
Abstract
Interval Type-2 Fuzzy Logic Control (IT2FLC) possesses a high control ability in a way that it can optimally handle the presence of uncertainty in a system dynamic. However, the design of such a control scheme is a challenging task due to its complex structure and nonlinear behavior. A Manta Ray Foraging Optimization (MRFO) is a promising algorithm that can be applied to optimize the control design. However, MRFO still suffers the local optima problem due to unbalance exploration-exploitation of the MRFO agents and hence limiting the performance of the desired control. In this paper, Standard, Quasi, Super, and Quasi-Reflected opposition strategies are integrated into the MRFO structure. Each strategy enhances the exploration-exploitation capability and offers different approaches of varying agent’s step size relative to the algorithm’s iteration. The proposed opposition-based MRFO (OMRFO) algorithms are applied to optimize the IT2FLC control design for a laboratory-scaled inverted pendulum system. Moreover, as the algorithms are also promising strategies to other problems, they are applied to solve 50D of 30 IEEE CEC14 benchmark functions representing problems with different features. Performance analysis of the algorithms is statistically conducted using Wilcoxon sign rank and Friedman tests. The result shows that the performance of MRFO and Quasi-Reflected-OMRFO are equal, while all other OMRFO variants show a significant improvement and better rank over the MRFO. The Super and Quasi OMRFO-IT2FLC schemes acquired the best responses for the cart and pendulum, respectively.
Keywords
Introduction
Metaheuristic optimization algorithm.
In recent years, a relatively new metaheuristic algorithm inspired from a cartilaginous fish called a Manta Ray Foraging Optimization (MRFO) has been introduced. 21 Manta ray is a large marine creature found mostly in the Indian Ocean, and tropical, sub-tropical, and warm oceans. Its body has a flat surface from head-to-tail and contains a pair of cephalic lobes located on their large mouth. It feeds on plankton which is a living microorganism in the ocean. Manta ray channels the plankton into its mouth by using its cephalic lobe and filters the plankton from the water using its gill. A matured manta ray requires up to 5 kg of plankton per day. The plankton location depends on the flow of the ocean tides and varies over the seasons. Amazingly, due to its foraging strategy, manta rays always find enough food even though the plankton locations are scattered in the ocean.
The first foraging strategy of manta rays is known as Chain foraging. Manta rays hunt in a group of up to 50 members. 22 They hunt in a line-up position; one behind another, forming a uniform line. Naturally, a small male manta ray hops on and swims on top of the female in order to match the rhythm of the female’s pectoral fins movement. 23 If there is any plankton missed by any manta ray in the front, the manta ray that follows behind will scoop up the plankton. This collaboration strategy draws a larger number of planktons into their mouth, and thus, improves their food bounty. Second, a manta ray employs the Cyclone foraging in its strategy. Once it has found an area that is full of plankton, all of the manta ray members in the group move closer toward each other. Next, they start to link-up to each other using their tails and heads to create a spiraling vertex in the form of a cyclone. In this approach, manta rays move toward the water surface while doing the spiral movement. This strategy is very important to trap and force plankton to become more concentrated in a closed area for ease of feeding. The third foraging strategy of manta rays is Somersault foraging. It is one of the uttermost magnificent settings in nature. Somersault is a series of backward movements and circling around the plankton area in order to draw the plankton toward them. Somersault features random, continual, local, and repetitive movements, which help the manta rays to maximize their feeding. The strategy of the MRFO algorithm mimics the Chain, Cyclone, and Somersault foraging strategies of the manta ray fish. 21
Literature states that the MRFO algorithm has a competitive performance over other well-known optimization problems in solving global optimization problems.24,25 These include unimodal, multi-modal, hybrid, and composite problems that have various fitness landscapes. 21 This is due to the unique randomness strategy, a combination of linear and spiral motions with an elitism concept in its Chain, Cyclone, and Somersault foraging. The promising performance of MRFO has attracted many researchers around the world to adopt the algorithm in solving various real-world problems.26–28 However, the algorithm still has limitations and suffers from stagnation problems; hence, unable to give the best accuracy solution. The search agents of MRFO insufficiently explore and exploit the whole feasible region. In both Chain and Spiral foraging strategies, agents move toward the region that consists of the current fittest agent and the front agent. There is a high possibility that the agents miss a better solution located on the mirrored sides or any opposite region in the feasible search space. Due to the heuristic nature of the algorithm, the current best-found solution is still not a guarantee that the solution leads other agents to the global optimal solution in the feasible region. This obviously occurs in a multi-modal fitness landscape in which there exist both local and global optimal solutions at various points in the region. A good strategy to encounter the problem is by improving the exploration and exploitation of search agents from the beginning until the end of the search operation. This is done through the incorporation of the opposition concept into the MRFO algorithm.
The term “opposite” is defined as “being the other of two complementary or mutual exclusive thing” and the term “oppositional” is defined as “placement opposite to or in contrast with other.”29,30 Through the opposition concept, a novel algorithm that is known as the Opposition-Based Learning (OBL) is introduced. The main idea of OBL is the concurrent evaluation of a solution candidate and its analogous opposite candidate in the feasible search area. 31 This mechanism enhances the exploration and exploitation strategies in such a way that a single agent can be used to evaluate two different locations in the search area. The two locations are the current and mirrored locations of the agent where the center point of the search area is taken as the mirror line. The OBL scheme alone, however, is useless. It is just an opposition-learning scheme which provides a solution to determine a mirrored-location of an agent and is commonly used with an optimization algorithm. The OBL complements the drawback of exploration and exploitation strategies imposed in the algorithm. Several opposition variants have been introduced in literatures to improve the original OBL. They are different than each other in a way that the opposite location of a current agent is determined. Different types of random features are incorporated into the OBL. The well-known OBL variants include Super, Quasi, and Quasi-Reflected Oppositions. Many researchers utilized OBL as a complementary strategy in soft computing technique. It is proven as a good learning scheme to enhance the accuracy performance of metaheuristic algorithms like GA, 32 PSO, 33 and DE.34,35 There are also works on incorporating OBL to speed up convergence rate as well as to improve accuracy of the parent algorithm.36,37 The authors incorporated greedy and weighted-opposition methods into Chimp optimization algorithm. The algorithm was tested on various real-world problems and showed superior performance over the original algorithm and other state-of-the-art algorithms. OBL also has been applied successfully in other applications including opposition-based reinforcement learning38,39 and opposition-based neural network. 40
The hybrid strategy between the OBL concept and MRFO algorithm is a good potential solution to solve a complex fuzzy control problem in engineering and robotics. An inverted pendulum system is a robotic system that has a typical control problem and is commonly used in control engineering. 41 The inverted pendulum system consists of an inverted pole or pendulum hinged at a center body of a cart. The cart moves horizontally on a guided track while the pendulum rod freely rotates in a 360° direction around its axis. The inverted pendulum system is a nonlinear and highly unstable system.42,43 At rest, the pendulum rod is pointing vertically downward due to the attraction of gravitational force on the pendulum mass. However, when in operation mode, the pendulum rod should be kept in a vertically upright position while the cart moves to a predetermined distance along its horizontal axis. Example applications of the pendulum system are a two-wheeled human transporter system and a two-wheeled mobile wheelchair. Launching a space shuttle rocket into the air is another sophisticated example application of the inverted pendulum system. Controlling the highly unstable inverted pendulum system with a complex structure of Interval Type-2 Fuzzy Logic Control (IT2FLC) is more challenging. The IT2FLC model is an advanced version of a fuzzy model and other closed-loop control strategies. 44 Its universe of discourse comprises of lower and upper boundaries.45–47 It added more complexity into the fuzzy model but has a more promising performance to handle the uncertainty of a controlled robotic system. The nonlinear relationship between the fuzzy input–output and a complex fuzzy model structure makes the design of the fuzzy control a highly challenging work. This includes determining fuzzy variables such as if-then rules, universe of discourses, firing angle, and fuzzy input–output gains. Through solely expert knowledge, the performance of a designed fuzzy control might not be at an optimal level. An OBL-based MRFO is a good strategy of optimization algorithm with a balanced exploration and exploitation and is a potential solution to solve the aforementioned complex control problem.
This paper presents Opposition-based Manta Ray Foraging Optimization (OMRFO) algorithms for global optimization and to solve IT2FLC design for an inverted pendulum system. Opposition-based learning (OBL) schemes are incorporated into the MRFO algorithm to enhance exploration and exploitation capabilities of the algorithm. Four variants of OMRFO are presented in the work, which comprises of Standard (St-) opposition, Quasi (Q-) opposition, Quasi-Reflected (QR-) opposition, and Super (S-) opposition. The objective of the paper is twofold. First, it shows the superiority of the proposed OMRFO over its parent algorithm in solving global optimization problems. This is shown in the performance test of the proposed algorithms in solving 30 black-box global optimization problems of CEC14 benchmark functions. The second objective is to show the superiority of the proposed algorithms in solving a complex structure of the IT2FLC model for a highly unstable inverted pendulum system. It is a real-life control problem in engineering, robotics, and control areas. The proposed algorithms optimize the structure of the IT2FLC, which includes its fuzzy if then-rules, universe of discourse, and input-output gains. The organization of this paper is as follows. The remaining sections of the paper explain the concept, structure of the IT2FLC, and its block diagram used for optimization and control for the inverted pendulum system; the details of the OBL, MRFO and the proposed OMRFO algorithms; the experimental setup, result and discussion for both benchmark functions; and finally the application to optimize the IT2FLC model. The paper ends with a conclusion of the work presented in the paper.
OMRFO-IT2FLC for an inverted pendulum system
An inverted pendulum system
The free-body diagram of an inverted pendulum system used in the work is shown in Figure 1. Its mechanical and electrical parameters are shown in Table 2. The inverted pendulum system consists of a cart that moves forward and backward in a translational motion on a guiding rail and a pole that is pivoted on the moving cart.
33
At rest, the loose end of the pole is pointing downward. This is due to the gravitational force that is imposed on the pendulum body. As the cart moves horizontally back and forth along the guided rail, the pivoted pendulum also moves linearly following the cart motion while at the same time rotates about 360° around its axis. The rotating axis of the pendulum is perpendicular to the side plane of the cart body and guiding rail of the cart. During operating mode, the cart is set to move to a certain distance while the pendulum should be kept in a vertically upright position at all times. A DC motor actuator is connected to the cart through a ball screw and drives the cart linearly along its axis. An encoder sensor is attached at the DC motor shaft to measure the actual linear position of the cart. A second encoder sensor is attached on the pivoted pendulum to measure the rotational position of the pendulum. The DC motor input is a continuous voltage signal from a controller. The outputs of the system are the rotational and linear positions of the pendulum and cart, respectively. The configuration defines the system as a single-input multi-output system.48–50 Free-body diagram of an inverted pendulum system. Parameter values of the inverted pendulum system.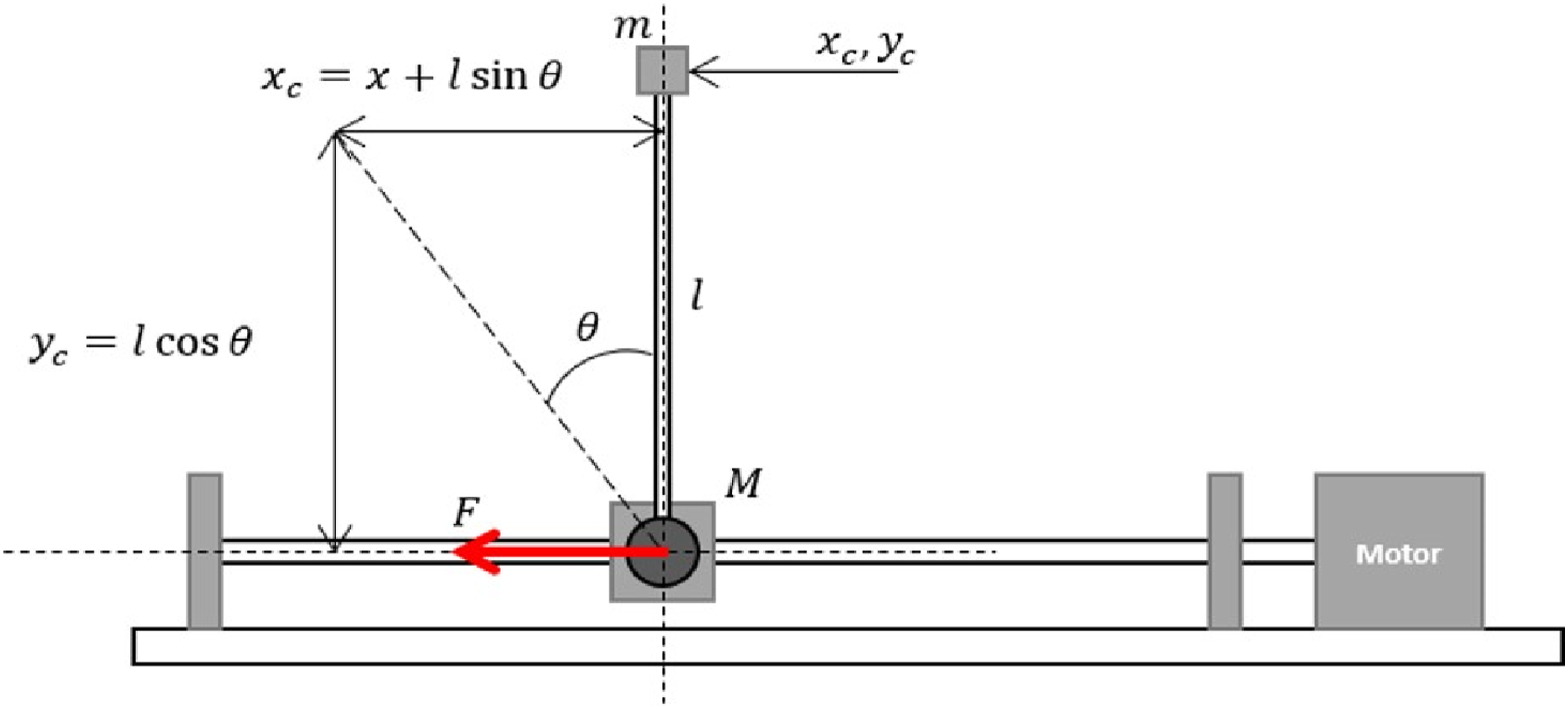

The mathematical model of the inverted pendulum system is derived using the Newtonian second law based on the schematic shown in Figure 1.51,52 Dynamic equations of the system can be simplified as (1) and (2).

Interval type-2 fuzzy logic control
The type-2 fuzzy logic (T2FL) model is an extension of a conventional fuzzy logic model or also known as type-1 fuzzy logic (T1FL) model. The major difference between type-1 and type-2 fuzzy logic models is shown by the fuzzy set
The general process of the T2FL model consists of a fuzzifier, an inference mechanism, a type reducer, and a defuzzifier. The process begins by fuzzifying the input crisp value of IT2FLC, which is converting the input value into type-2 fuzzy set using a fuzzifier. The general representation of type-2 fuzzy set is depicted in Figure 2. It consists of lower Interval type-2 fuzzy set.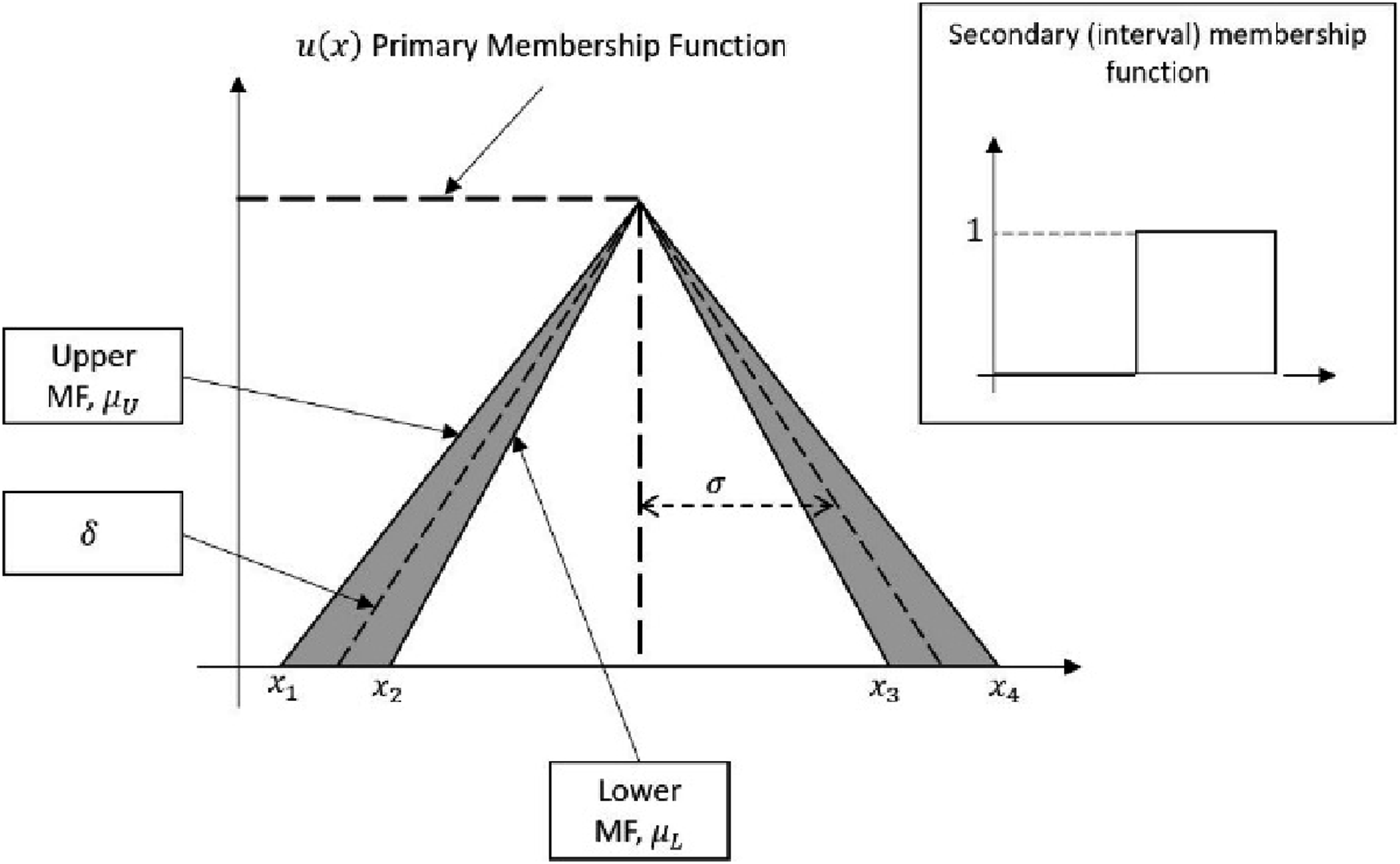
The interval type-2 fuzzy set is defined as (3).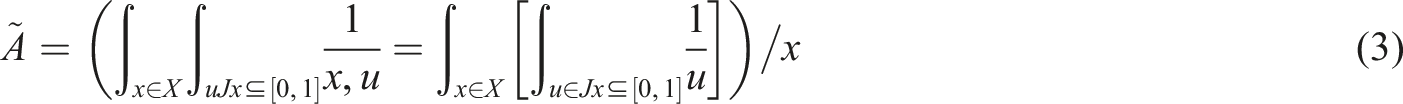



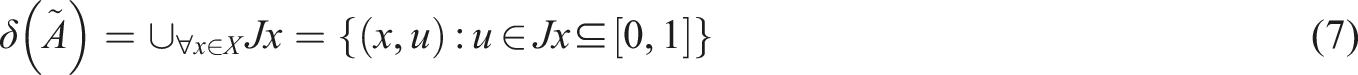
The inference mechanism interprets the fuzzy value based on a set of predefined fuzzy rules. In the work, a decomposition approach is utilized for both fuzzifier and inference mechanism.
48
They are decomposed into upper and lower parts which comprise of upper and lower membership functions, respectively. Three fuzzy sets are defined as Negative Small (NS), Zero (Z), and Positive Small (PS) to form fuzzy rules which consist of antecedent and consequence parts. The fuzzy rules are made from IF-THEN statements, which is generally represented as (8).
A type reducer is then utilized to convert outputs of the inference mechanism engine to a type-1 fuzzy output. The type-reducer can be mathematically expressed as (9).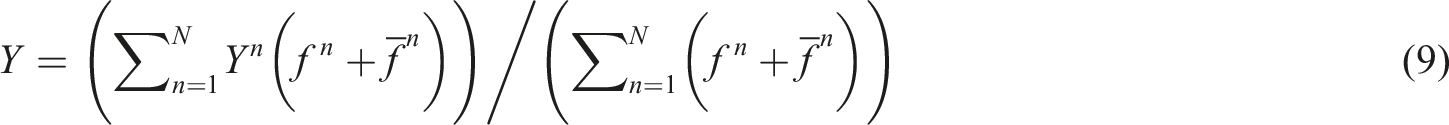
The final process of the T2FL is to defuzzify the type-1 fuzzy output to a crisp value. This is accomplished by computing the center-of-area (centroid) of the FOU using a geometrical approach. It represents the area under the upper and lower membership functions and is computed using (10).
OMRFO-based interval type-2 fuzzy logic control
The closed-loop block diagram of the OMRFO-based IT2FLC scheme for controlling the inverted pendulum system is illustrated in Figure 3. The outputs of inverted pendulum system are an inverted pendulum’s angle, Block diagram of the OMRFO-based interval type-2 fuzzy logic control.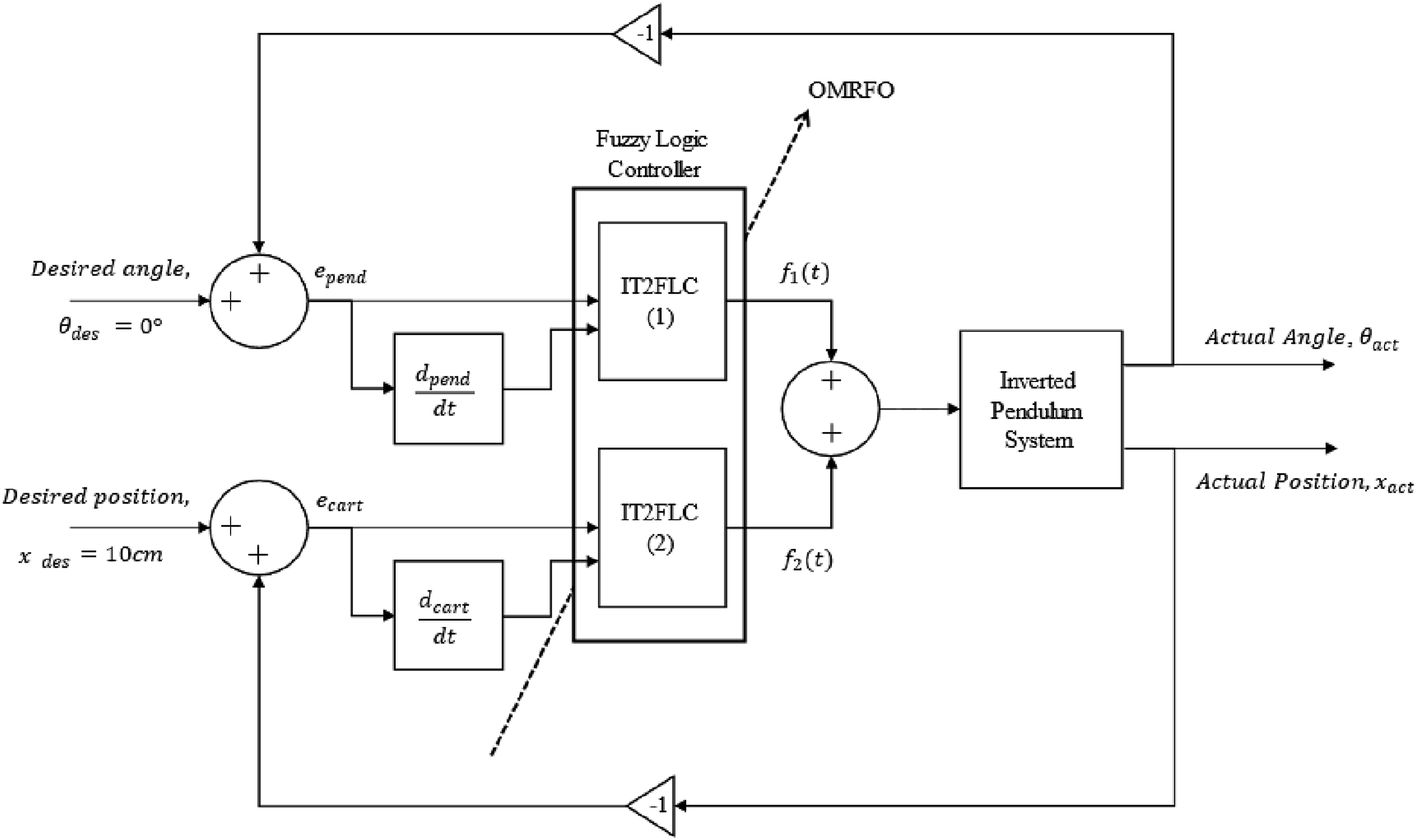
The difference between the actual and desired response is considered as the error of the cart’s position and is defined as (11).
The actual response of the pendulum is fed back and considered as the error of the pendulum’s angle, which is defined as (12).
The errors of the pendulum’s angle and the cart’s position are set as the first input of the first IT2FLC (IT2FLC-1) and the second IT2FLC (IT2FLC-2), respectively. The derivative of the errors of the pendulum’s angle and the cart’s position are set as the second input of the IT2FLC-1 and IT2FLC-2, respectively. Each of these two controllers produces a required value of a voltage signal, which is then combined and fed into the inverted pendulum.
From Figure 4, the mapping of input for the controllers for both error (rad) and derivative of error (rad/sec) is shown. The The mapping of input for the controllers for both error (rad) and derivative of error (rad/sec).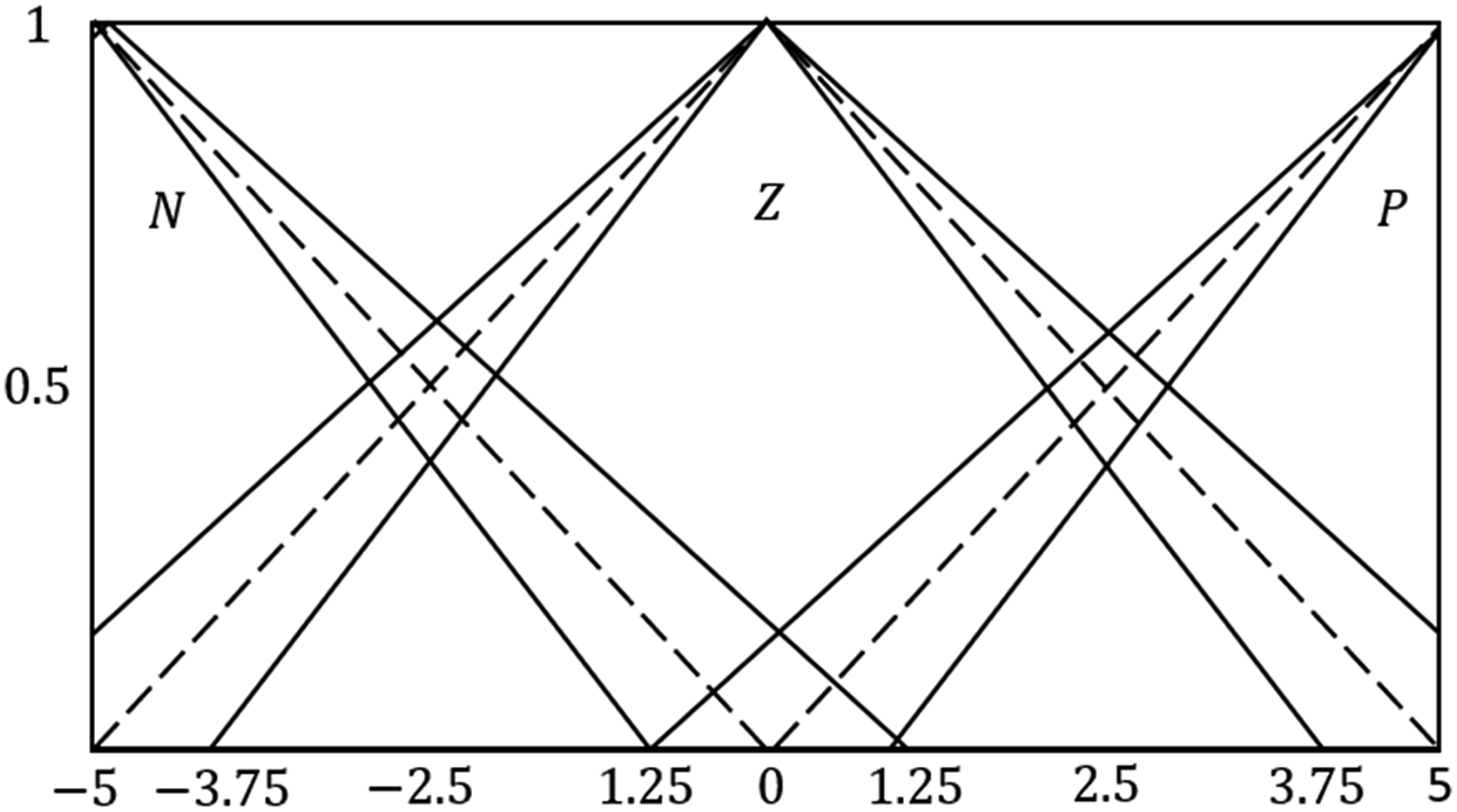
In the work, the proposed OMRFO variants were utilized to optimize both IT2FLCs’ performance. The optimized parameters of the controllers include the location and width of all upper and lower fuzzy membership functions on the universe of discourse and fuzzy rules. Each controller comprises of four variables used to vary the location and width of the membership functions on both fuzzy inputs and nine fuzzy rules. Considering both controllers, the total optimized parameters involved in the work were 26 parameters. The optimization process was initiated by feeding both errors from the cart and pendulum responses into the OMRFO. The summation of these two errors is called the cost function of the OMRFO and the root mean square (RMS) was adopted to complete the formula. Two constants 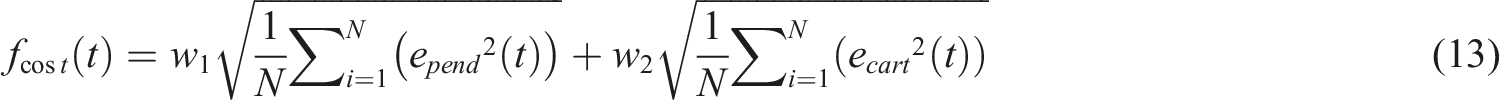
Opposition-based manta ray foraging optimization
Manta ray foraging optimization
The MRFO algorithm mimics the behavior of a group of Manta Ray population in the ocean in finding an area with high concentration of plankton. Searching agents in MRFO swim in a predefined feasible region to search for an optimal solution. The optimal solution is also known as the best solution in MRFO, which is equivalent to an area with the highest concentration of plankton in the ocean. All Manta Rays are considered as searching agents while an individual Manta Ray that finds an area with the highest concentration of plankton is considered as the fittest agent in the algorithm. There are three foraging strategies adopted in the algorithm, which are known as Chain, Cyclone, and Somersault foraging.
The Manta Ray foraging strategy is considered as a group-based strategy where there can be up to a maximum of 50 members during the foraging process. The first foraging process of the Manta Rays is called Chain foraging. As the name implies, the Manta Rays line up and form a chain by linking an individual Manta Ray to another individual Manta Ray. In this form, they swim and scoop all the planktons that come their way. Figure 5 depicts the formation of the Chain foraging of Manta Rays in a feasible region. It shows that the fittest agent, Illustration of chain foraging.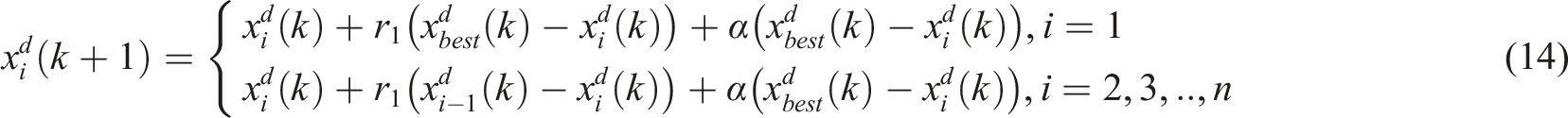

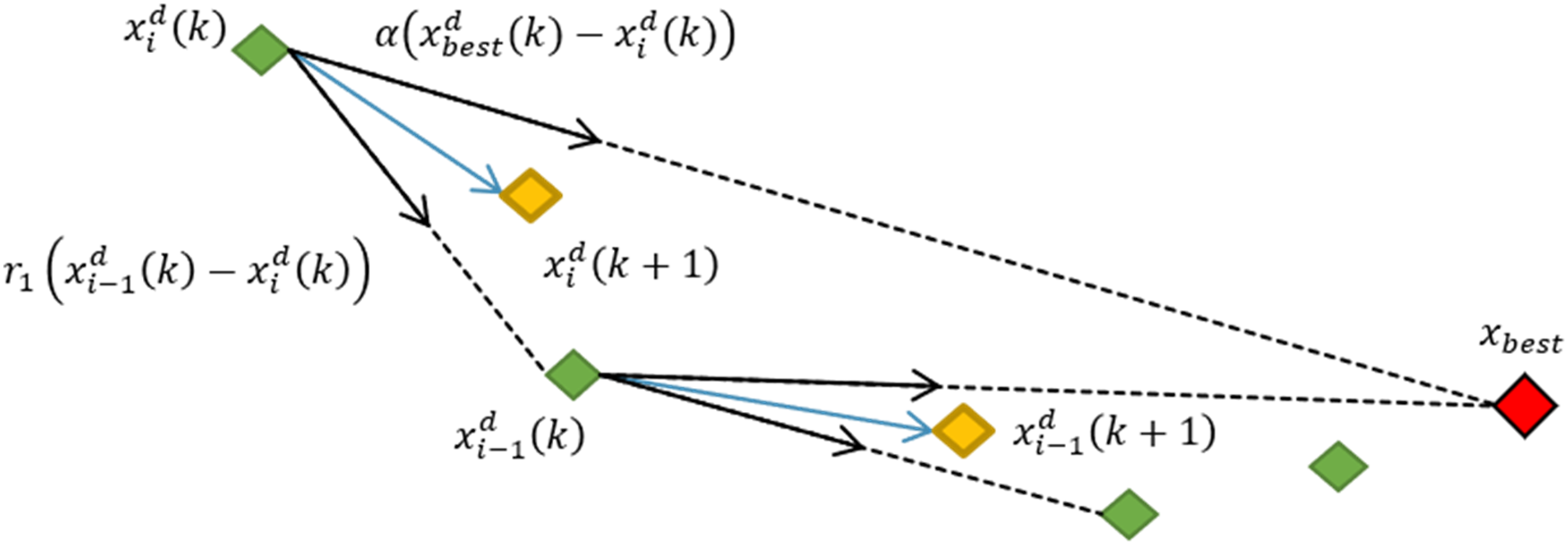
The Cyclone strategy is the second process of the Manta Rays foraging and it is illustrated in Figure 6. The red-diamond is the fittest agent found so far Illustration of cyclone foraging.
These two motions are mathematically expressed as (16) and (17).
21
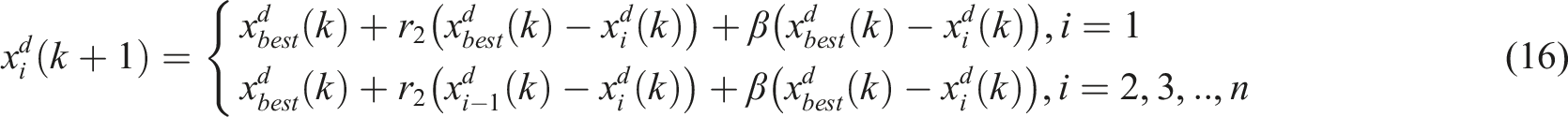

The position update equations show that the newly generated position is an updated location of 
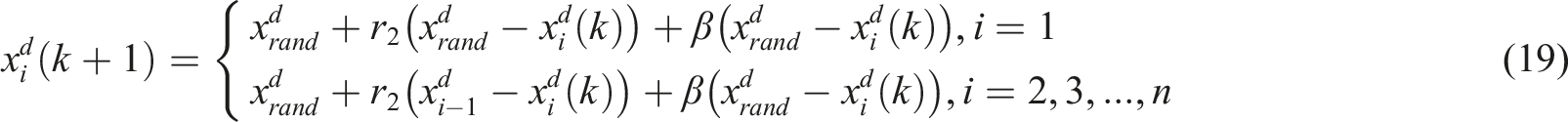
The third process of the Manta Ray foraging is Somersault foraging and it is depicted in Figure 7. Somersault foraging is the process where all searching agents move towards the other side of the fittest agent, Illustration of somersault foraging.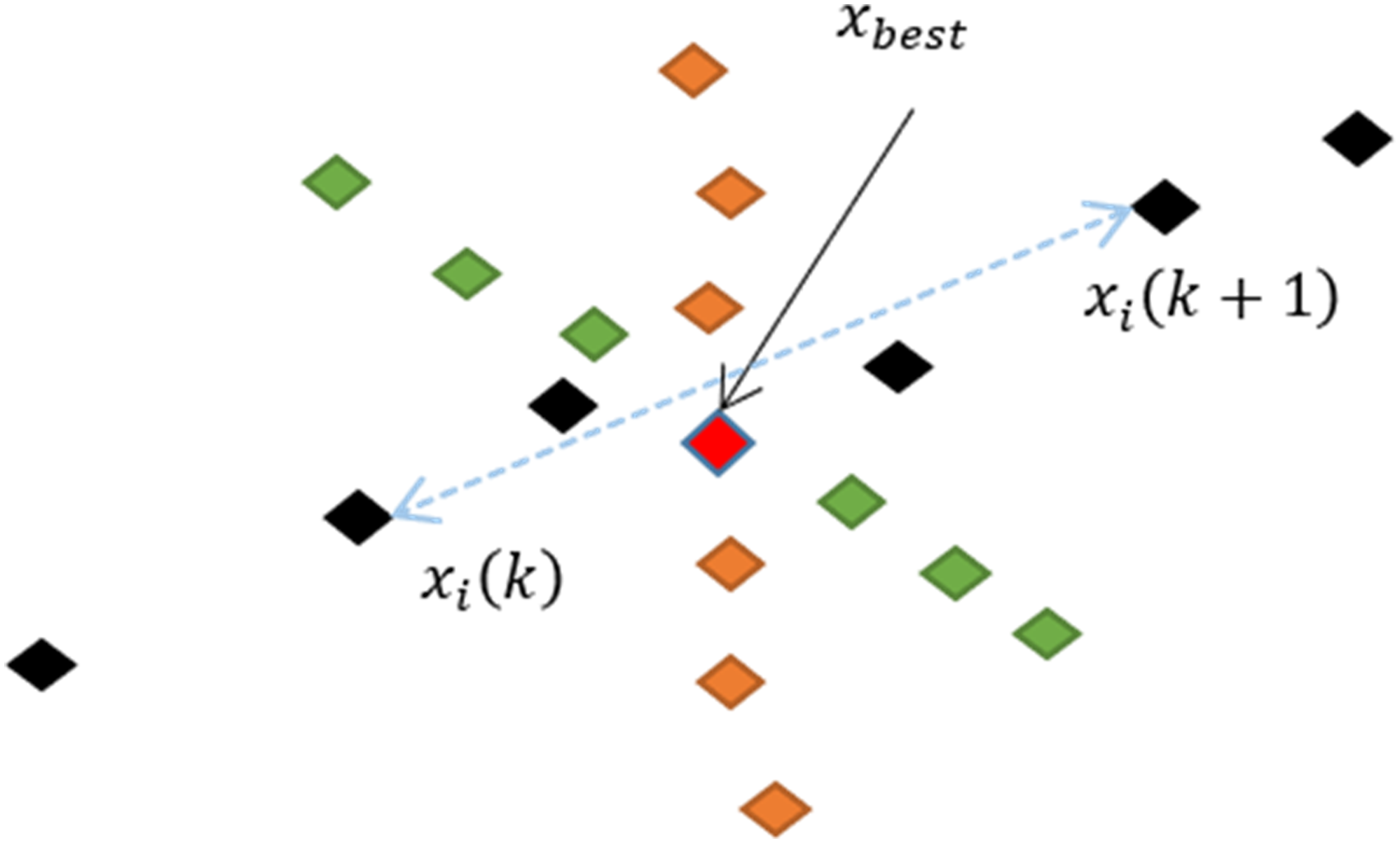
The mathematical expression of Somersault foraging is shown as (20).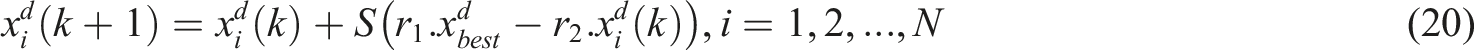
Oppositional-based learning
The general idea of OBL is to check for a possible optimal solution on the opposite side of the current location of an agent. Taking the boundaries of a feasible search space as both upper and lower bounds, the middle point of the search space can be determined. An opposite location of an agent is defined as a location of the agent mirrored at the middle point of the lower and upper bounds of the search space. An illustration of the idea is shown in Figure 8. Mapping of opposite individuals based on three types of OBL.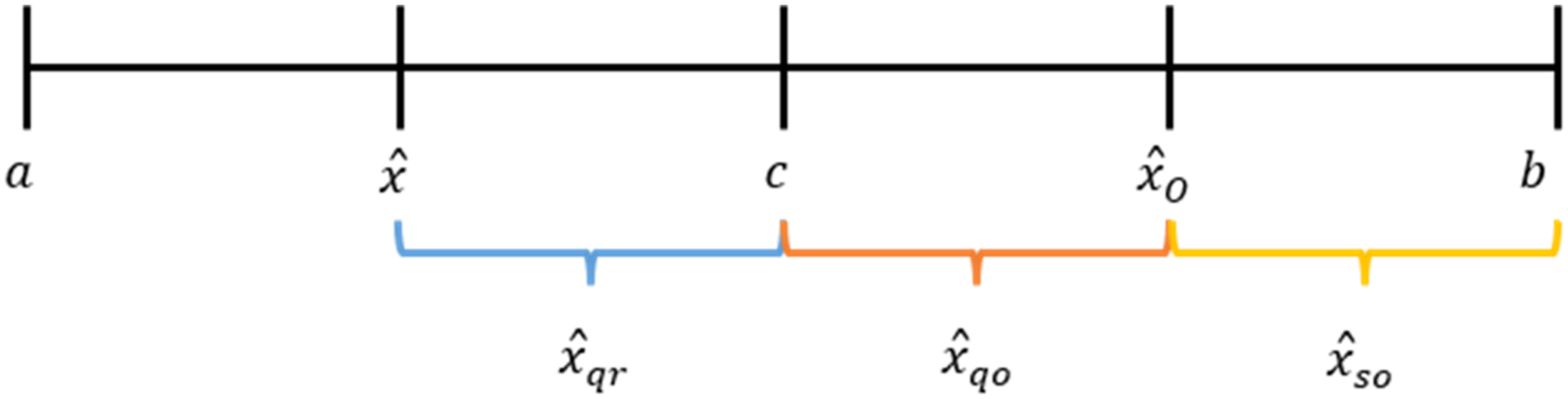
Consider 

Opposition-based manta ray foraging optimization
The OMRFO algorithm is an incorporation of opposition schemes into the original MRFO. The strategy complements several drawbacks of the MRFO algorithm in locating an optimal solution, and thus, offers several advantages which can be described as follows.
First, an integration of the opposition schemes into the standard MRFO improves an exploration strategy in locating an optimal solution. One of the stochastic natures of a group-based optimization algorithm is placing all searching agents into a feasible search space using a random feature. It allows an algorithm to distribute the searching agents thoroughly within a predefined searching boundary. However, the agents are not well and evenly distributed. Some of the small regions within the searching boundaries contain more agents than the other small regions. As the searching operation continues and iteration increases, the exploration of the agents does not thoroughly cover the whole search space. Some small regions might not be touched by the agents, and thus, leaving those regions unexplored. The following illustration elaborates the idea. For the case of MRFO, at the 

An illustration of the initialization of agents’ position based on (26) and (27) is shown in Figure 9. The blue-dots are the initial locations of searching agents while the grey area within the dotted line is a feasible search region. The middle line between the a and b boundaries of the feasible region is denoted as Initial and opposite locations of agents on a 2-dimensional search space.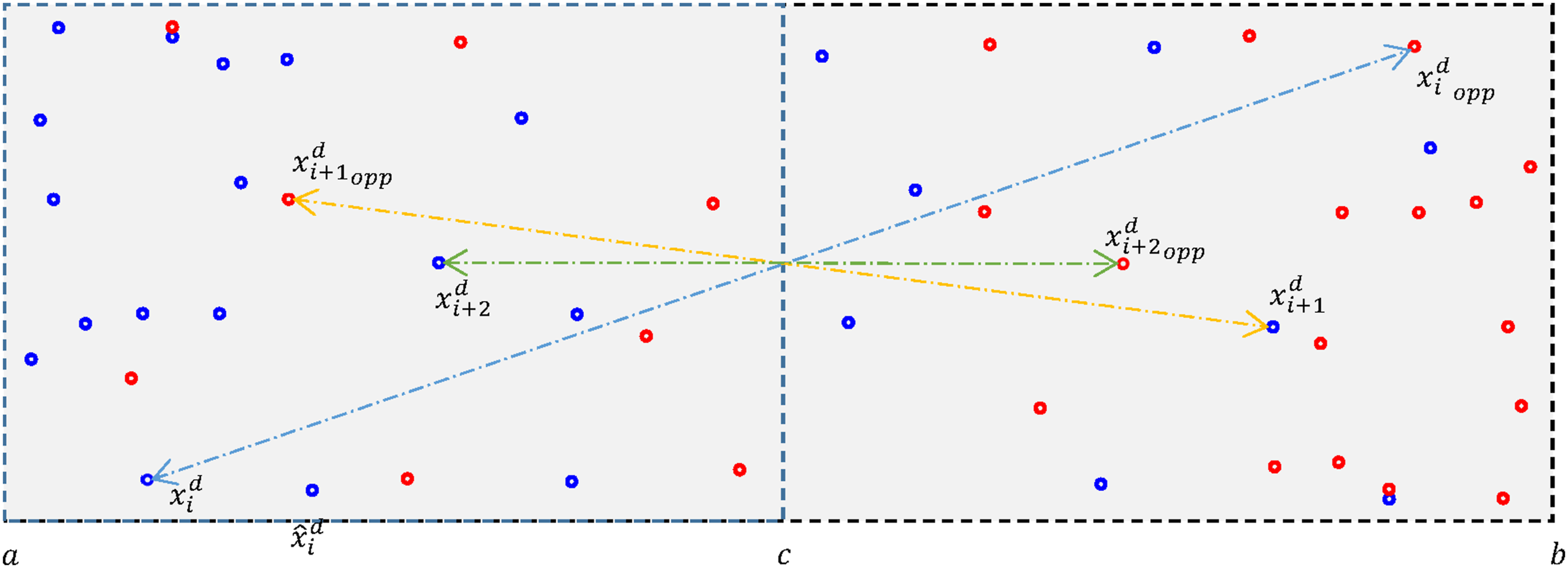
Second, the advantage of incorporating the opposition scheme into MRFO is that it improves the stochastic feature of the algorithm. Based on Q-, QR-, and S-opposition schemes, an additional random feature is incorporated into the formulas. The mirrored location of the newly generated agents does not follow the same distance of the agents to the reflection point. However, the distance of the resulting location is defined within a certain range with respect to a random number, and thus, improving the exploration capability. The third advantage of the opposition scheme is an adaptive strategy is incorporated to determine the resulting opposite location of the agents. The agent’s fitness cost is adopted into the formula to generate the opposite location of the agent. The adaptive feature allows the algorithm to generate a more dynamic mirrored distance for each agent and increase the dynamic behavior of the agents throughout the search operation. In the case where the agent has a smaller cost, the algorithm generates a smaller mirrored distance for the agent and vice versa. In the beginning of the search operation, the fitness costs of all agents are large enough and it generates a large mirrored distance and a good exploration. Towards the end of the iterations, the fitness cost approaches minimum value, and thus, leads to a better exploitation.
In the work, four variants of the opposition schemes, that is, St-, Q-, QR- and S-, are incorporated into MRFO. These four variants produce four variants of OMRFO. Each variant is implemented by applying the opposition schemes shown as (22), (23), (24), and (25), respectively. Details of the step-by-step pseudocode of the proposed OMRFO variants are shown in Figure 10. The number of agents in OMRFO is doubled via the opposition equations (22)–(25) where a total of 50 agents are utilized to find a solution similar to the number of agents in MRFO. In order to maintain the same number of agents during the search and for a fair comparison, the agents are sorted based on their fitness cost, and consequently, the first half of the agents’ population are retained while the rest are eliminated. In the sorting process, agents with the lowest and highest fitness costs are defined as the first and the last, respectively. In other words, the sorting process retains all the fittest agents in the population. This is also to avoid the increasing complexity of the algorithm which may lead to the increase of computation cost. Pseudocode of the proposed OMRFO variants.
Experimental setup, result and discussion
Benchmark functions
Experimental setup and evaluation criteria
Experimental setup for the performance test on CEC14 functions.

The generated result was statistically analyzed via the Wilcoxon sign rank as well as Friedman Tests. The Wilcoxon signed-rank test is a nonparametric statistical hypothesis test to correlate two complementary samples or related samples.62–67 It is also used to test a paired difference of N repeated measurements on two different samples by assessing their population mean ranks. 68 The Friedman test, on the other hand, is a nonparametric statistical tool that is used to measure performance difference across multiple or more than two algorithms.69–73 It compares the mean rank of all algorithms under study. Algorithms with the lowest and highest mean ranks are considered the best and worst performing algorithms, respectively. In both tests, a percentage of confidence interval was defined as 95 %. It indicates that if the test gives a two-tailed probability, p less than 0.05 or 5 % level of significance, the performance of one algorithm over another algorithm has a significant improvement. In the work, 51 independent runs were conducted, and thus, the repeated measurements, N, were defined as 51.
Parameter setting
Parameter setting for the performance test on CEC14 functions.

Performance comparison on result and discussion
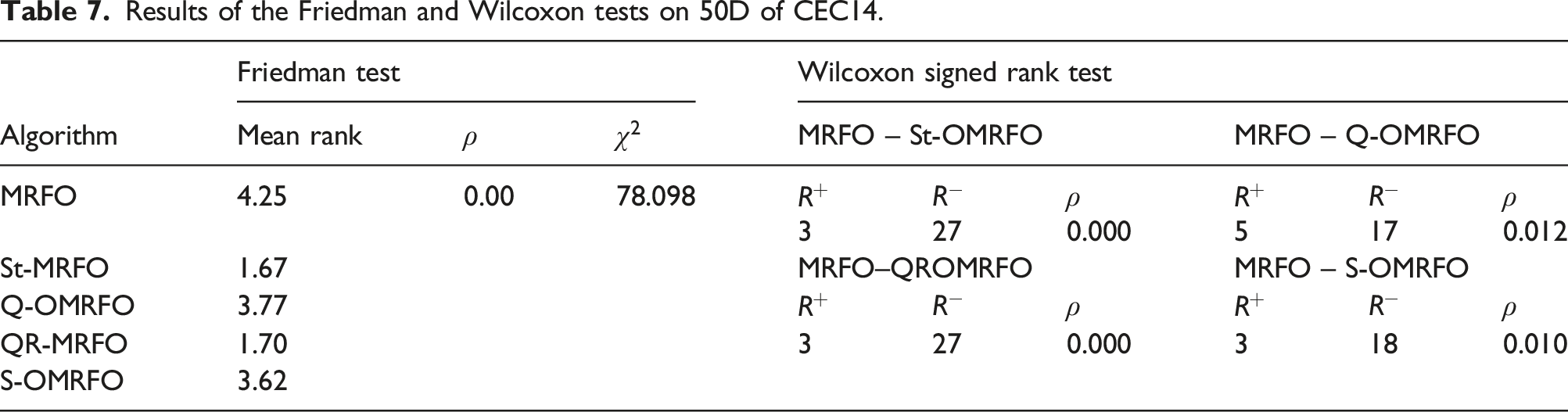
Results of the Friedman and Wilcoxon tests on 50D of CEC14.
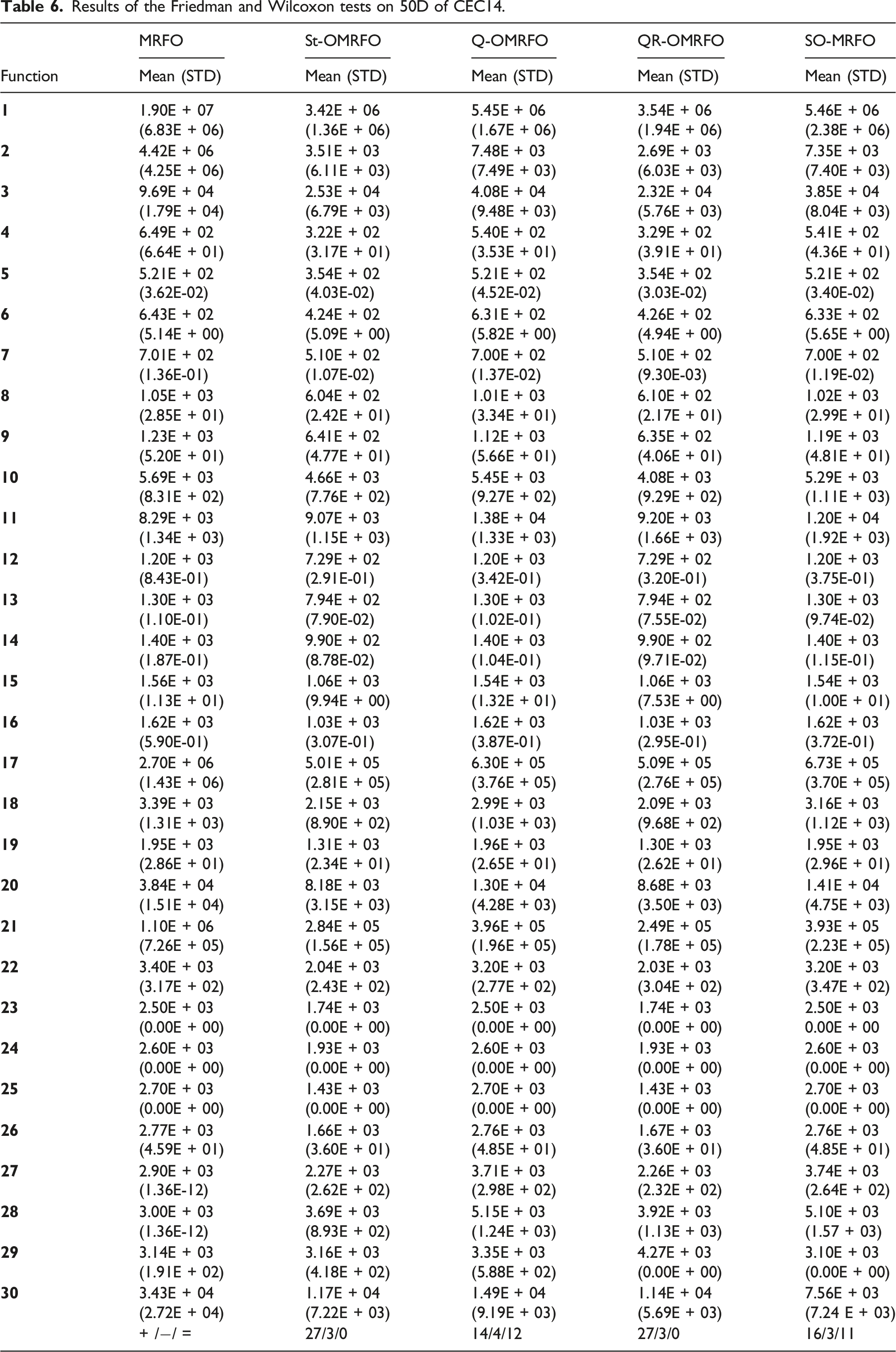
On the other hand, based on the SD value, MRFO attained the unshared worst performance among other algorithms for 18 functions which include f 1 –f 4 , f 7 , f 8 , f 12 –f 14 , f 16 –f 22 , f 27 , and f 28 . Q-OMRFO attained the unshared worst performance among the algorithms for 6 functions, f 5 , f 6 , f 9 , f 15 , f 27 , and f 29 . S-OMRFO attained the unshared worst performance among the algorithms for three functions, f 10 , f 11 , and f 28 . St- and QR-OMRFOs did not attain any unshared worst performance for 50D problems. All algorithms shared the worst performance for functions f 23 –f 25 . The worst performance for function f 26 was shared by Q- and S-OMRFOs. Considering both shared and unshared, the results show that MRFO led the worst performance on the consistency achievement followed by Q- and S-OMRFOs with the scores 17, 11, and 9, respectively. QR- and St-OMRFOs shared the fourth position on the worst performance with three scores. On the contrary, MRFO achieved the unshared best performance among the algorithms for two functions which include f 27 and f 28 . St-OMRFO achieved the unshared best performance among the algorithms for 11 functions, f 1 , f 4 , f 10 –f 12 , f 14 , and f 18 –f 22 . Q- and S-OMRFOs did not achieve any unshared best performance for 50D problems. QR-OMRFO achieved the unshared best performance among the algorithms for 11 functions, f 3 –f 8 , f 13 , f 15 –f 17 , and f 30 . All algorithms shared the best performance for functions f 23 –f 25 . QR-OMRFO shared the best performance with St- and S-OMRFOs for functions f 26 and f 29 , respectively. Taking into account both shared and unshared best performances, QR-OMRFO led the number followed by St-OMRFO, MRFO, and S- and Q-OMRFOs which attained 17, 15, 5, 4, and 3 scores, respectively. Considering both worst and best achievements, the results indicate that the proposed OMRFOs outperformed MRFO on the consistency performance for 50D of CEC14 problems.
Results of the Friedman and Wilcoxon tests on 50D of CEC14.
Application to optimize fuzzy control for an inverted pendulum system
Experimental setup and parameter setting
The proposed OMRFOs were applied to optimize the fuzzy model to control the cart’s position and pendulum’s angle of an inverted pendulum system. The parameters used for the work such as maximum number of function evaluation,
Performance comparison on result and discussion
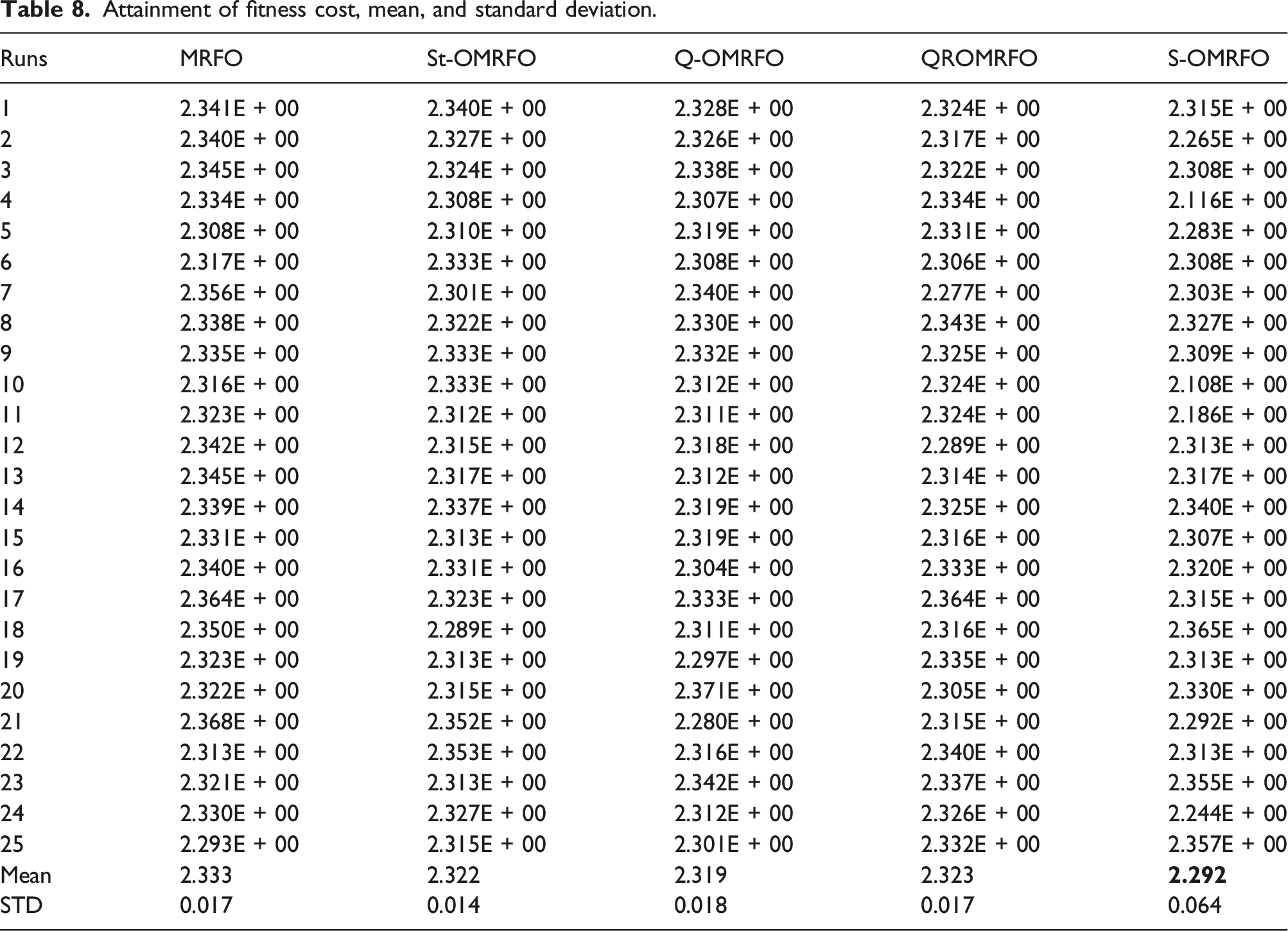
Attainment of fitness cost, mean, and standard deviation.
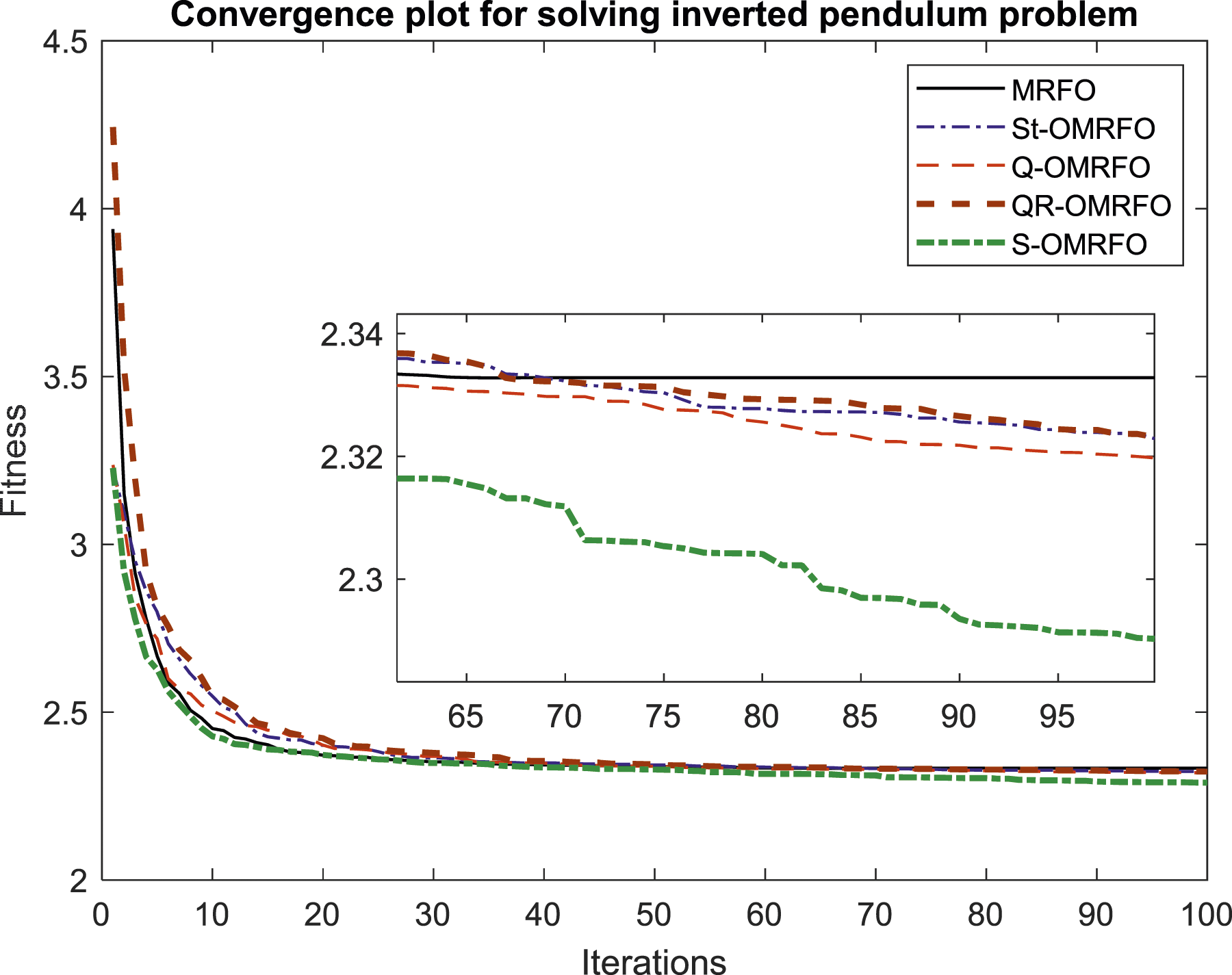
Convergence curves produced by the contested algorithms.
Results of the Friedman and Wilcoxon tests on inverted pendulum.

Figure 12 shows the output response of the cart’s position given a step input function as a test signal. The cart is required to move to the final position at 10 cm from its initial position, 0 cm at the center of the horizontal axis. In general, it shows that all the optimized fuzzy controllers had successfully controlled the cart to move to the desired 10 cm position. However, there is a little offset from the desired 10 cm position shown by the graphs, indicating that the cart did not settle at exactly the 10 cm position. The response is clearly observed from the zoomed-in picture. All the graphs show that the cart initially moved beyond the desired position. It then moved back and forth near the 10 cm location before it finally settled at the final location. Response of cart’s position.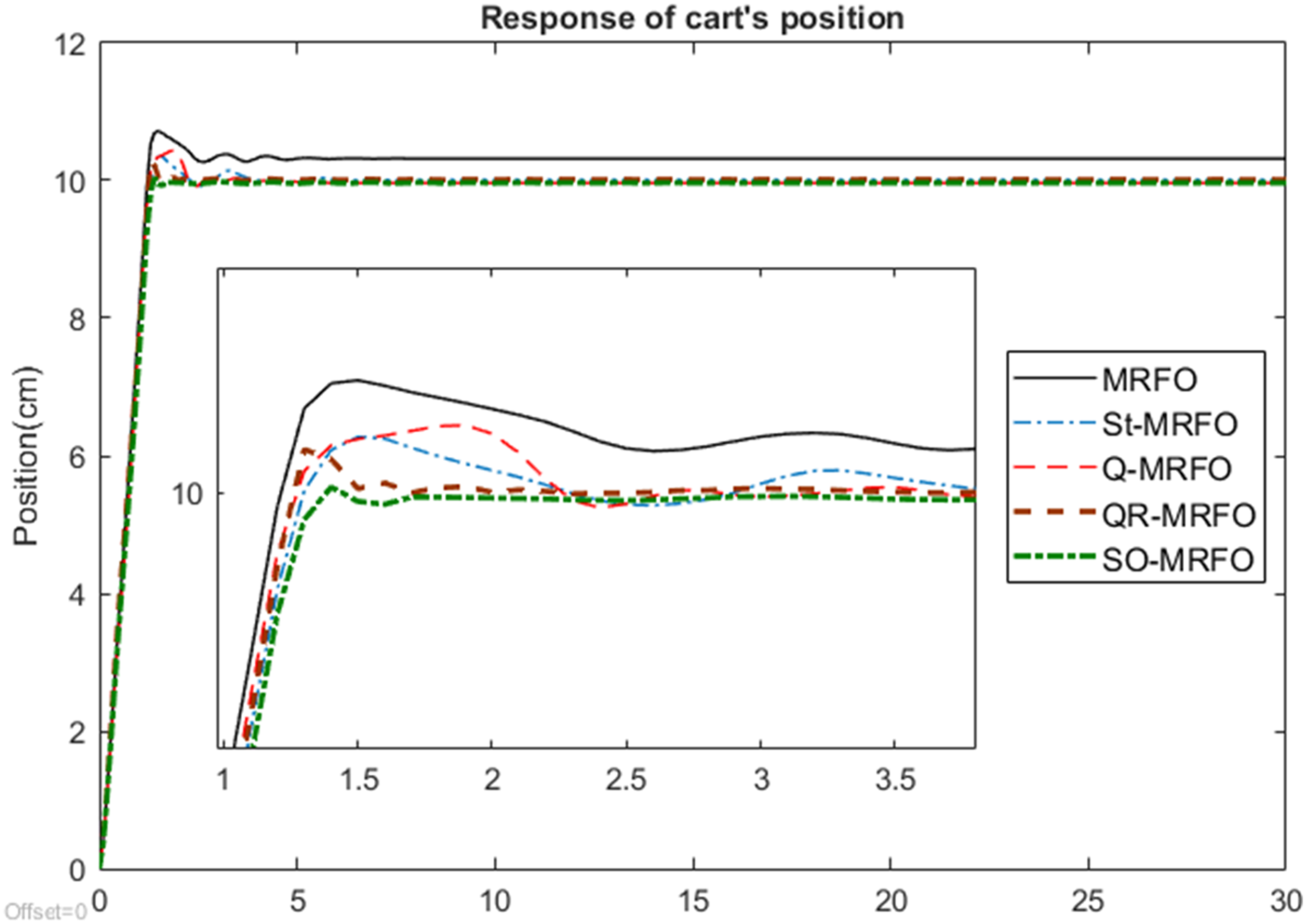
Time-domain performance of the cart’s response.

Figure 13 shows the output response of the pendulum’s angle based on a step input function applied on the cart. The pendulum is attached on the cart’s body and it has to be in a vertically upright position while in operation. In that particular condition, the corresponding angle of the pendulum is 0°. Response of pendulum’s angle.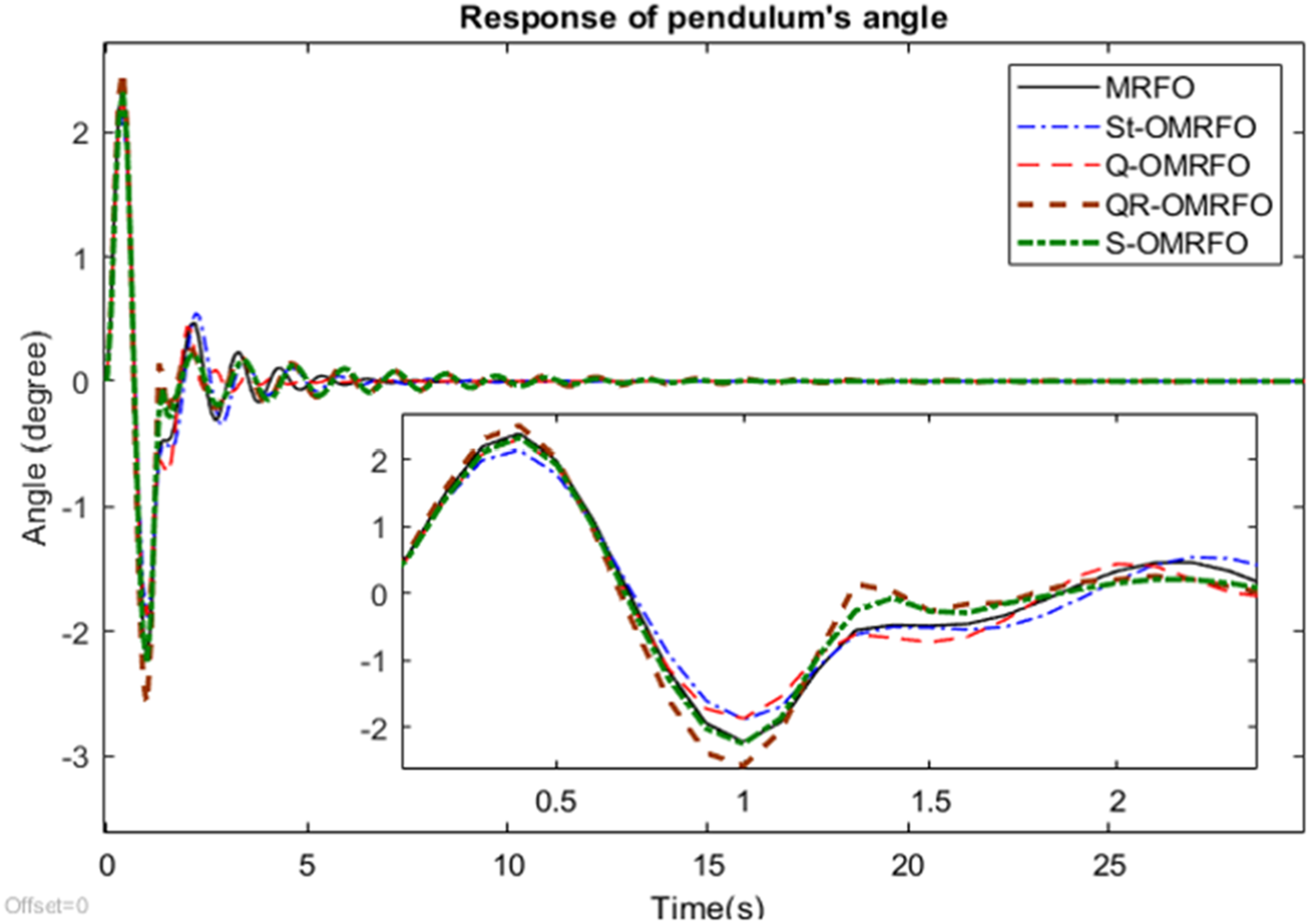
All graphs from the figure generally show that the pendulum finally settled at the desired 0° angle. It indicates the optimized fuzzy controller had successfully stabilized the pendulum and maintained its vertical upright position. In the first 12 s, the pendulum experienced a series of significant swings. This is due to its reaction on the initial cart’s movement towards the desired 10 cm location when a step input is applied. The swing continuously occurred as the cart moved iteratively in back and forth directions in order to achieve its desired 0° location. The swing significantly reduced over time before finally settling down to the final location showing that the controller had worked sufficiently well. The graphs show that the pendulum oscillation pattern in general is almost the same. However, from the zoomed-in picture, the pendulum responses vary from one to another.
Time-domain performance of the pendulum’s response.

For the overall performance on the application of the proposed algorithms to solve the real-world problem, it shows that Q-OMRFO achieved the best performance among other algorithms for the undershoot, settling time, and steady state-error, while St-OMRFO achieved the best performance for overshoot and rise time components. On the contrary, QR-OMRFO attained the worst performance among the algorithms for the overshoot, undershoot, settling time, and steady-state error, while S-OMRFO attained the worst performance for the rise time component. MRFO achieved neither best nor worst performances on the five components for the pendulum response. Based on these performances, the best algorithm for optimizing the pendulum’s response was achieved by Q-OMRFO, followed by St-OMRFO, MRFO, and S- and QR-OMRFOs.
Conclusion
The Opposition-based Manta Ray Foraging Optimization (OMRFO) algorithm has been presented in this paper. MRFO comprises a combination of random and deterministic spiral models in its Chain, Cyclone, and Somersault phases. The algorithm suffers insufficient exploration of search space which has led to a premature convergence and low accuracy performance. As a solution to the problem, an Opposition-based Learning (OBL) mechanism was incorporated into the original structure of the MRFO. The opposition scheme expanded the search area of every single Manta Ray agent. It offered the agents to explore the opposite region of its current location, which is unable to be reached by the conventional strategy of MRFO. Four variants of the opposition schemes had been adopted, which led to Standard-opposition (St-), Quasi-opposition (Q-), Quasi-Reflected Opposition (QR-), and Super-Opposition (S-) OMRFOs. The schemes utilized different strategies in the way they determined the opposite location of each agent. The accuracy performance of the proposed algorithms had been tested on 30 unconstrained problems adopted from the IEEE Evolutionary Computation, CEC14 test suite. A 50-dimension had been tested on each problem to comprehensively investigate the effectiveness of the proposed OMRFOs over MRFO for different problems. The algorithms also had been applied to solve a complex real-world problem in intelligent control system engineering. It was utilized to optimize parameters of 26 dimensions nonlinear fuzzy logic model to control the cart and pendulum positions of an inverted pendulum system. A total of 25 independent tests had been conducted on the inverted pendulum problem to acquire a set of data to perform a statistical analysis on the accuracy achievement. The result of the performance test of the proposed OMRFO algorithms on the 50-dimension of the CEC14 benchmark functions showed that all the proposed OMRFOs outperformed MRFO. This is evidenced from the statistical analysis on the Friedman test showing all proposed algorithms have acquired better rank. St-OMRFO achieved the best rank for the 50-dimension problems of the CEC14. The proposed OMRFOs also significantly improved the accuracy performance in searching for a theoretical optimum solution of the benchmark problems. This is evidenced from the statistical analysis on the Wilcoxon sign rank test showing the two-tailed result with 95% confidence that is lower than 5%. The statistical analysis on the result of the inverted pendulum system showed that S-OMRFO achieved the best mean accuracy. The result of the Friedman test showed that the final rank from the best to the worst orders is S-, Q-, St-, and QR-OMRFOs and MRFO. It is also evidenced from the Wilcoxon sign rank test on the result of the inverted pendulum that the two-tailed value for S-, St-, and Q-OMRFOs is less than 0.05, indicating the improvement over MRFO is significant. All the algorithms had satisfactorily controlled both cart and pendulum positions of the inverted pendulum system. The cart rapidly settled to its desired final location in less than 1 s. The pendulum oscillation due to its reaction to move the cart to the 10 cm location had been quickly attenuated and removed. Last but not least, as the proposed algorithms are not problem-specific algorithms, they might be considered as potential tools for solving other complex and nonlinear behavior of real-world problems.
Footnotes
Acknowledgments
The authors would like to thank the Ministry of Higher Education Malaysia for providing financial support under Fundamental Research Grant Schemes (FRGS) No. FRGS/1/2021/ICT02/UMP/03/2 (University reference RDU210116) and FRGS/1/2021/ICT02/UMP/02/2 (University reference RDU210110).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Fundamental Research Grant Schemes (FRGS) No. FRGS/1/2021/ICT02/UMP/03/2 (University reference RDU210116) and FRGS/1/2021/ICT02/UMP/02/2 (University reference RDU210110).