
Abstract
Introduction
The global COVID-19 pandemic resulted in sharp increases in online search activity about the disease, its spread, and remedial actions. 1 Search engines can significantly influence public perception of the disease and the efforts undertaken by the public.2,3 Autocompletes results are auto-generated queries that allow users to complete searches faster by populating information in the search engine’s text box as they type the search word. For example, when a user types “coronavirus is,” Google suggests autocompletes such as “coronavirus is contagious,” “coronavirus is man-made.” While convenient, the function may contribute to bias that, if left unchecked, can lead to health inequality experienced by marginalized and racial minority groups by providing different results for similar inquiries. 4 This becomes extremely important in pandemic scenarios where the public has little information and is likely to react sharply based on the (potentially biased) data they might receive. 3
The example in Figure 1 includes the Google autocomplete results for “coronavirus is [in English] …” and “coronavirus es [in Spanish]… ” as observed via the web interface during the early phase of the pandemic (Mar 6, 2020) in the New York area. The first three auto-complete results for “coronavirus is …,” in English include one question and two neutral-sounding statements. However, in the Spanish version, “coronavirus es …”, all the top auto-completes are perceived as negative. The information generated using autocompletes searches may differ, depending on the language preferred by the users for the search, despite facing the same medical and health threats. The autocompletes could shape public perception of the disease, the public’s reaction to the disease, and, ultimately, the outcomes of the disease.3,5–7 Differences across languages in search engine auto-completes about COVID-19 as observed in New York region on Mar 6, 2020.
The above example motivated the need to systematically examine the differences in COVID-19 related search autocompletes, raise awareness, and create scientific knowledge to mitigate an understudied form of cross-language health information bias. Hence, we proceeded to systematically collect and analyze Google autocomplete data in NY region with goals to: (1) Introduce the public health problem of cross-language bias in health-related search auto-completes. (2) Audit COVID-19 autocomplete search results in English and Spanish using logged 2020 data in New York region from Google search application programming interface.
Background and significance
The internet is a primary source of health information for many US adults, and during the COVID-19 pandemic, Google searches have been shown to correlate with case trends, offering predictive insights.5,8,9 The accessibility of online information has democratized health knowledge, yet it has also led to the spread of misinformation and bias, challenging the integrity of health information dissemination.5,8–10
Algorithms like Google’s autocomplete influence daily decisions, including those related to health, and may potentially carry inherent biases.4,10–12 In Google autocomplete, as soon as a user starts typing a query term in the search box, a set of predictions are shown below the search box. Autocomplete, initially were used for users experiencing hand disorders (e.g., carpel tunnel syndrome) by reducing keystrokes, now guides a broader audience’s search experience, saving time but potentially shaping user queries and perceptions.13,14,15 According to Google, these suggestions reduce typing significantly (about 25%) and save hundreds of years of typing time each day. 16 Autocomplete algorithms thus mediate an immense volume of search. While these algorithms facilitate efficient information retrieval, they also risk reinforcing stereotypes and spreading misinformation, which can have legal and societal implications.4,5,15
Research conducted by Noble has shown that auto-complete search results often reinforce stereotypes like presenting Black females in negative contexts more often than White females. 4 As auto-completes often mediate one’s information seeking, systematic bias in auto-completes affecting certain groups is problematic.4,17,18 Because health disparities are present in racial and ethnic groups, algorithms might intensify or generate disparate outcomes due to reinforcing racial, gender, and cultural bias, which can be especially problematic during a pandemic such as COVID-19.18,19
In this project, we focus on a large segment of the Spanish-speaking community population because Spanish is the second most frequently spoken language among Latinos in the US. 20 The Latino population represented 19% of the US population in 2021, making them (including native-born and foreign-born from Latin America and the Caribbean) the largest ethnic and racial minority group in the US. 21 By 2050, the Latino population will total roughly 132.8 million people, or 30% of the total population. 21 Nationwide, Latinos are more likely to live below poverty than White Americans, less likely to complete post-secondary education, and have poor health outcomes than their White counterparts.21,22 Latinos in the US have had significantly lesser access to information technology, and many continue to be impacted by the digital divide. 23 This gap remains despite the growth of mobile technology, which, in COVID-19, can exacerbate health outcomes. 24
Health equity is an essential concern in the COVID-19 pandemic.
25
Multiple studies have reported Latinos are more likely to experience severe COVID-19 illnesses and mortality than other racial and ethnic groups.26,27 In fact, the New York City Department of Health and Mental Hygiene determined that the spread of misinformation about COVID-19 was having a harmful health impact, particularly on communities of color with low vaccination rates.
10
The department set up a specialized ‘Misinformation Response Unit’ tasked with tracking and addressing the spread of hazardous misinformation across various media outlets. This includes vigilance over social media, non-English language media, international publications, and discussions within local community forums.
10
However, little empirical evidence exists in the literature as to whether autocomplete results during a pandemic differed between English and Spanish speakers access to COVID-19 information using Google search. Hence, this study’s central research question was: Are there any systematic differences between English and Spanish search autocompletes for COVID-related terms? We examine the research question in three dimensions: (1) (2) (3)
Materials and methods
The primary goal of this study is to audit and compare search autocomplete results in Spanish and English during the early COVID-19 pandemic in the New York metropolitan area. For this purpose, we collected daily autocomplete results for multiple COVID-19-related query terms from March 12, 2020, to July 9, 2020 using Google’s search Application Programming Interface (API), which allows one to specify the language for search. 28 Five query terms were considered, and it included terms related to the overall COVID-19 situation (i.e., “Coronavirus is …”, “Flu is …”, and “Pandemic is …”) and those about precautions (i.e., “Hand washing is …”, and “Face Mask is …”). While the first three terms were selected to consider some of the most common terms related to overall phenomena, the other two were intended to provide insights into behaviors that users might undertake to combat being infected by the COVID-19 virus. The style of this query (i.e. “X is …”) was selected to be like that described by Safiya U. Noble in past work for comparing autocompletes for different terms. 4
Each of the query terms was translated into Spanish, double-checked for accuracy by two bicultural and bilingual (English and Spanish) team members, and passed on to the search’s Spanish language version (API). 28 The API supports REST protocol and provides a list of autocomplete suggestions based on the provided query in JSON format. Queries were run using Python code running on a Jupyter notebook running in the “incognito mode” of the browser from a computer to minimize the odds of customization. The computer collecting the data was physically based in the New York metropolitan area. The data are missing for some days due to technical issues and are available for a total of 109 out of 120 days. Between 0 and 20 autocompletes were found for each query term on each of the days, yielding a total of 9164 individual autocomplete predictions. Data cleaning was undertaken in Microsoft Excel (Office 365) and SPSS version 28 was used for statistical analysis.
Since all the autocompletes for a query term on a given day are presented as a group to the user, we decided to consider such a query auto-complete daily group (QACDG) as the basic unit of analysis. Thus, 10 such QACDG (5 query terms * two languages) were considered daily for the 109 days for the analysis in this work. These data were analyzed in terms of the following three dimensions.
The number of autocompletes
The first dimension considered for comparison was the number of autocomplete options available in the QACDG. There were between 0 and 20 autocompletes found for each query term on each of the days. A significant difference in the number of autocompletes for comparable QACDGs, i.e., those that differed only in terms of the language used such as “coronavirus is” versus “coronaviruses”, was considered as an indicator of bias.
The average sentiment of the autocompletes
The second dimension of the study considered was the average sentiment conveyed by the autocompletes (QACDG). To quantify this aspect, we obtained a sentiment score (e.g., positive, negative, or neutral) for each of the autocompletes using Amazon’s sentiment recognition software, which works for English and Spanish.
29
The autocompletes that are likely to evoke positive emotion in the reader (e.g., “coronavirus is curable”) are assigned a positive sentiment label by the software, and those likely to evoke negative emotion in the reader (e.g., “coronavirus is deadly”) are assigned a negative sentiment. We denoted the scores numerically as +1 for positive, −1 for negative, and 0 for neutral autocompletes. As mentioned above, there were up to 20 such scores obtained for each QACDG. Next, we calculated four aggregate statistics: the number of positive autocompletes (+1), the number of negatives (−1), the number of neutral (0), and the total number of autocompletes. Once we obtained these statistics, we calculated the average sentiment score as
Topics covered by the autocompletes
The third aspect of this study analyzed the variation in topics covered by the QACDGs. The primary objective was to identify the main themes or subjects that would resonate with users upon exposure to a QACDG. Any differences observed will help to describe the relative levels of discussion on health, economic, and religious aspects between Spanish and English. For the labeling process we followed the IAB Taxonomy, a taxonomy developed by nonprofit research and development consortium that focuses on helping organizations implement global industry technical standards and solutions. 30 We used the Tier one categories to label our list of grouped autocompletes. This included medical health, healthy living, science, travel, religion, and spirituality, etc.
Codebook for labeling daily autocomplete data.

Statistical analysis
We employed statistical tests to evaluate the difference observed in autocomplete results. We computed the average number of autocompletes and the average sentiment of autocompletes for the five keywords daily. Student’s T-test (2 -sided, pairwise) was used to discern whether there are significant differences between the English and Spanish autocompletes. 33 In addition, Chi-square test was employed to test whether language played a significant role in the relative distribution of autocompletes across different topics. 33
Results
The number of autocompletes
Number of search autocompletes in English and Spanish and differences between them.
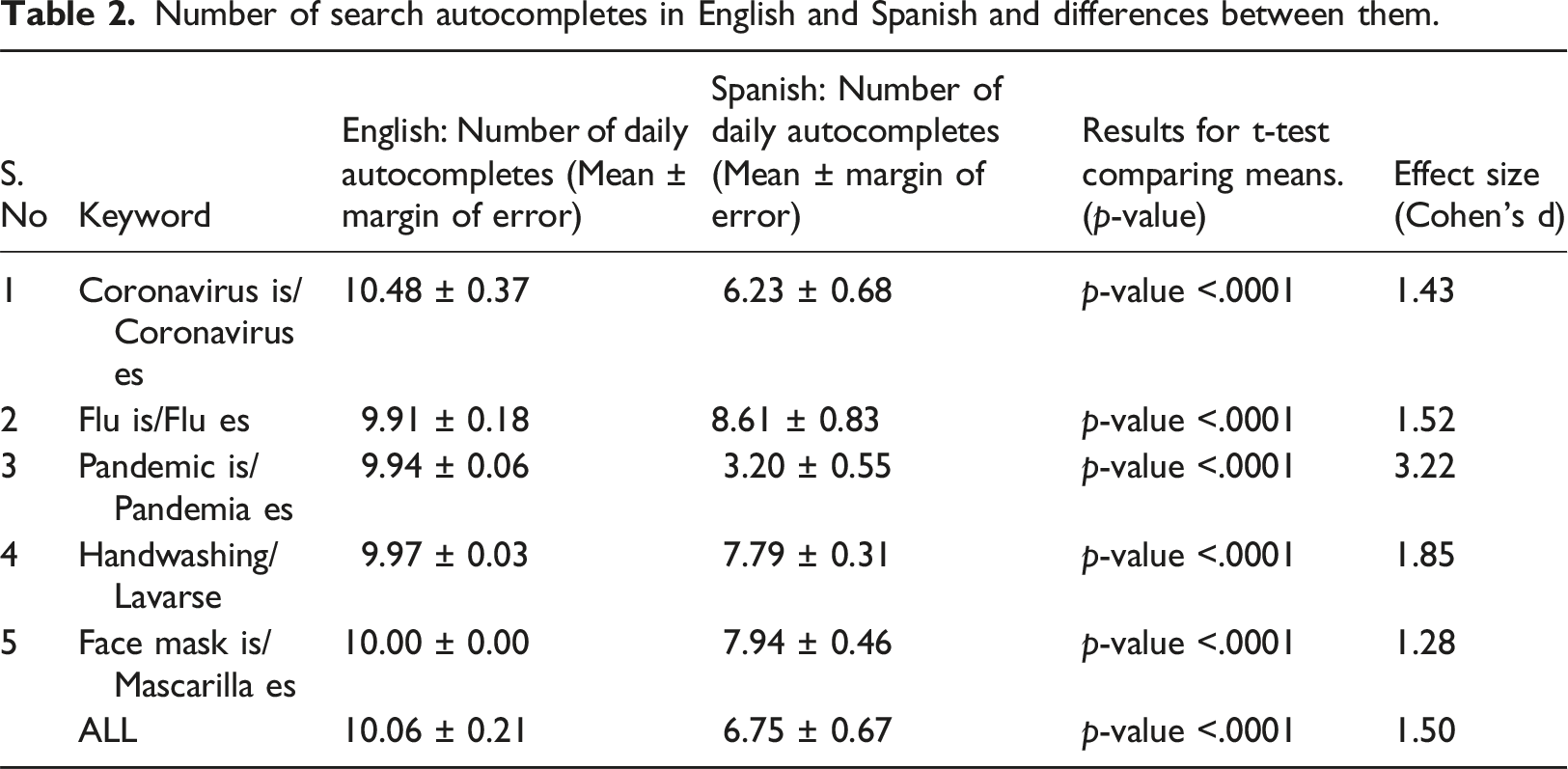
As shown in Table 2, the average number of autocompletes was lower in Spanish than in English for all the five keywords considered. We used a Student’s T-test (2 -sided, pairwise) with the average daily count values for English and Spanish to check if the differences were statistically significant. The results indicated that the differences were statistically significant for each of the five terms, with frequencies in English being higher than those in Spanish.
The average sentiment of the autocompletes
Average sentiment conveyed by the search autocompletes in English and Spanish and differences between them.
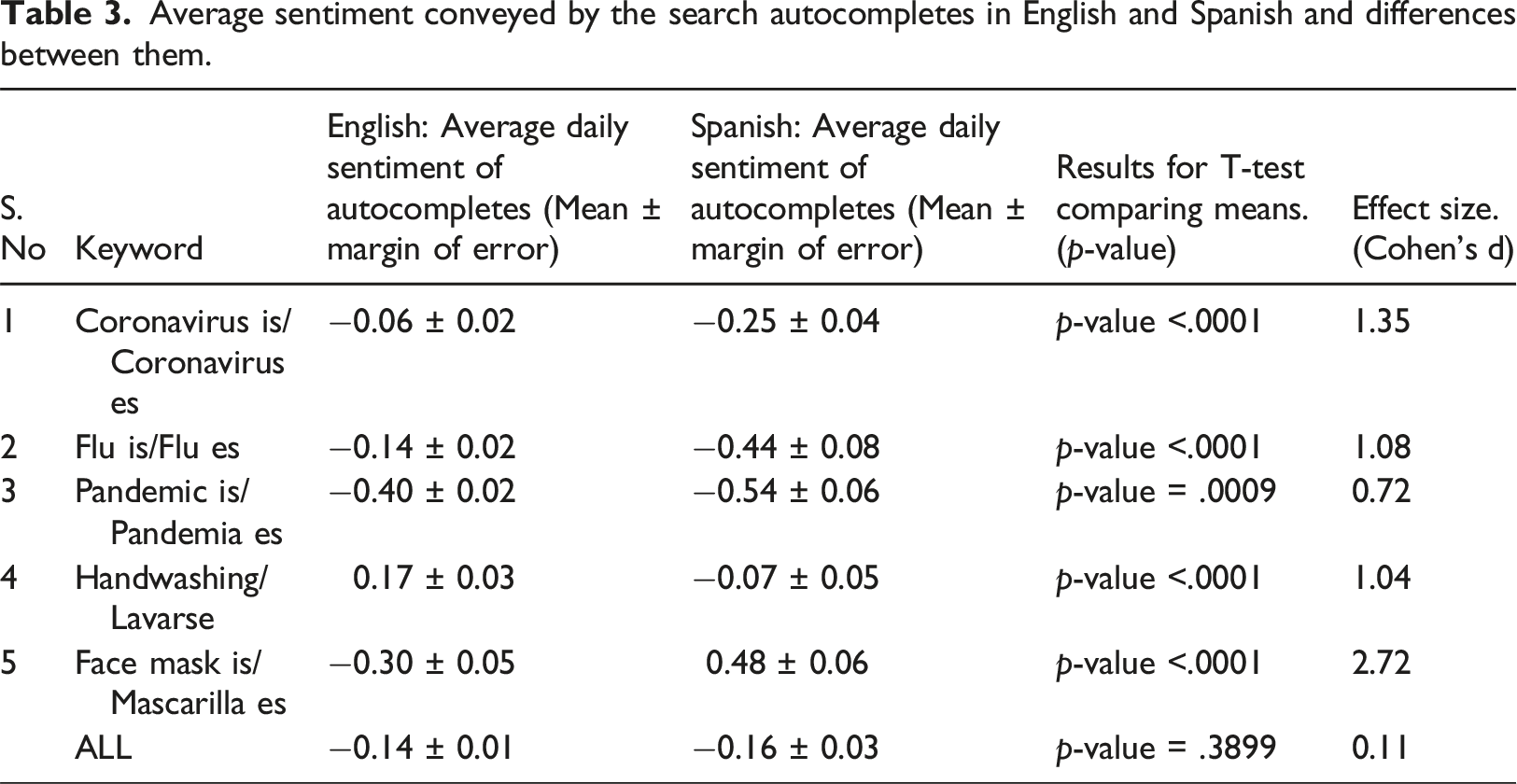
As we can see for four of the five Covid-19 related terms (‘Coronavirus is,’ ‘Flu is,’ ‘Pandemic is’, ‘Handwashing is’) in English, the average sentimental score for autocompletes is more favorable as compared to the corresponding terms in Spanish. A noteworthy difference is the keyword “face mask” where the sentiment for autocompletes in Spanish was more positive than English version. One possible reason is that face masks have a cultural association with festivities for the Latino community (e.g., Carnival and Diablada). This could explain the more positive connotation of face masks in Spanish autocompletes during the early phase of the pandemic. No other terms (e.g., coronavirus, flu, pandemic, handwashing) had a similar history of linkage with traditional festivities. The results of the repeated measures T-test indicated that the differences were statistically significant for each comparison between English and Spanish terms.
Topics covered by the autocompletes
We observed the differences in the topics of the autocompletes collected by examining the distributions of these topics using histograms. Histograms help plot the frequency of occurrences for the different topics/themes divided into classes, called “bins” for different keywords in the two languages considered. Figure 2 presents the histogram of the topics described in the two languages. Topics covered in the search results.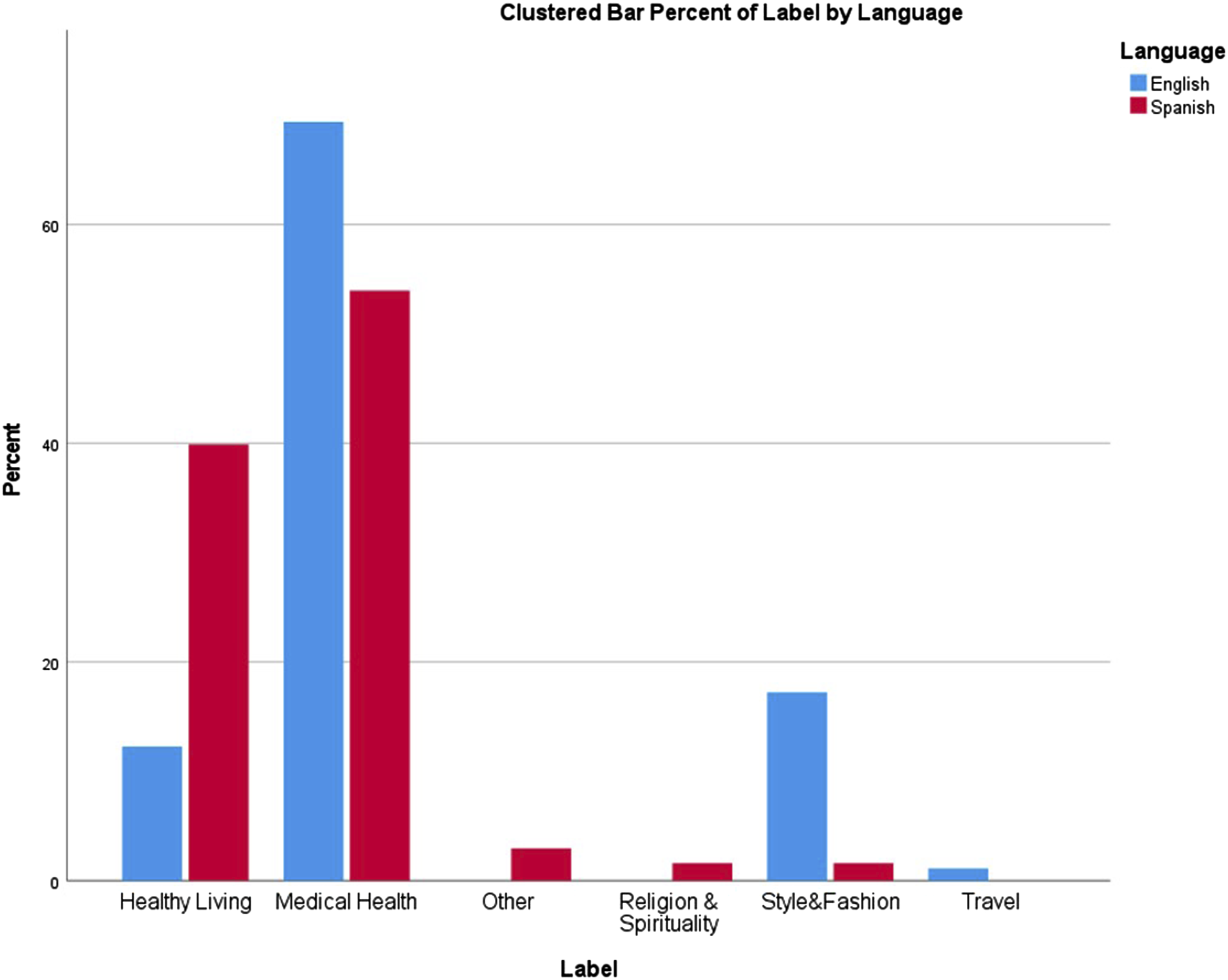
As can be observed in Figure 2, the distribution appears non-uniform across the different topics in the two languages. While “medical health” is the most common topic in both languages, the 2nd most frequent topic differs for the two languages. “Healthy Living” is the 2nd most common topic in Spanish, while it is “Style and Fashion” in English. The “Healthy Living” topic was frequently associated with hand washing in both English and Spanish. However, it had a more negative tone in Spanish, where it often focused on aspects like whether it causes chemical or physical changes to hands. The emergence of “Style and Fashion” as the second most common topic in English indicates that the discussions on aesthetics and comfort were much more common in English autocompletes than in Spanish. Similarly, “Travel” as a topic is only present in English. Interestingly, “Religion and Spirituality” as a topic appears only in Spanish. It included autocompletes like “coronavirus es biblico,” which connected coronavirus with a religious text. These results suggest that autocompletes focused on different aspects across the two languages.
To statistically test whether language played a significant role in the relative distribution of autocompletes across different topics, we used the Chi-Square test, which indicated that the differences were significant with a p-value less than 0.001 (statistic = 273.252, df = 5).
Discussion
Overall, our results suggest significant differences between the autocomplete results observed in English and Spanish in terms of the frequency counts, sentiment, and the topics covered. These observations should be considered alongside various theoretical frameworks and empirical findings presented in the existing literature.
Socio-technical complexity and legal debates surrounding Google Autocompletes
Google Autocompletes (GA) operate within a socio-technical system where user behavior, data collection, and algorithmic processing are deeply intertwined. This system’s complexity is reflected in the diverse outcomes of autocomplete suggestions, ranging from enhancing the search experience to inadvertently spreading misinformation.13,34 The legal discourse surrounding GA further adds to this complexity, with courts worldwide grappling with the liability of search engines for the content suggested by their algorithms.15,18 The varying judicial perspectives analyzed by Karapapa and Borghi (2015) demonstrate the challenge of establishing a consistent legal stance on the issue. 35
The ethical responsibilities of search engines like Google, as gatekeepers of information, are at the forefront of this debate. The legal ambiguity surrounding autocomplete suggestions—whether they are viewed as protected expressions of thought or as technical processes—raises significant ethical questions about the management of these predictions. 35 While some autocomplete suggestions may be legally permissible; they can still have substantial consequences for public discourse. It is crucial for Google to navigate this landscape responsibly, ensuring that the amplification of information through GA is balanced against the need to minimize biases.15,36,37 As the custodian of a system that shapes public perception, Google must consider both the legal precedents and the broader ethical implications of its autocomplete function, particularly in times of health crises when accurate information is paramount.
Public health and health equity impact
The disparities in autocomplete suggestions between English and Spanish, as revealed by this study, have significant implications for Spanish speakers and the Latino community, which has been disproportionately affected by the COVID-19 pandemic.38,39 The misinformation presented through autocompletes could influence Latinos’ health behaviors and beliefs, potentially exacerbating existing health inequities.3,40,41 Addressing these biases is therefore not just a matter of algorithmic fairness but also a public health imperative.
Moreover, the study’s findings underscore the importance of equitable access to accurate health information as a determinant of health outcomes. As search engines increasingly become primary sources of health information, the role of algorithms in shaping access to this information cannot be overlooked.42,43 The research calls for a collaborative effort between public health professionals, information technologists, and policymakers to ensure that search autocompletes do not perpetuate health disparities. By highlighting the need for algorithmic audits and bias correction, the study contributes to the ongoing efforts to achieve health equity and improve public health outcomes.
A recent related work by Valera et al. (2023) has shed light on the social implications of these biases. 3 Their findings from focus group meetings with English and Spanish speakers illustrate that autocompletes can influence the preselection of searches. Further, the limited choice of results for Spanish-speaking searchers is particularly concerning as it may contribute to the hesitation and concerns expressed by Spanish speakers, stemming from both social factors and a lack of comprehensive information about COVID-19. 3 It is not surprising that the New York City Department of Health and Mental Hygiene determined that the spread of misinformation about Covid-19 was having a harmful health impact, particularly on communities of color with low vaccination rates and decided to launch a misinformation response unit. 10
Methodological advancement: language equity audits for autocompletes
This study marks a methodological advancement to support language equity audits for search autocompletes, offering a scalable and replicable framework for future research. By combining automated analysis with human labeling of topics, the study comprehensively captures the breadth and depth of autocomplete suggestions, revealing nuanced biases.
The study’s approach underscores the importance of addressing digital equity, especially as disparities in digital access—such as internet and mobile phones—have been recognized as significant factors in health equity.23,24,40 By highlighting the latent layers of digital infrastructure, like search autocompletes, this research moves the conversation forward, emphasizing how unequal access in these areas can be a critical issue. The work intersects with current discussions on health misinformation and builds upon the gatekeeper theory suggesting that the role of search engines as “information gatekeepers” has evolved.10,44 With the shift from traditional sources like librarians and healthcare providers to search engines for health information, the potential for bias in autocomplete suggestions becomes a significant concern with far-reaching impacts on vulnerable populations.
Implications to public health and informatics
Based on the findings of this work, we propose specific policy recommendations to mitigate biases in autocomplete results.45,46 Each of these can be mandated by the governments, self-adopted by search engines, or actively demanded by users and advocacy groups. • • • • • •
Limitations
While providing valuable insights into language biases in search autocompletes, this study has limitations that impact the generalizability of the findings. The data was collected at a single location—New York City—using only Google’s search engine. While Google holds a dominant market position in search and New York City was a significant epicenter of the COVID-19 outbreak in Spring 2020, with a notably high number of cases within the Latino population, these factors may not fully represent global search behaviors or the nuances of autocomplete functions in other contexts.47,48 To improve the generalizability, as part of future research, we plan to expand the study to multiple geographical locations and include various search engines. This broader approach will enable a more thorough understanding of autocomplete biases and their global implications. Additionally, while the current study tried to minimize the influence of search personalization by utilizing an API in incognito mode, the efficacy of this approach is debated.17,49,50 As such, the impact of personalized search histories on autocomplete results remains an area ripe for exploration.
The reliance on automated analysis for quantifying the number of options and sentiment analysis presents another limitation, as it may constrain the depth of interpretability. Despite this, the study’s methodology is strengthened by an iterative human labeling process for topic analysis, which adds a layer of qualitative assessment to the quantitative data. Future studies could benefit from integrating more nuanced human interpretation to complement automated metrics, thereby enriching the analysis of autocomplete suggestions and their potential biases.
Conclusions
This study provides a pioneering systematic audit of language disparities in search autocompletes during a critical phase of the COVID-19 pandemic. It reveals that English and Spanish speakers received autocomplete suggestions that varied not only in quantity but also in sentiment and thematic content, despite confronting identical health threats. While these findings are specific to the early stages of the pandemic, they raise important considerations for the generalization of results to other health emergencies. As such, it is crucial for search engine providers, public health officials, and policymakers to consider the impact of autocomplete functions on public health messaging and individual health choices. In light of these insights, we call upon stakeholders to recognize the importance of equitable information access during health crises. Proactive audits and adjustments to autocomplete algorithms are essential steps to prevent the perpetuation of biases and ensure that all communities have access to empowering and accurate health information. By doing so, we can work towards minimizing the risk of unequal health outcomes and support informed decision-making across diverse linguistic groups in any future health emergency.
Footnotes
Author contribution
Conception and Development were done by V.K.S. and P.V. Theory and Computations were led by I.S. and R.S. with support from Y.B., Y.R. and V.K.S. Qualitative Analysis was undertaken by Y.B. and P.V. The work was supervised and coordinated by P.V. and V.K.S. All authors discussed the results and contributed to the final manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation under Grant 2027784.