
Abstract
Global streaming services have reshaped the media landscape, through their business and distribution models, and their unprecedented collection of and control over data. This article examines how researchers navigate data secrecy and access in contemporary media industries research. Building on critiques of the transparency ideal and black box metaphor, we approach data access as an ongoing, textured, and relational process. Drawing on multi-sited and mixed-method research from previous studies, this study maps the fragmented terrain of data access across research into production, platforms, and policy. By synthesizing these previously siloed approaches, we conceptualize varying levels of data secrecy, identify shared challenges, and discuss innovative hacks as well as tried-and-true methods for circumventing these barriers. We conclude by proposing a framework for streaming research founded on collaboration, industry partnerships, and reciprocity, addressing the infrastructural and ethical limits of open science in the streaming era.
Keywords
Introduction
The rise of global streaming services has pushed data, and struggles over its access, to the center of discussions around contemporary media industries. As one Dutch producer put it, Netflix is “a black box when it comes to data” (Idiz et al., 2021). In this instance, they were specifically referring to performance data, yet streamers have come under scrutiny for their perceived “data secrecy” (Rasmussen, 2024) around a myriad of different matters. Indeed, leading streaming services such as Netflix, Prime Video, and Apple TV base their business models on the systematic collection of user data. Very little of this data is shared with producers, reported to policymakers, or accessible to researchers. While data has always played an important role in the screen industry, datafication and algorithmization in streaming services exacerbate issues of opacity and access (Van Es, 2024).
Streaming data is critical to several parties. For producers, “access to data” is directly tied to their contractual relations and monetization (Idiz and Poell, 2024). For policymakers, regulating streaming services requires data disclosure (e.g. Hagedoorn and Becker, 2025). And for researchers, there are many practical challenges to researching streaming because “Data on catalogs, audiences, and usage are difficult to source and often commercially protected” (Lobato and Van Es, 2025). In spite of these shared needs, access remains highly uneven, research approaches fragmented, and dialogue between these groups limited. In response, scholars are developing diverse, sometimes improvised, methodological and relational tactics to work around these constraints, from creative uses of digital traces and proxies to increasingly collaborative and mixed-method research designs.
Simultaneously, scholars have questioned the idealization of “access” (Seaver, 2022) and “transparency” (Ananny and Crawford, 2018; Rieder and Hofmann, 2020). In this article, we build on these critiques to reframe how streaming data is approached. We argue that while data opacity presents genuine obstacles, diverse methodological innovations support crucial research insights. We go beyond an overarching review by de-siloing research approaches and identifying shared learnings as well as potential pathways for more collaborative futures. This is especially timely given the similarity with current debates around data opacity in artificial intelligence (AI) and creative industries, as well as the growing need for new skills, competencies, and forms of cooperation that can sustain resilient research in increasingly data-driven environments.
Researching “black boxed” systems
Pasquale (2015: 3) notes that secrecy has become integral to many industries from Wall Street to Silicon Valley. In this context, he explains, the concept of the black box serves as a powerful metaphor: “tracked ever more closely by firms and government, we have no clear idea of just how far much of this information can travel, how it is used, or its consequences” (Pasquale, 2015). The same is true for the screen industry, where various types of data have historically been essential for different industry stakeholders and researchers to access. Nowadays, streaming services are described as black boxes. As anthropologist Seaver clarifies, “access is not an event; it is the ongoing navigation of relationships. Access has a texture, and this texture—patterns of disclosure and refusal—can be instructive in itself” (2022: 15). In short, access is unequal, and has no defined boundaries between inside and outside. The metaphor of the black box thus falls short in that it implies a stable, contained system that can be made transparent. Rieder and Hofmann (2020: 3) rightfully note how “the image of the black box more or less skips the practicalities involved in opening it.”
Moving beyond the streaming black box to approaching the textures of streaming services is useful because it encourages considering the range of sources and methods through which access takes shape. We characterize the ways in which scholars navigate these textures as hacking. Hacking is defined by de Waal and de Lange (2019: 2) as, “bending the logic of a particular system beyond its intended purposes or restrictions to service one’s personal, communal or activism goals.” They describe these tactics as “playful, exploratory, collaborative and sometimes transgressive” (de Waal and de Lange, 2019: 3). As we discuss further on, there are varying degrees of secrecy within the screen industries that correspond to different forms and depths of access. These variations create distinct textures and encourage innovative thinking in the form of hacks in the pursuit of insights. Below we elaborate on these hacks.
In this article, we approach “data” not as a stable or self-evident category but as a contingent product of social, technical, and institutional processes (Beer, 2019; Gitelman, 2013; Kitchin, 2014). Data are neither neutral nor objective; they are shaped by human interpretation and organizational decision-making. Rasmussen (2024: 5245) usefully distinguishes among several types of “streaming data,” developed through an analysis of how screen media workers engage with, respond to, and negotiate their encounters with (the lack of) data. Her typology identifies performance data, behavioral data, production data, and a fourth category encompassing streamers’ broader strategic use of big data analytics, including data sourced beyond their own services (e.g. social media metrics) (Rasmussen, 2024). Our analysis builds on this categorization and derives its conceptualization of data from an examination of existing scholarship. Reviewing the rich literature on streaming data, we reverse-engineer a categorization of three different research “perspectives” based on the high-level research questions (RQs) observed: production, platform, and policy (see Table 1). We also include the types of data needed to answer these RQs.
Research perspectives.
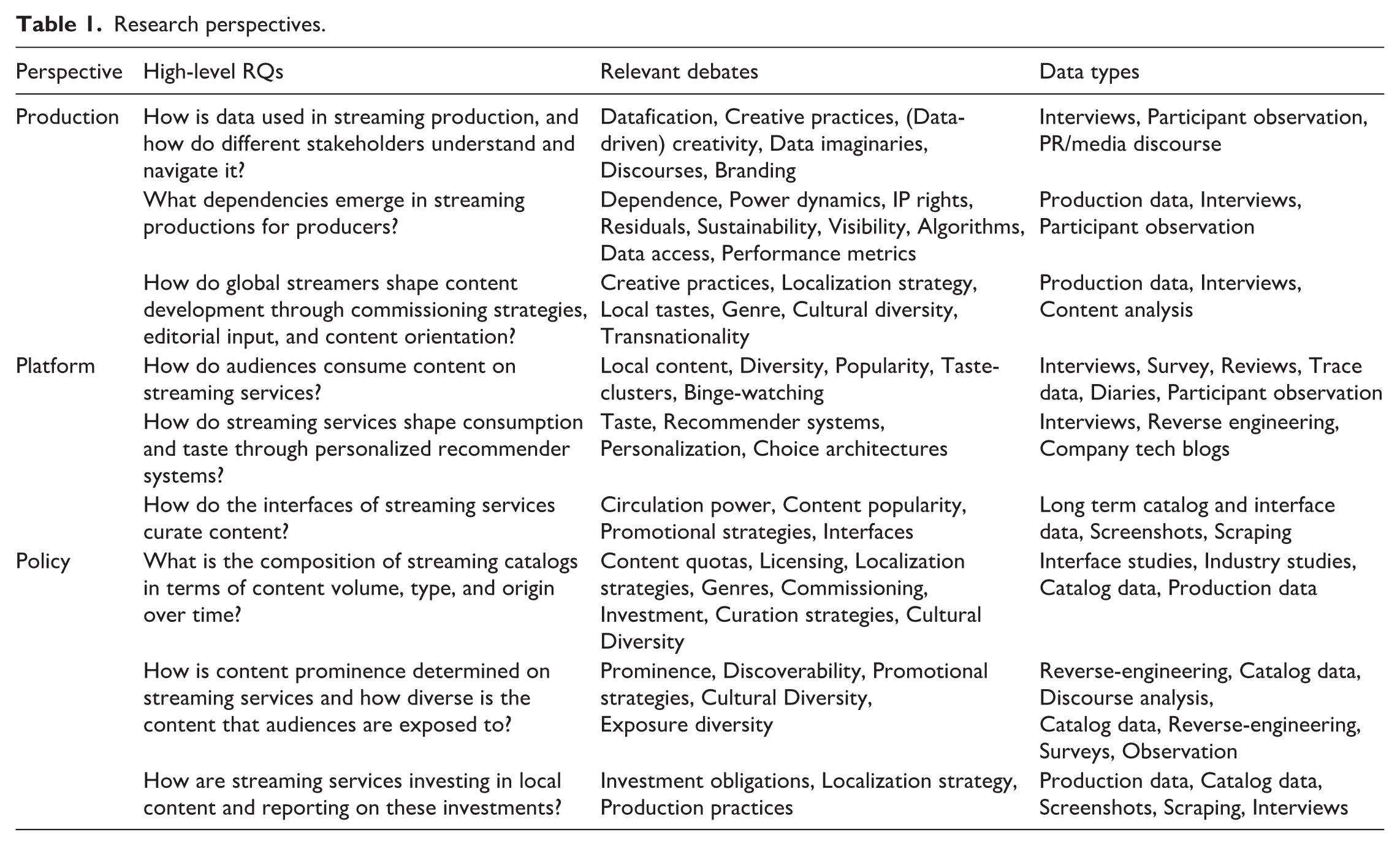
Thus, when we ask what kinds of data researchers require to investigate the domains of streaming production, platforms, and policy, the following categories of qualitative and quantitative data are identified:
Performance data: Information on how specific titles perform (e.g. views, completion rates).
Behavioral data: Insights into how audiences consume and interact with content and interfaces.
Production data: Information on investment levels, revenue generation, and commissioning practices across regions or markets.
Data practices data (building on Rasmussen’s (2024) fourth category): Data on streamers’ broader strategic use of big data analytics, including data sourced from beyond their own services (e.g. social media metrics). For scholars examining data practices in the media industries, this category is crucial, as it offers insight into how performance and behavioral data inform production cultures.
Catalog data: Information on the composition of streaming catalogs, including which titles receive the most exposure or prominence.
While this typology suggests distinct categories, in practice these forms of data are entangled. Their boundaries blur within research and within streaming services, where data are continuously aggregated, recontextualized, and repurposed for different strategic ends. For researchers, this underscores the epistemic opacity of the streaming industries: access to data is uneven, mediated, and often deliberately restricted. Consequently, attempts to delineate what kinds of data are needed for streaming research inevitably confront the same complex entanglements that characterize the streaming industries Recognizing this messiness is therefore not a conceptual or methodological flaw but an analytic necessity that makes visible the contingent, partial, and power-laden nature of data in the streaming ecosystem. In the following sections, we discuss existing hacks for examining key questions within the three research perspectives identified: production, platform, and policy.
Production perspective
A production perspective on streaming foregrounds these services as commissioners and producers of audiovisual content, highlighting how their practices are increasingly obscured by data secrecy and selective disclosure. Key insights to be gained from production studies include, broadly speaking, what content is produced, how it is produced, and the industrial impacts of streaming services—which can address a range of research questions. Production studies have long been a cornerstone of film/television/media industries studies (Caldwell, 2008; McDonald, 2013), where access to sites of production have always been challenging (Mayer, 2008; Ortner, 2010). Yet, there are several factors that exacerbate production research challenges in the streaming context, which researchers have been responding to through innovative, creative, and collaborative hacks.
Big data analytics and generative AI
Limited access into production raises questions around how big data and AI figure into content creation. Here, the traditional production studies approach of conducting interviews with screen workers and streaming executives remains the golden standard for accessing this otherwise inaccessible information, however we also highlight complementary tactics that reveal more textures of access.
Several interview-based studies have highlighted ways in which data informs Netflix productions (Idiz, 2024; Rasmussen, 2024) and how generative AI is perceived by screenwriters (Vainikka et al., 2024) or applied in the film industry (Chow and Celis Bueno, 2025). These collaborative studies are concerned with “production cultures” (Caldwell, 2008)—the meaning-making activities of the industry—providing insights into how screen workers sense, access, generate, and resist streaming data (Rasmussen, 2024). The specificities of streaming (e.g. significant power asymmetries, strict NDAs, cultural dynamics, datafication) require a tailored roadmap and creative approaches (Idiz and Rasmussen, 2025). For instance, Vainikka et al. (2024) used a visual elicitation method to concretize nebulous topics such as “data” and “AI,” while Rasmussen (2024) uses playful and creative drawing activities. Where most streaming production studies have focused on screenwriters and producers, recent research has also looked at the impacts of data-driven decision-making on art departments (Szczepanik, 2026). Szczepanik (2026: 268) argues that these are more difficult to identify, though still present, “under the veneer of continuity” in the latter context. This necessitates a tailored “sensitive approach to recognizing signs of distant power dynamics and decision-making processes, which only theory and triangulation with multiple data sources can uncover effectively” (Szczepanik, 2026).
An innovative ethnographic method outlined by Ortner (2010) is “interface ethnography,” which sees the researcher attending events in which the industry presents itself to the public. This can yield valuable insights into the broader discourse around streaming in the industry (e.g. Rasmussen, 2024). Some scholars have adopted a more embedded ethnographic approach that involves close collaboration with industry partners (Keilbach and Surma, 2022). Keilbach and Surma (2022) work demonstrates how local streamers selectively share behavioral and performance data with screen workers to enhance content production, and how these (still limited) forms of data transparency seem to differ markedly from the practices of services such as Netflix.
Finally, some additional sources can help illuminate how data and AI shape streaming productions. Discourse analysis of public facing materials and trade press has shown Netflix’s “strategic ambivalence” (Van Es, 2022) and evolving strategies around data in production. In the absence of direct access to the machine learning teams at these companies, job postings (Ivanova, 2023) and patents filed by Netflix and Amazon (Follows, 2025a, 2025b) can provide insights into their algorithmic infrastructures and aspirations.
Relations of dependence
A related concern focuses on how global streamers are reshaping labor dynamics as creative workers become increasingly dependent on these services (Idiz and Poell, 2025). While contractual and financial arrangements between streamers and producers remain strictly covered by NDAs, production studies provide a workaround. For instance, interviews with screen workers in parts of Europe and South Korea have raised the alarm around the erosion of IP rights and unfavorable remuneration arrangements for producers (Idiz et al., 2021; Kim, 2022). From interviews with film industry professionals in Nigeria, Simon (2022) demonstrates how the streaming market is characterized by a new form of precarity “shaped by the distinctive economic conditions of the streaming market.” Similarly, interviews with Indian creators have shown how powerful imaginaries around “the new screen ecology” (Mehta, 2020) directly impact the work they seek out.
Another avenue is research focused on worker collectives. For instance, Grohmann et al. (2025) engaged closely with representatives of the Writer’s Guild of America (WGA) through mixed methods grounded in both media and labor studies including interviews, but also analysis of campaigns, collective agreements, and social media outputs, to uncover how the 2023 Hollywood strikes represent a case of workers governing AI “from below” (Grohmann et al. 2025). These strikes along with collective action in Denmark and Canada responded partly to concerns around generative AI, but were especially focused on struggles over viewing data transparency and performance-based residuals from streaming services (Pham, 2022; Pugh, 2023; WGA, 2023). Research collaborations with guilds, unions, and associations negotiating around data transparency, fair remuneration, and AI use, not only provide insights into the beliefs and actions of screen workers, but also present opportunities for reciprocity whereby scholars can facilitate global solidarity through international research networks.
Diversity
A third strand of streaming production research can be characterized as focused on diversity. We understand diversity in a dual sense: first, as cultural diversity (referring to the national origin, audience orientation, linguistic and cultural representation, and cultural specificity of content); and second, as diversity of representation (encompassing on- and off-screen inclusion across race, gender, sexuality, and other identities). Here, too, secrecy shapes what researchers can and cannot know. While, for instance, diversity as branding is visible in PR discourse, the decision-making behind representation remains mostly opaque. Still researchers have found effective workarounds. Studies that fall into this category respond to a multitude of inquiries, ranging from how local screen workers experience cultural disconnects when working with global streaming executives in the Arab World (Haddad and Dhoest, 2021) to how Netflix wields diversity as a branding strategy (Asmar et al., 2023).
While textual analysis and secondary sources yield valuable findings related to the types of research questions encapsulated by this strand (see, for example, discourse analysis conducted by Asmar et al., 2025a), production studies can provide additional otherwise inaccessible data specific to the feedback and decision-making of streaming executives as negotiated by screen workers which shape content. For instance, Asmar et al. (2025b) examine the “streamer imaginaries” related to Netflix’s diversity strategy, as perceived by Flemish cultural producers. Meanwhile, O’Meara’s (2025) interviews with Australian screen workers trace the industry dynamics behind the proliferation of gender and sexually diverse representations in Australian scripted content, offering a more nuanced account of the role streaming services have played in this shift.
Research has demonstrated that global streaming content is characterized by a “grammar of transnationalism” (Jenner, 2024) and the vague ability to appeal to widespread audiences (Asmar et al., 2023). Yet the mediatization of local stories by global streamers can be problematic. For instance, a study from Brazil argues that Netflix’s local productions reveal its “imperialistic view of peripheral countries and their democracies, especially in regards to Latin American societies” (Meimaridis et al., 2021). In the context of a growing regulatory movement targeting global streamers with content quotas and investment obligations for local content (discussed in depth in a subsequent section), understanding how such content is produced and its cultural ramifications is vital. With little transparency around how much streamers are investing in particular countries or regions, or what content is being produced, letters to stakeholders and press releases can offer some (though incomplete) insights into their production strategies.
From a production perspective, many lines of scholarly inquiry continue to rely heavily on human participants. Thus, ethical, collaborative, and reciprocal engagement with the industry is essential, as are multidisciplinary frameworks from media studies as well as labor studies, cultural studies, law, and business. We also emphasize that across methods used in production research, robust data triangulation between interviews, ethnographic observation, secondary sources, and content provides the most comprehensive insights.
Platform studies perspective
Streaming services are often considered distinct from platforms because “they are not directly economically and infrastructurally accessible to third parties” (Poell et al., 2022: 6). Yet a platform studies perspective remains valuable, as streaming services are likewise data-driven and organized around recommender systems (Lobato, 2019). Here, several key challenges related to access emerge that center on audience data, personalization, and interfaces. Recently, scholars have begun to engage more explicitly with thinking through methodological innovations, or what we would consider hacks, to tackle these issues (see also Lobato and Van Es, 2025).
Audience data
When it comes to information about consumption, streamers have long held an anti-transparency data policy (Wayne, 2022). This has shifted to a phatic data policy (Van Es, 2024), as they have released some performance metrics. However, these have been more strategic and performative than informative, often reflecting aggregate numbers with limited context. For researchers, this marks a significant shift from the imperfect yet accessible forms of audience data characteristic of the broadcast era in which, for instance, Ang’s (1991) influential study was situated. Can we claim the end of mass media monoculture and rise of micro hits (cf. Lotz et al., 2025) without such empirical data? There have been hacks to engage with questions of popularity like the use of proxies. Scarlata (2022), for example, analyzed Australia’s top 10 lists over the course of a year, finding that audiences prefer Netflix Originals and titles from the United States. Wayne and Ribke (2024) contribute to the discourse of streaming diversity by analyzing two years of data from Netflix’s weekly Global Top 10 lists.
Without access to audience data, we have limited insight into what, when and how people watch content on streaming services more generally. Traditional methods for studying these questions include self-reporting via surveys, diaries, and interviews. Here again, Top 10 lists have been used as a proxy for understanding consumption practices. This time, downloading Netflix’s released engagement data, to explore consumption patterns with various computational methods, comparing between countries (Jang et al., 2021; Lee et al., 2025). Another route has been industry-university collaborations. For instance, a PhD candidate employed at the Estonian Public Broadcasting (ERR) explored the relations between audiences, content types, functions of platforms, and content popularity using interaction data from the broadcaster video-on-demand (BVoD) (Lobanov and Ibrus, 2025). A different example is Trouleau et al. (2016), who modeled binge behavior using 16 months of data from 3466 anonymized users of a pay-per-content streaming service. They were not allowed to disclose the specific US provider, so much contextual information was missing.
Subversive hacks used to access audience behavioral data involved installing a browser extension to track users’ content consumption (Cordeiro et al., 2021). Yet another study solicited data donations (Van Es et al., 2025). It was based on the fact that subscribers to global streaming services, backed by legislation in the EU and countries like Canada and Japan, can request their personal data and contribute it to research. However, the data that thereby becomes available for analysis is highly influenced by the commercial interests of the service under study.
Moreover, the above hacks for accessing behavioral data face practical challenges, such as recruiting participants and obtaining representative samples. Furthermore, many research questions in the humanities and social sciences require deeper contextual understanding, which typically calls for qualitative approaches. Interestingly, commissioned research projects by industry underscore how streaming services, despite their vast data collection, face significant challenges in understanding how people watch streaming services (see Esser et al., 2025; Scaglioni and Sfardini, 2025).
Personalization
Streaming services rely heavily on personalization to maintain user engagement. Recommender systems play an important role in shaping content visibility, yet information about how they work is often kept secret. To understand the inner workings of Netflix’s recommender system (NRS), Pajkovic (2022) employed a reverse-engineering approach (cf. Bucher, 2016). He created four Netflix profiles—three representing distinct taste persona—and monitored them for two weeks. By screenshotting their homepages and tracking their viewing activity, he examined how content curation and promotion varied based on user behavior. Česálková (2023) used a comparable approach to explore the curation and discoverability of classic films on Netflix.
To investigate how the Netflix recommender shapes cultural taste, Gaw (2021) broadly employed Bucher’s (2016) methodological tactics for “unknowing” algorithms. Gaw combined three approaches in her research. First, she utilized reverse engineering by analyzing technical documents from the Netflix Tech Blog and other public sources. Second, she reflected on unexpected or “strange” algorithmic encounters. Third, she synthesized these insights to uncover the underlying processes that position the NRS as a cultural force.
In a pilot study of thumbnail personalization and their operation as paratexts, Eklund (2022) examined thumbnails of 5 different Netflix titles across a collection of research participants. He asked them to examine the thumbnails of their Netflix account, take screenshots of these titles, and answer some questions. To understand personalization on the Chinese video platform iQiyi, Wang and Lobato (2019) used the walkthrough method (Light et al., 2018), analyzing aspects such as interface arrangements, functions and features, content and tone end symbolic representations They demonstrated a logic more akin to broadcast programming than algorithmic personalization.
Interfaces
Interfaces function as an important site of “media circulation power” (Hesmondhalgh and Lotz, 2020)—guiding a user’s attention to certain content and away from others. There is a bulk of research concerned with the interface, and the position of content (e.g. “Original” or “European”) within the landing page. Here screenshots are a valuable method for data collection and documentation. Taking these screenshots requires careful planning and tools that enable full-page screenshots and web recordings (Lassen, 2025).
Interface studies can take different foci. One strand of research, for instance, examines interface curation. For example, Frey (2021) offers a close critical analysis of how MUBI’s interface remediates legacy art film culture institutions, partaking in the broader discourse and business model of curation. The study included examining technological features, marketing rhetoric, business models, interviews, and audience studies. Yet another strand concerns “trans-programming” (Bruun, 2020) comparing streaming scheduling practices to broadcast television. For example, Bruun and Lassen (2024) conducted a quantitative analysis of the amount and type of content offered on linear channels and BVoDs during selected weeks in 2022. This was followed by both quantitative and qualitative analysis of content published during the channels’ and BVoDs’ “prime time” and “prime space.” Finally, a detailed qualitative analysis examined the communicative features of interstitials used in on-air schedules and on BVoD front pages. Analysis of VoD “scheduling” has also been conducted using computational methods enabling longitudinal studies (see Kelly and Sørensen, 2021). Such work often focuses on public service BVoDs (Sørensen, 2025), because they are easier to scrape and offer minimal personalization.
From a platform studies perspective, several methodological hacks and computational methods requiring new tools and skills evidently provide valuable insights. Yet, we also emphasize that established, qualitative approaches engaging with audiences and curatorial practices remain essential complements to emerging computational techniques. In particular, they remain important for their explanatory potential and to retain needed context for data.
Policy perspective
Researching streaming services from a policy perspective implies analyzing the power such services exert on the flow of cultural content and efforts to regulate them by media authorities. Policy research is closely linked to both the production and platform studies perspectives, as existing measures targeting streaming services broadly fall into three categories: content quotas, prominence/discoverability requirements, and investment obligations (IO).
Catalog studies
In catalog studies research has emerged to examine the compilation of streaming libraries or catalogs. Many of these employ close-readings of interfaces (Andersen, 2024; Kelly and Sørensen, 2021). However, another employed hack is the scraping of “free third-party indexes such as JustWatch” (Lobato et al., 2024a: 1335), as is the case in AVMSD related studies for the European Commission (European Commission, Directorate-General for Communications Networks, Content and Technology, 2024) and the European Audiovisual Observatory (Grece and Jiménez Pumares, 2021). Others enrich datasets based on manual catalog analysis with information from databases like JustWatch and IMDb (García Leiva et al., 2024).
An alternative process involves purchasing expensive datasets from third parties like Ampere Analysis (Lotz et al., 2022) or from the Lumiere VoD database of the European Audiovisual Observatory (Bengesser et al., 2025). Aside from the monetary hurdle, there is the epistemic challenge concerning the unclarity about the underlying methodologies for compiling the datasets. Moreover, these datasets require extensive “cleaning,” such as checking and correcting entries and inconsistencies.
Prominence and discoverability
The notion of prominence remains vague and hard to operationalize, but has gotten scholars interested in where and how content is positioned on the interfaces of global streaming services. Many qualitative studies used the exploratory hack of taking screenshots manually of full landing pages using extensions like Fireshot (e.g. Bruun et al., 2025).
Computational studies of prominence and discoverability include the work by Bideau and Tallec (2022) who used 20 automated accounts to examine the visibility of European content on Netflix. Building on this research, they established Arvester, a Paris-based consultancy, where they developed the Vignette dashboard, a tool for collecting longitudinal data on landing page composition across Netflix, Prime Video, and Disney+. This connects to another example, which points again to the importance of building industry–university relations as a valuable entry point for research. Van Es and Iordache (2025) examined the Amazon Prime interface as a super-aggregator, drawing on the Vignette dashboard and additional data provided by Arvester. The dashboard offered useful visualizations of landing page structures and heat maps indicating title-placement. The accompanying data included relevant information about row titles and their placement on landing pages for different user profiles over time. If not enabled through such industry-university collaborations, data from specialized firms and their automated analysis tools like Arvester, MTM, Looper Analysis, and AQOA mainly remain accessible to governments and corporations (Lobato et al., 2024a: 1339).
Another productive avenue into studying prominence and discoverability is by recentering the audience’s usage of the interface of streaming services or SmartTVs (Damásio et al., 2025; Johnson et al., 2023; Lobato et al., 2024b). Respective studies combine semi-structured interviews and ethnographic observations in the homes of study participants or employ five-day-long participant “media diaries” (Bengesser et al., 2022; Damásio et al., 2025) sent out via survey platforms.
Investment obligation and production data
To date, the majority of EU member states, Norway, Canada, and Australia have introduced an investment obligation (IO) either in form of a direct investment, a levy to national film funds, or a combination for foreign streaming services with substantial annual revenues (European Audiovisual Observatory, 2025; Government of Canada, 2023; Parliament of Australia, 2025). Discussions on potential future implementations of IOs for streaming services are ongoing in several other countries in Europe and Latin America (AVMSD Tracker; Albornoz and Krakowiak, 2023: 137–140). For instance, Brazil recently passed a bill in the lower house on streaming regulation and regional investment quotas (Camarotto and Roscoe, 2025). There has been a growing opposition from global streamers to these regulatory efforts in ongoing court appeals (see Dams, 2025; Tynes-MacDonald, 2025).
This shows the need for data access at different stages of policy formation and reporting to assess the effectiveness of the IO in national contexts by policy makers, media authorities, and researchers. As Hagedoorn and Becker (2025) note for the Netherlands, data on investment sums and production costs are often not accessible, even to policy makers or contracted data analysis companies. Their study therefore relies on open-access aggregated production data for the decade preceding the Dutch IO, drawn from a previous study. To update the data set with more recent productions, additional information was retrieved from national screenwriting awards and public service media. As with third party data in catalog studies, the different datasets needed to be laboriously merged, adjusted, and cleaned.
Another hack for accessing production data to assess investment in local productions involves computational (or manual) catalog or data scraping. Iordache (2022: 5), for example, used a web-scraping program on The Unofficial Netflix Online Global Search and enriched the results with release year, country of origin, language, format, and genre from IMDb. The comparative analysis of aggregated production data for Belgium, Romania, Spain, and Sweden shows how Netflix not only “reinforces imbalances between strong and weak audio-visual markets within the EU,” but how a lack of data transparency “conceals the complexities of the content licensing and investment strategies [the company] employed” (Iordache, 2022: 17–18).
IOs can also be studied through qualitative interviews, “interface ethnography” (Ortner, 2010), and analysis of accessible policy documents and ongoing hearings or consultations (Idiz, 2025). While these approaches are useful in the policy formation process, data accessibility remains problematic in the reporting stage since streamers report production titles and investment sums only to local media authorities, and the publicly released data is less detailed.
For instance, the annual reporting of streamers in Spain to showcase their compliance with the national IO is made available to the public in the form of a report listing investment sums. The Spanish reports, however, do not share information on the actual production type and titles (Kostovska, 2023: 11). Similarly, in November 2025, the Canadian media authority introduced a disclosure requirement for large streamers including annual broadcasting revenues and programming expenditures. Like the Spanish reporting, this data is aggregated at the entity level and made public. Addressing streamer complaints, the Commission states: “it is unlikely that any harm resulting from disclosure of that data would outweigh the public interest, given the relatively large size of the online undertakings [in question] and their associated large impact on the Canadian broadcasting system” (CRTC, 2025: para 211).
Hacks in policy research draw from a range of sources including policymakers, streaming professionals, regulatory frameworks, and production datasets. Here both qualitative and quantitative approaches are notably labor-intensive, whether cleaning and enriching production datasets or building industry-university collaborations, but consistently yields analytically rich insights.
Levels of data secrecy
With the emergence of global streaming services, there has been a shift around how data is collected, controlled, and circulated in the screen industries. This has created power asymmetry for producers dependent on these services, while simultaneously challenging researchers attempting to understand their social, political, economic, and cultural ramifications. Regulatory responses in parts of the world have sought to render streamers more transparent and accountable, yet these efforts are routinely contested by streamers, and the data made available to researchers remains highly aggregated, limiting meaningful analysis.
Despite these many barriers, streaming television has become a rich and prolific field of research, with scholars exhibiting many resourceful tactics. However, approaches remain broadly fragmented along three key research perspectives: production, platform, and policy. By synthesizing these approaches, we show how data access is an ongoing negotiation shaped by industry relations, disciplinary knowledge, and methodological innovations. In this article, we identify shared challenges and effective hacks to work around/through these. Some of these have been adapted from existing approaches in film, television, and media industries studies, while others draw inspiration from related fields like critical data studies, platform studies, computer science, and law. We also identify the need for new skills, competencies, and attitudes, including a critical engagement with digital data, recommender systems, and AI.
From the above non-exhaustive survey, we can distinguish between various levels of data secrecy navigated by scholars. There is data that is totally secret; data that is proprietary or technologically secret, difficult to understand, or irrelevant; and data that is accessible in specific contexts. At the extreme end, global streaming services like Netflix and Amazon function as walled gardens: researchers (to date) have extremely limited direct insights into internal decision-making, organizational practices, or the work of actors such as Netflix data scientists or Amazon executives. Yet, rather than creating gaps in research, by and large these conditions of secrecy have prompted scholars to develop inventive tactics for producing knowledge. Here we find a range of hacks from those more technological (e.g. scraping, data donations, browser extensions, and reverse engineering) to the use of proxies (e.g. top 10), and from collaboration for new forms of expertise (academic and professional) or access (commercial party data) to the revamping of traditional methods that have fallen out of vogue (particularly in the field of audience research). We also observe a trend toward mixed methods to triangulate data. With this article, we aim to contribute to the development of established methodologies for navigating the complexities of access in the streaming industry. But also, we seek to underscore the need for thinking creatively, carving out spaces to navigate textured access, and different forms of collaboration.
Future directions: thinking creatively and collaboratively
Based on these insights and looking to push this further, we call for greater cross-sector collaboration (between researchers, creative workers, audiences, streamers, and policymakers) and greater multidisciplinary and international collaboration in academia. However, relationship building takes time and often requires new skillsets, interdisciplinary approaches, and ethics of care built on trust and reciprocity. In relationship building with the industry, the development of “soft” skills is essential, encompassing the ability to build meaningful and lasting relationships with industry professionals, engage in industry events, and foster collaboration within teams and across disciplines. Such slow and relational processes remain at odds with much of the productive, extractive, output-driven nature of academic inquiry. They also clash with the academic realities and publishing pressures of our field(s), in which empirical research focused on gathering “new” data is rewarded and often seen as superior to conceptual work aimed at opening new research pathways. In many cases, approaching data access as a relational process requires rethinking research, from design to dissemination. We draw inspiration from process-heavy methods grounded in “trans- feminist and queer” traditions (Cowan and Rault, 2024) and feminist ethics of care frameworks (e.g. Luka and Millette, 2018). Luka and Millette (2018) offer several guiding questions for social media research that are equally useful for media industries researchers to consider: How can this research be collaborative and useful for the person(s) whose experiences are being scrutinized? In what ways and to what degree are we comfortable inviting members of the communities involved to collaborate on research design? [. . .] How do we disseminate the results in a respectful and useful way? If we are required to publish in journals for peers, how can we make this meaningful for the people whose involvement has contributed to these results? What are the other forms of reporting back, providing joint attribution or other analyses or descriptive expressions that we could commit to and involve participants in? Is a written format the best way, perhaps in a blog or newspaper? Would they prefer to be involved in an oral discussion (Online? In person?) A workshop? A collective art piece? (Luka and Millette, 2018: 7–8)
The problem of access also reflects systemic barriers within the academy itself. Open science frameworks offer valuable ideals of openness and transparency, yet in practice they pose ethical challenges, particularly when dealing with sensitive data such as personal details of creative workers breaking NDAs. Moreover, it introduces the significant administrative burden of preparing datasets for sharing as well as the financial burden of publishing open access.
We conclude that advancing streaming research requires both infrastructural and cultural shifts: a reframing and specification of “streaming data” that de-fetishizes transparency and access, upskilling to the demands of a digital society, greater institutional support, more reciprocal data sharing (between scholars as well as between scholars and the industry), and finally recognition of the time and relational labor such practices entail. In the current landscape where data secrecy and financial barriers continue to shape the research agenda, such collaborative, long-term, resourceful, and sometimes messy approaches are the key to moving beyond the black box and navigating the textures of the streaming industries.
Footnotes
Acknowledgements
Disclosure of generative AI use: In the course of preparing the manuscript, the authors used GenAI for editorial assistance. Specifically, the tool supported minor copyediting activities to improve clarity, coherence, and overall readability. No generative AI was involved in the development of the core content of this article; all ideas, analyses, and conclusions are solely those of the authors, who take full responsibility for the work as presented.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical approval and informed consent statements
There are no human participants in this article and informed consent is not required.
Data availability statement
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.