
Abstract
This study evaluated the intended and unintended effects of Instagram’s content moderation on #coronavirus for both the short- and long-term effects on misinformation and anti-Asian sentiment. We performed manual coding of images (N = 9648), and a series of supervised machine learning methods to classify three waves of comments (N = 22,676) published in 2020 on Instagram. Welch’s F tests were used to compare misinformation, emotions, toxicity, and identity attack across three time periods. The results showed that hashtag moderation had an intended effect in reducing misinformation, and an unintended effect in reducing anger, fear, toxicity, and identity attack. Images with people of East Asian descent were associated with more anger, fear, toxicity, and identity attack than images with people of other races. Prior to content moderation, misinformation was associated with identity attack. Stigmatization on social media, and content moderation of misinformation and hate speech are discussed.
Keywords
Social media companies embarked upon perhaps the largest effort to moderate content on platforms in response to the infodemic caused by the surge of user-generated content during the coronavirus disease (COVID)-19 pandemic. A portmanteau of “information” and “epidemic,” infodemic is the rapid dispersion of a plethora of information including inaccurate information that makes it difficult for the public to distill the essential facts and solutions for COVID-19 (World Health Organization, 2022). Instagram experienced unprecedented traffic early on in the pandemic (Meta, 2020). In response, on 10 February 2020 Instagram implemented a series of content moderation techniques for users who click on the #coronavirus hashtag (Chen, 2020). Because social media companies are not obligated to disclose its information practices, little is known about what has been the most significant intervention to moderate user-generated content. Meta only divulged the amount of content it removed, such as between April and June 2020, when 7 million posts identified as COVID-19 misinformation were removed from Facebook and Instagram (Paul and Vengattil, 2020). Beyond disclosures of the amount of content removal, there is no independent evaluation of the impact of the Instagram content moderation in terms of before versus after implementation of content moderation techniques.
While the intended effect of the Instagram content moderation was to reduce COVID-19 misinformation, the history of pandemics suggests that unrest, fear-mongering, and targeting blame toward specific groups of people are unfortunate common hallmarks of pandemics (White, 2020). The societal response to COVID-19 followed its pandemic predecessors with increases in anti-Asian sentiment—especially sinophobic scapegoating—in the form of toxic speech on social media (Tahmasbi et al., 2021) as well as a 339% increase of hate crimes against Asians in the United States (US) in 2021 (Levin and Venolia, 2022). The then US president Donald Trump calling the coronavirus the “kung flu” and the “Chinese virus” only fueled the anti-Asian vitriol (Tahmasbi et al., 2021) and stigmatization of people of Asian descent (Roberto et al., 2020).
This study aims to test the intended effects of Instagram #coronavirus content moderation effort to reduce misinformation, and its unintended effect on anti-Asian hate content in both the short- and long-term. We conceived the Instagram redirect for #coronavirus as a technological intervention, which was primarily designed and implemented to reduce misinformation. While misinformation and toxic hate speech are generally treated as distinct types of content for moderation (Kim and Kesari, 2021), there is much overlap such that when platforms target one content, unintended effects are likely to occur for the other. Relatedly, we also seek to test if stigmatization occurs with image posts that feature people of East Asian descent.
Content moderation of misinformation
Content moderation is defined as the organized practice of monitoring and screening user-generated content that is posted on social media platforms and Internet sites (Wright, 2006). Prior to the ambitious content moderation during the pandemic, social media companies were already compelled to reign in on user-generated content. Because of increased online incidents of trolling (Sobieraj, 2018), racist speech (Inara Rodis, 2021), promotion of anorexia (Gerrard, 2018), and misinformation (Vosoughi et al., 2018), social media platforms explored a hybrid process of content moderation with inputs from both human moderators and artificial intelligence (AI) algorithms (Gillespie, 2020). Of the externalities that compelled social media companies to employ content moderation, misinformation is arguably the leading reason.
Misinformation is defined as information that is factually inaccurate; and social disruption and uncertainty tend to sow misinformation (King and Wang, 2021). Content moderation for misinformation occurs in different forms including fact-checking (Kwanda and Lin, 2020), interactive blurring designs (Das et al., 2020), trigger warning labels (Kanai and McGrane, 2021), and removal of content (Laaksonen and Porttikivi, 2022). While misinformation flourished during the pandemic (O’Neil et al., 2022), studies generally do not compare the level of misinformation before and after a social media platform deploys content moderation. With the exception of a few studies (Gerrard, 2018; Papakyriakopoulos et al., 2020), there is limited research that has empirically evaluated the effects of social media content moderation.
The efficacy of content moderation in reducing misinformation has been questioned. The Instagram algorithm continued to recommend posts with misinformation through its “suggested post” and “explore” sections (The Center for Countering Digital Hate, 2021). Second, increasing reliance on AI models has led to some accurate information erroneously flagged as misinformation. Particularly during the first year of the pandemic, these mistakes were the result of heightened traffic on social media and reduction in human moderators because of COVID-19 shutdowns (Bond, 2020). The use of warning labels as a moderation technique, called “soft moderation,” was also prone to errors where 7.7% of misinformation content failed to have a warning label but 37.3% of benign content included warning labels (Ling et al., 2022). Third, there are ways to circumvent hashtag moderation, which is the type of moderation employed by Instagram for #coronavirus. While hashtag moderation makes it easier to identify content than non-tagged content, people have bypassed moderation by using signaling techniques (Gerrard, 2018) and employing linguistic variants (e.g. anorexia vs anorexiaa) (Chancellor et al., 2016). Even the banning of hashtags on Instagram for pro-eating disorders (pro-ED) did not prove effective in stopping pro-ED posts (Gerrard, 2018). These mixed findings on content moderation efforts from social medial platforms and the limited research on content moderation of image-based content behoove the question if the Instagram content moderation on #coronavirus was effective in reducing COVID-19 misinformation.
Emerging content moderation techniques: hybrid use of health communication campaigns
The limitations of hashtag moderations appear to influence Instagram’s approach to COVID-19 content in that it did not ban hashtags, but instead employed a variety of other techniques. Instead of directly listing posts related to coronavirus, a pop-up window appeared with a link to the US Centers for Disease Control and Prevention (CDC) website with a message that encouraged users to find credible information by visiting the CDC website. At the bottom of the pop-up window, users may choose to proceed to view posts with the #coronavirus hashtag (see Figure 1). In addition to the educational pop-up, Instagram also initiated “proactive sweeps” by removing content that their global third-party fact checkers deemed to be inaccurate (Meta, 2020).
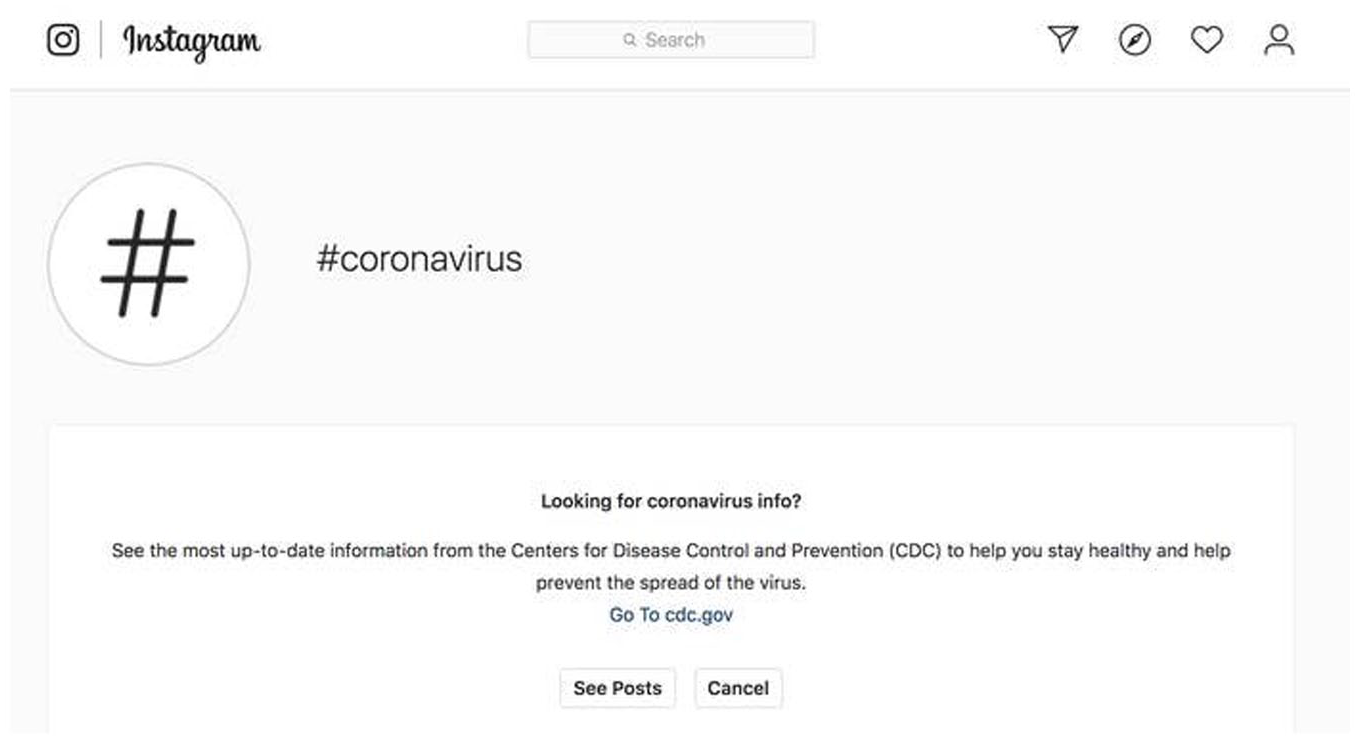
Pop-up window that appears with #coronavirus hashtag on Instagram.
Instagram utilized a combination of a hard moderation technique (i.e. removal of content), and a modification of a soft moderation technique (i.e. a pop-up warning label) with a message that is akin to traditional health communication campaigns where there is a cue to action for the audience to adopt a specific behavior (i.e. go to CDC.gov). In particular Instagram utilized the pop-up feature of its warning labels, with the message not being one that notifies users that the information may conflict with CDC guidance, but one that features components of the Health Belief Model (Janz and Becker, 1984) including a cue of action (i.e. prompt to the CDC website) with emphasis on the perceived benefits of the behavior adoption (i.e. “to help stay healthy and help prevent the spread of the virus”). Thus, this Instagram content moderation is a combination of hard moderation and modified soft moderation techniques.
Unintended effects: toxic comments and emotional response to Asians in Instagram images
Technological interventions often lend themselves to secondary unintended effects. The sociologist Robert Merton was the first to systematically examine “unanticipated consequences” (Merton, 1936). Occurring simultaneously with the implementation of the Instagram content moderation was a spike in crimes targeting Asians (Levin and Venolia, 2022), and vitriol targeting Asians on social media (Tahmasbi et al., 2021), resulting in a “secondary epidemic” of COVID-19 racism toward Asians (Ong and Lasco, 2020). Digital racism can be particularly toxic with the creation of fake accounts using images and names of Asian people that foster racist and anti-immigrant sentiments (Asian American Disinformation Table, 2022).
Because the increase in anti-Asian sentiment was sparked by the pandemic and associated with coronavirus-related hashtags on Twitter (Hswen et al., 2021), it is likely that any technological intervention related to content moderation of #coronavirus would have an impact on anti-Asian sentiment on Instagram. That social media platforms often moderate content based on the type of content (e.g. misinformation, hate speech) has led to two separate streams of research, yet there is increasing evidence that there is much overlap in misinformation and hate speech (Kim and Kesari, 2021). For COVID-19 in particular, and perhaps even for infectious disease outbreaks in general, people may use misinformation as a means to defend their hate speech (Kim and Kesari, 2021). That is, people use misinformation to mask their hate toward a group they blame for the pandemic.
Targeting blame on people of Asian descent occurred in 1900 bubonic plague which resulted in forced quarantines of Chinese Americans and the burning of Chinatowns in Honolulu and San Francisco. Historically, infectious disease outbreaks feed fear and suspicion toward a group often identified by race or ethnicity, who are viewed as “others,” distinct and separate from the rest of society (Censolo and Morelli, 2020). Called the “othering” hypothesis, survey research demonstrated that xenophobic behaviors are associated with anti-Asian attitudes, and that such associations are found for only attitudes toward Asians but not for other “outgroups” in the US (Reny and Barreto, 2022). Outgroups are “others” because they have an attribute that associates them to an undesirable characteristic, and race is a stigma that often differentiates in- and out- groups. A stigma is an attribute of a person that is associated with negative characteristics or stereotype (Goffman, 1963). Stigmatized groups are outgroups because they are marked and labeled to have attributes that deviate from the rest of society (Goffman, 1963; Link and Phelan, 2001).
Evidence of stigmatization of Asians during COVID-19 has been found in survey-based studies (Reny and Barreto, 2022; Tan et al., 2021), online news (Ng, 2021), and text-based social media platform such as Twitter (Fan et al., 2020; He et al., 2021; Hswen et al., 2021; Vidgen et al., 2020) and 4chan (Tahmasbi et al., 2021). Among Twitter data, hashtags can convey anti-Asian sentiment (Li and Ning, 2022), and hashtags can be stigmas whereby #chinesevirus was associated with more anti-Asian hashtags such as #bateatingchinese than non-stigmatizing hashtags such as #covid19 (Hswen et al., 2021). While there are cross-platform differences in how anti-Asian sentiment is expressed such as blaming Chinese people for the pandemic on Twitter or coining new sinophobic slurbs on 4chan (Tahmasbi et al., 2021), such differences are limited to text-based social media platforms. It begets the question that if hashtags can serve as stigmas (Hswen et al., 2021), then wouldn’t images with East Asian people do the same on social media. In the current study, we assess the association between images of East Asian people with hate speech (i.e. text of comments). In doing so, we build upon the literature by extending it to Instagram, and connecting text (i.e. hate speech) with images. In addition, whereas other studies are limited to a few weeks (Hswen et al., 2021) or months (Tahmasbi et al., 2021), our data set is longitudinal (across 9 months of 2020), and would provide a more encompassing sense of anti-Asian sentiment during the first year of the pandemic. Thus, this study contributes empirical evidence of the digital footprint of anti-Asian sentiment spurred by COVID-19 pandemic, providing further evidence of the continuing stigmatization of Asians across pandemics.
The Instagram content moderation for #coronavirus presents an opportunity to extend deindividuation effects to image posts on social media. In particular, we set this study to extend the social identity model of deindividuation effects (SIDE) (Reicher et al., 1995) by testing its explanatory power for the proliferation of hate speech toward Asians in computer-mediated communication (CMC) cyberspace during the pandemic, and for social identification in image-focused social media interactions. The traditional deindividuation theory posits that CMC offers a sense of anonymity that would encourage users to become volatile or even indulge in anti-social acts that they would not do in face-to-face communication (Spears, 2017). Critiquing and extending the earlier deindividuation theory (Le Bon, 1996 [1895]), SIDE states that users do not necessarily lose self-identity and self-control when they participate in online discussions, but “shift from the personal to the social level of identification” (Reicher et al., 1995: 177). Moreover, anonymity can support group norms when the group identity is particularly salient. According to SIDE, CMC affords not only anonymity but also identifiability. Identifiability is when the visibility of the other group members highlights the individual differences while undermining group salience, when the ability to match responses to individuals is compromised (Reicher et al., 1995). When an Instagram post features a face that appears to be an East Asian, a mental shortcut of stigma would lead the hate speech perpetrator to associate the character with a group identity of East Asians, reminding the perpetrator of their preexisting stigma about East Asians, in the premise of the perpetrator’s underlying self-categorization as a non-East Asian in-group member. However, the type of anonymity that CMC (especially social media) affords today has largely changed from the time the SIDE model was proposed. Instagram is an image-focused social networking platform where the revealing of facial or other identifiable information tends to be celebrated. Yet, users may also choose to keep their accounts private and are able to use the app with a high level of anonymity. Such shifting theoretical stances of image-based social media platforms presents a gap in current research regarding how—with a wide spectrum of anonymity—different identity-indicating images in posts (e.g. face, race) may be associated with other users’ response to the posts (e.g. hate speech, sentiments).
Race is a visible stigma that is often used to identify outgroups, and one that was arguably relied on for COVID-19. This is because while health stigmas can be both visible and invisible (Roberto et al., 2020), people with COVID-19 can be asymptomatic, making race a more accessible stigma to identify outgroups. Stigmatized groups often experience a loss of status in society, and with such devalued status comes discrimination (Link and Phelan, 2001) and aggression (Roberto et al., 2020). Evidence of stigmatization of Asians on social media has been limited to primarily text-based content (Tahmasbi et al., 2021), but given that race is a visible stigma, image posts featuring people of Asian descent would be associated with toxic speech in the comments.
Our study focuses on two responses in the comments of the Instagram posts—(1) emotions and (2) toxic hate speech. In particular, we seek to examine if there are changes in emotions and toxic hate speech over time, and if there are differences in emotions and toxic hate speech when at least one person of East Asian descent appears in the Instagram post. Emotional responses are common responses to threats (Plutchik, 1980), with anger, fear, sadness, and joy as the four main emotions commonly assessed. Each emotion has a unique behavioral expression and biological regulatory process. Anger, fear, and sadness are often conceived as negative emotions whereas joy is conceived as a positive emotion (Plutchik, 1980). Importantly, emotions—irrespective of positive or negative valence—can co-occur, and threatening events can elicit a diverse set of emotions given that people differentially appraise threats (Dillard et al., 1996; Smith and Lazarus, 1990). Because events can be complex, such as the COVID-19 pandemic, they are differentially interpreted by individuals, and thus can influence more than one emotional response (Dillard et al., 1996). Hence, co-occurrence of positive and negative emotions can be seen where a person can feel both joy (e.g. in getting vaccinated) and sadness (e.g. from the deaths associated with the pandemic) at the same time. Because of the possibility of co-occurrence of emotions, our machine learning model predicts each of the four emotions separately.
Toxicity pertains to harmful and unpleasant use of language (Sheth et al., 2022). Online hate speech is rampant in part because of the anonymity afforded by social media (Barlett et al., 2018). In particular, identity attack, a dimension of toxic online speech, pertains to the use of hateful and hostile language that is geared toward groups whose members can be characterized by a specific race, ethnicity, or other defining group characteristic (IBM, 2019). Racist online speech (Inara Rodis, 2021), the use of hateful and hostile language that targets members of a group that is defined by their race, would be an example of identity attack.
In summary, we construe content moderation as a technological intervention and we conceive our study as a natural online experiment (Leatherdale, 2019) where we evaluate the effectiveness of the Instagram content moderation in reducing the level of misinformation for both the short- and long-term effects. For unintended effects, we assessed (1) emotions (anger, fear, sadness, and joy) and (2) toxicity and identity attack. Finally, we extended the work on stigmas and hate speech to image-based content with basis in the SIDE model.
Methods
Study design
The study design is a natural experiment (Leatherdale, 2019) where 10 February 2020 represents the implementation of the Instagram content moderation. Because Instagram announced its COVID-19 content moderation plan on a weekend, on Sunday, February 9, 2020 (Chen, 2020), we chose the first business day to be the implementation day. Natural experimental studies are defined by the implementation of an intervention that is beyond the control of researchers (Leatherdale, 2019). In line with natural experiments, we did not initially conceive this study to be about content moderation and anti-Asian sentiment. Instead, the research design and purpose were determined upon knowledge of Meta’s effort to moderate coronavirus-related user-generated content. We learned about Instagram content moderation because our data collection suddenly stopped, and we learned that the Instagram Application Programming Interface (API) had changed to protect the hashtag, which was subsequently confirmed (Chen, 2020).
Critical to evaluating the effects of the content moderation is that data are collected synchronously. That is, data are collected on the calendar day rather than retrospectively. In particular for the time period prior to the intervention, data collected retrospectively would not reflect what content users were exposed to during those early months of the pandemic because the Instagram content moderation would have removed some content it deemed to be misinformation from its platform. Our data were collected synchronously at three time points: (1) before the content moderation implementation, (2) immediately after the intervention (short-term effects), and (3) six months after the intervention (long-term effects). In addition, we assessed (1) emotions (i.e. anger, fear, sadness and joy) and (2) toxicity and identity attack in the comments. Figure 2 depicts our study design, which was reviewed by the authors’ affiliated university and deemed not to involve human subjects.
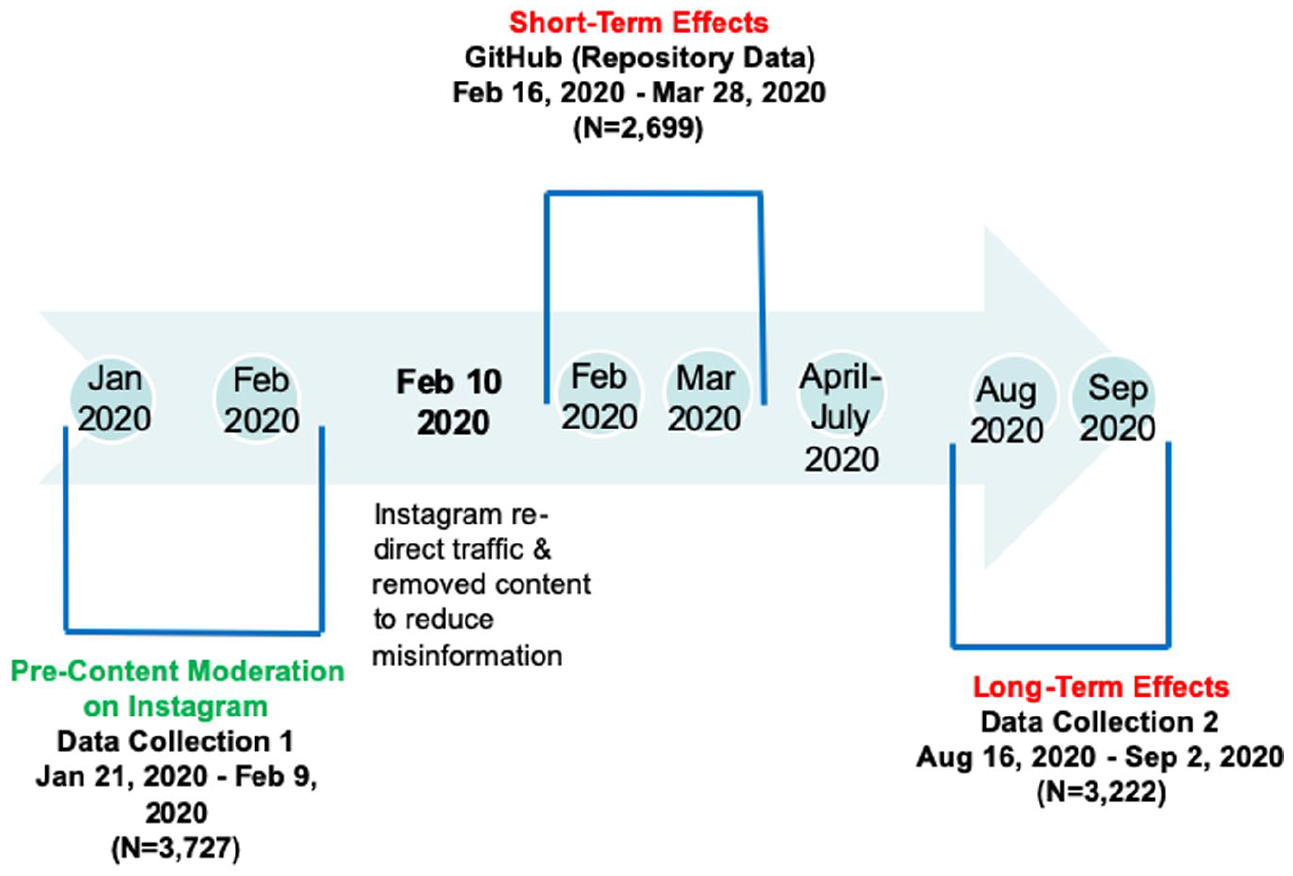
Study design to evaluate the short-term and long-term effects of the Instagram content moderation.
Data sets
We used multiple methods to collect Instagram posts that contained #coronavirus. For the pre-content moderation time period, we used the ForSight social media analytics platform from Crimson Hexagon (now Brandwatch) to download Instagram posts, after which we used the Python package Pyppeteer to collect comments associated with each of the sampled posts. ForSight utilizes Instagram API to collect data. For the pre-content moderation time period, data were collected between 21 January 2020 and 9 February 2020, resulting in 37,270 image posts with #coronavirus. We then randomly sampled 10% of the data, stratified by date, which resulted in 3727 posts for the pre-content moderation time period.
For the short-term effect time period, we used a coronavirus Instagram dataset publicly available on Github (Zarei et al., 2020). It contained 2699 Instagram posts with the #coronavirus hashtag, which were posted between 16 February 2020 and 28 March 2020.
To assess the long-term effect, we used the open-sourced Instagram scraper Instaphyte to collect Instagram posts between 19 August 2020 and 2 September 2020, resulting in 633,222 posts. To have a balanced sample size in line with the pre-content moderation sample (n = 3727), we randomly sampled 3850 posts (stratified by date), but discarded posts which were video-based as the pre-content moderation sample contained only images. This resulted in 3222 posts for the long-term effect time period. In summary, the final sample consisted of image posts (N = 9648) and the associated comments (N = 22,676).
Human annotation: coding Instagram posts and inter-coder reliability
We randomly selected approximately 10% (n = 385) of the sample stratified by date to determine inter-coder reliability for the human annotation. Upon determination of sufficient inter-coder reliability, the four coders then independently coded the remaining posts in the dataset (N = 9648), of which 4245 were relevant to coronavirus. Coders independently coded the posts (i.e. the post image and the associated caption) on five attributes, as described in Table 1, which also displays the average Cohen’s κ values for the coding categories. All Cohen’s κ values were above .70, indicating high inter-coder reliability agreement (Cohen, 1960).
Average Cohen’s κ values among four coders.

For misinformation, we operationalized misinformation to pertain to (1) whether a prevention solution in the Instagram posts is recognized by public health officials per 2020 guidelines, and (2) the presence of any of the 16 pre-identified misinformation topics about COVID-19 tracked by a social media monitoring center during the initial year of the pandemic (Carley, 2020), the World Health Organization (2020) that tracked the leading COVID-related misinformation circulating on social media at the time of the study, as well as those identified during the coding process. An aggregate measure of misinformation (presence/absence) was subsequently computed by combining this two-step operationalization of misinformation.
In determining if a prevention solution is recognized by public health officials, we first coded if a solution to prevent getting the coronavirus was conveyed in the post (yes/no), and if such conveyed solution to prevent coronavirus (in the post) is one of the solutions that was recommended from public health officials at the time of the study (yes/no). Thus, the first component of misinformation was subsequently operationalized by computing if the solution to coronavirus conveyed in the post did not meet a pre-defined public health solution per 2020 guidelines. These recommended public health solutions included hand washing, social distancing, avoiding crowds, avoid touching the face, staying home when sick, covering mouth when couching, wearing masks. Because vaccines had not been distributed during the time period of our study, misinformation to vaccine was not captured.
In determining if any of the pre-identified 16 misinformation was present, two trained coders double coded all the posts. Any disagreements were adjudicated by the lead author. Examples of these pre-identified misinformation pertained to the spread of COVID-19 (e.g. 5G, parcels from China), cures (e.g. chloroquine, drinking or injecting disinfectants such as Lysol), and preventions (e.g. antibiotics, garlic). In addition, coders identified posts that may have potential misinformation that was not in the pre-identified list. These posts were subsequently discussed and determined if they were misinformation by the research team. Examples of additional misinformation identified include COVID-19 being a bioweapon, that Bill Gates predicted the pandemic in 2018, and that eating bat soup was the cause of the pandemic.
Machine learning for coding comments
We employed two machine learning algorithms to detect (1) emotions and (2) toxicity and identity attack in the comments (N = 22,676).
Emoji customization and preprocessing
Emojis appeared in a large percentage of the comments and because emojis convey emotions, omitting emojis in emotion detection would severely limit its performance. Therefore, we transformed emojis from superficial expressions to appropriate meanings that can be understood with natural language processing (NLP), and we customized the emoji translation. We used a python package, emoji (Kim et al., 2022), to translate emojis to their surface meaning in English text strings (the function is called “demojize”). For example, “ ” would be translated into “thumbs_up.” However, this translation is a mere description of the emoji and does not convey the meaning behind the emoji. Therefore, we manually customized the translation of each emoji and combined the customized translation with the translation from the emoji python package. For example, the final translation for “” is “thumbs up approval.” We then removed the @handles and reduced multiple repetitive emojis in a comment to one emoji. For example, “
” would be translated into “thumbs_up.” However, this translation is a mere description of the emoji and does not convey the meaning behind the emoji. Therefore, we manually customized the translation of each emoji and combined the customized translation with the translation from the emoji python package. For example, the final translation for “” is “thumbs up approval.” We then removed the @handles and reduced multiple repetitive emojis in a comment to one emoji. For example, “ ” would be reduced to “.” Finally, we removed non-English text.
” would be reduced to “.” Finally, we removed non-English text.
Supervised learning for emotion detection
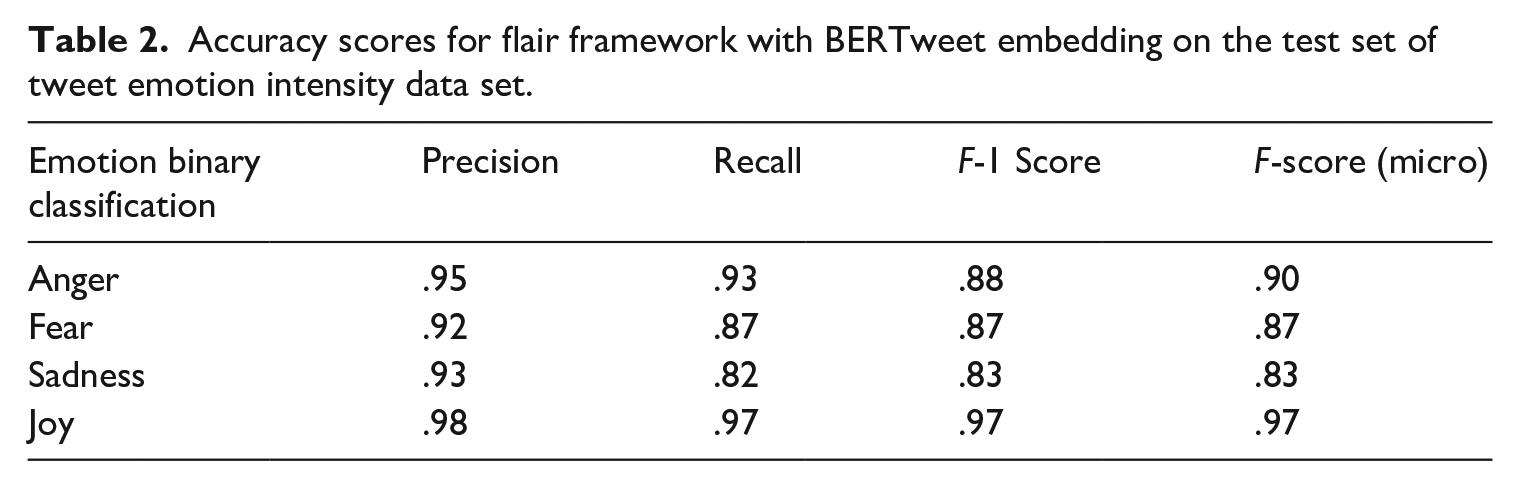
To train our model, we used the Tweet Emotion Intensity Dataset (Mohammad and Bravo-Marquez, 2017), which contains the four main emotions of joy, sadness, fear, and anger. We trained our model on the Flair framework to perform these four emotion classifications and applied the trained model on our preprocessed tweets. Flair is an NLP library built on top of PyTorch, one of the most popular deep learning frameworks. Flair allows users to combine different word/document embeddings, including Flair embeddings (Akbik et al., 2019), BERT embeddings (Devlin et al., 2018), and ELMo embeddings (Peters et al., 2018). We tested different combinations of embeddings as input features to a Long Short-Term Memory network and found that BERTweet embedding produced the highest accuracy scores. BERTweet, built on top of RoBERTa, uses a special tokenization scheme which translates emojis into text strings, and anonymizes Twitter handles into “@USER” and URLs into “HTTPURL” (Nguyen et al., 2020). The accuracy scores for our model using the Flair’s framework with a BERTweet embedding on the test set of the Tweet Emotion Intensity Dataset were all ⩾.92 (see Table 2).
Accuracy scores for flair framework with BERTweet embedding on the test set of tweet emotion intensity data set.
Detection of toxicity and identity attack
We used NLP to detect toxicity in the comments. The recent efforts in toxicity detection in online platforms in the form of Kaggle competitions (Jigsaw, 2020) produced several out-of-box toxicity detection tools. We used the Detoxify library (Hanu et al., 2020), which produces multiple probability score for each of the multiple labels about toxicity, such as “toxicity” and “identity attack” for each input text. Toxicity pertains to harmful and unpleasant use of language, while identity attack pertains to the use of language that invokes hatred, hostility, or violence toward members of a specific race, ethnicity, gender identity or other defining characteristics of a group (IBM, 2019).
The Detoxify library provides three individual models (from three respective Kaggle competitions), which are different versions of a transformer-based model fine-tuned on three different datasets. Since the multilingual model is able to understand multiple languages beyond English, we assembled the original and multilingual model predictions on the input text without any preprocessing. If either model predicts toxicity with probability higher than .5, we consider the text toxic. Table 3 displays a list of Detoxify models, their respective transformer models, and their performance on the respective test (Hanu et al., 2020). The series of toxic comment datasets were created by Jigsaw and Google (Wulczyn et al., 2017). We computed two toxicity scores for each comment: “toxicity” and “identity attack.”
Performance of detoxify models by transformer type.

Measurement
The three main dependent variables are: (1) misinformation, (2) emotions, and (3) toxicity. Misinformation was detected from the images and the associated captions in the human content analysis. The machine learning models detected emotions and toxicity which were measured for the comments associated with the image posts. Four emotions—joy, sadness, fear, anger—were labeled from our Flair framework for each comment. Because emotions can co-occur (Dillard et al., 1996), our model allows for the co-occurrence of these four primary emotions. Each emotion was measured as presence/absence (1 = presence). Toxicity in the comments was measured as presence/absence (1 = presence) based on the computational classification result regarding the label “toxicity.” Identity attack in the comments was measured as presence/absence (1 = presence) based on the computational classification result for the label “identity attack.” Because each post may have multiple comments, we summed the presence of each emotion, toxicity and identity attack, respectively, at the post level. For the dichotomous independent variable of East Asian (East Asian vs non-East Asian), only posts that contained a human image were coded for the presence of at least one human image of East Asian descent.
Statistical analyses
To evaluate the intended effects of the content moderation intervention, we conducted a one-way analysis of variance (ANOVA) to determine if the amount of misinformation in Instagram posts changed across the three time periods (see Figure 2). This longitudinal pre-post analysis is in line with natural experiments that have no control group comparison (Leatherdale, 2019). We also ran one-way ANOVA for the following: presence of East Asians, emotions (i.e. anger, joy, fear, sadness), toxicity, and identity attack. Because Levene’s F tests revealed that the homogeneity of variance assumption were not met, we used the Welch’s F test.
For the unintended effects of the Instagram content moderation we ran independent t-tests to determine if there were differences between images with East Asians vs non-East Asians in terms of emotions and toxicity in the associated comments. Finally, to determine if misinformation is associated with hate speech, we ran point-biserial correlations for misinformation and anti-Asian hate speech (toxicity and identity attack), based on the three time periods of our study design.
Results
Evaluating short-term and long-term effects of content moderation
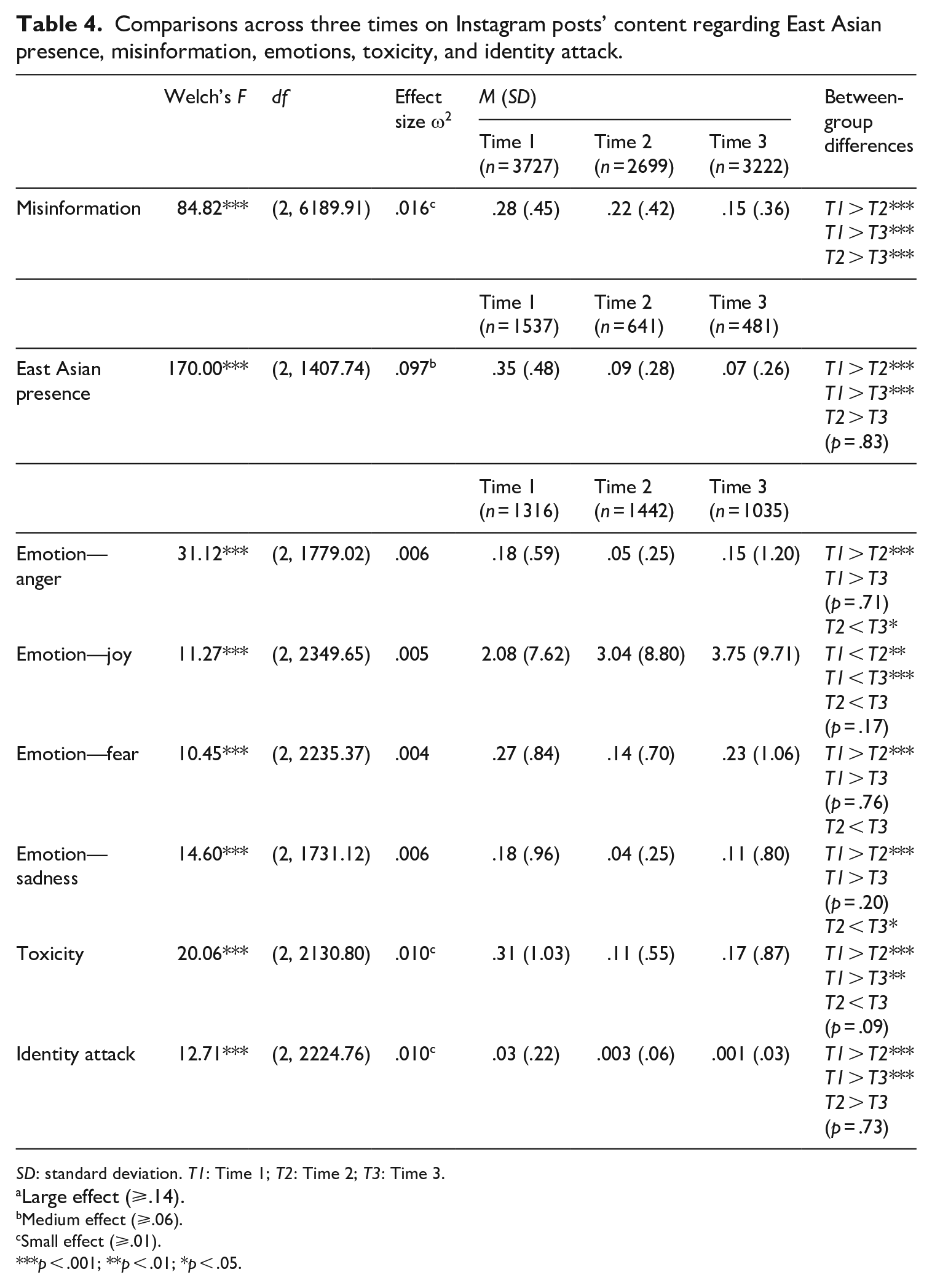
Table 4 displays the results for evaluating the short- and long-term effects of content moderation.
Comparisons across three times on Instagram posts’ content regarding East Asian presence, misinformation, emotions, toxicity, and identity attack.
SD: standard deviation. T1: Time 1; T2: Time 2; T3: Time 3.
Large effect (⩾.14).
Medium effect (⩾.06).
Small effect (⩾.01).
p < .001; **p < .01; *p < .05.
Misinformation
For intended effects, a one-way ANOVA of the three time periods on the measure of misinformation revealed a statistically significant main effect, Welch’s F(2, 6189.91) = 84.82, p < .001, ω2 = .016. Dunnett’s T3 post hoc tests (p < .05) revealed significant differences between the three time periods. Misinformation was highest prior to the content moderation (M = .28, SD = .45), and significantly higher than the short term (M = .22, SD = .42) as well as long term (M = .15, SD = .36). Likewise, misinformation was significantly higher in the short term than the long term. Figure 3 depicts the distribution of misinformation across the three waves of data.
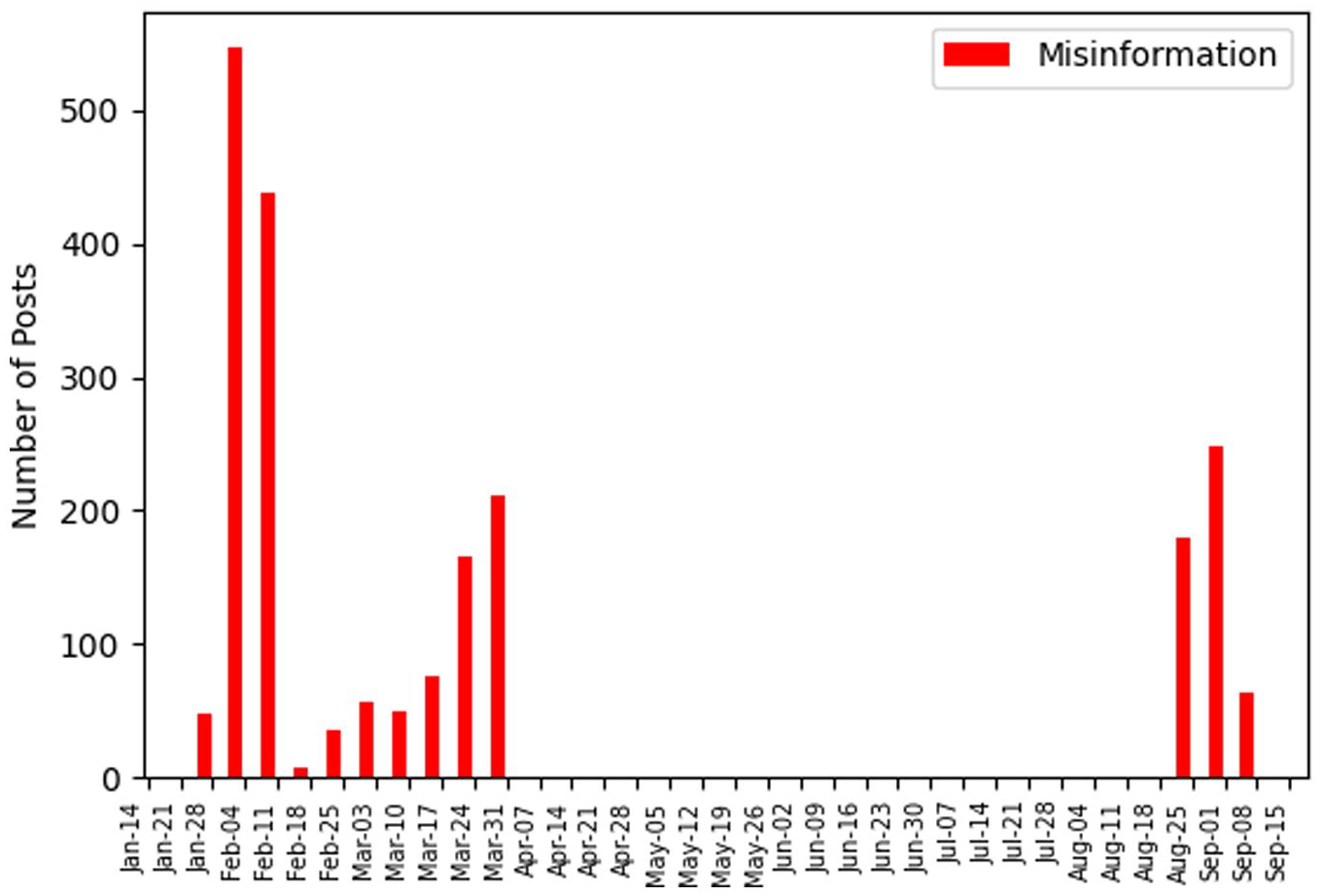
Distribution of misinformation.
East Asians
For unintended effects, a one-way ANOVA of the three time periods on the measure of presence of East Asians in image posts revealed a statistically significant main effect, Welch’s F(2, 1407.74) = 170.00, p < .001, ω2 = .097. Dunnett’s T3 post hoc tests (p < .05) revealed that the number of East Asians in images were greater in the pre-content moderation (M = .35, SD = .48) compared with short-term effects (M = .09, SD = .28) and long-term effects (M = .07, SD = .26). No significant differences were detected between short- and long-term effects.
Emotions
Among the four emotions, joy was the only emotion to increase across the three time periods, Welch’s F(2, 2349.65) = 11.277, p < .001, ω2 = .005. Dunnett’s T3 post hoc tests (p < .05) revealed that joy in the comments in the short-term (M = 3.04, SD = 8.81) was significantly higher than in pre-content moderation period (M = 2.08, SD = 7.63). Joy in the long-term effects (M = 3.75, SD = 9.71) was also significantly higher than the pre-content moderation period (M = 2.08, SD = 7.63). While joy increased from the short-term to the long-term effect, the difference was not statistically significant.
Anger (Welch’s F[2, 1779.03] = 31.13, p < .001, ω2 = .006), fear (Welch’s F[2, 2235.37] = 10.46, p < .001, ω2 = .004) and sadness (Welch’s F[2, 1731.12] = 14.603, p < .001, ω2 = .006) had a similar pattern across the three time periods whereby these emotions were significantly higher in the pre- content moderation period than in the short-term effects. However, these emotions bounced back in the long-term effects to levels similar to the pre-content moderation period.
For anger, Dunnett’s T3 post hoc tests (p < .05) revealed significant differences whereby anger was significantly higher in the pre- content moderation period (M = .18, SD = .60) than in short-term effects (M = .05, SD = .26). However, anger bounced back, increasing from the short-term (M = .05, SD = .26) to the long-term (M = .15, SD = .12) whereby there were no significant differences between long-term effects and pre- content moderation period.
Similarly, for fear, Dunnett’s T3 post hoc tests (p < .05) revealed significant differences whereby fear was significantly higher in pre- content moderation period (M = .27, SD = .85) than in short-term effects (M = .14, SD = .70). However, fear bounced back, increasing from the short-term (M = .14, SD = .70) to the long-term (M = .23, SD = 1.07) whereby there were no significant differences between long-term effects and pre-content moderation period.
For sadness, Dunnett’s T3 post hoc tests (p < .05) revealed significant differences whereby sadness was statistically higher in pre-content moderation period (M = .18, SD = .97) than in short-term effects (M = .04, SD = .25). However, sadness significantly increased from the short-term (M = .04, SD = .25) to the long-term (M = .11, SD = .80) despite both were post-content moderation periods, thus leading to no significant differences between long-term effects and pre- content moderation period. Figure 4 depicts the distribution of emotions across the three waves of data.
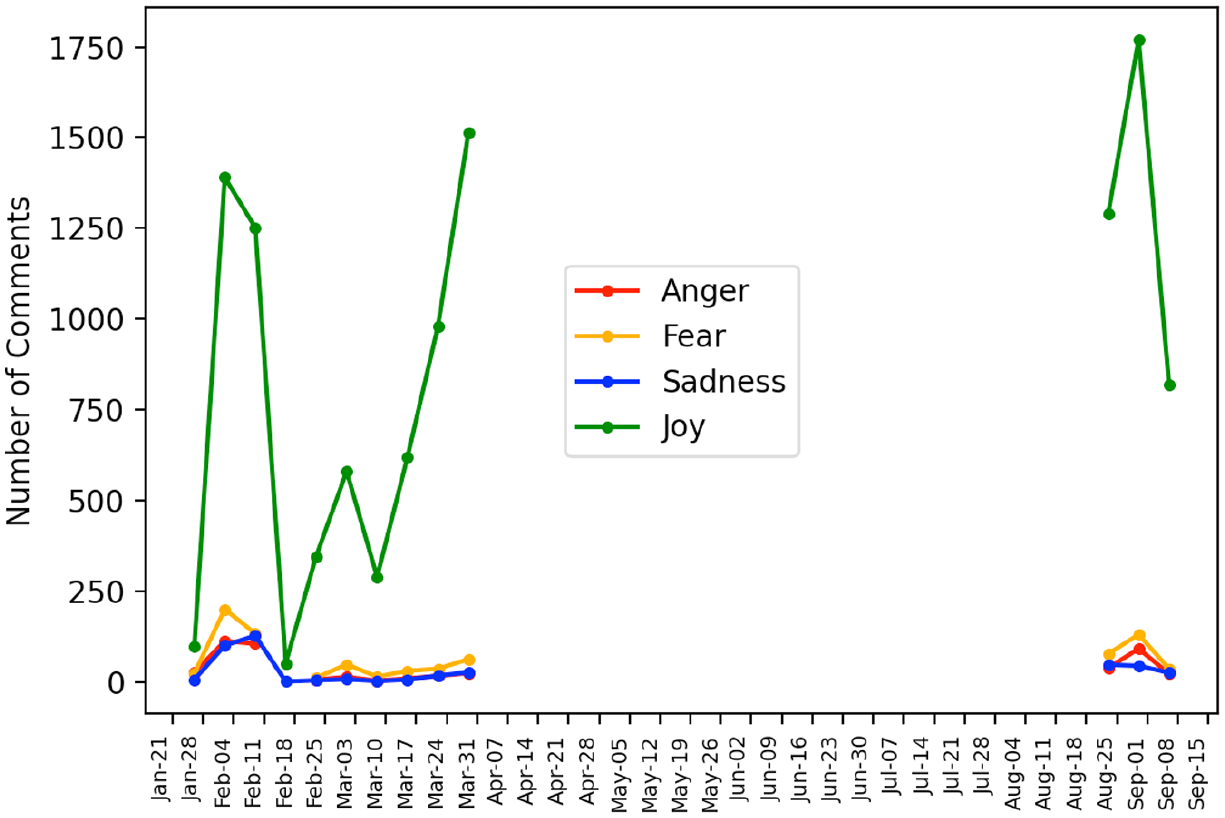
Distribution of emotions.
Hate speech: toxicity and identity attack
A one-way ANOVA of the three time periods on the measure of toxicity revealed a statistically significant main effect, Welch’s F(2, 2130.80) = 20.07, p < .001, ω2 = .010. There was a significant decrease in toxicity from pre-content moderation (M = .31, SD = 1.03) to short-term effects (M = .11, SD = .56), and leveling off such that toxicity levels in the long-term effects (M = .17, SD = .87) were not significantly different from the short-term effects.
For identity attack, a one-way ANOVA revealed a significant main effect, Welch’s F(2, 2224.77) = 12.72, p < .001, ω2 = .010. Identity attack was detected only in the pre-content moderation period (M = .02, SD = .18). Figure 5 depicts the distribution of toxicity and identity attack across the three waves of data.
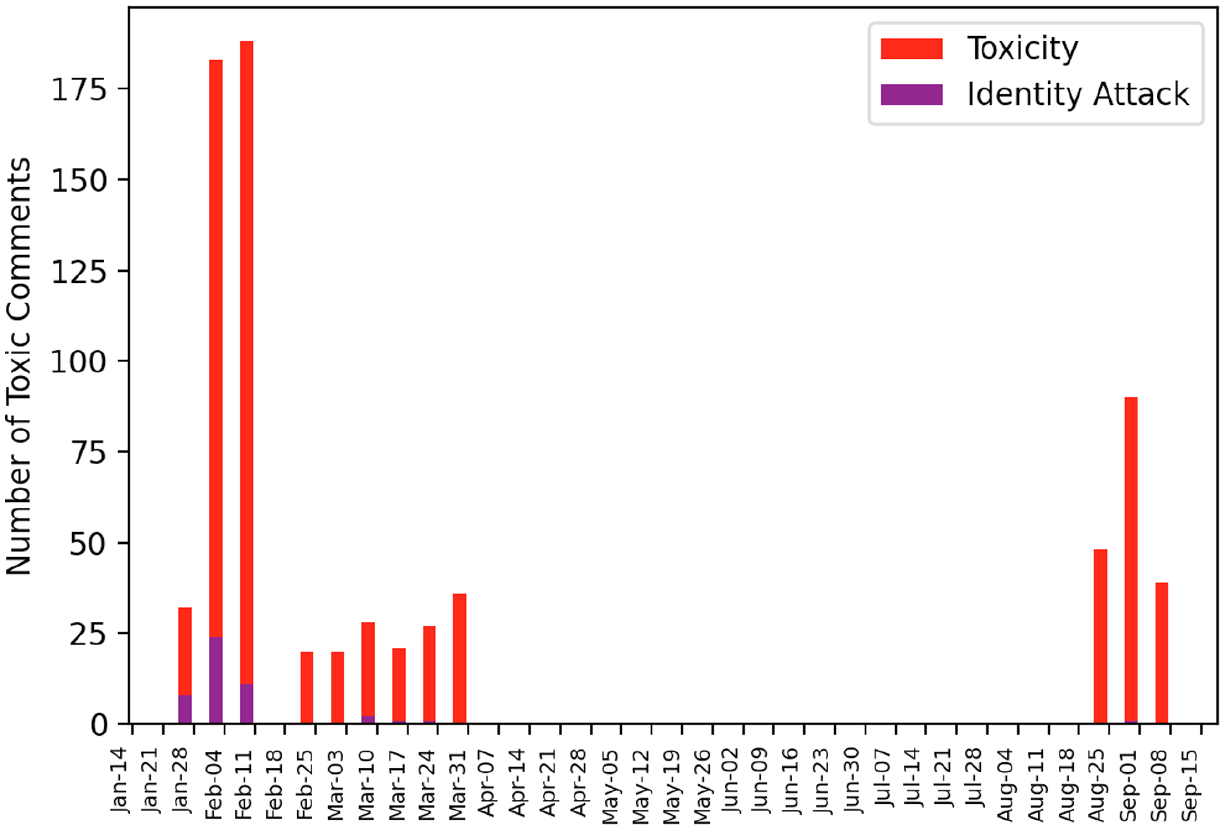
Distribution of toxicity and identity attack.
Comparing images with East Asians versus non-East Asians on emotions, toxicity, and identity attack in comments
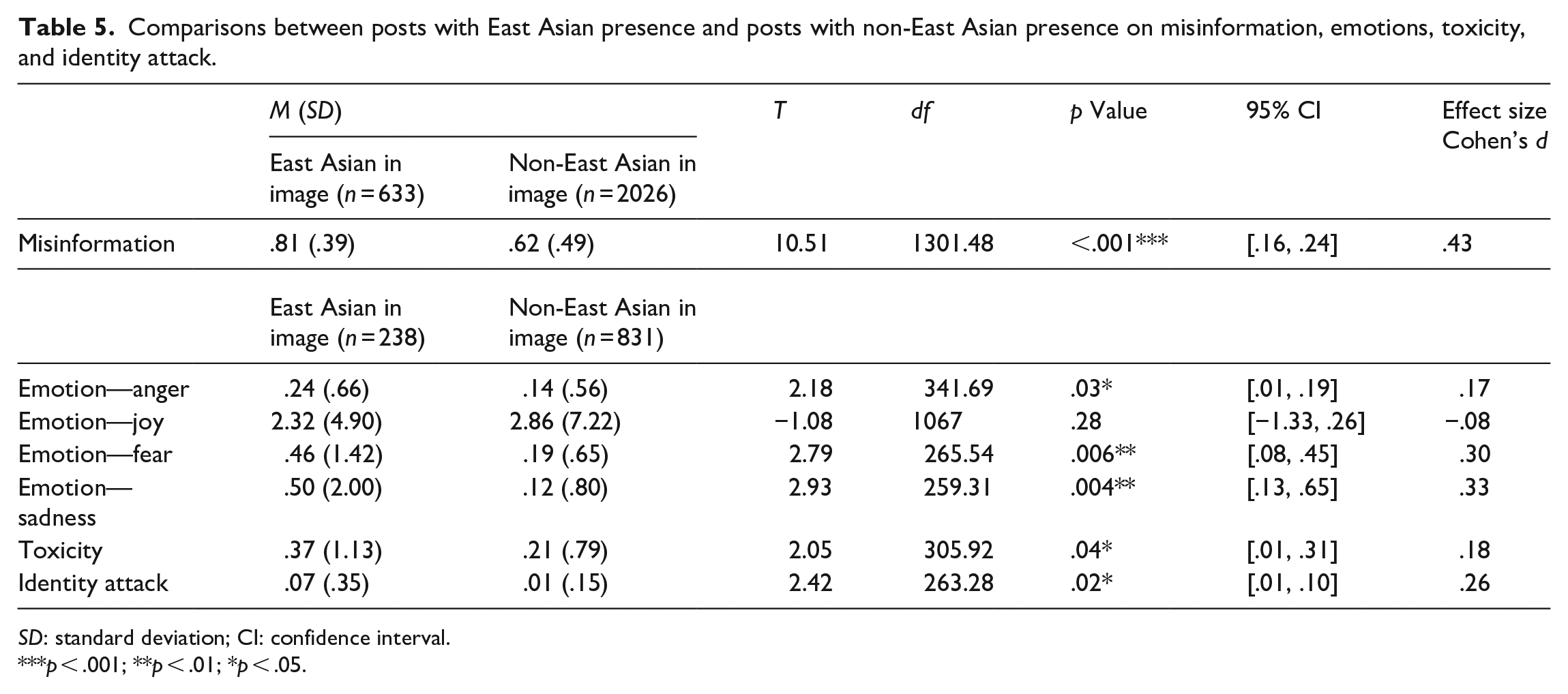
Table 5 displays the independent sample t-test results for comparing images with East Asians versus non-East Asians on the four emotions as well as toxicity and identity attack. All emotions except joy (t[1067] = −1.08, p = .28) were statistically higher in images with East Asians than images with non-East Asians. Anger in comments was significantly higher for images with East Asians (M = .24, SD = .66) than images with non-East Asians (M = .14, SD = .56), t(341.69) = 2.18, p = .03. Images with East Asians (M = .46, SD = 1.42) had significantly more fear comments than images with non-East Asians (M = .19, SD = .65), t(265.54) = 2.79, p = .006. Images with East Asians (M = .50, SD = 2.00) had significantly more sadness comments than images with non-East Asians (M = .12, SD = .80), t(259.31) = 2.93, p = .004.
Comparisons between posts with East Asian presence and posts with non-East Asian presence on misinformation, emotions, toxicity, and identity attack.
SD: standard deviation; CI: confidence interval.
p < .001; **p < .01; *p < .05.
Images with the presence of East Asians had significantly more comments with toxicity (t[305.92] = 2.05, p = .04) and identity attack (t[263.28] = 2.42, p = .02) than images with non-East Asians.
A significant correlation between misinformation and identity attack was found for the pre-content moderation period, rpb (1316) = .06, p = .04. No other significant correlations for other time periods, or for misinformation and toxicity were detected.
Discussion
This study found that the Instagram content moderation had an immediate and long-term effect in reducing misinformation, but like many other studies on technological interventions (Karppi and Nieborg, 2020; Li and Kyung Kim, 2021), it is the unintended effects that were most revealing. Instagram implemented its most ambitious content moderation program around 10 February 2020 (Meta, 2020), and our data revealed a precipitous drop in misinformation around that time. While the platform’s objective was to reduce misinformation (Meta, 2020), because misinformation was correlated with toxicity and identity attack, it appears that it inadvertently reduced anti-Asian sentiment as well. However, the data suggest a more nuanced conclusion about the state of hate and racism toward Asians, and in particular toward East Asians. It should be noted that hashtags can convey anti-Asian sentiment (Li and Ning, 2022), and hashtags can be stigmas whereby #chinesevirus begets more anti-Asian hashtags such as #bateatingchinese (Hswen et al., 2021). Thus, because it appears that Instagram only moderated #coronavirus (or other related COVID-termed hashtags) which is a more neutral hashtag than #WuhanVirus or #KungFlu, anti-Asian sentiment, tropes, slurs, hate speech were likely to be rampant and widely circulated on COVID-19 related content on Instagram, but went un-checked and unmoderated. #Coronavirus was one of the most popular hashtag on Instagram in 2020, and despite that we found a decrease in anti-Asian sentiment across time, we still detected significant findings on the stigmatization of East Asians and toxic speech targeted toward them. Below, we discuss the theoretical implications and implications for content moderation of misinformation and hate speech.
Our study extends previous social media and CMC research on stigmatization of Asians from text-based to image-based platforms. Text-based research on stigmatization is limited in its ability to demonstrate whether race, a visible stigma to identify outgroups, is associated with hate speech. By leveraging the images in conjunction with the corresponding comments, we demonstrated that East Asians in image posts are associated with anti-Asian sentiment in the corresponding comments. The presence of at least one East Asian person in an Instagram image elicited more anger, fear, sadness, toxicity and identity attack than images without people of East Asian descent. This supports the stigma literature that race is used as a visual stigma to mark outgroups who are deemed to be associated with undesirable characteristics (i.e. harbinger of diseases), and that the corresponding response is discriminatory and aggressive (Link and Phelan, 2001) as noted in our findings of toxicity and identity attack in social media image posts.
Notably, joy was lower when at least one East Asian person appeared in an Instagram image versus images without people of East Asian descent, although the difference was not statistically significant. This finding is similar to previous findings where joy was not associated with hate speech, but fear had significant association (Fan et al., 2020). Collectively, the association between presence of East Asian people in posts and increase in negative emotions, toxicity, and identity attack in the corresponding comments support the notion that East Asians are construed to be outgroups, separate and decidedly less than their in-group counterparts. While affirming other research that found a rise in anti-Asian sentiment on social media during the COVID-19 pandemic (Hswen et al., 2021; Tahmasbi et al., 2021), our study further contributes to the literature in this area by eliciting additional empirical evidence that is image-based—beyond textual evidence. Moreover, although anonymity per the SIDE model may result in prosocial behaviors (Reicher et al., 1995; Spears, 2017), our findings suggest that anonymity enhanced anti-Asian sentiment.
Per the SIDE model, perpetrators of identity attack considered hate speech to be normative of their in-group (i.e. social identity). However, because perpetrators of hate speech do not entirely lose their personal identity when social identity is dominant (Reicher et al., 1995) suggest that anti-Asian sentiment may be intractable, requiring more than normative approaches to address. Indeed, despite recent solutions to counteract the perpetuation of false narratives and stereotypes of Asians (Koyama, 2022), social media platforms are not equipped to combat mis- and disinformation about Asians and hate speech (Asian American Disinformation Table, 2022).
Another theoretical implication of our study is that COVID-19—perhaps other disease outbreaks as well—led to more “contextual salience” of demographic membership in a demographically diverse online community. In theorizing social identity and the process of self-categorization in interpersonal communication, previous literature has noted the role of contextual salience in fueling relationally disruptive behaviors (Hogg and Terry, 2000). In an organizational context, when “relations between demographic groups are conflictual and are emotionally charged” (Hogg and Terry, 2000: 127), diversity will make demographic membership more salient and strengthen adherence to demographic norms, rather than the collective organizational norms. Thus, a networked online community such as Instagram may have enabled COVID-19 to offer contextual salience to demographic membership (East Asians vs non-East Asians), pushing hate speech perpetrators’ in-group identification and outgroup derogation (Wojcieszak et al., 2022) to a higher level than the pre-COVID period. Our findings point to such an emotionally charged nature of the anti-Asian hate speech on Instagram, which has been exacerbated by the US–China tension at the beginning of the COVID-19 pandemic. This study provides empirical evidence to research in the SIDE model and CMC in general, highlighting the need for more future research to study contextual salience in online social identification and its subsequent online/offline influence on social justice.
Our findings affirm that misinformation and hate speech toward Asians are intractable (Ong, 2021). Because platforms often moderate content based on the type of content, the literature on misinformation and hate speech on social media has been developed separately, but there is increasing evidence that there is much overlap (Asian American Disinformation Table, 2022; Kim and Kesari, 2021; Ong, 2021). In particular for pandemics, misinformation may co-occur with racist hate speech because people use misinformation to hide their biases (Kim and Kesari, 2021), and anonymity afforded by social media allows hate speech to proliferate (Barlett et al., 2018; Spears, 2017). Our study’s results suggest that while in practice content moderation is by specific content, this is a very limited approach that overlooks potential overlaps in different types of content. Identifying content overlaps may be a more strategic and parsimonious approach to removing problematic content. However, that identity attack, and not toxicity, the more generalized forms of hate speech, was associated with misinformation suggests that misinformation and hate speech are indeed very interconnected. In that sense, more work needs to be done to counteract digital racism so that another “secondary epidemic” of COVID-19 racism toward Asians (Ong and Lasco, 2020) or another outgroup would not occur again given the toll racism has on both mental and physical health (Ong, 2021).
A limitation of our study is that we used a combination of data collection techniques. Although the data were collected synchronously, it is possible that differences in the three waves are artifacts of the data collection technique. However, the differences from pre-content moderation period (Wave 1) and the subsequent waves (short- and long-term) were quite drastic as to suggest that there was a significant change in misinformation, emotions and toxicity. The differences in short- and long-term may not be as distinct, particularly since we relied on a public data set for the short-term effect. In addition, ideally, the study design can be strengthened with a control group of non-moderated coronavirus hashtags. However, this was not possible given that when we commenced data collection it would not have been possible to foretell which hashtags would be moderated much less if or when content moderation would occur on Instagram. It should also be noted that while #coronavirus may have been popular in January 2020, #COVID-19 have since become more widely used since WHO officially named the virus COVID-19 on 11 February 2020. Thus, our study findings are limited to just #coronavirus and may not be reflective of hashtags with COVID-19 variants (e.g. #covid19). Finally, it is difficult to differentiate whether the effects of Instagram content moderation on reducing misinformation and anti-Asian content are attributed to the hard moderation technique of content removal or the modified soft moderation technique of pop-up windows with a health communication message. If more transparency were offered by technology companies on their content moderation practices, objective third-party researchers would have greater capabilities to evaluate the effect of content moderation, and its implications for social justice and equity, but platforms’ obscure moderation strategies only contribute to radicalized misinformation.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.