
Abstract
This article uses a 36-million word corpus of news reporting on Hurricane Katrina in the United States to explore how computer-based methods can help researchers to investigate the construction of newsworthiness. It makes use of Bednarek and Caple’s discursive approach to the analysis of news values, and is both exploratory and evaluative in nature. One aim is to test and evaluate the integration of corpus techniques in applying discursive news values analysis (DNVA). We employ and evaluate corpus techniques that have not been tested previously in relation to the large-scale analysis of news values. These techniques include tagged lemma frequencies, collocation, key part-of-speech tags (POStags) and key semantic tags. A secondary aim is to gain insights into how a specific happening – Hurricane Katrina – was linguistically constructed as newsworthy in major American news media outlets, thus also making a contribution to ecolinguistics.
Introduction
This article is concerned with analysing news values (Galtung and Ruge, 1965) with corpus linguistic techniques. It does so through a case study on one culturally important event: Hurricane Katrina, one of the costliest and deadliest storms in American history. Instrumental in how Hurricane Katrina has been conceptualised as a natural disaster is the vast amount of news reporting that has been published in the American news media. This is because the news media have traditionally been viewed as providing a ‘window on the world’ (Tuchman, 1978: 1), and as a result, we may say that news ‘defines and shapes’ events (Tuchman, 1978: 184). In addition, Bednarek and Caple (2014) suggest that linguistic analysis can reveal how an event is established as newsworthy.
This article therefore aims to make two contributions: first and foremost, it contributes to the study of newsworthiness/news values and the evaluation of corpus linguistic techniques. Second, by using a case study that focuses on an important environmental event, this article also makes a contribution to ecolinguistics, which is concerned with the relation between language and the environment (see Bednarek and Caple, 2010; Fill and Mühlhäusler, 2001, for overviews). From an ecolinguistic perspective, there is not much work on the reporting of environmental matters in the media (Mühlhäusler, 2003), although climate change news has seen some attention (e.g. Bell, 1991; Carvalho, 2007; Grundmann and Krishnamurthy, 2010), and Johnson et al. (2010) have analysed American television news on Hurricane Katrina from a critical discourse analysis (CDA) perspective. With respect to environmental disaster reporting, Cottle (2009) argues that we ‘need to better understand how the news media variously enter into their constitution and forms of response’ (p. 70).
A discursive approach to news values
The body of research on news values is vast and diverse, existing mostly within the discipline of journalism and communications studies (see Caple and Bednarek, 2013, for a review). By and large, news values are said to drive what makes the news, and the focus of this discipline is on answering the question why events make it into the news media. Within linguistics, news values are mainly discussed in passing, with only some exceptions, such as Bell (1991), Bednarek (2006) and Cotter (2010). Bell (1991: 76) proposes that language can be used to maximise news value, and Bednarek (2006) takes up Bell’s suggestion with a focus on evaluative language, whereas Cotter (2010) is concerned with ethnographic newsroom analysis. Caple and Bednarek (2013) and Bednarek and Caple (2014) provide further discussion of linguistic approaches to news values.
From the ‘discursive’ perspective that we are taking here, we are concerned with how an event is constructed as newsworthy through semiotic resources such as language, as summarised in Table 1 (for comprehensive discussion see Bednarek and Caple, 2012a, 2012b, 2014). 1
News values (alphabetical order).

One aim of such an approach is to analyse news reporting around an event to identify what values are emphasised and how each news value is constructed linguistically. To clarify, we will undertake a brief example analysis. The following text is from the front-page story of the Times-Picayune (New Orleans), published on Tuesday, 30 August 2005, the day after Katrina made landfall in Louisiana:
Headline: CATASTROPHIC Sub-head 1: STORM SURGE SWAMPS 9TH WARD, ST. BERNARD Sub-head 2: LAKEVIEW LEVEE BREACH THREATENS TO INUNDATE CITY Lead paragraph: Hurricane Katrina struck metropolitan New Orleans on Monday with a staggering blow, far surpassing Hurricane Betsy, the landmark disaster of an earlier generation. The storm flooded huge swaths of the city, as well as Slidell on the north shore of Lake Pontchartrain, in a process that appeared to be spreading even as night fell.
The headline, CATASTROPHIC, is an example of maximally intensified negative lexis, and simultaneously constructs Negativity and Superlativeness. The effects of the event (Impact) and its scale (Superlativeness) are emphasised through expressions such as swamps, threatens to inundate, with a staggering blow, far surpassing, flooded huge swaths and spreading even as night fell. The event is also established as highly relevant through references to places that would be well known to the local target audience of The Times-Picayune, constructing Proximity (e.g. 9th ward, St Bernard, Lakeview Levee, New Orleans, Slidell, Lake Pontchartrain). Timeliness is also established, as the event is identified as recent (e.g. on Monday) and ongoing (appears to be spreading as night fell), with the use of the present tense in the sub-headlines a conventionalised device of establishing a sense of immediacy (swamps, threatens).
This brief analysis demonstrates how the Times-Picayune emphasises the event’s high negative and ongoing impact for its local target audience. Methodologically, we have proceeded via manual discourse analysis. But, as Hunston (2011) notes, ‘ways have to be found to translate research questions prompted by discourse analysis into corpus interrogation questions’ (p. 167). In this article, we will test whether discursive news values analysis (DNVA) can be applied on a much larger scale through corpus linguistic techniques.
Corpus design and techniques
The Katrina corpus
This study is based on a specialised corpus of newspaper texts from an online news aggregator (Potts, 2013). The sampling unit is a single article (containing headline, byline, dateline, source name, publication date and publication section, where available), and the sampling frame consists of all database articles meeting the following parameters:
originally published in a major American print publication;
published between 25 August 2005 and 31 August 2006 ;
containing search terms Katrina AND (hurricane OR storm OR flood OR disaster).
This resulted in a corpus of 36,736,679 words in 41,964 texts from 24 publications. As texts were gathered from an online database, metadata pertaining to the original section and page number of texts is erratically included and often unreliable. Therefore, texts from various subgenres of reporting (e.g. letters to the editor, obituaries) are included in the corpus. Although the overwhelming majority of data is news, it is not possible to identify the exact proportion of other newspaper matter without manually checking metadata in 41,964 texts. However, by focusing on high-frequency items we may be able to limit the influence of non-news and the influence of special topic news (e.g. business, sports).
For corpus analysis, we used the web-based corpus analysis system CQPweb (Hardie, 2012), which annotated the data using the seventh version of the Unit for Computer Research on the English Language (UCREL) Constituent Likelihood Automatic Word-tagging System (CLAWS), and the UCREL Semantic Analysis System (USAS), assigning part-of-speech (POS) and semantic tags (semtags) to each text. CLAWS has an error rate of approximately 1.5%, with around 3.3% of ambiguities (such as multiple tags assigned to words that may belong to two classes) left unresolved (Leech et al., 1994: 625). Using the same corpus as in this article, Potts (2013) found that in approximately 90% of cases, USAS provided the most appropriate semtag for a word in its given context (in 85% of cases this was listed first in the string of candidates and deemed ‘most likely’ by the tagger). This leaves approximately 10% of (mostly low-frequency) types incorrectly matched or unmatched. These were deemed acceptable confidence thresholds for this study.
Using corpus linguistic techniques to analyse news values
In this section, we briefly explain the corpus techniques that have so far been employed in DNVA. Bednarek and Caple (2012b) use frequency lists and concordancing for analysis of news values in one environmental news story, complementing this with manual multimodal discourse analysis. Bednarek and Caple (2014) suggest that various corpus linguistic techniques can be used to study newsworthiness. However, for reasons of scope, they focus only on word/bigram frequency and keywords, applying two different methods to a small corpus (approximately 70,000 words).
The first method is to manually identify, from frequency/keywords lists, those forms that seem to have the potential to construct news values. These are called ‘pointers’ (Bednarek and Caple, 2014: 145) to newsworthiness and examples include yesterday (Timeliness), chief executive (Eliteness), the most (Superlativeness), England (Proximity for a British target audience), attack (Negativity) and the first (Novelty). Concordance analysis allows for qualitative examination of these forms, while range analysis can help to identify in how many different texts they occur.
The second method is to investigate topic-associated words using concordancing to gain insights into which news values are associated with particular concepts or entities. For example, the word car, which has no apparent potential to construct news value, is frequent in Bednarek and Caple’s corpus, and concordances can show what news values are discursively associated with it.
In this article, we provide a first case study on a large newspaper corpus, including both synchronic and diachronic aspects of analysis. The main aim of this case study is to apply and test the integration of corpus techniques in DNVA. We evaluate corpus techniques that were not tested previously, in particular tagged lemma frequencies, collocation, key part-of-speech tags (POStags) and key semantic tags.
The main statistic employed here is log likelihood (LL). We use the LL ratio for ranking keyness and identifying statistically significant collocates by measuring the confidence that results are not due to chance (Rayson et al., 2004). This tends to favour higher-frequency words, and is preferred here for this reason to avoid a potential skewing by low frequency and therefore less-dispersed collocates, which might occur in special topic news, obituaries or letters to the editor (cf. section ‘The Katrina corpus’). For this reason, we also set a minimum of five for frequency of node, collocate and collocation. We mainly use a window span of four words to the left to four words to the right (4L-4R), as this is the most commonly used in corpus linguistic studies on English, although a window of five is also common in computational linguistics (McEnery and Hardie, 2012: 129). We recognise that choice of statistic is not unproblematic. Ranking keywords by LL has recently been problematised (e.g. Gabrielatos and Marchi, 2012), but it remains the most widely used keyness statistic, and as a result, no other option has been offered to date in CQPweb and Wmatrix, the concordancers utilised here. Furthermore, since different collocation measures mean different results, this is an area where future experimentation could be undertaken – which collocation measures work best for identifying news values?
Although the main objective of this study is an investigation into the use of corpus-based techniques to explore newsworthiness, we are also working with discourses. Therefore, as a side effect, we will also gain insights into how a specific happening – Hurricane Katrina – was linguistically constructed as newsworthy in major American newspapers.
Findings
Sections ‘The tagged lemma frequency list’ and ‘Collocation’ focus on tagged lemma frequencies and collocation analysis, using a subset of the Katrina corpus, comprising the months August and September 2005. The storm touched down in the last week of August, which makes the data from this month potentially the richest. The subsequent month includes the largest amount of Katrina material. This subcorpus (9.65 million words) hence focuses on the earlier stages of the event and news cycle. Analyses will be synchronic.
In sections ‘Key parts-of-speech’ and ‘Key semantic tags’, we perform keyness analysis of POS and semantic tags across a short-term diachrony, to test whether key linguistic devices indicate changed news values in Hurricane Katrina reporting over time. For this section, we compare three subcorpora: August 2005 (608,985 words in 684 texts), September 2005 (9,043,083 words in 10,219 texts) and October 2005 (4,557,231 words in 5360 texts). The August subcorpus contains texts published as the event unfolded, whereas the September subcorpus reflects the immediate aftermath, and the October subcorpus encompasses coverage of the continuing fallout.
The tagged lemma frequency list
Table 2 shows a list of the top 200 most frequent lemmas used as a particular POS, categorised according to perceived potential to construct a specific news value and excluding punctuation (the tags are explained at http://www.natcorp.ox.ac.uk/docs/URG/codes.html#klettpos, accessed 12 June 2014). 2 This categorisation is based on hypothesis – no concordancing or collocation analysis was undertaken at this stage, because of the high raw frequencies of these top 200 (ranging from 4939 to 467,450), unless specifically mentioned below. Where specific examples are provided, they come from the corpus. We have avoided multiple categorisations, but do note occasionally when an item could also be placed in a different category.
Pointers to newsworthiness.

Of 5786 occurrences of
As expected, there are many function words that are not clearly identifiable as pointers to a specific news value. This is not to say that they cannot be used to construct newsworthiness, depending on the co-text (Bednarek and Caple, 2014: 147). The table also includes nouns, verbs and adjectives that tell us little in and of themselves about newsworthiness, although in a specific co-text they might construct news values. To give just one example, lemmas like
There is also a considerable amount of high-frequency verbs that do not clearly point to a specific news value, including reporting expressions (e.g.
Collocates of
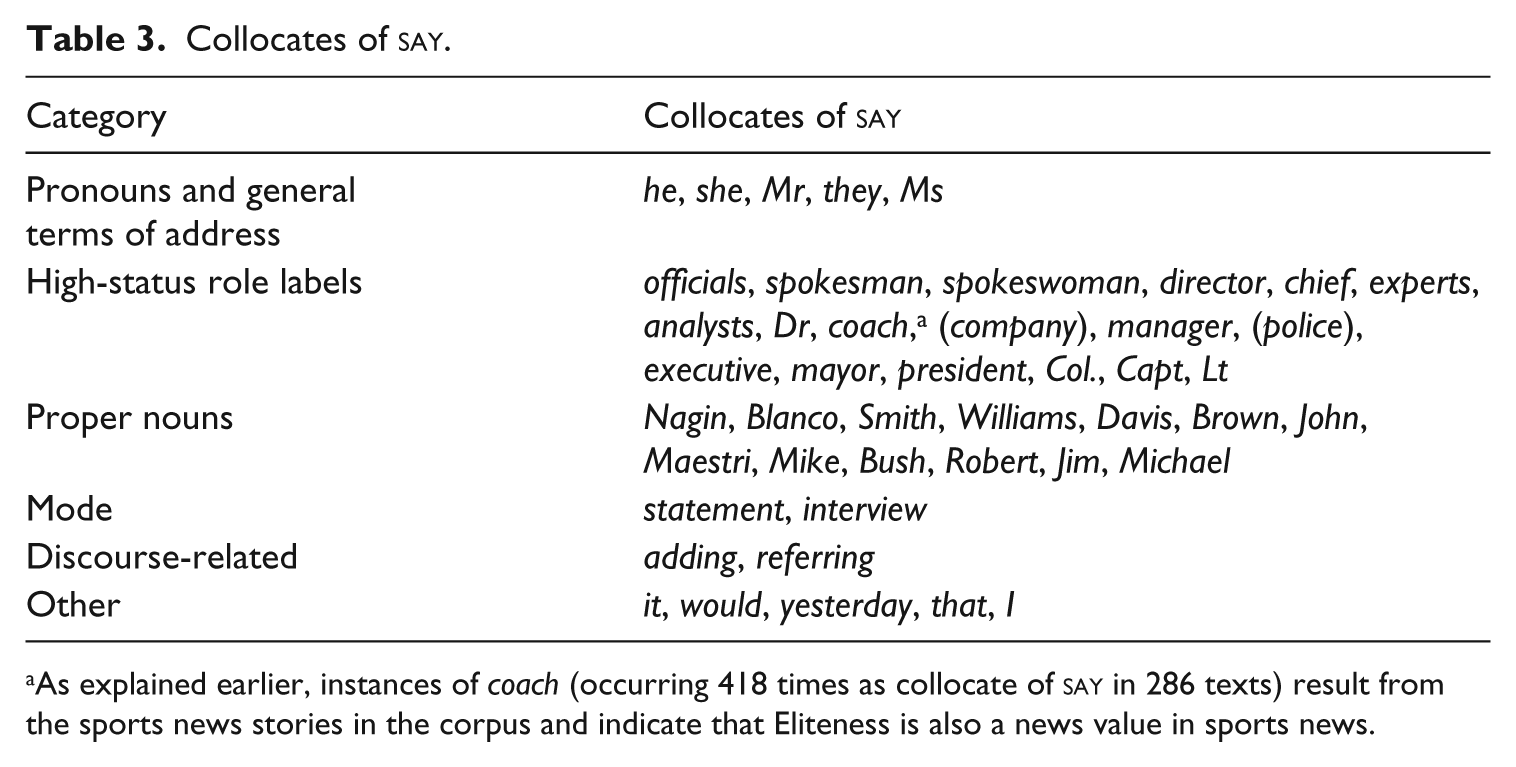
As explained earlier, instances of coach (occurring 418 times as collocate of
Table 3 suggests that elite sources are often cited, as indicated through the high-status or authority role labels such as officials, analysts or executive, and proper nouns referring to leading politicians (President George Bush, New Orleans Mayor Ray Nagin, Louisiana Governor Kathleen Babineaux Blanco). Concordancing shows that Maestri also refers to two less well-known news actors constructed as authority: Walter Maestri (Jefferson Parish Emergency Management Director) and William Maestri (superintendent of schools for the Archdiocese of New Orleans). Other collocates are not easily classifiable, either because they are pronouns or general terms of address or because they are common surnames (Smith, Williams, Davis, Brown) or first names (John, Mike, Robert, Jim, Michael), which can be used with both elite and ordinary news actors. Concordancing could be used to establish proportions of ‘ordinary’ versus ‘elite’ speakers here. Nevertheless, this very brief collocation analysis confirms the hypothesis that reporting verbs can be a useful starting point for investigating news values.
To return to the broader discussion of Table 2, it may appear surprising that the positive lemma
We now move on to those lemmas that can be classified as potential pointers to a specific news value (based on Table 1). For Eliteness, this includes the proper noun
For Proximity and Timeliness, we have included as ‘pointers’ all potential indicators of place and time, including expressions that may anaphorically, cataphorically or exophorically point to a place ( We know the devastation is worse
We must emphasise, however, that not all place and time references establish Proximity and Timeliness. The question is whether or not a particular place reference constructs the event as geographically or culturally near the target audience and whether or not a particular temporal reference constructs the event as recent, ongoing, about to happen or seasonal. Thus, lemmas like The water and sewage pumps in the coastal refinery city of Baytown malfunctioned during the hurricane, and residents were asked to conserve water Saturday
A word like The deaths were declared storm-related because
For Proximity, pointers further include the first person plural lemmas
To continue with our discussion of Table 2, pointers to Novelty comprise indications of ‘newness’ (
Pointers to Superlativeness include quantification and intensification. Even small numbers (
Finally, the last row in Table 2 includes pointers to both Negativity and Impact. They are included in the same category here because impact tends to be constructed as negative in disaster reporting. This category includes words which construct cause–effect relations (
Perhaps slightly more problematically, we have also included the lemmas
It is now time to evaluate the technique of using a tagged lemma list to explore news values. Where it appears superior to a pure frequency list is in its power to disambiguate. For example, the use of new tagged as substantive shows instances where it is used as part of a location name (New Orleans – Proximity), whereas its use as an adjective may construct Novelty. It also allows the identification of high-frequency lemmas such as
Collocation
As noted earlier, Bednarek and Caple (2014) use concordancing of topic-associated content words to find out what news values are constructed around a given entity. However, when using a large corpus, concordancing may not be viable, and other methods of exposing ‘non-obvious’ meaning – or ‘meaning which might not be readily available to naked-eye perusal’ (Partington et al., 2013: 11) – in discourse might be employed to better effect. Here, we explore whether collocation analysis could be used for the same purpose. To do so, we will focus on the top 100 right-hand collocates of hurricane (Table 4).
Right-hand collocates of hurricane.
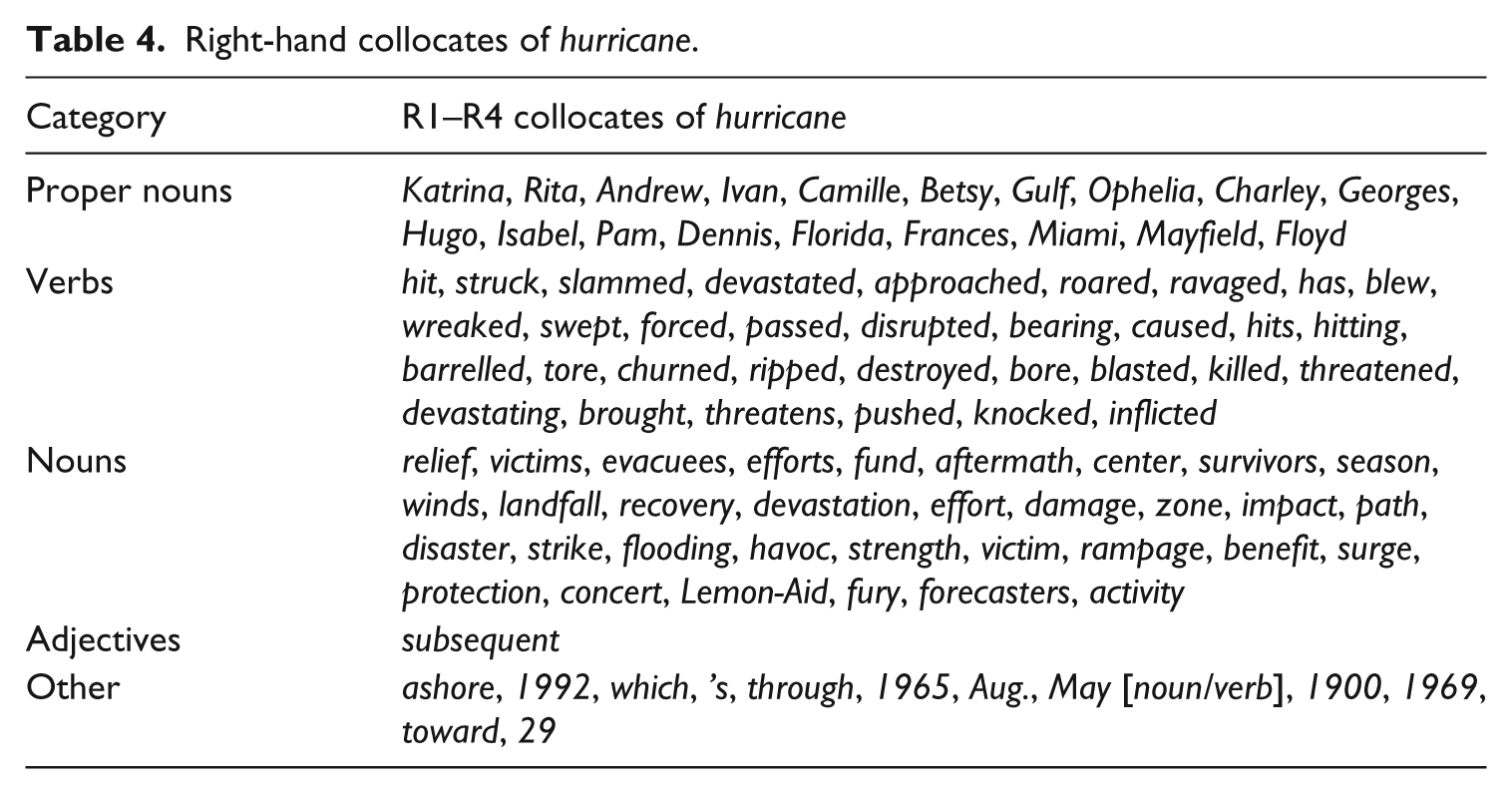
Table 4 shows that the top 100 right-hand collocates of hurricane include the names of various hurricanes and other proper nouns, the latter potentially constructing Proximity (Gulf, Florida, Miami). Furthermore, most of the noun collocates establish Negativity, Superlativeness and/or Impact, through reference to providing help (relief, efforts, fund, recovery, effort, benefit, protection, concert, Lemon-Aid), to the negative effects and power of the hurricane (aftermath, winds, devastation, damage, impact, disaster, flooding, havoc, strength, rampage, surge, fury), and to affected people (victims, evacuees, survivors). The latter also constructs Personalisation, as argued previously. Only some nouns appear unrelated to news values, referring to the stages/actions associated with hurricanes: season, landfall, zone, path, strike, activity. Similar to the nouns, most of the verb collocates construct Negativity (e.g. threatened), Superlativeness (e.g. slammed) or Impact (e.g. caused). Often all three news values are established simultaneously: for instance, devastated and ravaged construct the hurricane as high in negative impact. Only some verbs refer to the stages/actions of hurricanes, for example, approached, passed.
The adjective collocate subsequent primarily co-occurs with word forms referring to the negative impact of the hurricane (evacuation, flood, flooding, floodwaters, levee break, closing, damage, relief efforts), hence clearly constructing Negativity and Impact (Figure 1).

Concordances for hurricane + subsequent.
The year collocates (1992, 1965, 1900, 1969) indicate the importance of historical comparisons, which are sometimes used for Superlativeness and/or Novelty, and which may also explain the collocating hurricane names:
The magnitude of the disaster in St. Bernard Katrina would also be
Table 4 also indicates that ’s is a collocate, and follow-up analysis can be undertaken to investigate specific frames such as the hurricane’s * or Hurricane Katrina’s *. For instance, nouns that occur to the right (R1–R4) of hurricane’s include aftermath, path, impact, eye, winds, victims, devastation, wake, fury, wrath, effect, surge, effects, damage, destruction. Again, the news values of Negativity, Impact and Superlativeness are clearly visible.
We will conclude this section by briefly evaluating the use of collocation in DNVA. Overall, this method does show some promise, as it can be used with a large corpus and allows identification of those news values that are co-textually associated with a particular word. To explore news values constructed around the entity ‘Katrina’ more fully, we also need to consider the left-hand co-text as well as collocates for additional referential devices (storm, Katrina). Around the word form hurricane, repeatedly constructed news values are Negativity, Superlativeness and Impact. This is an unsurprising result, since we would expect disaster reporting to emphasise an environmental event’s high negative impact on the community. Since collocation analysis uncovers what we would expect it to uncover, rather than any counter-intuitive results, it may in fact be a useful technique for news values analysis: ‘“uncovering the obvious”… gives more credibility to other non-obvious findings’ (Baker et al., 2013: 30). This suggests that collocation analysis can indeed pinpoint repeated constellations of specific news values constructed around entities. However, since it focuses on the immediate co-text, rather than the whole news article, it can only provide a partial view of news values constructed around a particular issue. But there is also merit in showing how news values are constructed and collocation analysis has the power to identify recurring phraseologies (e.g. the co-occurrence of hurricane with high-intensity verb forms such as slammed, ripped, blasted), figurative devices such as metaphor/personification (e.g. roar, fury, wrath) and rhetorical strategies (e.g. historical comparison). It thus aids the identification of common conventions and clichés of hurricane news reporting.
Key parts-of-speech
Can corpus linguistic techniques help us to understand changes in the construction of newsworthiness over time? To test this, we now discuss a key POStag analysis on three subcorpora; these comprise August 2005, September 2005 and October 2005.
Key POStags from each of these subcorpora were generated using the other two subcorpora as reference. Keyness was calculated using LL with a significance cut-off point of 0.001%. 4 For reasons of scope, only the three items with the highest confidence scores in each category are explored here at greater length. To do so, we identified the specific lexical items making up the greatest proportion of each key POS category, and used collocation analysis to gain a broad understanding of meaning in use, through the lens of common context. When deeper analysis was needed (e.g. to disambiguate instances of polysemous words), we took randomly thinned samples of 50 instances and observed patterns at the concordance level. The first subcorpus to be discussed is August 2005 (Table 5).
Key part-of-speech tags in the August 2005 subcorpus.
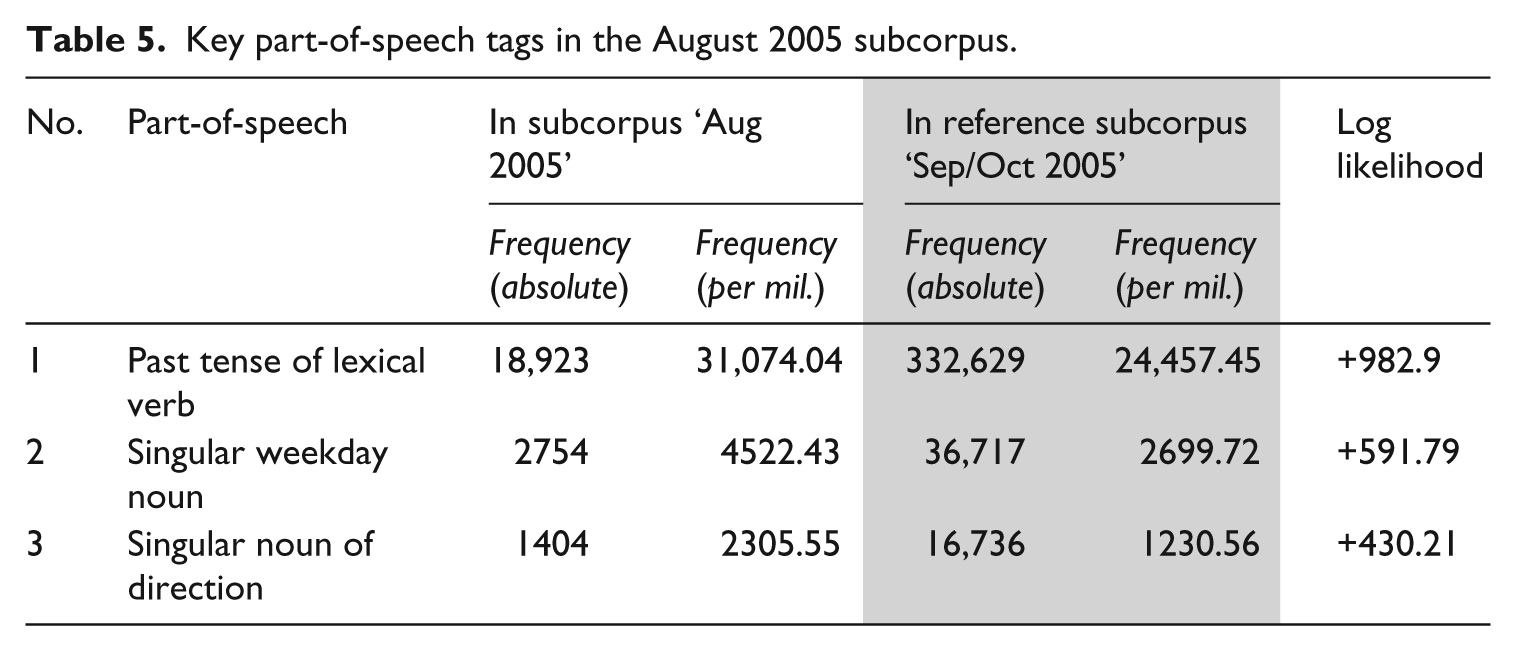
The POStag with the highest LL score in August 2005 is ‘Past tense of lexical verb’, which is somewhat surprising, given that this is the ‘breaking news’ subcorpus. While the past tense can construct events as recent (the news value of Timeliness), this depends on specific explicit or implied temporal reference (e.g. yesterday vs last year). A single item – said – accounts for over 30% of this result, and occurs with government officials and spokespeople (Eliteness), and, less frequently, ‘ordinary’ eyewitnesses (Personalisation); top collocates (span ±3, minimum frequency: 5, LL > 15.13) include he, she, officials, Mr., Blanco, Nagin, spokesman (see also section ‘The tagged lemma frequency list’ earlier). Other, dramatically less frequent, past tense lexical verbs (lost, killed, struck, died, warned, caused, canceled, urged) indicate Negativity and Impact.
‘Singular noun[s] of direction’ (e.g. north, south, east, west) are pointers to Proximity, although top collocates highlight a multitude of contexts: the nouns of direction collocate with proper and common nouns of place (Florida, shore), and measurement nouns and adverbs (miles, farther). All of these may indicate Proximity, but this relies on the distance between the location of its target audience and the mentioned locations. US locations (such as Florida) are culturally/geographically near a US audience (national Proximity), whereas references to local places construct Proximity for the target audience of local newspapers (local Proximity). Nouns of direction are good indicators of local Proximity when capitalised (e.g. ‘South
Finally, instances of ‘Singular weekday noun’ underscore Timeliness; in 49 out of 50 random concordance lines, these refer to instances in the (very near) past, reporting on the movements, statements, and impacts upon people in the previous week. ‘Singular weekday noun’ also appears as a key POStag in the September 2005 subcorpus, and is the only repeated key tag across the subcorpora (Table 6). Concordancing shows that these nouns refer to dates that are not recent in relation to the date of publication and hence do not construct Timeliness. Rather, they temporally situate events, such as the hurricane’s strike, in relation to the present, and contribute to establishing one of the ‘“five W’s and an H” – who, when, where, what, how, why’ – (Bell, 1991: 175) of news reporting.
Key part-of-speech tags in the September 2005 subcorpus.
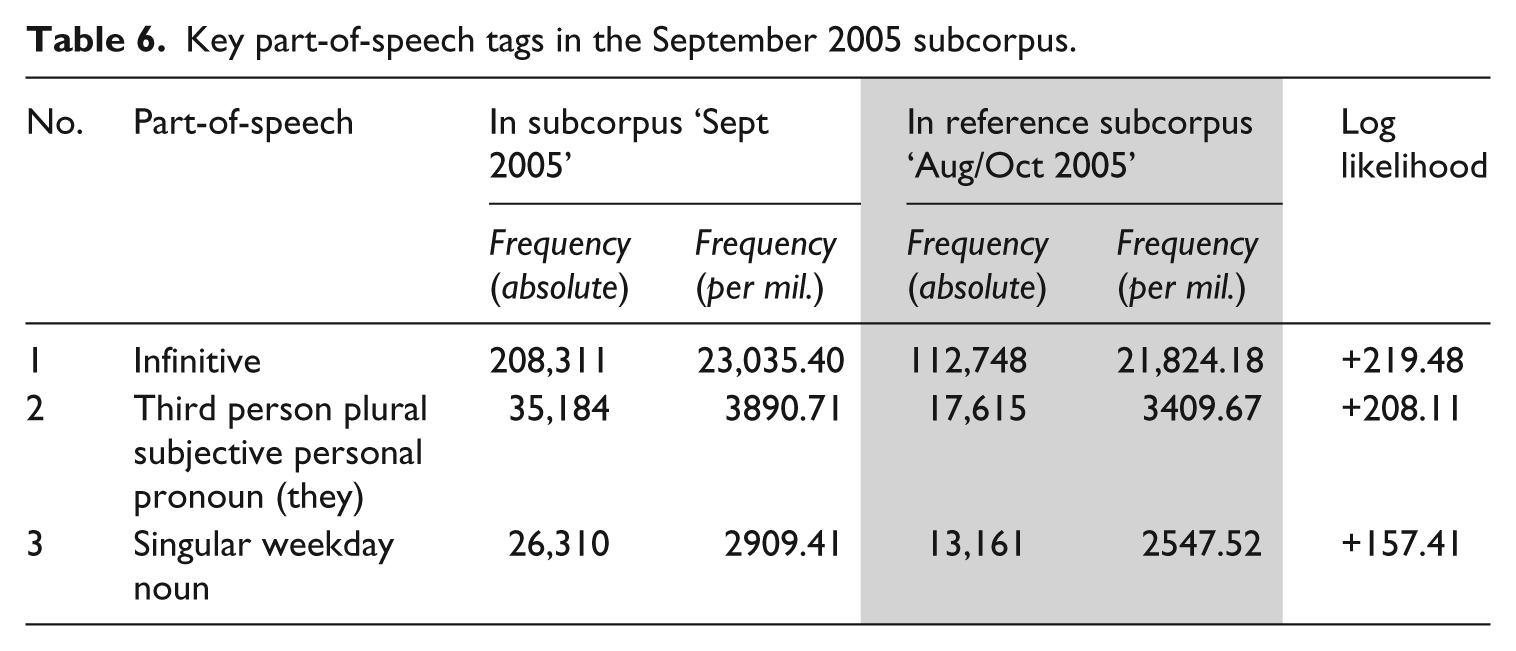
One key September POStag indicates clear shifts in comparison to August reportage: overuse of the ‘Infinitive’ in contrast to previous overuse of the past tense lexical verb. The infinitive in English is so flexible – taking its tense from auxiliaries – that it is not a reliable indicator of Timeliness (though it tends to be present-focused and forward-looking in concordance lines). Frequent items in this POS group favour mental/behavioural processes (see, know, want, think), including (pro)social activities (e.g. help). While the infinitive itself does not point to a news value, these lexical items convey both personal and national Impact. Mental/behavioural processes are individual, and help to convey personal accounts of speakers in their ‘own voices’, as eyewitnesses, offering Person-alisation. Many of these mental/behavioural processes (in the infinitive) are incorporated through inclusion of quotations:
‘It’s the worst situation you can ‘I have two guest rooms in my home that are sitting completely empty’, posted one Atlanta resident. ‘I would like to
While quotations from high-status professionals generally construct Eliteness, in the first example above, Louisiana Insurance Commissioner Wooley constructs himself as an eyewitness, with reference to his particular experience and emotions, thus also personalising the event. In the second example, an ordinary citizen is offering help through personally identifying with the affected residents.
What emerges from Table 6 as characteristic of September 2005 compared to the months before and after is overuse of third personal plural personal pronoun (they). In only 5 out of 50 sample concordance lines are they named individually in the extended context; they refers to generalised evacuees, government officials and employees of aid organisations. This indicates a weaker form of Personalisation, as people are incorporated as generalised referents rather than individualised actors who are associated with processes or quotations (see e.g. concordance below). Rather than hearing from individuals themselves about their experiences, we now hear about groups of individuals, some of whom are Elite. This is similar to the distancing and objectification in Hurricane Katrina reporting observed by Potts (2013):
‘The result is that many of
We move on now to discussion of the final subcorpus, representing the continuing aftermath of the storm. Compared to August and September, October 2005 features a high amount of measurements and numbers, two of its key POS (unit of measurement, cardinal number) contributing to this preference (Table 7).
Key part-of-speech tags in the October 2005 subcorpus.
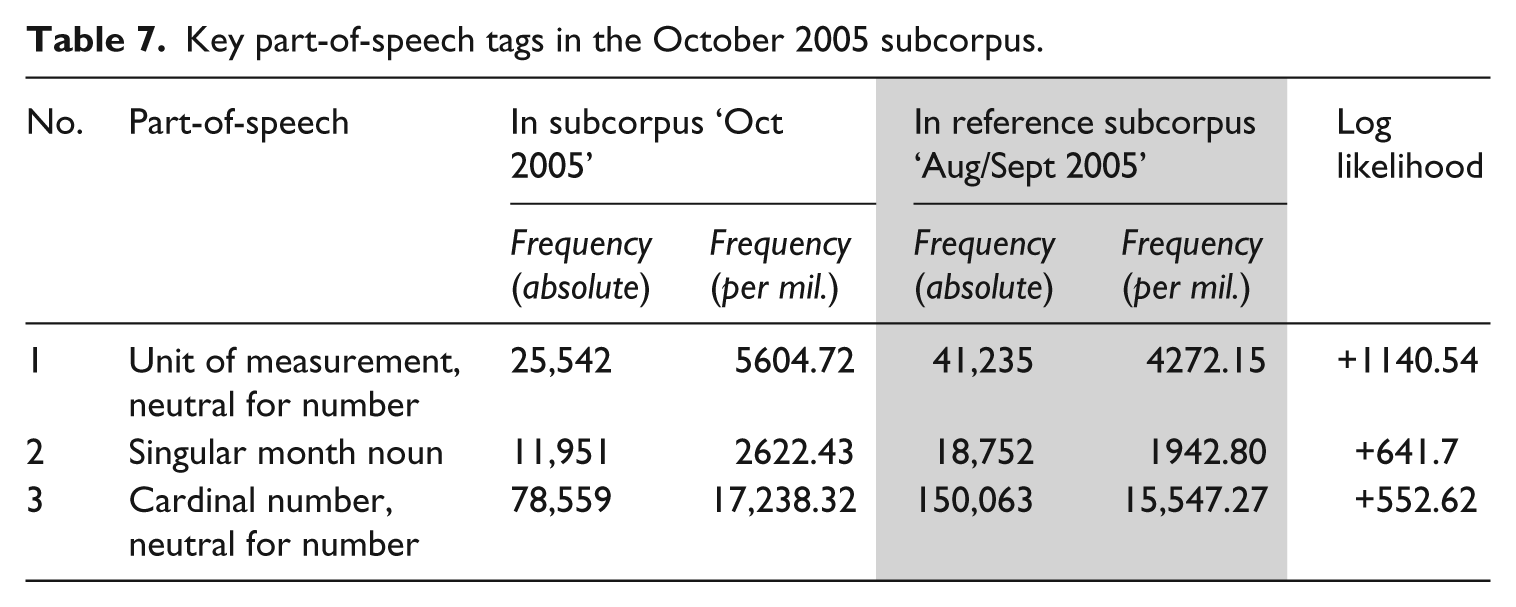
Cardinal numbers do not reliably indicate newsworthiness here, as these include dates (of varying distance from the present), counts (from small to great) and radio stations. However, units of measurement (over 20% of which comprises percent itself) construct elements of Impact and Negativity, conveying either financial cost or enumerating more emotional responses:
The quantity of debris was daunting: Pieces of roofs, trees, signs, awnings, fences, billboards, and pool screens were scattered across several counties. In a USA TODAY/CNN/Gallup Poll released today,
In the first example, $10 (unit of measurement) billion (numeral noun) in damages are estimated; in the second example, 72% of poll respondents say they are ‘worried’ about effects (Personalisation, Negativity, Impact), with the high unit of measurement (72%) adding Superlativeness. A total of 40 of the top 50 lexical items contained within ‘Unit of measurement’ are amounts in US dollars, highlighting the continuing negative impact on financial stability after the storm.
This subcorpus stands apart from the others in one final way: singular month nouns are key in October as opposed to singular weekday nouns, which were key in August and September. Events are no longer conveyed in terms of distance within a week, but in terms of months (i.e. maximally within a year from the present). The most frequent items within this POStag are Oct. (18.2%), Sept. (12.13%), September (10.48%), Nov. (8.94%) and August (7.38%), which still convey a degree of Timeliness, as they refer backwards and forwards in time only one (or, rarely, two) months into the past or future. It must be noted, though, that Timeliness is usually measured in terms of days rather than months, and one could argue that the use of month nouns in this subcorpus simply situates events in time.
In this section, we tested whether key POStags are useful for investigating the grammatical construction of newsworthiness across a diachrony. We suggested that key POS categories in August, September and October 2005 could be linked to differing emphases upon various aspects of newsworthiness. However, some key POStags are more easily linked to newsworthiness than others. On the whole, key POStags serve as good indicators of differences between various reporting periods, but involve many levels of analysis to uncover the relationships that may (or may not) exist between these occurrences and news values. This includes viewing the constituents of each POStag to gain a better understanding of prominent patterns contributing to keyness as well as collocation and concordance analysis of randomly thinned samples.
Key semantic tags
Using USAS, each corpus item was assigned a tag denoting its correspondence to 1 of 21 major discourse fields and 232 subdivisions. The semantic tags ‘show semantic fields which group together word senses that are related by virtue of their being connected at some level of generality with the same mental concept’ (Archer et al., 2002: 1). Items sharing semantic tags (e.g. say and claim) might not be frequent enough in isolation to make it to the top of a frequency list (as in section ‘The tagged lemma frequency list’), but in combination, may be a useful pointer for broader meanings. In this section, we consider key semantic tags in August 2005, September 2005 and October 2005 by comparing the corpora, as described above. We consider the categories in the first instance, then describe the most frequent constituents, and finally make use of collocation or concordance line analysis to illuminate patterns.
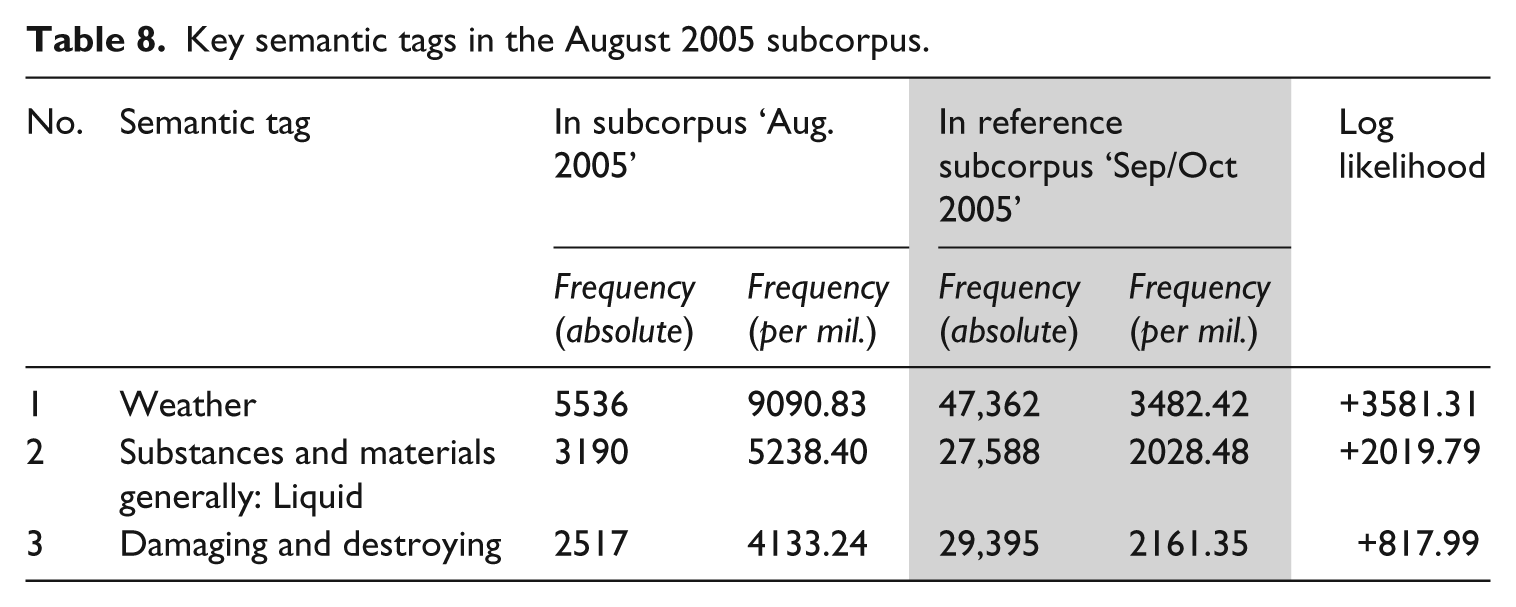
The most key semantic subcategories in August 2005, as Hurricane Katrina was travelling across the Gulf Coast, directly relate to the event: ‘Weather’, ‘Liquid’ and ‘Damaging and destroying’ all convey the Impact of the storm to varying degrees. Items from the ‘Weather’ category convey Negativity, and are additionally intensified by their collocates, which construct Superlativeness: Both hurricane and storm collocate with devastating, major, powerful, deadly and catastrophic; winds collocates with high, strong, heavy, fierce and powerful; flooding is frequently described as worst, severe, widespread and extensive (±3 span, LL > 15.13 minimum frequency: 5).
Items tagged ‘Damaging and destroying’ (e.g. damage, damaged, broken, broke, ripped, harm) describe the immediate aftermath of the storm in terms of negative impact (most prominently), but also in terms of Superlativeness (e.g. with intensified lexical items devastation, destroyed, destruction, collapsed, ravaged). In an interrelated pattern, words semantically tagged as ‘Liquids’ describe Impact in terms of direct and indirect consequences: the category contains 42.61% water and 5.11% waters, contrasting to 29.53% oil, 9.09% gasoline and 4.29% crude. These describe environmental/architectural Impact (flooding, oil spills), but also financial Impact (the rising cost of gasoline). Impact of both of these types is accompanied by Superlativeness; collocates include measurements (‘
In comparison to the key semtags of August 2005 in Table 8, the key semtags of September 2005 (in Table 9) appear at first glance markedly more ‘personal’. However, deeper examination uncovers patterns previously explored. The most key semtag in this month (‘Evaluation: Good/bad’) is made up of 60.35% disaster, 13.9% disasters, 6.91% catastrophe and 1.38% catastrophes. Less frequent are adjectives from the same word family (e.g. catastrophic, 4.22%; disastrous, 0.98%) and the negative evaluative adjective worst (1056 occurrences, 10.59% of semtags). This semantic tag thus incorporates both negative lexis and evaluative language (Table 1), but both types of resources construct the news values of Negativity and Superlativeness: with the word families ‘disaster’ and ‘catastrophe’, we are dealing with intensified negative lexis (used in the corpus to refer to environmental happenings or levels of destruction that are socially or scientifically defined, such as ‘was declared a federal
Key semantic tags in the August 2005 subcorpus.
Key semantic tags in the September 2005 subcorpus.
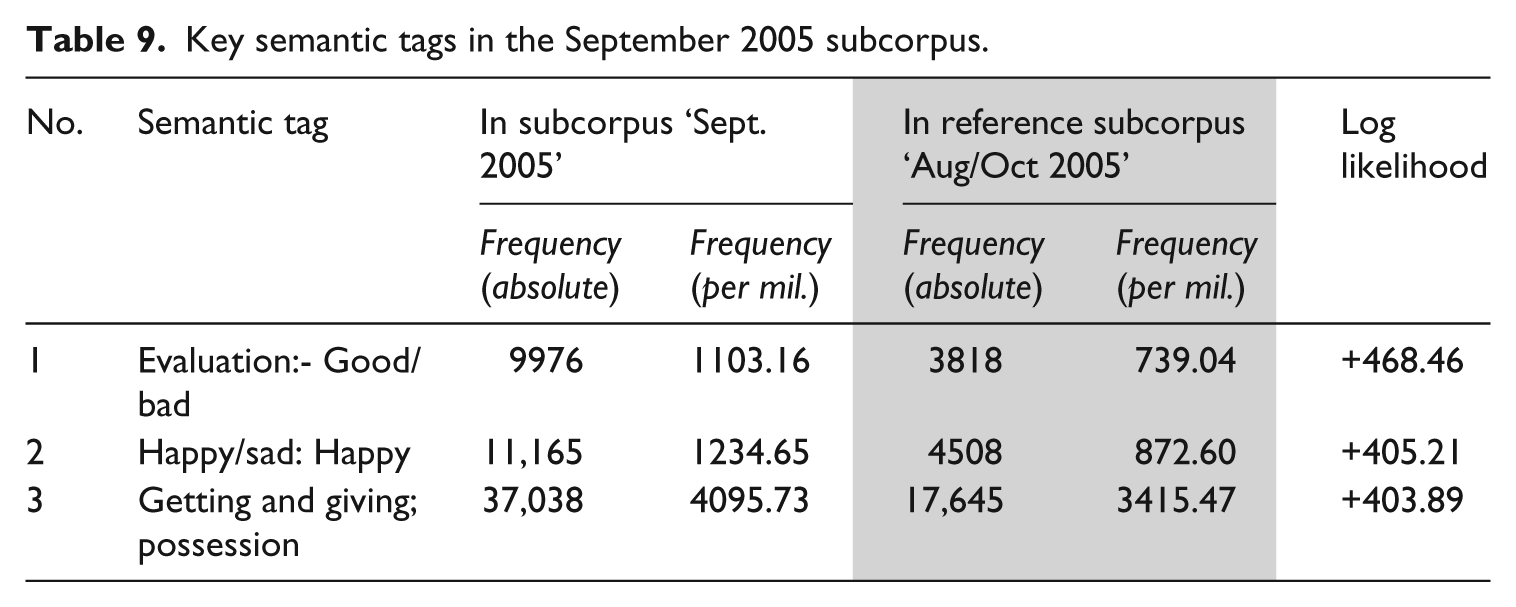
The next key semtag, ‘Happy’, seems a counter-intuitive concept in disaster reporting, but closer inspection reveals that 60% of this category comprises a single type: (disaster) relief. ‘Getting and giving; possession’ contributes to the same overall tendency: this category contains tokens such as supplies and donations, which, together with disaster relief, convey Impact, upon both the citizens and organisations providing aid, and the victims in need of it.
Key semtags from October 2005 (Table 10) also show a distinct semantic field preference. Patterns that were uncovered during key POStag analysis also hold strong in the focus on the monetary Impact of Hurricane Katrina: all three of the semantic subcategories are concerned with money and business.
Key semantic tags in the October 2005 subcorpus.
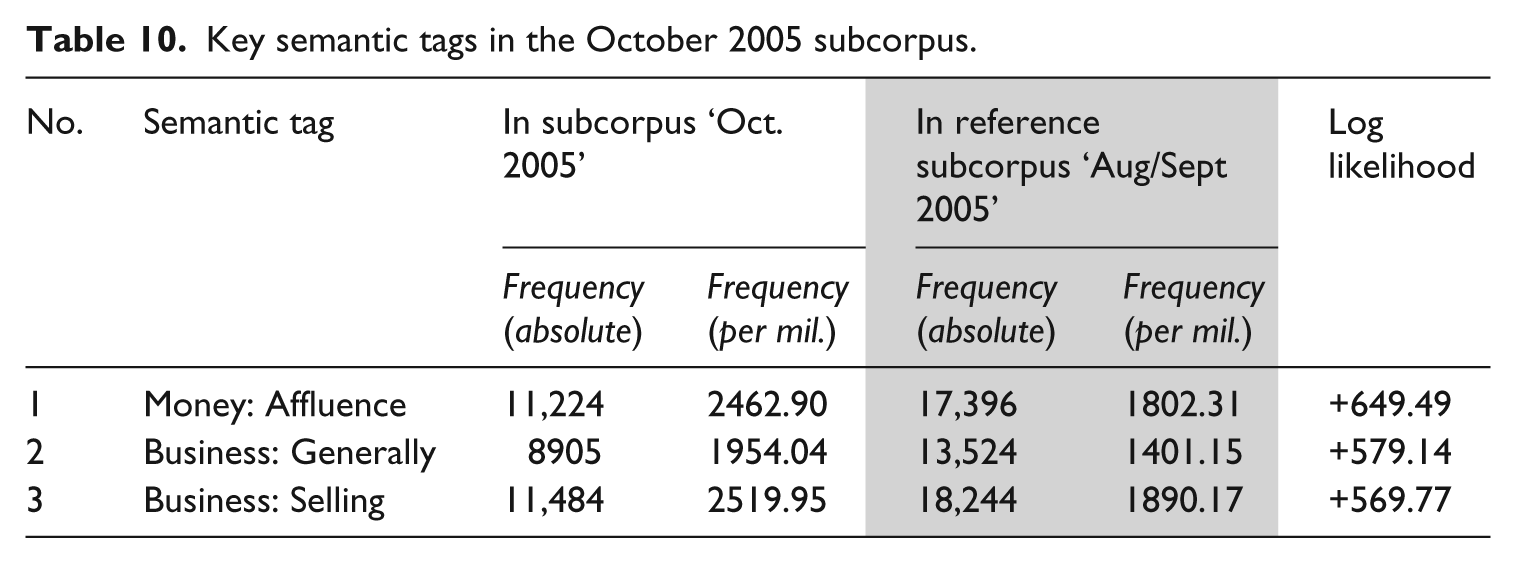
Items from ‘Money: Affluence’ (e.g. fund, earnings, income, profit, capital) and ‘Business: Generally’ (business, businesses, economy, inc. contracts, contract, corp) emphasise this financial Impact, as well as convey Eliteness (of large, powerful corporations and funds). Impact and Eliteness are also conveyed through the items belonging to the ‘Business: Selling’ semtag (e.g. sales, market, buy, trade, sold, sell, sale, markets), although Timeliness is also integrated, often through predictions of sales/markets futures ( But investors believe that
Such a comparison with 9/11 arguably constructs the hurricane’s impact both as severe, and as in line with expectations (Impact/Superlativeness/Consonance).
In this section, we devoted some time to exploratory analyses using key semantic tags. In contrast to key POStag analysis, which exposed grammatical features that ‘pointed’ to areas for deeper corpus-assisted investigation (e.g. through the use of frequency breakdowns, collocation, and concordance analysis), key semtag analysis provided results that were much more easily accessible, either from first glance, or once frequency lists of the constituent lexis were viewed. This is because semantic fields have much more in common cognitively than items sharing a word class. Items from a semantic field may share, for instance, specific negative meanings (as was the case with the negative impact category ‘Damaging and destroying’), or attract a set of (grammatically similar) collocates which establish a particular news value (as was the case with intensifying adjectival collocates of hurricane and storm from the ‘Weather’ key semtag). For an initial overview of key areas that may contribute to constructing newsworthiness in a given corpus, we recommend key semantic tag analysis over key POStag analysis for transparency and rapidity.
Conclusion
There are a number of reasons why it is challenging to analyse the construction of news values using corpus linguistic techniques. 5 First, there is no closed list of news value devices – news values can be constructed by an open-ended range of lexical or grammatical resources (word forms, lemmas, phrases, whole clauses or sentences). This means that we cannot search the corpus for a defined set of devices. However, as news discourse is conventionalised, we could search for selected devices that are known to be commonly used in news reporting to construct news values (e.g. temporal markers such as last, yesterday, common emotion nouns such as fear, hope, concern or semantically related adjectives such as unexpected, astonishing, shocking). Additionally, as we argue in this study, collocation analysis can be used to identify news values established in the immediate co-text of topic-associated content words (e.g. hurricane).
Second, if we consider newsworthiness as a property of texts rather than individual items, we also need to look at how it is constructed intra-textually. For this, we need to consider the text as a coherent communicative event – reading it horizontally and as a whole – which is not a recognised strength of corpus approaches (Tognini-Bonelli, 2001: 19). But where corpus linguistic methods excel is in the identification of inter-textual patterns in datasets. In so doing, these methods can help to quantify and identify repeated sequences, uncovering common practices and conventions in news reporting. As our study has illustrated, corpus techniques can help reveal how phraseologies, figurative devices and rhetorical strategies construct news value. For instance, in the Katrina corpus a cause–effect relation (Impact) is set up by
Third, the construction of news values is heavily co-text-dependent, because language is multifunctional. In Hunston’s (2011) words, ‘the meaning of any word cannot be identified reliably if the word is encountered in isolation’ (p. 14). Frequency lists and keyness measures, which calculate occurrences without co-text, can be used as input for hypotheses, but concordancing or collocation analysis needs to be undertaken to identify meanings. With a small corpus, this can be more easily achieved; the corpus allows qualitative investigation of all or most instances of a given lemma, POS or constituent of semantic domain. It would be possible, for example, to closely examine all indicators of place and time using automatic tagging with follow-up concordancing. When exploring a large corpus (such as the one used in this study), collocation analysis is helpful, but concordancing is restricted to randomly thinned samples. There is also the possibility of focusing on just one news value, as concordancing of more samples is then more manageable.
What are some of the next steps to be taken? More case studies on different topics and different types of news corpora are needed, and there are at least two additional methods that need to be tested on large datasets for DNVA: n-grams and p-frames, where word forms are not listed in isolation but rather with repeated co-textual patterns. 6 On a more theoretical level, the notion of (de)emphasis needs to be investigated in depth. While one approach would assume that (de)emphasis correlates with frequency of occurrence (repetition), another approach would be positional. From this perspective, news values that are constructed in the summary (Van Dijk, 1988), abstract (Bell, 1991) or nucleus (Feez et al., 2008) – headline and opening paragraph – may be considered as the most emphasised, because this part of the news story arguably comprises the ‘most important news element of the story in addition to the choice of angle or “hook”, or approach to the subject’ (Cotter, 2010: 162). Mahlberg and O’Donnell (2008) and Mahlberg (2009) show that news story structure can be usefully investigated from a corpus perspective.
This study suggests that all tested methods could provide useful insights into the construction of newsworthiness in a large corpus. While POStagged lemmas and POStags require comprehensive follow-up qualitative analysis, semtags appear the most insightful in themselves for providing an overview of newsworthiness, and collocation analysis may be useful for identifying news values established in the co-text of topic-associated words.
Footnotes
Funding
This work was supported in part by the ESRC Centre for Corpus Approaches to Social Science [grant number ES/K002155/1].