
Abstract
Discretization is a preprocessing technique used for converting continuous features into categorical. This step is essential for processing algorithms that cannot handle continuous data as input. In addition, in the big data era, it is important for a discretizer to be able to efficiently discretize data. In this paper, a new supervised density-based discretization (DBAD) algorithm is proposed, which satisfies these requirements. For the evaluation of the algorithm, 11 datasets that cover a wide range of datasets in the medical domain were used. The proposed algorithm was tested against three state-of-the art discretizers using three classifiers with different characteristics. A parallel version of the algorithm was evaluated using two synthetic big datasets. In the majority of the performed tests, the algorithm was found performing statistically similar or better than the other three discretization algorithms it was compared to. Additionally, the algorithm was faster than the other discretizers in all of the performed tests. Finally, the parallel version of DBAD shows almost linear speedup for a Message Passing Interface (MPI) implementation (9.64× for 10 nodes), while a hybrid MPI/OpenMP implementation improves execution time by 35.3× for 10 nodes and 6 threads per node.
Keywords
Introduction
Discretization is a preprocessing step in which continuous values of features are transformed into categorical. Specifically, in discretization, a finite number of intervals is provided and values that lie between two consecutive intervals are replaced by a value which characterizes that range. This process can also be considered as a dimensionality reduction methodology since the initial spectrum of a feature’s values is reduced to a smaller finite set of values.1,2 This paper focuses on supervised discretization, and specifically on its application as a preprocessing step for classification tasks.
The necessity of discretization is due to the fact that a number of existing classifiers and statistical tests, rely on having only discrete data as input. Additionally, with discrete data, the processing time of a classifier can be reduced 3 and the results can be easier to interpret, whereas the use of a discretized version of the data can also improve the obtained accuracy by a classifier.1,4,5 With the big data era, discretization algorithms need to be able to handle such data efficiently without compromising their performance. Hence, it is important to have discretization algorithms that are computationally efficient and can harness the power of high-performance computing, while minimizing the information lost.
Discretization algorithms can be categorized based on some of their main characteristics. 1 A main characteristic is if it is using the class label (supervised) or not (unsupervised), when deciding for the intervals. If a discretizer is independent of a learner then it is static, otherwise it is dynamic. Algorithms that discretize each feature separately are called univariate and if they consider all attributes multivariate. In case only a part of the information of a feature is used when deciding for an interval, the algorithm is considered as local, otherwise as global. Another characteristic is based on whether the intervals are selected simultaneously (direct) or one at a time (incremental). The last two main characteristics of discretizers are the evaluation measure used to select the most appropriate interval and the procedure used to create the intervals (splitting or merging). In the splitting approach, a discretizer starts with an empty set of intervals and each added interval divides the domain, whereas in the merging approach, it begins with a set of intervals which are being merged based on a criterion. In case the algorithm is incremental and uses the splitting approach, it is called Top-Down, whereas if it is using merging, it is called a Bottom-Up approach.
Supervised discretization
In supervised discretization, an algorithm tries to transform each feature from continuous to categorical by using the class label of each instance. By transforming continuous data to discrete, there is the risk of information loss, especially if a very small number of intervals is created. Hence, a discretization algorithm needs to find a balance between the number of intervals created and the information lost.
In Ref.[6], Fayyad and Irani presented an information theory-based discretizer known as MDLP. Its name is from the criterion used for deciding when to stop creating more intervals, the Minimum Description Length Principle, and uses a Top-Down approach. The values of a feature are initially sorted and each midpoint between two consecutive values is considered as a new interval. Then it recursively selects the interval that produces the minimum class information entropy until the stopping criterion is satisfied. A distributed version of MDLP has been proposed 7 allowing it to be used on big data. Numerous information theory-based algorithms have been proposed in the literature8–10 but MDLP is one of the most widely used discretizers.
ChiMerge 11 is a Bottom-Up discretizer that uses Pearson’s Chi Square test (χ2) to decide if two intervals need to be merged or not. It initially sorts the values of a variable and adds each value in a separate interval. Then it selects the two adjacent intervals with the lowest χ2 value and merges them. This is repeated until no adjacent intervals have a χ2 value below the predefined threshold. Again, many algorithms were proposed based on χ212–14 and were found to have good results in Ref [1].
Another Top-Down method is CAIM. 15 This algorithm also sorts the values of a feature and then considers the midpoints between the values as possible intervals. It then repeatedly selects the midpoint that maximizes the class-attribute interdependence as a splitpoint. If the current best value is smaller than the global maximum, the procedure stops. CAIM produces at least C intervals, where C is the number of classes. A version of CAIM that can better handle imbalanced datasets was also proposed, 16 whereas a version for handling multi-label data is also available. 17
Density-based discretization algorithms
The density of a feature can be estimated using parametric or nonparametric methods. Parametric methods are more appropriate when the distribution of the data of a feature follows a known distribution. For example, if the normal distribution is assumed, then a parametric method can be used to calculate the mean and variance of the distribution through maximum likelihood estimates. 18
Nonparametric methods are used when the distribution of a feature is unknown since they can fit different density forms. One such method is kernel density estimation in which a kernel is used with a smoothing parameter for estimating the density of a feature. A simpler method for visualizing such data is the use of histograms, in which the values of a feature are represented by bins and the density of the feature in each bin is shown by its height.
Two well-known discretization algorithms that use binning are the equal-width and equal-frequency discretizers. These are unsupervised methods since they do not take into consideration the class label of the data. Equal-width takes as input the wanted number of bins (k) and creates k equally sized bins. In equal-frequency, k bins with approximately the same number of values are created. These two algorithms did not have a good performance in general in the tests performed in Ref.[1]. A more sophisticated unsupervised density-based discretization (DBAD) algorithm is TUBE, 19 which uses the log-likelihood and cross-validation to select the intervals and decide when to stop splitting the data. It was shown that it can better estimate the density of the data compared to equal-width and equal-frequency in the majority of the tests, where variables had less than 20 unique values, but it is not as fast as equal-width and equal-frequency. A Gaussian mixture model discretization algorithm 20 has also been proposed for associative classification of medical data with promising results, but as is the case with TUBE, it is not as fast as the equal-width and equal-frequency approaches.
Contribution
The main contribution of this work is that it turns the fast equal-width unsupervised DBAD algorithm into supervised, while having a performance similar to the state-of-the art supervised discretization algorithms. It initially uses the simple binning approach of the equal-width discretization along with a statistical test to adaptively merge any consecutive bins that have a similar density on each class. Then the resulting intervals of each class are merged to produce a supervised discretization that is computationally efficient. Additionally, the algorithm is parameter-free, thus there is no need to rerun the algorithm multiple times on a dataset to test for different parameter values, which can be a big overhead when dealing with big data.
Methodology
Supervised DBAD
The proposed DBAD algorithm is based on the hypothesis that intervals with different densities can be used to characterize a class and essentially be used to help in separating instances of different classes. For example, Class 1 might have a higher density in the range [0,1], whereas Class 2 in the range of [0.5,2]. Based on this, the following intervals of interest can be created {[0, 0.5], (0.5, 1], (1, 2]} to discretize the data. It is also possible that low-density intervals of a class can help separate it with another class that has no instances in those ranges, hence one should not only focus on identifying the high-density intervals of each class, but instead should identify the intervals in which densities change.
Density-based discretization tries to emulate the way a human would identify similar density intervals with the help of a histogram. Figure 1 illustrates the process followed by DBAD. It begins with equal-width binning (histogram (a)) for estimating the density of a feature in different intervals (bins). Each of the created bins contains a number of instances, which defines the density of the feature in those intervals. The more instances in a bin the higher its density. Once the bins are created, DBAD removes any empty bins by allocating their range to their neighboring non-empty bins (histogram (b)). Then it identifies any consecutive bins with similar densities using a statistical test and merges them (histogram (c)). Interval identification for a single class of a feature using density-based discretization (left) and merging of the intervals of each class for identifying the final intervals of a feature (right). The top-left histogram (a) illustrates the initial equal-width binning. Histogram b, illustrates the effect of the removal of the empty bins. The bottom left histogram (c) shows the final bins after merging any consecutive bins with similar densities. The top right (d) histogram shows the intervals selected for Class 1, whereas underneath it (e) the intervals of Class 2 and the bottom-right histogram (f) the final intervals after the ones of the two classes got merged.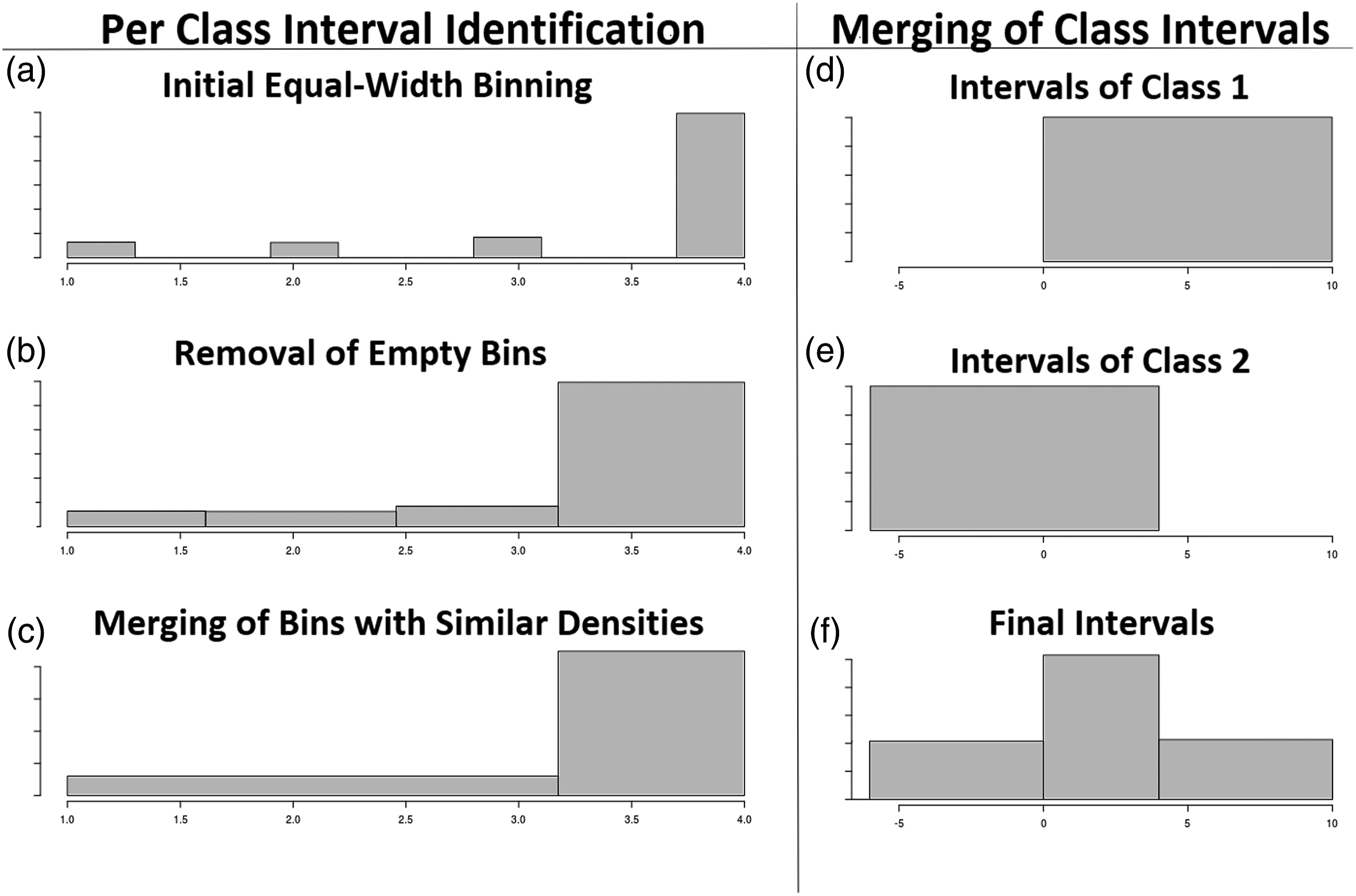
This procedure is performed on the instances of each class of a feature. Once the final intervals of each class are identified, they are merged to obtain the final discretization intervals. An example of the final step of DBAD can be seen on the histograms on the right in Figure 1. As illustrated, Class 1 intervals are in the range [0,10] (histogram (d)), whereas Class 2 intervals are in the range [-6,4] (histogram (e)), so the final intervals for this feature are {[-6, 0], (0, 4], (4,10]} (histogram (f)). Algorithm 1: DBAD 1: featureBins ←∅ 2: for each y ∈ 3: k ←⌈ log | 4: 5: 6: 7: 8: end for 9: 10: return
The steps followed by DBAD on a feature are shown in detail in Algorithm 1. The input values of DBAD are the vectors Require: bins 1: i = 1 #indexing starts at 0 2: 3: if 4: z = i 5: i = i + 1 6: 7: 8: 9: i = i + 1 10: 11: calculate w using (1) 12: 13: 14: 15: 16: i = i + 1 17: 18: 19:
With equal-width binning it is possible to end up with bins that have no instances in them. To eliminate such bins removeEmptyBins is used (see Algorithm 2). Initially, it merges consecutive empty bins by replacing the right interval of the left empty bin with the right interval of the right empty bin (step 7) and then removing the latter from the bins (step 8). Once the consecutive empty bins are merged, the new empty bin needs to be removed as well. To perform this removal, it is needed to assign its intervals to its surrounding bins. Initially, a new split point (w) is calculated (step 11) using (1) Require: bins 1: normalize the bins using (2) 2: i = 1 #indexing starts at 0 3: numBinsM = 1 #num of bins merged with current bin 4: 5: 6: 7: 8: maxMinSize = maxBinSize + minBinSize 9: 10: 11: 12: 13: 14: 15: numBinsM = numBinsM + 1 16: 17: 18: numBinsM = 1 19: 20: i = i + 1 21: 22:
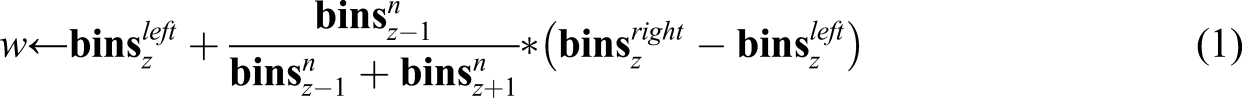
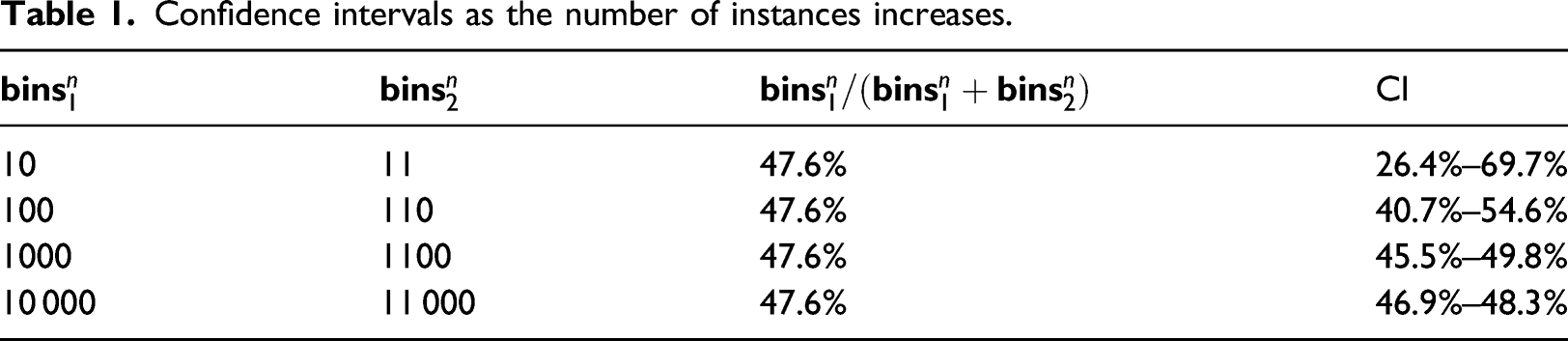
The next step of DBAD is to merge any consecutive bins with similar densities (similar number of instances) using mergeSimilarDensityBins. To decide if two consecutive bins have a similar density, a metric is needed which will be less strict with bins representing a small number of instances and stricter with bins of high density. This will enable the identification of intervals in which the densities have a significant difference. This can be tested with a two-tailed test of a population proportion in which the population is the number of instances in the two bins and the hypothesized value of the true population proportion between the two bins is 50%. Essentially the proportion test decides that two bins are similar if 50% is within the calculated confidence interval (CI).
The steps of mergeSimilarDensityBins are shown in Algorithm 3. Initially, two consecutive bins are selected and the bin with the largest and smallest number of instances out of the two is identified (steps 6–7). Then the percentage of the instances of the smallest bin to the sum of the instances of the two is calculated in step 9. Using the calculated percentage and the number of instances of the two bins, the CI at a 5% significance level is calculated (step 10). If 50% is within the calculated CI, the two bins are merged. Initially, the right interval of the bin on the left is set equal to the right interval of the bin on the right (step 12) and the size of the bin on the right is added to the size of the bin on the left (step 13). The bin on the right is then removed from the
Confidence intervals as the number of instances increases.
Hence, this approach behaves as needed on low-density bins but can be too strict as the bins’ density increases. To control the strictness of the metric, the sample size of the bins needs to be normalized to have at most α instances in the largest bin using (2)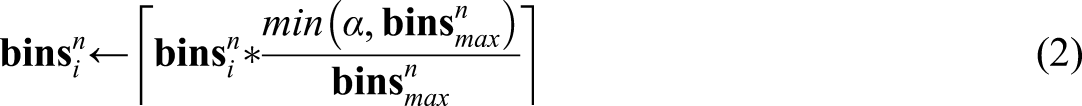
In DBAD, α was empirically set to the value 112, which allows to consider a bin that is consecutive to the largest one as similar if it has at least 75% of its instances.
Parallelization
The algorithm of DBAD can be easily parallelized and executed by multiple resources since each feature can be discretized independently. This is also known as an embarassingly parallel problem that can achieve high-levels of performance. A hybrid parallel version of DBAD that runs on both distributed and shared memory systems using the Message Passing Interface (MPI)
22
and OpenMP
23
has been implemented in C++. The algorithm creates multiple MPI processes that will be executed by the available nodes. Each MPI process is scheduled on a separate node in the system, where the DBAD discretization is further parallelized using OpenMP threads (see Figure 2). The algorithm uses as input multiple splitted files of the initial input file to allow processing big data that cannot fit in the RAM of a single node and at the same time reduce the communication overhead between nodes. Initially, MPI is used to distribute the input files evenly to the available nodes. Then each node reads one file at a time and splits its features to the available cores it has and each core executes DBAD on its features. When the cores finish with the discretization of a file, the node returns the discretized version of the file, and the master node merges all results to produce the final output. Parallelization of Density-based discretization.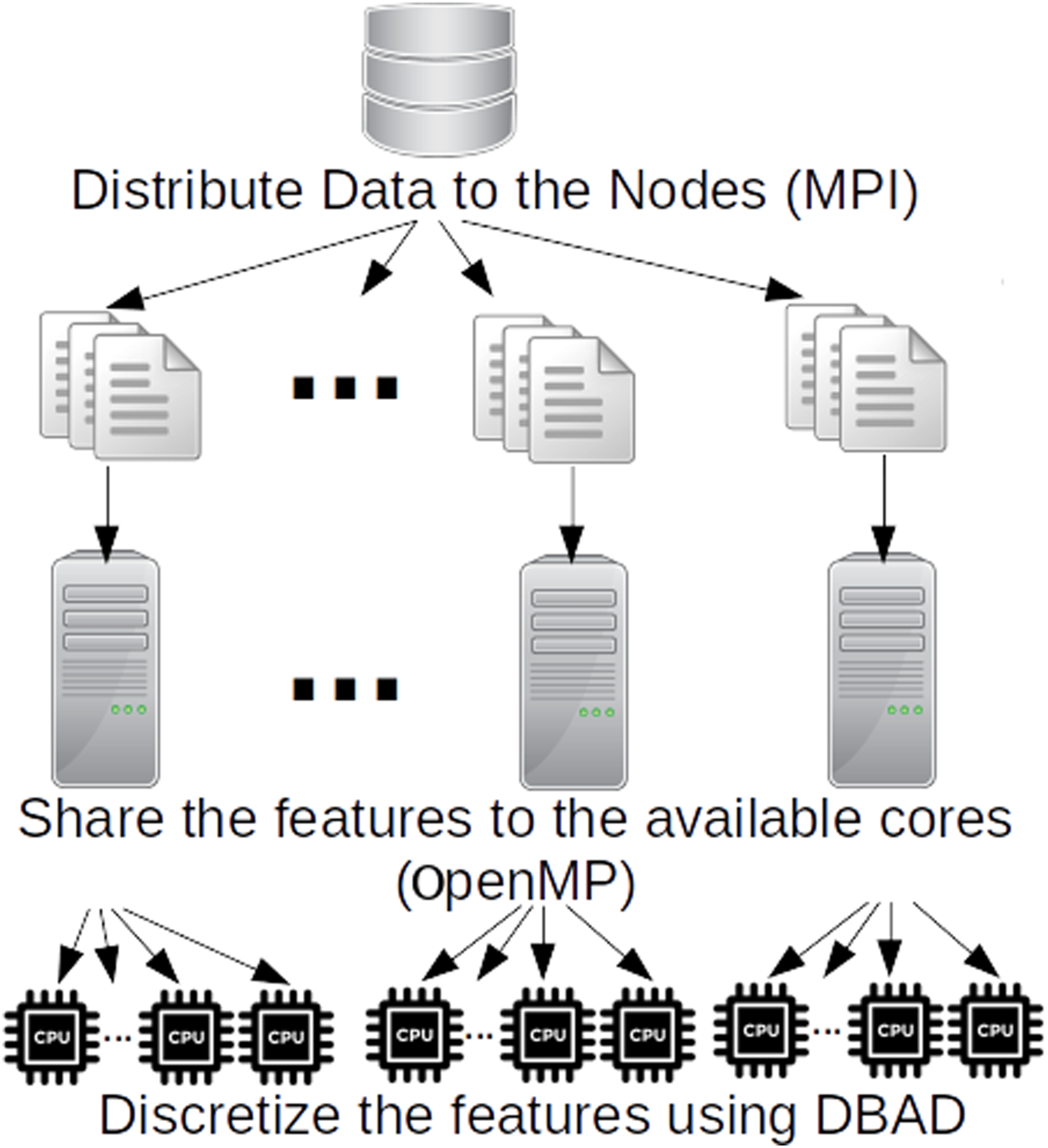
Datasets
Summary of the datasets investigated.
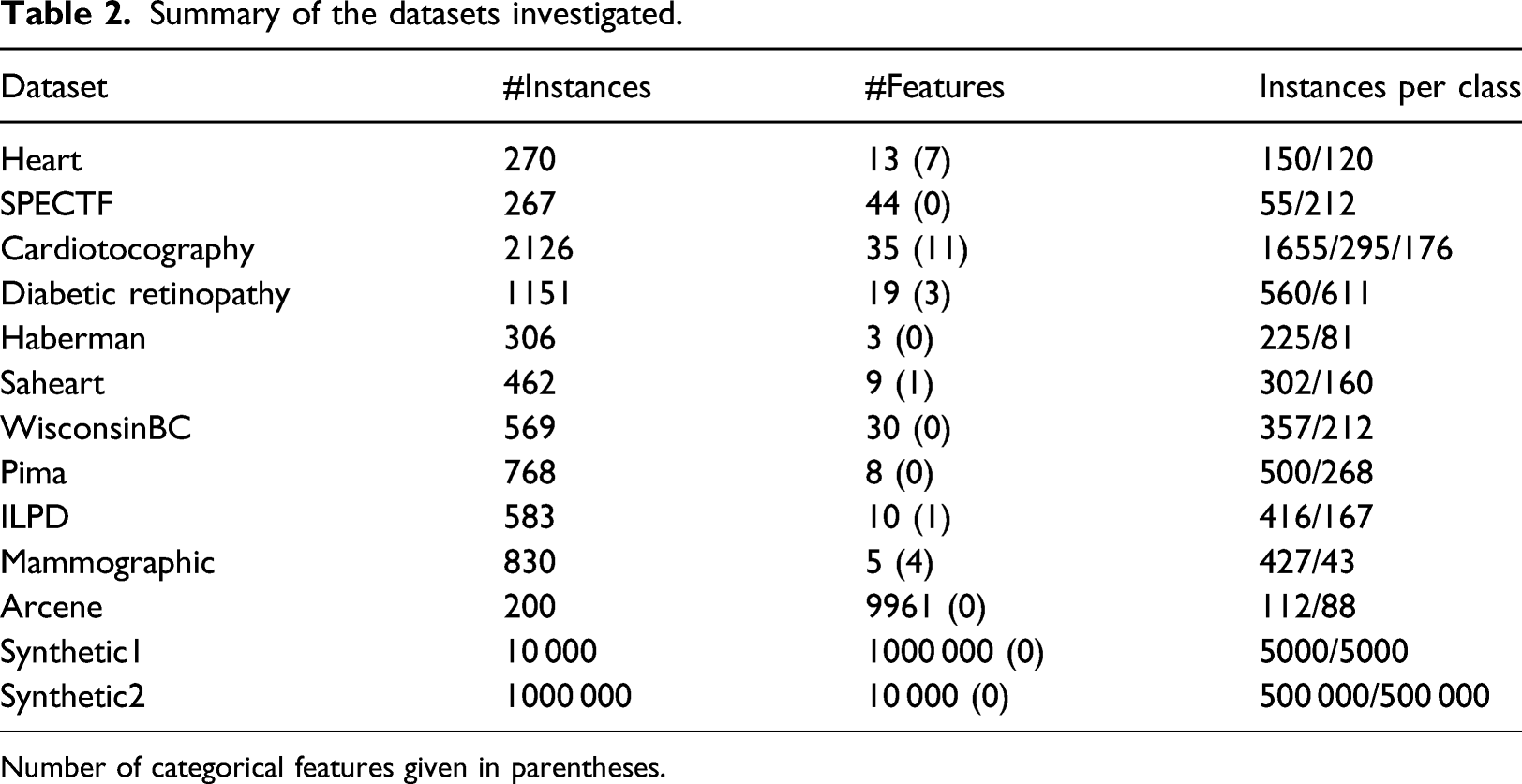
Number of categorical features given in parentheses.
The datasets from the UCI repository cover a wide range of datasets of the life sciences domain. They were selected so as to have different ranges of number of instances and features and have a variety of class balances. These datasets had a two-step preprocessing procedure. The first step was to replace any missing values using (3), which basically replaces the missing values of a variable with its minimum value minus one
The second was to remove any single-valued features since they did not contain any information that could help with the classification.
The two synthetic datasets were created using different continuous distributions (uniform, Gaussian, and beta) on each feature, to cover some of the common distributions a dataset might have. The Synthetic1 dataset has a large number of features, whereas Synthetic2 dataset has a large number of instances, to test how the algorithm is affected by the size of each dimension.
Evaluation methodology
To evaluate the effectiveness of DBAD at producing meaningful intervals, a 10-fold stratified Cross-Validation (CV) methodology was followed. Initially, the training folds were used by a discretizer so as to create the intervals for each feature. Using these intervals, the training and testing folds were discretized. Then a classifier was trained on the training folds and its accuracy and Cohen’s kappa value was measured on the testing fold. Specifically, the Support Vector Machine (SVM), 25 the Random Forest (RF), 26 and Naive Bayes (NB) were used for the classification task.
Additionally, the inconsistency rate of the discretizer was calculated on the testing fold. The inconsistency rate is calculated on each feature and it measures the percentage of instances that will be unavoidably misclassified if a single discretized feature is used in a classification. This is due to the fact that after the discretization of a feature, some instances will end up having the same value but their class will differ.
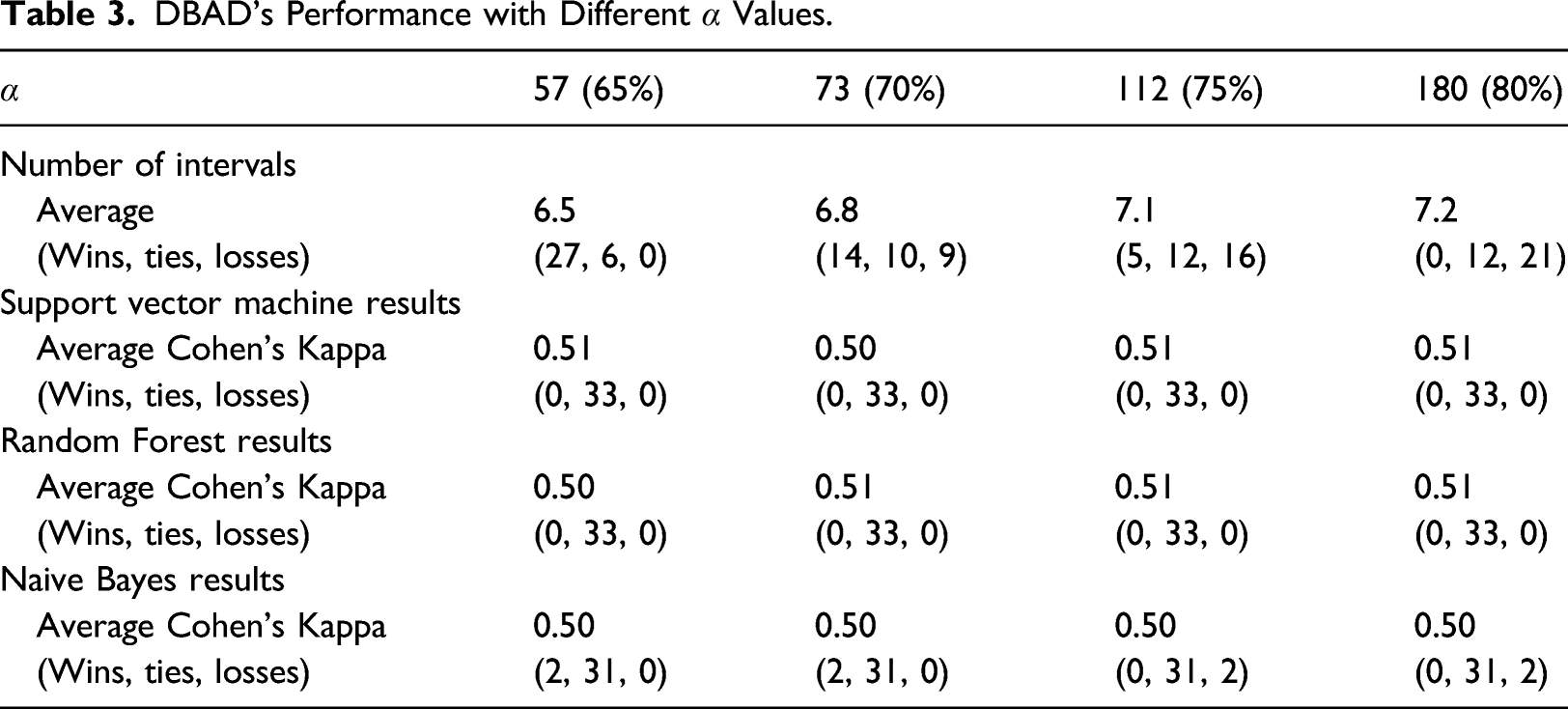
The evaluation was performed among DBAD and three more discretizers which were documented to perform well in the literature. 1 The selected discretization algorithms were CAIM and ChiMerge, which offer excellent performances in different types of classifiers and MDLP which provides a good trade-off between the number of produced intervals and accuracy. 1 To test how the α value of DBAD can affect its results, the values 57 (65%), 73 (70%), 112 (75%), and 180 (80%) were used. All algorithms used the same folds for training and testing during the CV to obtain comparable results.
To test if the intervals created by each discretization algorithm were superior or inferior to DBAD’s intervals, Wilcoxons’ signed-rank test was used on the evaluation measures mentioned above and additionally on the number of intervals produced by each algorithm and its execution time. For the statistical analysis on the sensitivity of DBAD on its α value, initially Friedman’s test was performed and if it was statistically significant, then Wilcoxons’ signed-rank test was used on the different pairs to identify which α value had better results in each scenario. The difference between two algorithms is considered statistically significant if the obtained p-value from the test is less than or equal to 0.05.
The aforementioned evaluation was performed in R. Specifically, from the e1071 package, 27 the SVM and NB were used, from the randomForest package, 28 RF was used, whereas for the discretization part, the discretization package 29 was used for the three discretizers. All of the aforementioned algorithms were used with their default parameters. The version of DBAD used for the aformentioned evaluation was implemented in R to have comparable results with the other discretization methods regarding their execution time.
To test the speedup of the parallel version of DBAD, Synthetic1 and Synthetic2 were split to 10 files each. Specifically, Synthetic1 was split to 10 files with 10,000 instances and 100,000 features each, whereas Synthetic2 was split to 10 files with 1,000,000 instances and 1000 features each. The splitting of the data was necessary for both the parallel and the sequential version of DBAD, so as to be able to load the data in memory, and hence was not considered in the speedup analysis. The speedup was calculated as T1/T k , where T1 is the execution time for discretizing a dataset using a single core and T k the execution time using k cores. The experiments were run at the Cyprus Institute HPC facility, on nodes with 48 GB of RAM and the Intel Westmere X5650 hexa-core CPUs without hyper-threading. The speedup was tested using a different number of nodes (1–10) and cores (1,2,4,6) per node. This enabled us to identify how the speedup was affected with the increase of the available processing units (cores) in a single node (without the effect of communication delays) and how well it could scale with the addition of more nodes.
Results
In this section, the evaluation results of DBAD are presented. Initially, the analysis on the sensitivity of DBAD’s performance on the α value is shown. Then DBAD’s performance is evaluated against the other discretization algorithms. Initially, results regarding the number of intervals created by each algorithm and the inconsistency rate are presented. Then metrics regarding the performance of the classifiers are shown, which can test the goodness of the intervals and the information lost. The execution time of each algorithm on different datasets is shown and finally the obtained speedup with the parallel version of DBAD is provided. To show if DBAD performed better or worse than another algorithm, the result of the statistical analysis is shown with a sign next to the measure tested. A positive sign indicates that DBAD performed better, whereas a negative sign shows that DBAD had worse performance.
DBAD’s Performance with Different α Values.
Average number of intervals.
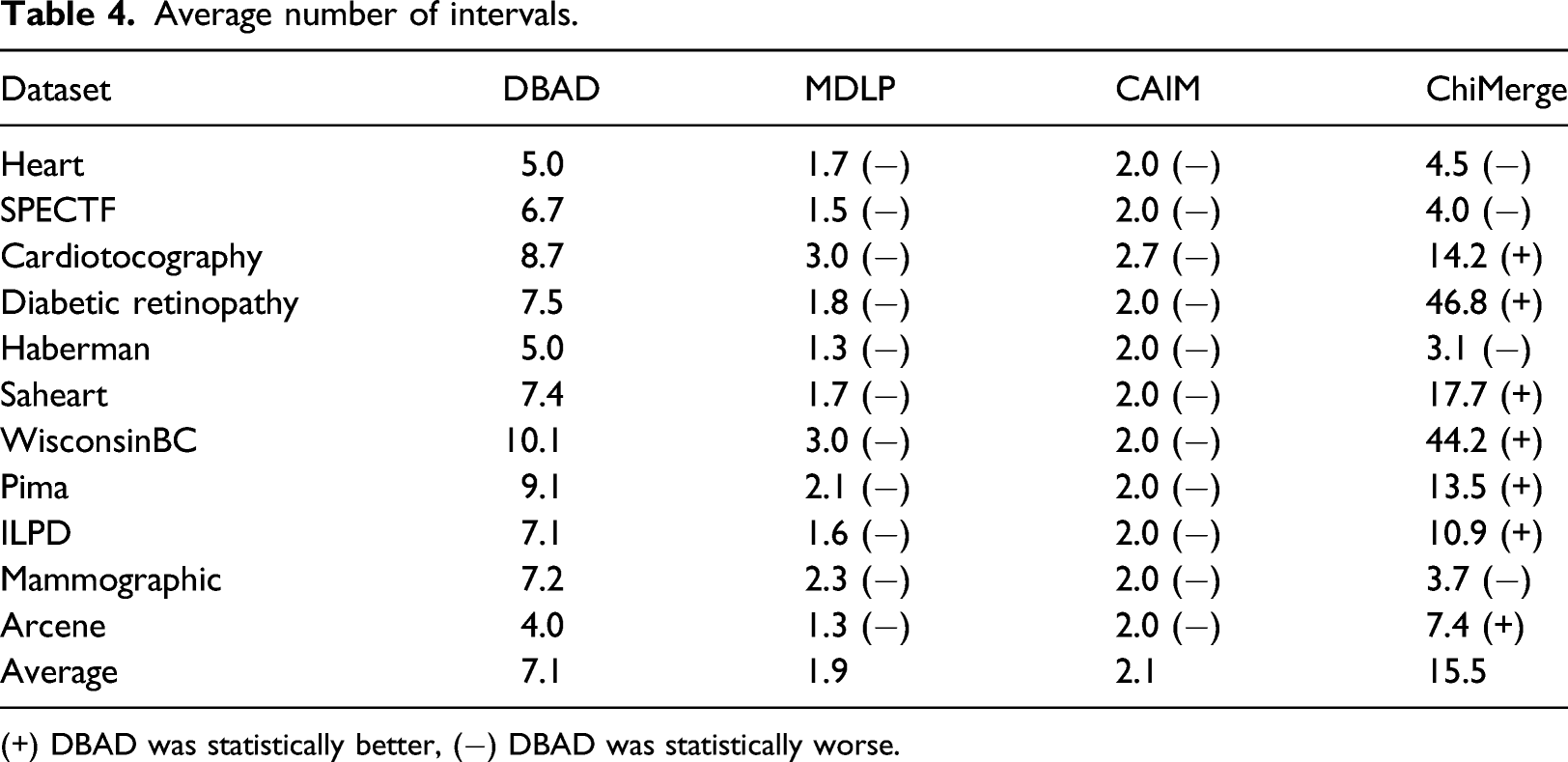
(+) DBAD was statistically better, (−) DBAD was statistically worse.
Average inconsistency rates.
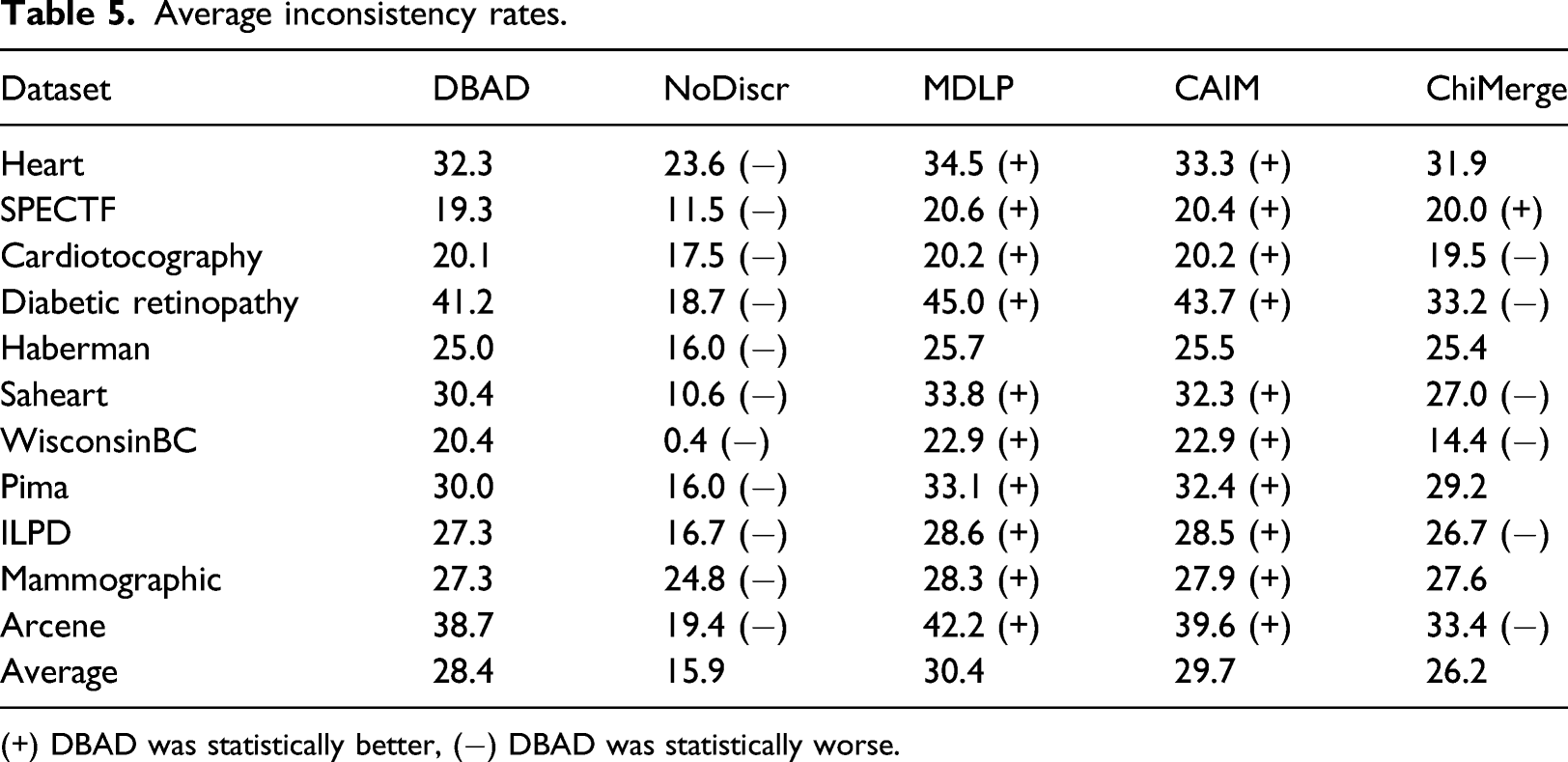
(+) DBAD was statistically better, (−) DBAD was statistically worse.
Classification accuracy.
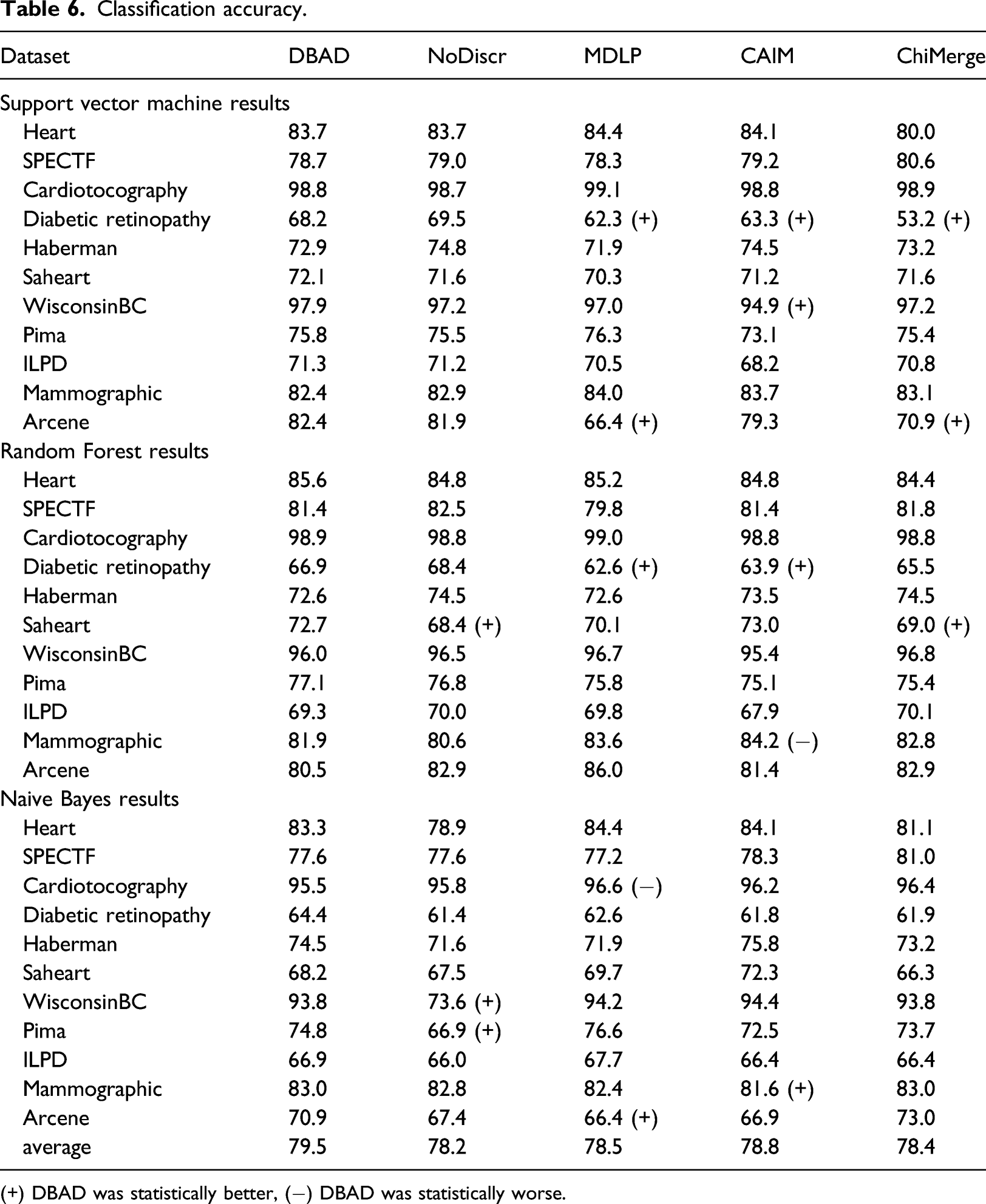
(+) DBAD was statistically better, (−) DBAD was statistically worse.
Sensitivity, specificity, and precision.
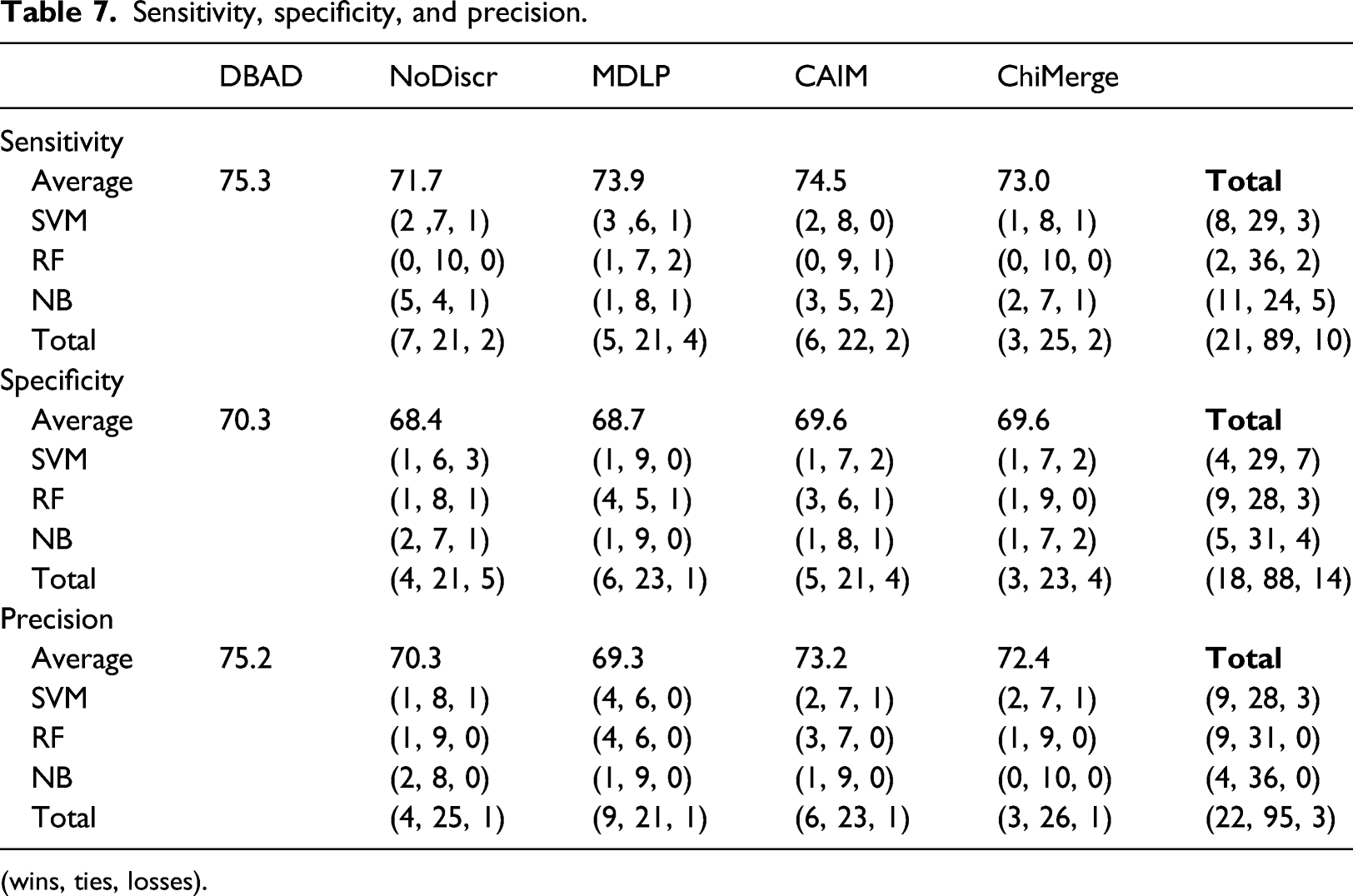
(wins, ties, losses).
Cohen’s Kappa values.
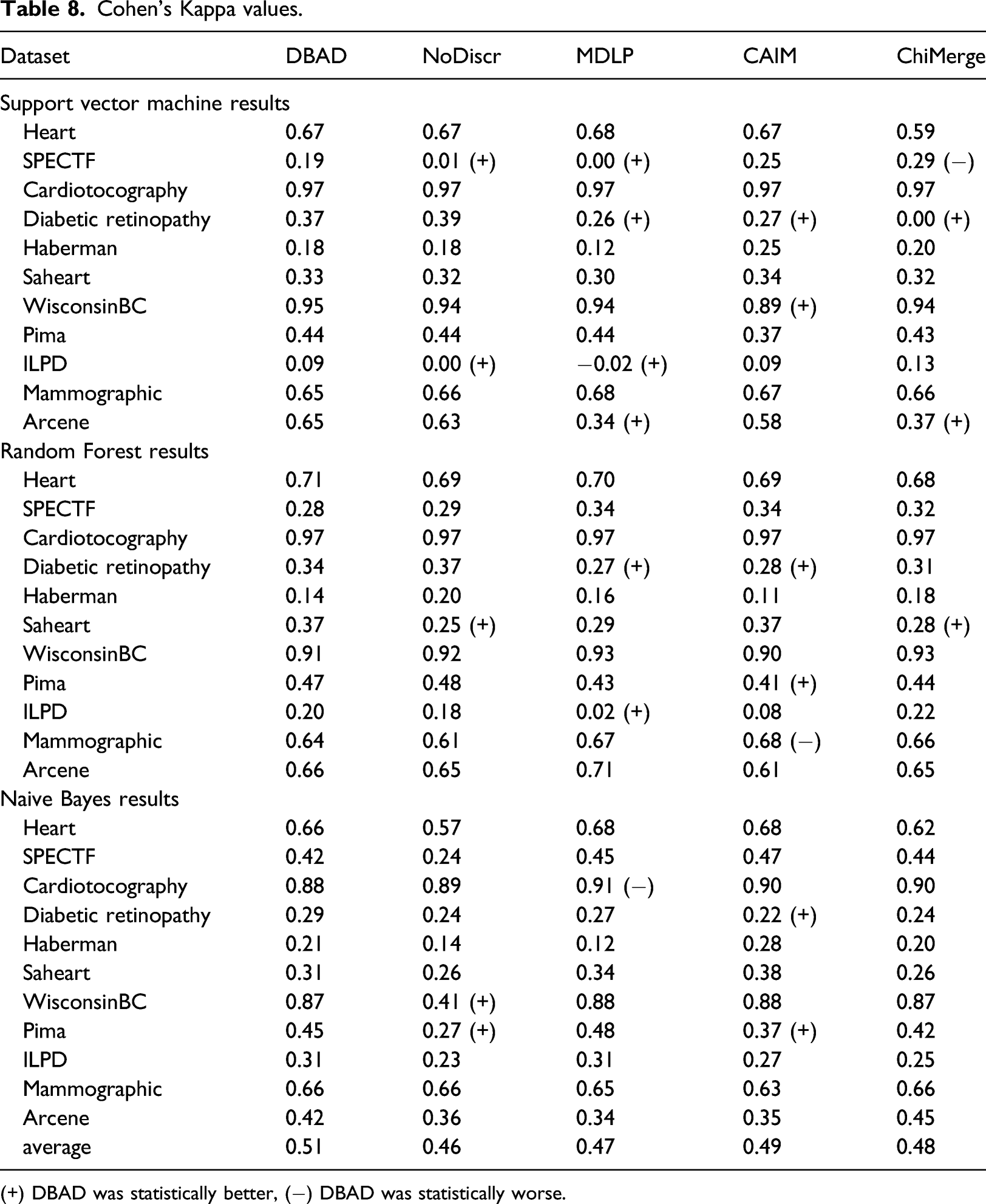
(+) DBAD was statistically better, (−) DBAD was statistically worse.
Average execution time in seconds.
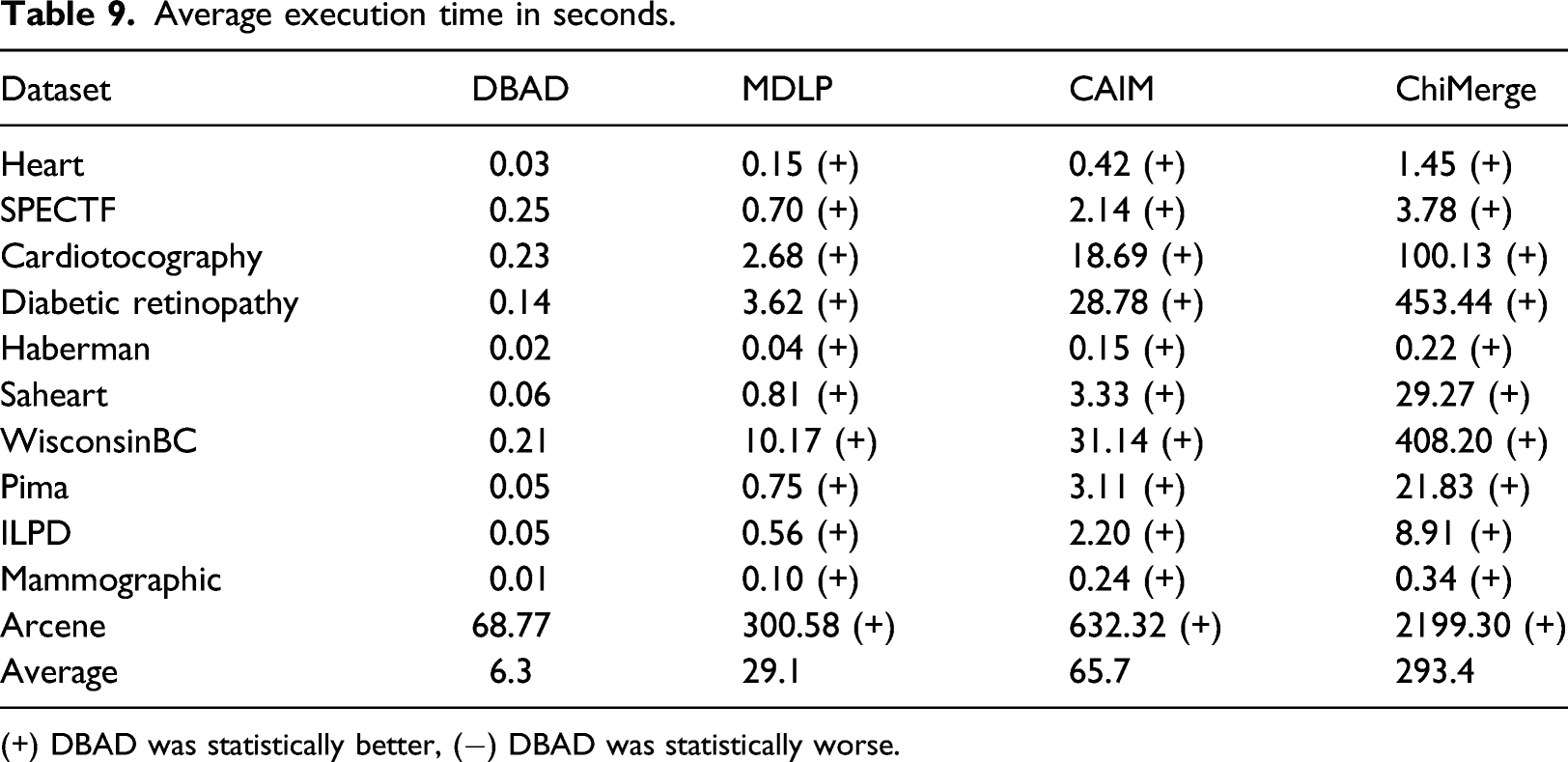
(+) DBAD was statistically better, (−) DBAD was statistically worse.
Speedup of the parallel implementation over the sequential execution time.
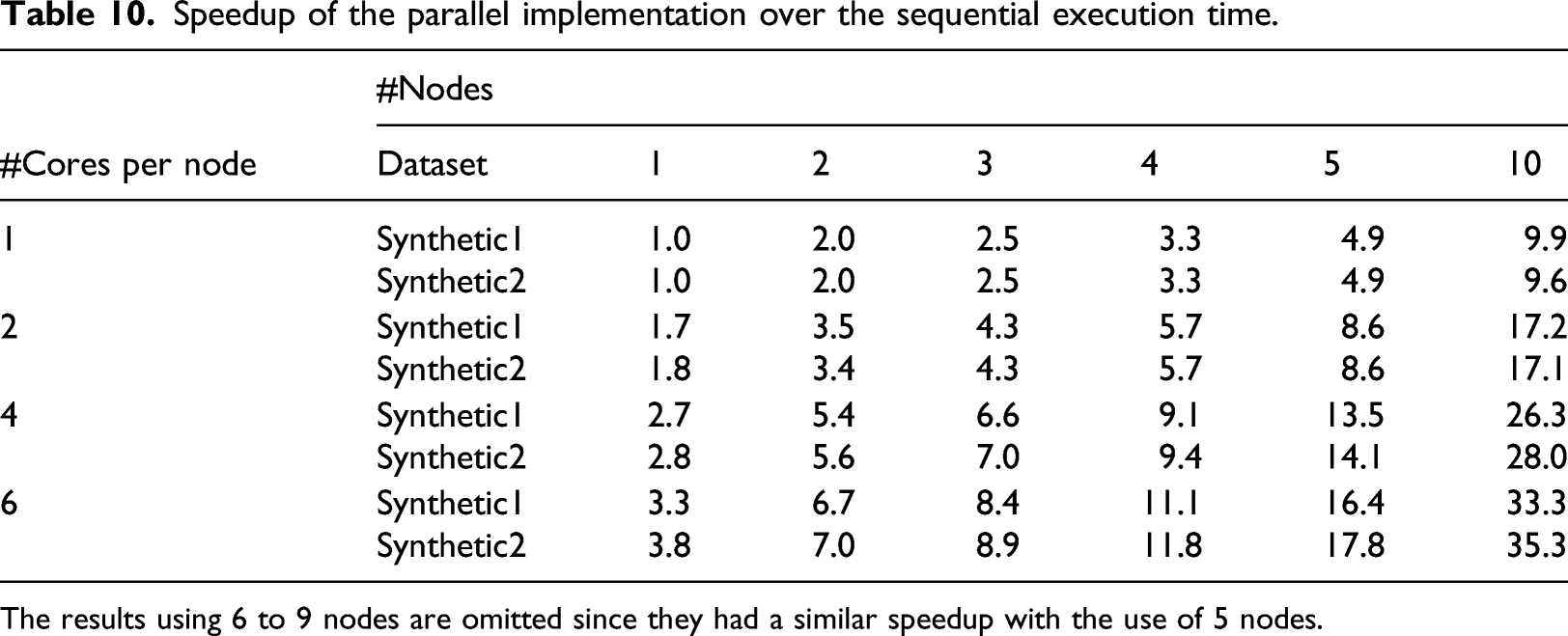
The results using 6 to 9 nodes are omitted since they had a similar speedup with the use of 5 nodes.
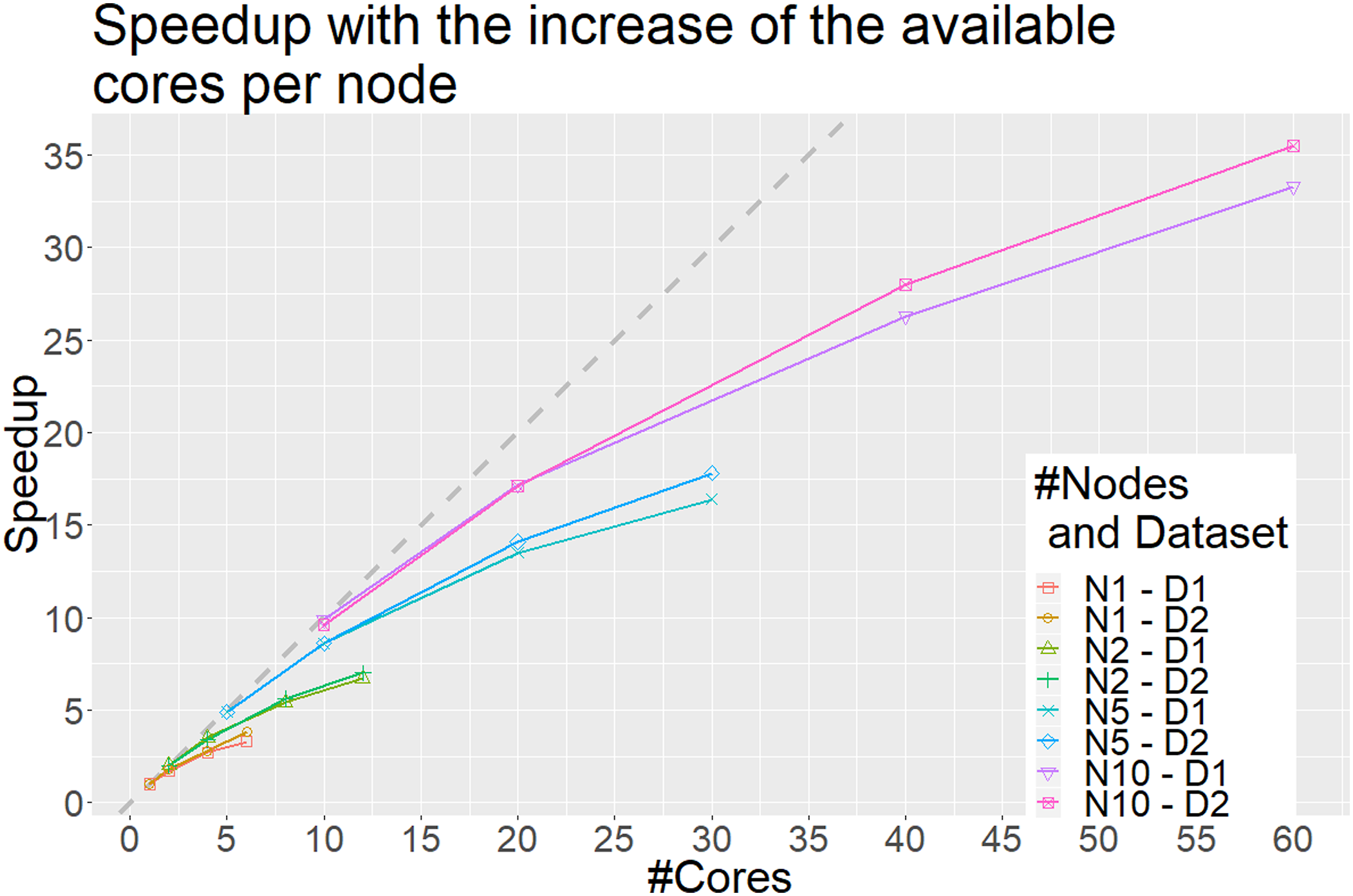
The x axis represents the number of cores and the y axis the obtained speedup compared to using a single node with a single core. Each line represents a different scenario. For example, N1–D1 represents the scenario in which a single node is used to discretize the Synthetic1 dataset (D1) with an increase in the number of available cores, whereas N10–D2 the scenario in which 10 nodes are used for the discretization of the Synthetic2 dataset with an increase in the number of available cores per node. Each point on the lines represents the total number of cores available when the speedup is calculated. The dashed gray line represents the optimal linear speedup. Only scenarios where the number of splits is divisible with the number of nodes are illustrated.
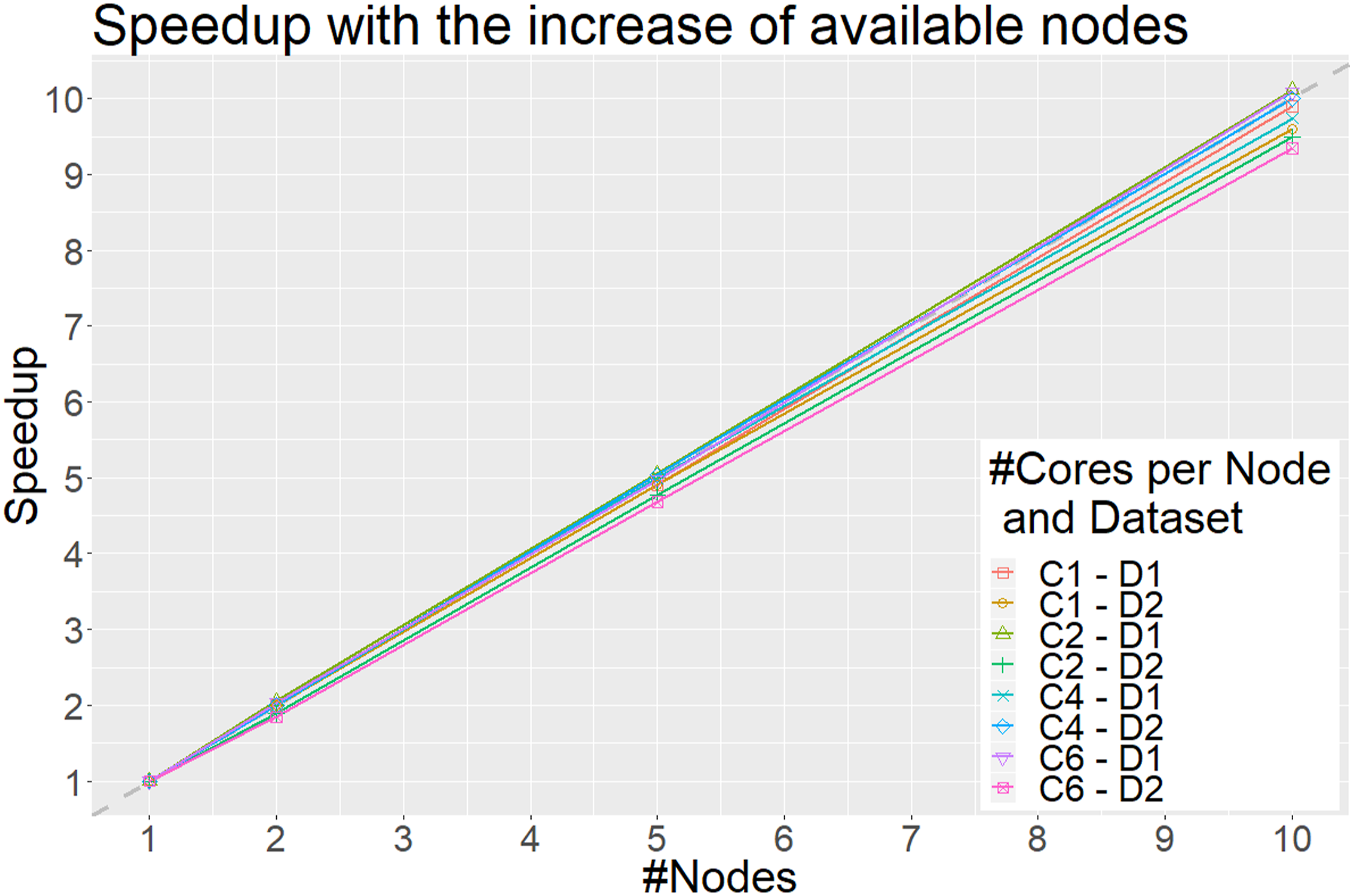
The x axis represents the total number of nodes and the y axis the obtained speedup when increasing the number of nodes (and hence also the number of total cores) compared to using a single node with a specified number of available cores. Each line represents a different scenario. For example, C1–D1 represents the scenario in which each node uses only a single core to discretize the Synthetic1 dataset (D1), whereas C6–D2 the scenario in which each node uses 6 cores to discretize the Synthetic2 dataset. Each point on the lines represents the total nodes used. The dashed gray line represents the optimal linear speedup. Only scenarios where the number of splits is divisible with the number of nodes are illustrated.
Discussion
An important feature of a discretization algorithm is to be able to produce a small number of intervals. Even though MDLP and CAIM performed better on this task, DBAD produced a reasonable number of intervals, whereas ChiMerge produced the largest number of intervals. DBAD might produce a large number of intervals in the case of datasets with many classes with different distributions. This is due to the fact that the intervals are created per class and if the densities are in different intervals on each class, we will end up with much more intervals. On the other hand, this might not negatively affect a classifier’s performance since it could further help with the separation of the classes.
The results regarding the inconsistency rates seem to be associated with the number of intervals produced by the algorithms. As was also found by Ref.[1] the more intervals an algorithm creates, the lower its inconsistency rate is. The performance on this metric does not seem to be correlated with the performance of the classifiers. If that was the case, then the non-discretized data would have produced better results than the discretized.
The results on the obtained accuracies, indicate that DBAD had a similar or better performance compared to the other algorithms in the majority of the tests and in only 2% of the performed tests its performance was worse. Additionally, when using the SVM classifier, it did not perform worse than any of the other methods. A positive outcome of this analysis is that DBAD’s discretization did not significantly reduce the information of the datasets since it performed equally or better than the original datasets in all of the tests. In general, discretization can help increase the accuracy of a classifier, since it can reduce noise from the data and hence reduce overfitting, 1 but in case there is high information loss from the process the opposite results will occur. 5 The results on specificity indicate that it had a similar performance with the other methods on this measure, while it was able to perform better than the other algorithms more times than they did when considering sensitivity and precision. Cohen’s kappa values also had more tests in which DBAD had a better performance than the other discretization algorithms (15 wins and 3 losses). Since this measure takes into consideration random hits 31 and many of the tested datasets were imbalanced, it is more appropriate as a measure to compare the efficiency of the discretization algorithms. On average, DBAD had the highest scores in all of the aforementioned measures and since the statistical analysis indicates that it performs similarly or better than the other algorithms in the majority of the tests, there is a good indication that using the regions in which density changes per class is a promising approach for data discretization.
For the aforementioned results, the datasets used in the experiments were of a small to medium size and did not include many non-binary classification tasks, hence some hypotheses could not be fully examined. Since only one dataset had more than two classes (Cardiotocography), it is not clear how well the algorithm can perform with such a dataset. In the Cardiotocography dataset, DBAD produced a larger number of intervals compared to its average, but this was also the case for the rest of the discretizers (except ChiMerge). The performance of the classifiers using DBAD’s discretized version of Cardiotocography was not negatively affected, except in the case of NB which had better results using MDLP’s version. Since there aren’t more tests on such cases, no clear conclusion can be made regarding the effect of the number of classes to the number of produced intervals and its effect on the classifiers’ performance. Finally, since there aren’t any real-world big datasets in the experiment, it is not possible to conclude if the algorithm would have created better intervals and help the classifiers’ performance since with more data it is expected that the true density of the variables would be revealed. Similarly, the other discretization algorithms could have also benefited from larger datasets and produce better intervals as well.
The proposed algorithm has a clear advantage over the others regarding its computational complexity. A dataset can be discretized by DBAD in O(m*n), where m is the number of features and n is the number of instances. Specifically, for a single feature, the binning and number of instances in each bin can be calculated with a single pass from the feature’s data (O(n)), whereas the removal of empty bins and the merging of similar density bins is O(log(n)) since this is approximately the number of bins that are initially created using Sturges’ rule. Algorithms like CAIM, MDLP, and ChiMerge, have a computational complexity of at least O(n* log(n)) for each feature, since this is the complexity for sorting the data. Then the Top-Down approaches have an additional cost of O(k*n), where k is the number of intervals created. For CAIM and MDLP, this value is close to the number of classes and since this is much smaller than the number of instances their complexity is O(m*n* log(n)). Due to the fact that ChiMerge merges two consecutive points/bins at a time, this means that it has an additional complexity of O((n − k)*n), and hence its complexity for discretizing a dataset is O(m*n2). Based on this analysis, it is clear that DBAD has a low computational complexity, which explains its small execution times on the performed experiments.
In addition to its low complexity, DBAD is an embarrassingly parallel algorithm, since each feature can be discretized separately, which enables the use of the algorithm on big data. This also means that the parallelization is limited by the number of features since we cannot use more cores than the available number of features in a dataset. When increasing the number of available cores in a node, the obtained speedup is not linear, similar to the results of the parallel version of MDLP 7 on a larger dataset, because the overhead of reading the dataset in memory and writing the discretized version of the dataset dominates the total execution time for discretizing the data. The reading and writing tasks are sequential and cannot be parallelized and once the parallel task of the discretization becomes faster than the time needed to read and write the data, no additional speedup can be obtained. Similarly to the results of the parallel MDLP, we expect that the obtained speedup will be lower in smaller datasets since the overhead of data distribution will be larger than the computational part of the discretization and hence the parallel version of DBAD should be applied on big data. On the other hand, when testing the scalability of the algorithm (Figure 4), as performed in Ref.[30] by adding more nodes that have the same number of available cores each, the algorithm shows that it can scale linearly. In Ref.[30], they were able to utilize 82% of the available processing power using four nodes with 8 computing cores each when they scaled from a single node of 8 computing cores, whereas in DBAD more than 90% is utilized using 10 nodes with 6 computing cores when we scaled from a single node of 6 computing cores, which shows that the algorithm has good scalability. Since the reading and writing of each file can be done in parallel in each node, it provides a linear speedup compared to only using a single node with the same number of available cores per node. To get the optimal speedup of DBAD in a distributed system, one should split the initial data to a number of files that is divisible with the number of nodes that will be used. This will allow an optimal load balancing to each node. It is also worth mentioning that the initial splitting of the dataset into smaller subsets will have an overhead which will depend on the speed of the storage disk of the system.
In general, DBAD is a good choice for the fast discretization of data for classification tasks. A limitation of the algorithm is that it will under-perform if for a feature, the data of each class to be discretized are from the same uniform distribution. In such cases, since the density is the same in the entire range of values for all classes, DBAD will not be able to identify any intervals and will return a single-valued feature. In case this feature is interacting with another one, then this information will be lost. On the other hand, DBAD has an advantage over methods that use measures based on class separability, in cases that the data of each class of features are from different distributions and have interactions with low main effects. In such cases, a single feature does not have enough information for separating the different classes unless it is considered in combination with other features, and hence a univariate method that uses a measure based on class separability will return a single-valued feature. DBAD would still be able to split such features based on their density differences and those splits could allow the identification of interacting features. Another limitation of the algorithm is that the initial number of bins selected per class using Sturges’ rule, is the same for all features and it is known that this rule works better on Gaussian data. 32 This limitation is handled up to a point by the adaptive merging of the initially created bins that have a similar density by DBAD, but there will be cases that this will not be enough if the initial number of bins is smaller than what is needed. A solution to this would be to use an adaptive algorithm for selecting the initial number of bins per feature,19,33,34 but usually such methods have extra parameters that need to be fine-tuned or are computationally expensive, which is not desirable when coping with big data.
Conclusions
A new supervised discretization algorithm has been proposed based on how the density of the values of a feature changes for each class. DBAD is a univariate discretizer and hence does not consider any possible feature interactions when selecting the best intervals for each feature, but results indicate that it does not significantly reduce the information contained in a dataset. It is a static discretizer since it is independent of the classifier that will be used at the processing step, which allows it to produce more generic intervals that can perform well with different classifiers. It initially creates all of the bins simultaneously and then follows a bottom-up approach for merging consecutive bins with similar densities, based on the CI of their percentage.
In the performed evaluation, DBAD produced an acceptable number of intervals and had comparable results with the other discretizers. An advantage it has over the other methods is its low computational complexity and the fact that it has no parameters that need to be optimized, hence discretization will be faster than the other tested supervised discretizers on big data. Another reason DBAD can be easily applied to big data is that it is an embarrassingly parallel algorithm since each feature can be discretized independently. Our experiments have shown that even though it doesn’t have a linear speedup with the addition of processing cores it can benefit from them and it scales linearly with the addition of more nodes.
The results of the evaluation indicate that DBAD is a promising approach and needs to be further investigated. One possible direction is to test different methods for the initial binning of the data since the current approach is based only on the number of instances and hence the true distribution of the data might be misrepresented. Another possible direction could be on having an additional step for further reducing the number of the final intervals of each feature based on other metrics.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was co-funded by the European Regional Development Fund and the Republic of Cyprus through the Research Promotion Foundation (Project Cy-Tera ΝΕΑ ϒΠΟΔΟΜΗ/ΣΤΡΑΤΗ/0308/31).