
Abstract
Background
AI tools are becoming primary information sources for patients with chronic kidney disease (CKD). However, as AI sometimes generates factual or inaccurate information, the reliability of information must be assessed.
Methods
This study assessed the AI-generated responses to frequently asked questions on CKD. We entered Japanese prompts with top CKD-related keywords into ChatGPT, Copilot, and Gemini. The Quality Analysis of Medical Artificial Intelligence (QAMAI) tool was used to evaluate the reliability of the information.
Results
We included 207 AI responses from 23 prompts. The AI tools generated reliable information, with a median QAMAI score of 23 (interquartile range: 7) out of 30. However, information accuracy and resource availability varied (median (IQR): ChatGPT versus Copilot versus Gemini = 18 (2) versus 25 (3) versus 24 (5), p < 0.01). Among AI tools, ChatGPT provided the least accurate information and did not provide any resources.
Conclusion
The quality of AI responses on CKD was generally acceptable. While most information provided was reliable and comprehensive, some information lacked accuracy and references.
Introduction
Chronic kidney disease (CKD), defined by KDIGO 2024 guidelines as abnormalities of kidney structure or function present for a minimum of 3 months [1], is a serious health problem worldwide. A systematic analysis as of 2017 found 697.5 million cases of all-stage CKD, for a global prevalence of 9.1%. 1 As CKD progresses, it considerably impairs the patient’s quality of life and causes economic problems due to high medical costs. 2 Self-management by patients themselves from the early stages of diagnosis is essential for preventing the progression of CKD, and information that can support patients’ health behaviors needs to be provided in a tailored and continuous manner.
Since OpenAI released ChatGPT, the first artificial intelligence (AI) chatbot based on large language models (LLMs), in November 2022, AI has been applied in various fields. In healthcare, AI provides highly personalized information for patients and the general public, bridging the knowledge gap between patients and healthcare professionals. This is no exception in the area of CKD, and AI can be a crucial information source and a consultant for patients with CKD.
However, AI may create an illusion of intelligence, so-called hallucination.
3
Hallucination is a phenomenon in which AI produces incorrect information. This phenomenon occurs when there are discrepancies in the given data when using a large training dataset, or when the prompts are ambiguous or inductive4,5
The objective of the study is to determine the reliability of AI-generated patient information about CKD and its potential to be applied to patient education. Therefore, we pose the following research questions as follows:
How reliable is the AI-generated patient information about CKD?
Which elements show challenges in the reliability of AI-generated patient information about CKD?
Which AI platform can generate the most reliable patient information about CKD?
Materials and methods
This is a cross-sectional study that quantitatively analyzed the responses generated by AI tools. This study was exempted from approval by the Research Ethics Committee as the materials were available to the public and did not include patient records or personal information.
Data collection
This study included responses from the top three AI chatbots by market share as of August 2024: ChatGPT -4o mini, Microsoft Copilot, and Gemini. 10 In every AI chatbot we used a version that is available online for free without the need to register for an account. We selected keywords that patients with CKD would frequently use. We used Google Trend to identify the most frequently searched keywords related to CKD in the year from July 22, 2023. We excluded the following keywords: (1) overlapping keywords (e.g., “chronic kidney disease CKD”), (2) unrelated keywords (e.g., “chronic kidney disease cat”), (3) keywords that sound unnatural when entered as prompts (e.g., “Can you tell me about ‘chronic kidney disease about’”), and (4) keywords for healthcare professionals (e.g., “chronic kidney disease nursing”). From July 27 to 29, we entered the prompt “Tell me about [keyword]” for each AI tool. The same prompt was entered three times to allow for possible fluctuations in the AI tools’ responses to the same questions, and all responses were exported to Word (Microsoft Inc.) each time. We did not provide specialized medical training to the AI tools used in this study to generate medical information. Instead, reflecting the typical usage patterns observed among patients and the general public, we employed simple, keyword-based prompts without additional context or guidance. The input history was cleared before entering the following prompt.
Evaluation methods
Previous studies have reported that AI-generated information is not accurate,8,9 and there is a high risk of misinformation if AI answers are provided as is to patients and the general public. Therefore, it is necessary to confirm that the generated information is medically accurate. In this study, we used the Quality Analysis of Medical Artificial Intelligence (QAMAI) tool 11 to analyze the reliability of the responses generated by AI tools. The DISCERN criteria, on which this indicator is based, were developed in 1999 by the University of Oxford research team to evaluate the quality and reliability of content related to consumer health information on treatment options. 12 The mDISCERN tool was modified by Singh et al. 13 and is based on a five-point Likert scale that examines goals, reliability of information sources, bias, areas of uncertainty, and additional sources. In 2024, Vaira et al. developed the QAMAI criteria, consisting of the following six elements—accuracy, clarity, relevance, completeness, provision of sources and references, and usefulness—to adapt mDISCERN for evaluating AI-generated health information. 11 Each of these six items was rated on a five-point scale, with scores ranging from 6 to 30 (Supplemental Table 1). The threshold for each item was set at four points or higher. The tool has been validated for structural validity, internal consistency, inter-rater reliability, and retest reliability. To evaluate accuracy and clarity, we used international guidelines 14 and standards of good clinical practice as references.
Statistical analysis
Descriptive statistics were used to summarize the characteristics of the AI responses and QAMAI scores. To compare scores between AI tools, the Kruskall-Wallis test was performed as a multiple comparison of nonparametric data. The chi-square test was used for multiple comparisons of binary data. Since the QAMAI tool is a subjective measure, two board-certified internal medicine specialists evaluated one-fifth of the AI responses independently. Intraclass correlation (ICC) was calculated to examine inter-rater reliability. ICC >0.75 or higher was determined to have good reliability. All statistical analyses were conducted using R (version 4.4.0; 2024-04-24). P < 0.05 was considered statistically significant.
Results
List of questions provided to the AI tools.
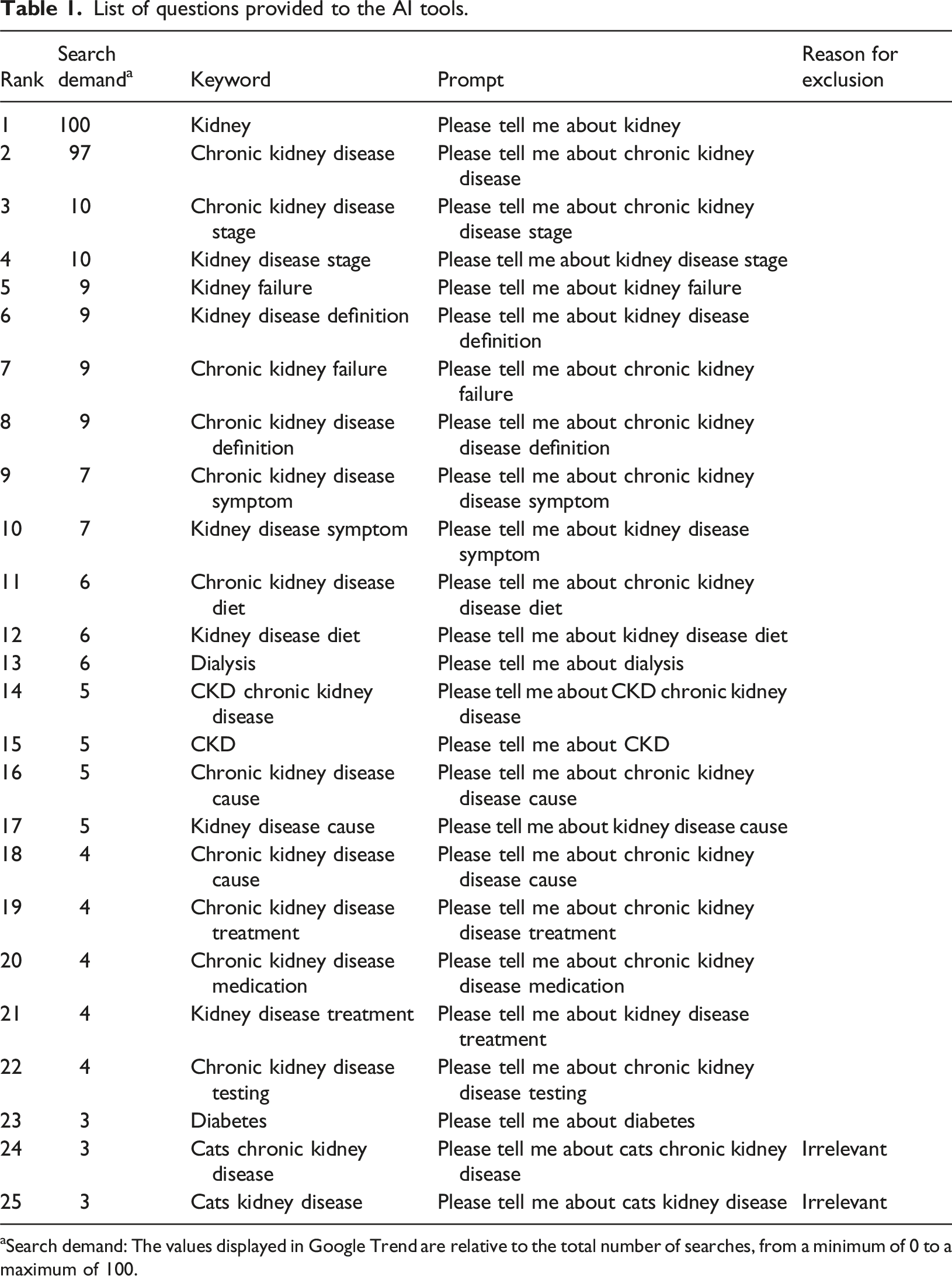
aSearch demand: The values displayed in Google Trend are relative to the total number of searches, from a minimum of 0 to a maximum of 100.
Issues regarding the quality of AI-generated responses
For each domain of the QAMAI tool, the median (IQR) values for accuracy, clarity, relevance, completeness, provision of sources and references, and usability were 4(2), 4(1), 4 (1), 4(1), 3(4), and 4 (1), respectively. The AI responses that met the item criteria (≥4 points) were 122 (58.9%), 118 (57.0%), 197 (95.2%), 152 (73.4%), 100 (48.3%), and 105 (50.7%), respectively. Provision of sources and references, which had the lowest median score among the items, the score distribution varied. Although 129 (62.3%) AI responses provided reliable information sources created by medical institutions or government agencies, 4 (1.9%) had invalid URLs, and 9 (4.3%) provided the name of a website but no URL. In addition, 5 (2.4%) presented only the URL of the top page, making it difficult for patients to access information about CKD.
Comparison of response quality among AI tools
Among the AI tools, Copilot exhibited the highest level of quality (median (IQR) of QAMAI score: ChatGPT versus Copilot versus Gemini = 18 (2) versus 25 (3) versus 24 (5), p < 0.01(Kruskall-Wallis test) (Figure 1). Table 2 shows the percentage of responses that met the criteria for each of the QAMAI tool items for each AI tool. For accuracy, none of the ChatGPT responses satisfied the requirements. In particular, three (4.3%) of the ChatGPT responses about CKD medications included references to fictitious drug names, and one response provided a false statement of the drug’s mechanism (e.g., spironolactone is used to promote the excretion of potassium). For the provision of sources and references, none of the ChatGPT responses provided references, while 67 (97.1%) and 33 (47.8%) of the Copilot and Gemini responses offered reliable references, respectively. However, two of the Copilot responses provided links to specific dietary supplements with a lack of clinical evidence in the description of CKD treatment. Relevance was the only item for which there was no apparent difference in the percentage of documents that met the criteria between the AI tools (ChatGPT vs Copilot vs Gemini = 95.7% vs 97.1% vs 92.8%, p = 0.61 (chi-square test)). Details of QAMAI score distribution. Number of responses that met the threshold for each QAMAI tool item for each AI tool. Chi-square test.

Discussion
This study showed that the AI tool returned good-quality responses to common patient questions about CKD. In particular, the AI responses satisfied the questions’ relevance and completeness. The variation in the quality of answers within the same AI tool was small, indicating a stable generation of quality medical information for patients. However, there were significant differences in performance among the AI tools. ChatGPT, which has the largest number of users, had the lowest QAMAI score among the three tools, especially in terms of accuracy of information and presentation of resources. Even in Copilot and Gemini, which returned higher quality responses than ChatGPT, some areas were not user-friendly, such as incomplete resource presentation in some cases.
Our findings are consistent with those of previous studies, which showed AI-generated responses were mostly appropriate.9,15–17 When comparing the quality of responses by AI tools in 2023 to 24, prior research has shown that the quality of responses varied depending on the AI tool. Some earlier studies found ChatGPT was more accurate than the other AI tools, including Bing AI and Google Bard, which were the predecessors of Copilot and Gemini, respectively.
18
However, more recent studies focusing on urological health information in 2024 reported that responses generated by ChatGPT were more difficult to read and understand compared to those produced by other tools19,20
This study is the first to test the reliability of AI-generated information in the field of CKD. The results of this study can provide a better understanding of the LLMs for frequently asked questions about CKD and provide suggestions for future development and updating of AI tools. For healthcare professionals involved in patient education, the results offer recommendations on what to remember when disseminating AI-generated CKD medical information to patients. Healthcare professionals must be aware that their patients are at risk of being exposed to misinformation more than ever through AI tools. Academic organizations and medical institutions have traditionally produced education materials that simplified evidence-based clinical guidelines for use by patients and the general public. Professional organizations should incorporate these materials with guidance on the risks of misinformation that the patient public is likely to face and how to confront information provided by AI.
This study has several limitations. First, this study has limitations in comprehensiveness. Since AI tools generate customized responses for each user, this study could not cover the information presented to all users. In addition, while users may further explore their questions based on AI responses, this study did not include follow-up questions. Second, our study evaluated responses from the generative AI as of July 2024; AI tools may be updated over time, which could alter their performance and the validity of current survey results. Additionally, since this research focused exclusively on text-based medical information, generative AI tools for images or videos were beyond the scope of our evaluation. Nonetheless, we recognize that audiovisual formats (e.g., videos, podcasts) are gaining popularity in patient education. Future studies may benefit from exploring a broader range of AI modalities to accommodate these evolving trends. Furthermore, although the QAMAI tool was verified for reliability and validity, it is unclear whether it is applicable in the Japanese healthcare context since we have directly adapted the original English version. Further research will be needed to develop and validate the Japanese version of the QAMAI tool.
Conclusion
This study demonstrated that AI responses to frequently asked questions about CKD were of acceptable quality. They provided mostly reliable and complete information; however, a few AI responses posed critical misinformation. Moreover, some of the responses lacked references, such as specific URLs, making it difficult for patients to access detailed information. As maintaining reliable information is crucial to safeguarding laypeople from potential harm, healthcare professionals should be aware of the quality of AI-generated medical information.
Supplemental Material
Supplemental Material - Reliability of AI-generated responses on frequently-posed questions by patients with chronic kidney disease
Supplemental Material for Reliability of AI-generated responses on frequently-posed questions by patients with chronic kidney disease by Emi Furukawa, Tsuyoshi Okuhara, Hiroko Okada, Yuriko Nishiie, Takahiro Kiuchi in Health Informatics Journal
Footnotes
Acknowledgments
We thank Dr Luigi Angelo Vaira of University of Sassari, for sharing the material on coding the QAMAI tool.
Ethical considerations
This study was exempted from approval by the Research Ethics Committee of the University of Tokyo Graduate School of Medicine and Faculty of Medicine as the materials were available to the public and did not include patient records or personal information.
Author contributions
EF designed the study, the main conceptual ideas, and the proof outline. EF and YN collected and analyzed the data. EF and YN analyzed and interpreted the results and drafted the manuscript. EF, TO, and HO aided in interpreting the results and worked on the manuscript. TK supervised the project.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Grants-in-Aid for Scientific Research (KAKEN) [grant number 24K23676].
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author, Emi Furukawa, upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.