
Abstract
For many people, the Internet is their primary source of knowledge in today’s modern world. Internet users frequently seek health-related information in order to better understand a health problem, seek guidance, or diagnose symptoms. Unfortunately, most of this information is inaccurate or unreliable, making it difficult for regular users to discern reliable sources of information. To determine online source reliability, specific knowledge and domain expertise are necessary. Researchers in health informatics studied a number of linguistic and non-linguistic indicators to assist ordinary individuals in judging medical web page credibility. This study proposes a method that automates the process of assessing the reliability of online medical sites based on textual and non-textual characteristics. To evaluate the proposed approach, we developed a real-world dataset of Arabic web pages that provide medical information. This dataset is the first Arabic medical web page dataset for content credibility evaluation. The hybrid approach was assessed using multiple machine learning and deep learning algorithms on the dataset, providing an accuracy and F1-score of 79% and 77%, respectively. We also identify the most observable patterns that help evaluate or detect unreliable web pages written in Arabic.
Introduction
The Internet nowadays has become peoples’ first adviser as a result of the massive growth of Internet users and increase in web content throughout the world. This information-loaded environment greatly influences people’s lives, as many users rely on the web as their primary information source to make decisions. This publicly available web-based information affects many aspects of individuals’ life including individuals’ purchasing behavior, lifestyle, and political choices. The open nature of the web, where anyone can produce and share content with others, has contributed to a lot of information being distributed without rigorous fact-checking.
The issue of information credibility validation is even more important for medical websites that people might rely on to diagnose specific symptoms or to know more about prescribed or over-the-counter medication. The Internet also has countless articles about alternative medicine or fringe medicine (i.e. an unproven practice to achieve the healing effects of medication). 1 The lack of credibility assessment systems has contributed to increased fake news, rumors, and non-credible information in many domains on the web. Despite this tremendous amount of misinformation on the web, many Internet users still rely heavily on web content without further investigating its veracity. For these reasons, there is a crucial need to automatically evaluate the credibility of information emerging on the Internet.
Credibility assessment has been an important topic in many domains like health and social media. Considerable attention has been paid to medical/health information credibility assessment that led to the establishment of the HON 2 foundation. HON, a non-governmental organization (NGO) internationally known for its pioneering work in the field of health information ethics, introduced eight principles to assess the credibility of health information on the Internet. Despite the huge interest in assessing the credibility of health and medical web content, only a few studies have investigated or studied the evaluation of health information credibility. Most of these studies have relied on limited features that were not acquired in a fully automated manner, and only a small number of studies3–5 have proposed the automatic evaluation of health content on the web. The entire body of literature on health credibility evaluation focuses on English language websites, and there have been no studies targeting Arabic language websites, despite the increased number of Arabic web users and the vast amount of non-credible Arabic health content available on the web.
Several studies show the significance of acquiring medical knowledge from the web. A study found that 59% of Americans use the Internet frequently to search for health-related information, and about 35% of the study sample had made health decisions based on information from the Internet. 6 Other studies show that 72% of USA users and 75% of UK users search the Internet for medical advice related to illness, treatments, and medical procedures.7,8 In a more recent study, results indicate that one in every three adults in the United States is using the Internet to diagnose or learn about a health-related problem. 9 Another European-based study found that about 6 of every 10 Europeans had sought health information on the Internet and that about 90% had used the Internet to advance their health knowledge. 10 To evaluate the impact of online health information-seeking practice on Arabic-speaking users, we conducted a survey in 2018 on 263 random participants from Saudi Arabia. Participants were of different ages ranging from 18 to 55 and with varying levels of education (i.e. undergraduate to graduate). The survey results showed that 77.9% of the sample had sought health information on the Internet, and 40% confirmed that they had been unable to distinguish whether the health information they read was credible or not. The survey results also showed that 35.6% of participants had used a medical prescription from the Internet. These various studies also confirmed that health information credibility is an important and common problem in the entire world.
Assessing the credibility of health web pages is a challenging task for regular individuals with no medical expertise. The amount of unreliable health information on the Internet is significantly increasing. Despite the fact that there are many Arabic health information contents on the Internet, there has been an absence of Arabic health website classifications according to international criteria. No previous study investigates automatic assessment of Arabic health content on the web. Therefore, in this paper, we propose a machine-learning/deep learning-based approach to automatically assess the credibility of Arabic health web pages by extracting and analyzing their textual and non-textual features. To achieve this, we first collected a dataset of credible and non-credible real-world Arabic health web pages that multiple medical experts annotated. This dataset was created as a result of the absence of benchmark health web page credibility datasets. Then, we implemented several machine learning and deep learning models using different features to assess Arabic medical web page credibility automatically.
Accordingly, the contributions of this research are threefold. First, this research is the first to explore the impact of both non-linguistic features and linguistic features in health-related web page credibility prediction. Second, this research is the first to investigate Arabic web pages’ credibility assessment. Third, in this research, we developed the first dataset of credible and non-credible Arabic web pages. The rest of the paper is organized as follows. The related works section provides a gist of credibility prediction. The methodology section describes the methodology followed by results and discussion in the results and discussion sections. Finally, the conclusion gives a summary of the proposed study and some future directions in the domain of credibility assessment.
Related works
Most of the literature on credibility assessment has focused on understanding the factors correlated with the credibility of any given information source.11–14 Understanding these factors is essential in building a predictive model that automatically assesses the credibility of a given content, as these factors will be represented as features or patterns that the model will be built upon. Many studies also have utilized different sets of features and feature selection strategies to assess the credibility of information found on the web. This section discusses research studies that have used textual, non-textual, and hybrid-based features (i.e. both textual and non-textual features) to assess information credibility in general. Then, a summary of studies that have analyzed web health content credibility is given.
Textual Features
Several credibility detection approaches have focused on analyzing the textual features of online content showing that the credibility of information can be assessed from the textual features of a given document. Fusilier et al. 15 and Feng et al. 16 proposed a deception detection model based on the textual content of online reviews and evaluated their proposed approach on a hotel review dataset using different machine learning algorithms and achieved high accuracy. Jaworski et al. 17 examined several hypotheses postulating that a web page’s credibility depends heavily on its textual content and that the credibility of a text is a function of the statements that compose that text. Singh et al. 18 proposed a new model that takes several textual features (keywords) as inputs to evaluate the credibility of a given web page, with an overall accuracy of 83%.
Non-textual features
Despite the importance of web pages metadata, much of the literature has focused on textual or hybrid (textual and non-textual) features for credibility evaluation, and there has been no study has utilized metadata features only for information credibility assessment. Kakol et al. 19 studied the impact and significance of using multiple non-textual features for credibility evaluation on a large dataset named of 5543 web pages grouped into five categories: medicine, healthy lifestyle, politics, and economy, personal finance and entertainment. Based on a set of factors that highly correlated with credibility, a predictive model for web content credibility was built and provided an accuracy of 70%.
Hybrid features
Unlike previous works that focused only on either textual or non-textual features to assess the credibility of information, several studies proposed models that combine textual features, and source reliability. Popat et al. 20 proposed a novel model that assesses the credibility of textual claims using two types of features: linguistic features and source reliability features. The model evaluated the use of different feature configurations: textual only, source reliability only, and using both types of features. The best result was obtained when combining textual and source reliability features. This emphasizes the importance of integrating textual and source reliability features in credibility prediction.
Another research study 21 was conducted to evaluate the credibility of emerging textual claims on the web and social media. The authors considered different features to assess the credibility of a given web page and used linguistic features including assertive verbs, active verbs, Hedges, implicative, report verbs, discourse markers, subjectivity, and bias. They also used a stance classifier that predicted how the text supported or refuted a claim. The approach was evaluated on two different datasets, namely Snopes and Wikipedia. The performance results showed good accuracy, with 73.69% on the Snopes dataset and 80% on the Wikipedia dataset. Despite this high accuracy, the source reliability features used in this research, such as page rank and Alexa rank, evaluated the web pages from the popularity and authority perspectives, and no credibility. For example, an Alexa rank is based on the number of website visitors who have the Alexa rank toolbar installed, which makes the source reliability features used in this research reflect weak evidence of a web page’s credibility. In the same manner, Olteanu et al. 10 attempted to automatically assess web page credibility by applying a supervised learning algorithm on a real-world dataset using four groups of features: text-based, social (i.e. the popularity of a website), content-based, appearance, and metadata features. Their model achieved 70% accuracy in predicting the credibility of web pages.
Health web page credibility assessment
Credibility assessment studies have focused on a range of domains such as health, finance, politics, and the environment. This section focuses on studies that target health-related content, as this is the focus of this research.
Several organizations have defined a set of criteria that determine the credibility of information on health-related web pages. HON Foundation, in collaboration with medical experts and the International Organization for Standardization (ISO), defines a number of standards that qualify medical websites’ credibility that include authority, complementary information, privacy, attribution, justifiability, transparency, financial disclosure (i.e. if any organization has received any support or contributions, they should state this clearly), and advertising policy (i.e. if advertising is a source of funding, it should be clearly stated). 22 Evaluations using these standards are typically conducted manually. Likewise, the Agency for Health Care Policy and Research (AHCPR), now known as the Agency for Healthcare Research and Quality (AHRQ), 23 established seven criteria to evaluate the quality of health information on the web that includes credibility (i.e. source credibility, author qualifications, information relevance, and review process for the information), content (i.e. complete and accurate content), disclosure (i.e. clear details on the site about financial sources), links, interactivity, caveats (i.e. the purpose of the website; whether it is commercial or other must be clarified). Similarly, DISCERN24,25 instrument defines a set of standardized criteria for evaluating the quality of public health information about treatment choice. DISCERN questionnaire provides guidelines for appraising information and outlines standards for information producers that can be used by health professionals, patients, and the general public. The questioner consists of 16 questions assessing health information from aspects of the information content such as explicit sources, dates, bias, risks, and benefits of treatment. The reliability, credibility, and overall publication quality are assessed from content only, and content presentation or delivery aspects are not covered in the questionnaire.
Several studies have analyzed the credibility of health information and factors influencing the credibility of information on health-related web pages. Flanagin et al. 26 demonstrated that the website interface design is considered to be strongly related to health websites’ credibility. Similarly, Eysenbach et al. 27 conducted empirical research investigating health websites’ credibility, and the findings of the study showed that several characteristics of a website influence their credibilities, such as completeness (i.e. topics are covered completely), readability (i.e. ease of reading and understanding), and design (i.e. the interface design of the website). Another study by Rains et al. 28 showed that structural features (e.g. images, design, statistics, author details, privacy policy statements) strongly correlate with credibility. Irwansyah et al. 29 defined several features that are considered significant to evaluate health websites’ credibility (e.g. accuracy, authority, objectivity, and information content). Previous studies show that features that have been proved to impact the credibility of health-related web pages can be utilized to build an automatic credibility assessment model.
Only a few approaches explored the automatic evaluation of health information on the web. Mukherj et al. 30 produced a probabilistic graphical model based on the fact that information credibility depends heavily on the linguistics, objectivity of the text, and the author’s trustworthiness. Those three features were jointly used to evaluate the credibility of different health content from the healthboard.com website. The stylistics and the effective characteristics of the text were manually extracted along with the author’s features from the web pages. Users’ authority was measured according to multiple factors such as age, gender, country, posts, answers, thanks received, and length of his articles. This model was evaluated in multiple experiments, achieving an accuracy of 56.7% in predicting the credibility of the web page.
Efforts to evaluate health websites were made by Weitzel et al., 2 who introduced a new framework that assesses the credibility of health-related web pages. The authors defined several quality indicator metrics such as source reference (i.e. authors qualification), HON certification (i.e. does the site have a HON certification?), and funding and sponsorship (i.e. funding may indicate conflicts of interest by a site’s owner). Those metrics are calculated by a function, and the results of a function give the trust score, which indicates the credibility of the website. Validation of this research was carried out by comparing the trust score of several websites with their Alexa rank. The results showed that the trust scores were very close to the Alexa rankings. In recent years, there has been a growing number of publications focused on analyzing factors that affect the credibility of health information on the web. Comparatively, only a few studies have proposed an automatic evaluation of health-related content and based on our knowledge and research. No evaluation studies have proposed an automatic evaluation of Arabic health websites. Thus, this study aims to build the first Arabic health website credibility model.
Methodology
As mentioned earlier, determining the credibility of health-related web pages is crucial, as it impacts people’s lives. The existing literature on content credibility assessment, as discussed previously, lacks a focus on automatically evaluating the credibility of web page content in general and health-related web pages in particular. These facts encouraged us to generate the first approach to automatically assessing the credibility of Arabic health web pages. Since no available datasets matched the aim of this study, a new dataset of health web pages was created. Multiple features were extracted from health web pages according to certain standards defined by other researchers in the medical field, in addition to features that were observed to be significant during the classification process. We, in particular, proposed a hybrid approach that examines both a predefined set of indicators of source reliability with other linguistic features obtained from the web page content. Labeling the web pages was delegated to field experts in order to guarantee a high accuracy of the annotation process. Several machine learning algorithms were trained and tested, and their performance was evaluated.
Data collection
To evaluate the performance of our proposed model, we built a dataset consisting of 500 web pages gathered from various Arabic health websites. To build the dataset, we started by randomly collecting a wide range of websites that contain health-related content. We, in particular, search with the following queries in Arabic “medical advice,” “medical information,” and “health information.” We then filtered the retrieved list to 100 websites that contained only Arabic health-related content. The health-relatedness was determined according to the content of the website. If web pages do not contain information about medical treatment, medication, illness, medical procedure, medical advice was excluded from the pool of websites. The list of websites covered a range of health topics (e.g. general health, diabetes, cancer, infection, mental health, etc.), and the websites also varied between governmental and commercial websites.
We then used web crawlers, also known as spiders or automatic indexers, to extract information from the websites. Web crawlers are Internet bots that crawl one web page and collect information about the website. A Web crawler starts with a list of URLs to visit, called “seeds.” As the crawler visits these URLs, it identifies all the hyperlinks on the page and adds them to a URL list. We used the Scrapy framework that was developed to build web scrapers. We built a python program that takes the URL of the initial website and automatically scrapes its web pages.
We fed the spider with the start URL list that exists in the main URL in order to allow the spider to return a list of all the web pages. The number of web pages scraped can also be specified. We then define several items or data to be extracted from each web page, such as the title of the article that exists in the heading tags, text which is the health information or the main content of the web page that resides in the body tag, the author or the writer of the article, the date in which the article was written, the reviewer who review and confirm the health information in the article, the information source which is the references of the article’s information, and the existence of advertisements in the web pages, Figure 1 shows an example of the extracted data. An example of a web page and extracted information (the title, author, date, content, references, and Ads).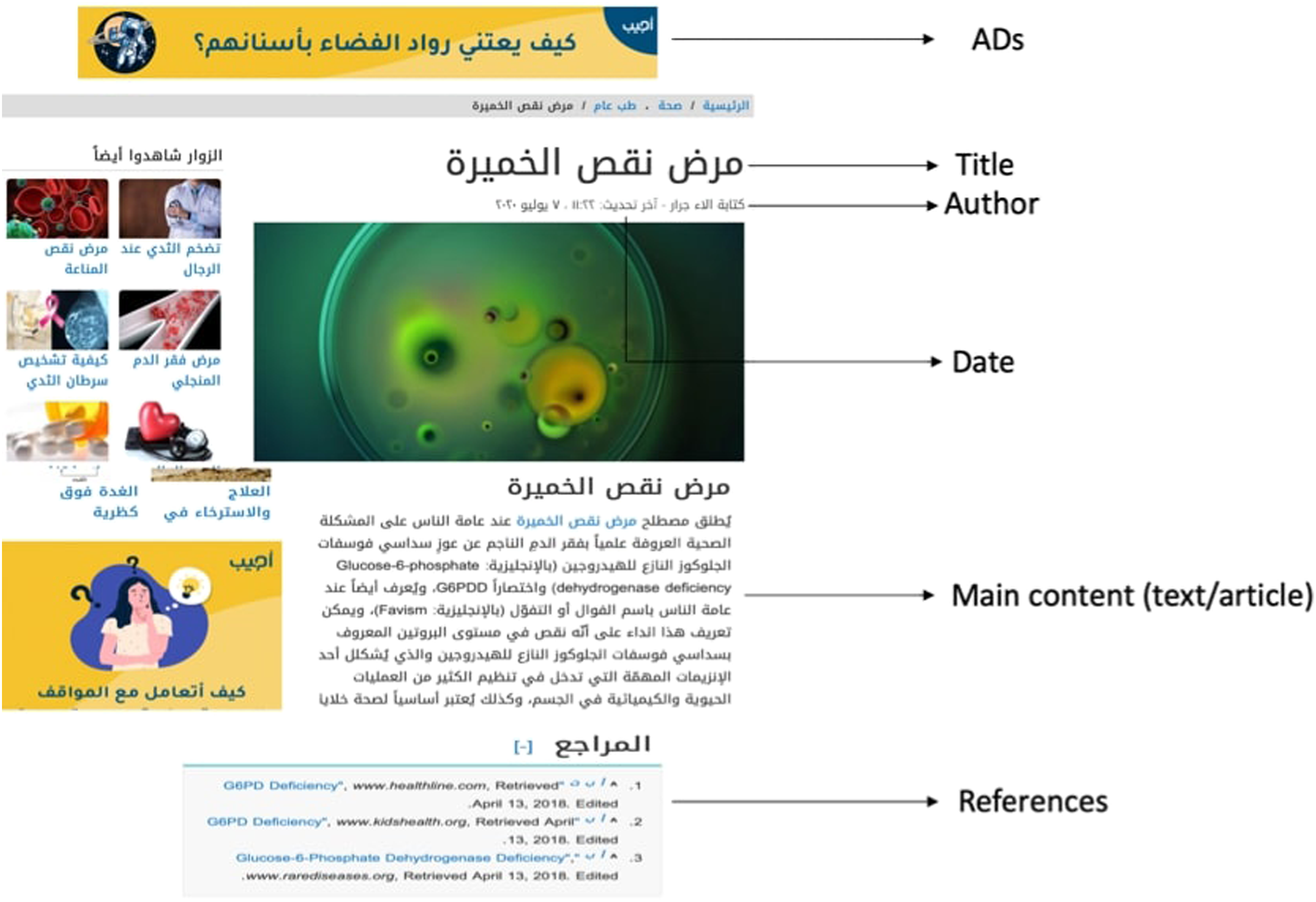
Some websites protect their data by blocking the spiders using defensive algorithms to limit the repeated request of the IP. To handle this issue, we use XML and HTML parser that can automatically extract websites’ data by parsing HTML or XML documents into a tree structure format. The same features specified earlier are also defined in the parser. Only a few websites were scraped using this method to collect our dataset. The tool used for this task is Python Library named beautifulsoup. 1 Also, Web crawlers can only understand HTML files only which makes it challenging to crawl JavaScript files. For that reason, we utilize a headless browser to control these web pages using a command-line interface.
After scraping different web pages from each website using the two techniques described previously, we ended up with 30 CSV files, a file per website. It is worth noting that our initial list of websites was shrunk down to only 30 websites due to several reasons; a large number of websites closed due to reasons related to license expiration, or their content had been changed to non–health-related content.
The CSV files were merged into one file consists of over 1000 web pages, but we had to minimize the size of the data due to the annotation process. We scraped 20 web pages from each website to finally end up with 500 web pages with their corresponding features. Several features per web page were extracted from each URL that was later saved in a CSV file format. The CSV files extracted from each website were combined later to create the final dataset. Each feature was extracted by feeding the crawler the tags of this feature, and then the extracted information was added to the CSV file. Figure 2 shows a part of our health dataset. Each row in the dataset corresponds to a web page with extracted features (i.e. author, title, content, etc.) and annotations. The Arabic health website credibility dataset each row represents web page with non-textual and textual features and the true classification provided by three annotators.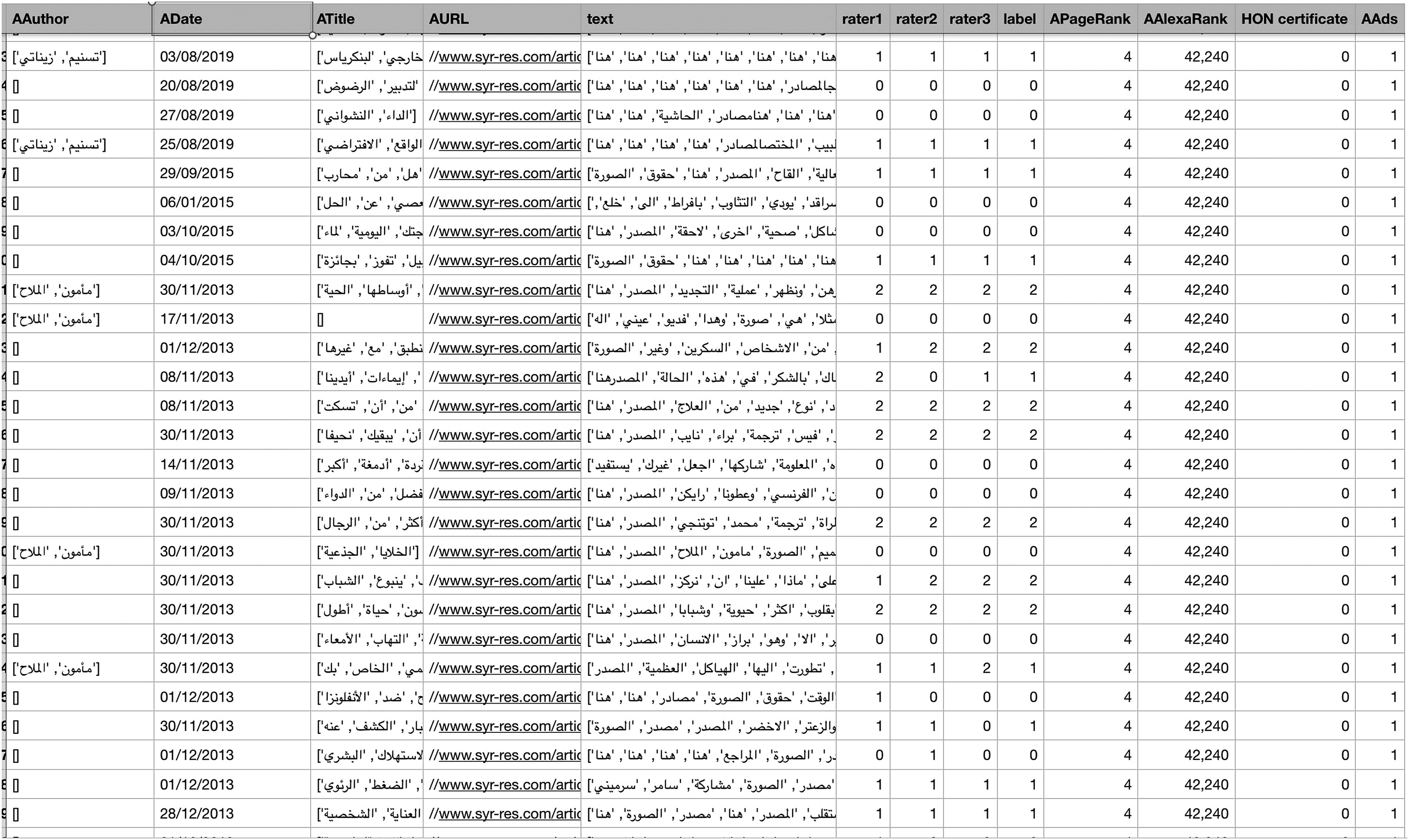
Annotation
The labeling task was delegated to annotators from the medical field, as health information is sensitive and judgments on such information need expertise. All annotators are Arabic native speakers, had a degree in medicine or nursing, had over five years of job expertise in the medical fields, and had good computer skills. The annotators received forms where they would click on the link to the website, read the article, and then choose their evaluation of the website. Pre-annotation instructions were given to guide them through the process. Labels were divided into four categories: Credible if all information on the web page is valid; Non-credible if the web page contains inaccurate information, and Unknown if the annotator cannot determine the validity of information in the web page. The option “URL not working” has been given because a large number of websites links were either expired or have been changed to other content. Each annotator was asked to label the web pages by reading each web page and then evaluating its content by one of the previously described classes: credible, non-credible, or unknown.
After the annotation, we ended up having three labels per web page from three different annotators. The most common label was considered as the final label for the article. If a web page was labeled differently by all the annotators, we excluded that web page to avoid any confusion. We also excluded web pages that were labeled as not working. After this step, the size of our dataset was decreased to 463 web pages. The last dataset had 236 credible web pages, 93 labeled unknown, and 136 web pages labeled as non-credible, Figure 3 shows the distribution of each class in the dataset. The distribution of the three classes (credible, non-credible, and unknown) in the dataset.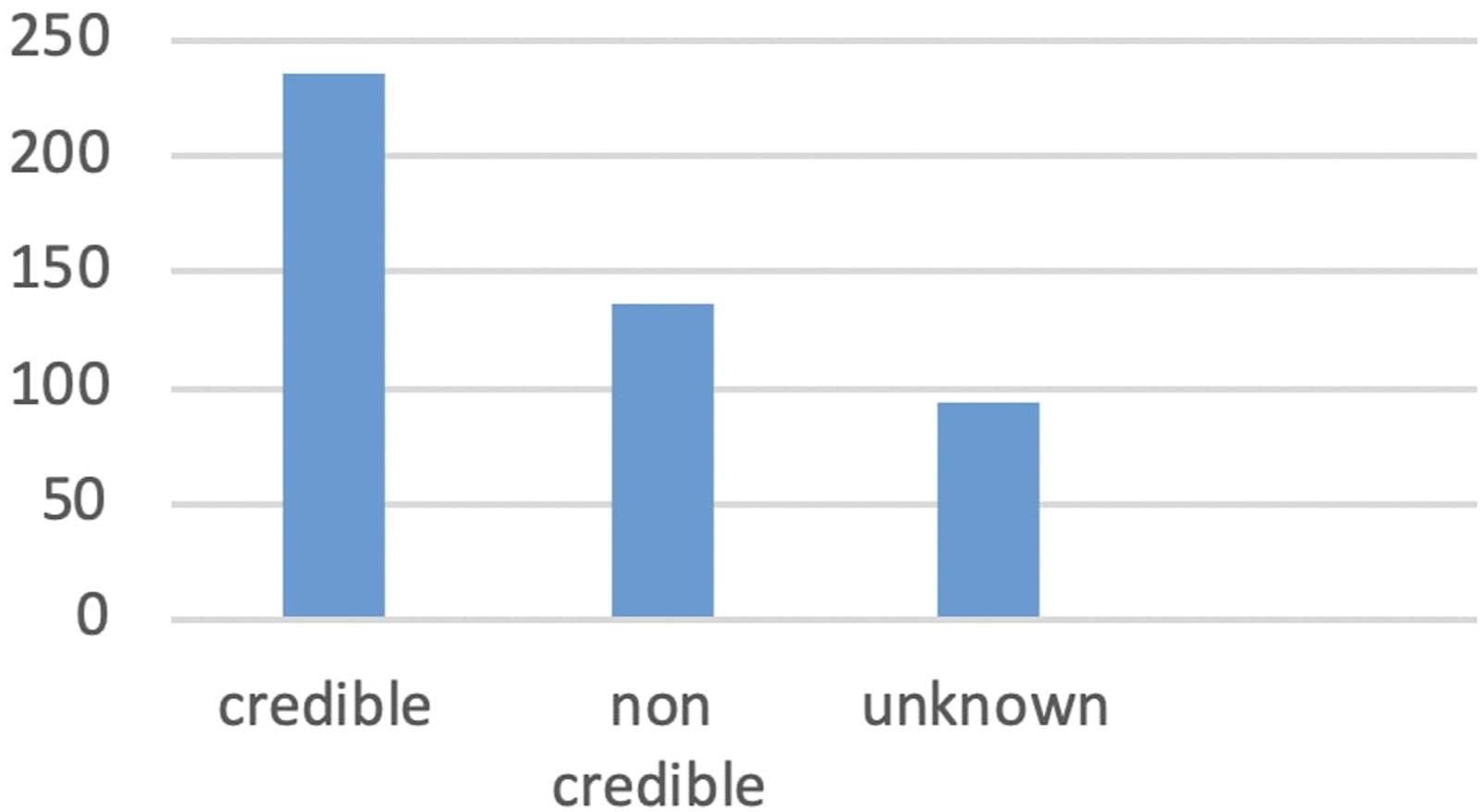
We calculated the inter-rater agreement between the three annotators using the Cohen kappa coefficient, and the results showed an agreement of 0.28 among the three annotators. This number indicates the complexity and difficulty of content reliability evaluation for experts rather than regular people. The number of non-credible websites was large, which may raise an important question about the significance of using a credibility prediction model.
Feature selection
Different types of features were explored for websites’ credibility evaluation in the literature and other health organizations (e.g. HON). These features could be grouped into two categories: content or textual-based features that were present on the web page or meta information features. In this research, we investigate both types of features: non-textual and textual features to assess web pages’ credibility, focusing on the features that could be acquired automatically from the web page properties/meta-data or content to support the automation of the model.
Non-textual features
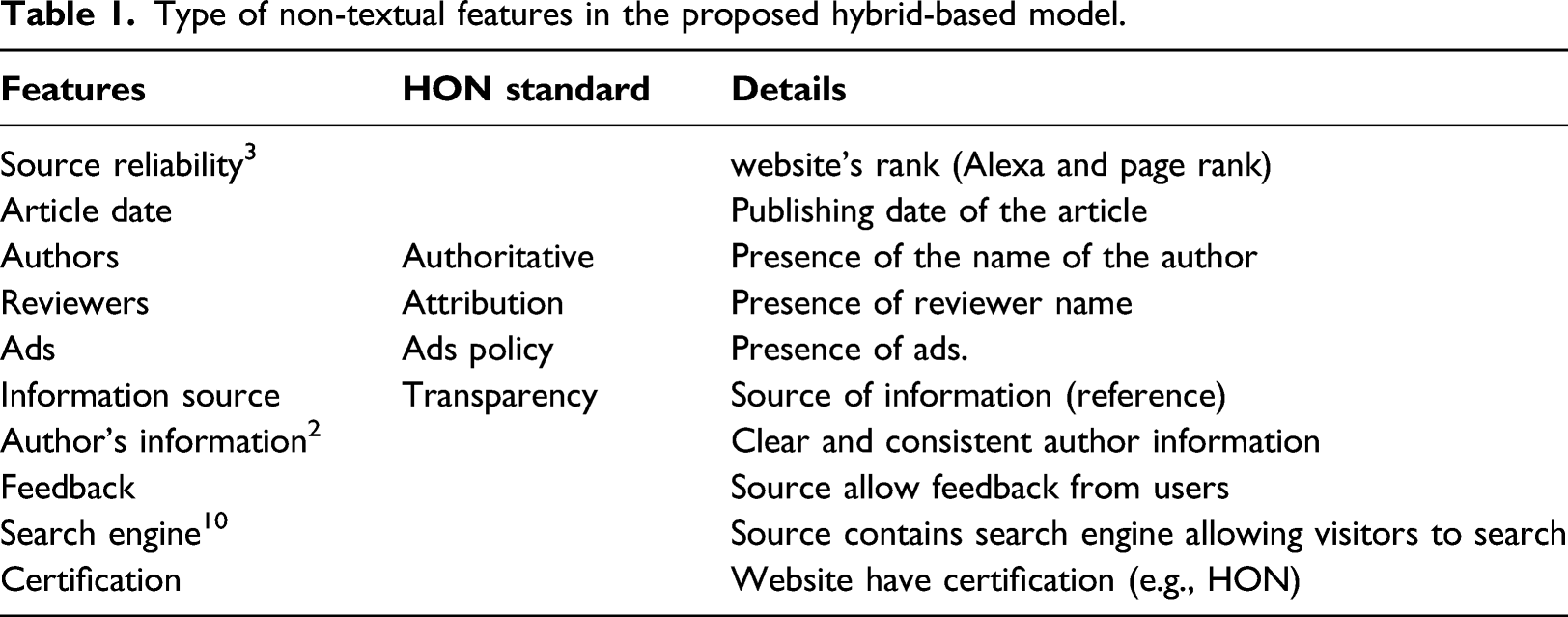
For non-textual features, we focused on some of the features corresponding to HON standards that can be acquired automatically. HON organization evaluates health information manually using human resources, and only a number of the standards cannot be extracted automatically. HON standardized evaluation criteria were chosen in this study because they are designed for a specific type of content (like DISCERN focuses only on treatment content), and they are based on both content and presentation of the online resources.
Type of non-textual features in the proposed hybrid-based model.
Textual features
To extract the textual features, we first perform text preprocessing and text representation on the web page’s content. Text features are rich content that may contain much unnecessary information that could negatively impact the performance of the machine learning models, such as Arabic stop words, HTML tags, and special characters. Text preprocessing is very important in our model, and thus in this step, we eliminated Arabic stop words (e.g. prepositions and pronouns) and cleaned the text from HTML tags, diacritics, non-Arabic words, and special characters using the PyArabic library. Finally, we removed words with lengths of three letters or less. After this step, the text features were ready for classification. To transform the raw textual data into a representational form that the machine learning and deep learning algorithms could handle, we used several word distributional representations. There are several popular text distributional representation techniques that vectorize and encode textual data into numerical vectors that capture the semantic properties of words. Two word representation models were used in this study: the Term frequency-inverse document frequency (TF-IDF) and neural word embedding. The TF-IDF model is one of the simplest and most popular text representation models that describe the occurrence of a word in a document in which the structure and the order of words in documents are not taken into account. Unlike Bag of the word and TF-IDF model, word neural embedding (word2vec) is capable of capturing the context of a word in a document, and AraVec 31 , an Arabic version of Word2Vec word embedding model. Both text representations were used in our model in separate experiments in order to assess the impact of the text features and their representation on our model’s performance.
Content credibility predictive model
As mentioned before, the web page credibility assessment has not been investigated enough in this domain. In order to investigate the effect of the features on credibility assessment, we tested the performance of several ML algorithms using different feature combinations: textual features, non-textual features, and hybrid features (i.e. a combination of both textual and non-textual). For textual features, we utilized various types of word representation models, as described earlier. Three machine algorithms were also used in the experiments: Logistic Regression (LR), Support Vector Machine (SVM), Decision Tree (DT), and a deep learning model Long short term memory (LSTM).
Machine Learning models
Logistic Regression (LR) is a simple yet powerful classification model that works by estimating a linear function that gives the probability of an input being of the positive class. If the probability is greater or equal to a predefined threshold (often = 0.5), the input will be classified as a positive class; otherwise, it will belong to the negative class. We implemented a grid-search algorithm to choose the optimal hyperparameters given a range and combination of hyperparameters values. The best hyperparameters of the LR were optimizer solver = “liblinear,” ridge regression (penalty) = “l2,” Inverse of regularization strength (C) value = “1.0,” and threshold decision = “0.5.”
We also implemented the SVM model as it often shows good results in many non-linearly separable problems. SVM creates a hyper-plane to separates the data into two sets with the maximum margin. SVM hyperparameters were also optimized to choose the optimal parameters for our problem. The best hyperparameters of the SVM were kernel = “linear” and C value = “100.”
The decision tree classifier (DT) was also examined in this study to classify the web pages into one of the predefined classes. For text classification problems, a decision tree is often constructed with internal nodes being the label, the branches represent weight, and the leaves represent the classes. The tree can classify an article by running through the query structure from the root until it reaches a certain leaf, which represents the goal for the classification of the article. We implemented the model using different depth sizes, and the optimal tree depth size was chosen.
Deep learning model
In addition to the machine learning models, we implemented a deep neural network model, namely Long Short Term Memory (LSTM). The architecture of the LSTM consists of one input layer (embedding layer), one LSTM layer with 128 neurons and one dense layer, and one output layer. We use SpatialDropout1D that performs a variational dropout in NLP models. Since we have three possible outputs, the number of neurons in the output layer is equal to three, and the activation function is Softmax. We use the categorical Crossentropy as our loss function and adam as the optimization solver.
Text representation
We utilized two different methods to represent textual data, namely Term Frequency-Inverse Document Frequency (TFID) and Neural word embedding based on word2vec (AraVec). For textual features, we used TF-IDF representation using the count vectorizer in NLTK 2 in order to vectorize each sentence by taking all the unique words in the sentence and creating the vocabulary. This vocabulary is then used to create the feature vector for the count of words. Each article or textual content in our dataset was represented as a vector, and these feature vectors can be used as inputs to ML algorithms. We also vectorized the title and authors’ textual features in the same manner.
For the neural word embedding, we represent each word in the article by its representative embedding in AraVec. If a word is not found in the AraVec dictionary, the word embedding values for the word are zero. A concatenated vector of the article’s words embeddings was created to represent each article.
Hybrid features fusion
In the hybrid features experiments, we combined two types of features textual and other non-textual data. To integrate both textual and non-textual data, we used different strategies for ML and DL. For the ML approach, we used the pipelines and feature unions method in python. First, we created one pipeline that accepts texts as input and preprocesses the text, as the second pipeline is created to accept non-textual data. The features from each pipeline are joined using the feature unions (concatenation) method to combine the two types of features from previous pipelines to generate a feature vector that can be used as input to the classifier. For the deep learning models, we made a few modifications to the LSTM model in hybrid features experiments by creating two sub-models. The first sub-model accepts textual data as input, and it consists of a shape layer and an LSTM input layer of 128 neurons. The second sub-model accepts the inputs in the form of meta information. This sub-model consists of an input layer and a dense layer. The output from the two sub-models is concatenated and used as input to another Dense layer. The last layer is the output layer with three neurons, and the activation function was Softmax.
Data splitting and performance evaluation
We divided the dataset into training and testing samples using stratified ten folds cross-validation to ensure that each fold has an equal proportion of the classes. In the next step, we tested the four algorithms using only the text features of our dataset as inputs. Then, we tested the performance of the algorithms on the non-textual features specified earlier, and in the last step, we combined all available features and fed them into each of the four algorithms as inputs.
The model performance was evaluated using accuracy and F-score. The accuracy in any classification is computed as the fraction of correctly classified instances. F-score is computed as the harmonic mean of both the precision and recall. Precision is equal to the true positive (TP) divided by the true positive (TP) and false positive (FP), and the recall is equal to the TP divided by the TP and false negative (FN). F1-measure is widely used as a classification metric as it is less sensitive to class imbalance. The following equations are the performance metric used in this study.

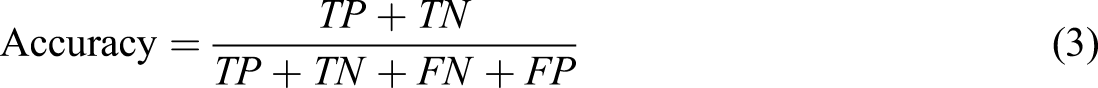
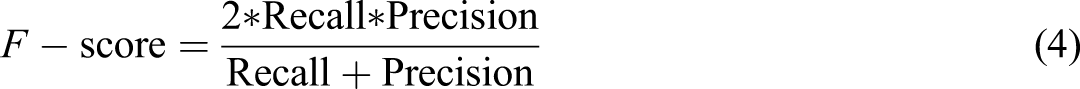
Results
In this section, the results of different experiments are presented. We performed three experiments. In the first experiment, we evaluated the three machine learning models on three different sets of features textual (TF-IDF), non-textual, and hybrid features.
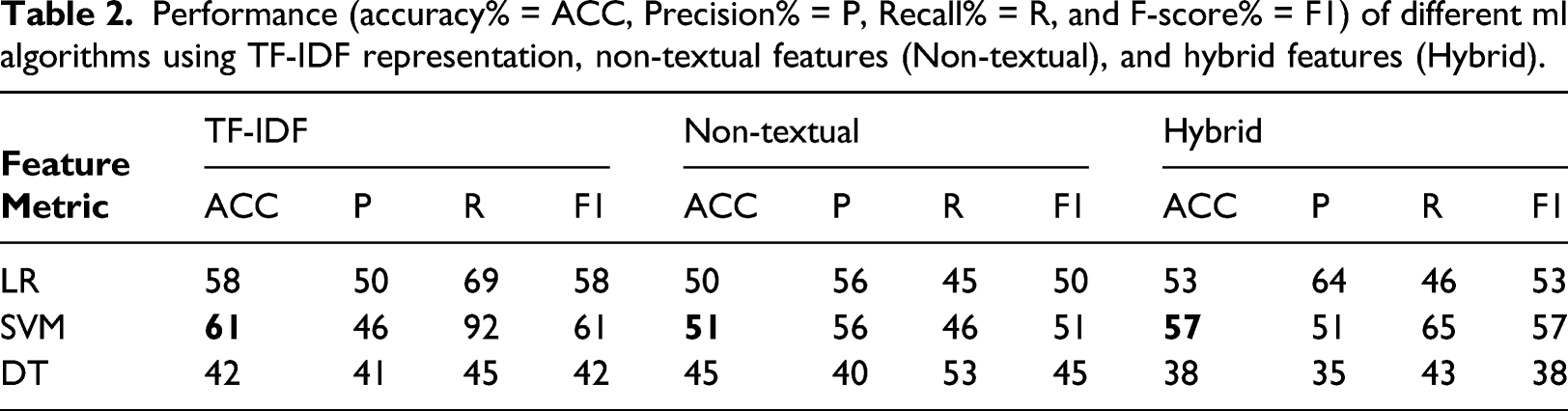
Performance (accuracy% = ACC, Precision% = P, Recall% = R, and F-score% = F1) of different ml algorithms using TF-IDF representation, non-textual features (Non-textual), and hybrid features (Hybrid).
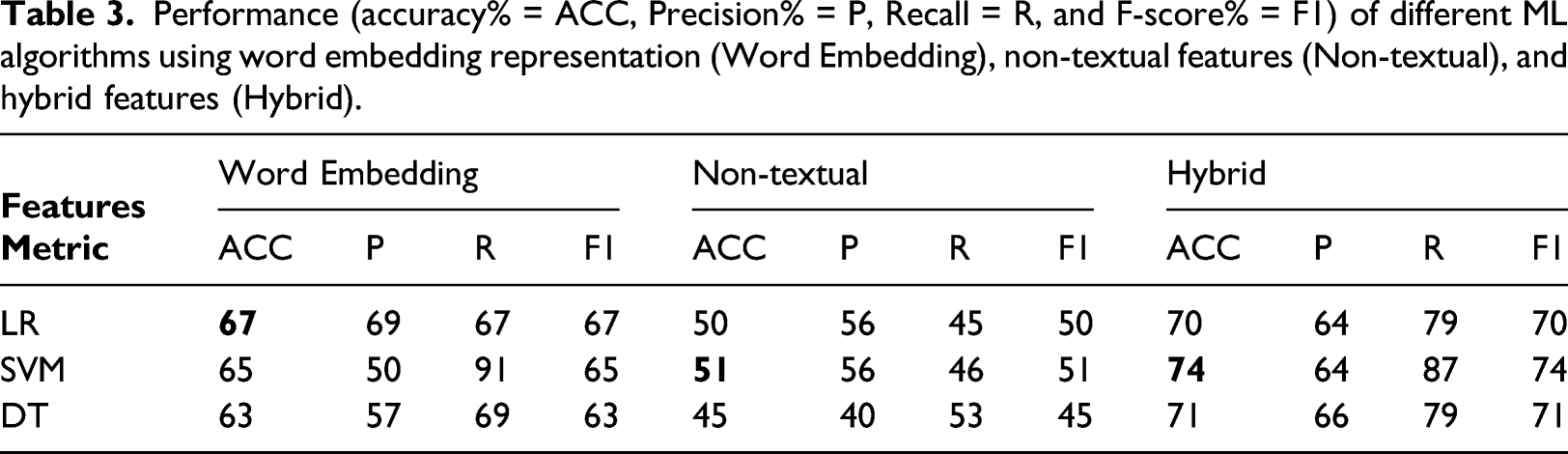
Performance (accuracy% = ACC, Precision% = P, Recall = R, and F-score% = F1) of different ML algorithms using word embedding representation (Word Embedding), non-textual features (Non-textual), and hybrid features (Hybrid).
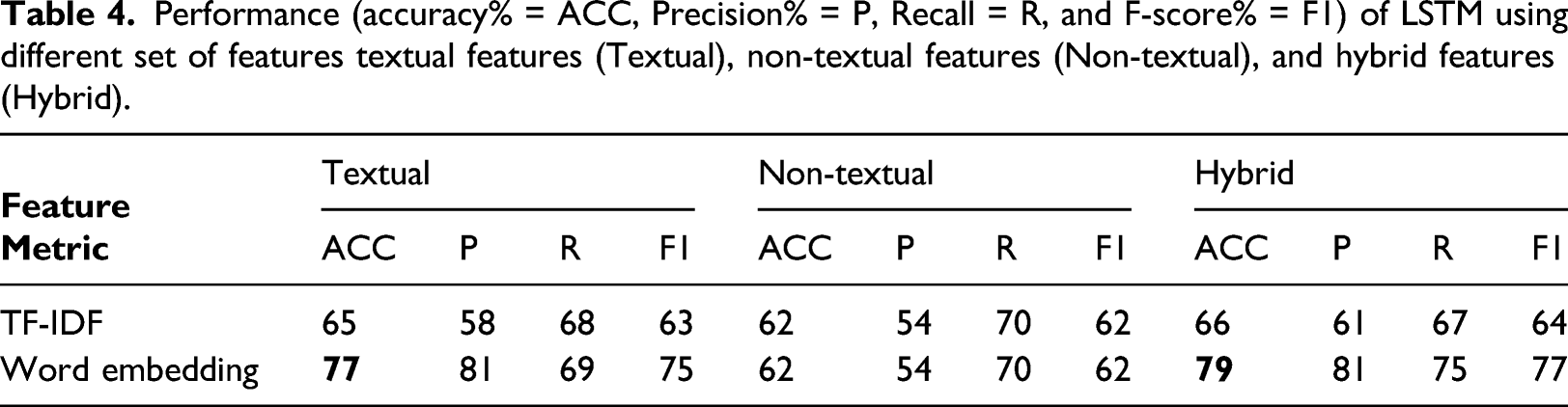
Performance (accuracy% = ACC, Precision% = P, Recall = R, and F-score% = F1) of LSTM using different set of features textual features (Textual), non-textual features (Non-textual), and hybrid features (Hybrid).
Discussion
The previous experiments examined the impact of feature selection on the model’s performance. The results obtained from the three experiments in Tables 2 and 3 indicate that the positive impact of using hybrid features in our model. In Table 2 using hybrid features, SVM significantly outperformed the non-textual and textual-based models achieving an accuracy of 74%. SVM also achieves the highest performance among all the machine learning algorithms. This is not surprising because SVM is powerful for sparse data such as text. From the above results, LSTM stands out with the highest score among all algorithms and for all features groups using word embedding.
In the experiments, we assessed the performance of several algorithms individually using different groups of features. Tables 2–4 show the average accuracy of the different algorithms employing the different sets of features. In contrast to the other features, the non-textual feature had a minimum impact on our classification. These findings might indicate that textual features play a vital role in classification regardless of the representation technique. However, there was an observed difference in the performance of the model when using different text representations. We measured the impact of applying TF-IDF versus word embedding. Tables 2–4 illustrate that accuracy benefits from word embedding more than TF-IDF, which results in the loss of valuable information.
We could also explicitly see how applying the LSTM enhanced the overall performance of our model among different experimental conditions. LSTM also led to an acceptable performance on our dataset.
In reviewing the literature, we can confirm that no previous research closely matches our study in terms of the methodology, type of data used, or even the dataset’s language. This fact makes it difficult to compare our findings with this research, still, by looking at 30 who provided a form for evaluating medical pages in English, using hybrid data, and obtaining 56.7% accuracy. We can say that the results we obtained are relatively better, which may be due to their use of only three non-textual data and their neglect of other factors that may significantly increase the model’s accuracy. Also, the use of deep learning increases the accuracy of the model. Increasing the dataset size increases the model’s performance. We were surprised when collecting the dataset that the Internet lacks an adequate number of Arabic websites, despite many Arabic speakers worldwide. This was one of the obstacles that made the volume of our data Limited compared with the datasets available in the English language. This fact may be one reason that prompted many researchers to turn to the English language and build models to evaluate the reliability of data on English sites. We mentioned previously that the design might indicate the reliability of the web page. We faced many difficulties with scraping non-textual features from Arabic websites during the data collection phase due to the shortage of professionally programming and design for many Arab websites.
Conclusion
In this article, we introduced the first automatic credibility prediction model for Arabic health websites. The study also examined the impact of text representation on credibility’s performance and has shown the significant impact of textual features on credibility evaluation performance. Besides the fact that this is the first study to investigate Arabic health information on the Internet, this work contributes to the research area by creating the first Arabic health dataset to be evaluated by medical experts. The study also examined the relationship between text representation and the performance of the classification model. Our model was able to predict the credibility of health web pages with an F1-score of 79%. However, considerably more work needs to be done to expand the size of our dataset to better understand the factors that impact health information credibility and increase the model’s performance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.