
Abstract
Diagnostic tests are widely used in emergency departments to make detailed investigations on diagnosis and treat patients correctly. However, since these tests are expensive and time-consuming, ordering correct tests for patients is crucial for efficient use of hospital resources. Thus, understanding the relation between diagnosis and diagnostic test requirement becomes an important issue in emergency departments. Association rule mining was used to extract hidden patterns and relation between diagnosis and diagnostic test requirement in real-life medical data received from an emergency department. Apriori was used as an association rule mining algorithm. Diagnosis was grouped into 21 categories based on International Classification of Disease, and laboratory tests were grouped into four main categories (hemogram, biochemistry, cardiac enzyme, urine and human excrement related). Both positive and negative rules were discovered. Since the nature of the data had the dominance of negative values, higher number of negative rules with higher confidences were discovered compared to positive ones. The extracted rules were validated by emergency department experts and practitioners. It was concluded that understanding the association between patient’s diagnosis and diagnostic test requirement can improve decision-making and efficient use of resources in emergency departments. Association rules can also be used for supporting physicians to treat patients.
Introduction
Most of the health services, such as ambulatory services, hospitals, clinics and many others, have employed information systems to store and manage their patient data. Although these information systems accumulate huge amounts of data in different forms (numbers, text, images, etc.), turning them into useful information that would enable to make important medical decisions is a big deal for a healthcare practitioner. In this context, use of data mining techniques becomes unavoidable for researchers to extract useful information from medical databases.
Data mining is an emerging technology combining statistics, artificial intelligence, and machine learning to extract valuable information from vast amounts of stored data in databases. Main functions of data mining are outlier detection, classification, cluster and association analysis, and forecasting. Particularly, functions of data mining can be applied in medical field to improve decision-making such as prognosis, diagnosis, and treatment planning. 1 Due to the high patient volumes, emergency departments (EDs) are the main units of hospitals which may have vast amount of the raw data of hospital’s information system. Besides, this overcrowding increases the complexity in operational planning. 2 Thus, use of data mining becomes more of an issue in EDs to make effective decisions. In the literature, there have been many studies which used different functions of data mining such as for clustering the patients,3–5 classifying them, 6 or generating predictions.7–9 However, to the best of the knowledge, use of association analysis or association rule mining (ARM) is very rare in ED context.
ARM is one of the most important functions of data mining. It is a structured method of discovering all frequent patterns in a data set and forming noticeable rules among frequent patterns. In other words, it is a way of discovering relations between items in big data. In medical field, ARM is used to discover frequent diseases in specific areas. 10 Particularly, in ED context, in addition to discover frequent diseases, relations between different types of diseases and diagnostic tests can also be highlighted by applying ARM to make rapid decisions and plan operations more efficiently.
The aim of this study was to discover frequent rules between diagnosis types and different types of laboratory diagnostic tests (LDTs) for patients of an ED using ARM. LDTs were combined in four main categories as: hemogram, coagulation, blood type; biochemistry; cardiac enzymes; and urine and human excrement. As one of the best and most commonly used algorithms, Apriori was used to extract association rules. Both positive and negative rules were generated to analyze which diagnosis types require or not require LDTs. The mined rules were discussed and validated by ED management. It is foreseen that while ordering LDTs, considering these rules will provide guidance for ED practitioners in decision-making.
Background
In this section, main concepts and definitions of ARM and the applied technique of ARM, namely, Apriori, were initially defined. Then, related studies aiming to discover association rules in the medicine literature were summarized.
Definitions
ARM
Mining the past transactions to extract association rules to discover relationships and dependencies within data set is called ARM. ARM was first introduced by Agrawal et al.
11
Let
The standard problem of ARM 11 is to discover all rules whose metrics are at least equal to user-specified values of minimum support and minimum confidence.
Apriori
Apriori algorithm which was first introduced by Agrawal and Srikant 12 has become a well-known and widely used approach for ARM. Data set containing transactions is given to Apriori as input to generate the association rules which represent frequent item set and have support or confidences greater than the given thresholds. In the algorithmic process of Apriori, item set I of length m is frequent if and only if every subset of I with length m – 1 are also frequent. In this regard, the Apriori algorithm evolves significant reduction of search space and allows rule discovery in computationally feasible time. Confidence, which is used to rank the discovered rules in Apriori, is the main accuracy criteria. 11
Related studies
Apriori algorithm which originally proposed for solving the market basket problem12,13, recently adopted for healthcare services for generating association rules between clinical events and various medications, tests, and many others. 14 In the medical literature, ARM has been widely used. One area of research was identifying risk patterns in medical data. Li et al. 15 discussed the problem of finding risk patterns in medical data where the risk patterns were defined by a statistical metric, relative risk. In that study, the problem of finding risk patterns was characterized as an optimal rule discovery problem. It was believed that the discovered rules were useful for medical research scholars. Li et al. 16 analyzed the problem of efficient discovering of risk patterns in medical data by proposing an algorithm for mining optimal risk pattern sets based on the anti-monotone property and concluded that the proposed algorithm was efficient in risk patterns exploration.
Majority of the research works in this context were based on the hospital data. In their study, Paetz and Brause 17 showed results of a data-driven rule generation with categorical septic shock patient-data by applying an efficient algorithm for frequent patterns generation, and by rating the performance of generated rules based on frequency and confidence measures, they presented the best rules. Brossette et al. 18 analyzed the problem of identifying interesting patterns in hospital infection control and public health surveillance data using the association rules. Ohsaki et al. 19 developed a rule discovery support system to discover interesting rules from the data set on chronic hepatitis diagnosis. Ordonez et al. 20 focused on finding association rules on a real data set to predict absence or existence of hearth diseases by introducing the greedy algorithm. Ordonez et al. 21 discovered association rules in medical data to predict heart disease. Their study introduced an improved algorithm to find constrained association rules and presented an experimental section summarizing several rules which were discovered. Other study by Nahar et al. 22 also aimed to detect contributing factors to heart disease by using association rules, and analyzed the information available on sick and healthy males and females. Ordonez 23 presented that the main problem about ARM in a medical data set is the huge size of the mined rule set where majority of them were irrelevant that causes slow search and difficult interpretation by the field expert. Thus, in his study, search constraints were introduced to discover only medically significant association rules in order to make the search more efficient and faster. For the experimental setting, Ordonez 23 used arteries data and found out the association rules for healthy and diseased arteries. In their study, Lee et al. 24 proposed ARM method which was able to discover interesting patterns including a medical data in Korean acute myocardial infarction registry where data were collected by 51 participating hospitals. The performances of target pattern were evaluated in terms of statistical measures such as lift, leverage, and conviction. Cheng et al. 25 designed and developed an intensive care unit (ICU) clinical decision support system, namely, icuARM, together with ICU clinicians by using ARM. icuARM was implemented with multiple association rules and easy-to-use graphical user interface for care providers to perform real-time data and information mining in the ICU setting. It was discussed that icuARM was able to provide valuable insights for ICU physicians to tailor a treatment based on clinical status of the patient in real time. Other publication by Exarchos et al. 26 presented an automated methodology for the detection of ischemic beats in long-duration electrocardiographic recordings. Nahar et al. 27 aimed to extract significant prevention factors for specific types of cancer by employing different ARM techniques. Chaves et al. 28 proposed a novel voxel selection method based on ARM and tested this method for the early diagnosis of Alzheimer.
Although ARM has not been widely used in ED context, a few research works focused on this particular field. Imberman et al. 29 analyzed clinical head trauma data set, in order to find indications for computed tomography, by the association rules based on Boolean analyzer method, and concluded that ARM method had broad applicability in medical domain. Petrus et al. 30 compared decision tree and optimal risk pattern mining for the analysis of emergency ultra-short stay unit data, and showed that compared to decision tree method which was inadequate for finding understandable patterns, optimal risk pattern mining was very powerful for medical practitioners. Chan et al. 31 investigated whether care-seeking patterns involve the use of healthcare services of various types prior to ED visits and examined the associations of these patterns with the severity of the presenting condition for ED visit and subsequent events. Bergmeir et al. 32 aimed to design more efficient, effective, and safe medical emergency team service using ARM techniques.
From the methodological perspective, different ARM methods have been employed in the literature. Some of those methods include data cutting and inner product (DCIP) method,33,34 extended FP-growth methods, 35 Boolean analyzer, 29 and Tertius. 27 However, many of the research works used Apriori to discover association rules in medical data sets,16,22,27 which makes ARM one of the popular and widely used methods without doubt.
Experimental study
Research architecture
Proposed study was composed of two main process layers—which were data preprocessing and ARM—as indicated in Figure 1. Preprocessing of data was the preparation of data set for the appropriate data representation model for ARM. ARM was the second layer to mine association rules for the given structured data set. By applying Apriori algorithm with customized parameters, positive and negative rule mining were performed for validation.
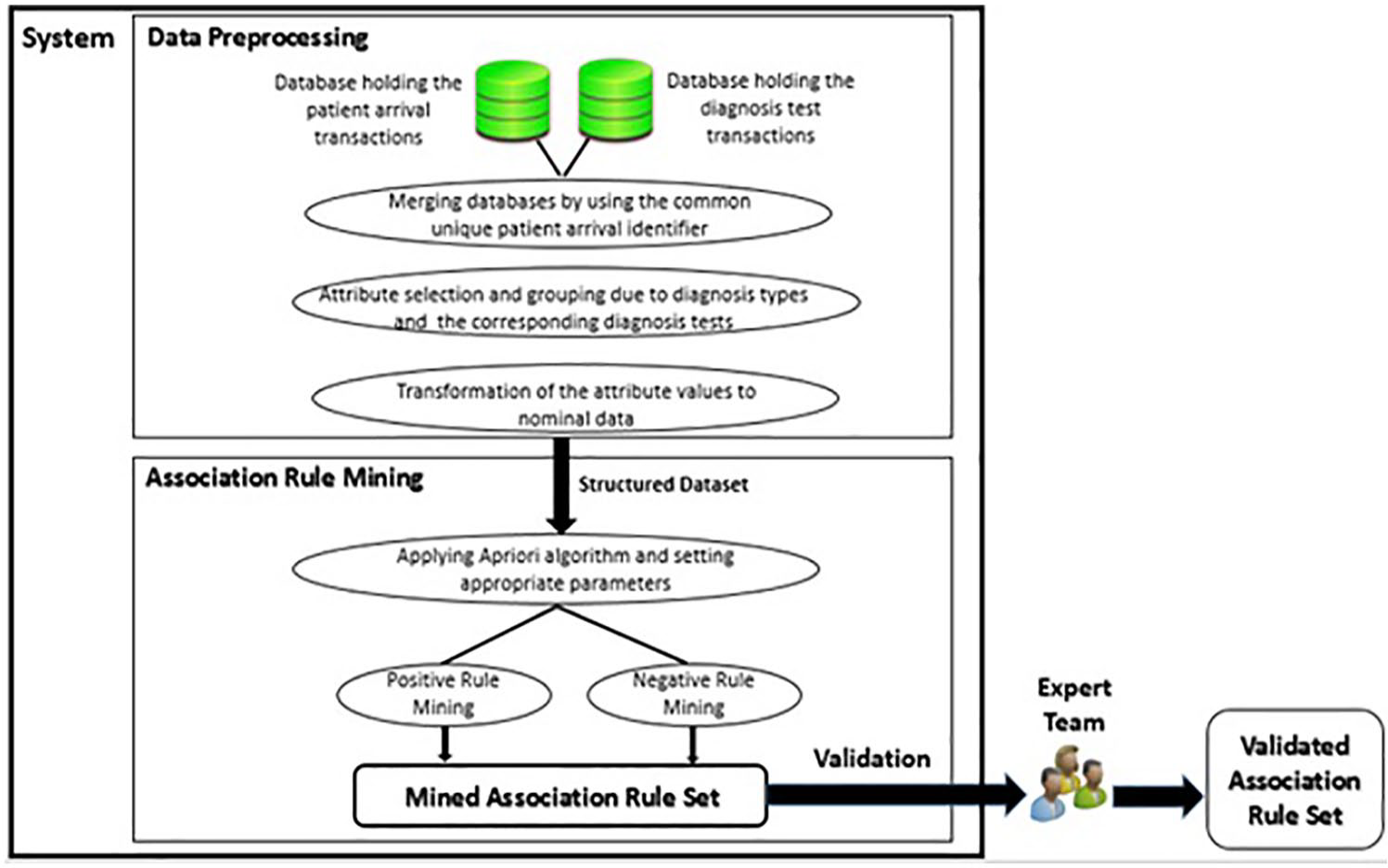
Research architecture.
Data preprocessing
EDs have data-rich ecosystem that raw data require preprocessing task to build reasonable ARM models. Raw data of this study were extracted from two distinct databases those were holding the patient arrival transactions and diagnosis test transactions. After elimination of missing values in raw data, first step was performed as preprocessing patient arrival transactions database specifically on the attribute: diagnosis code. Diagnosis was encoded in the form of codes which were listed in International Classification of Diseases (ICD) in the raw data. Due to the wide variety of diagnosis codes, ICD standard for an upper level grouping which resulted in 21 different diagnosis code types was performed. Instead of having the actual diagnosis code in the transactions, diagnosis codes were converted to these 21 groups to represent with nominal attributes for further preprocessing steps. Then, duplicate diagnosis codes were merged to represent the match between patient arrival identifier and corresponding diagnosis code groups.
First step was followed by merging the data sources using the patient arrival identifier, which was the common attribute in both databases that were holding the transactions of patient arrivals and diagnostic tests. Afterward, irrelevant attributes like name, age, and gender—which would not be involved in the mining of association relations—were eliminated from the processed data during attribute selection. Merged data set represented the match between the patient arrivals, corresponding diagnosis group codes, and applied diagnostic tests. Each diagnosis group code and test were the attributes which were represented in binary format for rule mining model. Each transaction was converted to the form of the interpretation, of which diagnosis codes existed and which diagnosis tests were applied for each patient arrival.
Next step was to build a data model for ARM to represent each patient arrival identifier with the mapping of diagnosis codes and applied tests to mine and extract rules from the given data set. Each diagnosis group and diagnosis test were modeled as the attributes of the model. To find the association rules between diagnosis types and LDTs (Table 1), rule mining model held the each patient’s arrival transaction, representing whether diagnosis codes existed or LDTs were required or not. For each transaction, diagnosis groups and LDTs were represented as “yes” and the other attributes were represented as “no” using binary values: true and false. Structured data set that has binary representation of transactional data was finally prepared for ARM task. Sample of the structured data set was illustrated on Table 2.
Diagnosis and laboratory diagnostic test groups.
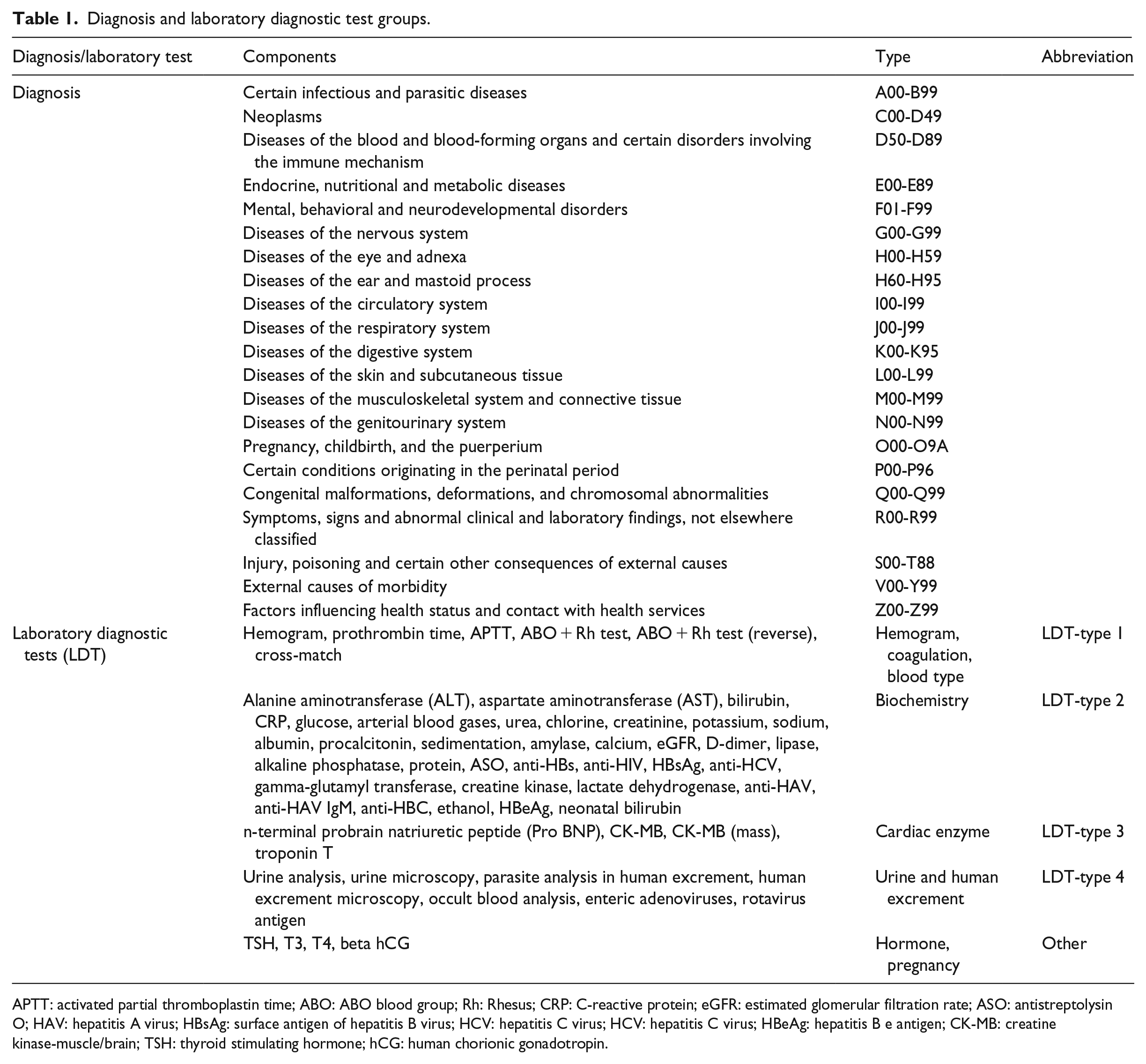
APTT: activated partial thromboplastin time; ABO: ABO blood group; Rh: Rhesus; CRP: C-reactive protein; eGFR: estimated glomerular filtration rate; ASO: antistreptolysin O; HAV: hepatitis A virus; HBsAg: surface antigen of hepatitis B virus; HCV: hepatitis C virus; HCV: hepatitis C virus; HBeAg: hepatitis B e antigen; CK-MB: creatine kinase-muscle/brain; TSH: thyroid stimulating hormone; hCG: human chorionic gonadotropin.
Sample of structured data set.
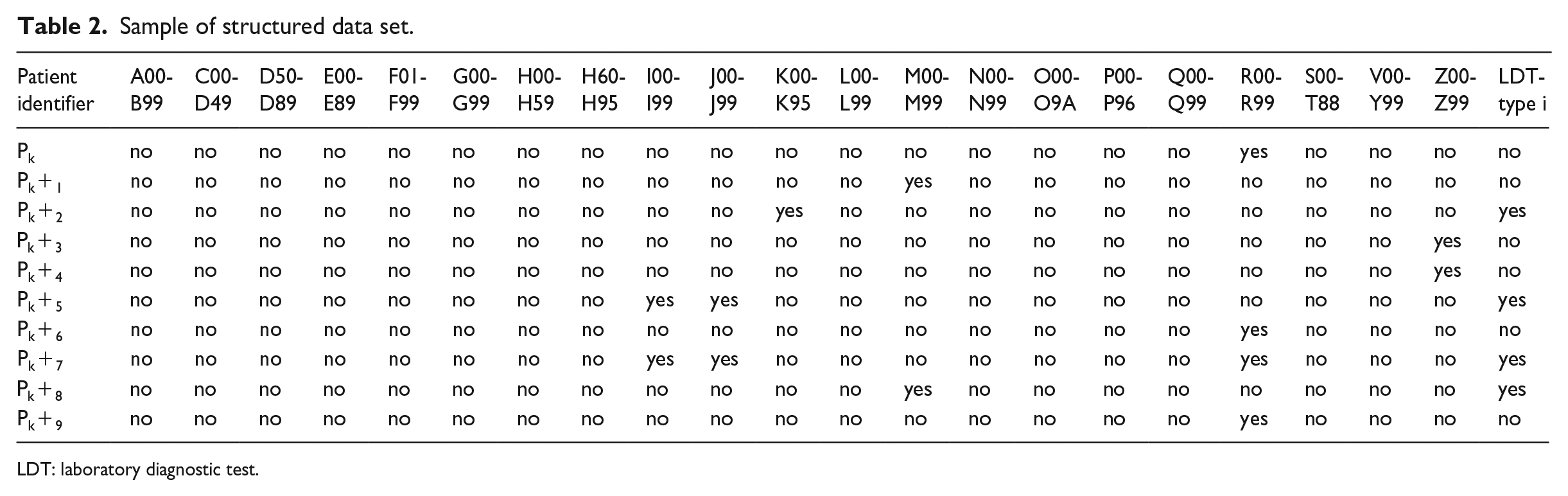
LDT: laboratory diagnostic test.
Experimentation
In this study, the experiments were built to focus on medical significance and applicability of predictive rules obtained by the ARM algorithm of Apriori. Context of ARM includes two main different ways of rule mining: positive rule mining considers the item sets only when they are frequent, whereas negative rule mining considers them for infrequent values. Dominance of the “no” values within structured data set caused to mine association rules between positive values and negative values distinctly for this study. Therefore, two types of ARM were performed for each type of LDT. Mined association rules for each type of LDT from both positive and negative rule mining models were extracted for expert team review and validation.
Experiments were performed on Waikato Environment for Knowledge Analysis (WEKA) environment. Apriori parameters were customized to gain insight due to the homogeneity of structured data set which was the outcome of the data preprocessing step. These parameters in WEKA environment and their definitions were represented as follows:
car (car association rule): Boolean data type representation is available for this parameter. Instead of mining all rules, only class association rules are generated if car parameter is set to true.
classIndex: index of the class attribute of the rule to be generated.
numRules: numRules is the parameter of upper bound for the number of mined association rules.
metricType and minMetric: metricType specifies the criteria to sort mined rules. In this study, confidence is used as a performance metric to evaluate the accuracy of a mined rule. For a given simple rule,
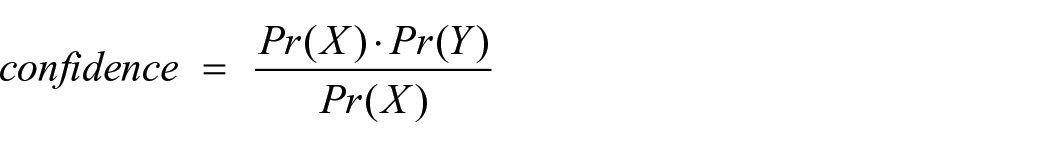
lowerBoundMinSupport (lower bound minimum support): support is the frequency of the given rule within transactions. Threshold parameter that constraints the lower bound for the minimum support value is named as lowerBoundMinSupport.
upperBoundMinSupport (upper bound minimum support): threshold parameter that constraints the upper bound value for minimum support is named as upperBoundMinSupport.
treatZeroAsMissing (treat zero as missing): Boolean data type representation is available for this parameter. Missing values in the data set are counted as zero, which means non-existence or setting the attribute value false if treatZeroAsMissing parameter is true.
For positive rule mining, the rules satisfying car = True, classIndex = 22 (index of LDT column in data set), numRules = 10, lowerBoundMinSupport ⩾ 0.015, metricType = confidence, minMetric ⩾ 0.5, and treatZeroAsMining = True are considered. On account of the negative value dominance in structured data set, in obtaining negative rules, it was required to customize the parameters properly. Corresponding parameters were lower bound minimum support and number of rules. For negative rule mining, the rules satisfying car = True, classIndex = 22, numRules = 6 (see section “Predictive association rules”), lowerBoundMinSupport ⩾ 0.02, metricType = confidence, minMetric ⩾ 0.7, and treatZeroAsMining = True are considered.
Results
Descriptive results
During the study period (January 2017) total number of arrivals to ED of interest was 32,753. In triage process, 15,516 (47.37%) of these arrivals were categorized as urgent or emergent, while the remaining arrivals were not urgent. The frequency distributions based on to “receive or not” any type of LDT for both of the urgent or emergent and not urgent patients are shown in Figure 2.
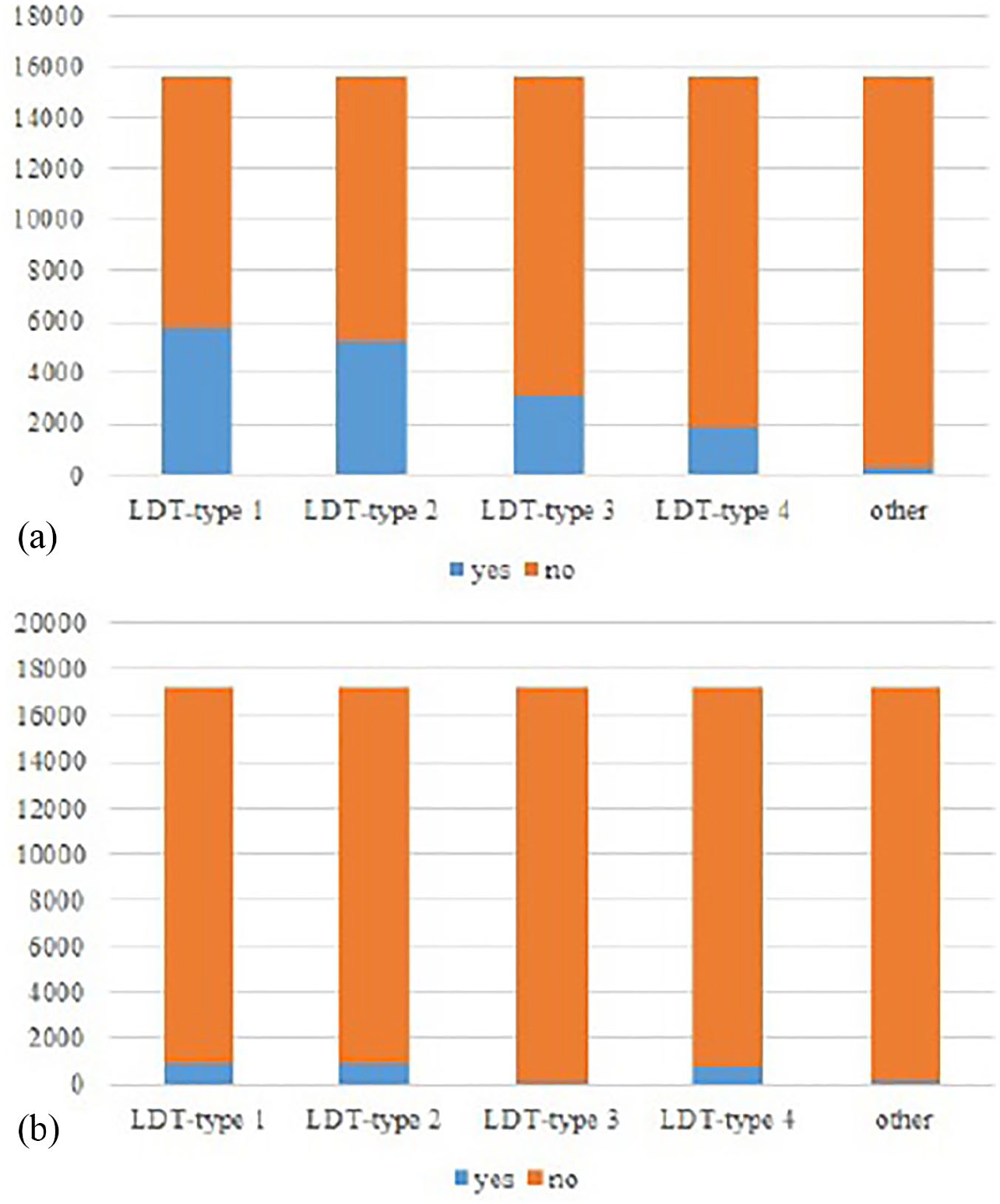
Frequency distributions of receiving/not receiving different types of LDT: (a) urgent or emergent and (b) not urgent.
From Figure 2(a), it was observed that for the patients categorized as urgent or emergent, the frequencies for receiving any type of diagnostic test were, respectively, as 5758 (37.11%), 5228 (33.69%), 3103 (20.00%), 1845 (11.89%), and 290 (1.87%) for LDT-type 1, LDT-type 2, LDT-type 3, LDT-type 4, and other. However, for not urgent patients (see Figure 2(b)), the respective frequencies were 995 (5.77%), 969 (5.62%), 101 (0.59%), 796 (4.62%), and 187 (1.08%). Thus, it was concluded that any type of LDT requirement was very low, almost below 5 percent, for the patients categorized as not urgent, while it sharply increased for those categorized as urgent or emergent. Since the frequencies of receiving tests were important especially for extracting positive rules in ARM, it was decided to consider only urgent or emergent cases and discover the meaningful rules between diagnosis and any type of LDTs in this article. Similarly, since the frequencies of receiving any type of hormone or pregnancy test (considered in other category) were very low even for urgent or emergent patients, these test types were also excluded from ARM analysis.
For each diagnosis categories, the frequencies of receiving any type of LDT are additionally represented in Figure 3.
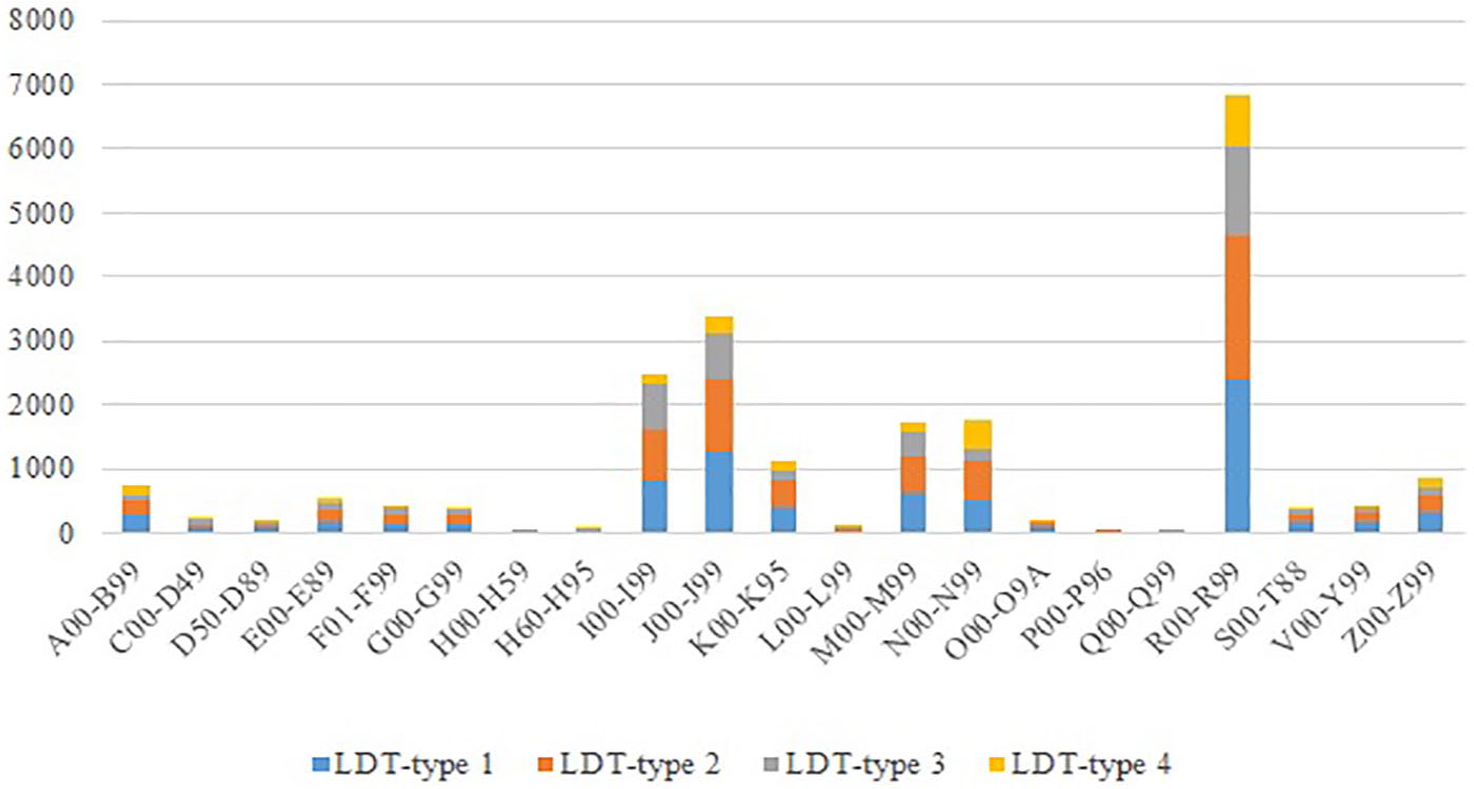
Frequencies of receiving any type of LDTs based on diagnosis types.
In Figure 3, it was observed that the highest number of LDTs was required by the patients having the diagnosis of “R00-R99,” “J00-J99,” “I00-I99,” “N00-N99,” “M00-M99,” “K00-K95,” and “Z00-Z99.” Thus, it was expected to discover many rules between these diagnosis types and LDTs.
Predictive association rules
Positive rules for four types of LDTs were summarized in Table 3.
Mined positive rules for each type of LDTs.
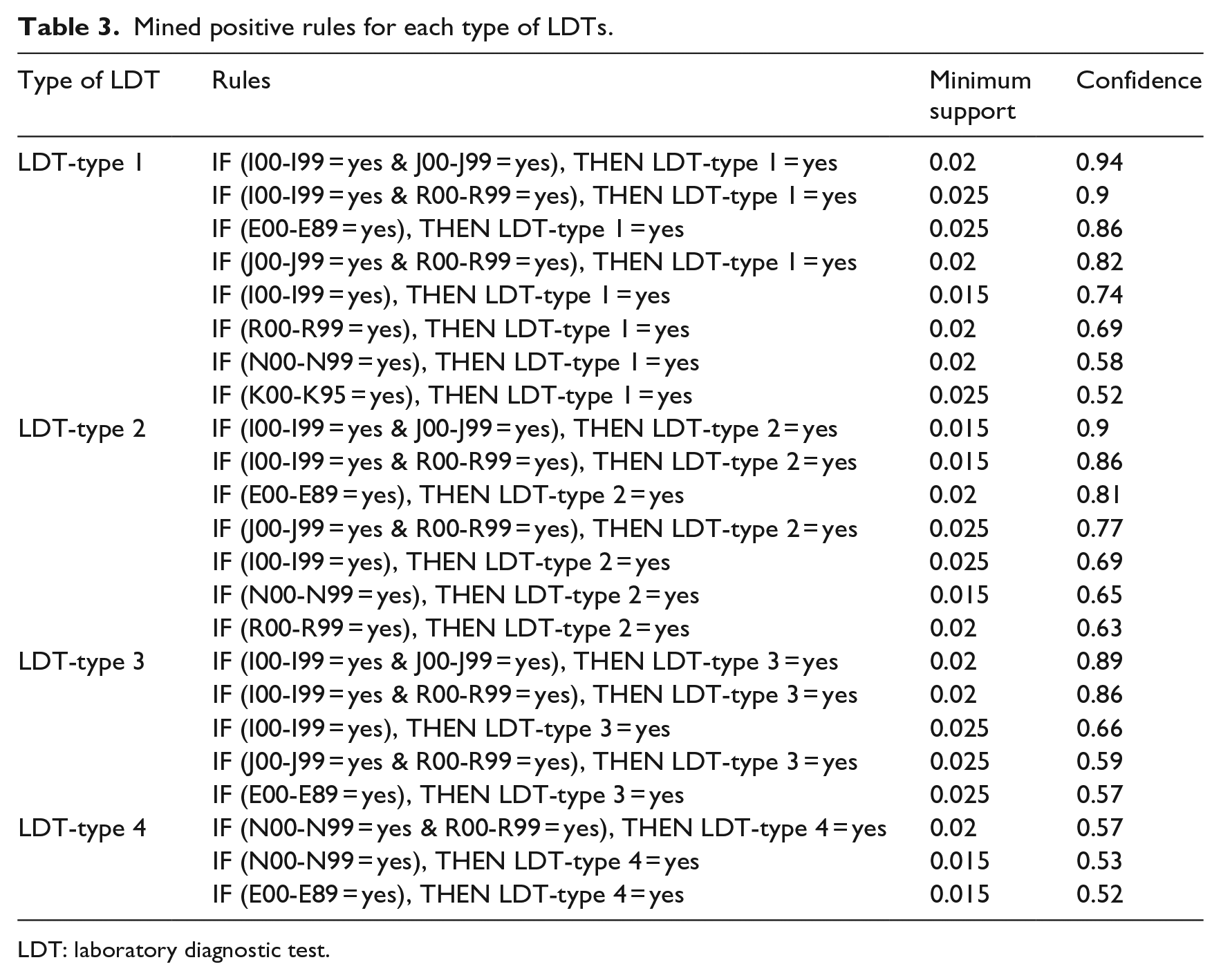
LDT: laboratory diagnostic test.
From the obtained rules presented in Table 3, it was mainly observed that the positive rules for the first three types of LDT (LDT-type 1, LDT-type 2, and LDT-type 3) were generally discovered with the diagnosis types of “I00-I99,” “J00-J99,” “R00-R99,” and “E00-E89,” whereas the positive rules for LDT-type 4 were associated with the diagnosis types of “N00-N99,” “R00-R99,” and “E00-E89.” When the rules of the first two LDTs (LDT-type 1 and LDT-type 2) were comparatively analyzed, it was observed that for the similar diagnosis types, these two tests, namely, hemogram and biochemistry–related tests, were generally ordered together, where the ordering frequencies were higher in the first type, LDT-type 1. However, for the diagnosis type of “N00-N99,” ordering frequency of LDT-type 2 was higher compared to that of LDT-type 1 (see confidences were 0.58 and 0.65).
Since the nature of the data had the dominance of negative values, higher numbers of negative rules were discovered. However, it was decided to present only first six rules for each types of LDTs, in order to be consistent in the presented numbers of positive and negative rules. Negative rules for all types of LDTs are also summarized in Table 4.
Mined negative rules for each type of LDTs.
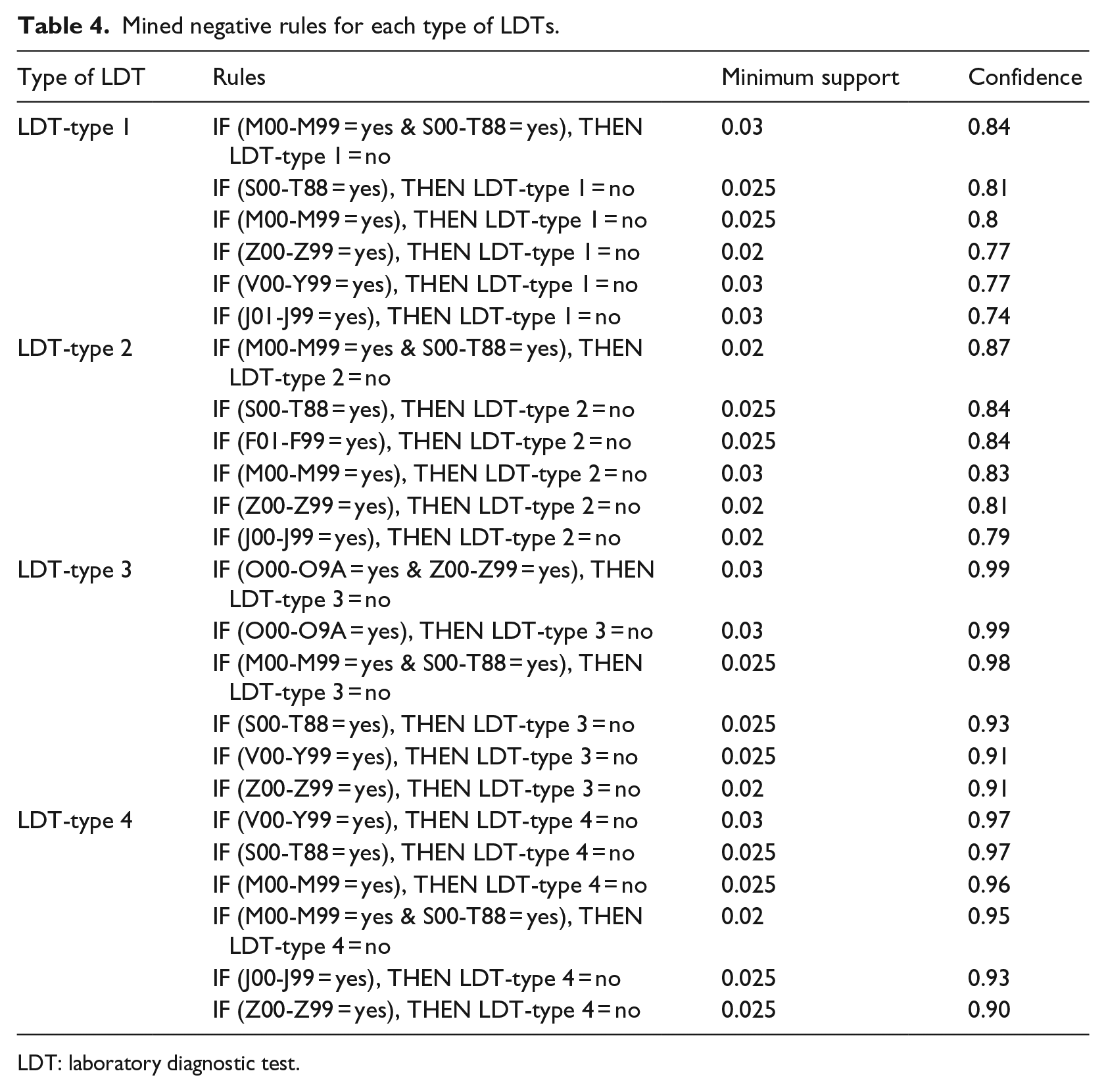
LDT: laboratory diagnostic test.
The main point that could be observed in Table 4 was the higher values of minimum support and confidence in negative rules compared to those of positive rules shown in Table 3. One important result that needs to be highlighted was related to the diagnosis type of “J00-J99.” If this specific type of diagnosis was observed in a patient together with the diagnosis types of either “I00-I99” or “R00-R99,” then it was highly probable for this patient to require both LDT-type 1 and LDT-type 2 (see Table 3). However, when this type of diagnosis was seen alone in a patient, then it was more probable for this patient to not to require any type of these tests. Additional worth-emphasizing result of Table 4 was that, for the same conditions representing negative rules of LDT-type 1 and LDT-type 2, confidences were higher in the latter one meaning that frequencies of not ordering LDT-type 1 were lower compared to those of LDT-type 2. Recall that the opposite of this result was found out in mined positive rules presented in Table 3.
Practical implications
Presenting easily understandable methodologies and tools to guide decision-makers is very valuable in EDs, since making correct decisions in a timely manner is essential for them. In EDs, especially for patients with specific diagnoses types, diagnostic tests are widely used to treat patients correctly. However, redundant use of diagnostic tests causes higher costs and waiting times for each patient and results in inefficient use of resources. Thus, understanding/emphasizing the relation between diagnosis types and requirement of any diagnostic test gains an importance in making decisions in EDs. Thus, in this article, using ARM, one of the widely used data mining techniques, it was aimed to discover meaningful rules between diagnosis types and diagnostic tests for EDs. In other words, it was aimed to highlight which diagnosis types were most probable to require any type of LDTs (positive rules) and which were most probable to not require types of LDTs (negative rules). Highlighting these positive and negative rules has many implications in practice. First, these extracted rules via ARM present a guide for ED practitioners while deciding if a patient with specific diagnosis type, or may be more than one type of diagnosis observed together, really requires any type of LDTs. Besides, since the practitioners are required to make decisions rapidly in EDs, using these rules in practice is expected to improve operational performance in such an overcrowded environment. Gaining time for each treated patient, which decreases the overcrowding in EDs, leads in a higher satisfaction and hospital reputation. Benchmarking these rules may ensure use of resources (laboratories, personnel, equipment, etc.) more efficiently, since only the patients who really require these tests will use them. Finally, combining the medical knowledge inferred from the associated rules with population demographics can guide the planning of operations in EDs such as designing laboratories, planning capacities, and managing stocks, in generating medium-to-long-term plans.
Conclusion
This research has presented the easiness of ARM to extract set of rules between diagnosis types and requirement of different LDTs using real-life data received from a large-scale urban hospital’s ED. As most common ARM algorithm Apriori was used to extract rules, and the performance of this algorithm was tested based on confidence level. Laboratory-related diagnostic tests (LDTs) were grouped into four: hemogram, coagulation, blood type (LDT-type 1); biochemistry (LDT-type 2); cardiac enzyme (LDT-type 3); and urine and human excrement (LDT-type 4). Diagnosis types were defined based on International Statistical Classification of Diseases and Related Health Problems (10th revision; ICD-10) classification system combining diseases in 21 groups. The attributes of this study were defined as nominal values representing the existence/non-existence of any group of 21 diseases and requirement/non-requirement of any type of four LDTs. Both positive, showing which diagnosis group/groups (together) were probable to require any type of LDTs, and negative, representing the diagnosis group/groups (together) those were highly probable to not to require LDTs, rules were discovered.
The findings based on the discovered rules were summarized as follows. While circulatory system (I00-I99); respiratory system (J00-J99); symptoms, signs, and abnormal clinical laboratory findings (R00-R99); and endocrine, nutritional, and metabolic diseases (E00-E89) were highly probable to require first three types of aforementioned LDTs (LDT-type 1, LDT-type 2, and LDT-type 3), diseases of the genitourinary system (N00-N99) were most likely to require LDT-type 4. Besides, for some certain situations (“I00-I99” and “J00-J99” were seen together, “I00-I99” and “R00-R99” were seen together, “E00-E89” was seen, “J00-J99” and “R00-R99” were seen together, “I00-I99” was seen, and “R00-R99” was seen), it was highly probable to require LDT-type 1 and LDT-type 2 together, where confidences were higher for LDT-type 1–related rules. Since negative dominance of values were seen in data set, the confidences and number of generated rules were much higher in extracting negative rules in comparison with positive rules. One emphasizing finding of this study was related to respiratory system–related disease (J00-J99). If this disease was seen alone in a patient, then it was highly probable for this patient to not to require any type of LDTs; however, if this disease was simultaneously seen with any of “I00-I99” or “R00-R99,” then it was likely for this patient to require some types of LDTs.
All these extracted rules were validated by emergency medicine specialist team and found as useful and emphasizing. Although this study was limited with its design which was based on the data of a unique hospital, it was believed that computer-based medical knowledge of this study could be generalized and served as a guideline for ED practitioners to enhance the decision-making and operational planning. As a future research direction, it is suggested to develop and integrate ARM module in a decision support system for specialized research fields in EDs.
Footnotes
Acknowledgements
The authors acknowledge Dr Mustafa Gökalp Ataman for his technical support. They also acknowledge Dr İlker Kızıloğlu for his general support. For providing writing assistance, the authors acknowledge School of Foreign Languages and Academic Writing Center of İzmir University of Economics, İzmir, Turkey.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.