
Abstract
This article addresses visual optimal innovations such as memes, advertising images and editorial cartoons which take Michelangelo’s fresco The Creation of Adam as input, and rework it so that novel meaning is created that takes the meaning of the input as base. The authors focus on the cognitive and structural aspects of these kinds of visual stimulus. They argue that visual optimal innovations are aesthetically rewarding owing to how they invite meaning construction, and they further demonstrate that these aspects of visual communication are encoded in human memory to make up entries in a ‘visual lexicon’. The main questions addressed are: What graphic procedures are employed to create such stimuli, and how are they structured? How are existing and novel meanings evoked by visual optimal innovations, and how are they aligned? How are visual optimal innovations processed and interpreted? And, finally, how is all this knowledge – structural and conceptual – cognitively represented?
Introduction
In her song ‘Am Gold’, Nicole Atkins sings ‘We’re stranded in the garbage of Eden’. Listeners who grasp the ‘Paradise Lost’ meaning implied here have processed more language than the line actually contains. To them ‘the garbage of Eden’ not only expresses what it does, but also brings to mind the fixed phrase ‘the Garden of Eden’, the earthly paradise inhabited by the first man and woman. Their understanding draws on aligning the meaning carried by these two phrases, one expressed and the other alluded to. This combination of novelty and familiarity exemplifies what Giora et al. (2004: 116) call optimal innovation, a stimulus that induces a novel . . . response to a given stimulus, which differs . . . qualitatively from the salient response(s) associated with this stimulus and, at the same time, allows for the automatic recoverability of a salient response related to that stimulus so that both responses make sense.
Hence, what is crucial for any kind of optimal innovation is the involvement of default familiar concept (e.g. ‘Garden of Eden’) in the non-default non-familiar ‘innovative’ component (‘garbage’).
Although it was first proposed as related to verbal stimuli, similar innovations can be made of patterned information in the visual modality as well to create visual optimal innovations (Arts & Schilperoord 2016. see also Giora et al., 2015, 2017). 1 Consider Figure 1.

Cover design for the Big Blue Bonus Book.
Just as Nicole Atkin’s line calls another verbal expression to mind, this advertisement recalls another highly familiar image – Michelangelo’s fresco The Creation of Adam 1 on the ceiling of the Sistine Chapel. Yet, it adds a novel element to it: the slice of pizza that God hands over to Adam. Hence, a ‘novel response’ is induced by the expression, but it still allows recovery of a ‘given stimulus’.
Optimal innovation thus applies across modalities, yet it also evokes particular responses in readers. The adjective ‘optimal’ accounts for the properties of these stimuli, i.e. the involvement of the familiar in the novel, that causes people to experience (aesthetic) pleasure, the Optimal Innovation Hypothesis. In a series of experiments, Giora et al. (2004) found that participants evaluated verbal optimal innovations like the garbage of Eden as more pleasurable than the familiar expression they stem from (the Garden of Eden), or a variant of it (‘In-A-Gadda-Da-Vida’) 2 but also more pleasurable than ‘pure’ innovations (‘The Pardon of Sweden’), which evoke only novel meaning but deny access to the familiar expression. Participants also judged optimal innovations to be less familiar than familiar expressions or variants of it but more familiar than pure innovations. This intermediate position may be evidence that optimal innovations actually induce ‘a novel response’ since they are less familiar than familiar expressions, while allowing ‘the recovery of a salient meaning’ since they are more familiar than pure innovations. To find out if such responses apply across modalities, tested the ‘optimal innovation hypothesis’ with regard to visual stimuli, such as Figure 1, and found that VOIs produced pleasure and familiarity ratings similar to those found for verbal stimuli.
The present article further elaborates on visual optimal innovations (VOIs hereafter) which take The Creation of Adam as visual input. However, instead of focusing on responsive aspects, we address their cognitive and structural aspects. We will argue that VOIs are aesthetically rewarding because of how they invite meaning construction, and it will be further demonstrated that these aspects of visual communication are encoded in human memory to make up entries in a ‘visual lexicon’. We address four questions: What graphic procedures are employed to create VOIs, and how are they structured? How are salient and novel meanings evoked by VOIs and how are they aligned? How are VOIs processed and interpreted? and How is all this knowledge – structural and conceptual – cognitively represented?
1 Visual Optimal Innovations
Optimal innovations are parasitic artefacts in that their defining characteristic is deviation of the form of a ‘base entity’ (Arts & Schilperoord, 2016) while the meaning-making they invite crucially rests upon the semantics of the base entity. Atkins’s line borrows the better part of its meaning from the meaning of the base entity ‘the garden of Eden’, and deviates from it formally by altering the base’s head noun ‘garden’ into ‘garbage’. Deviation explains why ‘the pardon of Sweden’ is not an optimal innovation since it blocks recognition of a base entity. It also explains why VOIs necessarily use some prefab, stock phrase, idiom or otherwise fixed expression, since only entrenched patterns provide recognizable bases for deviation.
In this view, a visual expression can be considered optimally innovative when it is possible to identify some visual base, i.e. a ‘visual fixed expression’, which it both refers to and deviates from. What we have in mind here comes close to Hariman and Lucaites’ (2008: 8) definition of ‘iconic photos’, that is: those photographic images produced in print, electronic, or digital media that are recognized by everyone, are understood to be representations of historically significant events, activate strong emotional identification or response, and are regularly reproduced across a range of media, genres, or topics.
In addition, in order to function as a base entity, an image ‘should constitute a graphic constellation of recurrent components and meaning conveying elements that allow omission, substitution or distortion without fundamentally altering the overall constellation’ (Arts and Schilperoord, 2016: 8).
The Creation of Adam meets all these criteria. 3 The fresco is ‘recognized by everyone’ and qualifies as a representation of some significant (here, Biblical) event – the apex of God’s creation of the heavens and the Earth. The image is also regularly reproduced across advertisements, political cartoons, internet memes and other popular media and genres, while its distinct components – the stretched arms, the hands, the bodies of God and Adam – as well as its spatial composition – allow for a range of graphic alterations without fundamentally altering the fresco or rendering it unrecognizable. As shown in Figure 1, the depiction of the two slightly bent hands emerging from the left and right already suffices to call the fresco to mind.
The remainder of this article argues that The Creation of Adam (CoA hereafter) functions in images like Figure 1 in a similar way to how ‘the garden of Eden’ functions in Atkins’ song line. So the first two questions that should be asked are: how precisely is the base image altered, and what meaning signified by CoA is used in CoA-based VOIs?
2 How are The Creation of Adam-Based Visual Optimal Innovations Created?
CoA-based VOIs offer different scopes of framing in their representation. In the Sistine Chapel, CoA is one of several framed scenes, and its totality depicts the whole body of Adam resting on a piece of land with the whole body of God descending from the heavens, surrounded by several angels. VOIs may use this full representation (see Figure 2a), or they might focus on specific meaningful parts. In particular, they often frame a depiction only on the two hands (as in Figure 1), or they present some intermediate evocation between the full depiction and the hands, such as the hands together with some other body parts, such as Adam’s knee (see Figure 2b).

Visual optimal innovations for The Creation of Adam: (a) painting by Patrick Lee: The Creation of Donald Trump; (b) advertisement for Absolut vodka; (c) advertisement for Itchguard Cream ‘Can’t resist scratching?’; (d) advertisement for Coca Cola; (e) meme by unknown designer.
When studying these variations in framing, what becomes apparent is that the focal region of most meaningful interest is the relationship between Adam’s and God’s hands. That is, the meeting of their hands is the primary cue of visual meaning in the scene. We do not find, for instance, VOIs that zoom in on other aspects of the scene, such as Adam’s foot, or God’s other hand in the midst of angels. Thus, VOIs that depict the hands alone focus on the primary locus of meaning derived from CoA, while also evoking a part–whole metonymy of the original depiction. This overall spatial composition, whether as a whole depiction or most specifically the relation of the hands, appears to be a fairly invariant feature of CoA-based VOIs. That is, these spatial relationships and their postural cues create an encoded visual depiction, a ‘graphic structure’ (Cohn, 2018) that comprises the characteristics that are of vital concern to allow recalling the base.
From this base, VOIs can be created using various graphic ‘operations’ that can target on any of the base entity’s components: the hands, the arms, the two figures or other morphs (cf. Cohn, 2018; Schilperoord, 2018). Figures 1 and 2(b) exemplify the first operation Insert: an entity ‘alien’ to the base – a slice of pizza, a bottle of vodka – is inserted into it.
The second operation is Erase, which is applied if one of the original entities of the base simply does not show up in a VOI. Figure 2(c) illustrates this operation: Adam’s stretched arm is erased from the scene. When Erase and Insert are combined, the result is Substitute: one entity is erased from the base and another is inserted in its place. Figure 2(a) exemplifies several applications of Substitute, such as Hitler and KKK members substituting for angels.
The final operation discussed here is Distort: an umbrella term for a range of operations that all somehow distort one of the base entity’s manner of appearance, or its location, but without changing or affecting its ontology. Figure 2(d) exemplifies the operation Relocate. In the fresco, God creates Adam by ‘giving’ him Life and Michelangelo appears to zoom into this event at the moment when God is about to perform the action. In Figure 2(d) the advertised product is not only Inserted, but also Relocated to Adam: we witness, as it were, what happens immediately after what is depicted in CoA. The famous ET movie poster is another Distort example. Not only are God’s and Adam’s hands Substituted by the hands of Elliott and ET, respectively, but the right-above-to-left-below orientation of the two hands is tilted to the right with ET’s hand now appearing above Elliott’s. A ‘pure’ example of Distort/Relocate appears in Figure 2(e), a meme commenting on the Covid-19 pandemic by stretching the distance between God and Adam to honour the obliged 1.5 metres, or to indicate that God has walked away from humanity.
Obviously, all four operations assume knowledge of the base. Detecting some Inserted entity requires knowing that this entity is not part of CoA. Likewise, noticing that an entity has been Erased assumes knowledge of its presence in the fresco. Next, we turn to the issue of what the base entity contributes conceptually.
3 How Do The Creation of Adam-Based Visual Optimal Innovations Create Meaning?
VOIs constitute a subtype of visual incongruities – visual expressions that depict things in ways recipients know not to be true or in accordance with ‘reality’ (cf. Schilperoord, 2018). Such expressions not only attract and modulate attention, for instance, the ‘novelty bonus’ (Krebs et al., 2009) or the ‘bizarreness-effect’ (Gounden and Nicolas, 2012), but they also push recipients to reconcile the discontinuity through ‘incongruity resolution’ (Forabosco, 2008). The way recipients manage to resolve the incongruity ultimately determines what the expression means to them. VOIs are special cases of visual incongruities because their discordance comes not from reality, but from alignment with a particular base entity. When looking at CoA-based VOIs, recipients know it alludes to Michelangelo’s fresco, while at the same time they notice that what is there ‘is not’ CoA. Figuring out why the image recalls the original while also deviating from it is the kind of meaning making process that VOIs invite.
Resolving the incongruities presented by a VOI starts with identifying what it ‘is about’, i.e. what topic it addresses. The critical insight here is that a VOI is never about its base. CoA-based VOIs do not address the fresco but instead use it to frame what the expression is about. This distinction relates to the cognitive domains evoked by the base and topic of the expression – a notion we take from Langacker (1987: 488), where it is defined as a ‘coherent area of conceptualization relative to which semantic units may be characterized’. 4 Let us start by formalizing the domain structure in general terms (see (1) below).
(1)
The entities and relations used to predicate something about the topic are represented by the auxiliary domain, while the reference domain represents everything the message refers to, or its topic – an object, an event or a person (cf. Van de Hoven & Schilperoord, 2017). Meaning-making then involves specifying the entities and relationships among them for both the auxiliary and reference domain, and specifying how these entities relate across domains. Applied to CoA-based VOIs, the auxiliary domain thus captures the conceptual specification of the fresco. This implies that CoA-based VOIs all share the same auxiliary domain, which is why they are not about the fresco.
To specify the CoA/auxiliary domain, we simplify it to represent an event of ‘giving’. This event takes three arguments: the giver (the actor), the receiver (the beneficiary) and the given (an object). The generalized conceptual structure (CS) of ‘to give’ is (2).
(2) CS [event
Using (2), the meaning evoked by CoA can be given as (3).
(3) CS [event
Obviously, (3) fails to represent the broadly evocative meaning of Michelangelo’s fresco; the summit of the creator’s ‘master plan’ (see Barolsky, 2013). The fresco depicts not just a give-event, but the ultimate act of giving – ultimate because of who is the giver, God, the one who creates by giving; because of what is given, Life, God’s ultimate gift to men; and because of who is the receiver, Adam, the first human and, according to the scriptures, the ‘chosen one’. To have (3) capture all this additional meaning would be asking too much, but it does at least properly identify the components from which all this additional meaning stems.
The given object (state?) Life is not visualized by Michelangelo. It is suggested by the near touching of God’s actively stressed finger and Adam’s passively receiving finger, by the eye contact between creator and creation, and by the right-to-left traversed path signifying what is given by whom to whom. The general domain structure (1) can now be elaborated as (4), which simplifies the formal notation.
(4)
The conceptual structure’s auxiliary domain (AD) denotes the interpretative starting point of any CoA-based VOI. The full meaning of a VOI should specify the contents of the reference domain (RD), including the topic, and how all this relates to the auxiliary domain.
Consider again Figures 2(b) and 2(d). The contents of the two domains for these cases can be given as (5)a and b, where the topic is marked with italics, while underlinings mark the auxiliary domain entities that are primarily affected by the applied operation.
(5) a. Domain structure for Figure 2b
AD [
RD [
b. Domain structure for Figure 2d
AD [
RD [
Domain structure (5a) exemplifies the most common type of CoA-based VOIs. Most entities (God, Adam) are left intact and a topical entity is Inserted. 5 In the case of Figure 2(b), the advertised product – a bottle of vodka – is inserted, and hence affects the ethereal entity Life. A more elaborated usage of the base is illustrated in Figure 2(d) (see notation in 5b). This VOI also Inserts its topical entity, but additionally Relocates it to Adam’s hand. By focusing on the moment Adam actually accepts what is given to him, the VOI puts emphasis on the ‘receiving’ instead of on the ‘giving’. Although these verbs may denote one and the same event including the same arguments, the verbs differ in terms of the argument they profile: ‘to give’ profiles the agent of the action while ‘to receive’ profiles the beneficiary (see Langacker, 1987: 183).
Let’s compare the more complex examples in Figure 2(a) and Figure 3(a), the domain structures for which are (6)a and b.
(6) a. Domain structure for Figure 2(a)
AD [
RD [
b. Domain structure for Figure 3(a)
AD [
RD [

Visual optimal innovations for The Creation of Adam: (a) cartoon by Dave Brown, The chosen one; (b) advertisement for Lego; (c) poster for the movie Creation; (d) painting by Harmonia Rosales, The Creation of God.
To create these VOIs, Substitute has been applied and targets on God, the angels and Adam (Figure 2a), and on God and Adam (Figure 3a). The given entity ‘presidency’ should be inferred from the entities in the reference domain, and conceptually takes the place of the given Life in the auxiliary domain (it is visualized in neither domain). By substituting God, the cartoons succeed in expressing a mocking view on what has made the presidency of Donald Trump possible: the Devil accompanied by his allies ‘hate’, ‘fear’, Fox News, KKK, Hitler, atomic weapons and big money (6a), or solely Putin (6b). That the entities substituting the God-role actually function as the topic of the VOIs is evident by their meaning being adequately rephrased by the question: ‘what/who has made Trump’s presidency possible? Answer: the Devil/Putin.’ The other possibilities seem less adequate, evident in rephrasings selecting the Adam-role as topic, ‘The Devil/Putin has made whose presidency possible? Answer: Trump’s’, or the Life-role, ‘The Devil/Putin has made what quality of Trump possible? Answer: his presidency’. 6
As a final case, we discuss the advertisement in Figure 3b – a case of focused evocation of the base. The domain structure is (7).
(7) Domain structure for Figure 3b
AD [
RD
The full base conceptual structure is present here, with God’s hand substituted by the hand of a child and Adam’s hand substituted by a toy hand, which yields ‘a child gives life to a toy’. Assuming the advertisement claims that its product ‘enables’ children to give life to lifeless toys, none of the core roles (God, Adam, Life) can be assigned the role of topic. The latter, i.e. the advertised product, instead has to be inferred from the immediate visual context. This explains the elaborated nature of the reference domain’s conceptual specification which now includes an event of ‘enabling’, with the product as actor/topic. This elaborated part is not overtly expressed; its inferential nature is marked in (7) with double underlines.
Having specified the domain structures of various CoA-based VOIs, we now address the question of how the two domains relate to each other and how the auxiliary domain functions in general terms in these VOIs. Note first that although, referentially, the auxiliary domain comes in second, conceptually it carries the bulk of the meaning engendered by any VOI based on it. Assuming the fresco represents the ultimate act of giving, i.e. giving that creates the beneficiary through what is given to him, we claim that VOIs appropriate it first and foremost as a piece of knowledge shared by members of a community to frame the addressed topic. The domains evoked by CoA-based VOIs therefore relate to each other by comparison, with the auxiliary domain functioning as standard by which to evaluate the contents of the reference domain.
Comparison of the reference domain to the auxiliary domain accounts for the persuasive invitation of most examples discussed here; it allows us to build an argument pro or con the itemized topic. When an advertisement for a soda adds its product to the depicted event, comparison yields equality: the advertised product equals God’s gift to men; it is ‘divine’ in nature. On the other hand, for the VOIs in Figures 2(a) and 3(a) comparison yields contrast: Trump’s presidency is the ultimate ‘bad’ gift because the givers are paragons of ‘badness’.
Finally, it is worth noting here that, while the incongruities in VOIs may be resolved through a metaphor (Schilperoord, 2018), this is not always the case. As formalized in (5) above, both Figure 2(b) and 2(d) use the CoA–VOI to comment on the ‘divinity’ of a particular product (vodka, soda), which makes no metaphorical mapping between a target and source domain (God giving soda to Adam is like God giving life to Adam?). This contrasts with the metaphoric correspondence between domains apparent in Figure 3(a) (Putin gave Trump his presidency is like God giving Life to Adam). Thus, metaphor provides one possibility for the resolution of meaning in visual incongruities, though it is not the only option for construal.
4 Making Meaning of The Creation of Adam-Based Visual Optimal Innovations
This section discusses how recipients of CoA-based VOIs actually make meaning out of it. We identify characteristics that lead to ‘successful’ readings, but also account for what can go wrong in interpreting, or how CoA-based VOIs are interpreted by those who lack knowledge of the base. The encompassing idea is that the entity (God, Adam, Life) that is rendered salient by the graphic operation to create the VOI will also be the one that determines the ‘core’ meaning of the VOI. This core meaning will be equal to what this entity contributes to the overall meaning captured by the auxiliary domain. So, when a VOI targets primarily on the God role, then this component’s contribution to the overall conceptual structure will also be salient for interpreting the VOI. For convenience, we will summarize the conceptual contribution associated with each of the base’s components as (i) ‘ultimate act’ (giving), (ii) ‘Master creator’ (God), (iii) ‘Chosen one’ (Adam) and (iv) ‘ultimate gift’ (Life).
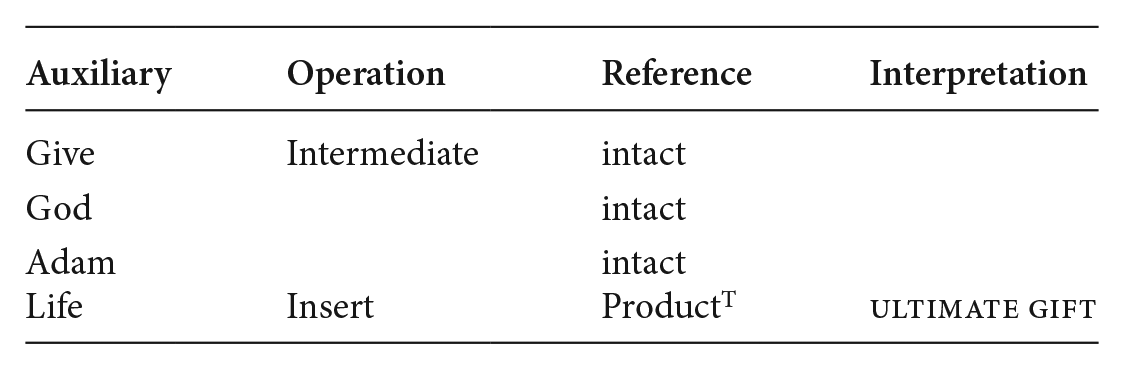
Consider again Figures 2b and 2d. In (8)a and (8)b the interpretive routes for these VOIs are represented as charts that map the auxiliary domain’s main components (column 1), the employed frame and graphic operations (column 2), the ways these components return in the reference domain: intact or ‘reworked’ (column 3) and the associated meaning that stipulates the interpretation (column 4). For convenience, the topical entity in the reference domain will be marked by the superscript ‘T’.
(8)a Interpretive inference for Figure 2b
(8)b Interpretive inference for Figure 2d
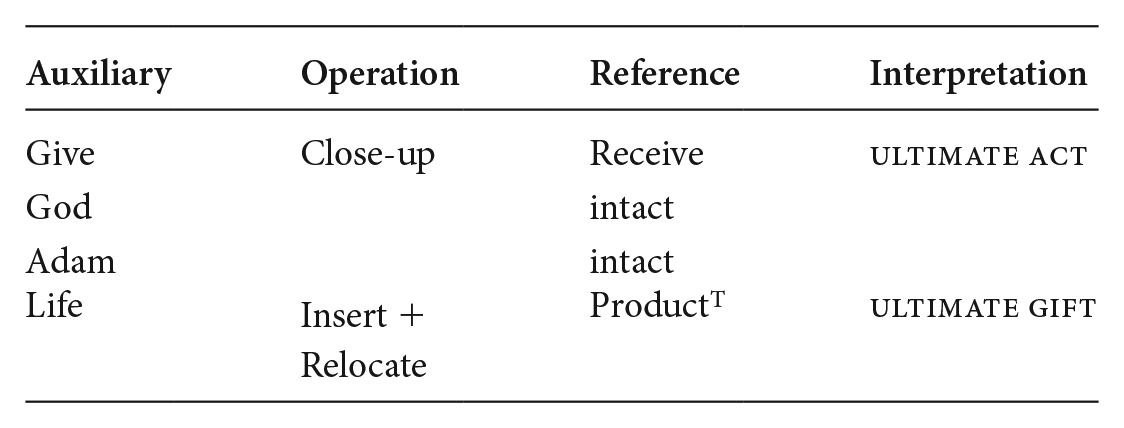
The ‘operation’ column specifies the ‘intermediate’ frame (8)a, and ‘close up’ frame (8)b, while distinct entities are specified in terms of the local operation that has applied; Insert (8)a, and Insert and Relocate (8)b. The ‘reference’ column lists the results of the operations. For example, Relocate in (8)b alters the auxiliary event ‘give’ to the effect of profiling it as ‘receiving’ in the reference column, while in both cases Insert yields the topical entities. If no operation has applied on an auxiliary entity, that entity remains intact, like ‘God’ and ‘Adam’ in (8)a and b. This column hence specifies both the innovation and the entities allowing access to the base. Interpretation is furthermore guided by comparing the auxiliary column entities with those intact or changed in the reference column entities and is determined by the entities that are changed. Its results are listed in the ‘interpretation’ column and yield the optimally innovative meaning: ‘product is ultimate gift’ in (8)a, and ‘product is ultimate gift and accepted by beneficiary’ in (8)b. This, then, is how incongruities posed by CoA-based VOIs are resolved to yield the intended meaning. Next, consider (9), the interpretive chart for Figure 2(a), the Devil-Trump image.
(9) Interpretive inference for Figure 2(a)
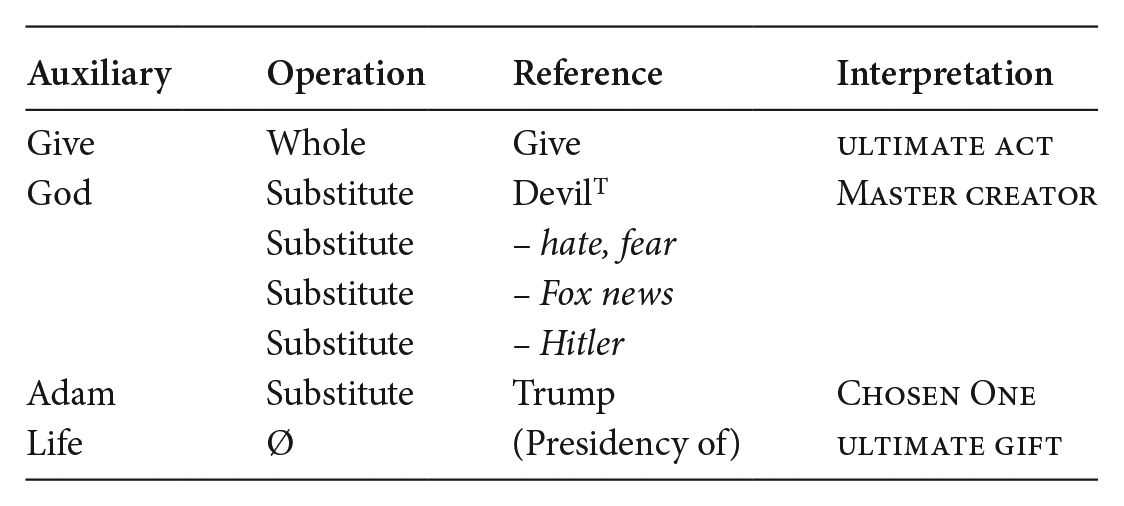
This chart looks considerably more complex, which adequately fits the intuition that a lot of meaning is implied here. Access to the base is provided only through the overall configuration of entities, depicted in ‘whole’, since none of the auxiliary entities remains intact. God, the angels and Adam are substituted for the Devil and his allies and Trump, while the non-visualized entity ‘Life’ appears in the reference domain as ‘presidency of . . .’, to be inferred from other entities (indicated by parentheses). Combining the salient entities and the one serving as topic, the meaning that this VOI suggests can be captured as ‘It is the Devil who is the ‘Master Creator’ of Trump’s (the ‘chosen one’) presidency (‘the ultimate gift’). The cartoon in Figure 3(a) basically expresses the same meaning, except that it puts Putin in charge as master creator, and this is one creator who does not need allies.
The charts can also provide an account of VOI-interpretation by readers lacking knowledge of the base or who fail to recognize the allusion to it; (10) captures this naïve route to interpreting Figure 2b (the vodka advertisement).
(10) Interpretive inference for Figure 2(b) for a reader without knowledge of the base
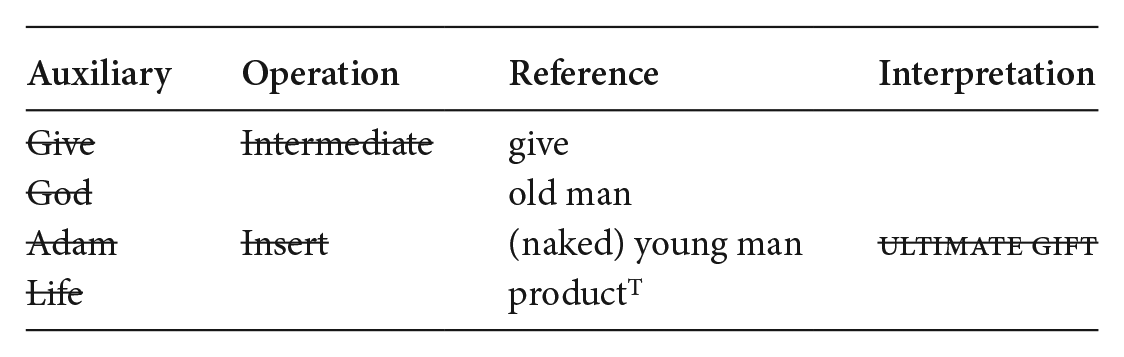
Because to ignorant readers the base is inaccessible, the ‘auxiliary’ column is empty. No inference occurs and all entities are represented in the reference column ‘as such’: an old man handling a bottle of vodka, the topic of this advertisement, to an (apparently) naked man; (10) hence accounts for the fact that to these readers Figure 2(b) simply isn’t a VOI.
We can also envisage readers who are aware of Michelangelo’s fresco, and acknowledge the reference to it in Figure 2(b), but who have little idea as to what the fresco signifies; (11) assesses the interpretation those readers arrive at.
(11) Interpretive inference for Figure 2(b) for readers with ‘fleeting’ knowledge of the base
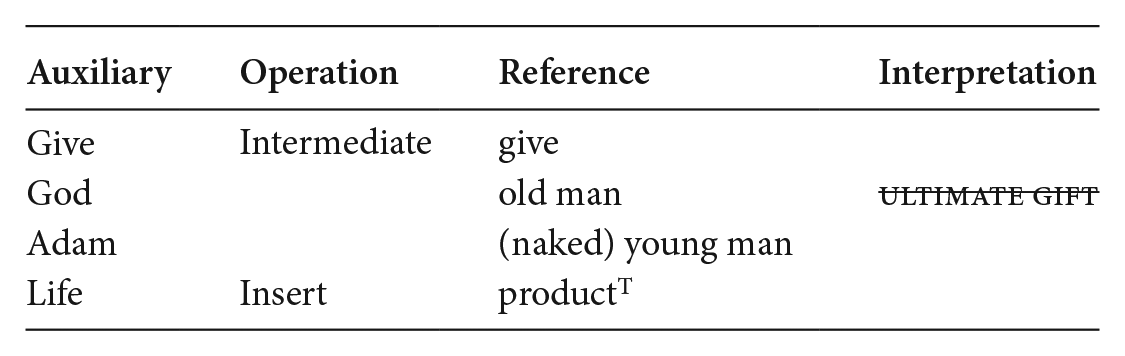
As (11) stipulates, to these readers the conceptual contribution the advertisement’s topic inherits from the auxiliary domain is lost. The VOI will strike them as merely a visual pun – a not-very-funny joke but not much more.
To finish this section, we discuss two cases of what appear to be regular CoA-based VOIs but on closer look are not. Consider Figure 3(c), the movie poster of Jon Amiel’s biopic Creation, dramatizing Charles Darwin’s relationship with his wife Emma and his daughter Annie. The allusion to the CoA is obvious here, but this VOI uses the fresco as auxiliary domain to actually address it. The fresco still functions as this VOI’s base but at the same time appears as topic in the reference domain. The graphic operation Substitute (God for Darwin and Adam for a Chimpanzee) suggests certain ‘corrections’ of the base. Life hasn’t been ‘given’, it has instead evolved through natural selection; and so it isn’t the Ultimate gift indicating some final state, but instead an ongoing event. Likewise, there is no master creator; there is a scientist whose ‘gift to humanity’ is not Life but the Theory of Evolution. Finally, our ancestor is not Adam, but an ape. The chart for this VOI can therefore be given as (12).
(12) Interpretive inference for Figure 3(c)
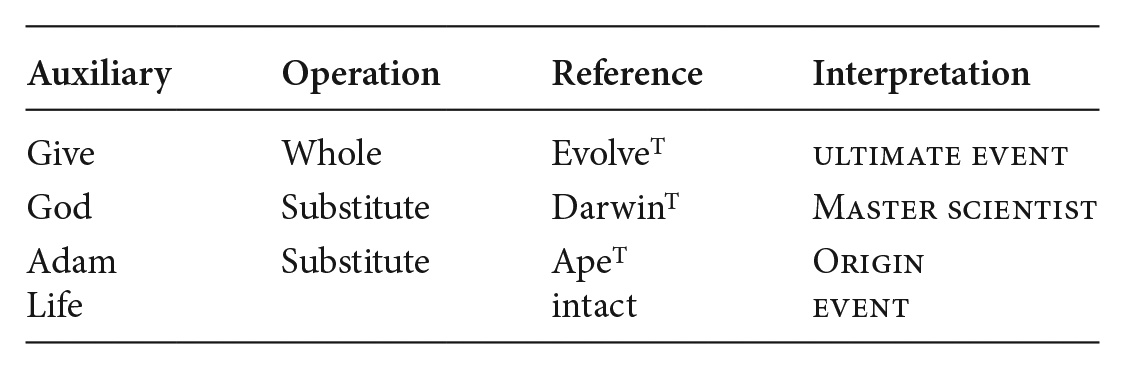
This way of addressing by quoting-and-correcting not only adds an ironic flavor to this VOI; it further supports the routinized nature of the standard VOI itself. This happens more often. Harmonia Rosales’s famous painted rendition of Michelangelo’s fresco (see Figure 3d), tellingly titled The Creation of God, is a VOI that retains the ‘creation’ aspect, but substitutes God and Adam by two black women while reversing the roles of actor and beneficiary (note the altered relative height of the hands) – implying a correction of the Eurocentric male–white original actors. These examples further suggest that our earlier statement, ‘a VOI is never about its base’, may not always be true.
5 A Visual Lexicon
Because the CoA and the VOIs based on it involve stored knowledge, we argue for their status as visual lexical items that are part of a more encompassing visual lexicon. Researchers in the field of visual cognition often consider drawings, paintings or other created images too ephemeral to allow storage as ‘fixed’ pairings of form and meaning, like, say, a verbal word. Such a view is connected to beliefs about drawings articulating what we see instead of systematic stored graphic patterns, and corresponding advocacy against imitation of other people’s drawings (for reviews, see Cohn, 2014; Wilson, 1988). Yet, close inspection of CoA-based VOIs reveals features that advocate the visual lexicon hypothesis.
According to Jackendoff’s Parallel Architecture model of language, a lexical item is a stored correspondence between a piece of phonology, a set of (morpho)syntax features and a piece of semantics (Jackendoff, 2002; Jackendoff and Audring, 2020). Knowing the word ‘person’ means knowing how it sounds (phonology), how it is used in a sentence and can be pluralized (morphosyntax) and what it means (semantics). The standard notation for this item is (13), where coindex 1 marks the correspondences across the three formal systems.
(13) Phonology /pз:rsn/1
Morpho-syntax N1
Semantics PERSON1
Speakers use items like (13) to draw their interlocutor’s attention to its semantic structure, so let us ask what knowledge is involved should one decide to draw a ‘person’ instead of uttering /pз:rsn/. The answer provided in Cohn (2012, 2018) and Schilperoord & Cohn (subm.) is a generalized model of lexical items as stored correspondences between meaning (unified across all modalities), modality-specific units and principles of combination (‘grammar’), and modality-specific primitives and features (‘modality’, see 14).
(14) Modality /. . . /1
Grammar . . . 1
Semantics PERSON1
The visual lexical item for ‘person’ would then be as in Figure 4, that links its semantics to a piece of graphic structure, the stick figure for ‘person’ and a piece of visual morphology, i.e. a monomorph: a visual form that can stand alone and can serve as a base for morphological ‘affixes’ like a speech balloon or motion lines (cf. Cohn, 2018).
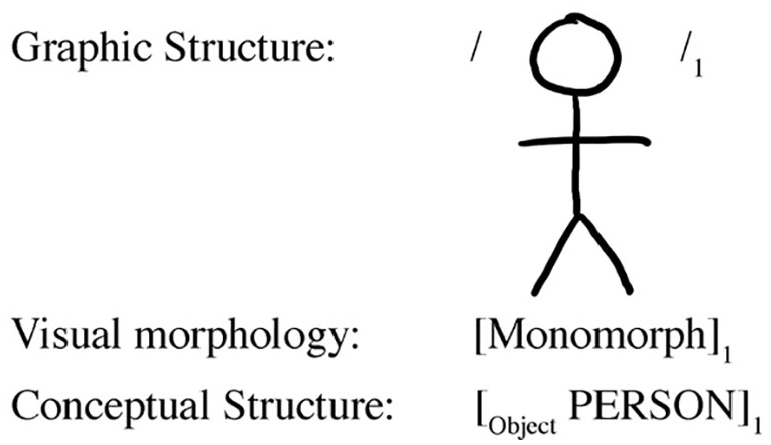
A lexical entry for a stick figure.
The semantic level is where the connection between the visual (Figure 4) and verbal (13) lexical items for ‘person’ meet, enabling us to ‘speak about what we see’ (cf. Culicover and Jackendoff, 2012), while the ‘lower’ levels of each item are built from their own characteristic primitives, principles of combination and modality-specific features.
Just like verbal lexical items, visual lexical items can be larger than a single monomorph. Several monomorphs can combine to form stored, internally structured macromorphs. Cases in point are the numerous multi-object traffic signs that we know, or Zallinger’s March of Progress. 7 In fact, any complex visual image that viewers recognize without having to put the distinct monomorphs together to interpret what they see constitutes such a larger visual lexical item. Among these larger items, we find CoA. People recognize (reproductions of) the image the moment they see it, they can describe, or even draw the fresco from memory, and they are capable of calling it to mind upon seeing impaired representations of it – like, for instance, the VOIs discussed in this article. The item’s formal notation is Figure 5(a), where gs abbreviates ‘graphic structure’, vms ‘visual morphological structure’ and cs ‘conceptual structure’.
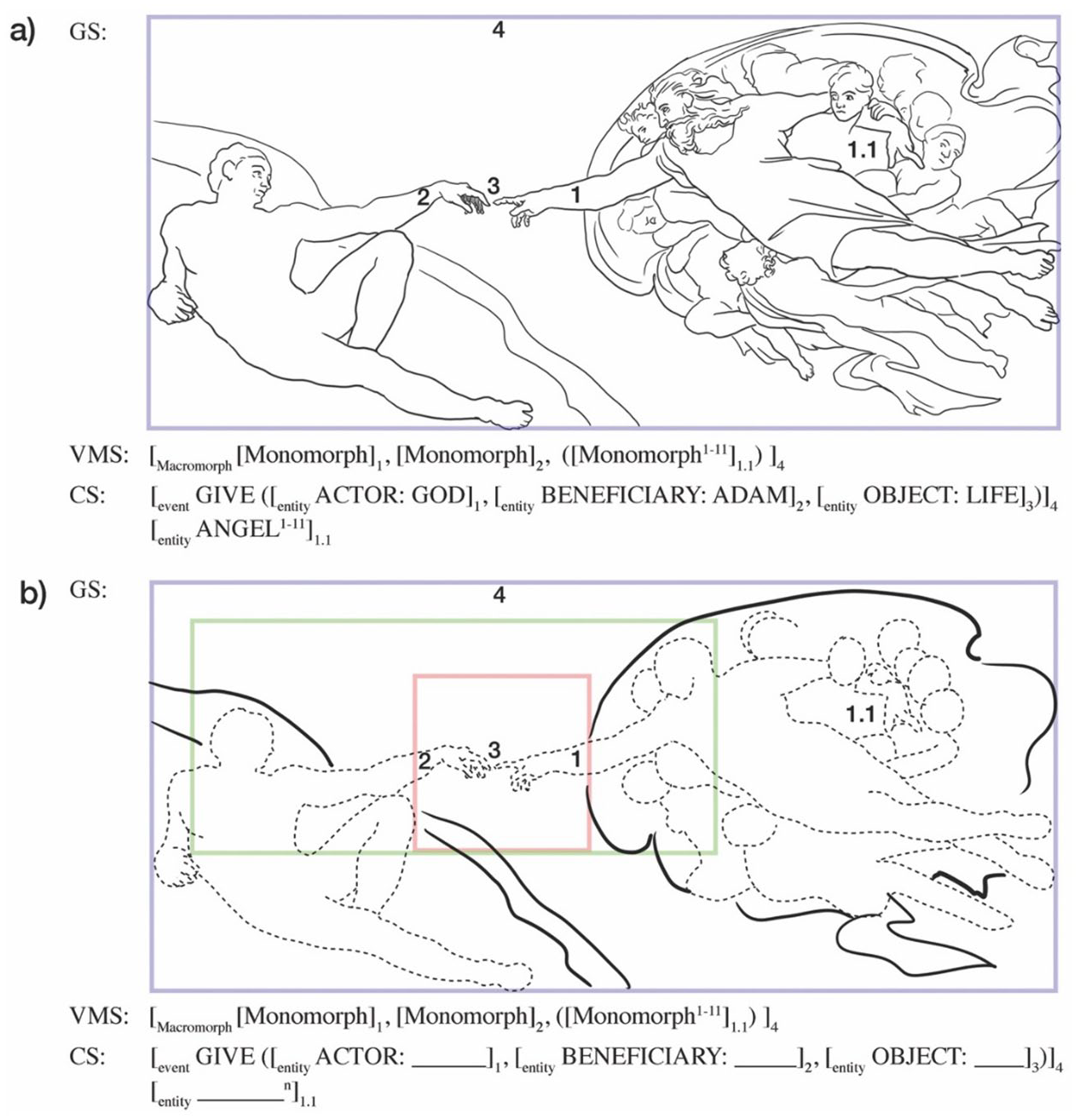
Stored information in the visual lexicon for The Creation of Adam: (a) specifies the full entry for The Creation of Adam, while (b) specifies the schematic-derived visual optimal innovation.
Coindices 1–4 link CS to the relevant parts at GS: God (1), Adam (2), the meeting of the hands suggesting the gift of life (3), and the entire event (4). The Life-entity has no corresponding unit at VMS since it is not visualized. VMS is characterized as a macromorph consisting of various monomorphs. The one addition to CS as presented earlier concerns the (eleven) angels surrounding God (coindexed 1.1). Because they do not participate in the Give-event, they constitute a separate part of CS.
The visual lexical item in Figure 5(a) belongs to the cognitive stock-in-trade of anyone who has encoded their familiarity with Michelangelo’s fresco and its meaning. But how is this involved in understanding (or creating!) CoA-based VOIs? To address this question, it is informative to imagine the state of mind of viewers who know the fresco (Figure 5a is part of their lexicon) but have never seen a VOI based on it. What happens when they are exposed to a series of them, say, the ones discussed in this article? In all likelihood, this will lead them to acknowledge that, apparently, both the graphic structure and the fixed conceptual slots in Figure 5(a) allow alternative instantiations. Apparently, God ‘can also be’ Putin, Darwin, or the Devil, although the semantic role these variants occupy in the overall CS is similar to the role of God in Figure 5(a). Likewise, Adam ‘can be’ a Black woman, a toy’s hand, Trump, or a chimp, but again, the role these substituting entities play is similar to the one played by Adam in Figure 5(a). The delicate interplay between what these readers already know and what is new to them, gradually ‘opens’ the fixed lexical item of Figure 5(a) into what Jackendoff and Audring (2020: 31ff) call a productive schema, i.e. Figure 5(b), with each newly encountered VOI reinforcing its productive potential.
Notice that Figure 5(b) not only includes the full entry of the original (i.e. Figure 5a), but also provides a set of open slots that allow instantiation through substitution, erasing, relocating, and so on. These slots can appear at the level of graphic structure (depicted in Figure 5b with dashed outlines for the primary figures), in addition to the framing of the entire scene (blue frame), an intermediate composition (green frame), or a focus of the hands (red frame). Variable slots also appear in CS, which can be filled in as in the VOI-examples described above. Essentially, the CS in Figure 5(a) shows the auxiliary domain, while the CS in Figure 5(b) specifies an abstracted version of any CoA-based VOI’s reference domain. The variety of possible meanings that fill these slots further accentuates the usefulness of a visual morphological structure to characterize the knowledge that some entity belongs here (‘monomorph’), but its semantics are flexible (man, woman, ape, toy, etc.). The schema is productive; regardless of the operations applied to various slots, the overall event–argument structure is preserved and inhabited by each VOI-instance of it (comparable to verbal constructional idioms like the resultative construction, cf. Goldberg and Jackendoff, 2004).
Coindices 1–4 not only mark the interfaces between graphic structure, visual morphology and meaning, but they also link the two items ‘horizontally’ (here depicted vertically!) so as to mark what Jackendoff and Audring (2020: 13ff) call relational links between corresponding levels and components of the two items. This explains why every VOI immediately activates the CoA-lexical item, i.e. how it allows ‘for the automatic recoverability of a salient response related to that stimulus’ (Giora et al., 2004: 116), and how meaning and interpretation of VOIs aligns the CS as auxiliary and reference domain (sections 3 and 4).
We have sketched one way for Figure 5(b) to become part of viewers’ visual lexicon. But let us return to the kind of reader introduced in section 4; those who are not familiar with Michelangelo’s fresco, but who occasionally stumble upon VOIs based upon it (without acknowledging their ‘optimal innovative’ nature). Noticing the graphic and conceptual properties these VOIs have in common may lead these readers to develop the links to Figure 5(b) as well. Crucially, however, the lexical repertoire of these readers lacks the relational link with the CoA-item – simply because the latter is not part of their lexicon. This explains the impaired interpretation these readers arrive at upon seeing a VOI – it lacks the ‘surplus’ of meaning carried by the base. In fact, we may envisage three different knowledge states, based upon what a reader does and does not know. Consider Figure 6(a–c).
VOIs appear in Figure 6(a) as ‘daughters’ from the productive VOI-schema (VOI-s) to form an inheritance hierarchy (cf. Goldberg and Jackendoff, 2004). Figure 6(a) characterizes all-knowing ‘CoA–VOI-s’ readers: those who know the fresco and what it signifies and have developed the VOI-schema in Figure 5(b). Figure 6(b) characterizes ‘only CoA’ readers: the knowledge state of readers familiar with the fresco but unaware of (the existence of) VOIs based on it. Figure 6(c) characterizes ‘only VOIs’ readers: readers having been regularly exposed to the VOIs of CoA without knowing the base. Although being aware of the kind of images we have discussed in this articles, these readers will fail to recognize their ‘optimal’ nature since they lack the CoA-item and its relational links to VOI-s. Ultimately, both Figure 6(b) and 6(c) may develop into Figure 6(a), but this will call for different types of novel input.
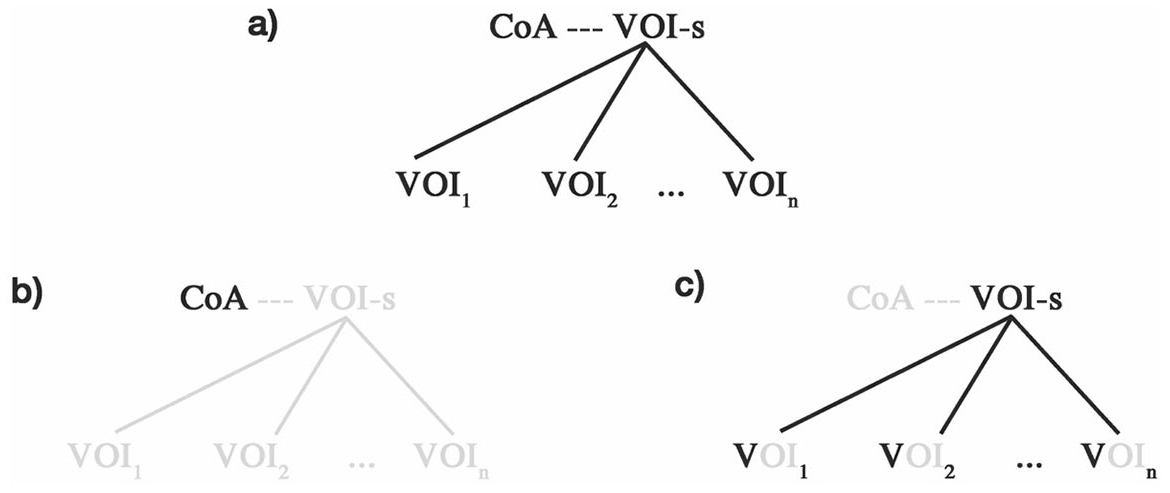
Inheritance hierarchies for The Creation of Adam and its visual optimal innovation: (a) characterizes the knowledge of both the original painting and its variations; (b) characterizes just knowledge of the original while disconnected from variations; and (c) characterizes a lexicalized knowledge of the schema for variations (Figure 5b) though without knowledge of the original painting.
Finally, consider again Figure 5(a/b). The complex item suggests that initial recognition of an image ‘as’ a CoA-based VOI is guided by knowledge represented at the level of Graphic Structure. This raises the question of what visual features (type–objects, postures, composition, etc.) must be retained as indicative in their graphic form to the original fresco, i.e. what counts as ‘permissible’ instantiations of Figure 5(b). Tentatively, we believe these required features come in two flavours: compositional and conceptual. In terms of composition, next to the overall ‘tilted’ composition, the frames at GS in Figure 5(b) mark the permissible sub-selections a VOI can employ: focus (red), intermediate (green) and entirety (blue). These particular framings therefore seem ‘lexicalized’ and patterned. Conceptually, predictions are riskier. We suggest that at least ‘hands’ should always be there. They may be real hands, the ‘fresco’ hands of God and Adam, a child’s hand, an alien hand, a toy hand, an X-rayed hand, a robot hand, an animal hand, an emoji hand . . . but at least one hand should be present. The one exception we found concerns a VOI that shows two titled forks substituting God’s and Adam’s hand. The visualized curved prongs suggest that mere similarity in shape between substituted and substituting objects allows access to the base. It can be doubted if that would still be possible had the two objects been spoons or knives.
To conclude, we have argued that Michelangelo’s The Creation of Adam serves as the base form for creative elaboration on various topics. As a visual optimal innovation, both this base form and its open slots are stored in typical viewers’ long-term memory as part of their usage-based visual lexicon. This both demonstrates that visual information can be encoded as systematic, patterned forms, but also that these forms can involve variables allowing productivity. Thus, just as the notion of an optimal innovation can operate across verbal and visual representations, so too can instantiations of both fixed and constructional forms, substantiating the notion of a lexicon pervading across modalities.
Footnotes
Funding
The authors received no financial support for the research, authorship and publication of this article, and there is no conflict of interest.
Notes
Biographical Notes
JOOST SCHILPEROORD is Assistant Professor affiliated at the Tilburg Centre for Cognition and Communication. He has a background in linguistics and speech communication. His main current interests are visual and multimodal communication and semantics, visual rhetoric and visual argumentation.
Address: Department of Communication and Cognition, Tilburg Centre for Cognition and Communication, Tilburg University, Warande 2, 5037 AB Tilburg, 5000 LE, The Netherlands.
NEIL COHN is Associated Professor affiliated at the Tilburg Centre for Cognition and Communication. He is a cognitive scientist and comic theorist. His main interests are the cognition and grammar of comics and comic understanding, and multimodal communication and semantics.
Address: as Joost Schilperoord. [ email: