
Abstract
Kidney Exchange Programs (KEP) are valuable tools to increase the options of living donor kidney transplantation for patients with end-stage kidney disease with an immunologically incompatible live donor. Maximising the benefits of a KEP requires an information system to manage data and to optimise transplants. The data input specifications of the systems that relate to key information on blood group and Human Leukocyte Antigen (HLA) types and HLA antibodies are crucial in order to maximise the number of identified matched pairs while minimising the risk of match failures due to unanticipated positive crossmatches. Based on a survey of eight national and one transnational kidney exchange program, we discuss data requirements for running a KEP. We note large variations in the data recorded by different KEPs, reflecting varying medical practices. Furthermore, we describe how the information system supports decision making throughout these kidney exchange programs.
Introduction
Living donor kidney transplantation (LDKT) is the preferred mode of treatment for patients suffering from end-stage kidney disease (ESKD). LDKT is associated with superior long-term recipient and graft survivals compared to deceased kidney donors.1,2 Unfortunately, in up to 50% of the otherwise appropriate potential live donor/recipient pairs, ABO blood group incompatibility or human leucocyte antigen (HLA) sensitization between donor and recipient are major barriers to LDKT. 3 One strategy to overcome HLA and ABO incompatibilities is through a Kidney Exchange Program (KEP). In the simplest case, KEPs consider pairs of incompatible recipients and donors. Two pairs are matched if both donors are compatible with the recipient in the other pair. This way, both recipients receive a LDKT.4,5 More elaborate schemes are possible, including longer cycles of donations, non-directed donors, etc. 6
KEPs have been established in many countries and successfully enable large numbers of additional LDKTs. 6 Due to the success of these KEPs, many countries are in the early stages of starting their own KEP. 7 This is a challenging endeavour, which can be made easier by learning from established KEPs. Through the Cooperation on Science and Technology (COST) Fund, the European Union is funding collaboration and mutual learning on KEP, specifically through the European Network for Collaboration on KEPs COST action (ENCKEP).
The goal of this paper is to give a clear overview of the data requirements and optimisation system needed for properly managing matching activities in a KEP. The paper is organised as follows. In the next two sections, we give a laymen’s description of immunological compatibility, as this is crucial to understand the importance of certain data elements. In the fourth section, we discuss the data elements required to run a KEP. The optimisation process associated with kidney exchange programs is described in the fifth section. The final section contains the conclusions.
Blood group and tissue typing determinants of immunological compatibility
The immunological graft-recipient compatibility between a kidney transplant candidate (= recipient) and a donor depends primarily on the blood type and HLA tissue type of the donor, and on the recipient’s antibodies against the blood group and HLA tissue.
Blood type is the first element to be considered in evaluating compatibility. It is determined by the presence or absence of antigens called A and B. Combinations of these antigens define the four basic blood types O, A, B and AB. Cells of an individual with blood type AB present both A and B antigens. While for blood O type neither of the two are present. Individuals produce antibodies against A or B if they do not express such antigens themselves. ABO antibodies in the serum are formed at an early age; their production is stimulated when the immune system encounters the ‘missing’ ABO blood group antigens in foods or in microorganisms. A donor generally can donate a kidney to a recipient only if the latter does not have antibodies against the donor’s antigens. Nevertheless, the level of anti-blood group-specific antibodies (ABO-ab) is not the same in all recipients. Some recipients may undergo pre-transplant ABO-ab removal procedures, which enables transplantation of a graft from a donor with an otherwise incompatible blood type. In some cases, the titre of ABO-ab is sufficiently low to allow transplantation across the blood group barrier without antibody removal. 8 Because of this, the records of a recipient may carry, besides his/her own blood type, also information about acceptable blood types which is equal to one of the following sets: {{A}, {B}, {A+B}}. This explicitly defines graft blood type acceptance, which may be a superset of blood types accepted implicitly based on the recipient’s own blood type as described above. When a graft is not ABO compatible with a particular recipient, but it is of one of the explicitly accepted blood types, this is called an ABO incompatible match (or ABOi match).
Besides blood type incompatibility, donor-recipient pairs may also be tissue type incompatible, if the recipient has developed antibodies to at least one of the antigens that characterise the donor tissue type (donor specific antibodies or DSA). Tissue type compatibility is related to human leukocyte antigens (HLA). The identification of HLA antigens is referred to as HLA typing. The typing is done for both donor and recipient. The most relevant HLA antigens for kidney transplantation are HLA-A, B, C (class I antigens) and HLA-DRB1, DRB3/4/5, DQA1, DQB1, DPA1, DPB1 (class II antigens). Class I antigens, are expressed on virtually all somatic cells, including the endothelium, as well as B and T lymphocytes, whereas expression of class II antigens is restricted to B lymphocytes, antigen-presenting cells (monocytes, macrophages and dendritic cells), and activated T lymphocytes. Unlike ABO antibodies, HLA antibodies are usually absent in normal individuals. Production of antibodies is based on the immune system previously encountering foreign antigens (allosensitization). Allosensitization usually occurs because of pregnancy in females, blood transfusions or previous organ transplant. If the level of antibodies targeting antigens present in the graft is too high, the recipient’s immune system is likely to reject the graft. The probability of rejection can be tested prior to organ transplantation with so-called ‘crossmatch test’. A crossmatch involves placing recipient serum (potentially containing donor-specific anti-HLA antibodies) onto donor lymphocytes. A cytotoxic reaction (deemed ‘positive’) suggests the presence of preformed DSAbs, indicating incompatibility. Virtual crossmatch is the process of assessing the results of HLA antibody identification assays to predict the results of a physical crossmatch.
Histocompatibility testing requirements for KEP
The goal of HLA typing is to identify which variants of these antigens the donor and recipient possess. Historically, serology-based HLA typing, which provides as low-resolution HLA typing, used to be the golden standard to support deceased donor solid organ transplantation. However, multiple alleles (variants of genes) can have the same serological specificity, but still elicit a different antibody response. Modern DNA based typing methods can distinguish individual alleles (variants of genes) 9 and allow HLA typing at high resolution. 10 HLA typing is generally designed to define the differences in the coding regions of alleles, that is, the variations in DNA sequences, which result in changes in the amino-acid sequence of the protein (HLA antigen). Differences in HLA alleles identify variations in the amino acid residues in the antibody-accessible sequence positions on the molecular surface of the HLA molecule and thus a different antigenicity. We refer to Marsh et al. 11 for a detailed description of HLA designations. A detailed classification of HLA at low and high resolution from the UK National Health Service can be found in NHS. 12
Testing of antibodies is performed exclusively in recipients. HLA antibodies are identified using multi-analyte profiling (Luminex) method, which detects reaction of antibodies in serum with particular antigens located on beads. The strength of this reaction is evaluated semi-quantitatively by MFI (Median Fluorescence Intensity) for each bead. Based on pre-determined cut off values, the MFI is often used as a surrogate to determine whether antigens are unacceptable. We refer to Sullivan et al. 13 for a discussion.
Panel reactive antibody (PRA) classification and calculated PRA (cPRA)
Some kidney transplant candidates have antibodies against donor HLA tissue antigens because of allosensitization. The allosensitization level of patients is assessed by a measurement termed panel reactive antibody (PRA). PRA is calculated from the result of crossmatch based on cytotoxicity method. By testing patient’s serum against a panel of donor lymphocytes, PRA is the percentage of positive crossmatch over total number of donor tested. The higher the PRA score, the more likely the recipient will be incompatible with a random graft. Recently, the concept of calculated PRA (cPRA) was introduced to overcome some weaknesses of traditional PRA measurement and to better utilise the more sensitive data produced by solid phase technology. cPRA is defined as the percentage of donors expected to have HLA antigens that are unacceptable for a candidate. The approach involves collecting a sample of donor HLA phenotypes and directly observes the percentage of incompatible donors for each patient based on their unacceptable antigens. Based on large databases of antigen profiles a cPRA score is then calculated.14,15 Based on the cPRA score, a recipient can then be classified as having a high-level, intermediate-level or low-level of tissue sensitization.
Data requirements for KEPs
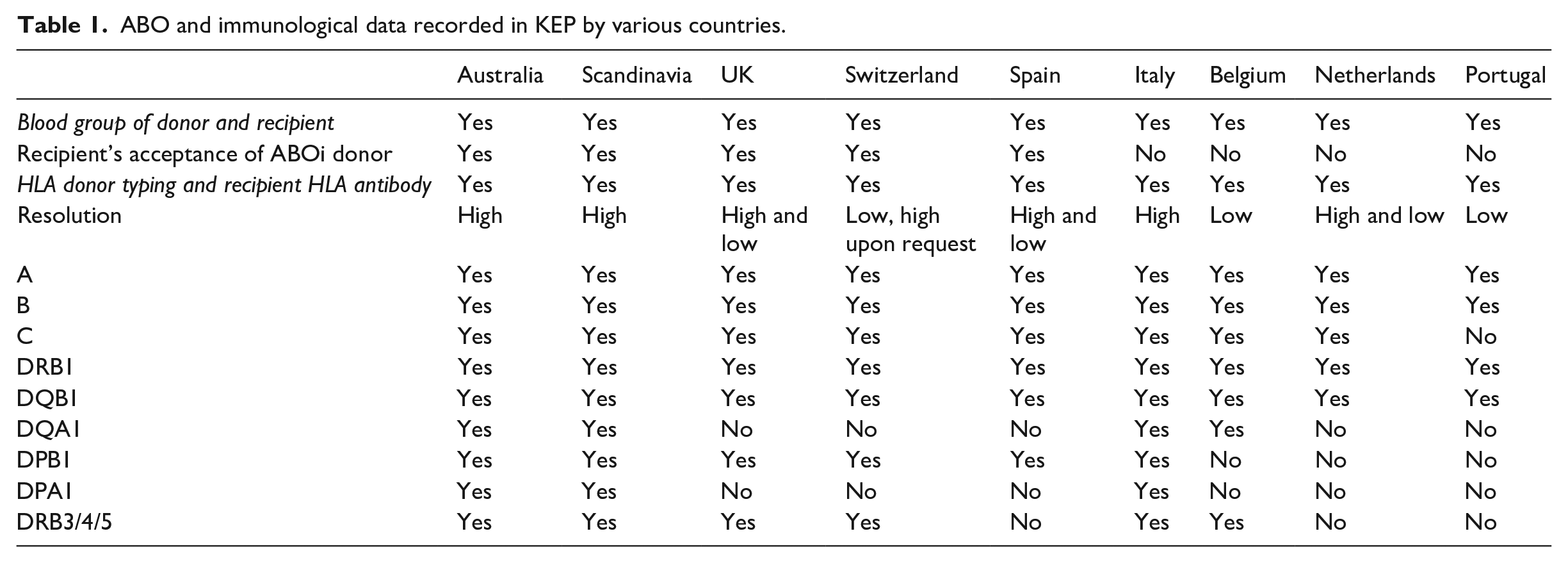
We evaluated responses to a questionnaire submitted to ENCKEP COST Action participating countries, regarding data recorded and used in their KEPs to elaborate a proposal on the dataset requirements for national KEP registries (Table 1) The questions of this questionnaire can be found in the Appendix. Key data elements, and their relationships, were identified through these questionnaires. The most detailed response was obtained from the UK in the form of entity-relationship diagram, shown in Figure 1. In this section, we discuss these data elements, and those reported by other countries. As described above, the ABO and immunological characteristics of recipient and donor are a major factor in determining their (in)compatibility. Accurate and detailed information on these characteristics can be used to identify preliminary incompatibilities, without having to perform a crossmatch test. The ABO and immunological data that are recorded varies by country (Table 1). These differences partially reflect different medical preferences, as well as practical constraints.
ABO and immunological data recorded in KEP by various countries.
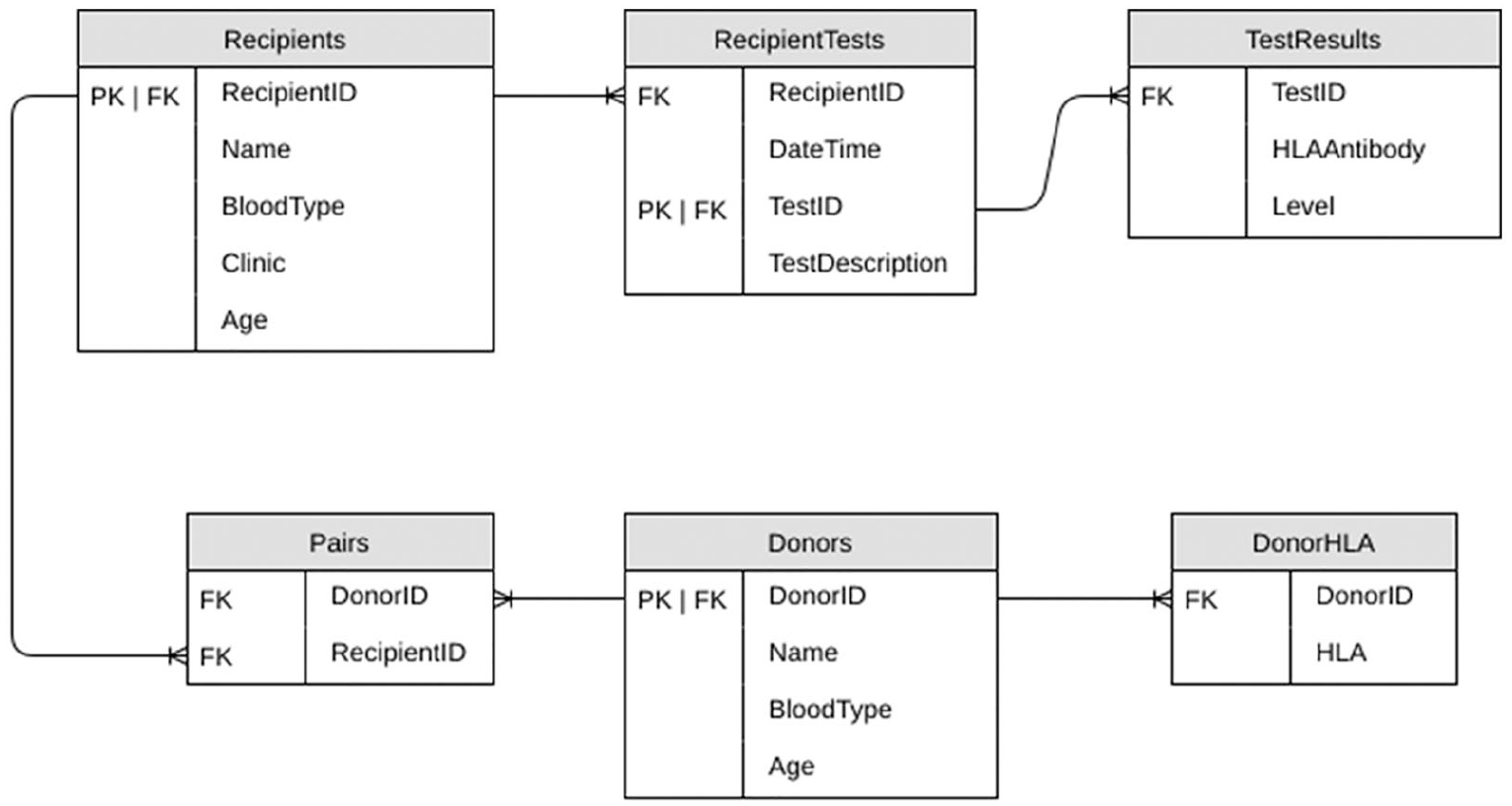
Example ER diagram containing essential data elements for KEPs.
Personal information
Personal data are necessary to unequivocally identify donors and recipients. The minimum set of personal data for donors and recipients should contain an identification number, the name, gender, date of birth, the referring hospital, the relationship between intended donor and the recipient and their place of residence.
Donor blood group and HLA data
The suggested data to be recorded for all donors are the blood group and the HLA typing. Regarding donor blood group, subtyping of blood type A donors is recommended in case ABO incompatible transplants are considered in the KEP. 16 For O recipients, depending on the anti-A titre, blood group A2 donors are acceptable, but A1 donors are usually not. There is significant variability among the respondents on the minimal dataset to record HLA-antigens. Adding high-resolution HLA-typing reduces the probability of positive crossmatches. In practice, Australia and Scandinavia exclusively record high resolution HLA-typing, while Belgium and Portugal exclusively use low typing. Spain allows both resolutions to accommodate HLA labs that do not have high resolution available. In the UK, most centres report at high-resolution, but these are then converted to low level to work out HLA incompatibility. This requires that the database can handle both kinds of data.
There is also a large variability concerning which HLA-antigens are recorded (Table 1). All respondents record HLA-A, B, DRB1 and DQB1. The majority also record HLA-C, DRB3/4/5 and DPB1. Only the Scandinavian and Australian KEP record all HLA-types (including DQA1, DPA1). Recent literature suggests the inclusion of all HLA-types for kidney transplant programs to minimise the risk of positive crossmatches after a KEP computer match.17,18
Recipient blood group and HLA data
Each respondent indicated that recipients must have their blood type and HLA antibody profile recorded. KEPs typically record the recipient’s anti-HLA antibodies. For each specificity, MFI values by Luminex technique are saved. Since antibody levels may change over time, regular testing is required. In practice, re-testing intervals vary from 3 months to 1 year. Potentially sensitizing events require an update of the antibody levels. Some KEPs provide the option to explicitly list unacceptable HLA donor antigens, even if the recipient has no antibodies to that particular antigen. For example, in the Australian program, this is used to disallow donor HLA with a high risk of post-transplant antibody generation and is used specifically to provide better matches for compatible pairs in the KEP. 19 All programs use cPRA to report the level of HLA sensitization of a recipient. cPRA should be calculated by a standardised formula reflecting the donor population within the KEP area. Calculators by transnational organisations, such as Eurotransplant or Scandiatransplant can be used to homogenise information across countries.
Furthermore, recipients should have their acceptable blood type matches and HLA tissue type documented. The majority of respondents only allow ABO-compatible transplants within their KEP; thus, recipient blood type determines acceptable donor blood type. The Australian, Spanish and UK programs allow low-risk ABOi transplants through the KEP. This practice requires that acceptable blood groups are explicitly recorded. Because in a KEP matching needs primarily to avoid pairing recipients with HLA antibodies directed against HLA antigens present in the potential donors, the recipient HLA typing carries little weight. Therefore, the recipient HLA-antigen record does not necessarily require the same level of HLA typing required for the donors. If the inclusion of compatible pairs is considered, recipients should also be fully HLA typed at high resolution. Finally, the reason of a positive cell-based crossmatch between a recipient and donor in a matched pair identified by virtual crossmatching should be registered to prevent future match breakdowns because of the same reason. 16
Clinical information
Since clinical information on the ESKD situation may influence recipient priority, it is important to record time on and type of dialysis treatment, as reported by the Netherlands. Furthermore, the cytomegalovirus (CMV) serological status of donors and recipients should be recorded. This information is important, because prophylactic antiviral therapy is used for instance in CMV+ donor to CMV- recipient transplants. Likewise, hepatitis B and hepatitis C status of donors, and an indication whether hepatitis B core antibody positive donors are acceptable to recipients is desirable. 6
Clinical information on donor and recipient anatomy may be important for some recipients (particularly those waiting for a second or third transplant). Allocation rules ensure recipients are not matched to donors with incompatible kidney anatomy. The suggested data to be recorded for the recipient are the need for left kidney only, single artery, single vein and long vein. The suggested data to be recorded for the donor are which kidney can be donated, presence of dual artery and length of vein for the right kidney. Taking such information into account from the onset will decrease the number of transplants being cancelled for medical reasons after the donors and recipients are matched. 20
Some other limitations related to the donated kidney make them unsuitable for all recipients (cysts, ureter anatomy). Such donors should not be accepted to the KEP and should be regulated by acceptance policies, and not by allocation rules (e.g. Melcher et al. 21 ).
Donor and recipient
In the most basic form of a KEP, one recipient is linked to one donor, as reported by most of our respondents. However, more complex relations are possible. For example, there may exist more than one donor joining the KEP linked to a single recipient, or we may consider non-directed donors. A flexible form of organising recipient and donor data, allowing for these cases, is to consider separate recipient and donor data structures. For both recipient and donor structures, a data-element is provided. This data-element shows any links with, respectively, donors and recipients in the database. For example, the UK reported using such a system.
Consensus on minimum datasets
We note there is large variation in the immunological data recorded by different countries (see Table 1). Such differences usually reflect varying medical practices. For example, countries allowing ABO-incompatible transplants through their KEP require additional data to identify which ABO-incompatible transplants are feasible. For this reason, we find little consensus regarding a ‘minimum’ dataset required to run a KEP, as data deemed essential to some countries are not recorded by others. We do note that over time the data requirements of KEPs increase, as additional modes of transplantation are incorporated. However, adding additional data elements to the dataset can be a time-consuming process as the software needs to be adapted and tested. For this reason, we advocate designing the databases and related systems to consider as many data elements as possible, even if they are not yet relevant to the current KEP practices. In this way, potential later changes in medical policies are least hindered by earlier choices.
Optimisation requirements for KEPs
Many phases are involved in organising transplants within a KEP. First, medical and immunological data are entered into the system. This data is then parsed to build the optimisation model, to decide which transplants will be planned. Next, this model is solved, and the resulting proposed transplants subjected to crossmatch testing. Depending on the KEP, a recourse step can then follow. Finally, reporting is necessary to allow for evaluation of the program. In this section, we will first detail the technological portions of a KEP, which touch on many, or all phases, before going into deeper detail on some of the individual phases.
Users, user interface and data formats
User authentication should be managed according to current best practices for online services. Three distinct roles that can be present in a KEP are: clinician, tissue typing scientist and administrator. Each donor-recipient pair can be managed by their own clinician, who should be able to view and update any medical details relevant to either the donor or recipient. The clinician should also be able to view the characteristics of a donor assigned to their recipient. Tissue typing scientists should have privileged access for entering and updating donor and recipient blood group and HLA data. Administrators, a central authority managing a program, should be able to run and assess matching runs. Other possible roles include systems administrator/developer roles, for maintaining the system or software. Such users can be restricted from accessing real data, but instead are able to access a suite of test data to verify the functionality of all components.
Most current KEPs offer a web interface to users. It presents a user with the current data and provides a simple method for updating or adding new data. The user interface may also include data integrity options and provide options for administrators to modify certain parameters in the modelling and solving phase, such as maximum cycle or chain length.
The use of data files and common data formats can facilitate collaboration between various KEPs. By using a common data format, software developed for one KEP could more easily be adopted by others if necessary. Common data formats also provide methods for archiving data at various phases within a KEP for future validation or analysis. Most existing KEPs use either XML or JSON for such purposes.
Interactions with other systems
A KEP may interact with deceased donor systems as a transplant candidate may simultaneously be listed on the KEP and on the deceased donor wait list registry. Most commonly, when a recipient is allocated a donor kidney through a living donation system, they will be temporarily suspended from a deceased donor system. Suspension from the deceased donor waiting list is crucial in a KEP to avoid post-match chain breakdown. Recent advances in kidney exchange increase the need for communication between systems. Chains initiated by deceased donors21,22 increase the interaction between deceased and kidney exchange systems. Furthermore, with increasing transnational collaboration on KEPs,23,24 the above-mentioned concerns should also be considered and addressed. It is possible to enter some data (such as HLA typing) directly from diagnostic equipment, and if such features are available it is important to verify that the equipment and the database can communicate.
Database and alternate sources of data
The data must be stored in a reliable database and backed up accordingly. Access to different types of information should be controlled by user level controls. To ensure that correct data is stored in the system, the database may require the verification of data input, when manual data entry is required. For example, several KEPs require that updates to certain data must be verified by an independent user. Such procedures reduce the risk of any transcription error. Tracing access and modifications to the database can also ensure data integrity. Much of the data required by a KEP is also required by related programs (e.g. deceased donor programs), so to reduce resource costs and avoid errors of omission, a KEP can either share a common database between such programs, or systems can be put in place to ensure that all such databases continuously update each other. Most of our respondents report data being copied from the deceased donor program (e.g. The Netherlands), or more integrated systems where the KEP makes use of the same database (Scandiatransplant, UK).
Modelling and solving
The optimisation process involves three steps: data parsing, modelling and solving. In the first step, preliminary compatibility between recipients and donors is determined through virtual crossmatching to produce a compatibility graph. Modelling is closely linked to the method of solving. Current KEPs use one of three paradigms: complete enumeration, heuristics and Integer Programming. In each case, the problem is formulated, and a solution is found.25,26
Modelling first takes data from the database and calculates compatibility information. Often this result is presented in the form of a compatibility graph: a graph where each vertex represents a recipient and their donor(s), and weighted edges indicate compatibility between a donor and a recipient. These weights are calculated from attributes of donors and recipients and can reflect, for example, recipient’s priority levels based on waiting time and level of sensitization. Each donor and recipient can be represented by an anonymous identifier, with only a minimum set of required data associated with each of them. 25
Once a matching run has been modelled, it needs to be solved. This is the process by which an optimal solution, comprising a set of exchanges, is determined. The input to a solver includes (but is not limited to) a compatibility graph. There are many ways of solving a model, and the actual implementation of a model is often strongly linked to the choice of solver. The simplest method is an exhaustive search – a search that finds all possibilities and lists them in descending order of preference. Such methods are often simple to implement and require no external libraries. As all possible solutions are listed, if a positive crossmatch is later detected, it is simple to start testing the next best solution. However, such methods will struggle in larger KEPs.
Larger KEPs use, in general, dedicated solver packages – third-party software packages that use various specialised techniques to find a guaranteed best solution. Such solvers come in both free and commercial variants.27 –30 On modern hardware, a matching run with up to 200 donor-recipient pairs, suitably modelled, can be solved in well under a minute using free solvers (see Mak-Hau 26 and Dickerson et al. 31 ). Commercial solvers offer superior performance, at a monetary cost, if required for larger programs.
Final crossmatch and transplants
The compatibility graph is in general based on preliminary assessment of the immunological compatibility. However, once a solution is proposed, laboratory crossmatching is usually performed on the pairs selected for transplant. This can unmask unanticipated incompatibilities and prevent transplants associated with the identified pairs to proceed. The risk of positive crossmatches can be reduced by, for example, testing for DQA and DPA antibodies, 17 but no system can guarantee zero positive crossmatches.
Different KEPs may have different methods of resolving these positive crossmatches. Any positive crossmatch will cancel the cycle or chain to which it belongs. Some KEPs maintain an exhaustive list of all solutions or allow for quick re-computation of solutions. As a result, they can iteratively test the best solutions until they identify one without any positive crossmatches. Such an approach is difficult to implement in larger KEPs due to the organisational challenges of the crossmatch testing. Most KEPs will not attempt to find a new solution from an updated compatibility graph. To reduce the consequences of positive crossmatches, KEPs can resort to some rules that anticipate possibility of failure. 25
Reporting
A series of reports can provide useful information regarding the long-term effectiveness and efficiency of a KEP. These should include, but are not limited to, the number of matches that have been identified, as well as matches proceeding to transplant; the cPRA levels of recipients in the pool and those allocated a kidney; the match probability of recipients being allocated a kidney; the number of transplants within each blood group, and between each pair of blood groups and the waiting times on dialysis and the waiting time on the KEP program of each recipients allocated a kidney. 32
Conclusions
Based on surveys amongst KEPs associated with the ENCKEP COST Action, we found limited consensus about the data requirements. All countries share a common core including identification of donor and recipients, blood type and some HLA information (A, B, DRB1, DQB1), although, mature KEPs indicate that extended second field high-resolution typing of the donor-recipient pairs across all HLA loci is relevant for the correct assessment of DSA. Beyond this core, differing medical practices employed within the various KEPs result in different data needs. Some countries report expanding the data they record as the program matures. Furthermore, incorporating additional modes of transplant (ABOi, compatible pairs, etc.) requires additional data. For this reason, we advocate including as many data elements as possible, to be able to cope with increasing needs for data as medical practices in the program change. Furthermore, increased data availability allows for easier international cooperation with countries whose programs do require this information.
The overall structure of the information systems is similar across KEPs. It typically involves gathering medically relevant data and then transforming this into a model whose solution is used to match donors and recipients in the KEP to identify possible transplants. Additionally, these systems often have options to deal with failures of assigned matches.
Footnotes
Appendix
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This article is based upon work from the ENCKEP COST Action (CA15210), supported by COST (European Cooperation in Science and Technology). The authors acknowledge travel reimbursements by COST. Financial support from the School of Computing Science, University of Glasgow, for the article processing charges, is also gratefully acknowledged.