
Abstract
Digital trace data and computational methods are increasingly being used by researchers to study mental health phenomena (i.e. psychopathology and well-being) in social media. Computer-assisted mental health research is not simply a continuation of previous studies, but rather raises ethical, conceptual and methodological issues that are critical to behavioural science but have not yet been systematically explored. Based on a systematic review of n = 147 studies, we reveal a multidisciplinary field of research that has grown immensely since 2010, spanning the humanities, social sciences, and engineering. We find that a substantial majority of studies in our sample lack a standardized form of ethical consideration, focus on specific constructs and have a rather narrow focus on specific social media platforms. Based on our findings, we discuss how computational elements have influenced mental health research, highlight academic gaps and suggest promising directions for future studies.
People’s mental health (MH) continues to attract public and scientific attention, particularly in the context of online communication (Wongkoblap et al., 2017). At the same time, the ongoing spread of social media (SM) into everyday life is creating manifold digital behavioural traces. These ever-growing repositories of observational data support researchers and practitioners both in the fight against mental disorders and illnesses and in the pursuit of MH improvement. Surveys have been the dominant method of MH research, and thus have been in the focus of existing academic reviews and meta-analyses on this topic (Huang, 2017; Meier and Reinecke, 2020). However, there is now a growing number of studies that use digital trace data from SM in combination with computational methods to determine the MH of people in online environments (Wongkoblap et al., 2017).
Computational methods allow for the investigation of large and unstructured data from SM and arise as new tools in contemporary social science research (Domahidi et al., 2019). Computational approaches have made behavioural observation studies increasingly viable for MH research and have enabled the use of objective metrics in addition to subjective reports (Montag et al., 2016), especially since our everyday thoughts, feelings and behaviours are now mediated, reflected and often recorded in SM (Lazer et al., 2021; Stachl et al., 2021). While computational MH research offers stunning possibilities, many issues arise that are not yet systematically reviewed. As a result, this review goes beyond previous by incorporating leading perspectives through an integrated conceptualization of MH based on the extended two-continua model of MH (Meier and Reinecke, 2020), a first systematic reflection on pressing ethical issues (Chancellor et al., 2019b) and a broad assessment of contemporary computational methods. Thus, we systematically review how computational elements have affected MH research, reveal academic voids and suggest promising directions for future studies.
Computational mental health research
There is no general agreement in the research literature on the concepts and indicators that can be attributed to the field of MH. Reviews on MH research are either focused on psychopathology (PTH; Balcombe and Leo, 2022; Guntuku et al., 2017; Wongkoblap et al., 2017) or psychological well-being (PWB; Best et al., 2014; Diener et al., 2018), often highlighting only specific MH indicators (for an overview, see Meier and Reinecke, 2020). Nowadays, the perspective that MH is ‘more than the absence of mental disorders’ (Meier and Reinecke, 2020: 10) is widely recognized (Saxena et al., 2013), and provides a comprehensive framework for the diverse conceptions offered by researchers to capture MH based on the two continua: PTH and PWB. PTH refers to ‘any pattern of behavior [. . .] that causes personal distress or impairs significant life functions, such as social relationships, education, work, and health maintenance’ (Lahey et al., 2017: 143). PWB is understood as ‘how well individuals are doing in life, including social, health, material, and subjective dimensions of well-being’ (Diener et al., 2018: 3). The extended two-continua model of MH builds on the assumption that both states (PTH and PWB) are simultaneously present and have various dimensions and manifestations while being affected by risk and resilience factors (Meier and Reinecke, 2020). Initial research building on this conceptualization identified the need for higher level integration of the research landscape and suggested that future reviews should include both continua (Meier et al., 2020). Here, we follow this perspective and review studies from both continua in order to address the fragmented field of MH research and widen the scope compared to existing reviews.
Other current efforts in the field include exploring the interaction between online communication and a variety of MH indicators, as well as seeking new data sources to supplement the long-prevalent surveys and self-reporting in MH research (Wongkoblap et al., 2017), which are prone to distortion (Matz and Harari, 2021) and socially desirable responses (Stachl et al., 2021). While the importance of surveys in this research field is clear in both individual studies and reviews (Eger and Maridal, 2015; Huang, 2017; Meier and Reinecke, 2020), current MH research is increasingly focused on SM data (Correia et al., 2020). Bayer et al. (2020) situate SM as a subclass of computer-mediated communication in reference to Carr and Hayes (2015), who describe SM as ‘[. . .] Internet-based, disentrained, and persistent channels of mass personal communication facilitating perceptions of interactions among users, deriving value primarily from user-generated content’ (p. 50). This broad view incorporates the complexity of current SM platforms, acknowledging ‘[. . .] that these sites are created by industry entities with economic (and other) agendas and now encompass a broad set of services integrated within one another’ (Bayer et al., 2020: 474). Following this approach enables us to integrate important venues of online communication such as blogs, interactive websites, forums, social networking sites, content sharing platforms, or message boards. In contrast, prior reviews on online communication and MH are centred around particular applications such as (mental) health-related online groups (Eysenbach et al., 2004; Foong et al., 2022; Van Eenbergen et al., 2017; Wright, 2016), social network sites (Chancellor and De Choudhury, 2020; Sinnenberg et al., 2016) or the interaction of Internet/SM use with MH indicators (Huang, 2017; Verduyn et al., 2017). Our scope comprises all these aspects, advancing the integration of research in the field.
Due to the vast amount of data from SM, researchers started emphasizing computational methods to study MH in online contexts. Hilbert et al. (2019) describe the application of computational methods as a transfer of computer science to questions of human and social communication. More specifically, computational methods can be defined as a research process that involves (1) large and complex data sets, (2) consisting of digital traces and other naturally occurring data, (3) requiring algorithmic solutions to analyse and (4) allowing the study of human communication by applying and testing communication theory (Van Atteveldt and Peng, 2018: 82). Consequently, computational MH research (CMH) can be considered a subfield of computational social science in which computational methods are used to measure MH constructs.
In sum, current reviews of MH research are limited in their insights into these new research directions. Most reviews only focus on limited data sources, mainly text (Conway and O’Connor, 2016; Luhmann, 2017), or investigate only specific subclasses of computational methods (e.g. AI, Graham et al., 2019; deep learning, Su et al., 2020) or the potential of online applications for mental healthcare distribution (Balcombe and De Leo, 2022; Chan et al., 2019). Accordingly, a broad systematic overview and discussion of current computational methods for MH research are missing. While existing reviews discuss diverse approaches and platforms for CMH (Correia et al., 2020; Liang et al., 2019; Wongkoblap et al., 2017), they remain limited in their assessment of MH indicators and neglect the ethical issues involved in computational exploration of MH and the use of SM data for this purpose.
Open questions of CMH research
In the following, we outline three main dimensions of issues encountered when implementing SM data and computational methods in MH research. We aim to address these pressing issues through our research and derive opportunities and challenges in the ‘Discussion’ section. First, we follow Meier and Reinecke’s (2020) proposal to include both continua of MH in our analysis, thus opening a way to sort out the conceptual fragmentation of the field. Second, we will offer the first systematic assessment of ethical considerations in a field that deals with sensitive data and research outcomes to raise awareness of these central aspects of research. Finally, we will review the methodological diversity including used methods, data sources or data types, to gain insights into the state of art in CMH.
Despite general agreement that MH is multidimensional, due to shared components and overlapping concepts (Wang et al., 2017), there is no consensus on which dimensions are central. As PTH and PWB are often treated as disjointed concepts, reviews focus on either PTH (Chancellor and De Choudhury, 2020) or PWB (Best et al., 2014) or only one construct of either continuum (Guntuku et al., 2017). Although this unidimensional view is often taken in reviews, studies in CMH investigate various constructs from both continua. This dates to the first implementation of computational methods in MH research in the 1970s and 1980s (Myers, 1998). Since then, considerable progress in CMH research has been made. Initially, it was based on clinical MH data (e.g. electronic health records), incorporating natural language processing, machine learning and the rich psychological tradition of lexicons (for an overview, see Graham et al., 2019). These early text analysis approaches (for an overview, see Martínez-Castaño et al., 2020) were strongly centred around constructs which are foremost related to the PTH-continuum (Graham et al., 2019). Later, gained insights were transferred to early MH prediction studies using SM data. Approaches on population-level as well as on individual-level were now incorporating constructs related to PWB as well. Kramer (2010), for example, provided one of the first large-scale happiness measurements based on SM data. Nowadays, not only text from SM is used for the computational analysis of MH, but also, for example, users’ language encoded as frequencies of each word or time of posts (Guntuku et al., 2017), images (Wang et al., 2017), or active and passive sensing (Saha et al., 2017). Although the field is undergoing profound change, there is evidence that individual constructs used to operationalize MH (Huang, 2010, 2017) as well as the relationship between the two continua (Meier et al., 2020) in the general field of MH, have remained relatively stable over time and tend to lean towards PTH. To gain insights on the conceptual diversity and its evolution in CMH, we ask,
RQ1. What (1) continua (PWB or PTH) and (2) constructs are studied by researchers in the field of CMH and have there been changes over time?
Ethical considerations are one of the most discussed issues in the academic debate around SM data and computational methods (for an overview, see Salganik, 2019). Current open questions include the distinction between public and private content (McKee, 2013), the obfuscating of sensitive and personally identifiable information, data de-identification, algorithmic inferences, dealing with deleted or removed data (Chancellor et al., 2019b), users revealing sensitive personal information about others (Bagrow et al., 2019), implanting meaningful protocols for gaining consent (Chancellor et al., 2019a) and integrating individuals’ perspectives, as well as holding users accountable for their past actions (Stachl et al., 2021). Furthermore, the evaluation of online MH is a sensitive area that can be isolating and stigmatizing, putting vulnerable populations and online communities at risk of harm (Chancellor et al., 2019a, 2019b; Kalluri, 2020). Connected to this is the risk of data misuse as well as unintended use of prediction results (Chancellor et al., 2019b), which is exacerbated by user misconceptions about algorithms and underlying platform structures (Fiesler and Proferes, 2018). Since all these aspects might vary under cultural and political norms (Choi, 2021), ethics committees and guidelines exist to assist researchers in their attempts to conduct harm-free research. Unfortunately, ethical guidelines similarly vary in form and degree of obligation as well as between departments, universities, regions and disciplines. In addition, ‘ordinary’ users are rarely involved in the process of creating these guidelines (Fiesler and Proferes, 2018). Recognizing these issues might lead people to intentionally change their behaviour (Lazer et al., 2021), which may be detrimental to future research.
Even though valuable contributions on the role of ethics in SM and MH research exist (Chancellor et al., 2019b) and first systematic considerations of SM and ethics have been made, for example, by observing the presence of ethical approvals (Fiesler and Proferes, 2018; Proferes et al., 2021), there is no systematic overview on ethical considerations in CMH studies. Some scholars do mention this topic in their reviews (Conway and O’Connor, 2016; Graham et al., 2019; Guntuku et al., 2017; Wongkoblap et al., 2017), but no one explicitly and systematically investigates CMH studies in terms of their ethical considerations or potential solutions to the many ethical issues. Therefore, we ask,
RQ2. How do researchers in the field of CMH discuss ethical issues and potential solutions over time?
Due to the beforementioned challenges of questionnaire-based self-reports, scholars are working to make use of the great variety of digital traces on SM (Stachl et al., 2021), aiming to enable more accurate ‘microscopes’ of individual human behaviour, as well as ‘macroscopes’ for collective phenomena (Correia et al., 2020). Most prominent are text features (Sinnenberg et al., 2016), specifically user comments, which are an important form of SM data across disciplines (Schindler and Domahidi, 2021). SM data might be used in multimethod studies and can be combined with traditional self-report measures of MH to enforce more encompassing insights. In summary, large-scale SM analyses offer cost-effective and non-intrusive ways to effectively work on improving individual and collective MH (Martínez-Castaño et al., 2020), but the greatest potential for future research lies in changing MH through SM (Luhmann, 2017).
Nonetheless, collecting and analysing SM data have many limitations, including biased or poorly representative samples due to missing ground truth and demographic indicators (Ramagopalan et al., 2020). SM data generally entail self-selected samples, since subjects are free to choose when to participate and what content to submit. This bias is compounded by a mix of access restrictions imposed by SM platforms (Ruths and Pfeffer, 2014), leading to convenience samples – SM data sets that are, due to standardization efforts, more widespread, accessible and convenient to use, although most likely not representative of the wider population and limited to a few platforms (Chancellor et al., 2019a; Correia et al., 2020). In addition, the way the data are stored and made available to researchers might disrupt aspects of human behaviour, which is further distorted by non-human posters and professionally managed SM accounts (Ruths and Pfeffer, 2014) as well as individuals trying to hide from being measured.
To understand and investigate these complex developments, existing reviews on SM and CMH have used a variety of approaches. Some focus on a description of the general analysis approach and the data source/platform (Luhmann, 2017; Su et al., 2020), others widen this perspective by either describing the data or method more thoroughly. Wongkoblap et al. (2017), for example, address data collection and sampling techniques as well as the languages of data sets. Guntuku et al. (2017) code the number of users, used performance/evaluation measures and the used model including used features. Others measure population, sample size (Graham et al., 2019) or the clinical status of observed users (Correia et al., 2020). Here, we will use a conglomerate of these approaches to gain a comprehensive overview of this methodological state of CMH, including whether researchers link their approaches and measures back to theory, which is one of the central features of computational methods (Van Atteveldt and Peng, 2018). We ask,
RQ3. Which (1) types of data and (2) methods are used to operationalize MH and have these changed over time?
Method
Identification of relevant studies
An extensive literature search was carried out to identify studies that used computational methods to examine concepts of MH in the context of SM. Various synonyms and combinations of the search concepts were used, as well as existing search terms from other studies (Eger and Maridal, 2015; Huang, 2010, 2017; Liu et al., 2019; Meier et al., 2020). Since research in this area is inherently interdisciplinary and dispersed across psychology, social sciences and health journals, as well as computer science conference and workshop proceedings, we applied our systematically developed search string (see online Supplemental Appendix 1) 1 to the meta-database EBSCOhost (for a list of the selected databases, see online Supplemental Appendix 2) and ACM Library on 21 October 2020.
To assess the extent, range and nature of research activity, we included academic journals and conference proceedings written in English. The following inclusion criteria had to be met: The study (1) examined communication processes on SM (e.g. blogs, interactive websites, forums, social networking sites, content sharing platforms or message boards); (2) under MH aspects, either PTH and related constructs (e.g. anxiety, depression) or PWB and related constructs (e.g. life satisfaction, social support; Meier et al., 2020); (3) used computational methods to either collect or analyse data connected to concepts of MH (Van Atteveldt and Peng, 2018); and (4) the study had to report at least three out of five quality categories, (a) a stated research objective, (b) method of data collection, (c) method of analysis, (d) results and (e) discussion (Sinnenberg et al., 2016).
Review process
The initial search resulted in a total of 810 records, 637 from EBSCOhost and 173 from the ACM Library. We identified and removed records without information on title, journal, abstract or authors (n = 23), as well as duplicates (n = 141). We then excluded books and trade publications (n = 25), resulting in 621 records that were screened based on title and abstract, using Codebook I, intra-coder reliability: Krippendorff’s alpha (K’s α) = 1 2 (see online Supplemental Appendices 3 and 4 for all codebooks and reliability tests). This resulted in a set of 404 records, as 217 were excluded due to the absence of communication processes on SM (n = 77) and/or a missing connection to MH (n = 34), and/or no computational approaches used (n = 171). Incorrectly assigned text types (e.g. systematic reviews, book reviews, error reports, comments, dissertations) were removed (n = 61, using Codebook I_I, intra-coder reliability: K’s α = 1), resulting in 343 records eligible for full-paper screening. Only 327 full-text articles could be retrieved and assessed for eligibility (using Codebook I_II, intra-coder reliability: K’s α ⩾ .78), whereas 180 did not meet our eligibility criteria and were excluded. Four records received a quality score below 3, 127 records did not measure MH, 22 records did not examine computer-mediated communication, 24 records did not use data from SM or reflected processes on them, and 114 records did not use computational approaches. In total, we excluded 663 articles and included 147 in the review (see Figure 1).
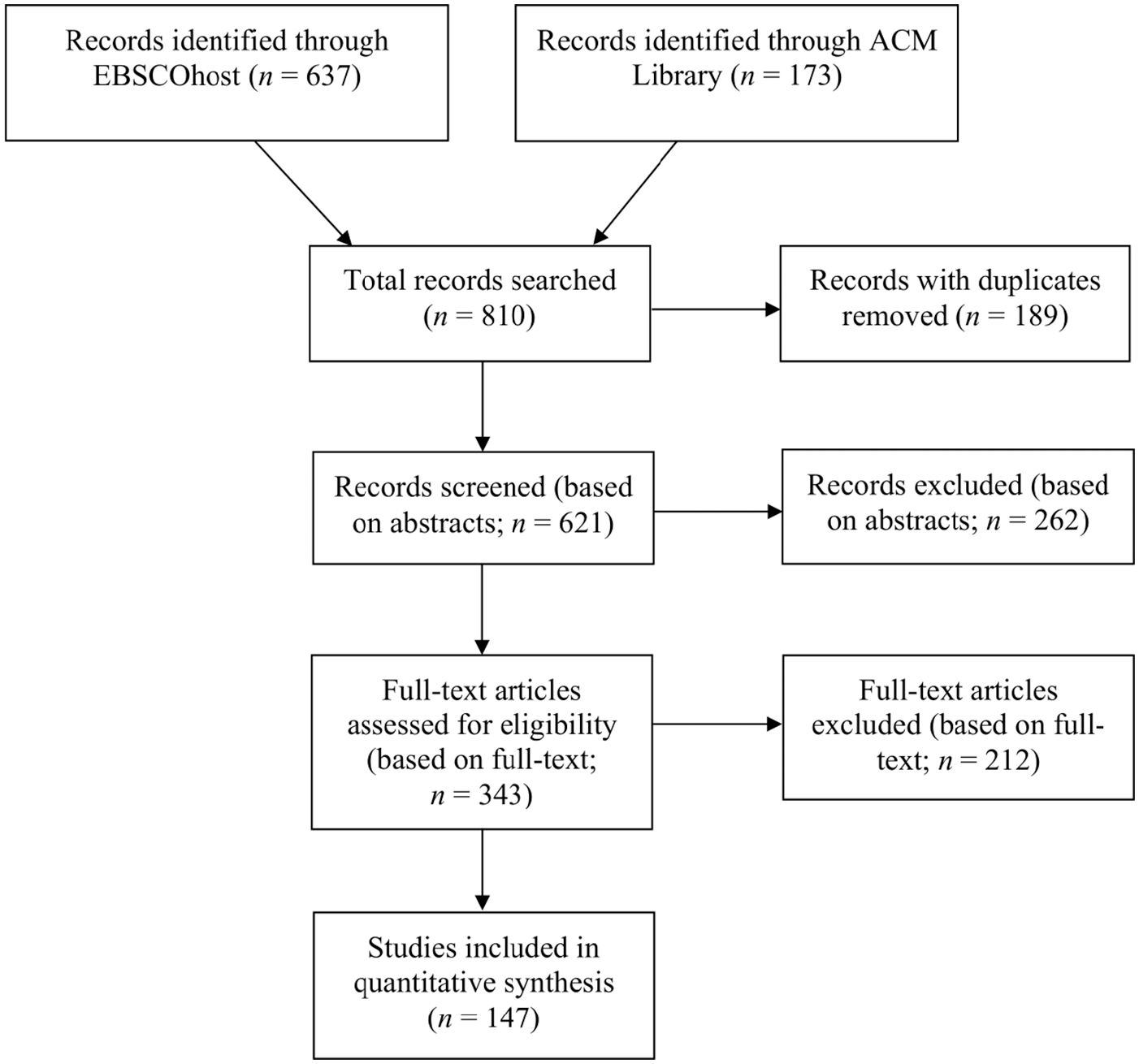
PRISMA diagram.
Analytical approach
An expert coding of all relevant studies (n = 147, see online Supplemental Appendix 5) by the first author through a self-developed codebook based on the existing literature (see Open questions of computational mental health research; Codebook II, intra-coder reliability: K’s α ⩾ .88) was conducted (see online Supplemental Appendix 3 for the code sheet). The codebook contains 19 categories, including two formal categories (discipline and ID). A thorough description, including definitions of all categories in all codebooks can be found in online Supplemental Appendix 3.
Categories regarding the conceptual fragmentation of CMH research (RQ1) rely on the extended two-continua model of mental health (Meier and Reinecke, 2020) and enable us to grasp which continua and constructs are prominent in CMH research and whether the found constructs and their operationalization were linked to theory.
Ethical considerations (RQ2) were categorized based on previous literature. We examined whether some form of standardized ethical report was present in those papers (Zimmer and Proferes, 2014) and whether and how ethical challenges (e.g. privacy, vulnerable populations, etc.) and solutions for those challenges were discussed or provided (Chancellor et al., 2019a, 2019b; Correia et al., 2020; Stachl et al., 2021).
To address methodological diversity (RQ3), we first coded which types of data were used by researchers and whether there was a description of the researched population or the clinical status of users/participants. We open-coded sample size, origin of data, the number of unique users and the employed sampling technique (Burke and Kraut, 2016; Liang et al., 2019; Stachl et al., 2021). We also coded the data analysis approach and specific method as well as if an evaluation of the used approach was reported.
Based on the Social Science Citation Index (SSCI)/Science Citation Index Expanded (SCIE) categorization or, if they could not be found in the SSCI, on journals’ self-descriptions and Internet searches, we assigned disciplines to each outlet in our sample to be able to illustrate differences between disciplines. When more than one main discipline was listed for a journal, we coded them as multidisciplinary. Conference papers were coded according to their self-descriptions (see online Supplemental Appendix 3).
Finally, to enrich the descriptive results, we have exemplarily included and highlighted publications in our ‘Results’ section.
Results
Sample
Of 147 articles reviewed, 135 were published from 2015 onward, while only 12 peer-reviewed articles were published between 2010 and 2015 and no article was published before 2010. The oldest record in our sample aimed to develop a metric that measures the overall emotional health of a nation based on Facebook data (Kramer, 2010). In total, 44 articles were found in the ACM library, while 103 articles stem from nine databases hosted by the meta-database EBSCOhost. The most prominent publication outlet was the Journal of Medical Internet Research (n = 14). The majority of our sample was published as journal articles (n = 110), and around one-fourth were published as conference proceedings (n = 37). We identified eight different disciplines in our sample: multidisciplinary sciences (n = 49), computer science (n = 39), healthcare (n = 35), psychology (n = 16), environmental studies (n = 3), communication science (n = 2), economics (n = 2) and social work (n = 1). In total, 124 studies exclusively focused on one SM platform, while six did not mention any. Four platforms are clearly in the researchers’ focus: Twitter (n = 55), Reddit (n = 23), Facebook (n = 21) and Sina Weibo (n = 15). Only 17 studies focused on more than one platform, with Tang et al. (2020) considering a maximum of five platforms to observe the role of community management in Chinese online depression communities.
Main findings
Conceptual fragmentation
Out of 147 studies, 82 focused mainly on aspects related to PTH, 51 studies were connected to PWB and 14 studies incorporated both perspectives. Studies with the perspective of PTH (n = 96) included a total of 113 constructs and were mostly concerned with depression (n = 50), suicidality (n = 18) and various disorders (n = 15), followed by stress (n = 13), anxiety (n = 12) and others (n = 5). Studies that included PWB (n = 65) measured a total of 63 constructs, mainly social support (n = 28) and happiness (n = 11), but also life satisfaction (n = 7), social capital (n = 7), quality of life (n = 3) and others (n = 7). Out of the 176 identified MH constructs, 118 were linked to theory and 58 were not. In the case of PTH, 73 were tied back to theoretical groundwork, and 40 were not. For PWB, 45 were linked to theory and 18 were not.
Apart from the general trend towards more publications, there are no remarkable changes over time. Both PTH and PWB are steadily increasing, reaching their maximum in 2020. For the individual MH constructs, the only notable increase is in research on depression in 2020, which was studied 17 times that year (2018: n = 9, 2019: n = 6). For PWB, happiness and social support are fairly constant over time, with happiness being the only construct present since 2010, yet vanishing in 2020. In addition, the proportion of operationalized constructs increases over time for PTH and PWB. This trend is even more pronounced in PWB than in PTH.
Ethical considerations
In our sample, we found ethical reports in only one-third of all publications (n = 47). The majority did not include any ethical reports (n = 100) or stated that no ethical review was required because only publicly available data were used (e.g. Tang et al., 2020). This uneven distribution could be found in most disciplines; only publications from psychology (11 records with reports, five without) and social work (one record with reports, 0 without) predominantly included ethical reports. Researchers in the field of healthcare also reported ethics quite frequently (16 records with reports, 18 records without), while communication science (0 records with reports, two without), economics (0 records with reports, two without), environmental studies (0 records with reports, three without), multidisciplinary sciences (13 records with reports, 36 without), and computer science (six records with reports, 33 without) have mainly relinquished ethical reporting. Between 2010 and 2014, no study (n = 12) included an ethics report. From 2015, the percentage of studies with ethics reports increased steadily, including an outlier in 2017, the only year in which more studies (n = 11) reported ethical considerations than studies that did not (n = 9).
We also looked for specific ethical challenges and potential solutions offered. Both aspects have only been covered since 2015. Privacy was addressed in 29 records, with 18 records providing solutions. Consent (14 records, seven with solutions), stigma/vulnerable populations (11 records, five with solutions), data misuse (eight records, three with solutions), varying norms or missing standards (five records, two with solutions), and biases (11 records, three with solutions) were also found and coded based on existing literature. Furthermore, the integration of experts and the community was mentioned once as a current challenge (which is simultaneously the proposed solution; Coppersmith et al., 2018). In addition, the responsibility of researchers as an ethical challenge was found as well (two records, one with a solution; Howard et al., 2020; Liu et al., 2018). Even those studies that were coded as discussing ethical challenges or proposing solutions did so superficially in most cases. Positive exceptions include the publications of Trotzek et al. (2020), who discuss in detail ethical challenges and potential solutions for the implementation of natural language processing for depression detection, and Shatte et al. (2019) who reflect on their responsibilities beyond the assessment of the relevant ethics committee and have taken several steps to protect their users screened for depression.
Methodological diversity
Researchers predominantly used text data (n = 144) to conduct research on CMH, followed by online traces (n = 82), survey data (n = 20) and images (n = 10). Text data and online traces have been utilized throughout, whereas images came into use as recently as 2015. Other types of data, such as biological or physical data, were rare (n = 19) but exist. For example, Zhou et al. (2015) used a combination of webcam video tracking, head movement analysis, heart rate analysis, eye blink analysis, pupillary variation analysis, facial expression analysis, user interaction tracking and content tracking to provide an instant and actionable reflection on users’ MH based on SM activities and physical signals, while Reis and Culotta (2015) examined the effect of exercise on MH by combining Twitter and physical activity data. The observed population was only described in 11 cases (e.g. Park et al., 2018; Yao et al., 2019), while the potential clinical status of users or participants was only reported in seven cases (e.g. Howard et al., 2020). Reporting in studies on both aspects has only begun recently. 77 of 147 records reported the origin of their sample(s), split into Northern America (n = 31), Europe (n = 22), China (n = 19), South/East Asia (n = 17), Australia (n = 5) and North Africa/Middle East (n = 2). Two studies included users from nine different countries, either to examine patient-reported clinical outcomes and health-related quality of life in real-world patients (Gries and Fastenau, 2020) or to combine facial expression recognition algorithms with spatial data to examine human happiness in locations around the world (Kang et al., 2019). Over time, publications using data from Europe and North America remain relatively stable, though increasing slightly. Most recently, the number of publications using Chinese data have increased. In total, 22 records did not report their sample size; the remaining sample has a median sample size of 99,156 (min = 25, max = 1e + 10). In contrast, 59 records did not contain information on the number of unique users included; the remaining papers had a median of 2639 unique users (min = 10, max = 3e + 08). The article with the highest number of unique users and the largest sample size described and tested a deep visual–textual multimodal learning approach to detect depression on SM (Lin et al., 2020). We could not observe decisive trends over time regarding the size of samples or the number of researched users. Finally, the vast majority of publications relied on convenience samples (n = 140), while other sampling methods were used to a lesser extent (cluster, random, systematic; n = 9) after 2017. For analysis, CMH research mainly incorporates supervised machine learning (n = 103) and dictionary-based approaches (n = 79); unsupervised approaches (n = 34) and network analysis (n = 18) were less prominent. These findings are reflected by the prevalence of classification studies in our sample (n = 120), followed by sentiment analysis (n = 45) and topic modelling (n = 23). While classification studies and sentiment analyses have recurred over time, topic modelling first appeared in our sample in 2016. Encouragingly, most records in our sample reported some form of evaluation (n = 120), even though we did not evaluate the quality of evaluation.
Discussion
Extending prior work and addressing open questions, this study synthesized the fast-growing literature on CMH through a systematic literature review. Our contribution to the literature is the identification and illustration of conceptual, ethical and methodological challenges in the field of CMH.
We identified a great diversity of constructs used in CMH research, reflecting the existing literature and a prevalence of the overarching dimension of PTH, as in the larger field of MH research (Meier et al., 2020). Nonetheless, we identified considerable differences between CMH and the larger field of MH regarding specific constructs. While Huang (2010, 2017) reported loneliness, depression, self-esteem and life satisfaction to be most present in MH research, the most common concepts in our sample were depression, social support, suicidality and various disorders. Depression remains a unifying element, but the shift in observed constructs raises the question of why this change is taking place. Due to the prevailing ambiguity in operationalization and conceptualization, two scenarios seem likely: First, computational methods allow researchers to analyse concepts that were previously difficult to capture, for example, social support can now be observed through harnessing enormous network data. In this case, CMH complements existing research on MH. The second option, however, would be that particular concepts are simply easier to measure using digital text data than others. Following this logic, social support might be easier to conceptualize in text data than self-esteem, which is why we find it more often. Concerningly, around one-third of conceptualizations in our sample are not tied back to theory, reflecting findings of current reviews (Chancellor and De Choudhury, 2020). The link back to social science theory is not only a central feature of computational methods (Van Atteveldt and Peng, 2018), but also a prerequisite for relevant research since social scientists are usually not interested in, for example, language statistics as purely technical artefacts. This also applies to SM as data source, which should be selected based on theory, while the obtained results should be extrapolated to the SM elements studied (Bayer et al., 2020). Accordingly, this finding calls for a stronger theoretical reconnection as well as an evaluation of computational approaches currently in use to measure MH. Encouragingly, we observed indications of a trend towards more theoretical reconnection over time in our sample. In summary, there is an observable shift towards computationally measurable concepts, though the field of CMH remains conceptually fragmented and pre-existing concepts continue to be important. Based on our work, we identify the following two major conceptual challenges for upcoming research:
Studies in CMH should not only focus primarily on problematic MH aspects but include both continua in the spirit of the extended two-continua model to obtain a more complete view of MH (Meier and Reinecke, 2020).
The development towards the study of more diverse constructs and data are desirable but must be theoretically justified and not based on computational feasibility alone.
Our results on ethical considerations show that a concerning majority of studies do not report any standardized form of ethical consideration, similar to general SM research where most studies do not undergo ethical review or do not report it (Zimmer and Proferes, 2014). We reveal striking differences between the reporting of disciplines. Disciplines such as psychology, which have long dealt with sensitive personal data, recognize the importance of ethical reporting. Conversely, we find a relative lack of reflection in fields like computer science or articles published in multidisciplinary outlets. Nonetheless, the intervention with human subjects calls for careful consideration of potential harms, which has not yet been standardized in these fields (Vitak et al., 2017). Many departments and even entire universities do not operate ethics boards. This is particularly concerning because, unlike participants in traditional MH research, SM users are mostly unaware that they are subjects of research (Fiesler and Proferes, 2018). In addition, researchers might include an ethical report, but state that since data are public, consent is not required. Besides the individual decisions of researchers, there are structural challenges to consider, namely the lack of consensus among disciplines, regions, universities or even departments regarding ethical reviews. We call on all institutions and individuals to consider ethical responsibilities and to implement effective systems or boards, which help to reduce harm and inconveniences for studied users (Salganik, 2019). Currently, researchers have no incentives to include an ethics report, especially since text-space is limited for publications.
Nonetheless, researchers in CMH have a great responsibility that goes beyond their accountability to individuals. In light of the increasing science scepticism and algorithmic resistance, political engagement is declining and damage to democratic institutions looms (Magalhães, 2022). Therefore, consideration of ethical principles and their active discussion in “normal” studies is important and should not be seen as a mere burden or waste of space. A viable workaround is to publish ethical reports or considerations in the Supplemental Appendix. However, we can already report an increase in the proportion of studies with ethical reviews or discussions of ethical challenges and solutions. Williams et al. (2017) proposed a checklist for CMH research, which can be seen as a starting point, even though we want to encourage the integration of (underrepresented) users in the process of guideline-building, since their views and concerns are currently overlooked (Kalluri, 2020). Drawing from our work, we derive two key ethical challenges for CMH research:
The consistent embedding of ethical principles in studies on CMH must be enabled and promoted as an individual task of researchers and a structural task of universities, journals, and third-party funders.
Best practices (e.g. participation of users; Kalluri, 2020) addressing the specific research field and the application of computational methods must be developed in an interdisciplinary context.
Regarding methodological diversity, we observed a relatively homogeneous field with little change over time. Most studies were limited to using text data or other online traces for supervised machine learning or dictionary-based approaches, and only a few articles were based on more than one platform. This narrow focus calls for caution in interpreting study results, as behaviours observed on different platforms or with different types of data could capture very different phenomena (Lazer et al., 2021). Most of the data used by computational social scientists today are owned by private companies who intend to maximize their revenues and control and regulate access (Sadowski et al., 2021). Therefore, it is no surprise that nearly all research on SM is done with convenience samples. Researchers rely on data that is often unknowingly constructed using inappropriate assumptions and harmful biases. These aspects are further complicated by the evolution of SM platforms over time, now integrating a ‘nebulous constellation of features’ (Bayer et al., 2020: 472), which offer various, often interlinked, social-psychological implications. Overall, methodological diversity is slowly emerging, but will further increase in the future. An upcoming challenge will be to ensure the generation of comparable knowledge in studies. One contemporary key question for CMH and the use of SM data is how to reflect media repertoires, especially when assessing individual MH (Liu et al., 2021).
Finally, the fragmentation of research over disciplines must be seen as an important challenge. First, various disciplines define terms and methods differently, which hinders the synthesis process. Second, different standards in disciplines might lead to more or less conscientious handling of data (see ethical considerations). These methods are being consolidated in the so-called computational social sciences and are gradually becoming institutionalized. Therefore, we postulate that common standards can gradually be developed and have to be one of the next steps in this field. Other aspects described, such as access to good data, cannot be solved by science alone. Political regulations are paramount to safeguard the public interest in these data against corporate interests. Therefore, we identify the following three methodological challenges for upcoming CMH research:
An expansion of research interest to other types of data (images, videos) and media repertoires rather than individual features or platforms is needed.
Linking the applied method and results back to theory is essential (see Van Atteveldt and Peng, 2018).
Interdisciplinarity is one of the key features in the field. This must be considered at all levels, including theory, ethics and method.
Limitations
Even though we created, tested and improved the extensive list of search terms, no list will be complete. Moreover, the population of relevant studies is unknown, databases can have systematic errors and researchers’ access to the database content is limited (in the case of EBSCOhost, for example, by the subscription purchased by each university). Thus, even a systematic approach has inevitable limitations, and not all studies, journals and disciplines might be represented equally well by this research, especially unpublished work that is not part of this study. Due to resource limitations, we could only include English publications in our sample. Furthermore, the field is still young, and any trends observed are not statistically relevant, especially given our small sample.
Due to time and resource constraints, we have only addressed a portion of the present and upcoming challenges in CMH research. Questions like ‘Are we really measuring what we aim to measure?’ are left to be addressed by future studies by evaluating and improving the integration of objective and subjective measurements. In addition, the influence of online platform design on human behaviour must be given much more attention, as SM platforms adapt known psychosocial phenomena to increase platform use and platform-specific temporal behavioural norms, co-shaped by algorithmic and human behaviour, evolve, which impact the observable behaviour and complicate the observation (Bayer et al., 2020; Lazer et al., 2021; Ruths and Pfeffer, 2014).
Conclusion
SM data allow researchers from various disciplines to explore one of the most important aspects of being human: our mental health. Our mapping of CMH research has documented a multidisciplinary research field that has grown immensely since 2010 and is nested across the humanities, social sciences, as well as technical sciences. It extends historical procedures, problems and practices of data collection and analysis. First, we theoretically identified crucial conceptual, ethical and methodological blindspots that cut across domains and scientific fields. Second, we empirically described these issues for the field of CMH, giving future researchers an idea of existing and upcoming challenges, but also opportunities. Finally, we call for more diverse, but theory-driven, research, since MH research needs to be sharp and cautious in its assessment of human behaviour.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The publication is funded by TAB (Thüringer Aufbaubank) as part of the project thurAI (Grant number: 2021 FGI 0008).
Supplemental material
Supplemental material for this article is available online.