
Abstract
Generative AI tools can produce images that visually mimic professional photojournalism. Our study examines how these tools simulate journalistic image production by reproducing news values commonly found in visual reporting. Using the Discursive News Values Analysis (DNVA) framework, we analyzed a dataset of 84 images-28 real and 56 AI-generated-based on news coverage of the Israel–Hamas conflict. The analysis compares the presence of 10 established news values, as perceived by journalism students, across real and AI-generated visuals. The study argues that while AI can mimic the form of newsworthiness, it may also blur the boundary between representation and simulation. Findings suggest that AI-generated visuals often foreground values such as negativity, personalization, and aesthetic appeal-mirroring dominant journalistic patterns. This alignment may contribute to a standardized visual language that simplifies complex events and reinforces existing representational norms in conflict reporting, shaping how such events are mediated and understood.
Introduction
The rise of OpenAI tools has sparked debate in journalism regarding their implications. Collaborations such as the Guardian Media Group’s with OpenAI and the adoption of AI tools at The New York Times, highlight how AI is gradually becoming part of everyday journalistic practice. Numerous scholars have already emphasized that AI use in the newsrooms risks shifting the news industry’s dependence on platform companies even more, while reliance on platform-based AI demonstrates isomorphic tendencies and may potentially constrain publishers’ autonomy, with little or no power to resist on synthetic representation (Schaetz and Schjøtt, 2025; Simon, 2024). At the heart of these concerns lies the question of newsworthiness-a concept central to journalism that shapes what is considered important, how events are framed, and how images are selected to represent reality. News values guide both editorial decisions and audience expectations, especially in contexts like war or humanitarian crises. In visual journalism, these values are communicated not only through text but through images that convey urgency, emotion, and relevance. Wu (2024) argues that journalists should embed their professional values into AI systems, while Møller (2024) shows that newsrooms already encode relevance and timeliness into algorithms to uphold journalistic standards.
Text-to-image systems generate realistic images from a given prompt written in natural language. Through a repeated process of adding and removing noise within the data, the model learns to create images based on text prompts inserted by users (Moran and Shaikh, 2022; Thomson et al., 2024). As AI tools gain traction in newsroom workflows, their use raises concerns about how journalistic news values-especially those surrounding newsworthiness-are being interpreted and potentially reshaped. This is particularly salient in war reporting, where visual representations of conflict have long played a powerful role in shaping public understanding and opinion (Fahmy, 2005), and where the integration of synthetic visuals may blur the boundaries between real and AI-imagery.
Our study examines how generative-AI prompting and image generation reflect journalistic representation practices and the news values embedded in generated images, assessing their visual newsworthiness through viewers’ perceptions. Rather than evaluating whether GenAI visuals simply ‘achieve’ newsworthiness, this study focuses on how specific news values are encoded and amplified through AI-generated imagery. We understand newsworthiness not as a fixed attribute, but as a discursive and semiotic construction, following Bednarek and Caple’s (2017) framework. Drawing from Laba (2024), we treat these outputs not as neutral simulations, but as representational acts that may shape the ways in which events are visually framed and the ways these tools might reflect and amplify hegemonic representational themes.
The study of AI-Generated Content (AIGC) may shed light on how news values are constructed in “real” news images, and how representation shapes narratives in journalism. The article focuses on 2023 Israel’s war against Hamas, a conflict heavily associated with AIGC (Lakhani, 2023) using the DNVA framework (Bednarek and Caple, 2017; Yu and Chen, 2023). This study is timely because it addresses how visual representations shape news storytelling-such as the use of emotionally resonant imagery, symbolic proximity, and aesthetic realism-simulated by AI systems. As AI-generated visuals become indistinguishable from real photographs, and as newsrooms begin experimenting with synthetic content to illustrate breaking stories, questions arise about how news values are embedded, challenged, or redefined by automated systems. By analyzing how news values are reproduced in AI-generated images, this study provides insight into the semiotic logic of visual news narratives in the age of generative AI. While we do not examine the real-world circulation of AI-generated visuals, this study highlights how their simulation of news values shapes constructions of newsworthiness. These findings provide a basis for future research on how GenAI images are received or mistaken for verified news content, and the risks journalists face when republishing them.
Visual news values and AI imagery
Visuals shape how news is represented and interpreted, framing narratives and evoking emotions. Their selection, guided by editorial gatekeeping, reflects practical, institutional, and cultural factors. Selection balances multiple, often competing criteria: aesthetic appeal, emotional impact, clarity, accuracy, and representational fairness (De Smaele et al., 2017). With the rise of generative AI, this balance becomes more complex. The generated hyper-realistic visuals may shift the criteria for what constitutes a ‘successful’ news image which is traditionally associated with relevance, proximity, and human impact. However, aesthetics, such as color saturation and composition, also influence both audience perception and editorial decisions, especially in feature photography. As Aitamurto (2019) illustrates, visual design contributes to credibility and emotional presence, demonstrating that audiences may trust or engage with content not only because of what is shown, but how it is shown.
Visuals also shape newsworthiness, often reflecting similar values as in selection and framing of news stories. Images are used not only to illustrate events but to communicate journalistic news values such as negativity, impact, personalization, proximity, timeliness, and aesthetic appeal (Bednarek and Caple, 2017; Fahmy, 2005). Conflict photography, for example, emphasizes human suffering (negativity, personalization), while portraits or action shots heighten resonance and immediacy (impact, timeliness). These values, often embedded in visual semiotics, guide both editorial decisions and audience perception, embedding urgency, and emotional relevance in imagery.
Despite the interest in AIGC, little research has examined how its visuals align with newsworthiness. This study advances the discussion by drawing on established news values theories. News values were first defined as ‘values by which one fact is judged more newsworthy than another’ (Bell, 1991: 155). Since then, other definitions of news values have flourished including: the criteria used by journalists to decide what qualifies an event as news (Brighton and Foy, 2007); the perceived preferences of the intended audience regarding newsworthiness (Richardson, 2007); the values that make certain events or facts more newsworthy, shared by both news producers and audiences (Galtung and Ruge, 1965); and the essential qualities or elements that render a story newsworthy (Cotter, 2010).
Scholarship on news values has remained largely unchallenged since Galtung and Ruge’s (1965) typology. What all have in common is that news values determine if an event is worthy as news, which involves many texts in the news process simultaneously, whether these are input materials or output materials (Bednarek and Caple, 2012; Yu and Chen, 2023). Therefore, news values are sometimes conceptualized as the inherent qualities of an event, which ‘either possesses them or does not possess them’ (Galtung and Ruge, 1965: 71). The DNVA framework has been applied in several studies (Makki, 2019; Yu and Chen, 2023) and proven useful in revealing the ideological and cultural nature of news values. Bednarek and Caple (2017) argue that news values are constructed through discourse, with media shaping newsworthiness via semiotic resources like language and images.
This approach is especially relevant in an era of AI, where the newsworthiness of an image is no longer solely determined by real-world facts, but by how well a visual artifact simulates expected journalistic values. A discursive approach for analysing the construal of news values in images thus involves recognizing the verbal manifestations that refer to the news values (Bednarek and Caple, 2017). AIGC can convey newsworthiness and aesthetic appeal when they incorporate visual cues linked to specific news values. The newsworthiness and aesthetic appeal can be conveyed when the AI-generated image embodies the news values, either in their entirety or through specific sub-values (see Appendix 1).
In this study, DNVA enables a dual-level analysis: first, how prompts encode verbal cues that signal news values, and second, how AI systems translate those cues into visuals that might reflect news values. This framework reveals which news values are reproduced, how AI affordances shape them, and whether these representations align with newsworthiness criteria. By applying DNVA in AI-generated imagery, we expand its application into a new domain, where news values are not simply reported-but potentially engineered.
AI affordances and generating images
Affordances refer to the possibilities for action enabled or constrained by a system’s design (Gibson, 1977; Stanfill, 2015). In platform studies, technologies are understood as artefacts designed and wielded by humans to achieve specific goals in a specific context (Troeger and Bock, 2022). In the case of AI, natural language processing affords machines the capacity to generate human-like discourse, thus enabling conversational forms of human–machine interaction (Ramaul et al., 2024). Davis (2020) argues that affordances have a dynamic way of being promoted, explained and circulated through audio-visual material, but they still depend on the interaction between technology and the end-users for whom it is designed. Although they encourage and discourage certain actions by the subject, the use of affordances rests upon the skills of users. Therefore, affordances are not only technical features but also sociotechnical arrangements that condition how content is made and interpreted.
Regarding AI tools, through prompts, affordances can mediate how discursive elements of newsworthiness are operationalized in synthetic media. Ramaul et al. (2024) distinguish between creational affordances which enable users to create or manipulate content, and conversational affordances, which facilitate contextual dialogue between uses and AI systems. Both AI tools used in this study, DALL-E and DeepAI, interpret prompts through their training data to generate images that simulate the affective and visual logic of conflict. These affordances are deeply entangled with the DNVA framework which treats news values not as fixed attributes but as semiotic constructions that emerge through language and imagery (Bednarek and Caple, 2017).
Prompts discursively frame what should be visualized-effectively embedding verbal cues for news values. The AI tool’s affordances then determine how effectively these values are realized in the visual output. Similarly, AI affordances are also sites of constraint. Certain visual expressions-such as graphic violence, specific ethnic identifiers, or politically sensitive symbols-may be blocked or softened by the systems. This means that some news values may be systematically underrepresented or distorted, which has implications for both editorial diversity and audience perception. For example, while DALL-E may emphasize stylized coherence and harmony, DeepAI might produce more literal but less visually polished interpretations, affecting perceptions of authenticity.
However, AI systems remain opaque, with their deep learning techniques functioning as black boxes that make it difficult to trace how content is generated. In addition, the degree to which users can shape these outputs depends on their prompting literacy-a skill that parallels, and increasingly intersects with, the editorial judgment of traditional newsrooms. As Robertson et al. (2024) note, prompt engineering functions as a form of storytelling, with verbal framing guiding visual representation. In this sense, affordances act not merely as technical features but as mechanisms shaping how synthetic images meet or challenge newsworthiness.
Methodology
This study investigates how DALL-E and DeepAI simulate journalistic image production by embedding established news values into AI-generated visuals. Rather than simply testing whether AI-generated images can reflect journalistic values, a finding that may be expected considering the tools’ rapid evolution, this study uses the DNVA framework to explore the semiotic construction of newsworthiness in AI-generated visuals. The study views newsworthiness as a representational construct shaped by the semiotic realization of news values (Bednarek and Caple, 2017) and examines how these values are encoded in AI-generated visuals so that future work can assess their impact on audience trust or credibility. To do this, the focus is not only on visual outcomes but also on the underlying prompt insertion that influences the generation of content. The paper therefore asks: (RQ1) To what extent do viewers perceive AI-generated images as simulating journalistic news values? (RQ2) How do text prompts for image generation contribute to the discursive construction of news values? It adopted a mixed-methods approach to investigate how AI-generated visuals reproduce news values, combining participant-based evaluation with a discursive analysis of prompts and visuals using the DNVA framework.
Visual materials
We first focused on a curated dataset comprising 200 images from news articles published by The Guardian and Al Jazeera to ensure a diverse and balanced perspective by using news outlets from different cultural backgrounds. Our focus was not on the Hamas-Israel 2023 war itself but on its visual representations as an unexpected event incorporated into the media agenda. This approach examined how the media visually constructed the newsworthiness of the event within the broader news cycle, rather than its political aspects. Only articles with named images were considered to ensure the authenticity of the visual content. The articles were methodically chosen from key events in the period October-December 2023, to minimize event-driven biases. Out of the 200 news images, only 28 were included in our study using a constructed week sampling approach. Two constructed weeks were created for each outlet, where the images were chosen so that each day of the week alternated between an image with and an image without human subjects.
The captions of the collected images were then given as text prompts to generate images using the DALL-E and DeepAI tools; each caption was used only once in each tool for image creation. This step allowed us to produce new visuals that retained the thematic essence of the original images. In both AI tools, the image captioner software was trained on ‘synthetic’ captions crafted by AI and included detailed descriptions of image elements, participants, locations, settings and visual features such as composition, colour, size and shape, as well as text appearances (Shi et al., 2020). The analysis unit used was the image-caption complex (Caple and Knox, 2019), based on which both the image and its caption are considered when coding news values. This reflects the strong link between images and captions, as captions can convey news values absent from the image itself (Bednarek and Caple, 2017).
Questionnaire
Eighty-four images were used: comprising 28 real images and 56 AI-generated counterparts (28 from DALL-E and 28 from DeepAI). This design ensured a balanced mix of real and AI visuals, allowing a thorough analysis of visual differences and perceptual biases. We therefore constructed 14 distinct questionnaires, each randomly presented to participants, to ensure diverse exposure and reduce potential biases. Each questionnaire consisted of two parts. The first part collected demographic information (age, gender, education). The second part included six randomly selected images: two reals, two from DALL-E, and two from DeepAI. Every image was paired with 15 evaluative questions designed to assess aspects related to news values of the image. Each news value was defined according to the DNVA framework (see Appendix 1). This approach aimed to assess participants’ perceptions of image newsworthiness and alignment with journalistic values, offering insights into how AI-generated and real images compare in news contexts.
The questionnaire was completed by 178 Cypriot participants (120 females, 53 males, 5 identifying as other genders), with an average age of 22. Participants were final-year journalism students, born between 1997 and 2002, and enrolled in undergraduate media and communication programs. This group was selected deliberately as they represent a generation of emerging media professionals who are both highly digitally literate and actively engaging with AI. Their educational background ensures familiarity with news values and visual storytelling, making them a relevant and informed population for evaluating the newsworthiness of AIGI. Though not professional journalists, the sample offers key insights into how future practitioners interpret AI-generated visuals. Moreover, Gen Z’s exposure to digital tools makes them a key demographic in shaping the future of professional journalism and audience expectations. Following Bednarek and Caple’s (2017) DNVA framework, the text prompts used to generate AI images were analyzed through linguistic coding and thematic content analysis by two independent coders. This allowed us to identify how specific lexical choices conveyed news values and influenced the AI-generated visuals. Coding focused on 10 news values, and intercoder agreement was established through a pilot round of coding, followed by discussion and refinement of categories to ensure consistency.
Findings
News values in AI-generated images
To answer the first research question, participants evaluated both real and AI-generated visuals using a five-point Likert scale across 10 established DNVA news values. Figure 1 presents the mean scores for all images allowing for a comparative analysis of how participants perceived the newsworthiness of each image type. Rather than assessing whether AI tools can ‘produce news’, this study examines how their outputs simulate journalistic imagery by drawing on discursive features and semiotic cues associated with news values. Mean scores for all images.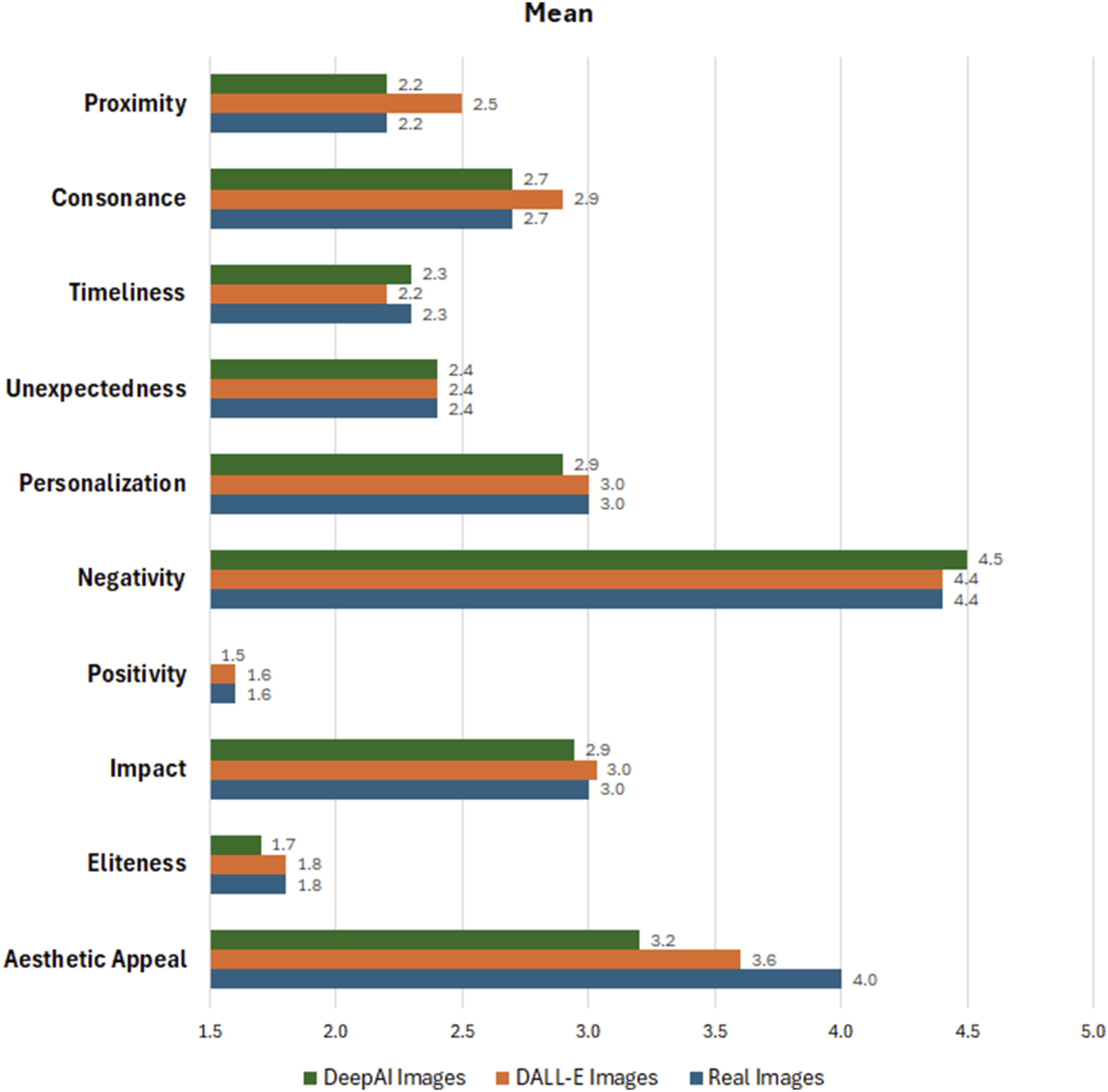
The results indicate the differences in the affordances of the two AI tools for creating news images, as reflected in the participants’ answers. The scores given to real and AI images were not notably different for eliteness, impact, positivity, negativity, personalization, unexpectedness and timeliness. The largest difference between real and AI images was observed for aesthetic appeal. Real images received the highest score followed by DALL-E and DeepAI images. This shows that AI tools, while capable of creating visually appealing images, have not yet achieved the aesthetic realism and natural visual harmony of real ones. A notable difference in scores was also achieved for proximity where DALL-E images scored the highest value, followed by real and DeepAI images.
Comparing the results of the AI tools, DALL-E demonstrated stronger capabilities in aesthetic appeal and consonance, which indicates its ability to create visually pleasing and harmonious images that rival real news images in terms of the typical features of compositions. It also performed equally with real images in terms of impact and personalization, showcasing its potential to create compelling and ordinary content. In contrast, DeepAI lagged DALL-E in most metrics, with lower scores in aesthetic appeal and proximity, which suggests that its outputs are less visually engaging and recognizable. However, DeepAI matched real news images in timeliness, which hints at its ability to produce relevant imagery. Both AI tools received high negativity scores, which suggests potential biases in training data or a tendency to generate images evoking adverse reactions.
Using a one-sample t-test, we assessed whether there were significant differences between real and AI-generated images for each news value. The results indicated significant difference only in aesthetic appeal across all comparisons (real vs DeepAI, real vs DALL-E and DeepAI vs DALL-E; p < .001). Real images were consistently rated as aesthetically superior to AI-generated images. Among the AI-generated images, DeepAI was generally perceived as the least visually appealing, while DALL-E images held an intermediate position in terms of aesthetic quality.
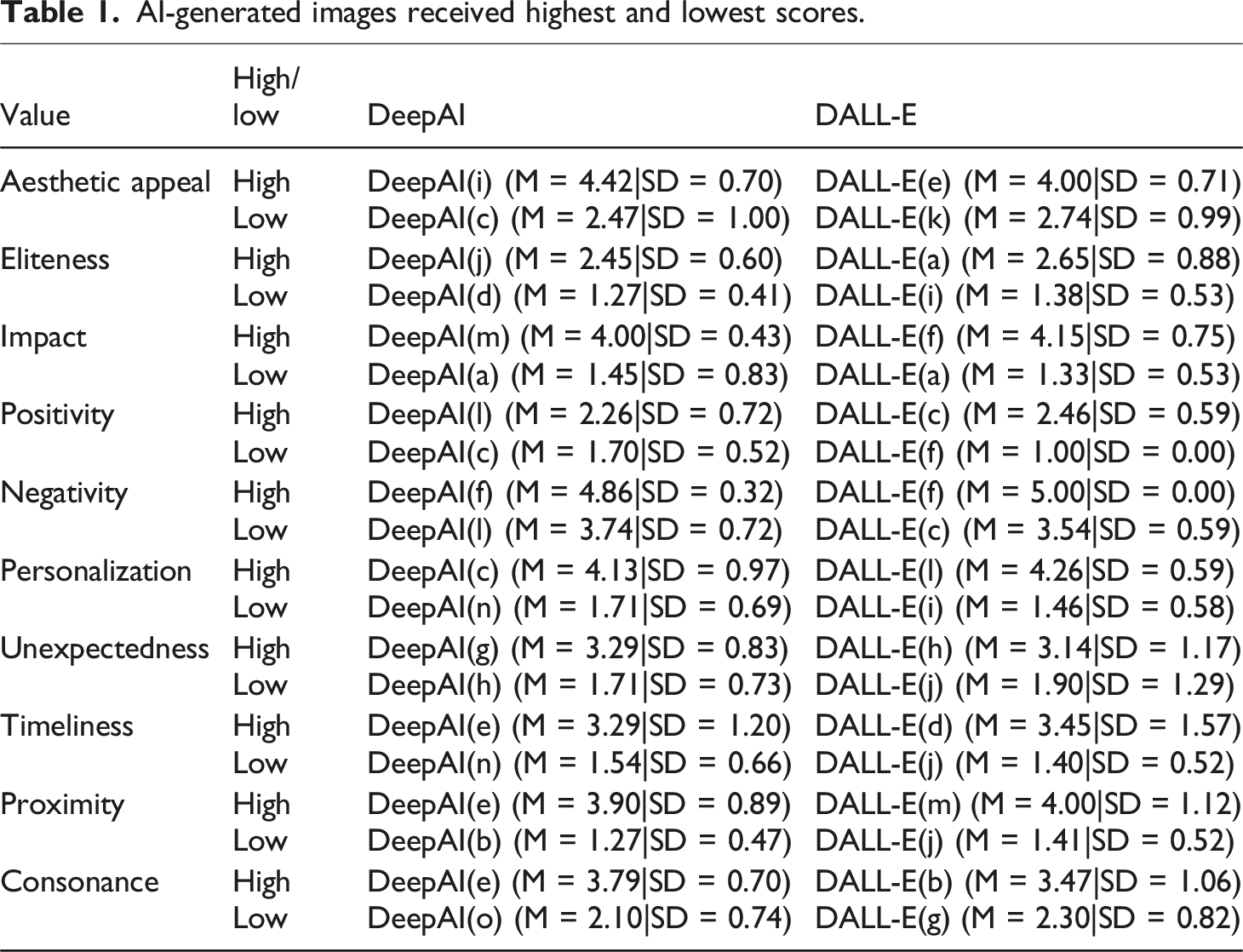
The results illustrate how AI tools perform compared to real news images, highlighting their strengths and weaknesses. Examples of AI-generated visuals appear in Figure 2, and the highest- and lowest-scoring images are listed in Table 1. Images generated by AI tools. AI-generated images received highest and lowest scores.
News values and text prompts
In this subsection, we explore how the text prompts used in AI tools might reproduce the newsworthiness in their generated visuals inspired by specific news values. Using the DNVA framework, the analysis focuses on the captions of the images that received the highest scores (see Table 1). By focusing on text prompts, we highlight the interplay between captions (Appendix 2) and AI-generated imagery (Figure 2) in producing content that reflects the news values of visual journalism and thus makes an event newsworthy.
Detailed spatial and contextual description
Text prompts with detailed spatial and contextual descriptions enhanced the affordances of DeepAI and DALL-E to generate images that aligned with the values of negativity, positivity and impact. Providing precise information about conflict settings, actors, or consequences allowed AI to produce visuals that felt emotionally resonant and contextually grounded. Negative evaluative language-such as ‘troops’, ‘flares’, ‘fired’-effectively triggered the generation of scenes evoking danger, destruction, or human suffering. These prompts successfully simulated editorial preferences often embedded in journalistic culture-especially in war reporting (El Damanhoury et al., 2025). However, while the prominence of negativity in AI-generated images might suggest bias in training data, it is important to recognize that negativity is also an entrenched value in journalism itself. As a news value, negativity reflects journalism’s tendency to prioritize stories involving conflict, which are traditionally seen as more newsworthy.
While our analysis focuses on model outputs, the prominence of negative representations likely reflects both algorithmic bias and sociotechnical conditions of model development. Since negativity and conflict are established news values, our findings suggest a recursive relationship between journalistic norms and the visual conventions AI models associate with newsworthy contexts. Recognizing non-transparent training data is crucial for understanding how these tendencies are reproduced and amplified, raising broader issues of copyright, licensing, and the systematic reinforcement of particular representational themes.
Although the value of positivity didn’t depict a high score, we consider that it could emerge particularly through the text prompts which refer to positive actions and positive entities (humanitarian aid and institutional support) when associated to a particular context. DeepAI(l)) and DALL-E(c) depict that the text prompt when mentioning the spatial context of the positive action, the Al-Ahli Arab Hospital’s with 140-year history of helping people presents a positive entity, can reinforce the narrative of resilience and care. Similarly, the humanitarian-associated trucks lined up at the Rafah border highlight positive actions, emphasizing efforts to provide relief in a crisis. These examples align with Bednarek and Caple’s (2017) framework, where positivity is often underrepresented in news discourse but can be constructed through narratives of aid, solidarity, and historical continuity when associated to a particular context.
DeepAI(f) and DALL-E(f) depict the images with the highest score for negativity created by the tools. In the case of DeepAI, the prompt strongly embodies the news value of negativity by using linguistic and contextual elements that emphasize conflict, tension and potential human suffering. The action-oriented phrase ‘flares being fired’ conveys an immediate sense of aggression or hostility, even though flares themselves may not be lethal. The prompt is associated with military operations through the term ‘being fired’, which intensifies the perception of an unfolding or escalating conflict. The geopolitical context given to the prompt as the primary spatial context where the conflict takes place adds another layer of negativity. The mention of ‘Israeli troops’ situates the action within a militarized framework, while ‘Gaza Strip’ evokes a region historically marked by war, destruction and humanitarian crises. The reference to Gaza immediately amplifies the emotional weight of the prompt, which is already often related to suffering, displacement and vulnerability even if it does not explicitly describe such outcomes. This combination of verbal elements (e.g., conflict-oriented lexis, implied human impact and geopolitical references) along with the evocative visual implications of danger and destruction creates a strong connotation for creating a specific image.
Similarly, the text prompt inserted in DALL-E is also vivid and emotionally charged. The use of explicit and graphic language, such as ‘mutilated and burned body parts’, immediately evokes a sense of horror and tragedy. The specific mention of an ‘Israeli attack’ situates the event within the broader context of ongoing conflict and adds layers of tension and political significance. The inclusion of personal details – that is, the naming of ‘Ibtihal al-Ra’i’ and emphasis on her role as a mother escaping with her children – humanizes the tragedy and draws attention to the impact of violence on civilians. The precise reference to time (‘17 October’) and location (‘al-Ahli Arab Hospital in Gaza City’) grounds the narrative in a tangible and immediate reality, thus enhancing urgency of the event. This combination of explicit imagery, personal storytelling and contextual specificity makes the verbal representation highly effective in conveying the negativity of the situation. This text prompt has also been used to create an image ranked among the highest scores for the news value of impact. This aligns with the findings of Yu and Chen (2023), who argue that negativity often co-occurs with impact. This example demonstrates that an image-caption combination can simultaneously construct multiple news values within AI tools.
Here the text prompts can effectively communicate negativity by drawing on the intersection of verbal precision, historical context and implied visual storytelling to create a vivid and emotionally charged narrative necessary for the creation of an image that seems almost real. In the text prompts analysed, the focus on fear associated with the context of war is part of the ‘discourse of horror’ (Pantti and Wahl-Jorgensen, 2007).
Generic references, human-centric elements and contextual specificities
When generic yet human-centric verbal elements are embedded in a specific conflict setting, the affordances of AI tools are activated to generate emotionally resonant visuals that align with the value of personalization. While personalization is a widely used journalistic value to connect audiences with complex events (Bednarek and Caple, 2017), in the context of AIGC, its implications become more layered. The interest lies not only in whether AI can reproduce this value, but also in how and why it does so, and what this reveals about the political and editorial implications of generative visual technologies.
For instance, the prompt inserted into DeepAI for the image in DeepAI(c) employs vulnerable figures (‘babies’) and a named context (‘Rafah’, ‘al-Shifa hospital’) to humanize the crisis. The specificity of ‘Al-Shifa hospital’ and ‘Rafah’ further grounds the event in a real-world context, thus enhancing the authenticity and relatability of the story and the immediacy of the unfolding humanitarian crisis. These prompts encourage AI tools to generate visuals that accurately reflect the context and enhance the realism of the image. These affordances are rooted in the AI’s ability to match prompts with highly specific and context-sensitive visual elements, such as ‘babies’ in vulnerable conditions. The prompt also used action-oriented verbs like ‘evacuated’ and ‘transported’, thus emphasizing the urgency and effort required to save these lives. These words highlight the infants' precarious state and the human effort in their rescue, while ‘lie in an ambulance’ vividly conveys vulnerability between rescue and treatment. This prompt personalizes the conflict by highlighting its impact on innocent individuals, framing the crisis as personal tragedies rather than a geopolitical issue. The generated image strongly reflects personalization by emphasizing fragility, care, and urgency. However, the significance of such imagery may not stem only from its emotional resonance, but from its disconnect with real-world happenings. Such scenes may be fictionalized in ways that contradict or obscure the actual conditions on the ground-for example, if infant evacuations in Gaza were actively prevented rather than occurring as shown. In this sense, the AI-generated image may inadvertently construct a narrative of hope or competence that does not reflect lived realities, raising critical concerns about misrepresentation in conflict reporting.
The DALL-E-generated image in DALL-E(l) uses a generic actor (‘a man’) to depict suffering within a specific spatial and political context. By interpreting the prompt’s description of the personal action (‘collects belongings’) within a specific geographic (‘Gaza city’) and temporal framework, the AI generated an image focused on human-centred storytelling, foregrounding the man amidst destruction and highlighting the aftermath of conflict. This action highlights the physical impact of the shelling but also the resilience of civilians attempting to save what little remains. The specific reference to ‘overnight Israeli shelling in Gaza City’ situates the event within a specific context, thus grounding the personal struggle in a real-world scenario grounded on the broader narrative of conflict in the region. The vulnerability of the man, combined with the absence of further personal details, symbolizes the collective suffering of civilians in war. This combination of individual focus, contextual specificity and emotional resonance transforms a large-scale tragedy into a human story. While this aligns with personalization through the representation of an individual’s hardship, the image’s perceived realism-and the skin tone or styling of the character-could unintentionally reinforce or distort ethnic or cultural identities. Again, the personalization here is not just an aesthetic function but a semiotic and political act, where editorial framing is simulated by a system without full awareness of historical, ethical, or situational nuance.
Thus, while personalization is common in editorial choices, its use by AI systems invites new questions: Who defines the human subject? What kind of stories are made visible-or invisible-through these visualizations? And how might personalization in AIGC reproduce or sanitize the suffering of marginalized communities in ways that risk editorial distortion?
Temporality, location, event association and representation of vulnerability
AI tools’ affordances encourage the creation of images that align with the values of timeliness, proximity and consonance when the text prompts include references to temporality, or explicit references to specific places; the same event; places which are geographically or culturally associated with an event; and vulnerable individuals. The image depicted in DeepAI(e) received the highest score for the news values of timeliness, proximity and consonance in the case of DeepAI. The given prompt encapsulates the news values of consonance, timeliness and proximity, which makes it a strong and compelling narrative. The consonance lies in its alignment with ongoing global narratives of conflict in Gaza, a region widely associated with violence and humanitarian crises both previous and ongoing. However, while consonance should verbally reference stereotypical attributes or preconceptions (Bednarek and Caple, 2017), in our case, this attribute is constructed within the image itself. A simple reference to an Arabic name (‘Ibtihal al-Ra’i’) prompted the AI to generate an image featuring two women and a child wearing traditional Muslim clothing (i.e., hijab). The graphic imagery of ‘mutilated and burned body parts’ also reinforces familiar patterns of devastation, while resonating with pre-existing perceptions of the human cost of war in this context. Timeliness is emphasized through the inclusion of a specific date (‘17 October’) that situates the story as an urgent event, while the dynamic verb ‘escaped’ conveys immediacy and peril to capture the attention of audiences as part of an unfolding crisis. Proximity is achieved both geographically and emotionally; the mention of ‘Gaza City’ anchors the story in a recognizable and newsworthy location.
Vivid verbal imagery
The affordances of both AI tools facilitated the generation of images that scored highly on the news value of aesthetic appeal, particularly when text prompts incorporated vivid spatial and emotional descriptions. The affordances of both tools facilitate the creation of images that align with the news value of aesthetic appeal, particularly when the prompts incorporated vivid verbal imagery (‘scene of destruction’) linked to a specific location that provided a broader symbol of vulnerability during a significant event. Caple and Bednarek (2016) argue that a balanced and aesthetically pleasing image can enhance an event’s newsworthiness, especially when combined with technical elements such as lighting, colour and contrast. In our case, the AI-generated images effectively represent these aspects without employing these specific technical elements - and therefore lacking artistic balance or refined composition. While the concept of aesthetic appeal can coexist with other news values and has been analysed across all the generated images, this part focuses solely on the two images that received the highest scores for this value. DeepAI(g) shows the DeepAI image for the prompt ‘Scene of destruction at al-Ahli hospital’, while DALL-E(e) shows the DALL-E image for the prompt ‘A satellite image taken on 11 November showing the al-Shifa hospital complex’.
For instance, DeepAI(g) shows a damaged building at ground level and emphasizes realism but lacks strong aesthetic appeal. The lighting appears natural yet flat; it provides little contrast and reduces the image’s overall impact. While the shot is mid-range, it does not capture the full extent of the destruction, which makes it less visually dramatic. The brightness is moderate but lacks strong highlights or shadows to create depth. The quality is decent, but some areas lack sharpness, particularly in the finer details. While the image effectively conveys destruction, its attractiveness is low due to the lack of dynamic framing of visual elements. This image while aligns with journalistic news values that prioritizes realism over aesthetic appeal, thus without representing participants.
Similarly, DALL-E(e) presents an aerial cityscape with a central complex. It demonstrates high aesthetic appeal through strong lighting, contrast and composition. The long, wide-angle shot provides a broad and structured view that captures intricate urban details while creating a sense of scale. The brightness is well balanced, with artificial lighting and shadows enhancing depth, making the image appear cinematic. Its high quality and sharp resolution contribute to an immersive look. The blue tones from the coastline add vibrancy and make the image visually compelling. Unlike DeepAI(g), this image appears more artfully constructed, likely benefiting from AI enhancement to make it more engaging and visually striking. While both images reflect significant events, the second one scored higher in terms of attractiveness and aesthetic appeal, thus aligning with an artistic or stylized news value rather than raw documentation.
However, differences emerged between DALL-E and DeepAI in users perceptions related to aesthetic realism and compositional strength of the generated images. This finding highlights an underexplored but important dimension of AI-assisted visual journalism: how different models encode “visual quality” and why audiences respond to this aesthetics differently. Participants consistently rated DALL-E images as more aesthetically pleasing than those generated by DeepAI, though both lagged real photographs. This suggests that DALL-E may offer more refined affordances for generating visually coherent, balanced, and professionally styled images. For instance, the DALL-E image in DALL-E(e) was highly rated for its clean composition, color balance, and dynamic viewpoint. The long shot and overhead perspective simulated conventional photojournalistic framing often associated with objectivity or surveillance, contributing to its perceived newsworthiness.
By contrast, DeepAI images-such as the one in DeepAI(i)-appeared more literal, less refined in contrast and depth, and often lacked the lighting or compositional nuance found in real photojournalism. While these images might convey realism in a documentary sense, they were often perceived as less engaging, possibly due to their flat lighting, unclear focal points, or awkward rendering of physical spaces.
These differences suggest that aesthetic appeal in AI-generated images is not just about visual beauty, but about how closely a tool can simulate the visual grammar of visual journalism-such as framing, perspective, depth of field, and even symbolic readability. This has direct implications for journalism: tools that produce images with stronger “aesthetic realism” may be perceived as more credible or professional, even in the absence of actual photographic sourcing. Aesthetic appeal is not only a news value but a semiotic shortcut to perceived legitimacy-raising ethical concerns about the persuasive power of AI-generated images. Importantly, these aesthetic differences also reflect how each AI model has been trained. DALL-E’s broader training dataset and reinforcement learning from human feedback may contribute to more stylistically consistent images, while DeepAI’s outputs suggest a narrower or more literal interpretation of prompts. This means that the choice of model becomes a critical editorial decision: some tools may be better suited for stylized or emotionally evocative visuals, while others may foreground rawness or immediacy. Further research should explore how these aesthetic tendencies shape audience interpretation and whether they influence trust, empathy, or recall in news contexts.
Conclusions
This study examined how generative AI tools, specifically DALL-E and DeepAI, mimic journalistic image production through the discursive construction of news values. Using the DNVA framework, we analyzed the relationship between AI image outputs, text prompts, and users’ perceptions of newsworthiness across 10 news values. Although we do not claim that AI-generated visuals currently undermine audience trust, their alignment with news values raises concerns. AI-generated images might be mistaken by audiences as authentic news visuals, which has significant implications for the spread of misinformation (Thomson et al., 2025). Aligned with Thomson et al. (2025), we argue that while AI can mimic the visual form of journalistic news values, it can also mislead and foster misinformation in the absence of editorial oversight. The authors highlight that journalists may be reluctant to adopt such visuals precisely due to concerns over credibility, ethical representation and transparency. This underscores the need for further research on how audiences interpret synthetic images in real-settings, and the potential implications for misinformation and media trust. Rather than claiming that AI-generated visuals are credible, this study emphasizes their capacity to simulate discursive patterns-raising important questions for how AI-visual authority might be reshaped in the context of generative media.
In this regard, our results demonstrate that AI-generated visuals can reflect many of the stylistic and emotional features traditionally associated with news photography-particularly negativity, personalization, aesthetic appeal, and impact-when prompted with sufficient narrative and contextual detail. However, what these findings suggests is that what AI generates is not “news” but the appearance of newsworthiness. These systems do not apply editorial decisions, verify facts, or consider the professional processes of such representations. They rely on prompts that encode discursive cues-often unintentionally and can activate affordances aligned with journalistic news values. It is important to clarify that this study does not assume AI-generated images are equivalent to real-world photo visuals. Rather, our findings suggest that the discursive representation of journalism-its visual values and narrative-can be effectively reproduced by generative tools. Therefore, there are several implications that need to be addressed.
First, a key concern arising from this is the erosion of editorial gatekeeping. If AI tools can mimic the visual logic of journalism-especially in conflict reporting -they may normalize synthetic content in places where accuracy, sourcing, and representational integrity are most vital. For instance, images depicting premature babies being rescued, while emotionally resonant, may contradict the realities on the ground. In such cases, AI tools do not merely reflect news values-they can misrepresent lived experiences under the guise of journalistic ideals, potentially shaping public understanding based on fiction. The variability in aesthetic realism across tools (e.g., DALL-E vs DeepAI) further highlights how some AI models may be better at simulating newsworhiness, not because they are more truthful, but because they produce visually familiar styles aligned with audience expectations of what ‘news’ should look like. This underscores the political significance of aesthetic choices: a visually pleasing image is not necessarily a trustworthy one but may nonetheless be perceived as more professional and persuasive.
Second, the ability of AI systems to replicate the aesthetic and narrative conventions of visual journalism carries significant political and ethical implications. While tools like DALL-E can simulate journalistic aesthetics and news values (impact, personalization), the key issue is what this simulation enables. The political significance of AIGC is not just that it can generate “news-like” images, but that it can do so without the institutional and ethical accountability that underpins professional journalism. When AI tools reproduce the visual grammar of news-through balanced composition, emotional resonance, or realism-they also risk producing synthetic narratives that appear credible but are untethered from reporting, verification, or consent. If images can look “newsworthy” without being produced by journalists, what becomes of the gatekeeping function of editors and photojournalists? As newsrooms adopt AIGC, the question is not only which tools are more aesthetically effective, but also how these tools might reshape the boundaries of journalistic practice. In this context, the aesthetics of AI-generated images are not merely a matter of style or appeal-they are semiotic performances that may obscure the absence of actual journalistic processes. While this may take place, at the same time we recognize that concepts such as authority and credibility are not fixed traits of images or producers, but socially negotiated between journalists, institutions, and audiences. As Carlson (2017) argues, journalistic authority is something that must be continually constructed and asserted, yet it does not guarantee audience trust or credibility. This raises important questions about who gets to “perform” journalism and how audiences are expected to distinguish between synthetic news narratives and those rooted in reporting and verification.
Third, while GenAI tools can simulate newsworthy visuals, they do not invent news values independently. Instead, they reproduce familiar cues drawn from journalistic routines and platform logics such as virality, emotional intensity, and visual clarity. As Laba (2024) notes, these systems amplify hegemonic representational themes, reinforcing dominant ways of seeing crises-often through stylized or emotionally charged imagery. Our findings show that AI visuals frequently reproduce familiar visual codes-war as rubble, suffering as babies, protest as flags-relying on tropes that align with journalistic aesthetics. Consequently, complex events are flattened into easily recognizable narratives, reflecting algorithmic and aesthetic biases. These patterns reinforce a narrow visual grammar that simplifies conflict and crisis. The news values most reproduced-negativity, personalization, and aesthetic appeal-closely mirror dominant representational choices, revealing a convergence between algorithmic affordances and established journalistic norms (Papa and Kouros, 2023). Future research should further examine how AI-generated imagery is shaped not only by prompt engineering and user inputs but also by the composition and provenance of training datasets, insofar as this can be studied.
While this study centers on the discursive construction of news values, the findings also carry material and normative implications. The capacity of AI tools to generate news-like images may disrupt newsroom routines, reducing reliance on professional photojournalists and reshaping editorial processes-issues tied to broader debates on the platformisation of news. It also raises labor concerns noted by Thomson et al. (2025), as journalists fear job losses and AI-driven staff reductions. Moreover, the growing use of synthetic imagery challenges journalism’s normative role as a truth-oriented public service. If such images circulate without transparent sourcing, they risk undermining journalism’s legitimacy and raising ethical concerns.
While our findings highlight that AI-generated visuals can simulate journalistic news values, we did not examine how these images are circulated or received by audiences. The pathway from AI image creation to audience interpretation remains an open area for future research. Understanding this process is vital for assessing implications for misinformation, trust, and credibility in visual journalism. Therefore, a key limitation of this study is its participant sample of final-year journalism students. While their media literacy offers valuable insights, it may not reflect how broader publics perceive AI-generated images. Our participant sample, composed of journalism students, may possess media literacy and thus interpret “newsworthiness” in ways aligned with professional norms. Future research should include more diverse audiences to explore variations in perceived newsworthiness, credibility, and realism across cultural contexts, media trust levels, and digital literacy, as well as how such visuals circulate across platforms.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical considerations
This article does not contain any studies with human or animal participants.
Data Availability Statement
The dataset will be available for downloading after sending a request to the corresponding author.