
Abstract
Against the backdrop of calls for greater platform transparency, this exploratory article investigates Meta’s ‘Why Am I Seeing This Ad’ (WAIST) feature, which is positioned as a consumer-level explanation of Meta’s advertising model. Drawing on our own walkthroughs of Facebook and Instagram and data from the Australian Ad Observatory, we find the feature falls short in two ways. First, the explanations do not always align with how the system and its audience-building tools are sold to and used by advertisers. Second, the feature is focused narrowly on single ads and individual users, doing nothing to generate understanding of the patterns and sequences of targeted advertising in relation to other users or over time. We propose both platform practices and independent research strategies that could help to fill this gap between individual explanations, population-level patterns of targeted online advertising and the societal issues associated with it.
Introduction
Advertising is both economically and socially significant. It has been historically subject to regulation in order to mitigate potential harms such as false, misleading, racist, discriminatory and predatory forms of marketing. Algorithmically targeted advertising on social media platforms has presented new challenges to public oversight, because it is more personalised, less observable, and more ephemeral than most mass media advertising, meaning that harmful (predatory or discriminatory) advertising practices may go unnoticed (Burgess et al., 2022). While public concern was historically focused on the content of ads, in the era of automated advertising, the weight of public concern has shifted to who is being targeted and how. This shift appears to reflect a consensus that if advertising’s cultural power is increasing, it is not because it has become more appealing, engaging or persuasive but because it has become better at targeting, predicting, and nudging us (Darmody and Zwick, 2020).
In response, some platforms have introduced transparency tools that are accessible to independent researchers to varying degrees (FARE, 2022). Meta has created an ad library that provides a dashboard of a selection of ads currently ‘live’ on their platforms. But while the dashboards provide an aggregated view of what ads are circulating, they provide very little meaningful information about whether, how and to whom they are targeted, as researchers attempting to use them to study electoral campaigns have quickly discovered (Mehta and Erickson, 2022). Targeting transparency is provided in a limited way in aggregate (primarily for political ads), but is provided in more detail to users on an individual basis through the ‘Why Am I Seeing This Ad’, or ‘WAIST’ feature. In terms of individual user-level explanations, Meta is ahead of other large platforms. Google has only recently (in late 2022) introduced a similar feature to WAIST for sponsored links in search results, called the Ad Centre – TikTok offers users no targeting information, only the ability to report, or like (or dislike), an ad.
In this article we approach Meta’s ‘Why Am I Seeing This Ad’ (WAIST) feature at face value: as an aid to both user experience and transparency. We investigate whether it constitutes a meaningful consumer-level explanation of how Meta’s advertising model works, and extrapolate from there to consider the extent to which it is useful as an aid to public oversight of automated advertising.
‘Explainability’ has become standardised and formalised in the field of AI and data ethics as a key element of responsible AI and has been incorporated into influential regulatory regimes, including the European Union’s General Data Protection Regulation and the Artificial Intelligence Act (Confalonieri et al., 2021). In this context, it is understood as key to transparency, and thus to conveying a sense of safety, trustworthiness and accountability to users by giving them information. However, there has been much discussion and debate in both humanities and technical disciplines about what elements of an automated decision-making system require ‘explanation’, for what pragmatic purpose, and for whose benefit (Mittelstadt et al., 2019). For example, ‘scientific’ versus ‘everyday’ explanations envision very different audiences, with different interests and reference points (Miller, 2019).
While there is not enough space to rehearse these debates in full, one point we take from them is that explanation is fundamentally an act of communication – concerning not only the transmission of accurate information but also the exchange of meaning in a social context. Because the WAIST feature is embedded in the user interfaces of Facebook and Instagram, it is especially relevant to this idea of explainable AI as communication. Further, an explanation is of no benefit unless the system in which it is embedded provides some avenue for responding to or acting in one’s own interests on the basis of the information it provides.
For our purposes in this article, then, we are normatively concerned with explanations that are both accurate and meaningful (hence, communicative), providing completeness at a level adequate to address the concerns that motivate the need for the explanation in the first place, and responsive or actionable by their subjects. Because the context of our study is so situated in everyday digital media use, we’re also motivated by ordinary users’ vernacular data literacies and ‘algorithmic gossip’ (Bishop, 2019), which are important practices in their own right and also demonstrate the need for and limits of platform-provided explanations, as well as the bottom-up capacities of users to collectively make sense of their experiences.
In the remainder of the article, we first offer a brief history and overview of the Meta WAIST feature, including media coverage and existing scholarship. Drawing on walkthroughs of our own Facebook and Instagram timelines, we examine the WAIST feature from the perspective of individual user experience, including the vernacular knowledge practices (such as speculation on the relationships between ad targeting and everyday practices) associated with it. We then draw on the affordances of the Australian Ad Observatory to compare the explanations provided within the user interfaces of Meta platforms with the ‘back-end’ ad targeting information attached to particular ads, grounding this analysis in a critical understanding of advertising industry practices. Finally, we offer suggestions about how platforms could improve the explanations offered to users, as well as the possibilities that coordinated data donation might offer for better public oversight and understanding of platform-based advertising systems.
The Meta WAIST feature
Introduced in 2014, the ‘Why Am I Seeing This Ad?’ (WAIST) feature enables individual users to click on a button on an ad in their Facebook or Instagram feeds to reveal information about why that particular ad was served to them. WAIST data is specific to Meta, and comprises information associated with users’ profiles including demographics, location, interests and businesses interacted with. ‘Interests’ is a category of WAIST data generated by Meta as users interact with their services: a constantly expanding and dynamically updated list of terms attached to user profiles that enable Meta to compare users and associate them with advertisers.
When Facebook launched the WAIST feature in 2014, they pitched it as helping users ‘see ads that are more relevant and useful’ (Facebook, 2014, emphasis added). The purpose was to help users improve their individual experience, rather than to respond to concerns about targeting or calls for transparency. Facebook’s emphasis on helping users to ‘see more relevant ads’ dominated their public explanations of the advertising model prior to 2016 and the sequence of events including the Cambridge Analytica scandal. In a 2019 update, product manager Ramya Sethuraman (2019) announced that the WAIST feature would now provide information such as whether an advertiser uploaded information about you or worked with another marketing partner to run the ad. The language of helping users get the most relevant ads was replaced by a ‘commitment’ to ‘giving people more context and control’. Later the same year, they added more detailed information to the explanations, including ‘the interests or categories that matched you with a specific ad’ and more specific information about where information came from, such as which advertisers uploaded it (Thulasi, 2019).
In February 2023, Meta explained that the WAIST feature was being updated to provide ‘more transparency about how your activity both on and off our technologies may inform the machine learning models we use to shape and deliver the ads you see’ (Pavon, 2023). These updates were undertaken because privacy experts and policy stakeholders consistently told Meta they should increase their transparency ‘around how our machine learning models contribute to the ads people see on our services’. By 2023, the language of relevance and control had been fully displaced by an emphasis on transparency, where WAIST is positioned as a way to ensure ‘that people are aware that this technology is a part of our ads system and that they know the types of information it is using’, helping ‘people feel more secure and increase our accountability’ (Pavon, 2023). In their submission to the Australian Government’s Digital Platforms Inquiry, Meta (2022) referenced the WAIST tool several times, explaining that it offers a ‘clear explanation of the factors that influence the posts and ads’ that users see. The development of the WAIST feature over time therefore illustrates Meta’s changing ‘vocabulary of explanation’ (cf. Crawford and Gillespie, 2016) about how algorithmic advertising works, as well as a shift in public positioning away from individual relevance to public accountability.
Research design and methods
The exploratory elements of the project we are reporting on here were grounded and structured through the use of the app walkthrough method (Light et al., 2018), which has been widely adopted in platform studies. The method involves researchers engaging in ‘the step-by-step observation and documentation of an app’s screens, features and flows of activity’. It is designed to ‘[slow] down the mundane actions and interactions that form part of normal app use in order to make them salient and therefore available for critical analysis’ (Light et al., 2018). The method also incorporates interpretative analysis, drawing on a combination of science and technology studies and cultural studies ‘to identify connections between these contextual elements and the app’s technical interface’ (Light et al., 2018).
In January 2023, two of us (J.B. and N.C.) conducted walkthroughs of Facebook and Instagram (the two main Meta products that carry visual advertising). The aims of the walkthroughs were: first, to document the basic interface and structure of the WAIST feature as a user would encounter them; and, second, to categorise the demographic and interest-based WAIST explanations we received. Given that explanation is a form of communication, which, in this context, necessarily involves the exchange of meanings between users, platform user interfaces and platform companies, a reasonably naturalistic account of the user experience of encountering the WAIST feature in the course of daily life was needed, and that is the purpose of the walkthroughs we conducted.
As a way to ground the later data analysis in the user experience, and as the first step in what we conceive of as a carefully sequenced explorative account of Meta’s WAIST feature (the first ever conducted, to our knowledge), we each conducted independent preliminary walkthroughs via the web browsers on our computers (for Facebook) and the mobile apps (for Facebook and Instagram), scrolling through our feeds and taking note of each ad that appeared. Throughout the process, we took screenshots and written notes reflecting on the overall patterns and any points of interest or confusion in the ads and/or WAIST explanations in the context of our social media use and everyday activities. We then developed three primary categories of WAIST explanations, or in the language of the system’s data structure, ‘WAIST types’ (discussed in detail below). We used these preliminary categories and broad observations to guide the design of a second phase involving the qualitative analysis of these explanations in the context of our personal app use. This second phase involved a more systematic collection of 10 ads per person from Facebook (browser), Facebook (mobile app), and Instagram (mobile app), totalling 30 ads and explanations per person, over 3 days, for a total of 180 ads and accompanying explanations. Using the constant comparison method, we formalised three primary explanation categories, and generated paradigmatic examples of each, as well as examples of implausible or confusing explanations, which we discuss in further detail below. In doing so, we drew on our lived experience and knowledge of the contexts of our own platform use to speculate on the relationships between the WAIST information and the likely reality of how these ads were targeted to us by the Meta advertising system for each platform, in much the same way as ordinary users (including ourselves) do as a routine element of their engagement with social and mobile media, albeit with the additional resources afforded by our existing knowledge of ad tech and the Meta advertising system. Finally, we compared 10 of our own observations collected by the Australian Ad Observatory with the ‘back-end’ WAIST data gathered through the Ad Observatory for those observations.
User experience walkthrough and qualitative analysis
The first step in the walkthrough was to thoroughly document the appearance and functions of the WAIST feature. As of February 2023, for any ad that appears in a user’s Facebook or Instagram feed, they could click ‘why are you seeing this ad?’ (Instagram) or ‘why am I seeing this ad?’ (Facebook) links, accessed via the vertical ‘three dots’, or ‘kebab’ menu at the upper right-hand corner of the ad. On doing so, a popup ‘card’ appears as an overlay on the ad. The card listed between two and five pieces of WAIST information related to the specific ad. Each item could be expanded to reveal more detail, as in the examples below. Below the WAIST items was a link to more detailed, but generic, explanations of how Meta’s advertising system works on the Facebook or Instagram websites, including an animated ‘explainer’ video (Meta, 2023a, 2023b), as well as another popup card entitled ‘How businesses use our ads system’ (Meta, 2023c), a link to the user’s Ad Preferences page within the platform’s privacy settings (Meta, 2023d), and the option to answer the question ‘was this explanation useful?’ by clicking ‘Yes’ or ‘No’. 1
Over three days in January 2023, J.B. and N.C. collected the first ten ads we saw each day in our Facebook browser, Facebook app, and Instagram app feeds, comprising 30 ads each per day, and 180 ads in total from 121 unique advertisers. We also took screenshots of the content and WAIST cards for each ad. When we analysed the WAIST cards attached to the ads in aggregate we identified three main types of explanations, which appeared to map consistently onto what we already understood to be the three audience types offered to potential advertisers:
A ‘core’ audience explanation – the information in the WAIST card refers to specific user characteristics such as age, (binary) gender, location or a descriptive interest.
A ‘custom’ audience explanation – points to a specific reason the user is seeing the ad, based on an interaction with that advertiser’s website, online store or Facebook or Instagram account. In some cases, this explanation notes that the user’s personal information was on a list provided by a third-party marketing agency or data broker.
A ‘lookalike’ audience explanation – outlines that the user is seeing the ad because they share ‘similarities’ to that advertiser’s customers.
In the WAIST feature, these categories were not exclusive. All explanations had a ‘core’ explanation that referred to some user characteristics, and then some also had a ‘custom’ or ‘lookalike’ explanation. No ad we found had both a ‘custom’ and a ‘lookalike’ explanation.
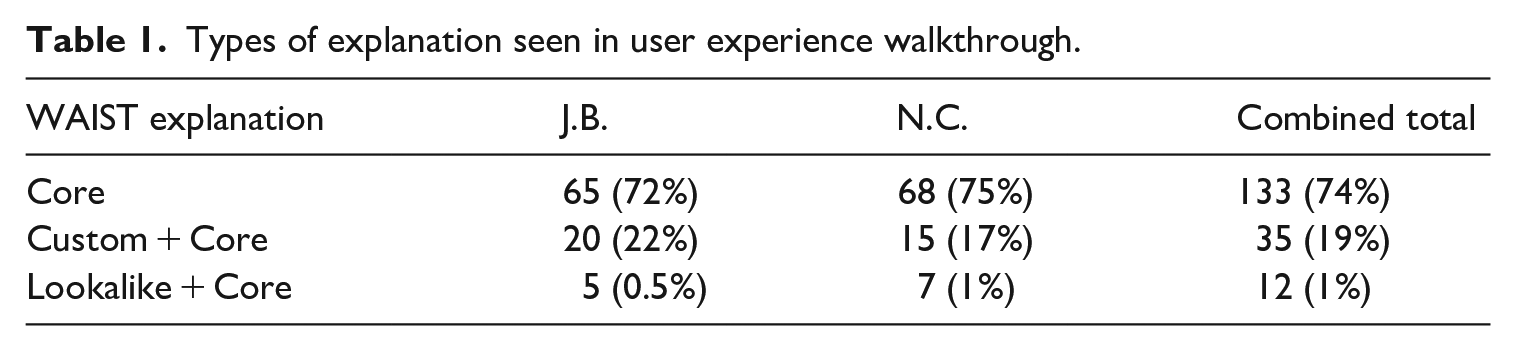
Table 1 summarises the findings from our walkthrough in terms of explanations received: while there was some variation between our two sets of results, in combination, 74% of the ads we collected contained only a ‘core’ explanation, 19% had a ‘custom’ and ‘core’ explanation and only 1% had a ‘lookalike’ and ‘core’ explanation.
Types of explanation seen in user experience walkthrough.
The ‘core’ explanations we saw took one of two forms. They either only contained basic demographic information like age, gender and location, or they also added descriptive interests related to lifestyles, tastes, pastimes and so on. For one of us, 66% of the ‘core’ explanations contained only basic demographic information, for the other, it was 82%. For example, an ad for the Queensland Performing Arts Centre (QPAC) came with the explanation (shown in Figure 1) beginning ‘qpac [sic] wants to reach people like you who may have . . .’ followed by two explanation lines, each beginning with an in-line icon that stands in for a WAIST category: the first, with a ‘person’ icon, is ‘set their age to 18 and older’, the second, with geolocation icon in the form of a map pin, is ‘A primary location in Australia’.
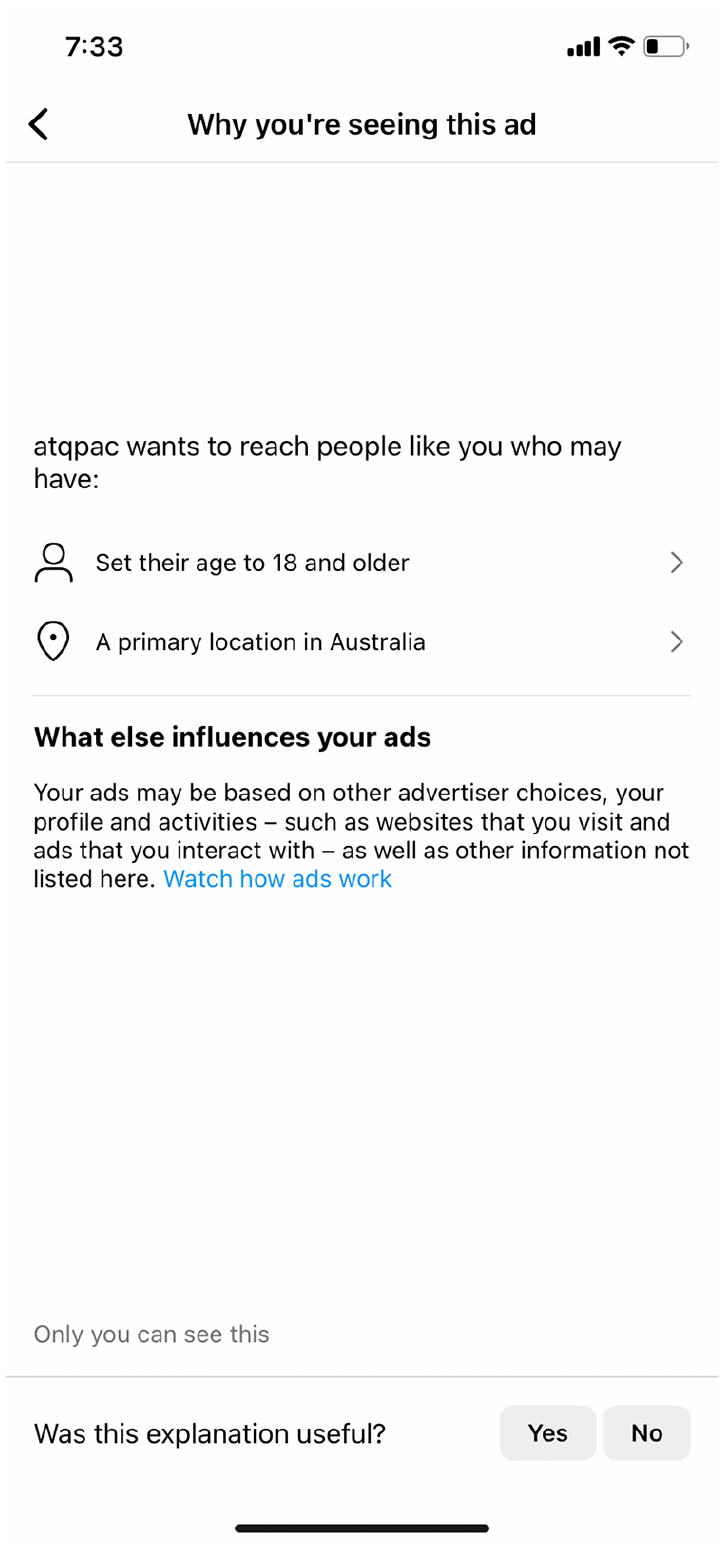
WAIST explanation card for a QPAC advertisement.
This explanation implied the advertiser was using the ‘core’ audience tool – but we believe it obscured how the ‘core’ audience operates. That is, even if starting with the ‘core’ audience tool, we know the Meta ad system uses machine learning to ‘optimise’ the ad placement – to ‘tune’ audiences over time, by refining the associations between users who have engaged with that ad or advertiser. The ad placement process might have begun with the advertiser specifying only a basic description of the audience such as their age, location and/or gender. But, given how implausible it is that an ad for a performing arts venue in Brisbane would be indiscriminately shown to Australians aged over 18, two alternative scenarios are more likely: either the advertiser did enter more precise targeting information, and the explanation doesn’t disclose it; or the advertiser did start with just age and location as the only targeting criteria and left Facebook to ‘optimise’ the ad placement based on who was clicking on that ad or had clicked on similar ads, and in that process many other ‘interests’ would have been salient to the ad placement. While the explanation is technically correct, it obscures by omission the machine learning process that drove the ad placement in practice.
The other form the ‘core’ explanation takes includes a descriptive interest. The WAIST card for an ad for Woxer (a contraction of ‘women’s boxers’) underwear indicates that the advertiser wants to reach people who may have ‘shown interest in Pride’ and ‘Set their gender to female and age to 18 and older’. This explanation illustrates how an interest like ‘Pride’ is used as a proxy for a particular sexual or gender identity – given the context of our walkthrough, it also demonstrated to us that Facebook’s hardwired binary gender trumps user-chosen gender descriptors because J.B.’s gender is not set to female in Instagram, where this instance of the ad was seen.
The ‘custom’ explanation is the most definitive because you are told a particular advertiser shared a particular kind of data with Meta that enabled them to ‘match’ you. These ads are often for businesses where users regularly shop, or where users have given them personal information as part of making enquiries. The WAIST card for N.C.’s ad for City Cave Paddington is an example: the advertiser wants to reach ‘people like you’ who may have ‘been on a hashed list that City Cave Paddington used’, ‘set their age to 18 and older’ and set ‘a primary location in Australia’. When N.C. clicked to the next screen from the ‘hashed list’ explanation they received further information as follows: city.cave.paddington uploaded a hashed list with your information to Meta technologies that we matched to your profile. Tfm.digital uploaded a hashed list with your phone number to Facebook. We matched the phone number with you. City.cave.paddington used this hashed list to show you an ad.
TFM Digital are a marketing agency based in the same city as the advertiser. They would have been given data by the advertiser to build the custom audience. In an example of a ‘lookalike’ WAIST explanation, an ad for a BMW electric vehicle included the explanation that BMW wanted to reach ‘people like you’ who may have ‘similarities to their customers’ as well as ‘set their age to 30 and older’ and had ‘a primary location in Australia’.
Looking across the audience types and corresponding explanations, the ‘core’ and ‘lookalike’ explanations were the most vague and partial. The ‘core’ explanations implied that an advertiser explicitly ‘selected’ this interest in choosing to target their ads. For instance, if Woxer are advertising pride-themed underwear they might explicitly select ‘pride’ as an interest that describes their target audience. But it isn’t clear if it might also be the case that the WAIST explanation was naming ‘pride’ as the interest that helped Meta optimise the audience – that people who shared an ‘interest’ in pride were proving to be most likely to click on the ad. This suggests that the descriptive interests generated and attached to our profiles, and then used to both target ads at us and explain why we are seeing those ads, are not necessarily ‘causal’ explanations but rather indications of the associative logic of the model.
The other way in which the ‘core’ explanation seemed partial is that it often listed only age, gender and location. Was this, we were left wondering, because advertisers do a broad audience buy and then let the tool ‘optimise’ that audience over time? Or, were the advertisers’ more specific targeting criteria choices being obscured? Sometimes the ‘core’ audience explanations seemed implausible. For instance, N.C. saw many ads for sneakers, the WAIST explanations for which said they were seeing them because of their age and location – but they recently had been searching for a new pair of sneakers and were seeing brands they’d specifically searched for (as well as new ones). It seemed implausible that age and gender were the most salient attributes here: surely it was the pattern of sneakers ads they were clicking on and online stores they were visiting?
As of February 2023, Meta was explaining to advertisers that the difference between the ‘core’ and ‘lookalike’ audience is that the ‘lookalike’ process begins with the advertiser pointing Meta’s ad model at an already-existing audience that it then emulates, while ‘core’ begins ostensibly with the specification of some descriptive interests (Meta Blueprint, 2023). Regardless of the starting point, Meta uses a similar machine-learning process to optimise the ad delivery over time. Meta (2023f) explained that a continuous, live ‘ad auction’ takes place on the platform to determine which users see which ads to benefit both users and advertisers. While optimisation means users see ‘relevant ads’ that they consider to be ‘high quality’, for advertisers, it means they ‘meet their goals at the lowest cost’ and the ad ‘delivery system uses machine learning to improve each ad’s performance’. This optimisation process refines the ad placement over time: Each time an ad is shown, the delivery system’s predictions of relevance become more accurate. As a result, the more an ad is shown, the better the delivery system becomes at determine where, when and who to show the ad to minimise the cost per optimisation event. We call the period where the delivery system still has a lot to learn about an ad the learning phase. (Meta, 2023f)
If we return to the ‘core audience’ explanation with the understanding that, while advertisers might specify interests to begin with, but Meta then uses machine learning to optimise the ad placement over time, it isn’t clear if the interests named in the explanation were those actually selected by advertisers or those that ended up being salient in the ad placement. Even if the WAIST explanation only ever stated interests specifically named by advertisers, many other interests that Meta associated with our profiles would have informed the ad placement.
We encountered some explanations that seemed puzzling or downright wrong in the context of our identities and everyday practices. For example, an ad N.C. received for Clark’s children’s school shoes had a ‘custom’ audience explanation indicating they had seen it because they had interacted with that brand’s Facebook and Instagram page, but they were certain this wasn’t the case, having bought these shoes for their child in a department store, but not having searched for them beforehand or ever interacted with their Facebook or Instagram accounts, nor was the brand listed in their Facebook ad interests data. They did, however, take a photo of the shoes and send it to their partner using the Meta app Messenger, whereupon they exchanged messages containing the brand name. It seemed far more likely that they were seeing the ad because of the Messenger exchange, or a store beacon, or because when they purchased them the cashier asked for their department store membership card and they gave them their partner’s mobile number as a way to locate the card on the system. We include this story here to highlight the kinds of vernacular theories (Bishop, 2019) that users (including ourselves) come up with in the face of the aura of ‘dark magic’ and mystery surrounding targeted advertising (on eavesdropping, for example, see Kröger and Raschke, 2019; Lau et al., 2018) – a mystery which the WAIST feature does not always help to clear up.
Patterns in WAIST Data from the Australian Ad Observatory
To achieve a level of observability (Rieder and Hofmann, 2020) above that of the individual user experience, additional approaches are required. Among others (see, for example, Andreou et al., 2018, 2019), one such effort is our own Australian Ad Observatory project, which draws on a browser-based data donation approach to investigate how Facebook ads are targeted to Australian users (Burgess et al., 2022; Angus et al., 2024).
When signing up to the project, participants complete a short demographic questionnaire that is used during data capture to link results to the demographic characteristics of the users who encounter them (including age range, gender, postcode, education level, annual income range, main language spoken, employment status, political preference and whether they identify as Indigenous). These optional responses are valuable in investigating whether and why different demographic groups encounter different advertisements but do not link our participants with their Facebook profiles, and nor do we know whether, for example, the gender they specify for our project differs from the gender option chosen for their Facebook account or the one advertisers target them under (binary gender remains a persistent characteristic of the Meta ad system, see Bivens, 2017). Users are assigned a unique private key that links their experience of Facebook advertising to a dedicated marker.
Once registered, the browser plugin triggers an ‘observation’ whenever a personalised ad is encountered through normal scrolling of Meta’s Facebook News Feed feature by the user. The plugin also provided our participants with a dashboard that enables them to monitor and reflect on the advertising that is targeted at them. By February 2023 the Australian Ad Observatory had 1817 participants. The demographics of our participants mostly follow that of the Australian Facebook population (see Hughes, 2023), with an oversampling of older demographics and skew towards male. As of February 2023, we had gathered a total of 336,568 unique ads via 789,557 observations. Many of these observations include WAIST metadata attached to the ad.
Ads can contain combinations of more than one of the codes identified here: an exclusive list of such combinations is provided in Figure 2.
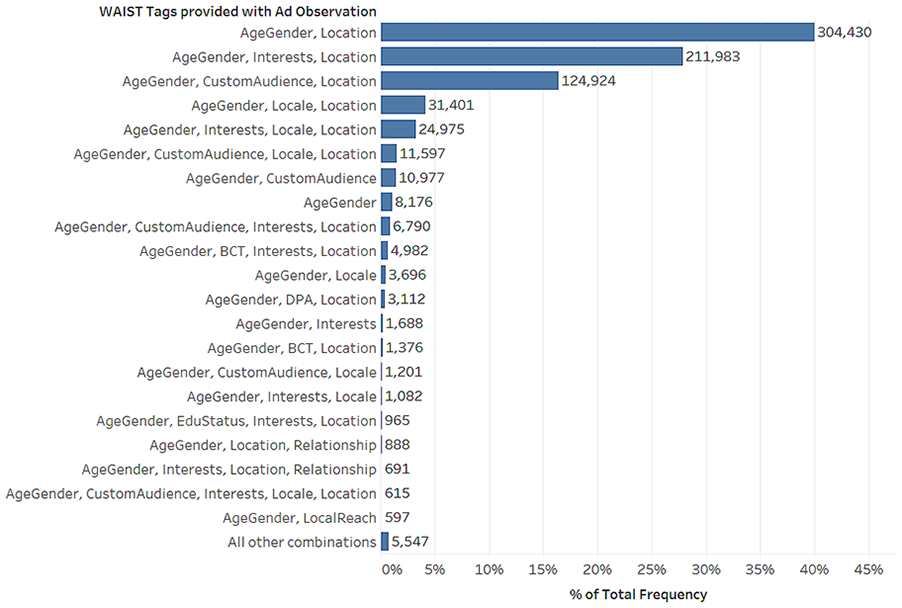
Exclusive combinations of WAIST tags.
In the previous section, we drew on a small-scale exploration of our own user experience to illustrate the basic and often partial explanations offered in the user interface for the WAIST feature; the explanations reflected the ‘core’, ‘custom’ and ‘lookalike’ audience products sold to advertisers.
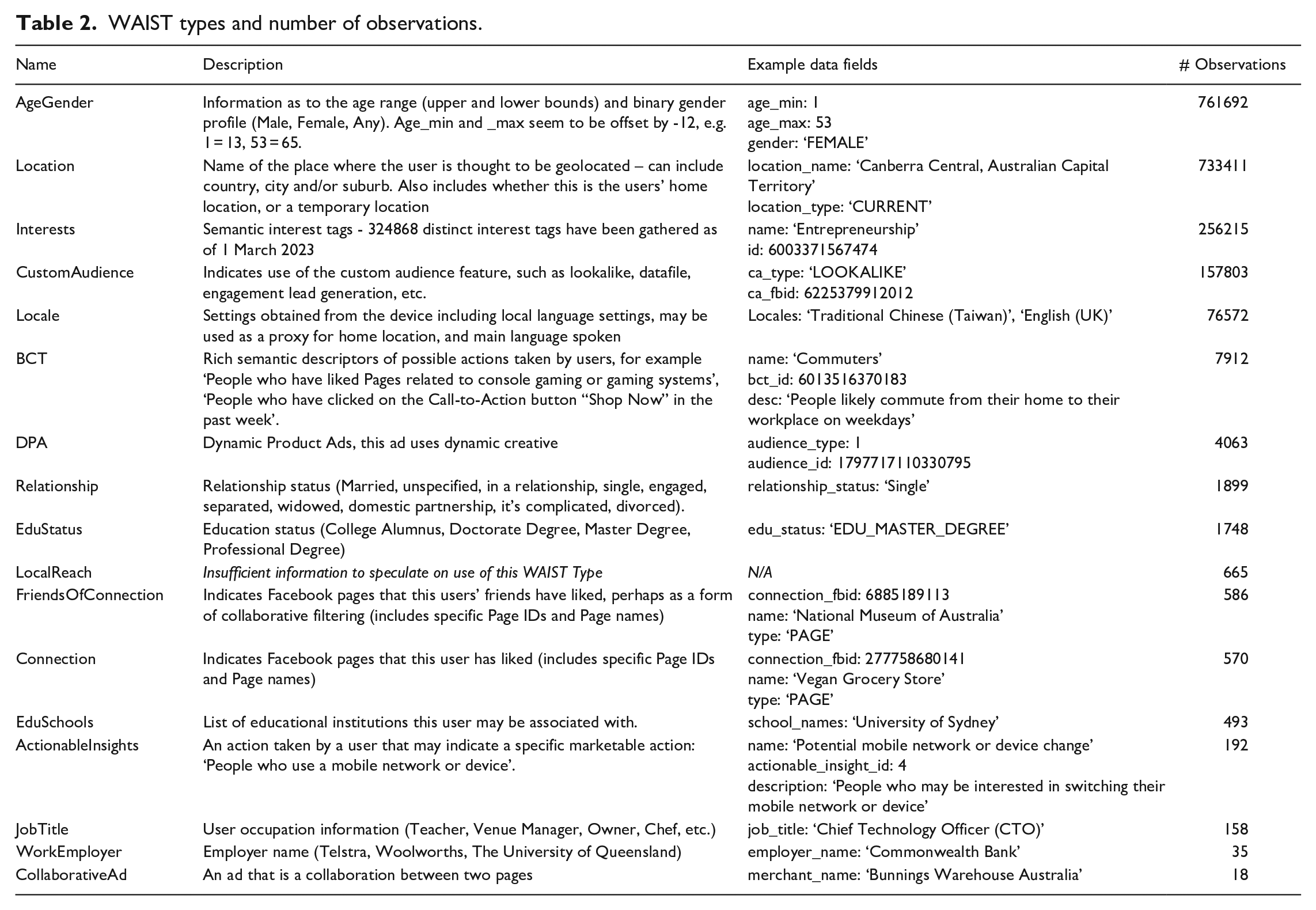
But, we can see from the Ad Observatory data that the WAIST metadata attached to the ads indicates a wider range of potential categories. There are 17 distinct WAIST codes present in the observation data we collect, although some are used frequently and others rarely, as detailed in Table 2. In terms of which explanations appear most frequently and in what combinations, the patterns in the 789,557 observations gathered to date reflect the patterns we observed in our own walkthrough and qualitative data analysis. As seen in Figure 2, the most common combination of WAIST metadata attached to ads is AgeGender and Location, accounting for 40% of all observations, followed by AgeGender, Location and Interests, accounting for 27% of observations. This combination maps onto the ‘core audience’ explanation we saw in our walkthrough where users are being told they are seeing the ad because of their age, gender, location and/or particular descriptive interest. Custom and lookalike audience explanations combined account for 20% of observations. Although presented to both users and advertisers as two separate kinds of audience (including in our own investigations), in the WAIST metadata attached to the ads as served to users on Facebook, ‘lookalike’ is represented as a sub-class of the ‘custom’ audience explanation.
WAIST types and number of observations.
The WAIST ‘interests’ data illustrate potential associations with identity categories. For example, Figures 3 and 4 list the top 30 most prevalent ‘interests’ included in ad explanations for ‘male’ and ‘female’ participants. While they share many interests in common such as ‘health & wellness’, ‘online shopping’ and ‘physical fitness’; the lists are marked by strongly gendered, mainstream product categories, in turn reflecting common gender stereotypes. Among the most prevalent ‘male’ interests are ‘camping’, ‘outdoor recreation’, ‘investment’, ‘technology’, ‘adventure travel’, and ‘sustainable energy’. Prominent in the ‘female’ list are ‘gardening’, ‘dogs’, ‘interior design’, ‘beauty’, ‘yoga’ and ‘crafts’. As the model actively produces these descriptive interests, they may come to function as proxies for existing social identity categories, rather than displacing their use in data profiling (as the discourse of ‘postdemographic’ audience measurement implies). While our data analysis here shows how interests might represent gender identity by proxy, we can think about how the model might do this overall across many other aspects of identity (Phan and Wark, 2021).
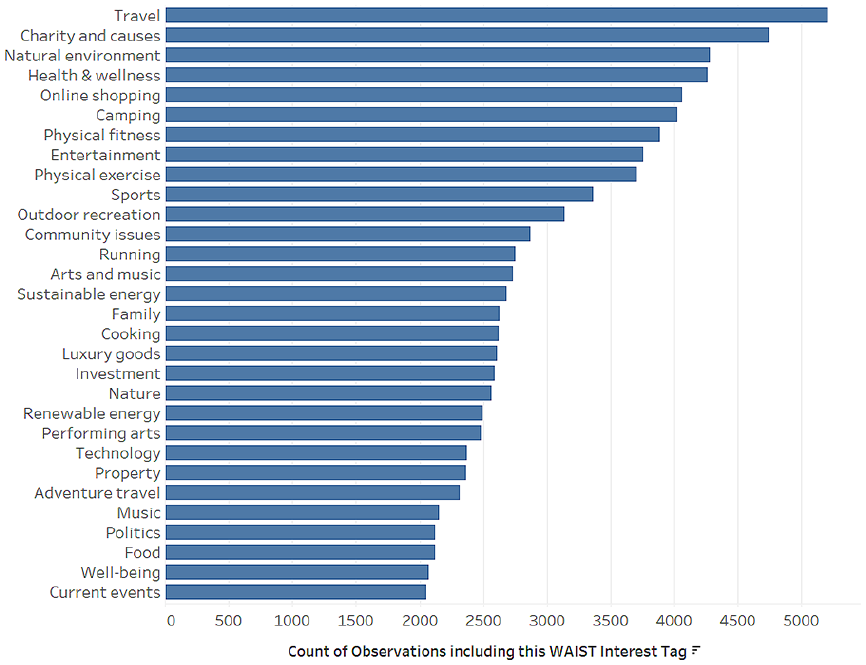
Top 30 interests (Male).
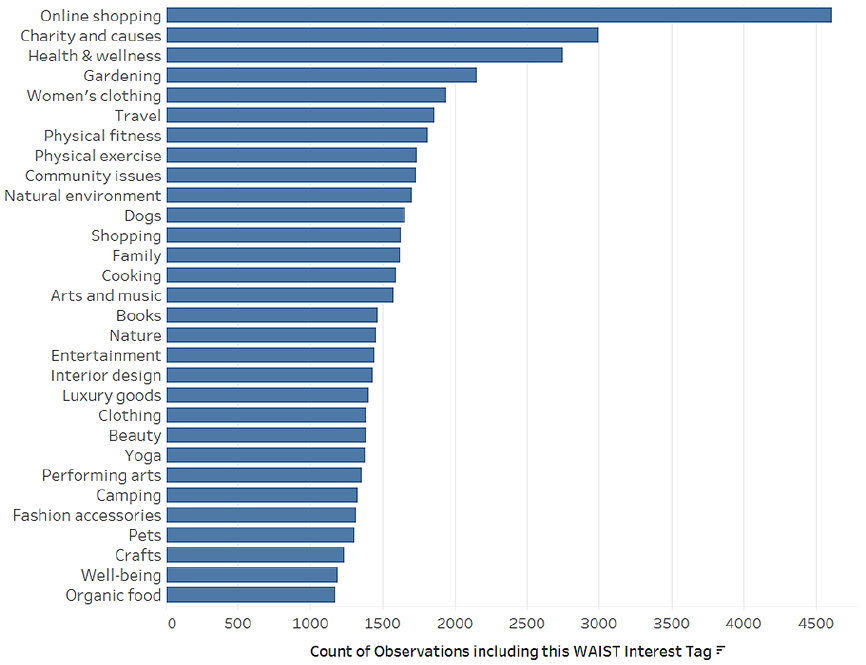
Top 30 interests (Female).
Our analysis of the WAIST metadata attached to our observations in the ad observatory illustrates that the limitations of the explanations we encountered in our individual walkthroughs are repeated at scale.
Forty per cent of the observations indicate the ad was targeted on the basis of age, gender and location. A further 27% indicate they were targeted based on some descriptive interest. This implies a linear or causal explanation for how targeted advertising works. These explanations both at the individual level, and at the larger social level, do not enable us to understand how the ad model optimises and tunes audiences over time. On the face of it, 40% of Facebook ads being targeted based only on age, gender and/or location is implausible. On the other hand, it might well be the case that advertisers do increasingly target using only these generic criteria. This could be for two reasons: one is that many advertisers seek a broad mass audience, especially for brand or product awareness campaigns; the second, and more important possibility, is that increasingly, the best results are gained by ‘tuning’ an audience from very broad criteria down to a more specific audience. Facebook’s updates to the description of its ad targeting to advertisers in early 2023 affirm this logic, suggesting that advertisers start with the ‘core’ audience tool to build and refine audiences over time that they can then use to create ‘custom’ or ‘lookalike’ audiences. That is, while the ‘lookalike’ explanation shows up for only about 1% of ad observation instances in the Australian Ad Observatory, in practice, all ads follow the ‘lookalike’ logic of continuous optimisation.
Through the WAIST feature, we can click through to a list of ‘topics’ that are attached to our profile, but this only enables individual reflection on whether these interests are ‘relevant’ to us. They would be more meaningful if we could understand them in relation to other users. Then, we could begin to see how Meta ‘learns’ who we are and who we look like and see how that is reflected in the feed of ads that we see. This becomes crucial for understanding how and whether advertising works as a cultural technology that tunes, amplifies or disrupts existing identity norms and (often stereotyped) patterns of consumption.
Conclusion
In this article, we have integrated am exploratory walkthrough and critical discussion of the WAIST feature from a user experience perspective with the analysis of data from the Australian Ad Observatory. We aimed to provide what we believe is the first scholarly account of WAIST’s affordances and limitations for explainability and its potential to contribute to public oversight of Meta’s advertising system.
The WAIST feature is a dynamic, ever-changing product of Meta’s efforts to shape and manage public understandings of and concern about their advertising model (Andreou et al., 2018). Like the ‘flags’ that enable users of digital platforms to report offensive or harmful content, WAIST data are ‘highly strategic’ devices that are created by platforms to manage the ‘negotiation around contentious public issues’ (Crawford and Gillespie, 2016). In practice, WAIST data prefigure and encourage particular theories of how the advertising model works: for example, that you are seeing an advertisement because an advertiser chose to target you based on some particular interests you have, evidenced by your own activities.
While earlier research showed that WAIST tools offer incomplete explanations that ‘reveal only part of the targeting attributes’ the ad model uses (Andreou et al., 2019), we understand the pragmatic realities of balancing user experience with user education – and as the complexity of the WAIST data structures discussed above demonstrate, ‘complete’ information might add more confusion than understanding. Of course, without further research, we have no way of knowing how many users engage with the WAIST feature at all – but this would be useful to find out in future work.
We have highlighted a number of puzzling gaps between the explanations WAIST provides and the products offered to advertisers by Meta. As one example, regardless of whether WAIST data tell users they were targeted as part of a ‘core’, ‘custom’ or ‘lookalike’ audience, the ad placement was driven by a dynamic, associative machine learning process. In this context, WAIST data might end up playing an obscuring rather than clarifying role by maintaining the fiction that the targeted advertising model of digital platforms still works much the same way as it did a decade ago, where advertisers had to ‘know’ who their target audience was and then ‘describe’ that target audience to the ad model. This created a public understanding of digital advertising as ‘hyper-targeted’ – that advertisers could now target us on very granular characteristics, that we were monitored as we used digital media platforms, and this revealed our preferences, which, if named by an advertiser would lead to us seeing an ad. The digital advertising industry presented this model as both organically meeting the needs and serving the interests of consumers by serving them relevant ads, while at the same time making those consumers available for behavioural manipulation by advertisers (Darmody and Zwick, 2020). We have also identified some potential examples of how the newer, more dynamic advertising model might reproduce categories like race, sexuality, gender and class – either on the basis of personalised ‘interests’, or as a by-product of other patterns of ad delivery, rather than via the explicit targeting of demographic niches (Phan and Wark, 2021).
To return to the normative and pragmatic criteria around explanatory AI we rehearsed in the Introduction, for the WAIST feature to be useful as a form of automated explanatory communication – beyond a simple notification that automated processes are at work – it would have to meet criteria of accuracy and completeness, meaningfulness and responsiveness.
At the most basic level, the ‘Why am I seeing this’ information would need to accurately reflect advertisers’ targeting parameters. This would require completeness – that is, the full set of parameters enumerated by the ad purchaser. A very high-level summary of these parameters is unlikely to satisfy this criterion. Thus, a user may be told that she is seeing an ad because she is an adult living in Australia. While this might be accurate, it is likely to omit important additional information – such as the fact that the ad was targeted based on recent browsing behaviour, party preference or any number of other details about the user.
Even this information, however, may be insufficient to learn how an ad is targeted in practice. Facebook’s algorithms can shape the audience by optimising the ad delivery based on the past performance of similar ads (Ali et al., 2019). The algorithms have also been demonstrated to target user ethnicity based on the inferred ethnicity of people portrayed in the ad content (Kaplan et al., 2022). In other words, there is no simple one-to-one correspondence between what advertisers ask for, in terms of audience and what they get. Completeness would then mean providing data not just about which audiences advertisers have ‘bought’ but also a breakdown of the actual audience to whom the ads were delivered. The question that emerges, then, is whether WAIST information simply reflects elements of the ad purchase (that is, criteria identified by the advertiser) or whether it also captures (automated) judgements made by Meta itself about who will be an optimal audience for the ad within the parameters set by the advertiser. Thus, even when an advertiser does not specify a gender skew for a particular ad, the algorithm might introduce one – in cases where gender bias is an ethical or legal issue (e.g. employment advertising), it would be important to know where to assign responsibility for the bias.
Even at the individual level, targeting information about a single instance of a single ad are superficial and brittle in the context of the overall pattern and sequence of ads over time, and this is where WAIST feature falls far short of a meaningful explanation. Moreover, the form of the explanations imply linear causality (‘you are seeing ad A for reason B’) that is little more than fiction. For example, the WAIST ‘interests’ are misleadingly named – they are not things a user is actively interested in, rather they are semantic ‘nodes’ that associate a user with an ad or advertiser in vector space. In an earlier version of Facebook’s algorithm they conceptualised this as ‘affinity’ – and in fact, that would be a more accurate explanation of how the ad model works. The third criterion we discussed in the Introduction, that is, the extent to which explanations work as an aid to user agency – is represented in the WAIST feature by the affordances that enable users to tweak ad preferences, set up to allow users to fine-tune the ad customisation process in keeping with their preferences – albeit limited to questions of individual relevance, convenience and privacy.
The WAIST feature is not in itself sufficient to address societal-level concerns, such as issues related to predatory or manipulative targeting, discrimination and harmful content. These are, at least in theory, addressed by Meta’s (2023g) advertising policies, which ban violent or graphic advertising, discrimination on the basis of protected categories, and ads for harmful or unsafe products; and users can deploy tools like the ‘Report ad’ button on their own behalf. However, there are social concerns that remain beyond the scope of these policies – such as, for example, the potential for the model to learn consumers have a preference for gambling or alcohol, or are high-volume consumers of these products, and then disproportionately target them. Moreover, even when it comes to Meta’s stated policies, the WAIST information will not necessarily be useful in providing users with the ability to identify instances when these rules have been violated – which limits the function of this data for accountability.
For the system to enable accountability beyond the individual user, detailed information about the intended and actual audiences would need to be publicly available through, for example, the Facebook Ad Library. But, at the moment, a paradox of Meta’s ad transparency tools like the Ad Library and the ‘Why Am I Seeing This Ad?’ feature is that the library enables a public exploration of the content of advertising, but information about the targeting of ads is only available to individual users. To understand the power of algorithmic advertising though, we need to be able to publicly observe the larger patterns of who sees what ads. Knowing that one user has been served an ad because of a particular demographic attribute (age or gender, for example) is not the same as also knowing that others with different attributes have simultaneously been systematically excluded – a fact that might provide evidence of discrimination. The critical challenge is to develop forms of transparency for both advertising content and targeting at scale.
In normative terms, then, if advertising-supported platforms want to provide explanations that improve user experience, support consumer rights and enable public transparency, they would need to provide, for each ad and for each instance of the ad being served to a user, a copy of the ad, and complete information about not only the ad purchase (the intended audience) but also the ad delivery (the actual audience). Ideally, users should also be provided with mechanisms to copy and store the ad and explanation for later reference. Such mechanisms could then be used in participatory research that goes deeper into how ad targeting relates to everyday life and identity than we have been able to do here and would be extremely useful as a supplement to co-walkthrough or ‘scroll-back’ interviews (Robards and Lincoln, 2017), for example. Access to their own archives would provide a major boost to data donation projects that could help support public understanding and collective action – and, as recent design experiments suggest, may even improve the trustworthiness of platforms from a user perspective (Barbosa et al., 2021).
Footnotes
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship and/or publication of this article: J.B. and D.A. have consulted in an advisory capacity with Meta Technologies.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This article reports on research that was supported by the ARC Centre of Excellence for Automated Decision-Making and Society (ADM + S) and partially funded by the Australian Government through the Australian Research Council (project number CE200100005).