
Abstract
Keywords
Introduction
Suicide is still a serious global public health problem, causing more than 700,000 deaths every year. It is estimated that there are around 20 times more suicide attempts than deaths. 1 People who survive a suicide attempt are at high risk of dying later or developing mental health problems, so they need special care and long-term follow-up. 2 These people also give important information that helps doctors, mental health workers, and forensic experts. The method used in a suicide attempt, such as the intentional ingestion of supratherapeutic quantities of medication, cutting, jumping, or hanging is very important in both medical and legal situations. The chosen method is often linked to how dangerous the attempt was, how severe the person’s mental illness is, and how likely they are to try again. 3 In medical practice, the suicide method helps decide how urgent the treatment should be and what kind of care the person needs. In legal situations, it helps with classifying the case, judging the level of risk, and making legal decisions. 4 Forensic psychiatric evaluations often require detailed information regarding the precise mechanism by which the suicide attempt was carried out. This helps experts understand the person’s intention, legal responsibility, and whether they need forced medical treatment. Even though it is very important, information about the suicide method is often missing, unclear, or only mentioned indirectly, especially during emergency situations where saving the person’s life comes before writing detailed notes. 5 This lack of clear information makes it hard to analyze the case later in medical or legal settings and creates problems in judging the person’s level of future risk.
Forensic psychiatric evaluations also impose considerable time and documentation burdens on clinicians, and the integration of AI-assisted analytic tools has the potential to streamline these processes by supporting greater efficiency, standardization, and consistency in medico-legal reporting.
Traditional clinical and forensic record systems often do not include enough detailed information to clearly understand how the suicide was attempted, especially when the reports are incomplete or unclear. 6 Moreover, standard structured data collection instruments are not designed to infer method-specific details from indirect indicators such as psychiatric history, impulsivity, or demographic profiles. 7 Because of this gap, more people are becoming interested in using Natural Language Processing (NLP) technologies, especially Large Language Models (LLMs), to solve problems related to making inferences from limited information. LLMs demonstrate significant promise in interpreting free-text clinical narratives, even when explicit markers of suicide methods are absent. 8 Recent developments suggest that LLMs can make logical clinical predictions from structured prompts that include incomplete or indirect information. 9
Nevertheless, the application of LLMs in psychiatric and forensic workflows entails significant methodological and ethical constraints. In addition to their propensity to produce confident but inaccurate inferences known as hallucinations, these models pose persistent challenges regarding confidentiality, data provenance, and the governance of sensitive medico-legal information, concerns that become particularly critical within forensic psychiatric evaluations.4,10
Nonetheless, the application of LLMs for suicide method prediction remains largely theoretical, with limited empirical validation in real-world forensic or clinical samples. 4
Although there are many studies on using LLMs for mental health diagnosis,11,12 few have systematically evaluated LLMs’ ability to predict suicide methods based solely on indirect clinical and psychiatric details. Most current studies focus on general risk levels for depression, anxiety, or suicide, but they do not explain which suicide method was used.3,8 One important problem is that forensic cases are rarely included in these studies. Many of them use general psychiatric groups or data from social media instead of proper forensic psychiatric case files.9,12 Also, studies that check if LLMs give the same predictions over time which is very important for using them in legal settings are very rare. 5 These deficiencies underscore the need for empirical research directly targeting LLM capabilities in forensic suicide method prediction, using rigorously structured forensic samples and temporal validation designs.
To address these gaps, the present study offers a structured evaluation of LLM-based suicide-method prediction using retrospectively collected forensic psychiatric case files, acknowledging that the analysis does not constitute a real-time implementation study. Uniquely, the language models were prompted only with indirect clinical and psychiatric indicators, without including any direct forensic details, in order to reduce potential bias. The main aims of this study were to evaluate the overall predictive accuracy of different LLM platforms; to examine their performance for common methods like drug overdose versus rarer methods like jumping or hanging; to compare the results across different models; and to assess whether each model produced similar predictions after 1 month. Through this approach, the study aims to provide critical insights into the forensic applicability of LLMs for suicide method prediction under realistic, constrained information settings. Also, by showing that it is possible to make indirect predictions, this study creates an early step for using AI-based decision support tools in forensic psychiatric evaluations. The goal is to improve objectivity, consistency, and legal-medical reliability.
The findings of this study are expected to contribute to the use of artificial intelligence techniques in forensic psychiatry by providing evidence-based insights into the capabilities and limitations of LLMs. Moreover, by addressing both method-specific prediction and temporal reliability, the study helps establish essential knowledge for the safe and ethical application of LLMs in critical forensic and clinical settings.
Methods
Study population and case selection
This study employed a retrospective observational design involving forensic psychiatric cases referred for medico-legal evaluation. The study population comprised individuals who attempted suicide, survived the incident, and were subsequently referred for formal forensic medical examination upon judicial request. Inclusion criteria required that each case: Presented to the emergency department following a suicide attempt, survived the attempt, underwent a comprehensive forensic medical evaluation with an issued medico-legal report, had complete documentation of demographic, psychiatric, and clinical data. Cases involving deceased individuals, autopsy reports, or incomplete documentation were excluded. A total of 92 cases met these criteria and were included in the final analysis. All eligible cases within the defined study period were included; thus, no prior sample size calculation or power analysis was conducted. Each case included in the study first underwent emergency medical stabilization immediately following the suicide attempt and was subsequently referred for formal forensic psychiatric evaluation under judicial mandate, thereby ensuring the legal-medical relevance of the cohort. The cases were retrospectively selected from forensic medicine, emergency medicine, and psychiatry examination records and medico-legal reports collected between January 1, 2019, and December 31, 2024, within a hospital-based forensic psychiatric evaluation context.
The reporting of this prediction model evaluation study conforms to the TRIPOD + AI (Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis plus Artificial Intelligence) guideline, 13 and the completed TRIPOD + AI checklist is provided as Supplemental Table S1.
Data sources and structured variable extraction
All data were obtained from institutional medico-legal records, incorporating documentation from both emergency department admissions and subsequent forensic medical evaluations. Sources included clinical files, forensic examination forms, and entries from the institutional medico-legal database. The dataset was structured to include the following variables: Demographic Variables: sex (male/female), age at the time of incident. Psychiatric Variables: primary psychiatric diagnosis, history of psychiatric hospitalization, psychiatric medication use, previous suicide attempts, impulsivity during the attempt (impulsive vs non-impulsive), consciousness status at the time of emergency medical evaluation. Clinical and Forensic Variables: presence of traumatic findings (e.g., incised wounds, contusions, fractures), number and class of ingested substances, total number of tablets ingested, and time interval (in days) between the suicide attempt and the forensic medical examination.
All included cases had complete information across all relevant variables; no missing data were observed. Data coding was independently performed by two forensic physicians. Discrepancies were resolved through a consensus process involving a third expert to minimize interpretive bias and ensure coding reliability.
Large language models-based suicide method prediction framework
Objective and conceptual design
The primary objective of this study was to evaluate the predictive capacity of large language models (LLMs) in identifying the most likely method of suicide attempt based solely on indirect clinical and psychiatric indicators. Importantly, no direct forensic details were provided to the models, ensuring a bias-minimized prediction framework.
Prompt development and data minimization strategy
A standardized input protocol was developed to preserve methodological integrity and prevent outcome leakage. Each case was converted into a textual scenario incorporating only indirect predictors: sex, age at the time of incident, psychiatric diagnosis, history of psychiatric hospitalization, history of psychiatric medication use, history of previous suicide attempts, impulsivity classification (impulsive/non-impulsive), consciousness status during emergency evaluation. Critically, no references to traumatic findings, specific drug names, quantities were included. The goal was to assess inferential prediction rather than recognition. This approach aimed to simulate realistic emergency and forensic evaluation scenarios, where detailed forensic findings such as traumatic injuries or substance specifics are often initially unavailable or unclear due to the immediacy of medical interventions.
Standardized prompt formatting and session initialization
The following fixed prompt was used across all LLMs to ensure standardization: Below is an anonymized case file containing demographic, psychiatric, and general clinical information of an individual who attempted suicide. The individual survived the suicide attempt and was subsequently evaluated during a forensic medical examination. Based on the information provided, please predict the most likely method used in the suicide attempt. Please respond in free-text format without any additional explanations or justifications.
An illustrative anonymized case provided was: A 24-year-old female with a primary psychiatric diagnosis of depression. She had no history of inpatient psychiatric treatment but reported prior use of psychiatric medications. She had no previous suicide attempts. The current suicide attempt was characterized as impulsive, and she was evaluated while being conscious.
Each case was manually entered into a newly initialized, memory-isolated session for each model to prevent memory contamination and ensure model independence.
Evaluated large language models
The following LLM platforms were evaluated: ChatGPT-4o (OpenAI), ChatGPT-4o Mini (OpenAI), ChatGPT-O3 (OpenAI), Gemini 2.0 Flash (Google DeepMind), Gemini 2.5 Pro (Google DeepMind), Gemini 2.5 Flash (Google DeepMind). Claude 3.7 Sonnet (Anthropic) was also tested but was excluded from performance analyses as it declined to generate predictions related to suicide methods due to embedded ethical safeguards. All models were tested between 22 May and 24 May 2025 and retested exactly 1 month later between 22 June and 24 June 2025, using identical prompts and input conditions at both time points to isolate temporal variation in model performance.
Prediction categorization and inter-rater coding protocol
All model-generated predictions were initially recorded in free-text format without predefined answer choices. Subsequently, each prediction was independently reviewed by two forensic medicine physicians blinded to the model identity. Responses were mapped to standardized categories: medication overdose, cutting, hanging, jumping, medication overdose combined with cutting, or other. Predictions containing synonymous, ambiguous, or related terminology (e.g., “drug ingestion,” “pill overdose,” “taking medications” for medication overdose; “self-harm,” “wound infliction” for cutting) were uniformly categorized under the appropriate class based on consensus. Any coding discrepancies were adjudicated through a structured consensus process involving a third independent forensic medicine physician to ensure inter-rater reliability and minimize classification bias.
Temporal reproducibility assessment
To evaluate intra-model stability, each model was re-tested 1 month after the initial prediction phase using identical prompts and standardized input conditions. Responses were archived for subsequent reproducibility analysis, details of which are provided in the Statistical Analysis section. Ethical approval for this study was obtained from the institutional ethics committee.
Statistical analysis
All statistical analyses were performed using SPSS Statistics version 26.0 (IBM Corp., Armonk, NY, USA) and R version 4.2.2 (R Foundation for Statistical Computing, Vienna, Austria). A two-tailed p-value <0.05 was considered statistically significant. Descriptive statistics were used to summarize demographic, psychiatric, and clinical characteristics. Categorical variables were expressed as frequencies and percentages, while continuous variables were presented as means with standard deviations or medians with interquartile ranges, depending on normality assessed via the Shapiro-Wilk test. Associations between suicide method and independent variables were examined using chi-square or Fisher’s exact tests for categorical variables, and the Kruskal-Wallis test for non-parametric continuous variables. Multicollinearity was assessed using Variance Inflation Factors (VIF), with all values below 2.5. Due to sparse data in certain categories, suicide method was dichotomized as pharmaceutical versus non-pharmaceutical for logistic regression analysis. Odds ratios (ORs), 95% confidence intervals (CIs), and p-values were calculated, and model fit was evaluated using likelihood ratio tests and pseudo-R2 metrics. LLM predictions were evaluated by comparing model outputs with actual case outcomes. Performance was measured using accuracy, precision, recall, and F1-score. Inter-model comparisons were conducted using McNemar’s test and Cohen’s Kappa for agreement. Intra-model consistency was assessed by re-running all models 1 month later under identical conditions. Temporal stability was evaluated using Kappa statistics, agreement rates, and prediction shift counts.
Results
Descriptive findings
Demographic and psychiatric profiles of suicide attempt survivors evaluated forensically.

Detailed clinical findings, including traumatic injuries, psychotropic medication use at the time of the attempt, and gastric interventions, are provided in Supplemental Table S2.
Inferential findings
Sex was significantly associated with the suicide method (p = 0.0357), with females more likely to use drug ingestion and males sharp objects. Age showed no association (p = 0.9884). Sparse distributions prevented reliable analysis for psychiatric diagnosis, prior psychiatric hospitalization, psychiatric medication use, previous suicide attempts, impulsivity, and consciousness status. No multicollinearity was observed (all VIF <2.5). The outcome variable was dichotomized: pharmaceutical versus non-pharmaceutical methods. Binary logistic regression revealed significant associations for sex (OR = 0.0537, 95% CI: 0.0050–0.5756, p = 0.016) and traumatic findings (OR = 0.0047, 95% CI: 0.0004–0.0547, p < 0.001). Other variables were non-significant (p > 0.05). Results are summarized in Supplemental Table 3.
Overall model performance and class-specific results
Overall performance metrics of large language models in predicting suicide methods.


Comparative accuracy (%) of evaluated large language models in predicting suicide method (n = 92).
Inter-model statistical comparison and bias analysis
Pairwise model comparisons using the McNemar test (Supplemental Table 4) demonstrated that Gemini 2.5 Flash significantly outperformed all OpenAI models in suicide method prediction accuracy (p < 0.001). No significant difference was observed between Gemini 2.0 Flash and Gemini 2.5 Pro (p = 0.7905), suggesting similar performance levels between these two models.
Assessment of inter-model consistency using Cohen’s Kappa (Supplemental Table 5) revealed generally poor agreement (κ < 0.20) across most comparisons. Moderate agreement (κ = 0.489) was observed exclusively between Gemini 2.0 Flash and Gemini 2.5 Pro, reflecting a closer alignment in their prediction patterns.
Bias analysis of Gemini 2.5 Flash (Supplemental Table 6) indicated a +23.6% overprediction toward the “medication overdose” category compared to real-world distribution. This dominant-class bias was consistent across models and underscores the models’ heightened sensitivity to majority class frequencies.
The confusion matrix for Gemini 2.5 Flash (Figure 2) further illustrates that while the model correctly classified the majority of “medication overdose” cases, rare methods such as “cutting,” “jumping,” and “hanging” were consistently misclassified, exhibiting zero recall. These findings highlight a critical limitation: although LLMs achieve high overall accuracy in frequent categories, their generalizability to rare suicide methods remains substantially restricted. Confusion matrix heatmap illustrating prediction performance of Gemini 2.5 flash across different suicide method categories.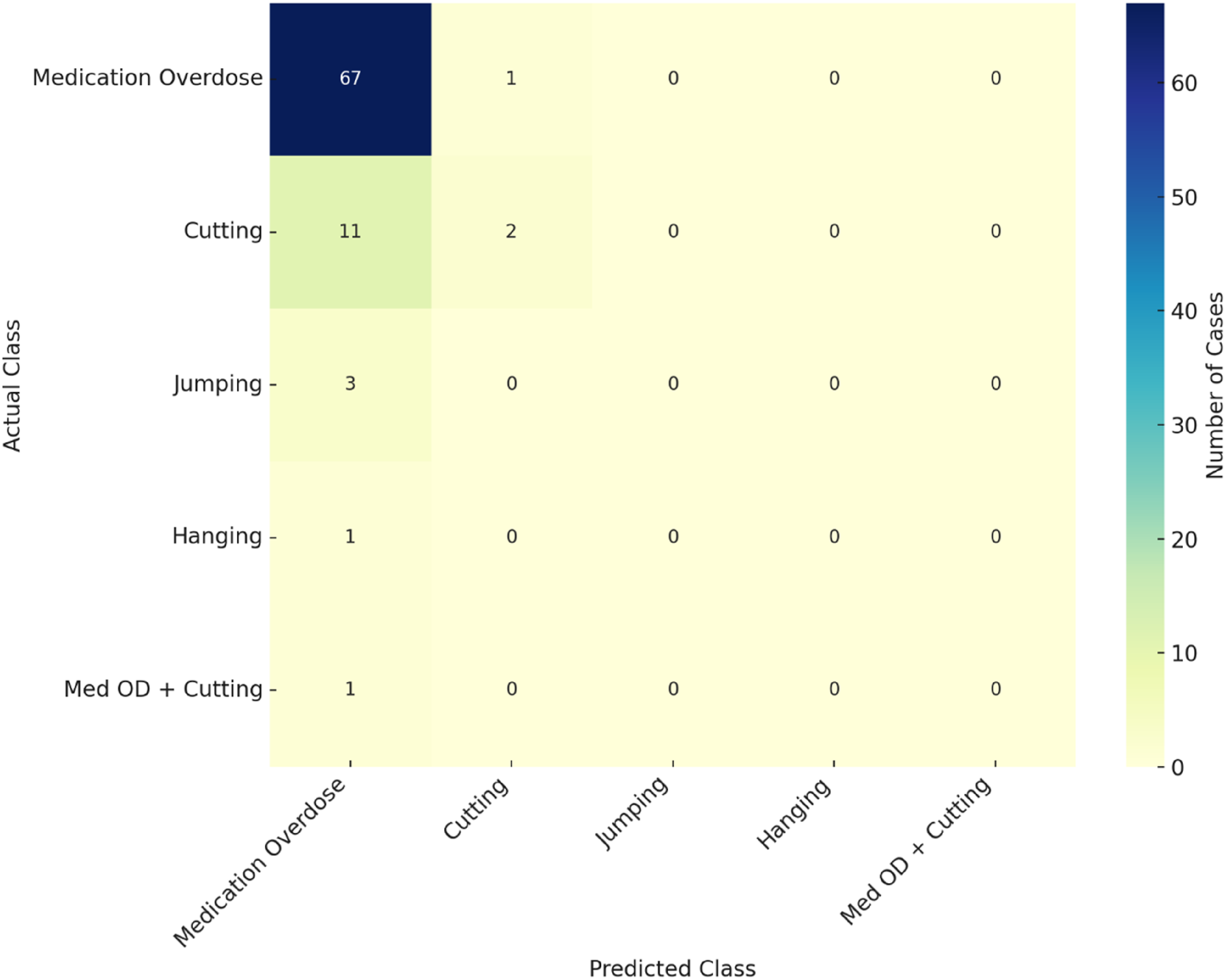
Temporal stability of large language models
The temporal reproducibility of each LLM’s predictions was assessed by re-executing all models on the same dataset 1 month after the initial evaluation under identical input conditions. Stability metrics included Cohen’s Kappa coefficients, overall agreement percentages, number of changed predictions, and class-specific shift rates. The detailed results are presented in Supplemental Table 7, and a graphical summary is provided in Figure 3. Intra-model temporal stability metrics (Cohen’s Kappa and agreement %) for large language models assessed at one-month interval.
Across all evaluated models, at least moderate temporal stability (κ > 0.41) was observed. Gemini 2.5 Flash achieved the highest reproducibility (κ = 0.582; agreement rate = 96.7%), indicating robust consistency in predictions over time. Conversely, ChatGPT-O3 and ChatGPT-4o Mini demonstrated greater variability, with over 30% of predictions altered upon retesting. Across all models, the “medication overdose” category exhibited the highest instability rates, suggesting that dominant classes remain sensitive to fluctuations under repeated evaluations. These findings highlight the critical importance of ensuring temporal reliability when considering LLM-based tools for forensic applications.
Discussion
Overall predictive performance of LLMs in suicide method inference
In our forensic psychiatric dataset, Gemini 2.5 Flash achieved 76.1% accuracy in predicting suicide method consistent with prior ML models in suicidology. A random forest trained on SHARE data distinguished suicide from accidental death with 79% accuracy, 14 while a transformer-based NLP system analyzing crisis chat data attained an AUC of 0.90. 15 Though marginally below some previous benchmarks, Gemini’s accuracy aligns with LLM performance trends. ChatGPT-4, for instance, matched clinician suicide risk assessments with 88.9% agreement, 11 and both ChatGPT-4 and Gemini Pro achieved 96.1% accuracy in identifying OCD from clinical vignettes surpassing mental health professionals. 16 These results suggest that advanced LLMs can approximate human level inference under structured psychiatric conditions. Gemini’s performance likely reflects the narrative ambiguity common in forensic records. Still, our findings confirm the viability of inferring suicide methods solely from indirect clinical and demographic features. This observation is consistent with prior studies reporting >70% accuracy using surrogate indicators.6,17 Key predictors in our model previous attempts, psychiatric illness severity, and substance use are well-established correlates of both suicide risk and method choice. 18 Moreover, NLP tools have effectively inferred cause of death from free-text records in forensic and medical settings.,19–21 validating the predictive utility of such unstructured data. Clinically, LLM-driven inference of suicide methods could potentially assist forensic psychiatrists and emergency clinicians in enhancing risk stratification, prioritizing clinical interventions, and optimizing early response strategies, especially in scenarios involving incomplete clinical histories. Importantly, these performance levels were achieved despite the fact that none of the evaluated models were specifically developed or fine-tuned for suicide-method inference, highlighting the unexpected adaptability of general-purpose LLM architectures in this context.
Comparative model performance: Gemini 2.5 flash versus other LLMs
Recent evaluations underscore pronounced architectural disparities across LLMs, directly impacting performance in inferential tasks. In neuroscience assessments, GPT-4 and Claude 3.5 achieved >81% accuracy, far exceeding Gemini 1.5 Flash (53.6%) and even medical students. 22 Similarly, GPT-4 reached 83% accuracy in historical cause-of-death classification, while Llama 2 trailed at 40%, placing Gemini 2.5 Flash’s 76.1% accuracy within a competitive range. 23 This improvement reflects architectural refinements and training optimizations. For instance, Gemini and GPT-4 surpassed earlier models in psychiatric reasoning and risk assessments. ChatGPT-4 aligned closely with clinician judgments in suicide evaluations, unlike ChatGPT-3.5, which underestimated risk. 11 Gemini also outperformed ChatGPT-3.5 in real-world veteran risk stratification, 24 while GPT-4 showed diagnostic superiority in licensing exams. 25 Gemini Ultra further excelled in factual accuracy, generating correct references in 77.2% of cases versus GPT-4’s 54.0%. 26 On visual diagnostic tasks, GPT-4 Vision outperformed Gemini Pro (67.8% vs 46.5%), confirming persistent model hierarchy. 27 Taken together, Gemini 2.5 Flash’s performance in our forensic-text task likely stems from such architectural gains. Its accuracy aligns with broader findings: newer LLMs consistently outperform earlier versions in complex classification settings, including ICD-10 coding. 23 These results affirm Gemini 2.5’s capacity for nuanced forensic inference even without direct semantic indicators.
Limitations in detecting rare or uncommon suicide methods
LLMs failed to detect rare suicide methods such as suffocation or corrosive ingestion yielding zero recall, a consequence of dominant-class bias stemming from severe class imbalance. 28 These low-frequency but high-lethality methods, including plastic-bag asphyxiation and toxic gas inhalation, were reported in only two instances each in a 21-case complex suicide series. 29 Sparse representation during training predisposes models to overpredict common categories like overdose or hanging, mirroring prior findings. 28 Such bias poses critical challenges in forensic inference, particularly with emerging or complex patterns. Charcoal-burning suicides 30 and multi-method cases, 31 while rare (1.5–5% of suicides), often fall outside model decision boundaries, leading to omission or misclassification. This undermines both preventive and postmortem assessments. Moreover, naïve mitigation techniques like SMOTE frequently degrade model calibration without improving minority-class detection. 32 These persistent misclassifications likely reflect structural data limitations rather than model flaws. Effective countermeasures may require synthetic augmentation, cost-sensitive learning, or few-shot training to enhance representation of infrequent suicide methods and promote equitable forensic predictions. Such misclassification may have meaningful clinical and forensic consequences, as failure to recognize a high-lethality method could lead to systematic underestimation of acute suicide risk and, consequently, insufficient escalation of monitoring, intervention intensity, or safety planning in real-world settings.
Temporal stability of LLM predictions
We assessed the temporal stability of Gemini 2.5 Flash’s predictions to evaluate its reliability over time. Despite the risk of concept drift, where model performance degrades due to evolving data distributions, only minimal accuracy fluctuations were observed across temporal subsets, suggesting linguistic stability in forensic suicide narratives. 33 This contrasts with dynamic fields like oncology and supports the feasibility of longitudinal LLM deployment in forensic contexts. Although few studies have examined long-term model stability in suicidology, Rus Prelog et al. demonstrated persistent predictive accuracy across cohorts over multiple years. 34 Conversely, Bodroža et al. reported temporal inconsistency in GPT models on personality assessments, highlighting that LLM stability cannot be assumed universally. 35 Our findings confirm high test–retest reliability within the same forensic dataset, affirming the robustness of domain-specific LLMs. However, even minor drifts may cumulatively degrade performance. Periodic validation and retraining should be implemented to preserve forensic admissibility and predictive reliability in legal and clinical applications.
Class imbalance effects and dominant class bias
Our dataset exhibited marked class imbalance, with medication overdose disproportionately represented. This skew inflated overall accuracy by favoring the majority class, while systematically underdetecting rare but lethal methods. Standard corrections such as oversampling and class weighting, often used to address such imbalance, proved ineffective, frequently impairing calibration and reducing generalizability. 32 Given the forensic implications, neglecting infrequent methods can distort both risk stratification and legal judgments. 18 In one case, a model reached 86% overall accuracy but yielded an F1-score just above 0.30 for the minority class, reflecting imbalance-induced bias. 28 Recent evidence suggests that ensemble-based approaches, such as iterative majority-voting, may improve classification robustness and balance, especially in psychiatric applications. 36 To ensure equitable and reliable forensic predictions, future models must incorporate advanced strategies like cost-sensitive learning or tailored ensemble modeling. This imbalance not only inflates overall accuracy but also obscures systematic failures in minority-class recognition, underscoring the need for rigorous evaluation frameworks that specifically quantify the forensic impact of rare-method misclassification.
Limitations
Several methodological constraints must be acknowledged regarding this study. The relatively modest sample size combined with its single-center design inherently restricts the external generalizability of findings, limiting their applicability across diverse forensic populations with varying demographic and clinical profiles. Moreover, the study’s reliance exclusively upon indirect psychiatric and demographic indicators, without integrating richer multimodal clinical or biological data streams, likely constrained the depth of inferential resolution and predictive accuracy of the evaluated LLMs. Although temporal reproducibility was systematically assessed, the absence of external validation involving independent forensic cohorts further limits the potential extrapolation of these findings to broader medico-legal contexts, thereby impacting their forensic admissibility and practical applicability.
Future directions
Future research endeavors should emphasize rigorous validation of LLM-based suicide method prediction models across multicentric and jurisdictionally diverse forensic cohorts, thereby enhancing external generalizability and broader forensic utility. Prioritizing the incorporation of multimodal clinical data including narrative clinical reports, detailed toxicological profiles, and relevant biological markers may substantially augment predictive precision, particularly for identifying uncommon or complex suicide methods frequently encountered within forensic practice. Additionally, methodologically robust exploration of fine-tuning techniques, advanced minority-class balancing strategies, and synthetic data augmentation approaches is critical to mitigate biases associated with class imbalance and to promote equitable predictive accuracy. Longitudinal studies and ongoing model performance reassessments must also be prioritized to confirm temporal stability and sustained reliability, essential prerequisites for clinical integration and forensic admissibility. Future research should incorporate methodological strategies specifically designed to counteract class imbalance, including cost-sensitive learning, minority-class augmentation, domain-adapted fine-tuning, and ensemble-based decision frameworks, all of which may meaningfully improve rare-method detection and enhance the forensic reliability of LLM-based inference systems.
Conclusion
This study provides a real-world empirical evaluation of Large Language Models (LLMs) for predicting suicide methods based exclusively on indirect forensic psychiatric indicators. While the Gemini 2.5 Flash model demonstrated the highest predictive accuracy (76.09%) among evaluated systems, critical limitations persist across all LLMs, including deficient detection of rare suicide methods, limited inter-model concordance, and moderate temporal stability. These findings emphasize the urgent need for systematic external validation, methodological innovations addressing class imbalance, and the development of rigorous forensic admissibility standards. Moving forward, the integration of artificial intelligence technologies into forensic psychiatry must be grounded in stringent methodological rigor, sustained longitudinal validation, and transparent interpretability, with ethical oversight at every stage. Ensuring human supervision remains indispensable, reinforcing the role of LLMs as supportive, adjunctive tools rather than replacements for expert forensic psychiatric judgment. Responsible adoption of LLMs requires a framework that prioritizes accuracy, fairness, and ethical accountability, safeguarding the integrity of both clinical practice and judicial processes. However, the persistent misclassification of rare suicide methods represents a critical limitation that must be addressed before these models can be safely integrated into clinical or forensic workflows.
Supplemental Material
Suppplemental Material - Inferential performance and temporal stability of large language models in suicide method prediction: A forensic psychiatric analysis
Suppplemental Material for Inferential performance and temporal stability of large language models in suicide method prediction: A forensic psychiatric analysis by Halit Canberk Aydogan, Hacer Yaşar Teke, Muhammet Sevi̇ndi̇k, Zeynep Unat Öztürk in Health Informatics Journal
Footnotes
Acknowledgments
Preliminary findings from this study were previously presented as an oral presentation titled “Determinants of Suicide Method Selection: Gender, Psychiatric Diagnosis, and Risk Assessment” at the 5th International and 21st National Forensic Sciences Congress, held in Antalya, Türkiye, on April 10–13, 2025. The authors utilized ChatGPT-4o, a large language model (March 2025 Version; OpenAI; ![]() ), to revise the grammar and English translation. The content of this publication is entirely the responsibility of the authors, who have reviewed and edited it as necessary.
), to revise the grammar and English translation. The content of this publication is entirely the responsibility of the authors, who have reviewed and edited it as necessary.
Ethical considerations
Approved by the Ordu University Non-Interventional Scientific Research Ethics Committee, Türkiye (Decision No. 2025/142; Meeting 08; Date 25 April 2025). Written informed consent was not obtained because the Committee formally waived the requirement in view of the study’s retrospective design, the exclusive use of fully de-identified medico-legal records, and the absence of any direct contact or intervention. All procedures adhered to the Declaration of Helsinki and applicable data-protection regulations.
Author contributions
HCA, HYT and MS was responsible for conceptualization, methodology, formal analysis, and writing original draft and review & editing. HYT, MS, HCA and ZUÖ contributed to supervision, validation, writing review and editing. ZUÖ, HCA and MS contributed to data curation and investigation. All authors have read and approved the final version submitted and take public responsibility for all aspects of the work.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data used in this study are derived from confidential forensic psychiatric case files and cannot be made publicly available due to national data protection laws and ethical restrictions. Access was granted under institutional ethics committee approval solely for the purposes of this research.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.