
Abstract
Guillain-Barré Syndrome (GBS) is a neurological disorder affecting people of any age and sex, mainly damaging the peripheral nervous system. GBS is divided into several subtypes, in which only four are the most common, demanding different treatments. Identifying the subtype is an expensive and time-consuming task. Early GBS detection is crucial to save the patient’s life and not aggravate the disease. This work aims to provide a primary screening tool for GBS subtypes fast and efficiently without complementary invasive methods, based only on clinical variables prospected in consultation, taken from clinical history, and based on risk factors. We conducted experiments with four classifiers with different approaches, five different filters for feature selection, six wrappers, and One versus All (OvA) classification. For the experiments, we used a data set that includes 129 records of Mexican patients and 26 clinical representative variables. Random Forest filter obtained the best results in each classifier for the diagnosis of the four subtypes, in the same way, this filter with the SVM classifier achieved the best result (0.6840). OvA with SVM classifier reached a balanced accuracy of 0.8884 for the Miller-Fisher (MF) subtype.
Keywords
Introduction
Guillain-Barré syndrome (GBS) is an autoimmune system disorder that affects the peripheral nerves and their roots. It is the most common cause of flaccid paralysis, causing rapid weakness of the facial, respiratory, and swallowing muscles and limbs. 1 GBS is commonly triggered by multifocal inflammation of the spinal roots and peripheral nerves. In severe cases, the prolongation of neurons responsible for driving the nerve impulse is also damaged. 2 The estimated annual incidence of GBS is 0.61–2 cases per 100,000 people and approximately 25% of patients with GBS require intensive care. Despite adequate supportive treatment, 3.5% die because of complications related to respiratory muscle paralysis, heart attack, or thrombosis. 3 This syndrome differs in terms of their appearance, duration, the symmetry of clinical manifestations and if they mainly damage myelin, axon, or mostly peripheral nerve fibers that are dedicated to the motor, sensory and autonomic functions. Therefore the GBS is divided into subtypes, of which four are the most common: acute inflammatory demyelinating polyneuropathy (AIDP), acute motor axonal neuropathy (AMAN), and acute motor. 4 Due to the variation in severity and treatment between sensory axonal neuropathy (AMSAN) and Miller-Fisher Syndrome (MF) subtypes, differentiation between them is crucial. Table 1 shows the difference between each GBS subtype.
One way to differentiate groups or subgroups in medicine today is through machine learning by creating predictive models. Machine learning is a technique that allows us to build a computational model that learns automatically, this model is then used to simulate and study the behavior of the variables under study. Thus, publications with clinical prediction models have increased in recent years. 8 For example, 9 identified and reviewed some of the machine learning and data mining applications in diabetes research as prediction and diagnosis, diabetic complications, genetic background and environment, and health care and management. They found that 85% of machine learning algorithms used a supervised learning approach 10 reviewed the importance of machine learning in the prediction and diagnosis of cancer, using supervised learning techniques such as Artificial Neural Networks (ANNs), Bayesian Networks (BNs), Support Vector Machines (SVM), and Decision Trees (DTs) 11 compared different machine learning algorithms such as SVM, Decision Tree (C4.5), Naive Bayes (NB), and k-Nearest Neighbors (k-NN) for the prediction and diagnosis of breast cancer; obtaining the best accuracy with the SVM model 12 employed supervised learning techniques to diagnose Parkinson’s disease and discriminate against Progressive Supranuclear Palsy patients, obtaining an efficiency of approximately 90% 13 applied a semi-supervised and self-advice learning model to diagnose skin cancer using labeled and unlabeled data. Their model was tested with 100 dermoscopic images and the classification outperformed the most popular methods used in machine learning 14 developed a machine learning model for the diagnosis of glaucoma. Their dataset included 399 cases for training and validation, and 100 cases for testing. Four different algorithms were applied: C5.0, Random Forest (RF), SVM, and k-NN, reaching more than 90% of performance in its results. Despite all the work done in developing prediction models in chronic diseases, there is little literature regarding work with the GBS. The diagnosis and prediction models efficiently improve the detection and classification of diseases. In particular, the diagnosis of GBS is complicated due to a large number of intervening variables.
Previously, diagnosis models for GBS have been created using machine learning algorithms and using the common variables reported in the literature,15,16 obtained a performance higher than 0.90% in the classification of GBS subtypes in a predictive model based on simple learning algorithms. They conducted experiments with 15 single classifiers in two scenarios and using a dataset with 16 relevant features out of an original 365 feature dataset. In this case, 4 of the 16 features were clinical, and the remaining features came from medical studies. Also, 17 in a predictive model based on the ensemble methods Boosting, Bagging, C5.0, RF, and Random Subspace, reached an accuracy of 0.9366.
In this work, we considered only clinical variables for the creation of our models. Our goal was to investigate if using only the clinical variables could create a diagnosis model for GBS with significant acceptable accuracy. The advantage of having a purely clinical model is that the variables used are detected in medical consultation without the need for complementary studies. We aimed at simplifying previous diagnosis models.
For experiments, we applied four classifiers with different approaches: C4.5 (tree-based), SVM (kernel-based), JRip (rules-based), and k-NN (instances-based). In order to investigate if feature selection can increase the model’s accuracy, we also used filters and wrapper methods. Five filters were selected: Chi-squared, CFS (Correlation-based Feature Selection), Consistency, OneR, and Random Forest. These filters evaluate the goodness of the features based on their intrinsic characteristics in a fast and simple way instead of based on the predictive model; this lead to detect which features are relevant for classification. Then, we choose six wrappers: GA (Genetic Algorithm), Random search, SFS (Sequential Forward Search), SBS (Sequential Backward Search), SFFS (Sequential Floating Forward Search), and SFBS (Sequential Floating Backward Search). The last four wrappers are Deterministic forward or backward search. Wrappers use a predictive model that scores feature subsets based on the error rate of the model, and produce the best selection of features in each iteration. Finally, the One versus All (OvA) binarization technique was used. We compared the balanced accuracy of each created model, where 4 models include all the features, 44 models were obtained using feature selection, and the remaining 16 models were obtained using OvA. Typical metrics evaluated the performance of the models in machine learning such as accuracy, balanced accuracy, sensitivity, specificity, Kappa statistic, and the receiver operating characteristic curve (ROC). Our main metric was balanced accuracy, since our dataset is imbalanced. We used the Wilcoxon non-parametric test 18 to find a statistical difference between the two best models. The two best models including all the features, the two models including only the relevant ones and the two best models with Ova technique.
This article is organized as follows: In section 2, we present a description of the dataset, the machine learning algorithms, and the performance measures used in the study. Section 3 describes the experimental procedure. In section 4, we present and discuss the experimental results. Finally, in section 5, we summarize the results, draw conclusions from the study, and suggest future work.
Materials and methods
Dataset
The dataset used in this work was collected at the Instituto Nacional de Neurología y Neurocirugía (National Institute of Neurology and Neurosurgery) in México from 1993 to 2002. There are 129 patient records, each 1 classified with a kind of GBS subtypes: 20 AIDP, 37 AMAN, 59 AMSAN, and 13 Miller-Fisher. The original dataset has 365 features of which the first 38 are considered clinical; the other 327 correspond to laboratory tests, treatment, and patient tracking. Serological and neuroconduction studies confirmed the subtypes in each patient in this dataset. 19 From the 38 clinical features, 13 were discarded because they represent metadata, such as case number, file number, hospital admission date, discharge date, and duration in days of different situations, leaving the 25 relevant clinical features shown in Table 2.
Dataset features used in this work.

v2 is 1 = Asbury, 2 = Ropper, 3 = both, 4 = not comply, 5 = no clinical neurography of the facial nerve (NF).
v6 is the previous event presented: 0 = not present, 1 = upper respiratory tract infection, 2 = gastrointestinal, 3 = viral infection, 4 = other infection, 5 = history of GBS.
v22 is if the weakness is equal right and left, subjective: 0 to 2.
v26 is PM = pelvic members, TM = thoracic members.
v27 is reflex peripheral nerve response, Hyporeflexia + = decreased, Reeflexia 0+ = without reflexes, ++ = normal, Hyperreflexia +++ = increased reflexes.
v29 is the muscles that move the eye and represent cranial nerves (CN) III, IV, VI.
v35 is the need for an artificial breathing machine when the patient cannot breathe, usually due to respiratory arrest.
v37 is a lower respiratory tract infection: 1 = LRTI, 2 = scars, 3 = depression, 4 = other, 5 = no, 6 = anxiety, 7 = LRTI and anxiety, 8 = LRTI and scars.
Machine learning algorithms
JRip
A ruled-based learner that implements the Repeated Incremental Pruning to Produce Error Reduction (RIPPER) algorithm. JRip identifies the classes by building a set of rules.
20
A rule has the form:
C4.5
Builds a decision tree from training data using recursive partitions. In each iteration, C4.5 selects the attribute with the highest gain ratio as the attribute from which the tree is branched, 21 resulting in a more simplified tree. C4.5 is a decision tree algorithm.
k-NN
Classifies by categories the untagged instances based on the majority class in the k-nearest neighbour in the training set. The classifier’s performance depends significantly on the distance metric used. 22
SVM
Given a set of training instances (input space), where the instances belong to class A or class B, SVM uses a mapping function (kernel) to transform the input space into a dimension space upper (feature space). 23 That is, if the input space is 2D, then it is assigned in a 3D space. In the feature space, SVM finds a hyperplane that gives the most significant separation between classes, called a maximum margin hyperplane. The maximum margin hyperplane has the most significant distance from the hyperplane to the closest training instances. Instances located on the boundaries of the hyperplane are called support vectors. However, the more considerable margin is not always the best solution since it can jeopardize the model’s generalization to new instances. SVM introduces a parameter C that creates a soft margin that allows some errors in the classification, but at the same time penalizes them. An adjustment procedure is necessary to find the best value of C.
Feature selection
The feature selection method allows feature reduction, removing them to increase, or improve the performance. There are three kinds of feature selection: Filter, Wrappers, and Embedded. In this work, we will use the first two. 24
Filters
Five filters were taken from the Fselector package: CFS (using correlation and entropy measures), Consistency (using consistency measure), Chi-squared (based on a chi-squared test), OneR (based on simple association rules involving only one attribute in condition part), and Random Forest (using the Random Forest algorithm). 25 The first two filters find a feature subset for discrete and continuous data, the remaining ones find weights of discrete attributes.
Wrappers
Six wrappers were taken from the mlr package: GA (genetic algorithm optimization method), Random search (where feature vectors are randomly created, up to a maximum number of features), SFS, SBS, SFFS, and SFBS (extending [forward] or shrinking [backward] a feature set). 26
One-versus-all
OvA is a powerful technique and is conceptually simple. OvA turns multiclass classification into binary classification, comparing one class with all the remaining ones. 27
Performance measures
Performance measures are a set of statistical techniques, created to describe the performance of models. Different sets of performance measures are applied to the single-label predictors and multi-label predictors. 28
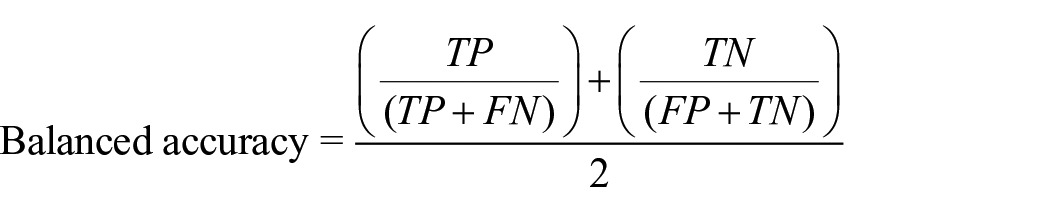
Balanced accuracy
Avoids inflated performance estimates in unbalanced datasets. It is the arithmetic mean of sensitivity and specificity or the average precision obtained in any of the classes. 29 It is considered more precise than the accuracy when the dataset is unbalanced.
Validation
The validation set approach we used for experiments was a train-test, a straightforward method. We divided two-thirds of the data for the training fitted to the model and one-third for testing and predicting. 30
Experimental design
From the dataset described in section Dataset, 64 diagnosis models were created employing the four selected classifiers: 4 diagnosis models using all the features, 44 models using subsets of features obtained after applying filters and wrappers, and 16 models were created using OvA.
For each diagnosis model, we made 30 executions with different seeds to approximate a normal distribution, taking the balanced accuracy as the main metric in each case. For the models with classifiers k-NN and SVM, a pre-execution tuning was performed.
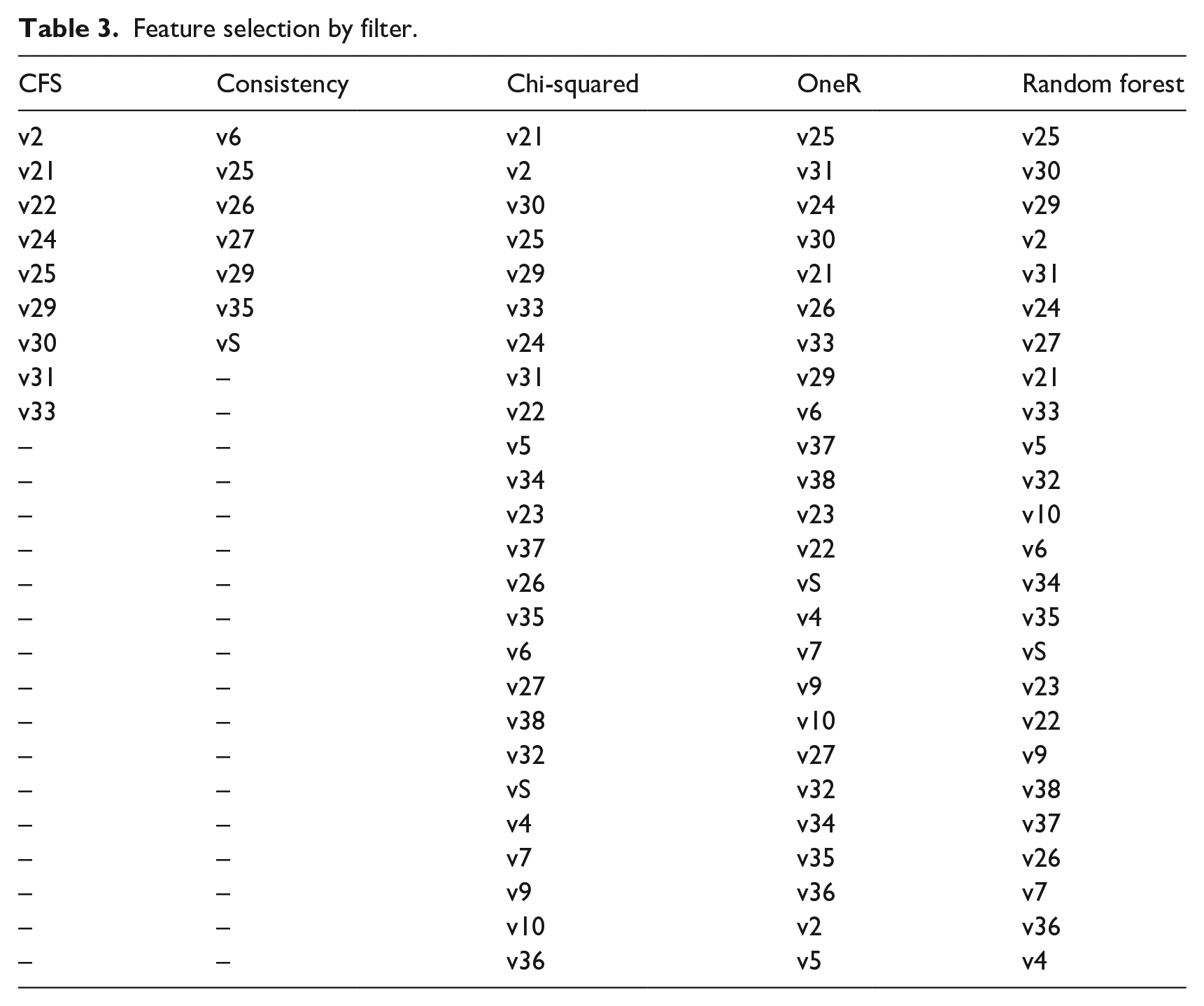
Regarding filters, CFS and Consistency provide a list of the most relevant features when executed, creating a subset of the original dataset. With these two subsets we performed the 30 executions with different seeds. Chi-squared, OneR, and Random forest give a feature ranking as a result, i.e., a ranking of the listed features from most to least relevant. We picked the two best attributes, the three best features from these rankings, and so on until we picked them all. We created subsets with each selection to find which subset of features gives the best performance. This evaluation was performed with 30 independent runs using each classifier.
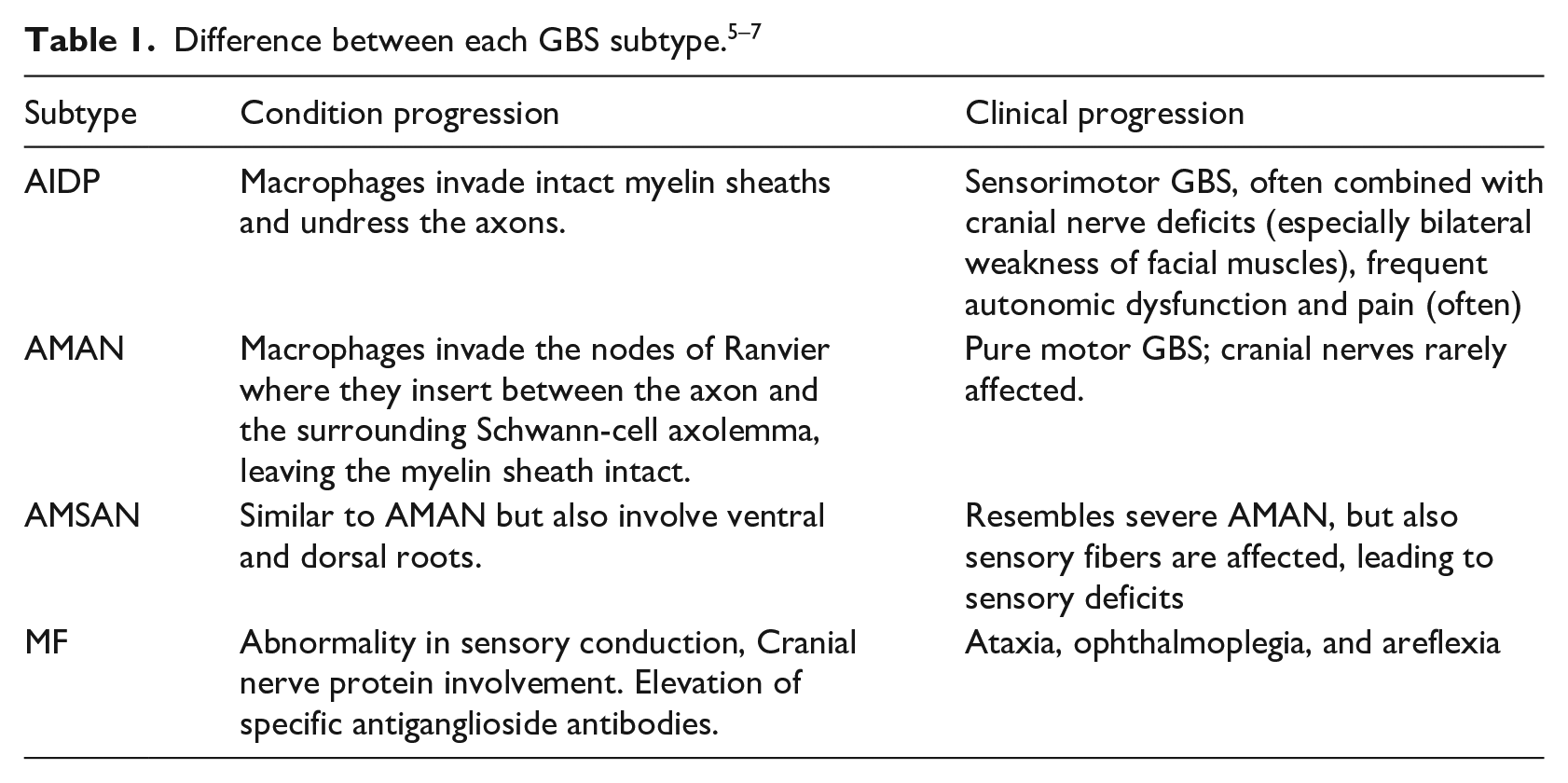
Results for Chi-squared are shown in Figure 1(a), for OneR in Figure 1(b), and Random forest in Figure 1(c). Table 3 shows the feature selection of CFS and consistency filters and the ranking of the Chi-squared, OneR, and Random forest filters.
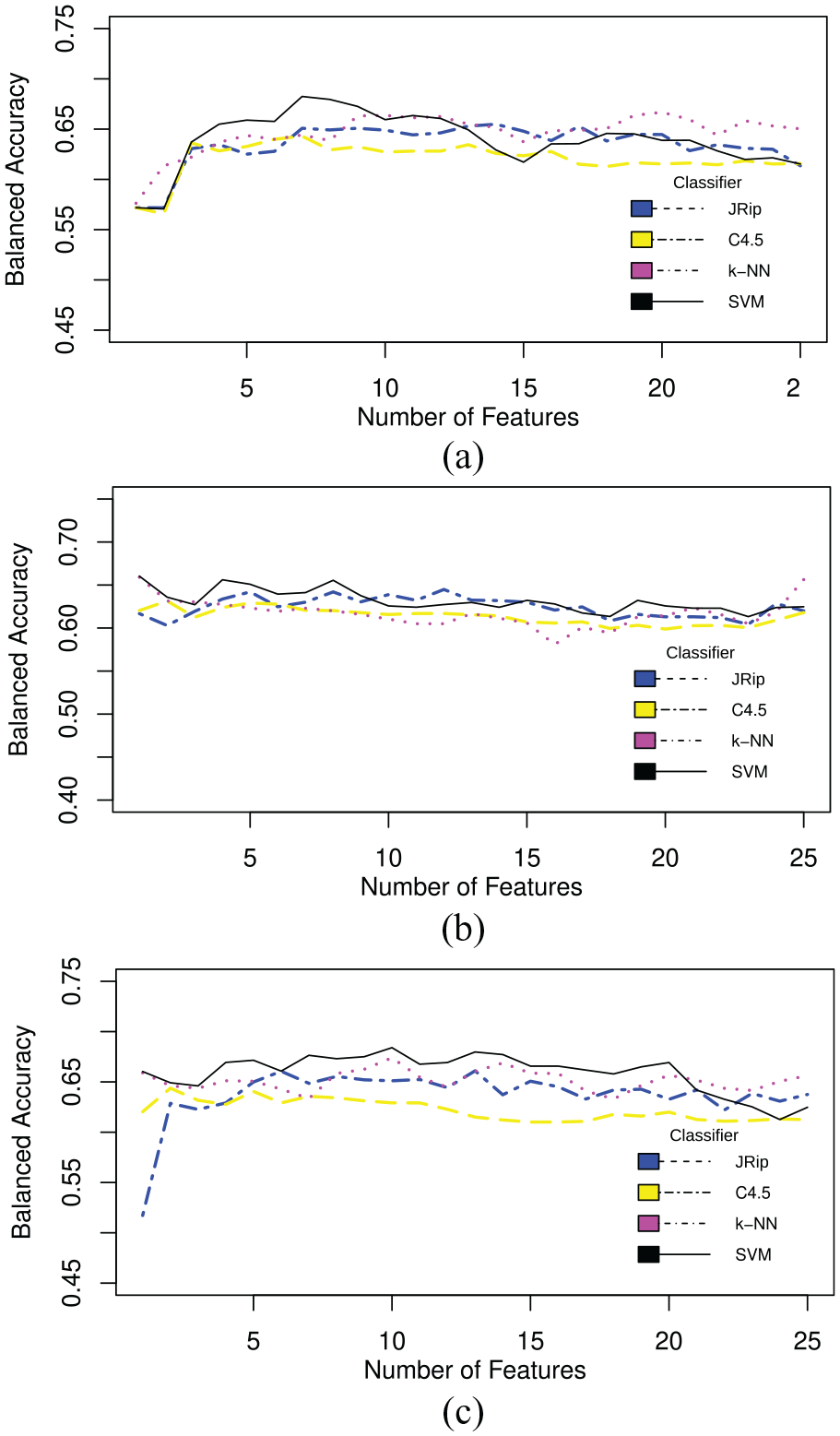
Balanced accuracy across 30 runs: (a) Chi-squared filter, (b) OneR filter, and (c) random forest.
Feature selection by filter.
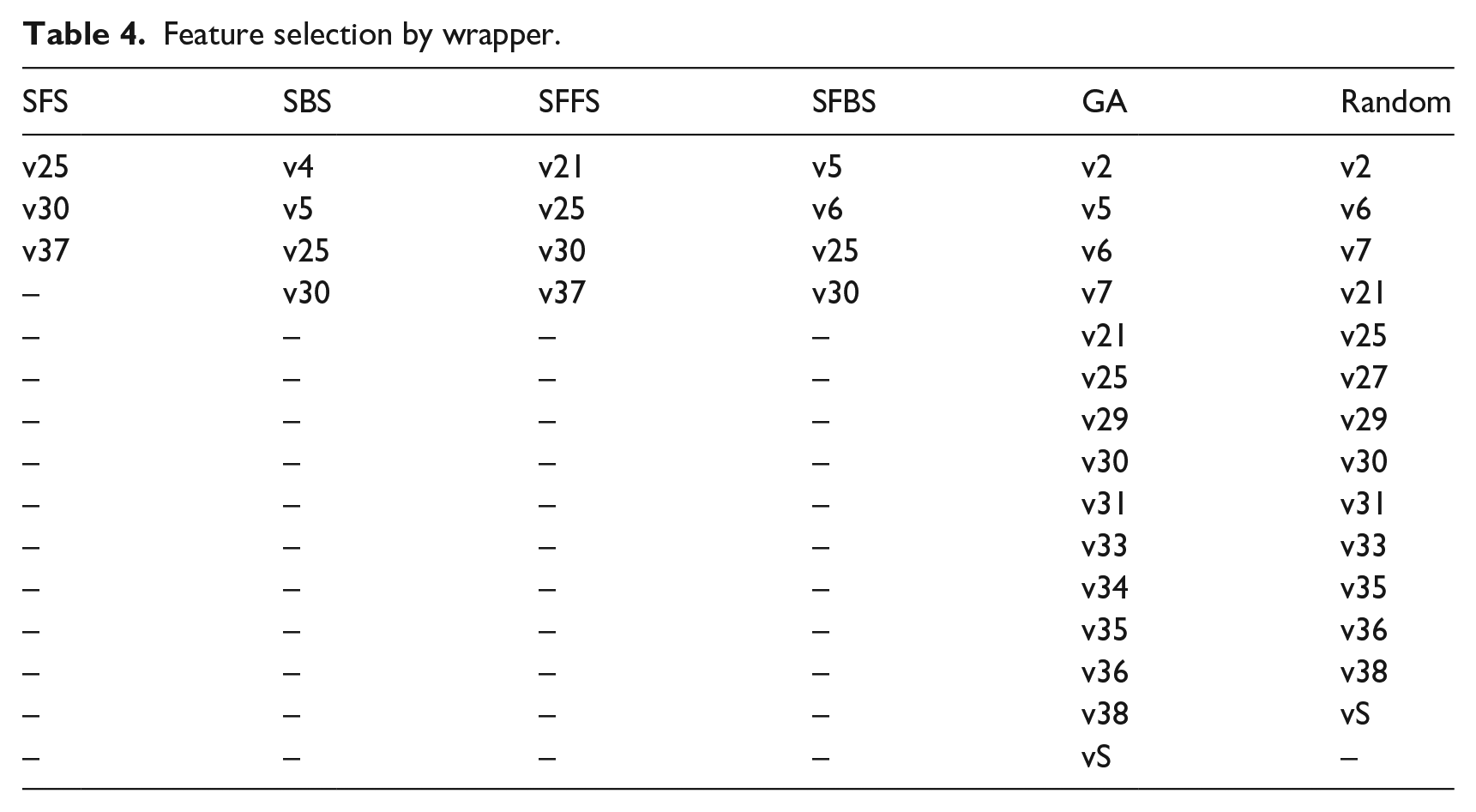
On the other hand, wrappers create a new subset with some features collected with the particular search type, whether Random search, GA, forward, or backward search. These new subsets were tested in each of the selected classifiers. Table 4 shows the chosen feature subset by wrapper.
Feature selection by wrapper.
In the case of OvA, we turned the multiclass problem into a binary problem, comparing one GBS subtype against the remaining three. The new datasets AIDP versus ALL, AMAN versus ALL, AMSAN versus ALL, and MF versus ALL were tested in each of the selected classifiers.
A Wilcoxon statistical test was conducted to compare the two best models using all features for detecting all the subtypes, and the two best models using a feature selection method. We used a significance value of 0.05. Similarly, we applied the Wilcoxon test on the two best models for the detection of a subtype with One versus All technique. We used a non-parametric test because the initial conditions that guaranteed the credibility of parametric tests could not be met, making the statistical analysis less reliable with this type of test.
Experiments using the R platform were performed in RStudio 1.1.463; we use the psych, Rweka, Fselector, caret, pROC, rJava, partykit, kknn, randomForest, and e1071 packages.
SVM and k-NN were optimized through the tune function, assigning the values of 0.001, 0.01, 0.1, 1, 10, 50, 80, and 100 for the C parameter in SVM, and the values 5–35 for k, distance 1 for Manhattan, and distance 2 for Euclidean in k-NN.
Results and discussion
Clinical variables are a group of variables used for the diagnosis of GBS. In the literature, all machine learning models include clinical variables plus complementary studies. The Instituto Mexicano del Seguro Social (Mexican Institute of Health) classifies GBS symptoms and signs in three types: typical, additional, and alarm. 2 The IMSS states that the Asbury and Cornblath criteria are useful for diagnosing conventional forms of Guillain Barré syndrome. The lumbar puncture and electrophysiological studies (the most sensitive and specific diagnostic tests according to 31 were used to diagnose GBS in the Western Balkans1. The WHO 3 defines GBS cases using the Brighton criteria, which are based on clinical and complementary tests such as neurophysiological studies and lumbar puncture. These diagnostic criteria were validated in another study with a population of 494 adult patients with GBS. 32
In the experiments performed in this work, only clinical variables were used. Table 5 shows the comparison of the best results obtained by each classifier with no filter, the corresponding filters, the average of the 30 executions, the standard deviation, the best, and the worst result. The highest average result obtained by each classifier is highlighted in bold. In Table 5 we can see that in most cases, using filters improves the balanced accuracy, except for Consistency in the JRip and k-NN classifiers.
Comparison of the best results by classifier and filter.
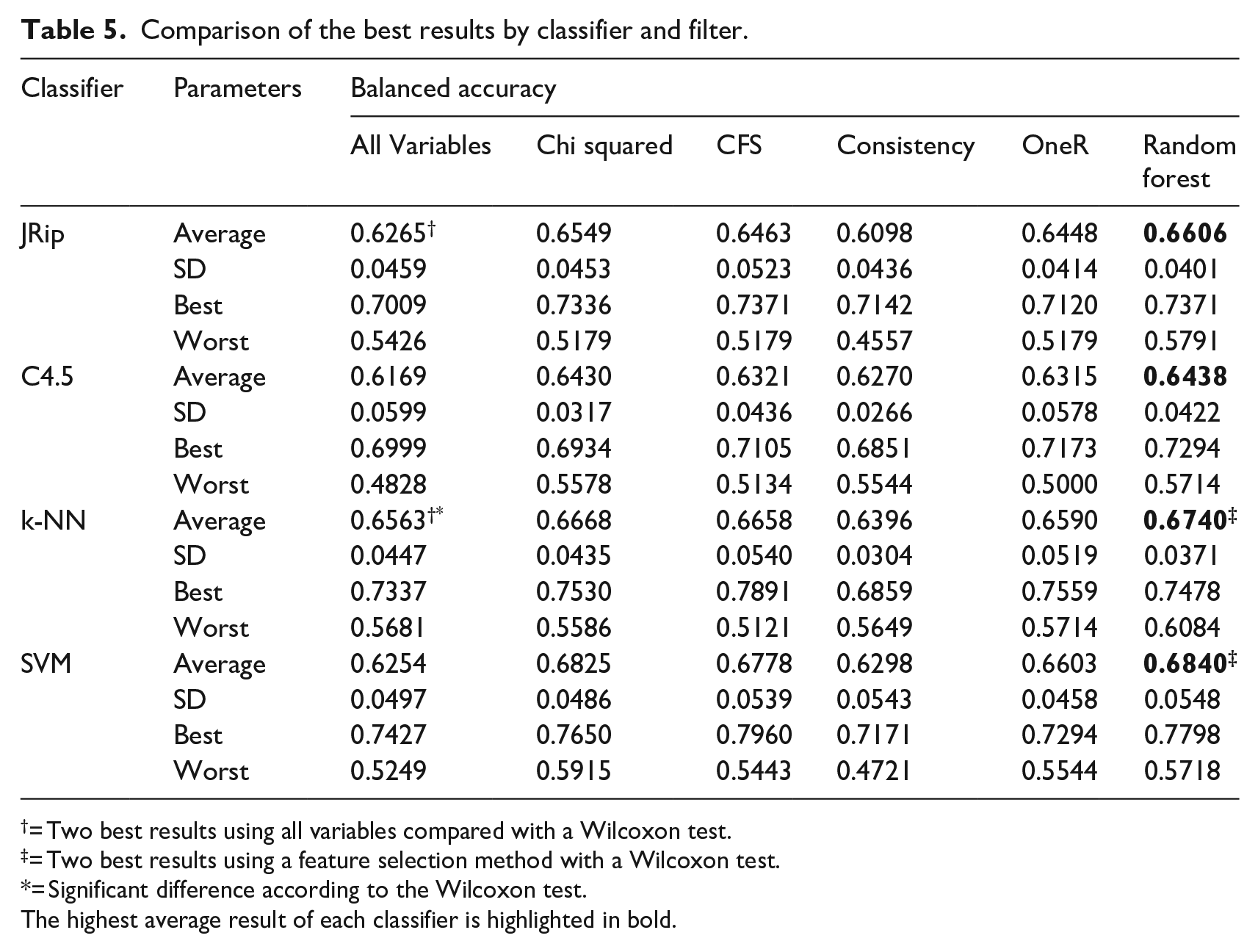
= Two best results using all variables compared with a Wilcoxon test.
= Two best results using a feature selection method with a Wilcoxon test.
= Significant difference according to the Wilcoxon test.The highest average result of each classifier is highlighted in bold.
For the two best models with all the variables for detecting all subtypes (denoted by † in Table 5), the best results were obtained using the k-NN classifier with a balanced accuracy of 0.6563 and, in second place, using the JRip classifier with a balanced accuracy of 0.6265. In this case, there was a significant difference according to the Wilcoxon test. For the two best models using a feature selection method (denoted by ‡ in Table 5), first we have the k-NN and SVM applying Random forest as a filter, reaching a Balanced accuracy of 0.6740 and 0.6840, respectively. In this case, there was not a significant difference according to the Wilcoxon test. For the best two models using the OvA technique (denoted by † in Table 7), we reached with the MF subtype and the classifiers k-NN and SVM a Balanced accuracy of 0.8728 for k-NN and a balanced accuracy of 0.8884 for SVM. In these models, we found no significance with the Wilcoxon test.
Table 6 shows the balanced accuracy obtained using wrappers. Again, the SVM classifier achieved the best performance, this time wit GA wrapper. However, results show that using wrappers for feature selection does not improve in comparison with filter selection.
Comparison of the best results by classifier and wrappers.
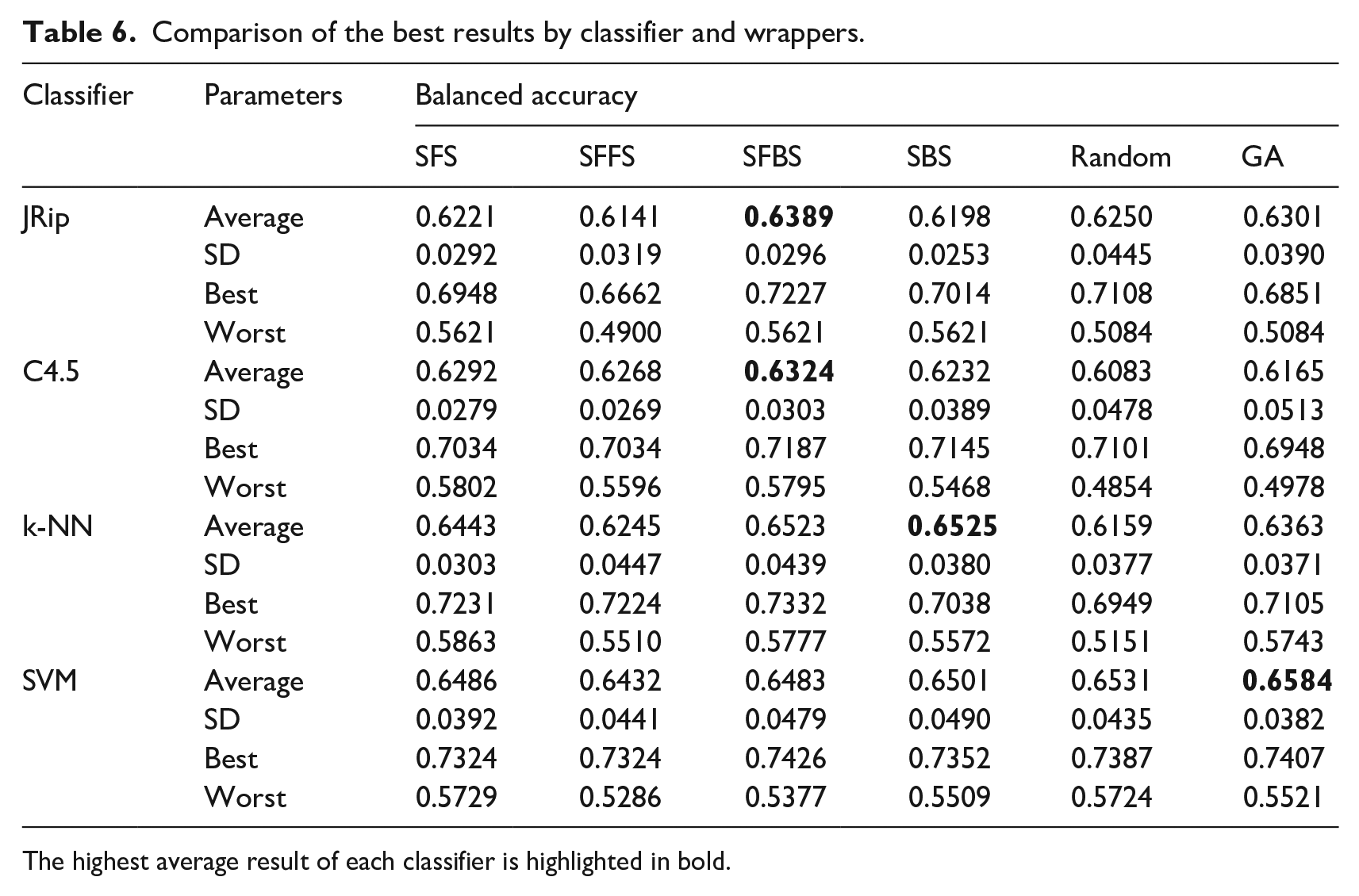
The highest average result of each classifier is highlighted in bold.
One versus All (OvA) classification was applied on the four classifiers to all variables, i.e., with no feature selection method. OvA means that one subtype is compared versus the remaining ones. AIDP versus All, AMAN versus ALL, AMSAN versus ALL, and MF versus ALL. The best result was obtained with SVM classifier and OvA Classification comparing Miller Fisher subtype versus All, reaching a balanced accuracy of 0.8884%. This is mainly due to that Miller-Fisher syndrome (MF) is considered the most common variant of Guillain-Barré syndrome and is characterized by the clinical triad: ophthalmoplegia, ataxia, and areflexia. 33 These clinical variables are represented in our work as the features v27, v30, and v32. Then, we can say that using only clinical variables, it is possible to identify the Miller Fisher GBS subtype from the others. Table 7 shows the average results across 30 runs.
Comparison of the best results by classifier and OvA.
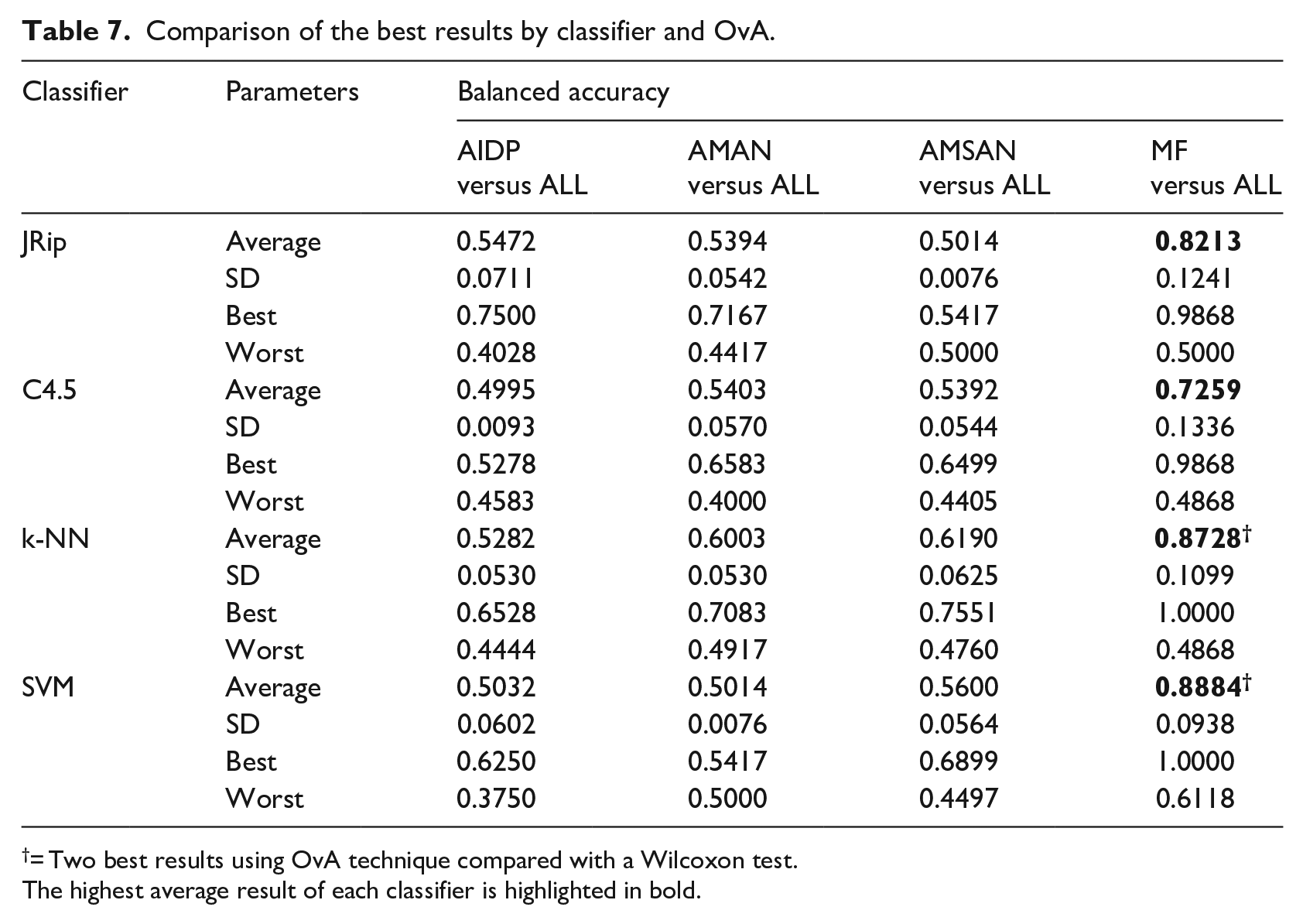
= Two best results using OvA technique compared with a Wilcoxon test.The highest average result of each classifier is highlighted in bold.
Conclusion
In this work, we investigated whether it is possible to create a purely clinical diagnosis model that could quickly and efficiently classify GBS subtypes, through simple classifiers, feature selection by filters and wrappers, and OvA classification. To our knowledge, this work is the first attempt to improve the efficiency of the predictive models of GBS in medical practice.
In this study, we compare the models’ performance with the balanced accuracy parameter. The best performance obtained for the diagnosis of all subtypes was with the SVM classifier and the Random forest filter, achieving a balanced accuracy of 0.6840. But, a performance of 0.8884 with the SVM classifier was reached with the OvA selection on the MF subtype. Currently, our model can be useful for a statistical study of patient records to suggest conclusions and support decision-making.
The results achieved in this study show a significant acceptable accuracy for the diagnosis of one GBS subtypes. Yet, we have not found a way to build a purely clinical model that distinguishes the four subtypes of GBS. Our limitations to achieve such model is that there is no public data about this disease to make comparisons. Also, there are clinical variables often used for diagnosis, e.g., tachycardia, orthostatic hypotension, vasomotor signs, etc. that are not present in our dataset. However, these can only be identified when the condition has progressed.
Serological and neuroconduction studies identified the subtypes suffered by the patients included in the dataset. These studies are not included in this study because our objective was to develop a predictive model that use only variables obtained in clinical practice, in order to help as a primary diagnostic means.
In future works, we consider other techniques to improve the diagnosis through a screening tool in an emergency unit, and for improving the performance of models with solely clinical features. In order to improve our model, we can consider different single classifiers and metaheuristics, ensemble methods, data balancing techniques, and the One versus One (OvO) technique.
Footnotes
Acknowledgements
To CONACYT (Ministry of Science in México) for supporting the Computer Science master’s program at the Universidad Juárez Autónoma de Tabasco.
Conflict of interest
The author(s) declare that there is no conflict of interest.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.