
Abstract
Keywords
Introduction
The internet has become a vital resource for accessing medical information in Germany, 1 with a significant portion of the population relying on online sources for health-related knowledge. However, this trend also brings to light prevalent problems associated with medical information online, including inaccuracies, lack of internet literacy, and misinformation.2–4 Moreover, the origin and motivation of available health information vary in quality and trustworthiness, with advertisements often mixed into crucial information on websites.
Approximately 70% of the German population actively engages in searching for health-related content online, and the trend is rising. 5 However, users often lament the lack of clarity regarding the trustworthiness of existing websites. Despite this surge in internet usage for health inquiries, the quality of health information online varies widely,6,7 leading users to perceive frequently visited and popular websites as reliable, regardless of actual content quality.8–12 Moreover, reliance on digital platforms for health information poses a significant challenge due to the substantial influence of search engine results. Users tend to rely on the first few search results displayed on the search engine result page, often advertisements, perceiving them as more trustworthy despite potential variations in information quality.8,11,13 Low health literacy and digital health literacy among the German population exacerbate these challenges.14–16 With up to 45% of the German population exhibiting problematic or inadequate internet skills, many individuals face navigational needs, relying on support to efficiently search and evaluate health information online, which, coupled with the growing amount of digital health information, raises concerns about misinformation and health-related misconceptions.17,18
In response to these challenges, the tala-med search engine was developed to offer users a safer alternative. It features a search index built from curated sources, verified by medical professionals, and free of advertisements. 19 Based on the knowledge gained in a related project, 20 criteria to assess web domains according to these needs were developed. Each domain was evaluated by experts accordingly based on random samples, estimating its quality in the four categories trustworthiness, recency, user-friendliness and comprehensibility. The interface provided users with the option of filtering their search results by four quality indicators to ensure transparency and provide the user with more power over their search results. 19 Specht et al. 19 performed an evaluation of the tala-med search, reporting a positive reception of the new independent, non-commercial medical search engine among initial users highlighting its role in enhancing the accessibility of reliable and evidence-based medical information on the internet, underscoring the imperative need for high-quality search results and addressing users’ navigational needs to promote health literacy and empower individuals to make informed health decisions. Throughout both the study period and the ongoing operation of the tala-med search engine, certain technical constraints concerning flexibility were identified.
The search engine was originally developed using open source tools and systems while Elastic’s AppSearch platform provided the main search functionality. The user-facing website was built with React 21 and material UI 22 and hosted with nginx. 23 This website then used the API provided by AppSearch for querying the search index, including filtering by the quality indicators, and retrieving search query suggestions.
The key issue with the existing tala-med search engine was the dependence on AppSearch 7.16 as a monolithic and proprietary search backend preventing core customizations. Therefore, the goal of the present work was to replace this monolithic architecture with a more flexible and customizable software stack inspired by Scheible et al., 24 steering towards a modular single-responsibility principle 25 using microservices and being database-centric. Our new implementation was designed to closely replicate the original functionality while improving performance in terms of query processing speed, as demonstrated through controlled evaluation.
This study is primarily a system development and evaluation project focused on addressing the technical limitations of the original system. It involves two major components: (1) System design and implementation, emphasizing modularity and maintainability by integrating advanced tools like Elasticsearch and subZero to enhance flexibility and extensibility; and (2) performance and similarity evaluation, which assessed the system through predefined query sets to ensure it produced results similar to the legacy system in terms of content and ranking, while also demonstrating improved query processing speed.
The study further demonstrates the extensibility of the new architecture through the integration of a fastText 26 model for synonym detection and the inclusion of an administrative interface to support day-to-day operations. While direct user evaluation was not conducted, the design and evaluation approximated real-world usage scenarios, providing a foundation for future user-based studies or A/B testing to validate and refine the system. The software components developed as part of this study are available under MIT.
Materials and methods
Architecture
In order to re-engineer the existing tala-med search engine, a new architecture was devised. The website was rebuilt and integrated with the new administrative interface powered by subZero,
27
featuring a refined filtering UI that enables users to customize their search more effectively. SubZero is a framework to create administrative tools by automatically generating a REST API with a web console from the database schema. At the core of the new architecture an API was built with ExpressJS
28
using Typescript
29
and running on Node.js.
30
This server was used to combine all components together, from integrating subZero for an authenticated admin interface to supply the frontend with configuration and search endpoints. To perform all those operations the API communicated with multiple secondary backend components, most importantly the Postgres database
31
which in turn was connected to an Elasticsearch (ES) cluster to facilitate full-text search queries. The API was also connected to a fastText
26
server to extract synonyms from a query to improve the relevance of the results. The data flow and interaction between these components are illustrated in Figure 1. The diagram shows how user queries are processed, starting from the frontend user interface, through the backend API, to the database, Elasticsearch cluster, and synonym server, before the ranked results are returned to the frontend. All components were dockerized for simple deployment and maintenance. Subsequent sections detail these components from the database layer to the web-frontend. Block diagram of the tala-med search engine architecture. The user initiates a query from the frontend user interface, which sends the query to the backend API (ExpressJS). The API processes the query by interacting with the database (Postgres + ZomboDB), Elasticsearch cluster, and fastText synonym server to retrieve relevant data. The system then filters and ranks the results before delivering them back to the user via the frontend interface. The modular backend architecture ensures scalability, flexibility, and efficient query processing.
ZomboDB and elasticsearch
For complex full-text search in the new search engine, we retained Elasticsearch as the backend, consistent with the legacy AppSearch. Simultaneously, we consolidated all data into a single source to simplify maintenance and enable data-layer optimizations. Consequently, we decided to store all our data, including the website index, in a Postgres database. This database was connected with an ES cluster, through the native Postgres extension ZomboDB, 32 which allows the seamless integration of ES queries into SQL queries. This approach has already demonstrated effectiveness in similar projects within the medical domain. 24 ZomboDB also facilitates field mapping and other ES functions allowing the use of advanced ES features. We used ZomboDB v3000.1.25 with Postgres 15 and ES in version 8.10.
Database layout
We opted for a central database containing the search index, aiming for a more adaptable and manageable structure compared to the legacy system. This move also enhanced the overall maintainability of our application. The database layout is shown in Figure 2. It was kept in Boyce-Codd normal form
33
and contains all application data alongside our index. The search index was stored in the documents table while the quality indicators were stored in relation to the domains table. These were separated into category and filter-value tables for additional flexibility, although the flexibility was restricted by the need to name the categories explicitly in the SQL script to build the required materialised views used during processing. The documents table was extended with a ZomboDB index to allow for ES queries to operate on this data as well as to configure custom field analyzers like stemming and autocomplete. Database schema; From left to right, main data, application configuration, views for import and domain-filter data for search and last the synonym table.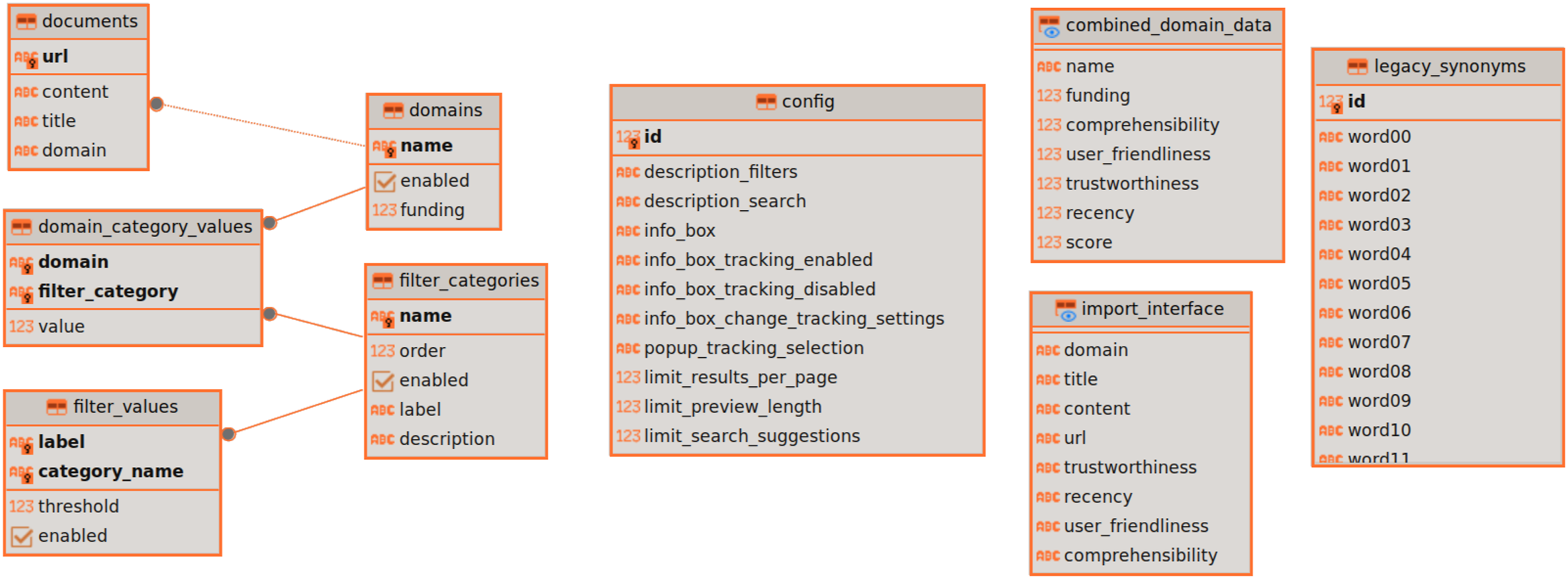
Backend API
As highlighted in the architecture diagram (see Figure 3), the key element used to merge all these different software systems was the API built using an ExpressJS server, handling four main aspects: the serving of the static website files, the search query API, the configuration retrieval endpoints and the endpoints for the admin interface powered by subZero. Search engine architecture.
The API server’s primary function was to search through the documents, facilitated by a unified API endpoint. This endpoint managed search queries, pagination, and filtering, and toggles between legacy and fastText synonym handling. It constructed the final SQL query, which replicated the search equation used in the legacy AppSearch system (see Multimedia Appendix 1 in Specht et al. 19 ) by incorporating full-text search and domain quality indicator values. A full-text ES search was constructed based extracted ES queries generated by AppSearch in the legacy system. This ES query combined the user query with any synonyms using a logical OR and a down boost of 0.75. Additionally, it considered the content-field with a stemming filter at a slightly lower factor. This implementation reflected the behavior and field generation of AppSearch but omited irrelevant ones like ”prefix” while including the stemming field, which was utilized in phrase and fuzzy queries. 34 Following the ES search, results were matched with domains and their quality indicators. These informed filtering and contributed to the document score, finalizing document ordering. Pagination was implemented using SQL limit and offset functions. In addition to the search endpoint, the API offered endpoints for the frontend website to access static configuration through public endpoints. This included filter categories and dynamic UI fields like help texts. Moreover, the API offered an endpoint for auto-complete functionality in the search field, utilizing Elasticsearch’s suggester in completion mode on the title-field, chosen for its dense information and suitability for potential search queries. As part of the modernization, an admin interface was added using subZero. It offers authenticated endpoints, login functionality, and a web interface for CRUD operations to manage application data and the index.
Synonym implementations
Legacy synonyms
Firstly, the synonym-set approach of AppSearch was reverse-engineered and reimplemented in the new system. In the present implementation, it is based on a predetermined set of 500 synonym relations each containing up to 32 synonyms, so-called synonym-sets. These relations were rebuilt in the new system using a simple Postgres table and an ES index on top of that to efficiently search for matches based on an input string. In this implementation, the lookup was done by using an ORed query with all words of the search query and a limit of the result number on the number of words in the query. After finding all matching synonyms, they were added to a secondary query which was ORed into the main query at a down boost.
FastText synonyms
In addition to the rebuild of the legacy system, a new synonym system was implemented to showcase the new flexibility gained by using our new architecture. Instead of extracting synonyms based on predefined synonym-sets or relations, we decided on using a combination of POS tagging and a fastText
26
powered k-nearest-neighbour (kNN) search to extract relevant synonyms from the search queries. To facilitate integration of this with our backend API server, a FastAPI-powered REST server was constructed. Figure 4 shows the architecture of this server, which performed the necessary steps and provided configurable access to the optional POS-tagging and amount of generated synonyms (k). Two fastText models were trained unsupervised on the German medical Wikipedia category exported on 8.1.2024 alongside a truecaser based on the pypi package truecase
35
which was inspired by tRuEcasIng.
36
One model was trained with uncased data while the second one used the original cased data. Generally, Wikipedia has relatively good grammar
37
which suggests that the casing of the training data should be of good quality. During inference, the truecaser was used in tandem with the cased fastText model to improve the relevance of the kNN search. The cased fastText model was used as default for the kNN search, which searched synonyms for the nouns in the search query. The Part-of-Speech (POS) tagging system of stanza
38
was used to target the fastText-kNN search only to relevant words (see Figure 3). FastText server components and data flow between them, as queried by the main API. The data flow shows the generation of k synonyms which is parameter-configurable.
Search query processing
The search functionality builds upon the equation introduced in Multimedia Appendix 1 in Specht et al.,
19
incorporating synonym handling by expanding the query Q into Q*, where:

The scoring function is based on the Okapi BM25 formula:


To incorporate field-specific weights and quality constraints, the weighted scoring function is defined as:
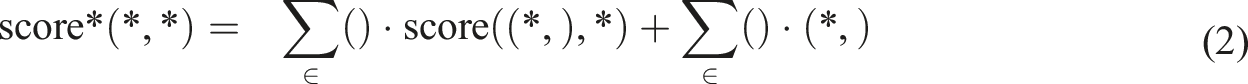

This approach combines the probabilistic relevance framework of BM25 with field-specific and constraint-based weighting, tailored for medical information retrieval.
Evaluation
Performance
To measure the performance of our system we created two sets of example queries. The first set consisted of 98 unique (compound-) words created from Google’s top & rising searches in the topic of medicine (Dec. 2023), the top 25 search queries used in a previous study of the tala-med search engine (see Multimedia Appendix 5 in Specht et al. 19 ) and a curated set of ChatGPT generated search queries. For the second set, the same list was used as a base and transformed into full-sentence queries. This was done manually and by generating and curating queries with ChatGPT in order to test the systems’ behavior on sentence queries. These two sets were then used to query the systems repeatedly. To ensure reproducibility of the ordering of the search requests, the evaluation runs were performed in a single thread on a separate machine. After an additional 10% warm-up phase, the results were gathered and averaged over 10 runs. Both sets were run independently in sequence on a virtual machine with four cores and 16 GB of RAM. Between different runs the machine was restarted to ensure a consistent clean state. The actual processing time was isolated from the transport time and this was used as the primary metric for the analysis. Since most users focus on the first results presented by a search engine, 39 the result size of the evaluation queries was limited to 60 (20 per page). For the used queries the median number of results found by both the legacy and new system was 60 (IRQ 60-60) with an overall mean of more than 50 in all cases. This guaranteed that all test queries produced matches and exercised the full retrieval and ranking pipeline, rather than hitting cases with few or no results.
Similarity
We evaluated the search result quality using identical runs as the performance evaluation, extracting and mapping the results to their respective URLs, which acted as unique identifiers for each website. In this evaluation, we lacked a gold standard for assessing the objective quality and ranking order of search results in our search engine. Thus, our analysis compares the legacy system with the new one, measuring the similarity of their results. Similarity was measured per query based on the overlap of results present in both the legacy and the new system. Additionally, the distance between the overlapping results was computed based on their ranking position in the results returned by each system. These two metrics formed the base of analysing how close the new system was to the legacy search engine.
Results
Performance
The comparative analysis in Figure 5 illustrates performance differences between the legacy and new systems across different query scenarios. The legacy system, shown in orange, exhibited substantial increases in query processing time when synonyms were enabled, impacting both single-word and phrase queries. Although the new system was generally faster than the legacy system, there was a slight exception observed with phrase queries lacking synonyms, where the new system was marginally slower by approximately 0.05 s, equivalent to 112% of the legacy system’s runtime. Additionally, the performance of the new system varied depending on the complexity of the synonym system used. For instance, the fastText synonym system demonstrated slower performance compared to the re-implemented legacy synonym-set system. Moreover, the introduction of the truecaser also resulted in a minor increase in processing time. Furthermore, aside from the baseline runs, the new system displayed slightly less consistent processing times compared to AppSearch, particularly noticeable in single-word queries where the new system exhibited a few more outliers. However, these discrepancies were minor when considering the overall performance gap between the systems. Performance benchmark results; Legacy system in orange boxes; ”Stemming” runs are runs with only the base features enabled (baseline); ”TC” = True casing enabled. The suffix ”W” indicates word-only queries and ”P” phrase queries.
Similarity
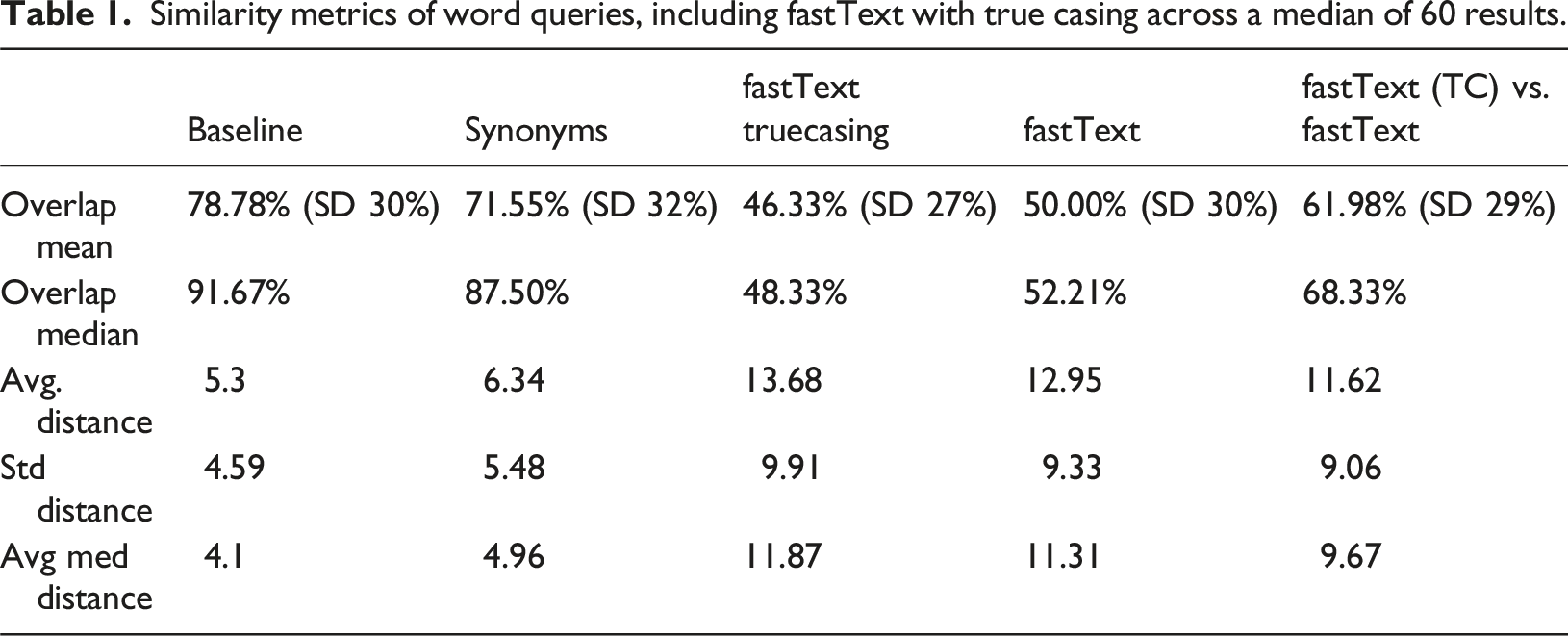
Similarity metrics of word queries, including fastText with true casing across a median of 60 results.
Similarity metrics of phrase queries, including fastText with true casing across a median of 60 results.
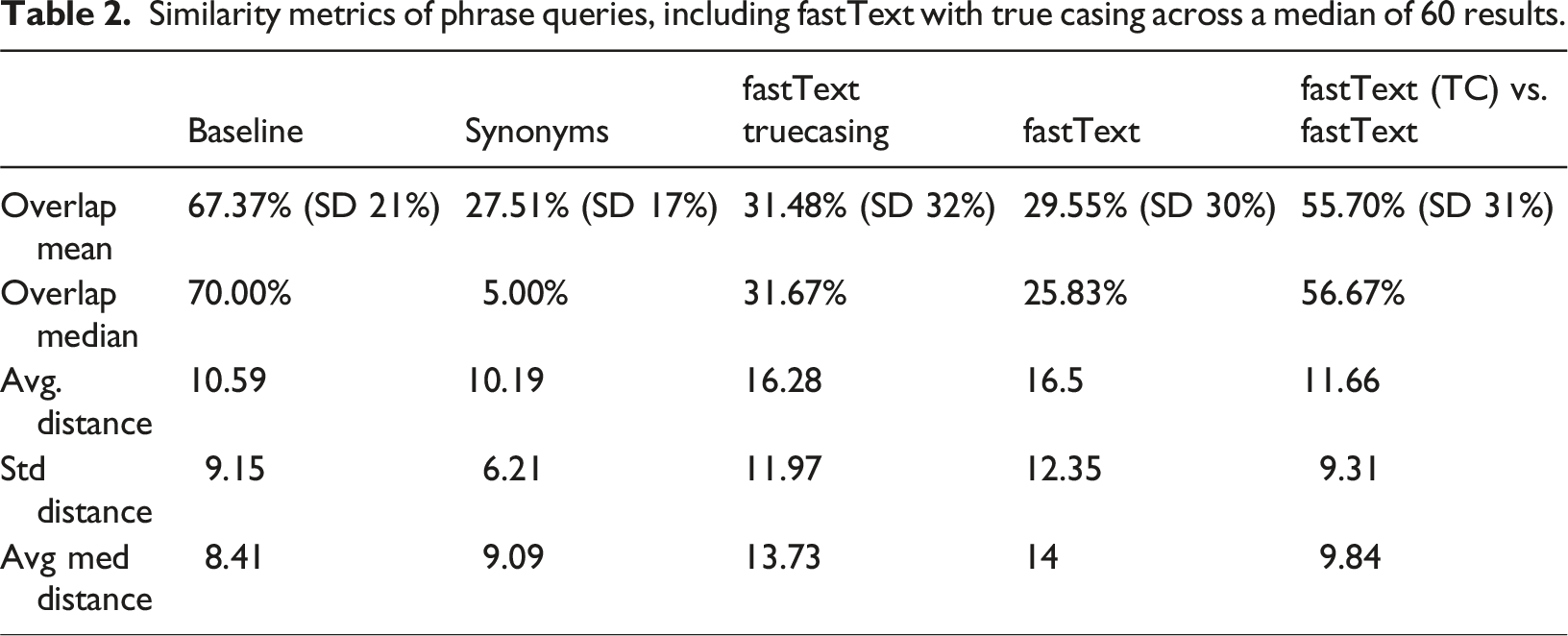
Table 2 presents the outcomes of the similarity analysis for phrase queries. In the baseline configuration, both the new and legacy systems remained closely aligned, although not as much as with single-word queries. However, the distance of overlapping results notably increased, averaging over 10. The introduction of synonym systems led to significant disparities in results, a trend that persisted with the fastText synonym systems. However, the fastText systems were closer to the legacy system compared to our synonym-set implementation. This deviation from the legacy system, though expected due to differing synonym handling in phrase queries by AppSearch, highlights a substantial difference in results. Similar to single-word queries, the fastText systems with and without true casing exhibited comparable performance when compared to the legacy system but displayed significant discrepancies when compared to each other.
Flexibility and final product
To evaluate the achieved flexibility of the new architecture, the integration of the fastText synonym system as well as the subZero admin interface, were built. Additionally, the index data was strictly separated from the quality indicators, which allowed easy updates to the data using the admin web page and only requires a quick rebuild of a materialised view also exposed through the admin console. Other parts of the application, like help texts, could be edited the same way and only required a website reload afterwards. Figure 6 shows the final seach UI and the admin dashboard. Screenshots of final search engine with filter UI and active filtering for “Verständlichkeit” (right picture) and subzero admin dashboard (left picture). The translations of the filter-categories can be seen in the left screenshot.
Discussion
Principal findings
The redesign and rebuild of the search engine aimed to enhance flexibility and control. This goal was realized by implementing a new architecture that supports the integration of additional features and tools. This architecture grants full control over data layout and optimizations, and facilitates the integration of any compatible service with the main backend server. For instance, domain evaluation could be directly integrated into the application, eliminating the need for separate third-party services. Leveraging plain Elasticsearch also enabled direct utilization of features not available through AppSearch, such as the Completion Suggester. 40
Our evaluation indicated a significant performance improvement with the new architecture. While some of this enhancement may be attributed to the newer ES version 8.10 utilized in the new system compared to ES 7.16 in the legacy AppSearch, 41 most of the performance gain in ES 8 is related to scalability aspects. Despite using a single-node ES cluster for the new system, which should have minimized scalability effects, the new system consistently outperformed the legacy system, even with performance-intensive synonym systems. Additionally, our evaluations revealed that AppSearch seems not to consider synonyms in full-sentence queries, whereas our new system effectively integrates synonyms in all query types.
While the absolute speed improvements observed in our system may appear marginal, prior research has shown that even sub-second reductions in response time can meaningfully impact user satisfaction, perceived usability, and engagement.42,43 More generally, Nah et al. 44 demonstrate that system response time is a key determinant of perceived usability and user experience in web-based applications. In the context of health information retrieval, where users often search under emotionally charged or time-sensitive conditions, responsiveness, in both the technical and informational sense, contributes not only to usability but also to trust and perceived system quality. Although Hesse et al. 45 do not investigate latency directly, they highlight a behavioral shift where users increasingly turn to the Internet as their first source for health information. Keselman et al. 46 further emphasize the importance of aligning health systems with user needs and competencies, underscoring the need for responsive, understandable, and trustworthy digital tools. This reinforces the imperative to deliver systems that are not only functionally reliable, but also competitively responsive.
Moreover, user expectations around performance are increasingly shaped by dominant platforms like Google and Bing. Arapakis et al. 43 demonstrate that even moderate response delays (under 1 s) in mobile web search can significantly increase user frustration, perceived sluggishness, and stress, even when delays are within traditionally acceptable bounds. Users today are not only sensitive to raw loading speed but are also more likely to interpret delays as indicators of poor system quality. In competitive search environments, where response time is part of the user experience baseline, a delay of even 500 ms can be enough to reduce engagement or trust.42,47
Given that tala-med positions itself as a high-trust alternative to commercial search engines, speed is not merely a technical metric. It is a requirement for credibility. Delivering fast and fluid interactions is essential to earning and maintaining user trust. This underscores the need to deliver trustworthy systems that are also competitively responsive.
Adopting a database-centric architecture enabled the new system to be finely tailored to our specific needs. For instance, we utilized materialized views to precompute aspects of search queries, reducing the need for recomputations with each query and minimizing abstraction layers, thereby enhancing system performance. Furthermore, this approach facilitated integration with the custom subZero administration tool and in future will allow the integration of extensions to accommodate research tasks like survey management and evaluation. Our selection of independent, highly customizable systems has substantially reduced dependency on Elastic, enabling us to implement new features without waiting for AppSearch support.
Significant differences were observed between the legacy and new systems, particularly in the similarity of results with synonyms in full-sentence queries. However, our analysis still indicated that the new system closely aligns with the legacy search engine, especially considering the prevalence of single-word queries in tala-med. 19 Additionally, the weighting between user input query and inferred synonyms (currently set at 0.75 boost) emerged as a relevant parameter for balancing synonym influence on ranking. Our analysis of the AppSearch-based system also revealed persistent challenges in synonym handling for search queries. In particular, the handling of compound words that refer to the same concept but appear as separate words during text processing have posed a challenge and could be explored further.
Our implementation of fastText-based synonym expansion builds on prior research demonstrating the effectiveness of word embeddings in biomedical information retrieval. Unlike rule-based synonym systems, fastText models include subword-level information, allowing them to generalize to inflected or compound biomedical terms, frequent challenges in health-related queries. Yeganova et al. 48 conducted a comparative evaluation of three popular word embedding models, word2vec, 49 GloVe, 50 and fastText, 26 to assess their ability to detect biomedical synonyms. While no single model outperformed the others across all scenarios, fastText demonstrated superior performance in identifying high-precision synonym pairs for different-stem terms, a scenario especially relevant for search applications like ours. As our system uses only the top-k ranked synonyms, this prioritization of precision over recall aligns well with our design objective: returning highly relevant suggestions rather than a large set of noisy expansions. In a complementary line of work, Agibetov et al. 51 showed that fastText achieves competitive performance in biomedical sentence classification, with much faster training and greater scalability compared to deep learning models. These findings validate our design decision to integrate fastText for dynamic synonym expansion, a feature in which the legacy system lacked support.
To support this and future extensibility, we re-engineered the search engine using a modular, database-centric architecture. Modular software designs are increasingly valued in health information systems for their adaptability and long-term maintainability. As Bathelt et al. 52 note, modularity enables independent evolution of system components, while Rasmussen et al. 53 highlight its role in solving interoperability and representation challenges in biomedical applications. Our architecture decouples the core services search, synonym processing, and administration. This makes it easier to integrate features such as ontology-based ranking or explainability modules. This approach not only modernizes tala-med but also contributes a replicable and extensible blueprint for future domain-specific search engines in healthcare.
Limitations
As there was no gold standard for ranking suitable to the tala-med search engine, our evaluation was limited to comparing the new system with the existing AppSearch. Hence, we couldn’t objectively measure the quality of our new search engine’s results. Additionally, differences were expected due to AppSearch being closed-source, lacking comprehensive documentation for complete replication.
The synonym solutions used, had their limitations and nuances. The rebuilt legacy system approximated which synonym sets to use based on the query’s word count, potentially differing from AppSearch’s approach. In contrast, the new system offers greater flexibility, with fewer constraints on synonym-set size and easy extension via its ES index. For instance, synonym-sets can now be used in phrase queries. The fastText and truecaser were not individually evaluated, leaving their potential limitations unknown. This aspect is evident in the similarity evaluation of the fastText model with and without truecasing. Further investigation could unveil valuable insights and clarify the impact of truecasing on the search.
The new architecture enhanced search engine flexibility but introduces higher development complexity. Previously reliant on a monolithic architecture centered around AppSearch and the UI, the current setup will necessitate separate maintenance and development of numerous components. However, the subZero admin interface and database-centric architecture streamlined system maintenance post-deployment.
Future works
First of all, the deployment of the new architecture in production is planned, which also requires integrations into existing extract, load and transform (ELT) processes and their adaption. Future work could focus on establishing a gold standard or objective method for evaluating search result quality. The newly added flexibility allows for the implementation of various methods to enhance the search engine. Inspired by TourBERT 54 the more sophisticated domain-specific machine learning model GerMedBERT 55 could be used to extract synonyms and leverage available domain knowledge. Similarly, ontologies and terminology systems could enhance the semantic relevance of search results by leveraging domain knowledge in medicine. For instance, instead of solely relying on an ML system to find synonyms, related terms could be identified through traversal of the SNOMED CT 56 terminology system. Additionally, the MeSH terminology system could annotate search index pages and refine search queries, akin to PubMed’s functionality. In addition, a user evaluation study similar to that of Specht et al. 19 or an A/B testing approach, as described by Strecker et al., 57 could provide valuable insights into the effectiveness, usability, and real-world impact of the newly implemented architecture. Such an evaluation would involve collecting user feedback, analyzing search behavior, and measuring both satisfaction with search results and overall user engagement. These types of evaluations represent an important next step to ensure that the system’s technical improvements translate into meaningful user benefit and real-world adoption.
Conclusions
In conclusion, we successfully replaced the monolithic AppSearch backend of the tala-med search engine with a more flexible and efficient software stack. This transition addressed previous limitations and improved system performance. Despite minor differences in search results compared to the legacy system, the new system is considered close enough to be a viable replacement. The new flexibility was demonstrated through the implementation of a fastText-powered synonym system, showcasing the system’s capabilities and setting a precedent for future extensions to the tala-med search engine. Furthermore, full-sentence queries now incorporate synonym usage, expanding search functionality. Future works can leverage the new search engine to integrate sophisticated enhancements, improving search relevance and exploring novel concepts in medical search engines. Additionally, extensions to facilitate research and analysis can now be directly incorporated into tala-med, eliminating the reliance on third-party services. This includes enabling domain evaluation by experts within the application. While promising, the study has several limitations. Due to the lack of a suitable gold standard for tala-med, evaluation was restricted to comparisons with the legacy system. Furthermore, the true impact of fastText-based synonym expansion and truecasing remains to be assessed in detail, and the increased complexity of the new modular system may require additional maintenance effort. Future work will focus on conducting user-centered evaluations (e.g., A/B testing), and exploring deeper integration of medical ontologies such as SNOMED CT and MeSH to further enhance relevance and interpretability. Finally, the modular and database-centric technology concept developed for tala-med, which we have released as open-source, can be adapted for a wide range of applications beyond medical information retrieval, providing a scalable and flexible framework for other domain-specific search engines and information systems.
Footnotes
Acknowledgements
The authors would like to thank Johann Frei for his feedback and proof reading of parts of the manuscript.
Author contributions
Conceptualization, Raphael Scheible-Schmitt; Data curation, Florian Albrecht and Raphael Scheible-Schmitt; Formal analysis, Florian Albrecht; Investigation, Florian Albrecht and Raphael Scheible-Schmitt; Methodology, Florian Albrecht, Ruslan Talpa and Raphael Scheible-Schmitt; Project administration, Raphael Scheible-Schmitt; Resources, Raphael Scheible-Schmitt; Software, Florian Albrecht, Ruslan Talpa and Raphael Scheible-Schmitt; Supervision, Raphael Scheible-Schmitt; Validation, Florian Albrecht; Visualization, Florian Albrecht; Writing – original draft, Florian Albrecht and Raphael Scheible-Schmitt; Writing – review & editing, Florian Albrecht, Ruslan Talpa and Raphael Scheible-Schmitt.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the German Ministry for Education and Research grant number (01ZZ2304A).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.