
Abstract
Introduction
With the aid of information technology (IT), human society is embarking on a new era of advancement. An economic framework anchored on intelligence, networks, and big data is taking shape, characterized by “fusion,” or the profound integration of IT and industrial manufacturing, humans and machines, and information and material resources. This integration has triggered a seismic shift in various facets of human life, including education, medical treatment, public service, and social interaction, moving from local to global intelligence, thereby altering people’s lifestyles and behavioral patterns. 1 Despite these gains, healthcare IT remains mired in inherent problems. Information construction lacks application scenarios, informatization design falls short in realizing complete informatization and digital operation, hospital information system (HIS) integration is poor, data center construction lags behind, and overall informatization is characterized by “reconstruction light use”. 2 The purpose of this paper is to shed light on the inherent dilemma of artificial intelligence (AI) technology in acquiring knowledge data through data governance in China’s healthcare informatics by briefly outlining the current state of healthcare data informatization, scientific governance technological advancements in clinical data, and meta medical data governance framework for generating knowledge data.
Informatization and medical data
In the era of AI, medical data serves as the cornerstone and foundation of hospital informatization.3,4 High-quality medical data support is essential for the effective functioning of medical AI applications. Hospital informatization in China started in the 1990s, with financial accounting and fees as the core of hospital management informatization. Over time, the HIS has gradually expanded to encompass all clinical business and life-cycle diagnosis and treatment data for a vast number of patients, aided by IT development. 5 However, for historical development reasons, there are several issues with the data. Informatization planning in most hospitals is not uniform, resulting in different information systems being introduced at various times to different business departments. This has led to scattered clinical diagnosis and treatment data across multiple information systems with varying data types, versions, structures, and formats, creating challenges for system interconnection and data integration.6,7 With the construction and extensive application of medical informatization platforms, more medical procedures rely on the HIS, and the volume, complexity, and sources of health medical data are skyrocketing. This explosion of data poses new challenges for the governance and application of healthcare data.
Poor data consistency and completeness
Data fragmentation resulting from the lack of interoperability between different business systems within hospitals has led to the emergence of information silos.8,9 The current state of hospital information systems (HIS) highlights some issues, such as incomplete data schema descriptions, unclear data connections between systems, and inconsistent system value domain standards. 10
The primary cause of poor data consistency is the lack of uniform data standards. For instance, multiple information systems in hospitals adopt different reference standards and coding modalities for the same subject dictionary. Some data entries are manually customized and not generated according to dictionary tables, such as customized medical orders and check items. The business table and the dictionary table field lengths are not set optimally, leading to truncated fields.
One reason for the poor data integrity is the lack of a verification mechanism in the information system, which results in inadequate quality control during data generation. This may be due to HIS construction not keeping pace with the development of medical management needs. 11 Another reason is inadequate integration, where data are dispersed among different systems, and logically linked data cannot be related because the association information is not stored in the database, such as lung function testing devices.
Disparities in data standards
Uniform data standards are essential for ensuring data consistency and improving data quality in the process of hospital informatization in China. The lack of such standards has resulted in issues such as illegal data formats, non-standard coding, and ambiguous business logic. 12 For instance, earlier versions of the International Classification of Diseases 10 (ICD10) used for case number coding in hospitals differ across provinces. Information shared across different business systems also varies in terms of format and content. Furthermore, standards for fields like gender, region, and occupation differ across systems. Without proper master data management, integrating data associations from various systems becomes challenging.
Data security and privacy protection
Currently, many HISs can no longer be physically isolated, and the construction of internet hospitals must be based on HISs to provide online medical services such as appointment registration, fee payments, report examinations, and health monitoring. However, data aggregation and outsourcing of such services can pose security risks such as data leaks, illegal access, and denial of service attacks. 13 With regard to personal privacy, hospitals have not fully recognized the significance of data analysis and utilization. Patient information desensitization services are inadequate, and targeted healthcare data security prevention systems have yet to be established.
Difficulties in data mining
In the HIS, structured, semi-structured, and unstructured data coexist, with a significant portion of medical data being stored in unstructured formats such as text and images. 14 Extracting valuable insights from unstructured medical text requires structured processing, posing a major challenge in data mining. Presently, an authoritative Chinese language medical terminology and text structuring tool is lacking, and effectively extracting accurate information from hospital textual data remains a significant challenge in structured medical natural language text. 15 For instance, medical records are often rife with irregular symbols, typos, and inconsistencies resulting from doctors’ writing errors.
China’s medical data issues are diverse and pressing, exposing four main problems: inconsistent standards, poor consistency and integrity of electronic medical record (EMR) data, difficulties in data mining and utilization, as well as security and privacy protection concerns. Addressing these data challenges necessitates urgent adoption of data governance strategies complemented by AI.
AI in data governance
A mounting number of medical institutions are realizing that medical data is underutilized due to poor quality. Effective medical data governance and data mining can provide vital support for medical information sharing, personal health planning, personalized clinical decision-making, diagnostic optimization of treatment processes, disease prevention and management, and national health strategy development. 16
Currently, there is no standardized definition of data governance at either domestic or foreign levels. The Global Data Management Community defines data governance as the exercise of authority and control (planning, monitoring, and enforcement) over the management of data assets. 17 The Chinese National Standard “Specification of data governance” defines data governance as a collection of control activities, performance, and risk management related to data resources and their applications. 18 The medical data governance platform comprises data storage, metadata management, data quality control, and data desensitization. To achieve this, we must develop various techniques, such as extraction, transformation, and loading (ETL) 19 ; textual information extraction and structuring 20 ; knowledge mapping; and multi-source data fusion. Additionally, the analysis and application of the data necessitate the use of a variety of statistical methods and AI algorithms.
Metadata management
As the key links of data governance, data integration faces difficulties mainly in poor data consistency and integrity. 21 Therefore, it is necessary to obtain a better understanding of the data in business systems through metadata management so as to assist in understanding data. Metadata are data that describe the attributes of data, which provide a means of identifying, defining, and classifying data in a subject domain. 22 Metadata management can facilitate the integration of data from multiple sources. 23
One of the core elements of metadata management is uniform and clear metadata standards. China already has relatively detailed industry standards, including the Specification for drafting of a health information basic dataset, the Electronic Medical Records Basic Framework, and the Data Standards. In terms of coding standards, there are Medical Subject Headings (MeSH), 24 the Unified Medical Language System (UMLS), 25 ICD, 26 the Systematized Nomenclature of Medicine-Clinical Terms (SNOMED-CT), and the Logical observation identifiers Names and Codes (LOINC). However, in practice, these standards are abridged and expanded to varying degrees depending on the purpose of the application. Therefore, establishing a metadata management mechanism based on metadata standards can help complement the standards and correlate different systems. In terms of technology, relational association rule mining, named entity recognition, and relation extraction can be applied to “metadata governance” of medical data.
Information privacy security architecture
With the rapid development of the Internet, cloud computing, 5G, and other information technologies, users have increasingly high requirements for network and data security. Specifically, in big data applications, data application security has become a top priority owing to the increasing amount of data. Owing to the unique sensitivity of medical data, medical institutions proactively strengthen data privacy protection measures to prevent active leakages. 27 The common approach is to follow the national framework of cybersecurity laws and regulations, as well as the national standard system of cybersecurity hierarchical protection, and give different access rights to medical data for different users.28,29 There are also AI methods such as bifactor and facial recognition, which enable human-machine isolation and in-hospital and out-of-hospital isolation so as to achieve data accessibility without abuse.
In addition to the abovementioned technical means, as medical personnel have direct contact with medical data, whether these personnel can adhere to the principle of protecting patient privacy directly affects the medical information security. At present, organizations at all levels in China regulate the patient privacy protection behaviors of medical staff by formulating policies related to patient privacy protection and imposing privacy protection requirements on medical staff. 30 Our team also promotes better patient privacy protection by constructing a theoretical framework for doctor-patient confidentiality. 31
Exploiting EMRs with artificial intelligence
An EMR contains information on demographics, medical history, vital signs, diagnoses, tests, treatments, and disease progression. In clinical data, in addition to structured data such as diagnoses and laboratory tests, there is also a significant amount of textual data such as medical records and examination text reports. Much of these data are stored in XML, HTML, TXT, and other formats. The data contain valuable information such as symptoms in the history of a present illness and tumor location in radiology reports, which need to be extracted from the free text by a certain technical means, that is, structuring medical text. At present, there are two ways to realize the structuring of medical text.
One is based on the natural language processing (NLP) algorithm model, which mainly includes steps such as named entity recognition and relation extraction. The NLP algorithm model is characterized by large-scale raw data that need to be labeled for algorithm training, a high labor cost in the early stage, and high requirements on computer performance. The effect and efficiency of the well-trained NLP model are better than those of regularization in large areas across multiple site texts.
In addition, based on a standardized coding system, it is relatively easy to extract structured medical data. First, keywords are extracted using term extraction technologies such as medical language extraction and an encoding system (MedLEE), UMLS, MetaMap, Hitex, 32 and the knowledge map concept identifier. Then, based on clinical experience and guidelines, rules are formulated by automatic rule generation methods such as the RETE algorithm, JBoss rule engine, feature selection algorithm, and discriminant analysis model. 33 For unstructured text, instead of extracting keywords and form rules from standardized medical language, we use NLP techniques such as coreference resolution, time analysis, assertion, semantic network, and unstructured information management architecture (UIMA).
Medical metadata governance framework
The acquisition of labeled data primarily involves annotating entities, attributes, and relationships within unstructured data found in EMR text and medical images. 25 The quality of labeled data plays a crucial role in training deep learning or neural network models. To ensure proper governance of labeled data, it is imperative to establish comprehensive labeling specifications for entities of varying granularity. This involves creating a medical terminology based on data from diagnoses, surgeries, tests, and pharmaceuticals, in conjunction with basic, bridge-building, and clinical disciplines. It is also necessary to standardize the management of all labeling process elements and perform cross-validation of labeling results. Data cleansing processes primarily consist of four steps: analyzing dirty data types, defining cleaning strategies, cleaning based on said strategies, and verifying data quality. The core component lies in defining the cleaning strategy, including standard data type definitions, data integrity constraints, and cleaning function rules.
Because knowledge-based data representation varies across agencies and complex relationships exist between knowledge, it is essential to uniformly represent knowledge-based data and clarify their relationships. Many informatization vendors have completed the initial governance of the database layer through a business understanding of integrated data, but useless for directly applied to clinical or scientific research tools.
Application scope of common medical related standards.
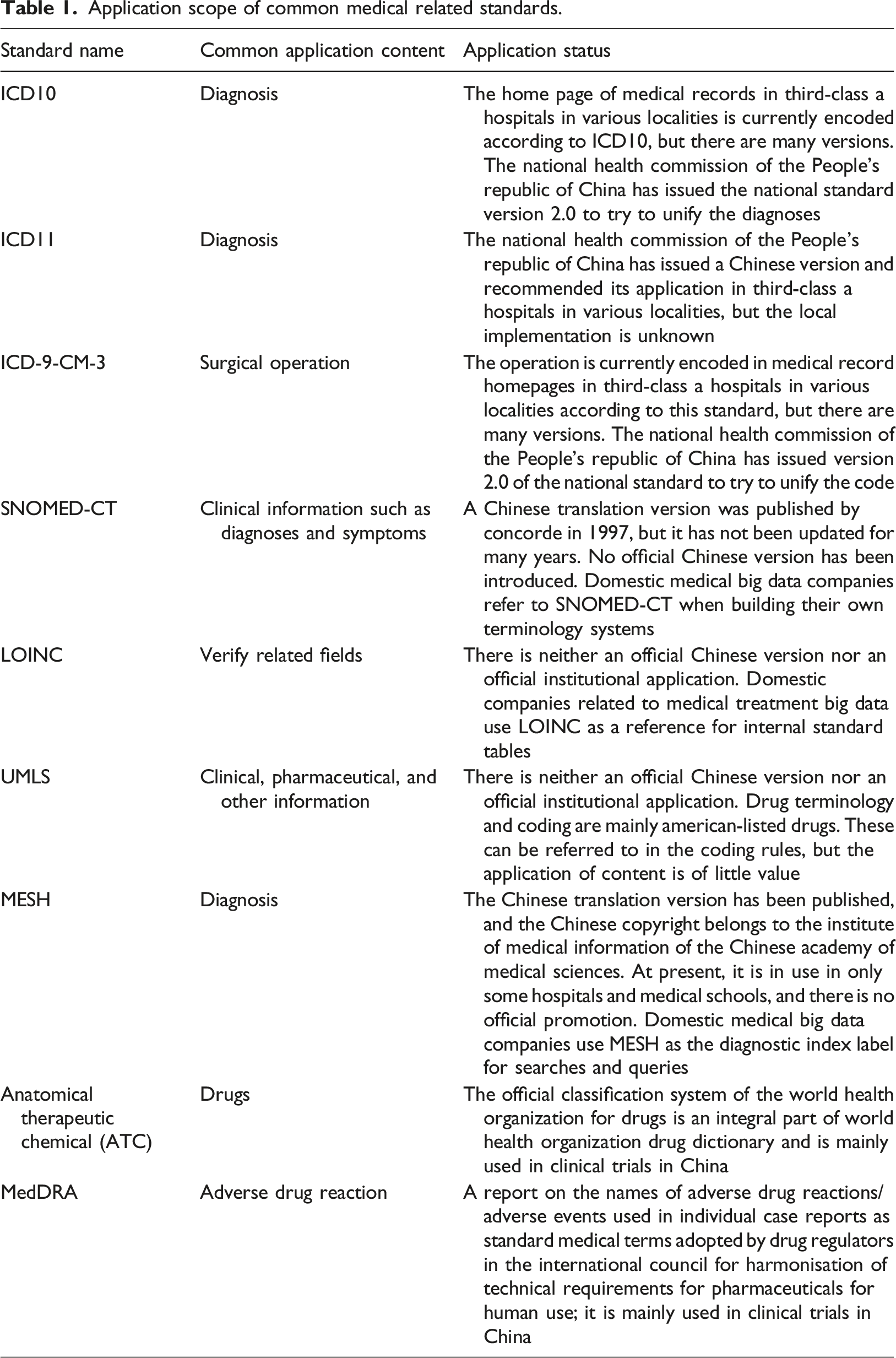
In summary, we believe that scientific governance of clinical data can only be achieved by integrating metadata management and master data management based on clinical practices, medical disciplines, and scientific exploration, within an information privacy security and medical law architecture. AI mining can successfully produce knowledge-based data based on this framework, which we call medical metadata governance, as depicted in Figure 1. Metamedical data governance framework. Similar to multivariate linear regression analysis, EMR data culminate in the formation of knowledge data based on clinical practices, medical disciplines, scientific exploration, metadata management, master data management, and AI mining. AI, artificial intelligence; EMR, electronic medical record.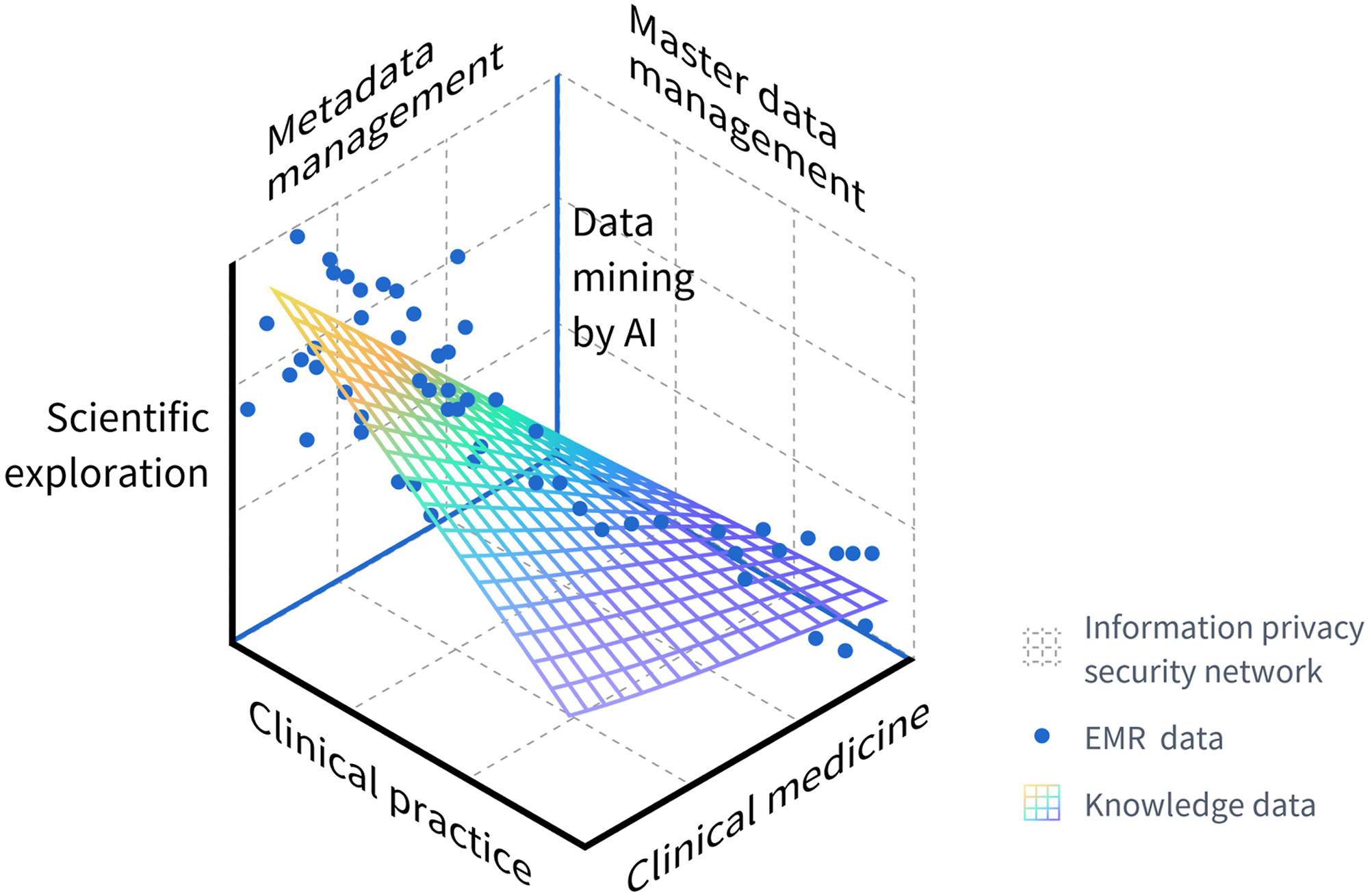
Application of SPRAY-type AI
Although the background of informatization and the weak connectivity of medical data make it difficult to transform the clinical research on EMR data, this does not prevent the use of the “Service, Patient, Regression, A-base/Away, Yeast” (SPRAY)-style AI application in the current environment. In selecting the acronym “SPRAY” for our custom designation, we were motivated by the observation that this application paradigm aligns seamlessly with the principles of stepwise development. While the foundation is indispensable, the progression is equally crucial. This represents a quintessential example of an artificial intelligence application in medical data that evolves from a focal point to a comprehensive coverage. Even if the problems of data consistency and integrity are solved through metadata management, data standard harmonization through master data management, data security and privacy protection through information security architecture, and mining difficulties through multiple AI tools, this is only a small segment of the scientific applications that have been completed for clinical data. To fully benefit from the value of EMR data, we must exploit all that AI has to offer. SPRAY serves the informational base parts, upholding patient-centeredness, giving back to clinical research in a sustainable manner, following the three laws of robotics, and always acting based on the three quadrants of medical ethics. We can thus finally realize the value of EMR data (Figure 2). Applications of SPRAY-type AI.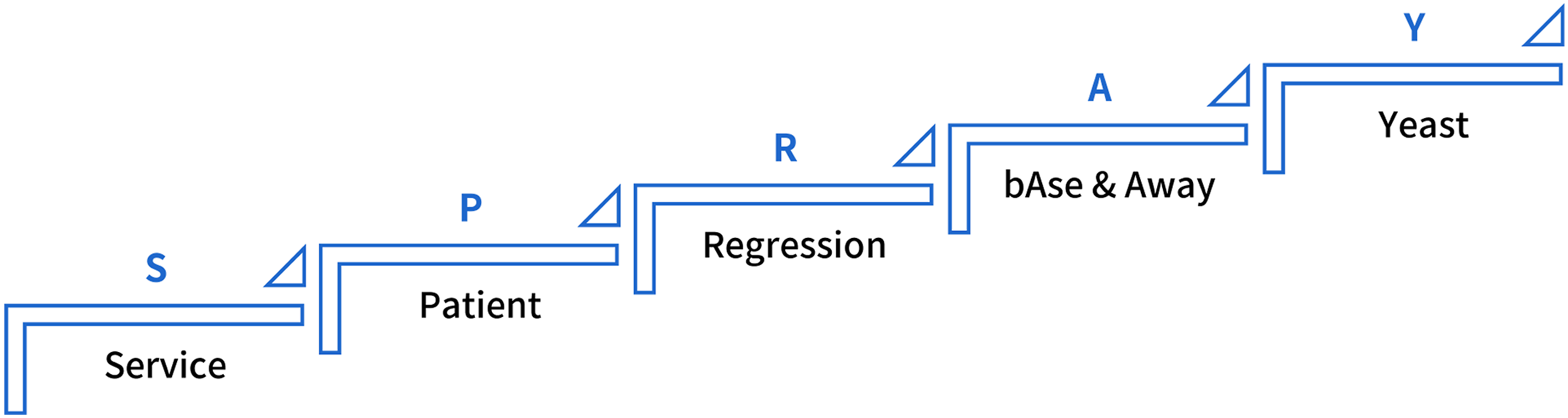
Base services
Over the past two decades, China’s hospital informatization has gradually caught up with other developed countries, but it remains a constantly evolving and optimizing process that requires updates and advancements in IT, particularly with the help of the Internet of Things, cloud computing, and machine learning. With the emergence of COVID-19 and its latest variant, Omicron, there is a growing trend towards strengthening hospital infrastructure, based on the principle of being prepared. Some cities and provinces have built “XiaoTangShan”-style hospitals that combine 5G, AI, the Internet of Things, and big data to deal with outbreaks. 34 The launch of health codes during the pandemic has made it more effective to implement epidemic prevention management in cities. The health code uses big data from multiple sources, such as healthcare, civil aviation, railways, and geographic location information. Big data governance and statistical analysis of real data are crucial. Hospital infrastructure, metadata governance, and the use of AI, including the classification of medical big data text, entity extraction, relationship extraction, event extraction, reading comprehension, normalization, and generation techniques, as well as medical imaging classification, segmentation, registration, detection, reconstruction, generation, hyper-resolution, denoising, deblurring, depolarization, and pseudo-imaging techniques, are essential for achieving high-quality data. Structured EMRs using NLP can process most NLP data and unstructured text into structured medical records.35,36 The convolutional neural network is used to identify medical images, including ocular fundus identification, tumor detection, tumor progression tracking, and pathologic interpretation. Emotional analysis can be used to improve patient education and doctor-patient communication through opinion mining, opinion information extraction, emotion mining, subjectivity analysis, bias analysis, emotion analysis, and comment mining on doctor-patient communication or social platforms. Heterogeneous clinical data should also be considered in the application process, with multimodal outcome exploration of clinical text data, image waveform data, and biomics data achieved through knowledge mapping or knowledge libraries in multimodal technologies and decision fusion.37,38
Patient-centeredness
How can hospitals effectively provide patients with their medical data in a patient-centered environment? Although the storage of medical data in a hospital’s electronic business system is necessary due to informatization requirements, challenges such as misinterpretation of medical data and litigation issues can limit solutions to this problem. Therefore, maximizing the clinical, scientific, and human value of patients’ personal data is crucial in real-world research data.
In December 2016, the US Congress approved the use of “real-world evidence” in place of traditional clinical trials for expanded indications, providing further insights into real-world research. 39 In 2018, China published its first Real World Research Guide, 40 and in 2021, the National Drug Administration’s Drug Review Center developed “Real-World Data Guidelines (Pilot) for Generating Real-World Evidence” to guide and standardize the use of real-world data by candidates to generate real-world evidence for drug development. 41 Our real-world data sources are categorized by functional type, including HIS data, Medicare payment data, enrollment research data, active monitoring of drug safety, natural population cohort data, mortality registration data, patient report outcome data from mobile devices, individual health monitoring data, and patient-specific follow-up data. Collecting real-world data has become the key direction for medical AI, which includes structured extraction from EMR systems, optical character recognition for electronic data capture, semantic analysis, and algorithmic models for clinically assisted decision-making.
Furthermore, out-of-hospital data collection requires distributed relational databases, real-time flow analysis, and the resulting model of whole-process intelligent patient services, which can comprehensively cover multiple scenarios such as pre-consultation, referral, in-hospital navigation, consultation, follow-up, and medication services to properly address the issues of “unmanaged health, unguided care, and undirected medication.” Edge-to-edge computing on IoT wearables is also essential. Only through the collection of these real-world data, combined with the application of AI algorithms in knowledge mapping, can we truly achieve patient-centered HISs and give back to patients.
Data regression
As patients serve as intermediaries between clinical and scientific research, data forms a crucial link in the entire healthcare process. The Chinese philosophy of “Yin and yang are what is called Dao” emphasizes the closed loop of “clinical-data-research-clinician,” with data discovery and regression being the key features of AI (Figure 3). AI is extensively utilized in personalized medicine, relying on various machine learning algorithms such as artificial neural networks, decision trees, random forests, and support vector machine.
42
In addition to the integration, governance, and structuring of data, which need to be aligned with EMR, there is a pressing need to optimize scientific computing with embedded statistical analysis modules, including conventional descriptive analysis, differential analysis, and impact factor analysis, as well as advanced techniques such as logical regression, support vector machine, simple Bayes, decision trees, stochastic forest, ascending tree, K-nearest neighbors algorithm, hierarchical classification algorithms, survival algorithms, and the Gaussian mixture model, to address clinical challenges. Data links for communicating clinical and scientific research and for use in pre-diagnosis, diagnosis, and post-diagnosis. In the diagnosis and treatment global link, real-world data from patients and real-world evidence complement each other.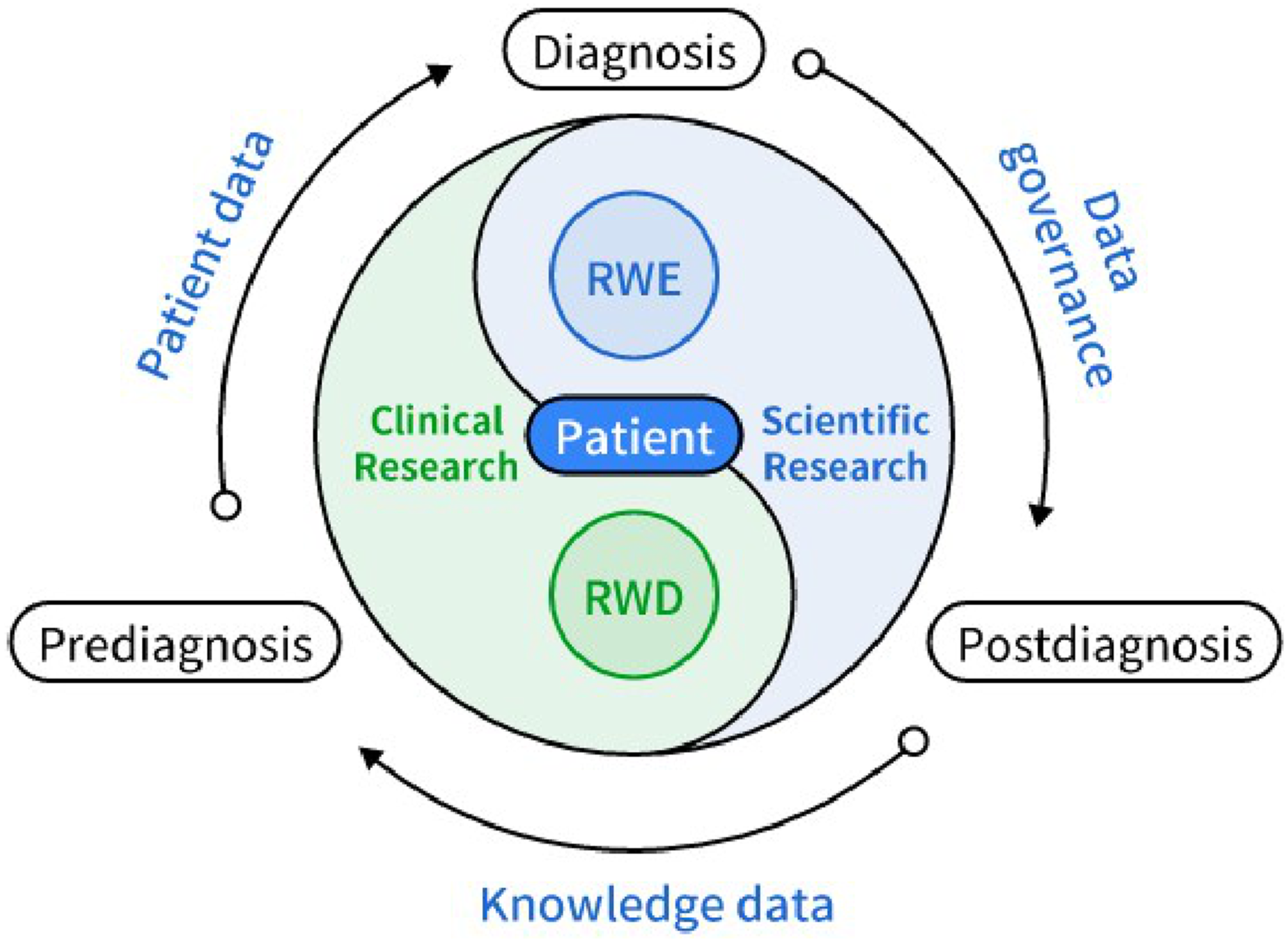
At the statistical analysis stage, dirty data can clearly indicate the problem and data cleansing provides a temporary solution rather than a permanent cure. The long-term remedy is to standardize data governance or EMR data entry stages and follow the rules of inversion of data acquisition based on scientific research requirements. The ideal approach involves adhering to real-world thinking in research design and data management, strictly implementing experimental design to collect data within and outside of hospitals, without limitations on collection systems or methods. As mentioned above, AI can be beneficial at every stage.
Medical AI rule: based on (bAse) doctors and not far away (away)
With the increasing popularity of medical data and the development of algorithms, AI has become a trend in healthcare.43,44 If there is one idiom to describe the relationship between AI and doctors, it is “be neither friendly nor aloof.” AI is designed to assist doctors and improve clinical and scientific efficiency. However, given the inherent thinking of the Three Laws of Robotics and the rapid development of AI, it is generally more difficult for the physician community to accept AI interventions in medical settings and to accept that doctors cannot be replaced.45–47 However, several studies have shown that the general public has a positive attitude toward AI technologies and applications in medical scenarios. Also, most people expected AI to completely or partially replace human doctors and have a more positive attitude toward medical AI. 48 Applications in which AI works more closely with doctors include clinical assisted decision-making, surgical robotics, and digital therapy. For medical ethics and robotics, and to strengthen the supervision and management of AI medical software products, the National Drug Administration has issued Guidelines for the Classification of Artificial Intelligence Medical Software Products. 49 Digital therapy is a mixed bag, drawing support and raising worry among experts.50,51 In summary, it is not hard to see how AI and doctors can work together at the intersection of medical data production. We strongly agree that AI in the medical setting is primarily about assisting and improving the efficiency of doctors’ clinical research, not substituting it. There is a common understanding that AI and doctors can work together.
Three quadrant diffuse development (yeast)
In the context of information privacy security, technology and medical personnel serve as favorable guarantees for firmly establishing the framework. Specifically, medical ethics, law, and technology form the three quadrants that ensure the safe operation of AI in healthcare. Among these, medical ethics is an indispensable barrier and the core of the application of medical big data. Following the publication of the Personal Information Protection Act, 52 the Health and Medical Data Security Guide, 53 and other laws and regulations, it has become necessary to train and assess the security of all participants to ensure their commitment and responsibility to complete big data-related work. Our team previously conducted an exploratory study on the intrinsic mechanism of doctors’ patient-protective behavior in Chinese public medical institutions and constructed a theoretical model framework for such behavior. 31 At the technical level, the privacy algorithm creates bridges between data elements and data values by employing multiple secure computing, blockchain technology, homomorphic encryption, and zero knowledge protocols, including anonymity, access control models, special processing and control, and role control models based on privacy expansion, encryption, and correlation technologies for datasets. We also require the adoption of decentralized storage solutions to safeguard data security. In a scholarly contribution to the field of medical ethics, Mueller, H. et al. Have delineated a compendium of ten foundational ethical principles intended to guide the practical application of AI in medicine. These principles are as follows: Identifiability, Communicative Transparency, Accountability, Transparency and Interpretability, Comprehensibility and Reproducibility, Explanation Based on Current Scientific Theory, Non-Misleading, Legality and Non-Maleficence, Non-Discrimination, and Objective Setting, Control, and Monitoring, serving as a beacon for the responsible integration of AI into the medical field, emphasizing the importance of ethical considerations in the pursuit of technological advancement. 54 Furthermore, the ethical considerations in the application of AI within healthcare encompass critical issues such as privacy, bias, and patient consent. The implementation of AI solutions necessitates a comprehensive approach that integrates ethical, legal, and societal considerations. This approach must include a clear ethical framework, interdisciplinary collaboration, and measures to ensure transparency and interpretability, alongside robust regulatory mechanisms. Such strategies are imperative to address the multifaceted challenges posed by the integration of AI in healthcare, thereby safeguarding the well-being of patients and upholding the highest standards of medical practice.55,56
In summary, we can realize medical ethical thinking based on the principles of autonomy, non-harm, advantage, and fairness by selecting relevant medical ethical processes such as privacy, informed consent, and data sharing at the application level. This guarantees the data application across the board and correctly guides the diffuse development of AI in big medical data. However, we can only achieve this with medical ethics at the core of a framework based on law and technology, and with three-quadrant management.
Conclusion
Hospital EMRs and related informatization supported by medical data still have some problems, such as inconsistent standards, poor integrity, lack of security and privacy protection, and difficulty in mining and application. Our “metadata governance” offers a good combination of clinical scenarios to achieve applications of medical knowledge data. In addition, by extending SPRAY-style medical AI, we propose creating more value for EMR data. In this paper, the data management of medical information in China and AI technology for transforming EMR data into scientific research achievements provide guidance and circumstantial evidence for the identification, cleaning, mining, and development of further applications of EMR data.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Projects of the Science and Technology Commission of Shanghai Municipality (STCSM) (20Y11909500 to H.L.F.).