
Abstract
This article presents three studies that evaluate the effectiveness of instructional pictures that visualize Heimlich maneuver thrusts. Firstly, a corpus study is used to describe a collection of 30 pictures employing a model in which the angle, perspective, body and hand positions of the first-aid helper and the victim, the thrust action and its depicted results are analysed. Results show a large variation in the visualizations of the same action. Secondly, 56 potential users of the pictures filled out a questionnaire to evaluate the clarity and correctness with which the action is displayed in five representative pictures from the corpus with Heimlich’s description of the thrust action as a reference. Results showed that the pictures were considered far from perfect. In particular, the clarity of the visualization of the helper applying pressure on the abdomen of the victim was considered the least clear and incorrect. Thirdly, six certified first-aid instructors gave their expert opinions on the five pictures. Their comments concentrate on the location of the hands which are depicted dangerously high on the front of the victim. These studies advance the annotation and evaluation methodologies for the investigation of visualized actions. Results serve authoring and analysis of multimodal instructions.
Keywords
The best rescue technique in a situation in which someone is choking is the Heimlich maneuver (HM). Heimlich (1975) presents the instruction for the HM procedure using the five actions reformatted on separate lines below: Stand behind the victim and wrap your arms around his [sic, the victim’s] waist. Grasp your fist with your other hand and place the thumb side of your fist against the victim’s abdomen, slightly above the navel and below the rib cage. Press your fist into the victim’s abdomen with a quick upward thrust.
An instructive text about the HM, such as first-aid instructions on posters, verbalizes a sequence of actions that should be carried out to perform a procedural task. Apart from the actions, verbal and pictorial presentations of the procedure may include control information that specifies, for example, the manner in which a particular action should be executed (with a quick upward thrust), the conditions that should apply (a person is choking and their life is threatened by a windpipe obstruction), the situational context (choking is signalled by an inability to speak, cough or breathe), advice and warnings to avoid undesirable effects (in the case of obesity or late pregnancy, apply chest thrusts instead of abdomen thrusts) (Van der Sluis et al., 2016a, 2017).
A quick search on the internet shows that HM instructions appear in many forms and very often contain more text than what is included in Heimlich’s description presented above. Discovery of the action structure in these ‘extended’ procedural instructions requires proper processing of mainly the verbs in the instructions (Steehouder and Van der Meij, 2005; Van der Sluis et al., 2018, 2022; Zhang et al., 2012;). Actions in instructions most often occur in imperatives (Piwek, 2001[1998]; Steehouder et al., 2000), but can also include gerunds (e.g. to specify manner, as in ‘standing behind the victim’). Alternative actions and contingencies are verbalized using modal verbs (e.g. ‘Small children can just be turned on their side facing downward’), negations (e.g. ‘There should be no pressure on the chest that can make breathing difficult’), or conditionals (e.g. ‘If the victim is pregnant’).
Visualized instructions
In general, as also discussed in Clark (2016) and Pustejovsky (2018), depiction aids verbal communication. Similarly, although a verbalized instruction may be perceived as comprehensive, many studies have shown that users of instructive texts benefit from accompanying pictures that visualize the procedure (Houts et al., 2006; Katz et al., 2006). For instance, in the HM example, a verbalized instruction may tell the reader to stand behind the victim, but an accompanying picture could show the reader exactly how to do this in terms of, for example, proximity and orientation. The affordance offered via the visualization of the action adds to the comprehensibility of the instruction (Glenberg and Robertson, 1999). Comprehension in the case of HM is of great importance because an incorrectly performed thrust can cause severe injuries, such as breaking the victim’s breastbone or piercing the victim’s lungs (Koop, 1985).
Illustrated instructional texts that present the HM contain one or more pictures. Each picture visualizes an individual action from the sequence of HM actions in progress. These visualizations very often also show the results of the actions that were performed earlier in the sequence. For instance, Figures 1a and 1b both show the result of the Stand action in which the helper has positioned himself behind the victim. In addition, Figure 1b shows the process in which the helper wraps his arms around the victim.
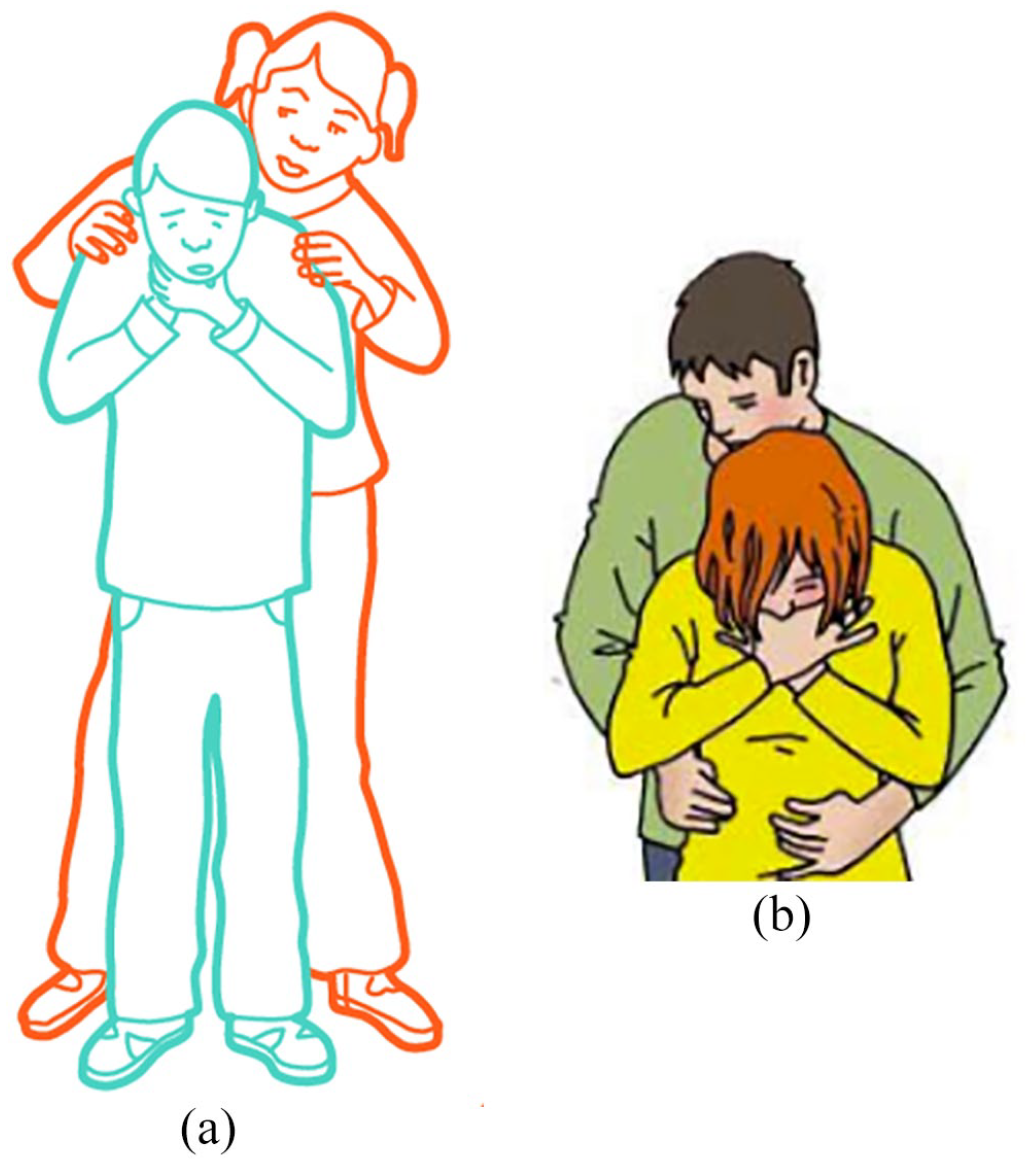
(a) Stand behind the victim; (b) Wrap your arms around his (the victim’s) waist.
To further support the users of these instructions, the included pictures may be enhanced with schematic forms such as lines or arrows with context-dependent meanings (Tversky, 2014). For instance, lines drawn close to a depicted person may indicate that the body is moving, arrows may point at a location or an object, or indicate a direction (Heiser and Tversky, 2006), and colour blobs may attract attention to a particular location and offer a symbolic meaning to the situation portrayed (Tversky et al., 2000). The comprehensibility of schematic forms, however, seems much dependent on demographic factors. For instance, for poorly educated South Africans, the use of motion indicating arrows and lines was found to be less effective to convey motion than the use of hands and body gestures (Carstens et al., 2006; Hoogwegt et al., 2009).
The diversity of HM instructions accessible via the internet also displays a variety of pictures that use the extensive potential of visual language to depict how the first-aid technique should be applied. Some examples included in the study presented in this article are displayed in Figure 2. This variety, especially in situations of life and death, raises questions like: How should authors visualize the actions? and Which visualizations are most effective?

Illustrations from left to right: (1) Mayo Clinic; (2) leereanimeren.nl; (3) Het Oranje Kruisboekje, 2011; (4) Het Oranje Kruisboekje, 2016; (5) Radiolab 1 .
Action identification, description and evaluation
Arguably, the evaluation of singular visualizations only makes sense when it is known how the content is depicted exactly. In our pilot studies (Van der Sluis et al., 2016b) we found that participants interpret and value pictures that accompany instructional texts very differently. In order to understand the meaning of effectiveness in the evaluation of pictures (i.e. to comprehend why particular visualizations are more effective than others), we advocate conducting corpus studies to describe and analyse the concept of investigation. Conceivably, the description of the various aspects used to visualize a particular action will allow the specification of the attributes that make a picture effective. There are numerous theories and methods proposed to describe visual content on its own as well as in multimodal contexts (Bateman, 2008; Bateman et al., 2017; Kress and Van Leeuwen, 2020; Rose, 2016; Smith et al., 2004). Various reviews and more concrete studies have also explored the schemes chosen by authors to present actions in static pictures (De Souza, 2008; De Souza and Dyson, 2008; Parkinson et al., 2020; Thomson, 2021; Tufte, 1997). In order to approach animated demonstration of actions in static visualizations, authors often use sequences of pictures to show the results of the various actions involved in the procedure. Other approaches, as discussed in Doran (2019), visualize movement in one picture by depicting an object in a number of stages in a sequence where the stages are connected with arrows. By analysing multiple pictures that visualize the HM thrust action as well as the result of some of the actions performed earlier in the sequence leading up to the thrust action, this article seeks to complement current methods to investigate visual content.
In addition, by specifying the aspects important to the visualization of actions, the proposed analysis may also be beneficial for current efforts to automatically caption pictures. Nowadays, it is possible to recognize visualized objects automatically. In the case of the HM pictures exemplified in Figure 1, the two depicted persons can probably be identified due to rapidly advancing techniques that employ (pretrained) CNN models (Lu et al., 2019, 2020; Tan and Bansal, 2019) for learning on large collections of pictures (Lin et al., 2014; Sharma et al., 2018). The identification of depicted actions – and thereby the inferences about the contextual roles of the objects or persons depicted – is still challenging (Birmingham et al., 2018; Jensen and Lulla, 2008; Karpathy and Fei-Fei, 2015; Socher et al., 2014; Stanfield and Zwaan, 2001). However, fusing techniques that combine vision and language modes seem promising (Bisk et al., 2020; Chen et al., 2020; Li et al., 2019; Su et al., 2020). Potentially, identification of the actions in the text can inform the identification of these actions (and/or their results) in the accompanying pictures (Ghanimifard and Dobnik, 2017; Hürlimann and Bos, 2016; Parcalabescu et al., 2021; Vedantam et al., 2015). For instance, in Silberer and Pinkal (2018), it is shown that spatial relations of the objects in a visual scene can be used together with syntax-based techniques to develop accurate models for image description generation. By investigating the characteristics of the visualization of actions in multimodal documents, such as the instructions from which the HM thrust visualizations used in this study are derived, we hope to contribute to the automatic identification of visualized actions.
Finally, the work presented in this article shares insights in evaluation methodologies set up to investigate the perception of visualized actions. As stated previously, visualizations can be described in many ways (e.g. perspective, drawing style, colouring, graphical enhancements), but the effectiveness of these aspects is likely to depend on the characteristics of the viewer. In the domain of first-aid communication, authors of multimodal instructions are relating to first-aid instructors as well as the general public. These audiences use the instructions for different purposes, for example, teaching how to perform the HM and using the HM to save a victim’s life, respectively. Therefore, perception studies that address the characteristics of the viewers (see Wilson and Landon-Hays, 2016; Zoss et al., 2010) are likely to result in a variety of pictorial aspects that add to the effectiveness of a visualized action.
Studying thrust visualizations
The three studies presented in this article serve to illustrate the iterative development of a model to annotate visualized HM thrusts and to evaluate their effectiveness. Different evaluation cycles are used to investigate the effectiveness and completeness of the descriptive categories. The studies aim to answer the research question: How should the thrust action of the HM be visualized in terms of clarity and correctness?
Firstly, a corpus study was conducted to describe pictures taken from illustrated verbal instructions that were written in Dutch or English. The studied corpus only includes pictures that visualize the thrust action in progress. As a starting point, the corpus was analysed employing a model with attributes to describe the composition of the pictures as well as content-related aspects that describe the visualized people. The corpus study was used to determine a balanced subset of pictures from the corpus for evaluation purposes.
Subsequently, two evaluation studies were conducted to investigate the perceived quality of five HM thrust visualizations as well as to further improve the annotation model. The studies target different audiences. The evaluation studies offer insight into aspects that the participants noticed and considered beneficial or harmful to the clarity and correctness of the HM thrust visualizations and that are therefore worthwhile analysing. The studies also show considerable differences between the two different user groups in terms of the visual aspects that they consider to be important.
Corpus Study
The corpus study presented below was set up to describe the way in which the thrust action is visualized. An annotation model was developed to find out more about the visual features used to depict the HM thrust action. The pictures are annotated and analysed accordingly.
Data set
The corpus study uses a subset of the PAT corpus 2 , a collection of over 300 first-aid instructions that include pictures and text (Van der Sluis et al., 2016a), complemented with new instances retrieved from the internet. The final corpus of the project presented in this article comprises 30 pictures that stem from different instructions that are meant to instruct the general public on how to execute the HM thrust action with the ultimate goal of saving life in a life-threatening choking situation. Given the variety of thrust visualizations discussed in the introduction of this article, the corpus is balanced in that it contains 15 drawings and 15 photographs. The drawings as well as the photographs differ in many ways, for example, drawing styles, colouring and backgrounds. As a result, the annotation model resulting from this corpus study will be applicable to describe the HM thrust action independent of the visualization. The corpus selection criteria were as follows:
Victim and helper are both visible.
Helper is standing behind the victim facing the victim’s back.
Victim is standing or sitting in front of the helper facing away from the helper.
Helper is performing the thrust action with arms placed around the victim’s waist and hands touching in front of the victim’s waist.
Annotation model
Table 1 presents the annotation model in terms of attributes and values. The corpus includes visualizations of victims that are either standing or sitting. Because the position of the victim is likely to affect the body position of the helper, some attributes were used to describe the pictures. For instance, the attribute Perspective specifies if the picture presents the scene using a Long shot in which helper and victim are fully visible, or a Middle shot where the helper and victim are visible from the waist up. The Angle, described from the perspective of the viewer, either shows a frontal view or a view from the side, where the helper and victim are both facing towards the Left or towards the Right. The model includes a description of the body posture of the victim (i.e. Standing, Sitting) and of the helper (i.e. Bent forward, Straight).
Annotation model for the HM thrust action.

Other attributes were included to describe the visualized performance of the thrust action and the scene in more detail. The model includes a description of the hand positions of the victim (i.e. Straight down, One hand on throat, Both hands on throat) and of the helper (i.e. Wrist grab, On top of each other, Not visible). The pictures in the corpus also include additional features to amplify the visualization of the thrust action, which are described as Lines around the body (e.g. lines aligned with the helper’s back to indicate movement), Shirt wrinkles, Arrows and coloured areas (Colour) specifying the compression performed by the helper at the front of the victim’s body. The Result of a successful thrust action, i.e. visualized as an obstacle ejected from the victim’s mouth, is described in terms of Object, Arrow and Line.
The annotation model was developed in an iterative process. Five annotators (four of whom attended a first-aid course that included HM) prepared a preliminary model by studying and analysing a test subset of the corpus (n = 8) together. Subsequently, the annotators individually applied the preliminary model to annotate the validation subset of the corpus (n = 22) employing the VGG Image Annotator (VIA) 3 . The agreement between the five resulting silver standard annotations was calculated with Fleiss Kappa (Fleiss, 1971; Fleiss et al., 2003) and valued according to the directions by Landis and Koch (1977). The agreement scores, together with the notes of the annotators, were used to find and resolve errors in the annotations and to improve the preliminary annotation model. For instance, for the attribute Helper’s hands, the value On top of each other was introduced because the visibility of the helper’s fingers was not always sufficient to determine how the hands were connected (e.g. in some cases the fingers seemed interlaced). Some values of the Thrust action turned out to include multiple features and the values were specified in more detail accordingly. Finally, the whole corpus (N = 30) was annotated with the improved annotation model (Table 1) and double-checked by two annotators.
Results
Table 2 presents the corpus in terms of the attributes specified in the annotation model for 15 photographs and 15 drawings separately. Most of the pictures present a Middle shot (83.3%; n = 25). The action is usually depicted using a Left or Right Angle (86.7%; n = 26) as opposed to a view from the Front (13.3%; n = 4). In 90 percent (n = 27) of the pictures, the victim is Standing instead of Sitting (10%; n = 3). The position of the victim’s hands varies: in 43.3 percent (n = 13) of the pictures the victim’s hands are hanging down, while in 56.7 percent (n = 17) one or both hands are located at the victim’s throat.
Frequencies and percentages for the attributes that describe the Perspective, Angle, Victim’s and Helper’s bodies and hands (with percentages calculated per attribute), as well as the number of pictures that include additional features to visualize the Thrust action and the Result of this action (where the percentages are calculated for the whole corpus as the values are not mutually exclusive). a

The ratio is offered via the frequencies and the total number of pictures in the set. The percentages, of course, give a coarse indication of the accuracy of the measurements, because they indicate parts of pictures instead of the pictures as a whole.
The helper’s body is mostly visualized in an upright position (86.7%; n = 26) instead of Bent forward (13.3%; n = 4). The helper’s hands are mostly placed On top of each other (60%; n = 18), or shown in a Wrist grab (26.7%; n = 8); in 13.3 percent (n = 4) of the pictures the position is Not visible. The Thrust action is amplified in some of the pictures in the corpus by using additional features (n = 30). In the photographs, mainly Shirt wrinkles were present (n = 11; 73.3%). In the drawings not only Shirt Wrinkles (n = 8; 53.3%) but also Arrows (n =8; 53.3%) were frequently added. Often more than one additional feature was present in one picture. Apart from the Shirt wrinkles, the other additional features (i.e. Lines around the body and Colour) were mainly used in the drawings. In eight pictures (26.7%; 4 photos and 4 drawings), there were no additional features included. The visualization of the result of the HM, where the item that caused the airway blockage comes out of the victim’s mouth, is depicted using additional features in six pictures (20%; 1 photo and 5 drawings). In these cases, different features (i.e. Object, Arrow, Line) are often combined.
User Judgements
The study presented below was set up to evaluate the clarity and correctness of five representative pictures from the corpus. As the pictures in this project stem from instructions that are targeting lay persons, the authors distributed a questionnaire via their LinkedIn networks.
Participants
To evaluate five pictures in which the thrust action is visualized, 56 participants (40 females and 16 males), aged between 20 and 68 (M = 33.3; SD = 12.5) filled out a Qualtrics questionnaire. The participants mostly resided in the Netherlands (n = 39) and Germany (n = 11) which matches the origin of the pictures used in the corpus. Of the total number of participants, 43 said that they knew what the HM is, 6 were unfamiliar with the term and 7 were unsure about their knowledge of HM; 32 participants had no experience with executing HM, 24 had experience with HM and chose one of the following options: they had either executed HM themselves (n = 4), seen somebody else perform HM (n = 5), or both (n = 1), or they had taken a first-aid course that included HM (n = 14). Although participants’ knowledge of the HM is lower than one would hope for in general, it was expected that the participants would not have any knowledge or experience with the HM at all and that all the participants would need time to familiarize themselves with the procedure to make proper judgements about the pictures to be evaluated in this study. Therefore, all participants were offered time to study the description and use of the HM before answering any of the evaluative questions.
Materials
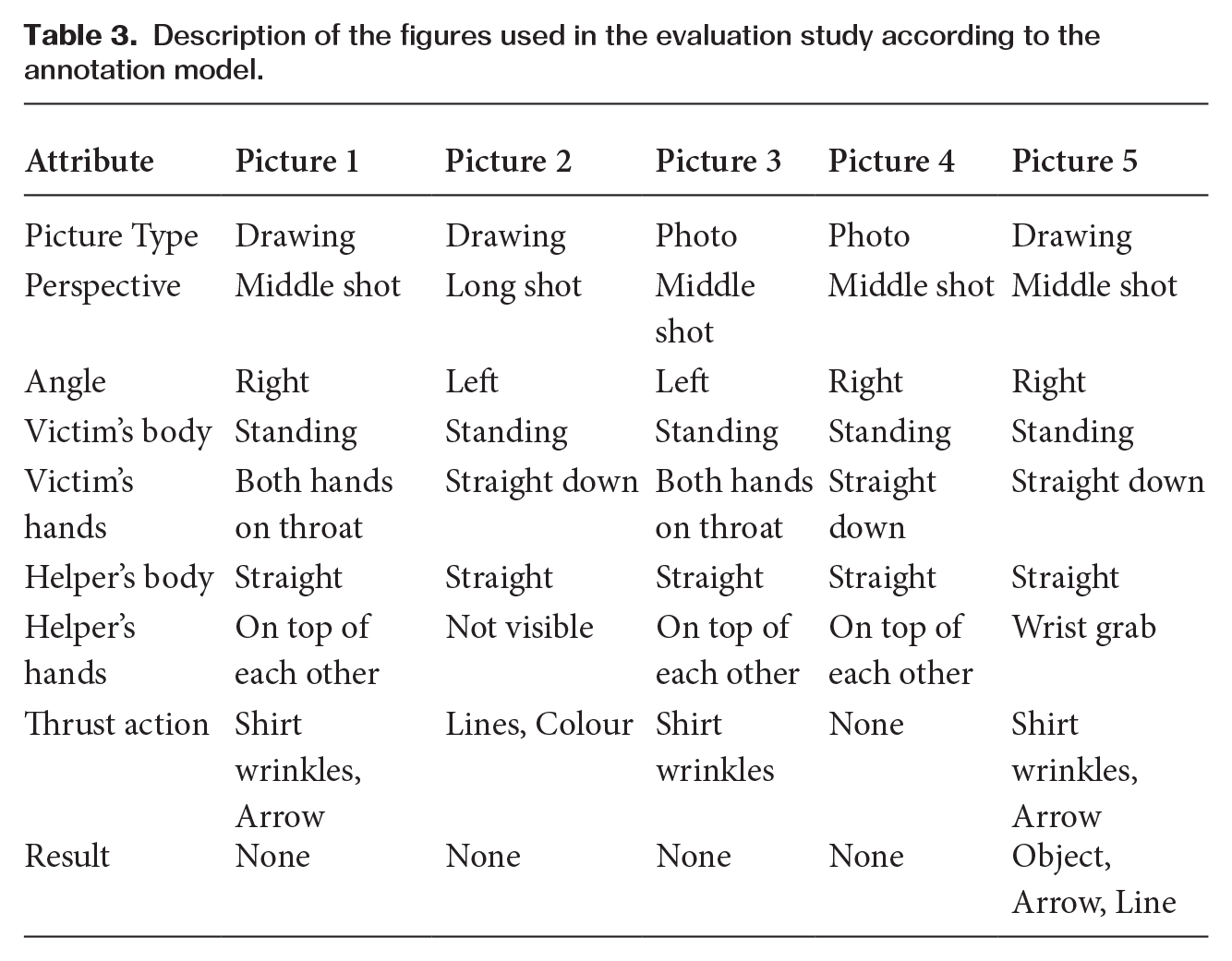
The five pictures evaluated in this study are presented in Figure 2. Table 3 presents a description of the pictures in terms of the corpus annotation. The pictures (2 photographs, 3 drawings) were chosen to reflect the variation in the corpus. Each of the pictures was presented, accompanied by the HM description (see Figure 3) and two questions about the visualization of the thrust action in the pictures.
Description of the figures used in the evaluation study according to the annotation model.

Presentation of HM instruction text.
Note that the HM description was presented as consisting of four steps, where the first step included the first two actions in the HM procedure: (1) as also presented in the introduction of this article (i.e. Stand behind the victim and Wrap your arms around his [the victim’s] waist). As the pictures stem from a corpus that includes only pictures in which the helper performed the thrust action, the result of the actions in this first step were entailed. The sentence was therefore not split but kept as Heimlich has presented it. In contrast, the second sentence of the instruction was split into two steps separating the two actions in it (i.e. Grasp your fist with your other hand and Place the thumb side of your fist against the victim’s abdomen, slightly above the navel and below the rib cage). Since the corpus analysis had shown that the description of the helper’s hands was not straightforward and since the annotators had difficulty judging the location of the hands, it was decided to investigate the judgements of the participants in the user study on these actions separately.
Firstly, the participants were asked to indicate how far they agreed that particular aspects of the thrust action were clearly visualized (see Figure 4). In this question we concentrated on the helper as described in the corpus study: Location of the helper’s hands, Connection of the helper’s hands, Pressure indication and Direction in which the pressure is applied, where we split the Thrust action attribute in terms of the application of pressure and the direction of the applied pressure. The Clarity question was presented using a seven-point Likert scale (1 = completely disagree to 7 = completely agree).

Presentation of Clarity question.
Secondly, participants were asked to indicate if the sub-actions included in the HM description (i.e. Stand & Wrap, Grasp, Place, Press) were incorrectly visualized, or explicitly indicate that all sub-actions were correctly visualized. The Correctness question was presented using check boxes, one for each of the sub-actions that was incorrectly visualized and one to indicate that all sub-actions were correctly visualized (see Figure 5).

Presentation of Correctness question.
Procedure
Table 4 presents the results collected with the evaluation study. The results did not differ significantly between the participants with and without first-aid experience; in terms of clarity and correctness, the participants without experience were slightly more critical with respect to Pictures 2, 3 and 4.
Means and standard deviations for Clarity on a 7-point scale (1 = unclear to 7 = clear) plus frequencies and percentages for Correctness for the sub-actions included in the HM description. 4
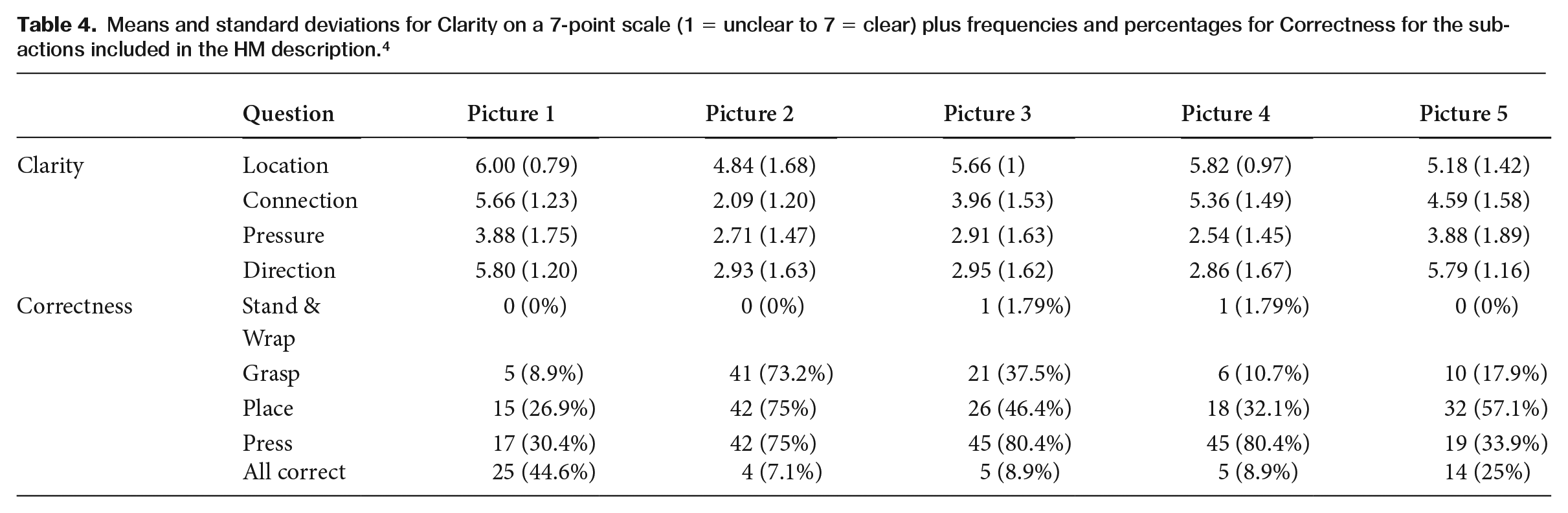
Clarity: The Location of the helper’s hands was generally perceived as clear. The Connection of the helper’s hands was perceived as unclear in Picture 2 (M = 2.09; SD = 1.20), Pictures 1 and 4 scored best in terms of the clarity of the connection; the view of the helper’s hands, in the drawing and photograph, respectively, is slightly more frontal compared to Picture 3, and not obstructed by arrows (cf. Picture 5) or by the victim’s arms (cf. Picture 2). Overall, the Pressure conducted by the helper’s hands was perceived as the least clear, where Pictures 2, 3 and 4 are unclear and Pictures 1 and 5, in which the pressure is indicated with additional arrows, scored almost neutral. The Direction of the thrust action was also perceived as unclear in Pictures 2, 3 and 4. Overall, in terms of clarity Pictures 1 and Picture 5 scored best.
Correctness: In general, as we expected, most of the 56 participants who took part in our study found that the helper is Standing and Wrapping correctly in the five pictures. However, the helper Grasps the fist of his other hand incorrectly in Pictures 2 (n = 41 ; 73.2%) and 3 (n = 21; 37.2%). Less than 20 percent determined the helper’s grasp to be incorrect in Pictures 1 (n = 5; 8.9%), 4 (n = 6; 10.7%) and 5 (n = 10; 17.9%), where the view of the helper’s hands is slightly more frontal compared to Pictures 2 and 3. More than half of the participants said that the helper does not correctly apply Pressure in Pictures 2 (n = 42; 75%), 3 (n = 45; 80.4%) and 4 (n = 45; 80.4%), where no arrows are included. Overall, Picture 1 with an L-shaped arrow and the victim with his hands placed at his throat scored best, 25 participants (44.6%) said that the helper performed the actions correctly.
Expert views
Six certified first-aid instructors (2 male, 4 female) volunteered to comment on the HM pictures presented in Figure 2. They were asked for their expert view; no further instructions were given. Results consist of 30 freely written text comments. In our analysis of these comments, a number of aspects of the visualized HM thrust action emerged and are addressed below.
Helper’s hands position: In 21 cases, the experts said that the helper placed his hands too high on the victim’s abdomen (Picture 1, n = 4; Picture 2, n = 5; Picture 3, n = 2; Picture 4, n = 4; Picture 5, n = 6). Two experts said that the helper’s hands are placed too high in all five pictures. In three cases (Picture 1, n = 2; Picture 3, n = 1) this aspect of the visualization was not commented on. Three experts find the helper’s hands in Picture 3 correctly placed. One expert explicitly said that the little finger of the helper in Picture 3 is more or less located on the victim’s belly button. The same expert remarked that maybe not on first sight, but when looking more closely at Picture 4, the helper’s fist is placed in the correct location. This expert acknowledged that, in drawings, the helper’s fist is often placed too high. One expert explained that, by placing the hands too high, the helper risks fracturing the bottom part (xiphoid process, Figure 6) of the sternum. Two experts said that, in general, if the helper placed his arms on the victim’s hips, the placement of the hands would be correct and result in a proper oblique pull.
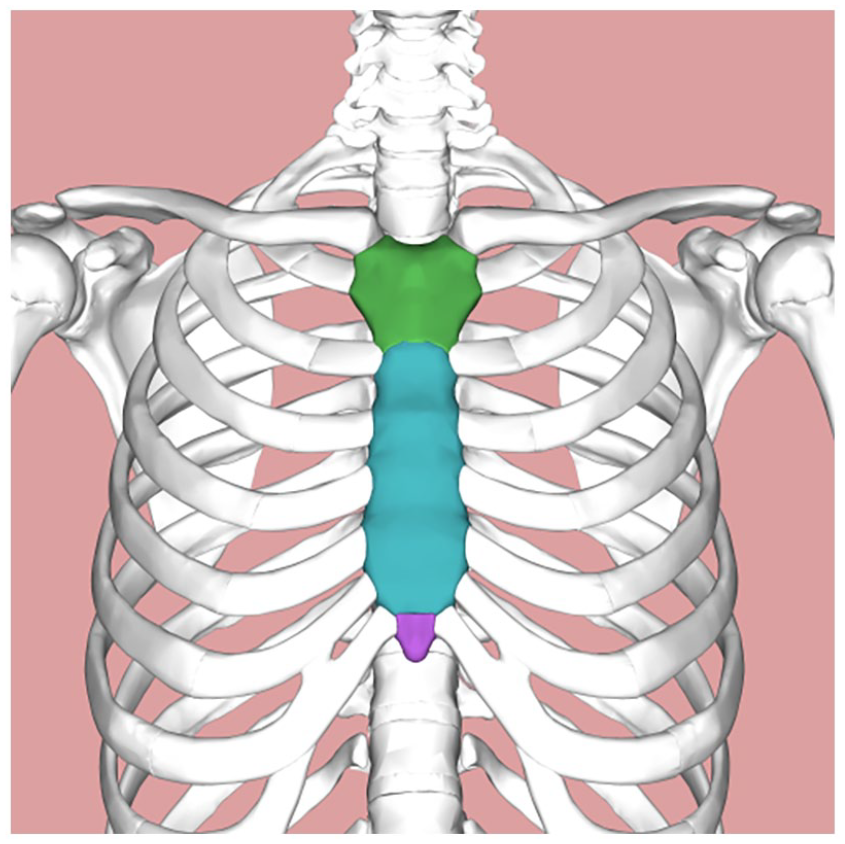
Parts of the sternum: manubrium (green), body (blue), xiphoid process (purple). Available at: https://en.wikipedia.org/wiki/ licensed under CC BY-SA
Body positions: Two experts said that the helper’s position, a bit on the side at the back of the victim, is clearly visible in Pictures 2 and 4. One expert also appreciated the forward bend of the victim’s body in Pictures 2 and 4, and also in Picture 5.
Additional features: The additional features in the pictures were valued by two of the six experts. Both said that the L-shaped pull is clearly marked by the arrow in Picture 1. One expert found the lines at the back of the helper in Picture 2 unclear. One expert found the lines drawn in Picture 5 unsuitable and that they blurred the helper’s hands, whereas one expert appreciated the visualized result in Picture 5.
Realism: One expert mentioned that she had never seen a victim grabbing his throat in the manner shown in Pictures 1 and 3. The expert hypothesized that this visualization may have been motivated by reasons of clarity. One expert found Pictures 4 and 5 the most realistic, although she acknowledged that the location of the helper’s hands was incorrect in both pictures. Two experts mentioned the blue face of the victim in Picture 3 which, while indicating the danger of the situation, may be distracting, according to one expert. In contrast, another expert found that the victim in Picture 4 could have looked a bit more anxious. This expert also said that sunglasses as worn by the helper in Picture 5 are not recommended when providing first-aid because they may be considered intimidating.
Clarity: One expert said that Picture 5 was the most clear because it shows what the helper should do even though the location of the helper’s hands is incorrect. Two experts found that Picture 3 presents the proper aid and two experts said the same of Picture 4.
Overall, the experts offered clearly motivated observations with which the attributes in the annotation model can be further developed, not only to describe the thrust action, but also to address the diversity of the corpus. In terms of correctness and clarity, it is key that the most important aspect of the thrust visualization (i.e. the location of the helper’s hands) is not obscured by any graphical enhancement (e.g. arrows or lines) nor by the visualization of the helper and victim themselves (e.g. the victim’s arms should not be obstructing the hands of the helper). In terms of completeness or coverage of the diversity of the corpus, various means can be used to emphasize the importance of particular aspects of the procedure (e.g. the direction of the thrust action) and the critical situation that potential viewers of the pictures should expect to encounter (e.g. the anxiety of the victim). The expert study was also invaluable for understanding the potential effects of details like the sunglasses, that initially were not taken into consideration in the corpus study.
Conclusion and Future Work
Discussion of findings
In the corpus study, eight attributes were identified to describe the HM thrust action visualized in 30 different instructions. Results showed that the thrust action is most often visualized with a Middle shot from a Left or Right Angle. The victim’s hands were either hanging Straight down, or the victim used one or both hands to grab his throat. It turned out that, when excluding the two pictures in which the victim was seated, the percentage of pictures in which one or both hands of the victim were located on the throat increased from 57 to 75 percent; no other differences were observed. The effect of the position of the victim’s hands on the visibility of the thrust action that the helper is performing needs further investigation. In some of the corpus pictures, the arms of the victim obstructed the view of the hands of the helper. The position of the victim’s hands may contribute to the indicated danger. However, in the instructive context in which these pictures are used, the actual state of the victim may be less important than the manner in which the helper performs the action.
Especially when knowing that one can cause damage by thrusting one’s thumbs into the victim’s abdomen, the depiction of the helper’s hands that perform the thrust action shows a surprising amount of variation. Given the description of the HM thrust action in the quote in Section 1 ‘Grasp your fist with your other hand’ we would expect the helper’s hands to be depicted in a Wrist grab, but this was the case in only eight pictures (26.7%). In 60.0 percent of the cases (n = 18), the more general description On top of each other was chosen to describe the position of the helper’s hands; no clear consensus could be reached amongst the five annotators on whether the helper’s fingers were interlaced or not. In 13.3 percent of the cases (n = 4) the helper’s hands were not even visible. Curiously, none of the experts mentioned the connection of the helper’s hands as a problem in the pictures. The helper’s fist was mentioned explicitly by three experts. Additional features such as lines and arrows to specify the thrust action were used mainly in the drawings. The direction ‘into the victim’s abdomen with a quick upward thrust’, i.e. in and upward, was specified with arrows in eight drawings.
The location of the helper’s hands was not described in the corpus study. Although we are inclined to think that, in a number of cases, the location of the helper’s hands is incorrect or indeterminable, we felt that experts were needed to ascertain if the pictures display the location correctly. This intuition was confirmed by the large differences between the users’ judgements and the expert views on the location of the helper’s hands. Given the results from the expert views, improvements in the annotation of pictures can be made by including the victim’s body description (i.e. add Bent forward, Straight) and indications of urgency (e.g. facial expressions).
Interestingly, the participants who filled out the questionnaire considered other aspects in the visualization of the thrust action than the experts. The participants in the questionnaire seemed to concentrate on the visualization of the pressure applied by the helper, while the experts first checked the location of the helper’s hands. Experts also checked the body positions of the victim and helper, and some appreciated indications of the urgency of the situation. Most experts did not comment on the additional features; perhaps these features were not noticed when included or were not missed when present. The experts’ comments on the additional features that were collected rendered mixed results. In our corpus, only eight pictures include an arrow to visualize the thrust action; the quality of these arrows (e.g. L-shaped or other) needs further investigation. In our current studies on instruction comics presented on posters (Wildfeuer et al., 2022) that present the HM procedure, and in first-aid instructions for children, these and other additional features appear often (cf. Bateman and Wildfeuer, 2014; Cohn and Maher, 2015; Forceville, 2011).
The questionnaire results showed that the drawing in Picture 1 is favoured in terms of clarity and correctness; in this picture, the arrow clearly indicates the pressure and the direction in which the pressure is applied. The added value of the arrow in Picture 1 is confirmed by two experts. Perhaps the non-experts are not so aware of the danger involved when placing the hands too high. The experts’ views show mixed results, Pictures 3 and 4 (both photos) are most correct in terms of the placement of the helper’s hands, while Picture 5 shows what the helper should do in the most realistic way. The preferred pictures (1, 3, 4 and 5) all use a Middle shot, but the Angle varies.
Guidelines for authors
The work presented in this article concentrates on visualized HM thrust actions. To answer the question, ‘How should the thrust action of the HM be visualized in terms of clarity and correctness?’, we can conclude that a middle shot of the HM thrust action is most clear and correct, only if the helper’s hands are placed at the correct location on the victim’s abdomen, ‘slightly above the navel and below the rib cage’, to avoid piercing the victim’s lungs with his own sternum. In addition, an L-shaped arrow, provided that it is not obstructing the view of the helper’s hands, could help viewers to understand the direction of the thrust action. Obviously, for HM thrust actions and other lifesaving first-aid operations, such as placing a victim in a recovery position or resuscitating a victim, it is a matter of life and death that the pictures included in an instruction visualize the necessary actions clearly and correctly.
Authoring multimodal instructions, such as the ones from which the pictures studied in this article are derived, also includes combining text and pictures. While coherence relations between text and pictures have been categorized at various levels of granularity (Barthes, 1977; Martinec and Salway, 2005), the finer-grained coherence relations – i.e. elaborations, extensions and/or enhancements as proposed by Bateman and Wildfeuer (2014) and Halliday and Matthiessen (1985) –seem useful for application in guidelines to authors of HM and plausibly also in other instructions. For example, the text elaborates on the content of the picture if it describes the way in which the helper should hold his hands while the accompanying picture does not show the hand grasp in detail. Alternatively, a picture that shows how the windpipe obstruction is removed as a result of the thrust action extends a verbal instruction in which this result is not mentioned. And, by showing the position and stance of the helper behind a victim, a picture enhances the text in which the exact location and orientation of the helper are not specified. Corpus studies as presented in this article benefit the discovery of the aspects involved in composing multimodal instructions. Guiding authors in distributing the information across modalities requires user studies to investigate to what extent visual and verbal content are best combined in terms of effectiveness (Van der Sluis et al., 2016b, 2017).
Visualization studies
This article presented an approach for studying the visualization of a particular action. The study of the HM thrust action started with text (i.e. Heimlich’s own description) and a variety of pictures that visualized the HM thrust action. Heimlich’s description was analysed as containing five different actions (e.g. Stand, Wrap, Grasp, Place, Press). Pictures in procedural descriptions show results of actions that were performed earlier in the sequence of actions. Also, in the HM thrust visualizations, the results of the Stand and Wrap actions are visible. Because the thrust action was the focus of this study, the Grasp, Place and Press actions were considered most important. Differentiation between the analysis of the visualization of actions in progress and the visualization of the results of actions, especially when the actions are sequential and display temporal relations, are left for future work. Further directions for analysis include sequential actions in other multimodal documents such as instruction comics (Wildfeuer et al., 2022) instruction videos and animated pictures (e.g. static pictures with moving arrows). Currently, our studies in which we apply the same HM action structure to an illustrated instructive texts and instruction comics show that additional categories such as talking to the victim are required to address the displayed actions of the helper in comics.
The work presented in this article shows the added value of alternating corpus studies and evaluation studies. As envisioned, the annotation model turned out to be applicable to a variety of pictures (15 drawings and 15 photographs) and helped the selection of a balanced set of pictures for evaluation. The user studies that we conducted resulted in aspects of the visualizations that can be employed to further enhance the annotation model to include effective attributes for description. The participants’ familiarity with and use of the visualized action clearly affected their perception and evaluation of the visualizations in terms of clarity and correctness. In future, versions of the annotation model attributes for addressing clarity, correctness, realism and graphical enhancement may turn out to be competing factors (e.g. a victim with his hands at his throat may not be realistic, but the stance offers a clear view of the helper’s hands). Moreover, these factors may be perceived differently by other audiences than the mostly Dutch and German participants in our studies. Future work should therefore also include visualizations and users from other parts of the world.
Footnotes
Acknowledgements
Our thanks to the anonymous reviewers for their very precise and useful comments on previous versions of this article. Thanks to Janina Wildfeuer and Gisela Redeker for useful comments on the presentation of our work. Thanks to Charlotte Nolting-Hauff for her help with the corpus study. Thanks to Arie Wolters and Marianne Gruis at the K.N.V. EHBO afdeling Groningen for their help with contacting certified first-aid instructors to evaluate the pictures.
Funding
The authors received no financial support for the research, authorship and publication of this article, and there is no conflict of interest.
Notes
Biographical Notes
IELKA VAN DER SLUIS is a computational linguist, specialising in the areas of human communication, multimodal information presentation, human-computer interaction, natural language generation, affective computing and multimodal interaction. She researches the production and processing of the visual and verbal means that people employ to communicate as well as the contexts of use in which this happens through collection and analysis of corpora and empirical experimentation. The data collected in her studies offers new insights in the workings of human communication that can be used to guide authors of multimodal documents and to improve computational models for use in real-life applications. Dr. Ielka van der Sluis is a member of the Center for Language and Cognition Groningen (http://www.rug.nl/research/clcg/) and an Assistant Professor at the Department of Communication and Information Science at the University of Groningen. In the past she has worked as a Research Fellow at the Computational Linguistics Group at the Department of Computer Science at the Trinity College Dublin in Ireland, the Natural Language Generation Group at the University of Aberdeen, and the University of Tilburg. Detailed CV: ![]()
Address: Center for Language and Cognition, University of Groningen, Oude Kijk in ’t Jatstraat 26, Harmoniegebouw 1312-428, Groningen 9712 EK, The Netherlands. [email:
GABRIELA MATOUŠKOVÁ is a graduate of the study programme Communication and Information Studies at the Faculty of Arts, University of Groningen. She currently holds the position of event and community manager at the Aletta Jacobs School of Public Health in Groningen, connecting researchers from different disciplines to work together on projects addressing public health challenges and communicating science to the public through various public engagement programmes. Besides that, she is interested in health communication and effects of social media on health.
Address: as Ielka Van der Sluis. [email:
HANNAH NIEMEIER is currently completing her bachelor’s in Communication and Information Sciences at the Faculty of Arts, University of Groningen. She is currently doing a minor abroad at Queens University, Kingston, Canada focusing on Linguistic features in Science Fiction and Fantasy literature. Besides that, she is interested in environmental communication and health communication.
Address: as Ielka Van der Sluis. [email:
SOPHIA POPP has completed here bachelors in Communication and Information Science at the University of Groningen and is currently pursuing her masters in Management of Information Systems and Digital Innovation at the London School of Economics and Political Science. She has conducted research in the fields of human-computer interaction, information communication technologies, digital networks, linguistics and multimodal information presentation. Moreover, she has gained insights into policy making research through an extracurricular program at the University of Groningen. Her most recent research interest is the field of data governance and generativity of digital platforms and infrastructures.
Address: as Ielka Van der Sluis. [email:
JOSEPHINE CARSTENS founded her own company,after graduating from the bachelor programme Communication Information Studies at the University of Groningen. In her company she is running a career as a cinematographer and marketing consultant. At this moment she plans, consults and conducts film productions and social media campaigns, working for companies and private clients in Germany, Austria and the Netherlands. Her research interest surrounds the effect and meaning of multimodal information presentation, particularly, videography in multimedia communication.
Address: as Ielka Van der Sluis. [email: