
Abstract
Digital false information is a global problem and the European Union (EU) has taken profound actions to counter it. However, from an academic perspective the United States has attracted particular attention. This article aims at mapping the current state of academic inquiry into false information at scale in the EU across fields. Systematic filtering of academic contributions resulted in the identification of 93 papers. We found that Italy is the most frequently studied country, and the country of affiliation for most contributing authors. The fields that are best represented are computer science and information studies, followed by social science, communication, and media studies. Based on the review, we call for (1) a greater focus on cross-platform studies; (2) resampling of similar events, such as elections, to detect reoccurring patterns; and (3) longitudinal studies across events to detect similarities, for instance, in who spreads misinformation.
Keywords
Introduction
The digitalization of media has accelerated the speed and reach of false and misleading information to an extent where it now transcends national borders, causing a problem of global concern. The most recent example of false information thriving online is the Russian–Ukrainian war, superseding to some extent the COVID-19 pandemic (Charquero-Ballester et al., 2021). Research suggests that false information travels faster and further than the truth (Vosoughi et al., 2018), and in some cases the reach of a single misinformed user can surpass the reach of established newspapers (Allcott et al., 2019). The overspill of false information from one country to others can challenge various aspects of society such as health efforts (Swire-Thompson and Lazer, 2020) and democratic processes (Tenove, 2020).
This review article aims at mapping the current state of academic research on digital false information at scale in the European Union (EU). That is, the focus is on the broad aspects of research on digital false information to identify blind spots regarding regional coverage, disciplines, and topics and thus future directions for research, rather than the applied theories and methods. In recent years, we have witnessed a global trend in academia toward studies conducted at scale ignited by big data (e.g. Abkenar et al., 2021; Schroeder, 2016). This offers new possibilities to study the patterns of false information. Since the 2016 US presidential election and the Brexit referendum vote, false information has gained traction across a variety of academic fields (Khan et al., 2021). Ever since 2016, the geospatial distribution of the research has been centered in the English-speaking world, primarily in the United States (Abu Arqoub et al., 2020). However, the EU has also invested massively in efforts to counteract false information (Anderson, 2021).
Previous reviews focusing on false information and related terms have had different focal points. For instance, Kapantai et al. (2021) and Tandoc et al. (2018) provided conceptualizations and operationalizations of disinformation and fake news, respectively. Other reviews have taken a thematic approach to false information, focusing on themes such as health (e.g. Gabarron et al., 2021; Wang et al., 2019) and political misinformation within the United States (Jerit and Zhao, 2020). Finally, a third group of reviews focused on fake news detection and/or classification models (e.g. Vishwakarma and Jain, 2020).
However, a review of research activities on false information at an EU level with large-scale data samples, or the intend to infer the findings to a larger population, is a blind spot that this article seeks to fill, the main question being, “What has been published on digital false information at scale by researchers interested in specific EU member states or affiliated with EU based institutions in various disciplines?” Here, “at scale” refers to the use of large-scale data sets and/or the ability of the study to infer findings to a larger population, rather than to the number of countries studied. This criterion was chosen, as digital false information is a considerable problem. Even with studies indicating that false information is a minority of digital information (e.g. Charquero-Ballester et al., 2021), studies have also found that false information is widely known and believed by the public (Tsfati et al., 2020). The extent of false information remains unclear as important digital platforms are not fully studied, for example, private Facebook pages, and chats. With the continuous creation of digital content, at scale studies are necessary to indicate patterns and characteristics of various aspects of false information.
By conducting a review across different fields, the article will not only identify existing gaps, for instance, countries that have yet to be studied at scale, but also function as a background to understand the position of new media and communication research in relation to other fields, and to foster new insights and collaborations. Research suggests that false information patterns and characteristics can vary on a regional and even country basis (Humprecht et al., 2020). Considering the prevalence of UK- and US-focused research, we wish to contribute to a better mapping of research conducted at scale on an EU level, providing information about where and to what extent research is taking place.
Digital false information at scale in the EU
In this article, we use “false information” as an umbrella term covering various kinds of false and misleading information which differ in terms of their veracity and intention (e.g. disinformation, misinformation, and conspiracy theories) (for further conceptualizations, see Kapantai et al., 2021; Tandoc et al., 2018).
We use the phrase “at scale” to refer to studies that aim to offer quantitative analysis of false information, including single, cross-national, and cross-platform studies. This criterion applies for the data set sizes and the methods applied by the identified research articles. We have focused on studies that investigate the general patterns of false information in the EU, that is, research that draws on large samples and/or refer to national or cross-national population behavior through trace data, survey, and/or experimental studies, for instance. This means that we excluded survey studies when based on non-representative samples and experimental studies that do not infer findings to a general population.
However, due to the interdisciplinary scope of the review, defining what is “at scale” or not in terms of digital content, trace, or log data studies is not trivial, as the definition may differ from field to field or from platform to platform. Consequently, we have worked with more flexible thresholds for what we define as “large samples,” depending on the platform studied. For instance, Twitter and open Facebook groups and pages have an open data access structure, so we included studies above 1000 tweets/posts for these sources. But for more closed data access structures like YouTube and closed Facebook communities, we set the threshold lower to include studies with 500 or more posts/videos (e.g. Donzelli et al., 2018). Website articles have a longer format compared with social media data such as tweets, so we have included studies containing more than 100 website articles. In case of cross-platform studies that are highly relevant from a propagation point of view, we have included studies that look at the top shared links across social media. The review also encompasses studies of, for instance, false information detection and logics of propagation if these are of general applicability and trained on large content samples.
For mapping research on an EU level with a focus on broad aspects of digital false information, we identified the following five points of departure for our analysis: (1) data sources, (2) themes and topics, (3) country of interest, (4) country of researcher affiliation, and (5) academic field. These five focal points are closely interrelated; data sources are relevant for the mapping of digital false information in the EU, as researchers’ choice of platform has implications for the generalizability of the results as audiences vary between platforms and between countries (Singh et al., 2012). An analysis of which EU member states have been studied, and of the prominent themes and topics, as well as affiliation of researchers, will help to evaluate in which countries and aspects digital false information is not yet properly mapped. In addition, it is relevant to get an overview to what extent specific countries and topics are studied as the context influence characteristics of false information such as spread or emotional valence (Charquero-Ballester et al., 2021).
The characteristics of false information vary across borders (e.g. Humprecht, 2019); hence, it is relevant to look at which countries are covered in academic research. Hereby, we also identify potential blind spots to subsidize more diversity in areas of interest. Similarly, we set out to map the country affiliation of researchers to examine a potential relationship between where research is conducted and the countries focused on. This information can strengthen cross-country collaborations by pointing out power-centers for academic inquiry into digital false information at scale. Finally, the field of research is considered as this knowledge may benefit interdisciplinary collaborations by providing insights into the methods and data sources used by different fields.
Methodology
To find papers studying false information at scale in the EU, we conducted a systematic literature review following the Preferred Reporting Items for Systematic reviews and Meta-Analyses (PRISMA) guidelines (Page et al., 2021). These guidelines are widely used for literature reviews (e.g. Bryanov and Vziatysheva, 2021; Saquete et al., 2020). In this section, we account for the methodology to secure the transparency and replicability of the methodology design applied.
Inclusion criteria
First, we have included research that focused explicitly on one or more EU member states, also if they do so in combination with countries outside the EU. If the research is not country-specific, it was only included if the authors are affiliated to EU-based research institutions or organizations to ensure contextual sensitivity to false information in an EU perspective. It is often the case in at-scale studies that they are non-country-specific as large data chunks are scraped from platforms without country-specific settings (e.g. Giachanou et al., 2020) and as there are no clear national borders in digital media. Furthermore, articles authored by EU-based researchers indicate where in the EU research communities are established and in which countries they need stronger support. Second, we have only included articles that are published in English, the standard language of international academia, thereby enabling as many scholars as possible to engage with the work presented here (search our database online here: https://edmo.eu/scientific-publications/). Third, the review only includes papers that study digital false information “at scale,” as defined in the previous section. Fourth, we included publications whose title contained search keywords related to false information (outlined in the next subsection) and keywords related to geographic focus anywhere in the publication. This choice was made to secure that false information is the main topic of the publication and the publication addresses the EU. Finally, the search timeframe started in 2015 as it was the year in which the manipulation of information during the Ukraine crisis led the EU Council to call for an action plan (Bentzen and Russell, 2015). In addition, this timeframe includes research on the influence of digital false information during the Brexit referendum campaign.
Keyword specification
With a view to complying as closely as possible with the objective of the literature search, the keywords were divided into two categories: category 1 contains words related to false information, while category 2 contains relevant country names.
The first keyword category comprises several keywords related to false information, namely, conspiracies, conspiracy theory, conspiracy, disinformation, fake news, false information, hoax, information disorder, malinformation, and/or misinformation.
The second keyword category contains (former and current) member states and relevant abbreviations: Austria, Belgium, Britain, Bulgaria, Croatia, Cyprus, Czech Republic, Czechia, Denmark, England, Estonia, EU, Europe, Finland, France, GB, Germany, Great Britain, Greece, Hungary, Ireland, Italy, Latvia, Lithuania, Luxembourg, Malta, Netherlands, Poland, Portugal, Romania, Scotland, Slovakia, Slovenia, Spain, Sweden, UK, United Kingdom, and Wales.
Search engine
The Danish Royal Library was chosen as an access point to the literature search, as it facilitates access to 10,113 collections, including the Web of Science and Scopus, 1 and enables the use of an extended keyword list (in contrast to Google Scholar).
Search results and filtering
Based on the search criteria described above, a search was conducted on the 28 January 2021, resulting in 2296 matching articles, proceedings, books, book chapters, and reports. The search results were manually filtered to ensure that only studies that fulfill the relevance criteria were included. The filtering process is illustrated in Figure 1.
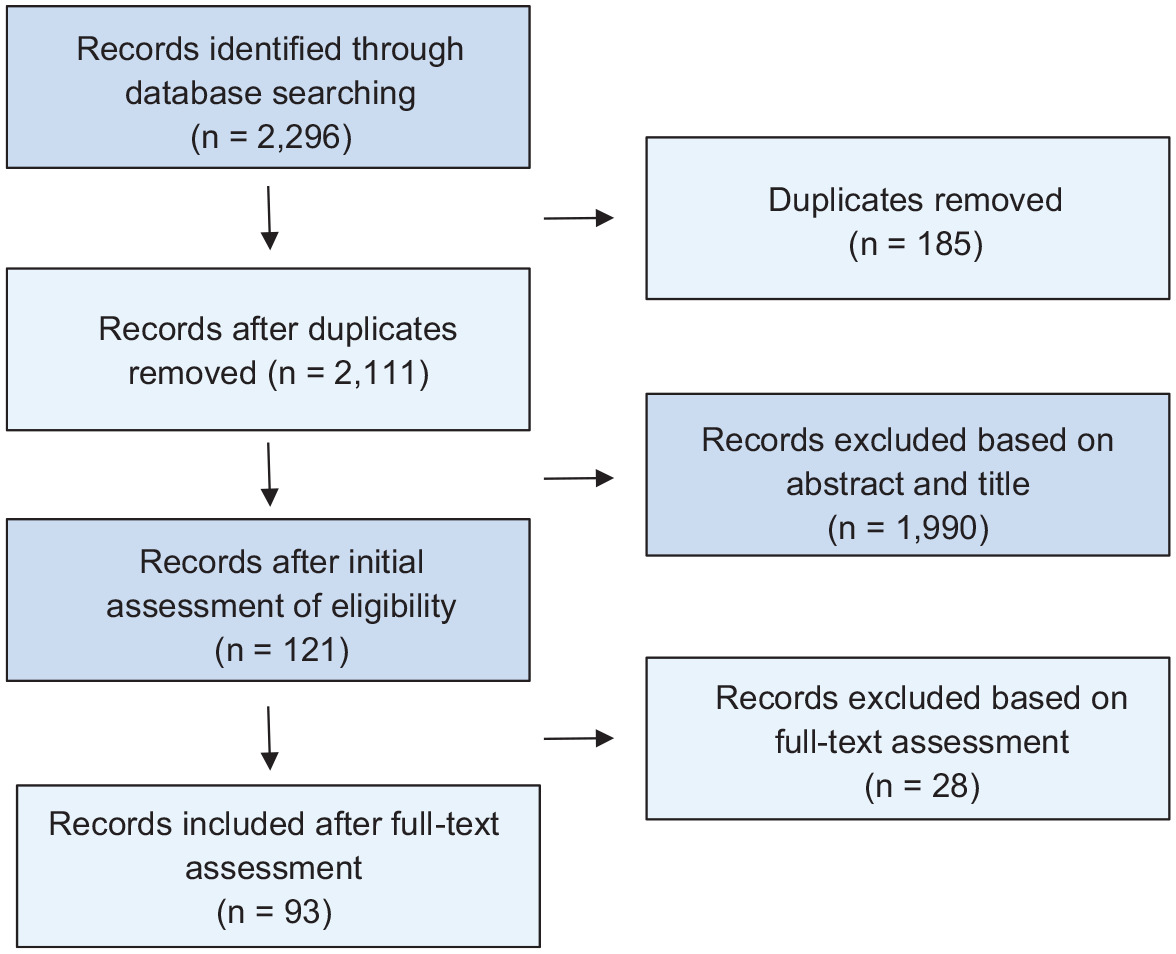
PRISMA flowchart showing the filtering process.
As illustrated in Figure 1, 93 academic publications remained and 2203 search results were excluded after finalizing the filtering process (see supplemental materials 1 and 2, also regarding main reasons for exclusion).
Results
We analyze the search results with a focus on data sources, themes and topics, country of interest and geographical blind spots, country of researcher affiliation, and field of research to map current research on digital false information at scale in the EU. Throughout the section, we highlight papers that represent special or common cases, respectively, to exemplify how false information in the EU is being studied. Overall, we see an increase in the number of academic publications matching our search criteria from 4 in 2015 to 41 in 2020 (see supplemental material 3). The improvement of computational methods for extracting large-scale data sets 2 is a possible explanation for this tendency.
Data sources
As shown in Figure 2, there is an almost even divide between papers using social media data (55) and other data sources (51), that is, digital news, websites, and so forth (multiple sources possible, for example, cross-platform studies).
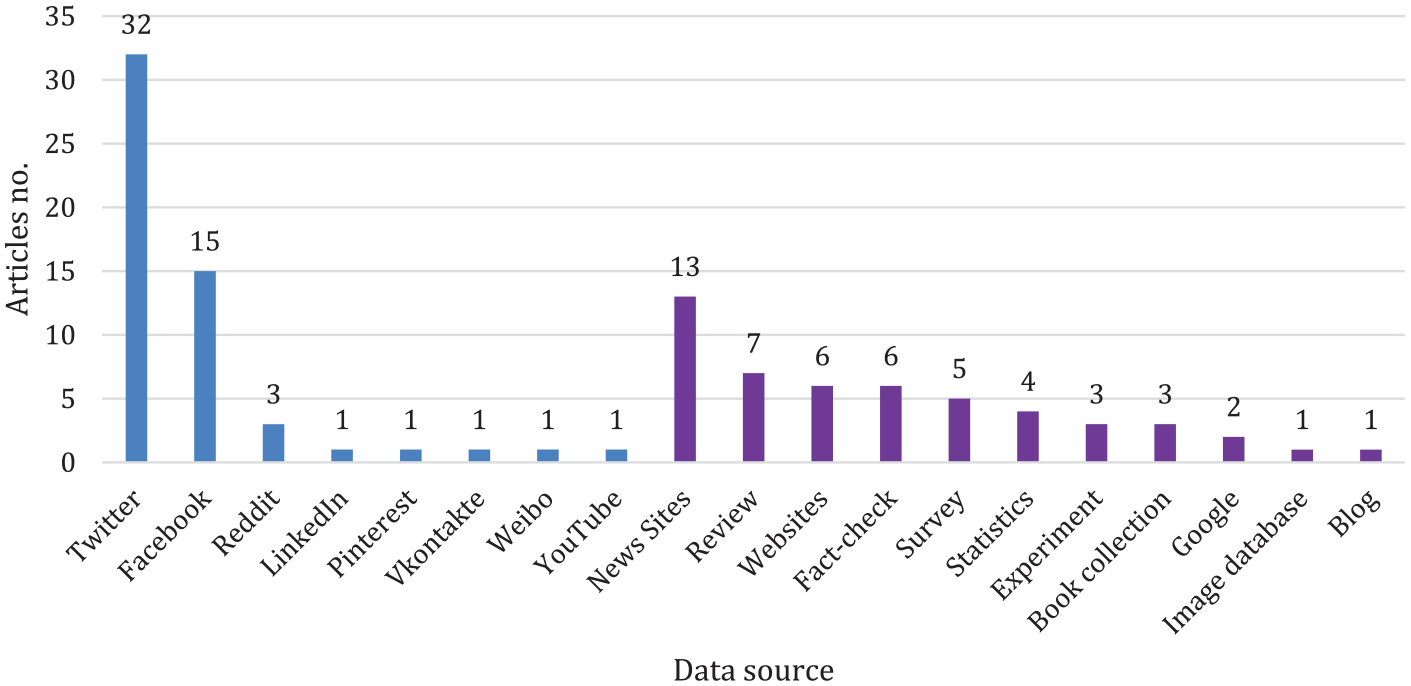
Distribution of data sources in digital false information research.
Twitter stands out as the most frequent data source and the research questions approached using Twitter data vary considerably. One group explores false information from a topical angle and monitors tweets during elections (e.g. Pierri et al., 2019), health issues (e.g. Ahmed et al., 2020), for instance. Other studies explore the possibility of improving false information detection (e.g. Masciari et al., 2020), classification tasks (e.g. Antoniadis et al., 2015), or on mapping the diffusion of false information (e.g. Pierri, 2020). The Twitter data sets often run into thousands, sometimes millions, of entries, for instance, Pla Karidi et al. (2019) who automatized the collection of tweets and ended up with a data set of 238,685,450 tweets.
Turning to cross-platform studies, Waszak et al. (2018) used the BuzzSumo application to conduct a cross-platform study of frequently shared health-related stories by searching for different keywords, for example, “cancer” or “neoplasm.” With this approach, the researchers got results from Twitter, Facebook, LinkedIn, and Pinterest. In another cross-platform study, Pulido et al. (2020) advanced methods to counter health misinformation through social data analysis focusing on Facebook, Twitter, and Reddit. The researchers applied different data extraction strategies: Twitter data were found through hashtag searches, two Facebook pages were selected for keyword search, and on Reddit a specific Subreddit community was chosen.
These cross-platform studies, however, are the exception, representing a research gap; thus, the two exemplary studies shown can serve as inspiration for future cross-platform research. YouTube is an example of a large but understudied platform. The domination of Twitter data signals that using the other platforms is still more challenging, for instance, Facebook restricts access to content outside the open groups and pages, and the analysis of YouTube videos requires more storage and computation capacity.
Themes and topics
We have taken two approaches to analyzing the themes and topics of interest in the papers: first, we created a keyword network which illustrates the keywords of the included papers and their internal network (see Figure 3); second, we coded the topic of the papers manually (see Figure 4).
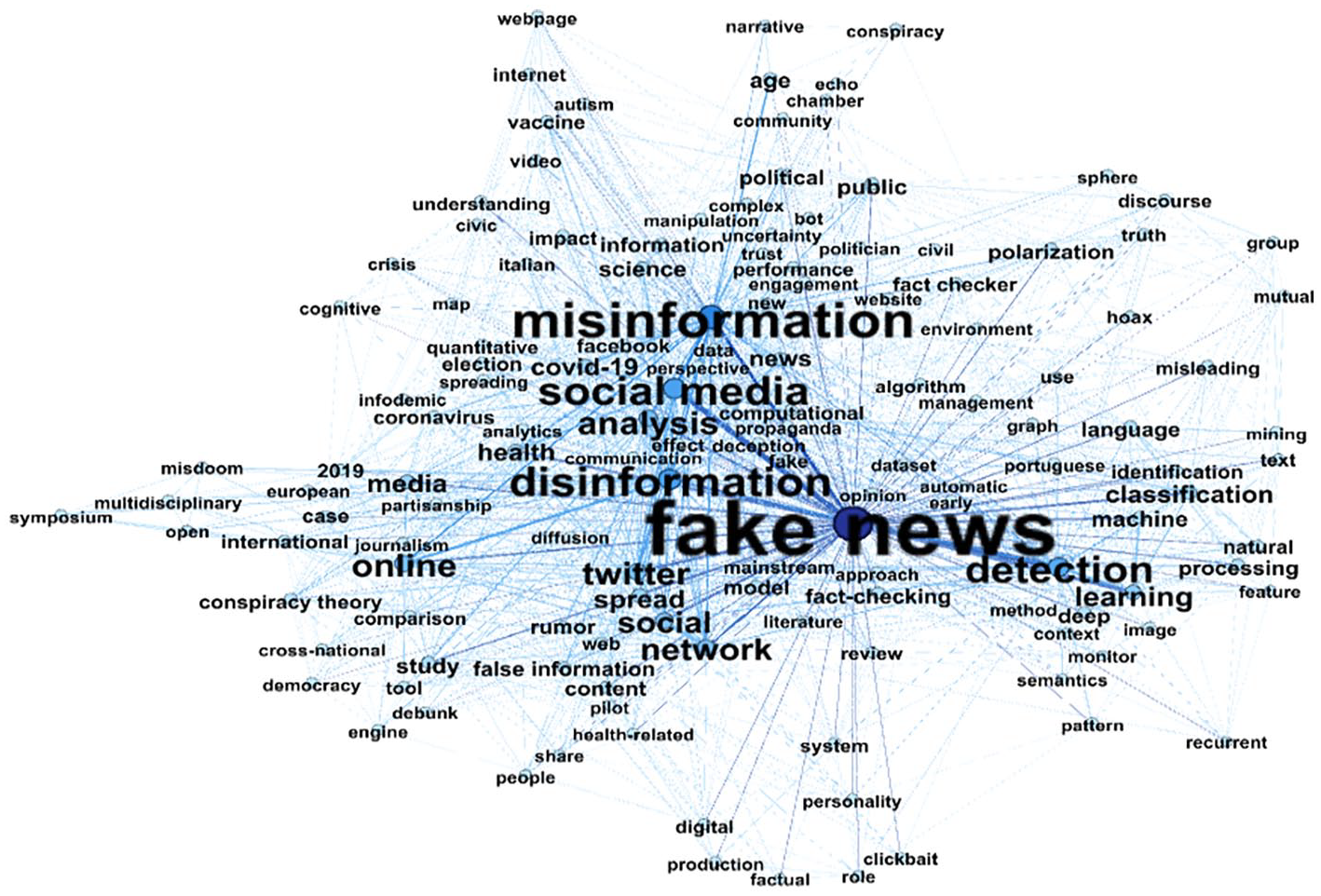
Network for keywords appearing in two or more papers (see supplemental material 4 for description and cloud with all keywords).
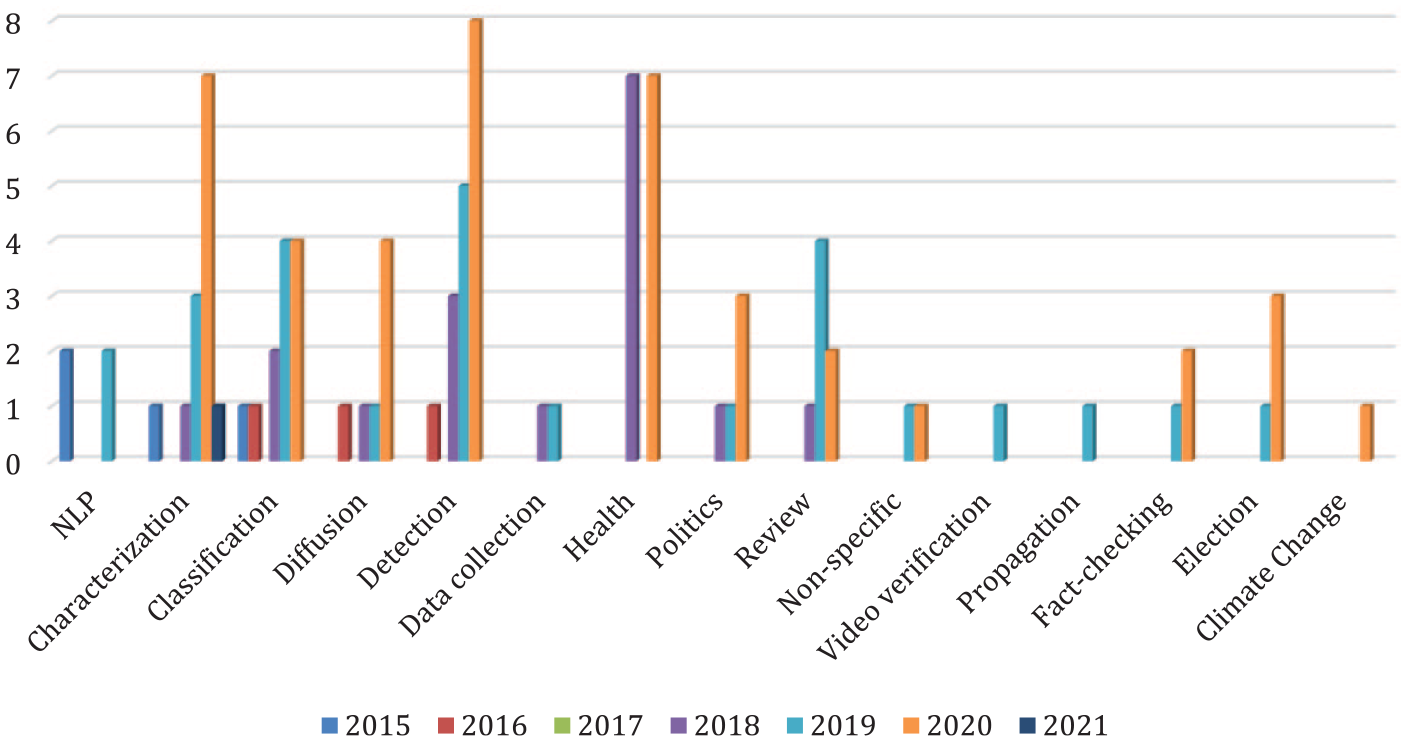
Evolution of topics from 2015 to 2021.
In Figure 3, the shade and thickness of the lines connecting the keywords indicate their prevalence in the data with thick lines and dark blue indicating a high prevalence. Keywords must have a minimum of two occurrences in the data set to appear in the network. Moreover, title keywords were included to avoid excluding papers that did not provide keywords and because researchers avoid selecting words included in the title as keywords.
As Figure 3 demonstrates, especially the bigram “fake news” appears frequently (53 times), followed by the words misinformation (30x), disinformation (23x), social media (22x), detection (20x), analysis (15x), online (15x), and Twitter (15x). Furthermore, we see strong ties from fake news to social media, misinformation, and detection. The connection between “fake news” and “detection” may be explained by the separation of the trigram “fake news detection” into “fake news” and “detection” in the keyword listed by the authors. However, “detection” occurs considerably more often than other aspects of analysis such as “classification,” “identification,” or “impact” indicating a focus of “at scale” studies on detection tasks. The prominence of the bigram “social media” correlates well with the previously identified popularity of social media data which, for instance, is used to improve fake news detectors (e.g. Abonizio et al., 2020; Masciari et al., 2020).
As for the terminology, Figure 3 suggests that “fake news,” “misinformation,” and “disinformation” are used frequently to describe false information. Related terms included in the search such as “conspiracy theory” and “hoax” are less prominent. As all keywords are a part of the search criteria, what is interesting is the combinations and the words that are absent. With this regard, it is noticeable that “malinformation” and “information disorder” do not appear at all (a figure for the complete keyword network is included as supplemental material 4). Furthermore, the keywords support the finding that studies so far focus on Twitter as data source, with Facebook being less prevalent and all other platforms even more neglected.
To explore the topics further, we applied a manual coding strategy for the topics based on an assessment of the title, abstract, and keywords. The coding was divided in papers exploring specific themes (e.g. health, elections) and method-oriented papers (e.g. detection, NLP) (the coding strategy is described in more detail in supplemental material 5).
Three topics appear to be widely studied: characterization, detection, and health. The first two have increased in frequency throughout the period, whereas health was studied with equal frequency in 2018 and 2020. Characterization is a wide category, including papers which offer characterizations of the online communities where false information is shared (e.g. Loos and Nijenhuis, 2020; Schatto-Eckrodt et al., 2020), as well as consumption patterns (e.g. Bessi et al., 2016) and false information characteristics (e.g. Acerbi, 2019; Humprecht, 2019).
Surprisingly, the number of health-oriented papers did not increase between 2018 and 2020 in the wake of the COVID-19 pandemic. A possible explanation for this is a delay in research as it takes time to gather large-scale data sets; hence, it is possible that an updated search would show a spike in health-oriented research. This is supported by an assessment of the papers from 2020, confirming that COVID-19 is the dominating theme, whereas there is greater variation in topics for health-oriented literature before 2020, for instance, on ineffective cancer treatments (e.g. Ghenai and Mejova, 2018), the quality of digital influenza vaccine information or anti-vaccine websites (e.g. Arif et al., 2018; Donzelli et al., 2018), and the spread of medical false information (e.g. Waszak et al., 2018).
Looking at the included studies, there is great variation in the approaches to false information detection and classification: from focusing on the propagation structures of tweets and retweets in real and fake news (Meyers et al., 2020), to combining either linguistic and personality patterns (Giachanou et al., 2020) or network and linguistic features (Van de Guchte et al., 2020). The highest accuracy in false information detection in comparison with other identified studies is reached by Van de Guchte et al. (2020) with an accuracy of 93% in distinguishing truth from false in near-real time settings. However, these studies are all optimized for English (Abonizio et al., 2020). For studying false information within the EU, an exciting prospect would be to develop a language-independent detector. Abonizio et al.’s (2020) study is a first step in this direction, as they create a language independent-detector based on complexity, stylometric, and psychological features from English, Portuguese, and Spanish corpora. The detector reached an accuracy of 85.3%, indicating that with more fine-tuning this could be a promising path toward language-independent detection.
Finally, a possible explanation for the distribution of topics could be the focus of this review on large quantitative studies and potentially it also reflects priorities in research funding, for instance, of health, politics, and detection tasks.
Country of interest and geographical coverage
Most of the articles included were not country-specific (59). This may illustrate a limitation to the use of digital media data, as platforms lack or do not share information about the location of their users. As previously stated, these are included, as the digital environment is characterized by no clear national borders, and they indicate where in the EU research is taking place. Twelve of the 93 studies were cross-country studies featuring up to 32 different countries (Ralston et al., 2018), with most of these studies using survey data. The remaining 22 studies were country-specific. The distribution of studies per country is illustrated in Figure 5 and the shade of the color indicates the number of articles studying the country in question.
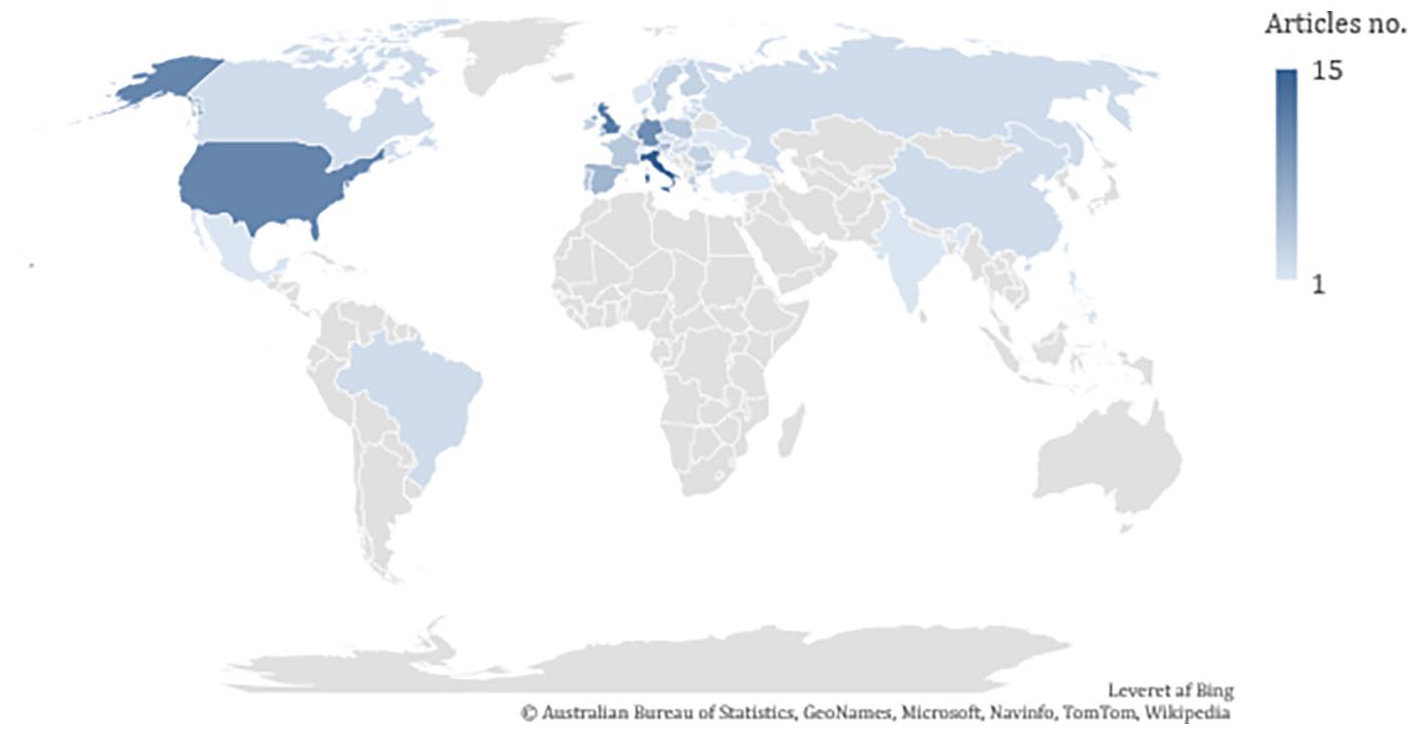
Distribution of research articles by geographic area of interest.
The countries studied most frequently are Italy (15), the United Kingdom (12), and the United States (11). This is interesting, as even after adjusting the search terms to optimize for EU-focused research, the United States and the United Kingdom appear in the top three. This is in line with the findings in Abu Arqoub et al.’s (2020) review, which indicated a high prevalence of US- and UK-focused research compared with all other countries. There is also considerable variation in the number of studies across member states: Eastern European countries only appear in a few studies and there are few studies dealing with large member states such as France, Spain, and Portugal. Future research should close this gap by focusing on these understudied areas.
Surprisingly, Italy is the country studied with the greatest frequency. The high Italian mortality rates during the first wave of COVID-19 may have inspired researchers to use Italy as a case study for false information during the pandemic (Chirico et al., 2021). Furthermore, the results show a broad representation of EU countries, although for 19 EU countries no country-specific studies have been conducted: Austria, Belgium, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Greece, Hungary, Ireland, Latvia, Lithuania, Luxembourg, Malta, Netherlands, Slovakia, and Slovenia. The multi-country studies predominantly rely on survey data, for example, the Flash Eurobarometer (e.g. Borges-Tiago et al., 2020) or statistics (e.g. Ralston et al., 2018), indicating that research on digital media data is still scarce in cross-country studies and on several individual countries.
While survey studies can provide insights into how attitudes toward false information differ across EU member states (Borges-Tiago et al., 2020) and into differences in resilience to false information (Humprecht et al., 2020), more research should use digital data to form a more precise idea of the false information circulating in the EU. In her study, Humprecht (2019) combined survey data with digital data from fact-checking organizations in Austria, Germany, the United States, and the United Kingdom to compare false information. The research indicated that false information in Austria and Germany is sensationalist and often targeted immigrant groups, whereas the United Kingdom and United States experienced partisan false information (Humprecht, 2019). Future research should develop new methods to collect data from other European languages at scale, to better understand false information at the country-level, and to conduct cross-country comparisons.
Country of researcher affiliation
As Figure 6 shows, countries both inside and outside the EU are represented to different degrees in terms of researcher affiliation. As expected, these correlate to some extent with the countries which are studied most frequently. Once again, the large number of researchers affiliated to the United Kingdom can be explained by the fact that the United Kingdom was part of the EU in most of the timespan of the literature search.
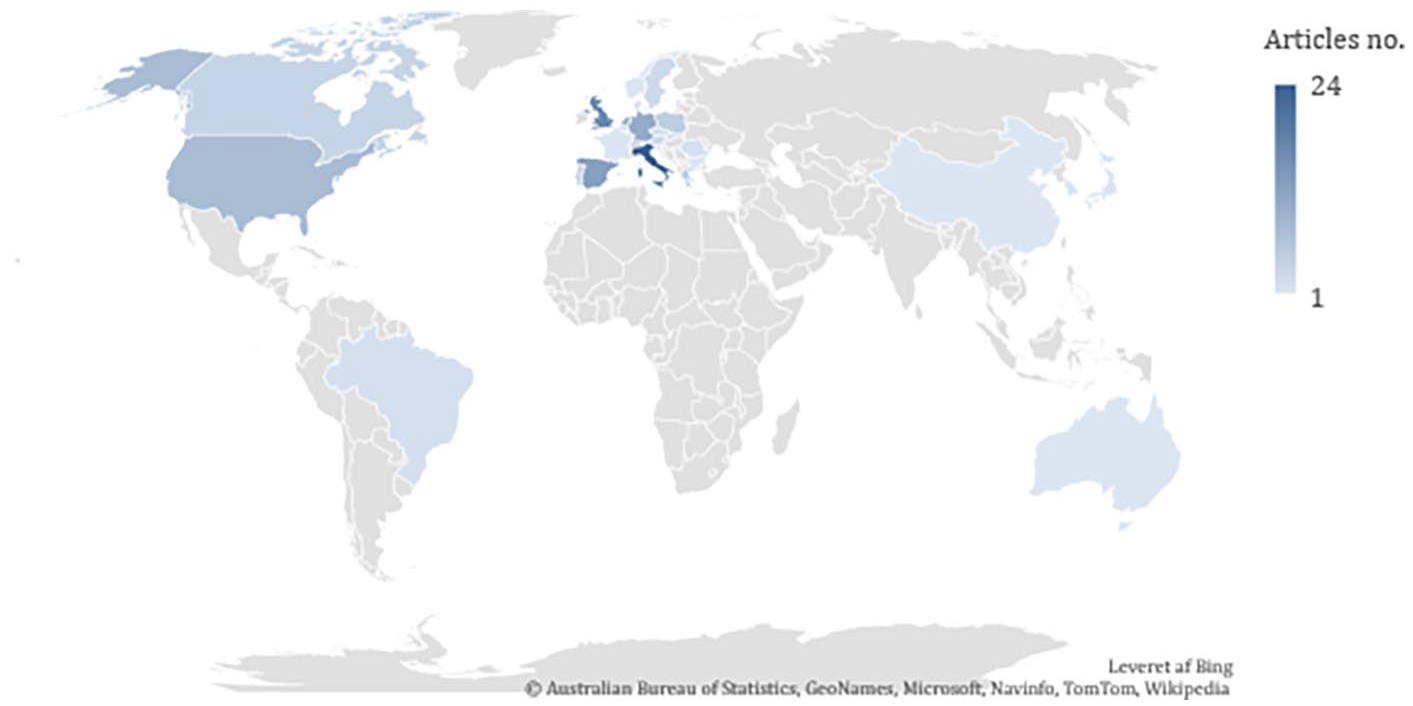
Distribution of researcher affiliation.
Finally, the included studies suggest that the research community acts collaboratively. Fifty of the 93 studies were conducted in collaboration between two or more authors from different institutions or organizations, and in 31 cases the collaborations took place across countries. It is surprising that France, one of the largest countries within the EU, is only represented with one article, especially considering the share of articles coming from the neighboring countries, particularly Italy, Spain, and Germany. Furthermore, there is only limited research activity in Eastern Europe. These differences might reflect differences in funding or publication strategies (as, for example, researchers in France might prefer publishing in French), but future research should address explanations for these differences.
Field of research
As illustrated in Figure 7, computer science and information studies contribute far more than any other field to the study of digital false information in the EU, which is likely due to the “at scale” criteria as these specific fields apply the methods needed to extract “at scale” data sets.
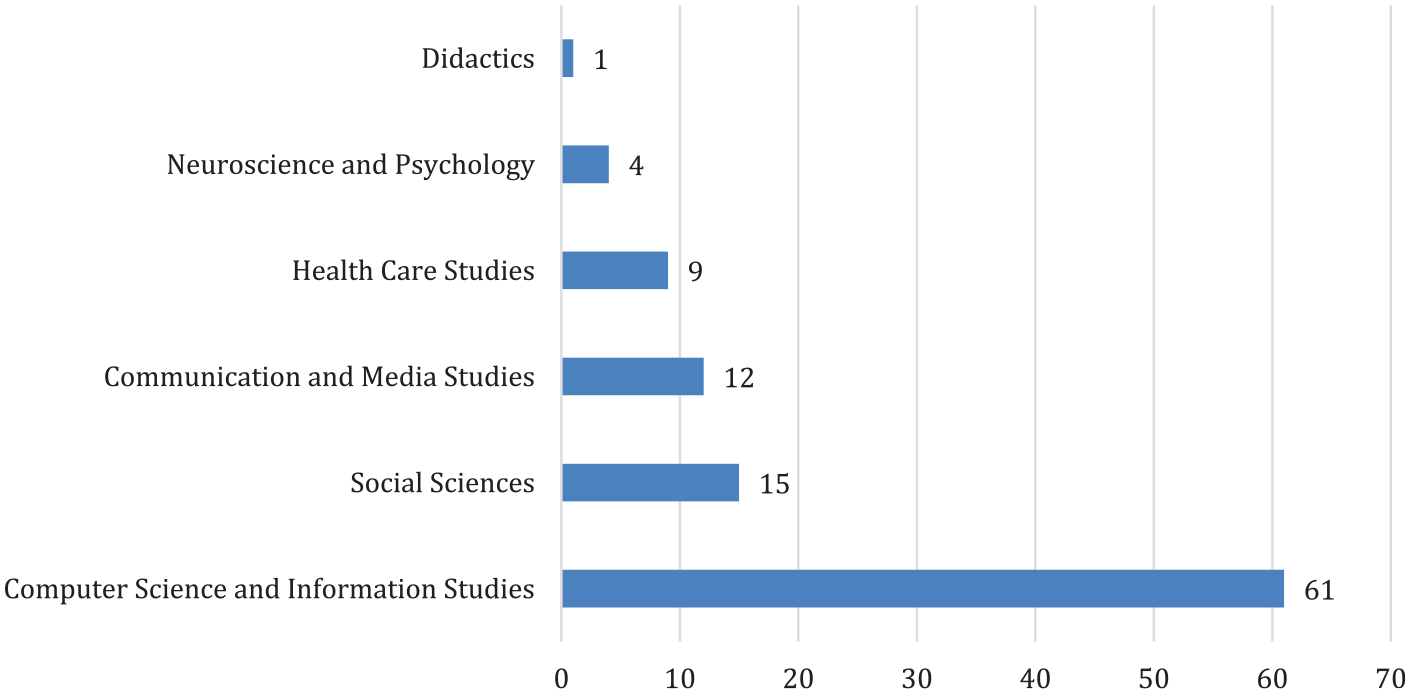
Distribution of research articles across fields.
Across the studies, there are examples of interdisciplinary work, for example, between linguists and computer scientists applying Natural Language Processing (NLP) methods (Giachanou et al., 2020), or between social sciences and computer science and information studies (e.g. Pernagallo et al., 2021).
It is surprising that the field of communication and media studies is not better represented, considering both its strong ties to journalism studies and the fact that false information spreads on digital media. The included articles from communication and media scholars are concerned with topics such as fact-checking (Humprecht, 2020; Luengo and García-Marín, 2020), the engaging effects of false information (Corbu et al., 2020), and the variation in false information across media systems (Humprecht, 2019). This demonstrates nicely the broad range of research questions to which this field can contribute in relation to false information. A possible explanation for the low representation, compared with the high interest in the topic from this field, may be that communication and media researchers are also engaged in conceptual work as well as in-depth qualitative content analysis, which are outside the scope of this review.
Of the 50 collaborative studies, only nine are interdisciplinary, for instance, social science and computer science researchers work collaboratively on studying the influence of false information in elections (e.g. Cinelli et al., 2020). However, the academic field was assessed based on departments of author affiliation which may have resulted in an underestimation of collaborations across fields, as it is possible that researchers in a computational department, for instance, have other backgrounds, and that research teams within one department or from the same field are interdisciplinary without this being reflected in the department’s name.
Discussion
This article has presented and analyzed an overview of where in the EU digital false information research has been conducted, the country-specific focus of this research, the use of different data sources and the topics addressed. Overall, we have found a broad representation of researchers affiliated with different countries inside and outside the EU. Furthermore, all the member states are studied to some extent mainly by country-unspecific studies as in 19 cases the country in question is only part of a cross-country study. One possible explanation for this is that digital false information might affect countries within the EU to different degrees. However, more studies are needed in the not represented countries (especially, Eastern Europe, Spain, Portugal, and France) and comparing different countries to fully justify this claim. There are different explanations for why the countries are not equally represented, for instance, that false information is not an equally prevalent problem in all countries, or because languages, other than English, are not frequently studied at scale, for example, because of the lack of analytical tools or due to the difficulty of collecting large scale data sets in these languages. A greater understanding of regional similarities and differences may aid policy makers, researchers, and fact-checkers in implementing efficient national, regional, or international initiatives to counter misinformation.
One common feature of all the articles with a specific topic is a focus on unique events such as elections or health crisis. For instance, Pierri et al. (2019) collected Twitter data from a 5-month period during the 2019 EU Parliament elections, while Baptista and Gradim (2020) focused on the Portuguese 2019 election. Across the papers reviewed here, there is a general pattern of focusing on limited time periods which makes it difficult to reach general conclusions. Consequently, future research could focus on a longitudinal perspective as this would allow for understanding false information in different contextual settings within the same country and across countries and events (e.g. elections, disease outbreaks). In doing this, researchers can find inspiration in papers that explore false information more generally. For instance, Del Vicario et al. (2016) compared the spreading patterns of scientific and conspiracy news by downloading a massive data set with Facebook posts from 67 public Facebook groups across a 5-year timespan. Finally, the variance in the frequency of the identified topics is possibly intwined with the represented fields of research and methods used, another possible explanation for the prevalence of the topics: climate change, health, and politics is a higher level of funding.
Our analysis has shown that approximately one-third of the articles analyzed Twitter data and that Twitter is studied more frequently than any other social media platform, which has some implications. Stephens (2020) pointed out that Twitter is not a reliable source to document the false information exposure of a representative sample of the population, so further studies are needed on other data sources. Privacy settings on the different platforms that in turn also affect how restrictive data access is for researchers are part of the reason why Twitter appears to be the most examined platform. On Facebook, for instance, users have the option to make their information private (Steinert-Threlkeld, 2018). Sensitivity of data might be one reason for social media platform providers to restrict access and platforms in general vary to a large extent in terms of how restrictive they are regarding data access.
The studies that have used other data sources than Twitter data have applied different approaches to gather large-scale data sets. Loos and Nijenhuis (2020) used Facebook ads to investigate whether the dissemination of false information is a matter of age and found that especially older age groups engaged with the content. Another example is Slavtcheva-Petkova (2016) who collected data on news websites discussion boards, while others, in turn, have focused on fact-checking sites as an easy access to already annotated content (e.g. Braşoveanu and Andonie, 2019). Taken together, the studies demonstrate the diversity of digital data and can serve as inspiration for future research to secure a better mapping of understudied platforms.
The advantage of gathering large amounts of trace data through social media is that it provides the opportunity to study people’s communicative behavior across space and time (Steinert-Threlkeld, 2018). This is reflected in the relatively large number of studies that are not country-specific. However, it has been argued that this trace data lacks contextual sensitivity (Anderson, 2021), so it would be interesting to explore multi-method approaches further, something which is beyond the scope of this review.
Finally, there are some limitations to our methodological design of the search and filtering process that have affected our results in the review. First, we chose to focus on ‘at-scale’ studies, so we favor academic fields that primarily use quantitative methods. The advantage is that we include papers which investigate potentially more general aspects of digital false information, but we have not accounted for potential deep contextual insights from smaller, qualitative, and ethnographic studies. Furthermore, future work could engage more with the identified articles to synthesis the methods and research findings; however, our scope has been broader in that we aim to give an overview of false information research in the EU. Second, the filtering process was carried out by a single coder, which might have caused biased interpretations. However, unclear cases were discussed among all the co-authors. In addition, the researchers contributing to this review come from the fields of linguistics, sociology, media, and communication studies, which may have biased the assessment of relevance as well as the formulation of keywords in this direction. Despite these biases, the review does incorporate many studies from health and natural sciences, as well. Finally, we chose to focus on research visible for a global research community by looking at English articles which may have resulted in the exclusion of potentially relevant contributions in other languages. We recommend that it would be most beneficial to rely on native speakers to extend our approach to other languages based on the rather complex filtering of the initial search results. Overall, we estimate that the risk of missing out on relevant literature is unavoidable, but we have mitigated this by carefully defining relevant search terms related to false information and member states.
Conclusion and future directions
Our review offers important insights into the academic work on digital false information at scale in the EU: we have mapped current states, pointed out areas that are currently understudied, and thus, provided directions for future research.
The systematic review revealed an overall increase in the number of academic publications from 2015 onward. Within the EU, Italian-based researchers are the most active, and correspondingly, Italy is studied more than any other EU country. All member states are studied, although 19 of the 27 countries have not been studied individually: Austria, Belgium, Croatia, Cyprus, Czech Republic, Denmark, Estonia, Finland, France, Greece, Hungary, Ireland, Latvia, Lithuania, Luxembourg, Malta, Netherlands, Slovakia, and Slovenia. This could be a task for future research. However, the lack of borders in the digital sphere might reduce the importance of applying country-specific studies.
Instead, future research should consider different geographical limits: there should be a tradeoff between country-specific, regional, and global studies, as research suggests regional differences in the digital false information landscape (Humprecht, 2019). Such an investigation would also allow for better evidence-based adjustments of national and regional tailored initiatives to counter false information. To this end, media and communication scholars could contribute by clustering countries with similar media systems to investigate whether these similarities transfer to the false information landscape.
The review has also shown that in digital false information research, Twitter and to some extent Facebook data are studied more often than other data sources such as YouTube, fact-checking websites, partisan websites, and other digital media outlets. To strengthen the field further, researchers should continue to try to establish firm collaborations with fact-checkers and other stakeholders who may be able to provide data.
Finally, the review shows that media and communication scholars are concerned with the efficiency of fact checks, engagement rates, and the use and assessment of sources. In the future, the field could benefit from stronger ties to computer science and information studies, as these are the dominating fields within false information studies in the EU context. Such a collaboration would be mutually beneficial, as computer scientists and information scholars can provide computational methods to collect and detect at scale data, whereas media and communication scholars have insights into the historical context of media, as well as an in-depth understanding of the contemporary media landscape. Stronger collaboration with healthcare scholars and social scientists could also create a better understanding of how mainstream media can cope with false information targeting health initiatives or democratic processes.
Supplemental Material
sj-docx-1-nms-10.1177_14614448221122146 – Supplemental material for Digital false information at scale in the European Union: Current state of research in various disciplines, and future directions
Supplemental material, sj-docx-1-nms-10.1177_14614448221122146 for Digital false information at scale in the European Union: Current state of research in various disciplines, and future directions by Petra de Place Bak, Jessica Gabriele Walter and Anja Bechmann in New Media & Society
Footnotes
Acknowledgements
The authors would like to thank Mathias Holm Tveen, research assistant at DATALAB, for his contribution to designing the search of relevant papers and formulating the inclusion criteria. Further, the authors acknowledge Athens Technology Center (ATC) for implementing the repository on the EDMO website.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by EDMO (LC-01464044) and EU CEF (2394203).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.