
Abstract
Introduction
The ability of GPT, created by OpenAI, to generate relevant answers to human input text conversationally makes writing and handling educational tasks, especially summarising and answering questions globally in higher education settings, appealing.1,2 The primary benefit of using AI technologies has lied in their ability to analyse large and complex datasets, uncovering patterns that might elude human observation. Although not explicitly trained for medical applications, AI-powered chatbots demonstrated exceptional proficiency in providing quick and reliable assistance. Their capability to search through documents, texts, scientific research, and medical literature has made them invaluable tools for medical professionals. 3
The characteristics of ChatGPT can also be valuable for clinical practice. The model can be used as a decision-support tool to help doctors with diagnosis and treatment by combining patient data with in-depth medical knowledge to produce evidence-supported suggestions. 4
Academic societies have acknowledged the positive evidence of ChatGPT’s performance in various medical examinations. Notably, 80.6% of responses were graded as “good,” demonstrating that ChatGPT-4 (GPT-4) surpasses ChatGPT-3.5 (GPT-3.5) in accuracy when addressing frequently asked questions about myopia. 5 Passing all the United States Medical Licensing Examination tests, 6 German state licensing exam level in Progress Test Medicine, 7 the National Premedical exam in India, 8 and Japan’s National Medical Licensing Examination 9 has implied that ChatGPT offers enormous transformational potential in healthcare education. Significant progress was seen as ChatGPT outperformed the average postgraduate year 1 (PGY)-1 level, and GPT-4 outperformed the average PGY-5 level. 10 Additionally, ChatGPT outperformed graduates in basic medical sciences, excelled in Obstretistics and Gynecology, but underpeformed in the anatomy and physiology subfields. 11 ChatGPT has emerged as a potentially useful tool in medical education. 12 Moreover, this tool was enthusiastically perceived as useful and applicable in healthcare professionals education. 13
However, professors and teachers must familiarise students with ChatGPT’s performance, highlighting possible drawbacks and teaching vigilance. Systematic reviews have emphasised issues related to its accuracy and reliability, including the potential for generating incorrect information and spreading misinformation, such as controversial medical advice and inaccurate explanations of medical concepts. 14 These inaccuracies, known as hallucinations, may appear scientifically plausible. 15
Additionally, it was recognised that the ChatGPT behaviour can change in a short period. 16 Previous studies16,17 have demonstrated that, due to its lack of critical thinking, generation accuracy, and critical assessment capabilities, ChatGPT needs to be supported by human judgment. For instance, a study involving the Vietnam high school graduation test showed that ChatGPT’s accuracy rate declined significantly at the most advanced levels as questions increased in difficulty. Despite recent advancements, language models like ChatGPT still face challenges in comprehending and solving complex mathematical problems and visualising data. 17
As the demand for critical evidence evaluation increases, complex clinical practice decision-making relies on statistical reasoning. Consequently, the need for statistical proficiency grows, necessitating the exploration of innovative methods for teaching, studying, and applying statistical concepts. Researchers have demonstrated that GPT models understand statistical principles well and exhibit at least average performance in solving biostatistical problems.6,18
While several studies have assessed the static performance of AI tools in biostatistics,18–20 there is a notable scarcity of research tracking the temporal evolution of such tools, especially for specific biostatistical tests.
Objectives
Therefore, the aim of the study is a longitudinal assessment of ChatGPT performance in solving correlation-related biostatistical problems, focusing on its accuracy, stability, and reproducibility over time. By assessing the progression of ChatGPT’s capabilities, this research seeks to provide empirical insights into its potential as a reliable educational tool in medical biostatistics and its practical implications for modern higher education classrooms.
Methods
The biostatistical task was selected from Statistics at Square One by Swinscow and Campbell. 21 The correlation analysis task was chosen due to its foundational role in biostatistics education and its standard inclusion in medical curricula. Additionally, correlation analysis involves multi-step computations, such as summation, squaring, and division, which test both basic arithmetic accuracy and logical reasoning, making it a suitable challenge for evaluating ChatGPT’s capabilities. 21
The correlation analysis task was classified based on its inclusion in the medical biostatistics syllabus. The task was selected to assess cognitive skills appropriate for university-level students, as it involved performing multi-step computations and applying advanced reasoning. The complexity of the test reflects the cognitive demand for understanding summation, variance, and covariance, as well as the calculation and interpretation of the Pearson correlation coefficient.
As a biostatistical problem, a correlation analysis was selected. If ChatGPT could not resolve a problem on the first try, we used other adjustments and provided the application with more information to ensure the issue was resolved accurately. We used the versions of GPT-3.5 and GPT-4. The conversations with GPT-3.5 and GPT-4 are performed on October 29 and 30, 2023, March 30 and 31, 2024, and July 13, 2024. The correlation analysis problem was pasted into the GPT-3.5 and GPT-4 interface dialogue. No additional guidelines or contextual knowledge was provided. Conversation files are provided as supplemental materials. We did not use the subjects in our research. It was only the conversation with ChatGPT. The variables were ChatGPT’s answers related to performing the correlation analysis. The data are from ChatGPT’s answers. The correctness of answers was assessed as “correct” or “incorrect.”
There was no bias in the script description for solving correlation analysis as a biostatistical problem because we did the work.
Study size
There was no need to calculate the study size. Only ChatGPT versions 3.5 and 4 were targeted for the study.
Statistical methods
Descriptive statistics were used to analyse the answers by ChatGPT-3.5 and 4. The binary respones (correct/incorrect) were collected in repeated measurements between October 2023 and July 2024. Differences in correct response rate between timepoints were estimates by Cochran`s Q test. The McNemar test was used as post hoc analyses to identify specific measurement pairs with significant diference. Statistical analysis was performed by using the R programming language.
Ethical considerations
This study was conducted without human participants; therefore, the study did not require an institutional ethics review.
Results
Performance of GPT 3.5 and GPT-4 in performing correlation analysis and calculating correlation coefficient within 9 months.

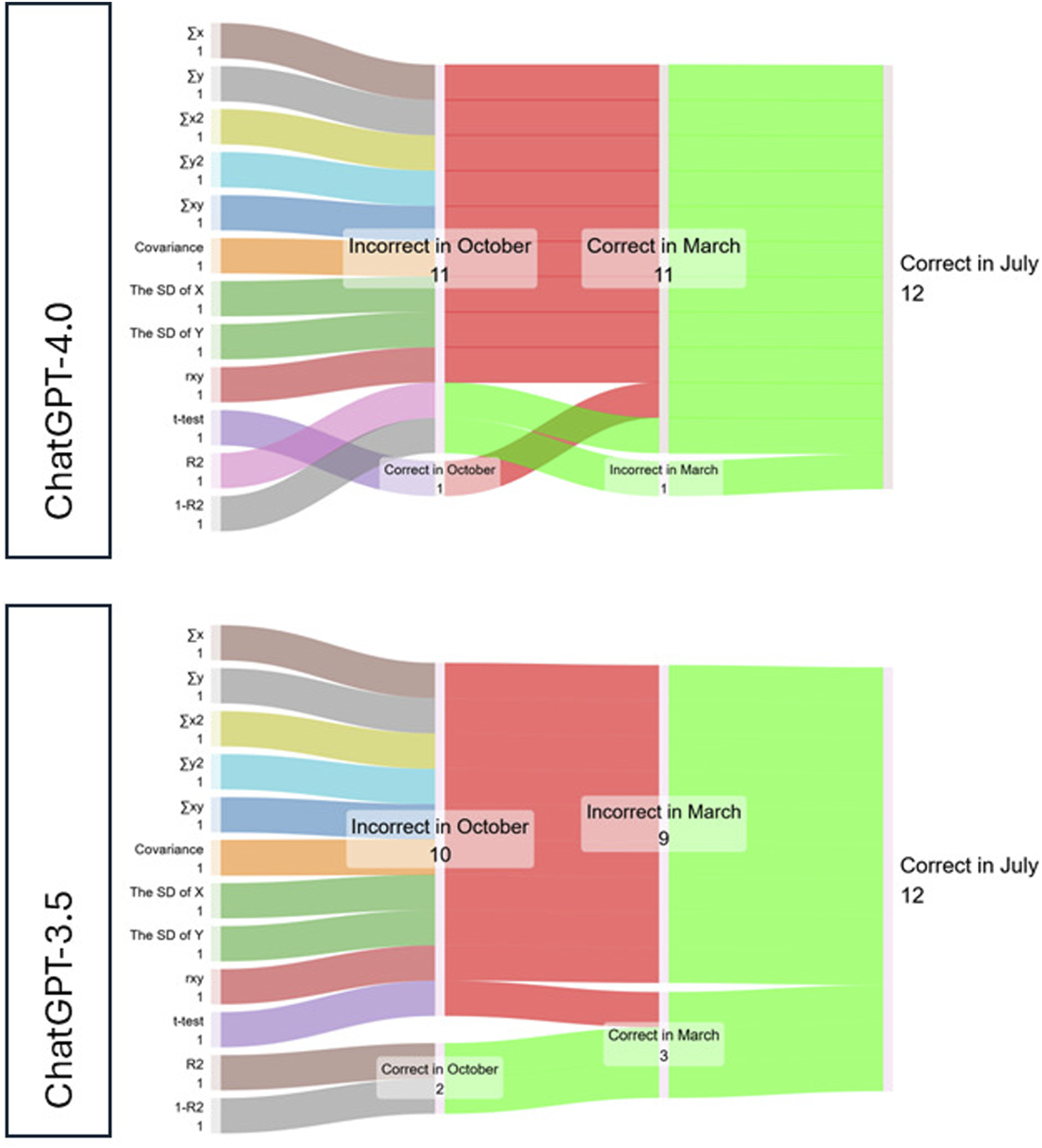
ChatGPT-3.5 and ChatGPT-4 performance in follow-up period.
The observed proportions of correct answers for CPT 3.5 were: October 2023: (16.7%), March 2024: (25.0%), July 2024: (100.0%) and for GPT-4 were: October 4 2023: (8.33%) March 2024: (91.7%), July 2024: (100.0%).
In the first attempt conducted on October 29, 2023, GPT-3.5 produced ten incorrect results out of twelve evaluated parameters, while GPT-4 made eleven errors, including an additional mistake in calculating the coefficient of determination (R2). Both versions miscalculated the sum of x (∑x) and y (∑y), the sum of squares of x (∑x2) and y (∑y2), the sum of the product of x and y (∑xy), Covariance (Cxy), Standard Deviation 1 (SD1), Standard Deviation 2 (SD2), and the Pearson correlation coefficient (Rxy).
A statistically significant change in correct response rates was established in repeated measurements in the period October 2023, March 2024, and July 2024 for GPT-3.5 (Q = 100.99, p < 0.001), GPT-4.0 (Q = 89.55, p < 0.001), respectively. The significant GPT-3.5 improvement was established between March 2024/July 2024 (p = 0.004), and between October 2023 and July 2024 (p = 0.008). The significant GPT-4.0 improvement was established between October 2023 and March 2024 (p = 0.004), and between October 2023 and July 2024 (p = 0.026).
After 6 months, on March 30 and 31, 2024, we repeated GPT-3.5 and GPT-4 testing. GPT-3.5 did not show statistically significant improvement compared to October 2023 (Χ2 = 0.0, p = 1.000), continuing to make similar errors in simple arithmetic operations, though it demonstrated improvement in calculating the Student’s t-test. Conversely, GPT-4 showed statistically significant progress (Χ2 = 8.1, p = 0.004), achieving 11 correct answers out of 12. Deviations in some parameter results from the reference values were attributed to different computational patterns, which GPT-4 justified through explanations in its chatbot responses. The only error it made was in calculating the coefficient of alienation (1-R2). Between March and July 2024, GPT-3.5 exhibited significant improvement (Χ2 = 7.11, p = 0.008), addressing prior inaccuracies and achieving 12 correct answers out of 12. GPT-4 maintained its performance with no significant changes during this period (Χ2 = 0.0, p = 1.0). Compared to baseline timepoint GPT-3.5 (Χ2 = 8.1, p = 0.004) and GPT-4 (Χ2 = 9.1, p = 0.026) achieved perfect accuracy, providing correct results for all 12 parameters by the third evaluation in July 2024.
Discussion
The present study documented the advancement of ChatGPT’s performance in solving biostatistical problems within approximately 9 months. Initial attempts to solve a specific biostatistical problem yielded poor results in GPT-3.5 and GPT-4. Initially, neither version could correctly perform basic mathematical operations such as addition, multiplication, and squaring. Both versions produced incorrect results for 10/11 out of the 12 provided steps in the first attempt. Similar findings, albeit in a snapshot, have already been reported in solving biostatistical problems where inaccurate results were documented in complex mathematical calculations such as the chi-squared testing and one-way analysis of variance. 18 The correlation analysis was selected for evaluation as a commonly used statistical analysis, usually compulsory in the introductory course syllabus. The present study specifically demonstrated improvement in calculation tasks within approximately 9 months. At the end of the follow-up, ChatGPT-3.5/4 solved and calculated all important parameters for correlation analysis in the first attempt. GPT-3.5/4’s progression from failing to provide correct results to achieving total accuracy within 9 months showcases the potential of AI models to improve significantly with targeted updates and training.
Also, occasional calculation errors in well-specified physics problems were reported at the end of 2023, 22 ranging from arithmetic to trigonometric errors. This study revealed three distinct directions of failures: failure to construct accurate models, failure to make assumptions about missing data, and calculation errors. Our study confirmed the initial suboptimal performance of ChatGPT in elementary-level math, which was already addressed. 23 Their mathematical capabilities were reported as somewhat limited. They can handle basic arithmetic and recognise mathematical symbols and expressions, but there have been issues related to optimisation for complex mathematical problem-solving, such as calculating function limits. It is important to point out that ChatGPT’s abilities are constrained by its programming and training. Therefore, while it can offer mathematical assistance, it is advisable to cross-verify its solutions with other reliable sources. 17 However, various variables, including the equation’s difficulty, the input data’s precision and quantity, and the commands provided to ChatGPT, may affect the efficacy and accuracy of the solutions provided by ChatGPT. 17 In that study, the authors note that when the figures used in the procedures are larger, ChatGPT becomes less accurate in arithmetic operations. Specifically, multiplication accuracy declines more quickly and dramatically than accuracy in addition and subtraction. They also found that GPT tends to add a single digit when using large numbers and complex mathematical operations. They assume this may result from the model’s inability to maintain track of extended operations; therefore, more research is required to determine the main reasons for this issue 23 and monitor ChatGPT performance continuously.
For academic community, this indicates that while initial versions of AI models may have limitations, continuous development can lead to highly reliable tools for complex statistical analyses. 24 Our findings on the advancement of ChatGPT’s performance in statistical analysis are consistent with the results of a study that compared the performance of ChatGPT with traditional statistical analysis software. 25 This comparative analysis of ChatGPT-4 with SAS, SPSS, and R demonstrated that ChatGPT-4 can be a powerful auxiliary tool for statistical analysis, but with limitations in result consistency and in applying more advanced statistical methods. Unlike the other statistical software, ChatGPT has not reached a highly consistent level, and the consistency was the lowest in correlation analysis. In that evaluation, ChatGPT-4 data proficiency is estimated at the junior level or even mid-level data analyst, but traditional biostatistical software persists as preferable for complex and advanced statistical analyses. 25
ChatGPT is user-friendly and versatile for beginners but lacks the precision of tools like R and SAS in advanced statistical computations. 25 Integration of the Python-oriented Jupyter Notebook environment into ChatGPT-4 could be a significant step in this progress. Integrating Python may simplify statistical analysis to a certain extent, but specific tasks might still require programming experience, computational efficiency, and precision in code control. 26 This integration allows robust Phyton data analysis tools to be used directly within ChatGPT, significantly enhancing its ability to solve mathematical problems and analyse data. 27 However, the integration comes with some limitations, such as restricted access to specific Python libraries, and the task execution process can be time-consuming and resource-consuming.
Specialised statistical software has a clear and straightforward interface, while natural language is used in human-ChatGPT communication. Therefore, human language is susceptible to changes and is influenced by question formulation. The two-way diffuculties in understanding questions and answers have been discussed 28 indicating possibility that students could get superficial grasp of the background instead of a comperhensive understanding.
Our study has demonstrated that reproducibility is conditioned by interface and communication skills, as accurate results were achieved by following additional instructions. Finally, at the end of follow-up ChatGPT-4 calculated the task almost without guiding, just following the requirements.
ChatGPT offers instant feedback, providing students immediate assistance in solving biostatistical problems. This assistance can also be personalised and adapted to students’ needs and pace. Even though there was considerable improvement in ChatGPT’s performance in the second attempt, the initial step showed that ChatGPT’s responses must be carefully considered. Provided definitions and detailed explanations of all steps indicate that ChatGPT has acquired a specific background and statistical thinking at an optimal level. At the same point and on the assessment request, ChatGPT became completely aware that the response was wrong and out of the meaningful range, but it could not solve successfully. Additionally, mistakes in both GPT versions in the attempts imply that students must be aware of the possibility of obtaining convincing but inaccurate responses and avoid over-reliance on the chatbot.
Empirical insights from our study offer practical implications for higher education, indicating that large language models (LLMs) assist teachers and students with writing, research, and individualised instruction. In addition to offering specialised resources for in-depth topic investigation, they give students tools for organising their ideas, summarising materials, and developing critical thinking and problem-solving abilities. In addition to developing lesson plans, customised resources, and practice questions, LLMs help teachers with grading, giving feedback, and identifying plagiarism. LLMs are valuable resources for contemporary education since they support language acquisition, professional growth, and raising understanding of ethical AI issues like prejudice and supervision. 29
A growing body of literature indicates that ChatGPT profoundly impacts education across diverse domains. 30 Different aspects of education can be revolutionised by adopting ChatGPT as a study tool. Arif et al. (2023) explored the dual nature of AI tools, such as ChatGPT, in the context of medical education. Their findings highlighted the potential of AI for scalability and providing instant feedback, making it a valuable tool for addressing repetitive and foundational queries. In contrast, traditional teaching methods were noted to excel in offering personalised, context-specific instruction and fostering critical thinking and in-depth mastery of subjects. The authors emphasised the complementary potential of integrating AI tools with traditional approaches to maximise educational outcomes effectively. 31
ChatGPT has a great deal of potential for healthcare education, and it is incomparable in its ability to speed up learning by giving users immediate access to a wealth of medical knowledge. It functions as an intelligent instructor who can answer questions quickly. Additionally, it simplifies and eases the process of learning healthcare-related information by breaking down complicated medical jargon. Additionally, providing information on demand might beneficially democratise the medical education of doctors, students, and the general public. 32
Scientists and researchers can stay on the cutting edge of medical developments by using ChatGPT’s capabilities for data extraction, hypothesis generation, and literature reviews. The ability to change the level of creativity, called temperature, has been described as a highly potential tool in promoting scientific results in society. 33 However, this feature of adopting creativity could be used to fine-tune and deliver more consistent outputs by lowering ChatGPT creativity to review patients’ symptoms and treatments. Increasing the temperature and creativity level will provide better outputs for less structured tasks, which could improve communication among clinicians and audiences. However, there are several difficulties in integrating ChatGPT into healthcare. Priority is given to ethical issues of informed permission, patient data protection, and responsible AI use. Furthermore, serious thought must be given to worries about bias in AI systems and possible errors in medical advice. 34 Also, ChatGPT use in healthcare education include the concern regarding the quality of training datasets that could result in biased content and inaccurate information limited to the period before 2021. Additionally, other concerns include the current inability of ChatGPT to handle images as well as its low performance in some topics (e.g., failure to pass a parasitology exam for Korean medical students), and the issue of possible plagiarism. 35
With its breakthrough multimodal features, the latest version of its AI software, ChatGPT-4o (the “o” stands for omni), allows inputs and outputs in text, image, audio, and video formats that are processed by a single neural network fixing the limitations which older versions had. GPT-4o may now optimise learning process. 36 This model demonstrated superior ability over GPT-4 in solving complex informatics, mathematics, and engineering problems, as well as benchmark medical question-answering datasets, 37 and should be evaluated in further studies.
A modern higher education classroom can be functional and optimised with ChatGPT as a supplemental tool, but it will still require the presence of an educator. Among other things, there is some evidence that ChatGPT did not motivate students to acquire new skills at the anticipated level. 28 However, there is also evidence to the contrary, stating that ChatGPT’s availability can be viewed as a motivator in healthcare education due to the individualised contact it offers, which facilitates effective self-learning and serves as a helpful supplement to group learning. 38
Results from this study confirmed the value of ChatGPT, but also warned that its effectiveness depends on the learning context and students’ perceptions of its role in education. Additionally, it is reported that higher knowledge transfer could be produced by using human-created hints compared to chatbot hints. 13 Inconsistent findings indicate the need further to analyse ChatGPT characteristics and its role in higher education.
Limitations
This study contains several limitations. First, we focused exclusively on a single assignment from the biostatistics domain, specifically correlation analysis. While correlation analysis is well-suited for testing ChatGPT’s performance due to its multi-step structure and mathematical complexity, it represents only a narrow aspect of biostatistics. Probably, the pattern captured in the study remains relevant and consistent across different statistical analysis techniques. However, the strength of this study likely lies in the dynamics of ChatGPT used in real-world educational settings and documenting track changes in this process. Second, a potential source of bias in the evaluation process could arise from the iterative adjustment of questions or guidance provided to the model when it produces incorrect results. This limitation implies the need to create guidelines for this type of research. Third, while we explored ChatGPT’s utility in medical education, this study did not investigate how its role might differ in other academic disciplines. Fourth, this study did not compare ChatGPT’s performance with that of other competing models, such as LLaMA, SAS and R programming. Finally, given the rapid advancement in artificial intelligence, future research should prioritise the investigation of other ChatGPT versions to assess their potential improvements in medical education. Our study began before the latest version was available. By addressing these limitations, future research can provide a more comprehensive evaluation of ChatGPT and its evolving role in academia.
Conclusions
Over 9 months, GPT-4 demonstrated consistent and statistically significant performance improvements in solving specific biostatistical problems. GPT-3.5 showed limited progress in the first 6 months, with significant improvements emerging between March and July 2024, culminating in perfect accuracy for both models. These findings highlight the evolution of GPT algorithms, with GPT-4 consistently outperforming GPT-3.5 and achieving better stability and reliability over time. Our findings contribute to the growing body of evidence about ChatGPT as an educational tool, documenting that it is a transformative tool and valuable tool for interactive learning and solving practical problems. Therefore, the academic community should support the use of ChatGPT in medical education while thoroughly and constantly testing the concept to ensure its limitations are not overlooked. This implies that educators and students must stay updated on technological advancements and thoughtfully plan the process of integrating them, supporting students. The integration of ChatGPT as a supplemental tool is a necessary step toward modern higher education classroom settings.
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Supplemental Material
Supplemental Material - ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education
Supplemental Material for ChatGPT’s progress over time: A longitudinal enhancing biostatistical problem-solving in medical education by Aleksandra Ignjatović, Marija Anđelović Apostolović, Lazar Stevanović, Pavle Radovanović, Marija Topalović, Tamara Filipović, and Suzana Otašević in Health Informatics Journal
Footnotes
ORCID iDs
Ethical considerations
This study was conducted without human participants; therefore, the study did not require an institutional ethics review.
Author contributions
All authors contributed to the conception and design of the study. AI, MAA and LS were responsible for data collection, analysis, and initial manuscript drafting. AI, PM, and SO contributed to data analysis and interpretation, and critically revised the manuscript. MT and TF were responsible for formal analysis, supervision and administration. All authors have approved the final version of the manuscript for submission.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by a research grant from the Serbian Ministry of Science and Technological Development – project number 451-03-137/2025-03/200113.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data are available in a repository and can be accessed via a DOI link. The data analyzed in this study were generated through interactions with the ChatGPT model, not extracted from publicly available datasets. All responses were produced in real-time based on my own queries, and no external datasets were accessed or referenced.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.