
Abstract
There is a growing need for alternative methodologies to evaluate digital health solutions in a short timeframe and at relatively low cost. Simulation-based research (SBR) methods have been proposed as an alternative methodology for evaluating digital health solutions; however, few studies have described the applicability of SBR methods to evaluate such solutions. This study used SBR to evaluate the feasibility and user experience of a clinical decision support (CDS) tool used for matching cancer patients to clinical trials. Twenty-five clinicians and research staff were recruited to match 10 synthetic patient cases to clinical trials using both the CDS tool and publicly available online trial databases. Participants were significantly more likely to report having sufficient time (p = 0.020) and to require less mental effort (p = 0.001) to complete trial matching with the CDS tool. Participants required less time for trial matching using the CDS tool, but the difference was not significant (p = 0.093). Most participants reported that they had sufficient guidance to participate in the simulations (96%). This study demonstrates the use of SBR methods is a feasible approach to evaluate digital health solutions and to collect valuable user feedback without the need for implementation in clinical practice. Further research is required to demonstrate the feasibility of using SBR to conduct remote evaluations of digital health solutions.
Introduction
Clinical trials in oncology are essential for the scientific advancement of treatments available to existing and future cancer patients. 1 They require the enrollment of suitable study participants to assess the clinical efficacy and safety of novel treatments. They also offer an opportunity for patients with cancer to try alternative new treatments provided they meet the strict, and sometimes lengthy, eligibility criteria outlined in trial protocols. 2 Anecdotal evidence from practitioners in the field suggests that manually screening patients for eligibility criteria is a time-consuming activity responsible to medical and non-medical practitioners, such as consultants, oncologists, and research nurses. It requires a review of patients’ records, including any previous medical history such as pre-existing conditions, medications, test results, as well as holistic information such as patient mentality to determine a patient’s eligibility. In a busy clinical environment, this could lead to some degree of bias or a lack of equal opportunity for patients. 2
NAVIFY Clinical Trial Match (NAVIFY CTM) is a clinical decision support (CDS) tool within NAVIFY Tumor Board (NAVIFY TB) (Roche Information Solutions Inc., Santa Clara, CA), a cloud-based workflow solution that is used to prepare for and conduct cancer multidisciplinary team meetings. CDS tools aim to improve healthcare delivery by enhancing medical decisions with targeted clinical knowledge, patient information, and other health information. 3 CDS tools are primarily used at the point-of-care for the clinician to combine their knowledge with information or suggestions provided by the tool. NAVIFY CTM has been developed to streamline the process of searching for and identifying clinical trials by using patient-specific data such as cancer stage, genomic alterations, and the treating institution’s postcode to perform an automated search for suitable clinical trials across 21 international trial databases. The tool has been developed to address the challenges of under-recruitment in cancer clinical trials, as well as the decision-making challenges faced by clinicians seeking to identify eligible patients from electronic health record data.4–6
Evaluating digital health solutions
Digital health solutions (DHSs) have been shown to address healthcare challenges in various disease areas and healthcare contexts.7,8 However, to justify their implementation in clinical settings and ensure public trust and patient safety, DHSs must be evaluated for usability, acceptability, clinical effectiveness, and cost-effectiveness.9–11 Randomized controlled trials (RCTs) have traditionally been recognized as the gold standard to demonstrate the clinical effectiveness of novel interventions and therapeutics. 12 However, few innovators have sought to evaluate DHSs using RCTs, possibly due to the fast-paced nature of product development and the arduous process of setting up an RCT in a clinical setting.12,13 The relatively high costs and resources associated with conducting an RCT reduces the return on investment and is therefore not a sustainable option for small and medium-sized enterprises (SMEs) or products in the early stage of development. 13 Furthermore, recruiting participants to RCTs and pilot studies to evaluate DHSs in real-life clinical settings comes with challenges such as patient data privacy and security concerns, the commitment required to participate in longitudinal studies for self-management interventions, and a lack of endorsement for trial participation from treating clinicians.13–16
The regulation and publication of guidance to evaluate DHSs is outpaced by the rapidly evolving digital health landscape and the increasingly diverse types of solutions entering the market.17,18 In addition, there is a lack of clarity regarding what evidence generation methodologies are appropriate to evaluate solutions in the early stages of product development. Evidence generation methodologies are required that can generate high-quality insights in a short timeframe and at relatively low cost.13,19 A perspective piece published in npj Digital Medicine on the challenges of evaluating DHSs proposed alternative methodologies that facilitate safe and responsible growth across the sector, such as the use of simulation-based research (SBR) methods. 13
Simulation-based research methods
Simulation is described as the replication of real-life events in an interactive manner, and has been applied in research and the trial of new healthcare interventions. 20 Simulation has also been widely applied to healthcare in the context of education and clinical rehearsal, and allows healthcare providers the opportunity to learn new protocols and procedures in a safe and controlled environment.21–26 SBR in the context of healthcare involves replicating clinical scenarios, with the aim of eliciting reactions and behaviors from healthcare professionals that are as close as possible to how they would react in a real situation. 27 The use of SBR methods could support faster evidence generation of the usability, acceptability, and effectiveness of DHSs without involving real patients and/or real patient data. Such simulations could take place outside of a clinical setting, providing opportunities to obtain behavioral and cognitive measures that would otherwise be impractical to gather in routine practice. 13 SBR methods have been used to evaluate non-digital healthcare interventions28,29; however, few studies have reported the use of SBR methods to evaluate DHSs and the results are seldom reported.13,30–32
To assess the feasibility of using SBR methods to evaluate DHSs, we sought to apply these methods to evaluate NAVIFY CTM, which primarily supports existing clinical services yet has no direct impact on patient outcomes. According to guidelines published by the National Institute for Health and Care Excellence (NICE), such solutions would be functionally classified as “Tier 1” and require the minimum standards of evidence for effectiveness. 19 The intended outcome would be to demonstrate that SBR methods could be used in the first instance to generate the minimum level of evidence required to support the adoption or larger-scale evaluation of any DHS.
The aims of this study is to assess the feasibility of using SBR methods to evaluate DHSs. The objective of this study is to use SBR methods to compare the efficiency, quality and cognitive burden of using NAVIFY CTM to match patients to cancer clinical trials with the use of publicly available online trial databases.
Methods
Study design and participants
We performed an experimental within-subject, non-blinded study to evaluate NAVIFY CTM using simulation-based research (SBR) methods. Participants were approached as previous participants of digital health studies conducted at the university or via the research team’s professional networks. Snowball sampling was used in this study to reach additional participants, which is a commonly used recruitment technique when engaging individuals in a specific population. 33 As per the inclusion/exclusion criteria for the study, participants were required to have experience matching patients to cancer clinical trials in the UK and must not have had prior experience using NAVIFY CTM. Roles eligible to participate in the study included consultant oncologists (i.e., board certified attendings), specialist registrars in oncology (i.e., senior residents), research nurses, and clinical trial practitioners.
Participation in this study was pseudonymous and ethics approval for this study was sought from and approved by the Research Governance & Integrity Team at the university (reference 19IC5457). Informed consent was obtained from participants at the beginning of each simulation session. The study was funded by F. Hoffman-La Roche Ltd, and participants were reimbursed for their time and travel expenses.
Synthetic patient case development
The research team identified 10 actively recruiting Investigational Medicinal Product (IMP) trials that represented a mix of trials for small cell lung cancer (SCLC) and non-small cell lung cancer (NSCLC). A total of 11 synthetic patient cases were created to match each of these trials (two of the cases were eligible for the same trial). The cases were developed by two consultant thoracic oncologists, one consultant histopathologist, and one consultant interventional radiologist, and included clinical details (e.g., past medical history and social history), pathology reports, and radiology reports with accompanying images. The patient cases were added to NAVIFY TB to facilitate trial matching using the NAVIFY CTM application. Online trial databases that are known to be in use in clinical practice were used as the study comparator. These databases are publicly accessible and are designed to enable members of the public, clinicians, and research staff to identify clinical trials. To facilitate trial matching using online trial databases, clinical details and reports were provided on a laptop computer in PDF format with images provided in JPG format.
Data collection
Participants were instructed to assume the role of a clinician or research staff member at St Mary’s Hospital in London who is preparing to see 10 patients at an outpatient clinic. Participants were advised to find at least one suitable clinical trial for each patient, with the intention of discussing trial enrollment, and to treat the session as they would a real-life clinical scenario.
The order of procedures during the simulation sessions.
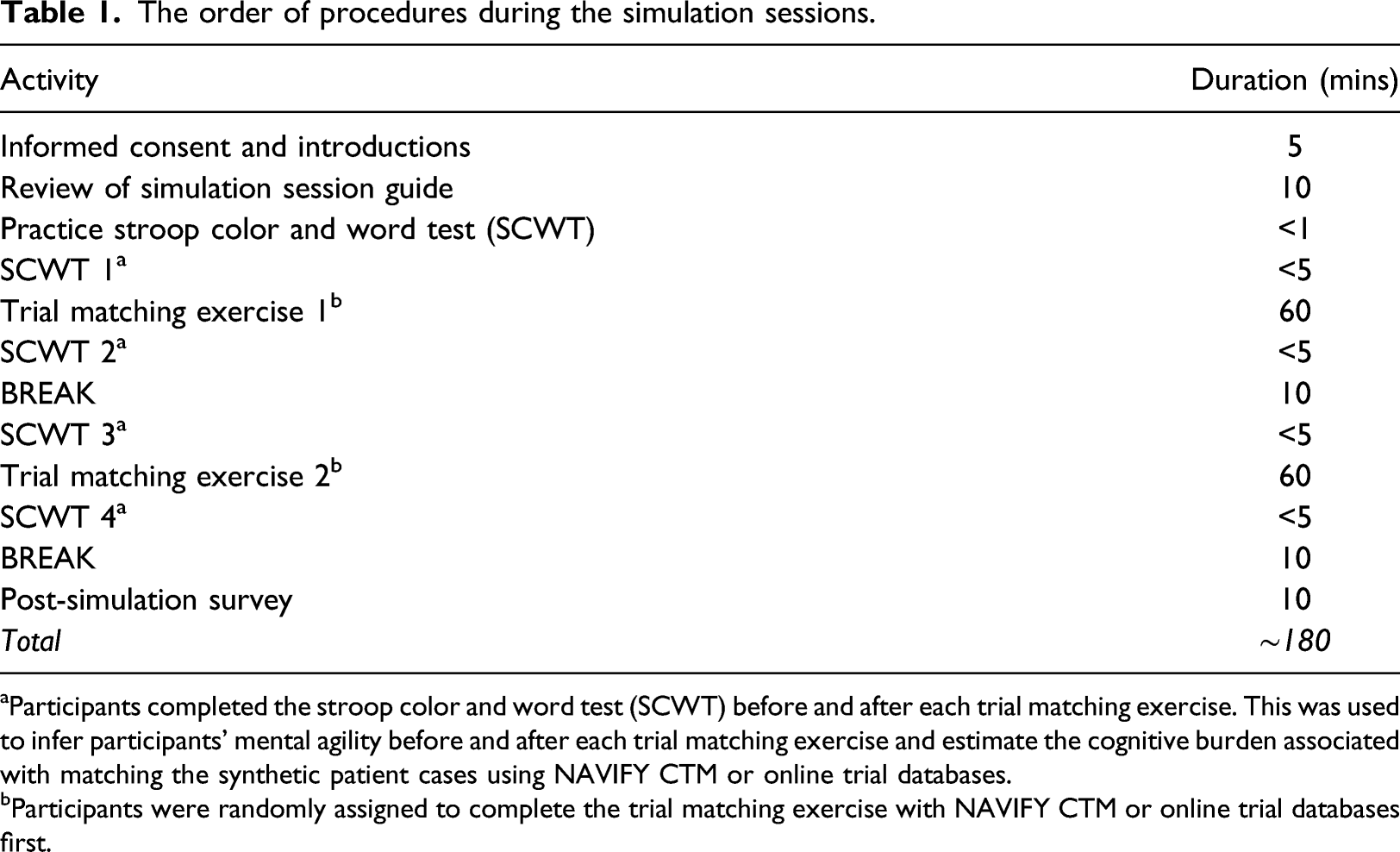
aParticipants completed the stroop color and word test (SCWT) before and after each trial matching exercise. This was used to infer participants’ mental agility before and after each trial matching exercise and estimate the cognitive burden associated with matching the synthetic patient cases using NAVIFY CTM or online trial databases.
bParticipants were randomly assigned to complete the trial matching exercise with NAVIFY CTM or online trial databases first.
Before the NAVIFY CTM trial matching exercise, participants were given a brief demonstration of how to navigate NAVIFY TB and how to access NAVIFY CTM. Participants were also provided with a printed copy of the NAVIFY CTM User Guide and shown a 5-min video on how NAVIFY CTM is used. For the comparator, participants were provided with a list of links to online trial databases that are used in clinical practice. Participants were free to use one or multiple of the databases to find a suitable trial. The online trial databases used in the study included ClinicalTrials.gov, 34 EU Clinical Trials Register, 35 National Institute for Health Research (NIHR) CRN Portfolio Search website, 36 NIHR “Be Part of Research” website, 37 International Standard Randomized Controlled Trial Number (ISRCTN) registry, 38 and North West London Clinical Research Network (NWL CRN) Lung Cancer Portfolio. 39
A simulation session guide was developed by the research team to describe the simulated clinical scenario. Participants were instructed to read this document at the beginning of each session. A member of the research team was present throughout each session to resolve technical issues and to ensure data collection procedures were adhered to.
To reflect the real-life time pressure of a clinician tasked with this responsibility, participants were given 60 min for each of the two trial matching exercises (i.e., an average of 12 min per patient). All trial matches were recorded by participants in Microsoft Excel. The simulation session concluded with an online Qualtrics survey. Questions in the survey were informed by a review of the literature related to clinical trial matching in the UK and by interviews conducted with oncologists and research staff. When all study procedures were accounted for, each simulation session lasted approximately 3 hours.
Measured outcomes
Using simulation-based research to evaluate digital health solutions
Participants completed a survey after the simulation session and were invited to provide feedback on the usability and potential applications of NAVIFY CTM in clinical practice, as well as their experience of participating in the simulation sessions and how realistic the synthetic patient cases were.
Trial matching efficiency
The start time of each trial matching exercise was recorded by a member of the research team. Participants were required to record the time they finished each case in Microsoft Excel. Screen recording software Snagit was used to record the computer screen during the simulation sessions. A web browser plug-in called Webtime Tracker was used to record the amount of time participants spent on each website during the sessions. In addition, participants were asked in the post-simulation survey whether they felt they had sufficient time to complete the tasks. This question was structured in a Likert scale with the following possible answers: Completely agree, somewhat agree, neither agree nor disagree, somewhat disagree, and completely disagree.
Quality of trial matches
The trial matches identified by participants were scored by a consultant thoracic oncologist. Trials were scored from 0 to 5 based on the following criteria: 0—No eligibility criteria matched; 1—Age, tumor type and location matched; 2—Age, tumor type, location and TNM staging matched; 3—Age, tumor type, location, TNM staging, performance status, RECIST criteria matched; 4—Age, tumor type, location, TNM staging, performance status, RECIST criteria, previous lines of treatment matched; and 5—Age, tumor type, location, TNM staging, performance status, RECIST criteria, previous lines of treatment, biomarkers, and all other eligibility criteria met. In addition, participants were asked in the post-simulation survey whether they felt trial suggestions provided by each database were relevant for the patient case. This question was structured in a Likert scale with the following possible answers: Completely agree, somewhat agree, neither agree nor disagree, somewhat disagree, and completely disagree.
Cognitive burden
Participants were required to complete an online Stroop Color and Word Test (SCWT) before and after each trial matching exercise (programmed using Psytoolkit.org). The SCWT measures participants’ reaction times and the accuracy of their response to text color and wording pairs (a “Stroop task”) each of which are either congruent between text and color (e.g., “GREEN”) or incongruent (e.g., “RED”). The SCWT has been used pre- and post-task to measure the mental agility of study participants who have completed mentally demanding activities. 40 The SCWT has been used to measure conflict-controlling selective attention/response inhibition and working memory.41,42 Each SCWT contained 40 individual Stroop tasks and the maximum response time of each task was limited to 1.5 s. If no response was detected within the response time, this task was considered an error. The post-simulation survey also included a subjective measure of mental effort via the Paas scale 43 which is a popular measure of cognitive load and has been used to validate other measures of cognitive load. 44
Data analysis
Free-text responses to the post-simulation survey underwent thematic analysis which was performed by one researcher using an inductive approach whereby the onus to derive themes was placed on them. 45 The free-text responses were reviewed line-by-line to identify recurring concepts or words, from which a list of codes was derived. The codes were then grouped into distinct themes, which described a positive or negative reflection of participants’ experience, until all codes were categorized under a theme. The free-text responses from each participant were reviewed once again and a numerical score was assigned to each theme based on the number of participants that had referenced a concept or word related to the theme.
All Likert scale questions were converted into a one (Completely disagree) to five (Completely agree) scale for analysis. The scores for the trial matches and the data from the SCWTs, Webtime Tracker, and survey were compiled using Microsoft Excel.
Data was imported into and analyzed on R version 4.0. 46 All outcome variables used in this analysis were non-normally distributed, as confirmed by Shapiro–Wilk test results. For assessment of trial matching efficiency, outliers were first identified using Ronser’s test (EnvStats package, version 2.4). 47 This method was selected as it allows simultaneous identification of multiple outliers within sufficiently large datasets. Trial matches over 30 min both belonging to matches found using the ClinicalTrials.gov database) were identified as outliers and subsequently removed from the analysis.
Quality of the trials found by the participants of the study was scored by a thoracic oncologist who was part of the team that developed the synthetic patient cases and who was blinded to participants. All matches were rated on a one (worst possible match) to five (best possible match) scale. Cognitive burden was measured in a Paas scale, and converted to a one (very, very low mental effort) to nine (very, very high mental effort) scale. All pairwise comparisons were performed using a Wilcoxon Signed-Rank test, and p values were adjusted using the false discovery rate (FDR) method due to the small number of comparisons being performed at each step. The p value significance threshold used for this study was 0.05.
Pilot of the methodology
Comparison of study design and data collection procedures between the pilot and study phases.
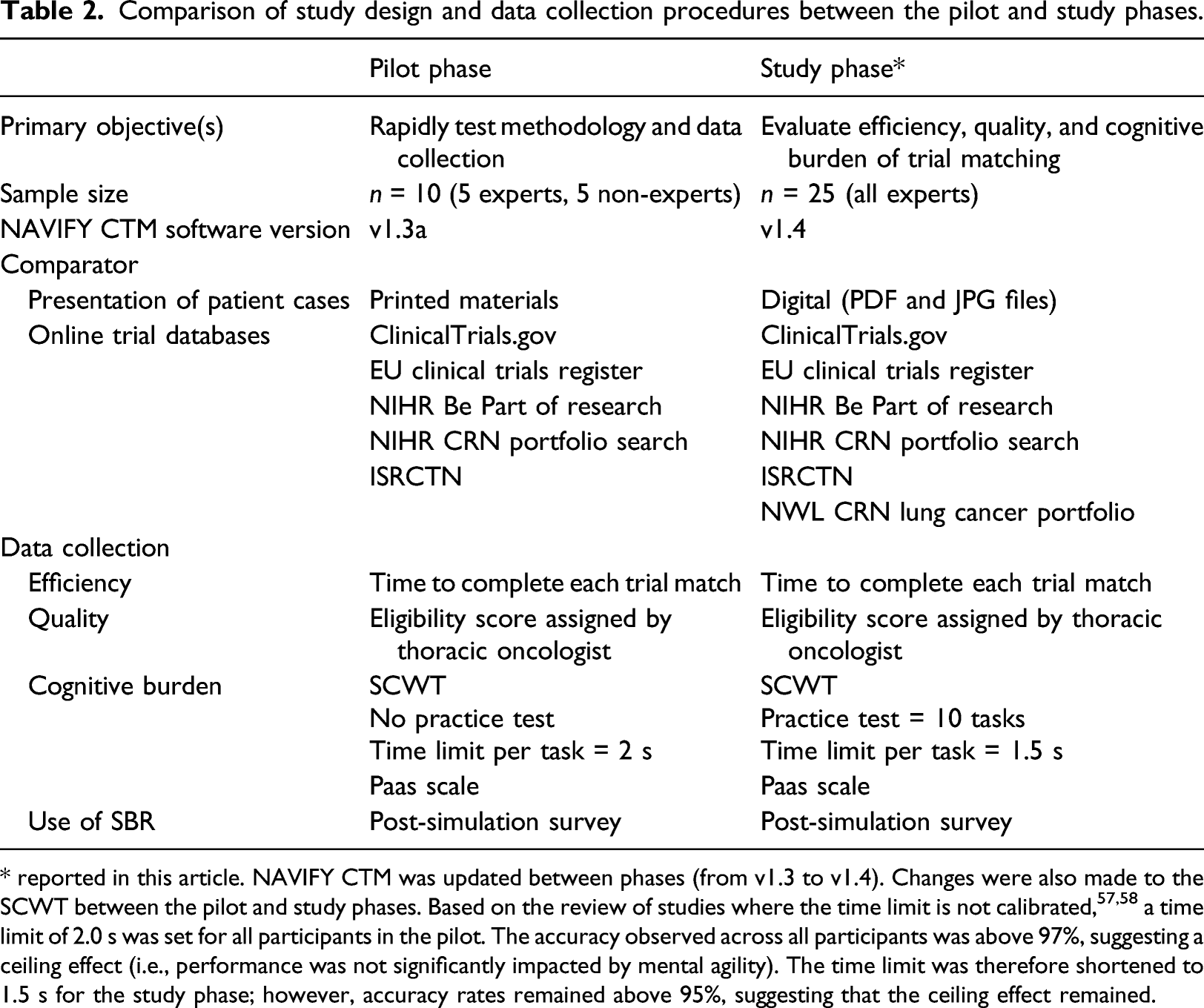
* reported in this article. NAVIFY CTM was updated between phases (from v1.3 to v1.4). Changes were also made to the SCWT between the pilot and study phases. Based on the review of studies where the time limit is not calibrated,57,58 a time limit of 2.0 s was set for all participants in the pilot. The accuracy observed across all participants was above 97%, suggesting a ceiling effect (i.e., performance was not significantly impacted by mental agility). The time limit was therefore shortened to 1.5 s for the study phase; however, accuracy rates remained above 95%, suggesting that the ceiling effect remained.
Results
A total of 25 clinicians and research staff with experience screening patients for clinical trials in oncology participated in the study. All participants had experience screening patients in public teaching hospitals operated by the National Health Service (NHS) in the UK. Roles of participants included clinical trial practitioners (n = 8, 32%), research nurses (n = 8, 32%), specialist trainees in oncology (n = 7, 28%) and consultant oncologists (n = 2, 8%). Approximately half of participants (n = 13, 52%) had less than 5 years’ experience screening patients for clinical trials in oncology.
Using simulation-based research to evaluate digital health solutions
Feedback on simulation sessions and synthetic patient cases
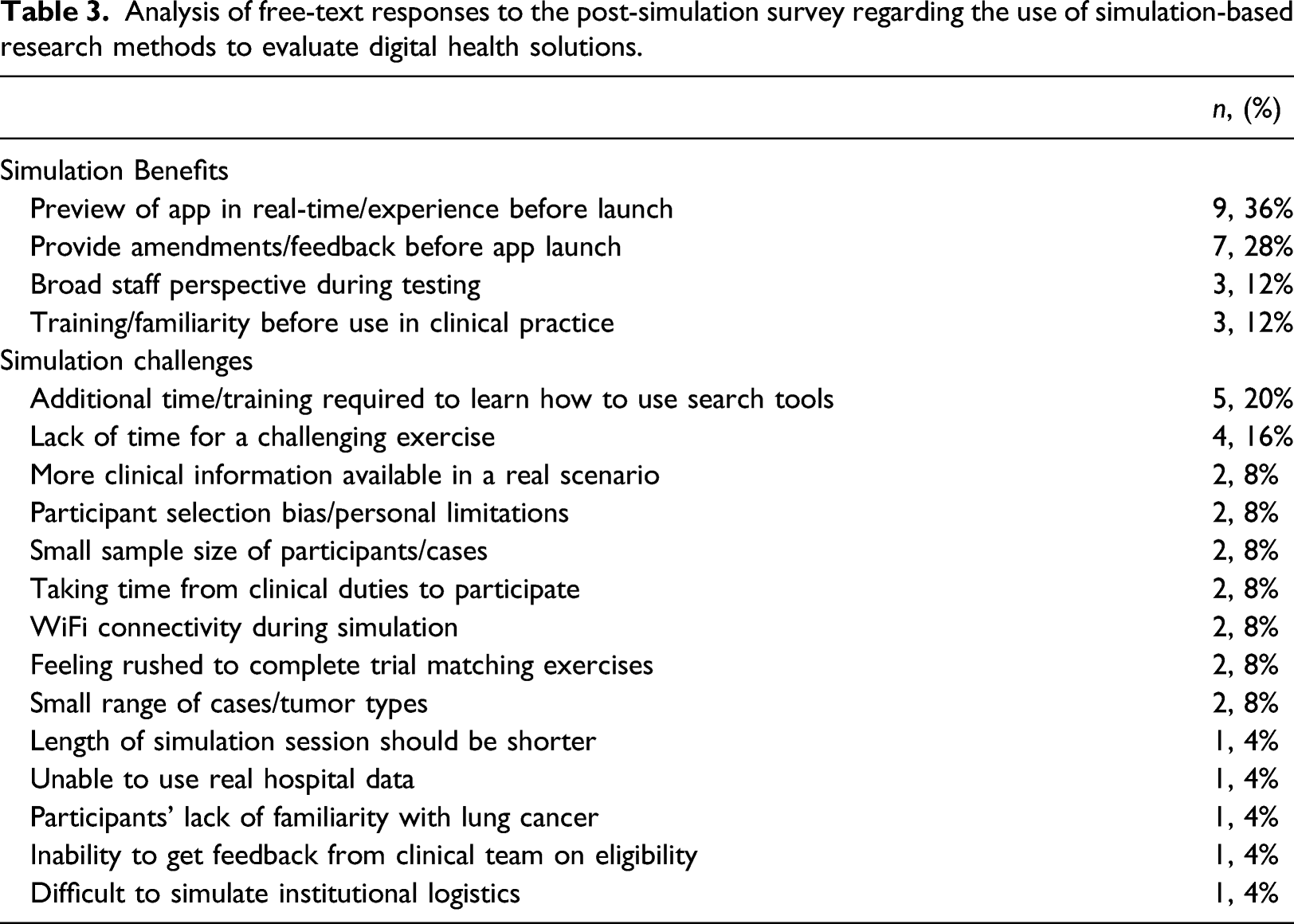
On the post-simulation survey, the majority of participants (n = 24, 96%) stated that they were provided with sufficient guidance to participate in the simulations and complete the trial matching exercises. Most participants (n = 18, 72%) also reported that they were provided enough clinical information in the synthetic patient cases. A small number of participants said that it would have been beneficial to have more histology information (n = 2, 8%), more information on previous treatments (n = 2, 8%), and the inclusion of clinical information via a referral letter (n = 1, 4%).
Feedback on the use of simulation-based research methods
Analysis of free-text responses to the post-simulation survey regarding the use of simulation-based research methods to evaluate digital health solutions.
Evaluating NAVIFY clinical trial match
Overview of trial matches
A total of 342 trial matches were made across the 10 synthetic patient cases. Of these, 172 trial matches were made using NAVIFY CTM and 170 using online trial databases. Participants failed to match a trial for 34 cases (14%), with 14 of these 34 failures occurring while using NAVIFY CTM and 20 while using online trial databases. Failing to match a case to a trial was not linked to a specific patient case, with six case match failures being the highest for any patient case. When using online trial databases, ClinicalTrials.gov was used for the majority of trial matches (71%) followed by the North West London CRN Lung Cancer Portfolio (12%).
Trial matching efficiency
Measured objectively, participants matched trials faster on average when using NAVIFY CTM (10 min) compared to the average across all online trial databases (11.7 min), although the difference was not significant (p = 0.063). Results were similar when outliers (n = 2) were removed from the dataset (p = 0.092) (Figure 1). Time to match patient cases to clinical trials, NAVIFY CTM versus all online trial databases combined. (Outliers illustrated as black dots and removed in the statistical tests). Participants matched trials faster using NAVIFY CTM, although the difference was not statistically significant (p = 0.092).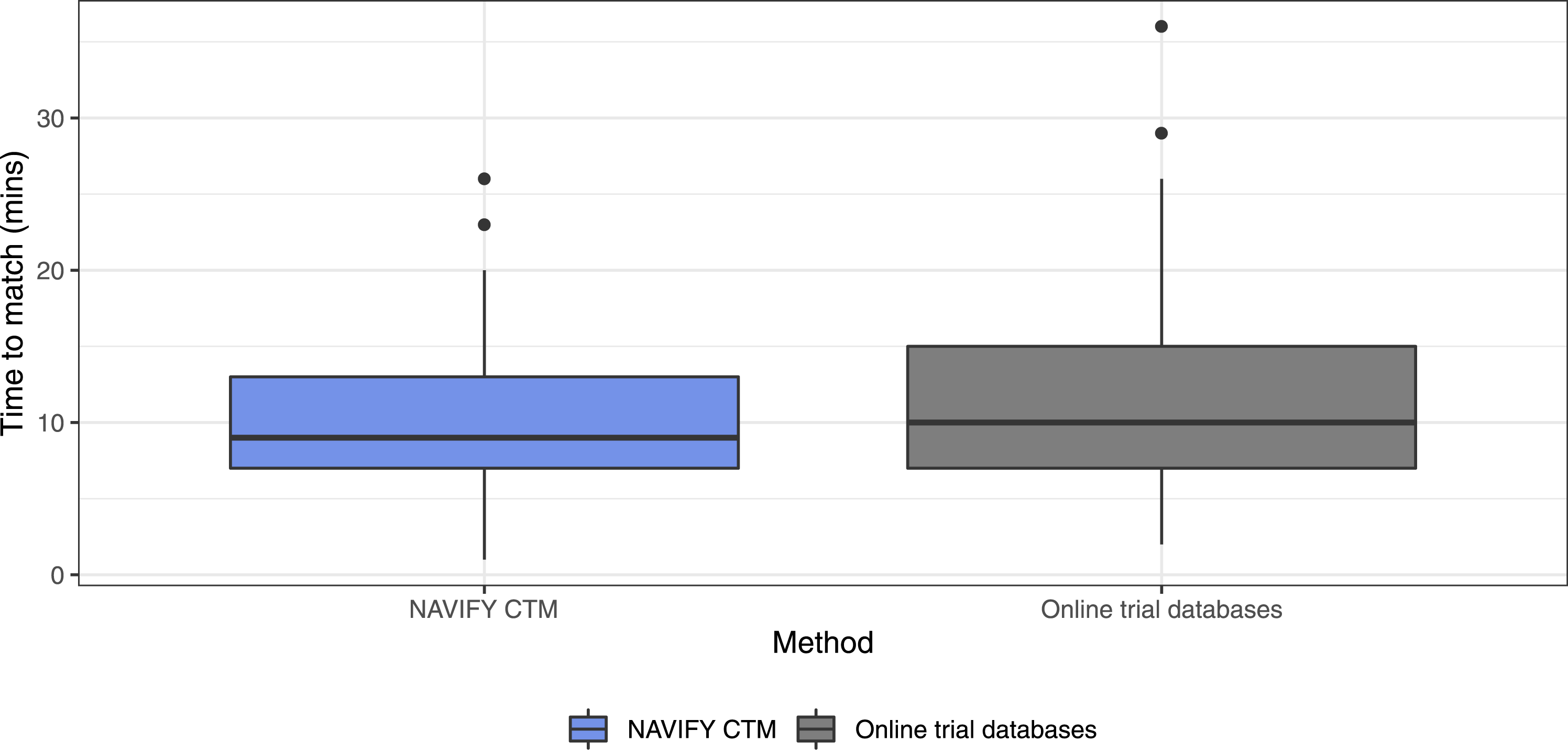
Summary of time to match patient cases to clinical trials (NAVIFY CTM vs. online trial databases).
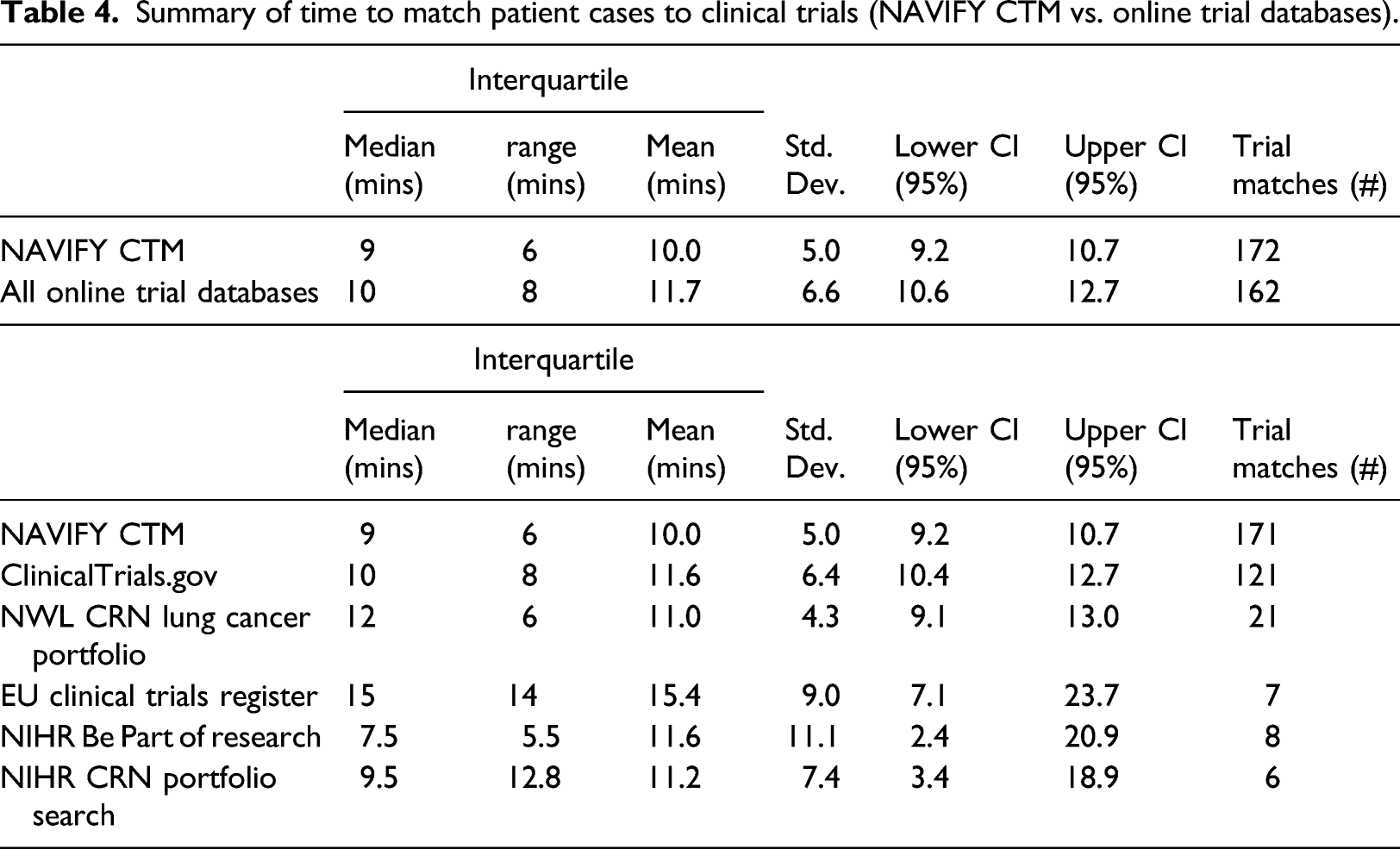
On subjective measurement in the post-simulation survey, we identified significant differences when comparing the perception of having sufficient time to match patients to clinical trials (Figure 2). Participants reported a significantly higher degree of agreement with having sufficient time to complete the trial matching exercise using NAVIFY CTM (p = 0.020). There was a larger proportion of individuals indicating they “completely agree” that they had enough time to complete the task using NAVIFY CTM (n = 14, 56%) compared to online trial databases (n = 6, 24%). Participants’ perception of having enough time to complete the trial matching exercise (by method). Participants reported a significantly higher degree of agreement with having sufficient time to complete the trial matching exercise using NAVIFY CTM (p = 0.020). Asterisk (*) indicates results of statistical significance.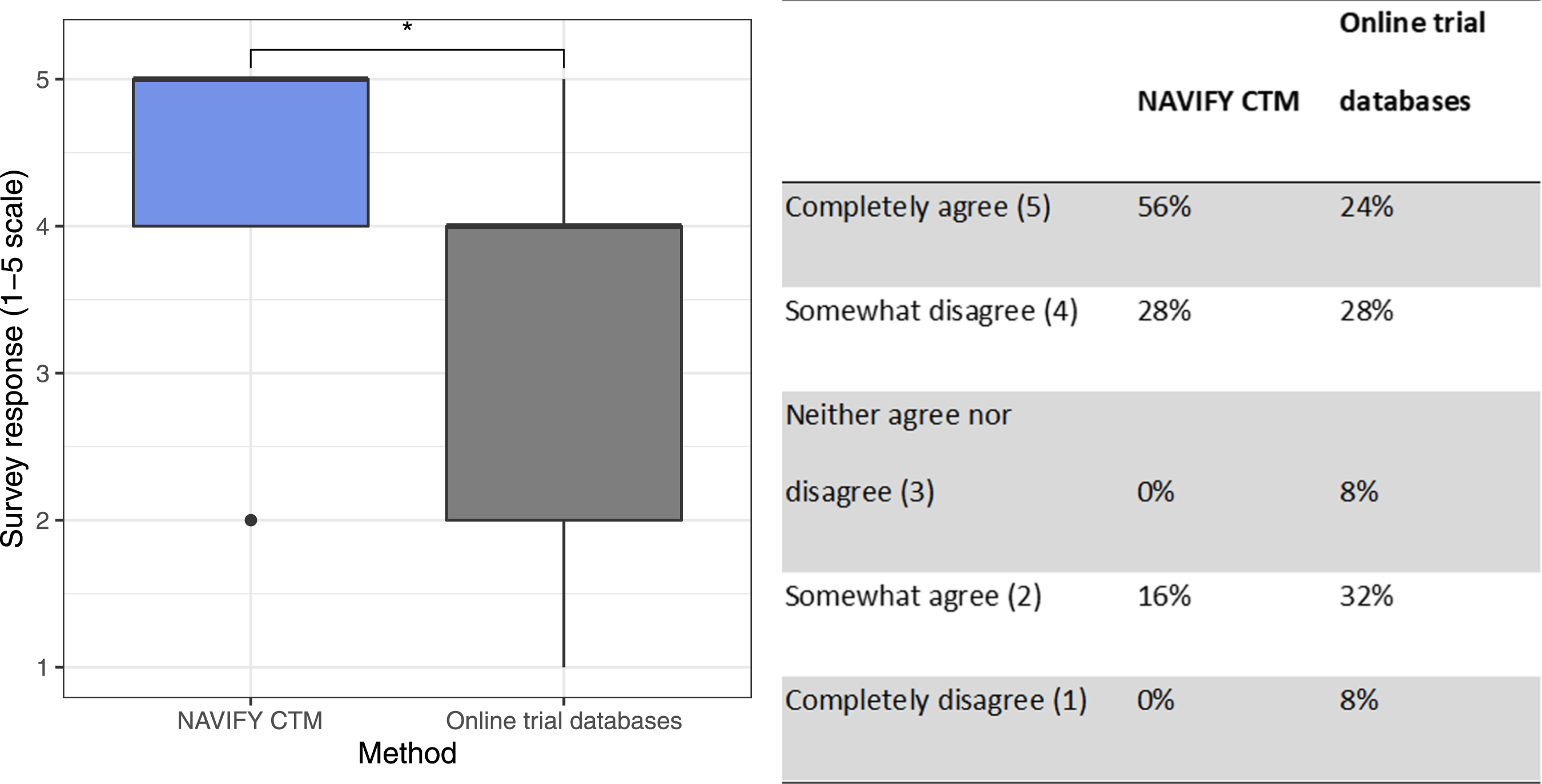
Quality of trial matches
There was no statistically significant difference in eligibility score for trials matched with NAVIFY CTM compared with all other online trial databases combined (p = 0.790). There was a statistically significant difference when comparing NAVIFY CTM to NWL CRN Lung Cancer Portfolio (p = 0.026) and NIHR Be Part of Research (p = 0.040), although there were few trial matches using these databases (n = 21 and n = 8, respectively). There were no statistically significant differences compared with ClinicalTrials.gov (p = 0.590), the EU Clinical Trials Register (p = 0.840), or NIHR CRN Portfolio Search (p = 0.690) (Figure 3). Comparison of eligibility scores for trial matches using NAVIFY CTM and using online trial databases. Single asterisk (*) indicates results of statistical significance, double asterisk (**) indicates non-significant results.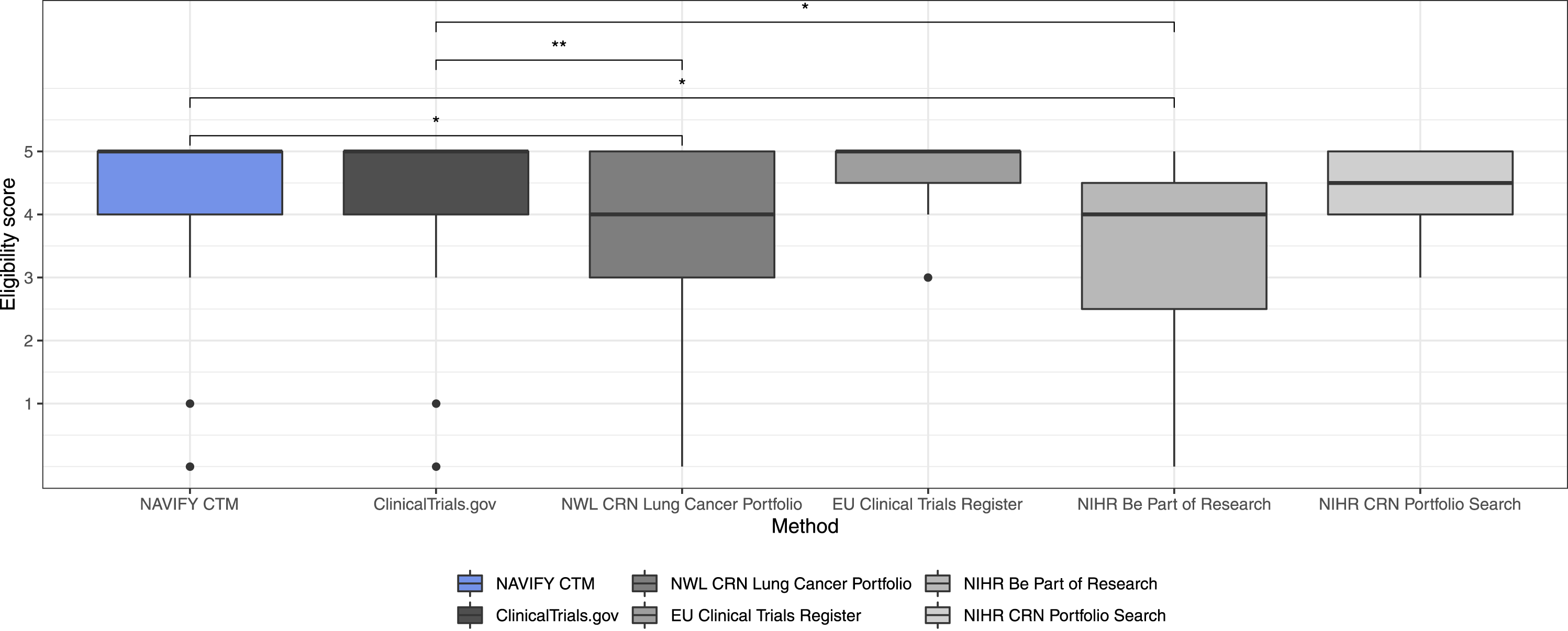
On the post-simulation survey, participants were more likely to agree that trial suggestions via NAVIFY CTM and ClinicalTrials.gov were relevant compared with other online trial databases. No statistically significant differences were identified between NAVIFY CTM and the next best scoring databases, ClinicalTrials.gov (p = 0.780), the EU Clinical Trials Register (p = 0.150), and NIHR Be Part of Research (p = 0.150). Both NAVIFY CTM and ClinicalTrials.gov scored significantly higher compared to NIHR CRN Portfolio Research (p = 0.049 and p = 0.049, respectively) and ISRCTN (p = 0.049 and p = 0.008, respectively) (Figure 4). Perceived relevance of top trial suggestions as per post-simulation survey (NAVIFY CTM vs. online trial databases). Participants were significantly more likely to agree that trial suggestions via NAVIFY CTM and ClinicalTrials.gov were relevant compared with the other online trial databases. Single asterisk (*) indicates results of statistical significance, double asterisk (**) indicates non-significant results.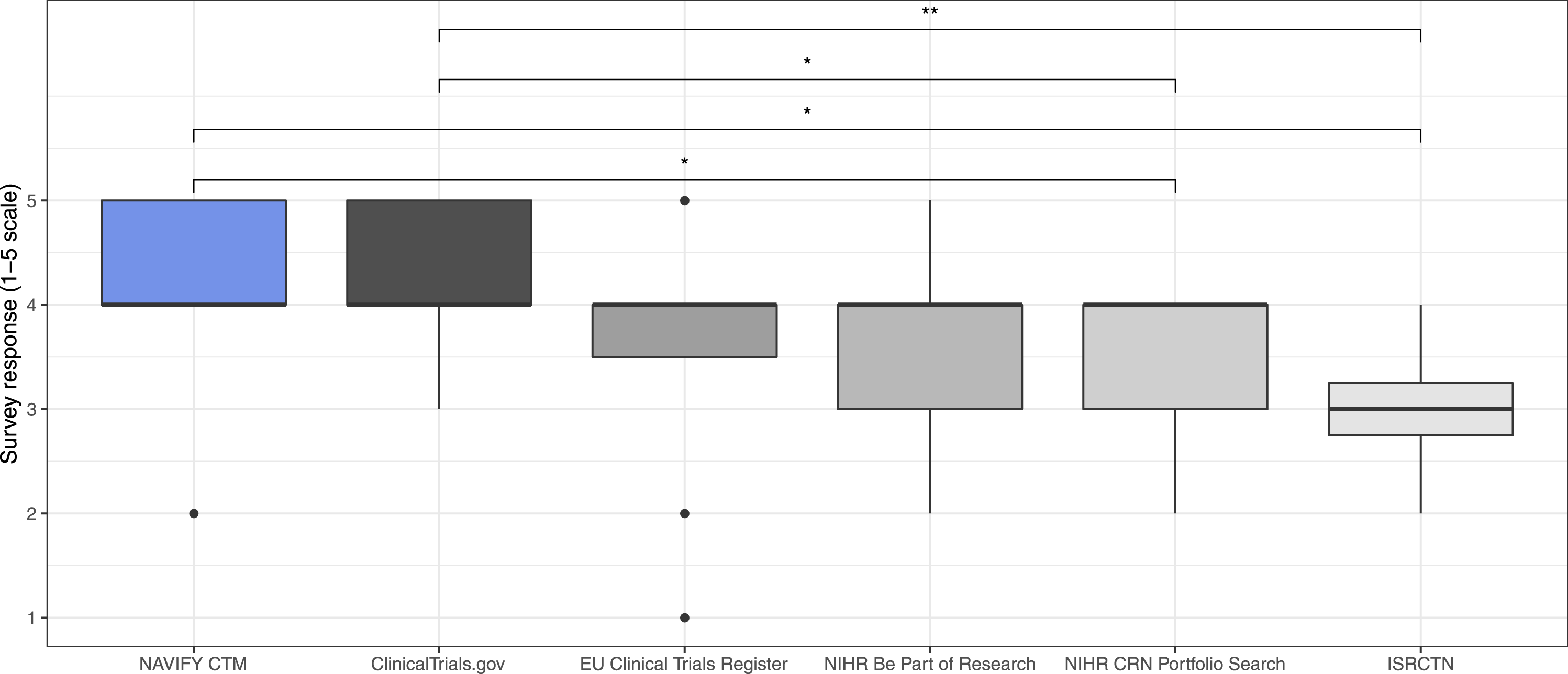
Cognitive burden
The Stroop effect—defined as the difference in average reaction times (RTs) for incongruent and congruent Stoop tasks—after using NAVIFY CTM was equal to the Stroop effect after using online trial databases. The difference in average RT before and after using NAVIFY CTM was smaller (28 msec) than the same difference for online trial databases (36 msecs), although the difference was not statistically significant (p = 0.662 and p = 0.776, respectively). Stroop task errors were higher before trial matching using online trial databases compared to after (3.1% vs. 2.4%). For NAVIFY CTM, errors were lower before trial matching compared to after (2.3% vs 2.6%). This difference in errors before and after each trial matching exercise was not statistically significant (p = 0.993 and p = 0.092, respectively).
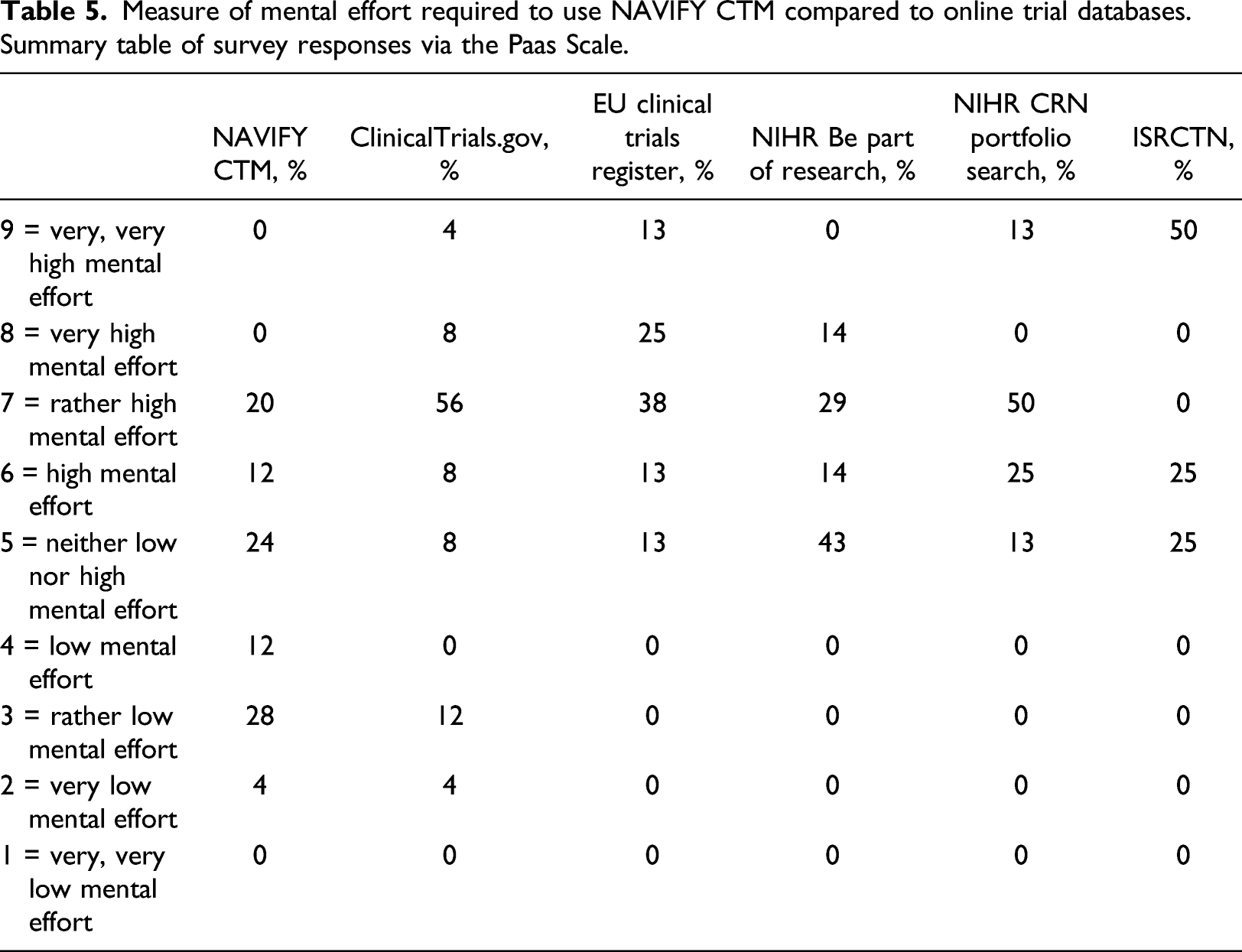
When cognitive burden was measured subjectively on the post-simulation survey, participants were significantly more likely to agree that less mental effort was required to complete trial matching using NAVIFY CTM compared to all other online trial databases combined (p = 0.001). The difference was significant when compared individually with each of the online trial databases, including ClinicalTrials.gov (p = 0.002), the EU Clinical Trials Register (p = 0.001), NIHR Be Part of Research (p = 0.047), NIHR CRN Portfolio Search (p = 0.005), and the ISRCTN (p = 0.039). Participants were more likely to require “very low,” “low,” or “rather low” mental effort to use NAVIFY CTM (n = 11, 44%) compared to all online trial databases taken together (n = 2, 8%). This difference remained when compared against online trial databases individually (Figure 5) (Table 5). Measure of mental effort required to use NAVIFY CTM compared to online trial databases. Participants reported that less mental effort was required to use NAVIFY CTM and this difference was statistically significant compared to all online trial databases (p = 0.001). Single asterisk (*) indicates results of statistical significance, double asterisk (**) indicates non-significant results. Measure of mental effort required to use NAVIFY CTM compared to online trial databases. Summary table of survey responses via the Paas Scale.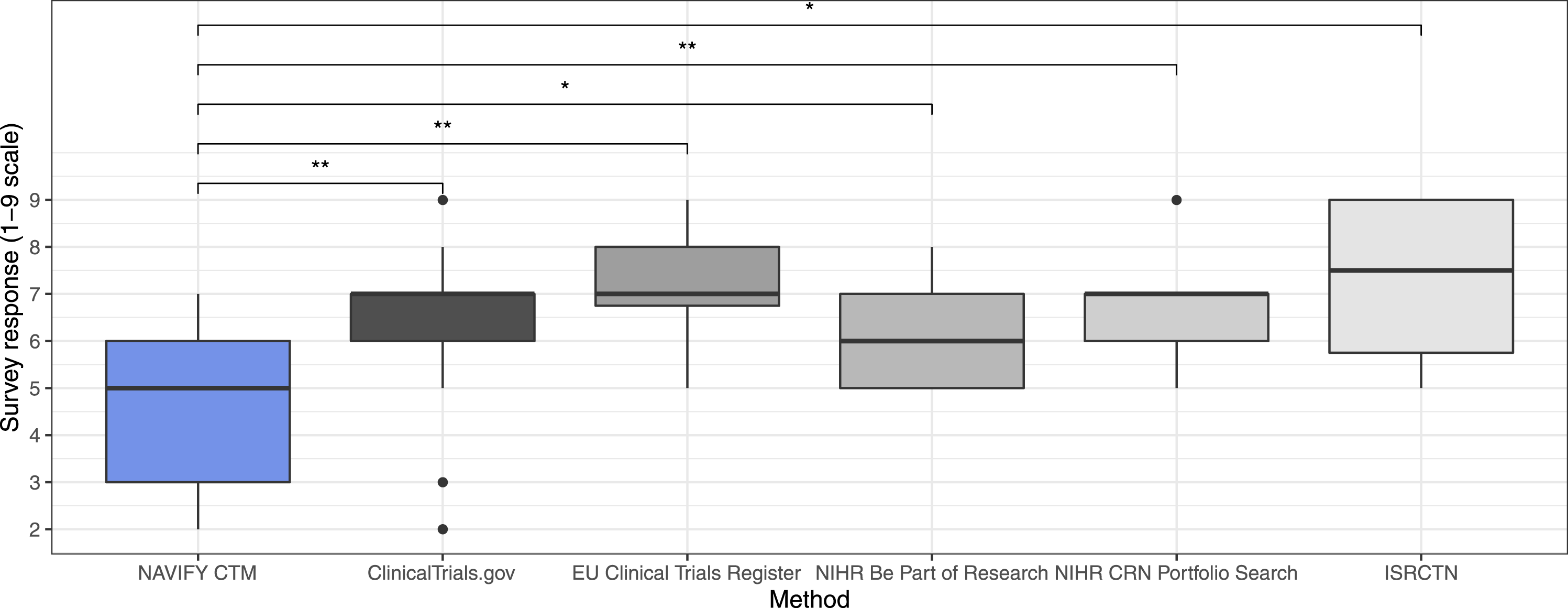
Discussion
Using simulation-based research to evaluate digital health solutions
This study demonstrates the ability to evaluate a novel clinical decision support tool in a simulated clinical scenario using synthetic patient cases. We were able to collect quantitative insights on the performance of NAVIFY CTM compared to online trial databases and to collect valuable user feedback without the need for implementation in clinical practice. The ability to reproduce the same simulated clinical environment before and after, and for all participants, also increases the confidence that any measurable differences between NAVIFY CTM and online trial databases can be attributed to the tools themselves as opposed to external factors. 20
This study demonstrated the value of using synthetic patient data to support faster evaluations of digital health solutions. Using real patient data in research introduces additional ethical and information governance considerations, such as data privacy and confidentiality. Ethics approval for this study was obtained via a university ethics committee and was completed within two to 3 weeks. Approval from the Health Research Authority in England—with a typical timeline of two to 3 months—was not required as the study did not involve real patients or real patient data, did not take place at an NHS organization, and participants were not recruited via the NHS. Using real patient data also typically involves de-identifying or pseudonymizing data, adding “noise” to data or grouping variables together. However, these approaches are subject to risk as well as delays obtaining data.48,49
Another benefit of SBR is the ability to collect measurements of participants’ responses during the study and simulated scenarios in ways that would be otherwise impossible or impractical in a clinical setting. We were able to obtain extensive measurements related to cognitive burden with the Stroop Color Word Test (SCWT), record screen activity and gather additional feedback from participants immediately after they conducted the trial matching exercises. It would not be practical or in the best interest of patient care to gather such measurements and feedback during a real-world evaluation conducted in a clinical setting.
One future area of research could be the use of SBR to conduct remote evaluations of digital health solutions. This has important implications in light of the COVID-19 pandemic, which has resulted in shifts to remote working. Guidance published by Public Health England has supported the use of remote approaches to evaluate digital health solutions, as opposed to face-to-face approaches. 50 For certain digital health solutions, such as clinical workflow solutions, teleconsultation services or any other software-based solutions, the design and methodology used in this study could be translated to remote settings and enable evaluations in different geographical locations simultaneously. This approach could generate evidence within a short timeframe, further enhancing the potential for return on investment for innovators.
Evaluating NAVIFY clinical trial match
The hypothesis of the study was that participants would identify trial matches quicker using NAVIFY CTM than online trial databases. While the difference in time-to-match between the tool approaches was not significant, participants were significantly more likely to feel like they had enough time to complete the exercise when using NAVIFY CTM. This effect could be explained by the lower mental effort required to use NAVIFY CTM or as a result of bias towards the solution being evaluated due to the absence of blinding. Risk of bias could be reduced using a single- or double-blind study design, however blinding of any kind can be difficult when evaluating a novel digital health solution. Alternatively, a between-subject study design could be used to mitigate bias amongst participants.
Participants subjectively reported that trial match suggestions from NAVIFY CTM and ClinicalTrials.gov were more relevant compared to the other online trial databases. This finding could be due to factors affecting user satisfaction which caused participants to favor NAVIFY CTM, such as information format, content, consistency and ease of navigation. 51 However, this effect could also be due to information biases which effect participants’ judgment, that is, participants may have been influenced or biased towards providing positive feedback about trial matches from NAVIFY CTM because they knew the tool was developed to provide better matches than other online trial databases. 52 Further studies could be conducted to explore the factors influencing the perceived quality of trial match suggestions.
The challenges associated with decision-making in healthcare contexts are well understood and associated with high levels of cognitive load. 6 Therefore, there is a need for solutions that reduce the cognitive load associated with decision-making processes, including clinical trial matching. However, there is limited research on sensitive and objective measurement instruments for the cognitive burden of a task placed on healthcare professionals. Behavior paradigms to measure executive ability or mental agility have been well established in the Experimental Psychology and Neuroscience.53–55 Future work could explore the use of other paradigms to measure the brain’s response to a cognitive event, such as the event-related potential (ERP) paradigm. 56
Limitations
This study was conducted during the COVID-19 pandemic and lockdown measures were in place which impacted travel,59,60 as well as the availability of clinicians to participate in research. This may have created a bias towards participants who were located closer to St Mary’s Hospital, London or who had more flexible clinical commitments. Furthermore, participants were recruited to complete trial matching exercises individually, while the literature on cancer clinical trial recruitment in the UK shows evidence of multidisciplinary team involvement in decision-making.4,61 Due to the clinical responsibilities of study participants, it was not reasonable to calibrate the reaction time limit for each participant and to control for sleep and caffeine intake (considered best practice when using the SCWT in experimental psychology). 40
Footnotes
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: C.H.G., M.P. and O.E. are currently employees of Roche Diagnostics. C.H.G., M.P., and O.E. hold Roche shares. J.H., G.F., and S.G. are Directors at Prova Health, which in turn holds consulting contracts with Roche unrelated to the work described in this manuscript.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was funded by F. Hoffman-La Roche Ltd.