
Abstract
Political communication research centers the definition of news around institutions and norms tied to professional journalism. However, qualitative audience research increasingly shows that this approach does not match the reality of citizens anymore – news has become a much more fluid, fragmented concept than just what has been produced by journalists. Not accounting for these changes means that researchers are missing out on important sources of political information, potentially leading to biased estimates of exposure. This is especially true in the area of digital trace studies in which researchers are faced with an abundance of detailed data but so far mostly limited their analyses to lists of popular news outlets to research political information exposure. The aim of this paper is threefold: Conceptually, we propose to combine existing conceptualizations of news into a taxonomy of news. Methodologically, we apply this taxonomy to classify domains in digital trace data of Dutch users, showing its applicability to study changes in information environments on a larger, quantitative scale. Empirically, we show the extent to which a focus on general interest newsroom journalism leads to distortions and blind spots in news diversity research. Our results show that there is much to be found when zooming in on the long tail of news, outside of larger newsroom journalism sources. In particular for the study of news diversity and media effects, throwing away part of the data for research-practical purposes leads to missing the nuances that might just be of interest.
Keywords
Introduction
“The term news is a primitive construct - one that requires no definition in ordinary conversation, because everyone knows what it is. (…) When asked to define a primitive term, it is difficult to do so without using the term in the definition.” (Shoemaker, 2006, p. 105).
When defining news in political communication research, the “news democracy narrative” (Woodstock, 2014) is dominant, which entails that news is concerned with politics, and aimed at values such as objectivity, accuracy, impartiality, and balance. However, especially qualitatively oriented research increasingly shows that this conceptualization centered around institutions and norms does not match the reality of citizens anymore (Edgerly and Vraga, 2020; Kümpel, 2020; Swart and Broersma, 2023; Swart et al., 2017). In a high-choice environment, news can be produced in a newsroom (written by journalists) but also increasingly outside of it (blogs, citizen journalism). The amount of different sources and platforms that provide new information has exploded, making it more difficult for both users and researchers to draw a line of what constitutes news and what not.
This mismatch between thinking about news in a professional general news reporting-democracy narrative and the everyday search for and exposure to information by citizens leads to challenges for media research. Focusing on only political news written by journalists for established outlets can lead to a misrepresentation of distributions of news sources and topics: When only a specific type of sources are included, no full overview of the information users are exposed to and the structures it was produced in can be given, leading to biased estimates of news exposure – the beginning of the causal chain of influences from media content to effects. Treating news outlets and political information as quasi-equivalent can lead to both over- and underestimation of exposure to political content (Wojcieszak et al., 2024): Politics can be encountered on non-news websites (e.g. tech blogs explaining privacy regulations) while news websites do not only serve (political) news content. These biases are especially relevant to media diversity research: When trying to estimate whether people are exposed to a diverse range of actors, topics, and perspectives by different sources, we need a comprehensive overview of all sources and content someone encounters.
We thus advocate taking a broad perspective to give more nuance and validity to the study of diversity in news consumption. The taxonomy of news we develop in this article defines news as concerning new information which further can be classified into four different categories based on sender and content characteristics which are rooted in existing research in journalism studies, communication science, and audience-centered research (Edgerly and Vraga, 2020). By also drawing from a social understanding of news as something new and useful for the individual (Kümpel, 2022b), our taxonomy aims at closing the gap between normative ideas on what news should be and real-life experiences of what news is.
In a second step, we apply our proposed conceptualization of news to digital trace data. Often, trace data are viewed as “unbiased” data that show behavioral traces less affected by issues plaguing survey research (Parry et al., 2021). However, the sheer amount of data also poses an increasing challenge for researchers to divide relevant from irrelevant visits. Usually this is done via lists of known news websites – which represent professional general news reporting, national-level outlets mirroring a narrow definition of news.
By applying our broader definition to trace data we investigate whether this approach leads to missing out on important data and to introducing concrete biases with regards to the diversity of sources and content in analyses. Additionally, when examining the content closer we can gather further evidence on the relevance of political content on different types of news (-related) platforms. Prior research has explored political information outside traditional news sources (Edgerly and Vraga, 2020; Wojcieszak et al., 2024). Our study expands this by applying a broader taxonomy to trace data, offering a comprehensive view of users’ news exposure.
The aim of this article is threefold: Conceptually, we propose to combine existing conceptualizations of news into a taxonomy of news. Methodologically, we apply this taxonomy to classify domains in digital trace data (browsing histories) of Dutch users, showing its applicability to study changes in information environments on a larger, quantitative scale. Empirically, we show the extent to which a focus on general interest professional general news reporting leads to distortions and blind spots in news diversity research. Although the sample size is limited due to the nature of data donation and the complexity of synchronizing browsing history, it provides an essential exploratory insight into the patterns of online news consumption, which can inform larger-scale future studies.
Theory
Reconceptualizing news
As Shoemaker (2006) pointed out, news is a basic concept that often is seen as warranting no further explanation. But researchers studying media content often need clear rules to distinguish news from non-news. The basic condition to decide between news and non-news is that it has to have an element of novelty to it: providing new information, being recent (Harcup & O’Neill, 2001). This does not imply that every article in an outlet has to be breaking news, as editorials and background reporting are also part of news. Still, the main purpose of a news outlet is to deliver new information, to set the agenda, and sound the “burglar alarm” (Zaller, 2003) in case important events are unfolding. News definitions that originate in the field of journalism studies tend to be focussed on journalism as institution and producer of news. In contrast, communication research in general often focuses on the content and, lastly, audience research is more aimed at the receiver perspective (Swart and Broersma, 2023). Firstly, journalism research often defines news as content produced by professional journalists or media outlets, while citizen journalism introduces amateurs as news producers (Örnebring, 2013). Many studies focus on content from professional outlets (Deuze and Witschge, 2018). Secondly, from a communication science perspective an item can be defined as news via its content. This includes approaches that extract and analyze sets of news values, including range, relevance or negativity (e.g., Galtung and Ruge, 1965; Harcup & O’Neill, 2001, 2017). Others classify an item’s topic to define what news is or to categorize different types of news such as “hard news” and “soft news” – a distinction that has become less distinct in the last few years due to the blurring genres, leading to hybrid constructs such as “infotainment”. Studies on news repertoires have indeed shown that one defining feature for distinguishing news outlets is based on content-features: News outlets can be general-interest news or special-interest news (Mangold et al., 2021).
Thirdly, the audience research strategy is aimed at the receiver: Here, news is something very individual, namely what a person perceives as news and relevant information. This can lead to very different definitions of “news-ness” (Edgerly and Vraga, 2020) and suggests to look at broad information repertoires that help users to make sense of the world, so-called news-related information as part of larger media repertoires (Schmidt et al., 2019; Schrøder, 2015). It has been shown that people use pathways to news that include search engines, Wikipedia, social media, interpersonal channels, and media traditionally not seen as news (Peters et al., 2022; Swart and Broersma, 2023). News is understood heterogeneously, going beyond originators, channels, and functions of news as traditionally used in journalism studies (Schneiders, 2023). These insights from predominantly qualitative audience research are challenging to incorporate into more large-scale investigations of news diets as these by default require more top-down approaches. However, these qualitative studies convincingly show that the definition of news needs to be broad enough to include said gray zones such as social media and search engines. Naturally, most of the things done on these platforms will not be related to news (Merten et al., 2022). However, the idea behind including them into a conceptualization of news nonetheless is to cast a net as broad as possible to identify all things that could potentially be news to audiences. Through this we further build on previous work which showed that (political) news can be found outside of more traditional news websites (Wojcieszak et al., 2024) but give a more detailed, theoretically grounded insight into these “non-news” places. This approach could also be used as pre-filtering before going into the data in more detail with a manual or more complex (semi-)automated approach or to examine it in collaboration with the audience (i.e. the person that donated the data; Welbers et al., 2024) to see their perspective on the news-ness of certain content or platforms.
A new(s) taxonomy
By combining the sender, content, and receiver perspective, we derive several different categories of outlets or platforms providing news and news-related information, as depicted in Figure 1. We define that news provides new information which distinguishes it from news-related information and non-news. We further propose four different kinds of news based on professionalism of the sender and the topical focus. The topical focus is either special interest (e.g. sports, entertainment) or general interest. However, politics is not placed in the special interest category but declared as general interest to stress that it has a broader applicability and societal relevance rather than other, more special interest topics (which also corresponds to audience perceptions of news-ness, Edgerly and Vraga, 2020). We do not use the terms “hard” and “soft” news to express that a general interest news outlet can encompass elements of both hard and soft news topics (e.g. sports and politics). The labels of the different categories can be seen as representing prototypical examples, not necessarily all-encompassing for all outlets that can be found in the category. Different types of news and news-related information.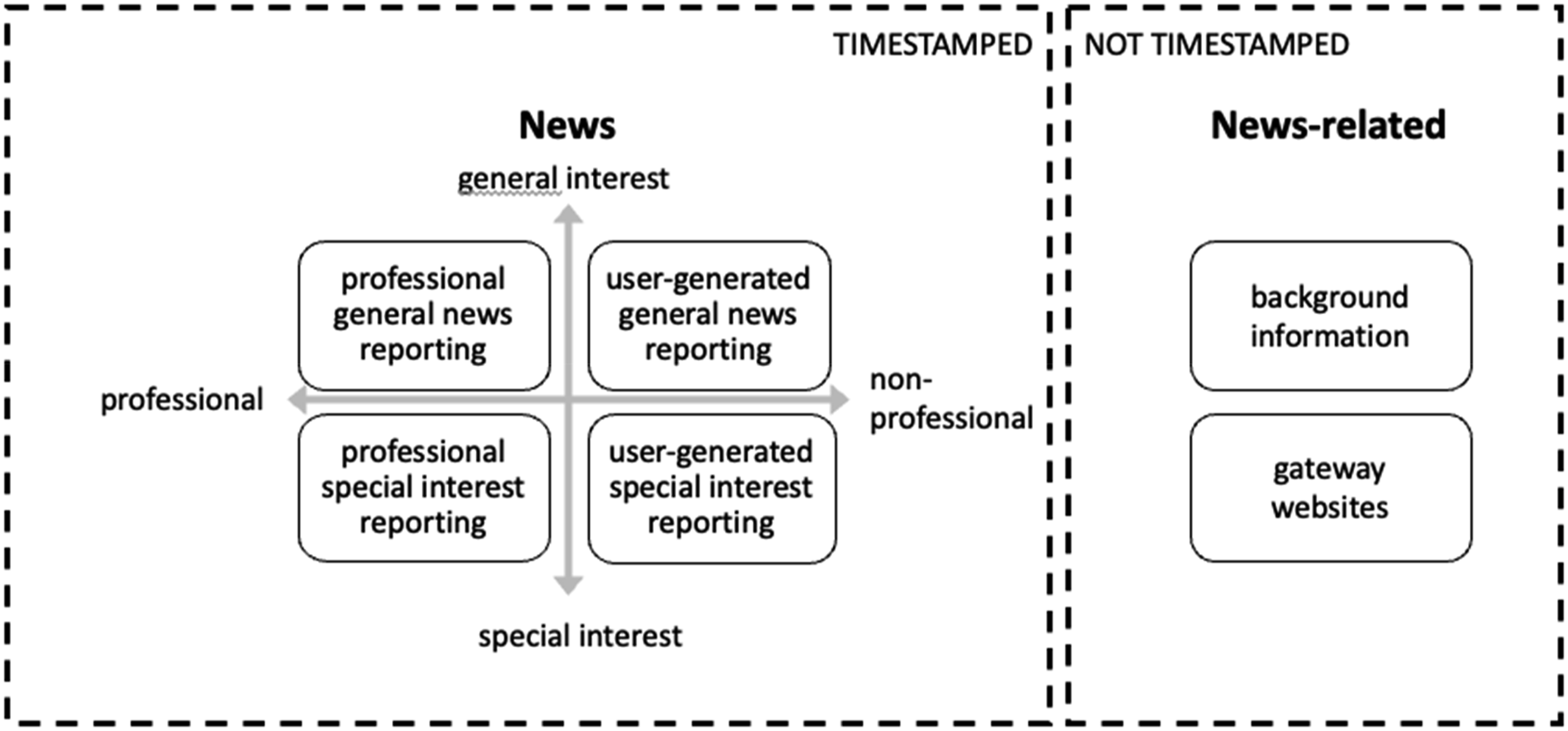
The first category (professional general news reporting) is the “classical” news often in the focus of political communication research, sometimes extended to the second category, professional special interest reporting (e.g. sports news). Category three is produced outside of professional structures by amateurs but still concerned with general interest news or politics (user-generated general news reporting) while the last category (user-generated special interest reporting) are special interest user-generated news which are usually not included in studies on news usage. The distinction between professional general news reporting and user-generated general news reporting websites can sometimes be fuzzy – with outlets of individuals being picked up by larger media companies; websites of individual users relying on external content produced by other sources with little curation; or blog-like publications run by professional newsrooms. Lastly, we further widen our conceptualization to also include news-related information. This includes websites providing background information (encyclopedias, websites of politicians). In our taxonomy, we define social media and search engines as ‘gateway websites'—platforms that do not primarily produce news content, but act as conduits through which users may access news, either intentionally or incidentally. While political information may be encountered on these platforms (Peters et al., 2022), they should not be categorized alongside traditional news outlets, which are dedicated to producing news content.
Consequences of excluding non-newsroom news
In the following, we investigate the role of the different types of news and news-related information in the information diet of users and how not including them in analyses can contribute to misrepresentations of sources, content, and users.
Misrepresenting sources providing the news
To what extent users are getting their information from different places has been a key concern in media diversity research. Even before thinking about what users are seeing, questions of structural diversity – the diversity of who supplies the information and the organizational context they are embedded in (Loecherbach et al., 2020) help in understanding potential shortcomings in news exposure to different content (actors, viewpoints, topics). But which sources should we look at when examining those structures to get a precise overview? Most research to date focuses on professional general news reporting. Specifically, the focus is put on larger and national news outlets that have the highest audience shares. This is especially true for digital trace data research which is faced with large amounts of data that need to be analyzed and categorized. Traditionally, lists of news outlets have been determined by using the Alexa top 500/1000, annotating the top n domains in the sample (Stier et al., 2020), accounting for the skewed distribution of Web site visits. However, when thinking more about the individual level, current trace studies often do not capture regional and (hyper-)local outlets visited by individuals (for a notable exception see Wojcieszak et al., 2024). Due to the focus on allow and block lists of the most popular outlets that are pre-defined as news, smaller outlets are missed. This might pose an issue especially when researching the diversity of sources accessed by users. To better investigate the diversity of accessed news sources in a person’s media diet, the long tail smaller professional general news reporting outlets focussed on the local and regional level needs to be examined. These websites usually do not make it on lists due to drawing less traffic or only being present in the trace data of one or two participants in a given sample. Two aspects of measurement come into play here, focussing on the structural rather than on the content level: variety and disparity (Stirling, 2007). While variety expresses how many different domains have been visited, disparity aims at the extent to which the domains are distinct from each other regarding for example their ownership.
While at first it seems obvious that local and regional news adds to both variety and disparity, several aspects come into place that might diminish the positive effect on structural diversity: Studies observe a growing concentration of online traffic and content. Online media usage is often much less fragmented than expected with high overlaps in audiences (Fletcher and Nielsen, 2017; Loecherbach et al., 2020). Additionally, the online news media market is often equally or even more concentrated than the offline media market, meaning that many domains belong to the same owner (Hendrickx, 2020).
It is thus not clear whether focussing on larger, national news outlets on allow lists indeed poses an issue for online diversity research and whether anything of importance is missed by leaving out these smaller outlets from analyses. We therefore ask: RQ1: To what extent do small news websites (on local and regional level) contribute to the diversity of consumed outlets of people’s online media diets with regard to variety and disparity?
Misrepresenting exposure to political content
One of the central questions in political communication research is to what extent citizens are exposed to political information. The ideal picture of the “informed citizen” has been discussed and challenged in the last few decades (Delli Carpini, 2000). Assuming that people have the motivation and resources to seek out news has been proven to be a rather theoretical assumption in light of low levels of news usage and even the turn to active news avoidance (Palmer and Toff, 2020). One possible solution for closing gaps between news-seeking citizens and those who are less interested in news was proposed by looking more at incidental exposure (Tewksbury et al., 2001). Incidental news exposure happens when users are seeing news while having a different usage motive (e.g. being entertained) or being engaged in a different activity (e.g. scrolling social media, Kümpel, 2022a). Online, incidental exposure is usually studied as finding stories from professional general news reporting providers via a social media platform (Kümpel, 2022a). In many cases, surveys are used to measure social media news usage, equaling incidental exposure with self-reports of seeing professional general news reporting on social media platforms (Park and Kaye, 2020), though there are also examples of conceptualizing and measuring the phenomenon more openly as accidentally encountering information online (Weeks et al., 2017).
This means that most studies on exposure to news via social media use rather narrow definitions of what news is – coming across a link to a professional general news reporting outlet in a different context is seen as incidental exposure. However, a lot of exposure to other forms of news might not be sufficiently captured by this approach. Incidental exposure to (political) news that shapes attitudes and opinions on current topics can easily happen via channels with a different main purpose (Wojcieszak et al., 2024). For instance, in providing infotainment, celebrity news websites might be covering stars getting vaccines – which has been shown to be more effective in changing opinions on vaccines than government information (Honora et al., 2022). These encounters might not happen very frequently. However, it can be argued that through the connection to a particular special interest, the personal relevance of the content is heightened (e.g. new privacy regulations applying to me as tech consumer), which could in contrast to “regular” incidental exposure lead to more systematic, in-depth processing and through this more lasting effects on opinions and knowledge (Wieland and Kleinen-Königslöw, 2020). This means that by tying the idea of incidental exposure to links to professional general news reporting domains on social media researchers could lose out on truly incidental encounters. However, before thinking about potential effects on political knowledge and attitudes, we should assess how common the phenomenon of coming across political information on websites other than professional general news reporting actually is. Earlier research looked at the prevalence of political content outside of lists of defined news more broadly (Wojcieszak et al., 2024) while our focus is on mapping political content to the different types of news identified in our news taxonomy. This allows us to further understand the news environment and sourcing practices of individuals. Therefore, we ask: RQ2: How prevalent is political content in the four different types of news?
Methods
Sample
To answer the questions above, trace data were collected from Dutch users making use of data donation of browsing histories (Welbers et al., 2024, more information in Supplement C) using a commercial panel provider sampling from the general Dutch population. In an initial wave, 425 participants were asked to give information on their device and browser usage. In a next step, when possible 1 they were instructed to set up synchronization of their mobile and desktop browsing and turn off private browsing to include as much of their browsing behavior as possible in the dataset and standardize the data input across participants. After this, they received questions on news consumption, habitual news usage (Diddi and LaRose, 2006), political attitudes, and trust, concluding wave one. Two weeks later, respondents were contacted to upload their synched browsing histories. They received instructions on how to locate their browsing history on their own device and upload it into an interface that allowed for visualization of their data and deletion of unwanted elements locally before upload (Araujo et al., 2022). Of 385 users in the second wave, 162 successfully uploaded their browsing history, and 100 synced both desktop and mobile histories 2 . Further information on the sample can be found in Supplement C, the survey items can be found in Supplement A.
Trace data
Initially, 5,333,226 visits to 120,408 different domains 3 were collected – however, the data were reduced to the last 3 months as this at the time was the time limit for Chrome browsing histories (largest data source), leading to 3,320,266 visits to 86,383 distinct domains. In the following, two steps were used to reduce the noise in the dataset: (1) automatically checking whether valid DNS settings could be found; and (2) training a classifier as explained in Faroughi et al. (2021) to split the dataset in core and support domains. Support domains are pages that most likely have not been intentionally visited by users (such as pop-ups, redirects), anything not classified as support domain is seen as core domain. The first step reduced the dataset to 3,216,170 visits to 37,703 domains. The second step used three variables: A dummy variable indicating whether the length of the content returned by the requests module is above 5000 characters 4 , a dummy variable whether a redirect code 302 is included in the redirection history of the domain and, lastly, the amount of non-alphanumeric characters in the domain name. Based on these variables, a binomial GLM classifier was trained to split the dataset into core and support domains. 500 domains were manually annotated for validation (250 core/support each), showing an accuracy of 0.87 (recallcore: 0.97, precisioncore: 0.76). After applying the classifier to the whole dataset, 1,664,039 visits to 23,954 domains remain. Thus, in total, 50% of the visits and 73% of the domains could be removed automatically as noise from the dataset.
Manual coding
After the automated removal, all 23,954 remaining domains were manually annotated by the first author and a student coder after two rounds of coder training. The coder first verified whether the Web site provided new information based on recent updates. While this is a simplified measure, it helps identify relevant content. For all domains providing new information, professionalism (information about editorial office present), topical focus (presence of different news categories) and geographical focus were coded. This information was used to put the websites into the four identified news categories. If the domain did not provide new information, it could still be classified as either background information or gateway Web site. A random sample of 1000 domains was coded by both coders, showing high intercoder reliability for the decision whether a Web site is primarily about news (Cohens κ = 0.897 after removing non-accessible websites), as well as for professionalism (κ = 0.766) and topical focus (κ = 0.836). For news-related information, only a few instances could be found in the random sample – nonetheless for background information sufficient reliability was achieved (κ =0 .704) and all three gateway websites were correctly indicated by both coders. Overall, this shows that the translation of abstract news conceptualizations into a reliable, easy to use coding scheme was successful. The complete codebook can be found in Supplement B. In addition, information about the ownership of all outlets identified as professional news outlets was obtained through several sources such as the Euromedia Ownership Monitor 5 to allow for a closer inspection of structural diversity features.
Content
For analyzing the content, a classifier for political information 6 (Wojcieszak et al., 2023) was applied to the titles of the Web site visits. For this, visits to home pages (i.e. without a path) were excluded, as they do not give any information about the content on the particular page but rather a general description of the Web site 7 . For 6.3% of visits no title was given in the data, ultimately 56,933 visits to 28,666 distinct URLs were included in the analysis of which percentage of content can be classified as political per Web site category. A set of 500 URLs was manually annotated for validation (precisionpol: 0.78, recallpol: 0.76, F1 score: 0.75), showing that the existing classifier can be applied to this dataset.
Results
The online news diet
We first examine the relative importance of the different categories for the online news diet. Figure 2 gives an overview of the distributions for distinct domains and visits. The largest part of browsing histories is not related to news – 93.7% of the annotated domains are not classified as belonging to any of the news or news-related categories. In total exactly 1000 news domains were identified (4.4%) and 432 news-related websites (1.8%). When looking at the amount of visits as opposed to the amount of domains (rather indicating actual usage), the picture changes slightly: Less than two thirds (61.8%) of visits are not classified into any of the news and news-related categories. This is in large part due to the news-related websites, particularly gateway websites (social media, search engines) which are drawing a large amount of traffic. A third (33%) of all online visits are to gateway websites. Among those the most popular are Google, YouTube, Reddit, Facebook, Instagram, Twitter, and Linkedin that all attracted over 10,000 visits. The overall proportion of visits to news websites remains stable (4.4%). However, we can see that professional general news reporting sources are by far drawing the most traffic, 3.9% of all visits are to these websites, all other kinds of news amount in total to 0.5% of the web traffic. On the person-level, there is quite some variation among users with some spending 50% of their visits on professional general news reporting general interest news websites or up to 20% on background information websites. Still, we can conclude that on the average the results mirror those of earlier studies: Most of the Internet is not connected to news or political information. Additionally, we see that gateway websites account for a lot of traffic, stressing their importance in the process of accessing information online and professional general news reporting continues to play a role – while other forms of news play only a marginal role on the aggregate. Amount of domains and visits per Web site category. The sub-category “Other news types” includes user-generated reporting (general and special interest) and professional special interest reporting.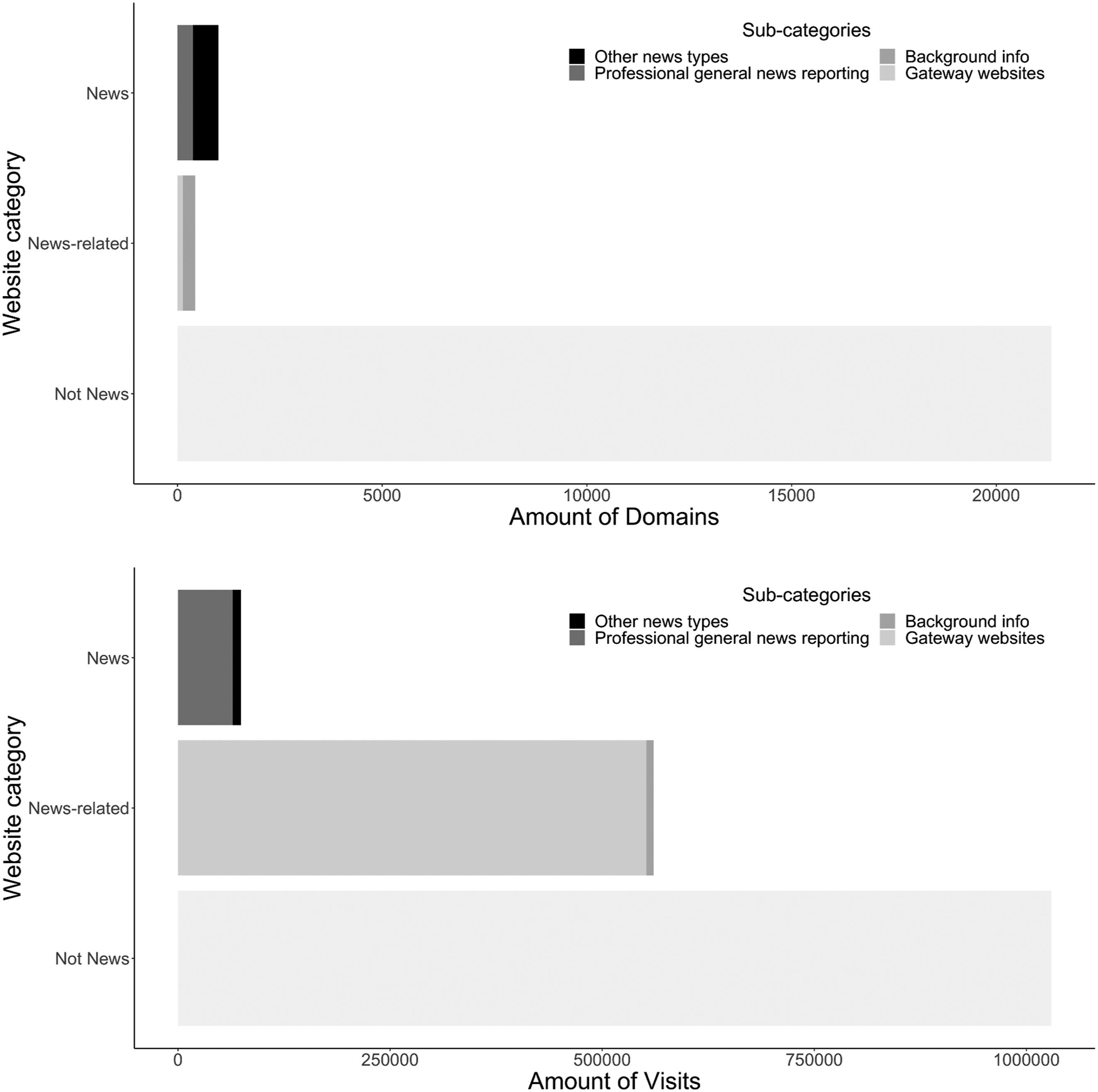
Smaller sources
The first research question zooms in on professional general news reporting visits and is concerned with the contribution of smaller news outlets (local and regional focus) to the structural diversity of news users. On the diversity dimension of variety (how many outlets?) Figure 3 shows that local and regional news outlets account for about 20% of the visits to professional general news reporting domains. The amount of local and regional domains is almost equal to national domains (157 national, 143 local). This pattern indicates that a lot of different local/regional outlets are visited but they are not frequently visited (M = 87 local visits vs M = 304 national visits). When concentrating on the person-level, local and regional news outlets add on average 129 visits (SD = 424) and 5.4 news sources (SD = 5.39) to the media diet of a user on top of national and international sources. Amount of domains and visits to professional general news reporting sources per geographical focus category (local/regional, national, international). Additionally, information on the ownership of national and local news is given.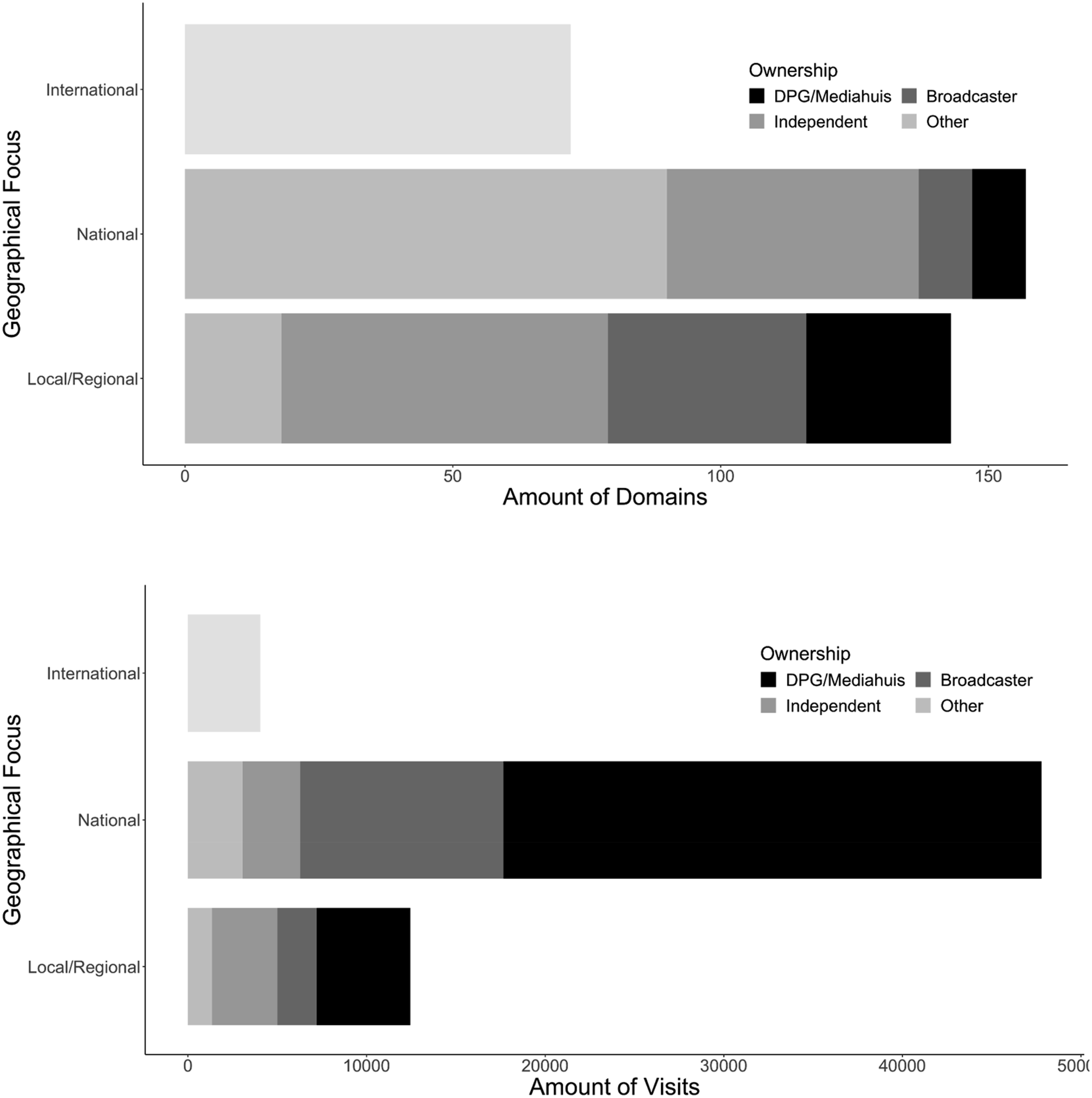
Looking at the disparity dimension of diversity, taking into account the ownership of the different outlets reveals somewhat of a diversity in name only: A large proportion of visits to local and regional news outlets are to websites that belong to DPG media and Mediahuis, two large Belgian news companies. As Figure 3 shows, the largest proportion of local news goes to outlets owned by those two companies (42%), followed by visits to independently owned newspapers (example: de-zuidwester. nl, regio15. nl, 29.5%) and public broadcasting stations (example: at5. nl, omroepbrabant. nl, 17.7%). The remaining 10% of the visits are to news websites owned by non-news companies such as consultancies. Thus, while most of the local and regional domains are from small owners (43%) they fail to draw much traffic, being surpassed by the outlets belonging to larger media companies. The same picture can be found for the national market. In addition to this, a common phenomenon are also visits to the regional sections of the national newspapers (e.g. ad. nl/amsterdam). About 8% of the visits to these outlets are to the regional sections, further replacing the smaller, independent outlets.
Overall, this shows that local and regional news still make up a substantial part of news domains visited and add to individual news diets. However, they fail to draw much traffic. Comparatively better off are outlets that belong to larger media conglomerates, while local publishers and public broadcasting struggle to attract users.
Political content in different news types
The second research question is aimed at the amount of political content in different types of news. The results of applying the political content classifier on the titles of all visits to the different types of news and background information websites show that all types of websites include political content. The category with the highest share of political visits are user-generated general news reporting websites – 44% of visits to this category are related to politics. A quarter of professional general news reporting outlets visits are political (23.2%), followed by background information (19.7%), professional special interest reporting (6.7%) and user-generated special interest reporting (4.5%). Especially the share for the professional and user-generated special interest reporting websites is interesting – as the definition of these Web site categories specifically excluded a focus on politics. Examples for websites that still include political content are tech news websites that discuss student protests 8 or entertainment and beauty websites that discuss political citizen initiatives 9 . Looking at the general interest outlets, user-generated outlets show a higher amount of political content than professional general news reporting – although for both fewer visits are to political content than to non-political content. About a quarter of visits to what is generally defined as news websites is concerned with political information.
Discussion
We set out with three goals: Developing a broad taxonomy for news by combining existing categorizations, operationalizing this taxonomy to be applied on a larger scale to digital trace data, and lastly giving a blueprint on how to investigate potential biases that occur when only focusing on larger, professional general news reporting outlets.
The developed taxonomy incorporates insights that have been gained from different frameworks on what news is. The definition of what to label as news is widened to also include outlets that are produced by non-professionals and that are aimed at special interests. Furthermore, the information repertoire perspective at the center of qualitative contributions to this field is acknowledged by explicitly including news-related information in the taxonomy. Overall, our conceptualization addresses the growing gap between conventional academic research and user experiences: Both due to normative (news-democracy narrative) and research-practical (too much data) reasons, quantitative research so far has mostly represented only part of the news experiences users report in audience studies.
Going one step further, we provide researchers with an example of a complete empirical workflow on how to apply such a taxonomy to digital trace data. We combine several techniques to filter out large parts of irrelevant visits from the dataset. This set of steps can be replicated without many resources, only few manual annotations for validation purposes are needed. This is followed by a codebook that operationalized the abstract conceptualization into a workflow with clearly defined steps that proved to be highly reliable after a short amount of training time, showing the actual practical merit of the conceptualization.
The empirical results first of all reveal that – similar to many other studies (Stier et al., 2020) only a small amount of Web site visits are related to news domains. Of these news domains, a sizable amount is to local and regional outlets that often do not find their way into allow lists – but only the ones connected to larger media conglomerates can still draw traffic. Zooming in on content, we found that users do come across political content in unexpected or less-examined places while vice versa less than a third of the visits to professional general news reporting sources are related to political content, further expanding on earlier results (Wojcieszak et al., 2024).
For researchers these results mean that it very much depends on the research interest whether it is worth the effort to go into the long tail of news to avoid biases in the data analysis: If the focus is on aggregate effects, sources as local news and user-generated general news reporting will not play much of a role due to the neglectable share of visits. Trying to make lists as exhausting as possible (e.g. Baluff et al., 2022) will serve the research purpose without missing out on too much information. Indeed, as pointed out by Clemm von Hohenberg et al. (2024), for many research fields it is non-consequential to ignore the long tail of domains. However, when the focus is much more on individual user (group)s, media diets or diversity, results might be distorted when not looking deeper. Especially considering that younger generations show less connections with news brands and their websites than ever before, accessing news via different pathways (Newman et al., 2023), we should continue to keep an eye on alternative conceptualizations of news and which role they play for different audiences. On the upside, applying the current list to a larger dataset collected for a different study showed that 80% of domains could be identified.
For researchers interested in media effects especially among the traditionally less politically interested segments of the population it is furthermore not enough to stop at the outlet level for understanding news exposure as users are confronted with politics in contexts that are not primarily about politics. Although these encounters are not very frequent, the connection to relevant topics and trusted figures (actors, influencers) could lead to a higher influence on shaping attitudes and knowledge. Future studies should investigate whether indeed effects of coming across political content on non-political news websites can be found. Likewise, the results also show that just treating all visits to professional general news reporting outlets as important for the political opinion formation as is often done by just taking the overall amount of visits as indication for political (ly relevant) news consumption is a clear overestimation of political news exposure. Being precise about our estimates of exposure (as trace data allows us to be) should be done by looking closer at the outlets that are excluded out of normative or research-practical reasons.
We set out to analyze online news consumption more in detail than most other studies did so far. However, some issues remain: Firstly, many data sources are not included: other devices, other browsers, news consumed using smartphone applications, and the content of social media feeds. Probably from all of these other sources most of the content will again be not news-related but still adding up to quite some more news content than could be captured in this study. Getting a full overview of the online diet across all devices and platforms still remains a challenging endeavor. Additionally, the sample of our study is small and with certain characteristics data donation studies typically suffer from (such as higher education, younger) and thus should be interpreted with caution. Nonetheless, the empirical results of our research match those of larger, more representative studies in the Netherlands and similar countries (Stier et al., 2020; Wojcieszak et al., 2024) and we provide a detailed blueprint for other researchers on how to apply alternative news categorizations.
Secondly, looking at the volume of visits still does not tell much about the quality of visits. The dataset collected in this study does not give any indication on time spent on a Web site and much less an indication of attention paid to a given Web site. It is fairly easy to amass many visits without much meaning. Additionally, more of our life moves online, generating many visits to various activities. Thus, even when the total amount of news visits stays the same or increases, it will represent a smaller share of our online life than before.
Lastly, we still do not have a good benchmark of what a “sufficient” share of news visits among all online visits would be. Considering that users still have many other ways of getting their news (offline media, interpersonal contact), at which point would we consider the amount to be right to be an informed citizen as envisioned in discussions on good and informed citizens (Delli Carpini, 2000)? Currently, about 5% of online visits are to news – which is a small proportion, but is it too small for staying informed? All these questions involve discussions on how much effort we think a citizen should have to make to get the information needed. Thinking more about concepts of monitorial citizens that hear the burglar alarm (Zaller, 2003), small proportions of news usage might not be enough to make you a political expert – but enough to pick up on the important issues of the day.
In conclusion, the empirical analysis showed that there is much to be found when zooming in on the long tail of news, outside of larger professional general news reporting sources. Media researchers studying news usage might be missing out on important parts of the picture by ignoring outlets outside of the traditional conceptualizations of news. In particular for the study of news diversity and media effects, throwing away part of the data for research-practical purposes leads to missing the nuances that might just be of interest. Looking at challenges we are currently facing (misinformation, news avoidance), considering what is going on beyond professional general news reporting sources will prove valuable. This article gives a handbook on how to approach the translation of a conceptualization of news into an empirical investigation.
Our approach broadens the scope of news sources studied (Schneiders, 2023; Swart and Broersma, 2023), but further research is needed to understand audience perceptions and effects using mixed-method designs. In next steps, we need to further integrate the description of digital trace data with the user perspective, for example combining qualitative work on news usage patterns (Groot Kormelink and Costera Meijer, 2018) with digital trace data. Through methodological approaches such as data donations the data can be visualized and used as a prompt for further analyses and interpretation. Additionally, we need to continue to invest work in collecting data across platforms, apps, and devices, capturing a better picture of the information diet users are confronted with. Especially combining online news consumption with more traditional news usage that still play a defining role for many citizens remains a challenge that requires substantial pooling of research resources in the future.
Supplemental Material
Supplemental Material - What is news? Mapping the diversity of news experiences in digital trace data
Supplemental Material for What is news? Mapping the diversity of news experiences in digital trace data by Felicia Loecherbach, Judith Moeller, Damian Trilling and Wouter van Atteveldt
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the NWO and the eScience center Joint eScience and Data Science grant (DTEC.2017.0).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.