
Abstract
This paper presents three studies on the design, use and effectiveness of multimodal online baking blogs that present cookie recipes in two forms: illustrated step-by-step Instructions with Pictures and printable text-only Recipe Cards. Firstly, a corpus study describes how authors combine text and pictures in 15 blogs. Secondly, an eye-tracking study was conducted to explore how 12 participants read and evaluate baking blogs and the Instructions with Pictures in them. Finally, a user study was conducted to explore how 4 teams of participants execute and evaluate either an Instruction with Pictures or a Recipe Card of a typical baking blog. Questionnaire data on the readers’ and users’ judgments of the comprehensibility, design and their (expected) performance of the instructions, as well as eye-tracker data and videos capturing the reading and baking practices were collected and analysed. Thus, the triangulation of exploratory studies displays how different research methodologies inform the relevance and evaluation of particular characteristics of multimodal presentations given the readers’ and users’ judgments as well as through objective measurements that provide complementary insights on multimodal baking instructions in terms of multimodal information presentation, reading strategies and situated use.
Introduction
Cooking and baking recipes have been around for centuries, presented in manuscripts, cooking books and various other written resources (Arendholz et al., 2013). In the current age of digital platforms, culinary enthusiasts have found a new home on the internet, where they can access a wealth of recipes on cooking and baking blogs, often accompanied by helpful pictures and videos. As the online realm continues to expand, it becomes useful to explore how the multimodal nature of online baking instructions impacts on the effectiveness of these culinary guides. Embracing this challenge, this paper delves into online baking blogs containing written step-by-step instructions and step-by-step pictures. Through triangulation of a corpus analysis, an eye-tracking study, and a user study, the research presented in this paper not only studies multimodal design and its impact on readers and users, but also displays how description and evaluation methods reinforce each other in terms of implementation, data processing and subsequent research questions.
Cookie baking instructions
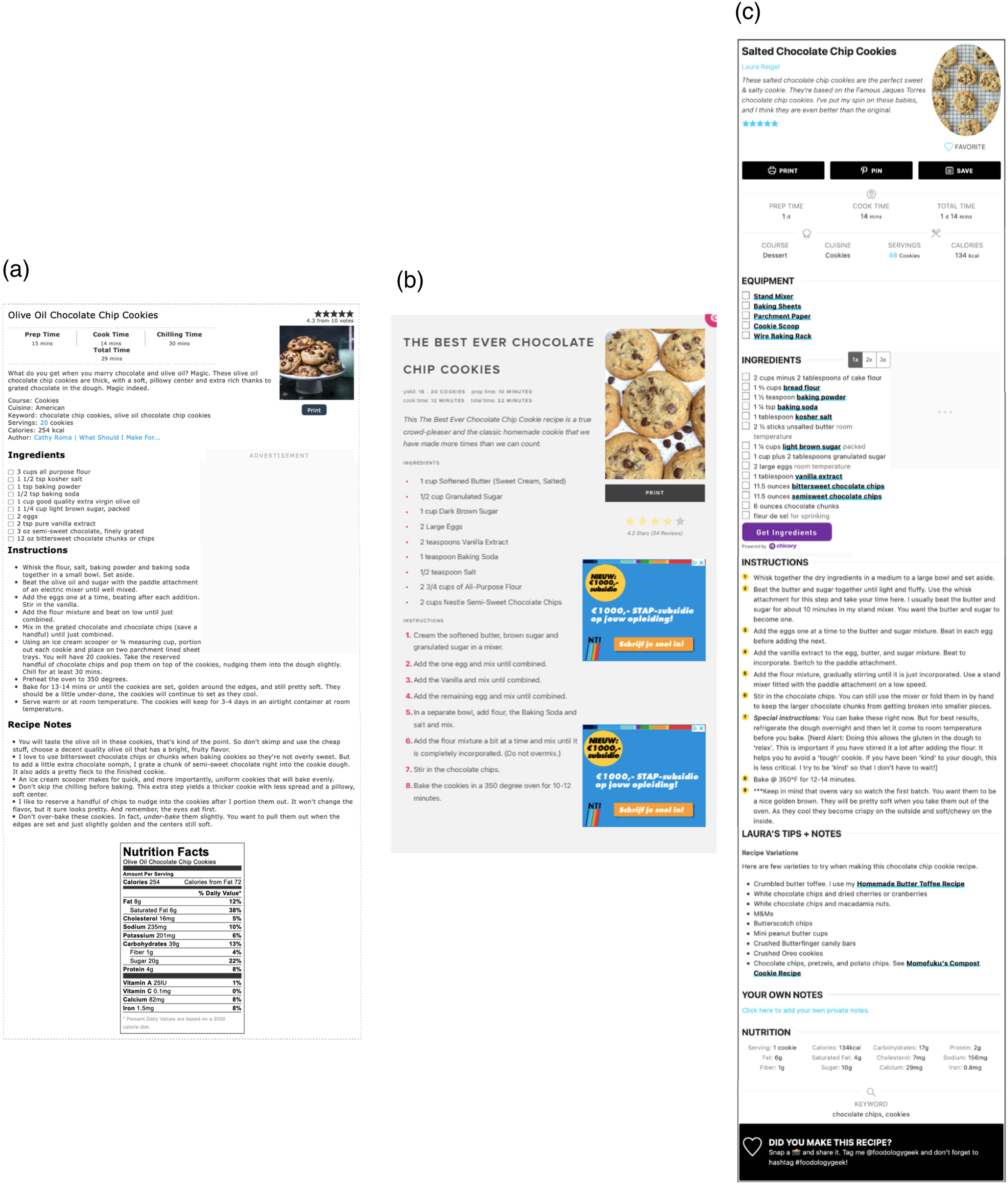
The baking recipes examined in the studies presented in this paper are considered multimodal instructions (MIs), which combine different forms of communication: text and pictures. Building upon existing research in multimodal analysis (cf. Bateman et al., 2017) and in reader and user studies (cf., Holsanova, 2014), this study specifically investigates multimodal baking instructions for chocolate chip cookies sourced from online baking blogs. Typically, these online baking blogs present recipes in two formats within the webpage. The blog text includes an embedded instruction with step-by-step pictures, which we will call the Instruction with Pictures. At the end of the blog, a printable card, which we will call the Recipe Card, provides instructions for the same recipe. Bowker (2021) differentiates the blog content from the Recipe Card by highlighting that the Recipe Card contains all the necessary steps and ingredients, while the preceding blog content allows for additional information and visualizations of particular states in the procedure. The current study focuses on the Instruction with Pictures (IWP), which combines textual and pictorial step-by-step baking instructions, as well as the Recipe Card (RC), which usually only includes a single picture of the end product. Examples of these two types of instructions can be found in Figure 1(a) and (b). Since both instructional texts present the same recipe, while only the IWP includes step-by-step pictures, the blogs provide an good opportunity for a comprehensive analysis of the presentation and effectiveness of text and pictures of the baking instructions. Thus, a corpus study was undertaken to provide a systematic description of the text, pictures, and the relations between them in both the IWP and the RC. Additionally, an eye-tracking study was designed to explore how individuals read and judge a baking blog as a whole and an Instruction with Pictures by itself. Finally in a user study, participants were instructed to bake cookies using either the Instruction with Pictures or the Recipe Card, to examine how the choice for either instruction influences performance in users. By presenting these three exploratory studies together, we show how different methods present complementary views on the same material, and how different research methodologies inform the relevance and evaluation of particular characteristics to study in multimodal presentations. (a) Instruction with pictures of MI 15. (b) Recipe card of MI 15. Source: https://selfproclaimedfoodie.com/pumpkin-chocolate-chip-cookies/.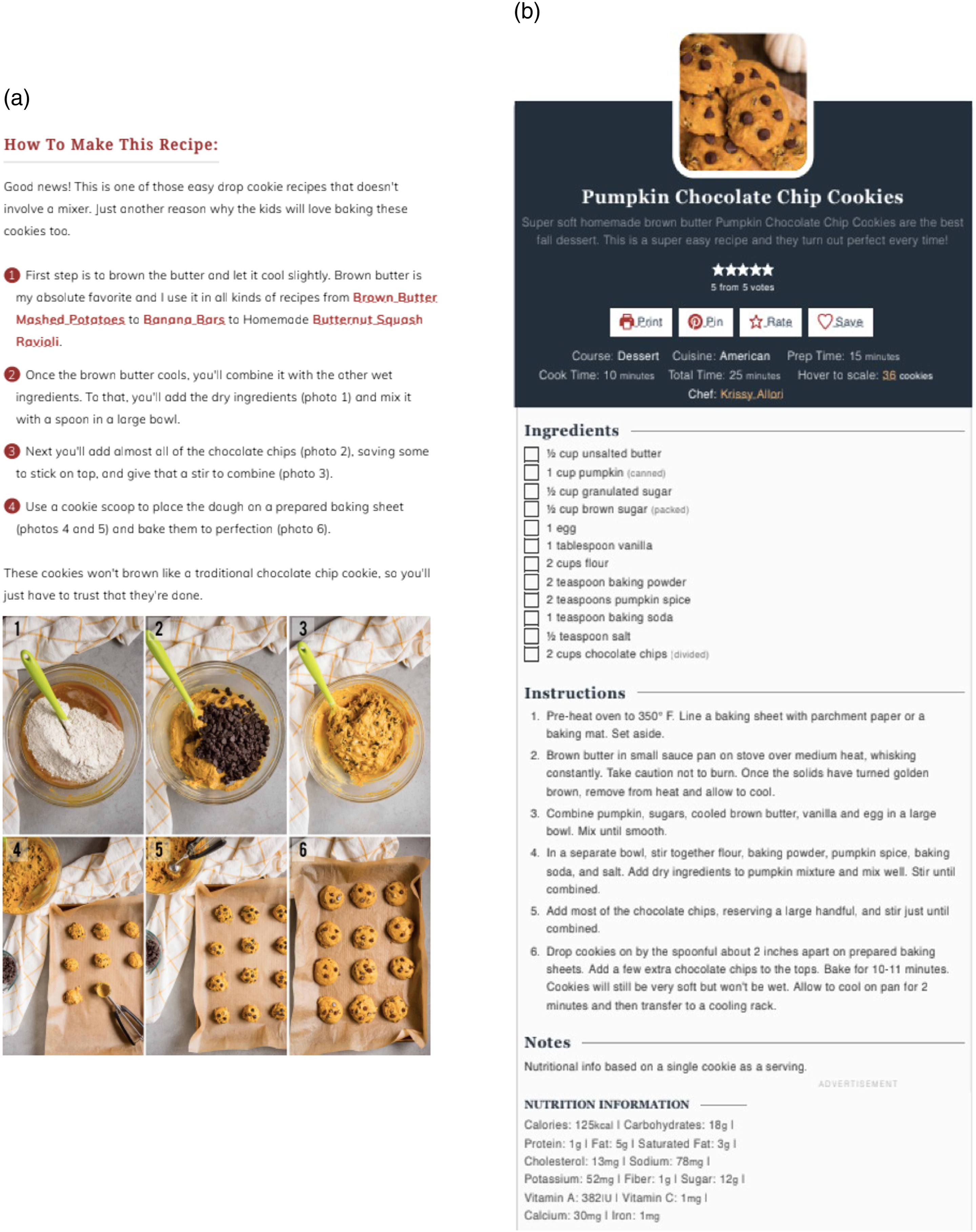
Research questions
To gain insights into the design of online baking blogs, the research begins with a corpus study that examines 15 step-by-step instructions. The study’s central research question is: ‘How can we describe the instructions in online step-by-step baking instructions and what are the relations between the different modes used in them?’
Using an action-based annotation model (Van der Sluis et al., 2016a, 2016b, 2017, 2022a, 2022b; Van der Sluis and de Jonge, 2024) the analysis focuses on the differences and similarities between the IWP and the RC and the multimodal coherence relations between text and pictures in the IWP. Equipped with an understanding of the multimodal design of baking blogs, the study progresses with an exploratory eye-tracking study involving 12 participants. This study aims to answer the question: ‘How do people read and judge online baking blog recipes containing multimodal instructions?’
Participants were asked to read and judge a complete webpage as well as an individual IWP. Observing participants’ eye movements uncovers how readers engage with instructive baking blogs as a whole as well as with multimodal IWPs in particular. The readers’ evaluations of the blogs and the IWPs they processed were collected via a questionnaire and a short interview.
Because it turned out that the participants in the reader study varied in their evaluations and interpretations of IWPs and RCs, a user study was set up to explore the actual use of baking blogs and to explore differences in judgments between readers and users. A user study was conducted in which participants actively engage in baking activities. Divided into two groups, participants follow either the IWP or the RC of a typical baking blog to bake cookies. The primary question addressed in this study is: ‘How does using either the Instruction with Pictures or the Recipe Card of a baking blog influence the user’s execution of the baking instruction and the user’s judgments of the comprehensibility, design and performance of the baking instruction?’
This study provides valuable insights into the users’ execution of a baking instruction, offering a glimpse into their decision-making processes. Through a comparison of the performance and experiences of IWP users and RC users, we also examined the effect of adding pictures to an instructional text.
With the three studies we aspire to contribute to the analysis, understanding and quality of online multimodal communication, especially multimodal instructions. This paper provides a deep dive into the design, human processing and use, and thus the effectiveness of baking blogs. The exploratory studies investigate the functionality and realization of recipe blogs and the relations between the text and pictures in them, uncovering how both readers and users judge and interact with these multimodal documents. Through a comprehensive approach encompassing a corpus analysis, an eye-tracking study, and a user study, we aim to illuminate the path toward enhanced baking instructions, to inspire future research on multimodal instructions, and to inform the development of research methods to investigate multimodality in our society.
Background
Multimodal instructions
Multimodality refers to a communicative situation where different forms of communication are used to make meaning (Bateman et al., 2017: 7). These different forms, or modes, can include speech, text, images, gestures and even sound. The broadness of multimodality makes it an interdisciplinary subject of research, with many different approaches to take and communicative situations to be explored (Bateman et al., 2017: 19–21). The current research focuses on multimodal instructions (MIs), specifically combining the modes text and picture. An instructive text has the goal of assisting people in executing a task (Karreman et al., 2013). This is done through procedural information, often presented in a step-by-step description of the tasks that need to be carried out, usually presented as a numbered list of actions (Karreman et al., 2013). MIs also contain declarative information alongside the procedural information (Ummelen, 1997). Declarative information, also called control information (Van der Sluis et al., 2022a), encompasses all the non-procedural details that are relevant to the process being described. This includes descriptions of appearances, explanations of how things work, and information about specific situations where certain procedures may or may not be applicable. Procedural information guides users through the necessary actions to accomplish a task, while control information provides supplementary details about the device or process being instructed. Together, these two types of information work in tandem to ensure that users have the necessary knowledge and understanding to successfully complete the instructed actions (Ummelen, 1997). To describe procedural instructions in more detail Van der Sluis et al. (2022a) introduce an additional category namely Specification. Specifications utilize adjectives, adverbs, and prepositional phrases to convey specific details regarding the manner in which an action ought to be executed, including factors such as position, direction, location, distance, time, or duration.
Nowadays, it is highly prevalent for communicative artifacts to utilize a variety of modes to present information (Bateman, 2014). When instructional texts are coupled with instructional pictures, they form MIs. This leads to the question of how these pictures are connected to the text. In an effort to address this, Barthes (1964) delineates three distinct types of text-picture relations. The first is anchorage, where the text supports the image, clarifying the intended interpretation of the image. The second is illustration, where the image supports the text, providing additional details about a predominantly textual message. Lastly, there is relay, in which both the text and image contribute equally to a unified message.
Bateman (2014) further expands on text-picture relations, focusing on how one mode expands the meaning of the other. He introduces three categories to describe this interaction: elaboration, extension, and enhancement. Elaboration occurs when the text or image restates or provides additional information at a similar level of generality. It can also involve presenting examples where either the text or image provides more specific details. For instance, when an action is described in the text, a picture may present the result of that action. Extension, on the other hand, involves adding semantically unrelated information where both the text and the image make their own contributions to the overall message. For instance, a verbal presentation of a recipe may be illustrated with pictures of happy and healthy people. Lastly, enhancement involves providing qualifying information related to aspects such as time, place, manner, reason, purpose, and other circumstantial restrictions. For instance, enhancement can be observed when the text identifies an action while the visual component reveals the utensils with which the action is best performed.
Ganier (2004) emphasizes the importance of using pictures alongside instructive text. Pictures may facilitate the human processing of instructions by reducing and/or distributing the load on human cognitive capacities, eventually helping people with action planning and integrating knowledge into their long-term memory. Sanchez-Stockhammer (2021) also supports this notion, highlighting that presenting instructions visually and verbally creates multimodal repetition, enhancing comprehension. Even sublexical cohesive relations, such as linking the word ‘apple pie’ with an image of an apple, contribute to the readability of a text through textuality (Sanchez-Stockhammer, 2021: 11).
There is a copious amount of research that proves that text- and picture-based instructions and learning materials are more effective than text-only documents (see, e.g., Butcher, 2014; Mayer, 2002). A lot of research on the effects of the use of text and pictures in instructions has been conducted in the domain of healthcare and medicine (e.g., Cline et al., 1999; Dowse and Ehlers, 2005; Mansoor and Dowse, 2003; Morrow et al., 1998, 2005; Sata et al., 2003; Sojourner and Wogalter, 1998). All these studies highlight the importance of adding pictures to healthcare information, as pictures proved to be an important source of information for patients. For example, in a study conducted by Morrow et al. (1998), 72 participants were asked to study an instruction for taking a hypothetical medicine. The instruction was presented either in text-only format or in a format that included text and a visual icon timeline indicating the timing of medication intake. After the participants finished their study of the instruction, they were asked questions about it. The results showed that questions about dose and time information were answered more accurately and quickly when the icon timeline had been present in the instruction. The visual timeline also caused a reduction in the study time that the participants needed.
Another large body of research focuses on the effect of text and pictures in a learning environment. For instance, it has been proven that pictures can facilitate and contribute to L2 learning (Andrä et al., 2020; Hagiwara, 2015; Morett, 2019). Andrä et al. (2020) investigated the effects of gesture-based and picture-based learning on 8-year-old children’s acquisition of new vocabulary in a foreign language. Three studies were conducted with German children over a period of 5 days. The results showed that both gesture and picture enrichment improved children’s performance in vocabulary recall and translation tests compared to non-enriched learning. These benefits persisted up to 6 months after the training, and they were observed for both concrete and abstract words. Contrary to the initial hypothesis, gesture and picture enrichment had similar positive effects on children’s language learning, suggesting that both modalities are effective in enhancing children’s learning outcomes over an extended period.
Morett (2019) compared the effects of viewing still images, iconic gestures, and glosses on the learning and retrieval of concrete words in early stage second language (L2) acquisition by 28 Hungarian undergraduate students. The results showed that concrete L2 words learned through viewing still images were better recalled than those learned through viewing iconic gestures. Additionally, results showed that L1 glosses did not facilitate L2 word learning in novice learners. These findings suggest that images are more effective than gestures or glosses in facilitating the learning of concrete L2 words for learners unfamiliar with the target language, indicating that glosses are not always necessary for effective L2 word learning.
Lastly, Hagiwara (2015) investigated the use of pictorial support in processing morphemic elements in multiclausal sentences for second language (L2) learners. Thirty-two learners of Japanese participated in elicited imitation tasks with and without pictorial support. The results showed that learners performed significantly better when provided with pictorial support. However, the effectiveness of pictorial support was limited for recently learned elements in sentence-final position, suggesting a difficulty in learners to automatize such items regardless of cognitive support.
Limitations to the use of combinations of text and pictures
The value of adding pictures depends on various factors, including the context, the performance measures, and the learners (Fisk et al., 1986; Reid and Beveridge, 1986; Zhao et al., 2020). In a study by Fisk et al. (1986), 70 participants were shown one of 5 instructions for sign language, each varying in their text-picture ratio. After studying the instructions, they were asked to first perform the signs, and subsequently, after a 2-min distraction task, they were given a picture and text recognition test of the signs. Participants who studied the instruction combining text and pictures significantly outperformed those in picture-only and text-only conditions in terms of performance accuracy. In terms of speed, participants in the picture-only conditions performed the best. In the memory test, participants in the picture-only condition had less accuracy in recognizing textual sign instructions. Thus, even though pictures can improve performance speed and accuracy, text can be applied to broader contexts more effectively, as it provides more flexibility in usage.
Zhao et al. (2020) also examined the roles of text and pictures in a learning context. Secondary school students received text-pictures units taken from geography and biology textbooks, and were either asked questions about them after reading (delayed-question) or before reading (preposed-question). Eye movement analysis showed that students in the delayed-question condition allocated more resources to text processing, while those in the preposed-question condition allocated more resources to picture processing. This suggests that texts provide explicit conceptual guidance during initial mental model construction, while pictures support mental model adaptation by providing specific information for task-oriented updates.
Additionally, Reid and Beveridge (1986) found that the effect of adding pictures can also depend on the learners’ ability level. They examined the impact of text and pictures on learning a science topic among 13-year-old children. In the study 272 students received texts with varying pictorial content. Learning was assessed using an objective test. The results showed that pictures did not have a general motivational effect on learning, but specific pictures had a beneficial effect for higher-ability students while being distracting for lower-ability students.
In some studies, the benefits of combining text and pictures do not seem to occur at all (Liu and Chuang, 2011; Rasch and Schnotz, 2009). In Liu and Chuang (2011), eight college students viewed web pages with text and pictures about atmospheric pressure and wind formation. The results showed that participants focused more on the text than on the pictures and that segmentation of the content in text and pictures did not cause an increased attention for the pictures. Participants alternated their focus on different parts of the pictures while concentrating on weather system explanations in the text. The text provided more detailed information and served as the primary resource for understanding. Rasch and Schnotz (2009) tested the effects of adding interactive and non-interactive pictures to a hypertext about time and date differences on the earth. One hundred university students participated in the study, and were assigned to different groups with varying combinations of text and pictures. The results showed that adding pictures to text had no significant effect on learning, and learning from text alone was more efficient than learning from text and pictures. Interactivity had a positive effect on one learning task but not the other. The visualization format influenced participants’ interaction with pictures but did not impact the learning outcomes. The authors give two possible explanations for these results: pictures can cause readers to superficially process text, as they partially replace the text as an information source with the pictorial source of information. Furthermore, pictures can be redundant if they portray what the reader has already made up in his/her mind based on the textual information (Rasch and Schnotz, 2009: 420).
Design choices and human processing
One thing that is clear from the studies on multimodal processing discussed in this paper, is that the design of an MI plays a crucial role in facilitating human processing of the procedural instruction presented. When relevant visual information is easily accessible, comprehension and learning are improved. Clear signaling and proper organization of multimodal content help to guide human attention, and enhance efficiency and effectiveness (Ozcelik et al., 2010; Tenbrink and Maas, 2016; Van der Sluis et al., 2017).
A problem that can arise from poorly organized MIs is the split-attention effect (Chandler and Sweller, 1992; Schroeder and Cenkci, 2018). The split-attention effect refers to a cognitive phenomenon that occurs when readers have to simultaneously process and integrate information from multiple sources that are spatially or temporally separated. Specifically, it refers to situations where learners need to integrate information presented in different modes, such as text and pictures. As learners have to divide their attention, they can experience a cognitive overload, which reduces the learning efficiency (Schroeder and Cenkci, 2018).
Another design problem that occurs is the redundancy effect (Kalyuga and Sweller, 2014). The redundancy effect refers to the phenomenon where presenting the same information through multiple modalities, such as presenting the same information in both visual and auditory formats, can lead to cognitive overload and hinder learning. It suggests that including the same information via multiple modalities may not necessarily enhance learning outcomes and can even have a negative impact on cognitive processing (Kalyuga and Sweller, 2014).
The baking blogs studied in this paper could present potential challenges related to both the split-attention effect and the redundancy effect. Readers and users of these baking instructions are required to process information from different modalities, namely text and pictures, which could lead to the split-attention effect. Additionally, at first sight the pictures in the baking instructions primarily serve as visual representations of the actions described in the text. It is not straightforward to reach a consensus about the redundancy in verbal and pictorial content, but at least a partial redundancy can be described as we will also show in the corpus analysis presented in this paper.
Describing text-picture relations
In the field of computational linguistics and natural language processing, an increasing number of studies focuses on the automatic description of procedural cooking instructions. These studies aim to build systems that allow computers to understand and extract practical knowledge from written instructions, enabling them to perform tasks based on human-like instructions (Zhang et al., 2012). In order to do so, large databases containing cooking instructions, as well as videos of people executing these instructions, have been collected (e.g., Regneri et al., 2013; Rohrbach et al., 2012; Salvador et al., 2017; Yagcioglu et al., 2018). Regneri et al. (2013) focuses on the problem of linking textual descriptions of actions to visual information extracted from videos. The authors present a corpus that aligns videos with multiple natural language descriptions of the actions portrayed in those videos, and they demonstrate how combining text-based models with visual information from videos can significantly improve the understanding and similarity assessment of action descriptions. This action-based approach to annotating large databases can provide valuable insights into the structure of MIs. However, there are still limitations to computational tools for automatically identifying and categorizing actions in instructive texts (e.g., Van der Sluis et al., 2018; Zhang et al., 2012). While Van der Sluis et al. (2018) concluded that accurate categorization of actions requires human intervention as an essential guiding factor, recent initiatives in natural language processing and generation are promising (e.g., Pustejovsky et al., 2021; Tu et al., 2022a; Tu et al., 2022b).
Manually annotating MIs can pose a significant challenge, not only because MIs contain multiple modes that cohere and make meaning together but also because the layout in which the text and pictures are presented varies considerably. The PAT annotation model is being developed within the PAT project. 1
Since 2016, various versions of the action-based PAT model have been used to describe (parts of) multimodal instructions according to the following principles: 1. The instructional text is split into clauses; 2. The clauses are identified as either Action clauses or Control Information clauses; 3. The text clauses and the accompanying instructional pictures are described using functional attributes (e.g., Action Type, Action Status, Action Aspect and Control Information, Specification) and using domain-specific content attributes (cf. Van der Sluis et al., 2016a, 2017, 2018, 2022a).
The categorization of the verbal and visualized content according to the same model allows for the specification of the text-picture relations in terms of for example, elaboration and enhancement (cf. Bateman, 2014; Halliday 1985: 216–221). The generalizability of the PAT model is shown by annotating multimodal instructions in different domains, such as first-aid instructions (Van der Sluis et al., 2017) and cooking instructions (Van der Sluis et al., 2016a; Van der Sluis and de Jonge, 2024), as well as through the annotation of multiple types of documents for example, instructional videos (Vijfvinkel et al., 2018) and instructional comics (Wildfeuer et al., 2023). In this paper, a further development of the PAT annotation model is used to achieve a description of a corpus with online baking instructions. The description allows for a thorough examination of the multimodal nature of MIs, considering both the form and content of the text-picture relations.
Reader and user studies
After establishing the structure of baking instructions through corpus annotation, our focus shifts to examining the impact of text and pictures on readers and users. To comprehend and register the way in which text and pictures in instructions are processed by human users and in order to enhance their instructional effectiveness, methodologies such as reader and user studies often integrate the utilization of eye-tracking methods (Alemdag and Cagiltay, 2018; Fisk et al., 1986; Ganier, 2004; Liu and Chuang, 2011; Ozcelik et al., 2010; Van der Sluis et al., 2017; Zhao et al., 2020). Eye-tracking is a widely employed method for assessing human processing of multimodal instructions (MIs). Holsanova (2014) explains that this technology enables researchers to meticulously track the reading and scanning process, gaining insights into what users look at, where their gaze falls, when they shift their focus, and how frequently they do so. Such information proves invaluable in understanding user interactions with multimodal messages, information integration across different modes, and factors that capture their attention. By measuring eye movements, researchers can uncover the allocation of visual attention, which serves as a behavioral indicator of ongoing visual and cognitive processes (Holsanova, 2014).
Several studies utilized eye-tracking to draw conclusions about human interactions with multimodal instructions. For instance, Zhao et al. (2020) utilized eye-tracking to reveal that participants allocated their attention differently to text and pictures depending on the given tasks, while in the work of Liu and Chuang (2011), the analysis of participants’ eye movements uncovered that the text received more attention compared to the pictures. Here, it was observed that participants alternated their gaze between relevant components of illustrations while focusing on key elements in the text. Scan paths further demonstrated that decorative icons within the pictures caused distractions and split attention effects. Consequently, the researchers concluded that eye-tracking proves to be a valuable tool for investigating the cognitive processes involved in learning from multimodal documents (Liu and Chuang, 2011).
Eye-tracking studies are often combined with user studies, where performance measures such as speed and accuracy are used to investigate the human processing of MIs (e.g., Fisk et al., 1986). After all, the effectiveness of an instruction is determined by how well participants actually execute it. Holsanova (2014) also suggests that eye-tracking measurements are especially useful when used along with verbal protocols, interviews, comprehension tests, and/or questionnaires. This helps researchers understand readers’ attitudes, habits, preferences, and problems related to their interaction with these messages (Holsanova, 2014). Van der Sluis et al. (2017) demonstrate how eye-tracking can be combined with performance measures, a comprehension test and a questionnaire. The participants’ eye movements and their performance was recorded while they executed a tick-removal instruction. Subsequently the participants were asked to fill out a questionnaire measuring their comprehension, recall of the instruction as well as their opinion on the instruction’s attractiveness. Finally the participants took part in a short follow-up interview. In addition to the eye-tracking data and the performance data, the questionnaire and the interview provided valuable insights. Participants were able to recall four out of five actions and demonstrated comprehension of the instruction. However, they reported difficulty in recalling the actions accurately. Overall, the questionnaire and interview complemented the eye-tracking data by providing a deeper understanding of participants’ experiences, perceptions, and preferences, enhancing the study’s completeness and validity.
In order to maximally elicit information from participants, Holsanova (2014) recommends using verbal protocols. This refers to the use of verbal reports as a technique to trace and understand cognitive processes and knowledge underlying task performance (Ericsson and Simon, 1993). Verbal protocols involve participants verbalizing their thoughts and actions while or after working on a task. Common techniques are the concurrent think-aloud method, the retrospective think-aloud method, and the co-participation method (Ericsson and Simon, 1993; Mayhew and Alhadreti, 2018; Miyake, 1982).
The concurrent think-aloud protocol (CTA) is a technique where participants verbalize their thoughts and cognitive processes while performing a task or solving a problem. Participants are instructed to articulate their thoughts, decision-making, and problem-solving strategies in real-time as they engage with the task or interface. The retrospective think-aloud protocol (RTA) method is a variation of the think-aloud technique. Unlike the traditional think-aloud method, participants in the retrospective think-aloud method complete a task or activity without verbalizing their thoughts in real-time. Instead, after completing the task, participants are asked to recall and retrospectively verbalize their thoughts, reasoning, and decision-making process while reflecting on their experience. This method allows participants to provide insights into their cognitive processes in a more reflective and deliberate manner. Both think-aloud methods were developed by Ericsson and Simon (1993). Lastly, the co-participation method (CP) involves usability approaches that incorporate multiple users working together in teams. The method was initially developed by Miyake (1982). It aims to explore the impact of shared knowledge and collaboration on the learning process and usability evaluation. All three methods have their advantages and disadvantages (Mayhew and Alhadreti, 2018). CTA provides real-time insights and is fast to implement, but may have data completeness, as participants prioritize task-solving over reporting all their thoughts (cf. Elling et al., 2012). RTA can feel more natural, but it relies on participants’ memory which can be fallible, leading to the loss of specific information. The CP method, which is implemented and reported in the current study, allows for collaborative evaluations, but increases testing costs and participant requirements (Mayhew and Alhadreti, 2018).
Corpus study: Describing recipe blogs
The corpus study described below aims to describe the structures and content of the Instruction with Pictures (IWP) and the Recipe Card (RC) of online step-by-step cookie baking instructions, whereby the relevance and generalizability of existing descriptive categories is explored. As a starting point for the analysis, two existing annotation models were combined and adapted to fit the current corpus. This study aims to answer the question: ‘How can we describe the instructions in online step-by-step baking instructions and what are the relations between different modes used in them?’ The study analyzes the similarities and differences between the IWP and the RC, as well as the text-picture relations within the IWP. Because each MI in the corpus includes an IWP and a RC to present the same recipe we do not expect significant differences between the descriptions of verbalized instructions types in the two instructions. Based on previous findings (Van der Sluis et al., 2016a; Van der Sluis and de Jonge, 2024) we do expect a difference between the verbalized and visualized actions within the IWP, where the text is expected to present actions as processes and the pictures are expected to present the results of actions. The findings obtained with the corpus analysis are used to make an informed choice in determining and motivating the content for the reader and user studies that are also presented in this paper. Moreover, the corpus analysis is used to support the interpretation of the data collected with the reader and user studies.
Data set
The materials for this research consist of 15 recipes taken from online baking blogs. The 15 recipes were selected from a larger corpus of 40 baking blogs. We developed selection criteria that allowed us to obtain a subset of the corpus with seemingly comparable blogs that would also offer enough variation in verbal and visual instructional content to study multimodal instructions and the text-picture combinations in them. We applied the following selection criteria: • The MI originates from a web source; • The MI describes the process of baking chocolate chip cookies; • The MI contains two ‘versions’ of the same recipe: an Instruction with Pictures, as well as a Recipe Card; • The Instruction with Pictures contains at least 4 step-by-step pictures; • The text in the Instruction with Pictures is split up into different steps; • The text in the Recipe Card is split up into different steps, and does not have the form of a coherent paragraph.
Annotation model
PAT variables to describe instructional text (based on Van der Sluis et al., 2016b, 2022a; Van der Sluis and de Jonge, 2024).
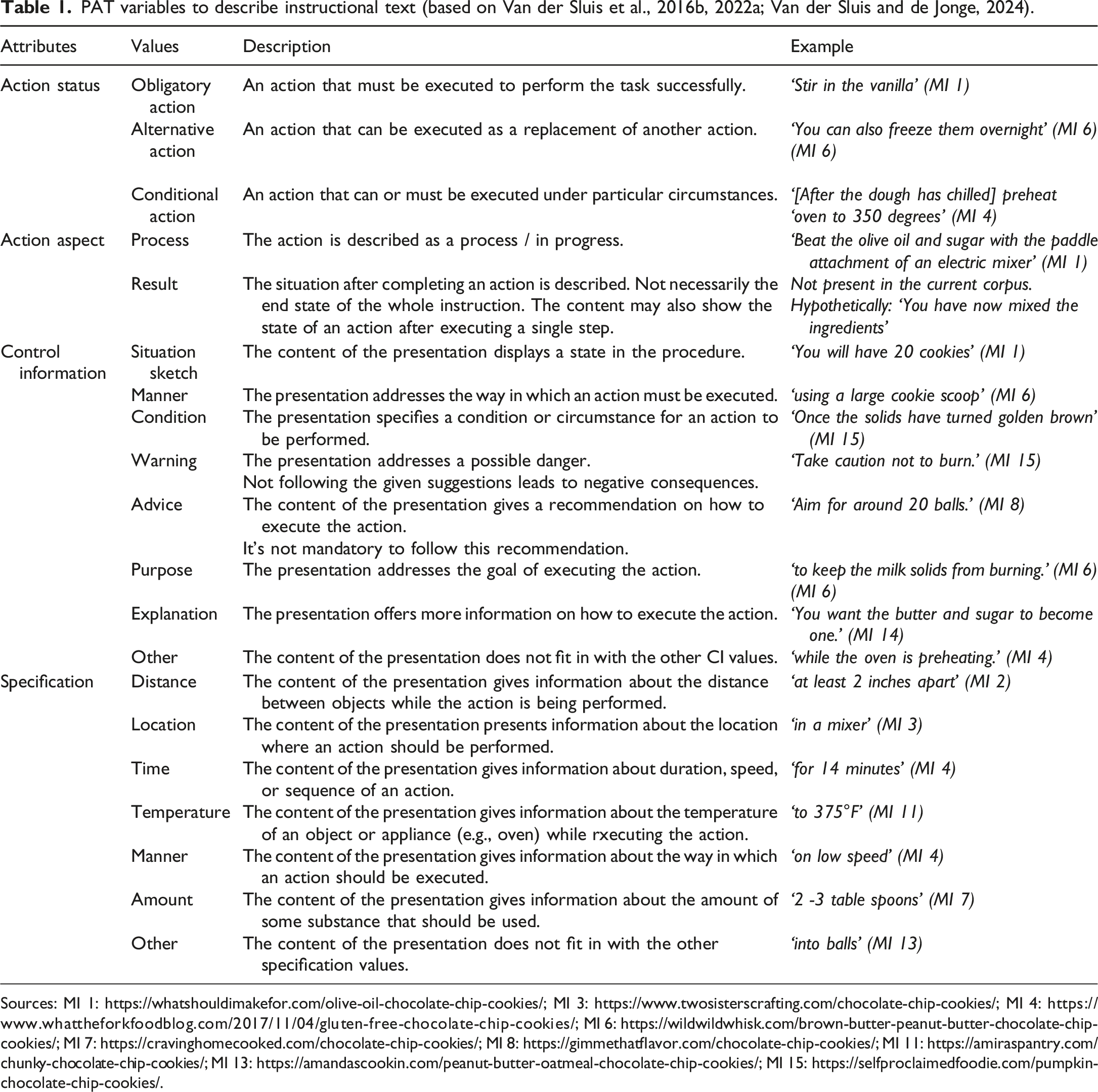
Sources: MI 1: https://whatshouldimakefor.com/olive-oil-chocolate-chip-cookies/; MI 3: https://www.twosisterscrafting.com/chocolate-chip-cookies/; MI 4: https://www.whattheforkfoodblog.com/2017/11/04/gluten-free-chocolate-chip-cookies/; MI 6: https://wildwildwhisk.com/brown-butter-peanut-butter-chocolate-chip-cookies/; MI 7: https://cravinghomecooked.com/chocolate-chip-cookies/; MI 8: https://gimmethatflavor.com/chocolate-chip-cookies/; MI 11: https://amiraspantry.com/chunky-chocolate-chip-cookies/; MI 13: https://amandascookin.com/peanut-butter-oatmeal-chocolate-chip-cookies/; MI 15: https://selfproclaimedfoodie.com/pumpkin-chocolate-chip-cookies/.
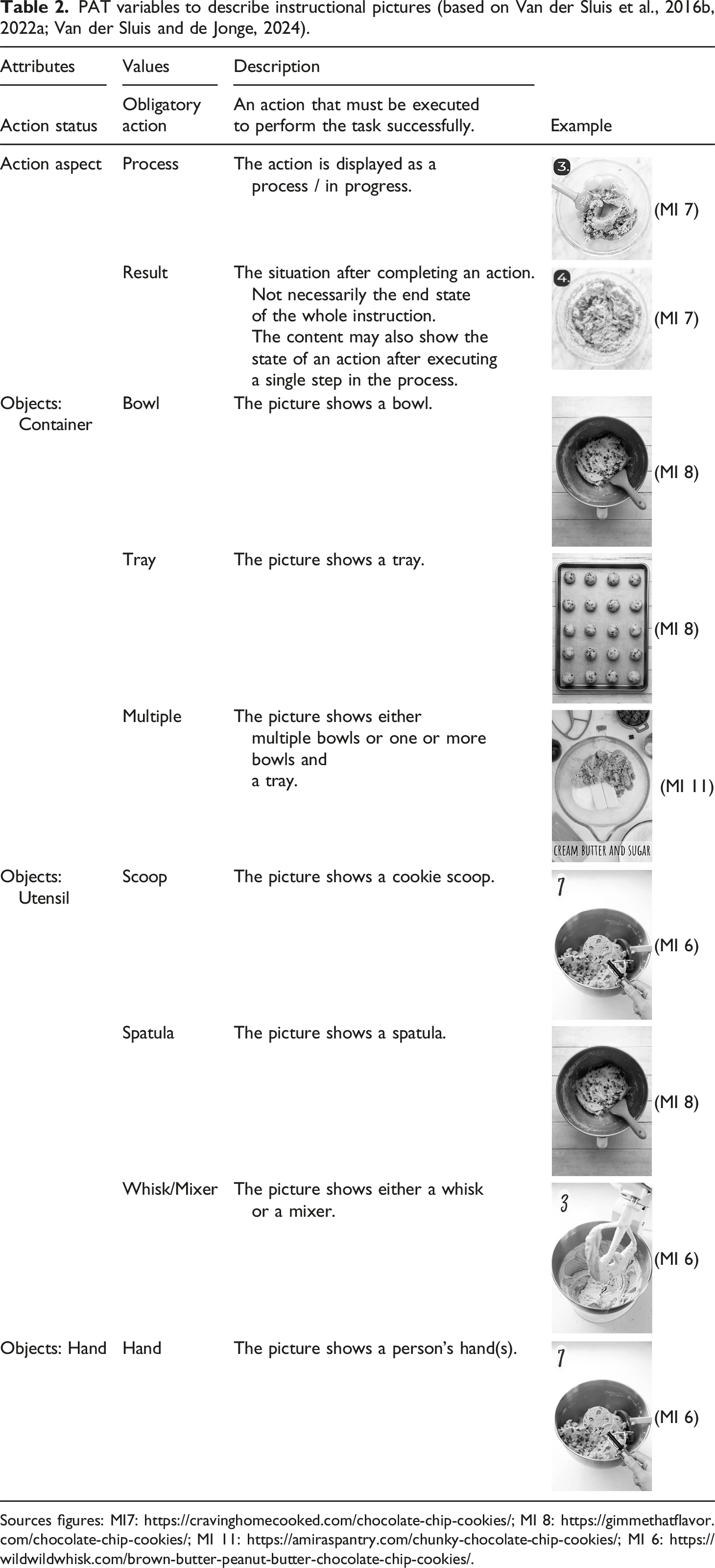
PAT variables to describe instructional pictures (based on Van der Sluis et al., 2016b, 2022a; Van der Sluis and de Jonge, 2024).
PAT variables to describe text-picture relations (based on Van der Sluis et al., 2016b, 2022a; Van der Sluis and de Jonge, 2024).
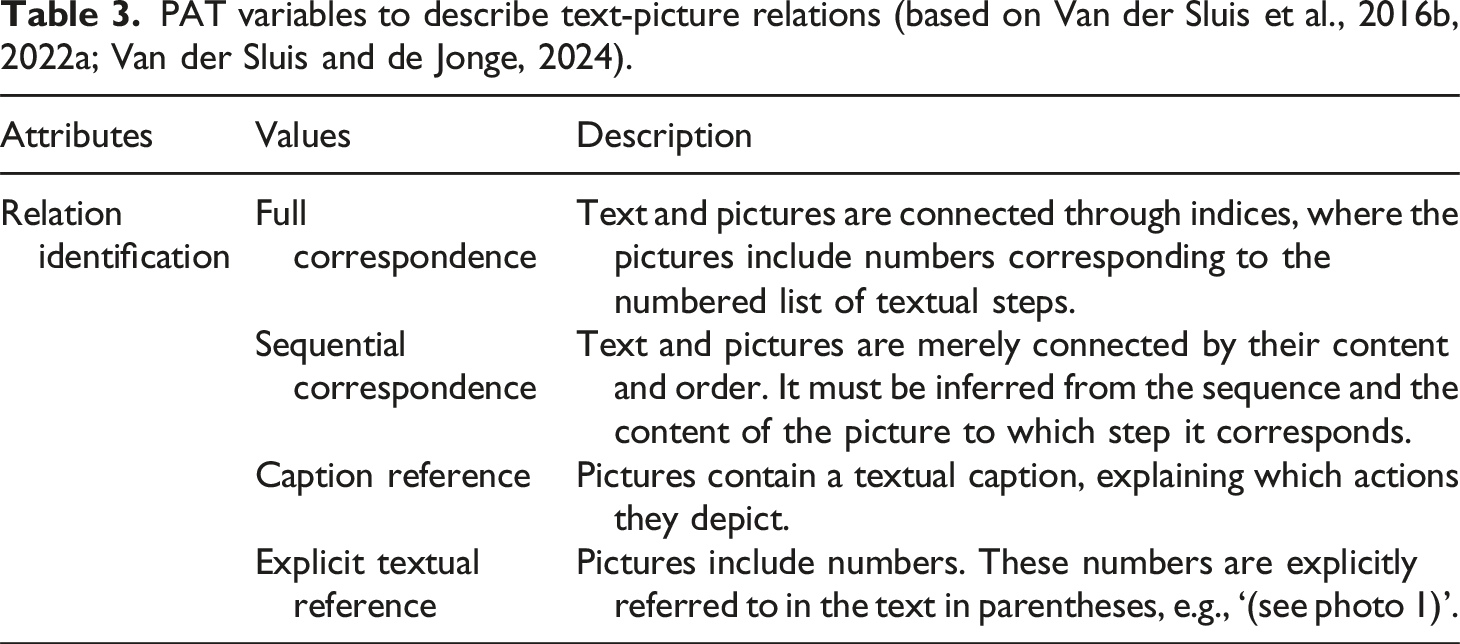
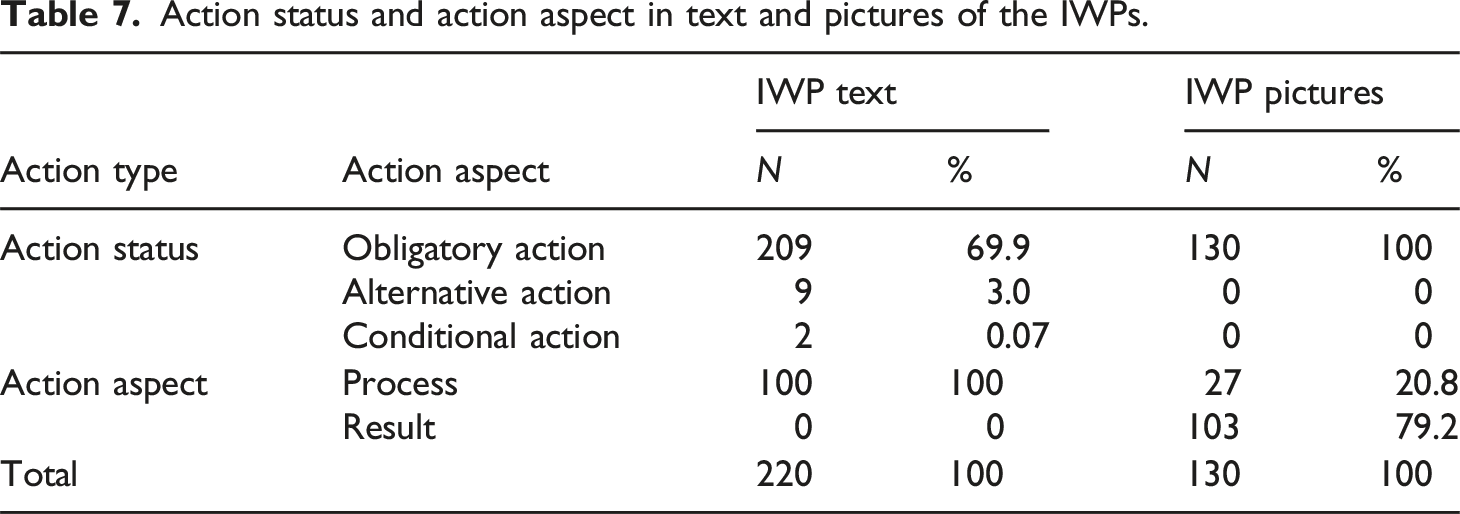
Regarding the text, the annotation model enables the identification of diverse types of Control Information and the identification of Specifications within the Action clauses (Table 1). Note that the pictures in the corpus only include actions with Action Status obligatory. Therefore the values alternative and conditional are not included in Table 2. In addition to the functional attributes, the picture annotation model does include a domain dependent description of visualized Objects, namely: Containers, Utensils, and Hands (Table 2). The text-picture relations are described in terms of a newly developed Relation Identification featuring multiple correspondence and reference types (Table 3).
Action Types and Subtypes used in the analysis of text clauses and pictures based on Van der Sluis et al. (2016a).
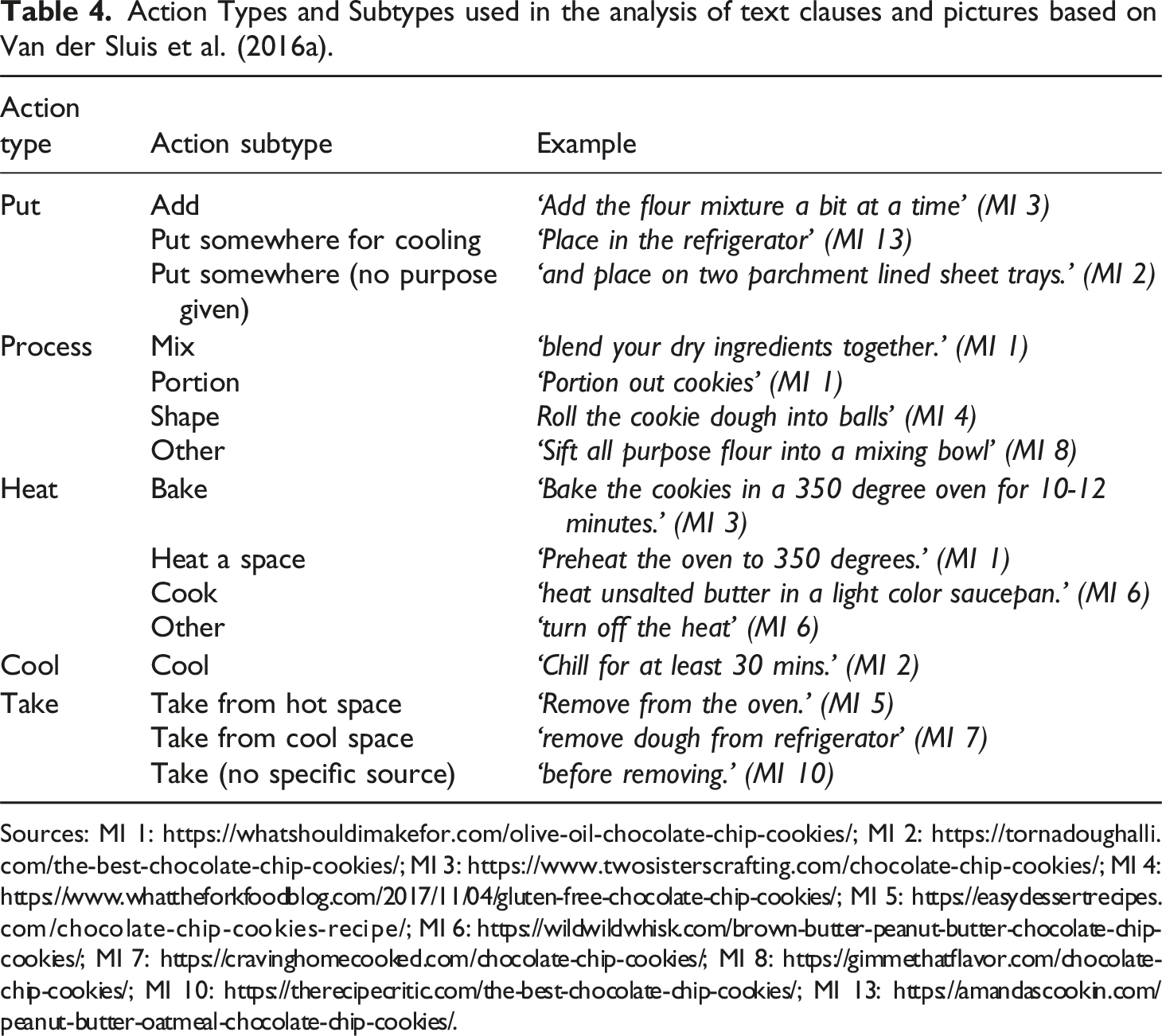
Sources: MI 1: https://whatshouldimakefor.com/olive-oil-chocolate-chip-cookies/; MI 2: https://tornadoughalli.com/the-best-chocolate-chip-cookies/; MI 3: https://www.twosisterscrafting.com/chocolate-chip-cookies/; MI 4: https://www.whattheforkfoodblog.com/2017/11/04/gluten-free-chocolate-chip-cookies/; MI 5: https://easydessertrecipes.com/chocolate-chip-cookies-recipe/; MI 6: https://wildwildwhisk.com/brown-butter-peanut-butter-chocolate-chip-cookies/; MI 7: https://cravinghomecooked.com/chocolate-chip-cookies/; MI 8: https://gimmethatflavor.com/chocolate-chip-cookies/; MI 10: https://therecipecritic.com/the-best-chocolate-chip-cookies/; MI 13: https://amandascookin.com/peanut-butter-oatmeal-chocolate-chip-cookies/.
Corpus annotation
The basis of the analysis are grammatical units in which either actions or control information are described (cf. Van der Sluis et al., 2022a). The units can be full or reduced clauses or stand-alone fragments that serve clause-like functions but that lack the grammatical properties of clauses. Clauses can be subordinate as in ‘If the kitchen is warm, keep the rest of the dough balls in the fridge while they’re waiting for their turn.’ (MI 6), which contains two clauses: [If the kitchen is warm,] and [keep the rest of the dough balls in the fridge while they’re waiting for their turn.], or coordinated as in ‘Take the reserved handful of chocolate chips and pop them on top of the cookies’ (MI 1), which also contains two clauses: [Take the reserved handful of chocolate chips] and [pop them on top of the cookies]. To annotate the corpus the MI text was divided into clauses. Each clause was identified as either an Action clause or a CI clause. For each of the Action clauses, Action Status and Action Aspect were determined (Table 1), and the Action Type and Action Subtype (Table 3) were identified. Each CI clause was attributed one of the available CI values. Specifications, for example, adjectives, adverbs, and prepositional phrases regarding the manner in which an action should be executed were annotated within the Action clauses (Table 1).
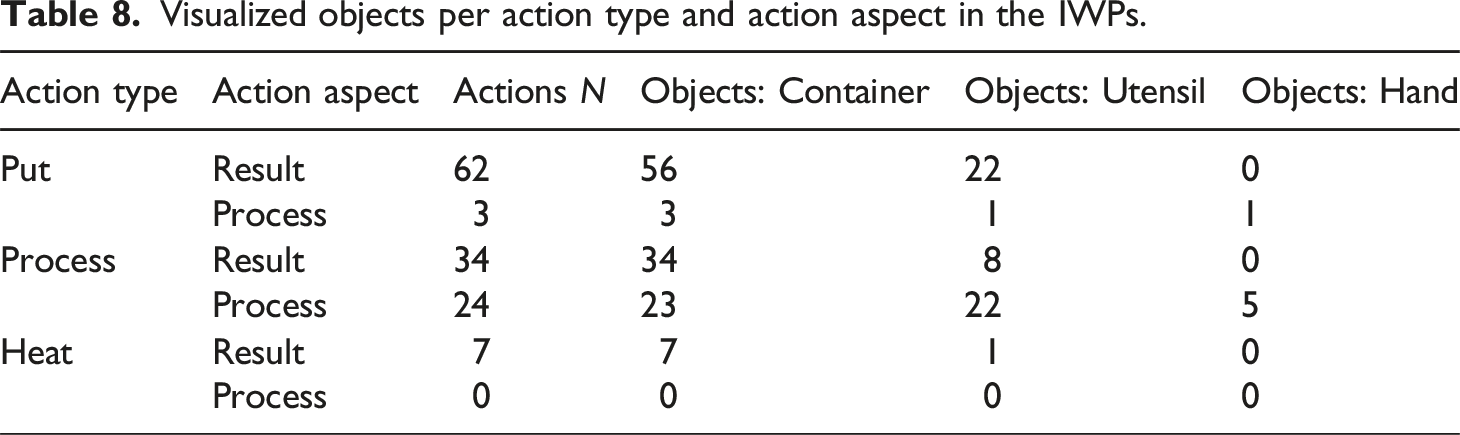
Each picture of the IWPs was described in terms of the visualized objects and the Action (Sub)Types (Tables 2 and 4). Note that not all pictures explicitly show an action being executed; sometimes the result of an action is visualized. For example, Figure 2 shows a bowl to which different ingredients have been added, which implies that the put action add was performed. Accordingly, the value of Action Aspect for Figure 2 is result. Besides the action attributes, a description of the visualized Objects (i.e., Container, Utensil, Hand) was used to gain insight in the way in which each of the actions was visualized. Picture 3 of the IWP of MI 13. Source: https://www.glutenfreepalate.com/paleo-chocolate-chip-cookies/.
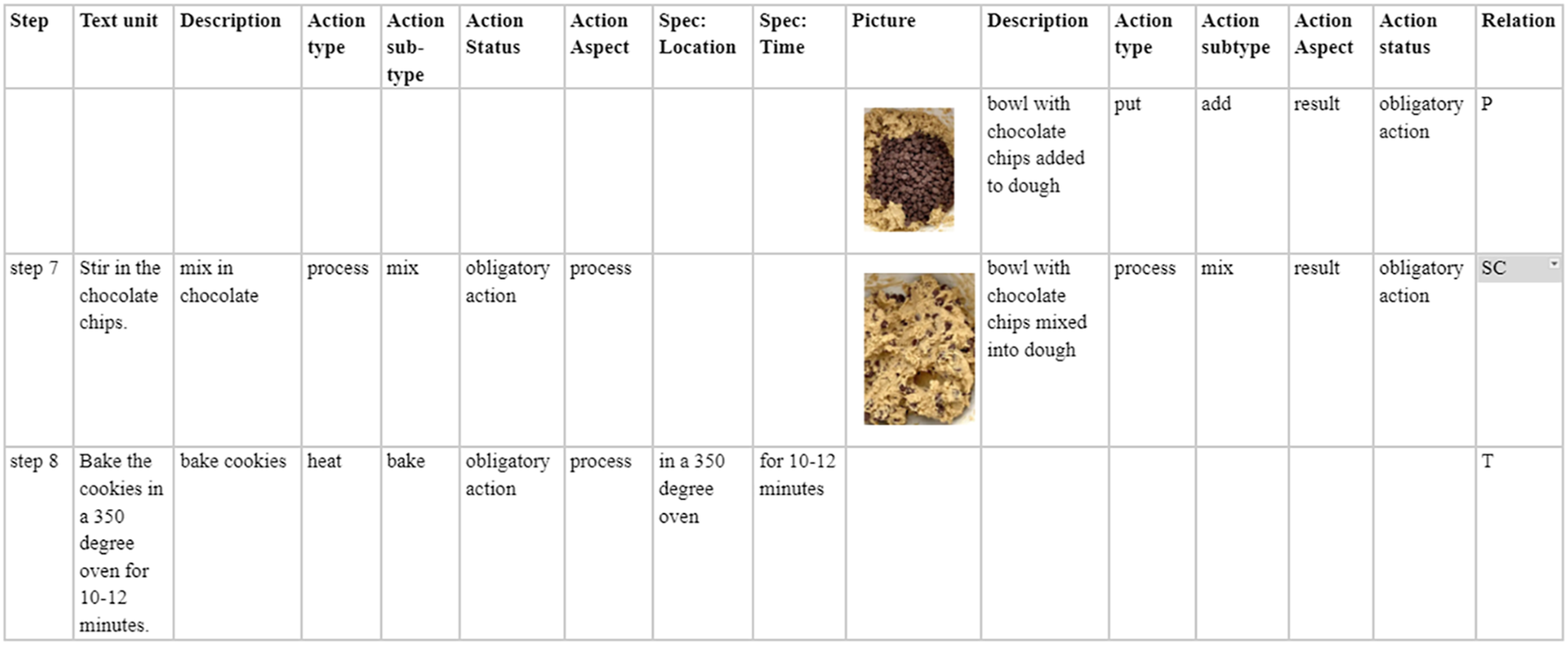
It is important to note that some Action clauses and some pictures respectively describe and visualize multiple of the same actions. For instance, in the clause: ‘Add in the almond flour, flax seed meal, salt, and baking soda’ (MI 13), four different ingredients are added, and therefore the put Action Subtype add is attributed four times to the Action clause, as well as to the accompanying picture presented in Figure 2, which shows all four dry ingredients added to the bowl.
The analysis of the annotations comprised two parts. First, the annotations in the IWP and the RC were compared to describe how the functional content is distributed and realized in these two different types of instructions. Next, the text-picture relations within the IWP were mapped out using the Relation Identification attribute (Table 3). To further investigate the realization of the text-picture relations within the IWP, the actions presented in the IWP text and the actions presented in the IWP pictures were compared. It was determined whether the text and pictures offer the same Action Type category, a different category, or whether the Action Type is only presented in the text, or only in the picture.
The annotation model was developed on the basis of the models described in Van der Sluis et al. (2016a, 2016b, 2022a; Van der Sluis and de Jonge, 2024). In multiple rounds of annotating a subset of the corpus, the models were adapted to fit the corpus. The resulting model was used by one annotator to describe the corpus. The annotation was discussed and improved based on multiple thorough discussions with a second annotator until all inconsistencies were resolved. Subsequently, the annotators realized that the descriptions of the text clauses needed more detail and it was decided to also annotate the various Specifications that were included in the text clauses. In a further iterative process, the Specifications were annotated by two different annotators until the annotators were in agreement, resulting in the final annotation model and corpus description presented in this paper.
Worked examples
Figure 2 presents the annotation of Step 4 from MI 15 (see Figure 1). In this example it is shown that the text clauses are described as either Action or Control Information clauses. The clause ‘Use a cookie scoop’ is identified as a Control Information clause, because it describes the manner in which the put Action in the next clause should be carried out. Figure 2 also illustrates that relations between the text and the pictures in an MI are solely based on identified actions. Accordingly, the Control Information clause ‘Use a cookie scoop’ is not related to a picture of MI 15 and the visualized process action with Action type portion is not related to an Action clause in the text. Figure 2 also exemplifies two relations between the text and the pictures of MI 15 in which the obligatory actions put somewhere and heat are both described and visualized.
Figure 3 presents the annotation of the third and fourth pictures of MI 3. Figure 4 presents steps 7 and 8 of MI 3. In this example, the add action, where the chocolate chips are added to the dough is only visualized and not verbalized. The clause in Step 7 and the fourth picture are related in that they respectively describe the process and visualize the result of the process action mix. Step 8 in the text describes a bake action enriched with respectively a Location Specification and a Time Specification. The annotation of the text and pictures in step 4 of MI 15, where the text clauses are annotated as either action clauses or control Information clauses (A/CI), which may include Specifications. The Relation between the text and the pictures (i.e., Picture or same category) is based on the verbalized and visualized actions which are described in terms of action types, action subtypes, action aspect and action status. also visualized elements are described. The annotation of the text and pictures in steps 7 and 8 and the third and fourth pictures of MI 3, where the relation between the text and the pictures (i.e., only picture, text or same category) is based on the verbalized and visualized actions which are described in terms of action types, action subtypes, action aspect and action status.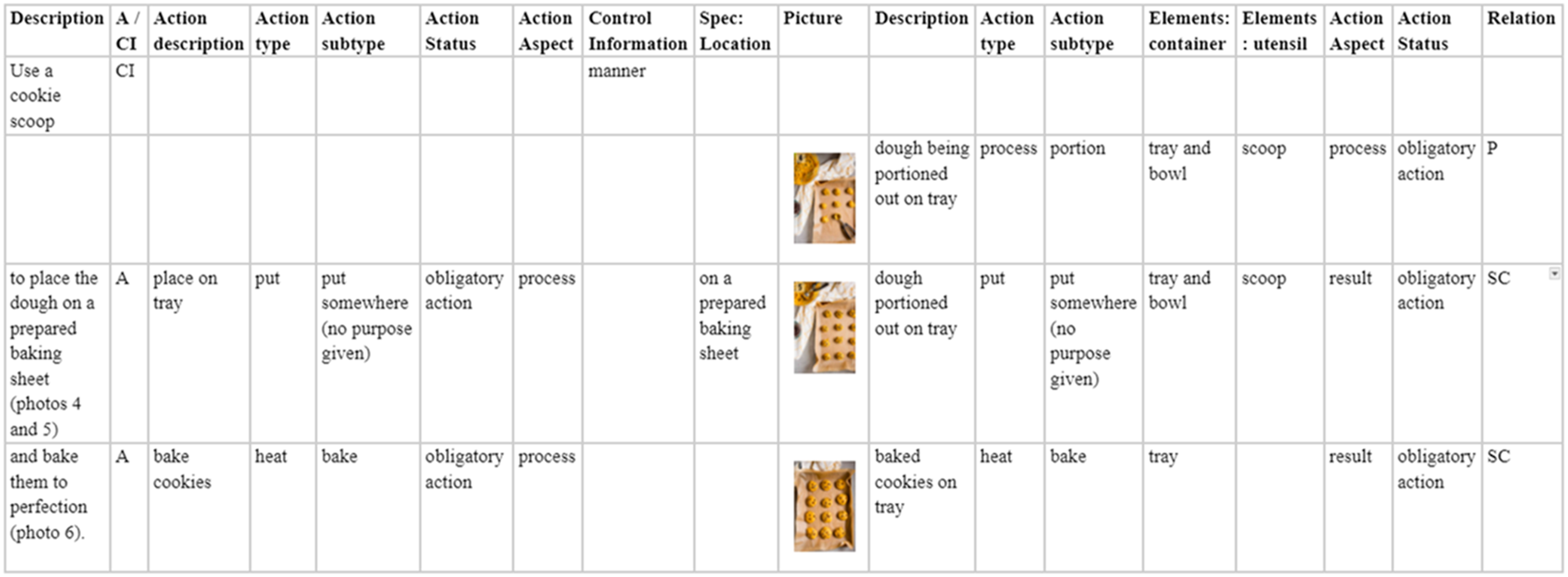
Results
IWP versus RC
Frequencies and percentages of Action clauses, CI clauses and Specifications for 15 IWPs and RCs.
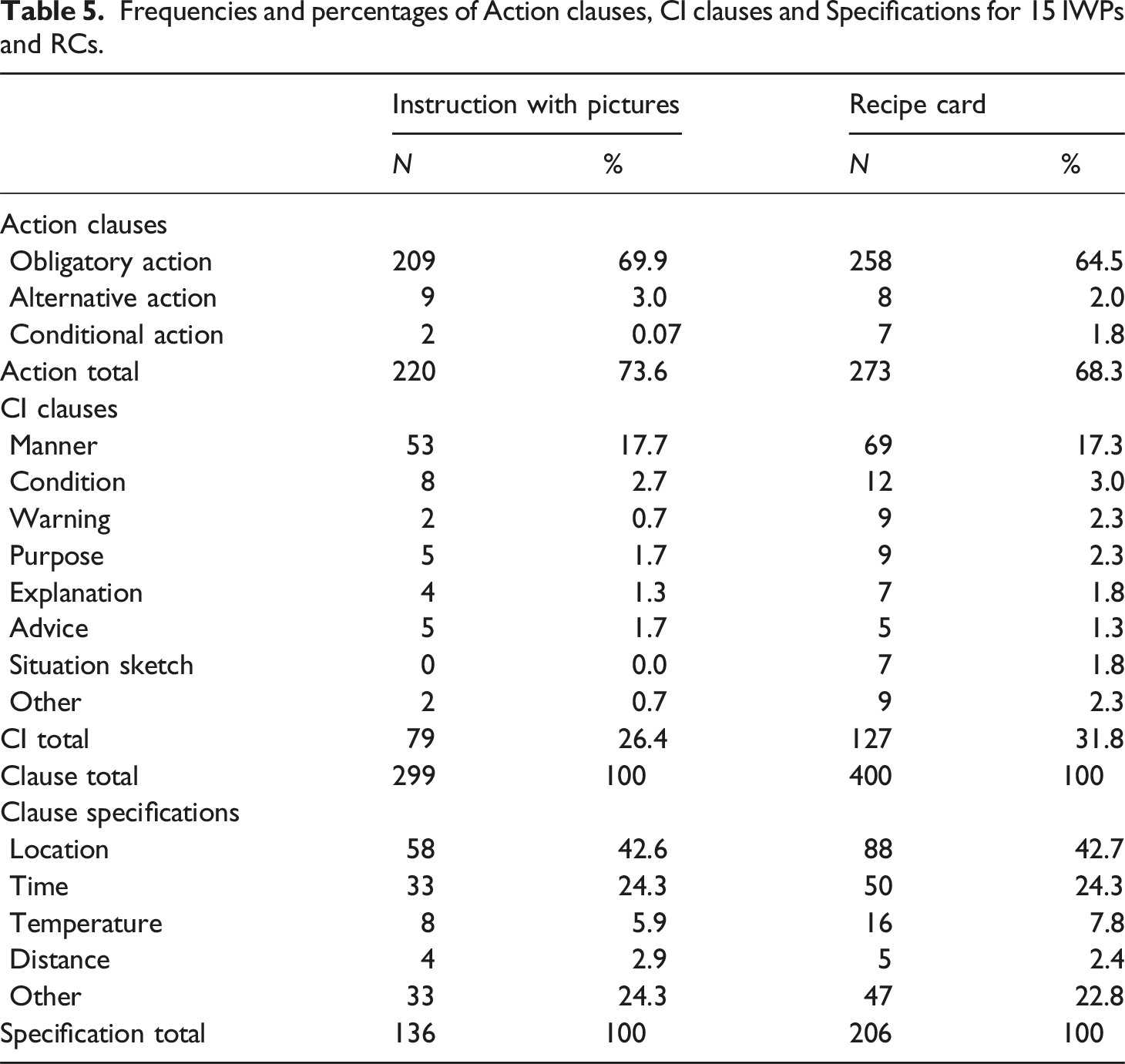
With respect to the CI clauses there is a clear difference between the two text types. As can be seen in Table 5, the RCs contain more CI clauses than the IWPs (127 vs 79). For both texts CI manner is the most common, but the RCs also contain CI clauses with the other values such as warning and situation sketch. The latter does not occur in the IWPs at all. The CI clauses with value other feature parallel events for example, ‘while the oven is preheating’ (MI 6), or ‘while the first batch bakes’ (MI 4), time indications for example, ‘This will take approximately 8 minutes and 30 seconds’ (MI 6), and statements in which the author expresses a favorite for example, ‘Brown butter is my absolute favorite and I use it in all kinds of recipes from Brown Butter Mashed Potatoes to Banana Bars to Homemade Butternut Squash Ravioli.’ (MI 15) or makes a reference, for example, ‘See notes for freezing the raw cookie dough.’ (MI 4).
The RC clauses also contain more Specifications than the IWP clauses (136 vs 206). The location and time Specifications are most common for both the IWP and the RC. There were also Specifications that did not fit the predetermined categories. For example, the corpus (WIP + RC) contains 30 instances of together as in ‘and mix together’ (MI 8). Fifteen instances specify a quality for example, ‘mix well’ (MI 10), ‘place them evenly’, ‘whisking constantly’ (MI 15), ‘to cool completely’ (MI 6). Ten instances specify a quantity for example, by the spoonful (MI 15), 1/2 cup at a time (MI 11), 8 cookies per baking sheet (MI 4). Ten specify a tool with which a process action should be performed by hand, with parchment paper, with the paddle attachment (MI 6). Seven instances specify the shape in which the dough has to be portioned, for example, ‘scoop cookie dough into balls’ (MI 13).
In general terms, the percentages show that the distribution of the Action Status values and Control Information values and the Specification values are, as we expected, similar within the IWPs and the RCs. Consequently, the differences between IWP and RC for each of these categories are not significant.
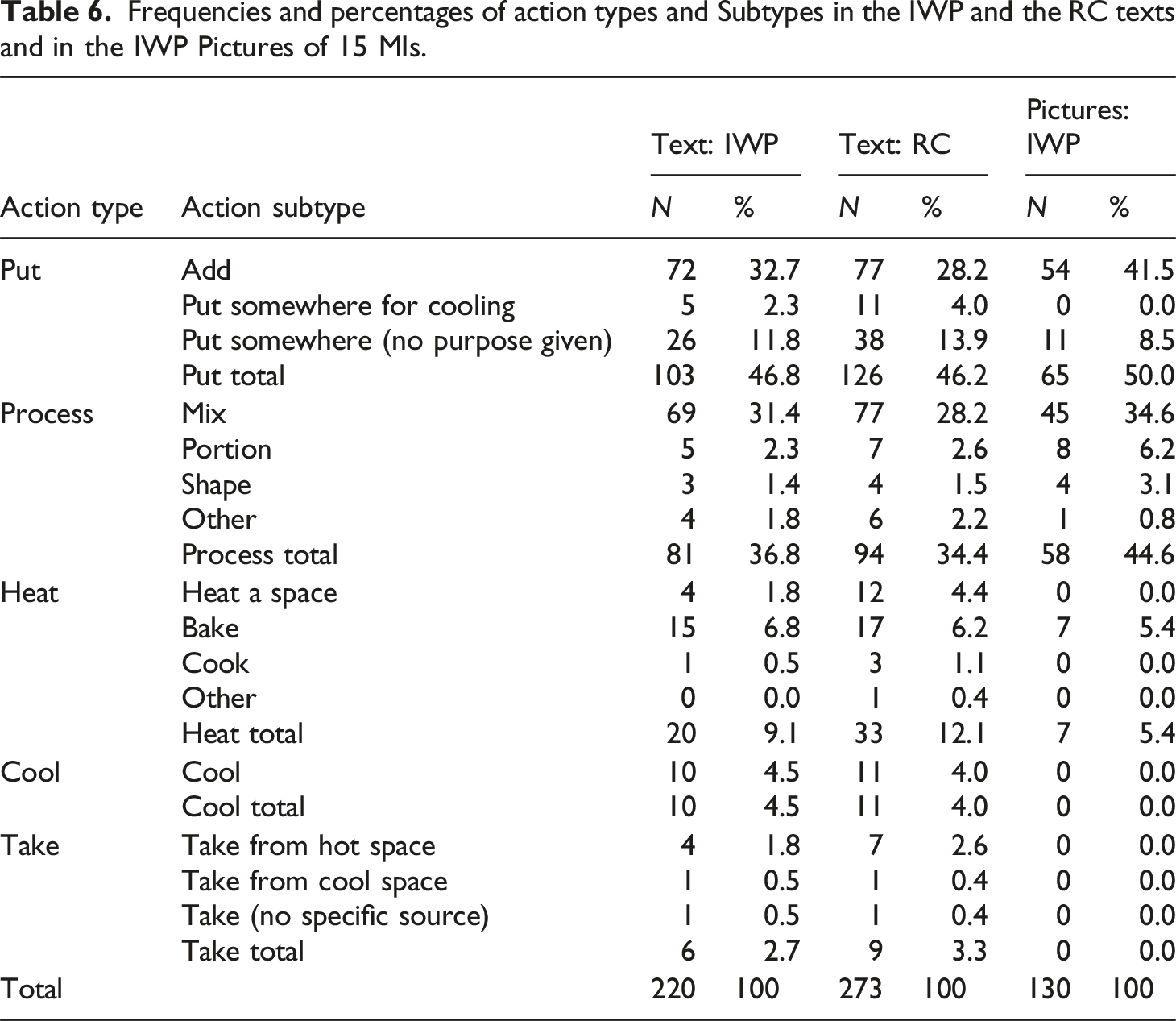
Frequencies and percentages of action types and Subtypes in the IWP and the RC texts and in the IWP Pictures of 15 MIs.
Text-picture relations in the IWPs
Action status and action aspect in text and pictures of the IWPs.
The Relation Identification category describes the forms in which the text and the pictures in the 15 corpus IWPs are linked.
Full correspondence
In MI 1, 4, 6, 9 and 13, the steps in the text fully correspond with the steps in the pictures. A number is added to the pictures to make it clear which textual step is referred to.
Sequential correspondence
In MI 2, 7 and 14, a number is also added to the pictures. This number, however, does not necessarily correspond to the textual step that the picture visualizes. Usually this happens because there are fewer pictures than steps in text. In MI 3, 5, 8 and 10, the pictures contain no indices at all. In these cases the correspondence between the text and the pictures can only be inferred from the order and the content of the pictures and the text.
Caption reference
In MIs 11 and 12, the pictures contain a caption that explains which action is visualized in it. The caption allows the reader to link the picture to a part of the text. MI 12 also contains indices, but these indices do not correspond to the indices of the textual steps.
Explicit textual reference
In MI 15, the pictures do contain numerical indices, which are referred to in text between parentheses. For example, step 2 in text says ‘To that, you’ll add the dry ingredients (photo 1)’. Even though the number in the picture does not relate to the number of the text step, it is still clear which step and which picture are related.
The text-picture relations within the IWP were also analyzed on the basis of Action (Sub)Types. Table 6 presents an overview of all the Action Types and Subtypes found in the pictures of the IWPs. There are several differences between the distribution of Action (Sub)Types presented in text and in pictures. In general, the pictures contain less actions than the texts. There are also several Action Types and Action Subtypes that do occur in the text, but are not visualized in pictures, such as the cool and the take Action Types, and the majority of the heat Subtypes.
Visualized objects per action type and action aspect in the IWPs.
Cross table overview of text-picture action type relations in the IWPs.
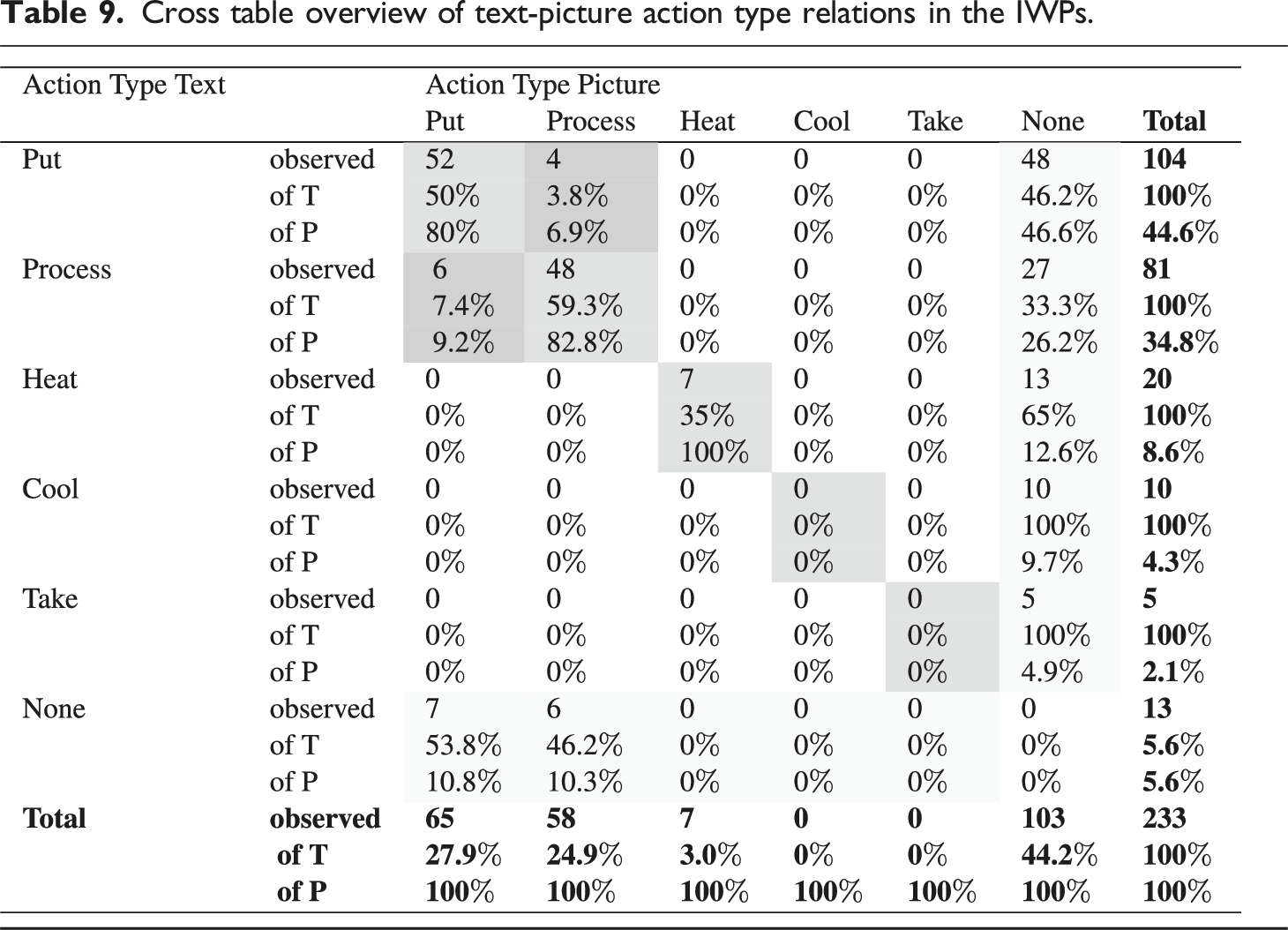
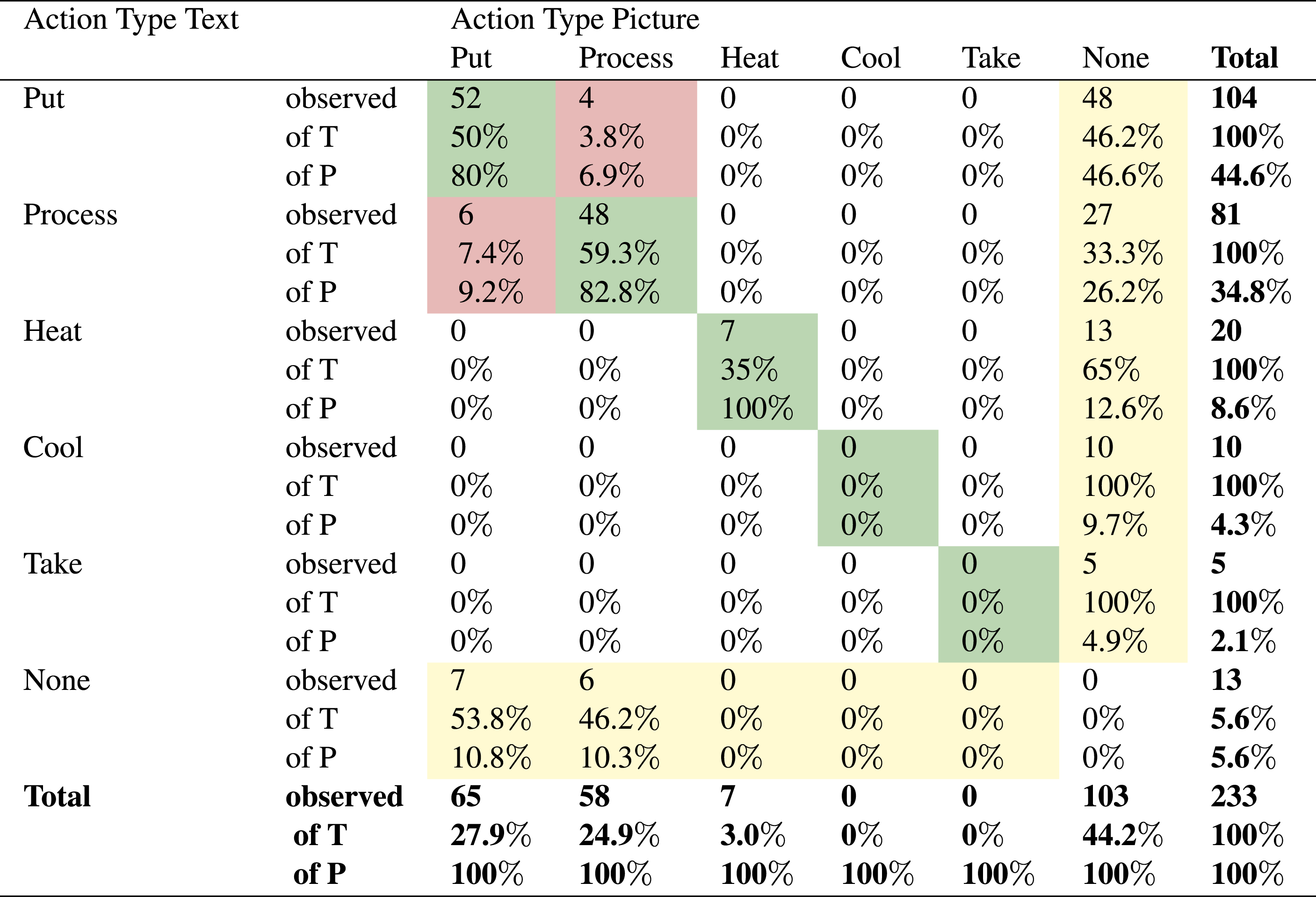
In general, the put and process Action Types are the ones that are most often presented in both text and picture. There are also 7 actions with Action Type heat that are verbalized as well as visualized. There are 4 cases where the picture shows a process action, while the text describes a put action, and 6 cases where it is vice versa. The two Action Types take and cool are only represented in text, without a corresponding picture. A total of 103 (44.2%) of the Action clauses has no corresponding picture. There are 13 actions visualized that do not have a corresponding Action clause. This is usually the case when the text says to either add an ingredient or mix in an ingredient, while there are two pictures showing both add and mix.
Preliminary discussion
In the annotation models used to analyse the corpus we have included functional categories (i.e., Action Status, Action Aspect, Control Information, Specification) as well as domain dependent categories to describe the realized Action Types (put, process, heat, cool, take) and the visualized objects in the IWP pictures (i.e., containers, utensils, hands).
Functional categories are useful variables to predict meaning interpretation in different recipes, or eventually multimodal instructions in other domains. In the presented corpus study the IWPs and the RCs of 15 MIs were analyzed by applying an annotation model that allows for the annotation of Actions and Control Information in the text and the pictures of the MIs. The corpus analysis shows that the IWPs and RCs in the baking blogs vary in terms of the amount of text clauses (IWP Mean = 19.9, Std = 6.24; RC Mean = 26.7, Std = 7.83) and the amount of pictures, where the IWP includes pictures (IWP Mean = 6.49, Std = 2.54) that visualize actions and the RC does not. A comparison of the IWP text and the RC text resulted in the observations that in general the IWPs contained fewer clauses than the RCs (299 vs 400). Compared to the RCs, the IWPs contain fewer Action clauses (220 vs 273) and fewer Control Information clauses (79 vs 127). Within the text clauses in the IWPs and RCs also the number of Specifications, which mostly specified location and time, differed (IWP = 136 vs RC = 206). The functional relations between the text and the pictures within the IWPs display some variation, but Full or Sequential Correspondence in 12 of the 15 MIs. Captions and explicit references are less common. Overall, as expected, the RCs and IWPs do not differ significantly in terms of the distribution of functional content and are thus comparable presentations of the same procedure, where the RCs contain more verbalized detail than the IWPs and where the IWPs contain pictures that visualize actions while the RCs do not. In addition and also as expected, within the IWPs the text and pictures differ in terms of the way in which they present the procedural actions, respectively process and result.
Apart from the functional analysis, we conducted a domain dependent analysis to explore the way in which the text-picture relations in the IWPs are realized, and to support the analysis of the way in which the verbal and visual presentations are read and used in a situated context. The verbalized (N = 220) and visualized (N = 130) actions in the IWPs were categorized into four main categories. As expected, the distribution of the domain dependent Action Types was similar in the IWPs and RCs texts. We were not able to identify a particular Action Type that is omitted in the IWPs. In the IWPs the major Action Type categories in both text and pictures are put and process. The Action Types cool and take are only verbalized and not visualized. In Barthes’ (1964) terms, one could say that the IWPs include pictures as Illustrations to support the text (N = 107). Relay appears only in a few cases where the text describes an Action Type different from the action that is visualized in the accompanying picture or vice versa (N = 10). In 103 cases the verbalized action is not visualized. In Bateman’s (2014) terms, the content relations between the text and the pictures in the IWPs can be identified as Elaborations and Enhancements. In Elaborations an Action Type is both verbalized and visualized. As expected, in terms of Elaborations the corpus displays a significant difference in that the pictures usually show the result of an action, while the action is presented in the text in the form of a process. In Enhancements the pictures show how to perform an action (e.g., which containers or utensils to use).
In the reader and user studies presented in the following sections of this paper, the effectiveness of the identified functionality and realization of the online baking instructions is explored in more detail to answer questions as: ‘How are the baking blogs read?’, ‘How are the instructions judged?’, ‘Do readers observe differences between a blog’s IWP and RC?’, and ‘how do readers interpret and value such differences?’. The description of the 15 blogs resulting from this corpus study is used to make informed choices in determining the content for the exploratory reader and user studies. Consequently, the corpus analysis also supports the interpretation of the collected reader and user data.
Eye-tracking study: Reading and judging recipes
The eye-tracking study presented in this section was designed to answer the question ‘How do people read and judge online baking blog recipes containing a multimodal instruction?’ Twelve participants were asked to read through and evaluate 1 of 3 baking blogs and 1 of 3 Instructions with Pictures. The research question introduces two concepts that need to be measured, Reading and Judging. Reading refers to the way in which participants look at and work their way through the documents, including the sequence in which participants look at the different elements, the amount of time that they spend looking at these different elements, and which elements are overlooked or ignored. Judging refers to how participants rate the Comprehensibility of the instruction, the Design of the instruction, and their Expected Performance of the instruction. Judging is measured with a questionnaire. The study comprises an analysis of three full baking blogs and an analysis of the individual IWPs in them.
Participants
Eye-tracking and questionnaire data from 12 participants was recorded (eight male and four female). All participants were students living in the Netherlands (N = 12) aged between 19 and 24 (M = 21.5, SD = 1.78). Even though the participants’ native language is Dutch, they all judged their comprehension of English texts as ‘good’. Each of the participants was shown one of three full baking blogs as a whole, as well as the IWP of one of the other two baking blogs. The materials were equally distributed, so that each baking blog and each IWP was viewed by four participants. During the data analysis, it was discovered that the eye-tracker had encountered issues in consistently recording the pupil movement of Participant 2. In order to ensure reliability, the eye-tracking data of Participant 2 was excluded from analysis. Consequently, for the webpage of MI 14 and the IWP of MI 1 presented in the next section of this paper, there is only gaze pattern data available for three participants instead of four. The questionnaire data of Participant 2 was complete and included in the analysis.
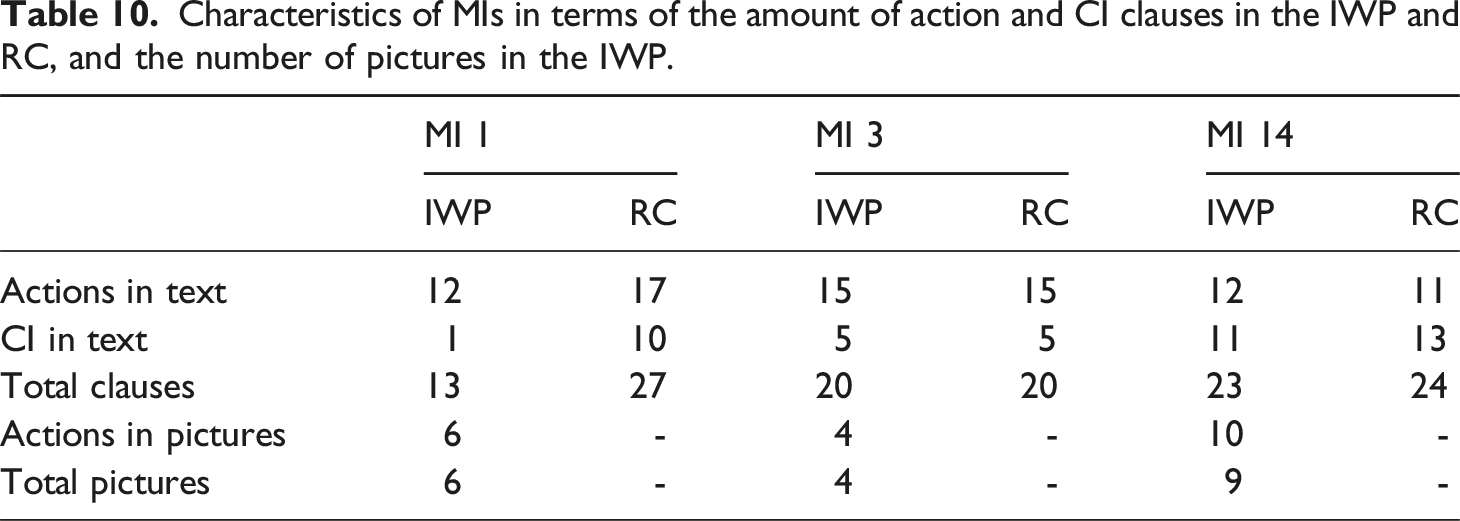
Materials and setup
Three MIs described in the corpus, MI 1, MI 3, and MI 14, were used for this study. The IWPs and RCs of MI 1, MI 3 and MI 14 are presented in Figures 5 and 6 respectively. To represent the variation in the corpus, the three MIs were chosen on the basis of the number of text clauses (IWP Mean = 19.9, Std = 6.24; RC Mean = 26.7, Std = 7.83) and the number of pictures in the IWP (Mean = 6.49, Std = 2.54). Table 10 presents the amount of textual and visual information of the IWPs and RCs per blog. The number of clauses in the MIs is similar, with MI 14 including the most clauses (N = 47) compared to MI 1 (N = 40) and MI 3 (N = 40). The distribution of the clauses within the blogs that is IWP versus RC, varies. In MI 1 the RC text includes more clauses than the IWP, while in MI 3 and MI 14 the number of clauses in IWP and RC is (almost) the same. Compared to MI 3 (N = 4) and MI 1 (N = 6), MI 14 includes more visualized actions (N = 10), where MI 14 picture 8 presents two actions namely portion and put somewhere (no purpose given). Note that the RCs presented in Figure 6 also all include a picture of the cookies that should result from carrying out the baking procedure. The RC pictures offer a situation sketch that visualizes the result of the whole procedure. (a) IWP of MI 1. (b) IWP of MI 3. (c) IWP of MI 14. Source: MI 1: https://whatshouldimakefor.com/olive-oil-chocolate-chip-cookies; MI 3: https://www.twosisterscrafting.com/chocolate-chip-cookies/; MI 14: https://www.foodologygeek.com/fleur-de-sel-chocolate-chip-cookies/. (a) RC of MI 1. (b) RC of MI 3. (c) RC of MI 14. Source: MI 1: https://whatshouldimakefor.com/olive-oil-chocolate-chip-cookies; MI 3: https://www.twosisterscrafting.com/chocolate-chip-cookies/; MI 14: https://www.foodologygeek.com/fleur-de-sel-chocolate-chip-cookies/. Characteristics of MIs in terms of the amount of action and CI clauses in the IWP and RC, and the number of pictures in the IWP.
In each of the three blogs, two Areas of Interest (AOIs) were defined that covered the Instruction with Pictures and the Recipe Card. The IWPs of the three blogs are given in Figure 5, while Figure 6 presents the RCs.
First and second set of questions, where the relevant document type (Full webpage or IWP) is indicated, and the concept that each question measures is given.
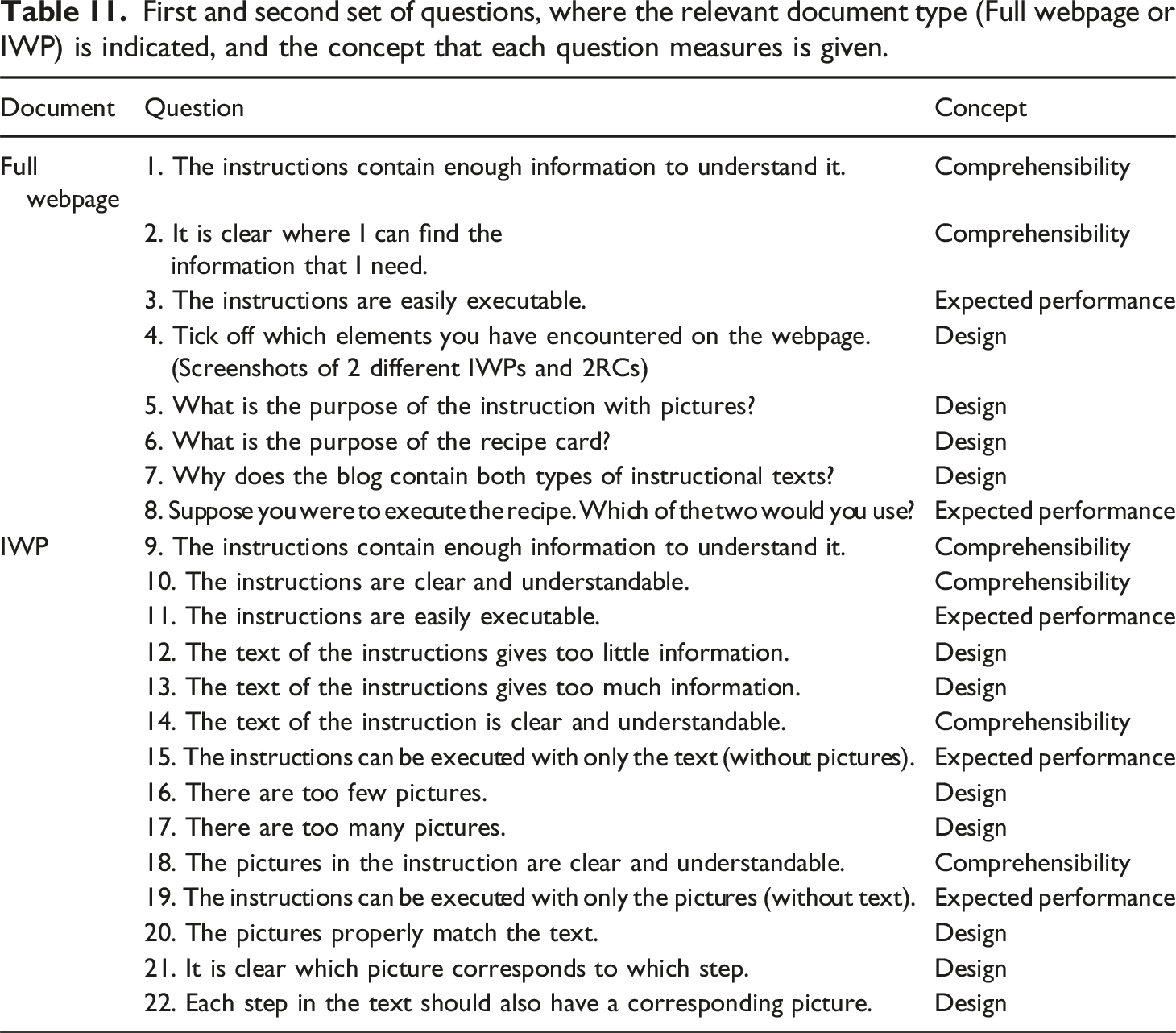
To obtain further insights in the participants’ observations and motivations, short interviews were included after the participant had filled out each part of the questionnaire. In these interviews the instructor went over the participants’ responses in the questionnaires, new questions were not included. The questionnaire also contained a set of demographic questions, in which participants were asked for their name, gender, age, highest level of education, first language and ability to read/comprehend English texts. Arguably, demographic characteristics have an effect on whether participants are familiar with cooking in general, more specifically baking cookies and reading and using recipes in English. The questionnaire also recorded whether they had experience using baking recipes, specifically for baking cookies, and, if so, how often they had done this and how long ago they baked cookies. These demographic questions were included to control for potential confounding factors and to provide a more nuanced understanding of the research findings.
The materials were presented to participants on a laptop connected to an Eyelink Portable Duo eye-tracker.2 This eye-tracker has a binocular sampling rate up to 2000 Hz, which results in very accurate and reliable eye-tracking data. The questionnaire was presented on a separate laptop. Figure 7 presents a simulated picture of the study setup. In terms of software, Weblink3 was used to present the materials and record eye movement, while Data Viewer
4
was used to process the data. Weblink is a screen recording software by SR-Research, in which participants can view and interact with websites, documents and images while their eye movement is recorded. The software compensates for scrolling movement, which means that the data on the whole webpage is accurately recorded. Simulation of the eye-tracking study setting, including questionnaire laptop (left) and eye-tracker laptop (right). The picture was generated with https://floorplanner.com/.
Procedure
The participants individually took part in the study. Each of the participants was welcomed into the lab. After receiving a short oral introduction to the study, the participants signed a consent form and filled out the demographic questions on the questionnaire laptop. Next, the participants switched to the other laptop, where the eye-tracker was calibrated to the participants’ pupils by the instructor. From that point onward, all tasks and instructions were presented visually on the eye-tracker laptop. The instructor stepped back from the study setup, but stayed in the lab at another desk. The participants read the task description, which told them to look at a baking blog webpage on the eye-tracking laptop, imagining that they were planning to use a blog recipe for baking cookies with the purpose of deciding whether the given recipe was to their liking. Note that with this task we envisioned to simulate a real life context, meaning the participants were not explicitly asked to read the whole webpage. The instructions also stated that they would be asked to answer a set of questions related to the shape, content, and function of different elements within the blog, to encourage them to pay attention to those aspects while reading the blog. After reading through the webpage, the laptop showed the instruction to switch to the questionnaire laptop and fill out questions 1–8. While the participants were reading the text and filling out the questionnaire, there was no conversation between the participants and the instructor. After filling out the first questionnaire, the instructor briefly interviewed the participants about their answers to the questions and about the webpage in general. Next, the instructor invited the participants to switch back to the eye-tracking laptop, and stepped back from the participants again. The laptop presented the instruction to look at an Instruction with Pictures (no specific prompt was given), and subsequently answer questions 9–22 on the questionnaire laptop. Again, the instructor was not involved during these steps. After the participants had filled out the questionnaire, the instructor did another short interview to discuss the participants’ answers to the questionnaire and views on the IWP. Finally, the participants were debriefed about the study and thanked for their participation.
Analysis
Areas of Interest (AOIs) for both document types.

For the individual IWPs, the reading strategy was also analyzed using heat maps. Heat maps visualize the amount of attention paid within an AOI. In this case it was recorded how participants distribute their attention between the text and pictures within three different IWPs (i.e., AOI IWP_Full). No heat maps were generated for the full webpages, as the size of the documents made this infeasible and most likely uninformative given our research question.
The numerical data collected with the questionnaires was processed by calculating means and standard deviations. The numerical data relating to Comprehensibility, Design and Expected Performance was compared for each of the MIs. The participants’ answers to open questions about the purpose and use of the IWPs and RCs in the blogs were summarized into categories inductively.
Results
The presentation of the results of the eye-tracking study below is split into the reading data of the eye-tracker, and the judgment results collected with the questionnaire.
Eye-tracker results
Webpage
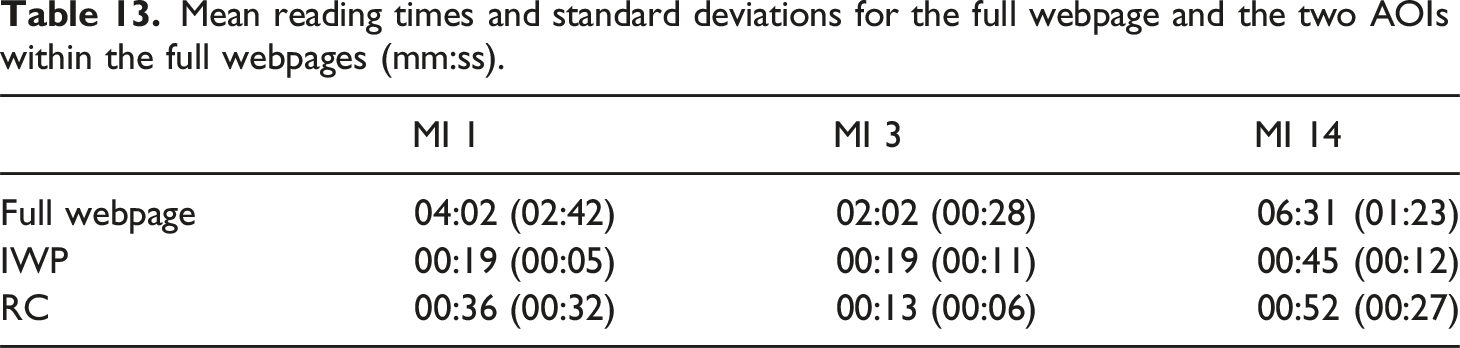
Mean reading times and standard deviations for the full webpage and the two AOIs within the full webpages (mm:ss).
Instruction with pictures
The reading strategy for the individual IWPs is very different from the reading strategy for the full webpage. When scrolling through the webpage, participants generally follow a linear reading, and also when looking at the IWP within the webpage, participants go through it linearly. However, when looking at the IWP as a separate component, participants switch back and forth between different elements. All participants begin and end their session looking at the pictures. In between, they switch back and forth between the text and the picture. Some parts of the sequences demonstrate how participants attempt to link the textual steps with the pictures. For example, for Participant 1, who read the IWP of MI 14, the following gaze sequence was recorded for the first four steps of the IWP: T1
In order to visualize the gaze distribution over the different elements within the IWPs, a heat map was created for each of the MIs. The heat maps are presented in Figure 8. The coloured overlay displays where the participants were looking, where the red areas are dwelled on the most. The heat maps show that there are no pictures or textual steps that are fully overlooked. The heat maps also highlight that the dwell time on the text is longer than the dwell time on the pictures. The first few textual steps of each IWP receive the most attention from the participants, but the attention gradually declines towards the end of the text. Heat maps for the IWPs of MI 1, MI 3 and MI 14 as generated with the Eyelink software (https://www.sr-research.com/eyelink-portable-duo/). (a) IWP of MI 1. (b) IWP of MI 3. (c) IWP of MI 14.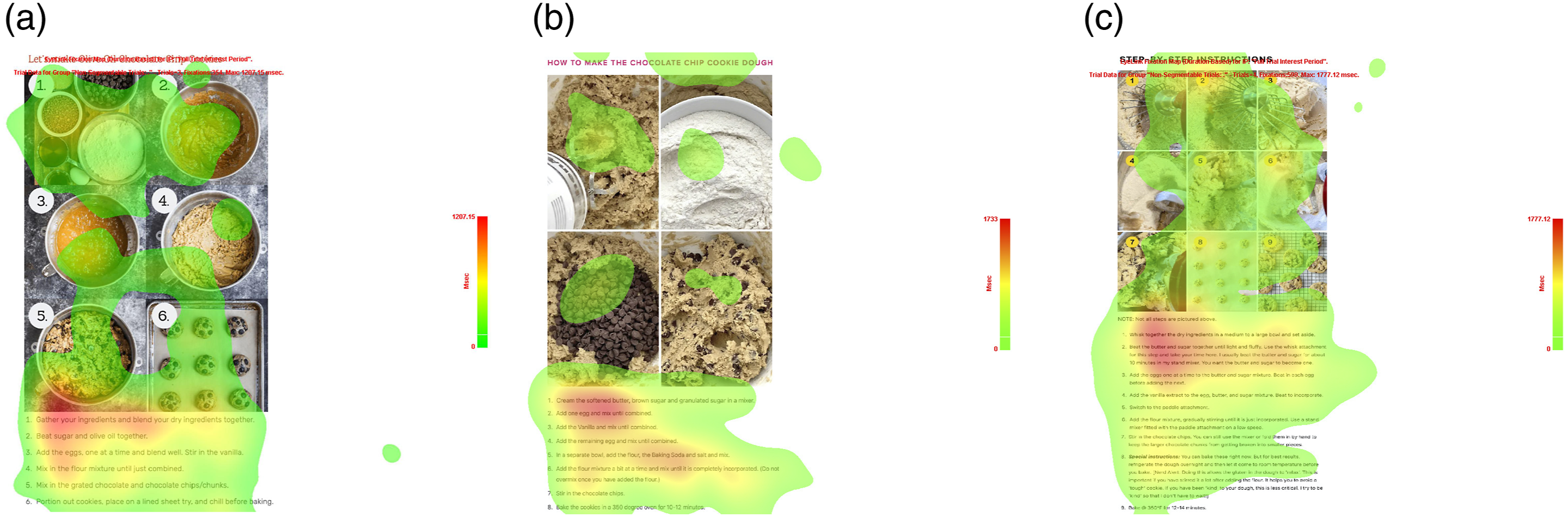
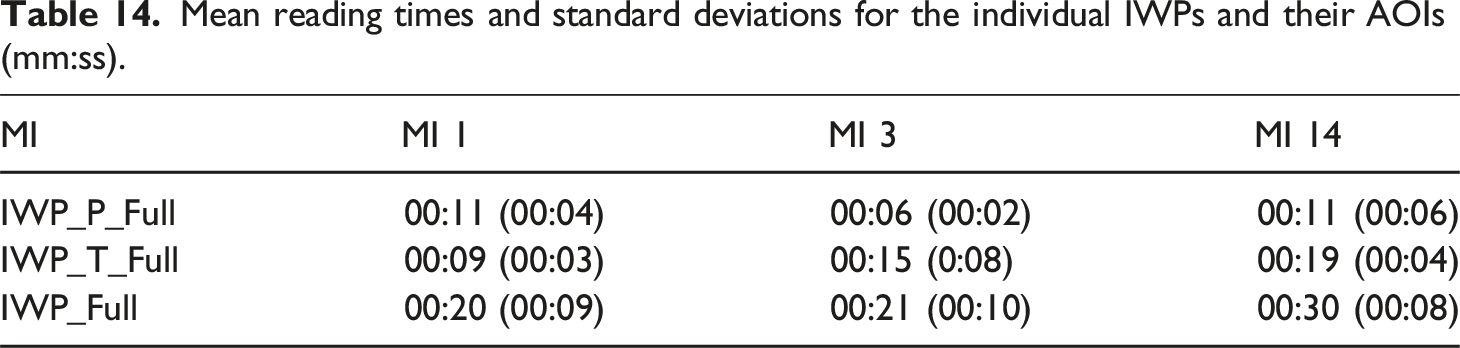
Mean reading times and standard deviations for the individual IWPs and their AOIs (mm:ss).
For the text, the dwell time corresponds to the amount of text. MI 1 has the lowest dwell time of 9 seconds, followed by MI 3 with 15 seconds, and MI 14 with 19 seconds. This is in line with the amount of text presented in the IWPs.
Questionnaire results
Webpage - Comprehensibility
Results for the webpage questionnaire questions measuring the participants’ judgments of the Comprehensibility of the instruction. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).

Webpage - Design
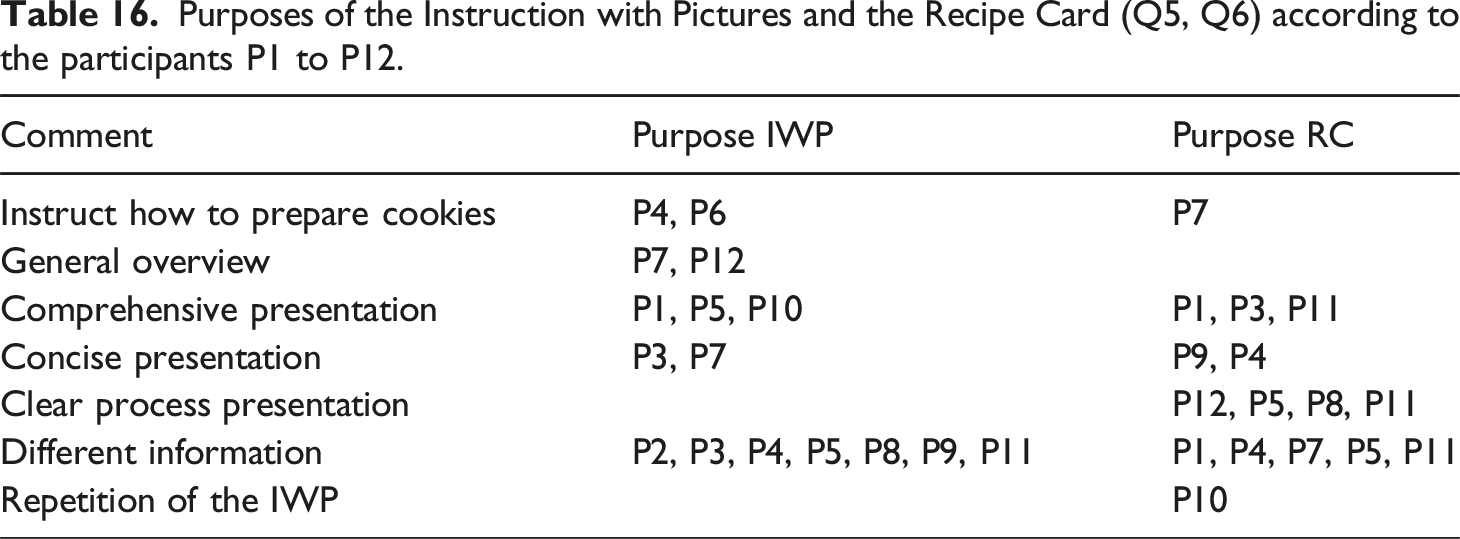
Purposes of the Instruction with Pictures and the Recipe Card (Q5, Q6) according to the participants P1 to P12.
Webpage - Expected performance
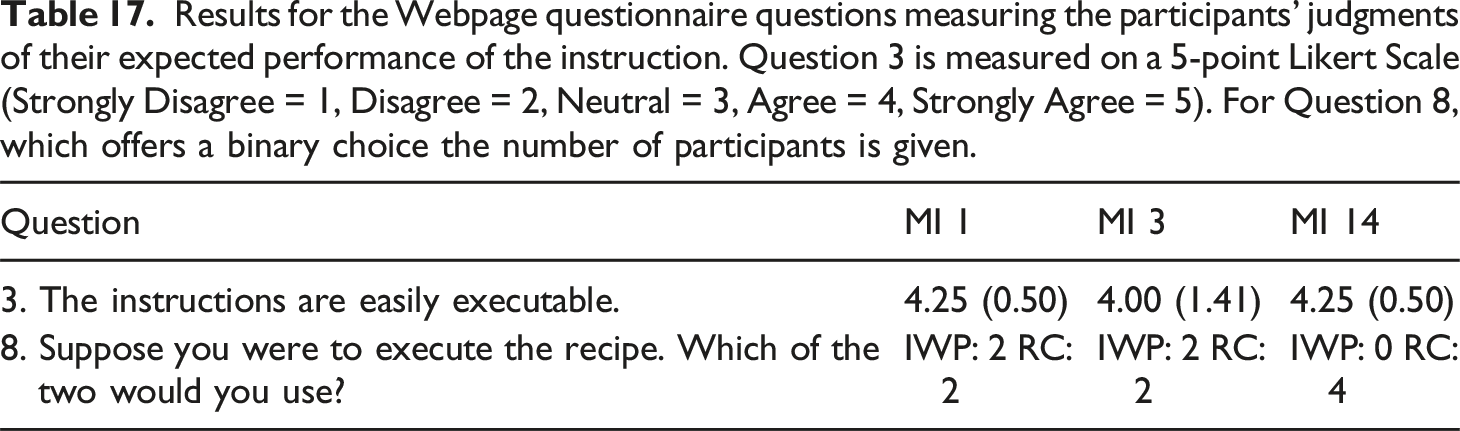
Results for the Webpage questionnaire questions measuring the participants’ judgments of their expected performance of the instruction. Question 3 is measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5). For Question 8, which offers a binary choice the number of participants is given.
IWP - Comprehensibility
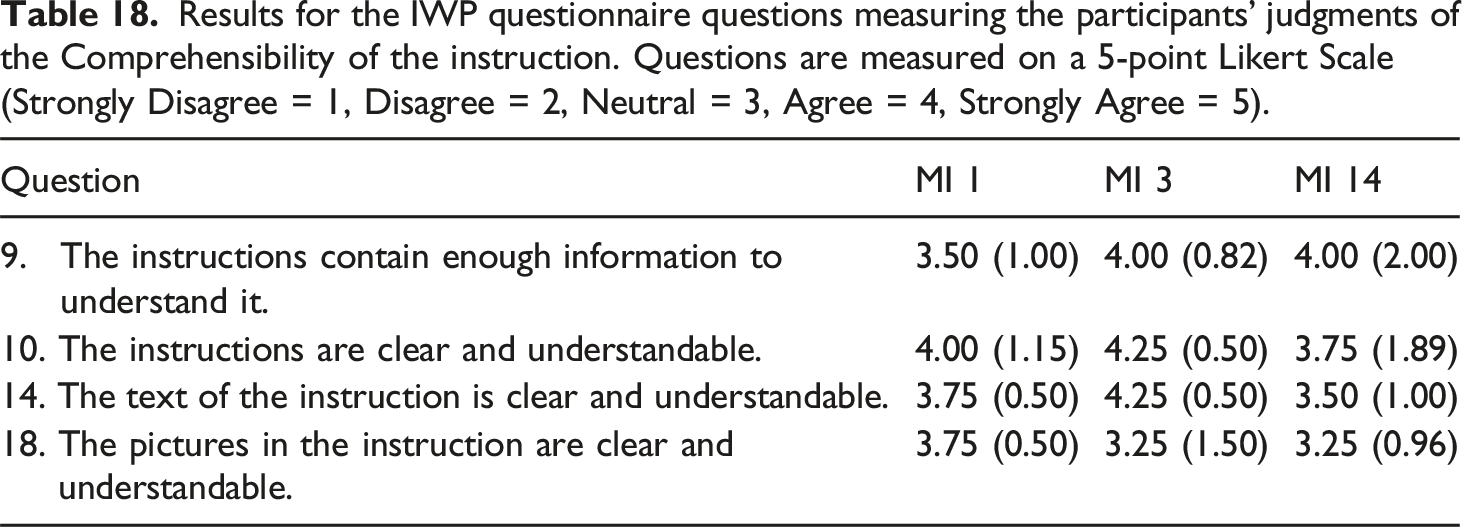
Results for the IWP questionnaire questions measuring the participants’ judgments of the Comprehensibility of the instruction. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).
IWP - Design
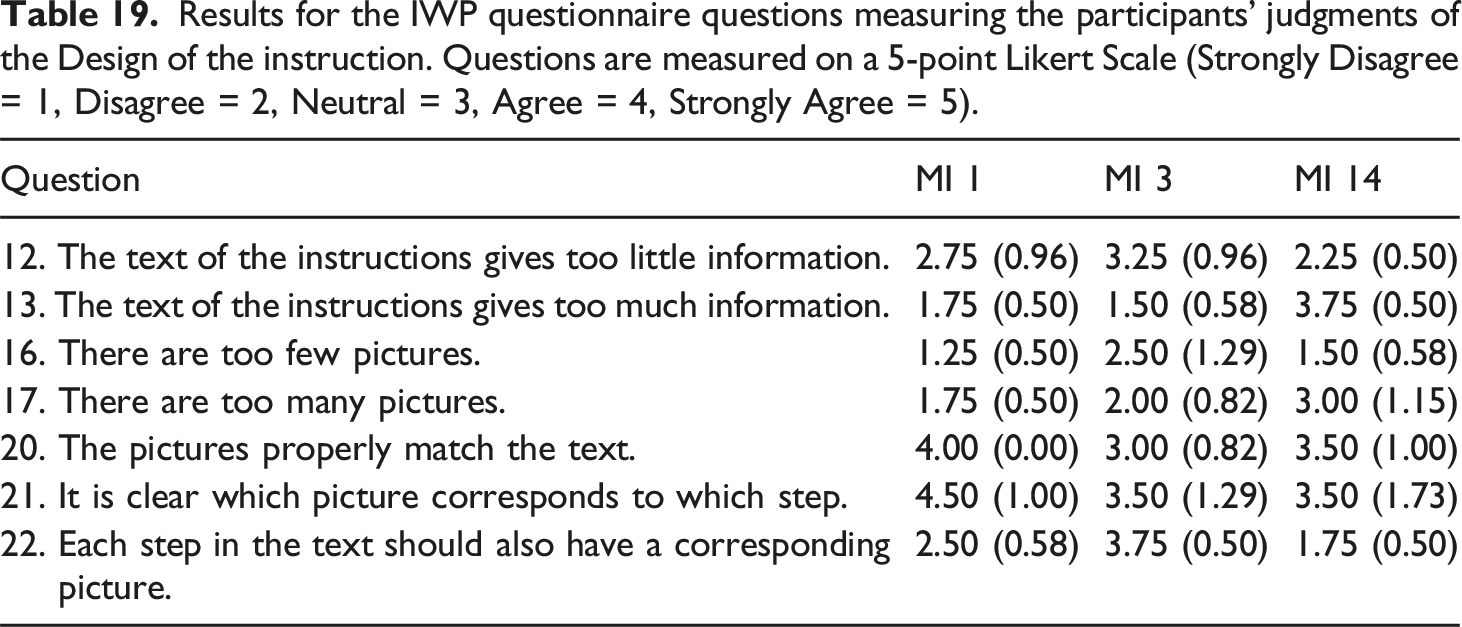
Results for the IWP questionnaire questions measuring the participants’ judgments of the Design of the instruction. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).
IWP - Expected performance
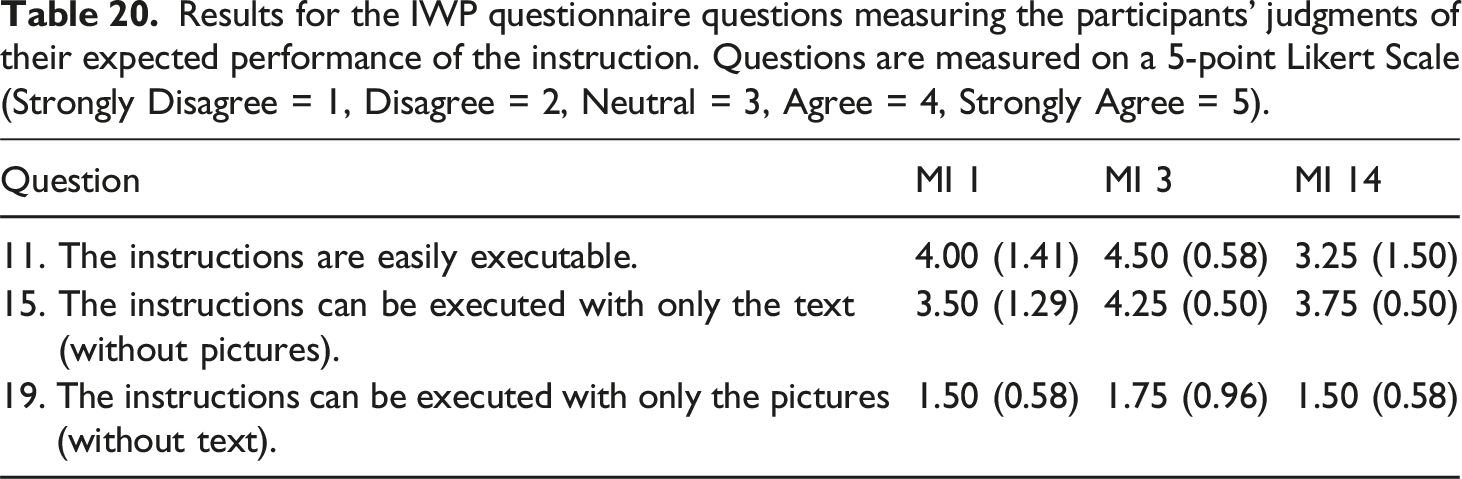
Results for the IWP questionnaire questions measuring the participants’ judgments of their expected performance of the instruction. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).
Preliminary discussion
The amount of time that participants spend on the blogs and IWPs corresponds with the length of the documents. Notably, only a small portion of the time that participants spent on the baking blog was spent on the Instruction with Pictures and the Recipe Card in it. Most participants read the baking blogs including the IWP within it in a linear fashion. In contrast, the participants’ processing of the individual IWPs shows a different reading strategy in which the participants move back and forth between the pictures and the text, which leads us to conclude that readers make an effort to establish content relations between the text and pictures. The time that participants spent on the IWP pictures suggests that a smaller number of pictures (N = 4), makes it easier to establish text-picture relations, while including more pictures (N = 6 or N = 9) and the type of Correspondence with the verbalized actions does not affect the time it takes that participants use to establish text-picture relations. Alternatively, the Type of the realized actions may have affected the perceived added value of the pictures.
Although some participants remarked that the blogs were lengthy and difficult to navigate, all the participants found the instructions clear and understandable, especially the text of MI 3 which is of medium length compared to MI 1 and MI 14 and the pictures of MI 1 which show the results of six actions without specifying the utensils used to obtain these results. All the participants thought that they would be able to use the instructions to successfully bake cookies even without the pictures but not with only the IWP pictures. Interestingly, the participants were divided on which part of the blog they would use to bake the cookies, the Recipe Card or the Instruction with Pictures.
The variation in the readers’ evaluations and interpretations of IWPs and RCs raises questions about the use of IWPs and RCs in a real live situation, and whether users and readers could differ in their judgments of the comprehensibility, design and their expected/actual performance of IWPs and RCs. Accordingly, the exploratory user study presented in the next section was set up. The reader study results as well as the corpus analysis informed the selection of the IWP and RC to offer to the participants in the user study in terms of verbal and visual content. Consequently, the results of the reader study and corpus analysis support the interpretation of the data collected through situated use of the RC and IWP. The reader study results also helped in compiling the materials for the user study. For instance, as it was noted in the reader study that the IWPs do not include an ingredient list which is crucial to prepare the cookie dough, we were able to prevent a situation in which users of the IWP and RC were prompted with different starting points.
User study: Baking cookies
The user study presented in this section was designed to test the following question: ‘How does using either the Instruction with Pictures or the Recipe Card of a baking blog influence the user’s execution of the baking instruction and the user’s judgments of the comprehensibility, design and performance of the baking instruction?’ The research question introduces three concepts that need to be measured, the Comprehensibility, Design and Performance of the instruction. Similarly to the operationalization in the reader study, these concepts were measured using a questionnaire. In the user study, Comprehensibility refers to how well participants think that they understand the instruction. Design refers to how participants rate the modalities used in the instruction and Performance refers to how participants rate their own performance in using the instruction to bake cookies. In addition to the subjective judgments of the participants towards their own performance of the instruction, we also measured User Performance objectively by analyzing the video data and screen tracking data collected during the baking process. Apart from investigating the effectiveness of the IWP and the RC based on their use, we are also interested in measuring the effectiveness of the instructions based on solely reading. Therefore the study was set up in such a way that the participants first read and used either the IWP or RC and evaluated it. Subsequently, the participants read the instruction that they had not used for baking and evaluated that instruction based on only their reading of it given their cookie baking experience.
Participants
The study was conducted with four teams of 2 participants, resulting in a total of eight participants (three males and six females). All participants resided in the Netherlands (N = 8), and were aged between 18 and 22 (M = 20.6, SD = 1.60). All participants were native speakers of Dutch who indicated that they had a good comprehension of the English language. In order to foster a natural environment and to evoke a dialogue about the instruction and procedure, the participants were asked to work in duos. The rationale behind this choice was the anticipation that teamwork would lead to increased verbal interaction (cf. Mayhew and Alhadreti, 2018; Miyake, 1982).We paired people who knew each other already. It has been established that trust in teams is positively associated with perceived task performance and team satisfaction (Costa, 2003), and helps in reaching unanimity and efficiency (Jones and Roelofsma, 2000).
The teams were divided into two conditions: the participants in the IWP Condition used the Instruction with Pictures to bake cookies, while the participants in the RC Condition used the Recipe Card of the same baking blog to bake cookies. After baking the cookies using their assigned instruction, the participants also read the other instruction from the same blog and subsequently rated it.
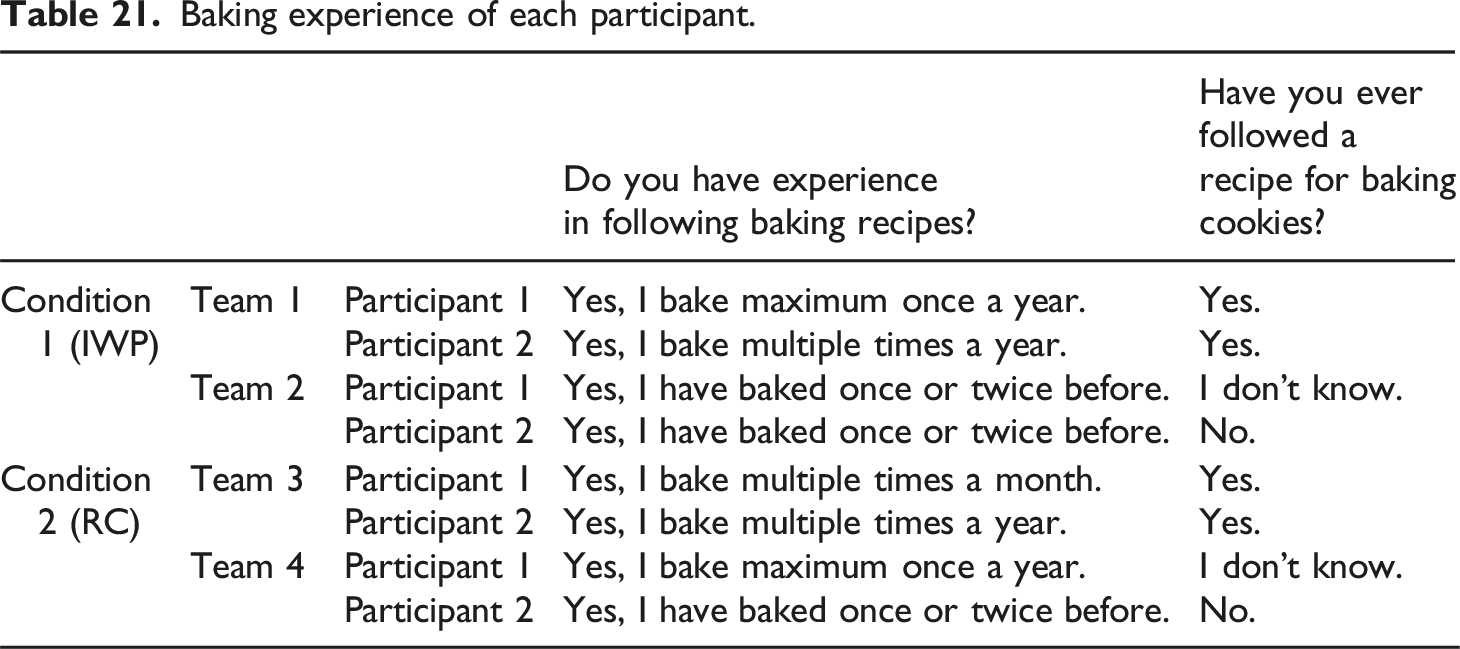
Baking experience of each participant.
Materials and setup
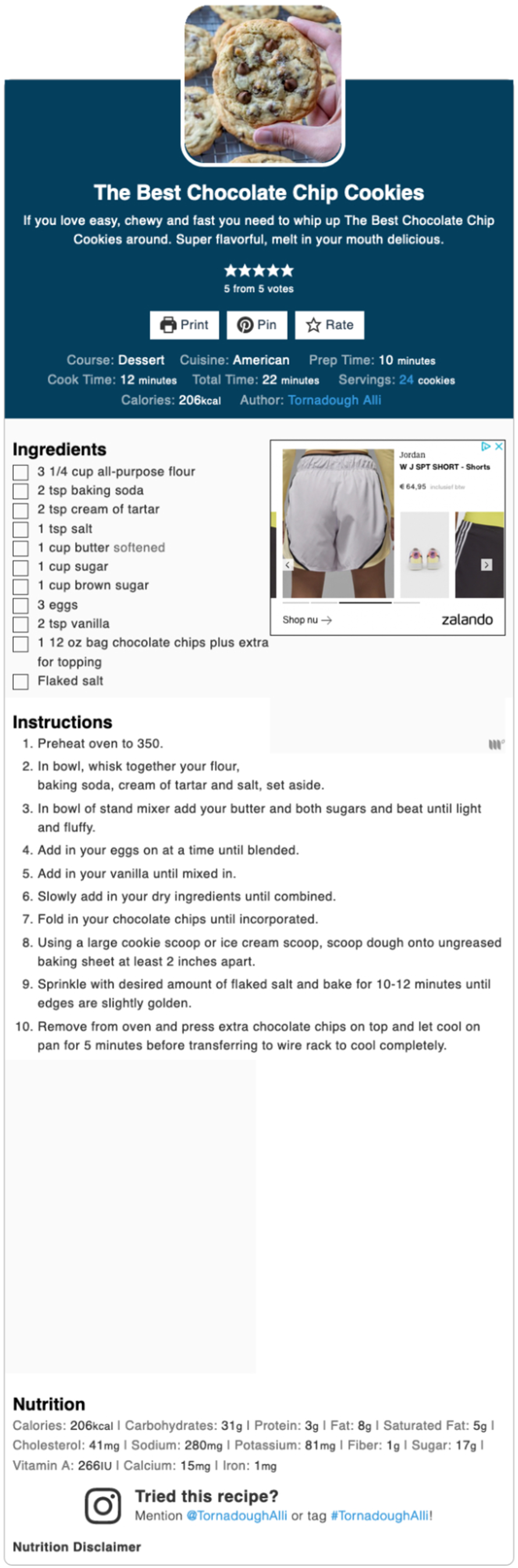
The Instruction with Pictures and the Recipe Card used in the reader study are presented in Figures 9 and 10. The figures present the fragments from the webpage of MI 2 that were analyzed in the corpus study. The motivation for choosing MI 2 is based on the corpus analysis and on the reader study results presented in this paper. The corpus study shows that the main difference between the IWP and the RC is the absence of pictures in the Recipe Card. In order to investigate the added value of the pictures in multimodal baking instructions, we decided to use an IWP and RC that are similar in terms of their verbal content and include an average amount of text and pictures given the IWPs in the corpus (clauses: Mean = 19.9, Std = 6.24; pictures: Mean = 6.49, Std = 2.54). In addition, the amount of visual and verbal information presented in MI 2 is in line with the preferences of the participants in the reader study. Although the corpus study shows that the Recipe Card generally contains more Action clauses and CI clauses, this is not the case for all MIs. In MI 2, both texts contain virtually the same amount of Action clauses that is 18 in Instruction with Pictures versus 19 in Recipe Card. The action that is omitted in the IWP compared to the RC is the first step of preheating the oven (Action Subtype heat a space). Both texts have the same number of CI clauses (N = 7). The similarity of the two instructions allows for a comparison on the basis of the layout and the presence/absence of pictures. Instruction with pictures (MI 2). Source: https://tornadoughalli.com/the-best-chocolate-chip-cookies/. Recipe card (MI 2). Source: https://tornadoughalli.com/the-best-chocolate-chip-cookies/.
In the reader study the participants observed that a Recipe Card contains the indispensable ingredient list while the Instruction with Pictures does not. To make sure that teams in the two conditions worked from the same starting point, the participants were provided with the exact amount of each of the ingredients necessary for baking the cookies. Note that providing the exact amounts of the ingredients is also expected to reduce potential errors in the participants’ performances, the duration of the sessions in which the teams executed the baking procedure and our own efforts in analysing the user study data.
The questionnaire questions, where the relevant MI types (IWP and RC) are indicated and where the concept that each question measures is given. Question 1 is measured on a scale from 1 to 10, questions 2–17 are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).

After filling out the questionnaire, the participants in the IWP Condition were shown the RC, and the participants in the RC Condition were shown the IWP. Participants did not have to execute these instructions, but were merely asked for their opinion on this alternative instruction using the relevant questions presented in Table 22. The participants in the IWP Condition now answered questions 1–6 and eight to rate the RC, and the participants in the RC Condition answered Questions 1–6, 9–11 and 13–17.
By asking participants to rate the questions presented in Table 22, different aspects of the MI in the given distribution based on their use or their reading of either the IWP or the RC, we recorded a comprehensive evaluation of the instruction. The collected data allows us to make comparisons between the Comprehensibility and Design of the instruction and the modalities used in it, as well as comparisons between readers and users of the IWP and the RC.
At the end of the study, the participants were asked to fill out the demographic questions that were also used in the eye-tracking study, in which they were asked for their name, gender, age, highest level of education, first language and their ability to read/comprehend English texts. The questionnaire also recorded whether they had experience with following baking recipes, specifically for baking cookies, and, if so, how long ago this had happened.
Figure 11 shows the setup in which each pair of participants was recorded. Participants were asked to stand behind a table. On this table, all of the ingredients were laid out in the correct amounts in bowls and/or containers. Participants were also provided with the utensils and tools necessary for the execution of the recipe such as empty bowls, a mixer, an oven etc. The recipe (either Instruction with Pictures or Recipe Card) was presented to the participants on a laptop screen. The screen was recorded to enable monitoring the specific parts of the instruction that participants looked at. A camera in front of the table with the bowls and the mixer recorded the baking process. User study setting with the workspace and a detail of ingredients in birds eye views, and a view from the side showing the counter with the oven, utensils and laptop that present the instruction.
Procedure
The instructor welcomed the participants into the lab and invited them to position themselves at the table with the ingredients and the laptop. The participants first read a short introduction to the study, then they were asked to sign a consent form regarding their voluntary attendance, privacy, confidentiality and our data collection. Subsequently the participants were given a task description, in which the setup of the study was explained. The introduction to the study, the consent form, and the task description were presented on the laptop. In the task description, the participants were advised to make a task division such that one of them kept track of the instructions on the laptop, while the other could mainly focus on executing the actions to bake the cookies using the tools and ingredients provided on the table. After the team had read the task description, there was one last opportunity to ask questions. When all questions were resolved, the instructor started the camera recording and the laptop screen recording, opened the baking instructions on the laptop for the participants, and left the room. From this point onwards, the participants were not allowed to speak with the instructor until they had finished the recipe. In the task description, the participant had been instructed to first read the recipe before starting the baking process. Note that the participants were not offered the whole webpage. The recipe (IWP or RC) was presented on the laptop, as a scrollable fragment of the webpage from which it originated. Once the cookies were in the oven, the participants called the instructor back into the room. The participants then sat down on a couch and were invited to fill out the questionnaire questions in Table 21 on their phones (they were of course offered only the relevant subset of questions). While filling out the questionnaire, they were able to look at the instructions they had used (IWP or RC) on a laptop in front of them. Subsequently, the participants who had used the Instruction with Pictures were offered the Recipe Card and vice versa. These instructions were also presented on the laptop. After reading this alternative instruction, participants filled out the questionnaire with the relevant questions presented in Table 22. Subsequently, the participants filled out the demographic questionnaire. Participants were explicitly instructed not to discuss their answers while filling out the questionnaires. Finally, the participants were debriefed and thanked for their participation.
Analysis
The data in the questionnaires was processed by calculating means and standard deviations for each of the questions. For the questions we used a 5-point Likert Scale with values: Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5. The questionnaire responses about the instruction that participants executed were analyzed by comparing the scores of the IWP Condition and the RC Condition. The questionnaire data was organized into subsets with respect to the three concepts that the questionnaire measures: Comprehensibility, Design and Performance.
Variables used in the video analysis to measure user performance.

We also analyzed the second part of the questionnaire, in which participants were asked questions about the alternate instruction which they had only read. This data was used to make a comparison between users and readers of both the RC and the IWP.
Results
The results are presented in two parts: the findings in the user data collected with the questionnaire and video recordings, and a comparison of users and readers of the IWP and the RC based on the questionnaire data.
User results
Comprehensibility
Means and standard deviations for the questionnaire questions measuring the participants’ judgment of the Comprehensibility of the instruction. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).

Design
Means and standard deviations for the questions measuring the participants’ judgemnt of the Design of the instruction. Question 1 is measured on a scale from 1 to 10, the other questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).
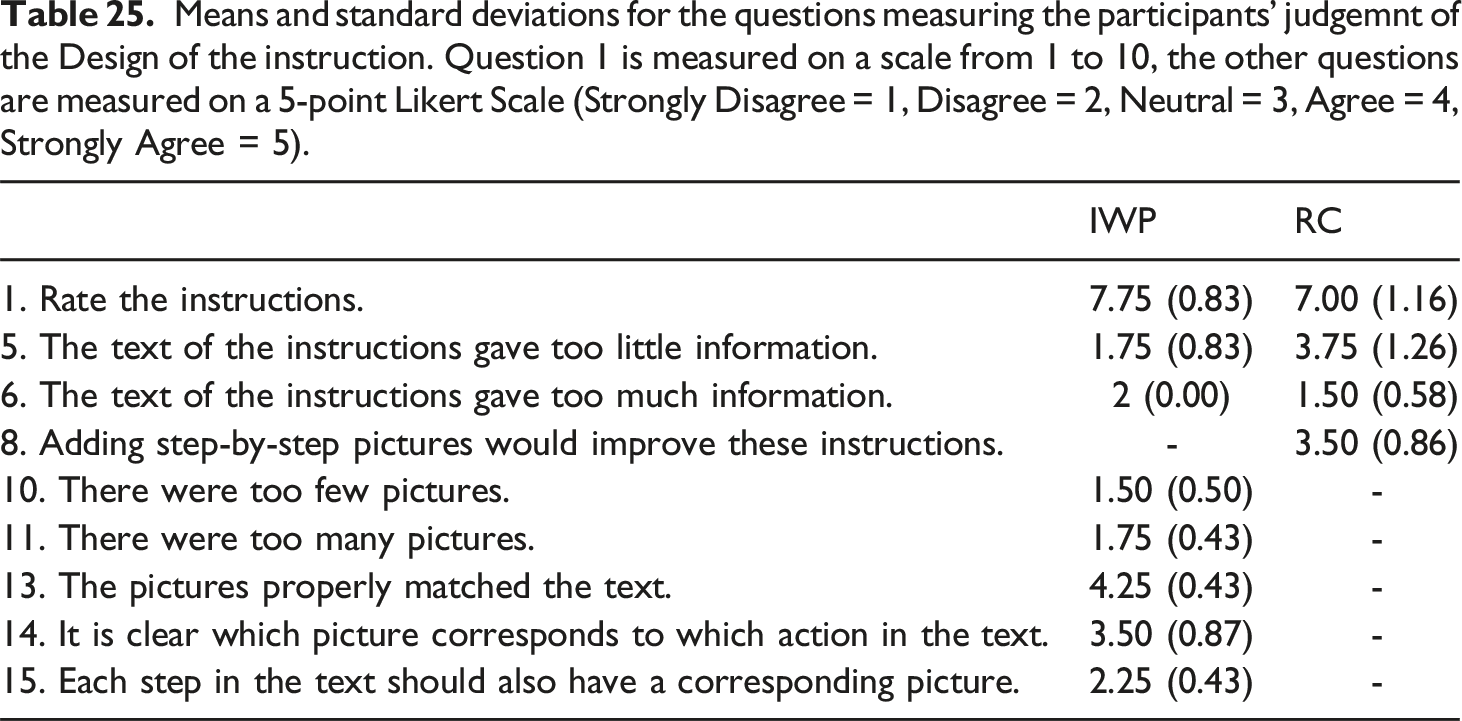
IWP participants found that the instruction contains a proper amount of pictures (Q10, Q11), and that these pictures properly matched the text (Q13). However IWP participants also found that the clarity of the correspondence between the text and the pictures in the instruction could be improved (Q14). Still, IWP participants do not think that each verbal step needs a corresponding picture (Q15).
Performance
Means and standard deviations for the questions measuring the participants’ judgemnt of their own Performance. Questions are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).

IWP participants scored their use of the pictures lower than their use of the text (Q12). IWP participants found that they would be able to bake cookies using solely the verbal instructions (Q16) and that the pictures were not really necessary (Q17).
User performance
Scores of the video analysis to measure user performance.
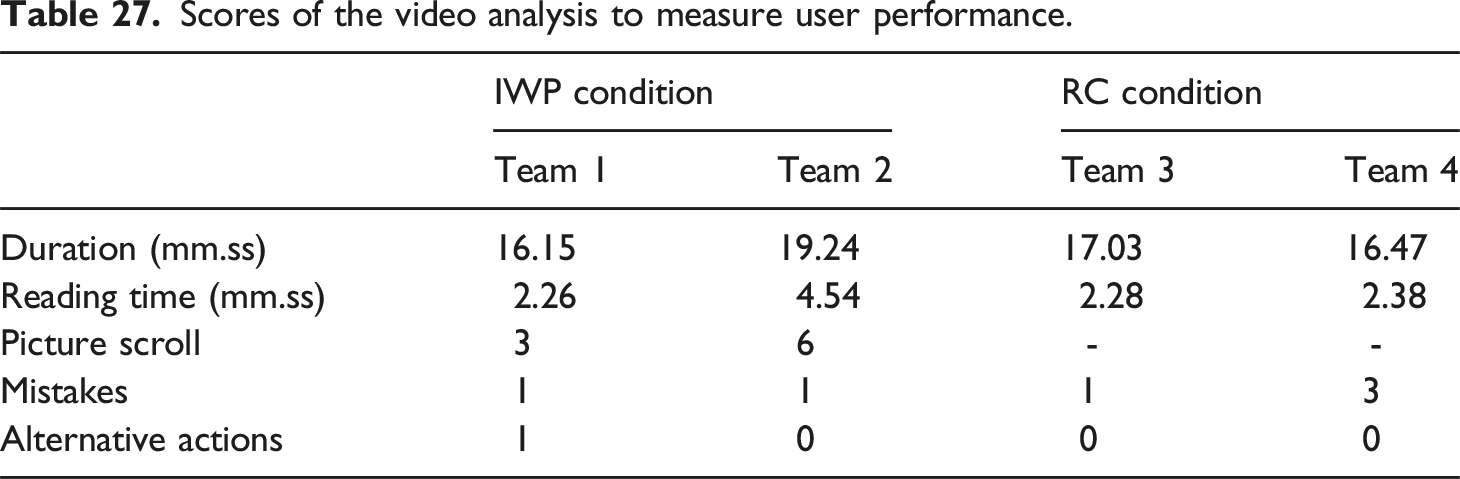
Three types of mistakes were made. RC Team 4 added the dry ingredients to the bowl of the stand mixer instead of to a separate bowl; Team 4 did not notice that in the RC text ‘bowl’ in Step 2 and ‘bowl of stand mixer’ in Step 3 refer to different objects (See Figure 10). In comparison, the participants in the IWP Condition used the text as their main guide for baking. The pictures were used, but mainly to resolve any uncertainties that arose in the process. For example, both IWP teams discussed whether they had to add the dry ingredients to the bowl of the stand mixer or to another available bowl. After scrolling up to the pictures, they both concluded that it had to be the other bowl.
RC Team 4 incorrectly mixed the chocolate chips in the dough with the stand mixer instead of with the spatula. Note that this RC team, who only had the text to work with, could not see the picture in which the spatula is shown with the mixed-in chocolate chips (See Figure 9: Picture 6). In the RC text, however, the verb mix is reserved for processing actions that should be performed with the stand mixer, while the verb fold in is used to incorporate the chocolate chips into the dough. In contrast, IWP Team 1 purposely decided to mix in the chocolate chips with the stand mixer, despite reading and correctly comprehending the instructions, and thus this was classified as an alternative action.
All teams made the mistake of not saving chocolate chips to top off the cookies after baking. The teams could only have known that they had to save a part of the chips if they had read the instructions as a whole before executing the individual steps presented in the instructions.
Note that the IWP teams did not heat the oven at the start of the baking procedure. Recall that the IWP, in contrast to the RC instruction, does not instruct the user to preheat the oven. Therefore the omission of the heating action in the IWP condition was not considered a mistake.
Users versus readers
Means and standard deviations for the questionnaire questions relating to using and reading of both instruction types. Question 1 is measured on a scale from 1 to 10, questions 2–17 are measured on a 5-point Likert Scale (Strongly Disagree = 1, Disagree = 2, Neutral = 3, Agree = 4, Strongly Agree = 5).
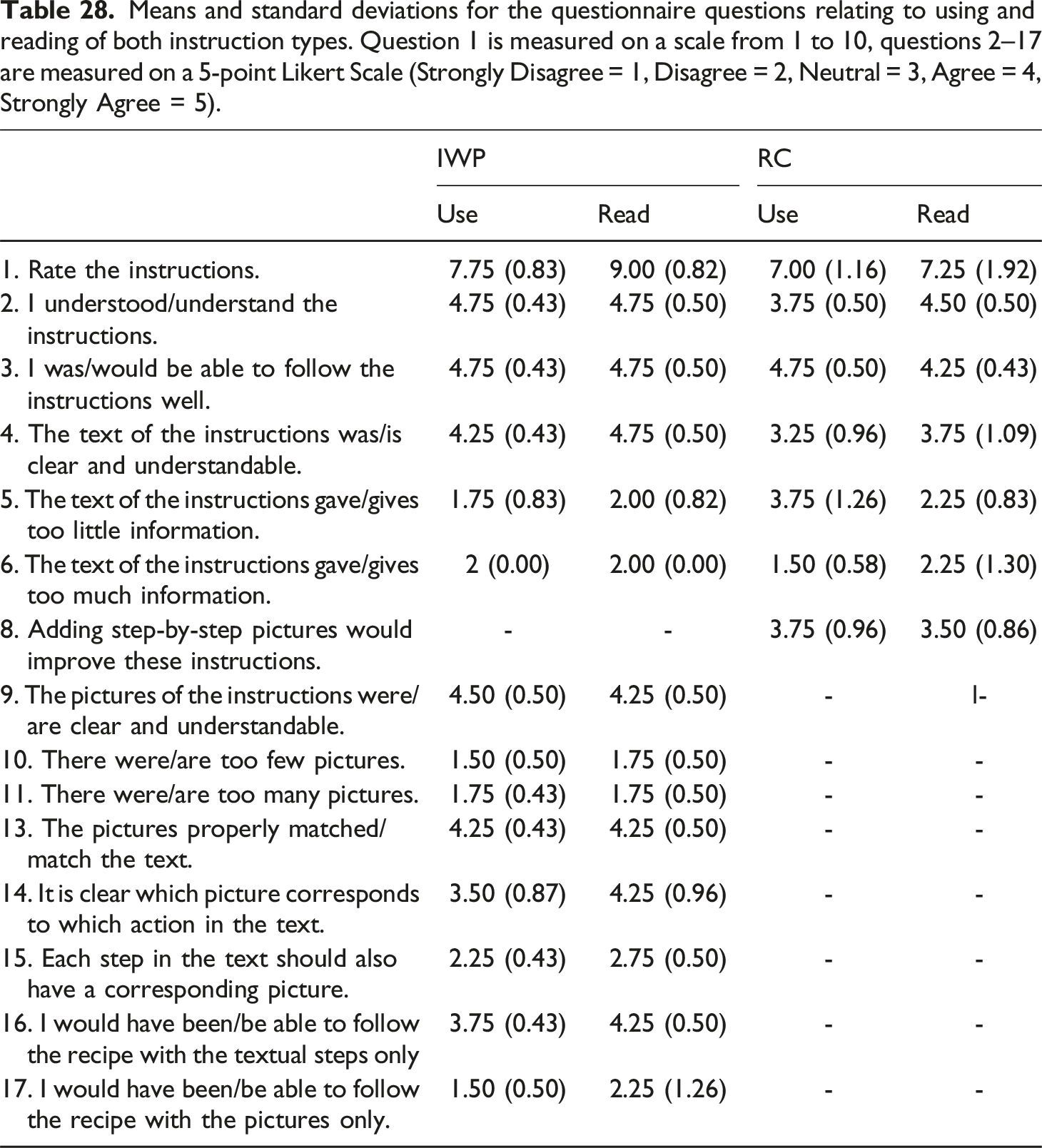
For the RC the ratings are similar for readers and users, but lower than for the IWP. There are a few questions in which RC readers give a more positive rating than RC users. For instance, in terms of Comprehensibility RC readers think the RC is more understandable than RC users (Q2), and in terms of the Design of the Instruction, RC readers find that the text gives too little information compared to RC users (Q5). This might be because using an instruction requires a different type of understanding than reading it.
In terms of the Design of the Instruction, IWP readers give a higher rating than IWP users (Q1). Readers also rate the clarity of text-picture relations higher than users (Q14). This may indicate that the IWP instruction can seem clear at first glance, but is perceived as less clear when it is actually used for baking. This would imply that executing an instruction requires a different type of understanding than reading it. Possibly, IWP readers also saw visualized information that they perhaps had missed while executing the RC.
In terms of Performance, IWP readers score higher in their expected ability to execute the recipe by only using the text (Q16) and by only using the pictures (Q17). This could be due to the fact that readers had already executed a text-only instruction, and were thus more confident in their ability to use a single-mode instruction. For the other questions, the ratings of both participant teams are similar. Both groups respond between ‘neutral’ and ‘agree’ to the question whether pictures would improve the RC instruction.
Overall, the IWP is judged as slightly better by the participants in all groups, independent of whether they executed it or only read it.
Preliminary discussion
In terms of Comprehensibility, the IWP users were more positive about the instruction they used compared to the RC users. The IWP instruction Design was also judged more positively by its users than the RC instruction. The users of the IWP instruction agreed that the pictures in the instruction were clear, informative and properly matching the instructional text. The RC users strongly agreed that the offered text was not informative enough and that pictures to accompany the text would be helpful. In terms of Performance, both the IWP users and the RC users agreed that they were able to follow the instructions to bake the cookies and that they used the text a lot in the baking process. The IWP users strongly agreed that they used the text and the pictures a lot. The IWP users also agreed that they would have been able to bake the cookies solely based on the IWP text, but not solely based on the pictures.
In terms of User Performance, none of the teams read through their instructions before they started the baking process even while they were advised to do so. As a result, all teams made the mistake of not saving a part of the chocolate chips for topping the cookies. The other mistakes made by the RC teams, that is, not using the advised utensils and not using the right bowl to mix ingredients are likely to be attributed to the fact that the RC teams did not have access to the visualized actions with which the instruction was enhanced, while the verbal references in the instructions were too subtle. One IWP team needed more time than the others to finalize the baking process, which may have been caused by the fact that at least one of the participants was less experienced in following baking recipes than the other participants in the study. The IWP teams only used the pictures in a few cases to resolve a question in the baking process.
Overall, in terms of Comprehensibility and Design, IWP readers rated the IWP instruction higher than IWP users. Possibly the IWP readers noticed aspects that they had missed while using the RC instruction, for instance on the visualized objects that were used in the execution of the procedural actions. In more general terms the difference suggests that using and reading a recipe require different types of understanding. The results show no large differences between RC readers and RC users in terms of Comprehensibility and Design. In general, the IWP was more positively received than the RC.
Discussion
Corpus study
Results of the corpus study
In the corpus that we analyzed, the text of the 15 MIs was split into clauses. As expected, the RC and IWP texts do not differ significantly in terms of the distribution of functional and realized text content. Thus the IWP and the RC can be considered comparable presentations of the same procedure. The IWPs contained a total of 299 clauses, while the RCs had 400 clauses. The RCs contain 53 more Action clauses, 101 more Control Information clauses and 70 more Specifications. These differences can be explained by a difference in terms of the purposes of the two texts (Van der Sluis and de Jonge, 2024). The IWP’s purpose could be to attract potential users to use the recipe by showing that baking is easy and results in delicious cookies. The IWP may also be considered as a coarse guideline, while the RC contains the necessary details to be followed to actually bake the cookies. In contrast, the Recipe Card can be considered to be a comprehensive printable overview containing all the information needed to study the recipe, properly execute the instructions and ultimately obtain the envisioned results (cf. Bowker, 2021). Thus it makes sense that the Recipe Card contains more detailed verbal explanations. Moreover, in the multimodal IWPs, text and pictures work together to make meaning (Bateman et al., 2017: 7). Arguably, some of the verbal content available in the RCs is replaced by visualizations in the IWPs.
As expected the text-picture relations within the IWPs display a significant difference between the content of text and pictures in terms of Action Aspect. While all actions in the text are described as a process, the majority of pictures show the actions as a result, meaning that the visualizations portray the situation after the action is performed. Generally, the pictures depict fewer actions than the number of actions verbalized in the text. Approximately 46% of the actions were presented in text and pictures, while 44% of the actions were presented only in text. This is in line with the findings of Van der Sluis et al. (2016b; Van der Sluis and de Jonge, 2024). The text appears to convey more precise information due to its inclusion of not just a greater number of actions but also by including more descriptive content through Control Information and Specifications. Based on these findings, it may appear that the IWP text plays a more significant role in conveying procedural information compared to the IWP pictures (cf. Liu and Chuang, 2011). However, the pictures also offer a distinctive added value by showing objects such as the utensils and containers that visualize the manner in which an action should be performed, or by showing the result of a particular action for example, the desired consistency of the dough after mixing. Consequently, the visualizations serve respectively as enhancements and elaborations of the text (cf. Bateman, 2014).
In the corpus, the organization of the relations between text and pictures varies across different multimodal instructions (MIs). In some cases, there was consistency, where the textual steps and their corresponding pictures were assigned the same numerical indices. However in other instances, the indices of the verbal steps did not correspond with the pictures included, or the indices were absent in either the text or the pictures or altogether. To ensure effective support for readers and users, it is crucial for the writers of these documents to carefully establish and maintain connections between the text and pictures. Previous research has demonstrated that a well-linked integration of text and pictures can significantly enhance the comprehensibility of instructions (Ozcelik et al., 2010; Tenbrink and Maas, 2016).
Method of the corpus study
The annotation of the corpus was done by two annotators who annotated parts of the corpus individually and used multiple rounds of meticulous and detailed discussions that resulted in revisions in the corpus annotation until a consensus on all the encountered issues was reached. In future work, an evaluation of the proposed annotation model is envisioned, in which multiple trained annotators will annotate a larger corpus with cooking instructions also containing more variation in terms of food types. To evaluate the annotation model and the resulting corpus annotation, multiple annotators will annotate the same MIs such that annotator agreement can be calculated. Accordingly, the model will be further improved and the accuracy and consistency of the annotated MIs will be secured.
The developed annotation models serve as a solid and broad foundation for the reader and user studies. The annotation models used to analyse the corpus include functional categories (i.e., Action Status, Action Aspect, Control Information, Specification). The functional categories are useful variables to describe and compare content presentations in different modalities (i.e., IWP text vs IWP pictures) and content presentations in different texts (IWP text and RC text). Potentially the functional categories can also be used to describe and compare other recipes (cf. Van der Sluis and de Jonge, 2024), multimodal instructions in other domains (cf. Van der Sluis et al., 2022a, 2022b), and multimodal instructions presented in different text genres (cf. Vijfvinkel et al., 2018; Wildfeuer et al., 2023). The proposed annotation model also includes domain dependent categories to describe the realized Action Types (put, process, heat, cool, take) and the visualized Objects in the IWP pictures (i.e., Container, Utensil, Hand). Investigation of domain dependent variables supports the understanding of text-picture relations such as the realization of enhancement and elaboration. In addition, studying realizations in multimodal presentations also supports automatic generation and interpretation of action visualizations as well as the prediction of action sequences (cf. Van der Sluis et al., 2017, 2022a, 2022b).
The distinction between Action and CI clauses is not always evident. For instance, phrases like ‘use a cookie scoop’, although containing an action verb, are classified as a CI clause instead of an Action clause. The rationale is that the clause describes the means to portion the dough and therefore should be annotated as CI manner. In a similar vein, clauses such as ‘until they are blended’ of course imply a ‘blending’ action, but their primary function is to describe the manner in which the ingredients should be mixed. Therefore, these clauses are also annotated as CI manner. In the current study, this reasoning resulted in the absence of verbalized actions with an Action Aspect value result. In addition, relations between the text and the pictures were solely based on the annotation of actions in the text and the visualization of actions in the pictures. Arguably, descriptions that explain how to perform a particular action such as in the Control Information clause ‘use a cookie scoop’ may also be related to the pictures in which a cookie scoop is used or perhaps only shown.
In addition, in future work a more detailed annotation model is envisioned to describe certain Specification categories in the verbal instructions. For instance, the time category currently encompasses sequence-related specifications (e.g., ‘after that’), duration-related specifications (e.g., ‘for 5 minutes’), and even speed-related specifications (e.g., ‘slowly’). Further refinement of this category would enhance the precision and clarity of the Specification annotations. Lastly, the model to describe text-picture relations proposed by Van der Sluis et al. (2016b) presented a challenge, as some instances in the current corpus display more complex relations. This prompted the annotators, for instance, to introduce new values for the Relation Identification Attribute that distinguish a full correspondence and a sequential correspondence of the relation between the text and the pictures.
It should also be noted that the corpus study presented describes a relatively small number of MIs. The MIs, however, were carefully selected from a larger corpus and are representative for cookie baking recipes. Other recipes, for instance recipes in which a meal is cooked on a stove, or in which cold snacks or beverages are prepared are likely to include different actions and different action sequences (cf. Van der Sluis and de Jonge, 2024). Currently, we are working on a recipe corpus that covers a wider range of food types. In general, the recipe blogs are composed similarly in that all the blogs include an Instruction with Pictures and a Recipe Card. Future work will expand the scope and representativeness of our MI description in the cooking domain as well as the description of the blogs in which they appear. A larger and more varied corpus will provide a more comprehensive understanding of the design features and especially of the text-picture relations in multimodal instructions.
Eye-tracking study
Results of the eye-tracking study
The participants in the reader study tended to use a linear reading strategy, without scrolling back and forth between the different parts on the page. In contrast when examining the individual Instruction with Pictures, participants exhibited a different reading strategy. They switched back and forth between different text and pictures, with some readers showing clear patterns of attempting to link textual steps with corresponding pictures. Heat maps of the individual IWPs showed that readers focused more on the text than the pictures within the IWPs. However, the individual pictures did all receive some attention. Accordingly, we can conclude that the readers focussed on understanding the instructions (instruction-based reading) rather than selecting specific information in an interactive way (task-based reading) (cf. Ganier, 2004). Analogously to the duration of the participants’ text processing being dependent on the length of the text, it seems that the duration of processing visual information depends on the number of pictures. With only four pictures the visual information provided in MI 3 received the least attention. An interesting find, however, is that the same amount of time was spent on the six pictures of MI 1 and the 9 pictures in MI 14. Further study is required to understand exactly how these findings should be attributed to the split-attention effect, whereby the division of attention among multiple elements hinders cognitive processing (cf. Schroeder and Cenkci, 2018).
The questionnaire data shows that in general the participants considered the baking blogs as a whole and the IWPs in particular understandable and executable. In terms of Design, readers varied in their evaluations in terms of the amount of text and pictures. Recall that the participants were asked to rate the amount of information in one of the IWPs after they had read a full recipe blog that contained one of the other two IWPs. The results show that the IWP of MI 14 was found to contain too much text and too many pictures, while MI 1 scored best in terms of text length and amount of pictures. The IWP of MI 1 also received the best score in terms of text-picture relations in that it is clear which picture corresponds to which action. This finding supports the research conducted by Ozcelik et al. (2010), Tenbrink and Maas (2016), and Van der Sluis et al. (2017), which emphasizes the significant impact of well-designed instructions on the processing experience. Thus through a proper organization of multimodal elements, MIs are more effective in conveying information, which is expected to result in an enhanced comprehensibility and learning. Interestingly, the participants also varied in their preferences to use either the IWP or the RC while baking. In the interviews, it was discovered that some participants would choose to use the Recipe Card because the ingredient list and the specified amounts were not included in the Instruction with Pictures and it would be difficult to bake cookies without this information. Other participants explained that they expected to benefit from the different modes of information or from additional visualizations offered in the IWP.
Method of the eye-tracking study
In the reader study, we envisioned to simulate a real life context by asking the participants to imagine themselves in a context in which they were looking for a recipe to bake cookies. It is of course questionable in how far the suggested context was achieved and whether it actually played a role. Note that the participants were not explicitly asked to read the whole webpage, but were asked to determine if the webpage contained a recipe that was useful for them in the given context. Given this setting, the participants were expected to pay little attention to the extraneous information on the webpage such as the advertisements and contextualization of the recipe. However, the time that participants spent on reading the IWP and the RC in the full blogs that were offered was very short; in the three conditions the participants spent less than a third of their dwell time on the blog on the actual recipes.
In this reader study we attempted to answer how people read and judge recipe blogs and the IWPs in them. In future work, a less controlled reader study in which participants are allowed to compare different cooking blogs and in which participants are offered a more general assignment such as ‘Search for a recipe that you want to use to bake chocolate chip cookies’, would expectedly approach a more lifelike situation and thereby shed more light on the recipe blog features that people use to determine the suitability of a recipe blog. In such a setting eye-tracker glasses would be useful.
In the interviews with the participants varied perceptions and potential biases were detected that readers may have had while filling out the questionnaire. For instance, the readers’ evaluation of the Instruction with Pictures may have been influenced by the absence of an ingredient list. Including an ingredient list in the IWP or an explicit statement about the omitted ingredient list in the task description of the study could have provided a more balanced starting point for the readers’ judgments. For future studies, we consider this a good example of the ease with which differences between participants can be introduced.
User study
Results of the user study
The questionnaire results show that the IWP users rated their understanding of the MI and the quality of the MI itself higher than the RC users. This seems to support the notion that visual elements can aid in conveying information effectively (e.g., Andrä et al., 2020; Cline et al., 1999; Dowse and Ehlers, 2005; Fisk et al., 1986; Hagiwara, 2015; Morett, 2019). Arguably, in contradiction to some of the previously mentioned studies, the results of the user study presented in this paper may also suggest that the IWP pictures did not play an important role in the baking process itself. For example, the screen tracking data shows that the pictures were not used much and the IWP participants rated the statement about using the pictures a lot between agree and neutral. In addition, the IWP and RC users evaluated their own performances equally positive, where the IWP users strongly agreed that they used the text a lot and the RC users merely agreed with this statement. Mistakes were also observed across all teams, including mixing dry ingredients in the wrong container and omitting the action to split the chocolate chips into two portions, while the use of the IWP pictures could have clarified uncertainties about these steps. Unfortunately, the time that the users spent on reading and baking does not allow for a reliable comparison due to an outlier in the IWP condition, i.e., the participant pair that spent considerably more time on the task had less baking experience than the other teams.
The questionnaire data confirms that the IWP and the RC users generally perceived the verbal instructions as understandable and executable. Thus, the IWP pictures cannot be considered as having a substantial effect on the users’ judgments of the comprehensibility and their own performance of the instruction. This could be due to the nature of the pictures in the IWP. The pictures are representations of the actions that are also conveyed in text, often showing the result of an action as an elaboration and sometimes showing the utensils to use to perform an action as an enhancement. In addition, the actions themselves were perhaps not very complicated.
Although the users were explicitly asked to read the recipe before starting the actual baking process none of the users did. Instead, the users immediately started interpreting and carrying out the instructions. As a result, the users, independent of their cooking experience, made mistakes (e.g., the chocolate chips were not split into a part for the dough and a part for topping the cookies). During the baking process the users of the IWP mainly relied on the textual information and only consulted specific pictures to support the baking process that is to aid or confirm their interpretation in cases of uncertainty. The users did not pay attention to every picture and thus did not aim for a complete understanding of the text-picture relations in the instruction. This suggests that, in contrast to the eye-tracking study in which readers employ an instruction-based processing strategy, the users employ a task-based strategy when working with the MIs (cf. Ganier, 2004).
Lastly, a notable result was found when comparing the ratings of users versus readers of the IWP. Compared to IWP users, the IWP readers generally gave the instruction a higher rating and also appreciated the clarity of text-picture relations more than the IWP users. This could be a result of the different processing strategies we observed in the readers and users (i.e., instruction-based vs task-based). Arguably, readers may have a better understanding of the text-picture relations in an MI, because they pay more attention to the compositional use of the modalities in an instruction. Possibly, the IWP readers also noticed aspects that they had missed when using the RC instruction for baking.
In addition, although they expect to be less successful in using the RC instruction, RC readers are generally more positive about the RC than the RC users. These differences may be due to the fact that RC readers are more experienced bakers, which means they were already more familiar with the pictures of the recipe. Overall both readers and users rate the RC lower than the IWP, which indicates that the instructional pictures are appreciated by both users and readers.
Method of the user study
The user study involved a small sample size of only eight participants who worked in teams. While valuable qualitative insights can be gained from our study, a larger participant pool would enhance the study’s statistical power and improve the generalizability of the results. The setup in teams is recommended however, because it incites the communication about the recipe and about the task to perform. The added value can be nicely illustrated by the fact that IWP Team 1, purposefully decided to use a different bowl than advised to mix ingredients. Because the reasoning behind this decision was transparent in the dialogue of the team members, it was obvious that we observed an alternative action instead of a mistake.
Although we used the transcripts and video data to detect mistakes and difficulties in the baking process, we did not analyze the rich video data in great detail yet. Arguably, incorporating a systematic annotation of the video data will provide additional insights and a more holistic understanding of the participants’ interaction with the multimodal instructions and of the interaction between them. For instance, a more detailed analysis may display causes for the difference in the time needed to read and to bake between the less experienced IWP Team 2 and the other teams. Ultimately, such an analysis may lead to the formulation of instructional requirements that are related to the proficiency of the user.
Finally, providing pre-portioned amounts of ingredients for the participants in the user study may be considered a deviation from the typical baking process in a real-world scenario. However, the corpus study showed that IWPs never include an ingredient list. Also, the MIs used in the user study do not include an instruction to gather the ingredients. Additional justifications for the setup with pre-portioned ingredients are that it ensures that the participants in the two conditions worked from the same starting point and that it facilitated the participants’ task as well as our data processing.
Bringing it all together
Results of the studies
With the triangulation of three exploratory studies, reader and user judgments as well eye-tracker data and video recordings were collected on multimodal instructions described in terms of functional attributes and their realization. The results offer the following complementary views on cooking instructions consisting of text and pictures which anyone can find on the internet: • How authors combine verbal and pictorial information to support readers and users of MIs; • How readers and users differ in their strategies to process MIs; • How readers and users judge the comprehensibility of MIs; • How readers and users judge the design of MIs; • How readers judge their expected performance of the task presented in MIs; • How users judge their performance of the task presented in MIs; • How readers and users value different forms of instructional support; • How users implement their interpretation of MIs.
The Comprehensibility, Design and Performance data that we collected in the eye-tracker study and in the user study can be situated in three different contexts: • Reader data from the eye-tracking study in which participants imagined a situation in which they were going to use a recipe to bake cookies; • User data from the user study in which participants used a recipe to bake cookies; • Reader data from the user study in which (experienced) users read an instruction different from the one they had used to bake cookies.
The corpus study showed that the distribution of the the function content and the realized action types in the IWP text and the RC text are comparable. According to the participants in the reader study the differences in the amount of verbal and visual information between the IWPs and the RCs can be explained in terms of the purposes and target audiences of the two instructions (cf. Bowker 2021). The RCs contain more information that explains and specifies how to perform a particular action. Arguably, in the IWPs some of these elaborations and enhancements are offered in visualizations. The corpus study showed that visualized actions in the IWP are usually of type adding and processing. Notably, the heating action is generally not verbalized nor visualized in the IWP. As a result, especially less experienced IWP users may not infer the preparatory the (pre)heating action from the verbalized action ‘bake in the oven’ (MI 2). Moreover, this inference can only be made if users read the whole instruction before starting the baking process. Note that none of the participants in the user study did read the instruction before the actual execution of it. In a similar vein a consequential action such as ‘reserve a part of the chocolate chips’ should be offered early in the instruction.
Users and readers do appreciate the pictures in the IWP, but why? Obviously the pictures make the recipe more attractive. In the corpus study, the added value of pictures is described in terms of the elaborations and enhancements of the actions that are also described in the text. Arguably, the pictures also fulfill another role, namely a means for users to visually compare and check the state they have reached in their own baking process with the state envisioned by the author of the recipe. In addition, the pictures can be used to see which Objects should be used to execute a particular action. The RC users felt that the RC text should have been more informative. Note that in the user study we used MI 2 with almost identical RC and IWP texts, while the RC texts in the corpus are usually richer than the IWP texts in that they include more Action clauses, Control Information clauses and more Specifications. Accordingly, a larger difference between the RC and the IWP text might have overcome the less positive judgment of the RC compared to the IWP.
In contrast to the eye-tracking study in which readers employ an instruction-based processing strategy, the participants in our user study employ a task-based strategy when cooking (cf. Ganier, 2004). As a consequence, effective instructions should be composed for two types of processing. The context of use also imposes requirements on the instructions. Because users are likely to switch back and forth from the recipe to the workplace in which they perform the instructed procedure, the steps in the instruction should stand out in the text and be clearly related with pictures so that the relevant subsequent action is easily found.
Given the results of the corpus, reader and user studies in this paper and the reflections on them presented in this section, we can compile the following authoring guidelines: • The function of the IWP should be recognizable and adequately explained in terms of its purpose and/or target audience; • The function of the RC should be recognizable and adequately explained in terms of its purpose and/or target audience; • The place where essential information such as an ingredient list is presented should be made explicit and motivated; • Verbal instructions should be enhanced and elaborated with visualizations of the procedure; • The added value of the pictures (e.g., enhancement, elaboration) should be clear, perhaps through a systematic implementation or through explicit references in the verbal instructions; • Relations between text and pictures in the IWP should be consistent and preferably explicit by using corresponding indices; • Preparatory actions (e.g., heating the oven) should have a salient position in the instructive text; • Consequential actions (e.g., reserving something for later) should have a salient position in the instructive text; • Related text and pictures should be placed closely together.
The setup of the studies
The three exploratory studies presented in this paper display how a triangulation of different research methods sheds light on the relevance and evaluation of particular characteristics of multimodal presentations. The blogs offer a good opportunity to describe and evaluate multiple multimodal presentations of the same content, not only because the blogs in the corpus share particular characteristics but also because each blog offers the same procedure in two forms (IWP and RC). However, it is also immediately clear that the choice of multimodal aspects included in the instructions that can be described and evaluated is immense if not infinite. By combining the three methods it was shown how description and evaluation methods reinforce each other in terms of implementation, data processing and subsequent research questions guiding the description and evaluation of relevant characteristics of multimodal presentations. Throughout our explorations, we were able to formulate research questions and to make informed choices in designing the methods to answer them, building on existing insights from for example, multimodal communication, document design research, cognitive processing and visual language.
The corpus analysis formed the basis for the research question: How are the baking blogs read and how are the instructions in them judged? Do readers observe differences between a blog’s IWP and RC at all and how do readers interpret and value such differences? The corpus analysis study results helped to select the materials for the reader and user studies, in that actual MIs were used that incorporated particular variations of design aspects such as the amount of text and the amount of pictures. The corpus study also helped to interpret the results of the reader and user studies, in that the participants’ preferences, evaluations and performances could be related to the location of particular information, the length and content of the text, the number of pictures, the visualized content and the text-picture relations.
The reader study brought to the fore that the participants were divided in which part of the blog they would use for baking. In addition, through the readers’ processing of the full web blogs and the IWPs the question arose of how users would process a recipe when actually baking cookies. The readers’ judgments informed the selection of the MI for the user study not only in terms of length and content but also concerning the similarities and differences between the IWP and the RC within it. Finally, because it was noted in the reader study that the IWP does not include an ingredient list, we were alerted to assure that all the participants in the user study had the same starting point for the baking process, where the ingredients needed were laid out in the right amounts.
Clearly, the corpus study supports the implementation of the reader and user studies as well as the analysis of the data obtained with such studies. Conversely, reader and user studies show which aspects of the multimodal instructions are important to describe in corpus studies. Eventually, the triangulation of the findings from our studies supports the evaluation of multimodal information presentation, and the formulation of authoring guidelines to present instructions effectively.
Future work
Several avenues for future research can be identified based on the limitations and findings of the current study. First, expanding the corpus study to include a larger number of multimodal instructions (MIs) would provide a more comprehensive analysis and potentially reveal additional patterns and insights. The description of the corpus used and extended the models to describe multimodal instructions used in previous corpus studies and is therefore generalizable and informative. Extensions of the annotation models may consider a distinction between preparatory actions and the actions described in the main procedure. In addition, a more fine-grained analysis of the specifications (i.e., usually adverbial phrases within the clauses) is envisioned. Conceivably, the description of content relations between the text and pictures such as enhancement and elaboration can in the future be based on the various aspects described in the text and the pictures individually. Of course by employing automated annotation techniques and involving more annotators the currently only manual annotation process can be optimized.
Further research could also explore in more detail the reasons why the Instruction with Pictures was favored over the Recipe Card in the user study, while no outstanding differences were found in the baking performance of users based on the IWP compared to those using the RC. Moreover, participants who read and utilized the IWP expressed positive judgments of the pictures, yet the participants also indicated that they believed that they could bake the cookies using the verbal instructions alone. Conducting additional research on the visualization of actions is warranted to delve into the underlying factors contributing to these seemingly conflicting results. Such studies should investigate the role of the pictures for example, attraction, enhancement, elaboration and/or confirmation, the effectiveness of the type of visualizations that is, either presenting a process or a result of an action, and the effectiveness of the various types of text-picture relations. Further studies may also show that more complicated tasks in other domains require more visual support such as healthcare manuals or assembly instructions.
Another valuable direction for future research would be to integrate eye-tracking in a user study, combining their strengths and insights for example by asking users to wear eye-tracker glasses during the baking process. Integrating eye-tracking technology into a user study would enable the collection of objective data on participants’ gaze patterns and visual fixations while they engage with the instructions and the actual baking process in tandem. This would provide valuable insights into which parts of the MI attract the most attention, how users navigate between different modalities, and how visual cues impact information processing and decision-making. Furthermore, the incorporation of a think-aloud protocol in which the participants are explicitly asked to think aloud in addition to debating the baking process with their teammate, would offer valuable insights into participants’ cognitive processes (Holsanova, 2014). By conducting eye-tracking and thinking aloud concurrently, we can obtain a more comprehensive understanding of users’ visual attention and cognitive processes, as well as their subjective experiences and performance when interacting with multimodal instructions.
In the user study participants were limited to using only a small part of the recipe blog webpage, specifically the Recipe Card or Instruction with Pictures, instead of the entire page. Conversely, participants in the eye-tracking study were provided with the complete webpage and had the opportunity to explore its contents. It would be beneficial for future research to involve users in interacting with the full webpage rather than with just a fragment. The scenario could be extended such that the participants also gather the ingredients themselves. Yet a further extension could be to ask the participants to find their own recipe for baking cookies. Provided that the participants choose from the same set of recipes, such a setup could show which design features are more or less appealing to users. Obviously, the more freedom allowed in the setup, the more variation there will be in the participants’ data, and thus the harder it would be to analyze it.
Conclusion
This paper has shown how different methods present complementary views on the same multimodal material while demonstrating how description and evaluation methods reinforce each other in terms of implementation, data processing and raising subsequent research questions about the relevance and evaluation of multimodal presentations. This study has focused on the analysis of the Instruction with Pictures and the Recipe Card in 15 baking blogs to understand the text-picture relations within these documents, as well as to understand how readers and users interact with multimodal documents.
In the corpus study, we have analyzed the Instruction with Pictures and the Recipe Card of 15 different baking blogs, to discover how text and pictures are used in these documents to guide the user through procedural steps. The research question central to this study was ‘How can we describe the instructions in online step-by-step baking instructions and what are the relations between different modes used in them?’ The analysis focused on two aspects: a comparison of the Instruction with Pictures and the Recipe Card, and the text-picture relations within the Instruction with Pictures.
The analysis revealed that the RCs had more clauses and more Specifications compared to the IWPs. This difference may be attributed to the purpose of the documents. The Recipe Card is designed to be a comprehensive overview of the instructions, including all the necessary information, while the IWPs may rely more on the multimodal nature of text and pictures to convey certain details visually. Within the IWPs, the text conveyed more actions than the pictures. This finding aligns with previous research by Liu and Chuang (2011) and Van der Sluis et al. (2016a, 2017), indicating that text is the primary carrier of information in multimodal instructions. Note that the pictures still offer a distinctive added value in terms of enhancements and/or elaborations of information that is also provided in the text. Arguably, the pictures also serve the attractiveness of the recipe and offer reassurance during the baking process.
The eye-tracking study was set up to investigate the question ‘How do people read and judge online baking blog recipes containing a multimodal instruction?’ The reading strategies of 12 participants who processed a full baking blog webpage, as well as a separately presented IWP were recorded and analysed. The participants were asked to imagine that they were planning to use a blog recipe for baking cookies and their goal was to decide whether the given recipe was to their liking. As was to be expected, readers took an instruction-based approach as opposed to a task-based approach (Ganier, 2004), paying attention to the instructions as a whole.
Both the eye-tracker data and the questionnaire data emphasize the importance of a transparent and coherent organization of text and pictures in MIs. The eye-tracker data for the IWPs revealed that readers go back and forth between the text and the pictures, likely in an attempt to connect the information in these two modes. Poorly organized MIs can lead to cognitive overload, particularly when learners need to integrate information from different modes such as text and pictures. The split-attention effect can hinder learning efficiency in such cases (Liu and Chuang, 2011; Schroeder and Cenkci, 2018). The processing data collected with MI 14, which contains more text and pictures compared to the other two MIs included in the study, shows evidence of this effect. The questionnaire data shows that participants judged the design of M14 as the least understandable in that it includes too many pictures compared to MI 1 and too much text compared to MI 1 and MI 3. Moreover, contrary to the other MIs for which the readers’ opinions were divided, none of the readers of MI 14 chose the IWP over the RC when asked which of the two they would use while baking. Although the corpus annotation revealed that the text of the MIs carries more information than the pictures, the readers’ judgments of the MIs show that pictures still add value. Readers of MI 1 and MI 14 expressed less confidence in their ability to execute the recipe without the pictures compared to readers of MI 3. This finding is noteworthy, since MI 3 had the least amount of pictures, suggesting that the presence of a few extra pictures can enhance readers’ confidence in successfully following the recipe.
Lastly, the user study aimed to investigate the question ‘How does using either the Instruction with Pictures or the Recipe Card of a baking blog influence the user’s execution of the baking instruction and the user’s judgment of the comprehensibility, design and performance of the baking instruction?’ The findings shed light on the effectiveness of these instructional formats and provide valuable insights for instructional design and user experience. Contrary to the readers in the eye-tracking study, users of the IWP employed a task-based approach, briefly glancing at the pictures only when the text failed to provide adequate information. This indicates the role of pictures in constructing and updating the mental model to meet specific task requirements (Zhao et al., 2020). Interestingly, although the type of instruction did not affect the User Performance, it did impact on the users’ judgments of the Comprehensibility and Design of the instruction. Users of the IWP generally held more positive opinions about the instructions compared to users of the RC, though the reasons behind this difference remain unclear. Furthermore, readers of the IWP rated the instructions even more positively than the users, both in terms of their overall impression and their assessment of the text-picture relations. The insights from the eye-tracking study help contextualize these findings. As observed in the eye-tracking study, readers paid close attention to each individual picture, while the users in the user study paid little attention to the pictures. In comparison to the users’ judgments, the readers’ more positive judgments on the understandability of text-picture relations can likely be attributed to their more attentive consideration of how different modalities were used together.
Unlike in other domains where pictures have shown a significant impact on comprehension and performance (e.g., Morett, 2019; Morrow et al., 2005; Rasch and Schnotz, 2009), the influence of visualizations appears to be less crucial in the context of multimodal baking instructions published in online recipe blogs. The corpus study revealed that the text provides more detailed information about the necessary actions, which is supported by readers’ higher attention to the text and the lack of picture-related influence on user performance. The pictures primarily serve as supplementary visual representations, depicting the outcomes of described actions and sometimes illustrating the utensils required to achieve those outcomes. Collectively, the three studies presented in this paper show how different approaches can offer different perspectives on the effectiveness of MIs.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Author biographies
![]() .
.