
Abstract
Extracting information from unstructured clinical text is a fundamental and challenging task in medical informatics. Our study aims to construct a natural language processing (NLP) workflow to extract information from Chinese electronic dental records (EDRs) for clinical decision support systems (CDSSs). We extracted attributes, attribute values, and tooth positions based on an existing ontology from EDRs. A workflow integrating deep learning with keywords was constructed, in which vectors representing texts were unsupervised learned. Specifically, we implemented Sentence2vec to learn sentence vectors and Word2vec to learn word vectors. For attribute recognition, we calculated similarity values among sentence vectors and extracted attributes based on our selection strategy. For attribute value recognition, we expanded the keyword database by calculating similarity values among word vectors to select keywords. Performance of our workflow with the hybrid method was evaluated and compared with keyword-based method and deep learning method. In both attribute and value recognition, the hybrid method outperforms the other two methods in achieving high precision (0.94, 0.94), recall (0.74, 0.82), and F score (0.83, 0.88). Our NLP workflow can efficiently structure narrative text from EDRs, providing accurate input information and a solid foundation for further data-based CDSSs.
Introduction
Electronic health records (EHRs) are official documents recorded by doctors which contain abundant medical information about patients including patients’ individual desire, physical examinations, radiological examination results, and lab tests.1–4 Medical information extraction from EHRs becomes a fundamental step for analyzing EHR data and constructing data-based models in many applications including hospital management, EHR template construction, decision support system research, etc. In our previous research, we constructed a clinical decision support system (CDSS) for removable partial denture design in dentistry. 5 As the denture design is associated with many determinants of the patient’s oral conditions that are sufficiently described in the oral examination section (OES) of electronic dental records (EDRs), we intend to extract information from EDRs to build data-based models for CDSS. In this study we focus on constructing an efficient workflow to extract information from narrative dental records and instantiate them with our ontology.
Our primary goal is to transfer textual data into well-structured instances which has not been solved properly by researches. Schleyer et al. 6 constructed the Oral Health and Disease Ontology and extracted information from the tables of their EDR system. However, the OHD covers general knowledge in dentistry instead of the specific concepts to support the CDSS for denture design. And their method could not handle EDRs in narrative format, which is a major challenge for information extraction.1,7,8 To deal with narrative EDRs, researchers have proposed and implemented some methods to deal with narrative dental records. Christensen et al. 9 used a sentence-level text analyzer ONYX, which is a semantic network based model, for semantic analyses of dental clinical text. Irwin et al. 10 described methods to develop and evaluate dental semantic representations for natural language processing (NLP). Both of the two researches extract partial information from EDRs involving a small fraction of entities, concepts, and relations, which makes the research less complex. And the rule-based or learning-based methods they proposed require intensive manual effort including summarizing expert rules and feature engineering. Considering the abundant information we intend to extract, it is labor-consuming to manually build rules that could cover all possible information and expressions.
In our study, we constructed a workflow to achieve information extraction (IE) from the OES shown in Figure 1. Our protocol is at first to read texts from the OES; then word segmentation is established by software Language Technology Platform (LTP). 11 The IE procedure comprises three tasks: attribute recognition, attribute value recognition, and tooth position recognition, corresponding to classifications of oral examination, relevant results, and tooth position, respectively. We compared the performance of Sentence2vec and bidirectional encoder representations from transformers (BERT) in our corpus and implemented Sentence2vec in attribute recognition. 12 We utilized Word2vec in attribute value recognition.13–15 Vectors representing sentences and words are obtained during the training process of the Skip-gram model. After the IE process, attributes, relevant values, and tooth positions are instantiated into our ontological paradigm.
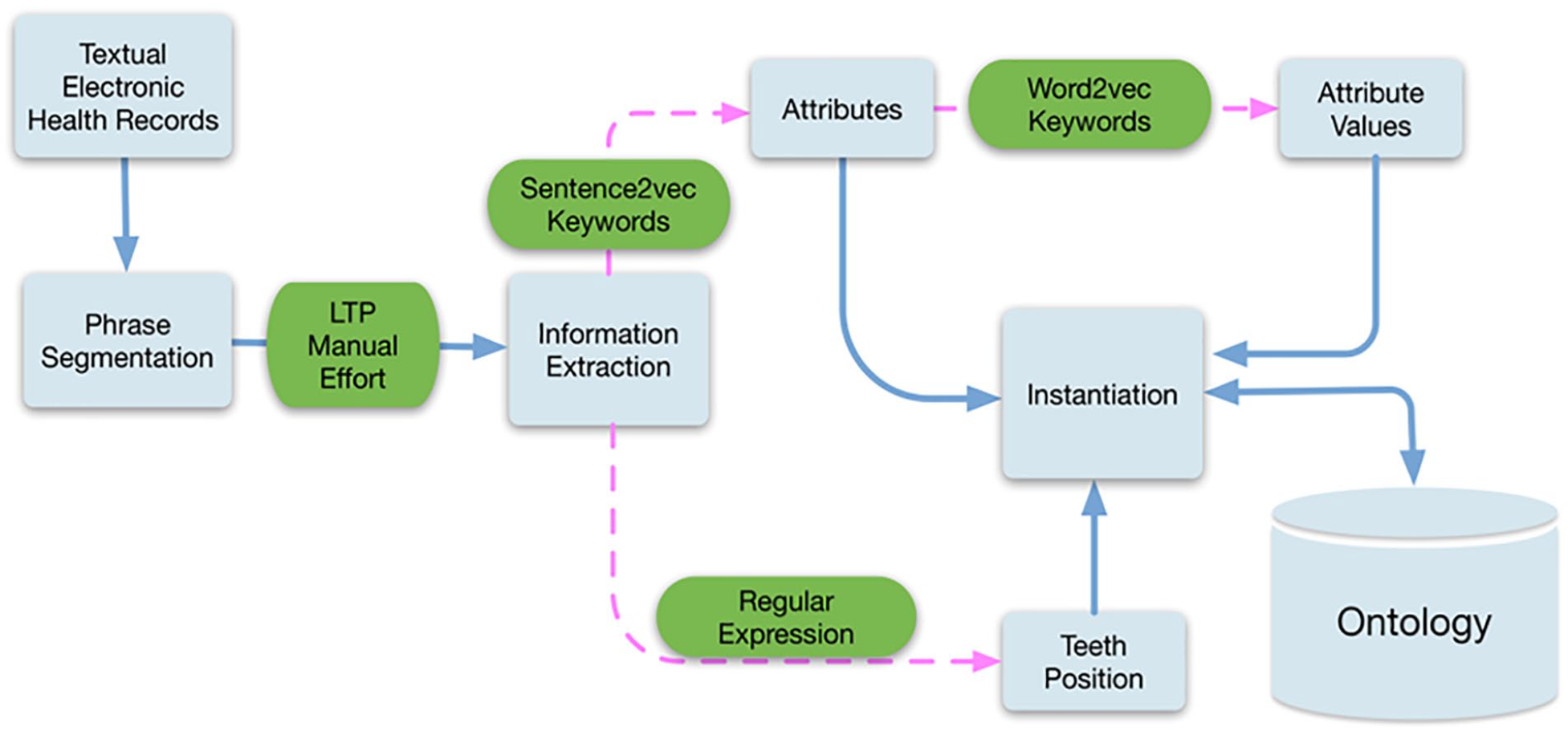
Framework of EDR structuring.
The entire workflow of EDR structuring is shown, in which blue squares represent every procedure and green squares represent methods we applied.
Methods
A piece of EDR in Peking University Hospital of Stomatology, electronically recorded by dentists in narrative formats, represents patients’ dental visiting information during one appointment. Six major sections comprise one complete record, namely chief complaint, medical history, oral examination, diagnosis, treatment plan, and disposal. Among them, we utilized the text of the OES with detailed description of patients’ oral conditions including physical examinations and imaging tests.
Our cohort involved 8000 de-identified EDRs from the database of Prosthodontics Department, Peking University Hospital of Stomatology. All private information was erased from the original records. According to our statistics, there are 10,492 different sentences, involving 76,327 words and 130,068 characters in total.
We annotated 2000 EDRs from the entire set. One dentist and two researchers designed the annotation guideline for attribute and value recognition (Appendix section); annotation in our study was labeled sentence by sentence. During annotation, the two researchers first annotated 200 records with an annotation program we developed. The dentist checked the annotations and discussed with the two researchers until three members reached agreements. Then the two researchers annotated the whole corpus separately. Cohen’s
Word segmentation
Words consisting of characters are the smallest units that could express semantic meanings in Chinese. Texts in the OES are semi-structured; Sentences are in a regular form as “tooth position, oral examination (corresponding to attribute), result (corresponding to attribute value).” For instance, “6/8765/4567/18剩余牙槽嵴中度吸收”(moderate resorption of residual ridge in tooth positions 6/8765/4567/18) could be segmented as “6/8765/4567/18,” “剩余牙槽嵴,” “中度吸收” (tooth position 6/8765/4567/18, residual ridge, medium resorption). We utilized the LTP tool for segmentation, which is produced by the Harbin Institute of Technology in China. 11
Information extraction
We separated the whole IE task into three parts as recognition of attribute, attribute value, and tooth position. For attribute and value recognition, 80% of the 2000 annotated EDRs were randomly selected as the training set; the remaining were treated as the test set.
Attribute recognition
We designed a hybrid method integrating sentence vectors with keywords of attributes for recognition (Figure 2(a)). For every input sentence, a 100-dimensional vector was acquired through Sentence2vec, then used to calculate cosine similarity values with all sentences in the training set. A keyword-based method was also applied for attribute recognition in the same sentence. Thus, attribute recognition for a particular input sentence is obtained either by similarity calculation or by keyword matching.
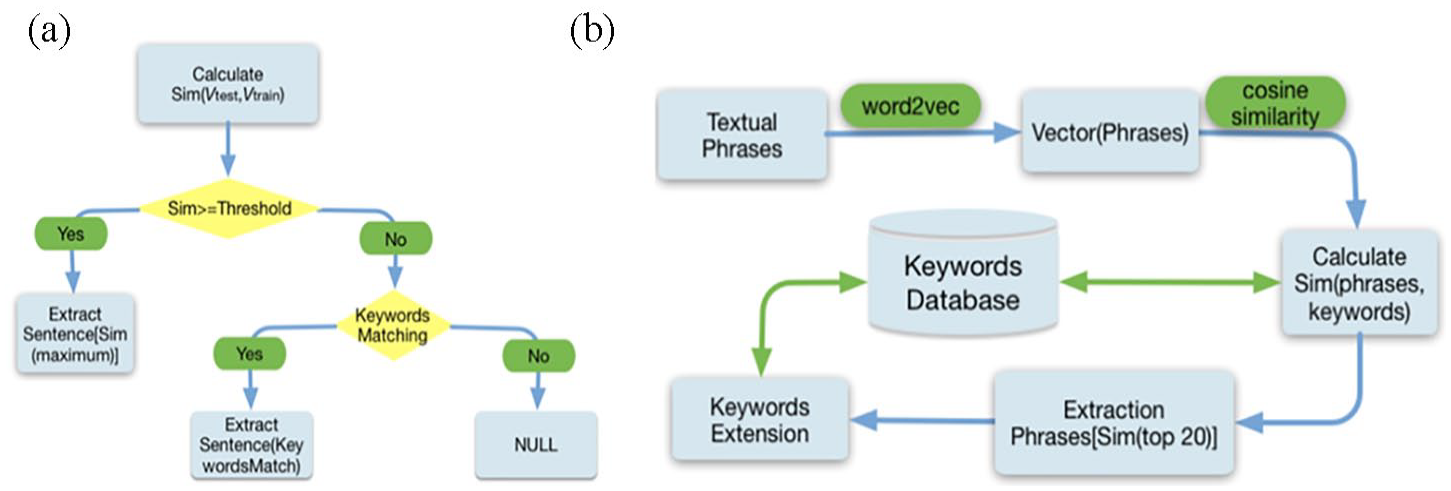
(a) Hybrid method of attribute recognition. Principles of attribute selection are described, using keyword-based and deep learning methods, and (b) workflow of attribute values recognition. Deep learning methodology was applied to generate new keywords to expand the keywords database.
The strategy to select attributes was as follows:
(a) If similarity value is larger than the threshold, the attribute of the input sentence is recognized as the sentence attribute in the training set.
(b) If similarity value is less than the threshold and matches the keyword, the attribute of the input sentence is the keyword attribute.
(c) If similarity value is less than the threshold and keyword matching fails, then the output is null and no information is extracted.
During attribute recognition, the threshold is set to switch between keyword-based and deep learning methods. To select a threshold value, we plotted precision, recall, and F1 measure at finite and discretized threshold values, shown in Figure 3(a) and (b). At various thresholds, attribute recognition achieves different levels of performance. The strategy of threshold selection involves a balance between high precision and high recall. Here, we set the threshold to be 0.9.
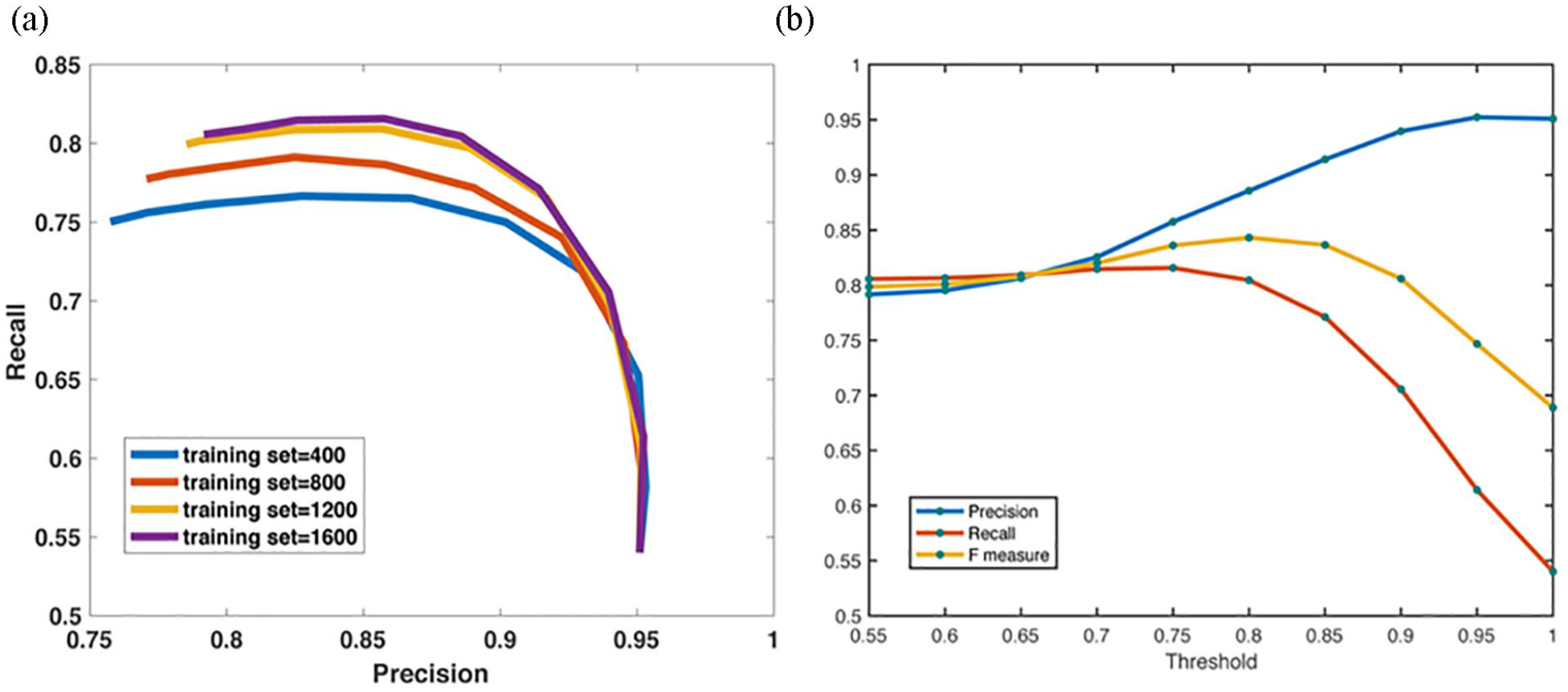
(a) Performance under different numbers of cases in the training set. The number of cases in the training set can influence the model’s performance. As seen in this figure, a larger training set increases recall and precision, which helped us to determine the ideal size of the training set, and (b) performance comparison with different thresholds. In defining the principles of attribute selection, the threshold of similarity value is demanding; thus, we set the threshold to maintain overall performance of our model.
Vector learning
We utilized Sentence2vec and BERT to train sentence vectors and applied Sentence2vec to better learn vectors of sentences from 8000 unlabeled EDRs. 13 Specifically, skip-gram model and hierarchical softmax optimization methods were implemented to learn 100-dimensional vectors from variable-length sentences. The skip-gram model was used to find word representations that could predict the neighboring words in a sentence. 14
Given a series of training words,

where c is the size of the training set, the objective of the skip-gram model was to maximize the log probability. After iteration, the largest probability value was calculated and word vectors were learned as parameters of the model. Sentence vectors are matrices involving word vectors with an additional sentence token in a sentence.
Similarity calculation
For attribute recognition, an input sentence, with a fixed-length vector, was compared with all sentences in the training set. It is acknowledged that semantically similar sentences exhibit similar vector representations in space. Therefore, cosine similarity was calculated between the vector of the input sentence and all vectors in the training set and similar sentences could be distinguished by high similarity values.
Attribute value recognition
For attribute value recognition, we constructed the keyword database with 366 words and concepts and expanded it via learning word vectors (Figure 2(b)). One or two keywords were initially manual selected to represent each attribute value according to medical vocabularies and textbooks. Then, all words representing the attribute’s values, in both the keyword dataset and the 8000 EHRs, were used to learn vectors, using the Skip-gram model.14,15,17 A 200-dimensional vector was learned for each word.
The strategy of expanding keywords is as follows. For each sentence in the training set, cosine similarity was calculated among vectors of words with given keywords in the keyword dataset. For every attribute value, 20 words with the highest similar values were extracted and added as potential keywords into the keyword database. Two annotators reviewed the top 20 words for each attribute value and selected the final keywords. Eventually 473 keywords comprised the database.
Tooth position recognition
Tooth positions were described in numbers and symbols, which are clear for use in construction of rules. Regular expressions were built for tooth position recognition.
Instantiation
After information extraction, all extracted attributes, values, and teeth position were mapped into the previously-built ontological paradigm. The ontology represents knowledge of denture design in a structured and formalized way and keeps consistent with the existing CDS model. 5 Based on data properties and object properties embedded in the ontology, the mapped information forms instances representing oral health information of a patient’s one appointment. To obtain instantiation, Class appointment was built to represent every patient appointment. Data properties tooth ordinal and tooth zone were added to represent tooth position. Object properties left_first_tooth and right_first_tooth were built to define boundaries of continuously missing teeth.
A relationship map of a patient’s instance is illustrated in Appendix Figure 5. Here, Patient A defines the patient, Appointment 1 refers to this visit, and Oral Conditions references patient A’s oral examinations. Specifically, Instances Tooth 26, Tooth 27, and Tooth 28 were constructed to describe examinations of teeth 26, 27, and 28 (FDI notation); Instance Edentulous Space was constructed to represent examination of edentulous spaces, and is connected with Instances Tooth 26, Tooth 27, and Tooth 28 by object properties left_first_tooth and right_first_tooth, indicating that missing teeth in the edentulous space are teeth 26, 27, and 28 (FDI notation).
Results
We performed the evaluation in the test set containing 400 annotated EDRs. 18 Precision (P), Recall (R), and F1 scores were calculated to quantitatively employ efficiency of the proposed methods where,



with tp being true positive, fn false negative, and fp false positive.
The tp indicates the number of extracted items (attributes or values) that are identical to annotated items, fn indicates the number of annotated items that remain unextracted, and fp refers to the number of extracted items that remain unannotated.
Moreover, we defined two extra metrics,
Equations are as follows,


where
We compared the performance of keyword-based, deep learning and the hybrid methods as illustrated in Tables 1 and 2. We reviewed 50 most frequent attributes and associated values from the overall 88 attributes to calculate
Performance of three approaches for attribute recognition.
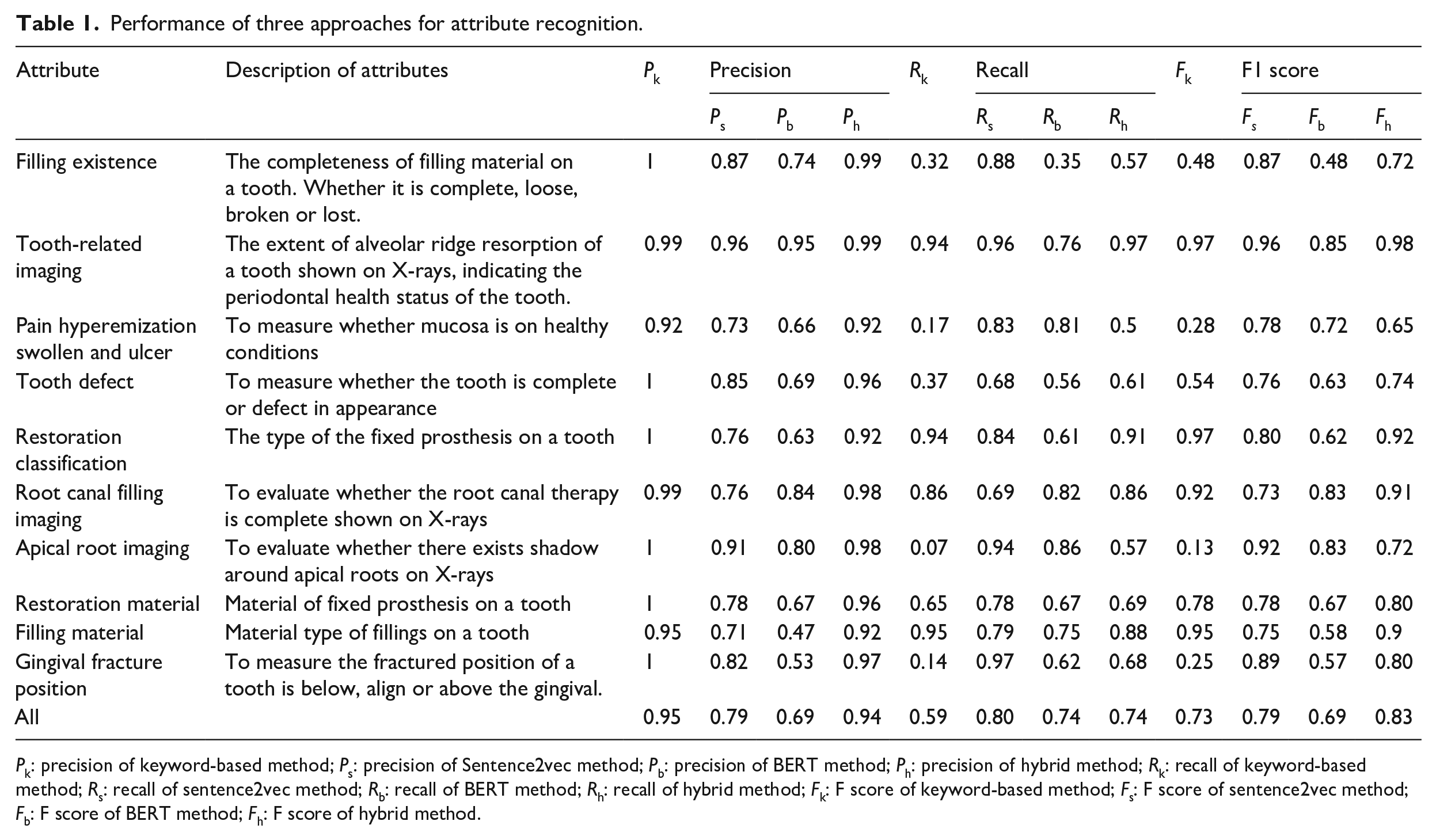
Pk: precision of keyword-based method; Ps: precision of Sentence2vec method; Pb: precision of BERT method; Ph: precision of hybrid method; Rk: recall of keyword-based method; Rs: recall of sentence2vec method; Rb: recall of BERT method; Rh: recall of hybrid method; Fk: F score of keyword-based method; Fs: F score of sentence2vec method; Fb: F score of BERT method; Fh: F score of hybrid method.
Performance of two approaches for attribute value recognition.
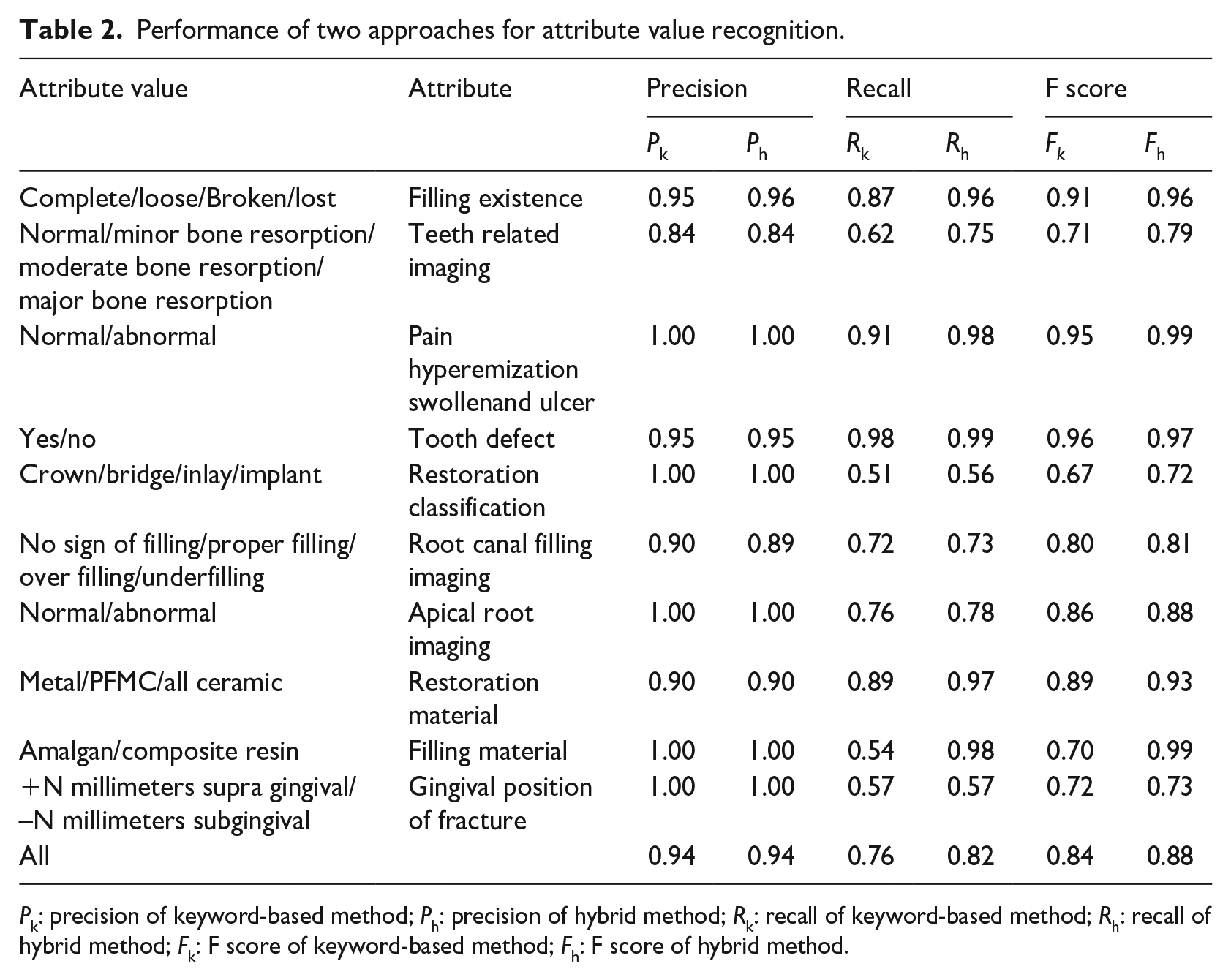
Pk: precision of keyword-based method; Ph: precision of hybrid method; Rk: recall of keyword-based method; Rh: recall of hybrid method; Fk: F score of keyword-based method; Fh: F score of hybrid method.
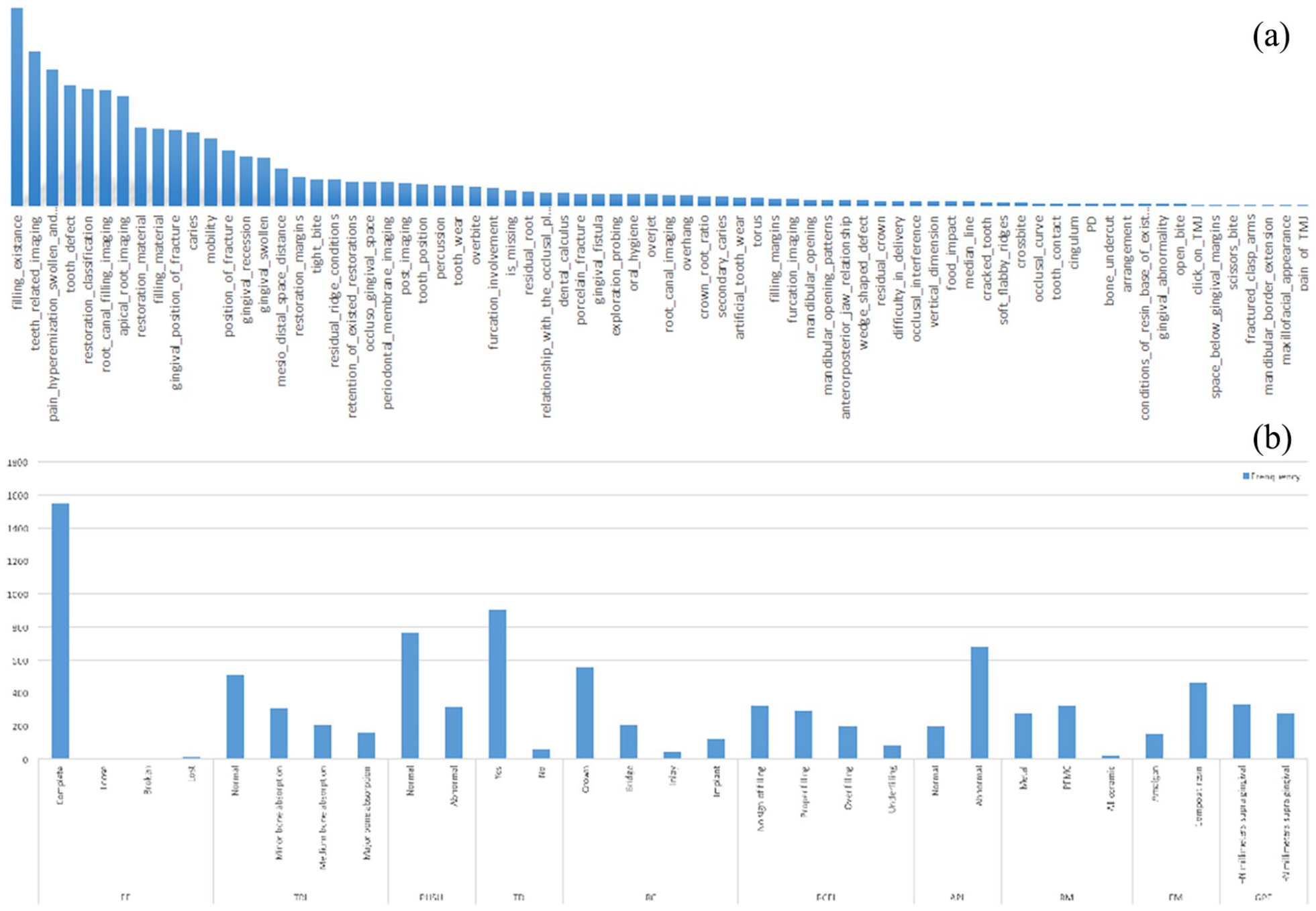
(a) Distribution of attribute frequencies. Obvious differences among attribute frequencies suggest the effect of different attributes on performance of our model, and (b) distribution of attribute value frequencies. Attribute value frequencies of the top 10 attributes show value frequency distributions in each attribute.
We listed P, R, and F score in three methods of the10 most frequent attributes in Table 1. Sentence2vec performs better than BERT in 9 of the 10 attributes and achieves higher
Discussion
Information extraction aims to extract problem-specific information and then convert it into structured form which can be used directly by classifiers. 19 Due to several disadvantages of clinical texts such as ungrammaticality, abounding with shorthand, being misspelling and unstructured, it poses greater challenges to information extraction on free-text. 1
Comparison with prior work
Some methods have been developed to address narrative text problems, but challenges still remain. 20 Most medical information extraction tasks require recognition of part of the context, including key phrases and words. In our study, 88 attributes are required to be extracted which almost covers all clinical text in the OES and dramatically increases difficulty and complexity. The keyword-based method is classically used in information extraction and characterized by its high precision. 21 When dealing with medical data, this method exhibits a low recall due to the constraints of key phrases and concepts. It also requires significant manual work to conclude keywords, where extensive information must be extracted. Thus, we applied a hybrid method, combining keyword-based and deep learning methods, to extract information, significantly improving the performance relative to the keyword-based method.
Principal results
Fixed-length vectors are learned through neural networks using deep learning models. Mikolov proposed word2vec model to represent sentences, 14 a semantic method that implies sentences with similar meanings comprise vectors with close proximity in multi-dimensional space. Word2vec transforms linguistic words into vectors for computing; Sentence2vec, constructed from Word2vec, learns sentence vectors for each sentence. 13 We ran the models with discretized dimensional vectors (50, 100, and 200 dimensions) separately and found that the models perform best with 100-dimesional vectors representing sentences and 200-dimesional vectors representing words. To the best of our knowledge, we are the first to apply a deep learning method to improve recall of information extraction using Chinese dental clinical data; we have shown its efficiency in recall improvement, which arises from similarity comparison that could distinguish words in similar semantics. Vectors allow multiple expressions of the same attribute to be recognized through similarity calculation. Notably, the attribute Pain hyperemization swollen and ulcer is labeled with two keywords, achieving 0.17 of recall; combining with sentence vector, recall improves to 0.5.
BERT is also a neural network-based model for language representation which can be pre-trained from unlabeled text by jointly conditioning on both left and right context in all layers. 12 We tried the BERT model to represent sentences which performs inferior to Sentence2vec (Table 1). The reason is that we used the open source Chinese BERT pre-training model based on corpus in general domain, which brings domain mismatch problem and results in poor performance compared to Sentence2vec-based vectors. The training of BERT model requires much more data than Sentence2vec model and our dental corpus cannot fulfill the needs to train a mature BERT model due to the limited data quantity.
Descriptions of attribute values are clear and simple, suitable for the keyword-matching method. Following word segmentation, vectors of all words are acquired and words with high similarity in vectors are added into the keyword database. An expanded keyword database yields higher recall in attribute value recognition.
In order to investigate a proper training set, we varied the number of EHRs and calculated the associated precision and recall, as shown in Figure 3(a). The increasing number of training sets supports the vector performance of our model. With an increasing number of training sets, overall model performance improves. We assume that the larger training set contains more descriptions of attribute values, thereby improving the recall of our model. Thus, collecting additional training samples will improve our study. Therefore, we set the training set as 1600 annotated EDRs. Evaluation reveals that the hybrid method outperforms the keyword-based and deep learning methods. In attribute recognition (Table 1),
Error analysis
Reviewing all error predict results, we found there exist some patterns of mistakes that were summarized below in detail. Cases of different errors are exemplified in Table 3.
Examples of four error types.
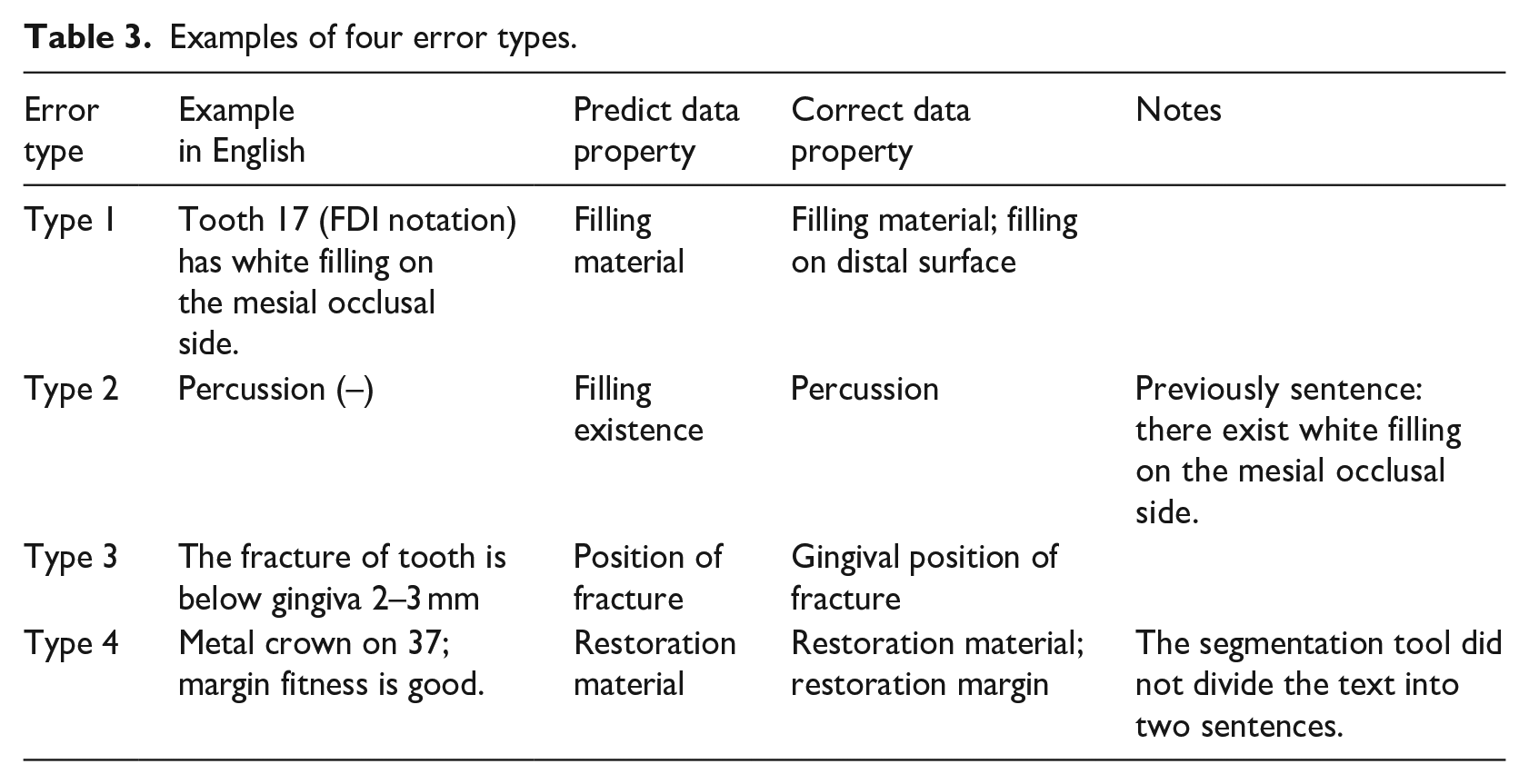
(1) Sentences match more than one attribute.
The sentences that are labeled with more than one attribute always are recognized with one attribute. The reason is that in our framework, we regard each sentence as a binary problem, and only extract one attribute with the highest similarity. For example, sentence “Tooth 17 (FDI notation) has white filling on the mesial occlusal side” labeled with two attributes is matched to one of them in our study.
(2) Sentences tend to be recognized with attributes of sentences in neighborhood.
This phenomenon is in relevant with the training model of vectors. In the unsupervised models, vectors are trained to take sentences nearby into consideration. Therefore, there exist some confusions to some extent.
(3) Sentences where the incorrect attributes matched were, in semantic, highly similar to sentences with these properties.
This is probably due to the nature of the vector training algorithms and keywords embedded. Sentences with high resemblance tend to be calculated high cosine similarities and recognized with wrong properties.
(4) Segmentation problem
A few sentences are segmented incorrectly with extra symbols, like (–), /. This has an impact on vectors training and results in wrong extraction.
Conclusion
We proposed a novel NLP workflow combining keyword-based and deep learning methods in extracting attributes and values from EDRs. Evaluation results indicate that the hybrid method outperforms both the keyword-based method and deep learning method. The workflow could be potentially utilized as an initial step to provide structured data for data-based models training. In future we will integrate our NLP workflow with data-driven CDSSs and apply it to more corpuses from diverse sources for more general use.
Footnotes
Appendix
Unlike ontologies previously built, 6 we designed an ontological paradigm to represent concepts and terms in the CDSS, which produces RPD designs by analyzing patients’ oral conditions. The ontology we built describes specific oral conditions of partial edentulism and RPD design treatments through defining 70 classes, 203 data properties, and 48 object properties.
Among those classes and properties, one major content is about patients’ oral conditions of each visit. Data properties among the ontology represent oral conditions, values of which represent results of the corresponding oral examinations. Forty-eight object properties describe interrelations among oral examinations, tooth positions, and RPD components. The study here utilizes classes and properties regarding oral conditions to extract information from the OES of EDR data.
In the ontology, classes represent upper levels of oral examinations; their data property represent lower levels of oral examinations. The lowest level of the data properties represent the detailed oral conditions, which directly link to the content of the OES in EDRs. Here we will introduce classes and properties related to this study in brief.
Define three classes representing top levels of oral examinations: oral conditions (representing the top level of oral examinations), tooth (representing oral examinations related to tooth positions), mouth (representing oral examinations of the whole mouth).
Define levels of data properties representing specific oral examinations in hierarchy. Table 4 shows parts of data properties of Class tooth. Only the lowest levels of data properties were defined data property values.
Define object properties representing relations among classes and data properties, namely has_part, is_part_of, tooth_object_property, left_first_tooth and right_first_tooth. Figure 5 shows an instance of the semantic network of oral conditions of partial edentulism.
Author contributions
Q.C. proposed methods, carried out the experiments and drafted the manuscript. X.Z. cooperated to revise the manuscript. J.W. helped to build the software infrastructure. Y.Z. supervised and reviewed the manuscript. All authors read and approved the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the youth fund of Peking University School of Stomatology of Qingxiao Chen, PKUSS20180108 and the “tianchenghuizhi” education promoting fund from Ministry of Education, Yongsheng Zhou, 2018A03001, 2019.