
Abstract
With the rapid development of urbanization, noise pollution has become a serious environmental issue affecting human health and quality of life. Timely acquisition of accurate information about noise sources is crucial for efficient and precise management and control of regional environmental noise pollution. However, traditional methods that rely on manual offline identification of noise sources are not only time-consuming and labor-intensive, but also the results have often lack timeliness. In this study, for real-time and automatically identifying the categories of environmental noise sources in urban areas, a deep convolutional recurrent neural network (DCRNN) based on the Convolutional Block Attention Module (i.e., the parallel CBAM-DCRNN model) was developed by studying different integration strategies. To enhance generalizability of the proposed model, a heavyweight urban environmental noise dataset encompassing 20 typical categories (totaling 13,654 labeled samples) was collected, which includes various spectral features of environmental noises. And also, the transfer learning method was introduced to further enhance the model’s training efficiency and also improve its scalability to larger datasets. As a result, the 92.63% accuracy validated the satisfactory performance of the proposed identification model in a large urban environmental noise dataset, significantly outperforming the classical DCRNN model, even for categories with few training data. Moreover, the experiment validated that the identification effect of the proposed parallel integrated model is significantly superior to this of the CBAM-DCRNN model using sequential integration strategy. The proposed model can be applied to design an environmental noise online automatic monitoring and identification instrument, for real-time automatic identification and early warning of environmental noise pollution sources in noise-sensitive urban areas.
Keywords
Introduction
With the worldwide high and growing urbanicity, the complex road networks, adjacent commercial buildings, frequent construction work, and dense population distribution, etc., have resulted in noise pollution becoming a serious environmental issue affecting human health and quality of life (Hong et al., 2023 1 ; Hong et al., 2022 2 ). Long-term exposure to noise-polluted environment will cause various diseases and increase the risk of illness, which will seriously affect human physical and mental health (Wu et al., 2024 3 ). Epidemiological studies have found noise associated with an increased risk of cerebro and cardiovascular diseases as well as diabetes and mortality (Thacher et al., 2023 4 ). It is crucial to develop real-time monitoring and identification technologies for various noise sources, in order to timely obtain information about regional noise sources. Thereby, precise and efficient management and control measures will be implemented.
Existing online noise monitoring technologies only measure physical indicators such as sound level intensity, but cannot discern the sources of the noise. For sound signals that exceed the sound level limit given in Environmental quality standard for noise (GB 3096-2008, China 5 ) or cause discomfort to people, currently, offline manual identification methods are commonly adopted to identify the main noise sources in the area. There are mainly two methods, one is investigation on site, and the other is to use human auditory perception to identify historical audio, or visually inspecting spectrograms generated from audio data. Obviously, both methods are time-consuming and labor-intensive, and with very low efficiency, which seriously restricts the timeliness of implementing noise management and control measures. Moreover, in cities, there are numerous types of environmental noise sources, and they often mix and overlap with each other, and also, many noises have highly similar spectra, which frequently makes it difficult for the human ear and eye to accurately identify the primary noise sources. Therefore, a real-time, high-accuracy, and automated environmental noise sources identification method is essential.
Environmental Sound Classification (ESC) is a classification task for non-stationary environmental sound signals (Su et al., 2020 6 ; Huzaifah et al., 2017 7 ). It has been widely applied in various fields such as noise pollution analysis (Aumond et al., 2017 8 ; Cao et al., 2019 9 ), surveillance systems (Crocco et al., 2016 10 ; Laffitte et al., 2019 11 ), machine hearing (Li et al., 2007 12 ; Lyon et al., 2010 13 ), soundscape assessment (Torija et al., 2014 14 ; Romero et al., 2016 15 ), and smart cities (Agha et al., 2017 16 ; Ntalampiras et al., 2014 17 ). In the early stages, the ESC tasks primarily relied on traditional acoustic models and perceptual models, such as Mel-Frequency Cepstral Coefficients (MFCC), Perceptual Linear Prediction (PLP), and Linear Predictive Coding (LPC) (Guo et al., 2003 18 ; Yue et al., 1997 19 ). With the rapid development of machine learning algorithms, after the 21st century, ESC gradually shifted from traditional pattern recognition tasks to machine learning tasks. Traditional machine learning algorithms such as Gaussian Mixture Models (GMM) and Multi-Layer Perceptron (MLP) were widely applied in ESC model research (Atrey et al., 2006 20 ; Cerezuela et al., 2016 21 ). These systems achieved certain success in specific scenarios, such as low signal-to-noise ratio environments.
In recent years, with the rapid development of big data technology, the increase in manually collected and labeled data has made deep learning-based ESC techniques gradually become a hot topic in various fields of research. Convolutional neural networks (CNNs) are currently the most commonly used classification models for ESC tasks due to their powerful feature extraction ability for two-dimensional spectra (İnik et al., 2023 22 ; Piczak et al., 2015A 23 ; Mushtaq et al., 2020 24 ; Mushtaq et al., 2021 25 ; Medhat et al., 2020 26 ; Demir et al., 2020 27 ; Zhang et al., 2020 28 ). Scholars have developed various high-performance ESC models based on convolutional networks by optimizing and extending CNN algorithms. Mushtaq et al. (2020 24 ) emphasized that the overlapping nature of environmental sounds adds to their classification complexity. A Deep Convolutional Neural Network (DCNN) model was established by deepening the network. The model achieved higher accuracies in ESC-10, ESC-50, and US8K datasets compared to shallow CNN networks.
Although convolutional networks have the powerful ability to extract high-dimensional spectral features, they are unable to characterize the temporal relationships in sound signals. Therefore, Recurrent Neural Network (RNN) and its extended models are becoming increasingly popular in the field of ESC due to their ability to extract the temporal dependencies of sound features (Medhat et al. 2020 26 ; Priyaa et al. 2022 29 ). In recent years, scholars have found that the CRNN model integrates the respective strengths of convolutional network and recurrent network, and it has been verified to have higher performance in ESC-10, ESC-50, and DCASE2016 datasets compared to individual CNN and RNN model (2020 28 ). In addition, drawing inspiration from the application of deep learning methods in fault monitoring, for instance, Zhang et al. introduced an unsupervised fault detection method based on an improved denoising autoencoder with a multi-head self-attention mechanism neural network, and developed a distributed federated learning-based multi-hop graph pooling adversarial network (Zhang et al. 2025, 30 2024 31 ). Applying these methods to noise source identification model research holds promise for enhancing multi-task feature extraction capabilities and improving the extraction of spatial information.
Transfer learning is an idea of using pre-trained network weights and has become very popular in the detection of various acoustic scenes and acoustic events (Arora et al., 2017 32 ; Hershey et al., 2017 33 ; Arandjelović et al., 2018 34 ). Mushtaq et al. applied transfer learning methods to optimize the DCNN classification algorithm. The optimized model has been verified to achieve superior performance in ResNet-52, ESC-10, and US8K datasets (Mushtaq et al., 2021 25 ).
Although scholars have developed various deep learning-based ESC models, based on existing publicly available datasets. Currently, the three datasets widely used for studying ESC tasks are ESC10, ESC50, and US8K (Piczak et al., 2015B 35 ; Salamon et al., 2014 36 ). However, the categories and quantities of sounds included in single dataset are very limited, and the sound source classes differ significantly from environmental noise sources in urban. Moreover, each of these datasets contains many categories that are not environmental noises. Therefore, the ESC models developed based on the publicly lightweight dataset cannot be transferred to the urban environmental noise sources identification task.
Convolutional Block Attention Module (CBAM) is a lightweight attention module newly developed at ECCV2018, which integrates a Channel Attention Module (CAM) and a Spatial Attention Module (SAM) (Woo et al., 2021 37 ). Research has demonstrated the universal applicability of CBAM across different architectures and different tasks. It can be seamlessly integrated into any CNN architectures to jointly train the combined CBAM-enhanced networks. The CBAM greatly improved the performance of various networks with negligible cost (Woo et al., 2021 37 ; Ma et al., 202438; Zhang et al., 2024 39 ; Li et al., 2024 40 ). The information above indicates that the integrated algorithm of CBAM and DCNN can further improve the performance of classification models, although there is currently no research on applying the CBAM method to the ESC field.
In the study, a parallel CBAM-DCRNN model with transfer learning was constructed for efficiently and accurately identifying various urban environmental noise sources. Firstly, by collecting a large amount of representative environmental noise data in urbans, a heavyweight dataset was constructed, which fills the gap in this type of dataset in the ESC field. Subsequently, a high-performance automatic identification model of urban environmental noise sources was constructed based on the DCRNN algorithm optimized with an attention module: CBAM. Its main tasks include studying the integration scheme of CBAM and the convolutional network, as well as designing the architecture and hyperparameters of the CBAM-DCRNN model. Furthermore, this study optimized the training process of the CBAM-DCRNN model by applying transfer learning methods. It greatly saved the hardware resources and runtime consumed during model training, thereby improving training efficiency.
As a result, the parallel CBAM-DCRNN model with transfer learning was developed by comparing parallel and sequential integration strategies. And, the model’s effectiveness, accuracy, and stability were validated by comparing it with the sequential CBAM-DCRNN method and the classic DCRNN method. Furthermore, the generalizability and scalability of the developed model were discussed. The experimental results indicated that deploying the proposed noise sources identification model on existing online noise level monitoring instruments will enable real-time automated monitoring and identification of environmental noise sources in the area. It will enable the municipal management departments to promptly implement precise and efficient management and control measures for noise pollution. Further, the accumulated vast amounts of noise level and noise source data can be applied to study spatiotemporal variation in noise exposure. Supplemental 1 illustrates the flowchart of the research work.
Materials and methods
Dataset acquisition
Environmental noise sources
The environmental noise sources that have a significant impact on residents in urban areas are composed of the main categories: human activities, traffic, machinery, and equipment. These noise sources exhibit distinct spectral and temporal characteristics. Such as, • Human-generated noise (e.g., crowd conversations, street music, restaurant clamor, and grocery store clamor) typically exhibits non-stationary broadband spectra with energy concentrated in the 200 Hz to 4 kHz range. The Fourier Transform of human activity noise, • Traffic noise, primarily generated by vehicles, typically exhibits a broadband spectrum with dominant frequencies ranging from 500 Hz to 2 kHz. The Fourier Transform of traffic noise reveals a characteristic pattern with energy distributed across multiple frequency bands. Notably, a significant portion of the energy is also concentrated in the low-frequency range (< 500 Hz), primarily due to engine noise and tire-road interactions. For instance, engine noise typically shows prominent peaks in the 50–200 Hz range. These low-frequency components are often perceived as a deep rumble and can propagate over long distances, contributing significantly to the overall noise profile.
In the time domain, traffic noise often exhibits non-stationary behavior with intermittent peaks corresponding to vehicle pass-bys, which can be effectively captured using the Wavelet Transform. The low-frequency engine noise, in particular, manifests as periodic fluctuations in the time domain, while mid-frequency components (e.g., tire noise) typically appear as quasi-stationary signals, and high-frequency components (e.g., brake squeal) appear as transient events superimposed on the low-frequency background. • Machinery and Equipment noise, often displays more distinct spectral peaks corresponding to specific mechanical components. For instance, the power spectral density (PSD) of Machinery noise typically shows prominent peaks at fundamental frequencies and their harmonics, which can be expressed as • Natural sounds, such as rain, generally have more random characteristics in both time and frequency domains. The spectrum of rain noise shows a gradual decrease in energy with increasing frequency, typically following a
The noises from these sources mix and overlap with each other, creating complex acoustic environments. Additionally, environmental noises are often mixed with various natural sounds and animal sounds, which add further complexity to the spectral and temporal characteristics. For instance, bird chirps typically show narrowband components with rapid frequency modulations, mathematically describable as
Together, these diverse noise sources impact the lives of residents in urban areas, creating unique acoustic signatures. The distinct spectral and temporal characteristics of each noise source provide valuable features for deep learning models to differentiate between various environmental noise categories.
Environmental noise dataset acquisition
Due to the fact that many categories of environmental noise sources have highly similar spectral features, and their spectra are usually mixed, the weights of deep network require more training data to achieve their optimal values. In order to improve the accuracy and generalization ability of the CBAM-DCRNN identification model, it is necessary to expand the diversity of noise features in the dataset as much as possible while ensuring their rationality. In the study, firstly, we collected a large number of urban environmental noise data from all existing public datasets, including US8K, ESC50, DCASE2016, and Birdsdata (Salamon et al., 2014 36 ; Piczak et al., 2015B 35 ; Mesaros et al., 2017 41 ; Birdsdata, 2020 42 ). These public datasets provided a solid foundation for the initial construction of the dataset, covering a wide range of urban noise sources. To further enhance the diversity and realism of the dataset, we conducted on-site recordings in various urban environments, including commercial and residential mixed areas, urban roads, and areas near flight paths. The recordings focused on capturing noise sources that were underrepresented in public datasets, such as Heat pump noises: recorded from HVAC equipment in residential and commercial buildings; Road traffic noises: captured at different distances from urban roads to simulate varying levels of traffic intensity; Airplane flight noises: recorded in areas surrounding flight paths to capture the distinct spectral characteristics of aircraft noise. These on-site recordings were conducted using high-quality audio recording equipment, ensuring minimal background interference and high signal fidelity.
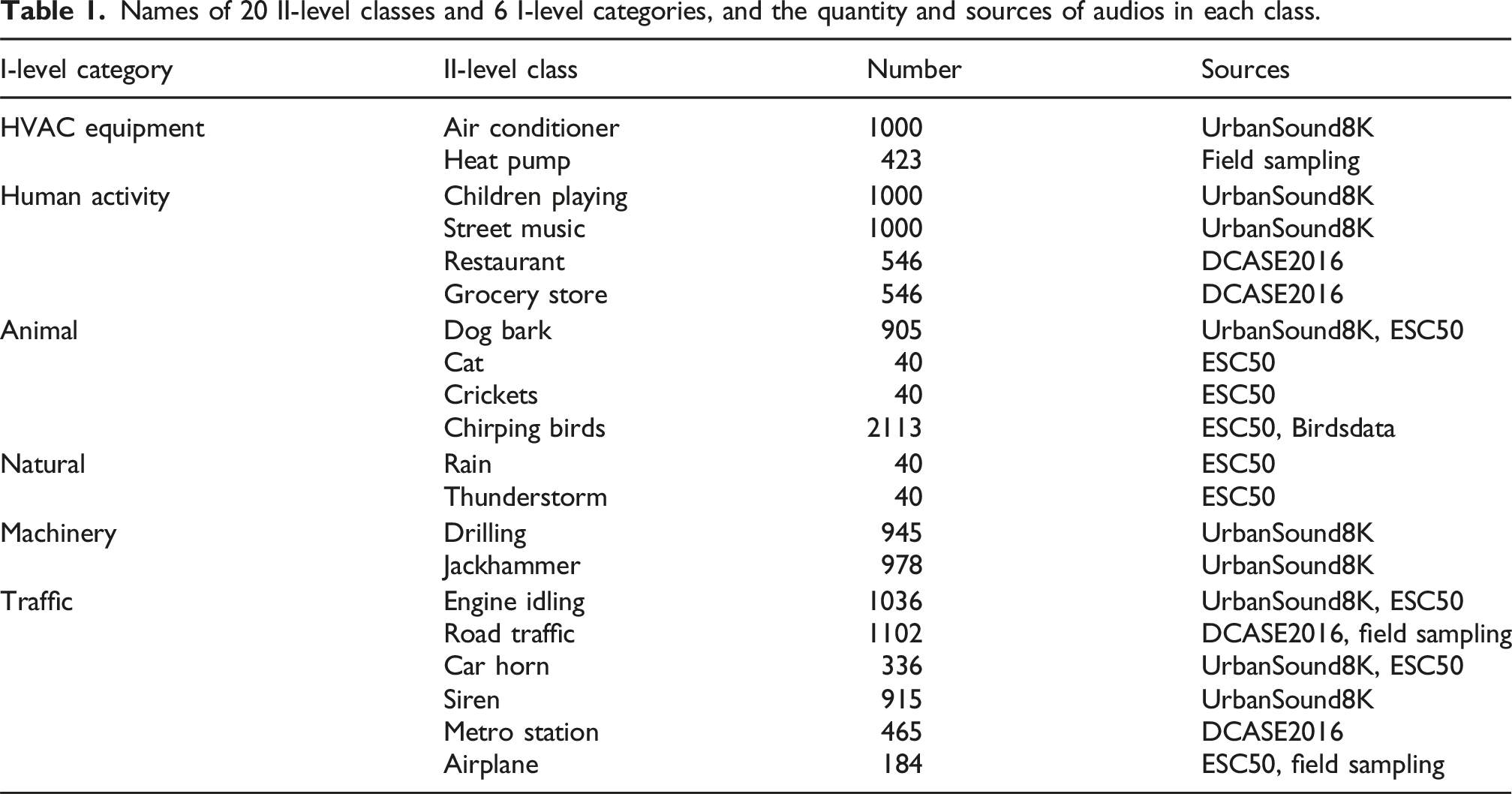
Thus, a heavyweight typical urban environmental noise dataset was constructed, which encompasses 20 representative classes of environmental noise sources in densely populated urban residential areas. These samples were all collected from the real environment. The final dataset is distributed across 20 II-level classes within 6 I-level categories. The I-level categories include: Heating and ventilation (HVAC) Equipment, Human activities, Animals, Natural, machinery, and Traffic. Each class was carefully selected to represent common noise sources in urban environments, ensuring that the dataset captures the complexity and diversity of real-world acoustic scenes. For the sake of convenience in description, in this paper, we defined the 6 main categories of environmental noise sources as I-level category, and the 20 classes as II-level class.
Dataset preprocessing
In the dataset, the original noise audios collected from on-site recordings, such as Heat pumps, Road traffic, and Airplanes, are all long-term recordings taken from the regional environment, which needed to be further trimmed and annotated. Another part of the samples collected from public sound datasets, whose records have been trimmed into sound clips of varying durations. Among them, audios from the Birdsdata have a duration of 2s (Birdsdata, 2020 42 ), each audio from the ESC-50 dataset is 5s long (Piczak et al., 2015B 35 ), each audio from DCASE2016 dataset is 30s long (Mesaros et al., 2017 41 ). And, the audio duration of US8K is generally 3–4 s, with a small number of audios lasting less than 1s (Salamon et al., 2014 36 ).
Names of 20 II-level classes and 6 I-level categories, and the quantity and sources of audios in each class.
Mel spectrogram extraction
A spectrogram is an audio waveform that is encoded as a visual representation before being fed into a network as training data. In the literature, state-of-the-art performance for ESC datasets can be achieved by replacing the audio files with their spectral images, thereby achieving higher classification accuracy, as shown in Ref. (Boddapati et al., 2017 43 ). The advantages of using spectrogram images over sound clips are that the audio signals are less periodic, weak ambiance, and shorter intervals (Mushtaq et al., 2021 25 ). Mel scaled spectrogram is preferred over the linear spectrogram to aid the spatially invariant nature of CNN, where CNN is incapable of interpreting frequencies expressed in a linear scale (Mishachandar et al., 2021 44 ). The bandwidth of the environmental noises studied in this work is bounded from very low to high; hence, Mel scaled spectrogram generation eased feature extraction.
This study utilized Mel spectrogram features, which extracted features from audio clips in the form of spectrogram images. The method didn’t require any fragmentation of whole audio recording into smaller windows or frames. After the transformation, the whole sound clip was converted into a spectrogram image. Moreover, Feature extraction using Mel spectrogram favors low computational complexity and suits for capturing features across all frequency bands, especially for characterizing low-frequency to mid-frequency broadband signals and amplitude-modulated sounds (Mushtaq et al., 2021 25 ; Mishachandar et al., 2021 44 ). Supplemental 2 provides Mel spectrogram samples extracted from different noise classes.
Parallel CBAM-DCRNN architectures
DCRNN applied in this work is a deep learning model that combines deep Convolutional Neural Network (DCNN) and Gated Recurrent Units (GRU). In the model, convolutional network is used to learn from the original spectrograms to capture their unique features, in order to obtain discriminative information between different classes, as well as common features among different samples within the same class; GRU is utilized to learn temporal information on features, making the features learned by the model more robust. The deep network structure means that the model has a stronger ability for learning data features, which has been proven to achieve higher performance in ESC tasks (Mushtaq et al., 2020 24 ; Mushtaq et al., 2021 25 ; Zhang et al., 2020 28 ).
Figure 1 shows the architecture of the parallel CBAM-DCRNN model proposed in the study. The model consists of DCNN modules for extracting features in the frequency domain and GRU modules for learning temporal relationships of features. And, CBAM attention modules are parallel integrated into each convolutional block of the DCNN to further optimize the performance of the model, forming the CBAM-Conv block. The application of the CBAM modules significantly enhances the model’s ability to extract and focus on critical features and suppress unnecessary ones. Specifically, the designed deep network includes 4 CBAM-Conv blocks, 4 pooling layers, 2 GRU layers, and 2 fully connected layers. The architecture of the CBAM-DCRNN model.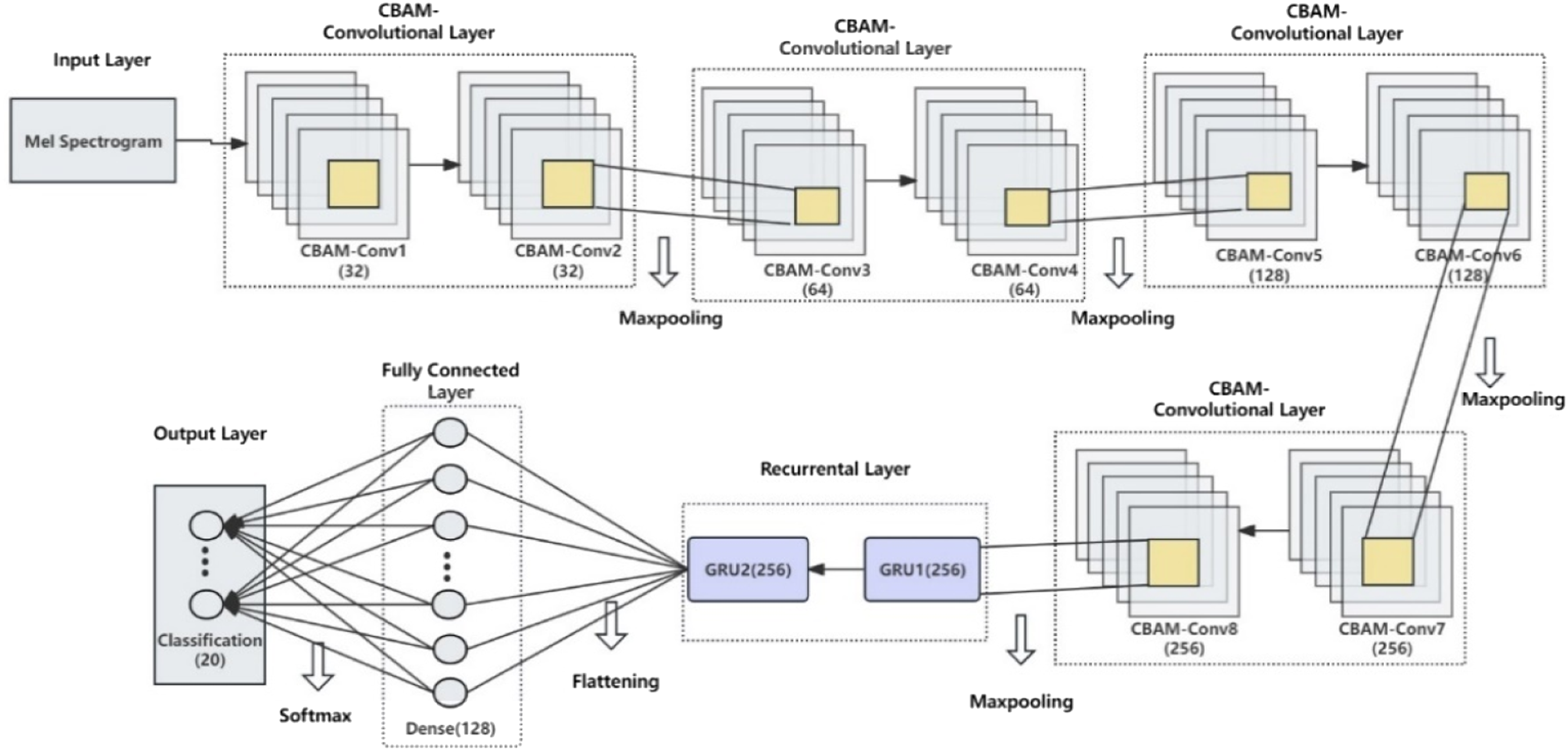
The inputs of the neural network are the extracted Mel spectrogram feature images described above. Each CBAM-Conv block is designed with two CBAM-Conv layers, which extracts local features of the image through convolution kernels while reducing the impact of unrelated factors. In the first CBAM-Conv block, that is, CBAM-Conv1.layer and CBAM-Conv2.layer, 32 convolutional kernels of size 3x5 are used as the basic feature extractor. In CBAM-Conv3.layer and CBAM-Conv4.layer, 64 small convolution kernels with a size of 3x1 are used to extract information from the frequency dimension. The CBAM-Conv5.layer and CBAM-Conv6.layer both use 128 kernels with a size of 1x5, which are utilized to extract features from the temporal dimension. In CBAM-Conv7.layer and CBAM-Conv8.layer, 256 3x3 kernels are used to extract joint information from both the time and frequency domains. Each CBAM-Conv layer is activated by the Rectified Linear Unit (ReLU) function. After each CBAM-Conv block, a Max-Pooling layer is used to reduce the feature sizes in the time and frequency dimensions. After 4 CBAM-Conv blocks, a GRU block follows, which consists of two GRU.layers using the hyperbolic tangent function (tanh) activation. To prevent overfitting, a dropout of 0.5 is used to regularize the GRU network. Then, the features extracted through attention-convolution, pooling, and recurrent operations are flattened into a one-dimensional structure through a flattening layer and then sent to two fully connected layers. The first fully connected layer contains 128 neurons, and uses the ReLU activation. Its network is regularized with a dropout of 0.5. Finally, the output layer outputs the probabilities of the samples being classified into the corresponding classes through the SoftMax function. The number of its neurons is the same as the number of noise source classes in the dataset. Supplemental 3 shows the detailed parameters of the deep network.
The combination of CBAM and DCRNN provides a robust framework for noise source identification in complex urban environments. The DCRNN component leverages convolutional layers to extract high-dimensional spectral features and GRU layers to model temporal dependencies. When integrated with CBAM, the model gains the ability to dynamically focus on the most discriminative features, even in the presence of overlapping noise spectra. For example, in scenarios where traffic noise and machinery noise overlap, CBAM helps the model distinguish between the two by emphasizing the unique frequency bands and temporal patterns associated with each source.
CBAM-Convolution module
Figure 2 presents the structure of a CBAM-Conv block integrated by convolutional block and CBAM attention module in parallel. The intermediate feature maps are adaptively refined through CBAM module integrated into every convolutional block of the DCRNN network. The CBAM attention module is integrated by CAM and SAM mechanisms. These mechanisms dynamically adjust the weights of feature maps, allowing the model to prioritize the most relevant frequency and temporal characteristics of noise signals. The study adopts the sequential structure of CAM and SAM, as it had been proven to exhibit a finer attention map than doing in parallel. Supplemental 4 shows the network structure of two sequential sub-modules: CAM and SAM (Woo et al., 2021
37
). The structure of a CBAM-Conv block. It is integrated by Conv block and CBAM module in parallel. The CBAM module has two sequential sub-modules: channel and spatial.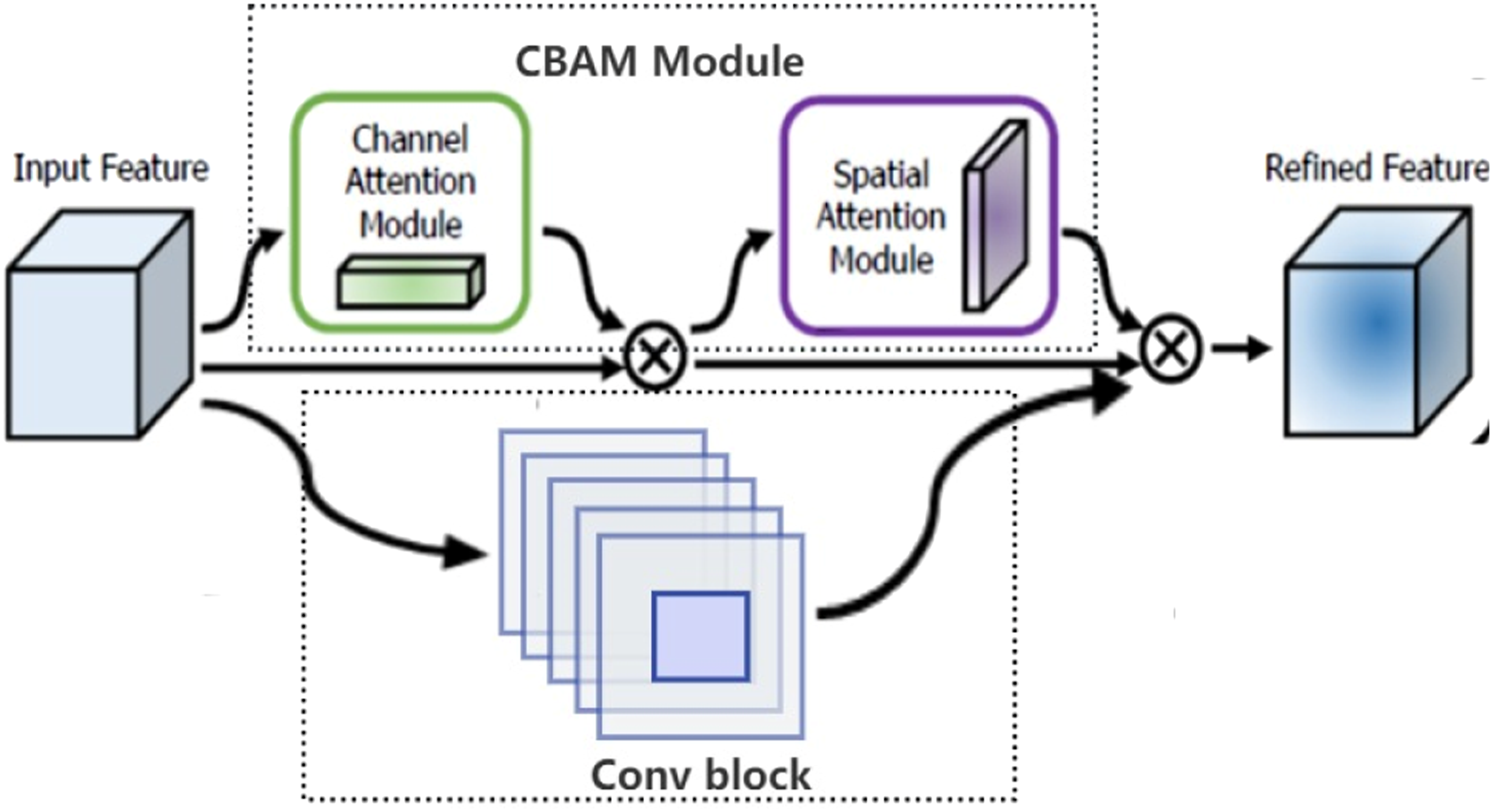
CAM
It focuses on identifying which frequency bands are most informative for noise source identification. Firstly, the H x W x C input feature map is processed through global max-pooling and global average-pooling, respectively, to obtain two 1 x 1 x C feature maps. Subsequently, they are fed into a two-layer perceptron (MLP): the number of neurons in the first layer is C/r (r is the reduction rate), and its activation function is ReLU; the number of neurons in the second layer is C. The neural networks in these two layers are shared. Then, the output features from MLP are merged using element-wise summation. This is followed by a sigmoid activation to generate the channel attention feature, denoted as M_c. Finally, the M_c is element-wise multiplied with the original input feature map to generate the input feature map required for the SAM. CAM enhances the contribution of critical frequency bands while suppressing less relevant ones. This is particularly useful in urban noise scenarios, where different noise sources may dominate specific frequency ranges.
SAM
It complements CAM by focusing on the spatial locations of important features within the spectrogram. Specifically, the feature outputted by the CAM is used as the input feature map for this module. Firstly, global average-pooling and max-pooling operations are applied along the channel axis to generate two feature maps of size H x W x 1. And, concatenate these two feature maps. Then, a convolution operation with the filter size of 7 × 7 is applied to reduce the channel dimension to 1, resulting in a H × W × 1 feature map. Subsequently, a sigmoid operation is performed to generate the spatial attention feature, denoted as M_s. Finally, element-wise multiplication on the M_s and the input feature of this module is performed to generate the output feature of the CBAM module. The SAM feature highlight regions of the spectrogram that contain significant temporal or spatial patterns, such as transient noise events or periodic signals. This allows the proposed model to better capture the temporal dynamics of noise sources, which is crucial for distinguishing between overlapping or similar noise patterns.
In summary, the integration of CBAM with DCRNN through a parallel strategy significantly improved the model’s ability to extract and focus on critical features in urban noise signals. By dynamically adjusting the weights of feature maps and jointly processing frequency and temporal information, the model achieved superior performance in identifying noise sources, even in complex and overlapping noise environments. This makes the CBAM-DCRNN model particularly well-suited for real-time noise identification in urban areas.
Model training
Hyperparameters
The design of hyperparameters controls the quality of model training, in particular by preventing early overfitting of the model and increasing the recall values. In this work, Adam optimizer was employed to optimize the proposed deep network, which has been proven to achieve better recall values than SGD (stochastic gradient descent) (Ahmad et al., 2023 45 ; Bottou et al., 1991 46 ; Kingma et al., 2014 47 ). The learning rate, batch size, and epochs were set to 10-3, 128, and 1024, respectively. And, the Cross Entropy Loss function was used as the loss function. To avoid overfitting and save computational resources, the tolerance of early stopping was set to 50. The hyperparameters used for training the model are presented in Supplemental 5.
Transfer learning
In the study, the transfer learning approach was applied to optimize the training process to further enhance the training efficiency and scalability of the proposed CBAM-DCRNN model. The application of the method primarily involves a two-stage training process. First, the model was pre-trained on a lightweight dataset composed of a subset of the constructed heavyweight dataset, enabling it to capture general features of environmental noise sources. This pre-training phase reduces the model’s sensitivity to random weight initialization, a common challenge in deep learning, and provides a robust starting point for further training. Subsequently, the model is fine-tuned on the collected heavyweight dataset that encompasses a broader and more diverse range of noise sources, and obtain its final weights. This two-stage process allows the model to leverage the knowledge gained from the lightweight dataset and adapt to the complex and diverse noise patterns in the heavyweight dataset, significantly improving both accuracy and generalization to unseen noise sources. The block diagram of transfer learning implementation is shown in Supplemental 6.
A key innovation of this approach is its efficient utilization of computational resources. By pre-training on a smaller dataset and fine-tuning on a larger one, the model achieves faster convergence and reduces overall training time compared to training from scratch. This efficiency is particularly advantageous for scaling the model to larger datasets or deploying it in real-time applications. Additionally, the transfer learning approach enhances the model’s scalability and flexibility. By decoupling initial weight optimization from fine-tuning, the model can be easily adapted to new datasets or extended to include additional noise classes, making it highly suitable for the dynamic and diverse nature of urban environmental noise monitoring.
The integration of transfer learning with the CBAM-DCRNN model also improves feature extraction. The pre-training phase enables the model to learn general noise features, while fine-tuning allows it to focus on more specific and nuanced characteristics. This hierarchical feature extraction, combined with CBAM’s attention mechanism, ensures accurate identification of noise sources, even those with highly similar spectral features. Furthermore, the approach alleviates data imbalance, a common issue in urban noise datasets, by leveraging pre-trained knowledge to better recognize underrepresented noise classes. This robustness to data imbalance is critical for real-world applications, where rare but important noise sources must be accurately identified.
Performance evaluation
The Accuracy and Recall were served as the model’s evaluation metrics. Where, Accuracy is defined as the ratio of the number of correctly classified samples to the entire sample size; Recall refers to the probability of being predicted as a positive sample among actual positive samples. Generally speaking, the higher the model’s Accuracy, the better its performance. Further, in line with actual environmental noise monitoring needs, Recall is also a crucial metric, which can evaluate the model’s ability to correctly identify positive samples. The Accuracy and Recall values are obtained via the following calculations (Ahmad et al., 2023
45
):


Results and discussion
Training performance of model
The dataset was split in two sets of training and test data as 80% and 20%, respectively, following previous research (Ahmad et al., 2023 45 ). The CBAM-DCRNN model was trained under two scenarios: with transfer learning and without transfer learning. The convergence graphs during the training phase are given in Supplemental 7 (A)-(B). When two figures are examined, it can be seen that the accuracy and validation accuracy graphs and the error and validation error graphs consistently follow the same trend and are very close to each other. Therefore, during both training processes, the models did not exhibit overfitting or underfitting phenomena. That is to say, both with and without the application of transfer learning, the proposed CBAM-DCRNN model ultimately converged to admirable results.
However, compared the convergence graphs during two training phases, it is evident that the CBAM-DCRNN model took 428 epochs to find the optimal weights (with a training time of approximately 7162 min) when transfer learning was not applied; the model achieved optimality after only 162 epochs of training (with a training time of about 2714 min) when transfer learning was utilized, due to the model being provided with prior weight information. Therefore, the application of the transfer learning method greatly enhances the training efficiency of the model on the heavyweight dataset, while significantly saving hardware resources and time consumed during the training process. Consequently, it improves the flexibility of the proposed CBAM-DCRNN model to be extended to larger and more diverse environmental noise datasets.
Identification performance of model
Overall performance
According to the confusion matrix as shown in Figure 3 (a), the overall identification accuracy of the CBAM-DCRNN model in the test set was about 92.63%. Among 20 II-level noise source classes, more than 95% of the recall value for Air conditioner, Drilling, Road traffic, Jackhammer, Siren, Chirping birds, Heat pump, Restaurant, and Grocery store were achieved. Over 91% of the recall for Engine idling and Metro station. As well as, the recalls for Car horn, Children playing, Street music and Rain all over 85%, for Dog bark was close to 84%. The favorable identification effect demonstrates the effectiveness and applicability of the CBAM-DCRNN model for urban environmental noise identification tasks. In addition, the model’s identification effect for Thunderstorm and Cat was relatively poor, with recall both at 75%. And, Airplane and Crickets had recalls of only about 64% and 63%, respectively. The main reason for this is that the model could not find enough data to learn the features of these 4 classes of noise sources because there is less training data for these classes. Especially, the classes of crickets, cat, rain, and thunderstorm each have only 32 training samples. The performance values given by confusion matrixes of (a) the parallel CBAM-DCRNN model, (b) the sequential CBAM-DCRNN, and (c) the DCRNN model.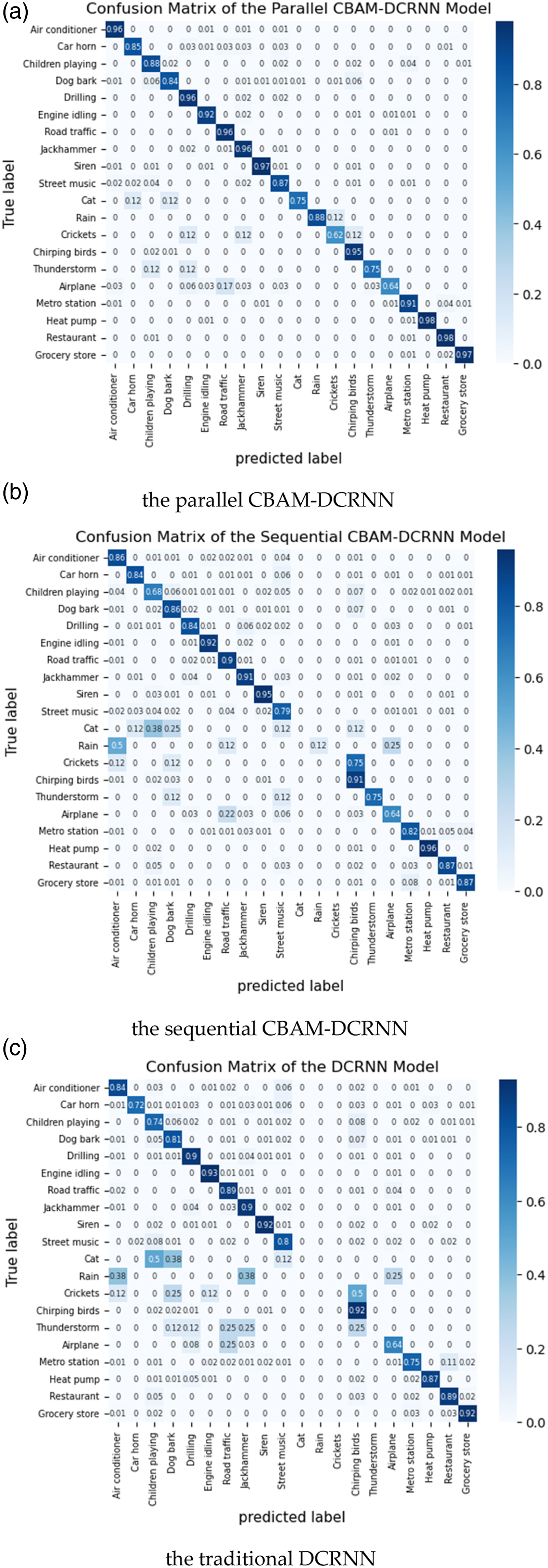
I-level category performance
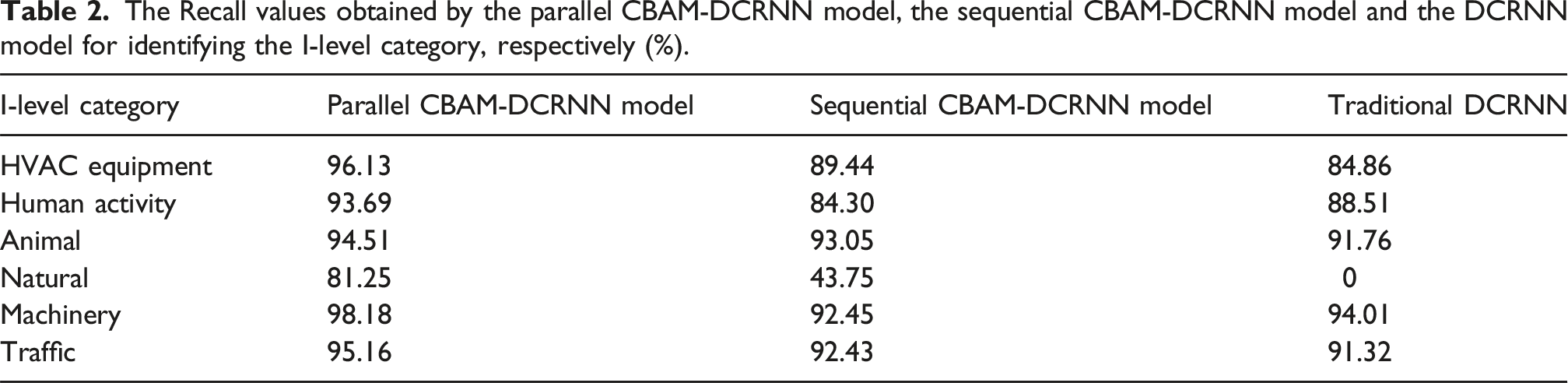
The Recall values obtained by the parallel CBAM-DCRNN model, the sequential CBAM-DCRNN model and the DCRNN model for identifying the I-level category, respectively (%).
Enhanced identification capability
On the one hand, the proposed model demonstrated robust performance in identifying noise sources with distinct spectral and temporal characteristics, such as Air conditioner, Drilling, Road traffic, Jackhammer, Siren, Chirping birds, and Heat pump, with recall values exceeding 95% for each. On the other hand, its ability to distinguish between noise categories with highly similar spectral features, such as Traffic and Equipment, is particularly noteworthy. Traditional models often struggle with these categories due to their spectral overlap. The introduction of an attention mechanism in the CBAM-DCRNN model significantly improved identification capabilities, achieving recall rates of 95.16% for Traffic and 96.13% for HVAC equipment. These improvements are attributed to the model’s ability to capture subtle differences in temporal patterns, facilitated by the CBAM module’s dynamic feature weighting capability.
Handling imbalanced data
The model also demonstrated robust performance on noise classes with limited training data, such as Rain and Cat (which each had only 32 training samples), achieving recall values of 75% and 63%, respectively. This suggests that the model’s attention mechanism and transfer learning strategy are effective in handling imbalanced datasets, although further improvements could be achieved by increasing the diversity and quantity of training samples for underrepresented classes.
In summary, the results from Figure 3 (a) and Table 2 indicate that the proposed CBAM-DCRNN model performed commendably for identifying both II-level classes and I-level categories, demonstrating its strong performance in identifying a wide range of urban environmental noise sources, including those with highly similar spectral features. Its ability to capture both spatial and temporal characteristics through the parallel integration of CBAM and DCRNN makes it particularly effective in handling complex and overlapping noise scenarios.
Comparison and evaluation
To further evaluate the performance of the proposed identification model, which integrates the CBAM module into the DCRNN model, in this section, the performance values of the proposed model were compared with those of the classic DCRNN model. Furthermore, to validate the super performance of the integration strategy proposed in this study, this section also compared the identification effects of the proposed parallel integrated model with those of the CBAM-DCRNN model using a sequential integration strategy.
The overall identification accuracy of the parallel CBAM-DCRNN model, the Sequential CBAM-DCRNN model, and the DCRNN model (%).

Further, examines the confusion matrices’ values of the three models as shown in Figure 3 (a)–(c), as well as the recall values for identifying the I-level categories shown in Tables 2, it can be observed that the parallel CBAM-DCRNN model exhibits the highest accuracy and stability for each class in both identifying 20 II-level classes and 6 I-level categories, significantly outperforming the DCRNN model and the sequential CBAM-DCRNN model. Especially for underrepresented noise classes, according Figure 3, the model achieves a recall of 75% for Cat and 88% for Rain, despite these classes having only 32 training samples each. In comparison, the sequential CBAM-DCRNN model and the classic DCRNN model struggle with these classes, achieving recall values of 0% and 12%, and 0% and 0%, respectively. This demonstrates that the parallel integration strategy, combined with the attention mechanism, significantly improves the model’s ability to learn from limited data. This further highlights the model’s robustness in handling imbalanced datasets. Table 2 presents the recall values for identifying I-level categories of environmental noise sources. The parallel CBAM-DCRNN model achieves recall values exceeding 93.5% for HVAC equipment, Human activity, Animal, Machinery, and Traffic. In contrast, the sequential CBAM-DCRNN model and the classic DCRNN model show lower recall values for these I-level categories. For example, the recall for HVAC equipment drops to 89.44% for the sequential model and 84.86% for the classic DCRNN model. This further emphasizes the superiority of the parallel integration strategy in capturing the diverse features of urban environmental noise sources.
In summary, the experimental results indicate that the proposed parallel CBAM-DCRNN model significantly outperforms both the sequential CBAM-DCRNN model and the classic DCRNN model in terms of accuracy and stability. The parallel integration strategy, combined with the attention mechanism, enables the model to effectively capture both spatial and temporal features of environmental noise, even in complex and overlapping noise scenarios. Additionally, the model demonstrates robust performance on underrepresented noise classes, making it highly suitable for real-world applications where data imbalance is a common challenge.
Analysis of generalizability, scalability, and stability
The experimental results in the Results and discussion section demonstrate the superior performance of the proposed model in identifying urban environmental noise sources. This section further analyzes the model’s generalizability, scalability, and stability.
Generalizability: From the perspective of spectral features, the collected dataset encompasses a wide variety of noise sources, including various traffic noises and machine operation noises in the mid and low-frequency bands, various chirping noises of insects and birds in the high-frequency range, and human activities that span across all frequency bands. The dataset not only covers a broad range of frequency bands but also includes numerous noise sources with highly similar spectral features. For instance, noise sources such as Road traffic, Airplanes, Engine idling, and Air conditioners, etc., often exhibit similar and overlapping spectra, making them difficult to distinguish. Similarly, the chirping sounds of birds and insects typically share similar spectral characteristics. Additionally, the collected noise recordings often overlap with various background sounds produced by traffic and human activities, as most of these audio clips were captured in real-world environments. This ensures that the dataset reflects the complexity and diversity of urban environmental noise, enhancing the model’s generalizability. The inclusion of a small number of pure sounds in the dataset further expands the diversity of the samples, ensuring that the model can handle both mixed and isolated noise sources. The transfer learning method applied in this study also contributes to the model’s generalizability by enabling it to leverage knowledge from a smaller, pre-trained dataset and adapt to a larger, more diverse dataset. This approach not only improves training efficiency but also enhances the model’s ability to generalize to unseen noise sources, making it highly suitable for real-world applications.
Scalability: The transfer learning approach significantly reduces the computational cost and training time, allowing the model to be efficiently scaled to larger datasets. By pre-training the model on a smaller dataset and fine-tuning it on a larger one, the model achieves faster convergence and better performance, even when extended to include additional noise categories or scenarios. Moreover, the model’s architecture is designed to handle a wide range of noise sources and scenarios without the need for structural modifications. This flexibility ensures that the model can be easily transferred to larger datasets or deployed in different urban environments, requiring only the optimization of the model’s weights.
Stability: The proposed parallel CBAM-DCRNN model demonstrates remarkable stability, particularly in handling imbalanced datasets and complex noise scenarios. The integration of the CBAM attention mechanism plays a crucial role in enhancing the model’s stability by dynamically adjusting the weights of feature maps, allowing the model to focus on the most discriminative features even in the presence of overlapping noise spectra. This attention mechanism enables the model to effectively distinguish between noise sources with highly similar spectral features, such as various traffic and machinery noises, which are often challenging for traditional models. Furthermore, the model’s stability is evident in its ability to handle underrepresented noise classes. As shown in Figure 3, the model achieves recall values of 75% for “Cat” and 88% for “Rain,” despite these classes having only 32 training samples each. This performance is significantly better than that of the sequential CBAM-DCRNN model (0% and 12%) and the classic DCRNN model (0%), which struggle with these underrepresented classes. The model’s robustness in handling imbalanced datasets is attributed to the combination of the CBAM attention mechanism and the transfer learning strategy, which allows the model to learn general noise features during pre-training and adapt to specific noise patterns during fine-tuning. Additionally, the model’s stability is also reflected in its consistent performance across different noise categories and scenarios. As shown in Table 2
In summary, the proposed parallel CBAM-DCRNN model with transfer learning exhibits promising generalizability, scalability, and stability. Its ability to handle complex and overlapping noise spectra, combined with its robustness in handling imbalanced datasets, makes it a highly effective solution for urban environmental noise source identification. The model’s stability is further enhanced by the integration of the CBAM attention mechanism and the transfer learning strategy, which enable it to focus on the most relevant features and adapt to new noise sources efficiently. These characteristics make the model highly suitable for noise monitoring and identification in urban environments, where data diversity and imbalance are prevalent challenges.
Analysis of competency and prospect
This study proposed a high-performance identification model for urban environmental noise sources by developing an integrated deep learning network, which can be applied to the development of online real-time automatic identification technologies. It does not require additional reliance on human ears to identify audios or human eyes to distinguish its spectra, nor does it require additional extraction and analysis of acoustic spectral features. This will greatly save on time and labor costs, and greatly enhance the timeliness of noise pollution sources tracing and control, enabling municipal management departments to take timely and precise management and control measures.
However, based on deep learning algorithms, the modeling effect is heavily dependent on the quantity and quality of samples in the dataset. To further optimize the performance of the proposed identification model, future research should include the following work: • Due to the wide variety of urban environmental noise sources, the collected dataset is difficult to cover all the categories of noise sources in cities. In the future, it will be necessary to continue expanding the dataset to cover more noise categories and scenarios. • In this study, the recall values for a few classes are relatively low, which is mainly related to the scarcity of samples of these categories in the training dataset. There was not enough data available during the model’s training process to learn the features of these classes. To address this issue, it will be necessary in the future to collect more samples of these classes and to utilize data augmentation techniques to further enrich the dataset.
Additionally, in conjunction with practical management needs, further researches could be conducted in the future to transfer the model to a specific area or scenario.
Conclusion
In this study, a novel parallel CBAM-DCRNN model for accurately and efficiently identifying urban environmental noise sources was proposed. The model integrates a deep CNN network, a GRU network and CBAM attention modules, and leveraging transfer learning to enhance performance and scalability. The key contributions and findings of this study are summarized as follows: (1) A heavyweight and diverse urban environmental noise dataset was constructed, encompassing 20 typical noise classes with a total of 13,654 labeled samples. The dataset provides a robust foundation for training and evaluating the proposed model, enabling it to achieve excellent stability and generalization capabilities. The diversity of noise sources in the dataset ensures that the model can handle a wide range of real scenarios. (2) The proposed parallel CBAM-DCRNN model introduces a novel integration strategy that combines CBAM attention mechanisms with DCRNN in a parallel manner. This approach significantly improves the model’s ability to capture both spatial and temporal features of environmental noise, particularly in complex and overlapping noise spectra. Experimental results demonstrate that the proposed parallel model achieved an overall accuracy of 92.63%, significantly outperforming the classical DCRNN model (85.37%) and the sequential CBAM-DCRNN model (85.88%). Notably, the model exhibits robust performance even for noise classes with limited training data, such as cat, crickets, rain, and thunderstorm, where other models often struggle. This highlights its ability to handle imbalanced datasets and its potential for real-world applications with underrepresented noise sources. (3) The introduction of transfer learning greatly improves the model’s training efficiency, reducing computational time and hardware requirements. With transfer learning, the model achieves optimal performance in 162 epochs, compared to 428 epochs without it. This not only accelerates convergence but also enhances the model’s scalability and flexibility, making it suitable for deployment in larger and more diverse datasets.
The proposed model can be rapidly deployed on existing noise monitoring devices at a low cost, enabling real-time automatic identification of noise sources in urban environments. It addresses the limitations of traditional offline identification methods, which are time-consuming and labor-intensive. By providing timely and accurate noise source identification, the model supports municipal management departments in implementing precise and efficient noise control measures, ultimately improving urban environmental quality and public health. Furthermore, the model can be applied to collect long-term noise level and source data, facilitating studies on the spatiotemporal variations of noise exposure in urban areas.
Future work will focus on expanding the dataset to include more noise categories and scenarios, further testing the model’s performance on larger-scale datasets and different urban environments, and enhancing its generalization ability. Additionally, data augmentation techniques will be explored to address the challenges posed by imbalanced datasets and improve the model’s performance on underrepresented noise categories.
Supplemental Material
Supplemental Material - An urban environmental noise source identification model based on parallel deep learning network with convolutional block attention
Supplemental Material for An urban environmental noise source identification model based on parallel deep learning network with convolutional block attention by Xiaodan Hong, Haomiao Nie and Wenying Zhu in Journal of Low Frequency Noise
Footnotes
Authors contribution
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Science and Technology Innovation Plan of Shanghai Science and Technology Commission: Shanghai “Science and Technology Innovation Action Plan” Morning Star Fund (Sailing Fund 22YF1438300); Shanghai Municipal People’s Government: Shanghai Environmental Protection Research Fund ([2020] No.17).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.