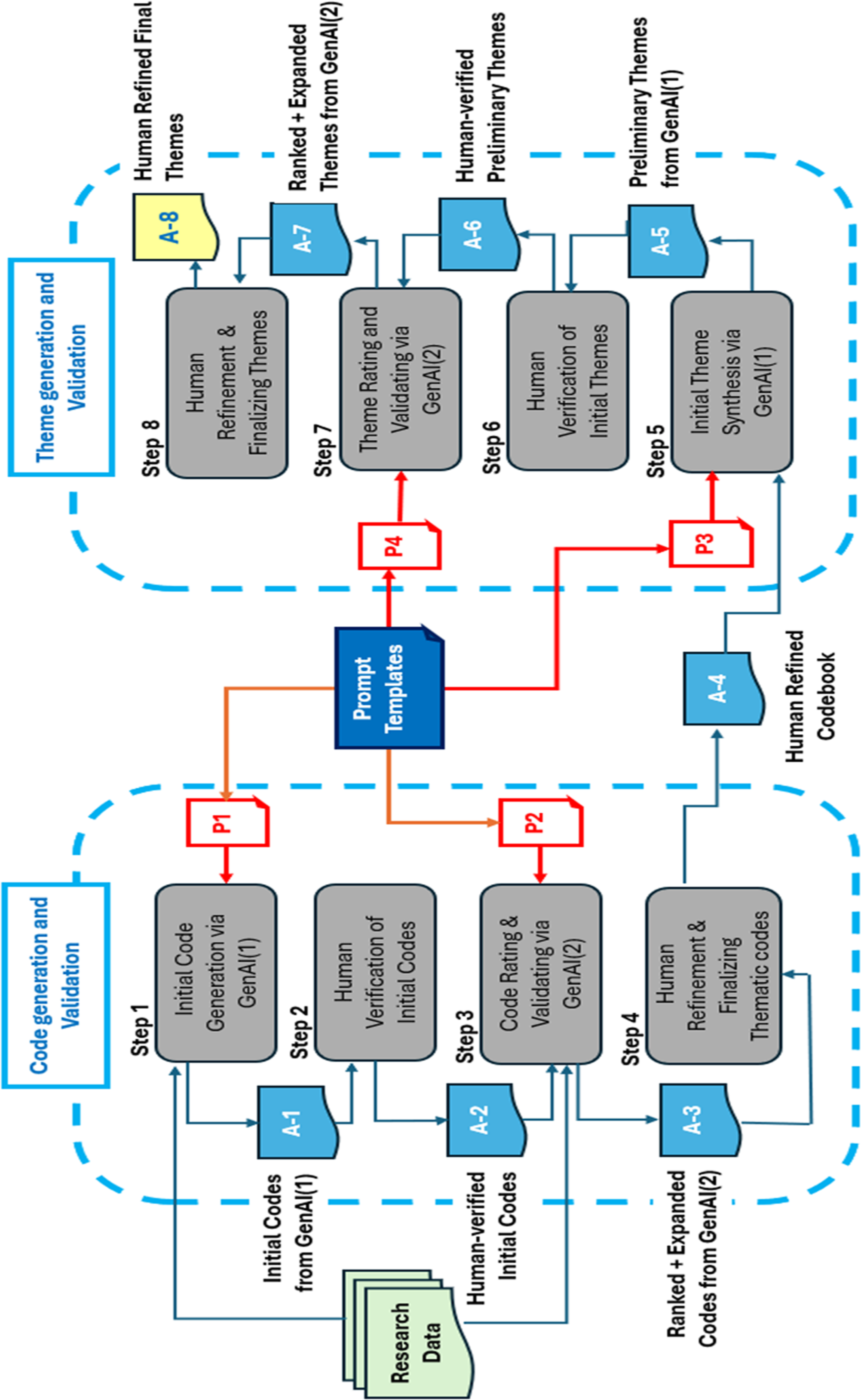
GAATA Prompt Templates
GAATA uses four prompts (P1–P4) to guide the gen AI tools in generating and validating codes and themes: P1: Generate codes using gen AI-1. P2: Rating and validating the codes using gen AI-2. P3: Generate themes using gen AI-1. P4: Rating and validating the themes in gen AI-2.
Researchers can tailor the GAATA process to their study by customising the prompt templates provided in Appendix A. These templates are intentionally designed to be easily adaptable, requiring users to replace the blue-highlighted placeholders with research-specific details. This design supports not only expert users but also those with limited experience in generative AI prompting. By following these structured templates, researchers can apply GAATA confidently and rigorously, without compromising the quality of their thematic analysis.
It is important to note that effective prompting with gen AI does not occur through a single one-off instruction. Instead, users must engage in an iterative conversation with the AI, requesting clarification or refinement as needed. As described by Ramlochan (2024), this approach which is referred to as conversational prompting, involves designing a prompt as a sequence of interrelated prompts, executed step by step. This method has become increasingly common, as it enables AI systems to produce more accurate and contextually aligned outputs through follow-up queries.
Accordingly, the prompt templates provided in Appendix A have been intentionally engineered as conversational prompts. The development of these templates, and the prompt engineering methodology, forms an integral part of this research and is detailed later under the section Experimental TA using GAATA.
Code Generation and Validation
GenAI-1 is used to generate initial codes from the source data using prompt P1. These codes are then reviewed and refined by human researchers. GenAI-2 then rates the validated codes based on their relevance to the research goal and their coverage of the dataset—helping to address potential biases or omissions by GenAI-1. For this task we use Prompt P2. Finally, human researchers conduct another round of review to produce a refined and comprehensive list of thematic codes.
Theme Generation and Validation
Using the finalized codes from above, GenAI-1 synthesizes themes using prompt P3. These are reviewed and amended by researchers, after which GenAI-2 rates the themes based on their relevance to the research goal using prompt P4. This process helps detect any algorithmic bias or gaps. A final human review is then conducted to consolidate and refine the themes, resulting in a trustworthy set of finalized themes.Having described GAATA in summary, next we explain each step in detail, using an experimental TA performed using GAATA. The research goal and dataset used for the experimental TA is presented in Figure 3. More detail about this experimental TA is provide later in the manuscript. Goals of the Experimental TA (4)
Step by Step Guide to GAATA with Illustrations
In TA, codes act as labels that assign meaning to data units, facilitating the identification of patterns and themes aligned with the research goal (Braun & Clarke, 2019). We use ChatGPT-4 3 as gen AI (1) and Humata 4 as gen AI (2), however, researchers can select any gen AI tool.
Step 1: Initial Code Generation by Gen AI (1)
As shown in Figure 2, using the provided research data files, initial codes are generated by gen AI (1) using the prompt P1. Every code should be relevant to the research goal and supported by data excerpts (phrases, sentences, or paragraphs) from the input data. Due to the capacity limitations, gen AI tools produce only a portion of codes at a time. Thus, we need to iteratively instruct gen AI to continue the process of generating more codes until saturation is reached. Hence, in our experimental TA, we designed P1 as a conversational prompt (see Supplemental Materials). P1.1: Instructs gen AI (1) to generate the first set of codes P1.2: Instructs gen AI (1) to generate more codes. This prompt is used iteratively to generate more codes until gen AI exhibited prolonged inactivity (10 to 15 minutes) indicating a saturation of developing new codes. P1.3: Instructs gen AI (1) to identify the tool saturation point formally to terminate step 1.
In our experimental TA, Step-1 generated 287 codes. An extract of A-1 is presented in Figure 4 due to space limitations and Full artefact is presented in Supplemental Materials materials-GAATA-Artefacts. Extracts From A-1
Step 2: Human Verification of Initial Codes
In step 2, researchers conduct a rigorous review of codes in A-1 and validate each code by confirming that it has valid excerpts from the source data. The codes lacking valid excerpts should be removed. This validation removes any inaccurate codes, (1) by misinterpreting the excerpts by gen AI due to lack of context and domain knowledge; (2) by inferring facts beyond the provided source data due to over-reliance on general knowledge from training data used by the gen AI tool; or (3) Irrelevant codes to the research goal generated due to gen AI limitations, errors or anomalies. In the example TA, we removed 21 codes based on the above criteria. An extract of A-2 is given in Figure 5 below and the full artefact with 266 coded is presented in Supplemental Materials-GAATA-Artefacts. Extracts From A-2
Step 3: Code Rating and Expansion via Gen AI (2)
Step 3 aims to mitigate potential biases and limitations in gen AI algorithms, ensuring that all relevant codes have been identified from source data. Here, we follow the sub-steps below (see Figure 6). Four Steps of Step 3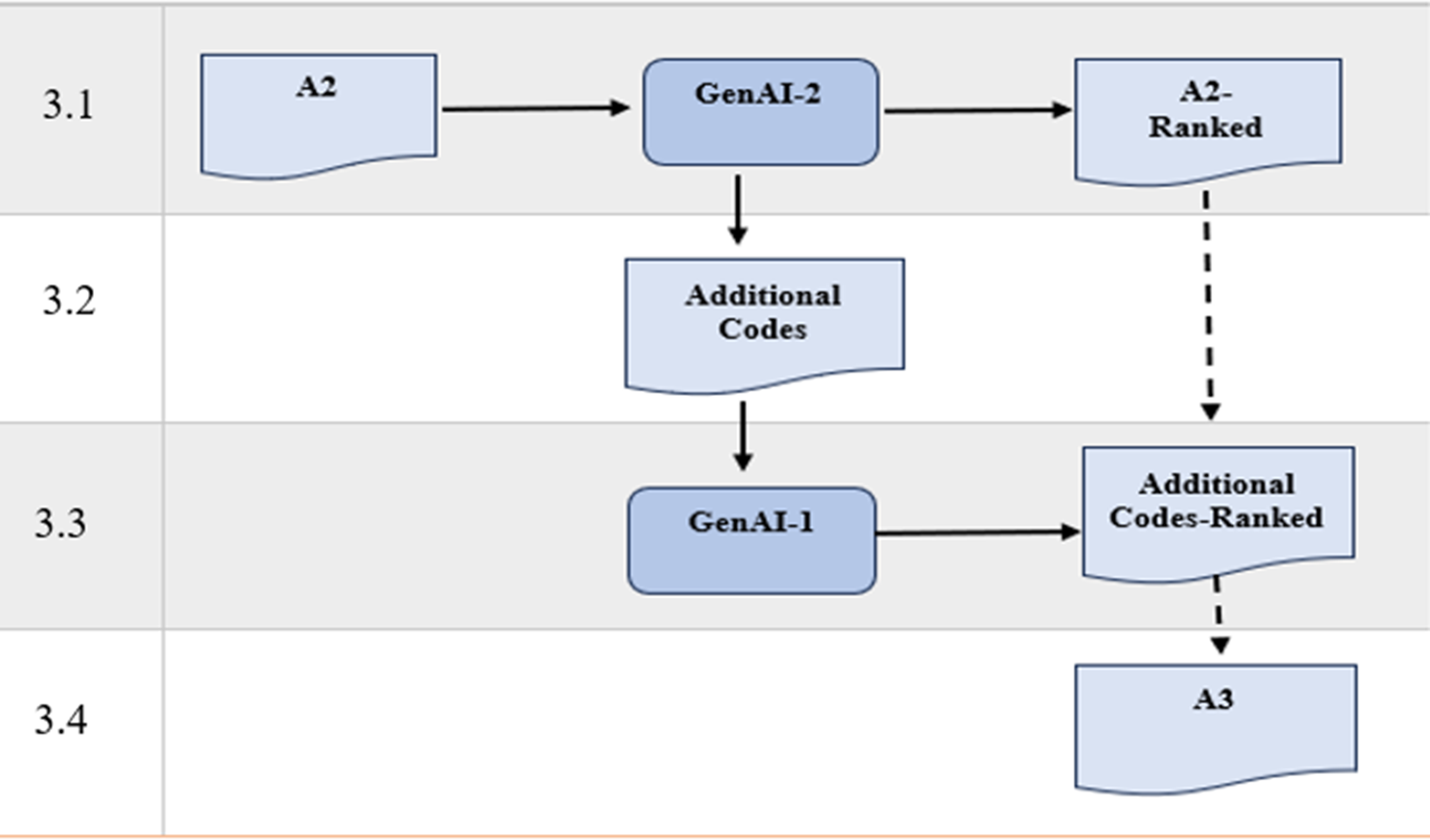
When a study involves multiple research goals (sub-step 1), each goal is treated as a separate rating dimension. In such cases, each code receives a distinct score for each objective.
In the experimental TA, we used Humata in sub-steps 1 and 2 and ChatGpt-4 in sub-step 3. The adapted prompts used in every step is provided in the Supplemental Materials. Humata produced 16 additional codes, and they were in turn rated by ChatGPT-4. An extract of A-3 in the example TA is provided in Figure 7, and the full artefact of 282 codes is presented in Supplemental Materials-GAATA-Artefacts. Extract From A-3
Step 4: Human Refinement and Thematic Code Finalisation
In step 4, the rated list of codes in A-3 undergo a rigorous review by the researchers, such that codes with zero rating are removed, and codes with ratings between 0-5 are examined by the researchers and a decision made to exclude or improve them. As Boyatzis (1998) argues, considering both semantics and pragmatics allows for the development of codes that are not only descriptive but also explanatory, facilitating the identification of complex patterns and themes that might be missed in a more superficial analysis.
All relevant codes that remain are refined into comprehensive thematic codes with suitable wording changes based on semantics and pragmatics. Step 4 enhances the analysis’s validity and reliability by fostering a more comprehensive interpretation of the codes (Nowell et al., 2017). An extract of A-4 produced in experimental TA is given in Figure 8 and the full artefact of 226 codes is presented in Supplemental Materials. Both gen AI tools produced 303 codes - out of which 56 (18%) were eliminated by human reviews. Changes were made to majority of the remaining codes to convert them to comprehensive thematic codes. Extract From A-4
Step 5: Initial Theme Synthesis via Gen AI (1)
This fifth step used gen AI (1) to generate themes from the validated codes using the prompt P3 as a single prompt to generate the themes. Constructing themes involves iteratively interpreting and synthesizing coded data into broader, meaningful patterns that addressed the research question (Braun & Clarke, 2006, 2019). Hence, we argue that the codes with high rating should be given priority in generating meaningful patterns in synthesising more relevant themes to the research goal. Themes should be internally coherent and clearly distinct from each other, ensuring that they capture unique aspects of the data (Patton, 2023). This principle helped to maintain the integrity of each theme, avoiding redundancy. Themes should be linked to the original codes used to create them, allowing researchers to trace them back to the original excerpts from the source data. Themes can be grounded on existing theories, particularly in the case of deductive TA (Sinclair-Maragh & Simpson, 2021) where the codes are synthesized using domain specific theoretical frameworks, pre-existing classifications available in the domain or classifications based on researchers’ expertise (Tuckett, 2005). In the experimental TA, our goal was to identify the pedagogical impacts of technology integration in marketing education. We grounded the findings in TPACK (Koehler et al., 2013), a well-established theoretical framework for technology-integrated pedagogy. TPACK emphasizes the intersection of content knowledge (CK), pedagogical knowledge (PK), and technological knowledge (TK) as essential for effective teaching. The P3 template in Appendix A was developed based on these four core principles and is included in the Supplemental Materials. In the experimental TA, 16 themes were developed, and an extract of A-5 is given in Figure 9. The full set of themes are provided in the Online Supplemental Materials-GAATA-Theme generation. Extract From A-5
Step 6: Human Verification of Initial Themes
Researchers review themes and check whether they adequately represent their underlying codes. If any inconsistencies exist, they can be refined at this stage. In our TA example, researchers reviewed the 16 themes and concluded that each theme represents their underlying codes - in line with the research goal. Thus, they did not have to amend the list. In the experimental TA the 16 themes were reviewed by the researchers and confirmed that they represent the underlying codes - hence no changes were required.
Step 7: Rating Themes in Gen AI (2)
This step aimed to mitigate potential biases in gen AI algorithms generating themes. The three sub-steps reflect what we performed in step 3 for codes. Sub-step 7.1 instructs gen AI (2) to rate the themes in A-6, indicating the relevance of the gen AI (1) generated themes compared with the research goal and the theoretical frameworks integrated in theme generation in step 6. Themes are rated from 0 to 10, based on relevance to the research goal: 0 being the least relevant and 10 the most relevant. This sub-step uses the prompting template P4 to instructs gen AI (2) to rate the themes. Sub-step 7.2 is to instruct gen AI (2) to generate additional unique themes not listed in A-6, ensuring the completeness of the gen AI (1) generated themes. Template P3 is adapted and used to instructs gen AI (2) to generate additional unique themes. The artefacts A-6 and A-4 (codes provided to gen AI (1) in step 5) are used as input data in this step. In sub-step 7.3, if additional unique themes were generated by gen AI (2) in 7.2, gen AI (1) rate them using the P4 with the same evaluation criteria as in 7.1. Finally, the researchers compile a consolidated list of rated themes by combining outputs of sub-steps 7.1 and 7.3 above. In 7.1, when the study involves multiple research goals, each goal is treated as a separate rating dimension. In such cases, each theme receives a distinct score for each research objective.
In the experimental TA, in sub-step 7.1, Humata rated all 11 themes pertaining to the given rating criteria. In sub-step 7.2, Humata generated five additional themes; and in sub-step 7.3, ChatGPT-4 rated the five new themes. Thus A-7 consisted of 16 themes. Ratings for each theme in A-7 had a value of 7 or above, indicating a higher relevance to the research question. A-7 sample is given in Figure 10. More details in Online Supplemental Materials-GAATA-Theme generation. Extract From A-7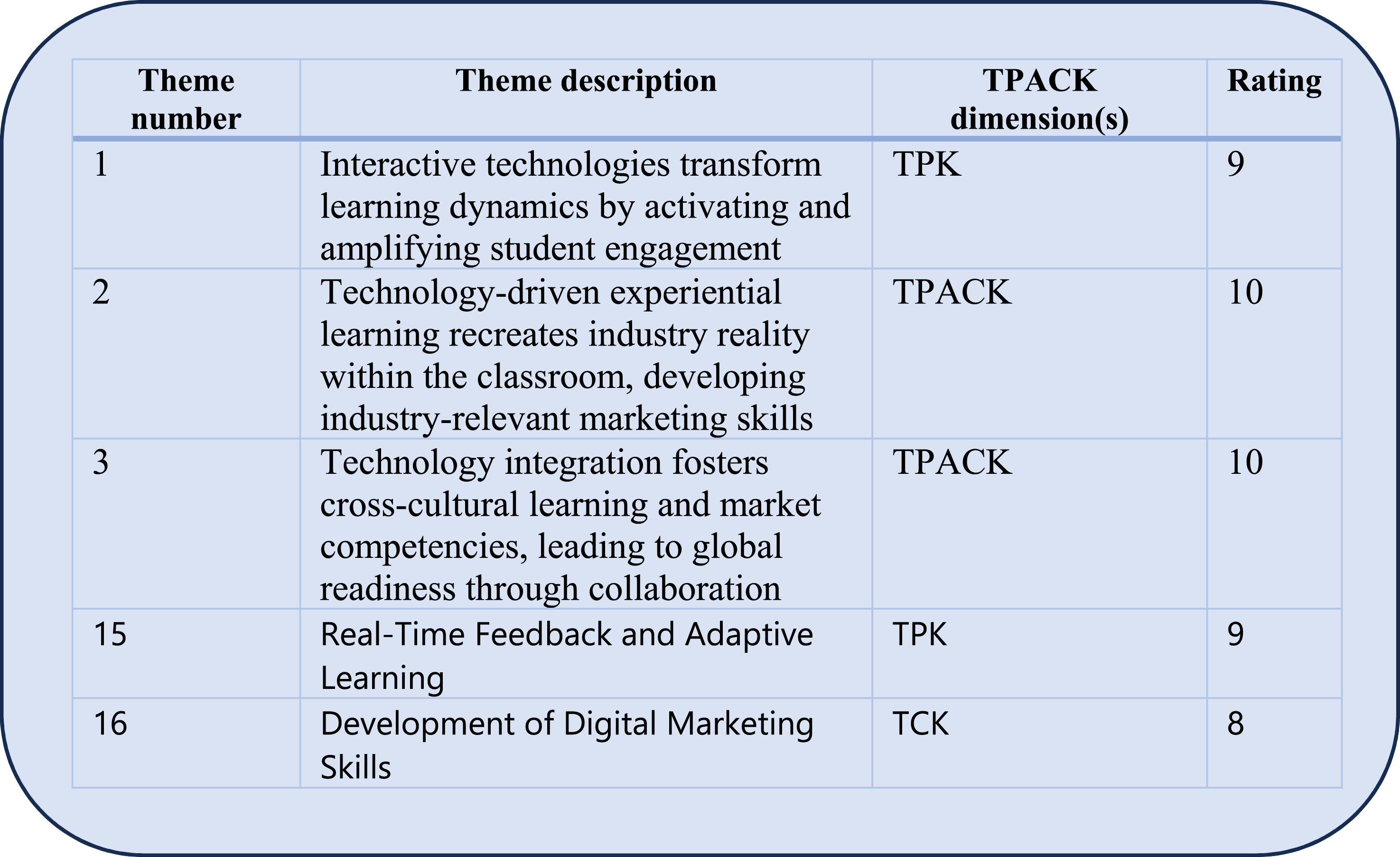
Step 8: Human Validation of Themes
After the researchers thoroughly reviewed A-7, along with its underlying codes, themes with low ratings (<5) are investigated along with their codes and removed or retained - depending on researchers’ judgement. Overlapping themes were identified and necessary consolidations made based on researchers’ expertise – coupled with gen AI driven insights where appropriate. Theme definitions and descriptions are improved and enriched by the researchers, using their expertise and gen AI-driven insights where necessary. Appendix A provides two simple prompts to support the above. In the experimental TA, the researchers discussed their findings and concluded that all additional five themes generated by Humata were in fact sub-themes of the original 11 themes generated by ChatGPT-4. More details of this consolidation are contained in the Online Supplemental Materials - GAATA-Theme generation.
Finally, the researchers collaboratively enriched the themes by introducing more appropriate wording and strengthening the themes with more specific domain concepts from the marketing discipline. For this exercise, the researchers used the gen AI-driven insights in collaboration with their expertise. The prompts used to enrich themes are listed in Appendix A. An extract of the enriched themes is provided in Figure 11. Extract From Finalized Themes
In this step, the researchers’ expertise shaped the final themes, ensuring they were duly informed by researche rs’ domain knowledge, their active role in the process, and their perspectives and insights, as emphasized by RTA (Braun & Clarke, 2019). Final themes are available under Online Supplemental Materials-GAATA-Final-themes.
Managing the Artefacts (A1-A8) in GAATA
To implement GAATA, researchers must manage a sequence of evolving artefacts (A1–A8) throughout the process. Gen AI outputs are typically copied or exported into Word or Excel files, which serve as working artefacts for validation and refinement. For instance, codes from step 1 are reviewed in Word (A1) and re-used in step 2. When multiple or iterative files are created, researchers consolidate them manually. For projects involving sensitive data, we recommend anonymizing content and using local or secure AI platforms to ensure confidentiality.
Experimental TA Using GAATA
This section presents an experimental TA conducted using GAATA. The experiment served two purposes: (1) it informed the development of the prompt templates included in Appendix A, and (2) it enabled a structured comparison between GAATA-generated codes and themes and those produced through traditional RTA, allowing us to assess GAATA’s methodological reliability.
Engineering Prompt Templates for GAATA through an Experimental TA
As outlined above, GAATA uses four tailored prompts to guide gen AI tools in data analysis. This section introduces the development process of those prompt templates—a central methodological contribution of this study.
In this experiment, we applied GAATA to a data set of marketing journal papers published between (2010-2024) with the aim of exploring the pedagogical impact of technology integration in marketing education (see Figure 3 above). The two authors engineered the required prompts for each step drawing on established prompt engineering best practices (see Appendix A). One author being an expert in prompt engineering and the other, an expert in marketing domain, but with a good understanding of gen AI prompts involved in this task. We identified five key elements essential for all few-shot prompts to align with GAATA’s analytical goals: (1) (2) (3) (4) • Relevant theories, domain knowledge, or contextual cues; • Requirements for transparency and traceability, e.g., instructing the AI to list and categorize source excerpts under each generated code, along with justifications. (5)
These five elements were then operationalized through a six-step structured prompt engineering process (Figure 12) as outlined below, ensuring prompts were systematically designed, iteratively tested, and refined for quality. (1) (2) (3) (4) (5) (6) Designing Prompt Templates for GAATA (5)
This process was executed separately for each of prompts P1–P4
Empirical Evaluation: Traditional RTA vs GAATA
To robustly assess the reliability of GAATA, we conducted a full manual thematic analysis on the same dataset used in the experimental TA conducted using GAATA. Two experienced qualitative researchers 5 , H and L (neither being co-authors), independent of the GAATA development process, manually analyzed the entire dataset using reflexive thematic analysis (RTA) principles (Braun & Clarke, 2019). They developed codes and themes through iterative reading, coding, and synthesis, with discrepancies resolved through discussion. The manual TA results (codes and themes) were considered as the benchmark and GAATA results were compared against the benchmark. Next, we present the comparison of the manual TA codes with GAATA codes (Tables 1 and 2).
Validation of Codes Using Inter-rater Reliability
GAATA produced 226 codes, and the manual TA produced 166 codes. Considering the manual TA codes as the benchmark, we analytically compare the two sets of thematic codes. To ensure consistency in comparison, we employed a rigorous five-step code mapping and reliability checking protocol designed based on Cohen’s Kappa (Cohen, 1960), calculated using a confusion matrix (Carletta, 1996). 1. Code normalization
All codes from both GAATA and manual TA were normalized to remove superficial linguistic variations. This included converting codes to lowercase, eliminating stop words, and standardizing synonyms (e.g., “student satisfaction” vs. “learner satisfaction”). 2. Align the codes based on excerpts
Excerpt Based Code Mapping Table

In this analysis, we observed that every manual TA code matched with one or more GAATA codes. Also, there were 16 GAATA codes that did not match with any manual TA codes, suggesting the potential for GAATA to identify novel patterns. 3. Assigning shared conceptual code categories (SCCC) for code pairs
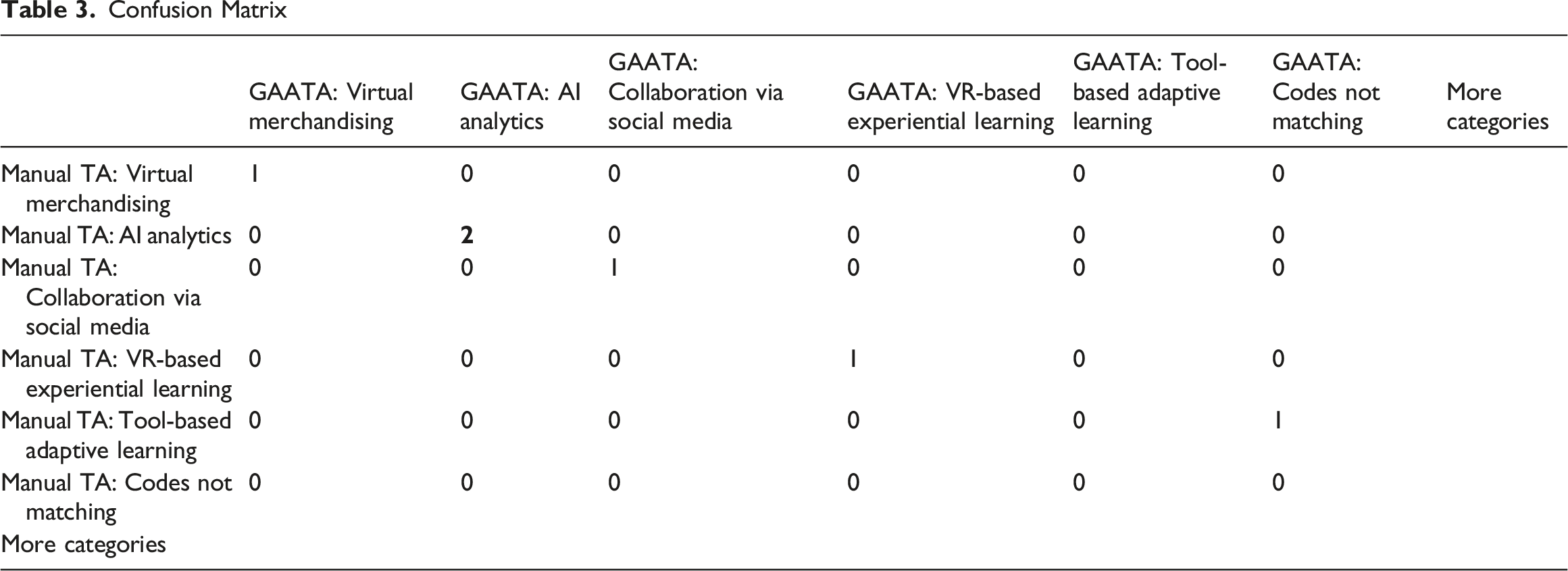
4. Aligning the shared conceptual categories and constructing a confusion matrix Assigning Conceptual Code Categories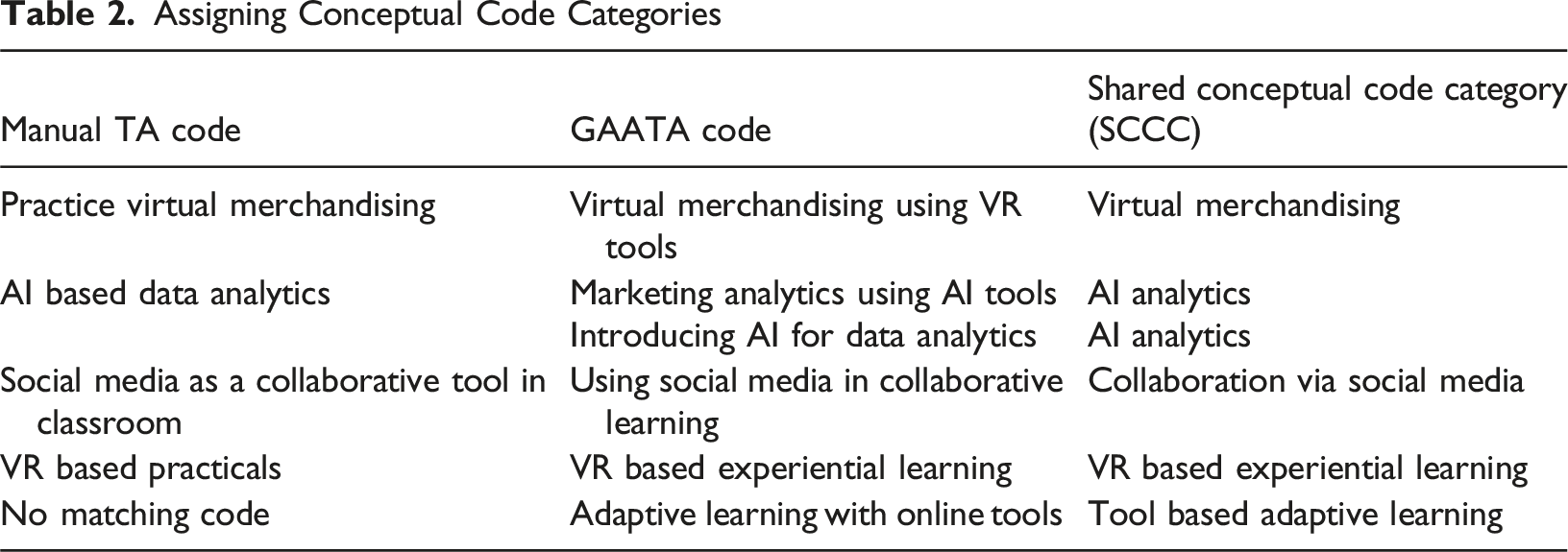
Confusion Matrix
5. Kappa Scoring. Summary of Theme Validation
Based on the final confusion matrix, the total number of observations was 240, with 226 exact matches along the diagonal (Supplemental Material-Confusion Matrix-Cohens-Kappa). This yielded a Cohen’s Kappa score of 0.9417. According to accepted benchmarks (Landis & Koch, 1977), this indicates an ‘almost perfect’ level of agreement, validating the alignment between GAATA and manual TA codes. The Kappa calculation was implemented using a custom Python script developed for this study. The script is available in Online Supplemental Materials-Python script. This validation process strengthens the empirical support for GAATA by demonstrating high consistency with human interpretation.
Validation of Themes
To enable a systematic comparison of themes generated through the two different analytical processes, four key dimensions were adopted from established literature in qualitative research. These criteria provided a structured lens through which the thematic outputs could be examined for clarity, depth, and theoretical alignment. The methodology consisted of four sequential steps, drawing on established practices in qualitative research and educational theory. The same two coders, H and L, involved in the manual TA conducted this analytical process.
Dimension 1: Conceptual Mapping via Shared Conceptual Code Categories (SCCC)
Here we assessed the degree of conceptual alignment between GAATA and manual themes using shared conceptual categories as an intermediary. A mediated mapping approach by two coders was used to identify conceptual overlaps. First, each theme (manual and GAATA) was associated with one or more shared conceptual categories derived from prior code-level mappings (e.g., Reflective Learning, Gamification, Data Analytics). A theme-to-theme alignment matrix was then constructed, classifying matches as: • Exact Match – strong overlap in codes due to 3 or more exact matches of SCCC • Partial – one or more SCCC overlapping but with differences in emphasis, scope, or focus (e.g., a manual theme focusing broadly on “Technology Use” and a GAATA theme specifically on “Mobile Learning Tools” might be a partial match if both share an SCCC related to “digital learning”) • None – no shared SCCC alignment
A theme comparison matrix indicating match type, shared categories, and alignment notes. This method supports analytical triangulation and deeper cross-method validation (Braun & Clarke, 2006; Jick, 1979; Nowell et al., 2017).
Dimension 2: Thematic Specificity and Focus
According to Braun and Clarke (2006) qualitative themes should be clearly bound, conceptually coherent, and analytically useful. Each theme was assessed based on its clarity of focus, internal consistency among supporting codes, and the absence of conceptual sprawl. Themes were then categorized as having high, moderate, or low specificity. The independent coders (H & L) conducted this assessment and reached consensus on the rating for each theme through discussion and comparison against pre-defined examples. • High – distinct and well-bounded (e.g., AI-Enhanced Critical Thinking) • Moderate – coherent but broad (e.g., Technology in Education) • Low – vague or overly general (e.g., Student Engagement)
The above draws on Braun and Clarke’s (2019) recommendations for thematic rigor in qualitative research.
Dimension 3: Theoretical and Pedagogical Alignment (TPACK Framework)
This step assessed the theoretical and pedagogical alignment of each theme using the TPACK framework (Koehler et al., 2013). Each theme (manual and GAATA) was analyzed to determine the extent to which it incorporated all three dimensions. The rating levels assigned and agreed upon by the independent researchers, • Strong alignment – all TPACK domains present • Moderate alignment – two domains evident • Weak alignment – one or none explicitly addressed
This theoretical lens ensures that emerging themes reflect meaningful educational integration, not merely technological adoption (Koehler et al., 2013).
Dimension 4: Comparison of Time Utilization
To empirically assess GAATA’s efficiency, a critical dimension for its practical application, the time dedicated to each phase of both the GAATA-driven experimental thematic analysis and the equivalent manual thematic analysis conducted by H and L was meticulously recorded and analyzed.
Theme Validation Results
Comparison of Time Utilization - Manual TA vs GAATA

Conceptual mapping
Out of eleven GAATA-generated themes, ten showed direct conceptual alignment with their corresponding manual themes, indicating strong thematic convergence. One theme (G-Thm-8), however, revealed a conceptual divergence, suggesting the emergence of a novel construct not identified through human-led analysis. (G-Thm-8: Challenges in Technology-Integrated Marketing Education: Navigating Negative Perceptions and Pedagogical Strain)
This discrepancy may stem from the differing epistemological orientations of manual and AI-assisted approaches. Human coders, even in RTA, often unconsciously adhere to positivist tendencies—favouring observable patterns—due to cognitive biases and a preference for empirical certainty (Guba & Lincoln, 1994; Tversky & Kahneman, 1974). These biases can limit the identification of more abstract or latent themes.
In contrast, GAATA operates without such cognitive constraints, enabling it to detect nuanced semantic patterns across large datasets. Its algorithmic processing can surface insights that might elude human analysts due to data volume or the subtleties of pattern recognition (Hwang & Wu, 2025). The unique theme produced by GAATA demonstrates its potential to complement and extend human interpretation by uncovering deeper layers of meaning and broadening the analytical horizon (Jucker et al., 2013).
Thematic Specificity
All eleven GAATA themes were rated high in specificity, indicating tightly bound, well-articulated constructs. Seven (of ten) manual themes received a high rating, with others assessed as moderate. This suggests that GAATA produces themes with greater conceptual sharpness and less thematic diffusion. The use of large language models in GAATA likely contributes to its ability to synthesize patterns across vast textual input, leading to more delineated thematic structures (Blei, 2012; Devlin et al., 2019).
Theoretical and Pedagogical Alignment
All GAATA and manual themes were rated as strong, showing a high level of theoretical conformity, affirming its relevance for pedagogical inquiry. In this section we presented conceptual and empirical evaluations of GAATA against traditional TA. The findings collectively suggest that GAATA is a viable alternative for manual TA and a potentially superior method in thematic contexts within qualitative research.
GAATA vs Manual TA: Time Utilization
Here we present a comparison of the time taken to conduct each phases (Braun & Clarke, 2006, 2019) in manual TA and equivalent GAATA phases.
Aa above, GAATA takes less than a third of the time of manual TA. It should be noted that this timing is for analysis of 213 abstracts of journal articles. Manual TA could comparatively take more time than GAATA when analysing large datasets due to the human fatigue, leaving GAATA a preferred alternative in domains like marketing which has severe time constraints (online customer feedback analysis etc).
Conceptual Evaluation: Traditional RTA, AI-Only TA, and GAATA
In addition to the empirical validation conducted against traditional RTA, we also performed a conceptual comparison between GAATA, traditional reflexive thematic analysis (RTA), and AI-only TA where the latter representing fully automated approaches that depend exclusively on AI-generated outputs with no human intervention.
Comparative Features of Traditional TA, AI-Only TA, and GAATA
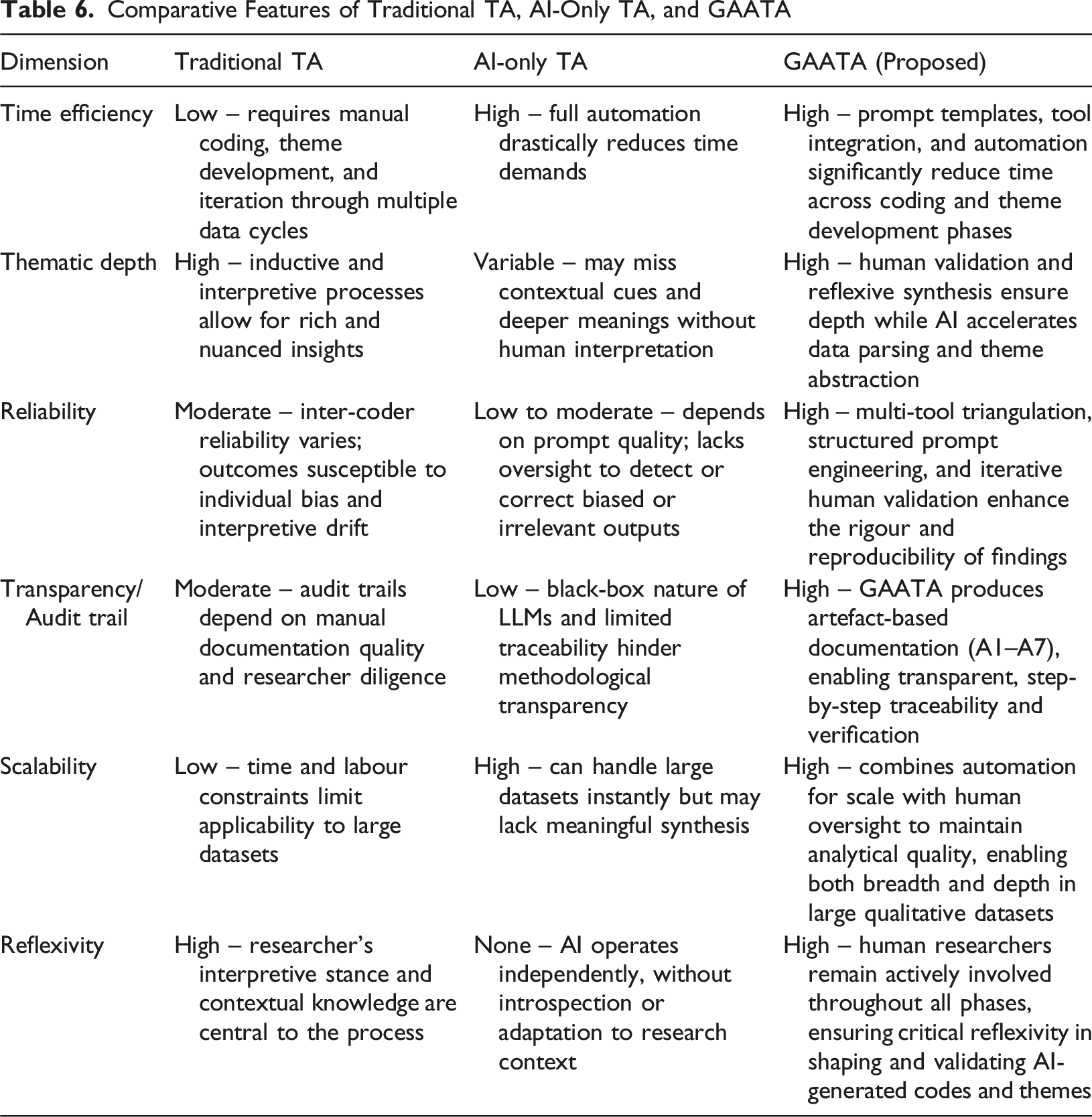
This comparative framework illustrates GAATA’s distinct position as a hybrid methodology, strategically integrating the strengths of both human-led and AI-driven approaches. Unlike AI-only TA, GAATA maintains methodological transparency, contextual sensitivity, and human reflexivity, while offering significant efficiency and scalability gains beyond what is achievable through traditional RTA.
By leveraging prompt engineering, dual-tool triangulation, and structured human validation, GAATA delivers a scalable, efficient, and rigorously controlled TA process, making it particularly well suited for data-intensive and time-sensitive contexts such as marketing research.
Additional Empirical Validation: Applying GAATA to Consumer Data
To validate GAATA’s methodological robustness beyond controlled academic contexts, the framework was applied to an empirical corpus of airline customer feedback, comprising passenger reviews sourced from commercial airline platforms (each containing detailed narratives of travel experiences, complaints, and post-flight reflections). These authentic, emotionally charged, and linguistically diverse narratives provided an ideal foundation for testing GAATA’s capacity to extract meaning from naturally occurring consumer data.
Research Goal: To Identify Key Drivers of Customer Dissatisfaction and Service Experience Gaps in the Commercial Airline Industry
Themes Generated From Airline Customer Feedback

Collectively, these thirteen themes form a multidimensional map of customer dissatisfaction, spanning from macro-level systemic issues (e.g., operational inefficiency, policy rigidity) to micro-level service experiences (e.g., slow boarding, staff indifference). GAATA demonstrated strong alignment with human-coded validation, confirming its capability to uncover semantically coherent, theoretically grounded patterns of meaning.
Discussion
The GAATA methodology significantly advances traditional TA by leveraging gen AI to augment reflexive TA, ensuring the active involvement of human researchers in every step. GAATA significantly reduces the time required for initial code and theme generation– freeing researchers’ cognition for higher-level analysis and enabling them to analyze larger datasets more efficiently. GAATA addresses the limitations of using gen AI for qualitative data through three enablers: prompt engineering, tool triangulation, and human validation.
GAATA is a comprehensive process for designing high-quality and structured prompts which defines five mandatory elements to account for the unique attributes of each research question, thereby specifying data analysis instructions to gen AI tools. GAATA actively integrates researchers’ expertise into the prompt design and validation phases, ensuring that AI-generated outputs are grounded in domain-specific knowledge. Prompt templates developed in this study (Appendix A) based on experimental TA, serve as adaptable templates for any TA, ensuring effective instructions for gen AI tools for conducting a TA. Hence, researchers with limited experience in prompt engineering can use these templates by customizing them to their own research goals.
Second, GAATA employs a triangulation strategy to eliminate the bias in codes/themes generated by one gen AI tool through a rating process using a second gen AI tool. Triangulation is also used to mitigate the limitations of gen AI tools and to eliminate subjective human interpretations of data.
Third, human validation remains a cornerstone of GAATA, ensuring the human element prevails by keeping researchers in the loop iteratively. This fosters a reflexive TA approach in which researchers critically examine their interpretations (Braun & Clarke, 2006). Continuous human validation enhances the credibility of generated codes and themes by identifying potential inconsistencies.
The intermediate artefacts (A1 to A7) maintain detailed documentation of each step, like a codebook in RTA, reflecting the transparency and validity of data analysis. The underlying LLMs in gen AI tools have an extensive repository of knowledge that surpasses human cognitive capabilities. GAATA leverages this vast knowledge base to enhance the quality of results, particularly in the development of finalized themes, achieving a level of insight unattainable by human efforts alone.
While gen AI has many strengths with regards to qualitative data analysis, it is important to acknowledge that LLMs in AI tools are limited in their ability to access latent meanings. These include symbolic references, emotional undertones, or context-specific subtexts that are often evident only through deep cultural familiarity or prolonged researcher immersion (Franken & Vepřek, 2025). Further the extensive knowledge in LLMs can infer things beyond the given data and include them in the analysis.
Moreover, there is a risk of over-reliance on AI-generated insights, particularly when researchers adopt outputs without sufficient critical review. AI may reproduce dominant discourses encoded in training data and may underrepresent marginalised perspectives or subtle divergences in meaning (Passi & Vorvoreanu, 2022).
GAATA mitigates these concerns by integrating structured human validation at each phase, ensuring that gen AI serves as an assistant not a substitute for interpretation. In the templates provided with GAATA, we have provided instructions to mitigate these problems, giving users the flexibility to include further instructions to handle the above problems depending on the nature of the domain. Researchers are encouraged to remain reflexive, apply theoretical frameworks critically in the templates, and triangulate AI outputs with domain expertise and contextual judgment.
Finally, our comprehensive evaluation demonstrates that GAATA can generate high-quality themes comparable to those produced through expert-led manual TA. Drawing on both theoretical analysis and empirical validation, including high code alignment (Cohen’s Kappa = 0.94), strong thematic convergence, and significant gains in efficiency—our findings suggest that GAATA is not only a feasible alternative but, in many respects, a superior method for researchers working with large qualitative datasets in time-sensitive and resource-constrained environments like marketing.
Theoretical and Practical Implications
The experimental TA presented here adopts a deductive approach, using the pre-existing TPACK framework to guide the analysis, thus ensuring that the generated themes are contextually relevant and theoretically sound (Koehler et al., 2013). Traditionally, such moderation requires significant cognitive effort. GAATA leverages gen AI to automate this moderation within a deductive TA framework, significantly reducing researchers’ workload.
Conversely, GAATA could also facilitate inductive TA, a data-driven approach in which themes emerge organically from the data. By omitting theoretical frameworks from the data analysis instructions in prompts, researchers could allow gen AI to explore the data freely, aligning it with the inductive approach (Guest et al., 2011). This would foster a more exploratory and potentially nuanced analysis.
The advent of gen AI has created new avenues for enhancing the efficiency and accuracy of qualitative market research. Gen AI tools, equipped with capabilities to analyze and generate human-like text, offer the potential to automate and augment the data analysis process, thus addressing the traditional challenges of scale and subjectivity (Kaplan & Haenlein, 2020). Despite these technological advances, the integration of gen AI into qualitative market research is still nascent. Significant gaps exist in respect of methodological frameworks capable of leveraging gen AI effectively without compromising the depth of consumer or marketer insights (Gupta et al., 2024; Kshetri et al., 2023). The airline customer feedback analysis conducted in this study reveals that GAATA has the capacity to analyze emotionally charged, and linguistically diverse customer feedback to generate practically useful themes. Integrating gen AI into market research can help mitigate the subjectivity inherent in traditional methods while enabling scalable, time-efficient analysis of large qualitative datasets.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Supplemental Material
Supplemental Material - Generative AI-Augmented Thematic Analysis
Supplemental Material for Generative AI-Augmented Thematic Analysis by Vimukthi Jayawardene, Michael T. Ewing in International Journal of Market Research.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.