
Abstract
This discussion paper aims to take stock of the main uses and critiques of topic modelling in studies that combine corpus linguistics and discourse analysis. Topic modelling is a cover term for a collection of semiautomated techniques that aim to analyse the content of texts. While the paper does not provide a complete synthesis of the use of topic modelling in corpus linguistics, it aims to give an overview of recent uses and critiques of topic modelling within corpus-based discourse analysis and related fields. Such recent uses include topic modelling for corpus exploration and combining topic modelling with other analytic techniques such as keywords analysis, showing an increasing engagement with topic modelling in corpus linguistic studies of discourse(s). However, the critiques levelled at topic modelling are not inconsiderable, although some researchers do see it as a strong and effective method. One conclusion from the research reviewed in this article is that topic modelling can be enhanced through the use of methods from both corpus linguistics and discourse analysis which can reduce some of its limitations. In this respect, it can be argued that linguists have a lot to offer to non-linguistic fields where topic modelling is widely used and that interdisciplinary collaborations could be a fruitful endeavour. The paper is accompanied by invited expert commentaries written by linguists with relevant experience in applying topic modelling. These commentaries provide further comment on its uses and critiques in relation to corpus-based discourse analysis, confirming, challenging, elaborating or extending the points made here. While this article primarily focuses on corpus-based discourse analysis, many of the points should also be of interest to scholars in other fields. Taken together, it is clear that continued exploration of and debate on topic modelling is a worthwhile endeavour, and that new technological developments necessitate such critical engagement.
Keywords
Introduction
Recent years have seen something of an increase in the use and evaluation of topic modelling (TM) as a technique for discourse studies and related fields. For example, in a previous issue of Discourse Studies, Brookes and McEnery (2019) critically evaluated whether TM can make a contribution to discourse studies, answering in the negative (as detailled further below). However, research on this topic has generally pointed out that linguistic studies using the method are still rare or in their infancy, that the use of TM is still being debated, and that continued discussion is valuable (see Busso et al., 2022: 233; Jaworska and Nanda, 2018: 396; Wang, 2022: 229). Thus, it is the aim of this short discussion paper to take stock of the main uses and critiques of TM, specifically in studies that combine corpus linguistics and discourse analysis (corpus-based discourse analysis; corpus-assisted discourse studies, corpus-based critical discourse analysis, etc). While this article primarily focuses on this field, most of the points should also be relevant to related areas such as corpus pragmatics, for example. In sum, this article does not aim to provide a complete synthesis of the use of TM in corpus linguistics or adjacent fields such as Digital Humanities and Computational Social Science, but rather aims to give an overview of the use and critiques of topic modelling within corpus-based discourse analysis (broadly defined). It consists of three sections: The first section briefly introduces TM, with a focus on how it functions rather than giving technical details. The next section then outlines the main uses to which TM has been put so far in the field. This is followed by a consideration of the main critiques that have been levelled at TM by relevant scholars. The discussion paper finishes with some concluding remarks and recommendations, and is accompanied by four invited expert comments.
What is topic modelling?
Topic modelling (TM) is a cover term that refers to a collection of methods and algorithms (Törnberg and Törnberg, 2016), and has been described as a semi-automated machine-learning technique that aims to analyse the content of texts (Grundmann, 2022: 396). TM can broadly be divided into supervised, seeded approaches with human intervention and unsupervised data-driven approaches (or a combination of an initial unsupervised, data-driven TM followed by a subsequent human-supervised TM). In essence, TM techniques retrieve a number of ‘topics’ from text collections (corpora), where a ‘topic’ refers to ‘clusters of words that co-occur according to certain probabilistic patterns’ (Busso et al., 2022: 232). In other words, ‘topic’ is used as a specialised term rather than how we might use it in everyday language or in discourse studies (Brookes and McEnery, 2019: 6–7; Jaworska and Nanda, 2018: 382; see for example van Dijk’s, 1977, 1980 work on propositional topics as semantic macrostructures). More precisely, ‘topics’ are lists of words which have a high probability of co-occurrence within a ‘span’ that is set by the researcher, but that is typically of hundreds or thousands of words. The co-occurrence, therefore, lies within a whole text, or a few paragraphs, but not within the short span used in studies of collocation. These groups of cooccurring words characterise ‘topics’, and researchers may choose to refer to them using topic-like titles, but these are only convenient abstractions from lists of words. (Murakami et al., 2017: 244)
TM is ‘a computer-assisted methodology’ (Busso et al., 2022: 232) and requires the input of the researcher, both in relation to the parameters used in retrieving topics and in how the retrieved topics are subsequently interpreted. For example, if researchers choose a larger number of topics this will result in more granular topics than if a smaller number is chosen (Murakami et al., 2017: 245). In fact, a number of different parameters and choices determine the outcome of TM. We will return to this issue when discussing critiques of topic modelling below.
Adapting points made by other scholars in the field, Gillings and Hardie (2023) suggest that there are four main assumptions behind TM:
The overall corpus, or collection, consists of a large number of documents.
A topic is a collection of words that have different probabilities of appearance across the documents.
Each document features [different] topics to varying degrees.
Underlying topics organize the collection, and there are a finite number of these topics.
(Gillings and Hardie, 2023: 531)
A further point is worth mentioning here: TM is what is called a ‘non-deterministic method’, which means that ‘the topics generated by the computer are subject to some degree of randomness and may be different each time the procedure is run’ (Brookes and McEnery, 2019: 5), unless a technique is used to allow reproduction of results by ‘fixing’ the random numbers that are used (Eduardo Altmann, p.c.).
As mentioned above, different methods or models of doing topic modelling exist and new methods continue to be developed. For example, Gerlach et al. (2018) and Hyland et al. (2021) propose an approach to topic modelling that is based on stochastic block models (see further https://topsbm.github.io/), which has been used in a Jupyter notebook (Chan and Altmann, 2024) recently developed by the Australian Text Analytics Platform (ATAP) team (www.atap.edu.au). However, most corpus linguistic studies mentioned in this article have either used Latent Dirichlet Allocation (Blei et al., 2003) or Structural Topic Modelling (Roberts et al., 2016). Latent Dirichlet Allocation is the most widely-used technique in the studies reviewed below (and also used in another ATAP notebook created by Schweinberger, 2024a), 1 while Structural Topic Modelling is a more recent technique which allows the modelling of topic variation according to external variables (Busso et al., 2022). A technical explanation of the computational and statistical processes involved in both techniques is beyond the scope of this article and can be found in the cited studies. For an accessible overview of TM for discourse analysts see further Brookes and McEnery (2019) and for a general non-technical review paper see Blei (2012). Further explanations of TM are also found in most of the publications that are cited in the reference list. An explicit comparison of TM with the corpus linguistic techniques of semantic tagging, keywords analysis, collocation networks and concgrams is offered by Murakami et al. (2017), while Gillings and Hardie (2023: 541) state that TM has the most in common with keyword analysis. The next section now outlines the main uses to which TM has been put so far in corpus-based discourse analysis (as broadly defined, i.e. including but not limited to corpus-based Critical Discourse Analysis) – taking both a chronological and a thematic approach in discussing such studies.
Uses of TM in corpus-based discourse analysis
It is not clear exactly what constitutes the earliest use of topic modelling in corpus-based discourse analysis, but Jaworska and Nanda (2018: 381) cite a talk by Lischinsky (2014) presented at Critical Approaches to Discourse Analysis across Disciplines (CADAAD, 2014) as using this technique, although this does not appear to have been published. In 2016, Anton and Petter Törnberg published an article in Discourse & Society (Törnberg and Törnberg, 2016). The scholars explicitly position their study of an internet forum as combining TM with Critical Discourse Analysis, focusing on the discussion of Islam and feminism. They use topics to retrieve ‘discursive fields’ (Törnberg and Törnberg, 2016: 408) in the forum combining this with CDA of associated documents, ‘as complementing steps in the analysis’ (Törnberg and Törnberg, 2016: 409). They argue that TM is useful when it is combined with other approaches which can offer ‘both theoretical depth and more elaborated analytical techniques for interpretation’ (Törnberg and Törnberg, 2016: 418).
Although (strictly speaking) not a discourse study, Murakami et al. (2017) proposed topic modelling as a new data-driven method for ‘initial scoping studies of a target corpus’ (Murakami et al., 2017: 244), as a ‘way of studying “aboutness”’ (Murakami et al., 2017: 245). In essence, the technique is used by these authors to identify different themes that may be present in a corpus. Thus, they retrieve 60 ‘topics’ in their 4.1 million word corpus of 675 research papers from the journal Global Environmental Change, including their distribution across sections within papers and over time. Thompson and Hunston (2019: 216–241) present a similar investigation of a different corpus.
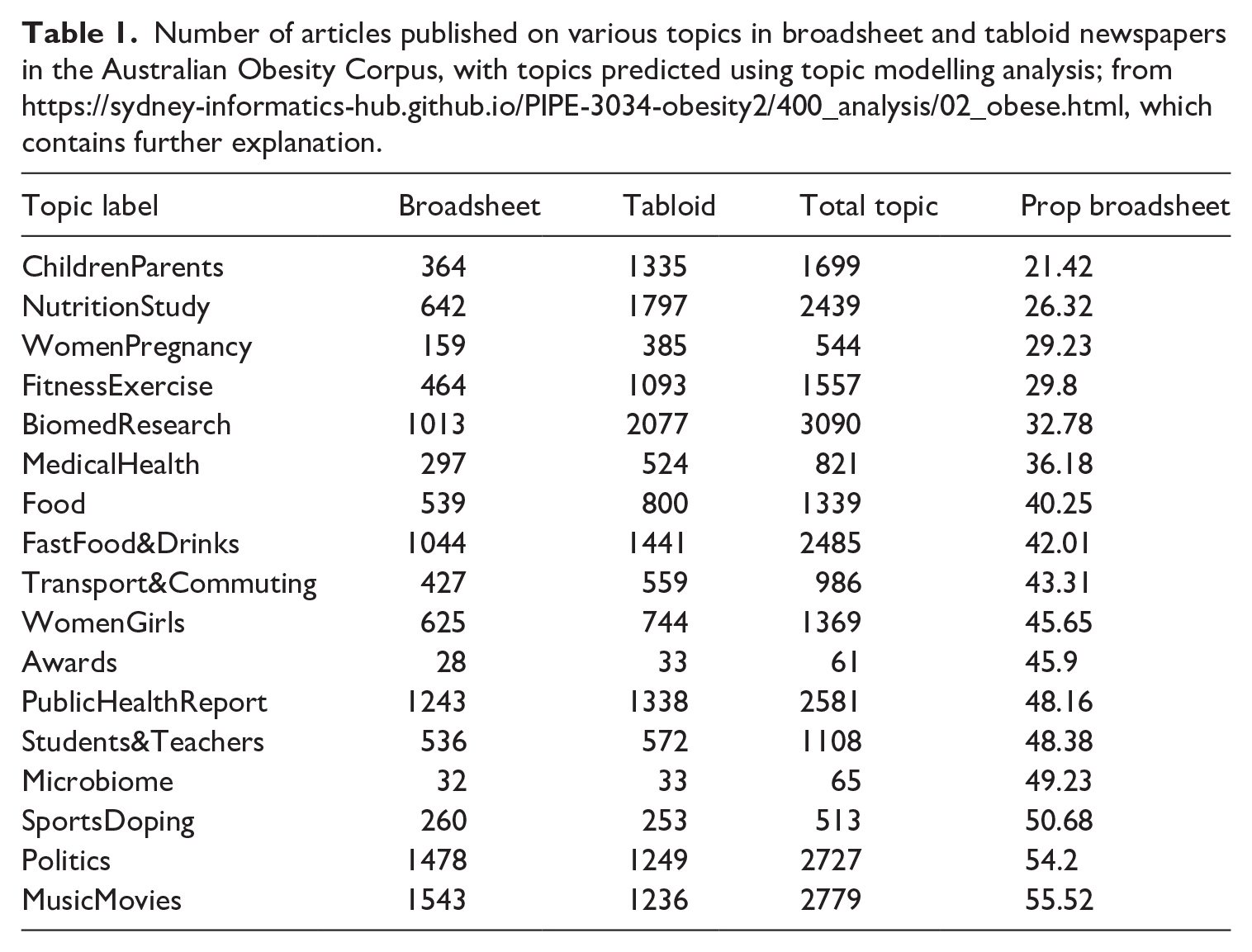
Continuing with corpus exploration, Vanichkina and Bednarek (2022) identified 17 topics in the ~26,000 articles of the Australian Obesity Corpus as part of the process of corpus construction and documentation. Vanichkina (2022) then showed that certain topics (‘ChildrenParents’, ‘NutritionStudy’, ‘WomenPregnancy’ and ‘FitnessExercise’) were approximately three times more frequently reported on in tabloid texts than in broadsheet texts, while topics like ‘Politics’ and ‘SportsDoping’ were evenly distributed (see Table 1). In addition, different topics had varying frequencies regarding the use of the word OBESE, with articles annotated as ‘Awards’ and ‘Bio-medical Research’ using more instances per 1000 words than articles discussing politics, schooling, transport and commuting. Bednarek et al. (2023) subsequently noted with respect to their own findings that such ‘[t]opic-based differences in the use of adjectives suggest the need for further research into article content and whether this affects the observed difference between tabloids and broadsheets’ (p. 17). It is possible that this is also the case in other newspaper corpora that contain both tabloid and broadsheet newspapers. In essence, the corpus exploration by Vanichkina (2022) suggests that linguistic differences between popular and quality press may be mediated by a preference for different topics or themes.
Number of articles published on various topics in broadsheet and tabloid newspapers in the Australian Obesity Corpus, with topics predicted using topic modelling analysis; from https://sydney-informatics-hub.github.io/PIPE-3034-obesity2/400_analysis/02_obese.html, which contains further explanation.
Above, we have already seen that TM has been combined with CDA (Törnberg and Törnberg, 2016). In addition, a range of studies published since 2018 have combined topic modelling with corpus linguistic techniques, showing that TM can be complemented or even enhanced through the use of ‘classic’ methods from corpus linguistics. For example, Huntley et al. (2018) combine topic modelling with keywords analysis, concordance and collocation analysis to investigate questionnaires from a survey of veterinarians in the UK. Similarly, Jaworska and Nanda (2018) use topic modelling with corpus linguistic techniques to identify thematic patterns in corporate social responsibility reports, including change over time. They combine topic modelling with collocation and concordance analysis, starting with TM before analysing the collocational profiles of two identified terms. They also examine the use of lexical items in the corpus to detect their senses and to assign an appropriate topic label, and they report the top collocations and bigrams for topics.
Similar mixed-method research of this type, which combines topic modelling with corpus linguistic techniques, includes the following selective and illustrative studies:
Liu and Lei (2018), who use TM and sentiment analysis together with analysis of ‘companion words’ (identified through word2vec) and qualitative analysis of selected utterances to identify themes and sentiment in speeches by Clinton and Trump during the 2016 election;
Rao and Taboada (2021), who combine TM with keywords analysis and analysis of dependency bigrams to examine how topics are associated with female and male sources that are quoted in 24 months of data from English-language Canadian news websites (i.e. whether women/men are quoted more frequently depending on particular topics);
Schweinberger et al. (2021), who combine TM and sentiment analysis with keywords analysis (using an adaptation of a collostructional approach) to study Twitter (X) discourse around COVID-19 in Australia and its change over time;
Wang (2022), who examines the main topics in COVID-19 briefings by the UK government (including change over time), combining structural TM with collocation analysis and examining words in their context;
Mirocha (2023) who uses TM, collocation analysis and analysis of sample texts to contrast the representation of migration in two Serbian newspapers with different political orientations.
Schweinberger (2024c), who utilises keyword analysis and a combination of unsupervised and supervised, seeded TM to examine the private section (letters and diary entries) of the Corpus of Oz Early English (COOEE), exploring topics and themes in the corpus to assess what early settlers in Australia wrote about and how these topics changed over time.
Such a combination of TM with corpus linguistics has also been used in fields beyond corpus-based discourse analysis; to give just one example here, Busso et al.’s (2022) forensic linguistic study of abuse letters employs structural TM together with qualitative analysis of topic-related concordance lines retrieved from n-grams analysis.
In sum, we have seen that there is indeed evidence of an increasing engagement with TM in corpus linguistic studies of discourse(s). However, this does not mean that TM has always been viewed favourably by relevant scholars or that TM has been applied uncritically. The next section reviews some of the critical issues and debates in the field.
Critical issues and debates
It is important to note that some researchers see TM as a strong and effective method. For instance, Murakami et al. (2017) point to a number of strengths of the topic modelling approach to corpus exploration, and Jaworska and Nanda (2018) claim that it is more ‘effective than other established corpus-based methods’ to extract semantic domains from a corpus (p. 376). Other researchers have expressed strong critiques of the method, 2 most notably Brookes and McEnery (2019), who are critical of TM as ‘a set of methods that ‘discover’ topics on the basis of individual, unordered and ultimately de-contextualised words’ (p. 7). The following section aims to synthesize some of the common critiques raised by these and other linguists.
A first issue concerns the usability of TM as a technique for discourse analysts, with respect to transparency and expertise/awareness. Regarding transparency, scholars who are not trained in mathematics may find it difficult to understand the equations used in such algorithms (Jaworska and Nanda, 2018: 382), and the way that TM is used invites a ‘black box’ experience (Busso et al., 2022: 235). This is even though the models are in fact much more transparent than pre-trained large-language models, since they are explicitly defined, the method does not involve pre-training, and the hypotheses about the text generation are explicit (Eduardo Altmann, p.c.). Regarding expertise/awareness, as further explained below, TM requires a range of methodological decisions to be made, and researchers need to be suitably informed of the effects of these decisions (Gillings and Hardie, 2023: 530). However, the extent of user intervention depends on the approach to TM that is applied – for example, topic modelling based on stochastic block models does not require user intervention to ‘tune’ the hyperparameters of the algorithm (Jack Chan, p.c.).
The use of off-the shelf TM programs – instead of more flexible programming languages – has also been critiqued (Busso et al., 2022: 234). Using such programming languages would again require considerable expertise, although new tutorials and tools may help (see e.g. Schweinberger, 2024a, 2024b). In addition, experiments should be performed in order to identify how to optimally set the parameters in TM for analysis (Rao and Taboada, 2021: 4–7), and it is unlikely that many discourse analysts would have the necessary knowledge to do so. However, this first set of issues could arguably be addressed through the formation of interdisciplinary teams.
A second set of issues concerns the subjectivity of TM, as a technique where initial decisions affect subsequent results. Most researchers discuss this in relation to the number of topics selected and how they are interpreted and labelled (e.g. Brookes and McEnery, 2019; Busso et al., 2022: 232–233; Gillings and Hardie, 2023; Jaworska and Nanda, 2018: 395–396). For instance, Murakami et al. (2017) explain that ‘the decision on how many topics a corpus will be deemed to contain is a subjective one and the answer may be defended on the grounds of usefulness but not on the grounds of accuracy’ (p. 250). Others have argued that diagnostics can be used together with researcher intuition to identify a statistically sound number of topics (e.g. Busso et al., 2022: 233; Wang, 2022: 231).
In relation to the interpretation of topics and their labelling, a wide-spread approach where topics are identified based on inspection of word lists alone has attracted the most criticism. Brookes and McEnery’s (2019) study combines two phases for interpreting topics: (i) inspecting topic word lists and (ii) genre-sensitive discourse analysis of texts with focus on social actors, processes and places, each phase involving both researchers undertaking independent analyses with subsequent discussion. They then compare the results from both phases and show that only three of twenty topics had close correspondence between phases 1 and 2 (with eight topics featuring no or limited correspondence and nine topics having mixed correspondence). Correspondence here means whether their ‘initial analysis of the word-list for these topics accurately reflected, for the majority of the texts in the topic, the reality of those texts.’ (Brookes and McEnery, 2019: 13). In addition to such limited correspondence, the analyses in the first phase were not able to interpret all themes present in the texts that were analysed in the second phase. They conclude that ‘eyeballing’ topic word lists is of limited use for the interpretation of topics produced in TM and that close discourse analysis of texts offers a ‘more refined and complex view’ (p. 17) of topics (conclusions that are mirrored by Gillings and Hardie, 2023). They thus recommend that the initial phase of topic word-list examination should be followed by qualitative text analysis, even though this is time-consuming (Brookes and McEnery, 2019: 19).
In addition to the approach used to interpret and label topics, the number and expertise of the researchers involved in the labelling of topics is also important. To reduce subjectivity at least somewhat, the labelling of topics can be achieved collectively, by more than one researcher (e.g. Busso et al., 2022: 238) and can potentially be improved by including experts in the field covered by the corpus data (e.g. Jaworska and Nanda, 2018: 383). Gillings and Hardie (2023) agree that specialist knowledge impacts on topic interpretation.
Importantly, it has been argued that topic modelling is particularly affected by researcher subjectivity, since it is highly sensitive to various parameters and settings used in the technique (Törnberg and Törnberg, 2016: 406). 3 One such issue is the question of whether stop words should be used or not (i.e. words that are excluded from the analysis), and if they are used how many and which type – for example grammatical, lexical, discourse, proper nouns, emoji, hashtags, numbers, frequent versus infrequent (see e.g. Murakami et al., 2017; Schweinberger et al., 2021). It is worth mentioning that it is possible for TM to include stop words; that is, they do not have to be excluded. For those interested in this specific matter, Gillings and Hardie (2023) offer a comparison of TM with inclusion/exclusion of stop words. However, this issue of researcher subjectivity goes beyond the number and interpretation of topics and the use of stop words, and also affects multiple other decision and choices, including:
The unit and level of analysis, that is, whether a text as a whole or text blocks of particular lengths are analysed and how the latter are defined or operationalised (e.g. Murakami et al., 2017; Reverter-Rambaldi, 2022).
Whether words are lemmatized or stemmed (Murakami et al., 2017: 249), whether tokenisation/lemmatisation is performed on unigrams or n-grams (Rao and Taboada, 2021: 14), or whether it is performed at all (Brookes and McEnery, 2019: 9).
Whether thematically-close topics are merged (e.g. Jaworska and Nanda, 2018: 384) or not; whether hyperparameter optimization is used which allows some topics greater prominence (Gillings and Hardie, 2023).
For analyses of topic changes/shifts – the unit of time (day, month, year, etc) chosen to identify such changes or shifts in topic.
This issue of researcher subjectivity interacts with the first issue raised earlier regarding awareness and expertise – since TM results are influenced by the above-mentioned (and other) choices, an informed use of the technique is necessary for producing high-quality findings. This means that time and effort need to be invested to learn how to use TM appropriately (Törnberg and Törnberg, 2016: 418) if the technique is new to the discourse analyst – unless they collaborate with others who have the relevant expertise.
Others have challenged the very underpinnings of TM as not being informed by ‘linguistic sensitivity’. Brookes and McEnery (2019: 5–7) point out that TM disregards the context of words, including their order; it excludes grammatical/functional words which may have important functions; it collapses the different word forms of lemmas which express different discourses; and that the concept of ‘topic’ is ill-defined and not grounded in linguistic theory. In addition, they question the assumption that the ‘topics’ that are identified by TM have thematic coherence. In their own study, the majority (14/20) of the identified topics lacked such coherence, and only three of the six topics with thematic coherence provided good starting points for discourse analysis (Brookes and McEnery, 2019: 17). Grundmann (2022: 396) similarly notes that some identified topics may not be robust, although Schweinberger (2024c: 78) reports thematically coherent topics in his own study (which combines unsupervised data-driven TM with semi-supervised seeded TM).
In addition, TM is not likely to cover ‘[d]ifferences of perspective or in how subject matter is construed’ (Gillings and Hardie, 2023: 541). Brookes and McEnery (2019) recommend that researchers ‘engage more deeply with linguistic theory when inferring the presence of topics in their textual data’ and hope that such engagement ‘could give rise to more standardised procedures for topic discovery’ (p. 18). Similarly, Reverter-Rambaldi (2022) finds that TM may need to be adjusted for the analysis of spontaneous speech, since most analyses have been undertaken of formal, written data and concludes that natural language processing ‘may have a lot to learn from corpus linguistics’.
A final issue that has been mentioned by several researchers concerns the lack of reproducibility/replicability. 4 In this respect, Brookes and McEnery (2019: 7–8) mention researcher decisions concerning the number of topics and procedures taken for filtering, selecting and interpreting them (as already discussed above) as well as the fact that TM is non-deterministic, which means exact repetition of a TM analysis is not possible. The latter is also noted as an issue by Gillings and Hardie (2023: 534). However, this may be a result of how TM is used by discourse analysts, since in practice it is possible to fix a ‘seed’ on a computer so one can get reproducible result for parts of the algorithm that use randomly generated numbers (Jack Chan and Eduardo Altmann, p.c., see also Schweinberger, 2024b).
Further, Rao and Taboada (2021: 15) argue that ‘our numerous experiments over multiple months of news data confirm that this does not affect topic interpretability or the overall robustness of the process’. Gillings and Hardie acknowledge that statistical results can be credible even if they are not exactly reproducible but argue that it requires statistical expertise ‘to judge whether the randomness in an analysis affects or does not affect the credibility of the results, and to make appropriate allowances for it’ (Gillings and Hardie, 2023: 543). Statistical and mathematical expertise as well as considerable experience using TM could thus alleviate this problem, as could be transparent and systematic notation and justification of all decisions taken during the application of TM.
In sum, it has become evident that the critiques levelled at TM are not inconsiderable. However, these typically relate to the use of (unsupervised, data-driven) TM alone, rather than its combination with other methods. Mirocha (2023: 257–258) offers solutions for addressing some of these criticisms, including through the use of corpus and discourse analysis. Similarly, Wang (2022) suggests that some of Brookes and McEnery’s (2019) limitations ‘can be partly overcome through a qualitative analysis, aided by traditional corpus linguistics tools such as collocation and concordance’ (p. 229). Other suggestions for addressing or reducing particular limitations have been integrated in the above overview or can be found in the expert commentary associated with this article. A final point to make is that this article has taken for granted that ‘topics’ in TM are not defined in the same way in which we may conceptualise them in discourse studies, for instance as defined semantically and propositionally rather than in terms of word collections. It bears repeating that the ‘topics’ that TM retrieves are lists of words and that this approach comes with its own inherent limitations.
Concluding remarks
On the whole, topic modelling has not commonly been used in discourse analytic research (Gillings and Hardie, 2023: 531). However, we can observe an apparent trend in corpus-based discourse analysis, namely an increased engagement with the technique of topic modelling in recent years. This observation provided the motivation for this short discussion paper.
Having reviewed the uses and critiques of TM in this field, it is clear that there is not necessarily full agreement among scholars regarding its usefulness for discourse studies. One might say that one conclusion that can be drawn from this article is that scholars in linguistics should aim to take a critical stance and draw on their linguistic knowledge in deciding whether to use TM in their study. One conclusion could be not to use TM due to doubts over its usefulness (Brookes and McEnery, 2019: 18) but rather to use a corpus linguistic approach such as keyword analysis instead (Gillings and Hardie, 2023: 542) or to undertake manual discourse analysis of smaller corpora. However, if we do decide to use TM, the research reviewed in this article clearly suggests that TM can be enhanced through the use of methods from both corpus linguistics and discourse analysis which can reduce some of its limitations. In this respect, it can be argued that linguists have a lot to offer to non-linguistic fields where topic modelling is widely used and that interdisciplinary collaborations could be a fruitful endeavour – if such collaborations are appropriately supported and rewarded, both through individual institutions and academia more generally. In the invited expert contributions that accompany this article, linguists with relevant experience in applying TM further comment on its uses and critiques in relation to corpus-based discourse analysis, confirming, challenging, elaborating or extending the points made above. It is clear that continued exploration of and debate on TM is a worthwhile endeavour, and that new technological developments necessitate such critical engagement.
Footnotes
Acknowledgements
The author acknowledges the technical assistance provided by the Sydney Informatics Hub, a Core Research Facility of the University of Sydney. Special thanks are also due to Eduardo Altmann, Jack Chan, and Martin Schweinberger for giving feedback on a previous draft of this article and to Kelvin Lee for formatting the references. The generosity of my colleagues in accepting my invitation to provide their own comments on topic modelling on the basis of this article is also much appreciated. Unfortunately, Gavin Brookes and Tony McEnery had to withdraw from providing an invited commentary due to sudden and unexpected competing commitments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project received investment from the Australian Research Data Commons (ARDC), which is funded by the National Collaborative Research Infrastructure Strategy (NCRIS). The TopSBM Jupyter notebook development was rendered possible through the Language Data Commons of Australia via the HASS Research Data Commons and Indigenous Research Capability Program (![]() ).
).