
Abstract
Introduction
One of the most prevalent disorders in ophthalmology is eye infections. These infections affect either the outer or inner components of the eye. 1 Endophthalmitis is the term used to describe inflammation of the vitreous and/or aqueous humor, usually caused by infections or other external factors. The sources of the condition include surgical procedures, injections, blisters, physical injury, and inflammation of the cornea.2–5
Endophthalmitis is considered an ophthalmologic emergency. Hence, its diagnosis and treatment should be conducted immediately after any evidence of its emergence. 6 The prevalence of this disorder has increased with the introduction of cataract surgery, therefore, acute postoperative endophthalmitis is currently the most frequent cause. 7 Although endophthalmitis has become common in the context of cataract extraction, gradual increases in its incidence rate have been reported in association with other variables, particularly with the increased use of antivascular endothelial growth factor (anti-VEGF) injections.4,8
Large language models (LLMs) are increasingly utilised in patient education and medical decision-making, with the potential to significantly impact ophthalmology by acting as a catalyst for medical artificial intelligence.9–12 Numerous ophthalmology studies have assessed how well LLMs respond to patient inquiries and provide medically accurate information to eye specialists regarding a range of ocular conditions, including cataracts, retinal diseases, and glaucoma.12–14 LLMs such as ChatGPT are increasingly being used by patients who want to learn about their eye health through the Internet. 15
Ophthalmology will greatly benefit from integrating LLMs into current clinical treatment, considering the abundance of digital data from electronic records, imaging databases, and electronic communication with patients. Although LLM technology is in its early stages, its potential for major advancements and numerous applications for patients and physicians, could significantly revolutionize healthcare delivery.16,17
Endophthalmitis is an ocular emergency and its incidence is increasing due to the increasing frequency of cataract surgery and intraocular injections. It is a rapidly progressive, life-threatening infection for which early diagnosis and treatment are crucial for optimal care and the prevention of disease progression. As such, it differs from other eye infections. In conclusion, artificial intelligence systems in large-language chatbots have the potential to help improve patient outcomes by reducing the number of missed or delayed diagnoses. 18 Therefore, further research is required to determine whether patients receive accurate information from artificial intelligence chatbots like A-Eye Consult, ChatGPT, Copilot, and Google Gemini. These four chatbots were selected for the study due to their popularity and are frequent comparison in research on eye diseases.19,20
To the best of our knowledge, no study in the literature has investigated the effectiveness of chatbots for endophthalmitis. This study aimed to compare the effectiveness, accuracy, readability, and advantages and disadvantages of responses from the four chatbots to 25 frequently asked questions about endophthalmitis.
Materials and methods
The study included 25 questions about endophthalmitis asked by Internet users while using Google (Alphabet Inc.), comprising frequently asked questions doctors receive regarding their patients’ diagnoses and disease treatment. The 25 questions were selected by an ophthalmologist (SD), based on previous studies on the accuracy and readability of chatbots, without a specific rationale for choosing 25 questions.14,19 These questions and the answers provided by the four chatbots are available in the electronic supplementary material. Irrelevant answers to the questions or answers with grammatical errors were excluded from the study
The recorded responses were evaluated separately by two attending ophthalmologists (SD,ICT) using the five-point Likert scale that was previously used to evaluate the accuracy of LLMs, and responses were rated between one and 5. 21 After debating and utilizing the criteria to resolve discrepancies in the Likert scale ratings, the ophthalmologists agreed that the consensus score represented the final assessment. The scoring was as follows: 1: Strongly disagree; 2: Not in agreement; 3: Neither in agreement nor dispute; 4: Accept; 5: Completely concurred.
The DISCERN scale was used to assess the accuracy and reliability of the responses in more detail. 22 The system assigns a score between one and five to each of the 15 questions, assessing the impartiality and comprehensiveness of medical treatment data. The total score ranges from 15–75, with categories: outstanding (63–75), acceptable (51-62), ordinary (39–50), bad (27–38), and severely awful (15–26).
Finally, the well-known Flesch–Kincaid readability test scale, encompassing the Flesch Reading Ease (FRE) and Flesch–Kincaid Grade Level (FKGL) tests, was used to evaluate the responses’ comprehensibility and complexity, respectively. The FRE score ranges from 0–100, with higher scores indicating more reading ease and lower scores indicating more difficult in understanding. 23 The FRE score quantifies the ease of understanding of the text, whereas the FKGL index evaluates the educational level needed to comprehend the text and its intricacy, with higher scores indicating greater complexity of content. In order to evaluate the chatbots’ performance, the responses from each bot were collectively assessed using the DISCERN score and the FRE and FKGL readability scale. Each model received a single composite score as a consequence of this assessment.
Statistical analysis
The Kolmogorov–Smirnov test was performed to assess the normality of the data. The dataset was summarized with descriptive statistics. Categorical variables were represented by numbers and percentages, and quantitative variables were presented as means ± standard deviations or medians (minimum-maximum). The mean values of the DISCERN, FRE, and FKGL scales were reported. The data were processed using IBM SPSS Statistics Version 25 (Armonk, NY, USA). The Friedman test was used to compare the LLMs; if a significant difference between the four LLMs was found, pairwise subgroup analyses were performed using the Wilcoxon rank-sum test. A p-value of <0.05 was considered statistically significant. In pairwise group comparisons, statistical significance was determined at p < .01 following Bonferroni correction.
Results
The Likert scores of the 25 answers given by the large language models for the questions asked.

Mean ± Standard Deviation scores of the four large language models in the total question categories.
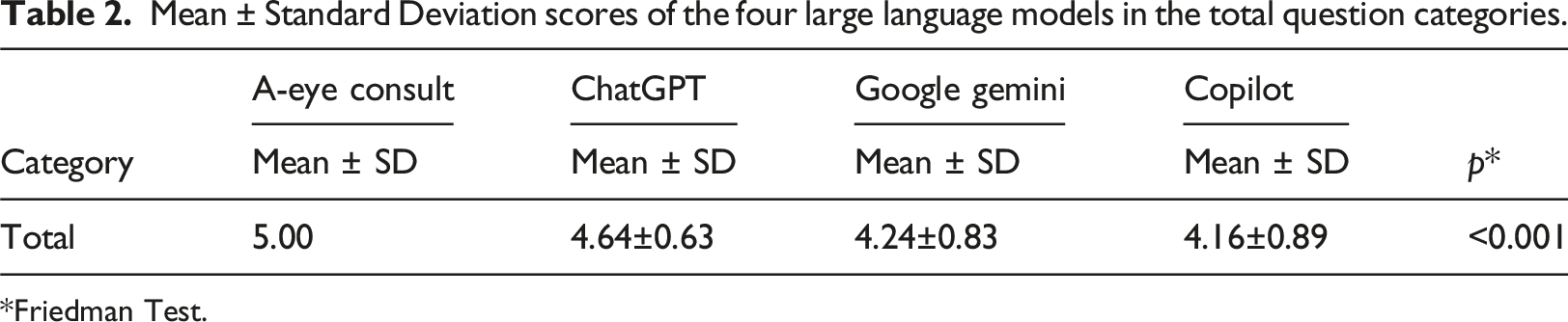
*Friedman Test.
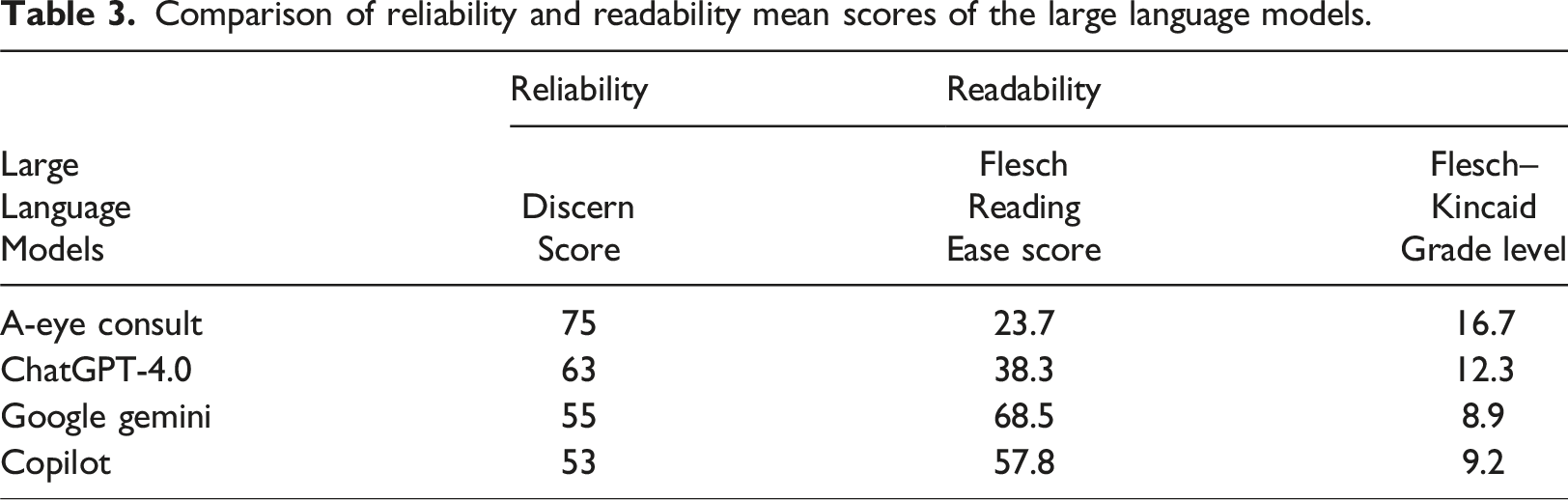
Comparison of reliability and readability mean scores of the large language models.
Discussion
In this study, A-Eye Consult had the highest DISCERN score of 75 points among the four LLMs, followed by ChatGPT-4.0, Google Gemini, and Copilot with 63, 55, and 53 points, respectively. This result shows that A-Eye Consult, a chatbot for eye diseases, provides more reliable information about endophthalmitis. Furthermore, the DISCERN score for ChatGPT-4.0 was excellent, while those of Google Gemini and Copilot were acceptable. In the analysis for the FRE readability score, the lowest FRE score was 23.7 points for A-Eye Consult, while the highest score was 68.5 points for Google Gemini. Furthermore, in the analysis of the FKGL score, Google Gemini received the lowest score (8.9; middle school level for FKGL), while A-Eye Consult received the highest score (16.7; postgraduate level for FKGL). These results indicate that Google Gemini performed the best among the four LLMs in terms of readability and comprehensibility, while A-Eye Consult performed the worst in terms of readability and comprehensibility.
The world is currently interested in artificial intelligence and its potential applications in medicine. When applied effectively, AI can enhance patient awareness of diseases and facilitate early diagnosis. 24 One such condition is endophthalmitis, wherein the intraocular fluid is inflamed; it can be a serious medical emergency causing permanent loss of vision. This inflammation typically develops after recent keratitis, intraocular injections, trauma, or eye surgery. 4 Approximately 10% of endophthalmitis cases result in a visual acuity of 20/800 or worse, posing a serious risk to visual functioning, even though in the majority of cases, nearly normal vision is regained. 6 A meta-analysis on endophthalmitis, which is very common among patients and physicians, reported an incidence of 0.056% following intravitreal eye injections with anti-VEGF agents, translating to one case occurring in evert 1779 injections. 25 Early diagnosis of endophthalmitis is critical for optimal care and the prevention of disease progression. 18 Consequently, it is believed that the employment of artificial intelligence systems in broad-language chatbots can help to improve patient outcomes by decreasing the number of missed or delayed diagnoses.
Large Language Models (LLMs) are computer systems capable of understanding, synthesizing, and inferring from user problems. 26 They serve as a resource for patients and aid healthcare professionals in addressing electronic patient communications. They are user-friendly, efficient, and dependable.27,28 Previous research has demonstrated that users are generally eager to look for health advice via chatbots, implying that LLMs can be viewed as an alternate source of knowledge for patients in specific scenarios where it is impossible to reach a physician.29–31 Since endophthalmitis is a serious disease that can lead to blindness if it progresses, it is critical that patients use LLMs to obtain accurate, reliable, and clear information and that correct facts are accessed. To the best of our knowledge, this is the first study in the literature to evaluate the accuracy and readability of the responses given by LLMs regarding endophthalmitis. LLMs have been used to build artificial intelligence applications such as ChatGPT-4.0, Google Gemini and Copilot. OpenAI’s newest language model, ChatGPT-4.0, was built with a LLM and was publicly introduced in March 2023. Similarly, Google Gemini and Copilot language learning initiatives were announced in 2023. These are current AI language programs with characteristics similar to ChatGPT.32,33 This study found that A-Eye Consult and ChatGPT-4.0 chatbots provided more detailed and accurate answers to patient questions about endophthalmitis than Google Gemini and Copilot, with 100% and 92% of A-Eye Consult’s and ChatGPT-4.0’s answers, respectively, falling into the “agree” or “strongly agree” categories. This rate was found to be 76% for Google Gemini and 68% for Copilot. In a study of large language models assisting glaucoma surgery, Carla et al. reported a 58% success rate for ChatGPT and 32% for Google Gemini (p < .001). 34 In another study conducted by Lee et al. that compared LLMs in bariatric and metabolic surgery, a significant difference was found between the three LLMs: ChatGPT-4 85.7%, Bard 74.3%, and Bing 25.7%. 35 The results of this study were consistent with the literature in terms of comprehensiveness and readability. For example, in a study comparing Google Gemini and ChatGPT on cataracts and cataract surgery, Cohen and colleagues found that, consistent with the findings of this study, ChatGPT provided a more accurate and actionable information on eye health for patients with high health literacy. Additionally, the answers provides by ChatGPT were longer and written at a higher reading level. 14
These results may be attributable to the fundamental differences in the aims and structures of the four LLMs. A-Eye Consult, an ophthalmology chatbot primarily developed by Dr. Singer, MD, was built using GPT-4 (the LLM that powers the public chatbot ChatGPT-4), LangChain, and Pinecone; it primarily uses the GPT-4.0 architecture. A-Eye Consult’s database includes the 2021–2022 American Ophthalmology Basic and Clinical Science Course textbook and the seventh edition of the Wills Eye Manual. Although the data in this study are not statistically higher than ChatGPT-4.0 as the Likert scale of the Aeyeconsult chatbot (p = 0 0.038), it scored significantly higher than other chatbots in the Likert scales (p < .001, p < .001, respectively). A-Eye Consult, which was developed as a chatbot specialising in ophthalmology, is at an advantage because it uses the ChatGPT-4.0 architecture and textbooks of ophthalmology in its database. 36 It is thought that the reliability, accuracy, and complexity of ChatGPT-4.0’s responses to the questions about endophthalmitis, compared to those of the other two chatbots— Google Gemini and Microsoft Copilot— are attributable to its advanced algorithms. Various data sources are used to train ChatGPT-4.0 to generate conversational experiences that resemble human interactions. To encourage in-depth conversations, ChatGPT-4.0 offers more comprehensive and educational answers. Unlike Google Gemini and Copilot, it has its own database. ChatGPT generates accurate and contextually relevant responses by utilising supervised and reinforcement learning approaches. Conversely, Google Gemini and Copilot are artificial intelligence systems designed to streamline information access and search, with an emphasis on conciseness and clarity. Furthermore, Copilot and Google Gemini can pull web searches and information from a variety of unreliable websites. Although Copilot uses the ChatGPT-4.0 architecture, it also accesses resources with the help of an Internet search engine likely contributing to the performance difference between these two chatbots. 37 As with many previous language program comparisons, this is also why the ChatGPT-4.0 algorithm is considered to be successful when compared to other language programs in the field of ophthalmology today.
Limitations of the study
This study has some limitations. A major limitation is that only questions about a single eye infection, endophthalmitis, were included in the study. Furthermore, only four chatbots were investigated and other frequently used chatbots, such as Claude or LlaMA, were not included
Conclusion
In this study, we aimed to evaluate the accuracy, reliability, and readability of answers provided by four chatbots in response to questions about endophthalmitis. A-Eye Consult, which uses ChatGPT-4’s architecture and is a specific ophthalmological chatbot, was found to be worse than other chatbots in terms of readability and comprehensibility, although it gave highly reliable and accurate answers to the questions asked. Similarly, although ChatGPT-4.0 provided more accurate and reliable answers to the questions than those by Google Gemini and Copilot, they were more complex than those of Google Gemini and Copilot in terms of comprehensibility. The main difference between the LLMs is that each chatbot has its own algorithm and architecture.
To the best of our knowledge, this is the first study to assess the effectiveness, accuracy, and readability of responses to endophthalmitis-related questions provided by LLMs. This study findings suggest that artificial intelligence LLMs, particularly those utilizing their database in addition to the GPT-4 architecture, such as A-Eye Consult and ChatGPT-4.0, have substantial potential as reliable tools for answering endophthalmitis-related inquiries. Artificial intelligence chatbots, which are projected to be widely utilized by patients in the next few years, are thought to be crucial for providing patients with accurate and reliable information on acute eye problems like endophthalmitis. AI language programs should be considered a useful resource for both physicians and patients, rather than an alternative for clinicians. However, further studies investigating the effectiveness of AI chatbots for endophthalmitis and eye emergencies are needed.
Supplemental Material
Supplemental Material - Evaluation of the reliability and readability of answers given by chatbots to frequently asked questions about endophthalmitis: A cross-sectional study on chatbots
Supplemental Material for Evaluation of the reliability and readability of answers given by chatbots to frequently asked questions about endophthalmitis: A cross-sectional study on chatbots by Suleyman Demir in Health Informatics Journal.
Footnotes
Acknowledgements
Author contributions
Suleyman Demir: Conceptualization, Methodology, Validation, Formal analysis, Investigation, Resources, Writing - Original Draft, Writing - Review & Editing, Visualization, Supervision, Project administration, Funding acquisition
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethical statement
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.