
Abstract
Visual representations in news media contribute to the social construction of health concerns such as obesity. Media representations of obesity, however, have been shown to be stigmatizing, focusing on disembodied abdomens or depicting people in ill-fitting clothing, for example. In addition, analyses of image representations have typically focused on small datasets and relied upon inductive thematic coding. This article presents the application of Google Cloud Vision – an automated image annotation tool – to a collection of images collected from articles on obesity in the UK press. In addition, the World Obesity Federation (WOF) has produced an image bank designed to support journalists in offering respectable depictions of people with obesity, alongside its general guidelines for media representations. The authors compare the images from the news with the WOF Image Bank, on the basis of the tags generated by Google Cloud Vision. They use corpus methods to highlight frequently occurring tags that demonstrate similarities and differences between what is represented in the news and what is provided by the WOF. They observe only minimal consistencies between the datasets in that, while both image collections often depict people with obesity in relation to food, the WOF Image Bank provides a greater variety of activities that include food purchase and preparation. In the news, the analysis finds a greater occurrence of ‘body positive’ representations but also a continuation of the focus on abdomens and pinched skin. In the WOF Image Bank, the authors observe more ‘body neutral’ representations, with people engaged in a greater range of recreational activities and socializing with others. The article reflects on the utility of Vision as an automatic tool for capturing salient elements of visual representations in images.
Introduction
The World Health Organization (WHO) reports that over 650 million people worldwide are classified as obese and that rates are on the rise (WHO, 2021). Classification of obesity relies heavily upon measures of Body Mass Index (BMI); however, there are discrepancies between professional health bodies as to how they diagnose obesity and individual differences exist in the percentage of body fat for a given BMI, depending on sex, ethnicity and age (Lin and Li, 2021). Furthermore, obesity is a complex condition with a variety of genetic, epigenetic and social environmental factors. In light of this, Gaspar et al. (2022: 2) argue that obesity is a ‘great example of a socially constructed disease’, where the development of measures such as BMI and weight classifications are defined in contrast to a socially idealized body size. They subsequently characterize the views articulated about the body in most contemporary Western cultures as fatphobic, i.e. as discriminating against and stigmatizing people with obesity (Gaspar et al., 2022: 1). In order to examine the social construction of meanings related to a given phenomenon – in this case, obesity-we can systematically analyse the representations that are available across semiotic modes (Hall, 1997) in publicly available texts such as the news media. As Lyons (2000) asserts, media representations shape and are shaped by social constructions and these, in turn, contribute to public and professional understandings of important health issues, such as obesity.
In this study, we are particularly interested in the representation of obesity in images provided alongside news articles on the topic. Studies that critically examine the visual representations of obesity in media texts have tended to focus on small datasets or have otherwise developed and applied a restricted set of inductive codes (e.g. Heuer et al., 2011; Puhl et al., 2013). The labour intensiveness of such thematic coding makes it difficult to analyse media representations on a larger scale and their specificity to the data means that it is difficult to make comparisons across cases. Therefore, in this article, we demonstrate the application of an automated image annotation tool, Google Cloud Vision, to a combined image corpus of 783 images to demonstrate how automatic annotation can enable the analysis of a larger collection of images across studies. Furthermore, visual representations of people with obesity in the media have been shown to contribute to stigmatization (see section 2) and the World Obesity Federation has generated an image bank for use by journalists to assist them in providing more respectful representations. We analyse images provided by the World Obesity Federation as exemplars of appropriate representations of people with obesity and compare these with images that appear in the UK press. Through this application, we consider the potential of the automated image annotation tool for conducting large-scale analyses of media representations using procedures from corpus linguistics and we reflect on the representations of obesity that are currently provided in the news media.
Media Representations of Obesity
Researchers have increasingly looked to media texts to explore the ways in which our perceptions and experience of health are shaped by what we learn from mass media in its varied forms (Lupton, 1999). In relation to obesity, Brookes and Baker (2021) have shown through a systematic analysis of UK news articles published between 2008–2017 that the press contributes to the stigmatization of people with obesity through shaming discourses, evidenced in the language used to refer to individuals and groups, as well as purported qualities and behaviours.
Visual representations of obesity have also been shown to be stigmatizing; Heuer et al. (2011), for example, report that in their analysis of 500 online news website photographs from five major news websites, 72 percent of images met at least one of the criteria they determined to be stigmatizing. Features they coded as stigmatizing included emphasizing the abdomen, images of people not wearing clothes or wearing ill-fitting clothes, not showing heads/faces, or showing people eating unhealthily and being sedentary. Furthermore, people with obesity were less likely to be shown fully clothed, in professional clothing or exercising, compared with pictures of people who do not have obesity (Heuer et al., 2011). Similarly, Puhl et al. (2013) found that, in online news videos about people with obesity or who are overweight, 65 percent of adults and 77 percent of young people were portrayed in a negative, stigmatizing manner. The effects of using negative portrayals on readers’ perceptions have been documented in experimental studies. McClure et al. (2011), for example, show that providing an image that negatively represents people with obesity alongside a ‘neutral’ news article results in higher levels of reported weight bias. Thibodeau et al. (2015) have shown similar effects with verbal representations, demonstrating that being presented with causal narratives that blame the individual with obesity (considering it a sin or an addiction, for instance), encourages readers to support punitive policy interventions towards those with obesity.
Recognizing the influence that media representations can have on perceptions of (people with) obesity, the World Obesity Federation (WOF) has produced guidelines designed specifically ‘to support journalists so they are able to cover obesity-related topics accurately, thus enabling them to avoid stigmatising and stereotypical portrayals of individuals with obesity’ (https://www.worldobesity.org/resources/image-bank/image-bank-guidelines). These guidelines relate to both image and verbal content, advising for example that journalists use ‘people first’ language, i.e. referring to ‘people with obesity’ rather than ‘obese people’. With respect to images, key recommendations include:
– Using pictures that include a person’s whole body, rather than specific body parts with the head removed;
– Avoiding images that perpetuate stereotypes, such as people with obesity being sedentary, looking sad or isolated;
– Avoiding images with unnecessary exposure of skin, e.g. images showing a bare midriff or inappropriate fitting clothing to emphasize excess weight around the abdomen.
Along with these guidelines, the WOF provides an image bank of photographs that are free to use (for media reporting and research purposes, but not for commercial purposes) and which put into practice their recommendations. A random selection of WOF images is shown in Figure 1. We have collected the full set of photographs, along with a corpus of images from news articles on the topic of obesity in the UK press to investigate how current journalistic practices compare with these recommendations.

A selection of images from the World Obesity Federation Image Bank. © World Obesity. Reproduced under Terms of Use.
The principles that characterize the WOF’s image guidelines also accord with similar recommendations emerging from systematic investigations of image representations provided by leading global health organizations. Specifically, Charani et al.’s (2022: 1) framework emphasizes the inclusion of appropriate health-related images that are ‘relevant to the topic, respect the integrity of all individuals depicted, are accompanied by evidence of consent, and are equitable in representation’. In this way, the framework is intended to avoid ‘inherent biases that lead to insensitive content and misrepresentation, stigmatisation, and racial stereotyping’. This wider concern for image-based representations of health and illness demonstrates the value of empirical analyses of media representations that can help us to review current standards and develop guidelines that support more dignified, equitable and accurate representations. Corpus linguistics has supported large-scale analyses of how news texts represent people in relation to health issues such as obesity (Brookes and Baker, 2021) and mental illness generally (Price, 2022); however, such studies have tended to discount visual (i.e. image, video) content as a result of the practical challenges associated with documenting these elements in a format that is conducive to corpus query and analysis. In the next section, we review some of the efforts towards image annotation that would support the large-scale computation and study of images.
Automatic image annotation
In their summary of Barthes’ (1967) writing on Elements of Semiology, Kress and Van Leeuwen (2006: 18) recount his proposition that images are ‘too polysemous’ and that visual meaning is a ‘floating chain of signifieds’ that theorists and analysts have tried to document and understand via translation into a verbal code (among other modes). Corpus linguists face a similar problem in that one of the fundamentals of corpus construction is that the content is (made) ‘machine-readable’ (McEnery and Hardie, 2012: 2). This typically involves converting elements of an image – and other visual materials – into some form of annotation or coding. Kress and Van Leeuwen (2006: 1) present their visual ‘grammar’ as a framework for describing ‘the way in which depicted elements – people, places and things – combine in visual “statements” of greater or lesser complexity and extension’. However, they warn that their detailed considerations of narrative and conceptual representations, modality, materiality and composition are ‘only the beginning’; they do not consider their work to be comprehensive – rather, it is flexible to helping analysts account for the various ‘representational and communicational needs that humans have in their social lives’ (p. 266). Subsequently, researchers have selectively drawn on the principles outlined in this grammar as they relate to their aims and the data involved in the study. Thus, analyses of images are necessarily partial and typically separate from an analysis of verbal content (see, for example, Caple, 2019; Manca, 2016). Alternatively, manual qualitative approaches to documenting and quantifying image elements tend to be inductive (e.g. Collins, 2020; Stones et al., 2022) and, subsequently, applicable only to the data under investigation.
These analytical practices reflect the challenges of documenting the myriad elements of an image, which is a labour-intensive process and for which there is no standard coding framework. Attempts to distribute the work involved in coding images has led to crowdsourced projects (e.g. Gatt et al., 2018; Rashtchian et al., 2010); however, there are issues with quality control relating not only to what is annotated but also to user judgements on the quality of those annotations. Automatic image annotation has the potential to offer consistency, both in relation to the application of codes across a single dataset and across studies, providing it achieves the appropriate balance of detail and generality. Christiansen et al. (2020) also argue that an effective approach to quantitative image analysis should offer simplicity, i.e. minimal re-adjustment of existing (manual) practices in order to encourage widespread adoption. Their study of Twitter data demonstrates how Google Cloud Vision, a cloud-based interface, automatically detects and reports features of an image, including objects, faces and text (p. 150). We build on that work by using the Vision tool to analyse the images provided by the WOF and images we have collected from news coverage of obesity to further test its applicability to (corpus-assisted) investigations of representations of health and illness. Through our combined corpus of 783 images, we demonstrate how the automated image tags can be analysed using corpus methods and the Vision tool has the capacity to process much larger datasets in this way.
Data Collection and Methodology
Image files
The WOF Image Bank comprises 425 images created to reflect ‘the global face of obesity’ and is organized according to the themes of Family, Social and Home, Food, Physical Activity and Working Day (https://www.worldobesity.org/resources/image-bank). Users can also search the archive according to Region (Americas, Asia Pacific, etc.), Age Group (Children, Adults, Older adults), Gender (Male, Female), Orientation (Horizontal, Vertical, Square) and Setting (Internal, External). The images are freely available to download and include in news/research materials, according to the WOF’s Terms of Use (see Figure 1).
Our aim in this study was to carry out an analysis of the images provided by the WOF in comparison with a similarly-sized collection of images presented as part of the news coverage of obesity. While the Vision tool has the capacity to process much larger datasets, we also wanted to critically examine the tags themselves, restricting the size of our corpus to a number that we could, in principle, also review manually. As such, we carried out a search of the online news repository LexisNexis using the terms ‘obese’ or ‘obesity’ in UK National Newspapers for articles published over the course of September 2022. This resulted in a collection of 149 news articles (following deduplication and relevance-checking). We then had to manually retrieve the images from these articles from the relevant news publication’s website. We did encounter some accessibility issues in that certain articles were behind a paywall. In such cases, it was usually possible to retrieve the image that appeared at the top of the article (15 instances, 10.07%). We were able to collect the full range of images from 121 (81.21%) articles; however, in 12 instances (8.05%), we were unable to retrieve the original article and therefore unable to determine how many images it included. Our resulting image corpus comprised 358 images and Table 1 demonstrates how these were distributed according to publication. 1 These images were annotated automatically using Vision and analysed in comparison with the annotated WOF Image Bank.
Number of images from articles about obesity.

Google Cloud Vision
Vision constitutes one of a range of services that utilizes Google’s proprietary machine learning algorithms to, in this instance, provide automatic image annotation. A free demo allows images to be tagged one at a time and registering an account enables users to tag batches of images (currently, the first 1,000 images can be tagged for free; after that, it costs US$1.50 to tag each subsequent batch of 1,000 images), according to the default annotation categories. 2
Vision is customizable in that its machine learning capabilities can be applied to image collections and ‘trained’ according to bespoke annotation labels. However, in order to assess its potential as a ready-made annotation tool, we applied the default annotation categories, which can be summarized as follows:
– Face detection: locating faces with bounding polygons according to facial landmarks, such as eyes, ears, nose, mouth, etc. This also returns likelihood ratings for the emotion categories joy, sorrow, anger, surprise and for general image properties, i.e. underexposed, blurred, headwear present.
– Image properties: returning the dominant colours of an image, displayed as a block palette and with the hexadecimal code and percentage for each colour.
– Label detection: providing a generalized, textual description for the image as a whole and a confidence score for each element (only labels with over a 50% confidence score are provided).
– Landmark detection: providing the name of a landmark, a confidence score and coordinates for the detected entity.
– Logo detection: providing a textual description, confidence score and bounding polygon for recognized logos in the image.
– Object localization: providing a textual description, confidence score and bounding box annotation for multiple objects recognized in a single image.
– SafeSearch annotation: providing likelihood ratings for the explicit content categories adult, spoof, medical, violence and racy.
– Text detection: providing optical character recognition (OCR).
Figure 2 represents one of the photos from the WOF Image Bank and Table 2 demonstrates how it is tagged by Vision. Reproduced under Terms of Use.

Coffee break at work. © World Obesity. Reproduced under Terms of Use.
Annotation tags provided by Vision.

In the Face detection and SafeSearch annotation categories, dimensions are scored according to probability (Very Unlikely, Unlikely, Possible, Likely, Very Likely). For the purposes of our analysis, we only included those elements that appeared as Possible, Likely, or Very Likely and only recorded their presence, i.e. we did not include information distinguishing Possible from Very Likely. Additional Face detection information (roll, tilt, pan) provides an indication of the position and angle of the face; however, this information was extraneous to our study and so was not retained in the corpus compilation. With respect to Image properties, we only recorded the dominant colour, in the form of its hexadecimal code (e.g. #F8B431). We did not retain confidence scores for any of the categories, only the descriptive tags.
Google provides documentation offering guidance on how to customize settings and allowing users to see the code that has been applied through its tools; however, it is difficult to establish the full range of category identifiers available. In relation to Label detection, for instance, we are told that the tool can identify ‘general objects, locations, activities, animal species, products and more’ (https://cloud.google.com/vision/docs/labels) but, since these descriptors correspond with Google’s Knowledge Graph, the potential number of label options is indeterminate. Some additional description is provided for the SafeSearch categories Adult, Spoof and Racy, but not for Medical or Violence (discussed in Section 5.4). The ambiguity of the coding schema remains one of the challenges with working with proprietary tools that are also subject to constant development.
Corpus compilation and analysis
What we compared between the Obesity News Image corpus and the WOF Image Bank corpus were Vision’s annotations for each image file. We converted the JSON output generated by Vision into text files that could be processed using the corpus analysis software package #LancsBox (Brezina et al., 2020). #LancsBox supports annotation that can be applied simply by adding an underscore to the text content and since Vision generates the tags according to their respective categories, the addition of these tags can be done semi-automatically using the Find and Replace functions of a word processor. We used the following structure to record the different annotation tags according to their category, i.e.:
– Headwear_FACE
– Person_OBJECT, Hat_OBJECT
– Sleeve_LABEL, Gesture_LABEL, FashionDesign_LABEL, etc.
We removed spaces between multi-word tags so that one annotation tag would be represented by one token in the corpus. This helped to simplify the computation of tags in terms of counting occurrences and distribution across image files. We did not apply a TEXT label, since #LancsBox provides automatic Part-of-Speech (POS) tagging, 3 allowing us to investigate text content in terms of individual types or at the level of singular nouns, modal verbs, etc.
We generated a text file for each image and carried out keyness analysis between the Obesity News Image corpus and the WOF Image Bank corpus. Keyness was determined according to a minimum of 10 occurrences and a combination of the statistical measures Log Likelihood (to establish a confidence score, p < 0.01) and Log Ratio, to identify the greatest differences between the two corpora in terms of effect size. We were also interested in what was similar between the corpora, so we generated a list of tags that occurred with the same relative frequency in each corpus (setting a minimum frequency of 10 occurrences in at least one of the corpora). We cross-checked the confidence score (measured according to Log Likelihood) with a Simple Maths (Kilgarriff, 2009) calculation to identify key tags that occurred within a range of 0.9–1.1, where a score of 1.0 indicates equivalence between relative frequencies.
In what follows, we report our select observations of how Vision’s annotation enabled us to refer to features of the respective image corpora that were prevalent, as well as discussing the extent to which images in the news are consistent with the principles advocated by the World Obesity Federation.
Findings and Discussion
We documented the tags according to the full range of categories offered by Vision; however, there was variability in terms of how frequent and accurate they were when applied to our obesity image data. Table 3 shows the occurrence of the tags according to Vision’s annotation categories. This does not include TEXT labels, which are defined according to the POS-tagger in #LancsBox.
Occurrences of tags according to annotation category.
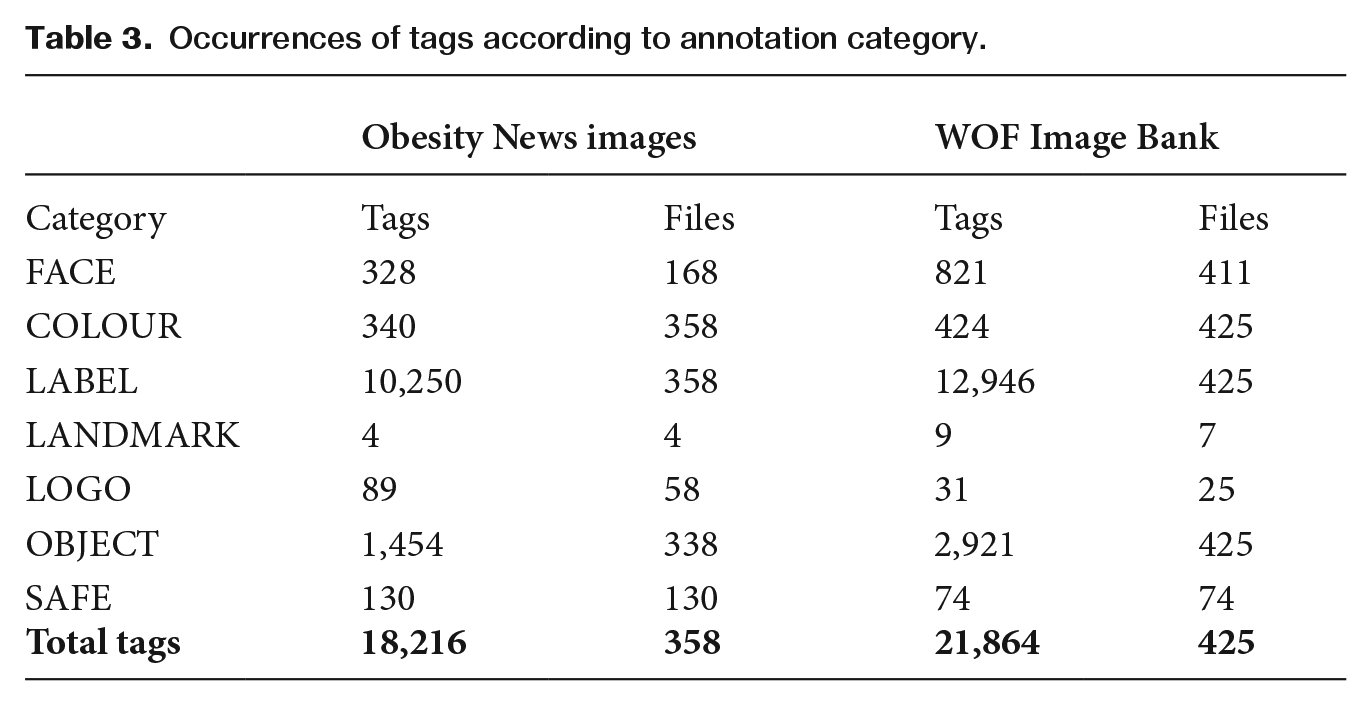
With respect to COLOUR tags, the labelling of the dominant colour is highly specific and, in fact, it was very rare for the same colour to dominate more than one image. Indeed, when the same colour code occurred in the Obesity News Image data, this was an indication that the same image was used in more than one article (with the highest reoccurrence totalling four instances of the same image). LANDMARK tags were infrequent in the data and in certain cases could not be verified. LOGO tags were somewhat frequent, though we observed errors both in terms of misidentifying a logo that appeared in the data, as well as missing instances that could be observed manually in the data. Manual checking showed that just 28 (31.46%) of the LOGO tags in the Obesity News Image corpus and 12 (38.71%) in the WOF Image Bank were accurate. Based on these low occurrences and inaccuracies, we will only discuss the LABEL, OBJECT, FACE, SAFE and TEXT tags in our exploration of differences and similarities between the Obesity News Images and the WOF Image Bank.
LABEL tags
Label detection offers a ‘generalized, textual description’ of the image file and a single image could be annotated with as many as 50 LABEL tags. There were 1,425 different LABEL tags in the Obesity News Image corpus and 1,195 different LABEL tags in the WOF Image Bank corpus, demonstrating the breadth of this category. Thus, while our sample of images from the UK news coverage only covers one calendar month (September) and, as such, might not demonstrate the full variety of representations that might be available over the course of the year, the annotation of the data generated a greater number of tags than the number produced for the WOF Image Bank, which is categorized according to a range of themes (i.e. Family, Social and Home, Food, Physical Activity and Working Day).
We begin by discussing the LABEL tags that occurred with comparable frequency in each image corpus (see Table 4). We have categorized the individual key tags, based on the semantic relations between their referents, to foreground recurrent themes.
Key LABEL tags that occur with similar frequency in the Obesity News Image and WOF Image Bank corpora.

The largest thematic category of shared key LABEL tags refers to Food and dining, demonstrating that obesity is often conceptualized in terms of people’s relationship with food. The tags that appear in both corpora tend to refer to the serving of food, as a meal or in server ware, for example, and multiple food-related tags would often appear in the same file; for instance, in the Obesity News Image corpus, 52 (91.23%) of the images that featured the most frequent food-related tag cuisine also featured the second-most frequent tag dish. With respect to the other categories, there is some evidence for representations that take place in both domestic and professional spaces, representing beauty as well as recreational activities; however, the number of tags in each case is small, suggesting that the two image corpora are similar in only a very restricted number of ways. Indeed, while there were 69 tags that occurred with similar frequency, there were 67 tags that characterize the Obesity News Image corpus and 184 tags that were more characteristic of the WOF Image Bank.
We now turn our attention to those LABEL tags that were overrepresented (to a statistically significant degree) in the Obesity News Images, compared with the WOF Image Bank – as a reflection of current UK news practice. These key tags are presented in Table 5, according to categories of recurrent themes.
Key LABEL tags in the Obesity News Image corpus.

The main theme represented in key tags for news images directly relates to concerns articulated in the WOF’s media guidelines around a focus on body parts, particularly around the abdomen (navel, stomach, abdomen, humanbody, chest, trunk). Furthermore, the WOF cautions against ‘unnecessary exposure of skin’, which we find evidence for in the tags flesh and barechested, and which we can also infer from the types of clothing that are tagged, i.e. lingerie, undergarments and swimwear. When we consider the co-occurrence of these body parts with the image descriptors selfie, artmodel and fashionmodel, it is important to acknowledge the ‘body positive’ messaging that was particularly frequent in articles from The Daily Star (see, for example, Schwab Dunn, 2022). However, an alternative perspective that advocates for ‘body neutrality’ emphasizes an appreciation for functionality over body image, i.e. recognizing what the body allows the individual to do rather than what it looks like (Horn, 2021). Arguably, this perspective aligns more closely with the WOF’s principles for ‘neutral’ representations that demonstrate people involved in a range of professional and recreational activities.
In the Obesity Image News corpus, we also find evidence of design features of infographics, indicated in the tags rectangle, slope, font, graphicdesign, number, atlas, map, circle and line. The WOF Image Bank is principally concerned with representations of people and reported statistics for rates and prevalence of obesity that are not documented in its image archive (although they are available in other sections of the website). Research and surveys related to obesity are likely to be newsworthy (Brookes and Baker, 2021) and documents accompanying press releases of such work can include graphs and charts that journalists can repurpose in their articles. This was particularly the case in The Daily Mail, accounting for 61.93 percent of occurrences of these tags and citing sources such as the Centers for Disease Control and Prevention (see Tilley, 2022).
The food-related tag packagingandlabeling contrasts with the mealtime representations discussed in the previous section, demonstrating a focus on food at the point of sale. From this, we can infer an interest in food industry practices, which contributes to media coverage of obesity in a way that extends beyond the remit of the WOF Image Bank. The tags friedfood and bakedgoods also suggest a focus on poor-nutritional food, in contrast with superfood and staplefood, which were identified in the previous section as appearing in both image corpora.
With respect to Military category tags, rather than representing obese people participating in military activities, the images were attached to articles highlighting low enlistment rates in the US military, with obesity a reported cause. These tags were not frequent across the corpus, appearing in a total of 10 images as part of just 5 news articles.
The key LABEL tags for the WOF Image Bank are presented in Table 6. To a large extent, these reflect the thematic categories identified by the WOF and used to organize the archive, namely: Family, Social and Home, Food, Physical Activity and Working Day.
Key LABEL tags in the WOF Image Bank corpus.

True to the WOF’s guidelines, these LABEL tags attest to representations of people across a range of domestic, public and professional spaces, performing various roles and engaging in recreational activities. One of the concerns expressed in the guidelines relates to representing people with obesity as isolated and so, in addition to capturing movement around public spaces – both manufactured, in the form of places of business and homes, and natural, in the form of woodland and grassland – a key feature of the image bank is the social dimension, highlighted in the tags collaboration, interaction, sharing, etc.
The food-related tags that are key for the WOF Image Bank appear to be oriented towards high-nutrition foods and sustainability, as indicated in the tags localfood, wholefood, vegannutrition, fruit, leafvegetable, vegetable and naturalfoods. Ultimately, the WOF Image Bank offers a greater variety of representations of food, which also relates to people’s interaction with food as it is purchased and prepared, alongside how it is consumed.
The range of tags related to bicycles/cycling, as shown by Recreational activity tags, suggests that some aspects of the coding may be specified to a greater degree than others. Taken together, the 17 tags that include a reference to (bi)cycle or bike amount to 320 occurrences, however they appear in just 26 (6.12%) image files. As such, it is important not to overstate the significance of bicycle-related elements in the corpus, which may appear more prominent in the data as a result of the over-specification of this theme in the coding scheme.
OBJECT tags
OBJECT tags document the number and description of the discrete objects identified in the image file by Vision and so the repetition of a tag such as person should correspond with the number of people observable in the image. The range of OBJECT tag types in each corpus was similar, with 118 different OBJECT tags in the Obesity News Image corpus and 112 different types in the WOF Image Bank corpus. However, the occurrence of OBJECT tags was notably different, with 1,454 tags (in 338 files) in the news corpus, compared with 2,921 OBJECT tags in the image bank. This initially suggests more complex compositions in the WOF Image Bank, involving greater interaction between elements such as people, objects (including food) and features of the surrounding space.
Arguably, the most notable difference between the two corpora was in the number of people represented in the image files. There were 992 person tags across 413 (97.18%) files in the WOF Image Bank corpus, indicating an average of 2.40 people per image. This compares with 401 person tags in 216 (60.34%) files in the Obesity News Image corpus, representing an average 1.86 people per image. This disparity in number of person tags relates to three meaningful differences between the corpora. Firstly, in the news coverage there are images that frame only part of the human body. Indeed, the OBJECT tags clothing, hat, shirt and tie were key for both datasets; however, when the image features only a person’s abdomen, Vision can discern the presence of, for example, a shirt and/or tie, but not the full figure of a person. Secondly, images in the WOF Image Bank were more likely to depict interactions between multiple people. Indeed, 255 (60.00%) images in the WOF Image Bank featured 2+ people, compared with only 82 (22.91%) of images in the news. Finally, the inclusion of graphs and other visualizations in the Obesity News Image corpus also affected the relative frequency of people. In the WOF Image Bank data, the 12 images that did not feature a person tag included some depiction of food, as a meal or a fruit stall, for example. In the news data, there were also images of food (without people), along with locations establishing the context for the article content and information in the form of graphs, where no discernible ‘object’ was present. In total, 142 (39.66%) files in the Obesity News Image corpus did not feature a person OBJECT tag and 20 (5.59%) files had no OBJECT tags at all.
Along with person, key tags for the WOF Image Bank included references to:
– Clothing and accessories: handbag, jacket, pants, bag, dress, luggage&bags, jeans, shoe, outerwear
– Transport: tire, car, wheel, bicycle, bicyclewheel
– Domestic objects: couch, laptop, chair
– Food and dining: tabletop, food, tableware
These tags reiterate some of the observations reported in relation to LABEL tags, as they evidence people taking part in activities, navigating public spaces, as well as spending time at home or around the dinner table, which would also tend to be activities involving other people.
FACE tags
The differences observed in relation to the number of people represented in images (and evidenced by the OBJECT tags) is also reflected in the FACE tags. Face detection not only records the presence of faces, but also codes for the probability of emotional expression. There were no key FACE tags for the Obesity News Image corpus, but the key tags for the WOF Image Bank reiterated that the presence of a person in the data typically entails the presence of a face, which was not always the case in the news coverage. Photographers capturing images of members of the public for news image repositories may avoid including faces on the basis of privacy concerns; nevertheless, this results in dehumanizing representations of individuals who are likely unaware that images of their bodies are being used in this way. In the Obesity News Image corpus, 168 (46.93%) image files featured at least one FACE tag and of the 328 total faces that were identified, 163 (49.70%) were coded as having no discernible emotional expression. In the WOF Image Bank corpus, 411 (96.71%) files featured a FACE tag which, more often than any other expression (including no discernible expression), was recorded as expressing joy (385 occurrences, 46.89%). Indeed, the joy tag was key for the WOF Image Bank corpus, reiterating that, when representing people, the WOF almost always included their face and depicted people enjoying the activities in which they are engaged.
SAFE tags
SafeSearch annotation flags explicit content categories and what was shown through our comparative analysis was a prevalence of medical tags in the Obesity News Image corpus, which could also be combined with racy and adult tags. There is no explanatory description for the medical tag in the Google documentation; however, a manual review of the (48) images tagged with this descriptor in the news coverage data revealed a tendency to include the type of image that the WOF guidelines caution against: images with unnecessary exposure of skin, typically bare midriffs exposed through ill-fitting clothing. It is also common for such images to depict pinching or grabbing of the skin, or having tape measures wrapped around the abdomen, ultimately serving to index excessive weight.
The SAFE tag racy was shown to occur with comparable frequency between the two image corpora and is characterized by depictions of ‘skimpy or sheer clothing, strategically covered nudity, lewd or provocative poses, or close-ups of sensitive body areas’ (https://cloud.google.com/vision/docs/reference/rpc/google.cloud.vision.v1#google.cloud.vision.v1.SafeSearchAnnotation). In the news data, images with this tag typically appeared as part of articles about social media influencers or performers championing a body positive perspective (see Schwab Dunn, 2022). Attesting to the more humanizing aspects of this type of representation, in 68 (60.71%) of cases, the racy tag appeared alongside a FACE tag, which in 32 (47.06%) cases, was tagged joy, i.e. indicative of a smiling face. The images – which often came from the subject’s own social media profile – typically showed the individual modelling or posing in clothing that would generally be captured in the LABEL tags discussed above, i.e. relating to undergarments, lingerie and swimwear. While the relative frequency of racy tags was comparable between corpora, when we referred back to Vision’s original annotation we observed statistically significant differences between probability scores: 77.14 percent of occurrences of racy in the WOF Image Bank corpus were coded ‘Possible’, whereas in the Obesity News Image corpus, 68.97 percent of occurrences of the racy tag were rated ‘Likely’ or ‘Very likely’ by Vision. Images in the WOF Image Bank coded as racy tended to show exposed forearms or people in reclining poses, for example, but this difference in probability scores arguably matches what a manual observer would discern as distinctions between body positive advocates posing in lingerie (in the Obesity News Image corpus) and people wearing ‘skimpy’ clothing appropriate to the climate or activity (e.g. exercise) in the WOF Image Bank. Figure 3 demonstrates a WOF image that was coded ‘Possible’ for the racy tag by the Vision tool. The results for probability scores, particularly with SafeSearch annotations, demonstrates the potential value in retaining the probability codes when comparing data sets.

On the beach 3. © World Obesity. Reproduced under Terms of Use.
TEXT tags
TEXT category annotations highlighted two notable aspects of images in the Obesity News Image corpus that are distinct from those in the WOF Image Bank: the use of infographics and the inclusion within the frame of captions that cite the owner/source of the image. As such, key tags for Obesity News Images include references to data, prevalence, percentages, dates and categories such as high/low and obese/overweight that would appear on graphs, charts and other data visualizations. Key tags also included getty images, shutterstock, instagram and ©, indicating common sources for images in news articles. Both the use of infographics and the labelling of the image’s source were practices that were particularly characteristic of The Daily Mail. In comparison, there was no need for images in the WOF Image Bank to feature credits since they have been produced by the WOF and users are advised to provide a caption alongside the image that acknowledges ownership.
It is worth noting that in both image corpora, there was a high occurrence of parts of words, independent letters and characters. This, to some extent, reflects the framing of images wherein objects (including people) may obscure signage in the background or text may extend beyond the edges of the frame. However, it was also common for Vision’s OCR feature to falsely identify text characters in, for instance, the folds of clothing. The tool therefore is effective in capturing text which may even be a challenge for the manual observer to identify but would also appear to be oversensitive to recognizing characters when they arguably, are not present.
Conclusion
We set out to conduct a critical analysis of the representations of obesity that are available in the UK press, in comparison with an exemplar image bank provided by the World Obesity Federation. Through our computer-assisted approach that drew on automatic image annotation and procedures from corpus linguistics, we were able to report only minimal consistencies (in terms of specific tags) between images appearing in news articles and images developed by the WOF according to its principles for a ‘new standard’ for representing people with obesity. In both datasets, food was shown to be central; however, we observed differences in terms of the types of food represented in each corpus (e.g. differences in nutritional value and source), as well as different representation of people’s involvement in food preparation. The focus on individuals’ participation in a range of activities, observed in the image bank, reflects one of the fundamental principles of the WOF’s guidelines.
News media coverage is concerned not only with the representation of people with obesity but the wider context, which was also reflected in images depicting some aspect of the food industry (such as supermarket shelves) as well as the higher frequency of image elements related to infographics. Journalists may use charts to project a sense of facticity and, while the WOF provides its own materials and information relating to causes, prevalence and prevention of obesity, these were not aspects covered in its media guidelines. This type of information could just as likely appear in the text content of a news article, and other work on this dataset has discussed the text–image relations and multimodal construction of representations of obesity, including how these compare across publications (Baker and Collins, 2023). Investigations of the associated text with these images would help to discern, for example, which publications present a more critical view of the contribution of food industry practices to rates of obesity (see also Brookes and Baker, 2021).
Our analysis highlighted frequent tags describing body parts, and looking at combinations of the specific descriptors and annotation categories provided by Vision supported us in distinguishing when a focus on body image contributed to body positive representations, from when there was a more dehumanizing emphasis on pinched (faceless) abdomens. The trend for ‘headless’, stigmatizing depictions of squeezed abdomens has been documented in previous work (Heuer et al., 2011; Puhl et al., 2013); however, in the prevalence of body positive models we observe a development on the trends reported in Brookes and Baker (2021), which included minimal coverage of body positive messaging and counternarratives to individual responsibility frames based on their comprehensive analysis of the verbal content of news coverage of obesity. These ‘racy’ body positive depictions represented a marked difference between the news coverage and the WOF Image Bank, with the latter adopting what is arguably a position of ‘body neutrality’ in focusing more on representations of people engaging in a range of activities, rather than on body image.
We have discussed how the coding scheme may be unbalanced towards over-specification in some areas and, when applying it, analysts still have to decode what the tags mean, based on what is seen in the results. The granularity of the coding likely reflects the data on which the tool has been trained and so it is important to bear this in mind when applying its default coding across different contexts. While certain categories did not prove to be particularly relevant or effective in our analysis, we would not dismiss them entirely; Gonçalves and Paiva (2021), for example, have shown that Vision’s automatic processing of text, logos and landmarks was particularly effective in a prototype application designed to assist visually impaired people in navigating their environments. This suggests that, rather than taking Vision’s annotation wholesale, researchers may be better suited to focusing on particular categories or parts of its informational output to carry out more thorough analyses on the basis of fewer (categories of) tags. Since we have been able to highlight some meaningful differences between representations of obesity in the news and the examples offered by the WOF, and since Vision was not developed specifically to investigate the topic of obesity, there are indications that it offers a suitable level of generality to be applied across studies. Automated image tagging can help to streamline the coding process and our corpus-based analysis of the annotation offers a demonstration of how researchers might continue to test the applicability and replicability of computer-assisted approaches to image analysis.
Footnotes
Data Availability Statement
Data sharing is not applicable to this article as no datasets were generated or analysed during the current study.
Funding
This work was undertaken within the ESRC Centre for Corpus Approaches to Social Science (CASS) at Lancaster University (Grant reference ES/R008906/1).
Notes
Biographical Notes
LUKE COLLINS is a Senior Research Associate with the ESRC Centre for Corpus Approaches to Social Science. His work is concerned with applications of corpus approaches in health communication contexts and his research also addresses methodological challenges with working with digital discourses. He has written books assessing the impact of a health intervention using corpus methods and on how to conduct corpus linguistics in the context of online communication.
PAUL BAKER has published widely on the application of corpus linguistics to the study of language, identity and health. He has written 22 books, which include: Using Corpora for Discourse Analysis (Continuum, 2006), Using Corpus Methods to Triangulate Linguistic Analysis (Taylor & Francis, 2019), The Language of Patient Feedback (Taylor & Francis, 2019) and Obesity in the News: Language and Representation in the Press (Cambridge University Press, 2021). He is the commissioning editor of the journal Corpora.