
Abstract
The goal of the study was to identify big data analysis issues that can impact empirical research in the healthcare industry. To accomplish that the author analyzed big data related keywords from a literature review of peer reviewed journal articles published since 2011. Topics, methods and techniques were summarized along with strengths and weaknesses. A panel of subject matter experts was interviewed to validate the intermediate results and synthesize the key problems that would likely impact researchers conducting quantitative big data analysis in healthcare studies. The systems thinking action research method was applied to identify and describe the hidden issues. The findings were similar to the extant literature but three hidden fatal issues were detected. Methodical and statistical control solutions were proposed to overcome the three fatal healthcare big data analysis issues.
Keywords
Introduction
Scholars already know about the major challenges faced by big data analytics practitioners across all disciplines which are described as the five Vs1,2 or sometimes more. 3 The big data five Vs are commonly phrased as high volume, 4 complex variety, 5 large velocity, 6 strategic value, 7 and more recently veracity. 8 Value in big data can be viewed as a constraint because it can be challenging to derive a benefit from analytics that is worth the investment time and cost to accommodate the other factors. Big data veracity can refer to ethics, accuracy, validity, or truthfulness 9 as well as social-cultural relevance. 10 In addition to the above characteristics, each discipline and industry has unique big data analytics issues.
In the healthcare discipline, researchers have posited that privacy is one of the biggest problems associated with the big data paradigm.11–15 Most countries have legislation to uphold the privacy of individuals, such as the Health Insurance Portability and Accountability Act (HIPAA) in the United States. 16 However, we propose there are important hidden big data analytics issues in the healthcare industry that are not documented in the literature. In this study, we review the literature and collect information from practitioners about tacit problems associated with healthcare big data analytics and then summarize the results in a visual model.
The big data paradigm is relatively new since it formally commenced in 201117–19 so there is roughly half a decade of research at the time of writing. Most of the published big data research has been focused on technology-related keywords like data mining, cloud computing, machine learning, electronic data processing, algorithms, and others. 19 According to a recent meta-analysis of the big data literature, only 2 percent of peer-reviewed publications examined privacy and security topics including healthcare during 2011–2016 that decreased to 1 percent for the first 3 months of 2017. 19 Many researchers have called for more studies about big data privacy,4,17,20–22 and particularly in healthcare.14,23 This is strong evidence that more research about healthcare big data analytics is needed. This also implies that there may be unseen risks that practitioners know exist in healthcare big data analytics. We attempt to articulate these obscure issues in healthcare big data analytics through a literature review and from discussions with other practitioners.
Methodology
We utilized the systems thinking technique popularized by Checkland 24 which Strang 25 classifies as an action research method where practitioners apply a pragmatic ideology toward a study. “The action research method starts by the researcher reviewing the literature either before or after the analysis, so as to validate or improve upon existing theories” (p. 59). 25 This systems thinking technique differs from the critical analysis method in that the latter attempts to find gaps or inaccuracies in the literature using only the literature with deductive reasoning, but the former also collects practitioner or process data and attempts to find a solution to an institutional problem. 25 An advantage of the systems thinking approach over other traditional research methods is that it helps to “understand group and nonhuman processes” (p. 403) 25 such as in healthcare informatics. This approach is ideal for examining the complicated hidden big data analytics problems in the healthcare discipline which is dominated by subject matter specialists and leading edge technology.
A pragmatic ideology is pluralistic in that a study “begins with research questions focused on a problem, with a process improvement unit of analysis and a community of practice level of analysis,” using mixed data types interpreted by the researcher and participants (p. 23). 25 This may be contrasted to a positivistic worldview where the data are fact-driven and hypothesis testing is often employed, or at the other philosophical extreme point is a constructivist ideology where participants provide rich data and communicate their own socio-cultural meaning reported verbatim by the researcher. 25
In this study, we do not make any cause–effect, correlation, deductive, or inductive propositions, nor do we merely report practitioner opinions—we interpret what we discover in an open-minded practical manner. We first review scholar perspectives from the literature, we collect big data analyst practitioner opinions, and then we integrate results produced by statistical techniques. The practitioner opinions were collected through two channels. The first was direct interviews and discussions during the IEEE Big Data Conference held at Washington, DC 3–5 December 2016. The second was also from direct discussions with practitioners through emails and using discussions on the Research Gate scholar social network system during the first 6 months of 2017.
According to Checkland, 24 after the literature review and subsequent knowledge assessment are completed, the key output of the systems thinking method is a visual model of the proposed critical real-world and tacit processes needed to solve the problem(s). The systems thinking model has two areas separating the known practices from the uncertain issues or processes with strategic links intended to bridge the gap or reduce risks. The model does not replace a discussion, but rather it summarizes the findings in a systematic diagram. A visual model will assist in communicating the findings to the healthcare discipline stakeholders as well as to researchers in this or any related discipline.
A pragmatic action research systems thinking type of project does not necessarily follow the introduction–literature–method–results–discussion paper sequence. The rationale for choosing a pragmatic ideology is that proven techniques must often be adapted to accomplish the research goal(s) because formal methods do not necessarily accommodate messy problems or the complex mixed data collected. 25 Our research design is pragmatic, with a manuscript containing an introduction to the problem(s), methodology explanation, literature review, subject matter expert discussions, synthesis and assessment of data, recommendations to solve problem(s), conclusions, and references. Here, we integrate our discussion into the literature review and close with a combined “Recommendations and conclusion” section.
Literature review and discussion
Overview of big data literature
Chen and Zhang 4 reviewed the literature several years ago and came to the conclusion that privacy was not adequately investigated within the big data body of knowledge. However, in addition to being dated, they did not perform a longitudinal structured review of the literature. Therefore, we conducted a thorough review of the big data literature published during the last decade.
We start with a summary of the literature before we review the relevant healthcare data analytics papers. Using “big data” as the search term, we closely examined 13,029 manuscript titles, abstracts, and keywords published in journals during 2011–2017 (only the first 3 months of 2017 were included). We used the title, abstract, and keywords to a dominant theme for every article. We counted the frequencies of the themes which resulted in 49 topics consisting of one to three words like “data mining,” “artificial intelligence,” and “online social networks.” We then factored the journal big data from 2011 to 2017 into a displayable short-list of 10–15 dominant themes using the frequency and grouped all remaining low-count topics into a new category called “<1%.” We created an exploded pie chart to illustrate how the most frequent themes compared to one another, as shown in Figure 1.
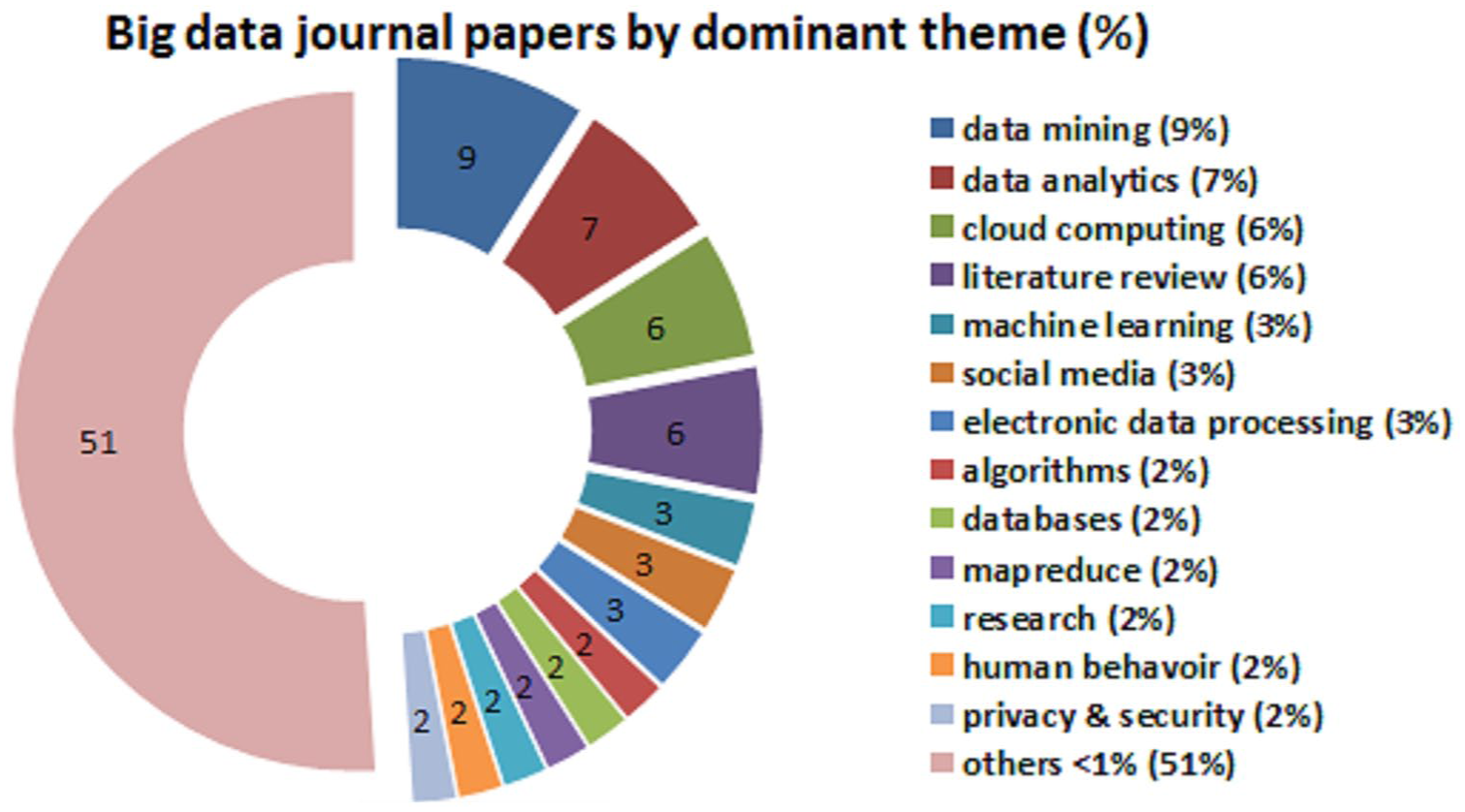
Relative production of healthcare big data privacy topics versus others over last 10 years.
The results from Figure 1 reveal that the most frequent big data topic published in journals were data mining (N = 1186) at 9.1 percent. The next three topics were similar in frequency, namely data analytics (N = 979, 7.5%), cloud computing (N = 808, 6.2%), and literature reviews (N = 784, 6.0%). For reference purposes, we could classify the current study as either a big data literature review or under the others topic. Machine learning (N = 493, 3.8%) and social media (N = 466, 3.6%) came next but were a third less frequent than data mining. The following seven big data topics were somewhat equivalent in frequency: electronic data processing (N = 455, 3.5%), algorithms (N = 388, 3.0%), databases (N = 360, 2.8%), map reduce (N = 358, 2.7%), research methods (N = 302, 2.3%), human behavior (N = 282, 2.2%), and privacy and security (N = 280, 2.1%). As shown in Figure 1, the remaining articles generated frequencies at or less than 1 percent so all were grouped into the “<1%” category which amounted to 6752 or 51 percent of the manuscripts in the meta-analysis. This other category included 36 topics like information technology, concepts or frameworks, Hadoop, acquisition of data, computer algorithms, as well as healthcare.
These 13 dominant topics represented 49 percent of the big data body of knowledge production in scholarly journals during the literature review sample time frame. Only a very small proportion of the privacy and security articles were grounded in the healthcare discipline. Thus, it was clear that published research about privacy in big data was scarce (at 2.1%) and this included all disciplines not just healthcare. This shows that there was a shortage of big data analytics research about privacy.
In our literature meta-analysis of big data, we grouped privacy and security together because researchers often did that despite that they meant one or the other term. To clarify, privacy in big data is the claim of individuals to have their data left alone, free from surveillance or interference from other individuals, systems or organizations.5,13 In the healthcare discipline, privacy can be further defined as an individual’s right to control the acquisition, use, or disclosure of his or her identifiable health-related data even if it does not contain personal identifiers. In contrast, big data security refers to the technology, software, policies, procedures, and technical measures used to prevent unauthorized access, alternation, theft of data, or physical damage to devices and systems.1,7 In the healthcare discipline, security is further refined as the physical, technological, or administrative safeguards or tools used to protect identifiable health data from unwarranted access or disclosure. In this study, we focus on healthcare big data privacy and not security—not that the latter is any less critical but it is beyond the scope.
Positive impact of big data in healthcare
Notwithstanding the five or more challenges with big data (volume, velocity, variety, value, veracity), there are many positive benefits for healthcare practitioners and researchers. Detailed big data on people can be used by policymakers to reduce crime or terrorism, improve health delivery, and better manage cities.2,26 Organizations and nations can benefit from big data because research indicates that data-driven businesses were 5 percent more productive and 6 percent more profitable than their competitors.4,18 The macroeconomic impact is that the gross domestic product of a country could increase due to big data analytics. 7
We have seen big data analytics used to help combat global and domestic terrorism.8,27 The American military has tapped into big data to uncover and mitigate terrorist plots. 28 For example, geo-location smartphone big data was helpful for investigating the Boston bomber and his accomplices 29 and many other terrorist plots have been foiled. 30
Big data analytics can assist with decision making in all disciplines and industries, from commercial entities to government policy makers.5,21 Big data are valuable to commercial businesses to improve target marketing and thereby increase effectiveness on a microeconomics level but the benefits go further to the macroeconomic environment as a cost reduction and increased goods production using the same scarce resources. 22
The benefits of big data analysis for improving healthcare medical research are well known.11,31 These benefits include facilitating evidence-based medical research to detect diseases at the earlier stages,15,32 minimizing drug surpluses and inventory shortfalls in pharmaceutical, 33 and better tracking of viruses through location-enriched social media big data. 34 As with the other disciplinary benefits, this has a positive domino effect by improving microeconomics and macroeconomics. 4
Environmental monitoring has generated useful big data that can help to identify virus and disease spreading patterns through global position system (GPS) location-coding33,35 and from patient symptom-related messages in social media posts.23,36 Hospital executives and management have used administrative big data to monitor patient quality and staff feedback, which affords information that may not otherwise be forthcoming. 12 Interestingly, when individual patient data are aggregated together for an entire hospital or facility, fluctuations in vitals could indicate a major problem such as poor air quality or a pandemic like pneumonia. 13 , 23
Healthcare researchers have gained the most from big data because this has become another rich data-collection avenue providing more volume, velocity, variety, and potential value, as compared with surveys, observation, and physical vitals capture.13,31 Healthcare big data tends to be categorized into two streams: vitals and social. The vitals are the obvious value-laden form of big data in healthcare. However, social big data can also be useful to the healthcare industry by allowing practitioners to detect attitudes through sentiment analysis.7,37
Unintended healthcare big data access
The literature is ripe with the benefits of big data but there are also some unadvertised pitfalls. In these next three sections, we will examine the three hidden problems of healthcare bug data analytics. Wireless micro-technology advances have given healthcare professionals insights into diseases and medical conditions. What puts wireless healthcare technology into the big data analytics domain is that micro-technology implants and devices can generate huge volumes of high velocity and a wide variety of valuable “personal data.” Personal data generated by healthcare devices and implants may contain date of birth, social security number or other healthcare patient identification, gender, address with geo-location coordinates, along with the high-volume high-velocity probe readings such as blood pressure and counts.31,38
Wireless healthcare devices and implants are similar to SCADA systems used for environmental monitoring in that a huge amount of readings are generated—more big data could possibly be stored or analyzed. 8 Likewise in healthcare wireless devices or implants, there are so many probe readings that only a small number are processed by the receiving station. 14 The personal identification data are more extensive during the initiation sequence with a receiving station (to authenticate the connection), and while this may be encrypted, it is transmitted either randomly or at specific intervals to maintain a connection with a receiving station. 31
Healthcare wearable devices or internal implants are generally connected to servers through a pervasive computing application, with the purpose to monitor a patient from sensor readings so as to warn physicians if a pattern changes for the worst or for the better. 31 Sensors are not new technology because they have been used with pervasive computing applications to gather data from the physical environment such as binary (1 = on or 0 = off) sensors attached to household objects or infrastructure like movement detectors, door sensors, contact switch sensors, and pressure pads. 39 Healthcare-specific devices or implants tend to collect readings on body temperature, blood pressure, pulse, blood–oxygen ratios, heart ECG or glucometers, movement (e.g. a fall), and chemical presence. 34 Radio frequency identification data (RFID) chip tags or Quick Response (QR) codes can be used to uniquely identify and locate tagged objects (e.g. a medical device presence) or to store (a link to) relevant information such as medication instructions. 40 Similarly, Bluetooth or modulated illumination-based beacons deployed throughout the user’s environment can be used to transmit unique location identification codes, which a hand-held device or wearable badge can detect in order to locate the user through GPS coordinate. 40
Some type of personal identification is included in every healthcare wireless broadcast to ensure that a receiving station does not confuse the patient’s device device/implant with another close by patient. Although the identification in pure data reading transmissions may be a unique number generated for the patient, it is nevertheless linked to the patient as well as to the location of the patient. This is what makes wireless healthcare personal big data subject to the veracity or viability characteristic—many people do not want their wireless-transmitted personal data to be picked by anyone other than the intended receiving station. Unfortunately, the nature of wireless transmissions is that even encrypted data could be easily intercepted and decoded with currently available software. 41
The capability of identifying individuals in big data even when personal attributes have been removed is a risk. There are several well-known cases in the literature. Likelihood algorithms have been used to link big data streams without personal identifiers to a master file based on information that could estimate age, gender, location, and employment characteristics.42,43 If the social media big data include even a few direct identifiers, like names, address, cell phone numbers, social security numbers, or company numbers, the risk is high that a match could be made with organizational or government data.37,43
Most healthcare devices or implants have physical machine addresses (MACs) and Internet Protocol (IP) addresses if they are online. The MAC address is hard-coded at the factory and is detectable in cellular data networks or on the Internet, while IP addresses are usually active only when on the Internet but they can still be read with the appropriate software. 43 These addresses are necessary for the device/implant to connect to a peer or network receiver in order to transmit their data. 43 The problems are that since these network addresses can be accessed, they can be linked to location and device owner so that when combined with the transmitted data it could identify an individual including financial and other confidential information. There are free open software applications that can track cell phone locations and social media user names through the MAC and GPS big data which are being used for malicious reasons.39,44
At the other end of the situation is the informed consent presented to the healthcare patient and/or physicians. Usually a healthcare device/implant contains a privacy policy declaration that must be signed before surgery or application. Second, any mobile software being used in conjunction with the device/implant, such as a smartphone application, would contain a privacy policy that would require patient consent. However, the Internet generation of people is accustomed to seeing software agreements due to downloading applications on smartphones, laptops, and other products so there is a tendency to hastily recklessly agree out of frustration or habit. Therefore, more attention must be given to informed consent when wireless healthcare big data collection is being authorized.
Most developed countries have legislation to protect individual privacy in healthcare big data, such as the HIPAA regulations under the Privacy Rule of 2003 in the United States. 16 HIPAA requires healthcare providers to remove 18 types of identifiers in patient data, including birthdate, vehicle serial numbers, image URLs, and voice prints. 16 However, even seemingly innocuous information makes it relatively easy to re-identify individuals through wireless healthcare big data, such as finding sufficient information that there is only one person in the relevant population with a matching set of unique conditions. 20
Data generated by interacting with recognized professionals, such as lawyers, doctors, professors, researchers, accountants, investment managers, project managers, or by online consumer transactions, are governed by laws requiring informed consent and draw on the Fair Information Practice Principles (FIPP) legislation.2,16 Despite the FIPP’s explicit application to protect individual data, the rules are typically confined to personal information such as social security number and do not encompass the large-scale data-collection issues that arise through location tracking and online social media postings or Internet site visits. 2
Ultimately, the major drawback of wireless healthcare big data is that it takes place in the open public domain outside of a healthcare provider jurisdiction, and therefore not covered in privacy legislation. 16 Two practitioner examples from colleagues of the first author illustrate the extreme risk of what can happen. In one case, a licensed medical physician from Sydney Australia specializing in pediatric immunology (children allergies, asthma, rhinitis, sinusitis, atopic dermatitis, urticaria, anaphylaxis, and immune disorders) missed 2 days of the IEEE Big Data conference. When he was pulled aside for a detailed interview at the Dulles Washington International airport immigration, he did not realize that his foreign passport contained a readable electronic passive chip that contained his place of birth, which happened to be Tehran but his parents had emigrated from Iran to Australia when he was 1 year old. It is easy to sympathize with anyone held up in immigration-customs especially in his predicament where he was asked “so prove to me that you are a doctor in Australia.” After several hours of interrogations, he was able to produce several of his journal papers stored on his laptop and by later in the evening EST the Sydney clinic had opened for their early morning so they were able to confirm his identity through a Skype call. During immigration apparently humans are guilty until proven innocent.
A piping engineer in the oil-gas industry was living in Houston, TX, while completing his doctorate at an American university under the guidance of the first author. Since he traveled frequently for work and university, the engineer used a wireless pass card for toll roads and he had an enhanced driver license that facilitated his passing through land and water borders between the United States and Mexico. When he was finishing his dissertation, he took several months off and became annoyed at receiving what he thought were scam collection letters in the mail. After a visit with his bank and discussions with a credit counselor, he found that his identity had been stolen and over US$20,000 in debt had been incurred in his name in addition to his student loan. Investigators believed that the wireless passive chip in his driver license had been read to furnish his birthdate, citizenship information, and address, and some credit card data along with other vehicle identifiers were somehow captured from the toll-pass-card and their billing system. The culprits were professionals because there was no evidence to charge them so he was forced to declare bankruptcy.
The prevalence of multiple digital devices of the sample person being connected to the Internet has resulted in personal information being inadvertently collected by legitimate providers, which when combined across sources can become powerful big data. For example, as Ohm 45 proved, a marketing specialist or a hacker could re-identify more than 80 percent of Netflix clients using an individual’s zip code, birthdate, and gender along with viewing history. Netflix is a popular entertainment site but it is unlikely that high ranked officials would necessarily want their viewing information or other online behaviors revealed to the world. Another example of big data caveats occurred when Target was able to predict a teenage girl was pregnant due to her online browsing activity and sent baby coupons to her house which were not well received by her father. 46 The same problems can occur in the healthcare discipline because professionals may have their online Internet behavior linked to their personal identity, or patients may have their Internet activity, location, and other personal details connected together using big data analytics.31,35
Earlier we stated that there are many benefits to having wireless healthcare big data, but if it is used unethically or outside of a personal privacy stipulation, the result can be harmful to individuals. For example, high blood pressure and other poor health indicators could trigger higher insurance premiums or prevent being hired. Inadvertent release of personal healthcare information such as a patient’s mental illness, dementia, or other cognitive impairments could result in losing a job, losing their driver license, failing to obtain a mortgage/loan, losing friends, and at the extreme it could lead to depression, premature forfeiture of independence to caretakers, or even suicide.
We will overlook the pure technology-related issues with healthcare big data problems. For example, electromagnetic interference could scramble some or all of the data, a natural or anthropogenic disaster could compromise the device/implant or server, and device or server could simply overheat and fail. These problems are beyond the scope of our healthcare big data privacy study—but these risks do exist and they ought to be examined by other researchers.
We will categorize the above risks associated with wireless/remote healthcare device/implant big data being available and usable outside of its intended purpose as the hidden problem of unintended healthcare big data access. Although we found most unintended access was through wireless technology, this definition should also encompass other media, such as inadvertent use or covert theft of a clinic’s data files along with other big data in ways that were not originally authorized.
The first proposed solution to this “unintended healthcare big data access” problem seems intuitive. Strong public or private key encryption could be added as a security layer, and actually this is already being done. As software becomes more powerful, encryption algorithms will run fast enough to permit more real-time use. In addition, a government managed security clearing network could be built to serve as an intermediary between healthcare devices/implants and the outside connection to another other system. That is obviously a monolithic costly suggestion if implemented at the national or global level. The other potential solution is simple: eliminate factory-coded MAC addresses and instead use temporary ones. Actually that is more difficult to achieve in practice due to the dependencies of the MAC address. Another constraint associated with MAC addresses is that they are useful to investigate criminal activity as well as domestic and global terrorism.26,28 More research into this problem and these proposed solutions will be needed.
Healthcare big data statistical sampling violations
Healthcare big data and big data in general tend to measure patterns in behavior (physical or mental), not internalized states like attitudes or beliefs that would be captured through other collection methods such as interviews, surveys, observations, or literary records. Healthcare big data is near-real-time and has a high granularity of details, owing to the high volume, velocity, and variety.
Healthcare big data are usually high in volume and velocity but at any given point there are very few variables or fields transmitted. Social media big data often contains only a GPS location code and a text message. 8 In healthcare big data, it is typical to see four fields: an identifier, a timestamp, a GPS coordinate, and some sensor reading. 8 Some sensor readings contain several numbers but others are simplistic, such as a decimal 1 or 0 meaning yes or no, on or off, and ok or not ok. In a technical sense, a single byte has 8 bits which could each be a code. In a simple example, let’s say a medical device transmitted a patient number, the time, their location, and their body temperature, every second, which would result in 3600 records per hour, 86,400 per day, and 31,536,000 per year, for every device per patient. This is why healthcare devices/implants generate big data. Let’s say that researchers want to determine whether there is a correlation or a cause–effect between the drugs administered to their 100 patients and their body temperatures during the year, and that an equally sized data were generated per patient for the drug administration processes. This would conceptually require 6,307,200,000 records which we can round up to 6.4 billion.
The problem is that it is difficult for healthcare researchers to perform statistical analysis on healthcare big data because even without the addition of the drug information for this anecdote, the desktop version of one of the most powerful statistical software programs SPSS can hold only 2 billion cases in a data set since the file format includes a count of the cases in a 32-bit signed integer with the high order bit devoted to the sign; 47 thus, the largest record number that can be stored is 2(31)-1 = 2,147,493,647. Thus, we could not store all the healthcare big data even for a simple drug-temperature analysis! No problem though, IBM has a mainframe version of SPSS without these big data file size constraints that can be purchased with hardware facilities for a few million USD.
Actually, several researchers had already pointed out that a barrier to performing big data analytics was that most statistical software could not handle the large file sizes. 9 However, researchers have found ways around the big data five Vs—at least the volume, velocity, and variety attributes—by using cloud-based and distributed software such as Hadoop along with sampling techniques to reduce the five Vs.8,48,49 Nonetheless, this is where another hidden healthcare big data problem lurks. There are several tacit issues that revolve around research design assumptions and statistical sampling assumptions.
Social media big data were once criticized for being focused on the young generation but paradoxically the modern products like Facebook and Twitter are now used by older baby-boom adults, whereas Instagram and Snapchat tend to be preferred by the younger generation. 6 In the healthcare industry, medical devices/implants that generate wireless big data are used by people with injuries, viruses, diseases, or illnesses. 15 In addition, the popular social media products with big data available are predominately in English. 14 In laymen terms, researchers of social media big data do not know who in the population is excluded, who is not texting or responding, or even the true extent of the underlying population. Thus, it is clear that there is a sampling bias beyond nonresponse in the entire big data paradigm.48,49 Almost an entire global generation and many worldwide non-English-speaking cultures could be missing in popular social media big data files, depending on the situation.
Obviously if only sick people are included in most healthcare big data analytics, this would be a biased very small sample of humans. More so, it could be difficult to convince a significant sample of healthy people to have medical devices implanted to participant without offering a huge monetary incentive and even if they agreed it could present a new obstacle of statistical self-selection bias. In addition, healthcare big data usually represent a large volume of readings collected from a very small number of patients in close proximity at a medical facility. 50 For example, in the anecdote above, the healthcare big data collection of body temperature reading records at 86,400 is well beyond the minimum statistical sample size of 30 but it is useless for estimating correlations or cause–effect predictions to the underlying population. Likewise, when social media big data are applied for healthcare research, generational, language, and socio-cultural barriers would likely confound the statistical sampling principles. Therefore, it is likely that all healthcare big data collected violates the statistical sampling principles of randomness and population representation. 25 There are exceptions to this problem in healthcare big data analytics because some medical devices are used for single patient emergency monitoring and decision making such as spatiotemporal sensing to alert staff when a patient falls or if vitals abruptly change—there is no logical reason to improve sampling of this type of healthcare big data.
The difference between primary and secondary research collection is that primary research data collection involves conducting research oneself, or using the data for the purpose it was intended for. Secondary research data, on the other hand, was collected by a third party or for some other purpose. 48 An advantage of using primary data is that researchers are collecting information for the specific purposes of their study. In essence, the questions the researchers ask are tailored to elicit the data that will help them with their study48,49 such as to test hypotheses or answer complex research questions. Researchers collect the data themselves, using surveys, interviews, direct observations, or from records (namely, reports or transaction files designed to capture information specific to the study). This is called the research design, that is, the articulation of the study goals, unit of analysis, and generalization targets. 25 In the healthcare discipline, most scholarly research takes place in the field—the hospital or clinic—using primary data-collection techniques like observations (of physical vitals included), visual observations, interviews, and sometimes surveys if controlled experiments are conducted. The hidden problem is that healthcare big data is being used as a replacement for accessing secondary data, but the issue is the secondary data were not collected as a proper research design.
There are substantial risks associated with replacing traditional data-collection methods, such as a misallocation of resources. For example, there have been many social media big data studies to improve emergency management practices during natural disasters like hurricanes 51 and tornadoes. 52 On the other hand, there has been an overreliance on Twitter data in deploying resources in the aftermath of hurricanes which has led to the misallocation of resources toward young, Internet-savvy people with cell phones and away from elderly or impoverished neighborhoods lacking in social medial access and literacy. 45 A famous example of poor survey methodology led the Literary Digest to incorrectly predict the 1936 presidential election results. 45 Inadequate understanding of sample coverage, incentive, and the lack of a comparison control group when analyzing administrative criminal big data records unfortunately led to incorrect inferences being made that a death penalty policy reduces state crime. 45
One of the main reasons for applying statistical techniques and the Central Limit Theorem is for inferential thinking, that is, to show there is a link between variables or a predictive cause–effect trend in the entire underlying population by using an efficient cost-effective sample.48,49 Therefore, much work must be done to adapt statistical techniques that can exploit the richness of healthcare big data but preserve inference principles. 49 We will categorize the above risks associated with wireless/remote healthcare device/implant big data collection as “statistical sampling violations.” A straightforward solution to this “statistical sampling violations” is to correct the research design using stratification, systematic or other generally accepted sampling technique to collect a more representative sample. Due to the big data five Vs, this will likely require sampling from multiple sources and combining the results as a single input to parametric or nonparametric statistical techniques. Strang and Sun 8 discussed how this could be done with global terrorism big data so this could be applied to healthcare big data analytics.
There may be other solutions to the “statistical sampling violations” healthcare big data analytics problem. Much of our discussion in this section has been positivist, but a pragmatic approach could also be taken. Healthcare big data could be collected about each patient from multiple sources so as to achieve data triangulation. Healthcare big data could be collected to sample the entire context of the patient including the room conditions, nearby patient readings, atmospheric radiation, and so on. A constructivist approach could also supplement healthcare big data by adding qualitative patient feelings and physician opinions into the file to be analyzed.
Healthcare big data statistical false positives
We found more hidden problems with healthcare big data. Other researchers have articulated the data quality issues with big data, such as missing incomplete data, errors due to technical interference like delays or magnetic fields, and duplicated values.6,12 For example, going back to Table 1 anecdote, how could we be sure that the temperature of 50°F was not created through imputation, with the remaining 50 values being created by copying the change from 97 to 50, or maybe simple duplication, or perhaps a spurious value of 50 created by wireless network delays. Of course the same arguments could be made against the small sample too.
Descriptive statistics of anecdotal healthcare small and big data samples.
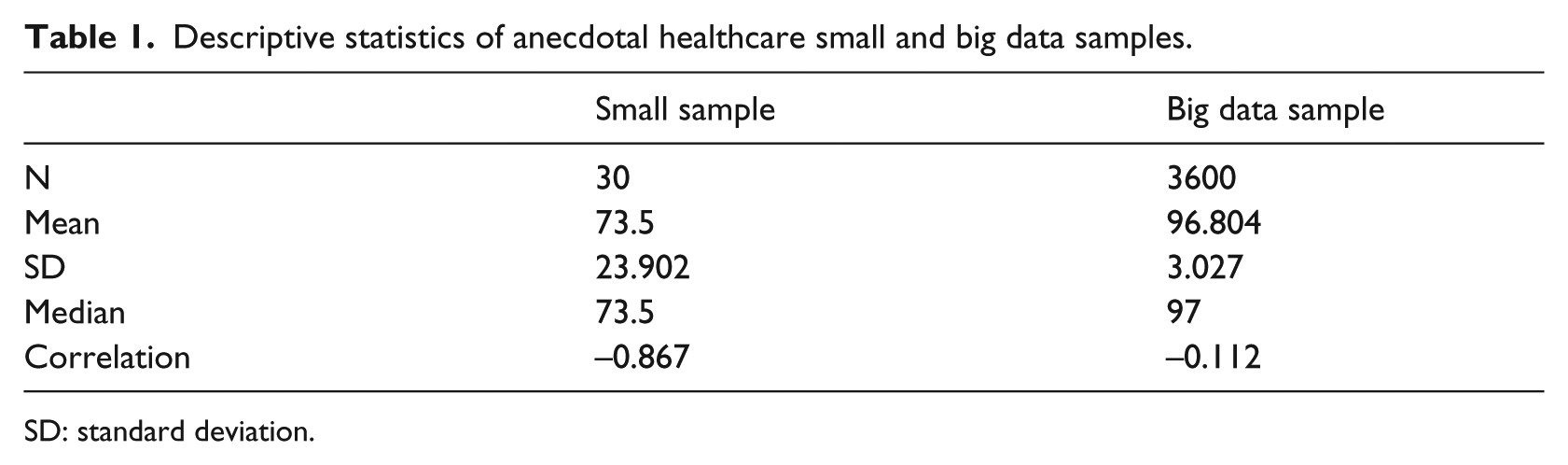
SD: standard deviation.
A common error with healthcare big data is inaccurate or erroneous labeling of the column data.48,53 As an example of this error, consider a hospital register that may include a column labeled “number of employees” defined in the data dictionary as the number of persons in the company who received a payroll check in the preceding month but instead the column contains the number of persons on the payroll whether they received a check last month or not, including persons on leave without pay. Other types of big data healthcare errors could rest with the analysts if they perform manipulation or transformation of the values. For example, perhaps changing a timestamp signed integer into a character field representing a calendar day, or transforming ordinal data into a low-medium-high scale. Transformation of data is acceptable for some types of regression and categorization analysis, but since it is literally impossible to see the big data, care must be taken when researchers are transforming values. In addition, traditional content errors use for master files in a healthcare big data analysis could cause errors, such as keying, coding, or editing of drug or patient characteristics in a master file which is linked to the healthcare big data sensor stream. However, these errors are not unique to healthcare big data—the problem of data entry errors and incomplete, inaccurate data is widespread with all manual or machine-coded data.
On the other hand, there is potentially a new hidden problem associated with healthcare big data. A well-known example of this healthcare big data risk was the error produced by the Google Flu Trends series, which used Google searches on flu symptoms, remedies, and other related keywords to provide near-real-time estimates of flu activity in the United States and 24 other countries worldwide. 54 The USA Centers for Disease Control (CDC) regularly predicts the flu trends in order to ensure there will be enough vaccinations and healthcare facilities to accommodate the need. According to Lazer et al., 54 Google Flu Trends provided a remarkably accurate indicator of the flu cases in the United States between 2009 and 2011, which was significantly more accurate than the CDC predictions. However, Google Flu Trends was inaccurate thereafter for 2012–2013, more than twice as high as the CDC predictions of which the latter were accurate. 54 Thus, Google Flu Trends used healthcare big data analytics to incorrectly forecast future flu trends resulting in more than double the proportion of vaccinations and doctor visits scheduled.
The Google Flu Trends healthcare big data incident may have been caused by social media herd-behavior and commercial search engine manipulation. Apparently the healthcare big data–generating engine at Google was modified in such a way that the formerly highly predictive search terms eventually failed to work, for example, when a user searched on fever or cough, Google’s other programs started recommending searches for flu symptoms and treatments, which had a domino impact on other user searches because they would be redirected to flu sites which was counted in the predictor variable. 54 These types of problems are programming errors made by Google. There have been similar problems reported by other social media platforms like Twitter, Facebook, and Microsoft Bing in their attempt to improve the user experience. 54
Fan et al. 55 stood out in the literature as researchers that identified several legitimate hidden healthcare big data problems, which they referred to as (1) noise accumulation, (2) spurious correlations, and (3) incidental endogeneity. To illustrate noise accumulation, suppose a practitioner is comparing patients in two hospital wards A and B based upon the values of 1000 features (or variables) in a healthcare big data file, but unknown to that researcher the mean value for participants in A is 0 on all 1000 features while participants in B have a mean of 3 on the first 10 features and a value of 0 on the other 990 features. A big data machine learning classification rule based upon the first m ⩽ 10 features performs quite well, with little classification error, but as more and more features are included in the rule, classification error increases because the uninformative features (i.e. the 990 features having no discriminating power) eventually overwhelm the informative signals (i.e. the first 10 features). We agree with this if you are using contemporary big data machine learning algorithms. We suggest that big data algorithms be used in parallel with other recognized statistical techniques as methodical triangulation. 25
Fan et al. 55 describe spurious correlations as healthcare big data files that have many unrelated features but which may be highly correlated simply by chance, resulting in false discoveries and erroneous inferences. For example, using simulated populations and relatively small sample sizes, Fan et al. 55 proved that with 800 independent features, there was 50 percent chance of observing an absolute correlation that exceeded R = 0.4 which would be statistically significant (p < 0.05) and amount to a small effect size of 16 percent (r2 = 0.16). Their results suggest that there are considerable risks of false inference associated with a purely empirical approach to predictive analytics using high-dimensional data. We agree and we will explore this in more detail later.
Third, 55 assert that endogeneity is a problem when performing regression analysis on big data that results in a model with covariates correlated with the residual error. For high-dimensional models, with many factors, this can occur purely by chance. We agree this is possible but statistically it is an extension of the same spurious correlation phenomenon identified above. Regarding all the above potential hidden problems, we suggest that all but the spurious correlations could be avoided by following the “statistical sampling violations” solution of improving the research design through rigorous sampling collection plans. In addition, the recommendations of Hair et al. 56 should be reviewed when designing complex multiple or multivariate regression models in any discipline regardless of whether the healthcare big data is sourced.
The third category of hidden healthcare big data analytics problems is also statistical in nature. When Dr Gauss invented the Student’s t test using the normal distribution, he probably did not envision the large sample sizes characteristic of the big data five Vs. The root of this problem that stems from the sample size is used in many nonparametric and parametric formulas. 25 For example, the well-known formula for standard deviation (SD) is shown in equation (1), where X is the big data value, µ is the mean, and N is the total sample size

Going back to the patient temperature anecdote, let’s say that we received 30 readings in a small sample and 3600 readings in a small big data sample over the span of 1 h (60 s × 60 min). All the temperature readings were 97°F except that last 15 readings were 50°F to simulate patient going into a serious medial trauma. In the big data file, all the values were 97°F except for the last 15. Any practitioner or researcher could easily reproduce the data in this anecdote. Table 1 lists the descriptive statistics of these two samples (all estimates rounded for display).
The anecdotal descriptive statistics in Table 1 illustrates the fallacy of healthcare big data. By the way each has the same minimum and maximum readings. In the small sample, the mean (M) is 73.5°F with a huge SD of 23.902, which is a coefficient of variation of 33 percent (SD/M*100). The median is also 73.5°F. This clearly indicates the patient is in medical trauma distress. Unfortunately, the healthcare big data descriptive statistics shows that despite recording data for an hour, the mean temperature is 96.8°F with a minor SD of 3.027 which is a small effect size of about 3 percent (SD/M). The healthcare big data makes us believe the patient is doing well, maybe feeling a bit chilly so they could use a sweater. The median is 97°F which is further misleading. Actually, having more data would only further obscure the medical emergency for this healthcare patient.
Another problem with healthcare big data is that parametric statistics will be unknowingly impacted by the sheer sample volume, velocity, and variety. In the anecdote, assume we have the time sequence number for each reading and we performed a correlation of the temperature against the time sequence. In the small sample of Table 1, the correlation was significant between time and temperature with R = −0.867, p < 0.05 (two-sided). The effect size of the small sample correlation of temperature with time was 75 percent (r 2 = 0.751, N = 30) which shows a significant negative correlation between temperature and time, meaning that temperature is quickly falling as time progresses. This is valuable to know because the healthcare staff could be alerted and the patient could be treated in order to save their life.
Unfortunately, based on Table 1 anecdote with the healthcare big data sample, the correlation between temperature and time sequence was −0.112 (p > 0.05) which was insignificant. This could be interpreted that there is no statistically significant relationship between patient temperature falling and time. Perhaps the big data value in this would be that the hospital will soon have an extra bed available in their facility. The same phenomenon occurs when using more advanced parametric statistical techniques such as regression to estimate cause–effect predictions on healthcare big data.
As further test we used was random sampling on the 3600 healthcare big data records in Table 1 anecdote, and after 360 iterations (10% of the data) all values were 97°F. Thus, even random sampling of healthcare big data is not reliable for parametric statistics. The fallacy of healthcare big data should now be obvious. Therefore, even if the earlier “statistical sampling violations” hidden problem was not present, the large sample size of healthcare big data could present a type I error or rejecting the null hypothesis when in fact it was true there was no statistically significant result, which is known as a false positive. 25 We will classify this hidden healthcare big data problem as “statistical false positives.”
The solution we propose to the hidden healthcare big data problem of “statistical false positives” is to use nonparametric techniques. This advice has been applied to analyze terrorism big data as well as financial market collapse portfolio manager behavior big data. To prove our point, we applied nonparametric techniques in SPSS and Minitab software to test a medical-related hypothesis that the anecdotal patient temperature is no different than an expected average of 97°F. The distribution-free one-sample Wilcoxon signed-rank test on the small sample from Table 1 verified as anticipated that the patient temperature was significantly different than the benchmark median of 97°F, based on the results of W(30) = 15, p = 0.001 (two-sided). The interesting finding was same as that from the healthcare big data sample in Table 1, with a W(3600) = 15, p = 0.001 (two-sided). Thus, the nonparametric test on the healthcare big data sample was able to correctly identify that the patient temperature was significantly different than the expected median. We ought to disclose though that parametric one-sample t tests on the same data produced the same results. Nonetheless, we highly recommend nonparametric statistical techniques to become the norm when analyzing healthcare big data.
Recommendations and conclusion
Our literature review of 79,012 journal articles from 2011 to 2016 confirmed the astonishing situation that healthcare privacy- and security-related topics accounted for only 2 percent of the total research production, and this rate had fallen to 1 percent during the first 3 months of 2017. Healthcare big data analyst practitioner interviews were therefore used to supplement our research.
The results of our literature review and practitioner interviews verified that the healthcare discipline suffers from the same problems endemic to any type of statistical analysis, namely data entry, coding, mislabeling, missing/inaccurate values, and poor research design. In addition, healthcare big data suffers from electromagnetic interference, network delays or outages, and the same factors which affect any technology. The same cautions would thus apply to mitigate against those risks. In addition, the healthcare big data faces the big data five Vs: high volume, complex variety, large velocity, strategic value tradeoffs, and more recently veracity (accuracy, ethics, privacy, socio-cultural meaning).
Healthcare big data analytics in particular is prone to veracity privacy violations, perhaps more so than other disciplines. Although most countries have legislation to protect patients against inappropriate use of their data, this only forces providers within the healthcare domain to avoid recording certain identifying attributes. Even the HIPAA in the United States allows a hospital to override the rules if they have a justifiable reason—which seems hard to fathom for a healthcare big data collection context. In addition, informed consent may not be getting the scrutiny it deserves from patients or physicians. Healthcare medical devices/implants transmit wireless readings which could be intercepted. For example, a patient driving through a weight station, toll bridge, parking lot, and border entry could have their personal data read without their knowledge or consent. Encryption may be a solution to this common big data privacy problem when software and hardware improve to make it faster and affordable in the healthcare industry.
Although there were many issues found, we considered these to be already encompassed into the big data five Vs. We uncovered several insights about the hidden healthcare big data analytics risks. We grouped these new hidden problems into three logical categories, and we also provided recommended solutions for each. Furthermore, we applied the action research systems thinking technique to organize the insights into a diagram, as summarized in Figure 2. This diagram will facilitate communicating the information to other stakeholders such as healthcare practitioners, researchers, decision makers, and policy administrators. The three hidden healthcare big data analytic problem categories are briefly enumerated below:
Unintended healthcare big data access—inadvertent or intentional wireless eavesdropping—this could be mitigated by using strong public or private key encryption once software becomes more powerful and affordable for the healthcare industry/patients.
Statistical sampling violations—non-coverage, lack of random selection, nonresponse, self-selection bias caused by lack of a research design—this could be fixed by a research design using stratification, systematic, or other generally accepted sampling technique to collect a more representative multiple-sourced sample (pragmatic and constructivist approaches were also mentioned).
Statistical false positives—caused by mathematical formulas that use sample size in calculations resulting in spurious relationships, correlations, and other inaccurate estimates (a healthcare big data simulation was used to prove this)—this risk could be reduced by applying nonparametric statistical techniques and methodological triangulation (use of multiple parametric, distribution free, and qualitative methods).
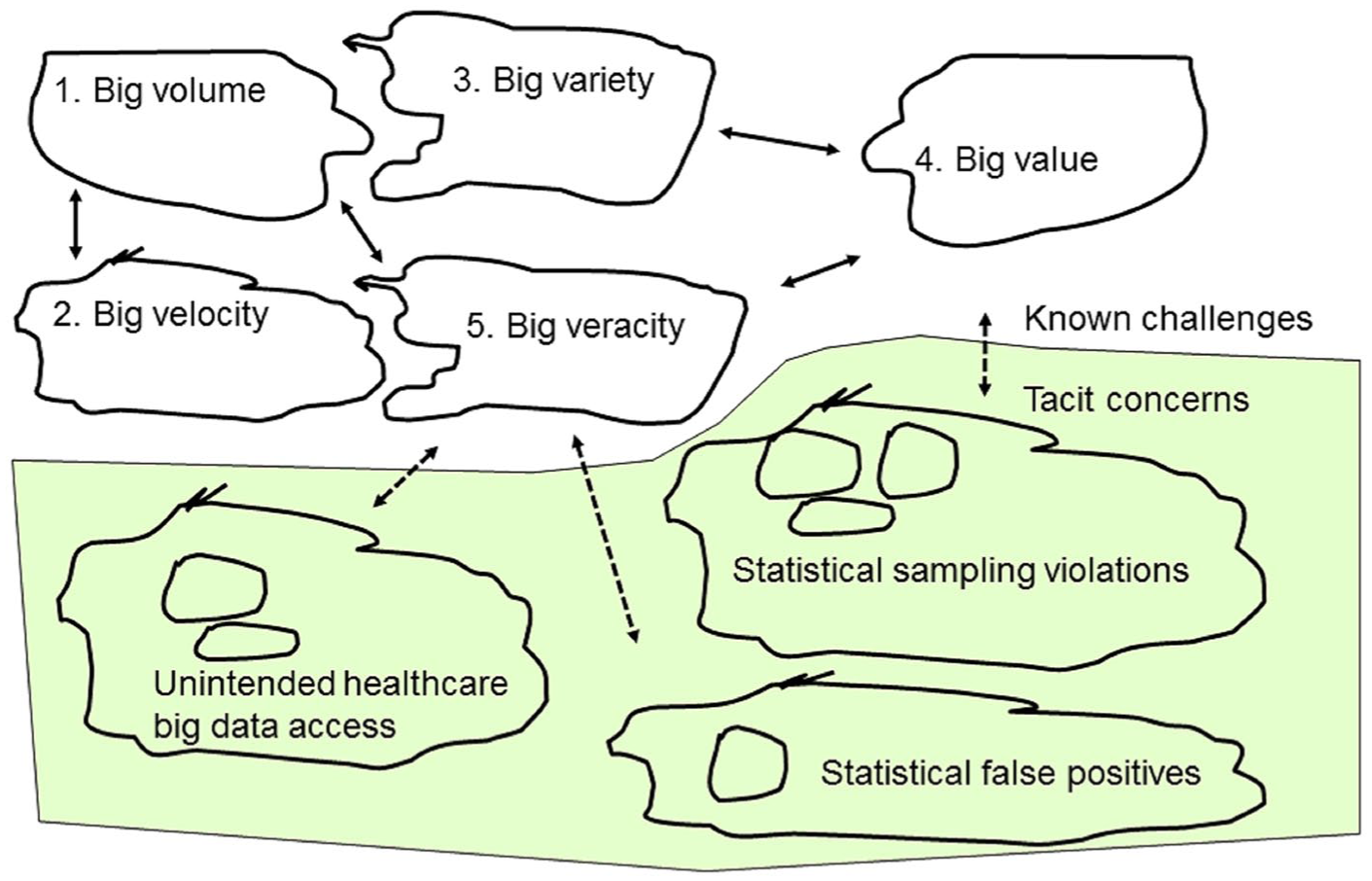
Systems thinking analysis of healthcare big data analytics issues
This research uncovered several insights about the hidden healthcare big data analytics problems. The methodology applied in this research was unique and worth considering by other researchers. We utilized the systems thinking technique popularized within an action research framework. We used this approach because our ideology was pragmatic, the problem at hand was complex and institutional (healthcare discipline), and we needed to understand the problems from both a practitioner group and nonhuman process (technology). We used the literature review summarized above along with practitioner interviews collected at a big data conference. According to the systems thinking methodology, after the literature review and subsequent knowledge assessment were completed, we organized the key results into a visual model of the proposed critical real-world and tacit processes that could identify and solve the problems.
In conclusion, healthcare big data privacy is an important topic that was not adequately covered in the existing literature, so more research is needed. In addition, while our findings that the traditional five big data challenges also impact the healthcare discipline, we identified three new tacit issues that are essential to address in future studies. We could not locate any other publication that identified and explained these three new hidden problems in healthcare data analytics so we feel this is a worthy contribution to the community of practice literature. In closing, we will make our data available to anyone by request to the corresponding author.
Footnotes
Author’s note
Kenneth David Strang is now affiliated with APPC Research and Walden University, College of Management & Technology,100 Washington Ave South, Minneapolis, MN 55401, USA.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.